What Is a Failover? Clustering and Replication Use Cases
The availability of VMs is essential for ensuring business continuity. When the services running on business- and mission-critical VMs become unavailable, companies can lose money and customer trust. To restore VM availability immediately after a failure, you should use appropriate failover techniques.
Failover to a VM replica can be part of disaster recovery to restore data and operations with minimal disruption to regular workflows. The VM failover process should be described in an organization’s business continuity and disaster recovery (BCDR). Let’s look into VM failover types and use cases in more detail.

What Is a Failover?
Failover is the process of resuming a virtual machine (VM) on a secondary system (and sometimes at a secondary location) following a failure of the primary system. The secondary system contains all the needed data to maintain business operations. A system in this context can be a server, database, virtual machine, etc.
In virtual environments, there are two common failover methods:
- Using a VM replica (usually located on another virtualization server) is used to perform failover if a primary VM fails
- Using a failover cluster (no replication required)
Failover requires less time to restore workloads compared to recovery from a backup and, as a result, you can achieve a lower recovery time objective (RTO). However, using VM replication or clustering doesn’t remove the need to create VM backups. A backup (usually compressed) is useful when you need to recover data from the old recovery point.
Let’s go over the basic VM failover terminology for replication-based disaster recovery.
Failover glossary
- Failure: Any problem with hardware or software as a result of a system crash, power outage, network issues, ransomware attack, etc., that takes a system offline.
- Primary system: The system running live operations in the production environment.
- Secondary system: The redundant stand-by system, which is regularly updated with copies of the primary system. The secondary system can be housed on-premises or at a remote location.
- Replication: The essential process to prepare for VM failover. Replication creates an exact copy, that is, replica, of the primary VM for a given point in time.
- VM Failback: Failback is the process of switching back to the primary system from the replica VM after the incident is resolved.
Failover Types
There are three types of failover:
- A planned failover is used for scheduled migrations of workloads from one system/site to another. Use cases include performing maintenance on the primary system, electrical works performed at the production site, and expected disaster scenarios. For example, a weather alert about a tornado may require a planned failover to ensure availability.
- An unplanned failover is a failover performed when an unexpected failure occurs resulting in a critical VM or the entire primary site going offline. The failure can be caused by any of a number of natural disasters, accidents (a power outage), a malware attack, or any other incident. For an unplanned failover, hosts and replicas should be prepared in advance.
- A test failover, as the name suggests, is used for testing purposes. Testing scenarios can include rehearsing unplanned failover scenarios to ensure that
The Failover Sequence
During a VM failover, the failover sequence of actions and VM start order are essential to ensure successful resumption of workflows. They must be defined at the development stage of your organization’s disaster recovery plan. The sequence should capture the dependencies between different services that run on different VMs.
For example, the authentication for some services and applications that run on VMs may be using Active Directory, which is running on another VM. A database server might be running on the first VM, an application server on the second, and the web server on the third one.
The VM with Active Directory Server must be started first. Then the VMs with services that use Active Directory for authentication can be started. The VM with the database server must be started before the VM with the application server, because the application server connects to the database. Once the VMs with the database server and the application server have been started, the VM with the web server can be started.
Main Failover Solutions
The main solutions used in virtual environments are:
- failover clustering
- failover using VM replicas
Let’s consider each of them.
Solution 1. Failover clustering
A failover cluster is a group of at least two servers or nodes that are configured to take over workloads when one node is down or unavailable. Clustering is an enterprise-class automated solution that can be used for the most important, business-critical VMs. Microsoft Hyper-V offers a Failover Cluster made up of several Hyper-V hosts. VMware’s equivalent is a High Availability cluster, which is made up of ESXi hosts.
In the first diagram below, you can see a cluster in which both hosts (also called nodes) are functioning properly. The VMs are running on hosts, and the VM files are located on shared storage that is accessible by both hosts.

When one of the hosts goes down, the ownership of the connection to the VM (which was running on the offline node) is transferred to another node that is still online. This is the failover process. A highly-available VM may need to be restarted.

Failover clustering requirements
The following requirements must be met to build a failover cluster:
- Shared storage connected to the hosts with a dedicated high-speed network with low latency. A clustered file system must be used to ensure that multiple hosts can concurrently access the data located on the storage.
- The hosts on which the VMs are running must have the same hardware or, at least, hardware of the same family. The processors must support the same instruction sets to ensure compatibility for the VMs to run properly after migration from one host to another during failover.
- A high-speed redundant network with low latency. There should be multiple, separate cluster networks, that is, a cluster must have different networks for storage, management, VM migration, connection of hosts amongst each other, etc.
Use cases
Failover clusters are used to recover VMs from server failure, providing high availability for critical VMs. If one of the hosts (which are called nodes) within a cluster fails, then the VMs that were running on the failed host migrate (failover) to other healthy hosts. Depending on your settings, the VMs that were failed over can be migrated back to the host on which they were running before the incident once the failure is resolved.
Advantages
A failover cluster has advantages that provide strong protection:
- A failover cluster provides automatic VM failover. You don’t need to start the failed VMs manually on other hosts.
- Upon failover, you experience near-zero data loss. The downtime is usually limited to the time it takes to load the VM, the operating system (OS), and the software running on the VM.
- The
Fault Tolerancefeature that is included in theVMware High Availabilitycluster ensures VM failover with no downtime and no data loss.
Disadvantages
A failover cluster does not protect against:
- Software failure of VMs. Software bugs or viruses can cause a system crash in a VM.
- Accidental deletion of files inside the VM.
- Shared storage failure. The cluster fails if shared storage fails. The shared storage is a crucial component of the cluster; the virtual disks that belong to the VMs within a cluster are stored on the shared storage.
- A disaster that makes the whole physical site unavailable.
For more information on what is a failover cluster, read the complete guide about VMware clustering.
Solution 2. Failover using VM replicas
VM failover relying on VM replicas can be executed by specialized applications, which can replicate the VMs and start the replicas when prompted by the administrator. In addition to data protection software, you need ESXi or Hyper-V hosts (depending on your environment) that have been prepared in advance to run the VM replicas when the source VMs fail.
In the diagram below, you can see two hosts connected with one another via the network. The VMs are using the disks of the hosts. The source VMs are running on the first host, and the VM replicas, which are exact copies of the source VMs at a particular point in time, are located on the second host in a powered-off state.
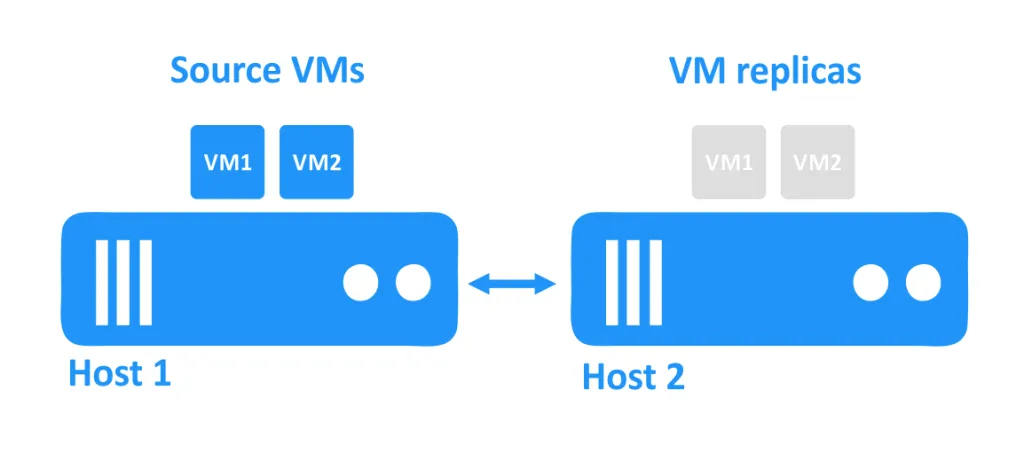
When one host goes down, the VMs that were running on that host also become unreachable. The VM replicas that are located on another host are then powered on by the administrator.
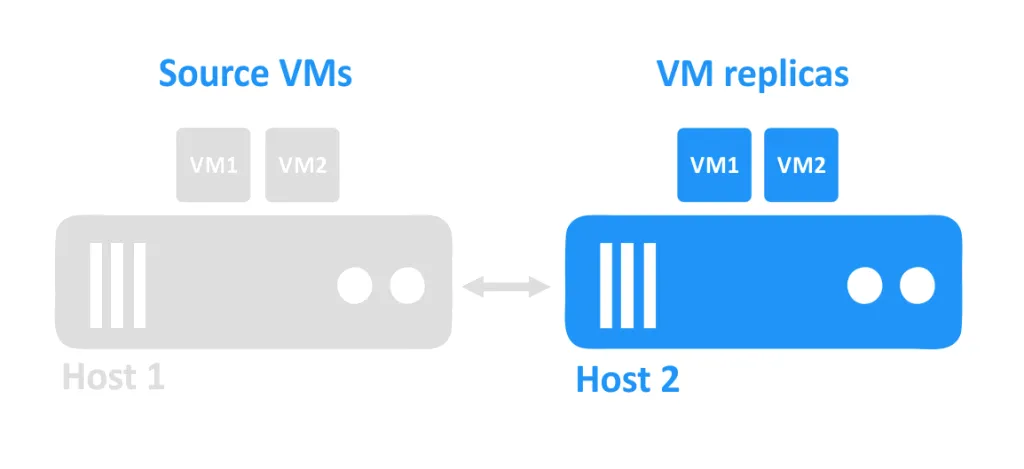
VM replication requirements
The basic requirements for VM replication are two or more hosts and a replication solution. A source VM running on the first host is replicated to the second host. The VM replica is located on the second host.
Use cases
Failover using VM replicas can be used when hardware or software failure occurs. ESXi or Hyper-V host failures are an example of hardware failure. Examples of software failure can be failed updates, software bugs, virus attacks, or accidental deletion of files by a user.
Advantages
The main advantage of VM failover to a replica is the possibility of failover to a remote site. When a VM replica is being created, the data copied from a source VM can be transmitted over a network connection (with limited bandwidth) to a remote site. The remote site could be located in a nearby office or on the other side of the world. The VM replica may also be located at the primary production site.
Disadvantages
The list of disadvantages for a failover using VM replicas:
- There is a short period of downtime between a failure and the starting of the replica on the second host.
- Failover must be initiated manually.
- The data written since the last replication can be lost during an unplanned failover. VM replication is often not a real-time (synchronous) process, as synchronous replication places a significant load on resources. Replication is usually carried out at regular time intervals depending on your chosen settings.
- The network settings of the VMs must (often) be changed upon failover to another site. The VM networks of the remote site may differ from the networks of the primary site. Hence, the IP addresses might also be different, and must be checked and changed along with the other network settings during failover.
Clustering vs Replication-Based VM Failover
| Failover with clustering | Failover using a replica | |
| Purpose | High availability | Disaster recovery |
| Protection against | Hardware failures only | Hardware and software failures |
| Administration | Launched automatically | Launched manually |
Downtime duration (RTO) |
Failover is faster, so VM downtime is short (short RTO) | Failover takes more time, so VM downtime is longer |
| Requirements | More requirements | Fewer requirements |
| Solution Price | Clustering solutions are usually more expensive | Replication solutions are more cost-efficient |
Data Loss (RPO) |
Near-zero data loss (very low RPO) |
Data loss depends on frequency of replication |
Combined Use of Clusters and Replicas for VM Failover
Cluster and replica failover solutions are sometimes viewed as alternatives, but they can be used to complement each other. Let’s look at some examples of how using both failover solutions can help protect your VMs against both server- and site-level failures.
- Example 1: You can replicate the VMs running within a cluster to a host at a remote site. Moreover, you can replicate the VMs running within one cluster to another cluster. Thus, if a host fails, the failover cluster keeps those VMs online. If the entire site experiences a disruption, then you can fail over to the VM replicas stored at a remote site.
- Example 2: A virus damages files inside some VMs. A failover cluster cannot protect against such failures. But if you have VM replicas with multiple recovery points, you can restore each VM to a point of time before their files were damaged or deleted.
Using the NAKIVO Solution for Automated VMware VM Failover to Replica
NAKIVO Backup & Replication is a backup and disaster recovery solution that can protect VMs running within a cluster, replicate VMs, fail over to replicas, and orchestrate complex DR sequences. Clusters as well as standalone ESXi or Hyper-V hosts are supported as source and destination points for replication. The solution automatically tracks the host on which a VM is residing so it can replicate that VM. This is useful because VMs can migrate from one host to another within a cluster after failover events or load balancing events (a cluster is usually configured in conjunction with load balancing). That’s why the software that you use for replicating a VM from a cluster must be able to track the host on which the VM is residing.
The NAKIVO solution can change the VM network settings automatically upon failover; just use the Network Mapping and Re-IP features when configuring a replication or failover job.
Let’s consider an example of Automated VM Failover (with Network Mapping and Re-IP) in NAKIVO Backup & Replication. We’ll start by creating a VM replica.
Configuring replication required for VM failover
On the Jobs dashboard, click Create > VMware vSphere replication job if you have a VMware virtual environment. Note that you can create a replication job for a Microsoft Hyper-V VM or an Amazon EC2 instance in the same way.
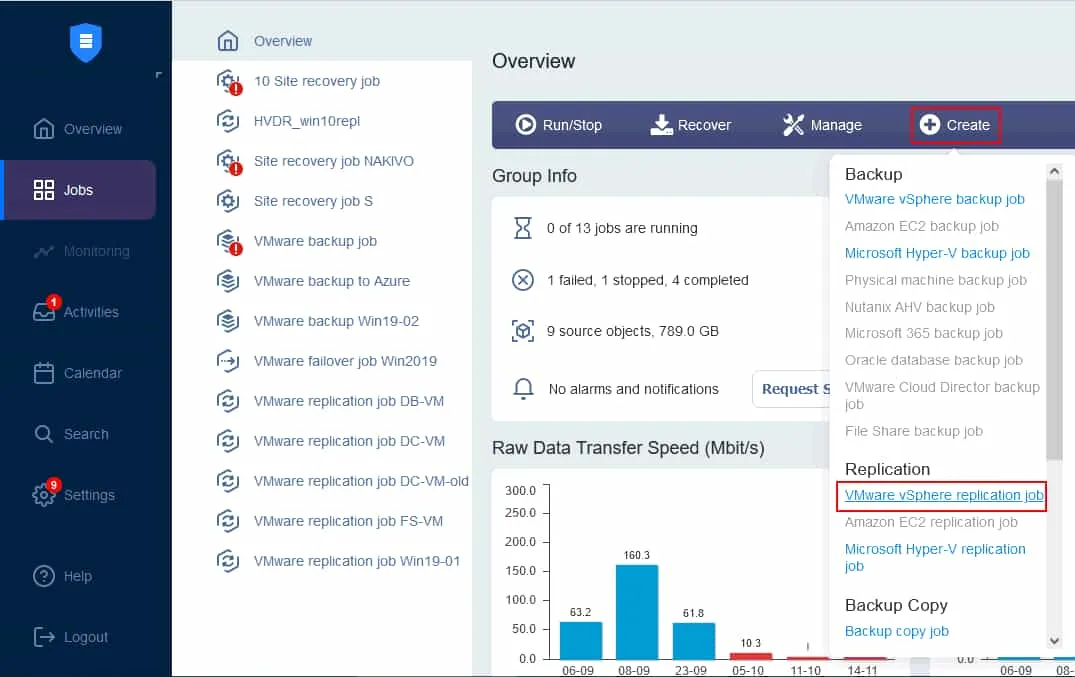
The replication job wizard is launched.
- Select the virtual machines that you want to replicate. In this example, the
Server2019VM, which is running theWindows Server 2019as the guest operating system, will be replicated. ClickNext.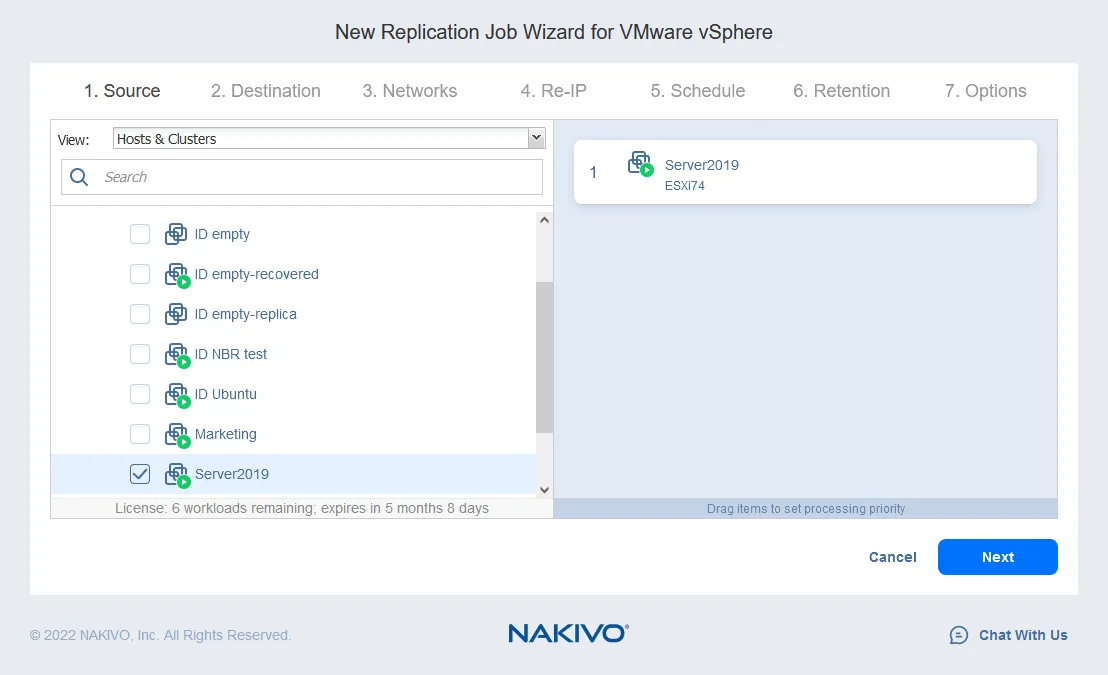
- Select a destination host for the VM replica to run on (
10.10.10.90in our case). Select the datastore mounted to the selected host for placement of the VM files. ClickNext.
- You can set
Network MappingandRe-IPoptions when configuring a replication job or a failover job. In this walkthrough,Network MappingandRe-IPwill be configured later when the failover job is configured. Thus, you can skip this step for the moment and just clickNext.
Re-IPconfiguration will be explained during configuration of the VM failover job in this walkthrough. ClickNext.
- Select your scheduling settings. Click
Nextwhen you are done.
- Set the retention settings. Remember that you can set up the grandfather-father-son retention policy at this step. Click
Next.
- Select the replication job options and click
Finishor theFinish & Runbutton. Wait while the replica is created.
Configuring VM failover
Now that you have a VM replica created, you can perform VM failover to this replica.
On the home page in the dashboard, click Recover> VMware Full Recovery (VM replica failover). The New Failover Job Wizard opens.
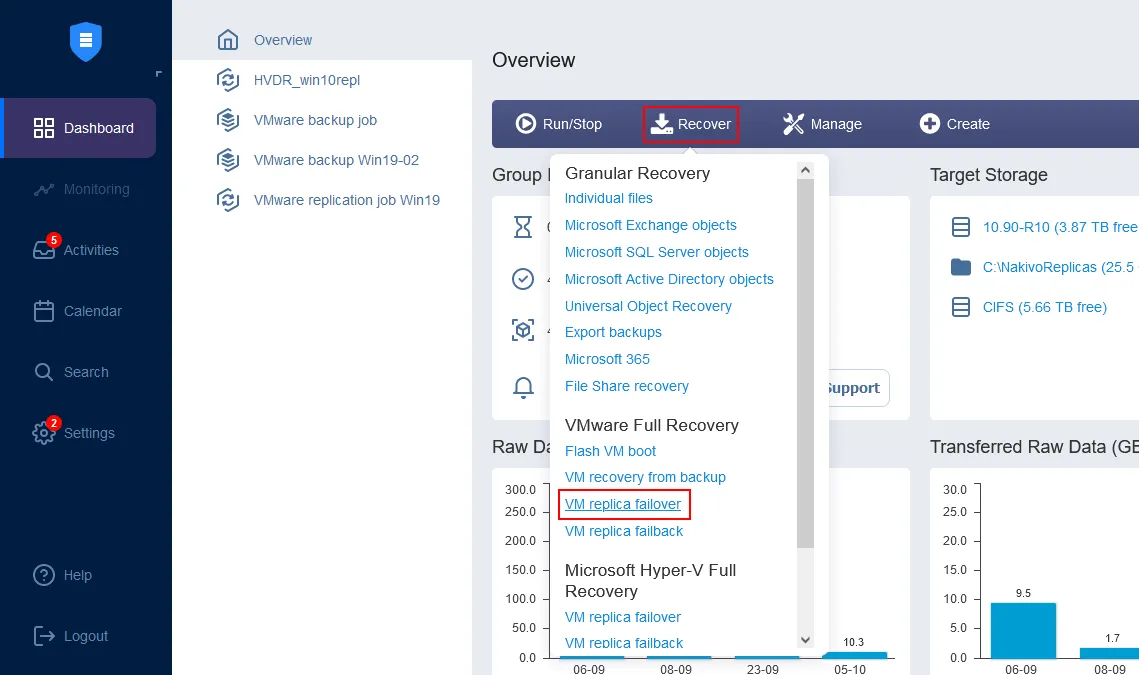
- In the left pane, select the VM replica to be used for failover. In this walkthrough, the
Server2019-replica, which was just created, is selected.In the right pane, select a recovery point. The latest recovery point is selected by default in the solution. ClickNext.
Network Mappinghelps you change the network to which the VM is connected. The source and destination ESXi hosts likely have different virtual switch settings. Since a VM replica is an exact copy of the source VM, the virtual networks to which the source VM is connected are preserved in the VM replica.Generally, you should check the network settings of a VM replica and manually change the network. NAKIVO Backup & Replication can map the source network to a destination network automatically. You just need to set up Network Mapping when configuring the replication or failover job.
- To enable
Network Mapping, select the checkbox. If you have previously created a network mapping rule, you can clickAdd existing mapping. If there are no network mapping rules, clickCreate new mapping.
-
To create a new network mapping rule, select the source network and destination network. The source network is the network to which the source VM is connected. The destination (target) network is the network to which the VM replica should be connected.
Note: The VM network name is not the same as the IP address or network address.
Click
Saveto save the network mapping rule, and then clickNextto proceed in configuration.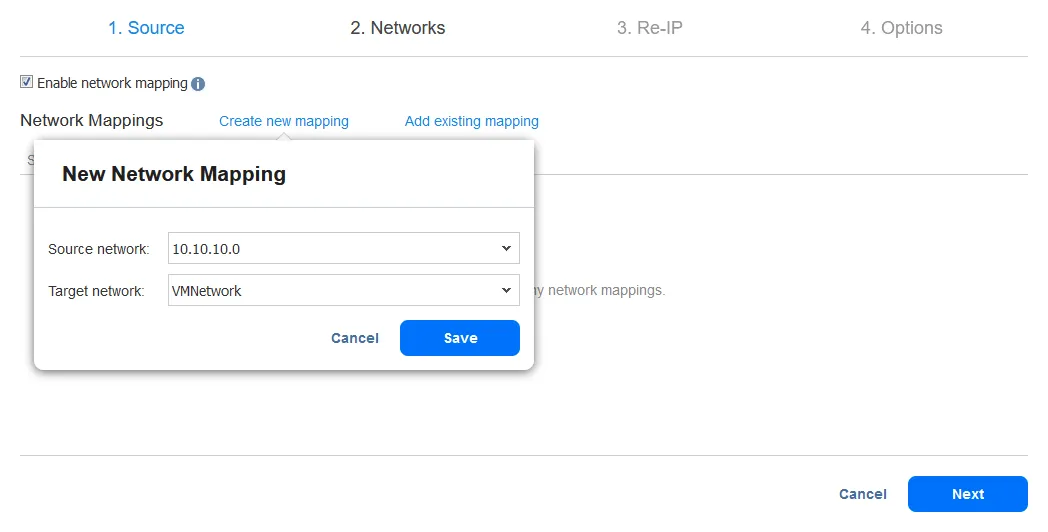
- To enable
- The
Re-IPfeature allows you to change the IP settings of the VM replica. It can be used for static IP addresses. Select theEnable Re-IPcheckbox if you want to enable this option and then create a Re-IP rule or add an existing rule. ClickCreate new ruleif there are no rules created before. A popup menu appears. - The source VM settings are the IP address and network mask that need to be changed.
-
The target settings are the settings to be applied for the VM replica when failover occurs.In this example, the [*] character covers the last octet. The [*] signifies any number from 1 to 254. If the source IP addresses are, for example, 10.10.10.1, 10.10.10.96, and 10.10.10.222, the destination addresses would be 192.168.10.1, 192.168.10.96, and 192.168.10.222 respectively. The last octet of the IP address is preserved.
Click
Saveto save your Re-IP rule and proceed.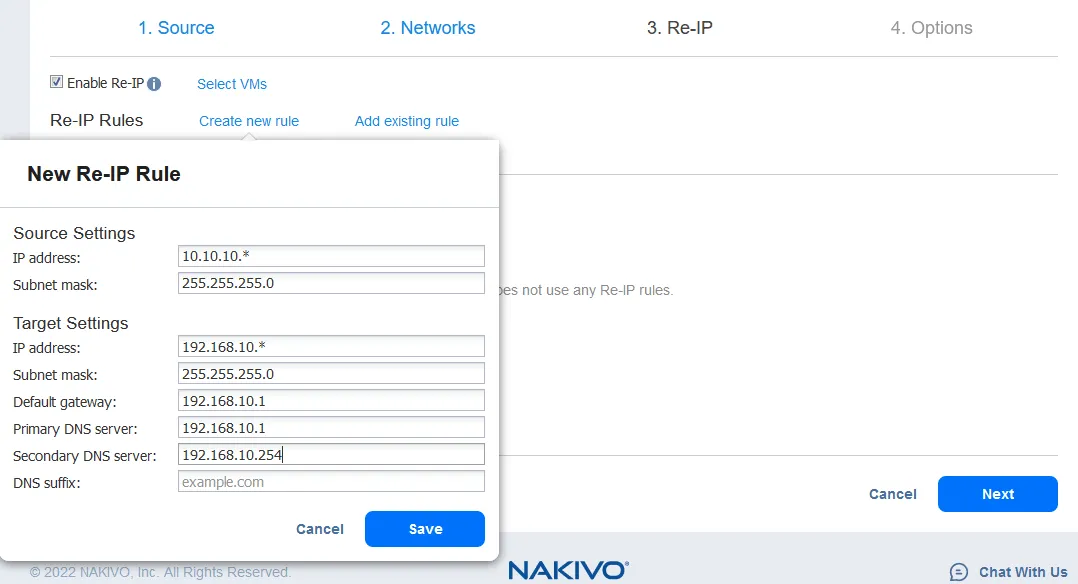
After adding the Re-IP rule, your screen should look like this:
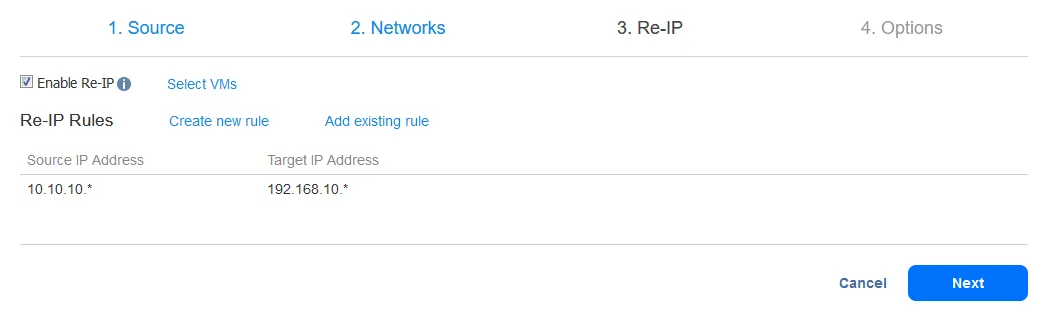
Now select the VMs for which the Re-IP rules should be applied. The failover job in this example contains only one VM replica, so select the one checkbox.
Then select the credentials for each VM. Click
Manage credentials>Add credentialsto add new credentials. The added credentials can be selected from the dropdown list.Note: The credentials are needed for NAKIVO Backup & Replication to access the network settings of the operating system inside the VM and apply the script that changes those settings. VMware Tools must be installed on VMware vSphere VMs, and Hyper-V Integration Services must be installed on Microsoft Hyper-V VMs.
When you have configured all these settings, click
Next.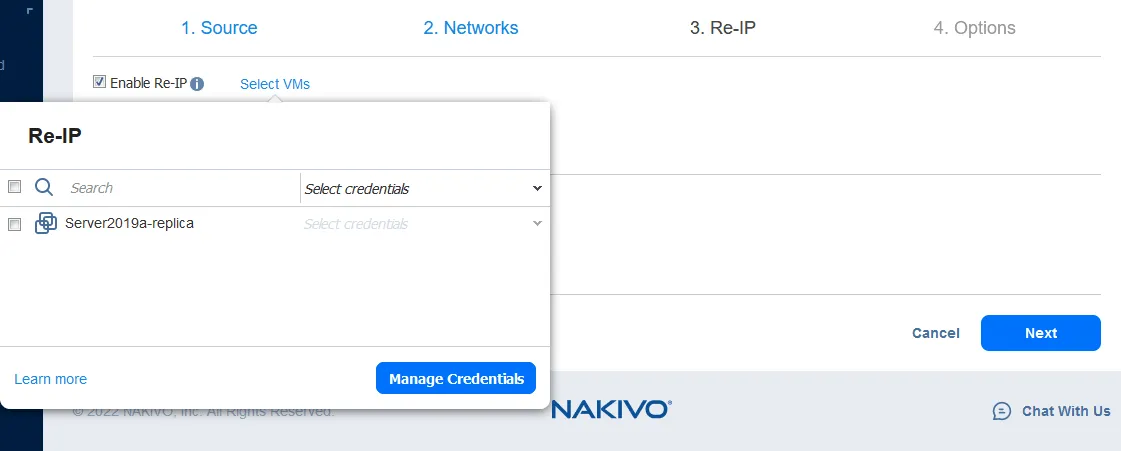
- Now, configure the VM failover job options. You can select the
Power off source VMscheckbox. It may be useful to prevent a conflict of IP addresses if the both source and replica VMs use the same network or have the same IP addresses.After configuring all the options, clickFinish & Run.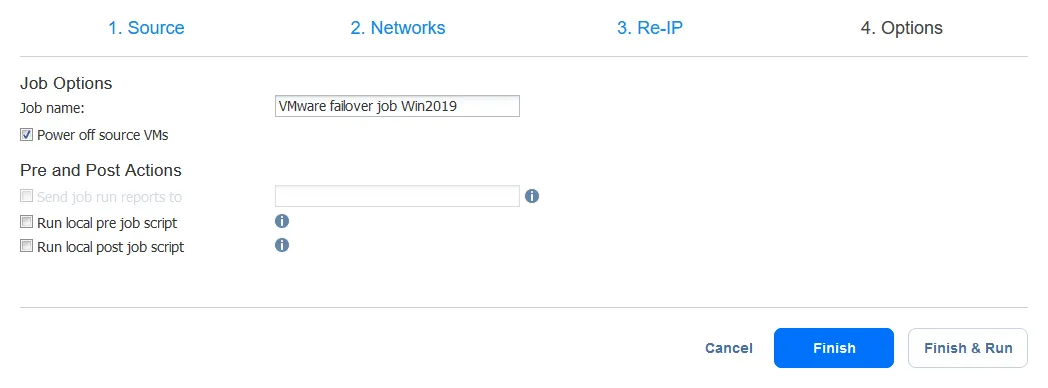
Wait until the VM failover job is complete.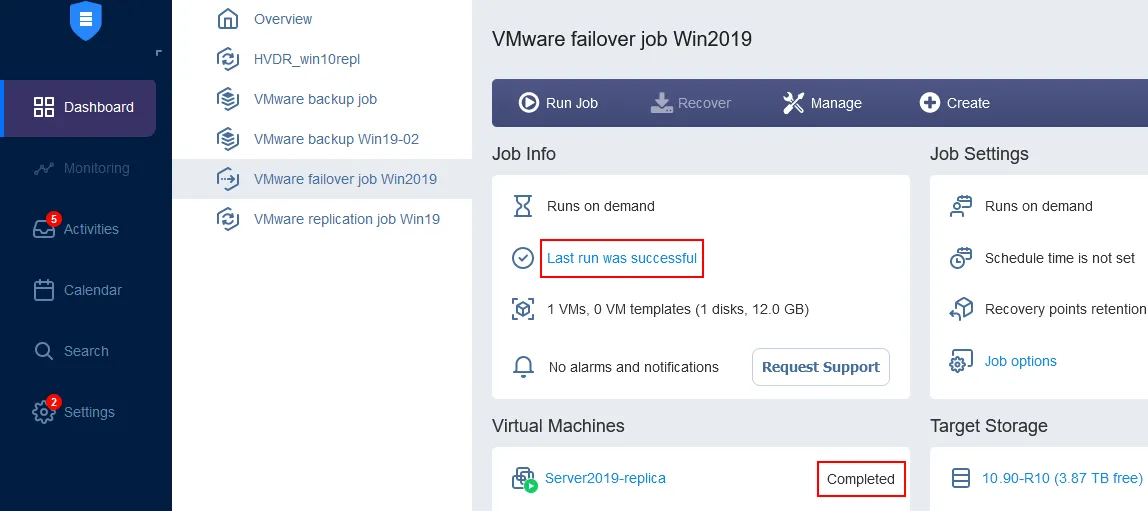
Now you can ensure that the VM replica is running. Go toConfiguration>Inventoryand click theRefresh Allbutton. After refreshing, you can see that theServer2019-replicaVM is already running on the target ESXi host. You can also manage the credentials, network mapping rules, and Re-IP rules from this page (theInventorypage).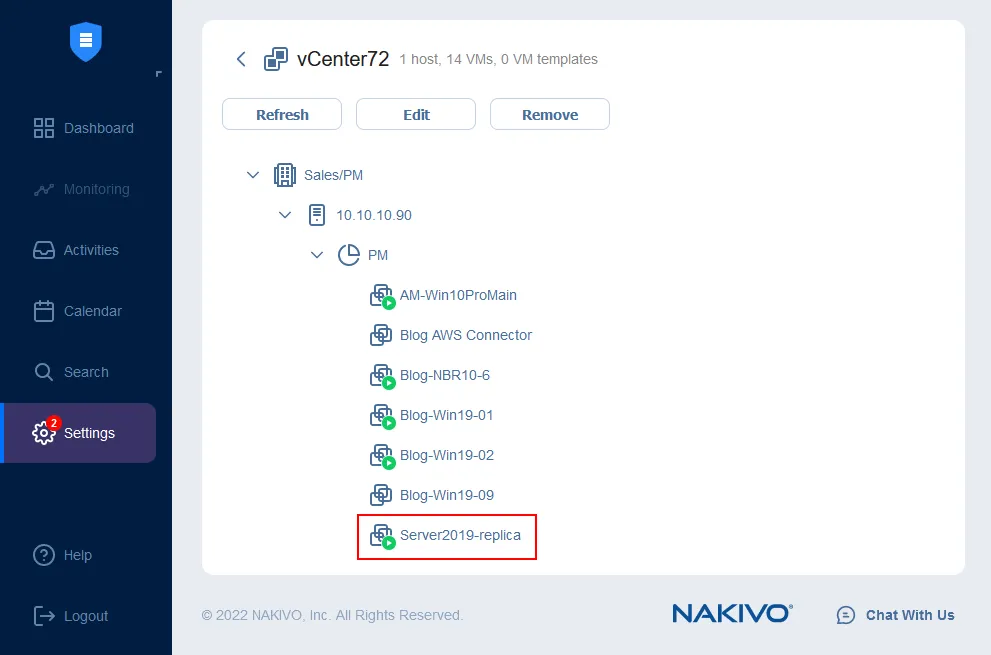
Conclusion
VM failover is useful for disaster recovery scenarios with many virtual machines or for recovering even one VM to ensure operational continuity and high availability. However, it is important to understand that any disaster recovery plan should be coupled with a solid backup strategy for more reliable and efficient data protection.
Consider using NAKIVO Backup & Replication, a fast, reliable, and affordable VM protection solution, to protect VMs using the failover to replica method. The solution also supports backup and granular recovery for virtual, physical, cloud, and SaaS environments from a centralized web interface.



