High Availability vs Fault Tolerance vs Disaster Recovery: An Overview
When it comes to keeping an organization’s IT infrastructure up and running 24/7, there still seems to be some confusion between the three core terms used: high availability (HA), fault tolerance (FT), and disaster recovery (DR). The three terms involve maintaining business continuity and access to IT systems. However, each term has its own specific definition, methodologies, and use cases.
In this blog post, we are going to define what high availability, fault tolerance, and disaster recovery are in practice and explore how the terms overlap as well as why they are important to implement.

What Is High Availability?
High availability is a system’s ability to operate (uptime) and be accessible to users for a specified period of time without going down. Uptime is the time during which a server is operational without unplanned rebooting or being powered off.
High availability (HA) is calculated as the percentage of time that a system is operational during set times, without counting planned maintenance and shutdowns. HA is not expected to deliver 100% uptime, which is difficult and impractical to achieve. Downtime of up to 5 minutes and 26 seconds per year is considered to be acceptable, which translates into 99.999% of operational uptime. However, even this value may not be a reasonable target for many organizations. Depending on the organization, industry and resources, the required HA value can be lower.
How does high availability work?
The high availability objective for an organization is achieved through the elimination of a single point of failure in a system by using redundancy and failover components. This means ensuring that the failure of a single component does not lead to the unavailability of the entire system.
In virtualization, high availability can be designed with the help of clustering technologies. For example, when one of your hosts or virtual machines (VM) within a cluster fails, another VM takes over (failover) and maintains the proper performance of the system.
While having redundancy components is the ultimate condition for ensuring high availability, these components alone not enough for the system to be considered highly available. A highly available system is one that includes both redundant components and mechanisms for failure detection and automatic workload redirection. These can be load balancers or hypervisors. DRS in VMware vSphere is an example of a load balancer.
When is high availability important?
A high availability architecture is necessary for any critical workloads that cannot afford downtime. If the failure of a system or application jeopardizes the survival of the business, HA can be used to minimize downtime. According to Statista, the cost of one hour of downtime was between USD 300,000 and 400,000 for 25% of businesses in 2020. This means that even the very high availability value of 99.999% – 5 minutes 26 seconds of downtime per year – can cost some businesses around USD 35,000.
Besides significant financial losses, downtime may have other serious implications such as productivity loss, an inability to deliver services in a timely manner, damaged business reputation, and so on. Highly available systems help avoid such scenarios by handling failures automatically and in a timely manner.
What Is Fault Tolerance?
Fault tolerance is the ability of a system to continue operating properly without any downtime in the event of the failure of one or more of its components. A fault tolerant system includes two tightly coupled components that mirror each other to provide redundancy. This way, if the primary component goes down, the secondary one is immediately ready to take over.
How does fault tolerance work?
Fault tolerance, like high availability, relies on redundancy to ensure uptime. Such redundancy can be achieved through simultaneously running one application on two servers, which enables one server to be able to instantly take over another when the primary one fails.
In virtualized environments, redundancy for fault tolerance is achieved through maintaining and running identical copies of a given virtual machine on separate hosts. Any change or input that takes place on the primary VM is duplicated on the secondary VM. This way, in the event that the primary VM is corrupted, fault tolerance is ensured through the instant transfer of workloads from one VM to its duplicate.
When is fault tolerance important?
Fault tolerant design is crucial for systems that cannot tolerate any downtime (zero downtime). If there are mission-critical applications, and even the slightest downtime translates into irrevocable losses, you should consider configuring your IT components with fault tolerance in mind.
Fault tolerance vs high availability
When comparing HA vs FT, fault tolerance is a costlier solution. But fault tolerance and high availability also differ in two main respects:
- Fault tolerance is a stricter version of high availability. High availability focuses on delivering minimal downtime, while fault tolerance goes further by delivering zero dowmtime.
- However, in the fault tolerant model, the ability of a system to deliver high performance in the event of failure is not the top priority. In contrast, it is expected that a system can maintain operational performance, even if at a reduced level.
What Is Disaster Recovery?
Disaster recovery is a process used by organizations to respond to incidents that affect systems and swiftly recover the functionality of the IT infrastructure. Disaster recovery includes a DR plan, a DR team, a dedicated disaster recovery solution, a recovery site, etc. This approach involves using hot, warm or cold sites depending on the RTO value defined in the disaster recovery plan and available resources.
The two main metrics of DR are recovery time objectives (RTOs) and recovery point objectives (RPOs) to minimize downtime and data loss respectively.
How does disaster recovery work?
Disaster recovery requires having a secondary location where you can restore your critical data and workloads (whether entirely or partially) in order to resume sufficient business operation following a disruptive event.
To transfer the workloads to a remote location, it is necessary to incorporate a proper disaster recovery solution. Such a solution can take care of the failover operation in a timely manner and with little input on your part, which allows you to achieve your designated RTOs.
What are the components of disaster recovery?
Disaster recovery is a much broader and more complex concept than high availability and fault tolerance. It refers to a strategy with a comprehensive set of components including: risk assessment, planning, dependencies analysis, remote site configuration, staff training, testing, automation setup, and so on. Another aspect of DR that goes beyond high availability and fault tolerance is its independence from the production site.
When is disaster recovery important?
Disaster not only refers to a natural catastrophe, but to any kind of disruptive incident that hit that hits the entire production site and leads to significant downtime, including cyberattacks, power outages, human errors, software failures, among others. This means that such incident can happen at any time unexpectedly. In most cases disasters are impossible to predict or avoid, and organizations should take measures to strengthen their disaster recovery preparedness, as well as optimize their DR strategies on a regular basis.
Disaster recovery vs high availability
Disaster recovery, unlike high availability and fault tolerance, deals with catastrophic consequences that render entire IT infrastructures unavailable rather than single component failures. Since DR is both data- and technology-centric, its main objective is to recover data as well as get infrastructure components up and running within the shortest time frame after an unplanned incident.
Regarding the difference between high availability and disaster recovery, high availability and fault tolerance cannot help you recover data in case of disaster and data loss caused by an unpredicted incident. This is the scenario where disaster recovery can provide you an independant DR infrastructure and point-in-time copies of your data (recovery points) to minimize downtime and avoid data loss. Note though the differences between disaster recovery and backup.
Using NAKIVO Backup & Replication for Disaster Recovery
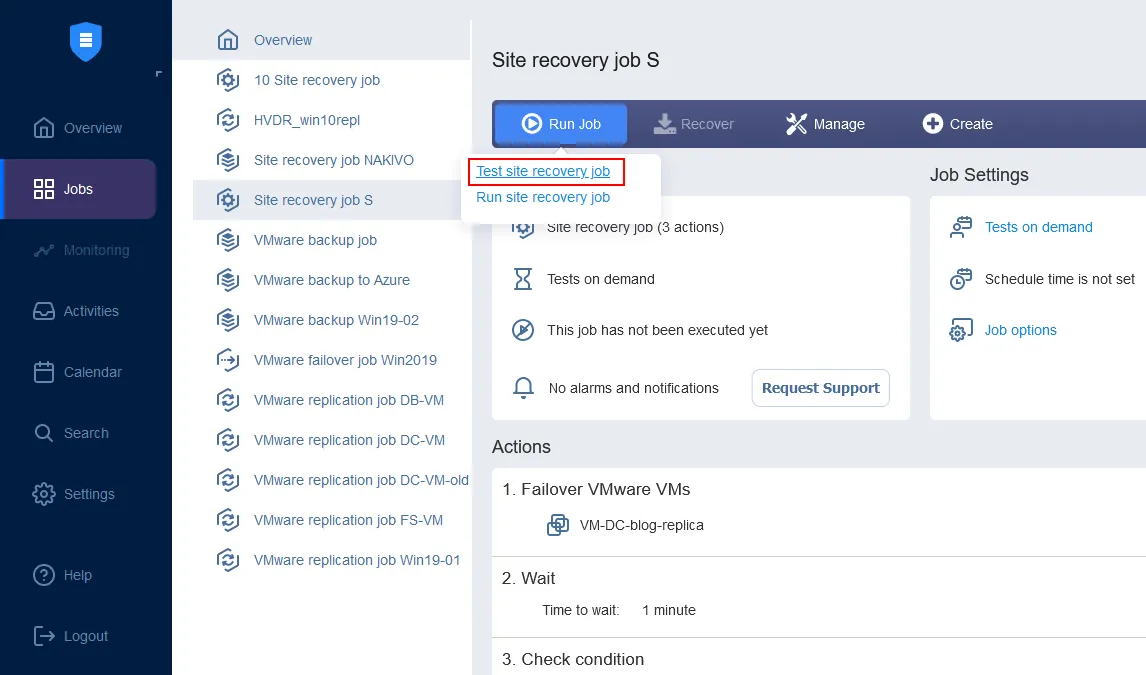
NAKIVO Backup & Replication is a fast, reliable, and affordable solution. It combines high-end data protection and disaster recovery functionality – the Site Recovery feature – designed to simplify and automate DR operations.

If you have a remote site configured, as required by DR best practices, it is easy-to-use and configure while allowing you to build complex recovery workflows.
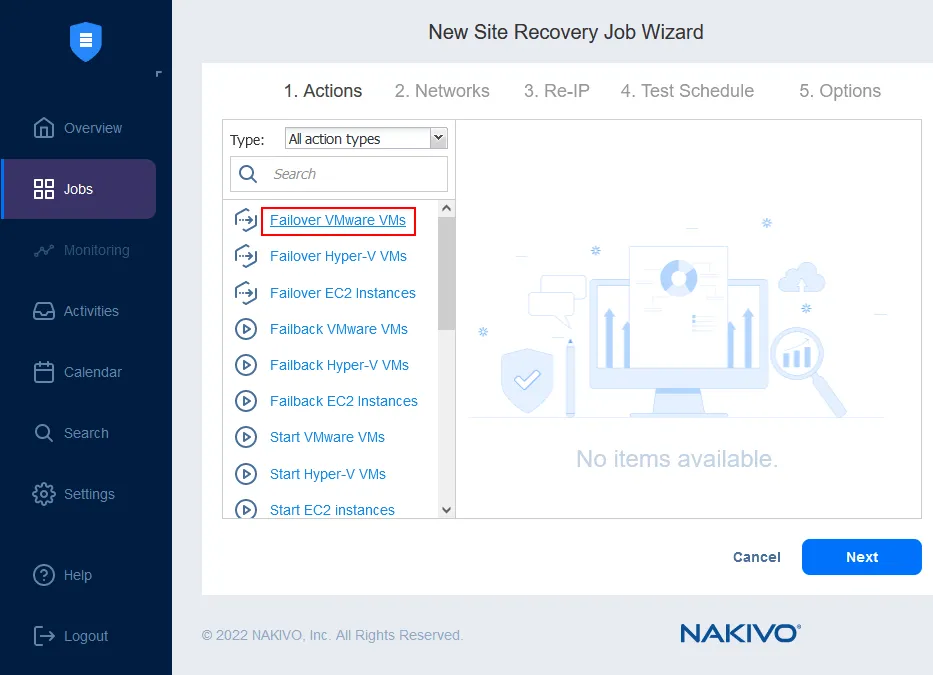
You can combine up to 200 actions in one workflow (job) to fit different disaster scenarios and serve different purposes, including: monitoring, data center migration, emergency failover, planned failover, failback, etc. In the event of a disaster, any of the created workflows can be put into action immediately, with a single click, allowing businesses to achieve the shortest time to recovery.
With Site Recovery in place, you can perform automated non-disruptive disaster recovery testing. This way, you can make sure that your site recovery workflows are valid, that they reflect all recent changes that took place in your IT infrastructure, and that there are no weaknesses before actual disaster hits.