How to Configure HA in VMware vSphere
When you have critical virtual machines and critical services running on them, their availability must be ensured during your organization’s operating times. One of the ways of achieving high availability is using a cluster to ensure continuously running services and applications.
The VMware vSphere virtualization platform allows you to use a cluster for running virtual machines (VMs) and use vSphere High Availability (HA). This blog post explains VMware vSphere HA configuration to familiarize you with the parameters to configure.

What Is HA in VMware vSphere?
VMware High Availability (HA) is a feature providing optimal availability for vSphere virtual machines, including applications and services running on the VMs, to minimize downtime in case of failures. High Availability (HA), or the ability of a virtual environment to withstand host failures, is one of the important reasons that you would choose to deploy VMware vCenter and a cluster as opposed to a standalone VMware ESXi host.
When HA is running on a VMware cluster, an agent is installed on each host participating in the cluster. Each host agent communicates with the other and monitors the reachability of the hosts in the cluster via heartbeats. If a 15-second interval passes without the receipt of heartbeats from a particular host and pings to the host also fail, the host is declared as failed. The VMs running on the compute/memory resources of that failed host are failed over to a healthy host and restarted on that host.
HA in vSphere can monitor the hardware health of your hosts to proactively move VMs off hosts that have hardware issues. There are also restart priorities and orchestration incorporated into HA and, as a result, designated VMs are brought online before others in the event of a failover. These features are available in the VMware vSphere 6.7 and vSphere 7 versions.
VMware Cluster Requirements
There are a few requirements from VMware to create a VMware cluster with HA enabled. The requirements include:
- Hosts in the HA cluster must be licensed for vSphere HA. VMware vSphere Standard or Enterprise Plus, including vCenter Standard licenses, must be applied.
- Two hosts are required to enable HA. Three or more hosts are recommended.
- Static IP addresses configured on each host is the best practice.
- You need at least one management network common across the hosts.
- In order for VMs to run across all hosts in case they are moved to different hosts in the cluster, the hosts need to have the same networks and datastores configured.
- Shared storage is required for HA.
- VMware Tools need to be running on VMs being monitored in HA.
VMware HA Configuration Step by Step
You can enable VMware HA while you are creating a cluster or when you have already created a cluster. In this vSphere HA configuration walkthrough, we are focused on configuring High Availability and we have an already created cluster. We use VMware vSphere 7 to explain VMware HA configuration step by step.
How to enable HA in VMware vSphere
In order to enable HA in VMware vSphere in an existing cluster, do the following:
- Open VMware vSphere Client in your web browser.
- Go to
Hosts and clustersand navigate to your cluster. - Right-click the cluster name in the Navigator pane.
- Click
Settingsin the context menu.

- Select
vSphere Availabilityin theServicessection of theConfigurepage for your cluster. - Click
Editnear vSphere HA that is turned off in our case.
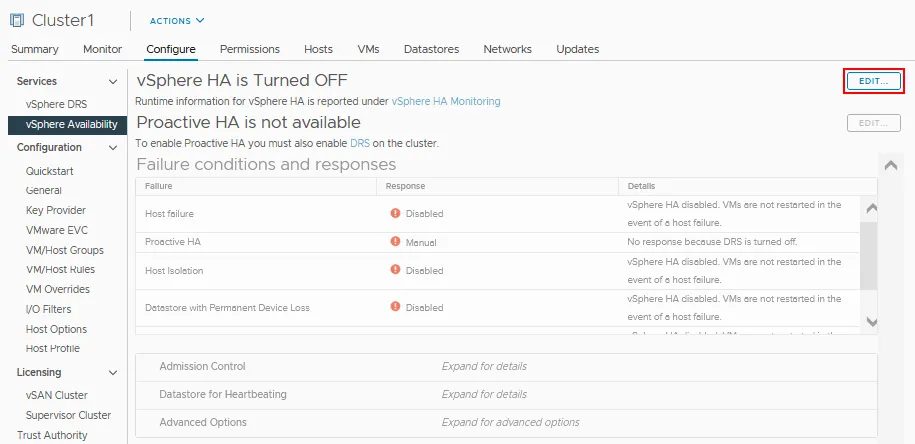
- Click the
vSphere HAswitcher to enable High Availability.
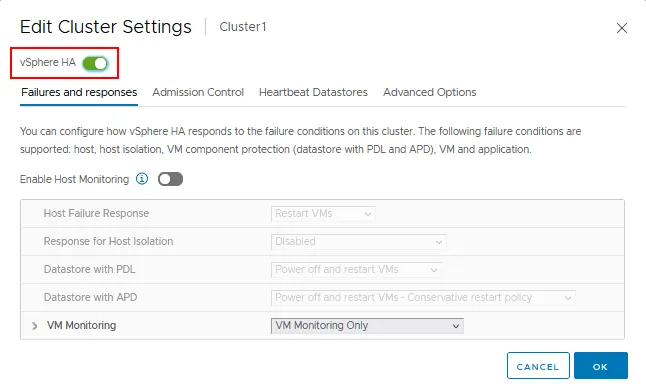
There are four tabs with vSphere HA settings:
- Failures and responses
- Admission Control
- Heartbeat Datastores
- Advanced Options
Let’s look at the vSphere HA configuration that you can do by editing the settings in these tabs.
The Failures and responses tab
The Failures and responses tab is used to customize the behavior of an HA cluster and set what to do with VMs in different situations.
Enable Host Monitoring. Enable this option to allow ESXi hosts to exchange heartbeats in the cluster. A VMware vSphere HA cluster uses heartbeats to detect when any cluster components are unavailable. Disable this option when performing network maintenance to avoid unwanted VM migration and failover.
Let’s review all the settings in the Failures and responses tab.
Host Failure Response
Failure Response.Use these settings to set how an HA cluster responds to the failure conditions on this cluster. Two modes are available:Disabled– ESXi host monitoring is turned off.Restart VMs– VMs are restarted in the determined order in case of host failure.
Default VM restart Priority. This setting is used to determine which VM group should be restarted first. There are five values: Lowest, Low, Medium, High, and Highest. The VMs are restarted in order of priority, one group at a time.VM dependency restart condition. Select a condition that when it is met, a cluster detects that VMs have been successfully restarted, and the next batch of VMs can be restarted. Four conditions are available:- Resources allocated
- Powered On
- Guest Heartbeats detected
- App Heartbeats detected
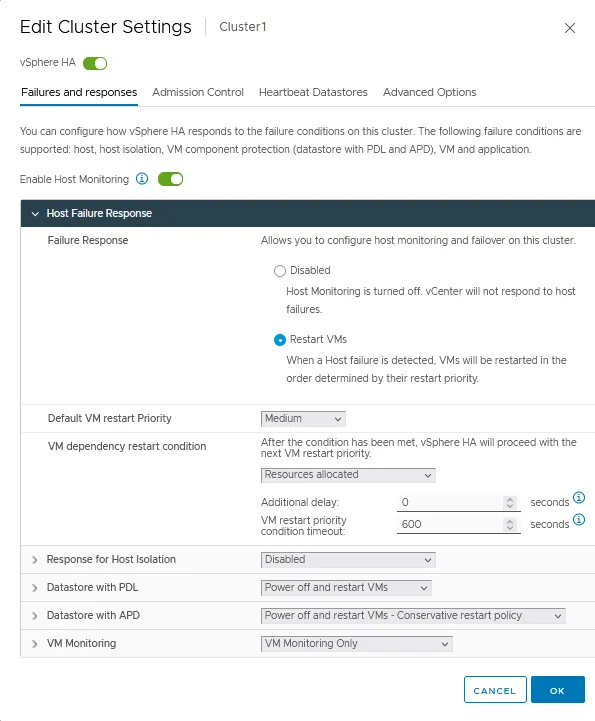
Response for Host Isolation
The Host isolation response option allows you to set the behavior of an HA cluster when an ESXi host continues to run but loses management network connections:
- Disabled
- Power off and restart VMs
- Shut down and restart VMs

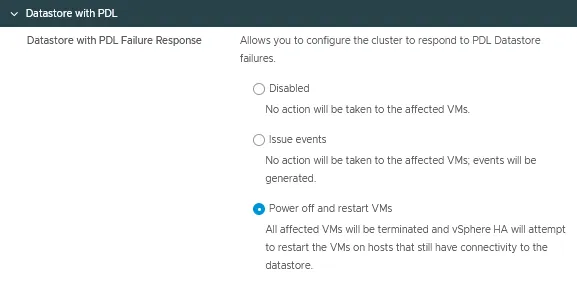
Datastore with PDL
Datastore with permanent device loss (PDL) failure response can be configured to detect datastore inaccessibility by an ESXi host and initiate an automated failover of affected VMs.
There are three modes for this vSphere HA configuration option:
- Disabled
- Issue events
- Power off and restart VMs
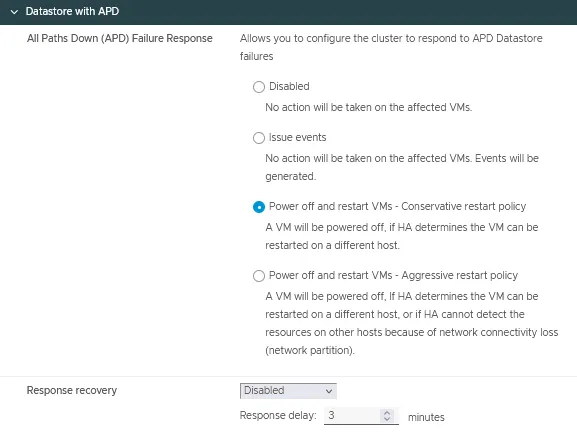
Datastore with APD
All Paths Down (APD) Failure Responseis the condition that allows a cluster to respond when all paths are down, and there is no indication of whether this is temporary or permanent device loss.
Four options are available for this setting:- Disabled
- Issue events
- Power off and restart VMs – Conservative restart policy
- Power off and restart VMs – Aggressive restart policy
Response recoveryhas two options:- Disabled
- Reset VMs
You can set the response delay in minutes.
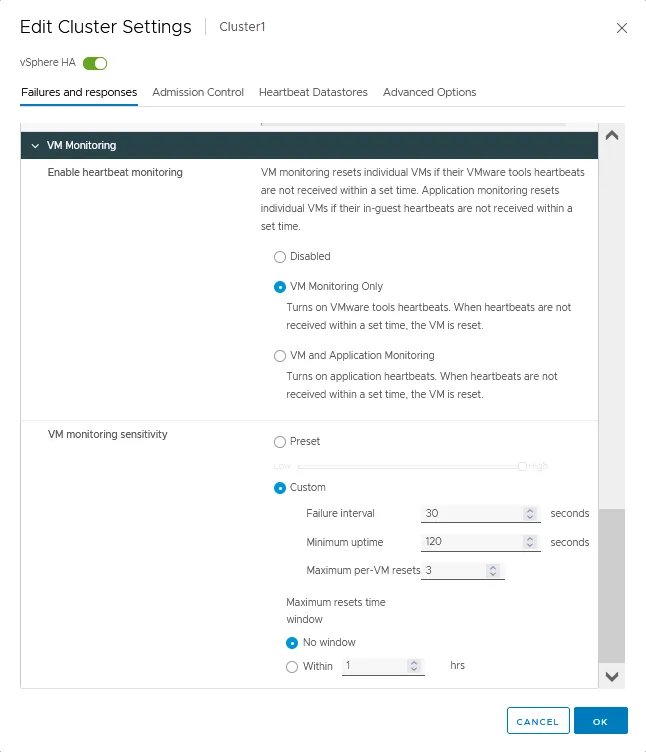
VM Monitoring
Enable heartbeat monitoringfor virtual machines by using VMware Tools running on them. You can also configure application monitoring by using these capabilities. If VM heartbeats are not received in time, VM restart is initiated. There are three options for this setting in VMware cluster configuration:- Disabled
- VM Monitoring Only
- VM and Application Monitoring
VM monitoring sensitivityis used to set the time after which a VM is classified as unavailable and an HA cluster can initiate VM restart.- Preset. You can move the switcher from the low to high value.
- Custom. Set custom sensitivity parameters, including failure interval, maximum uptime and maximum per-VM resets. Maximum resets time window can be set to a custom value in hours.
Note: You can also use a VM monitoring solution to detect failures and issues for VMs that are not in a cluster.
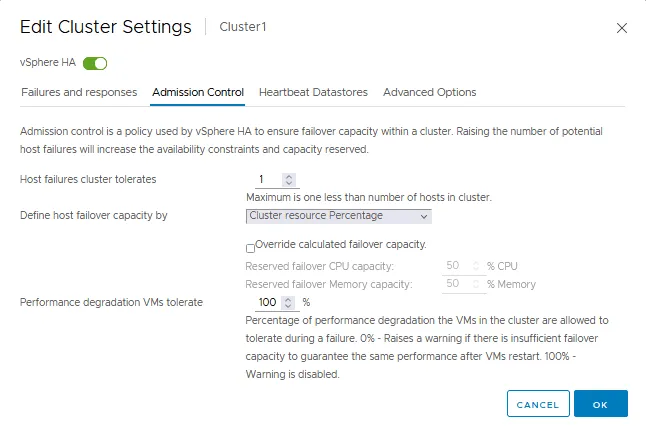
The Admission Control tab
Admission control is a policy used to ensure enough resources are reserved for running virtual machines in case of a failover in a VMware HA cluster. Admission control settings ensure failover capacity. If an action violates admission control settings, the action is not permitted. These disallowed actions can be powering on a VM, migrating a VM, and increasing CPU and memory settings for a VM.
- Admission control defines
how many failures an HA cluster can tolerateand still make VM failover possible (a guarantee to fail over VMs). - You can
define host failover capacityby:- Cluster resource percentage
- Dedicated failover hosts
- Slot policy
If you disable admission control, you cannot ensure that the expected number of VMs will be restarted in an HA cluster in case of failover.
Performance degradation VMs tolerateis the setting that defines the percentage of performance degradation your cluster can tolerate. 0% means that the same level of VM performance must be guaranteed after VM failover/restart. Otherwise, the warning is displayed. 100% means that the warning is disabled and a cluster tries to restart a VM anyway.
The Heartbeat Datastores tab
Heartbeat datastores provide a secondary way to monitor the availability of ESXi hosts by using datastores if the network connection to ESXi hosts is unavailable and a management network has failed. This approach allows vSphere to distinguish between host failure and unavailability of the host via the network. Use heartbeat datastores in VMware HA configuration to monitor hosts when an HA network is failed.
The heartbeat datastore selection policy has three options:
- Automatically select datastores accessible from the hosts
- Use datastores only from the specified list
- Use datastores from the specified list and complement automatically if needed

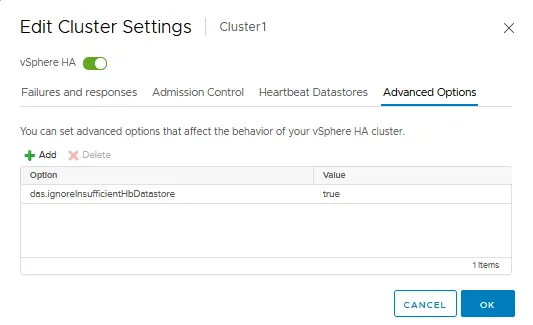
The Advanced Options tab
The Advanced Options tab allows you to configure vSphere HA by manually entering an option and value in each string. You can use advanced options when you cannot tune an HA cluster in the standard settings we explained before, which are available in the GUI of VMware vSphere Client.
As with VMware Distributed Resource Scheduler (DRS), once we click OK, the VMware cluster is reconfigured for the HA settings that were configured above.
VMware vSphere Proactive HA
Proactive HA is a feature that makes a cluster react to an issue before a failure of all ESXi hosts and VMs residing on that host occurs. Issues can happen with different components of an ESXi server, and vSphere Proactive HA can detect the hardware conditions of a server.
For example, Proactive HA can be notified that there are issues with a power supply to an ESXi server. VMs continue to run on this server, but this issue can lead to a server failure soon. To prevent possible VM failure, vSphere Proactive HA can initiate VM migration to other ESXi hosts of a cluster. Proactive HA supports reacting to issues relating to power supply, fan, storage, memory, and network.
You need to enable and configure Distributed Resource Scheduler (DRS) in a vSphere cluster before you can enable Proactive HA. You can configure vSphere HA and DRS together for a cluster.
Concluding Thoughts
The real power, resiliency, and scalability of the VMware vSphere ESXi platform are unlocked once the vCenter Server is provisioned and the ESXi hosts are added to a vSphere ESXi cluster. Configure vSphere HA and DRS to effectively provide protection against host failures as well as balance and schedule resources for VMs. Both DRS and HA are even more powerful since vSphere 6.5 as VMware has added more proactive and intelligent monitoring and insight to both of these cluster features, allowing them to be agile and proactive.
Don’t forget to perform VMware VM backup even if your VMs are running in the cluster to avoid data loss.



