VMware vSphere HA and DRS Compared and Explained
A VMware hypervisor allows you to run virtual machines on a single server. You can run multiple virtual machines on a standalone ESXi host and deploy multiple hosts to run more virtual machines. If you have multiple ESXi hosts connected via the network, you can migrate virtual machines from one host to another.
Sometimes using multiple hosts connected via the network to run VMs is not enough to meet business needs. For example, in cases where one host fails, all VMs residing on that host will also fail. Also, VM workloads on ESXi hosts can be imbalanced, and migrating VMs manually between hosts is routine. To deal with these issues, VMware provides clustering features such as VMware High Availability (HA) and Distributed Resource Scheduler (DRS). Using vSphere clustering allows you to reduce VM downtime and consume hardware resources rationally. This blog post covers VMware HA and DRS as well as the use cases for each clustering feature.

What Is a vSphere Cluster?
A vSphere cluster is a set of connected ESXi hosts that share hardware resources such as processor, memory, and storage. VMware vSphere clusters are centrally managed in vCenter. A cluster’s resources are aggregated into a resource pool, so when you add a host to a cluster, the host’s resources become part of the resources of the whole cluster. ESXi hosts that are members of the cluster are also called cluster nodes. There are two types of vSphere clusters: vSphere High Availability and Distributed Resource Scheduler (VMware HA and DRS).
VMware cluster requirements
To deploy VMware HA and DRS, a set of cluster requirements should be met:
- Two or more ESXi hosts with an identical configuration (processors of the same family, ESXi version and patch level, etc.) must be used. For instance, you can use two servers with Intel processors of the same family (or
AMDprocessors) andESXi 7.0 Update 3installed on the servers. It is recommended that you use at least three hosts for better protection and performance. - High-speed network connections for the management network, storage network, and vMotion network. Redundant network connections are required.
- A shared datastore that is accessible for all ESXi hosts within a cluster. Storage Area Network (SAN), Network Attached Storage (NAS), and VMware vSAN can be used as a shared datastore. NFS and iSCSI protocols are supported to access data on a shared datastore. VM files must be stored on a shared datastore.
VMware vCenter Serverthat is compatible with the ESXi version installed on the hosts.
Unlike a Hyper-V Failover Cluster, no quorum is required and you don’t need to use complex network names.
What is VMware HA in vSphere?
VMware vSphere High Availability (HA) is a clustering feature that is designed to restart a virtual machine (VM) automatically in case of failure. VMware vSphere High Availability allows organizations to ensure high availability for VMs and applications running on the VMs in a vSphere cluster (independent of running applications). VMware HA can provide protection against the failure of an ESXi host – the failed VM is restarted on a healthy host. As a result, you can significantly reduce downtime.
Requirements for vSphere HA
Requirements for vSphere HA must be taken into account together with the general vSphere cluster requirements. In order to set up VMware vSphere High Availability, you must have:
- A
VMware vSphere Standardlicense - Minimum 4 GB of RAM on each host
- A pingable gateway
How Does vSphere HA Work?
VMware vSphere High Availability checks ESXi hosts to detect a host failure. If a host failure is detected (VMs running on that host are also failed), then the failed VMs are migrated to healthy ESXi hosts within the cluster. After migration, the VMs are registered on the new hosts, and then these VMs are started. VM files (VMX, VMDK, and other files) are located on the same resource, which is a shared datastore, after migration. VM files are not migrated. Only the CPU, memory, and network components utilized by the failed VMs are provided by the new ESXi host after migration.
The downtime is equal to the time needed to restart a VM on another host. However, keep in mind that there’s also the time needed for the operating system to boot and for loading the needed applications on a VM. VMware HA is a solution that works on the VM layer and can be also used if applications don’t have native high availability features. VMware vSphere High Availability doesn’t depend on the guest operating system installed on the VM.
The workflow of a vSphere HA cluster is illustrated in the diagram below. There is a cluster with three ESXi hosts in this example. VMs are running on all hosts. The connections of the VMs and their files are illustrated with dotted lines.
1. The normal operation of a cluster. All VMs are running on their native hosts.
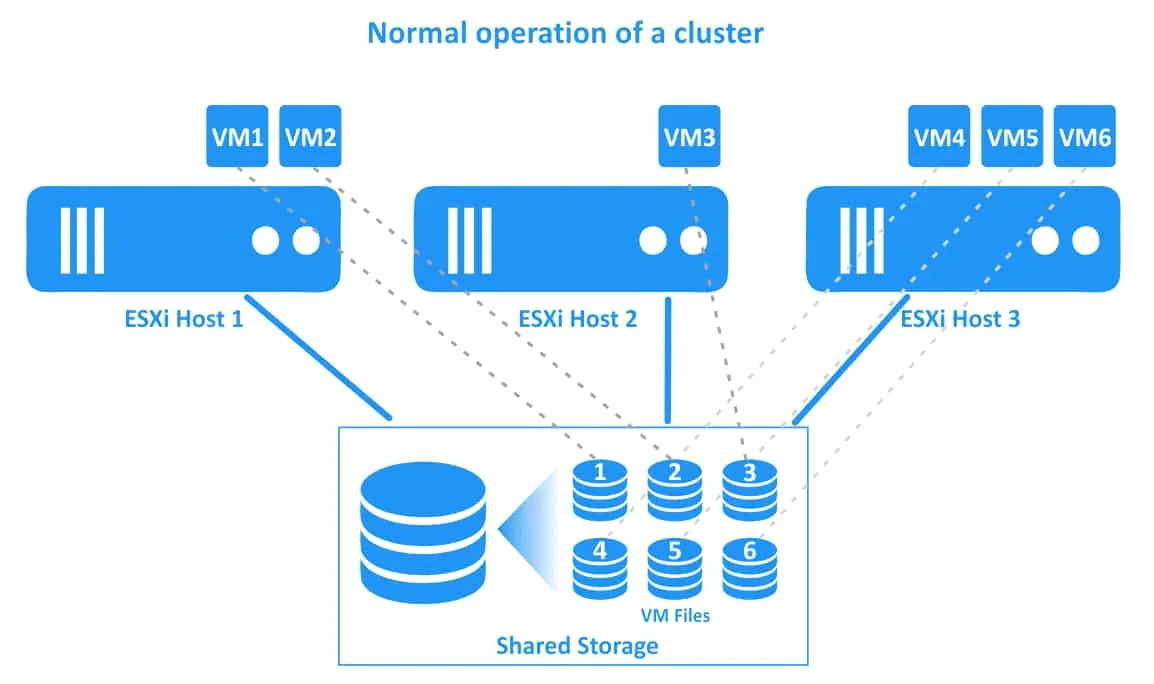
2. ESXi host 1 fails. VMs residing on ESXi host 1 (VM1 and VM2) are failed (these VMs are powered off). A vSphere HA cluster initiates VM restarts on other healthy ESXi hosts.
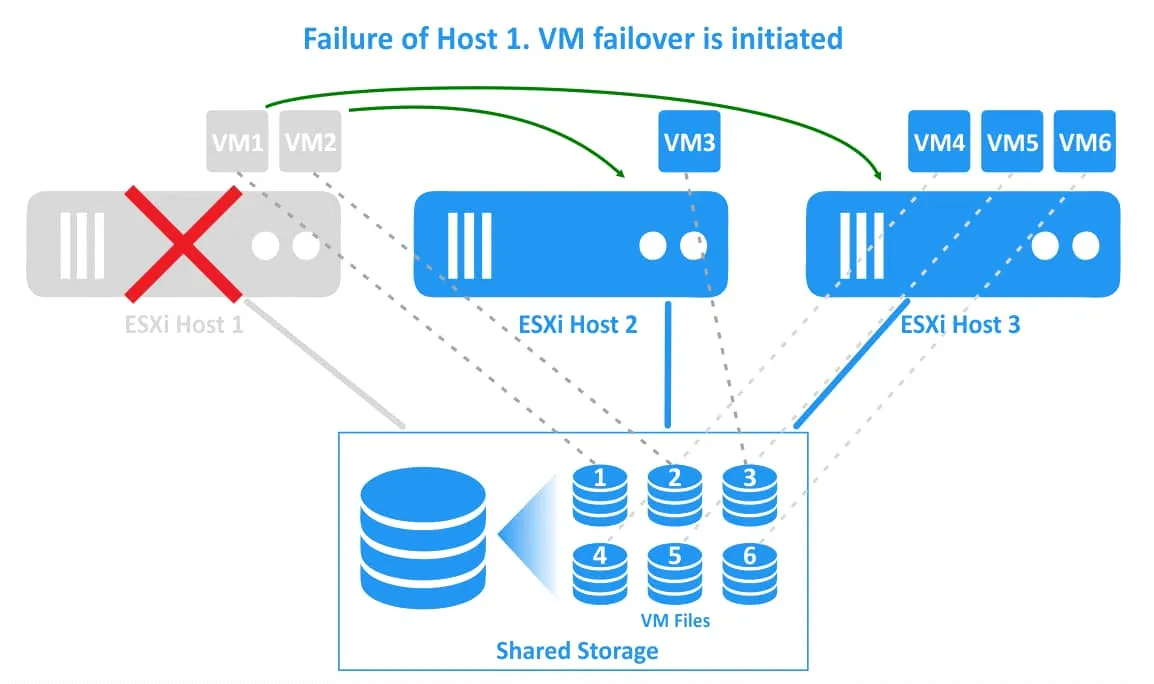
3. VMs have been migrated and restarted on healthy hosts. VM1 has been migrated to ESXi host 2, and VM2 has been migrated to ESXi host 3. VM files are located in the same place on the shared storage that is connected to all ESXi hosts of the vSphere cluster.
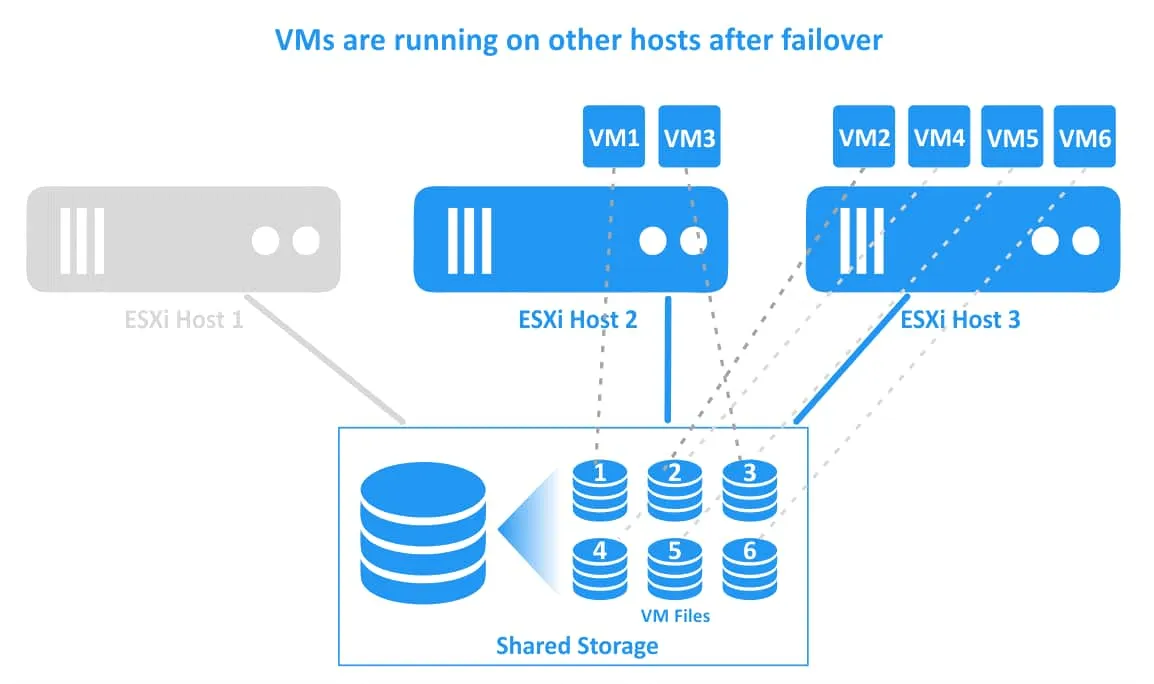
HA master and subordinates
After vSphere High Availability is enabled in the cluster, one ESXi host is selected as the HA master. Other ESXi hosts are subordinates (slave subordinate hosts). A master monitors the state of the subordinates to detect host failure in time and initiate the restart of failed VMs. The master host also monitors the power state of virtual machines on cluster nodes. If a VM failure is detected, the master initiates a VM restart (the optimal host is selected by the master before restarting the failed VM). The HA master sends information about the HA cluster’s health to vCenter. VMware vCenter manages the cluster by using the interface provided by the HA master host.
The master can run VMs just as other hosts within the cluster. If a master host fails, another master host is selected. The host that is connected to the highest number of datastores has the advantage in the election of the primary ESXi host. Hosts that are not in the maintenance mode participate in the election of the primary host.
Subordinate hosts can run virtual machines, monitor the states of VMs, and report updated information about VM states to the HA master host.
Fault Domain Manager (FDM) is the name of the agent used to monitor the availability of physical servers. The FDM agent works on each ESXi host within an HA cluster.
Host Failure Types
There are three types of ESXi host failures:
Failure. An ESXi host has stopped working for some reason.
Isolation. An ESXi host and the VMs on this host continue to work, but the host is isolated from other hosts in the cluster due to network issues.
Partition. The network connectivity with the primary host is lost.
How failures are detected
Heartbeats are exchanged to detect failures in a vSphere HA cluster. The primary host monitors the state of secondary hosts by receiving heartbeats from the secondary hosts every second. The primary host sends ICMP pings to the secondary host and waits for replies. If the primary host cannot communicate directly with the agent of the secondary host, the secondary host can be healthy or failed but inaccessible via the network.
If the primary host doesn’t receive heartbeats, then the primary host checks the suspicious host by means of Datastore Heartbeating. During normal operation, each host within an HAcluster exchanges heartbeats with the shared datastore. The primary ESXi host checks if the datastore heartbeats have been exchanged with the suspicious host in addition to sending pings to that host. If there is no datastore heartbeat exchange with the suspicious host, and that host doesn’t send ICMP requests, then the host is designated as a failed host.
Note: A special .vSphere-HA directory is created at the root of a shared datastore for heartbeating and identifying a list of protected VMs. Note that vSAN datastores cannot be used for datastore heartbeating.
If the primary host cannot connect with the agent of the secondary host, but the secondary host exchanges heartbeats with the shared datastore, then the primary host marks the suspicious host as a network isolated host. If the primary host determines that the secondary host is running in an isolated network segment, the primary host continues to monitor the VMs on that isolated host. If the VMs on the isolated host are powered off, then the primary host initiates the restart of these VMs on another ESXi host. You can configure the vSphere HA cluster’s response to an ESXi host becoming network isolated.
Monitoring individual VMs. VMware vSphere High Availability has a mechanism for monitoring individual VMs and detecting if a particular VM has failed. VMware Tools installed on a guest operating system (OS) are used to determine the virtual machine state. VMware Tools send guest OS heartbeats to the ESXi host.
Heartbeats and input/output (I/O) activity generated by VMware Tools are monitored by the VM monitoring service. If the primary ESXi host in the HA cluster detects that VMware Tools on the protected VM are not responding and that there is no I/O activity, the host initiates a VM restart. Monitoring VM I/O activity allows an HA cluster to avoid unnecessary VM resets if VMware Tools don’t send heartbeats for some reason but the VM is running. You can set monitoring sensitivity to configure the time period after which a VM must be restarted if guest OS heartbeats generated by VMware Tools are not received by the ESXi host. VMware vSphere HA restarts the VM on the same ESXi host in case of a single VM failure.
VMware Tools heartbeats are sent to hostd on the hypervisor level (ESXi), not by using the network stack. Then the ESXi host sends the received information to vCenter. VMware Tools heartbeats can be received by an ESXi host if a VM is disconnected from a network and even if there is no virtual network adapter connected to the VM.
VM and application monitoring. You can use SDK from a third-party vendor to monitor whether a specific application installed on a VM has failed. The alternative option is to use an application that already supports VMware Application Monitoring. Application heartbeats are used for application monitoring on VMware VMs running in a vSphere HA cluster.
Key Parameters for HA Cluster Configuration
Before you start to configure an HA cluster, you need to define some key parameters.
Isolation response is a parameter that defines how an ESXi host acts when it does not receive heartbeat signals. The options are Leave powered on, Power off (default), and Shutdown.
Reservation is a parameter that is calculated based on the maximum characteristics of the most resource-hungry VM within a cluster. This parameter is used for estimating Failover Capacity. An HA cluster creates reservation slots by using the value of the Reservation parameter.
Failover Capacity. This parameter is measured in integer and defines the maximum number of servers that can be failed in the cluster without a negative impact on workloads (the cluster and all VMs can still operate after the failure of this number of ESXi hosts).
The number of host failures allowed. This parameter is defined by a system administrator to set how many hosts can fail to continue the operation of the cluster. Failover Capacity is taken into account when setting the value for this parameter.
Admission Control is the parameter used to ensure that there are sufficient resources reserved to recover VMs after an ESXi host fails. This parameter is set by an administrator and defines the behavior of the VMs if there are not enough free slots to start VMs after ESXi host failures. Admission Control defines the failover capacity, that is, the percentage of resource degradation that can be tolerated in a vSphere HA cluster after failover.
Restart Priority is set by an administrator to define the sequence for starting VMs after the failover of a cluster node. Administrators can configure vSphere HA to start critical virtual machines first and then start other VMs.
Failover capacity and host failure
Let’s look at two cases, each with three ESXi hosts but with different failover capacity values. In the first case, the HA cluster can work after the failure of one ESXi host (see the left side of the image below). In the second case, the HA cluster can tolerate the failure of two ESXi hosts (see the right side of the image).
1. Each ESXi host has 4 slots. There are 6 VMs in the cluster. If one ESXi host fails (the third host, for example), then the three VMs (VM4, VM5, and VM6) can migrate to the other two ESXi hosts. In my example, these three VMs are migrating to the second ESXi host. If one more ESXi host fails, then there will be no free slots to migrate and run other VMs.
2. Each ESXi host has 4 slots. 4 VMs are running in the VMware vSphere HA cluster. In this case, there are enough slots to run all VMs within a cluster if two ESXi hosts fail.
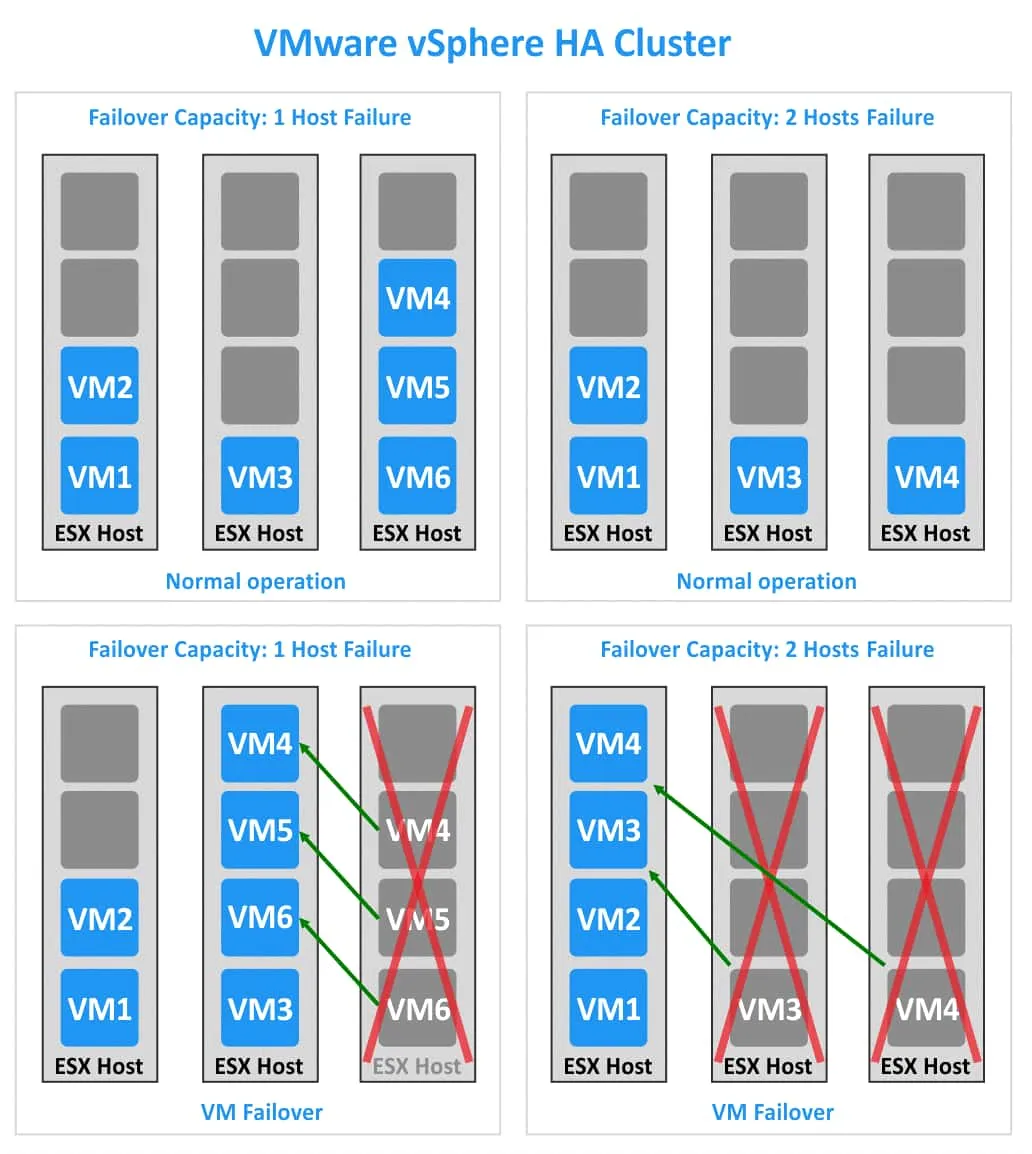
In order to calculate Failover Capacity, do the following: From the number of all nodes in the cluster subtract the ratio of the number of VMs in the cluster to the number of slots on one node. If you have a non-integer (a number that is not whole) as a result, round the number to the nearest lowest integer. Let’s calculate Failover Capacity for the two examples.
Example 1:
3–6/4=1.5
Round 1.5 to 1. All VMs in an HA cluster can survive if 1 ESXi host fails.
Example 2:
3–4/4=2
There is no need to round down, as 2 is an integer. All VMs can continue operating if 2 ESXi hosts fail.
Admission Control
As mentioned above, admission control is the parameter needed to ensure that there are enough resources to run VMs after a host failure in the cluster. You can also define the Admission Control State parameter for more convenience. Admission Control State is calculated as the ratio of Failover Capacity to Number of Host Failures allowed (NHF).
If Failover Capacity is higher than NHF, then the HA cluster is configured properly. Otherwise, you need to set Admission Control manually. There are two options available:
1. Do not power on virtual machines if they violate availability constraints (do not power on VMs if there are not enough hardware resources).
2. Allow virtual machines to be started even if they violate availability (start VMs despite the lack of hardware resources).
Choose the option that fits your vSphere High Availability cluster use case best. If your objective is the reliability of the HA cluster, select the first option (Do not power on VMs). If the most important thing for you is running all VMs, then select the second option (Allow VMs to be started). Be aware that in the second case the behavior of the cluster can be unpredictable. In the worst-case scenario, the HA cluster can become useless.
VM overrides
VM overrides (or HA overrides in the case of an HA cluster) the option that allows you to disable HA for a particular VM running in the HA cluster. You can configure your vSphere HA cluster at a more granular level with this option on the cluster level.
Fault Tolerance
VMware provides a feature for a vSphere HA cluster that allows you to achieve zero downtime in case of an ESXi host failure. This feature is called Fault Tolerance. While the standard configuration of vSphere High Availability requires a VM restart in case of failure, Fault Tolerance allows VMs to continue running if the primary ESXi host on which the VMs are registered fails. Fault Tolerance can be used for mission-critical VMs running critical applications.
There is the overhead to achieve zero downtime for the highest level of business continuity because there are two running instances of a VM protected with Fault Tolerance. The second ghost VM is running on the second ESXi host, and all changes to the original VM (CPU, RAM, network state) are replicated from the initial ESXi host to the secondary ESXi host. The protected VM is called the primary VM and the duplicate VM is called the secondary VM. The primary and secondary VMs must reside on different ESXi hosts to ensure protection against ESXi host failure.
The two VMs (primary VM and secondary VM) are running simultaneously and consume CPU, RAM, and network resources on both ESXi hosts (thus a VM protected with the Fault Tolerance feature consumes twice as many resources in the vSphere HA cluster). These VMs are continuously synchronized in real-time. Users can work only with the primary (original) VM and the secondary (ghost) VM is invisible to them.
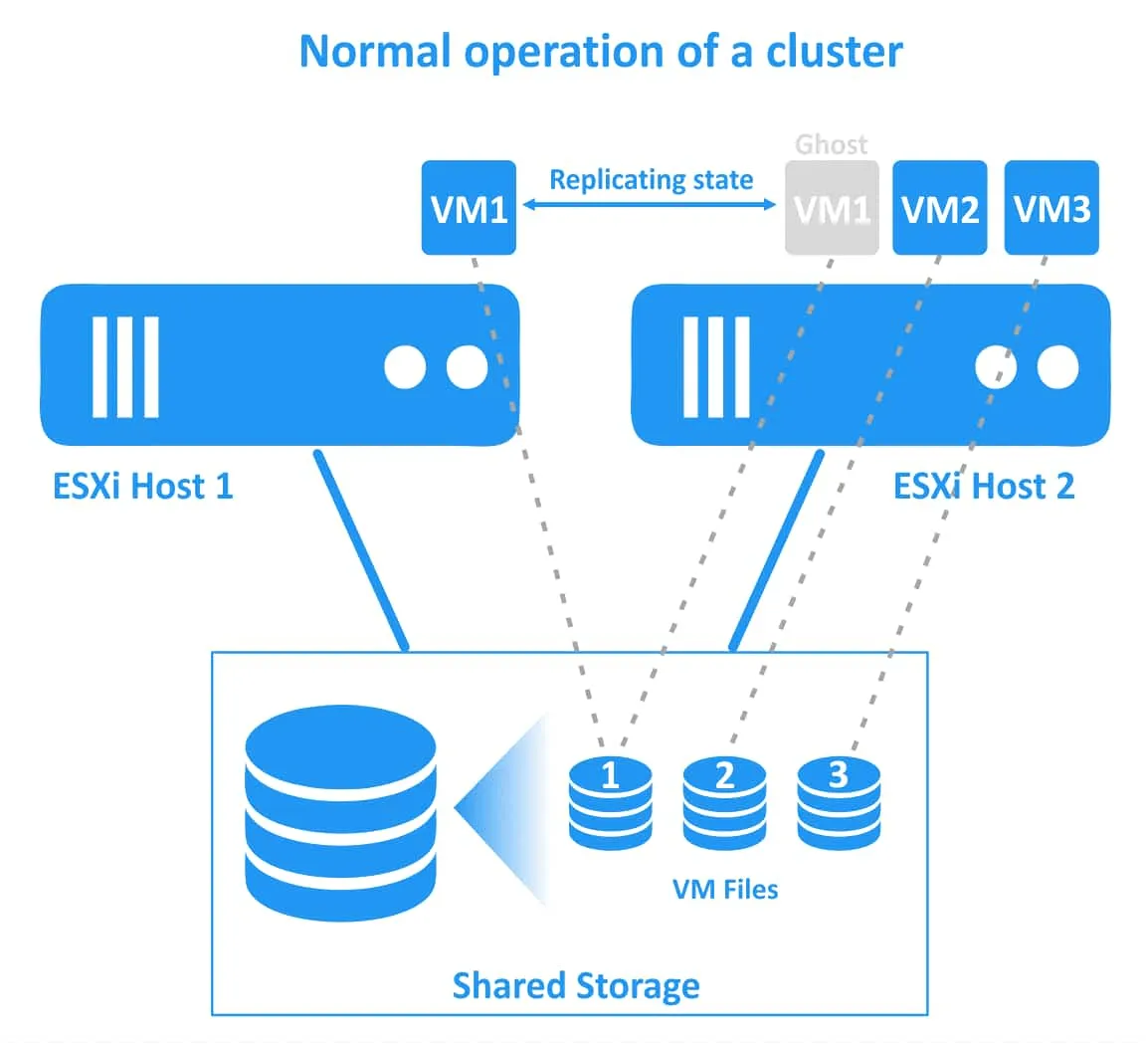
If the first ESXi host fails (the host on which the primary VM is residing), then the workloads are migrated to the secondary VM (that is the VM clone or the ghost VM) running on the second ESXi host. The secondary VM becomes active and accessible in a moment. Users can notice a slight network latency during the moment of the transparent failover. There is no service interruption or data loss during failover. After the failover was done successfully, a new ghost VM is created on the alternative healthy ESXi host to provide redundancy and continue VM protection against ESXi host failure.
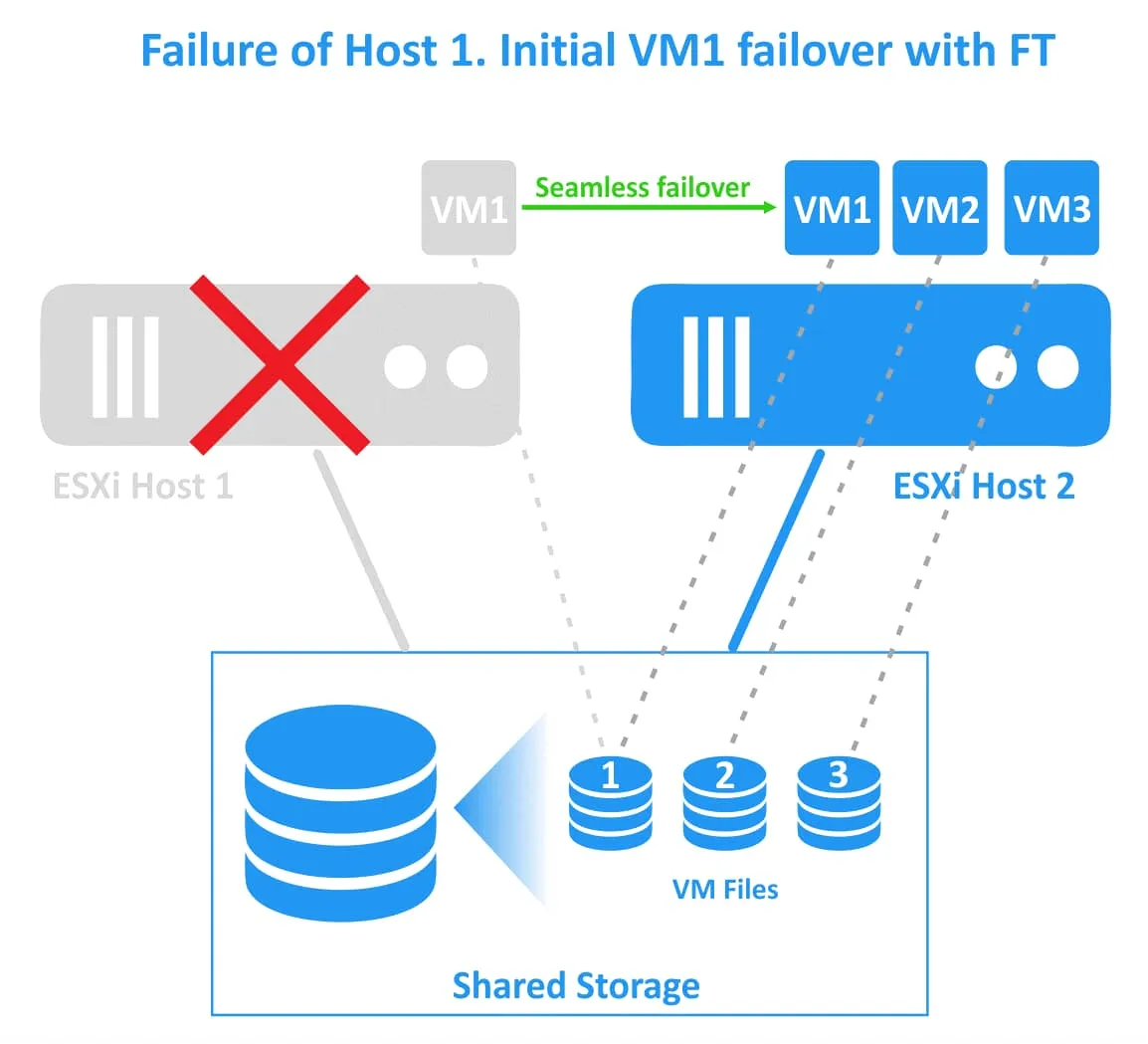
Fault Tolerance avoids split-brain scenarios (when two active copies of a protected VM run simultaneously) due to the file locking mechanism on shared storage for failover coordination. However, Fault Tolerance doesn’t protect against software failures inside a VM (such as guest OS failure or failure of particular applications). If a primary VM fails, the secondary VM also fails.
Requirements for Fault Tolerance
- A vSphere
HAcluster with a minimum of two ESXi hosts. vMotionandFT logging.- A compatible CPU that supports hardware-assisted
MMUvirtualization.
Using a dedicated Fault Tolerance network in the vSphere HA cluster is recommended.
A license for Fault Tolerance
- ESXi hosts must be licensed to use
Fault Tolerance. - vSphere
StandardandEnterprisesupport up to 2 vCPUs for a single VM. - vSphere
Enterprise Plusallows you to use up to 8 vCPUs per VM.
Fault Tolerance limitations
There are some limitations to using VMware Fault Tolerance in vSphere. VMware vSphere features that are incompatible with FT:
- VM snapshots. A protected VM must not have snapshots.
- Linked clones
- VMware
vVoldatastores
Devices that are not supported:
Raw device mappingdevices- Physical CD-ROM and other devices of a server that are connected to a VM as virtual devices
- Sound devices and USB devices
- VMDK virtual disks which size is more than 2 TB
- Video devices with 3D graphics
- Parallel and serial ports
Hot-plugdevicesNIC (network interface controller)pass-throughStorage vMotion(must be temporarily disabled to migrate VM files to another storage)
What is DRS in VMware vSphere?
Distributed Resource Scheduler (DRS) is a VMware vSphere clustering feature that allows you to load balance VMs running in the cluster. DRS checks the VM load and a load of ESXi servers within a vSphere cluster. If DRS detects that there is an overloaded host or VM, DRS migrates the VM to an ESXi host with enough free hardware resources to ensure the quality of service (QoS). DRS can select the optimum ESXi host for a VM when you create a new VM in the cluster.
VMware DRS allows you to run VMs in a balanced cluster and avoid overloading and situations when there are not enough hardware resources for virtual machines and applications running on VMs for normal operation (there must be enough resources in the whole cluster in this case).
DRS Requirements
The requirements for DRS, along with the general requirements for a vSphere cluster, include:
- vSphere
Enterpriseor vSphereEnterprise Pluslicense - A CPU with
Enhanced vMotion Compatibilityfor VM live migration withvMotion - A dedicated
vMotionnetwork
A configured VMware vMotion is required to operate a DRS cluster, unlike an HA cluster, where vMotion is required only if using Fault Tolerance. Also, the vSphere license required for VMware DRS is higher than the license for using vSphere High Availability.
The role of vMotion
Migrate VMs from one ESXi host to another with vMotion, which we mentioned when explaining how Fault Tolerance works. With VMware vMotion, VM migration (CPU, memory, network state) occurs without interrupting running VMs (there is no downtime). VMware vMotion is the key feature for the proper work of DRS.
Let’s look at the main steps of vMotion operation:
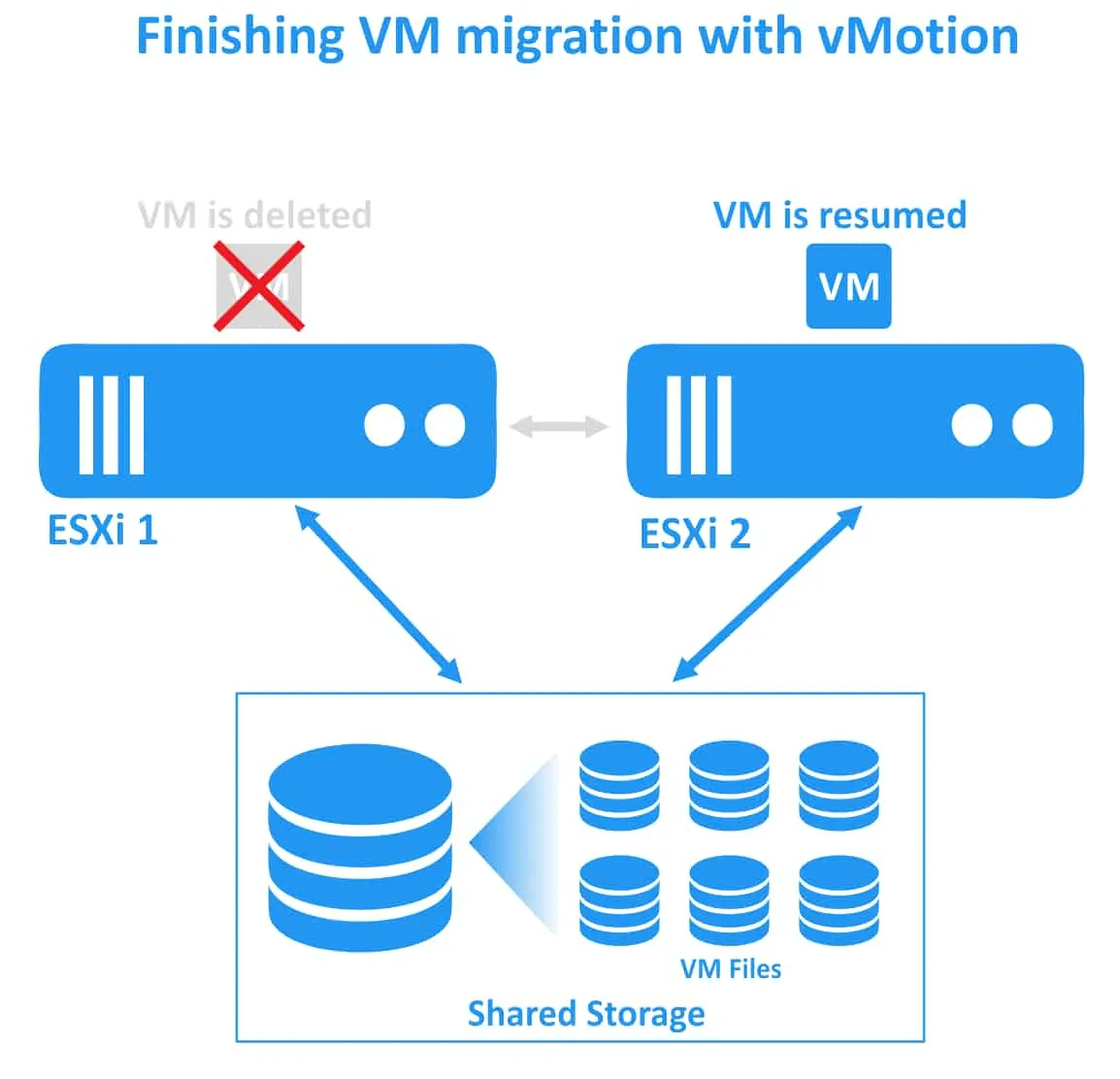
1. vMotion creates a shadow VM on the destination ESXi host. The destination ESXi host pre-allocates enough resources for the VM to be migrated. The VM is put in the intermediate state and the VM configuration cannot be changed during migration.

2. The precopy process. Each VM memory page is copied from the source to the destination by using a vMotion network.
3. The next pass of copying memory pages from the source to the destination is performed, because memory pages are being changed during the VM operation. This is an iterative process that is performed until no changed memory pages remain. The changed memory pages are called dirty pages. It takes more time for VM migration with vMotion if memory-intensive operations are performed on a VM because more memory pages are changed.

4. The VM is stopped on the source ESXi host and resumed on the destination host. Insignificant network latency can be noticed inside the migrated VM for about a second at this moment.
The Working Principle of DRS in VMware
VMware DRS checks the workloads from the CPU and RAM perspectives to determine the vSphere cluster balance every 5 minutes, which is the default interval. VMware DRS checks all of the resources in the resource pool of the cluster, including the resources consumed by VMs and the resources of each ESXi host within the cluster that can be provided to run VMs. Resource checks are performed according to the configured policies.
The demands of VMs are also taken into account (the hardware resources that the VM needs to run at the moment of checking). The formula is used for VM demand calculation for memory:
VM memory demand = Function(Active memory used, Swapped, Shared) + 25% (idle consumed memory)
CPU demand is calculated based on the number of processor resources that are currently consumed by a VM. VM CPU maximum values and VM CPU average values collected during the last check help the DRS to determine the trend of resource usage for a particular VM. If vSphere DRS detects an imbalance in the cluster and that some ESXi hosts are overloaded, then the DRS initiates live migration of VMs running on the overloaded host to a host with free resources.
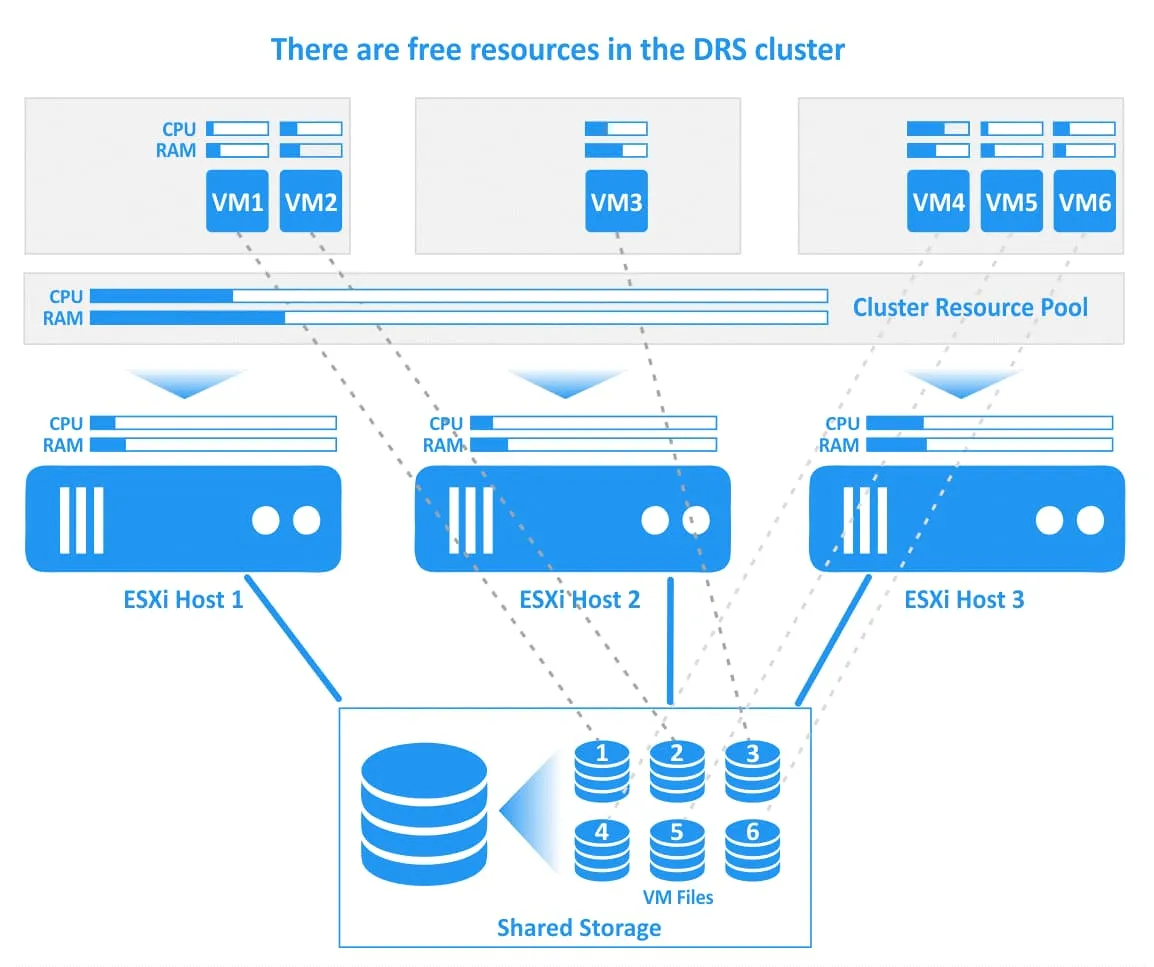
Let’s look at how vSphere DRS works in VMware using an example with diagrams. In the diagram below, you can see a DRS cluster with 3 ESXi hosts. All the hosts are connected to shared storage, where VM files are located. The first host is very loaded, the second host has free CPU and memory resources, and the third host is heavily loaded. Some VMs on the first (VM1) and third (VM4, VM5) ESXi hosts are consuming almost all the provisioned CPU and memory resources. In this case, the performance of these VMs can degrade.

VMware DRS determines that the rational action is to migrate the heavily loaded VM2 from the overloaded ESXi host 1 to ESXi host 2, which has enough free resources and migrate VM4 from ESXi host 3 to ESXi host 2. If the DRS is configured to work in the automatic mode, then running VMs are migrated with vMotion (this action is illustrated with green arrows in the image below). VM files including virtual disks (VMDK), configuration files (VMX), and other files are located in the same place on the shared storage during VM migration and after VM migration (connections of VMs and their files are illustrated with dotted lines on the image).
Once the selected VMs have been migrated, the DRS cluster becomes balanced. There are free resources on each ESXi host within the cluster to run VMs effectively and ensure high performance.

The situation can change due to uneven VM workloads, and the cluster can become imbalanced again. In this case, DRS will check the resources consumed and free resources in the cluster to initiate VM migration again.
Key Parameters for vSphere DRS Configuration
VMware vSphere DRS is a highly customizable clustering feature that allows you to use DRS with higher efficiency in different situations. Let’s look at the main parameters that affect the behavior of DRS in a vSphere cluster.
VMware DRS automation levels
When DRS detects that a vSphere cluster is imbalanced, DRS provides recommendations for VM placement and migration with vMotion. The recommendation can be implemented by using one of three automation levels:
Fully automated. Initial VM placement and vMotion recommendations are applied automatically by DRS (user intervention is not required).
Partially automated. Recommendations for the initial placement of new VMs are the only ones applied automatically. Other recommendations can be initiated and applied manually or ignored.
Manual. DRS provides recommendations for initial VM placement and VM migration but user interaction is required to apply these recommendations. You can also ignore the recommendations provided by DRS.
DRS aggression levels (migration thresholds)
DRS aggression levels or migration thresholds is the option to control the maximum imbalance level that is acceptable for a DRS cluster. There are five threshold values from 1, the most conservative, to 5, the most aggressive.
The aggressive setting initiates VM migration even if the benefit of VM placement is slight. The conservative setting doesn’t initiate VM migration even if significant benefits can be achieved after VM migration. Level 3, the middle aggression level, is selected by default and this is the recommended setting.
Affinity Rules in VMware DRS
Affinity and anti-affinity rules are useful when you need to place specific VMs on specific ESXi hosts. For example, you may need to run some VMs together on one ESXi host within a cluster, or vice versa (you need two or more VMs to be placed only on different ESXi hosts, and VMs must not be placed on one host). Use cases can include:
- Virtual domain controller VMs (a primary domain controller and additional domain controller) on different hosts to avoid the failure of both VMs if one host fails. These VMs must not run together on a single ESXi host in this case.
- VMs running software that is licensed to run on the appropriate hardware and cannot run on other physical computers due to licensing limitations (for example, Oracle Database).
Affinity rules are divided into:
- VM-VM affinity rules (for individual VMs)
- VM-host affinity rules (relationship between groups of hosts and groups of VMs)
VM host rules can be preferential (VMs should…) and mandatory (VM must…). Mandatory rules continue to work even if DRS is disabled, which doesn’t allow you to migrate the appropriate VMs with vMotion manually. This principle is used to avoid violation of the rule applied to VMs running on ESXi hosts if vCenter is temporarily unavailable or failed.
There are four options for DRS affinity rules:
Keep virtual machines together. The selected VMs must run together on a single ESXi host (if VM migration is needed, all these VMs must be migrated together). This rule can be used when you want to localize network traffic between the selected VMs (to avoid network overloading between ESXi hosts if VMs generate significant network traffic). Another use case is running a complex application that uses components (that depend on each other) installed on multiple VMs or running a vApp. This could include, for example, a database server and an application server.
Separate virtual machines. The selected VMs must not run on a single ESXi host. This option is used for high availability purposes.
Virtual machines to hosts. VMs added to a VM group must run on the specified ESXi host or host group. You need to configure DRS groups (VM/Host groups). A DRS group contains multiple VMs or ESXi hosts.
Virtual machines to virtual machines. This rule can be selected to tie VMs to VMs when you want to power on one VM group and then power another (dependent) VM group. This option is used when VMware HA and DRS are configured together in the cluster.
If there is a rule conflict, then the older rule takes precedence.
VM Override for VMware DRS
Similar to the use of VM override in a vSphere HA cluster, VM overrides are used for more granular configurations of DRS in VMware vSphere and allow you to override global settings set at the DRS cluster level and define specific settings for an individual VM. Other VMs of the cluster are not affected when VM override is applied for a specific VM.
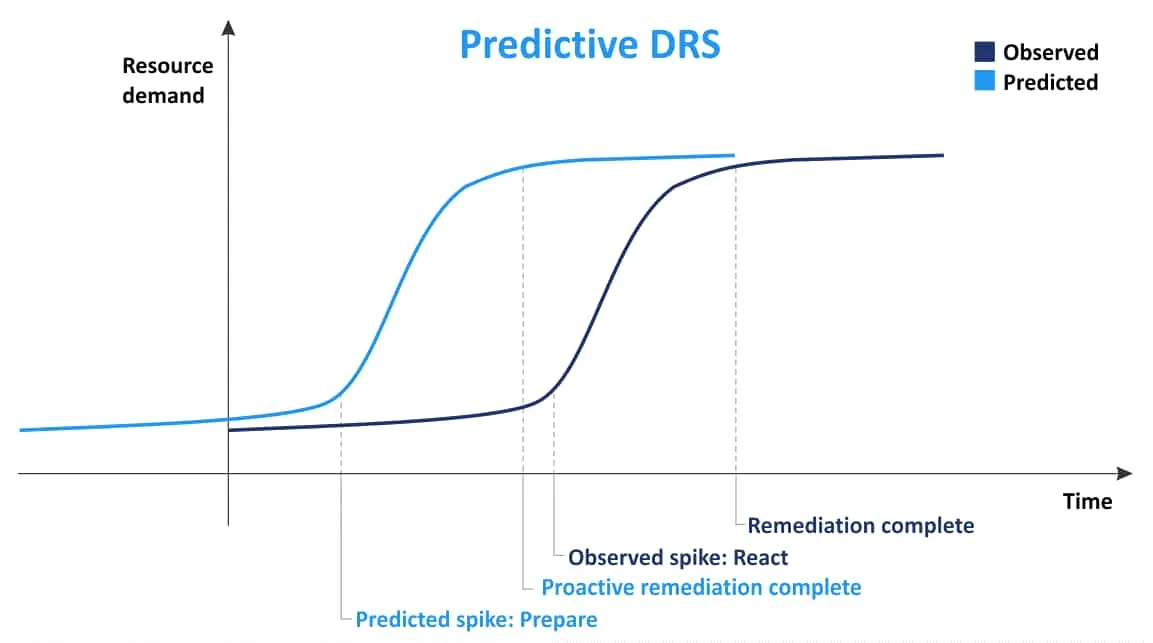
Predictive DRS
The main concept of Predictive DRS is to collect information about VM placement and then, based on the previously collected information, predict when and where high resource usage will occur. Using this information, Predictive DRS can move VMs between hosts for better load balancing before an ESXi server is overloaded and VMs lack resources. This feature can be useful when there are time-based demand changes for VMs in a cluster. Predictive DRS is disabled by default. VMware vRealize Operations Manager is required to use Power DRS.
Distributed Power Manager
Distributed Power Manager (DPM) is a feature used to migrate VMs if there are enough free resources in a cluster to shut down an ESXi host (put a host into the standby mode) and run VMs on the remaining ESXi hosts within the cluster (remaining hosts must provide enough resources to run the needed VMs).
When more resources are needed in a cluster to run VMs, DPM initiates a server that was shut down to wake up and operate in normal mode. One of the supported power management protocols is used to power on a host via the network. These protocols are Intelligent Platform Management Interface (IPMI), Hewlett-Packard Integrated Lights-Out (iLO), or Wake-On-LAN (WOL). Then DRS migrates some VMs to this server to distribute workloads and balance a cluster. By default, Distributed Power Management is disabled. DPM recommendations can be applied automatically or manually.

Storage DRS
While DRS migrates VMs based on CPU and RAM computing resources, Storage DRS migrates virtual machine files from one datastore to another based on datastore usage, for example, free disk space. Affinity and anti-affinity rules allow you to configure whether Storage DRS must store a VM’s virtual disk files together on the same datastore. For example, you can configure the anti-affinity rule to store the VMDK files of a VM that performs I/O intensive operations on different datastores. You do this to avoid performance degrading of the VM and initial VM datastore (I/O disk workloads will be distributed across multiple datastores when using the anti-affinity rule).
Storage DRS is useful when using VMs with thin provisioned disks in case of overprovisioning. Storage DRS helps avoid situations when the size of thin disks grows, and as a result, there is no free space on a datastore. Lack of free space causes the VMs storing virtual disks on that datastore to fail. Virtual machine disk files can be migrated from one datastore to another with Storage vMotion while the VM is running.
Monitoring CPU and memory consumption
VMware provides the ability to monitor resource usage in the web interface of VMware vSphere Client. You can monitor CPU usage in the cluster by going to Settings > Monitor > vSphere DRS > CPU Utilization. There are also other options for monitoring the memory and storage space for separate ESXi hosts. VMware monitoring is supported in NAKIVO Backup & Replication 10.5. Read more about infrastructure monitoring in the blog post.
Using VMware HA and DRS Together
VMware HA and DRS are not competing technologies. They complement each other, and you can use both VMware DRS and HA in a vSphere cluster to provide high availability for VMs and balance workloads if VMs are restarted by HA on other ESXi hosts. It is recommended that you use both technologies in vSphere clusters running in production environments for automatic failover and load balancing.
When an ESXi host fails, VM failover is initiated by HA, and VMs are restarted on other hosts. The first priority in this situation is to make VMs available. But after VM migration, some ESXi hosts can be overloaded, which would have a negative impact on VMs running on those hosts. VMware DRS checks the resource usage on each host within a cluster and provides recommendations for the most rational placement of VMs after a failover. As a result, you can always be sure that there are enough resources for VMs after failover to run workloads with proper performance. With both VMware DRS and HA enabled you can have a more effective cluster.
Conclusion
VMware provides the powerful functionality of clusters in vSphere to meet the needs of the most demanding vSphere customers. We are covered VMware DRS and HA and explained the working principle and main parameters for each of these clustering features. VMware DRS and HA complement each other and make the final result of using a cluster better.
Even if you use VMware DRS and HA, don’t forget to back up VMware VMs in vSphere. Download NAKIVO Backup & Replication Free Edition for VMware backup in your environment.



