Disaster Recovery vs Backup: Key Differences
Data loss and security breaches are increasingly common in today’s business landscape, with cyberattacks reaching a record high in 2021. An organization’s systems and data must be protected as they are expected to be readily available at all times. That’s why the importance of backups cannot be overestimated. However, while backing up crucial data is an integral part of any business’s IT strategy, having backups is not the same as having a disaster recovery plan.
This brings us to what the difference is between data backup and disaster recovery. These concepts are often mistakenly used interchangeably. In order to explain the differences, let’s take a look at each concept separately first and then compare use cases and characteristics.

What Is Backup?
Backup is a copy of data created to be used for recovery in the event that the original data is lost or unavailable. Backup also refers to the process of creating such copies.
A backup plan is a strategy implemented for backing up an environment, either manually or automatically, based on a schedule and an organization’s recovery objectives.
Your backup plan should ideally include several backups stored in different locations, including in a separate data center in a remote location, as well as stored on different media (such as disk, tape, cloud, etc.). This practice is informed by the 3-2-1 backup rule.
What is the 3-2-1 rule?
The 3-2-1 backup rule is the backbone of any backup and recovery planning. It states that you should have:
- At least 3 copies of data
- 2 of which should be kept on different media
- 1 copy should be stored offsite.
Note that the 3-2-1 backup rules can be extended to include 1 copy stored in immutable storage for recovery after a ransomware attack.
However, simple backups are not enough to maintain uninterrupted operations and continue to service customers. Maintaining business continuity in the face of any disaster or unforeseen event is a must as any downtime translates into lost revenue, lost customers and a tarnished reputation. This is where disaster recovery comes in.
What Is Disaster Recovery?
Disaster recovery (DR) is a set of measures to ensure the timely recovery of data, apps and systems to a separate site following a system failure, natural catastrophe or a ransomware attack. These measures allow an organization to maintain availability and access to critical business IT systems and infrastructure while avoiding data loss. Disaster recovery also includes the measures to resume regular operations at the primary site after resolving the unplanned disruption.
A disaster recovery plan is a documented procedure for setting the disaster recovery (DR) measures in motion with respective priorities and responsible persons.
Disaster recovery is an integral part of business continuity (BC), which is a wider concept that includes measures designed to continue business operations as usual when disaster strikes. As a wider set of measures to continue providing services to customers and partners, a business continuity plan includes the measures regarding employees, sites, suppliers and everything else needed to continue core business functions.
Implementing disaster recovery
Disaster recovery in virtualized environments usually relies on a dedicated backup and disaster recovery solutions. This type of software allows you to:
- create replicas of business-critical VMs
- transfer workloads of your IT infrastructure to replicas at a separate DR location in case of a disruption (known as failover)
- transfer workloads back to the primary site once the disruption has been resolved (known as failback)
These solutions also reconfigure network settings during failover, allowing VM replicas to start working almost immediately. In addition, many solutions allow you to automate and orchestrate several actions for swifter recovery.
What Is the Difference Between Disaster Recovery and Backup?
Disaster recovery and backup are not interchangeable. Depending on resources and needs, an organization may only use data backup or may complement it with a comprehensive disaster recovery strategy. It is not possible to compare and contrast data backup and disaster recovery, as DR comprises processes such as replication, failover, failback, etc. In this context, backups are used for operational recovery (more on that below).
In this disaster recovery and backup comparison, we focus on the differences between backups and replicas in terms of usage scenarios, resources required for implementation, and recovery objectives.
Use cases
Backups are used to recover a lost or damaged file or object, such as an email message from an email server, a PowerPoint presentation or other application objects. Backups are also often used for long-term data archival or data retention (for compliance purposes, for example).
Basically, backups come in handy quite often during day-to-day workflows for quickly restoring a single file or a full VM from a particular point in time. This is known as operational recovery and can often be initiated at the request of an employee who has lost access to one of resources of the IT infrastructure.
Replicas, on the other hand, are used in disaster recovery scenarios to restore systems and machines right after an unforeseen event and to ensure that core business operations are not disrupted.
With both a DR site and DR solution in place, you simply perform a failover to transfer workloads to the VM replicas at the DR location. The organization can continue to function as normal even if the production site is unavailable. Once the disruption to the primary site has been resolved, you can perform a failback.
Recovery objectives
Defining the recovery time objective (RTO) and recovery point objective (RPO) is one of the crucial steps in a backup and disaster recovery plan.
- RTO is the amount of time your organization can allow to recover data/operations after a disruption before any significant consequences to the organization.
- RPO is the maximum amount of data that your organization can afford to lose before suffering serious consequences. RPO is determined by backup/replication frequency and retention policies.
The values for RTO and RPO differ for operational recovery and disaster recovery. Backups can have longer RTOs and RPOs, given that a missing file does not necessarily bring business operations to a halt.
On the other hand, a disruption to a primary site or to critical machines can lead to employees not able to access critical systems, unsatisfied customers, etc. This is why disaster recovery DR requires much shorter RTOs and RPOs, especially for mission-critical workloads.
Resources for implementation
Resources for backups and replicas/DR include two aspects: storage and facilities (data centers).
Backups can be stored in different storage types: local disk, NAS, enterprise-grade deduplication appliances, a public cloud, tape, etc. Top-of-the-line backup solutions nowadays offer many features to reduce the size of backups and by that reduce storage space requirements. These include compression, deduplication and change-tracking technologies.
Depending on the media, they may require little to no additional costs and can be restored even years after the initial backup (consider tape, for example). If using a public cloud as a backup target, actual facilities are not a requirement. In short, backup costs mainly relate to storage media and maintenance.
Disaster recovery, on the other hand, requires a separate site to be used in a disaster recovery environment and redundant hardware (including DR servers and storage systems) to be used in parallel with the primary site. DR also involves the costs associated with utilities and staff needed to maintain that site.
This DR site is usually a fully operational IT infrastructure that is ready for a possible failover at any time. This is also known as a “hot site” and includes all the hardware (servers), software and networking needed to transfer operations as soon as a disaster strikes. Other more budget-friendly options can include outsourcing to MSPs for disaster recovery as a service (DRaaS) or maintaining a “cold site”.
Comprehensive planning process
The backup process is less complicated than a DR plan. Usually, you need to define retention policies, backup frequency, and the number of backup targets to avoid a single point of failure. With disaster recovery, things instantly become more complicated:
- Prioritization to evaluate the importance of business applications and prioritize the recovery order of the VMs running such applications. For instance, the VM housing your CRM data is most likely more important than the one with HR data.
- DR site preparation and maintenance to house the replicas and be operational for potential failover operations.
- Assigning responsible staff and making sure they have access and permissions to carry out their duties during a disaster recovery. In addition, identifying the person(s) who are responsible for making the decision to initiate disaster recovery.
- Extensive testing. Every comprehensive DR plan requires extensive testing, as failure to execute the plan during an actual disaster can have dire repercussions.
What Disaster Recovery Solutions Should You Choose?
A short answer is that you should integrate both backup and disaster recovery planning into your data protection strategy. Modern business landscape values the “always-on” principle, which means that an organization should be ready to deliver services or goods to the customer at any time, whatever the circumstances.
Backups should mostly be used for operational recovery and long-term archival purposes. When it comes to VMs with business-critical systems and apps, they should be a part of your disaster recovery planning and should be replicated to a separate site. A comprehensive data protection strategy that combines both approaches ensures business continuity while protecting your organization’s data and maintaining data compliance.
Backup and Disaster Recovery with NAKIVO’s Solution
If you have chosen to invest in backup and disaster recovery planning for your organization, you may want to consider choosing the appropriate solution first. Such a solution should be not only reliable, but also flexible in order to allow for multiple testing options as well as accommodating virtualized infrastructure of any size.
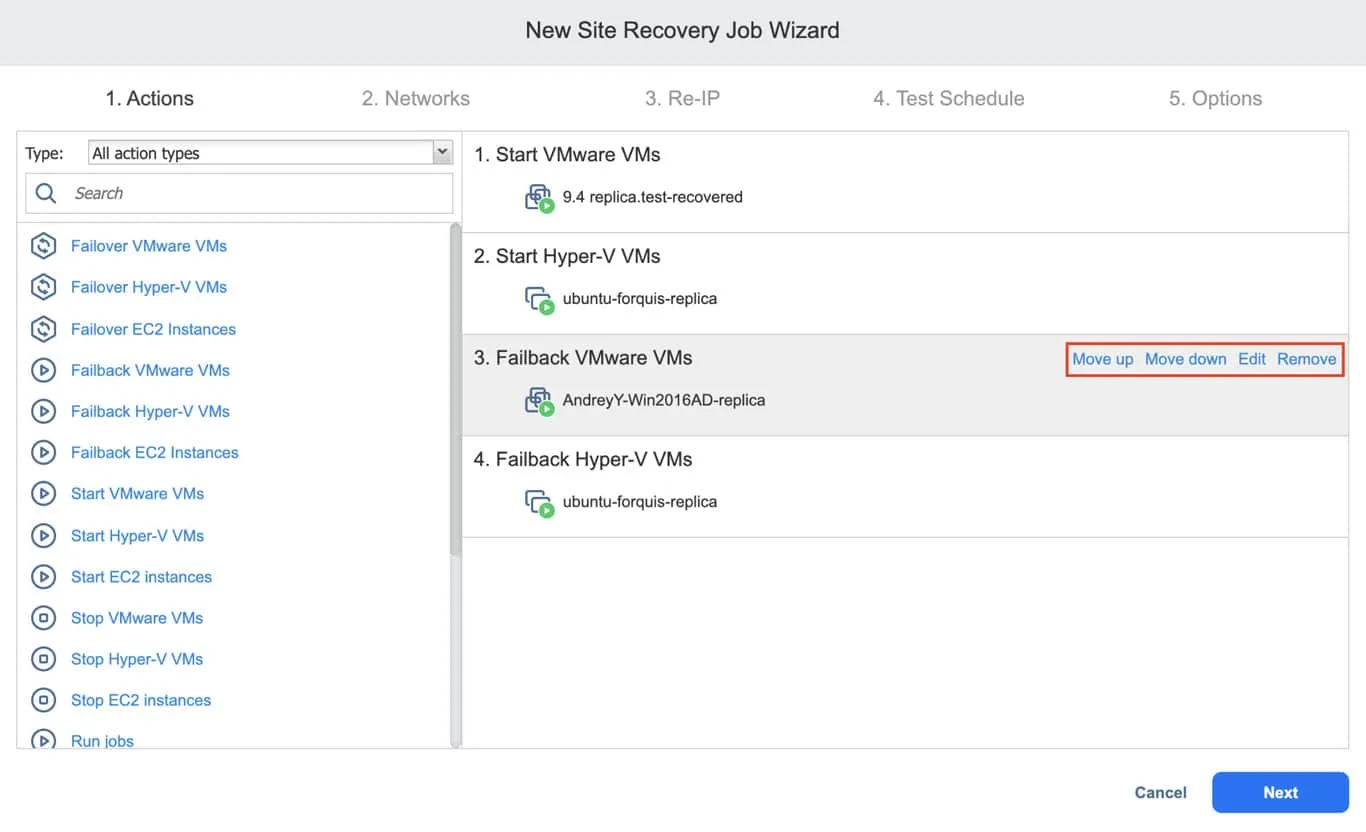
NAKIVO Backup & Replication has the in-built Site Recovery functionality that allows you to create recovery workflows of any complexity and has a flexible test scheduling system to make sure that your environment is always ready in the event of a disaster.
Site Recovery enables you to construct sequences combining specific actions, such as stopping or starting specific VMs, performing failover, running a script, etc. By using these actions, you can create either a simple workflow that performs a failover of your virtual environment, or a multi-layered, complex one that starts specific jobs or uses other Site Recovery workflows in the process.
Conclusion
Performing regular backup is not the same as having a disaster recovery plan in place. Backing up your VMs effectively means copying your data with the aim of either data retention or long-term archival. Having a disaster recovery plan is a part of a business continuity strategy, which ensures that your critical systems continue to operate after or even during a disaster or other unforeseen circumstances. Although it is recommended that you implement a disaster recovery plan in addition to a backup policy, the decision may ultimately depend on whether your business truly needs it and if you have the resources to be ready to invest in it.
NAKIVO Backup & Replication offers the full package of backup and disaster recovery solutions from a single pane of glass. Download the full-featured Free Trial to test out the solution in your own environment!



