Backup Types Explained: Full, Incremental, and Differential
Backing up data is essential for organizations and individuals alike. The efficiency of data backup in each case depends on the selected backup method because parameters such as required storage, backup time, and ease of recovery differ for each backup type. This blog post explains the most used types of backup to help you choose the type suitable for you.
How Many Types of Backup Are There?
There are three main types of traditional backups:
- Full backup
- Differential backup
- Incremental backup
There are also variations on these traditional backup types with characteristics from one or more of these types:
- Mirror backup
- Reverse-incremental backup
- Smart backup
- Continuous
There are also more modern backup types:
- Synthetic full backup
- Forever-incremental backup
Below you can see how they differ and the pros and cons of each. First, let’s look at full, differential, and incremental backups as the foundational types.
What Is a Full Backup?
A full backup creates a complete copy of the source data set. When it comes to recovery, the full backup contains all that is required to recover a machine or objects.
A full backup can be made in two ways:
- as a set of files that are exact copies of original files; or
- an image file containing all these files with the possibility to enable compression and encryption if supported by the backup solution
PRO TIP: Since each full backup image file contains the entire set of an organization’s critical data, this file can be vulnerable to unauthorized access and other threats. One way you can avoid this risk is by using data encryption if supported by your backup solution.

Full Backup Advantages and Disadvantages
This backup type is considered to be the best option in terms of simplicity and the high speed of recovery, especially with the entire data set stored in a single file. However, due to the large volume of data to be copied for each backup round, the full backup approach has several disadvantages:
- It is a highly time-consuming process, as it can take up to 10 times more time than with other backup types.
- It imposes a considerable load on the network and disks each time a backup runs, thus, interfering with routine operations of your infrastructure.
- Continuously added full backups consume a lot of storage space in the backup repository.
That is why most organizations create full backups only periodically and instead also use other backup types as part of their data protection and retention strategy. Thus, a full backup is often a starting point for implementing other backup types.
What Is a Differential Backup?
A differential backup is a backup type that saves the data that changed since the initial full backup or the most recent full backup. Therefore, the full backup is a constant reference point for subsequent backups.
The differential backup requires only two pieces of backup to recover data – a full backup and the latest differential backup (or the relevant differential backup for an older recovery point).

Differential Backup Advantages and Disadvantages
In terms of backup/restore speed, the differential backup type has some advantages:
- Backups are completed faster than full ones.
- Consumes less storage space than a full backup.
- Data recovery is faster than using an incremental backup with many increments.
The disadvantages of differential backup are:
- Recovery is slower than when using a full backup.
- Not the most optimal backup type in terms of storage space consumption.
The storage space required for differential backups is, at least for a certain period, smaller than that needed for the full backup and bigger than that necessary for the incremental backup. The catch is that increments of the changed data sets in a differential backup can grow as time progresses, and every differential backup may take up even more storage space (and time) than regular full backups.
What Is an Incremental Backup?
Incremental backup is a backup type that involves copying only data changes since the latest backup (which can be a full, incremental, or differential backup). This backup type reduces the amount of time and the load on the network compared to full backups.
The starting point for an incremental backup is creating an initial full backup first and subsequently copying only those blocks of data that have changed since the last backup job, that is, sending increments to the backup repository. Depending on the backup retention policy, a new full backup can be created at specific intervals as a start for a new cycle of incremental backups.
To illustrate the incremental backup process, suppose you make a full backup on Sunday and create incremental backups for the rest of the week:
- On Monday, only data that changed since the full backup is backed up.
- On Tuesday, only data that changed since Monday is backed up.
- And so on.
Thus, incremental backups can be run almost as often as required since each time, only the most recent changes, if any, are backed up and stored in the backup repository.

Incremental backups are fast and require much less storage space than the full backup type. Still, the recovery process is more time-consuming since you must restore both the latest full backup and the whole chain of consecutive increments. If one increment in the chain is missing or corrupted, it is impossible to perform full recovery of the latest data.
Incremental Backup Advantages and Disadvantages
The advantages of incremental backups are:
- Backup windows are smaller, as only the data changes are backed up.
- Less storage space is required compared to full and differential backup types.
- Less load on hardware and infrastructure.
- Can be run as often as needed, each increment being an individual recovery point.
Disadvantages of incremental backups are:
- Slow restore of data, as you need to restore both the initial full backup and all subsequently created increments.
- Successful data recovery depends on the integrity of all increments in the chain.
Comparison Table of 3 Main Backup Types
| Full | Differential | Incremental | |
| Storage space use | High | Medium to high | Low |
| Backup speed | Slow | Medium | Fast |
| Recovery speed | Very fast | Fast | Slow |
| Recovery requirements | The most recent backup or relevant backup for the required point in time | One full and one differential backup | Full backup and all subsequent incremental backups |
| Ease of use | Easiest | Medium | Medium |
What Is a Mirror Backup?
A mirror backup type involves creating an exact copy of the source data set with only the latest backup data version stored in the backup repository. This backup type is similar to a full backup but without the possibility of saving multiple recovery points.
In contrast to other backup types, all individual backup files are stored separately (just as they are in the source) and not in a single compressed/encrypted container file. After connecting the drive containing the mirror backup, the files can be accessed in a file manager such as Windows Explorer or in Linux bash shell. This gives direct access to backup files without performing a restore operation. The source data is “mirrored” by the mirror backup file, and the mirror backup copies only modified files.
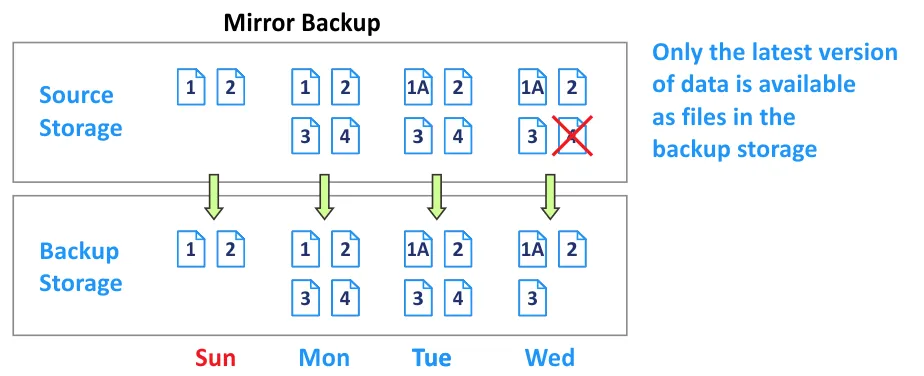
This backup type is advantageous in certain aspects, like fast recovery and the convenience of direct access to individual files. However, the mirror backup type has its drawbacks: high storage space requirements, high risk of unauthorized access (because files are not packed inside an encrypted backup image), and high risk of data corruption or misuse
Another weakness of this approach is that any change (malicious or accidental) in the source data is “mirrored” in the backup data. For example, when a file in the source is deleted, the same file in the “mirror” is also deleted. This implies that any undesirable modifications in the source due to human error, accident, sabotage, or malware will lead to the same in the backup data.
Mirror backups can be useful for recovery from hardware failure but cannot protect data in case of corruption or deletion. If you use mirror backups, you should use an additional backup scheme, such as full backups or full with incremental backups, etc., with multiple recovery points to be prepared for other data loss scenarios.
Reverse Incremental Backup
The reverse incremental backup type involves an initial full backup followed by that are reversibly “injected” into the full backup. Thus a full backup is synthesized, which is the latest version of the data set.
Moreover, all incremental backups applied to the full backup are also retained in the backup repository, “jumping” back in a backup chain behind the continuously updated full backup. This allows rolling back to the recent full backup in case you need to restore some older versions of your data.

The reverse incremental backup method is advantageous in terms of fast recovery of the latest data version since it contains the most recent full backup file. The recovery speed from the full backup is very high. Another advantage is the ability to restore data from the latest recovery point if one of the incremental backups is corrupted.
Reverse-incremental backup is used when a backup strategy requires fast recovery of the latest version of data and a short recovery time objective (RTO).
Smart Backup
A smart backup is a combination of full, incremental, and differential backups. Depending on the backup objectives and available storage space, smart backup provides for efficient backup data and storage space management. The method follows a certain “smart” pattern to manipulate backup, cleaning, and merging operations. The table below gives an idea of how this backup type works.
| Backup # | Source Data Action | Smart Backup Operations |
| 1 | Add 2 GB of initial files | 2 GB – Full |
| 2 | Modify 500 MB | 500 MB – Incremental |
| 3 | Modify 500 MB | 500 MB – Incremental |
| 4 | Modify 500 MB | 500 MB – Differential |
| 5 | Modify 500 MB | 500 MB – Incremental |
| 6 | Modify 500 MB | 500 MB – Differential + backups # 2 & 3 are deleted |
| 7 | Modify 500 MB | 500 MB – Incremental |
| 8 | Modify 500 MB | 500 MB – Differential + backups # 4 & 5 are deleted |
| 9 | Modify 500 MB | 500 MB – Differential + backups # 4 & 5 are deleted |
| 10 | Modify 500 MB | 500 MB – Differential + backups # 6 & 7 are deleted |
By using the smart type of backup, you get the benefit of having multiple recovery points and an efficient storage sape use strategy.
Continuous Data Protection (CDP)
In contrast to other backup types running on a periodic basis, continuous data protection, sometimes called “continuous backup”, logs every change in the source data set, similar to the mirror backup. The difference is that in CDP, the changes log can be rolled back to restore older states of data.
Continuous backup is also called a real-time backup because all changes are backed up as soon as possible. Organizations use the continuous backup type when they need to achieve the shortest recovery point objective (RPO).
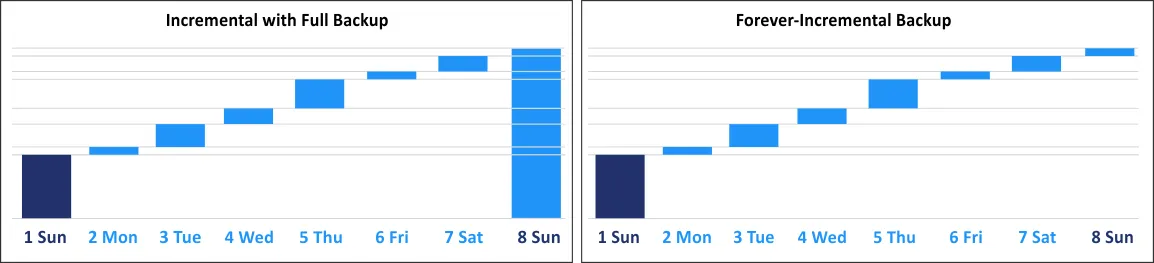
Synthetic Full Backup
A synthetic full backup involves creating an initial full backup, then running incremental backups, and synthesizing a full backup at regular intervals from the increments rather than the source data. This means that at set times, incremental backups are consolidated and applied to the existing full backup to synthesize the most recent full backup as a new starting point without relying on any source machines. The data set contained in a backup synthesized at the backup server side is the same as if copied from the source server.

The synthetic full backup type has all the advantages of regular full backups while consuming less time and storage space.
Advantages of the synthetic full backup are:
- Fast backup and restore operations
- Better storage management
- Low storage space requirements
- Low network workload
- Low disk and processor load on source servers
Forever-Incremental Backup
A forever-incremental backup involves an initial full backup as a reference point to track changes, followed by only incremental backups. No other backup types, like periodic full backup, are used and hence the name is forever incremental.
To illustrate this, suppose that you create a full backup on Sunday. Starting the next day, incremental backups are created on a daily basis:
- Monday: Two new blocks, A and B, are created in the source data set.
- Tuesday: Block A is deleted, and a new block C is created in the source data set.
- Wednesday: Block B is deleted, and a new block D is created in the source data set.
With this schedule, the forever-incremental backup tracks daily changes, without retaining duplicated data blocks in the backup repository to reduce storage space consumption. At the same time, references are added to recovery points indicating related data blocks and the restore sequence.
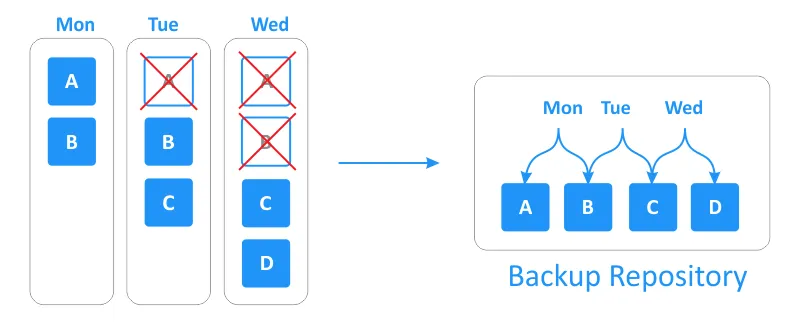
Depending on the backup retention policy, after creating a series of incremental backups, the expired recovery points are removed to free up storage space in the backup repository. All stored backup data is organized in a way that both the initial full backup and retained increments enable full restore operation together.
In the image below, you can see an example of how the forever-incremental backup type works when we set the retention policy to keep the three latest recovery points.

Advantages of the forever-incremental backup are the same as those of the synthetic full backup type:
- Fast backup and restore operations
- Better storage management
- Low storage space requirements
- Low network workload;
- Low consumption of source server’s hardware resources
Conclusion
There is no one backup type that can work in all environments and cases. The choice depends on your specific organization’s requirements as dictated by the protection policies, available storage, resources, and media, network bandwidth, service-level agreements, critical data areas, etc. On the other hand, forever-incremental and synthetic full types of backup have decisively modernized the backup process and are the most up-to-date and efficient data protection techniques designed to meet the needs of most organizations.
NAKIVO Backup & Replication is a modern data protection solution that provides both incremental with full (active or synthetic full) and forever-incremental backup types, as well as other security and performance features like encryption, compression, deduplication, etc.



