Differential Backup vs. Incremental Backup
Modern backup solutions deliver different technologies to help save on storage space requirements, cut backup windows, improve performance, etc. Controlling the storage space required for backup data remains one of the biggest concerns of organizations of all sizes. There are multiple backup types and each type can be preferable in a particular situation.
Read on to learn more about full, incremental and differential backup differences and the pros and cons of each. Determine which backup types are best for a reliable data protection strategy for your organization.

Full vs Incremental vs Differential Backup
Understanding the difference between incremental and differential backup can be confusing at first glance. Let’s look at the three main backup types and their working principle to understand these differences.
What is a full backup?
A full backup is an approach whereby all source data is copied to a backup destination. A full backup can be an exact copy of files on a medium, an image file in a backup repository, etc. In more detail, all files on a partition with a file system are copied by copying all blocks that contain data, that is, data not marked as empty or ready to be written.
| Advantages | Disadvantages |
|
|
In practice, organizations usually don’t use full backup for daily data backups. A full backup can be a suitable option when you back up data at long intervals, for example, monthly or once a year. In addition, a full backup is required initially before you can proceed with incremental and differential backup types.
What is an incremental backup?
An incremental backup is an approach whereby only data changes (referred to as increments) are copied since the last backup of any type, whether full or incremental. As a result, you obtain a chain of backups starting from a full backup and followed by the increments.
In practice, there are two types of incremental backups:
- Forever-incremental means that all backups after the initial full backup are incremental. This is the traditional incremental backup method.
- Incremental with full means that you periodically make a full backup to avoid using the long chain of incremental backups. This is a traditional incremental backup type.
Note that forever-incremental backups can reduce backup windows. However, recovery is slower from this type of backup than from an incremental with full or a full backup. Using incremental backups with periodical full improves the reliability of backups and recovery speed, that is why they are the best practice in most situations.
| Advantages | Disadvantages |
|
|
The incremental backup is the recommended approach if you need to back up data frequently. For virtualized environments, backup solutions usually rely on native VMware Changed Block Tracking or Microsoft Hyper-V Resilient Change Tracking technologies to create incremental VM backups.
Learn More: Read about how VMware’s Changed Block Tracking works in this blog post.
What is a differential backup?
A differential backup is an approach whereby all data that has changed since the initial full backup is copied. All subsequent differential backups contain all the data changes since the last full backup and not since the previous differential backup.
This method sits somewhere in between a full backup and a traditional incremental one when it comes to backup and recovery speed and storage space requirements.
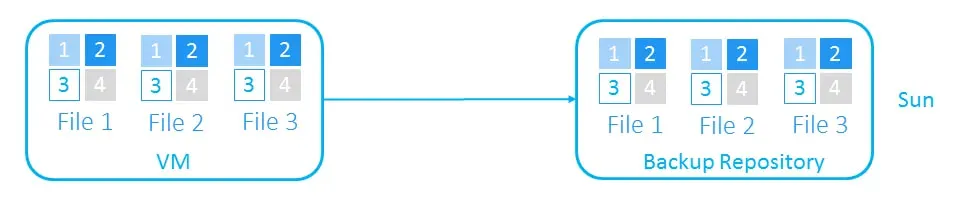
Let’s look at how the differential backup works using an example of a VM backup. We will use the following test setup: 3 files on a VM, with each file containing blocks 1, 2, 3, and 4.
Example
- On Sunday, we create a full backup of the VM.
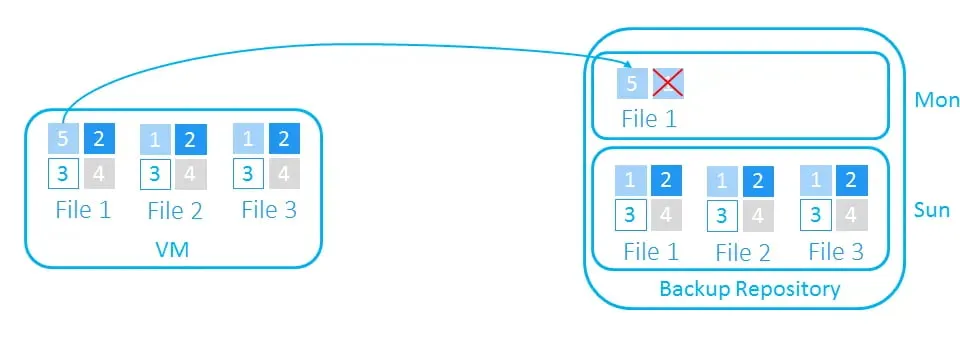
- On Monday, we change block 1 to 5 in File 1.
With the differential and incremental backup methods, a backup application copies the modified block of File 1 and informs the backup repository where it should be placed.
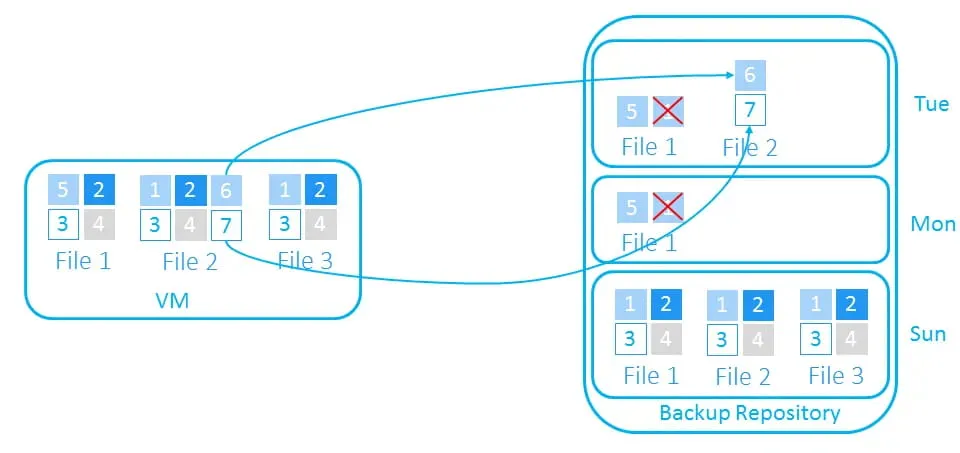
- On Tuesday, we add blocks 6 and 7 to File 2.
With the differential method, the changed block of File 1 from Monday is copied along with the new changes.
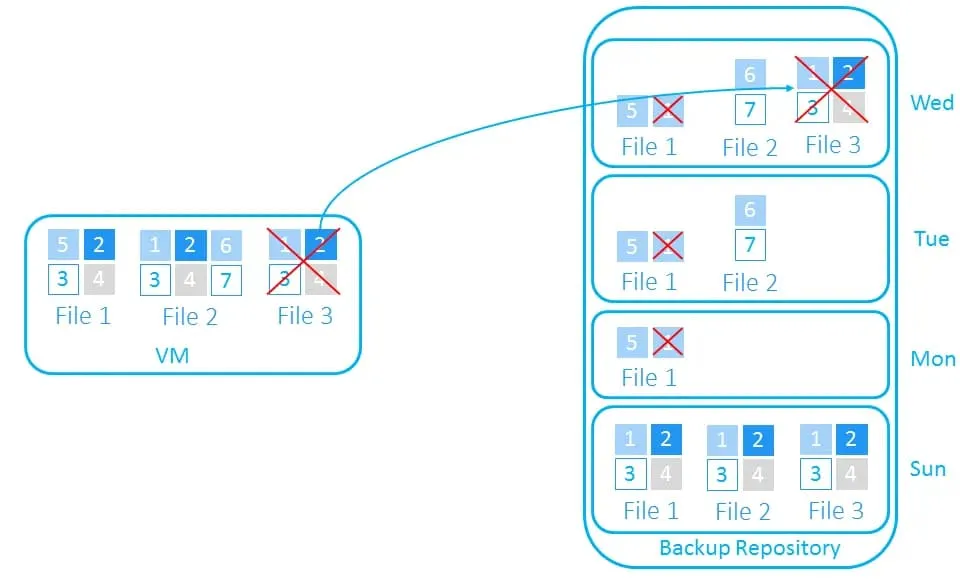
- On Wednesday, we delete File 3.
All changes are copied during the backup: the change in File 1, the additional two blocks in File 2, and the information that File 3 was deleted.
| Advantages | Disadvantages |
|
|
In the next section, we are going to explain the difference between incremental and differential backup to understand which can best benefit a data protection strategy.
Incremental vs Differential Backup: Which One Is Better?
Let’s compare differential and incremental backups based on three parameters: backup speed, recovery speed, and the size required in the backup repository.
- Backup speed. During the first backup, the time needed to complete the job is similar for both the incremental and differential approaches as they transfer the same data during the backup following the initial full backup. However, the differences grow over time, and more time will be needed to complete the job. The incremental backup, on the other hand, will copy only changes made since the previous job run each time.
- Recovery speed. When the time for recovery comes, the differential backup may seem to be a winner because it requires only two operations: restoring the initial backup and applying the last differential set, while the incremental backup has to rebuild all the increments.
With the same amount of data, the incremental backup requires more resources to put the data in the right places. However, if the incremental backup is bundled with synthetic data storage, the backup application knows which blocks of data should be used to restore a VM. Thus, the recovery time is similar to the time required to restore data from a full backup.
- Backup repository size. The biggest drawback of the differential backup is the storage space required. Over time, the space requirements grow exponentially. Very soon, it becomes more reliable just to perform one more full backup rather than continue making differential backups.
Here is a graph illustrating how drastically differential backup occupies space. The model for the graph is a 2-TB VM with daily changes of 5% of its size (approximately 100 GB per day). In just a week, the backup size will be twice as big as the source VM. At the same time, the forever-incremental backup will reach this point only in three weeks.
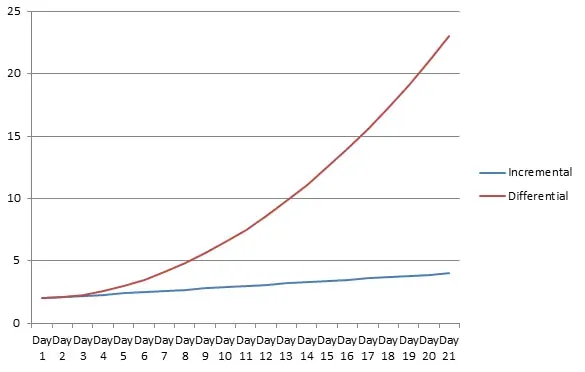
This leads to the fact that differential backup requires a periodical full backup, as it can occupy the whole backup repository in a matter of days. On some busy days, for example, when there’s a major OS or software update arrives, a differential backup may just fail because there is not enough space. Thus, the incremental backup is a winner in all three categories.
Conclusion
In the incremental vs differential backup comparison, the incremental backup has the upper hand due to its universality, fast backup speed and storage space savings. However, you can use the differential backup in some exceptional scenarios when the interval between full backups is not long and to have fewer dependencies between backups. A full backup is a point to start for both backup types.
NAKIVO Backup & Replication is the universal data protection solution that supports the forever-incremental backup and periodic full with incremental backup.
Download the Free Edition of the NAKIVO solution for reliable and fast backups and recoveries for different IT infrastructures.



