What Is Deduplication in Backup Data Storage
Today’s large virtual infrastructures generate a vast amount of data. This leads to an increase in backup data and in expenditure on backup storage infrastructure, which includes storage appliances and their maintenance. For this reason, network administrators look for ways to save storage space when creating frequent backups of critical machines and applications.
One of the widely-used techniques is backup deduplication. This blog post covers what data deduplication is, deduplication types, and use cases with a focus on backups.

What Is Deduplication?
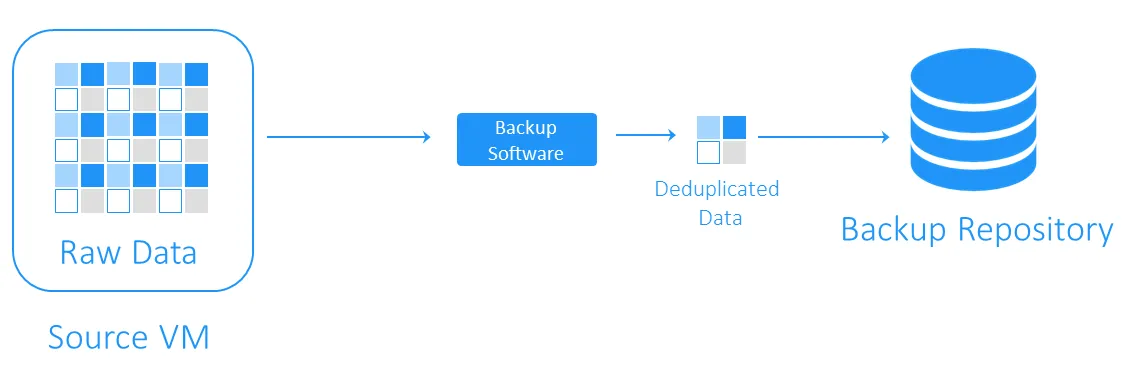
Data deduplication is a storage capacity optimization technology. Data deduplication involves reading the source data and the data already in storage to transfer or save only unique data blocks. References to the duplicate data are maintained. By using this technology to avoid duplicates on a volume, you can save disk space and reduce storage overhead.
Data deduplication origins
The predecessors of data deduplication are the LZ77 and LZ78 compression algorithms introduced in 1977 and 1978 respectively. They involve replacing repeated data sequences with references to the original ones.
This concept influenced other popular compression methods. The most well-known of these is DEFLATE, which is used in PNG image and ZIP file formats. Now let’s look at how deduplication works with VM backups and how exactly it helps save storage space and costs spent on infrastructure.
What Is Deduplication in Backup?
During a backup, data deduplication checks for identical data blocks between the source storage and target backup repository. Duplicates are not copied, and a reference, or pointer, to the existing data blocks in the target backup storage is created.

How Much Space Can Data Deduplication Save You?
To understand how much storage space can be gained with deduplication, let’s consider an example. The minimum system requirements for installing Windows Server 2016 is at least 32 GB of free disk space. If you have ten VMs running this OS, backups will total at least 320 GB, and this is just a clean operating system without any applications or databases on it.
The odds are that if you need to deploy more than one virtual machine (VM) with the same system, you will use a template, and this means that initially, you will have ten identical machines. And this also means that you will get 10 sets of duplicate data blocks. In this example, you will have a 10:1 storage space saving ratio. In general, savings ranging from 5:1 to 10:1 are considered to be good.
Data Deduplication Ratio
The data deduplication ratio is a metric used to measure the original data size versus the data’s size after redundant portions are removed. This metric allows you to rate the effectiveness of the data deduplication process. To calculate the value, you should divide the amount of data before deduplication by the storage space consumed by this data after being deduplicated.
For example, the 5:1 deduplication ratio means that you can store five times more backed-up data in your backup storage than it is required to store the same data without deduplication.
You should determine the deduplication ratio and storage space reduction. These two parameters are sometimes confused. Deduplication ratios don’t change proportionally to data reduction benefits as the law of diminishing returns is bound to come into play beyond a certain point. See the graph below.

This means that the lower ratios can bring more significant savings than the higher one. For example, a 50:1 deduplication ratio is not five times better than a 10:1 ratio. The 10:1 ratio provides a 90% reduction of the consumed storage space, while the 50:1 ratio increases this value to 98%, given that most of the redundancy has already been eliminated. For more information on how these percentages are calculated, you can see Storage Networking Industry Association’s (SNIA) document on data deduplication.
Factors that Impact Data Deduplication Efficiency
It is difficult to predict data reduction efficiency until the data is actually deduplicated due to several factors. The following are some of the factors that have an impact on data reduction when using deduplication:
- Data backup types and policies. Deduplication for full backups is more effective than for incremental or differential backups.
- Change rate. If there are many data changes to back up, then the deduplication ratio is lower.
- Retention settings. The longer you store data backups in backup storage, the more effective the deduplication of data on this storage can be.
- Data type. Deduplication for files in which data has been already compressed, such as
JPG, PNG, MPG, AVI, MP4, ZIP, RAR, etc., is not effective. The same is true for metadata-rich and encrypted data. Data types containing repetitive parts are better for deduplication. - Data scope. Data deduplication is more effective for a large scope of data. Global deduplication can save more storage space compared to local deduplication.
Note: Local deduplication works on a single node/disk device. Global deduplication analyzes the whole data set on all nodes/disk devices to eliminate data duplicates. If you have multiple nodes with local deduplication enabled on each, deduplication would not be as efficient as with global deduplication enabled for them.
- Software and hardware. Combining software solutions and deduplication hardware can offer better deduplication ratios than software alone. For example, NAKIVO’s backup solution delivers integration with
HP StoreOnce,Dell EMC Data Domain, andNEC HYDRAstordeduplication appliances for deduplication ratios of up to 17:1.
Backup Deduplication Techniques
The backup deduplication techniques can be categorized based on the following:
- Where data deduplication is done
- When the deduplication is done
- How deduplication is done
Where data deduplication is done
Backup deduplication can be done on the source side or on the target side, and those techniques are called source-side deduplication and target-side deduplication respectively.
Source-side deduplication
Source-side deduplication decreases network load because less data is transferred during the backup. However, it requires a deduplication agent to be installed on each VM or on each host. The other drawback is that source-side deduplication may slow down VMs due to calculations required for the identification of duplicate data blocks.

Target-side deduplication
Target-side deduplication first transfers the data to the backup repository and then performs deduplication. The heavy computing tasks are performed by the software responsible for deduplication.
When data deduplication is done
Backup deduplication can be inline or post-processing.
- Inline deduplication checks for data duplicates before it is written to a backup repository. This technique requires less storage space in a backup repository as it clears the backup data stream from redundancies, but it results in longer backup time as the inline deduplication happens during the backup job.
- Post-processing deduplication processes data after it is written to the backup repository. Obviously, this approach requires more free space in the repository, but backups run faster, and all necessary operations are made afterward. Post-processing deduplication is also called asynchronous deduplication.
How data deduplication is done
The most common methods to identify duplicates are the hash-based and modified hash-based ones.
- With the hash-based method, the deduplication software divides data into blocks of fixed or variable length and calculates a hash for each of them using cryptographic algorithms such as
MD5, SHA-1,orSHA-256. Each of these methods yields a unique fingerprint of the data blocks, so the blocks with similar hashes are considered to be identical. The drawback of this method is that it may require significant computing resources, especially in the case of large backups. - The modified hash-based method uses simpler hash-generating algorithms such as
CRC, which produce only 16 bits (compared to that of 256 bits inSHA-256). Then, if the blocks have similar hashes, they are compared byte-by-byte. If they are completely similar, the blocks are considered to be identical. This method is a bit slower than the hash-based one but requires less computing resources.
Choosing Backup Deduplication Software
Backup deduplication is one of the most popular use cases of deduplication. Still, you need to have the appropriate software solution and hardware for storage to implement this data reduction technology.
NAKIVO Backup & Replication is a backup solution that supports using the global target post-processing deduplication with modified hash-based duplicates detection. You can also take advantage of source-side deduplication by integrating a deduplication appliance such as DELL EMC Data Domain with DD Boost, NEC HYDRAstor and HP StoreOnce with Catalyst support with the NAKIVO solution.