Introduction to Amazon S3: How Object Storage in the Cloud Works
Amazon Simple Storage Service (S3) is a popular cloud storage service part of the Amazon Web Services (AWS). Amazon S3 cloud storage provides high reliability, flexibility, scalability and accessibility. The number of objects and the amount of data stored in Amazon S3 is unlimited. S3 cloud storage is attractive for business because you pay only for what you use.
However, terminology and methodology may lead to misunderstanding and difficulties for new Amazon S3 users. Where is S3 data stored? How does Amazon S3 storage work? This blog post explains the main concepts and working principle of Amazon S3 cloud storage.

About Amazon S3 Storage
Amazon S3 was the first cloud service from AWS and was launched in 2006. Since then, the popularity of this storage service has been growing. Now Amazon provides a wide list of other cloud services, but Amazon S3 cloud storage is the most widely used one. In addition to Amazon S3 storage, AWS offers Amazon EBS volumes for EC2 and Amazon Drive. But the three services have different uses and purposes.
EBS (Elastic Block Storage) volumes for EC2 (Elastic Compute Cloud) instances are virtual disks for virtual machines residing in the Amazon cloud. As you can understand from the EBS name, this is a block storage in the cloud that is the analog of hard disk drives in physical computers. An operating system can be installed on an EBS volume attached to an EC2 instance.
Amazon Drive (formerly known as Amazon Cloud Drive) is the analog of Google Drive and Microsoft OneDrive. Amazon Drive has a smaller range of features than Amazon S3. Amazon Drive is positioned as a storage service in the cloud to back up photos and other user data.
Amazon S3 cloud storage is an object-based storage service. You cannot install an operating system when you use Amazon S3 storage because data cannot be accessed on the block level as it is required by an operating system. If you need to mount Amazon S3 storage as a network drive to your operating system, use a file system in userspace. Read the blog post about mounting S3 cloud storage to different operating systems. Google Cloud is the analog of Amazon S3 cloud storage.
Amazon S3 Main Concepts
If you are going to use Amazon S3 for the first time, some concepts may be unusual and unfamiliar for you. Methodology of storing data in S3 cloud is different from storing data on traditional hard disk drives, solid state drives or disk arrays. Below is an overview of the main concepts and technologies used to store and manage data in Amazon S3 cloud storage.
How does S3 store files?
As explained above, data in Amazon S3 is stored as objects. This approach provides highly scalable storage in the cloud. Objects can be located on different physical disk drives distributed across a datacenter. Special hardware, software, and distributed file systems are used in Amazon datacenters to provide high scalability. Redundancy and versioning are features implemented by using the block storage approach. When a file is stored in Amazon S3 as an object, it is stored in multiple places (such as on disks, in datacenters or availability zones) simultaneously by default. Amazon S3 service regularly checks data consistency by checking control hash sums. If data corruption is detected, the object is recovered by using the redundant data. Objects are stored in Amazon S3 buckets. By default, objects in Amazon S3 storage can be accessed and managed via the web interface.
What is S3 object storage?
Object storage is a type of storage where data is stored as objects rather than blocks. This concept is useful for data backup, archiving, and scalability for high-load environments.
Objects are the fundamental entities of data storage in Amazon S3 buckets. There are three main components of an object – the content of the object (data stored in the object such as a file or directory), the unique object identifier (ID), and metadata. Metadata is stored as key-pair values and contains information such as name, size, date, security attributes, content type, and URL.
Each object has an access control list (ACL) to configure who is permitted to access the object. Amazon S3 object storage allows you to avoid network bottlenecks during rush hour when traffic to your objects stored on S3 cloud storage increases significantly. Amazon provides flexible network bandwidth but charges for network access to the stored objects. Object storage is good when a high number of clients must access the data (high read frequency). Search through metadata is faster for the object storage model.
Read also about Amazon S3 encryption that can help you protect data stored in Amazon S3 cloud storage and enhance security.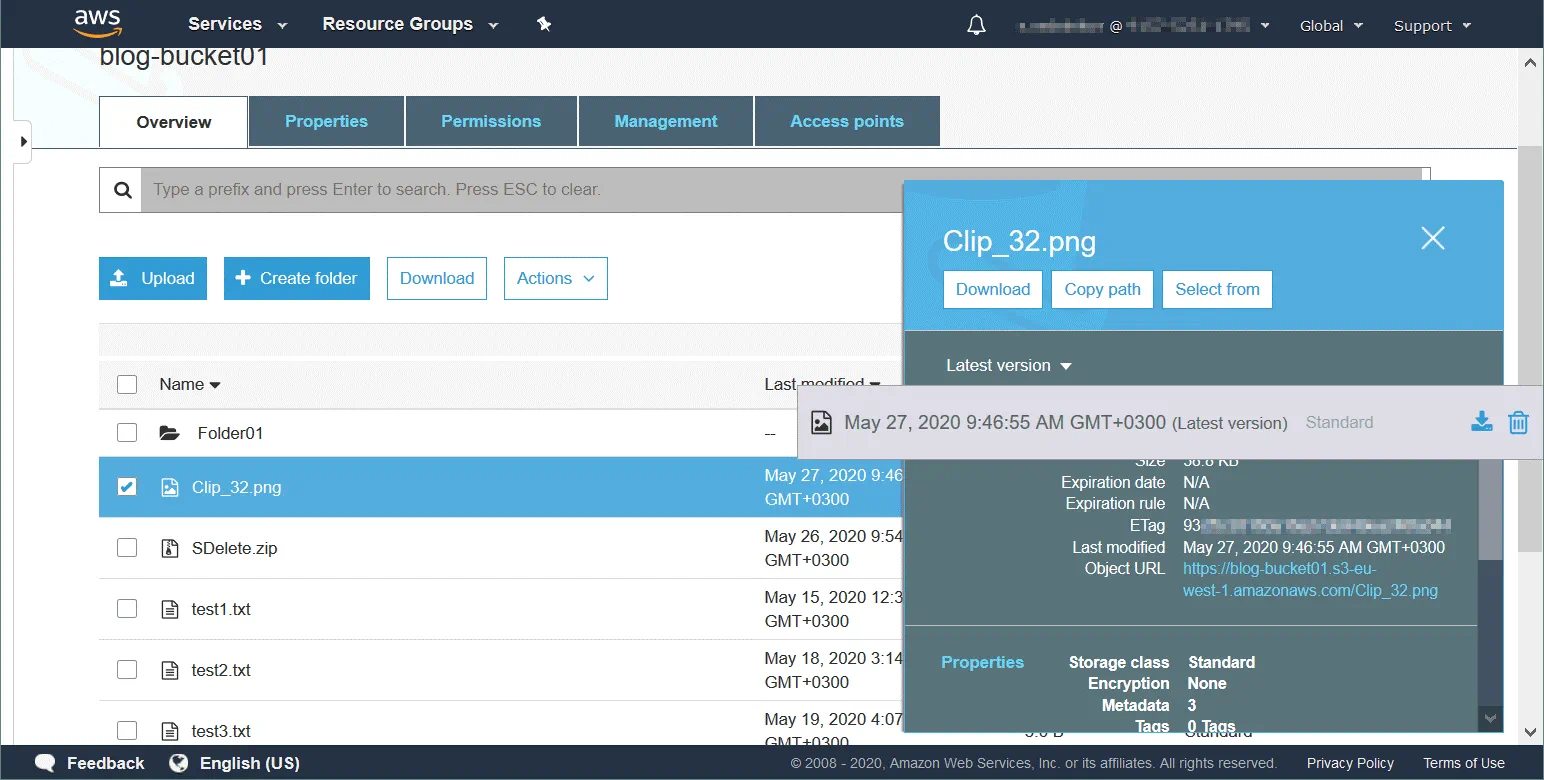
Buckets
A bucket is a fundamental logical container where data is stored in Amazon S3 storage. You can store an infinite amount of data and unlimited number of objects in a bucket. Each S3 object is stored in a bucket. There is a 5 TB limitation for the size of one object stored in a bucket. Buckets are used to organize namespace at the highest level and are used for access control.
Keys
An object has a unique key after it has been uploaded to a bucket. This key is a string that imitates a hierarchy of directories. Knowing the key allows you to access the object in the bucket. A bucket, key, and version ID identify an object uniquely. For example, if a bucket name is blog-bucket01, the region where datacenters store your data is located is s3-eu-west-1 and the object name is test1.txt (a text file), the URL to the needed file stored as the object in the bucket is:
https://blog-bucket01.s3-eu-west-1.amazonaws.com/test1.txt
Permissions must be configured by editing object attributes if you want to share objects with other users. Similarly, you can create a TextFiles folder and store the text file in that folder:
https://blog-bucket01.s3-eu-west-1.amazonaws.com/TextFiles/test1.txt
There are two types of the URL that can be used:
- bucketname.s3.amazonaws.com/objectname
- s3.amazon.aws.com/bucketname/objectname
AWS Regions
Amazon has datacenters in different regions across the globe including the USA, Ireland, South Africa, India, Japan, China, Korea, Canada, Germany, Italy, and Great Britain. You can select the region you want when creating a bucket. It is recommended that you select a region that is closest to you or to your customers to provide lower latency for a network connection or minimize costs (because the price for storing data is different depending on the region). Data stored in a certain AWS region never leaves the datacenters of that region until you migrate the data manually. AWS Regions are isolated from each other to provide fault tolerance and stability.
Each region contains Availability Zones that are isolated locations within an AWS Region. At least three Availability Zones are available for each region to prevent failures caused by disasters such as fires, typhoons, hurricanes, floods, and so on.
The Data Consistency Model
The read-after-write consistency check is performed for objects stored in Amazon S3 storage. Amazon S3 replicates data across servers and datacenters within a selected region to achieve high availability. After a successful PUT request, the changed data must be replicated across the servers. This process can take some time. A user can get the old data or updated data in this case, but not the corrupted data. This is also true for deleted objects and buckets. Object locking is not performed when new objects are sent to S3 buckets. The latest PUT request wins if multiple PUT requests are performed simultaneously. You can create your own application with a locking mechanism that works with objects stored in Amazon S3 storage.
Amazon S3 Features
The concept of object-based storage allows Amazon to provide useful features and high flexibility for storing data in Amazon S3 storage and management. Let’s review these features.
Versioning
Object versioning allows you to store multiple versions of an object in one bucket. This feature can protect objects stored in Amazon S3 storage against unintended editing, overwrites, or deletions. After changing or deleting an object you can restore one of the previous versions of that object. Versioning is implemented due to using the object storage approach. You can use versioning for archival purposes. Versioning is disabled by default.
A version ID is assigned to each S3 object even if versioning is not enabled (in this case the version ID value is set to null). If versioning is enabled, a new version ID value is assigned to a new version of the object after writing changes. Versioning can be enabled on the bucket level. The version ID value of the first version of the object remains the same. When you delete an object from an S3 bucket (with versioning enabled), the delete marker is applied to the latest version of the object.
Storage classes
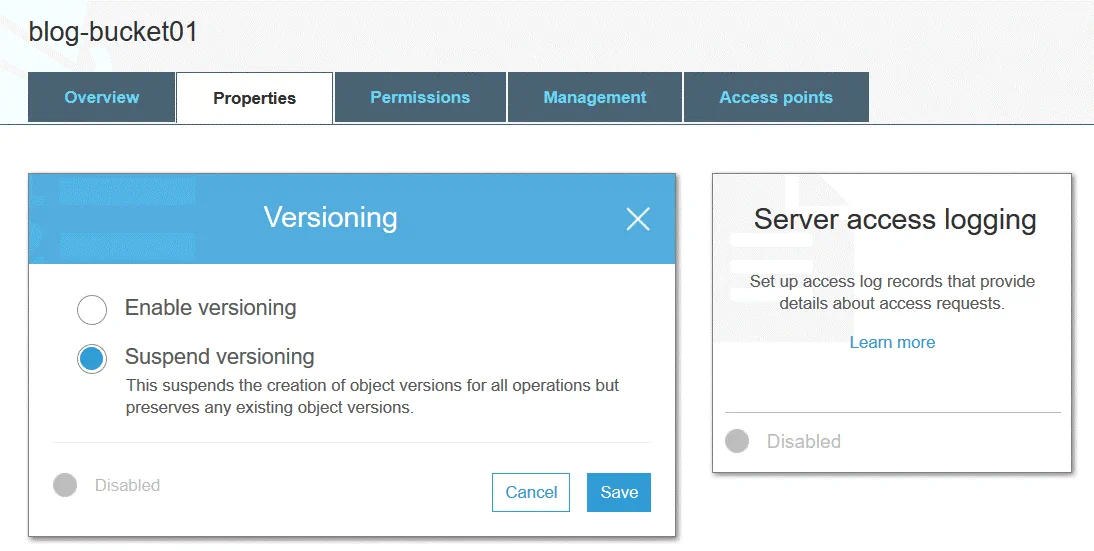
Amazon S3 storage classes define the purpose of the storage selected for keeping data. A storage class can be set at the object level. However, you can set the default storage class for objects that will be created at the bucket level.
S3 Standard is the default storage class. This class is hot data storage and is good for frequently used data. Use the Standard storage class to host websites, distribute content, develop cloud applications, and so on. High storage costs, low restore costs, and fast access to the data are the features of this storage class.
S3 Standard-IA (infrequent access) can be used to store data that is accessed less frequently than in S3 Standard. S3 Standard-IA is optimized for a longer storage duration period. There is a charge for retrieving data stored in the S3 Standard-IA storage class. Additionally, in both S3 Standard and S3 Standard-IA you have to pay for data requests (PUT, COPY, POST, LIST, GET, SELECT).
S3 One Zone-IA is designed for infrequently accessed data. Data is stored only in one availability zone (data is stored in three availability zones for S3 Standard) and as a result, a lower redundancy and resiliency level is provided. The declared level of availability is 99.5%, which is lower than that of the other two storage classes. S3 One Zone-IA has lower storage costs, higher restore costs, and you have to pay for data retrieval on a per-GB basis. You can consider using this storage class as cost effective to store backup copies or copies of data made with Amazon S3 cross-region replication.
S3 Glacier doesn’t offer instant access to stored data, unlike the other storage classes. S3 Glacier can be used to store data for long term archival at a low cost. There is no guarantee for uninterrupted operation. You need to wait from a few minutes to a few hours to retrieve the data. You can transfer old data from storage of a higher class (for example, from S3 Standard) to S3 Glacier by using S3 lifecycle policies and reduce storage costs.
S3 Glacier Deep Archive is similar to S3 Glacier, but the time needed to retrieve the data is about 12 hours to 48 hours. The price is lower than the price for S3 Glacier. The S3 Glacier Deep Archive storage class can be used to store backups and archival data of companies that follow regulatory requirements for data archival (financial, healthcare). This is a good alternative to tape cartridges.
S3 Intelligent-Tiering is a special storage class that uses other storage classes. S3 Intelligent-Tiering is intended to automatically select a better storage class to store data when you don’t know how frequently you will need to access this data. Amazon S3 can monitor patterns of accessing data when using S3 Intelligent-Tiering, and then store the objects in one of the two selected storage classes (one which is for frequently accessed data and another is for rarely accessed data). This approach gives you optimal cost-effectiveness without compromising on performance.
For example, if you access an object stored in a storage class for infrequently accessed data, this object is moved automatically to a storage class for frequently accessed data. Otherwise, if an object was not accessed for a long time, the object is moved to the storage class for unfrequently used data. Objects can be located in the same bucket and storage class is changed at the S3 object level.
Access control lists
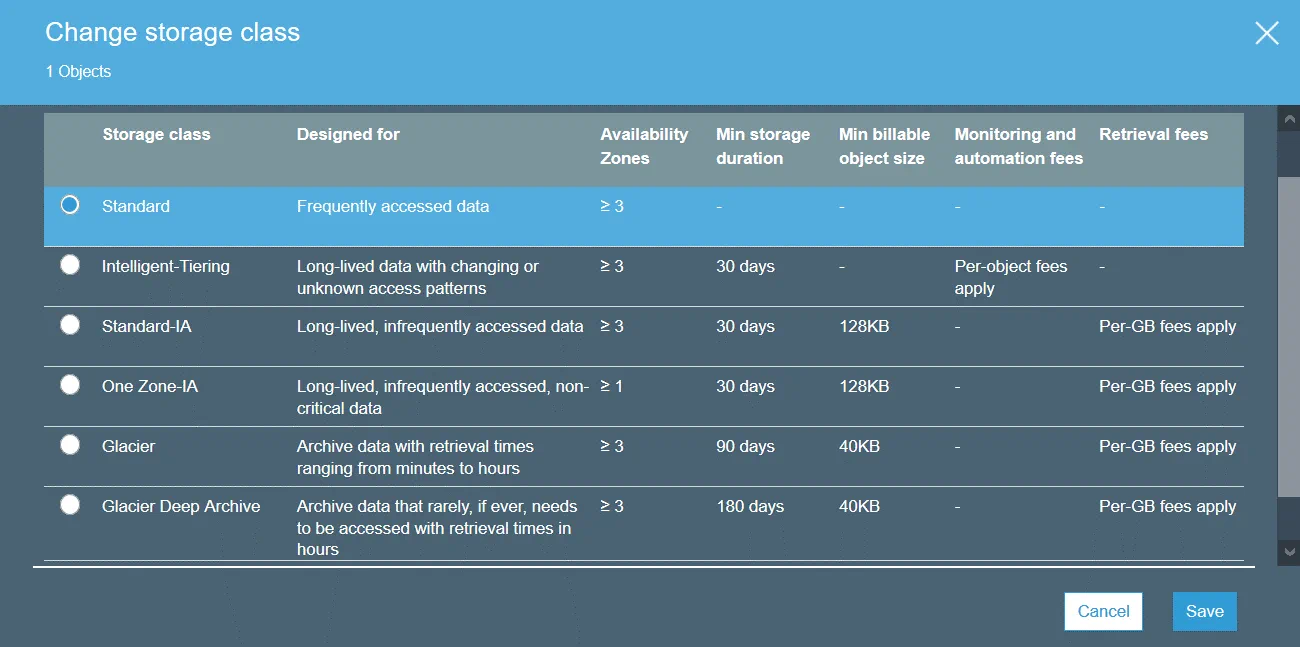
An access control list (ACL) is a feature used to manage and control access to objects and buckets. Access control lists are resource-based policies that are attached to each bucket and object to define users and groups that have permissions to access the bucket and object. By default, the resource owner has full access to a bucket or object after creating the resource. Bucket access permissions define who can access objects in the bucket. Object access permissions define users who are permitted to access objects and the access type. You can set read-only permissions for one user and read-write permissions for another user, for example.
The complete list of users who can have permissions (a user who has permissions is called grantee):
Owner – a user who creates a bucket/object.
Authenticated Users – any users who have an AWS account.
All Users – any users including anonymous users (users who don’t have an AWS account).
User by Email/Id – a specified user who has an AWS account. The email or AWS ID of a user must be specified to grant access to this user.
Available types of permissions:
Full Control – this permission type provides Read, Write, Read (ACP), and Write ACP permissions.
Read – allows to list the bucket content when applied on the bucket level. Allows to read the object data and metadata when applied on the object level.
Write – can be applied only at the bucket level and allows to create, delete, and overwrite any object in the bucket.
Read Permissions (READ ACP) – a user can read permissions for the specified object or bucket.
Write Permissions (WRITE ACP) – a user can overwrite permissions for the specified object or bucket. Enabling this permission type for a user is equal to setting Full Control permissions because the user can set any permissions for his/her account. This permission is available for the bucket owner by default.
Bucket policies
Bucket policies are resource-based AWS identities and access management policies that are used to create conditional rules for granting access permissions to AWS accounts and users when accessing buckets and objects in buckets. You can use bucket policies to define security rules for more than one object in a bucket.
The bucket policy is defined as a JSON file. The bucket policy configuration text must meet JSON format requirements to be valid. The bucket policy can be attached only on a bucket level and is inherited to all objects in the bucket. You can grant access for users who are connecting from specified IP addresses, users of specified AWS accounts, and so on.
Below you can see the example of a policy that grants full access to all users of one account and read-only access to every user of another account.
{
"Statement": [
{
"Effect": "Allow",
"Principal": {
"SGWS": "95381782731015222837"
},
"Action": "s3:*",
"Resource": [
"urn:sgws:s3:::blog-bucket01",
"urn:sgws:s3:::blog-bucket01/*"
]
},
{
"Effect": "Allow",
"Principal": {
"SGWS": "30284200178239526177"
},
"Action": "s3:GetObject",
"Resource": "urn:sgws:s3:::blog-bucket01/shared/*"
},
{
"Effect": "Allow",
"Principal": {
"SGWS": "30284200178239526177"
},
"Action": "s3:ListBucket",
"Resource": "urn:sgws:s3:::blog-bucket01",
"Condition": {
"StringLike": {
"s3:prefix": "shared/*"
}
}
}
]
}
Users can access Amazon S3 storage by using access keys (Access Key ID and Secret Access Key) without entering the username and password. This approach allows you to enhance security and is used to create applications that use APIs to access Amazon S3 cloud storage.
APIs for Amazon S3
Amazon provides application programming interfaces (APIs) to access S3 functionality and develop own applications that must work with Amazon S3 storage. There are REST and SOAP interfaces provided by Amazon. The REST interface uses standard HTTP requests to work with buckets and objects. Standard HTTP headers are used by the REST API. The SOAP interface is another available interface. Using SOAP over HTTP is deprecated but you still can use SOAP over HTTPS.
The Paying Model
Amazon S3 provided the “pay only for what you use” model. Minimum fee is not required – you don’t need to pay for a predetermined amount of storage and network traffic. There are usage categories for what you must pay:
Storage. Pay for objects stored in Amazon S3. The amount of money you have to pay depends on the used storage space, the time of storing objects in Amazon S3 storage (during the month), and the storage class used by stored objects.
Requests and data retrieval. You must pay for requests made to retrieve data stored in Amazon S3 cloud storage.
Data transfer. You must pay for all used bandwidth (inbound and outbound traffic) except incoming data from the internet; outgoing data that is transferred to Amazon EC2 instances that are located in the same AWS Region as the source S3 bucket; data outgoing from an S3 bucket to CloudFront.
Management and replication. You must pay for using storage management features like analytics and object tagging. Amazon charges for cross-region replication and same-region replication.
Use Amazon S3 calculator to estimate your payments.



