Kubernetes vs Docker – What Is the Difference?
Hardware virtualization provides a list of advantages such as scalability, security, isolation, etc. by using hypervisors for sharing physical hardware with virtual machines (VMs). At present, virtual machines are not the only form of virtualization, as containers have also become quite popular. While VMs share physical hardware of underlying machines, containers share the kernel of the underlying operating system. Containers are not lightweight virtual machines, but are standardized executable packages used to deliver applications, including applications that are developed by using the microservice-based software architecture, and include all components necessary to run applications.
The Docker engine is the most popular platform for running containers. Kubernetes is a term you may hear about at increasing frequency in the sphere of containerization and cloud computing. But what is better – Docker or Kubernetes? It’s a popular topic of debate, but to phrase it this way is not technically correct. For example, you cannot ask: “What is better – hot or blue?”
What Is Docker?
Docker is an open source standalone application which works as an engine used to run containerized applications. It is installed on your operating system (OS), preferably on Linux, but can be also installed on Windows and macOS, which in turn runs on a physical or virtual machine.
An application running in a container is isolated from the rest of the system and from other containers, but gives the illusion of running in its own OS instance. Multiple Docker containers can be run on the single operating system simultaneously; you can manage those containers with Docker, and Docker can run without Kubernetes. If you have multiple hosts for running containers, managing them manually can be difficult, and it is generally better to select a centralized management tool or an orchestration solution.

Docker Compose is a basic container orchestration tool used for running multi-container Docker applications. You can configure one YAML (yml) Docker Compose configuration file to define multi-container applications instead of configuring manually separate Dockerfiles for each container. After configuring the single YAML file, you can run all needed containers with a single command in your Linux console. Using Docker Compose is one way to orchestrate your Docker containers, but there is a powerful alternative to Docker Compose available that is called Kubernetes.
What Is Kubernetes?
Kubernetes is an open source container orchestration solution that is used for managing containerized software and services with a high degree of automation.
Kubernetes is a Google project intended to automate deployment, scaling and availability of applications running in containers. You can increase the number of hosts running containers up to 11 or more hosts. Moreover, you can create a cluster of Docker containers with Kubernetes in order to ensure high availability and load balancing.
Hosts that are used in a cluster are called nodes. The architecture type of Kubernetes is master-slave – the cluster consists of master nodes and working nodes. The minimum recommended number of nodes required by Kubernetes is four. While you can build a cluster with one machine, in order to run all the examples and tests you need at least four nodes. A Kubernetes cluster that handles production traffic should have a minimum of three working nodes. Using two master nodes protects your cluster against failure of one master node. You can use more than two master nodes if needed.
Master nodesare used to manage the state of a cluster, which includes accepting client requests, scheduling operations with containers, running control loops, etc. A copy of the etcd database that stores all data of the cluster needs to be run on each master node. The master node runs a set of the three processes: kube-apiserver, kube-controller-manager and kube-scheduler.Working nodesare used to execute application workloads by running containers. The two Kubernetes processes run on the non-master node: kubelet (for communicating with the master nodes) and kube-proxy (for reflecting Kubernetes network services on each node).Replication Controlleris a component used to ensure that Pod replicas whose number is specified are always running at any given moment in time. Thus you can make sure that Pods are always available whenever you need them. Different CLI and APIs are used for communicating services with each other if Kubernetes is used. There are also specific terms that are used for naming objects and resources of the RESTful API which are components of the cluster built with Kubernetes.
Different CLI and APIs are used for communicating services with each other if Kubernetes is used. There are also specific terms that are used for naming objects and resources of the RESTful API which are components of the cluster built with Kubernetes.Podis a basic scheduling unit in Kubernetes. This is a group of resources in which multiple containers are able to work. Containers that belong to one Pod can run on the same host, and use the same resources and the same local network. Containers in the Pod are isolated but can communicate with each other quite easily. Thus, Pods are generally used in Kubernetes but if you use a standalone Docker application, only container pools are available.Serviceis a set of containers that work together providing, for example, functioning of a multi-tier application. Kubernetes supports the dynamic naming and load balancing of Pods by using abstractions. This approach ensures a transparent connection between services by the name, and allows you to track their current state.Labelsare key/value pairs that are bound to Pods and other objects or services, in addition to allowing to group them easily and assign tasks.Namespacesis a method that allows for logically dividing the united Kubernetes cluster to multiple virtual clusters. Each virtual cluster can exist within a virtual environment limited by quotas without having an impact on other virtual clusters.
Kubernetes can be used with Docker, though Docker is not the only container platform with which Kubernetes can be used. Kubernetes can also work in a conjunction with Windows containers, Linux containers, rkt, etc. K8s is the name of Kubernetes that can be sometimes found in technical documentation.
Kubernetes vs Docker: Networking Comparison
Let’s review the networking options for each solution.
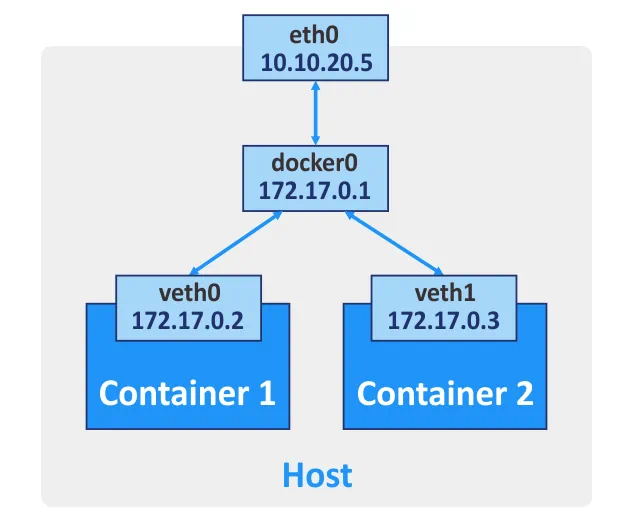
Docker provides three network modes for network communication between containers.
Bridge. This mode is used by default, creating a virtual layer-3 bridge. The network name on your host is docker0 for this network. Docker automatically creates a layer-3 network bridge and configures masquerading rules for the external network interface, using the network address translation (NAT) principle, which allows containers to communicate with each other and connect to external networks. You can configure port forwarding for the network interface of the host machine if you would like to connect to a container from other hosts and external networks. Thus, by connecting to the appropriate port of the host machine you are forwarded to the necessary port of the Docker container. You can create more than one network interface for a Docker container if need be.
Host. In this mode a host network driver ensures that a container is not isolated from the Docker host. The container shares the host network stack, and the container’s host name is the same as the host name of the host operating system. If you run a container on which a TCP port 8080 is listened, the container application is available on the TCP port 8080 of the host machine’s IP address. The host networking driver is available only for Linux machines.
None. No IP addresses are configured for a given container’s network interface except the 127.0.0.1 address for the loopback interface. There is no access to external networks if the None network mode is set.
Multi-host networking for Docker containers. If containers are running on different hosts, they can communicate with each other after you configure the overlay networking. A valid key-value store service (Consul, Etcd, or ZooKeeper) must be configured for creating such networks.
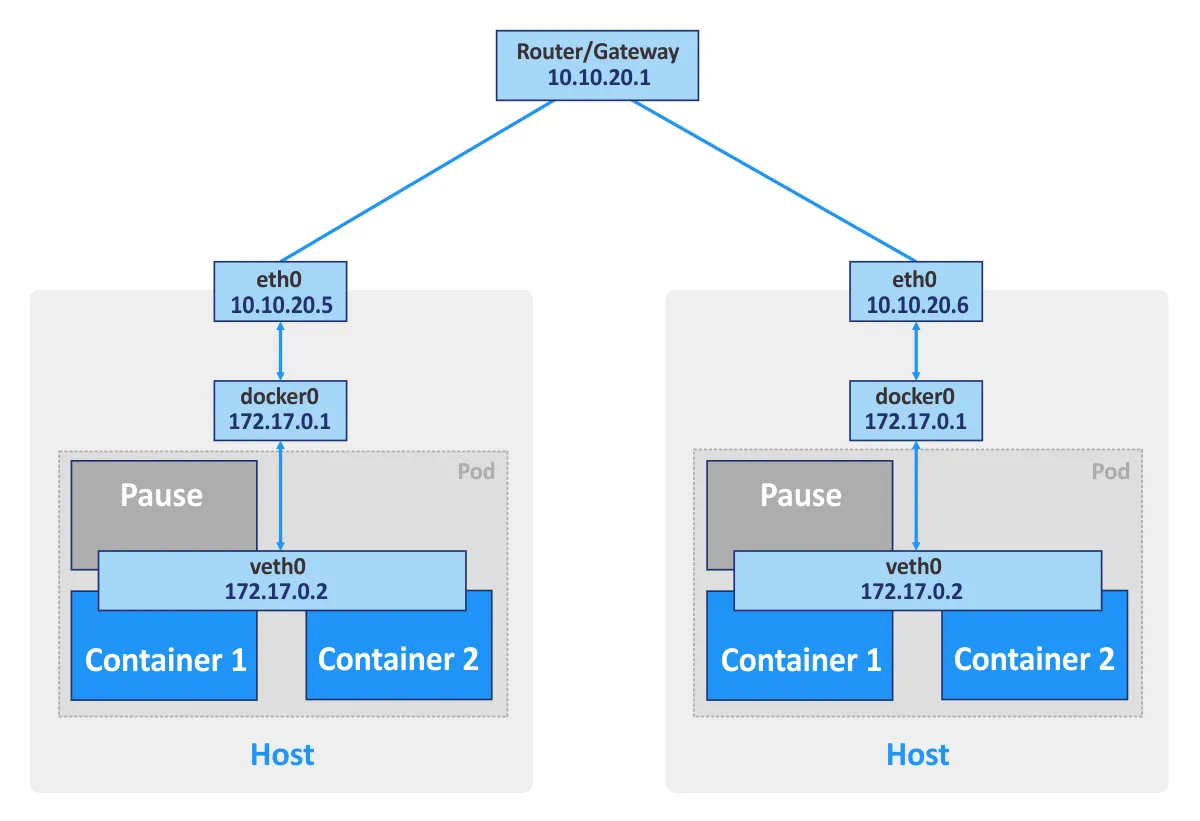
Kubernetes. If you use standalone Docker containers, each container can be considered as a basic unit that communicates via the network by using the appropriate network interface. If you are using Kubernetes, Pods are the basic units of the container cluster. Each pod has its own IP address and consists of at least one container. A Pod can consist of multiple containers which are used for related tasks. Containers of the same Pod cannot open the same port simultaneously. This type of restriction is used because a Pod that consists of multiple containers still has a single IP address.
Moreover, Kubernetes creates a special pause container for each Pod. This special container is intended to provide a network interface (for internal and external communication) for other containers, and is usually on pause (in a sleep mode). These pause containers wake up when Kubernetes sends a “SIGTERM” signal.
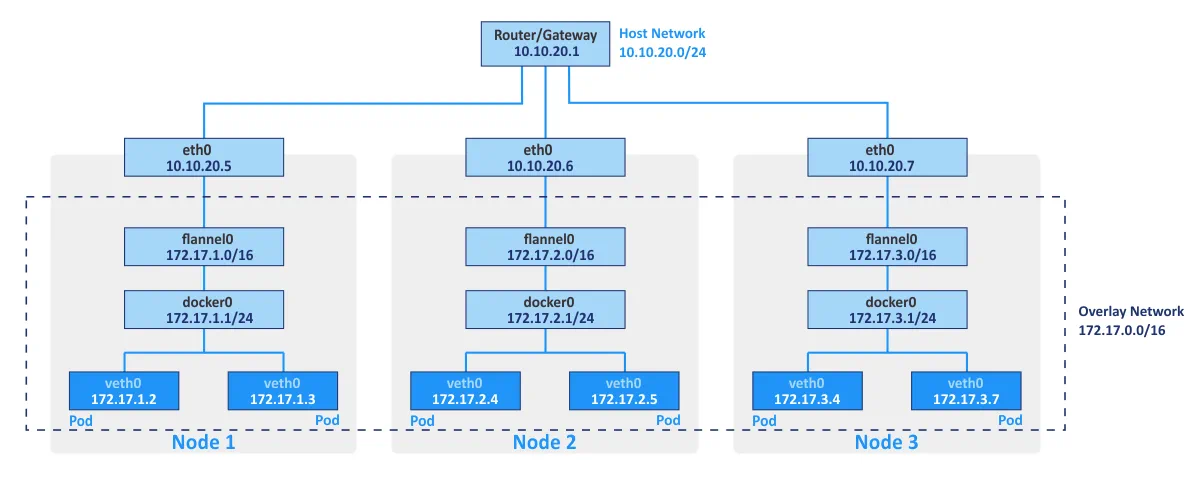
Flannel is typically used as a network fabric for connecting containers in Kubernetes by using principles of network overlay. The overlay networking allows you to run containers by communicating via the logical network different physical hosts of the cluster (which are referred to as nodes). The open source etcd key/value store is used to save the mappings between the real IP addresses assigned to containers by the hosts on which containers are running, and the IP addresses in the overlay network.
Kubernetes networking can be integrated with VMware NSX-T by using the NSX Container Plugin. This integration allows you to use multi-tenant network topology that is not available “out of the box” in Kubernetes.
The Kubernetes networking model provides the following features:
- All containers can communicate with any other containers within a cluster without NAT.
- All cluster nodes can communicate with all containers within a cluster without NAT. Inversely, all containers can communicate with all cluster nodes.
- Containers see their own IP addresses and those IP addresses are seen by other components of Kubernetes.
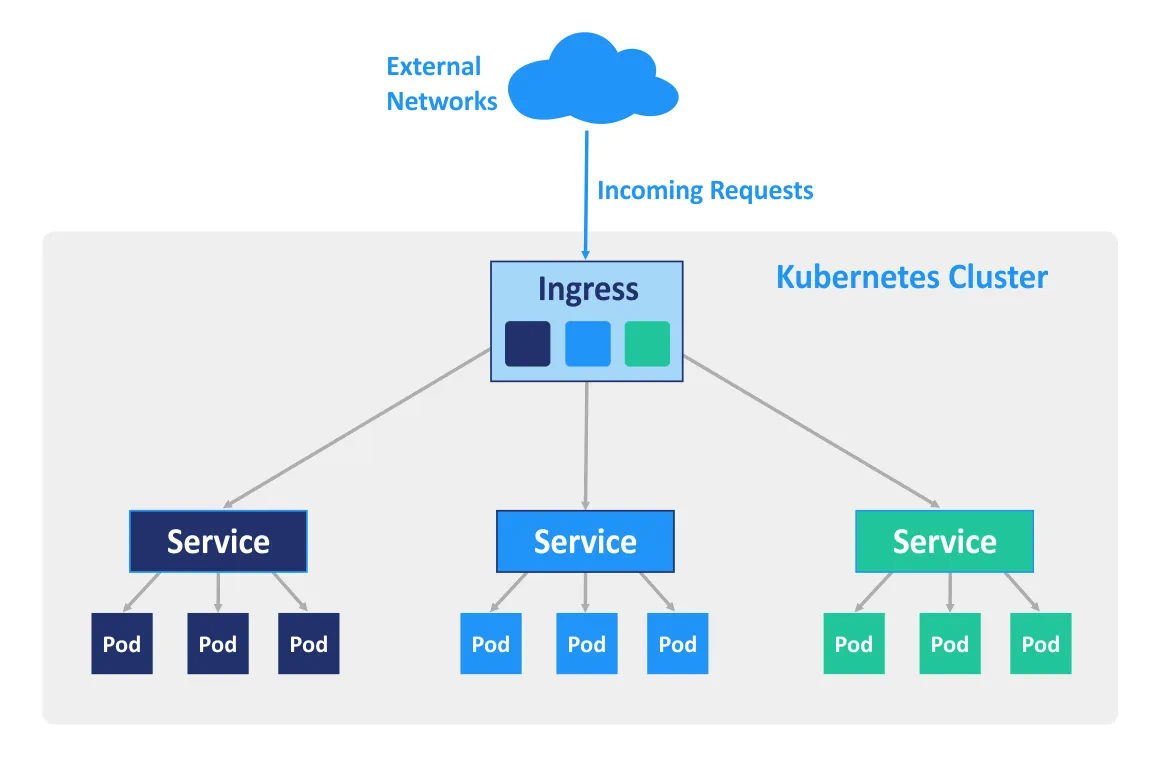
Ingress is an API object of Kubernetes that is used for managing access to services in the cluster from outside (primarily HTTP and HTTPS). You can configure Ingress to perform external access to the containerized services, for load balancing, SSL termination and name-based virtual hosting. An Ingress controller must be deployed on the master node in order for the ingress rules to work.
Use Cases
Using Docker as a standalone software is good for development of applications, as developers can run their applications in isolated environments. What’s more, testers can also use Docker to run applications in sandbox environments. If you wish to use Docker to run a high number of containers in the production environment you may encounter some complications along the way. For example, some containers can easily be overloaded or fail. You can manually restart the container on the appropriate machine, but manual management can take a lot of your valuable time and energy.
Kubernetes allows you to resolve these issues by providing key features such as high availability, load balancing, container orchestration tools, etc. As a result, Kubernetes is most suitable for highly loaded production environments with a high number of Docker containers. Deploying Kubernetes is more difficult than installing a standalone Docker application, which is why Kubernetes may not always be used for development and testing.
Kubernetes vs Docker Swarm
Docker Swarm is a native clustering tool for Docker that can turn a pool of Docker hosts into a single virtual host. Docker Swarm is fully integrated with the Docker Engine and allows you to use standard APIs and networking processes; it is intended to deploy, manage and scale Docker containers.
Swarm is a cluster of Docker hosts that are called nodes. Let’s consider the following main components of a cluster when you are using Docker Swarm before comparing the cluster deployment with Kubernetes and Docker Swarm:
Manager nodes are used to perform control orchestration, cluster management and task distribution.
Worker nodes are used for running containers whose tasks are assigned by Manager nodes. Each node can be configured as a Manager node, Worker node, or as both so as to perform both Manager and Worker node functions. Do note that worker nodes run swarm services.
Services. A service of Docker Swarm defines the required optimal state for each containerized service. A service controls such parameters as the number of replicas, the network resources available for it, the ports which must be made accessible from outside networks, etc. Service configuration, such as network configuration, can be modified and applied to a container without requiring you to restart the service with the container manually.
Tasks. A task is a slot in which a single container is running. Tasks are the parts of a Swarm service.
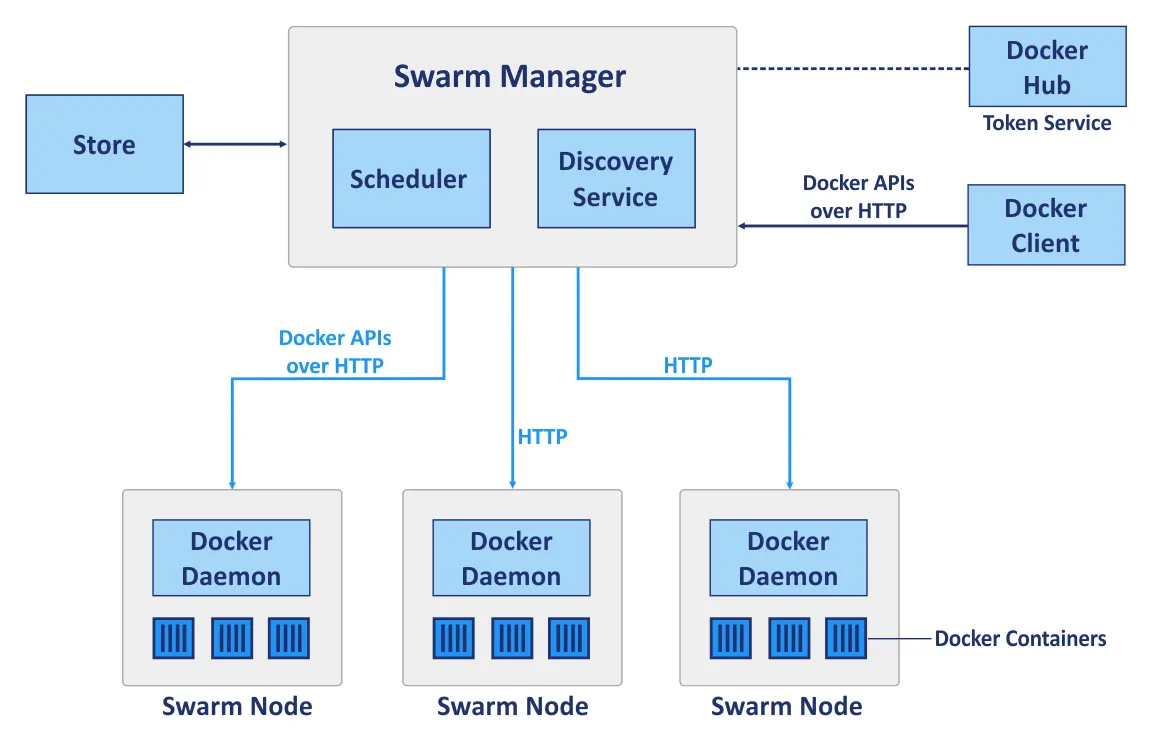
Thus, Docker Swarm and Kubernetes are two different platforms used for similar purposes. Now it’s time to compare them in an appropriate set of categories.
Cluster deployment
Docker Swarm. A Standard Docker API allows you to deploy a cluster with Swarm by using a standard Docker CLI (command line interface) that makes deployment easier, especially when used for the first time. The ease of deployment for Swarm when compared to Kubernetes is also achieved by the ability of a single Docker master to decide how to distribute services. No Pods are used in Docker Swarm.
Kubernetes requires you to use specified commands which are different from standard Docker commands. Specified APIs are used in Kubernetes, meaning that even if you know commands for Docker management, you may also need to learn to use an additional set of tools for Kubernetes deployment. The nodes must be defined manually in the Kubernetes cluster – you should select the master node, define the controller, scheduler, etc.
Scalability
Docker Swarm. Thanks to the simple API provided by Docker, deploying containers and service update in large and small clusters can be done faster. A command line interface (CLI) is quite simple and easy to understand. As a result, Swarm can be considered a more scalable solution when compared with Kubernetes.
Kubernetes provides comparatively unified APIs, and a number of features which frequently result in a slower deployment process. There are three types of components which must be configured: Pod, Deploy, and Service. When it comes to auto-scale, Kubernetes is preferable due to its ability to analyze server loads in addition to providing the opportunity to scale up and down automatically in accordance with the given requirements. Kubernetes is the optimal choice for large distributed networks and complex systems.
High availability
The two solution options each possess similar service replication and redundancy mechanisms, and in both cases the system is self-regulated and does not require manual reconfiguration after a failed node turns back into a cluster.
Docker Swarm. Manager nodes handle the resources of worker nodes and the entire cluster. The Swarm cluster nodes attend in replication of services.
Kubernetes. Unhealthy nodes are detected by load balancing services of Kubernetes, and are eliminated from the cluster. All Pods are distributed among nodes, thereby providing high availability, should a node on which a containerized application is running fail.
Load balancing
Docker Swarm. Load balancing is a built-in feature and can be performed automatically by using the internal Swarm network. All requests to the cluster are distributed and redirected to the cluster nodes; any node can connect to any container. A DNS element is used by Docker Swarm to distribute incoming requests to service names.
Kubernetes. Policies defined in Pods are used for load balancing in Kubernetes. In this case, container Pods must be defined as services. You have to configure load balancing settings manually, while Ingress can be utilized for load balancing.
Creating and running containers
Docker Swarm. The vast majority of commands that are available for Docker CLI can be utilized when Docker Swarm is used, thanks to the standardized API of Docker Swarm. Docker Compose defines work with volumes, and used networks, in addition to defining which containers must be grouped together. The precise number of replicas can be set with Docker Compose for Docker Swarm.
Kubernetes. Kubernetes has its own API, client, and needs YAML files to be configured. This is one of the key differences, as Docker Compose and Docker CLI cannot be used to deploy containers in this case. In Kubernetes, the system for defining services follows a similar working principle as for Docker Compose, but is more complex. The functionality of Docker Compose is performed by using Pods, Deployments, and Services in Kubernetes, within which each layer is used for its own specified purpose. Pods are responsible for container interaction, while deployments are responsible for high availability and networking for a single node in the cluster (much like the Docker Compose for a standalone Docker application without Swarm), and Kubernetes services are responsible for configuration of service operation inside the cluster, fault tolerance, etc.
Networking
Docker Swarm. There is one default internal network for communication of containers within a cluster, onto which more networks can be added if needed. Networks are protected with generated TLS certificates. Manual certificate generation is supported for the encryption of container data traffic.
Kubernetes. The network model of Kubernetes is quite different and is implemented by using plugins, one of which is Flannel, the most popular option. Pods interact with each other, and this interaction can be restricted policies. There is an internal network managed by the etcd service. TLS encryption is also available, but should be configured manually. The Kubernetes networking model presumes configuring two CIDRs, Classless Inter-Domain Routing, which is also known as supernetting.
Monitoring
Docker Swarm. There are no built-in tools for monitoring and logging, though you can manually set up third-party monitoring tools. ELK or Reimann can be used for this purpose.
Kubernetes. Inbuilt tools are provided by Kubernetes for logging and monitoring. Elasticsearch and Kibana (ELK) can be used to monitor the entire cluster state, while Heapster, Grafana, and Influx are supported for monitoring container services.
Graphical User Interface (GUI)
Docker Swarm. The GUI can be enabled with third party tools such as Portainer.io which provides a user-friendly web interface. As an alternative, you can use the Enterprise Edition of Docker that provides a graphical interface for cluster management.
Kubernetes. The GUI provided by Kubernetes is a reliable dashboard that can be accessed via a web interface with which you can easily control your cluster. The GUI can be a highly valuable tool for users with minimal experience in managing Kubernetes with the CLI.
Conclusion
Docker Swarm is a native Docker solution that primarily uses Docker API and CLI. Kubernetes, in contrast, is Google’s project which is used for deploying a cluster on which containers are running.
Both Docker Swarm and Kubernetes provide high availability, load balancing, overlay networking, and scalability features. Docker Swarm is the easier of the two for deployment, as most of its features configuration is automated, and it consumes few hardware resources. Functionality is limited by Docker API, however, and native monitoring tools are missing.
Kubernetes, meanwhile, is a modular solution with a high level of flexibility which has been supported by the majority of large corporate entities for a number of years. Built-in tools for monitoring services and the entire cluster are available for Kubernetes, though deployment and configuration is more difficult, making this resource a more demanding solution. Kubernetes is not compatible with Docker CLI and Docker Compose. Using Kubernetes is preferred in large environments where highly loaded multi-container applications are running.



