Porównanie i omówienie funkcji VMware vSphere HA i DRS
Hypervisor VMware umożliwia uruchamianie maszyn wirtualnych na jednym serwerze. Na pojedynczym hoście ESXi można uruchamiać wiele maszyn wirtualnych, a w celu obsługi większej liczby maszyn wirtualnych można wdrożyć wiele hostów. Jeśli dysponujesz wieloma hostami ESXi połączonymi w sieć, możesz przenosić maszyny wirtualne z jednego hosta na drugi.
Czasami użycie wielu hostów połączonych przez sieć do uruchamiania maszyn wirtualnych nie wystarcza, żeby sprostać potrzebom biznesowym. Na przykład, jeśli jeden host ulegnie awarii, wszystkie maszyny wirtualne na nim też przestaną działać. Ponadto obciążenia maszyn wirtualnych na hostach ESXi mogą być nierównomierne, a ręczna migracja maszyn wirtualnych między hostami jest rutynową czynnością. Aby rozwiązać te problemy, firma VMware udostępnia funkcje klastrowania, takie jak VMware High Availability (HA) i Distributed Resource Scheduler (DRS). Korzystanie z klastrowania vSphere pozwala skrócić przestoje maszyn wirtualnych i racjonalnie wykorzystywać zasoby sprzętowe. Ten wpis na blogu dotyczy rozwiązań VMware HA i DRS , a także przypadków użycia każdej funkcji klastrowania.

Czym jest klaster vSphere?
Klaster vSphere to zbiór połączonych hostów ESXi, które współdzielą zasoby sprzętowe, takie jak procesor, pamięć i pamięć masową. Klasterami VMware vSphere zarządza się centralnie w vCenter. Zasoby klastra są agregowane w puli zasobów, więc po dodaniu hosta do klasterzasoby tego hosta stają się częścią zasobów całego klastra. Hosty ESXi należące do klastra nazywane są również węzłami klastra. Istnieją dwa typy klastrów vSphere: vSphere High Availability oraz Distributed Resource Scheduler (VMware HA i DRS).
Wymagania dotyczące klastrów VMware
Aby wdrożyć VMware HA i DRS, należy spełnić zestaw wymagań dotyczących klastra:
- Należy użyć co najmniej dwóch hostów ESXi o identycznej konfiguracji (procesory tej samej rodziny, wersja ESXi i poziom poprawek itp.). Na przykład można użyć dwóch serwerów z procesorami Intel tej samej rodziny (lub
AMDprocesorami) oraz {12} zainstalowanymi na serwerach. Zaleca się użycie co najmniej trzech hostów w celu uzyskania lepszej ochrony i wydajności. - Szybkie połączenia sieciowe dla sieci zarządzania, sieci pamięci masowej i sieci vMotion. Wymagane są redundantne połączenia sieciowe.
- Wspólny magazyn danych, do którego mają dostęp wszystkie hosty ESXi w klastrze. Sieć pamięci masowej (SAN), sieciowa pamięć masowa (NAS) oraz VMware vSAN mogą służyć jako wspólny magazyn danych. Do uzyskania dostępu do danych we wspólnym magazynie danych obsługiwane są protokoły NFS i iSCSI. Pliki maszyn wirtualnych muszą być przechowywane we wspólnym magazynie danych.
VMware vCenter Serverkompatybilny z wersją ESXi zainstalowaną na hostach.
W przeciwieństwie do Hyper-V Failover Clusternie jest wymagane kworum i nie ma potrzeby stosowania skomplikowanych nazw sieciowych.
Czym jest VMware HA w vSphere?
VMware vSphere High Availability (HA) to funkcja klastrowania zaprojektowana w celu automatycznego ponownego uruchamiania maszyny wirtualnej (VM) w przypadku awarii. VMware vSphere High Availability pozwala organizacjom zapewnić wysoką dostępność maszyn wirtualnych i aplikacji działających na maszynach wirtualnych w klastrze vSphere (niezależnie od uruchomionych aplikacji). VMware HA może zapewnić ochronę przed awarią hosta ESXi — awariowa maszyna wirtualna jest ponownie uruchamiana na sprawnym hoście. W rezultacie można znacznie skrócić czas przestoju.
Wymagania dotyczące vSphere HA
Wymagania dotyczące vSphere HA należy uwzględnić wraz z ogólnymi wymaganiami dotyczącymi klastra vSphere. Aby skonfigurować VMware vSphere High Availability, należy posiadać:
- A
VMware vSphere Standardlicencja - Co najmniej 4 GB pamięci RAM na każdym hoście
- Brama, z którą można nawiązać połączenie ping
Jak działa vSphere HA ?
VMware vSphere High Availability sprawdza hosty ESXi w celu wykrycia awarii hosta. Jeśli wykryta zostanie awaria hosta (maszyny wirtualne działające na tym hoście również ulegną awarii), wówczas uszkodzone maszyny wirtualne są migrowane na sprawne hosty ESXi w obrębie klastra. Po migracji maszyny wirtualne są rejestrowane na nowych hostach, a następnie uruchamiane. Pliki maszyn wirtualnych (VMX, VMDK i inne) po migracji znajdują się na tym samym zasobie, którym jest współdzielony magazyn danych. Pliki maszyn wirtualnych nie są migrowane. Po migracji nowy host ESXi zapewnia jedynie Procesor, pamięć i komponenty sieciowe wykorzystywane przez uszkodzone maszyny wirtualne.
Czas przestoju jest równy czasowi potrzebnemu do ponownego uruchomienia maszyny wirtualnej na innym hoście. Należy jednak pamiętać, że należy również uwzględnić czas potrzebny na uruchomienie systemu operacyjnego oraz załadowanie niezbędnych aplikacji na maszynie wirtualnej. VMware HA to rozwiązanie działające na poziomie maszyn wirtualnych, które można wykorzystać również w przypadku, gdy aplikacje nie posiadają natywnych funkcji wysokiej dostępności. VMware vSphere High Availability nie zależy od systemu operacyjnego gościa zainstalowanego na maszynie wirtualnej.
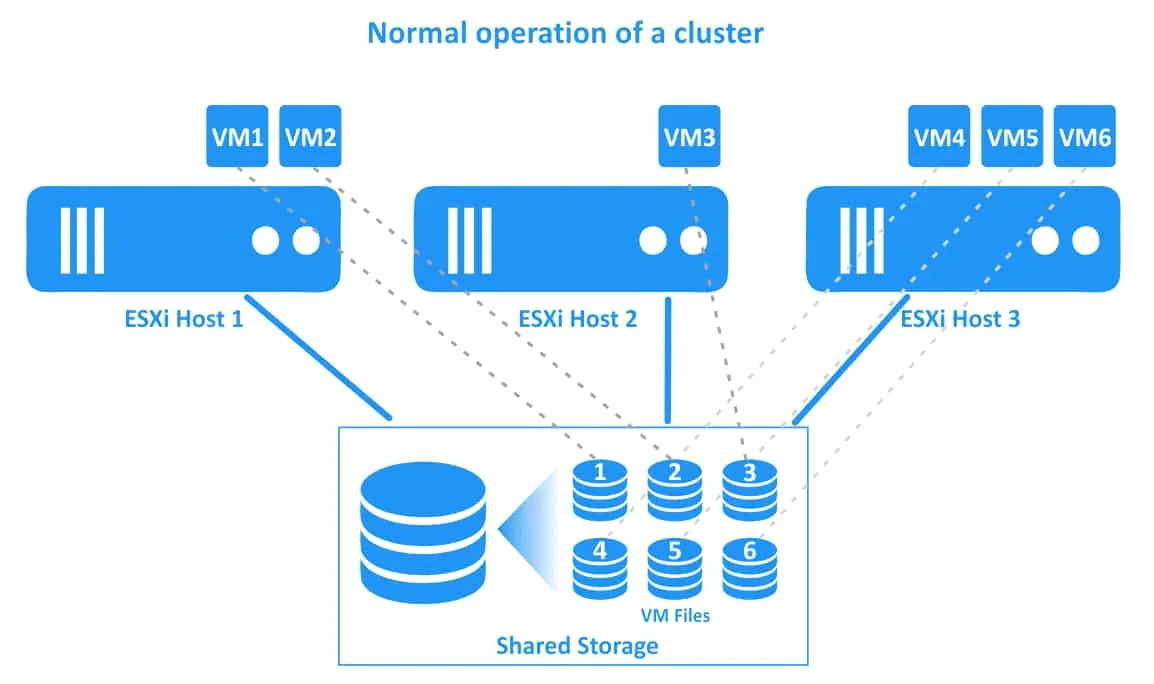
Przebieg pracy klastra vSphere HA został przedstawiony na poniższym schemacie. W tym przykładzie mamy klaster składający się z trzech hostów ESXi. Maszyny wirtualne działają na wszystkich hostach. Połączenia maszyn wirtualnych i ich plików są przedstawione liniami przerywanymi.
1. Normalne działanie klastra. Wszystkie maszyny wirtualne działają na swoich natywnych hostach.
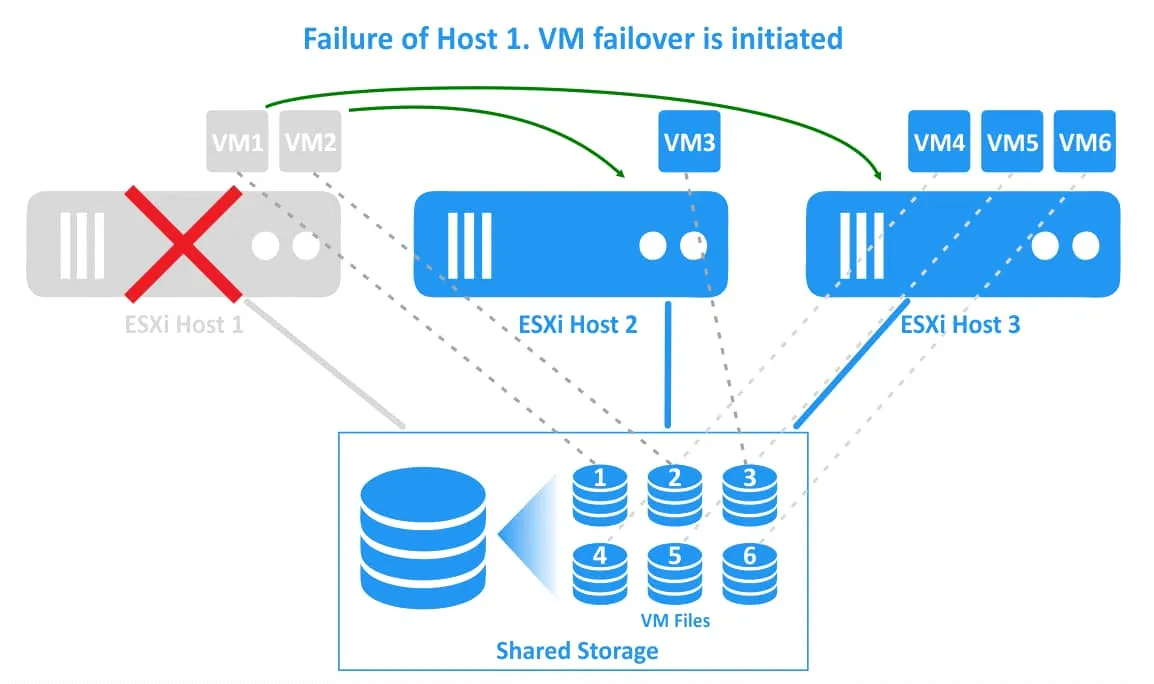
2. Awaria hosta ESXi 1. Maszyny wirtualne znajdujące się na hoście ESXi 1 (VM1 i VM2) ulegają awarii (są wyłączone). Klaster vSphere HA inicjuje ponowne uruchomienie maszyn wirtualnych na innych sprawnych hostach ESXi.
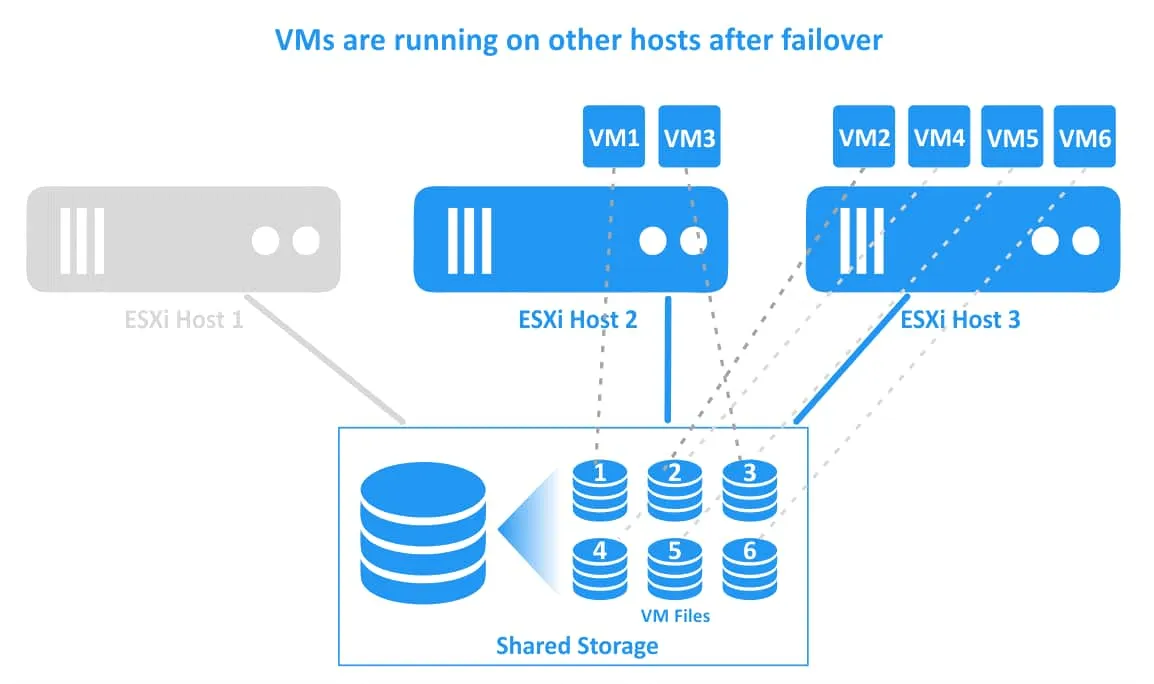
3. Maszyny wirtualne zostały przeniesione i uruchomione ponownie na sprawnych hostach. VM1 została przeniesiona na host ESXi 2, a VM2 na host ESXi 3. Pliki maszyn wirtualnych znajdują się w tym samym miejscu na pamięci współdzielonej, która jest podłączona do wszystkich hostów ESXi klastra vSphere.
HA master i podległe
Po vSphere High Availability włączeniu w klastrze jeden host ESXi jest wybierany jako HA master. Pozostałe hosty ESXi są podległe (hosty podrzędne typu slave). Host główny wykonuje monitorowanie stanu hostów podległych, aby na czas wykryć awarię hosta i zainicjować ponowne uruchomienie maszyn wirtualnych, które uległy awarii. Host główny wykonuje również monitorowanie stanu zasilania maszyn wirtualnych na węzłach klastra. W przypadku wykrycia awarii maszyny wirtualnej host główny inicjuje jej ponowne uruchomienie (przed ponownym uruchomieniem awaryjnej maszyny wirtualnej host główny wybiera optymalny host). Host główny HA przesyła do vCenter informacje o stanie klastrowego środowiska HA . VMware vCenter zarządza klastrem za pomocą interfejsu udostępnianego przez host główny HA .
Host główny może uruchamiać maszyny wirtualne tak samo jak inne hosty w klastrze. W przypadku awarii hosta głównego wybierany jest inny host główny. Host podłączony do największej liczby magazynów danych ma pierwszeństwo w wyborze głównego hosta ESXi. W wyborze głównego hosta biorą udział hosty, które nie znajdują się w trybie konserwacji.
Hosty podrzędne mogą uruchamiać maszyny wirtualne, monitorować ich stan oraz zgłaszać aktualne informacje o stanie maszyn wirtualnych do HA hosta głównego.
Fault Domain Manager (FDM) to nazwa agenta używanego do monitorowania dostępności serwerów fizycznych. Agent FDM działa na każdym hoście ESXi w klastrze HA .
Rodzaje awarii hostów
Istnieją trzy rodzaje awarii hostów ESXi:
Awaria. Host ESXi z jakiegoś powodu przestał działać.
Izolacja. Host ESXi i maszyny wirtualne na tym hoście nadal działają, ale host jest odizolowany od innych hostów w klastrze z powodu problemów z siecią.
Podział. Utracono łączność sieciową z hostem głównym.
Jak wykrywane są awarie
W celu wykrywania awarii w klastrze vSphere HA wymieniane są sygnały kontrolne. Host główny wykonuje monitorowanie stanu hostów pomocniczych, odbierając co sekundę sygnały kontrolne od hostów pomocniczych. Host główny wysyła ICMP sygnały ping do hosta pomocniczego i oczekuje na odpowiedzi. Jeśli host główny nie może komunikować się bezpośrednio z agentem hosta pomocniczego, host pomocniczy może być sprawny lub awaryjny, ale niedostępny przez sieć.
Jeśli host główny nie odbiera sygnałów kontrolnych, sprawdza podejrzany host za pomocą Datastore Heartbeating. Podczas normalnej pracy każdy host w klastrze HA wymienia sygnały kontrolne ze wspólnym magazynem danych. Główny host ESXi sprawdza, czy sygnały kontrolne magazynu danych zostały wymienione z podejrzanym hostem, oprócz wysyłania do niego sygnałów ping. Jeśli nie ma wymiany sygnałów kontrolnych magazynu danych z podejrzanym hostem, a host ten nie wysyła żądań ICMP , wówczas host zostaje oznaczony jako host z awarią.
Uwaga: W katalogu głównym współdzielonego magazynu danych tworzony jest specjalny katalog .vSphere-HA służący do wysyłania sygnałów kontrolnych i identyfikacji listy chronionych maszyn wirtualnych. Należy pamiętać, że magazyny danych vSAN nie mogą być używane do wysyłania sygnałów kontrolnych magazynu danych. Jeśli host główny nie może nawiązać połączenia z agentem hosta pomocniczego, ale host pomocniczy wymienia sygnały kontrolne ze wspólnym magazynem danych, wówczas host główny oznacza ten host jako host odizolowany sieciowo. Jeśli host główny stwierdzi, że host pomocniczy działa w odizolowanym segmencie sieci, kontynuuje monitorowanie maszyn wirtualnych na tym odizolowanym hoście. Jeśli maszyny wirtualne na izolowanym hoście są wyłączone, wówczas host główny inicjuje ponowne uruchomienie tych maszyn wirtualnych na innym hoście ESXi. Można skonfigurować reakcję klastra vSphere HA na izolację sieciową hosta ESXi.
Monitorowanie poszczególnych maszyn wirtualnych. VMware vSphere High Availability posiada mechanizm monitorowania poszczególnych maszyn wirtualnych i wykrywania awarii konkretnej maszyny wirtualnej. {45} zainstalowane w systemie operacyjnym gościa (OS) służą do określania stanu maszyny wirtualnej. VMware Tools wysyłają sygnały kontrolne systemu operacyjnego gościa do hosta ESXi.
Sygnały kontrolne oraz aktywność wejścia/wyjścia (I/O) generowana przez VMware Tools są monitorowane przez usługę monitorowania maszyn wirtualnych. Jeśli główny host ESXi w klastrze HA wykryje, że VMware Tools na chronionej maszynie wirtualnej nie odpowiadają i nie ma aktywności I/O , host inicjuje ponowne uruchomienie maszyny wirtualnej. Monitorowanie aktywności maszyn wirtualnych I/O pozwala klasterowi HA uniknąć niepotrzebnych resetów maszyn wirtualnych, jeśli VMware Tools z jakiegoś powodu nie wysyłają sygnałów kontrolnych, ale maszyna wirtualna działa. Można ustawić czułość monitorowania, aby skonfigurować okres czasu, po upływie którego maszyna wirtualna musi zostać ponownie uruchomiona, jeśli host ESXi nie odbiera sygnałów kontrolnych systemu operacyjnego gościa generowanych przez VMware Tools . VMware vSphere HA restartuje maszynę wirtualną na tym samym hoście ESXi w przypadku awarii pojedynczej maszyny wirtualnej.
VMware Tools sygnały kontrolne są wysyłane do hostd na poziomie hiperwizora (ESXi), a nie za pomocą stosu sieciowego. Następnie host ESXi wysyła otrzymane informacje do vCenter. VMware Tools sygnały kontrolne mogą być odbierane przez host ESXi, jeśli maszyna wirtualna jest odłączona od sieci, a nawet jeśli do maszyny wirtualnej nie jest podłączona żadna wirtualna karta sieciowa.
Monitorowanie maszyn wirtualnych i aplikacji. Można użyć SDK od zewnętrznego dostawcy, aby monitorować, czy określona aplikacja zainstalowana na maszynie wirtualnej uległa awarii. Alternatywą jest użycie aplikacji, która już oferuje wsparcie dla monitorowania aplikacji VMware. Sygnały kontrolne aplikacji są używane do monitorowania aplikacji na maszynach wirtualnych VMware działających w klastrze vSphere HA .
Kluczowe parametry konfiguracji klastra HA
Przed rozpoczęciem konfiguracji klastra HA należy zdefiniować kilka kluczowych parametrów. Reakcja na izolację to parametr określający sposób działania hosta ESXi w przypadku braku sygnałów kontrolnych. Dostępne opcje to Leave powered on, Power off (domyślna) oraz Shutdown.
Reservation to parametr obliczany na podstawie maksymalnych parametrów maszyny wirtualnej o największym zapotrzebowaniu na zasoby w klastrze. Parametr ten służy do szacowania Trybu failover. Klaster HA tworzy sloty rezerwacyjne przy użyciu wartości parametru Reservation.
Tryb failover. Ten parametr jest mierzony w liczbach całkowitych i określa maksymalną liczbę serwerów, które mogą ulec awarii w klastrze bez negatywnego wpływu na obciążenia (klaster i wszystkie maszyny wirtualne mogą nadal działać po awarii tej liczby hostów ESXi).
Dopuszczalna liczba awarii hostów. Ten parametr jest definiowany przez administratora systemu w celu ustalenia, ile hostów może ulec awarii, aby klaster mógł nadal działać. Przy ustalaniu wartości tego parametru brana jest pod uwagę pojemność Trybu failover .
Admission Control jest to parametr używany do zapewnienia, że zarezerwowano wystarczające zasoby do odzyskania maszyn wirtualnych po awarii hosta ESXi. Ten parametr jest ustawiany przez administratora i określa zachowanie maszyn wirtualnych, jeśli nie ma wystarczającej liczby wolnych slotów do uruchomienia maszyn wirtualnych po awarii hosta ESXi. Admission Control określa pojemność Trybu failover, czyli procent spadku wydajności zasobów, który może być tolerowany w klastrze vSphere HA po Trybie failover.
Restart Priority jest ustawiany przez administratora w celu określenia kolejności uruchamiania maszyn wirtualnych po Trybie failover węzła klastra. Administratorzy mogą skonfigurować vSphere HA tak, aby najpierw uruchamiać maszyny wirtualne o krytycznym znaczeniu, a dopiero potem pozostałe maszyny wirtualne.
Tryb failover a awaria hosta
Przyjrzyjmy się dwóm przypadkom, w których występują po trzy hosty ESXi, ale o różnych wartościach pojemności Trybu failover. W pierwszym przypadku klaster HA może działać po awarii jednego hosta ESXi (patrz lewa strona poniższego obrazka). W drugim przypadku klaster HA może tolerować awarię dwóch hostów ESXi (patrz prawa strona obrazka).
1. Każdy host ESXi ma 4 gniazda. W klastrze znajduje się 6 maszyn wirtualnych. Jeśli jeden host ESXi ulegnie awarii (na przykład trzeci host), wówczas trzy maszyny wirtualne (VM4, VM5 i VM6) mogą zostać przeniesione na pozostałe dwa hosty ESXi. W moim przykładzie te trzy maszyny wirtualne migrują na drugi host ESXi. Jeśli zawiedzie jeszcze jeden host ESXi, nie będzie wolnych gniazd do migracji i uruchomienia innych maszyn wirtualnych.
2. Każdy host ESXi ma 4 gniazda. W klastrze VMware vSphere HA działają 4 maszyny wirtualne. W tym przypadku jest wystarczająco dużo gniazd, aby uruchomić wszystkie maszyny wirtualne w klastrze, jeśli zawiodą dwa hosty ESXi.
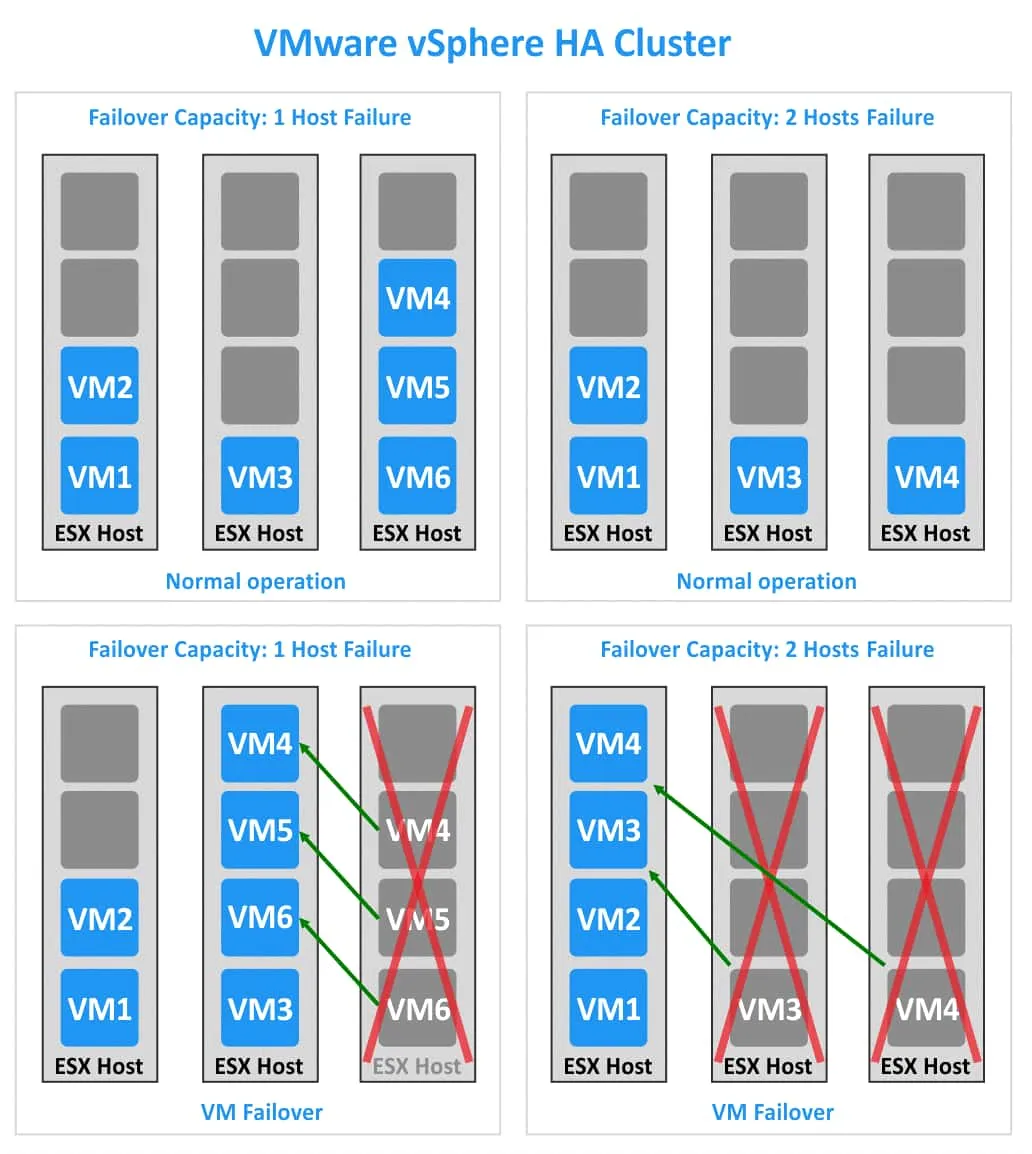
Aby obliczyć Failover Capacity, wykonaj następujące czynności: Od liczby wszystkich węzłów w klastrze odejmij stosunek liczby maszyn wirtualnych w klastrze do liczby gniazd w jednym węźle. Jeśli w wyniku otrzymasz liczbę niecałkowitą (niebędącą liczbą całkowitą), zaokrąglij ją w dół do najbliższej liczby całkowitej. Obliczmy Failover Capacity dla dwóch przykładów.
Przykład 1:
3–6/4=1,5
Zaokrąglij 1,5 do 1. Wszystkie maszyny wirtualne w klastrze HA mogą przetrwać, jeśli 1 host ESXi ulegnie awarii.
Przykład 2:
3–4/4=2
Nie ma potrzeby zaokrąglania w dół, ponieważ 2 jest liczbą całkowitą. Wszystkie maszyny wirtualne mogą kontynuować działanie, jeśli 2 hosty ESXi ulegną awarii.
Kontrola dostępu
Jak wspomniano powyżej, kontrola dostępu to parametr niezbędny do zapewnienia wystarczającej ilości zasobów do uruchomienia maszyn wirtualnych po awarii hosta w klastrze. Dla większej wygody można również zdefiniować Admission Control State parametr. Admission Control State jest obliczany jako stosunek Failover Capacity do Dopuszczalna liczba awarii hostów (NHF).
Jeśli Failover Capacity jest wyższy niż NHF, oznacza to, że klaster HA jest poprawnie skonfigurowany. W przeciwnym razie należy ręcznie ustawić Admission Control . Dostępne są dwie opcje:
1. Nie włączaj maszyn wirtualnych, jeśli naruszają one ograniczenia dostępności (nie włączaj maszyn wirtualnych, jeśli nie ma wystarczających zasobów sprzętowych).
2. Zezwól na uruchamianie maszyn wirtualnych, nawet jeśli naruszają one dostępność (uruchamiaj maszyny wirtualne pomimo braku zasobów sprzętowych).
Wybierz opcję, która najlepiej pasuje do Twojego vSphere High Availability przypadku użycia klastra. Jeśli Twoim celem jest niezawodność HA klastra, wybierz pierwszą opcję (Do not power on VMs). Jeśli najważniejsze jest dla Ciebie uruchomienie wszystkich maszyn wirtualnych, wybierz drugą opcję (Allow VMs to be started). Pamiętaj, że w tym drugim przypadku zachowanie klastra może być nieprzewidywalne. W najgorszym scenariuszu klaster HA może stać się bezużyteczny.
Nadpisywanie maszyn wirtualnych
Nadpisywanie maszyn wirtualnych (lub HA nadpisywanie w przypadku klastra HA ) to opcja, która pozwala wyłączyć HA dla konkretnej maszyny wirtualnej działającej w klastrze HA . Za pomocą tej opcji na poziomie klastra można skonfigurować klaster vSphere HA na bardziej szczegółowym poziomie.
Odporność na awarie
Firma VMware udostępnia funkcję dla klastra vSphere HA , która pozwala osiągnąć zerowy czas przestoju w przypadku awarii hosta ESXi. Funkcja ta nosi nazwę Fault Tolerance. Podczas gdy standardowa konfiguracja vSphere High Availability wymaga ponownego uruchomienia maszyny wirtualnej w przypadku awarii, Fault Tolerance pozwala maszynom wirtualnym na dalsze działanie, jeśli główny host ESXi, na którym są zarejestrowane, ulegnie awarii. Fault Tolerance można wykorzystać w przypadku maszyn wirtualnych o znaczeniu krytycznym, na których działają kluczowe aplikacje.
Osiągnięcie zerowego czasu przestoju w celu zapewnienia najwyższego poziomu ciągłości działania wiąże się z dodatkowym obciążeniem, ponieważ istnieją dwie uruchomione instancje maszyny wirtualnej chronionej za pomocą Fault Tolerance. Druga maszyna wirtualna typu „ghost” działa na drugim hoście ESXi, a wszystkie zmiany w oryginalnej maszynie wirtualnej (Procesor, pamięć RAM, stan sieci) są replikowane z pierwotnego hosta ESXi na hosta ESXi pomocniczego. Chroniona maszyna wirtualna nazywana jest maszyną główną, a jej duplikat — maszyną pomocniczą. Maszyny wirtualne główna i pomocnicza muszą znajdować się na różnych hostach ESXi, aby zapewnić ochronę przed awarią hosta ESXi.
Obie maszyny wirtualne (główna i pomocnicza) działają jednocześnie i zużywają zasoby procesora, pamięci RAM oraz sieci na obu hostach ESXi (w związku z tym maszyna wirtualna chroniona funkcją Fault Tolerance zużywa dwukrotnie więcej zasobów w klastrze vSphere HA ). Maszyny te są stale synchronizowane w czasie rzeczywistym. Użytkownicy mogą pracować wyłącznie z maszyną wirtualną główną (oryginalną), a maszyna wirtualna pomocnicza (ghost) jest dla nich niewidoczna.
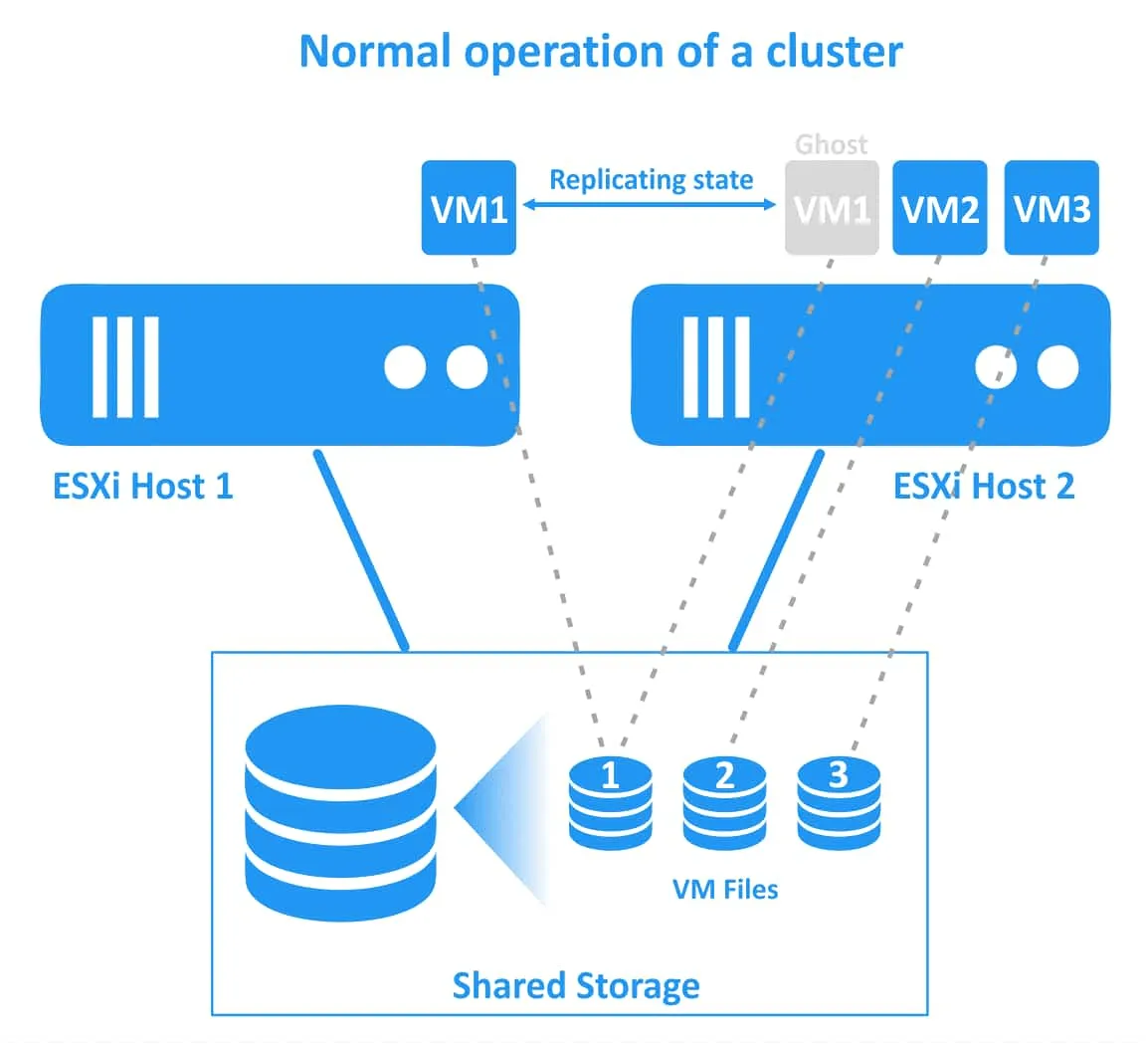
Jeśli pierwszy host ESXi ulegnie awarii (host, na którym znajduje się maszyna wirtualna główna), obciążenia są migrowane do maszyny wirtualnej pomocniczej (czyli klonu maszyny wirtualnej lub maszyny wirtualnej typu ghost) działającej na drugim hoście ESXi. Maszyna wirtualna pomocnicza staje się aktywna i dostępna w ciągu kilku chwil. Użytkownicy mogą zauważyć niewielkie opóźnienie sieciowe w momencie Trybu failover. Podczas Trybu failover nie dochodzi do przerwy w działaniu usług ani utraty danych. Po pomyślnym zakończeniu Trybu failover na alternatywnym, sprawnym hoście ESXi tworzona jest nowa maszyna wirtualna typu ghost, aby zapewnić nadmiarowość i kontynuować ochronę maszyny wirtualnej przed awarią hosta ESXi.
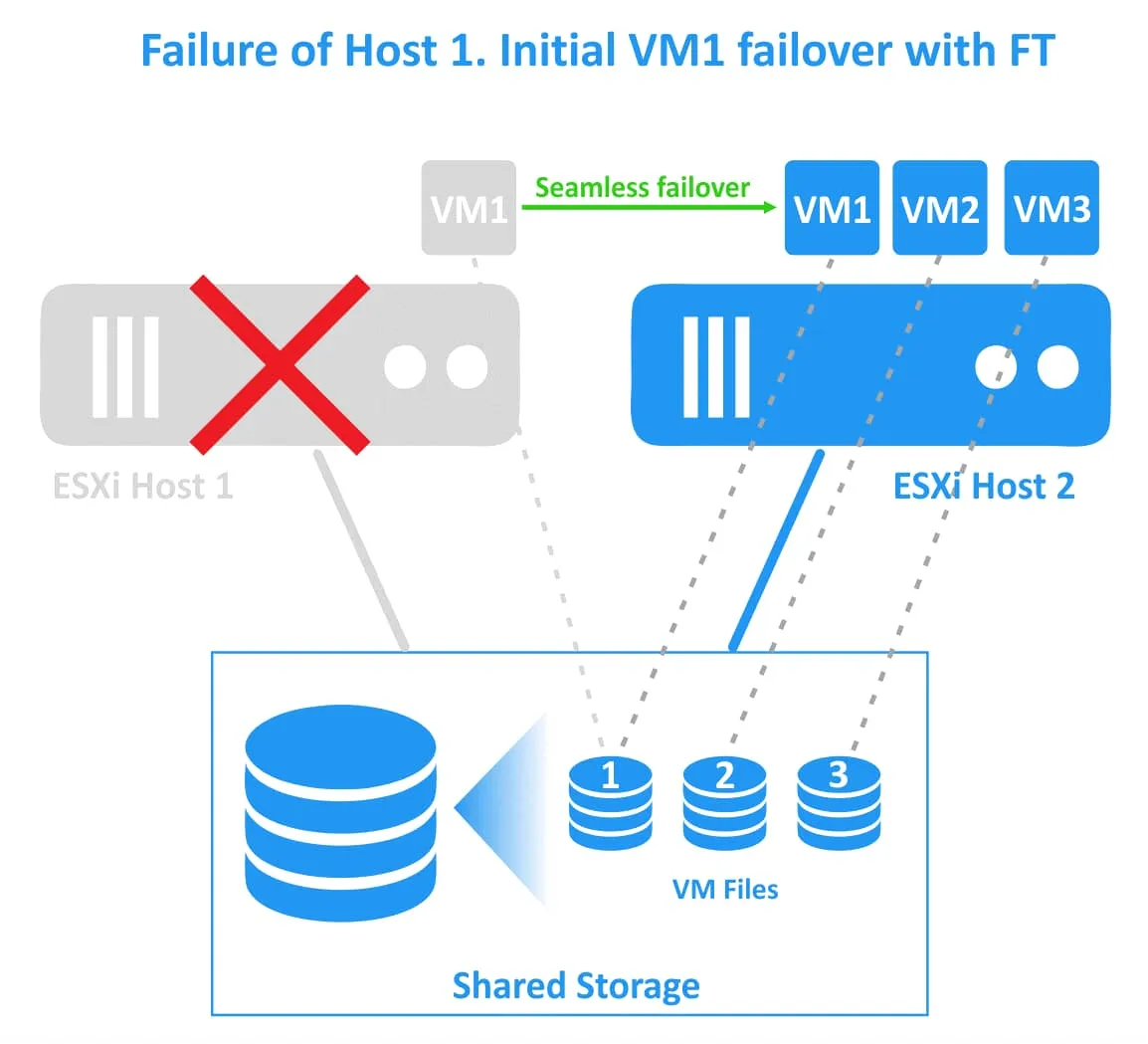
Fault Tolerance unika scenariuszy typu split-brain (gdy dwie aktywne kopie chronionej maszyny wirtualnej działają jednocześnie) dzięki mechanizmowi blokowania plików w pamięci masowej współdzielonej, służącemu do koordynacji Trybu failover. Jednak Fault Tolerance nie chroni przed awariami oprogramowania wewnątrz maszyny wirtualnej (takimi jak awaria systemu operacyjnego gościa lub awaria poszczególnych aplikacji). Jeśli główna maszyna wirtualna ulegnie awarii, awarii ulegnie również maszyna wirtualna rezerwowa. Wymagania dotyczące Fault Tolerance
- Klaster vSphere
HAskładający się z co najmniej dwóch hostów ESXi. vMotionorazFT logging.- Kompatybilny Procesor obsługujący wirtualizację wspomaganą sprzętowo
MMU.
Zaleca się korzystanie z dedykowanej sieci Fault Tolerance w klastrze vSphere HA .
Aby korzystać z Fault Tolerance,
-
Fault Tolerancehosty ESXi muszą posiadać odpowiednią licencję. - vSphere
StandardiEnterpriseobsługują do 2 vCPU dla pojedynczej maszyny wirtualnej. - vSphere
Enterprise Plusumożliwia korzystanie z maksymalnie 8 vCPU na maszynę wirtualną.
Fault Tolerance ograniczenia
Istnieją pewne ograniczenia dotyczące korzystania z VMware Fault Tolerance w vSphere. Funkcje VMware vSphere, które są niezgodne z FT:
- migawki maszyn wirtualnych. Chroniona maszyna wirtualna nie może posiadać migawek.
- Klony połączone
- VMware {118} magazyny danych
Urządzenia, które nie są obsługiwane:
Raw device mappingurządzenia- Fizyczne napędy CD-ROM i inne urządzenia serwera, które są podłączone do maszyny wirtualnej jako urządzenia wirtualne
- Urządzenia dźwiękowe i urządzenia USB
- Wirtualne dyski VMDK o rozmiarze większym niż 2 TB
- Urządzenia wideo z grafiką 3D
- Porty równoległe i szeregowe
Hot-plugurządzeniaNIC (network interface controller)przełączanie bezpośrednieStorage vMotion(musi być tymczasowo wyłączone w celu migracji plików maszyny wirtualnej do innej pamięci masowej)
Czym jest DRS w VMware vSphere?
Distributed Resource Scheduler (DRS) to funkcja klastrowania VMware vSphere, która umożliwia równoważenie obciążenia maszyn wirtualnych działających w klastrze. DRS sprawdza obciążenie maszyn wirtualnych oraz serwerów ESXi w klastrze vSphere. Jeśli DRS wykryje przeciążony host lub maszynę wirtualną, DRS migruje maszynę wirtualną na host ESXi z wystarczającą ilością wolnych zasobów sprzętowych, aby zapewnić jakość usług (QoS). DRS można wybrać optymalny host ESXi dla maszyny wirtualnej podczas tworzenia nowej maszyny wirtualnej w klastrze.
VMware DRS pozwala na uruchamianie maszyn wirtualnych w zrównoważonym klastrze i unikanie przeciążenia oraz sytuacji, w których nie ma wystarczających zasobów sprzętowych dla maszyn wirtualnych i aplikacji działających na maszynach wirtualnych do normalnego działania (w tym przypadku w całym klastrze musi być wystarczająca ilość zasobów).
DRS Wymagania
Wymagania dotyczące DRS, wraz z ogólnymi wymaganiami dla klastra vSphere, obejmują:
- vSphere
Enterpriselub vSphereEnterprise Pluslicencja - Procesor z
Enhanced vMotion Compatibilitydo migracji maszyn wirtualnych na żywo za pomocąvMotion - Dedykowany
vMotionsieć
Do obsługi klastra vMotion wymagane jest skonfigurowane środowisko VMware DRS , w przeciwieństwie do klastra HA , gdzie vMotion jest wymagane tylko w przypadku korzystania z Fault Tolerance. Ponadto licencja vSphere wymagana dla VMware DRS jest wyższa niż licencja do korzystania z vSphere High Availability.
Rola vMotion
Migracja maszyn wirtualnych z jednego hosta ESXi na drugi za pomocą vMotion, o czym wspominaliśmy podczas wyjaśniania działania Fault Tolerance . Dzięki VMware vMotionmigracja maszyn wirtualnych (Procesor, pamięć, stan sieci) odbywa się bez przerywania pracy uruchomionych maszyn wirtualnych (nie ma przestoju). VMware vMotion jest kluczową funkcją zapewniającą prawidłowe działanie DRS.
Przyjrzyjmy się głównym etapom działania vMotion:
1. vMotion tworzy maszynę wirtualną-cień na docelowym hoście ESXi. Docelowy host ESXi wstępnie przydziela wystarczające zasoby dla maszyny wirtualnej, która ma zostać przeniesiona. Maszyna wirtualna zostaje umieszczona w stanie pośrednim, a jej konfiguracja nie może być zmieniona podczas migracji.

2. Proces wstępnego kopiowania. Każda strona pamięci maszyny wirtualnej jest kopiowana ze źródła do miejsca docelowego przy użyciu sieci vMotion .
3. Wykonuje się kolejną iterację kopiowania stron pamięci ze źródła do miejsca docelowego, ponieważ strony pamięci ulegają zmianom podczas działania maszyny wirtualnej. Jest to proces iteracyjny, który jest wykonywany do momentu, aż nie pozostaną żadne zmienione strony pamięci. Zmienione strony pamięci nazywane są stronami brudnymi. Migracja maszyny wirtualnej przy użyciu vMotion zajmuje więcej czasu, jeśli na maszynie wirtualnej wykonywane są operacje intensywnie wykorzystujące pamięć, ponieważ zmienionych jest więcej stron pamięci.

4. Maszyna wirtualna zostaje zatrzymana na hostach źródłowym ESXi i wznowiona na hoście docelowym. W tym momencie w migrowanej maszynie wirtualnej można zauważyć nieznaczne opóźnienie sieciowe trwające około sekundy.
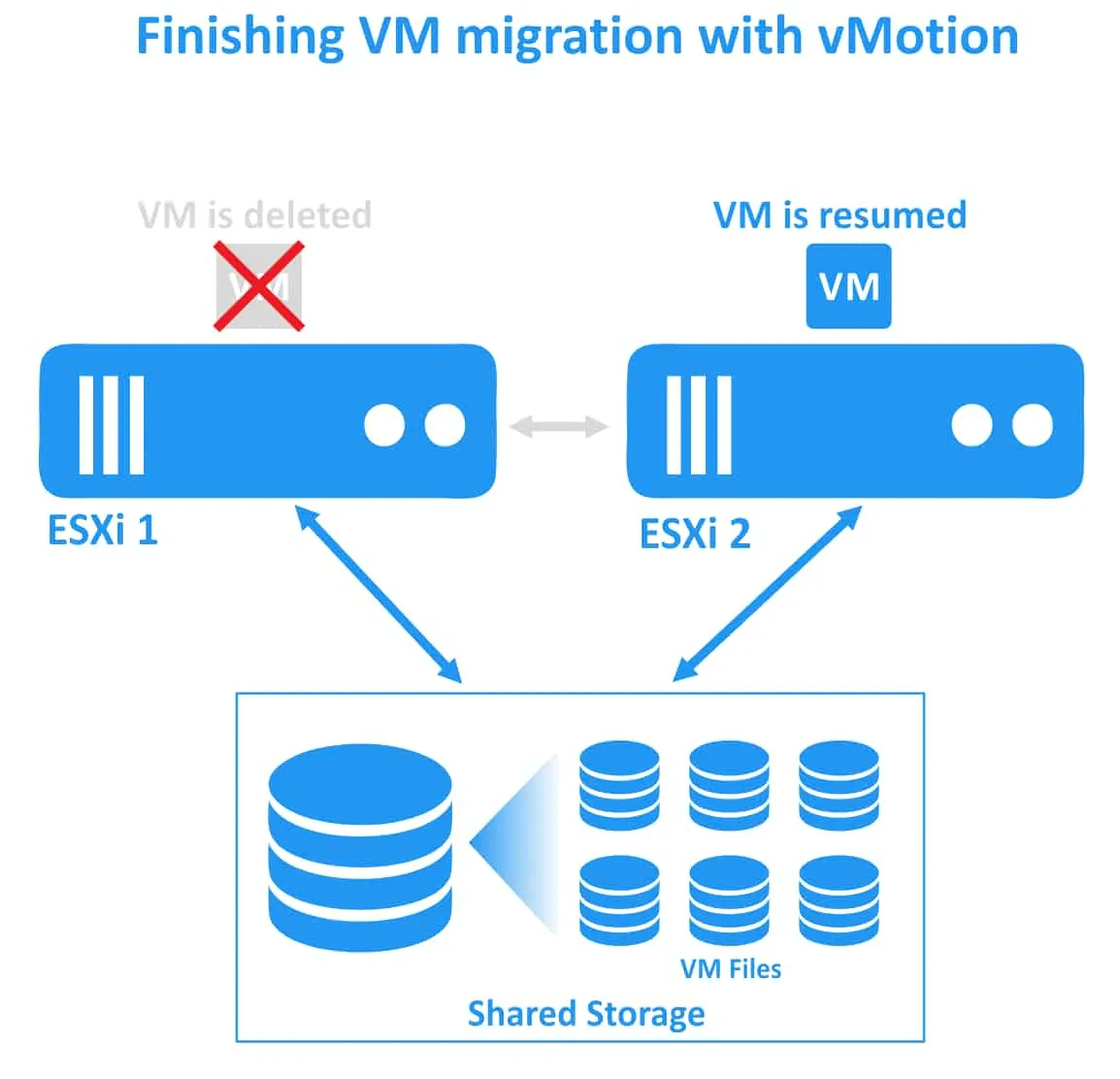
Zasada działania funkcji DRS w VMware
VMware DRS sprawdza obciążenia z perspektywy Procesora i pamięci RAM w celu określenia równowagi klastra vSphere co 5 minut, co jest domyślnym interwałem. VMware DRS sprawdza wszystkie zasoby w puli zasobów klastra, w tym zasoby zużywane przez maszyny wirtualne oraz zasoby każdego hosta ESXi w klastrze, które mogą być udostępnione do uruchamiania maszyn wirtualnych. Sprawdzanie zasobów odbywa się zgodnie ze skonfigurowanymi zasadami.
Uwzględniane są również wymagania maszyn wirtualnych (zasoby sprzętowe, których maszyna wirtualna potrzebuje do działania w momencie sprawdzania). Do obliczenia zapotrzebowania maszyny wirtualnej na pamięć stosowany jest następujący wzór: Zapotrzebowanie pamięci maszyny wirtualnej = Funkcja(aktywnie wykorzystywana pamięć, pamięć zamieniona, pamięć współdzielona) + 25% (pamięć zużywana w stanie bezczynności)
Zapotrzebowanie na moc obliczeniową Procesora jest obliczane na podstawie liczby zasobów Procesora aktualnie wykorzystywanych przez maszynę wirtualną. Wartości maksymalne i średnie mocy obliczeniowej Procesora maszyny wirtualnej zebrane podczas ostatniego sprawdzenia pomagają serwisowi DRS określić trend wykorzystania zasobów dla konkretnej maszyny wirtualnej. Jeśli vSphere DRS wykryje brak równowagi w klastrze i przeciążenie niektórych hostów ESXi, wówczas DRS inicjuje migrację na żywo maszyn wirtualnych działających na przeciążonym hoście na hosta z wolnymi zasobami.
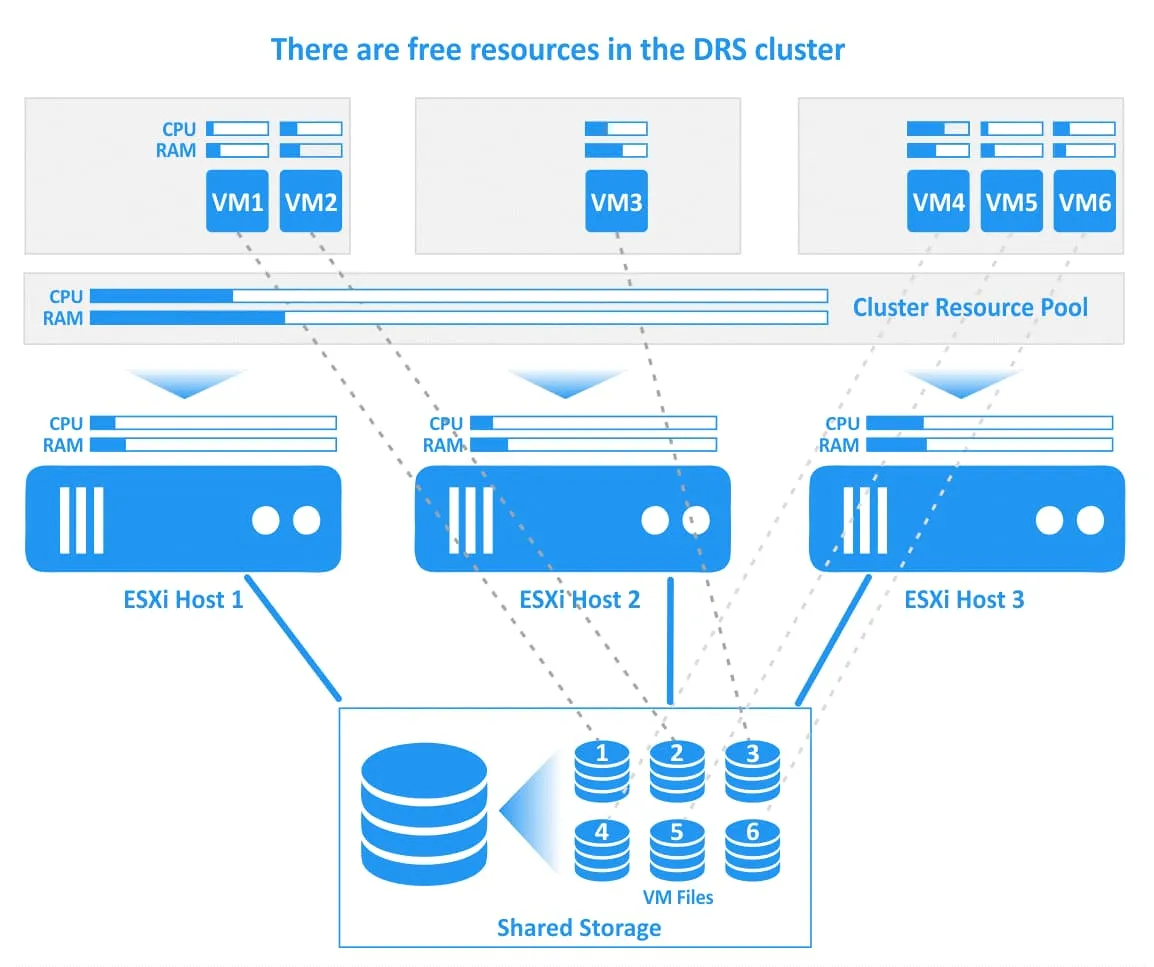
Przyjrzyjmy się, jak działa vSphere DRS w VMware, korzystając z przykładu z diagramami. Na poniższym diagramie widać klaster DRS z 3 hostami ESXi. Wszystkie hosty są podłączone do wspólnej pamięci masowej, w której znajdują się pliki maszyn wirtualnych. Pierwszy host jest bardzo obciążony, drugi host ma wolne zasoby procesora i pamięci, a trzeci host jest mocno obciążony. Niektóre maszyny wirtualne na pierwszym (VM1) i trzecim (VM4, VM5) hoście ESXi zużywają prawie wszystkie przydzielone zasoby procesora i pamięci. W tym przypadku wydajność tych maszyn wirtualnych może ulec pogorszeniu.

VMware DRS ustala, że racjonalnym działaniem jest migracja mocno obciążonej maszyny wirtualnej VM2 z przeciążonego hosta ESXi 1 na host ESXi 2, który ma wystarczające wolne zasoby, oraz migracja maszyny wirtualnej VM4 z hosta ESXi 3 na host ESXi 2. Jeśli DRS jest skonfigurowany do pracy w trybie automatycznym, uruchomione maszyny wirtualne są migrowane za pomocą vMotion (działanie to jest zilustrowane zielonymi strzałkami na poniższym obrazku). Pliki maszyn wirtualnych, w tym dyski wirtualne (VMDK), pliki konfiguracyjne (VMX) oraz inne pliki, znajdują się w tym samym miejscu na pamięci współdzielonej zarówno podczas migracji maszyn wirtualnych, jak i po jej zakończeniu (powiązania między maszynami wirtualnymi a ich plikami zaznaczono na rysunku liniami kropkowanymi).
Po migracji wybranych maszyn wirtualnych klaster DRS osiąga równowagę. Na każdym hoście ESXi w klastrze dostępne są wolne zasoby, które umożliwiają efektywne uruchamianie maszyn wirtualnych i zapewniają wysoką wydajność.

Sytuacja może ulec zmianie z powodu nierównomiernego obciążenia maszyn wirtualnych, a klaster może ponownie stracić równowagę. W takim przypadku DRS sprawdzi zużyte zasoby i wolne zasoby w klastrze, aby ponownie zainicjować migrację maszyn wirtualnych.
Kluczowe parametry konfiguracji vSphere DRS
VMware vSphere DRS to wysoce konfigurowalna funkcja klastrowania, która pozwala na bardziej efektywne wykorzystanie DRS w różnych sytuacjach. Przyjrzyjmy się głównym parametrom, które wpływają na działanie DRS w klastrze vSphere.
VMware DRS poziomy automatyzacji
Gdy DRS wykryje, że klaster vSphere jest niezrównoważony, DRS przedstawia zalecenia dotyczące rozmieszczenia i migracji maszyn wirtualnych za pomocą vMotion. Zalecenia można wdrożyć, korzystając z jednego z trzech poziomów automatyzacji:
Fully automated. Początkowe rozmieszczenie maszyn wirtualnych oraz vMotion zalecenia są stosowane automatycznie przez DRS (nie jest wymagana interwencja użytkownika).
Partially automated. Zalecenia dotyczące początkowego rozmieszczenia nowych maszyn wirtualnych są jedynymi, które są stosowane automatycznie. Inne zalecenia można zainicjować i zastosować ręcznie lub zignorować.
Manual. DRS dostarcza zaleceń dotyczących początkowego rozmieszczenia maszyn wirtualnych oraz ich migracji, ale do zastosowania tych zaleceń wymagana jest interakcja użytkownika. Można również zignorować zalecenia dostarczone przez DRS.
DRS poziomy agresywności (progi migracji)
DRS poziomy agresywności lub progi migracji to opcja pozwalająca kontrolować maksymalny poziom nierównowagi, który jest akceptowalny dla klastra DRS . Istnieje pięć wartości progowych od 1, najbardziej konserwatywnej, do 5, najbardziej agresywnej.
Ustawienie agresywne inicjuje migrację maszyn wirtualnych, nawet jeśli korzyść z ich rozmieszczenia jest niewielka. Ustawienie konserwatywne nie inicjuje migracji maszyn wirtualnych, nawet jeśli po migracji można osiągnąć znaczące korzyści. Poziom 3, średni poziom agresywności, jest domyślnie wybrany i jest to zalecane ustawienie.
Reguły powinowactwa w VMware DRS
Reguły powinowactwa i anty-powinowactwa są przydatne, gdy trzeba umieścić określone maszyny wirtualne na konkretnych hostach ESXi. Na przykład może zaistnieć potrzeba uruchomienia niektórych maszyn wirtualnych razem na jednym hoście ESXi w klastrze lub odwrotnie (trzeba umieścić dwie lub więcej maszyn wirtualnych wyłącznie na różnych hostach ESXi, a maszyny wirtualne nie mogą być umieszczone na jednym hoście). Przypadki użycia mogą obejmować:
- Maszyny wirtualne wirtualnych kontrolerów domeny (główny kontroler domeny i dodatkowy kontroler domeny) na różnych hostach, aby uniknąć awarii obu maszyn wirtualnych w przypadku awarii jednego hosta. W tym przypadku maszyny wirtualne nie mogą działać razem na jednym hoście ESXi.
- Maszyny wirtualne z oprogramowaniem, które ma licencję na działanie na konkretnym sprzęcie i nie może działać na innych komputerach fizycznych z powodu ograniczeń licencyjnych (na przykład baza danych Oracle).
Reguły powinowactwa dzielą się na:
- Reguły powinowactwa VM-VM (dla pojedynczych maszyn wirtualnych)
- Reguły powinowactwa VM-host (związek między grupami hostów a grupami maszyn wirtualnych)
Reguły VM-host mogą być preferencyjne (maszyny wirtualne powinny…) i obowiązkowe (maszyna wirtualna musi…). Reguły obowiązkowe działają nawet wtedy, gdy opcja „ DRS ” jest wyłączona, co uniemożliwia ręczną migrację odpowiednich maszyn wirtualnych za pomocą vMotion. Zasada ta służy uniknięciu naruszenia reguły stosowanej wobec maszyn wirtualnych działających na hostach ESXi w przypadku, gdy vCenter jest chwilowo niedostępne lub uległo awarii.
Istnieją cztery opcje reguł powiązania w ramach „ DRS ”:
Utrzymuj maszyny wirtualne razem. Wybrane maszyny wirtualne muszą działać razem na jednym hoście ESXi (jeśli konieczna jest migracja maszyn wirtualnych, wszystkie te maszyny muszą zostać przeniesione razem). Z tej reguły można skorzystać, gdy chcesz zlokalizować ruch sieciowy między wybranymi maszynami wirtualnymi (aby uniknąć przeciążenia sieci między hostami ESXi, jeśli maszyny wirtualne generują znaczny ruch sieciowy). Innym przypadkiem użycia jest uruchamianie złożonej aplikacji, która wykorzystuje komponenty (zależne od siebie) zainstalowane na wielu maszynach wirtualnych lub uruchamianie vApp. Mogą to być na przykład serwer bazy danych i serwer aplikacji.
Oddzielne maszyny wirtualne. Wybrane maszyny wirtualne nie mogą działać na jednym hoście ESXi. Ta opcja jest używana w celu zapewnienia wysokiej dostępności.
Maszyny wirtualne do hostów. Maszyny wirtualne dodane do grupy maszyn wirtualnych muszą działać na określonym hoście ESXi lub w grupie hostów. Należy skonfigurować DRS grupy (grupy maszyn wirtualnych/hostów). Grupa DRS zawiera wiele maszyn wirtualnych lub hostów ESXi.
Maszyny wirtualne do maszyn wirtualnych. Tę regułę można wybrać, aby powiązać maszyny wirtualne z maszynami wirtualnymi, gdy chcesz włączyć jedną grupę maszyn wirtualnych, a następnie włączyć inną (zależną) grupę maszyn wirtualnych. Ta opcja jest używana, gdy VMware HA i DRS są skonfigurowane razem w klastrze.
W przypadku konfliktu reguł pierwszeństwo ma starsza reguła.
Zastąpienie maszyny wirtualnej dla VMware DRS
Podobnie jak w przypadku zastąpienia maszyny wirtualnej w klastrze vSphere HA , zastąpienia maszyn wirtualnych służą do bardziej szczegółowej konfiguracji DRS w VMware vSphere i pozwalają na zastąpienie ustawień globalnych określonych na poziomie klastra DRS oraz zdefiniowanie konkretnych ustawień dla pojedynczej maszyny wirtualnej. Zastosowanie zastąpienia maszyny wirtualnej dla konkretnej maszyny nie ma wpływu na inne maszyny wirtualne w klastrze.
Predictive DRS
Główną ideą funkcji Predictive DRS jest gromadzenie informacji o rozmieszczeniu maszyn wirtualnych, a następnie, na podstawie wcześniej zebranych informacji, przewidywanie, kiedy i gdzie wystąpi wysokie zużycie zasobów. Korzystając z tych informacji, funkcja Predictive DRS może przenosić maszyny wirtualne między hostami w celu lepszego równoważenia obciążenia, zanim serwer ESXi zostanie przeciążony, a maszynom wirtualnym zabraknie zasobów. Ta funkcja może być przydatna, gdy występują zmiany zapotrzebowania na maszyny wirtualne w klastrze w zależności od pory dnia. Funkcja Predictive DRS jest domyślnie wyłączona. VMware vRealize Operations Manager jest wymagane do korzystania z funkcji Power DRS.
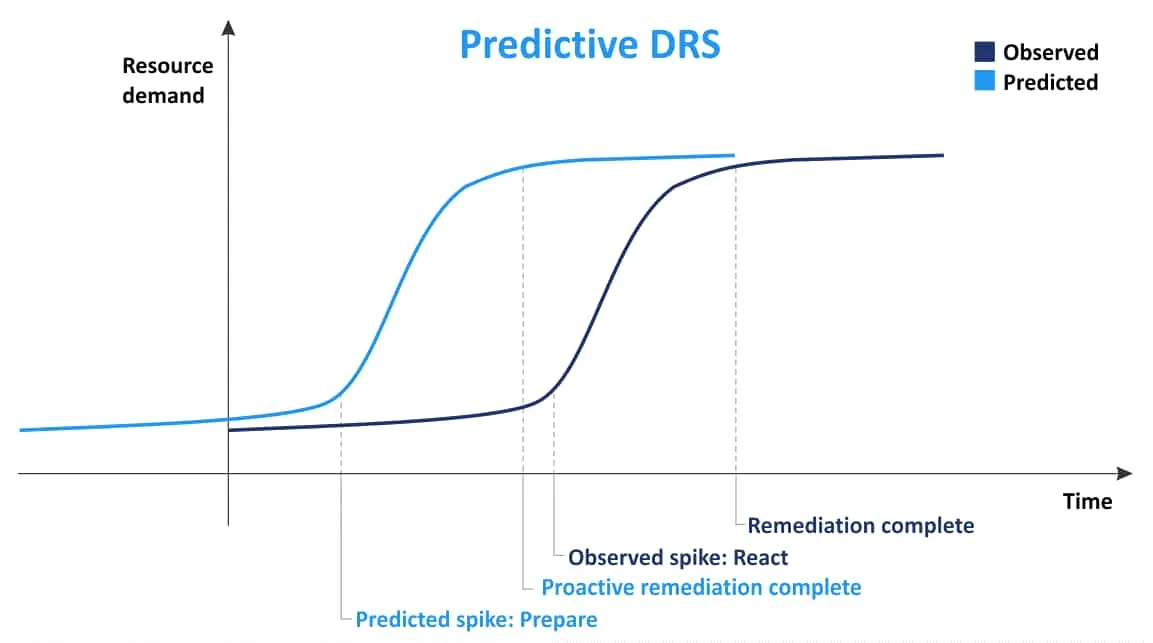
Distributed Power Manager
Distributed Power Manager (DPM) to funkcja służąca do migracji maszyn wirtualnych, jeśli w klastrze jest wystarczająco dużo wolnych zasobów, aby wyłączyć host ESXi (przełączyć go w tryb gotowości) i uruchomić maszyny wirtualne na pozostałych hostach ESXi w klastrze (pozostałe hosty muszą zapewniać wystarczające zasoby do uruchomienia potrzebnych maszyn wirtualnych).
Gdy w klastrze potrzeba więcej zasobów do uruchomienia maszyn wirtualnych, DPM inicjuje wybudzenie wyłączonego serwera i przywrócenie go do trybu normalnego. Do włączenia hosta przez sieć wykorzystywany jest jeden z obsługiwanych protokołów zarządzania zasilaniem. Są to protokoły Intelligent Platform Management Interface (IPMI), Hewlett-Packard Integrated Lights-Out (iLO)lub Wake-On-LAN (WOL). Następnie DRS migruje niektóre maszyny wirtualne na ten serwer w celu rozłożenia obciążenia i zrównoważenia klastra. Domyślnie Distributed Power Management jest wyłączony. DPM zalecenia można stosować automatycznie lub ręcznie.

Storage DRS
Podczas gdy DRS migruje maszyny wirtualne w oparciu o zasoby obliczeniowe Procesora i pamięci RAM, Storage DRS migruje pliki maszyn wirtualnych z jednego magazynu danych do innego w oparciu o wykorzystanie magazynu danych, na przykład wolne miejsce na dysku. Reguły powinowactwa i anty-powinowactwa pozwalają skonfigurować, czy Storage DRS musi przechowywać pliki dysków wirtualnych maszyny wirtualnej razem w tym samym magazynie danych. Na przykład można skonfigurować regułę anty-afiniczną, aby pliki VMDK maszyny wirtualnej wykonującej I/O operacje intensywne były przechowywane na różnych magazynach danych. Robi się to, aby uniknąć spadku wydajności maszyny wirtualnej i początkowego magazynu danych maszyny wirtualnej (I/O obciążenia dyskowe będą rozdzielane na wiele magazynów danych przy użyciu reguły anty-afinicznej).
Storage DRS jest przydatne podczas korzystania z maszyn wirtualnych z przydzielane dynamicznie dyskami w przypadku nadmiernego przydzielania zasobów. Storage DRS Pomaga uniknąć sytuacji, w których rozmiar dysków typu thin rośnie, a w rezultacie brakuje wolnego miejsca w magazynie danych. Brak wolnego miejsca powoduje awarię maszyn wirtualnych przechowujących dyski wirtualne w tym magazynie danych. Pliki dysków maszyn wirtualnych można migrować z jednego magazynu danych do drugiego za pomocą Storage vMotion podczas działania maszyny wirtualnej.
Monitorowanie zużycia procesora i pamięci
VMware zapewnia możliwość monitorowania wykorzystania zasobów w interfejsie internetowym VMware vSphere Client. Można monitorować wykorzystanie procesora w klastrze, przechodząc do Settings > Monitor > vSphere DRS > CPU Utilization. Istnieją również inne opcje monitorowania pamięci i przestrzeni dyskowej dla poszczególnych hostów ESXi. Monitorowanie VMware jest obsługiwane w NAKIVO Backup & Replication 10.5. Więcej informacji na temat monitorowania infrastruktury można znaleźć w wpis na blogu.
Wspólne używanie VMware HA i DRS
VMware HA i DRS nie są technologiami konkurencyjnymi. Rozwiązania te wzajemnie się uzupełniają i można korzystać zarówno z VMware DRS jak i HA w klastrze vSphere, aby zapewnić wysoką dostępność maszyn wirtualnych oraz równoważyć obciążenia w przypadku ponownego uruchomienia maszyn wirtualnych przez HA na innych hostach ESXi. Zaleca się stosowanie obu technologii w klastrach vSphere działających w środowiskach produkcyjnych w celu zapewnienia Trybu failover i równoważenia obciążenia.
W przypadku awarii hosta ESXi Tryb failover maszyny wirtualnej jest uruchamiany przez HA, a maszyny wirtualne są ponownie uruchamiane na innych hostach. W tej sytuacji priorytetem jest zapewnienie dostępności maszyn wirtualnych. Jednak po migracji maszyn wirtualnych niektóre hosty ESXi mogą być przeciążone, co miałoby negatywny wpływ na maszyny wirtualne działające na tych hostach. VMware DRS sprawdza wykorzystanie zasobów na każdym hoście w klastrze i przedstawia zalecenia dotyczące najbardziej racjonalnego rozmieszczenia maszyn wirtualnych w Trybie failover. Dzięki temu zawsze masz pewność, że po Trybie failover maszyny wirtualne dysponują wystarczającymi zasobami do obsługi obciążeń z odpowiednią wydajnością. Po włączeniu zarówno VMware DRS jak i HA możesz uzyskać bardziej efektywny klaster.
Wnioski
VMware zapewnia zaawansowane funkcje klastrów w vSphere, aby zaspokoić potrzeby najbardziej wymagających klientów korzystających z vSphere. Omówiliśmy VMware DRS i HA oraz wyjaśniliśmy zasadę działania i główne parametry każdej z tych funkcji klastrowania. VMware DRS i HA uzupełniają się nawzajem i poprawiają końcowy efekt korzystania z klastra.
Nawet jeśli korzystasz z VMware DRS i HA, nie zapomnij o wykonaniu kopii zapasowej maszyn wirtualnych VMware w vSphere. Pobierz bezpłatną edycję NAKIVO Backup & Replication dla Tworzenie kopii zapasowej VMware w swoim środowisku.



