Odzyskiwanie awaryjne z wykorzystaniem NAKIVO: planowanie, wdrożenie i testowanie
Wykonać kopię zapasową i odzyskać dane po awarii stanowi podstawę strategii ochrony danych w różnych organizacjach i branżach. Odzyskiwanie awaryjne to proces odzyskiwania maszyn wirtualnych oraz usług na nich działających w lokalizacji zapasowej (zwanej lokalizacją odzyskiwania awaryjnego) w sytuacji, gdy lokalizacja produkcyjna staje się niedostępna. Lokalizacje te, w których znajdują się redundantne serwery, komputery i sprzęt sieciowy wraz z niezbędnym oprogramowaniem, Wtórne lokalizacje DR mogą być różnego rodzaju w zależności od poziomu redundancji.
NAKIVO Backup & Replication zawiera funkcję Odzyskiwania lokacji, która pozwala tworzyć zaawansowane sekwencje odzyskiwania (w Trybie failover pełnym), które można uruchomić jednym kliknięciem, gdy główna lokalizacja przestaje działać. Przeczytaj ten wpis na blogu, aby dowiedzieć się więcej o kluczowych elementach strategii odzyskiwania awaryjnego, takich jak planowanie odzyskiwania po awarii IT, testowanie i przeprowadzanie odzyskiwania awaryjnego za pomocą zintegrowanego rozwiązania NAKIVO.

Krok 1. Planowanie odzyskiwania awaryjnego
Jako niezbędny element skutecznego odzyskiwania awaryjnego, planowanie powinno obejmować ocenę potrzeb organizacji w zakresie odzyskiwania danych oraz uzyskanie pełnego zrozumienia, jakie elementy, etapy i procedury należy uwzględnić w procesie odzyskiwania danych po awarii.
Planowanie odzyskiwania awaryjnego: najlepsze rozwiązania
1. Przeprowadź analizę wpływu na działalność
Analiza wpływu na działalność ( analiza wpływu na działalność (lub BIA) ) służy do określenia potencjalnego negatywnego wpływu poważnych incydentów lub klęsk żywiołowych na działalność biznesową. Analiza ta obejmuje ustalenie kolejności priorytetów dla różnych maszyn wirtualnych (VM), sekwencji odzyskiwania oraz czasu dostępnego, zanim zakłócenie znacząco wpłynie na działalność biznesową. Na przykład awaria jednej maszyny wirtualnej może spowodować opóźnienia i niedogodności, podczas gdy awaria innej maszyny wirtualnej może doprowadzić do całkowitego zakłócenia operacji krytycznych dla działalności.
2. Ocena ryzyka
Przed rozpoczęciem planowania odzyskiwania po awarii należy zebrać odpowiednie dane dotyczące zagrożeń dla działalności organizacji i ciągłości biznesowej. W niektórych regionach długotrwała awaria zasilania lub atak wirusa są bardziej prawdopodobne niż tornado, ale w innych klęski żywiołowe są częstym zjawiskiem. Ocena ryzyka pomaga określić odpowiedni poziom ochrony przed określonymi zagrożeniami oraz opracować środki mające na celu zminimalizowanie ryzyka i złagodzenie skutków. Mimo że nie da się całkowicie wyeliminować ryzyka, będziesz lepiej przygotowany na scenariusze katastrof, z którymi prawdopodobnie będziesz musiał się zmierzyć.
3. Opracuj dokumentację dotyczącą odzyskiwania awaryjnego
Po zidentyfikowaniu ryzyka i jego potencjalnego wpływu na działalność firmy lepiej zrozumiesz, na czym należy skoncentrować wysiłki podczas planowania procesów odzyskiwania awaryjnego. Procedury odzyskiwania dokumentów, szczegółowo opisując wszystkie kluczowe kroki i środki odzyskiwania awaryjnego, oraz regularnie aktualizuj dokumenty, aby odzwierciedlały zmiany wprowadzone w środowisku. Dokumentacja powinna zawierać:
Disaster recovery scope.Oceń znaczenie każdego elementu sprzętowego i programowego w swojej infrastrukturze i uwzględnij te, które są niezbędne do operacji o znaczeniu krytycznym, w swoim planie odzyskiwania awaryjnego. Maszyny wirtualne przechowujące krytyczne informacje, systemy IT i aplikacje, których działanie jest niezbędne do zapewnienia ciągłości świadczenia usług, powinny być Twoim priorytetem przy odzyskiwaniu.VM recovery order.Niektóre maszyny wirtualne mogą być zależne od oprogramowania lub informacji przechowywanych na innej maszynie wirtualnej, co oznacza, że nie mogą działać oddzielnie ani być uruchamiane w dowolnej kolejności. Należy określić kolejność odzyskiwania, aby usprawnić proces odzyskiwania danych i wyeliminować ryzyko konfliktów oprogramowania w lokalizacji DR. Na przykład maszyna wirtualna z kontrolerem domeny Active Directory musi być uruchomiona, zanim będzie można uruchomić maszynę wirtualną z serwerem plików korzystającym z uwierzytelniania Active Directory.
Innym przykładem są usługi internetowe, które często opierają się na oprogramowaniu zainstalowanym na kilku różnych maszynach wirtualnych. Konieczne może być wdrożenie następującej sekwencji:
- Najpierw należy uruchomić maszynę wirtualną z serwerem bazy danych.
- Następnie można uruchomić maszynę wirtualną z serwerem aplikacji.
- Dopiero wtedy można uruchomić maszynę wirtualną z serwerem internetowym.
RTO and RPO in disaster recovery.W planie odzyskiwania awaryjnego należy ustawić cele związane z czasem odzyskiwania (RTO) i cele punktu odzyskiwania (RPO) dla maszyn wirtualnych o różnym priorytecie. Na przykład maszyny wirtualne z systemami finansowymi mogą mieć krótsze cele odzyskiwania niż te używane do przechowywania zarchiwizowanych dokumentów.Dependencies.Określając łańcuch zależności między personelem a komponentami IT, współpracuj z pracownikami i uwzględnij ich opinie, aby uniknąć słabych ogniw, które mogą prowadzić do niepowodzenia odzyskiwania. Na przykład maszyna wirtualna używana przez dział księgowości może wymagać odzyskania w pierwszej kolejności, jeśli pracownicy innych działów są zależni od tych operacji finansowych w swojej pracy.Staff. Przydziel role i obowiązki członkom zespołu, którzy uczestniczą w procesach odzyskiwania po awarii. Jeśli będą pracować w lokalizacji DR, upewnij się, że są tam skonfigurowane stacje robocze z całym wymaganym wyposażeniem, meblami biurowymi i sprzętem, aby mogli kontynuować pracę przy minimalnych przerwach. Jeśli pracownicy mogą pracować zdalnie podczas awarii, skonfiguruj dostęp do VPN i zapewnij konta VPN z wyprzedzeniem.Hardware requirements. Sukces planu odzyskiwania awaryjnego zależy w dużej mierze od wydajności i możliwości sprzętu znajdującego się w lokalizacji DR. Należy wziąć pod uwagę kilka czynników:- Serwery muszą mieć wystarczającą moc procesora, pamięć i pojemność dyskową, aby obsłużyć przeniesione obciążenia. Niska wydajność procesora i niewystarczająca pamięć mogą wpływać na szybkość maszyn wirtualnych, a niewystarczająca prędkość dysku skutkuje słabą wydajnością maszyn wirtualnych.
- Sieci muszą zapewniać wystarczającą przepustowość, aby odzyskane maszyny wirtualne mogły komunikować się między sobą, z pamięć masowaoraz z użytkownikami w razie potrzeby.
Krok 2. Przygotowanie do odzyskiwania awaryjnego
Po zebraniu dokumentacji można przystąpić do przygotowań do odzyskiwania awaryjnego poprzez przygotowanie lokalizacji awaryjnej oraz skonfigurowanie replikacji kluczowych obciążeń do tej lokalizacji. Replikacja jest wymagana w przypadku Tryb failover maszyny wirtualnej w celu utworzenia replik maszyn wirtualnych na wypadek awarii infrastruktury głównej.
Czym jest replikacja maszyn wirtualnych?
Replikacja maszyn wirtualnych to proces tworzenia identycznej kopii źródłowej maszyny wirtualnej (zwanej „repliką maszyny wirtualnej”) na innym hoście (hosta docelowym). Replika maszyny wirtualnej to zwykła maszyna wirtualna, która pozostaje w stanie wyłączonym, dopóki nie jest potrzebna (wówczas może zostać uruchomiona na swoim hoście niemal natychmiast).
Sprawdź, jak utworzyć i skonfigurować zadanie replikacji VMware w NAKIVO Backup & Replication, aby uzyskać więcej szczegółów.
Proces przełączania obciążeń z maszyny wirtualnej źródłowej (produkcyjnej) na replikę maszyny wirtualnej w lokalizacji DR w celu utrzymania ciągłości działania i wysokiej dostępności nazywany jest Trybem failover.
Najlepsze rozwiązania dotyczące replikacji maszyn wirtualnych
Istnieją szereg najlepszych rozwiązań w zakresie replikacji zapewniające większą niezawodność i skuteczność procesu. W tym miejscu skupimy się na dwóch kluczowych kwestiach:
Perform VM replication at the{10}. Warstwa wirtualizacji jest warstwą pośrednią pomiędzy sprzętem fizycznym a systemem operacyjnym gościa działającym na maszynie wirtualnej. Replikacja wykonywana na poziomie wirtualizacji nazywana jest replikacją na poziomie hosta i jest bardziej wydajna niż replikacja na poziomie gościa.Use application-aware replication to avoid data loss.Jeśli migawka maszyny wirtualnej potrzebna do replikacji zostanie wykonana podczas działania tych aplikacji bez podjęcia dodatkowych działań, efekt będzie podobny do nieoczekiwanej utraty zasilania i wyłączenia, a dane mogą zostać utracone.
Dzięki metodom spójnym z aplikacją aplikacje są zamrażane (wstrzymywane), pamięć jest opróżniana, a dane nie mogą być zapisywane na dysku przed wykonaniem migawki. Po wykonaniu spójnej migawki można utworzyć replikę maszyny wirtualnej. Takie repliki maszyn wirtualnych można pomyślnie przywrócić, a aplikacje w nich zawarte działają poprawnie.
NAKIVO Backup & Replication obsługuje spójną z aplikacją replikację na poziomie hosta dla maszyn wirtualnych VMware, Hyper-V oraz instancji EC2, oferując specjalne funkcje dla serwerów Microsoft SQL Server, Exchange Server oraz kontrolerów domeny Active Directory.
Krok 3. Tworzenie procesu odzyskiwania awaryjnego
Aby utworzyć proces odzyskiwania awaryjnego, potrzebne jest specjalistyczne rozwiązanie do odzyskiwania awaryjnego, takie jak NAKIVO Backup & Replication, które zapewnia wbudowaną funkcję Odzyskiwania lokacji do orkiestracji i automatyzacji sekwencji odzyskiwania awaryjnego.
- Czym jest proces odzyskiwania awaryjnego?
- Dostępne działania w ramach procesu DR
- Jak stworzyć procedurę odzyskiwania awaryjnego
- Przewodnik po konfiguracji rozwiązania Odzyskiwanie lokacji firmy NAKIVO
Czym jest sekwencja działań w ramach odzyskiwania awaryjnego?
Sekwencja działań w ramach odzyskiwania awaryjnego to ciąg czynności wykonywanych w ramach procesu odzyskiwania awaryjnego, mający na celu bezpieczne i szybkie przełączenie obciążeń na repliki. Sekwencja ta organizuje Tryb failover, uwzględniając działania związane z maszynami wirtualnymi źródłowymi, docelowymi, warunkami, które muszą zostać spełnione itp. Należy określić kolejność wykonywania tych działań, ponieważ niektóre procedury odzyskiwania awaryjnego mogą zależeć od wyników wykonania innych.
Dostępne działania Odzyskiwania lokacji
Funkcja Odzyskiwania lokacji pozwala tworzyć złożone sekwencje DR poprzez łączenie działań i warunków w jednym przepływie pracy. Każde działanie może być wykonywane wyłącznie w trybie testowym, wyłącznie w trybie produkcyjnym lub w obu trybach (jest to ustawienie domyślne) w NAKIVO Backup & Replication.
W sekwencji można uwzględnić dowolne lub wszystkie z poniższych działań:
Failover– inicjuje Tryb failover na repliki maszyn wirtualnych VMware, maszyn wirtualnych Hyper-V lub instancji EC2.Failback– przywraca obciążenia z repliki maszyny wirtualnej do maszyny źródłowej. Zmiany wprowadzone w replice maszyny wirtualnej od momentu Trybu failover są zapisywane w maszynie źródłowej podczas operacji powrotu po awarii. Maszyny wirtualne są zsynchronizowane, a maszyna źródłowa ponownie znajduje się w rzeczywistym stanie produkcyjnym.Start– uruchamia maszyny wirtualne VMware, maszyny wirtualne Hyper-V lub instancje EC2.Stop– zatrzymuje uruchomione maszyny wirtualne VMware, maszyny wirtualne Hyper-V oraz instancje EC2.Run job– uruchamia zadanie tworzenia kopii zapasowej, replikacji, odzyskiwania lokacji, kopiowania kopii zapasowej lub szybkiego uruchomienia maszyny wirtualnej Flash.Stop jobs– zatrzymuje zadanie (dowolne z zadań wymienionych w poprzednim punkcie).Run script– uruchamia skrypt na jednym z następujących celów: serwerze z Director, zdalnym serwerze Windows, zdalnym serwerze Linux, maszynie wirtualnej VMware, maszynie wirtualnej Hyper-V lub instancji EC2.Attach repository– dołącza repozytorium kopii zapasowych używane przez NAKIVO Backup & Replication do przechowywania kopii zapasowych.Detach repository– odłącza repozytorium kopii zapasowych.Send email– wysyła e-mail z treścią, którą skomponujesz, do jednego lub więcej zdefiniowanych odbiorców.Wait– czeka przez wyznaczony okres czasu przed przejściem do następnej akcji.Check condition– na podstawie wprowadzonych danych (całej lub części nazwy zasobu) sprawdza jeden z następujących warunków:- Zasób istnieje
- Zasób jest działa
- Adres IP/nazwa hosta jest dostępna
Jak utworzyć zadanie Odzyskiwania lokacji
Przyjrzyjmy się przykładowi tworzenia zadania Odzyskiwania lokacji w NAKIVO Backup & Replication.
Nasza konfiguracja
Oto konfiguracja, którą będziemy rozważać: lokalizacja główna (produkcyjna) z maszynami wirtualnymi VMware vSphere oraz lokalizacja DR w odległej lokalizacji:
- DC-VM to maszyna wirtualna z systemem Windows, na której działa kontroler domeny Active Directory.
- FS-VM to maszyna wirtualna z systemem Windows, na której działa serwer plików (do udziału plików używany jest protokół SMB). Do uwierzytelniania użytkowników używana jest usługa Active Directory. Zrzuty bazy danych Oracle są przechowywane na serwerze plików.
- Ora-DB to maszyna wirtualna, na której działa baza danych Oracle.
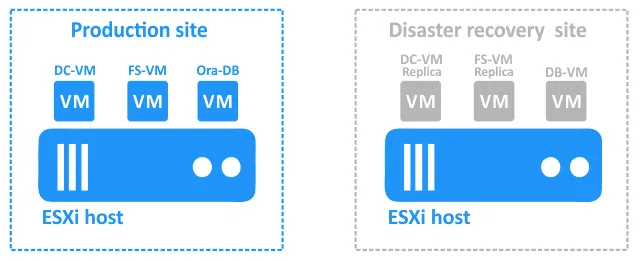
Witryna odzyskiwania awaryjnego zawiera następujące maszyny wirtualne:
- DC-VM-replica oraz FS-VM-replica są replikami maszyn wirtualnych produkcyjnych. Mogą one służyć jako cele Trybu failover.
- DB-VM to maszyna wirtualna oparta na systemie Linux z Zainstalowano oprogramowanie Oracle Database ale nie zawiera żadnych baz danych.
Kopia zapasowa bazy danych jest wykonywana za pomocą NAKIVO Backup & Replication na poziomie bazy danych do FS-VM w witrynie produkcyjnej (ta Wykonać kopię zapasową bazy danych Oracle jest spójna z aplikacją). FS-VM i DC-VM są replikowane na poziomie hosta do lokalizacji DR za pomocą rozwiązania NAKIVO.
Kolejność odzyskiwania maszyn wirtualnych
Podczas incydentu powodującego awarię lokalizacji produkcyjnej komponenty muszą zostać odzyskane w lokalizacji DR w następujący sposób:
- Tryb failover DC-VM na DC-VM-replica.
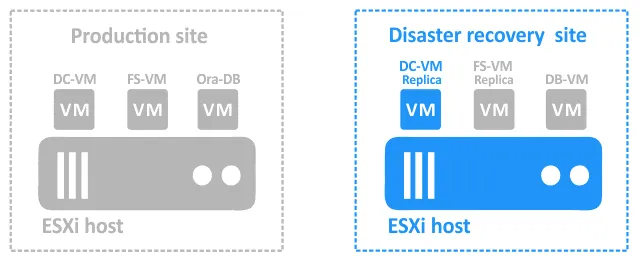
- Gdy DC-VM-replica będzie już uruchomiona, należy wykonać Tryb failover FS-VM na FS-VM-replica . Należy postępować w tej kolejności, ponieważ FS-VM wykorzystuje DC-VM do uwierzytelniania użytkowników na serwerze plików.
- Gdy te dwie maszyny wirtualne będą już działać, DB-VM będzie mogła uzyskać dostęp do katalogu współdzielonego na serwerze plików, w którym przechowywany jest zrzut. Teraz można uruchomić DB-VM .
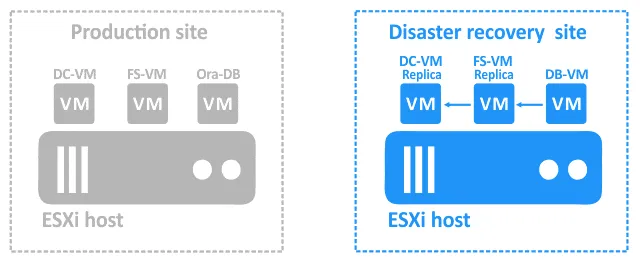
- Gdy DB-VM działa, uruchom skrypt, który przywróci bazę danych z zrzutu znajdującego się na serwerze plików. Niebieskie strzałki na powyższych schematach pokazują zależności.
Należy pamiętać, że uruchomienie usług na włączonej replice maszyny wirtualnej po Trybie failover i przed przełączeniem na następną replikę lub odzyskaniem aplikacji lub bazy danych może zająć trochę czasu. Ten czas oczekiwania powinien stanowić część sekwencji DR.
W przypadku tej sekwencji Trybu failover maszyn wirtualnych należy utworzyć zadanie Odzyskiwania lokacji w NAKIVO Backup & Replication z następującą logiką:
Action 1: Tryb failover maszyny wirtualnej DC . Przed przejściem do następnego kroku należy poczekać na zakończenie tej operacji. Zatrzymaj zadanie, jeśli ta akcja się nie powiedzie.Action 2. Poczekaj przez 3 minuty.Action 3. Sprawdź stan repliki maszyny wirtualnej kontrolera domeny . Sprawdź, czy zasób działa. Jeśli zasób działa, przejdź do następnej akcji w zadaniu Odzyskiwanie lokacji. Jeśli nie, zatrzymaj zadanie i zgłoś jego niepowodzenie.Action 4. Przełącz maszynę wirtualną systemu plików . Poczekaj, aż ta akcja się zakończy, zanim przejdziesz do następnej akcji. Zatrzymaj zadanie, jeśli ta czynność zakończy się niepowodzeniem.Action 5. Odczekaj przez 3 minuty.Action 6. Sprawdź stan repliki FS-VM . Jeśli zasób działa, przejdź do następnej czynności zadania Odzyskiwanie lokacji. Jeśli nie, zatrzymaj i zakończ zadanie niepowodzeniem.Action 7. Uruchom DB-VM . Odczekaj, aż ta czynność zostanie zakończona, zanim przejdziesz do następnej czynności. Zatrzymaj zadanie, jeśli ta czynność zakończy się niepowodzeniem.Action 8. Odczekaj przez 5 minut.Action 9. Uruchom skrypt . Typ celu: maszyna wirtualna VMware. Maszyna wirtualna docelowa: DB-VM. Ścieżka skryptu: /home/oracle/restore_db.sh (podczas dodawania tego kroku należy wprowadzić nazwę użytkownika i hasło konta posiadającego uprawnienia wystarczające do uruchomienia skryptu).
Przewodnik po funkcji Odzyskiwanie lokacji firmy NAKIVO
Utwórzmy nowe zadanie Odzyskiwania lokacji w oparciu o plan przedstawiony powyżej. Na stronie Jobs instancji NAKIVO Backup & Replication kliknij Create > Site recovery job.
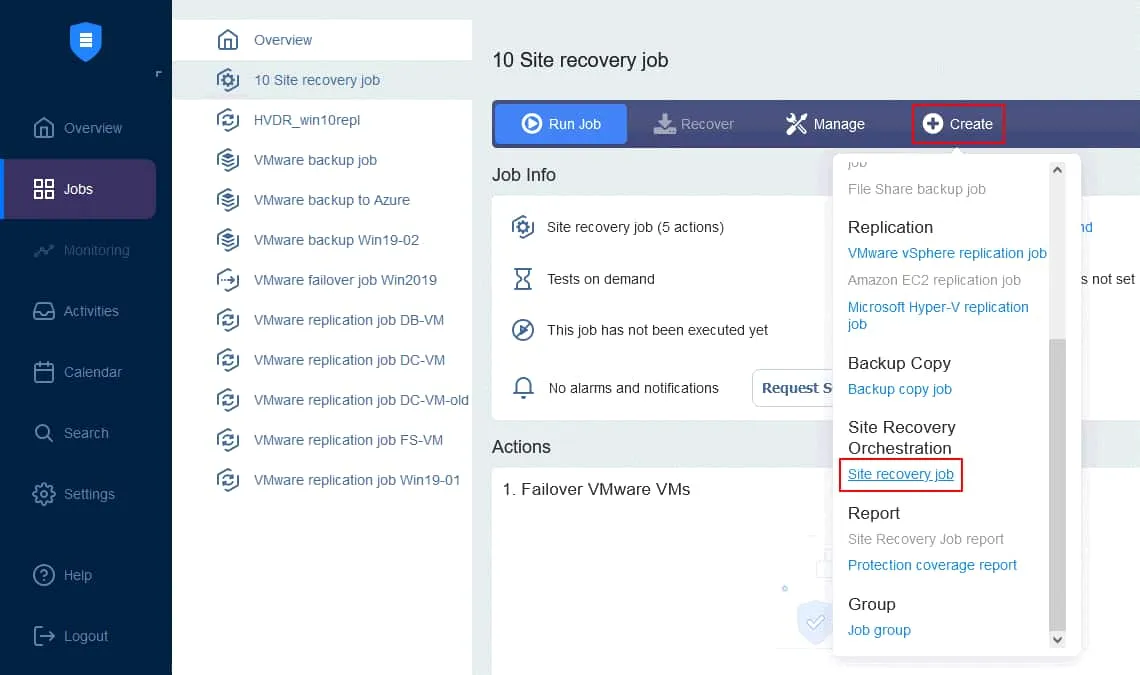
1. Działania
Uruchamia się Kreator nowego zadania Odzyskiwanie lokacji . W lewym panelu znajdują się działania, które można dodać do zadania. Wystarczy kliknąć działanie, aby dodać je do sekwencji. Należy pamiętać, że w jednej sekwencji nie można łączyć działań dla różnych platform (tworzymy zadanie dla maszyn wirtualnych VMware).
Czynność 1. Tryb failover maszyny wirtualnej DC
- W lewym panelu kliknij
Failover VMware VMs.
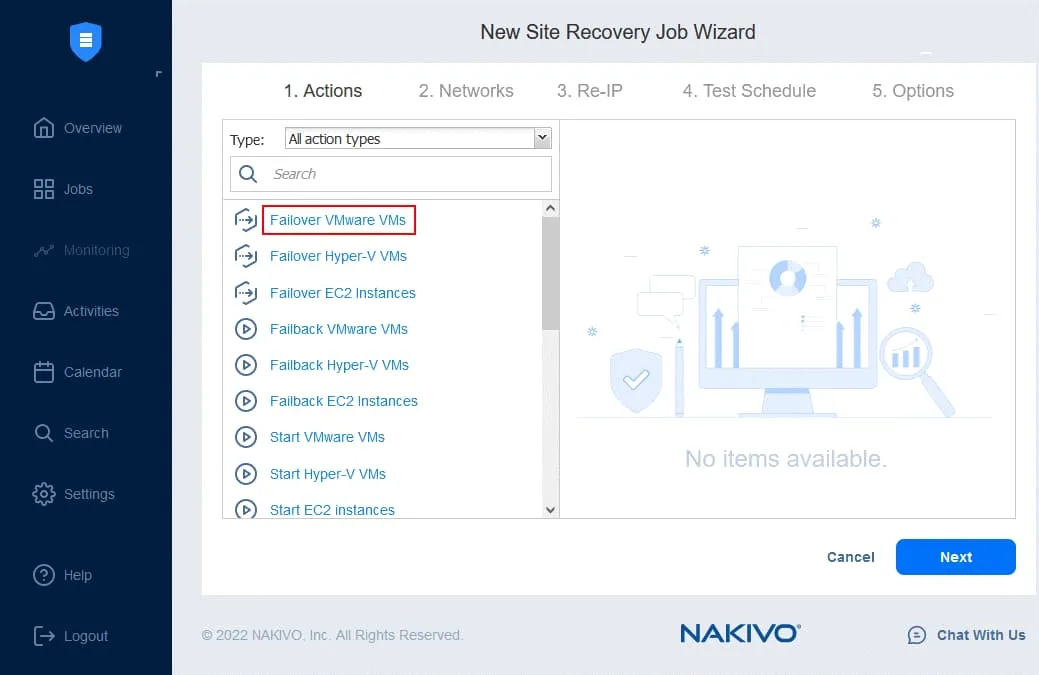
- W lewym panelu wybierz replikę maszyny wirtualnej z istniejącego zadania replikacji. W naszym przepływie pracy Tryb failover do DC-VM-replica jest pierwszą czynnością. W prawym panelu można wybrać punkt odzyskiwania. Domyślnie używany jest najnowszy punkt odzyskiwania.
Kliknij Next , aby kontynuować. 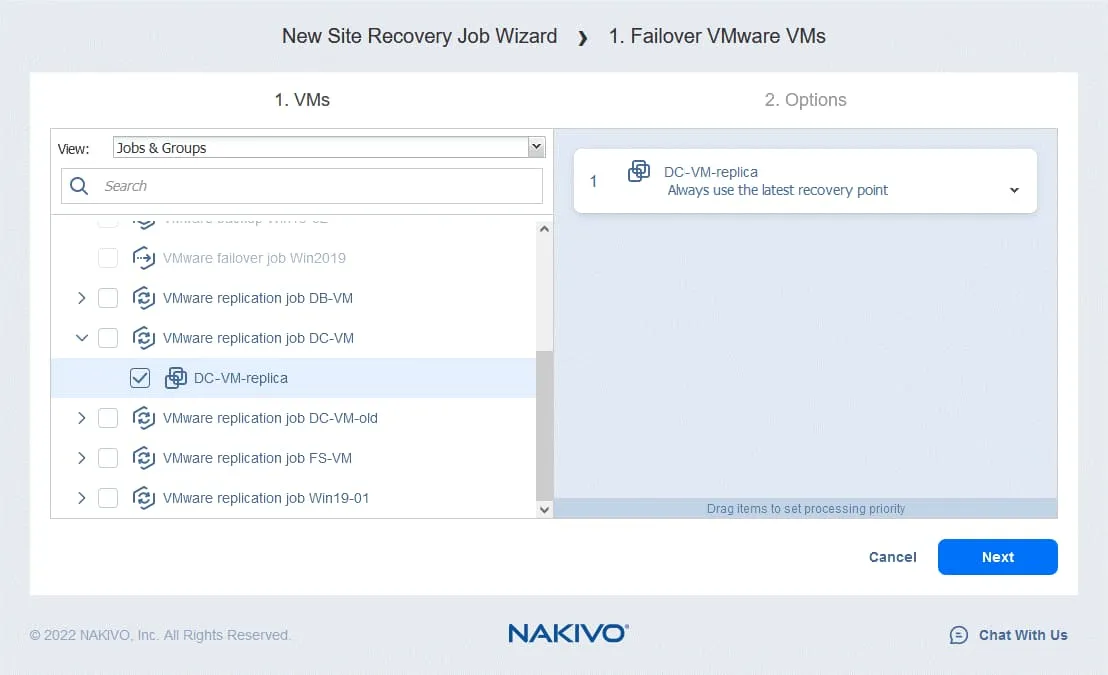
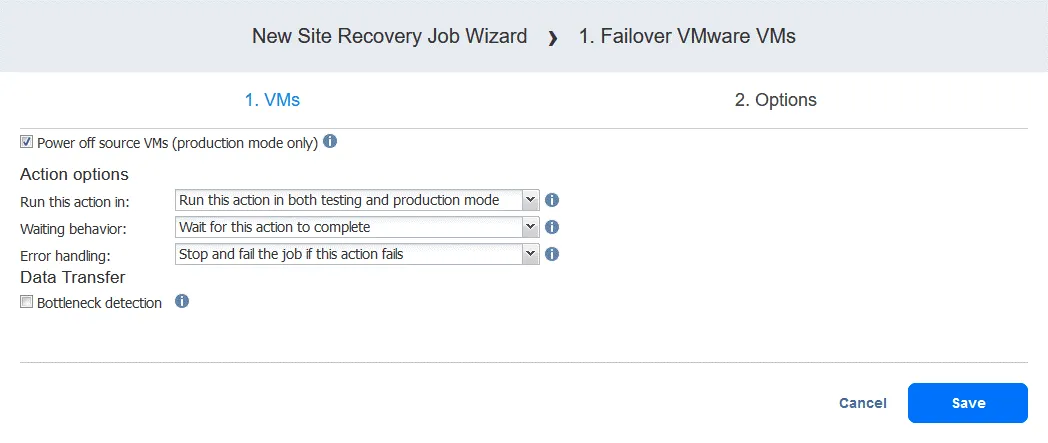
- W przypadku opcji odzyskiwania awaryjnego i Trybu failover można odznaczyć opcję
Power off source VMs– opcja ta służy do zapobiegania konfliktom adresów IP, jeśli maszyny wirtualne źródłowe i repliki korzystają z tych samych sieci.
Zgodnie z powyższą logiką wybieramy następujące opcje:
- Uruchom tę akcję w:
Run this action in both testing and production mode - Zachowanie podczas oczekiwania:
Wait for this action to complete - Obsługa błędów:
Stop and fail the job if this action fails
Kliknij Save , aby zapisać utworzoną akcję.
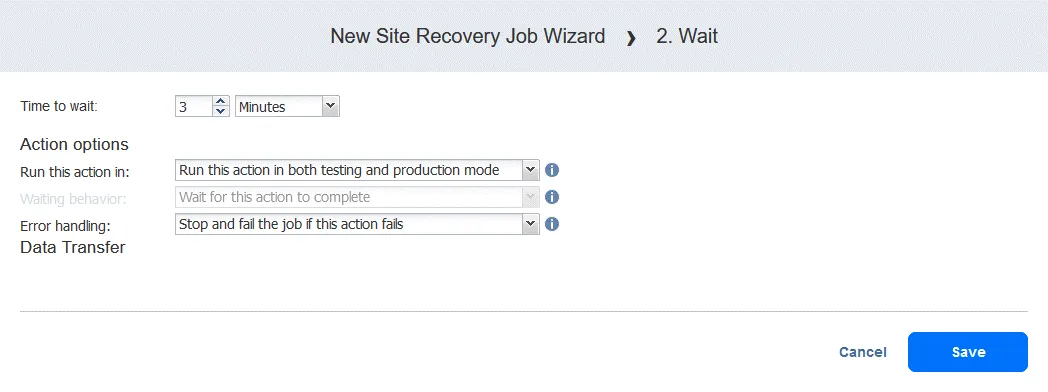
Czynność 2. Poczekaj 3 minuty
Czynność wait jest przydatna w tym przypadku, ponieważ następująca po niej czynność Trybu failover w przepływie pracy (przełączenie do FS-VM-replica ) wymagałaby, aby DC-VM-replica była uruchomiona i działała już z usługami domenowymi Active Directory.
- W lewym panelu ekranu Actions kliknij
Wait.
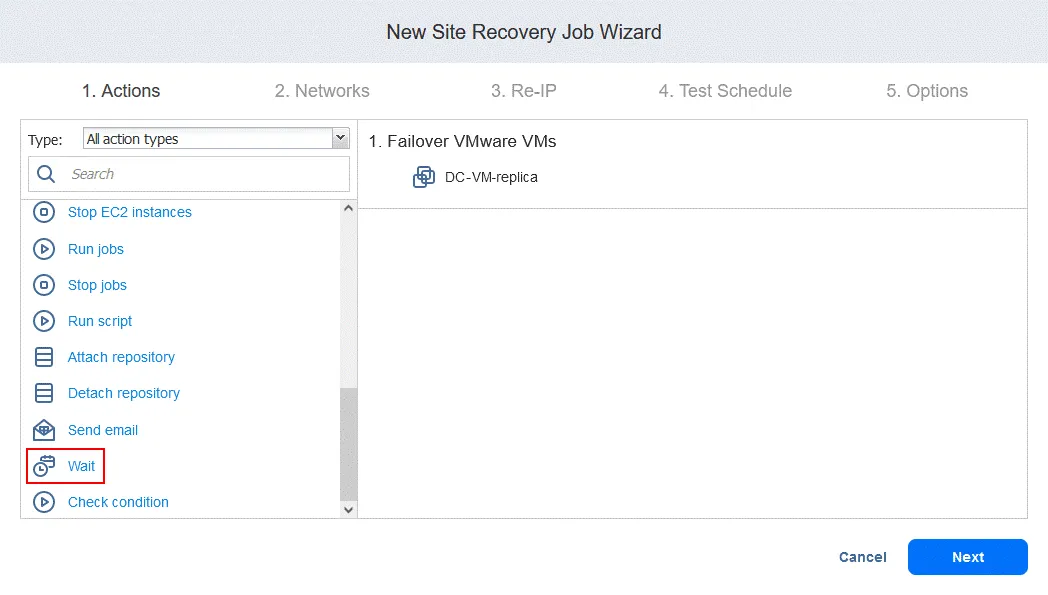
- Wybierz czas oczekiwania (używamy 3 minuty ).
Wybierz opcje akcji tak samo, jak w przypadku pierwszej akcji, i kliknij Save.
Nowa akcja zostanie dodana po poprzedniej akcji, na dole listy. Możesz zmieniać kolejność, edytować lub usuwać akcje. Wystarczy najechać kursorem myszy na akcję, aby wyświetlić opcje.
Akcja 3. Sprawdź stan DC-VM-replica
- W lewym panelu ekranu Akcje kliknij
Check condition, aby sprawdzić, czy maszyna wirtualna, która została przełączona w pierwszej akcji, działa.
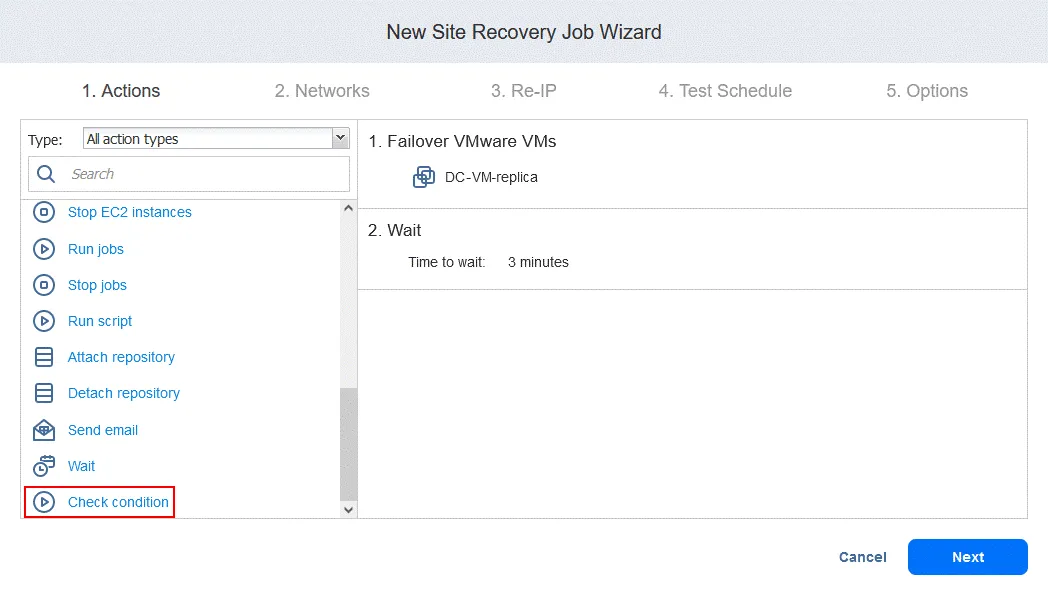
- Skonfiguruj tę akcję w następujący sposób:
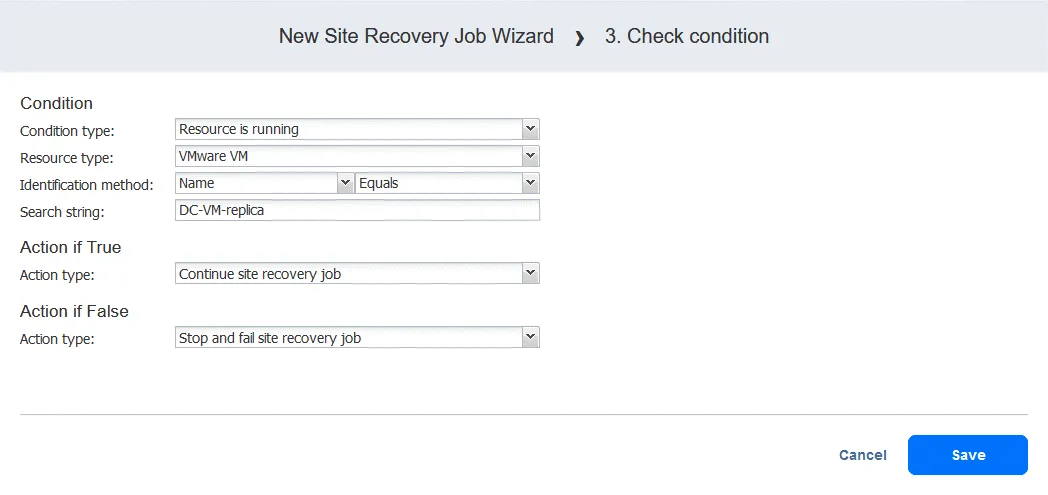
- Wybierz typ warunku:
Resource is running. Inne opcje to zasób istnieje lub adres IP/nazwa hosta jest dostępny. - Wybierz typ zasobu:
VMware VM. - Wybierz metodę identyfikacji:
Name(inną opcją jest ID ) w celu zidentyfikowania danej maszyny wirtualnej. Możesz użyć dowolnej części ciągu znaków maszyny wirtualnej. W tym przypadku znamy dokładną nazwę, więc używamy funkcjiEquals. - Zdefiniuj ciąg wyszukiwania:
DC-VM-replica.
Teraz mamy akcję, która sprawdza, czy maszyna wirtualna VMware o nazwie DC-VM-replica jest uruchomiona. Kliknij Save , aby kontynuować.
Czynność 4. Tryb failover maszyny wirtualnej FS-VM
- Tak samo jak w przypadku Czynność 1 , kliknij
Failover VMware VMs.
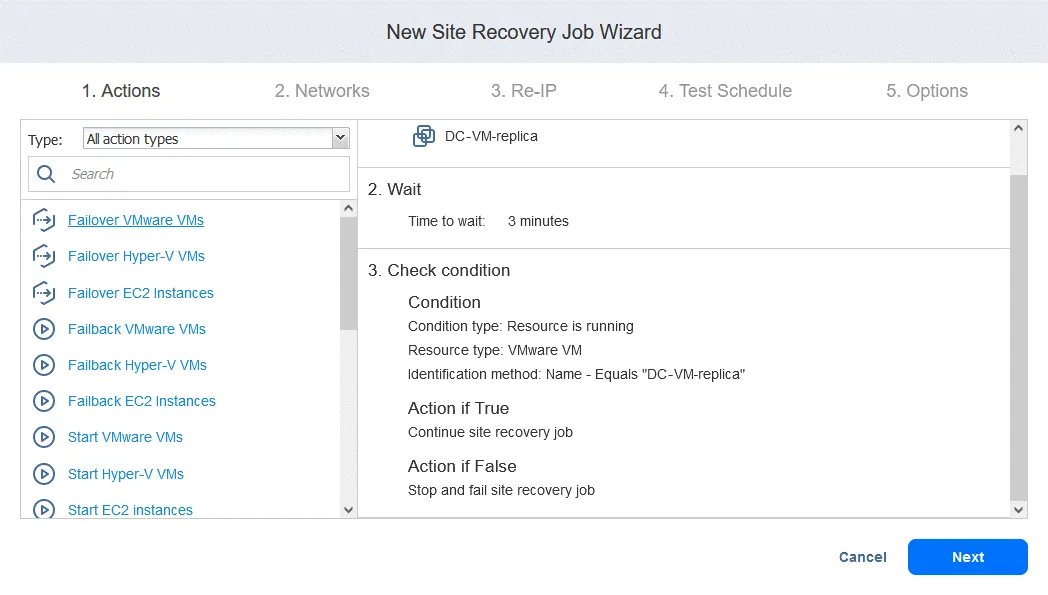
- W tym przypadku wybieramy FS-VM-replica . Kliknij
Next, a następnie wybierz te same opcje dla akcji Trybu failover, co w Czynność 1 i kliknijSave.
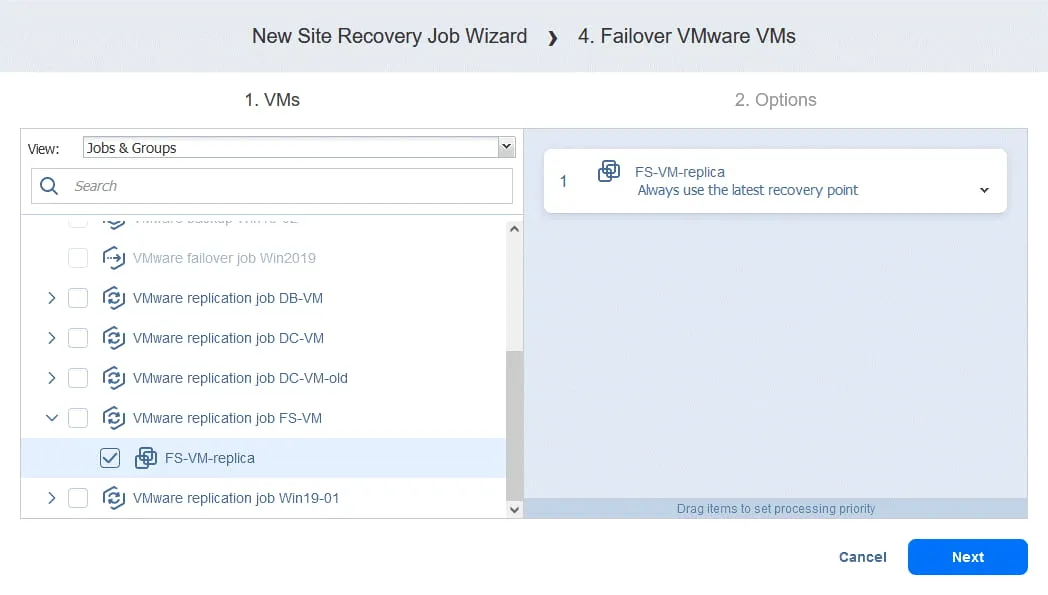
Czynność 5. Odczekaj 3 minuty
Kliknij Wait i skonfiguruj tę akcję tak samo, jak w przypadku akcji 2 . W naszym przypadku podany czas to ponownie 3 minuty .
Akcja 6. Sprawdź stan FS-VM-replica
Kliknij Check condition , aby sprawdzić, czy maszyna wirtualna VMware FS-VM-replica działa. Zapoznaj się z akcją 2 i wybierz te same opcje – oczywiście z wyjątkiem nazwy maszyny wirtualnej.
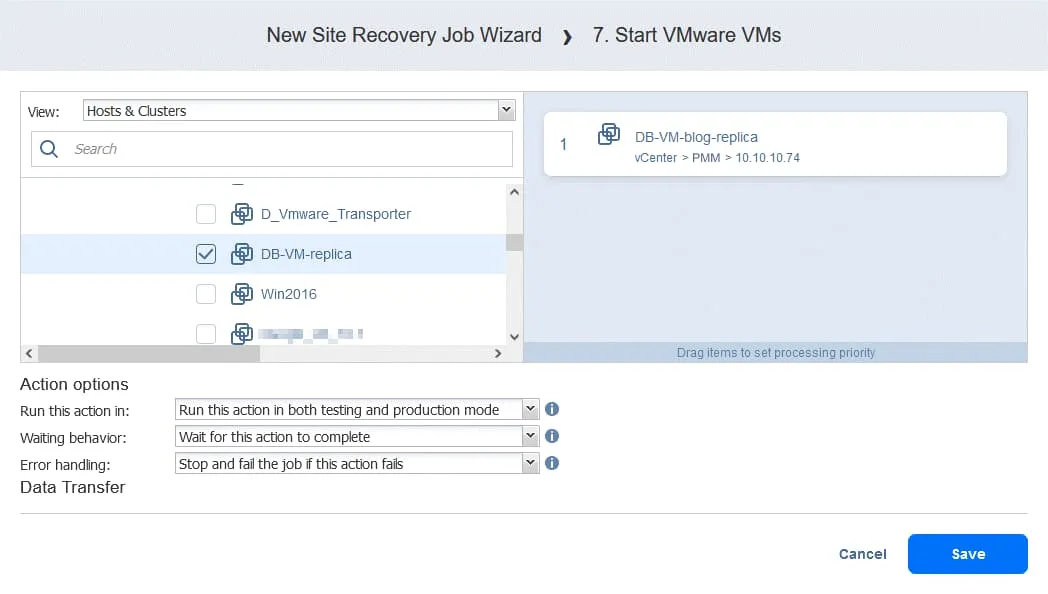
Czynność 7. Uruchom DB-VM
- Kliknij
Start VMware VMsw lewym panelu ekranu Czynności .
- Wybierz DB-VM . Tę maszynę wirtualną można uruchomić, gdy upewnisz się, że FS-VM-replica działa. W dolnej części strony wybierz te same opcje czynności, co w poprzednich czynnościach. Następnie kliknij
Save.
Czynność 8. Odczekaj 5 minut
Odczekaj 5 minut. Kliknij Wait i skonfiguruj tę akcję podobnie jak w przypadku akcja 2 . Powinno to wystarczyć, aby uruchomić usługę Oracle na DB-VM .
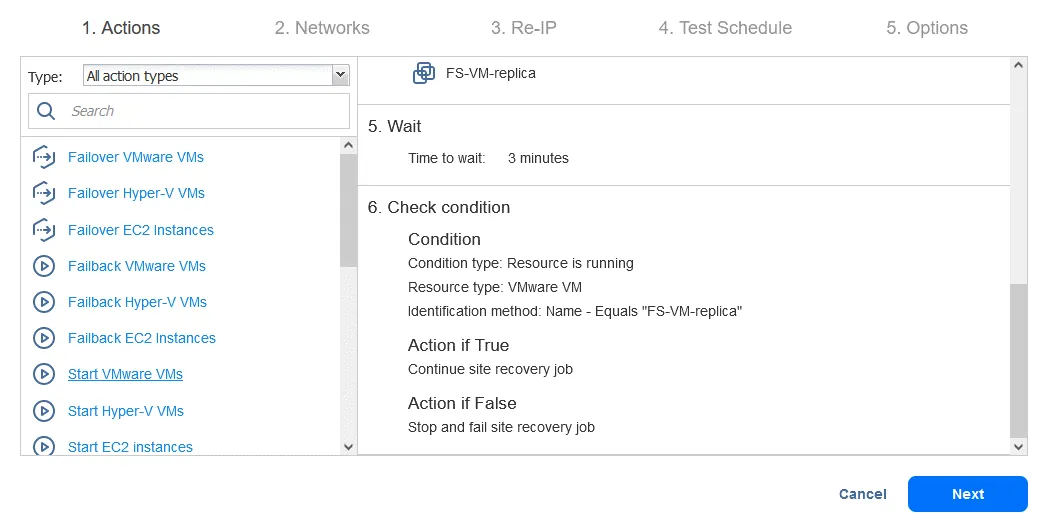
Akcja 9. Uruchom skrypt
- Na ekranie Akcje kliknij
Run script. Przypomnijmy, że skrypt ten ma na celu odzyskanie bazy danych Oracle na poziomie bazy danych z zrzutu przechowywanego na FS-VM-replica .
- Zdefiniuj opcje skryptu. W naszym przypadku:
- Typ docelowy: VMware VM
- Docelowa maszyna wirtualna: DB-VM
- Ścieżka skryptu: /home/oracle/restore.db.sh
- Nazwa użytkownika: oracle
- Hasło: (hasło)
Twoja ścieżka skryptu, nazwa użytkownika i hasło będą się różnić. Nie zapomnij upewnić się, że plik skryptu jest wykonywalny, a użytkownik ma wystarczające uprawnienia do uruchomienia skryptu. W tym przykładzie opcje akcji są skonfigurowane w zwykły sposób.
Kliknij Save , gdy będziesz gotowy do kontynuowania.
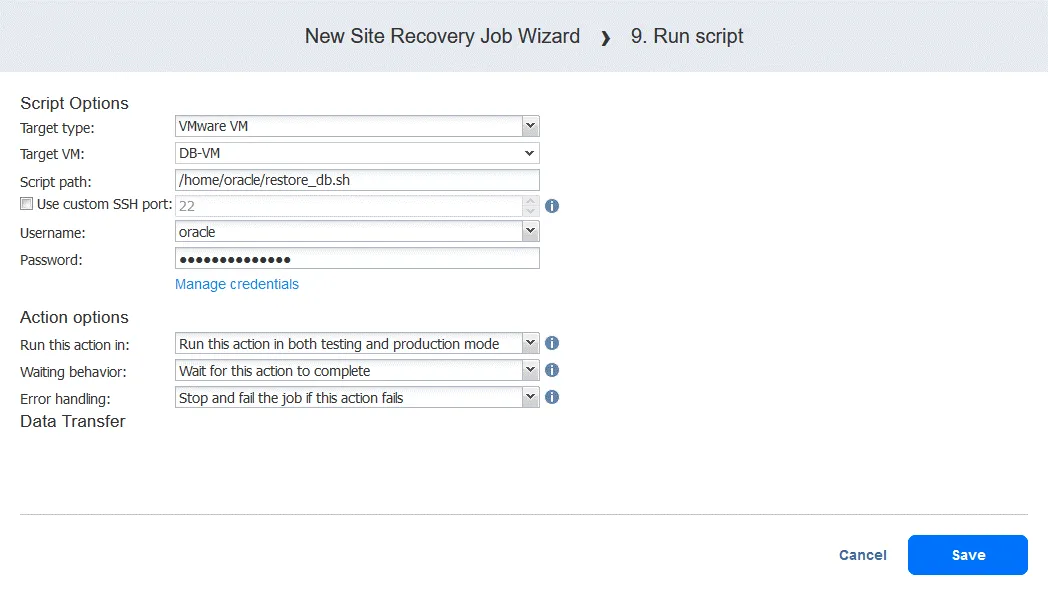
- Teraz możesz zobaczyć wszystkie skonfigurowane akcje. Kliknij przycisk
Next, aby kontynuować konfigurację zadania Odzyskiwania lokacji zgodnie z planem odzyskiwania awaryjnego.
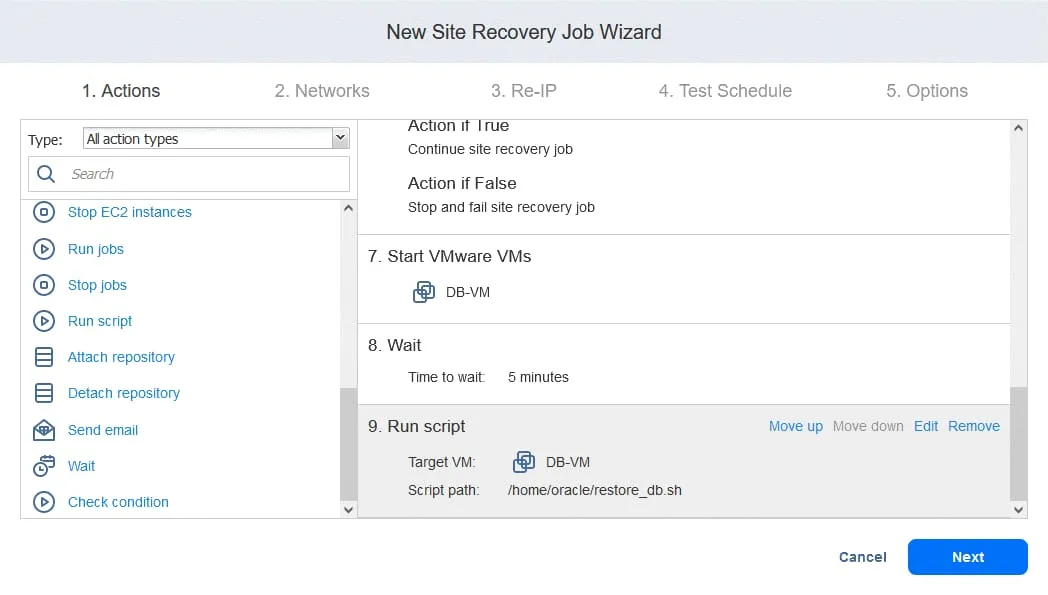
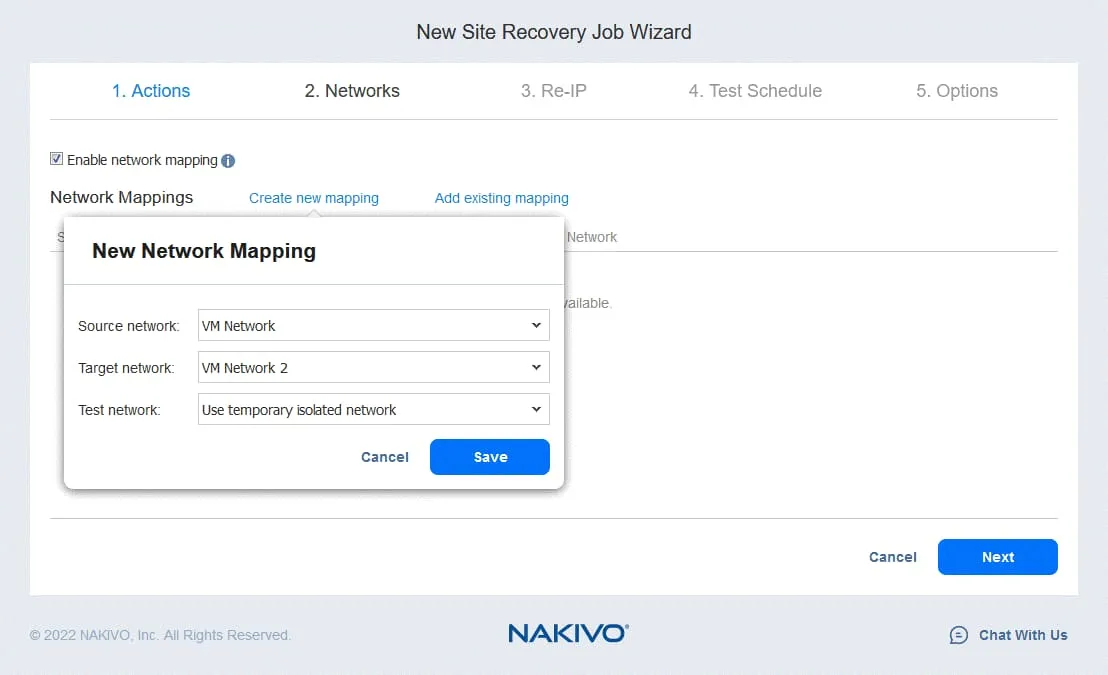
2. Sieci
Jeśli maszyny wirtualne w lokalizacji produkcyjnej i lokalizacji DR są podłączone do różnych sieci, wybierz Enable network mapping. Kliknij Create new mapping, a następnie w oknie podręcznym wybierz sieć źródłową, sieć docelową oraz sieć, która ma być używana do testowania zadania Odzyskiwania lokacji.
Kliknij Save , aby zapisać regułę mapowania sieci, a następnie kliknij Next.
Uwaga : Można również skorzystać z istniejących reguł mapowania, jeśli zostały one skonfigurowane w innych zadaniach replikacji, Trybie failover lub Odzyskiwaniu lokacji.
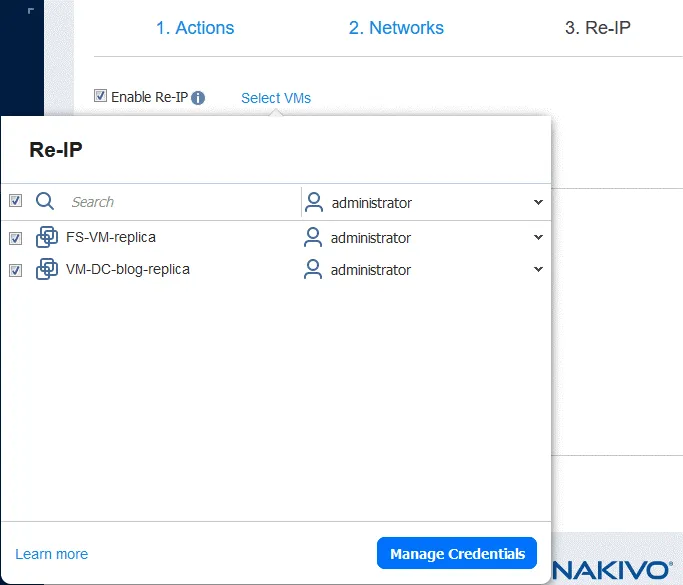
3. Re-IP
Jeśli sieci używane do połączenia maszyn wirtualnych w lokalizacji źródłowej i docelowej mają różne adresy, należy włączyć funkcję Re-IP, wybierając Enable Re-IP.
- Utwórz nową regułę Re-IP, klikając
Create new rule. Zdefiniuj ustawienia źródłowe i docelowe, a następnie kliknijSave.
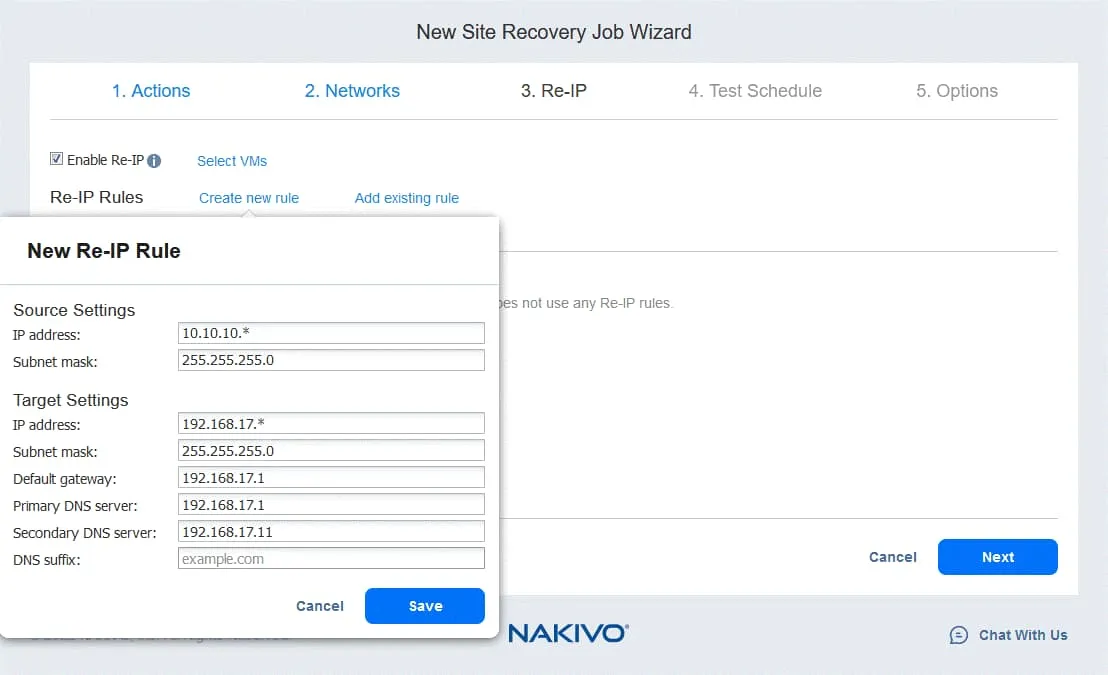
- Kliknij
Select VMsi wybierz maszyny wirtualne, dla których ma być używana funkcja Re-IP. Należy podać poświadczenia użytkownika posiadającego wystarczające uprawnienia do zmiany ustawień sieciowych w systemie operacyjnym gościa maszyny wirtualnej.
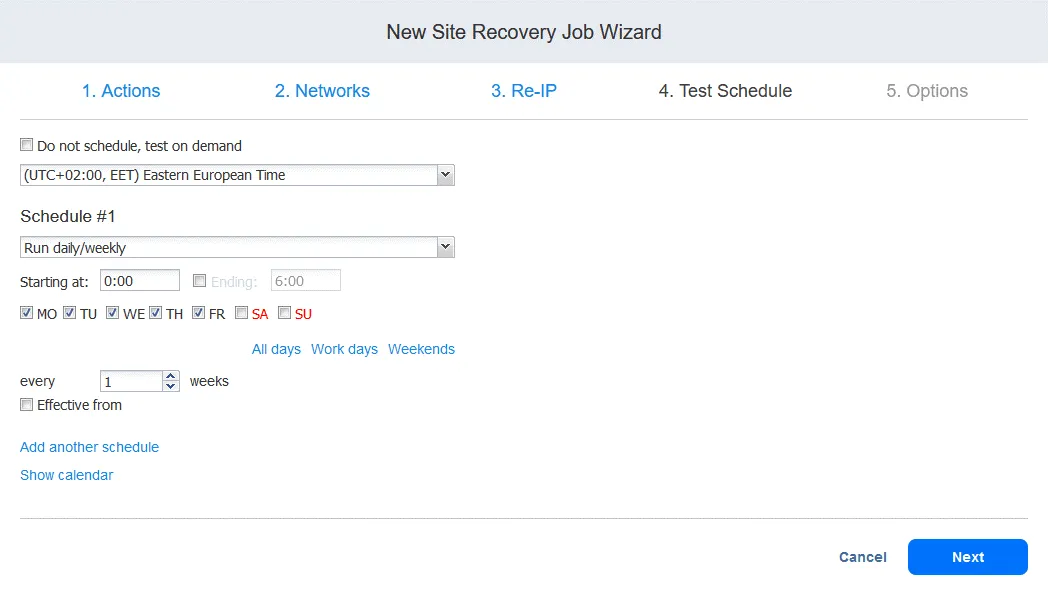
4. Harmonogram testów
Można utworzyć harmonogram specjalnie w celu uruchamiania zadań Odzyskiwania lokacji w trybie testowym i przeprowadzania testów odzyskiwania awaryjnego. Pozwala to sprawdzić, czy zadanie może zostać pomyślnie wykonane w wymaganych ramach czasowych. Po zakończeniu kliknij Dalej.
Bardziej szczegółowo omówimy testowanie zadań Odzyskiwania lokacji w kroku 6.
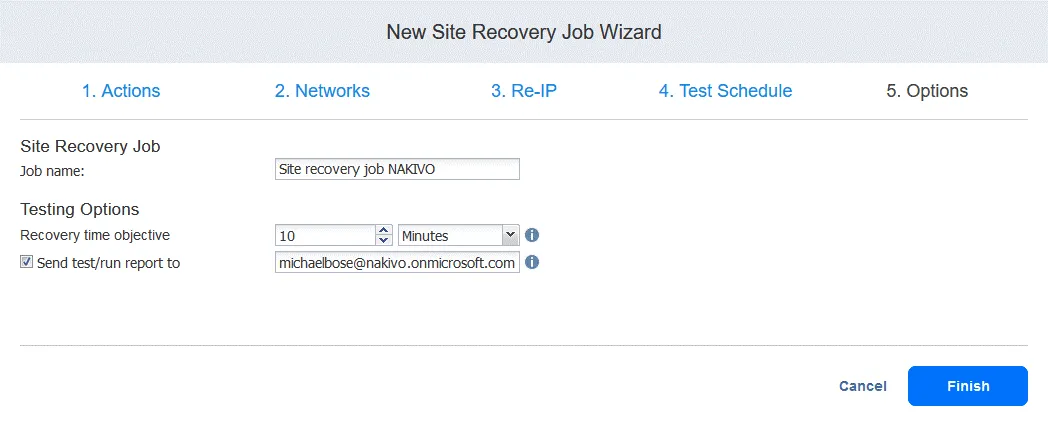
5. Opcje
Wpisz nazwę zadania i cele związane z czasem odzyskiwania. Po zakończeniu konfiguracji kliknij Finish .
Krok 4. Ponowne zabezpieczenie środowiska
Po przełączeniu maszyn wirtualnych i migracji obciążeń do lokalizacji DR oryginalne maszyny wirtualne produkcyjne są teraz w trybie offline, a repliki w lokalizacji DR są obecnie jedynymi działającymi kopiami. Jeśli włączona replika maszyny wirtualnej ulegnie awarii, nie będzie możliwości szybkiego przywrócenia danych i obciążeń.
Aby zabezpieczyć maszyny wirtualne działające w lokalizacji DR, należy je zreplikować do innego bezpiecznego miejsca. Dzięki temu w przypadku awarii maszyny wirtualnej działającej w lokalizacji DR można szybko przełączyć się na nową replikę maszyny wirtualnej.
Funkcja Odzyskiwanie lokacji umożliwia skonfigurowanie automatycznej replikacji zaraz po zakończeniu Trybu failover maszyny wirtualnej. Oto przykładowy przewodnik pokazujący, jak ponownie zabezpieczyć maszyny wirtualne za pomocą zadania Odzyskiwania lokacji po Trybie failover.
- Na stronie
Jobskliknij prawym przyciskiem myszy nazwę niedawno utworzonego zadania Odzyskiwania lokacji. W menu kontekstowym kliknijEdit.
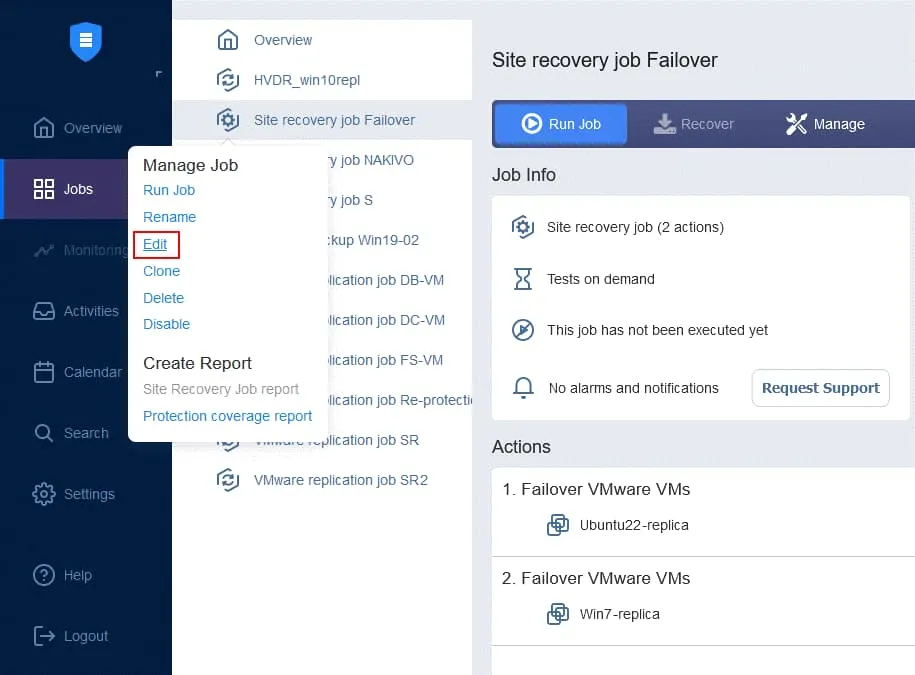
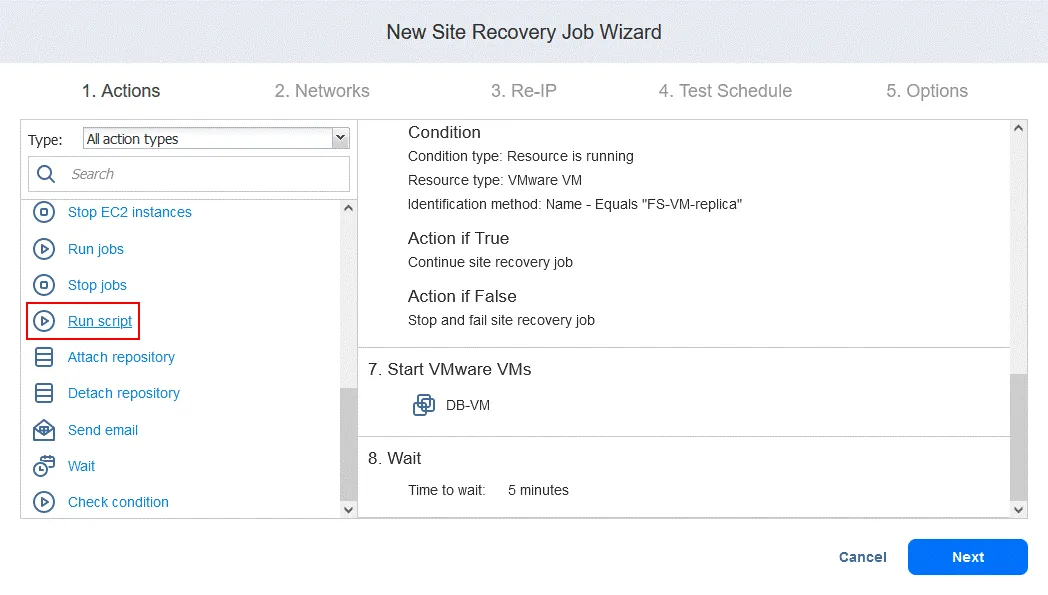
- Możesz zobaczyć swoje działania związane z Trybem failover dodane wcześniej do zadania Odzyskiwania lokacji. Znajdź i kliknij
Run jobsna liście działań znajdującej się w lewym panelu ekranu Odzyskiwania lokacjiActions.
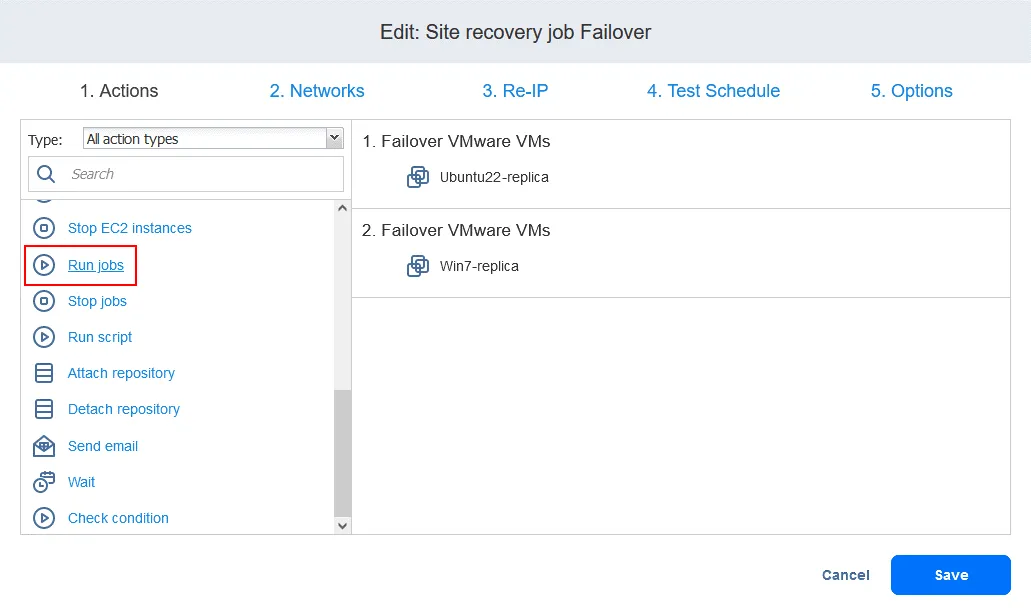
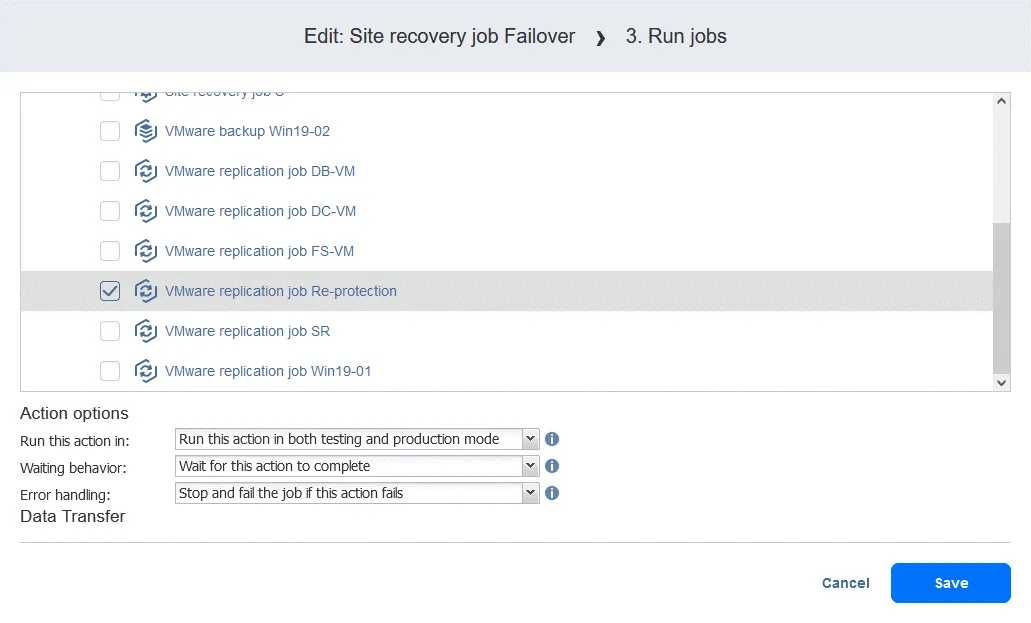
- Wybierz zadanie replikacji z listy zadań. Wybierz opcje akcji w zwykły sposób i kliknij
Save.
- Dodaj akcję Wait między akcją Trybu failover a zadaniem replikacji. Da to replice maszyny wirtualnej trochę czasu na uruchomienie się i załadowanie systemu operacyjnego (nie można replikować wyłączonej maszyny wirtualnej). Na liście Actions w lewym panelu kliknij
Wait.
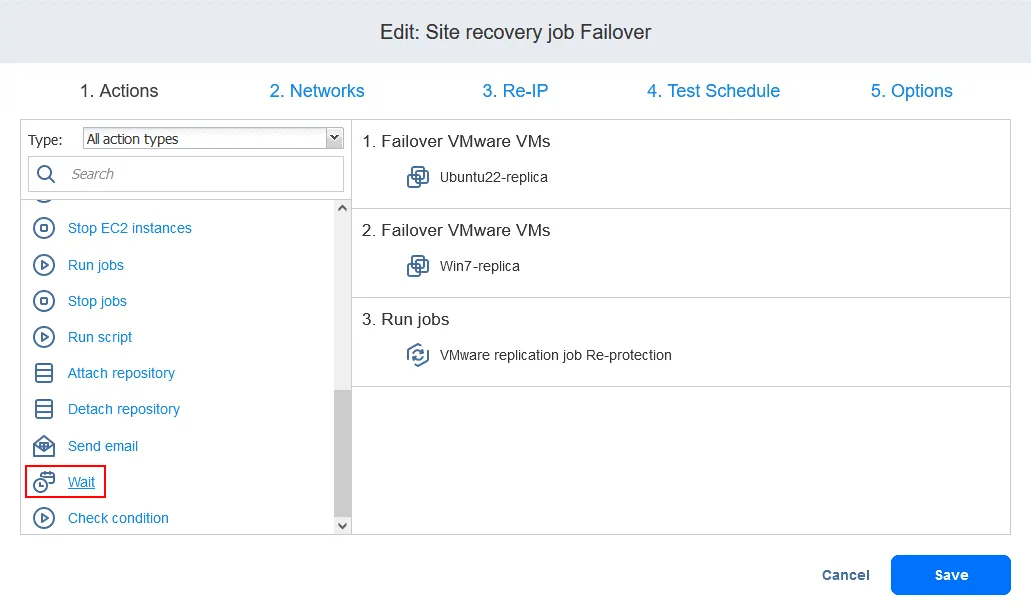
- Wybierz czas oczekiwania – 5 minut powinno wystarczyć. Wybierz opcje akcji i kliknij
Save.
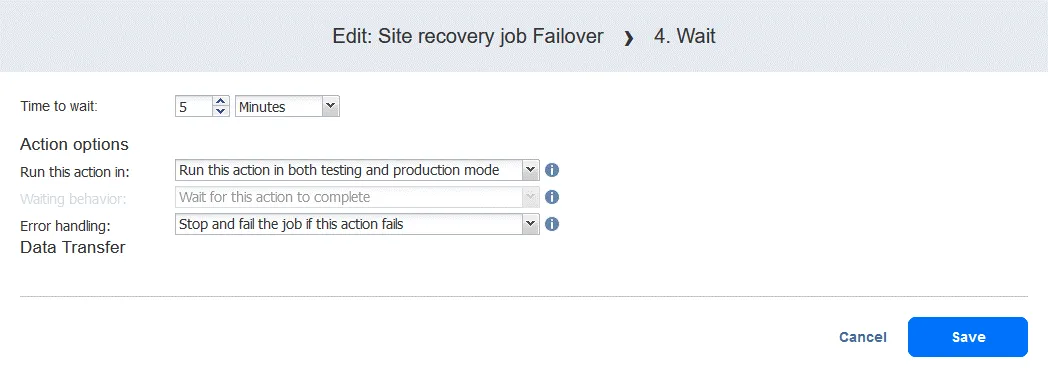
- Po dodaniu akcji zostanie ona dołączona na końcu listy akcji. Kliknij
Move upi przenieś akcję Wait z czwartej pozycji na trzecią — musi ona nastąpić przed replikacją.
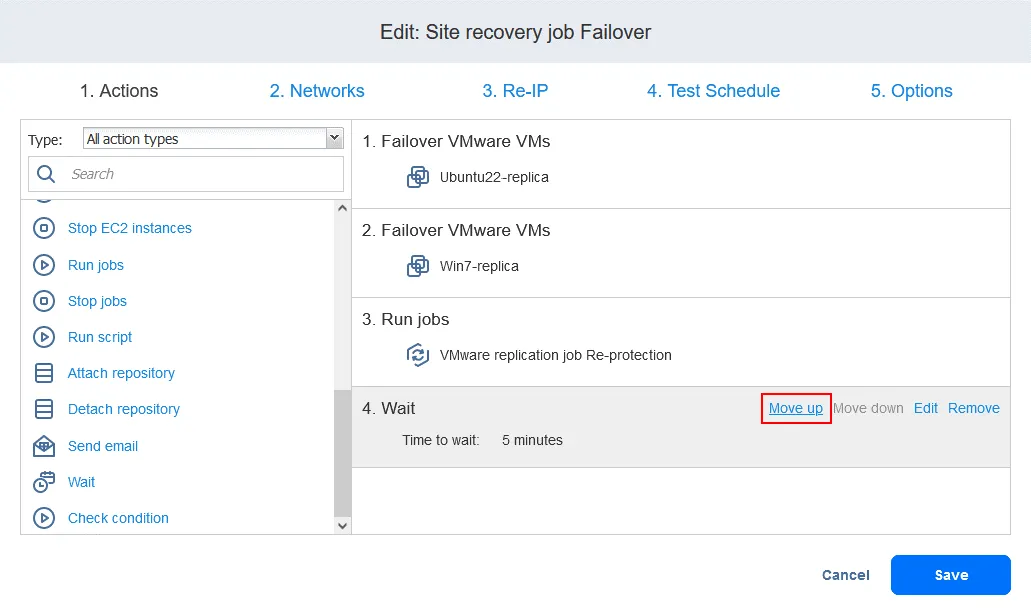
Teraz akcje są ułożone w wymaganej kolejności.
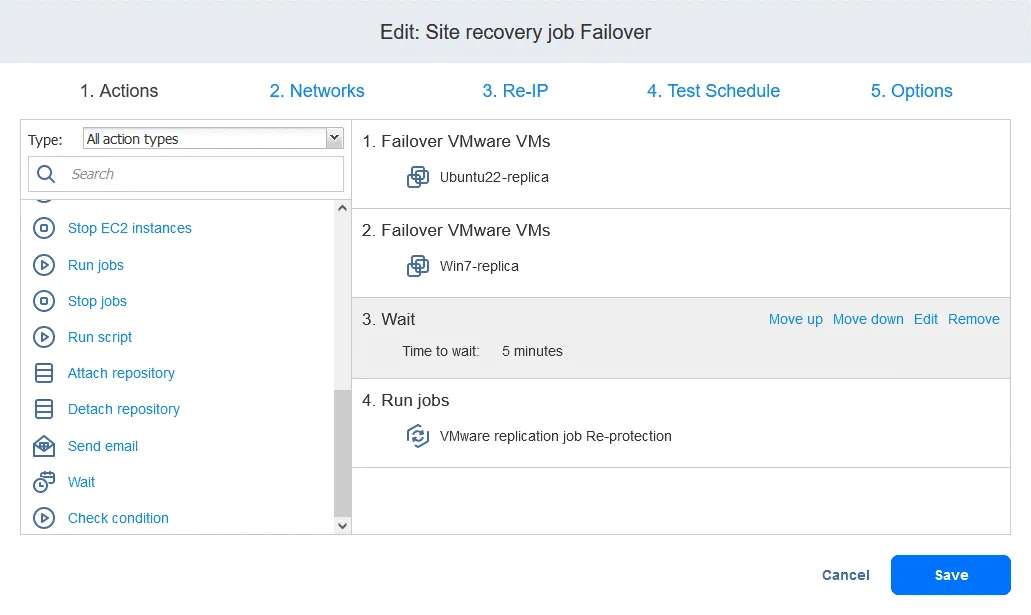
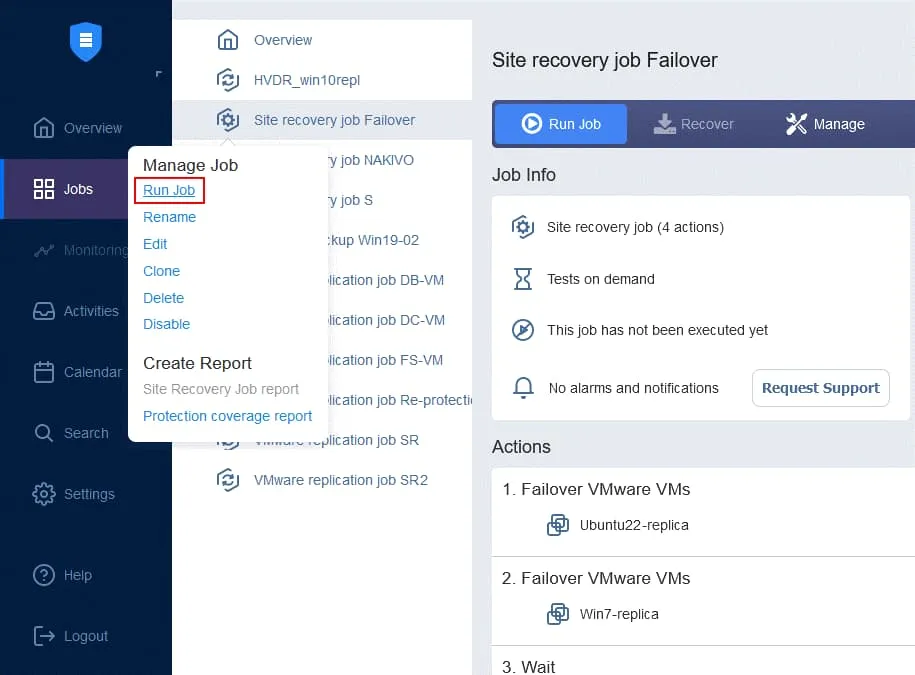
- W końcu zadanie Odzyskiwania lokacji jest gotowe do użycia w celu wykonania Trybu failover maszyny wirtualnej oraz automatycznego ponownego zabezpieczenia replik maszyn wirtualnych używanych do Trybu failover. Kliknij prawym przyciskiem myszy nazwę zadania Odzyskiwanie lokacji na stronie głównej i wybierz opcję „
Run job” z menu kontekstowego.
Krok 5. Powrót po awarii
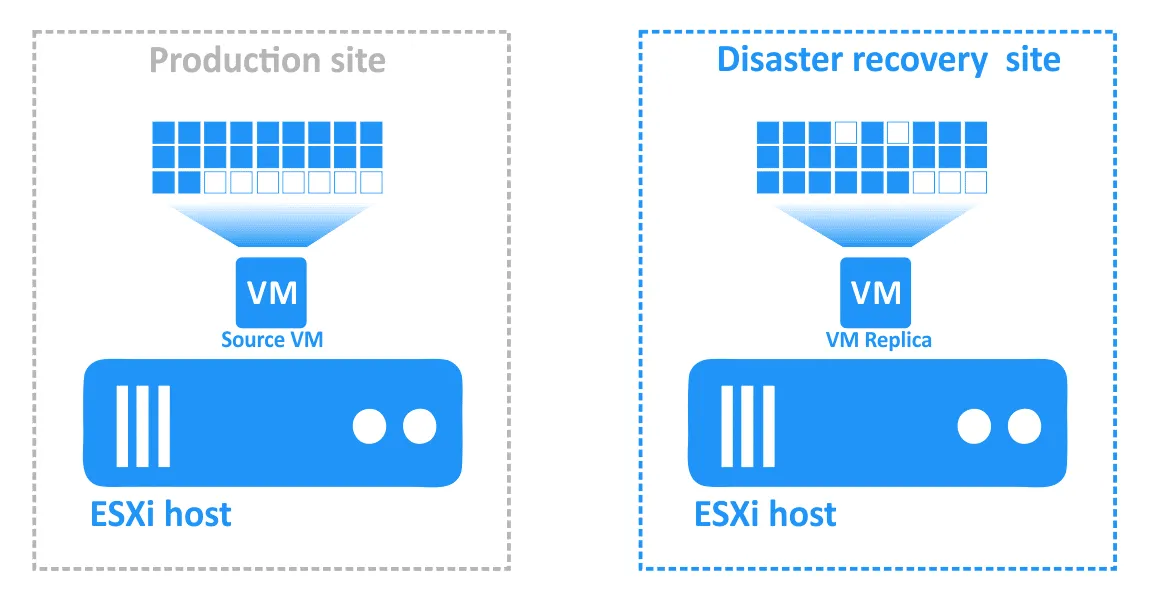
Powrót po awarii to proces przywracania maszyn wirtualnych w ich najnowszym stanie z lokalizacji DR z powrotem do pierwotnej lub nowej lokalizacji produkcyjnej. Aby zrozumieć, dlaczego potrzebne jest powrót po awarii, przypomnijmy sobie, jak działa Tryb failover:
- W przypadku wystąpienia awarii (lub prognozy jej wystąpienia) wykonywane jest Tryb failover na replikę maszyny wirtualnej.
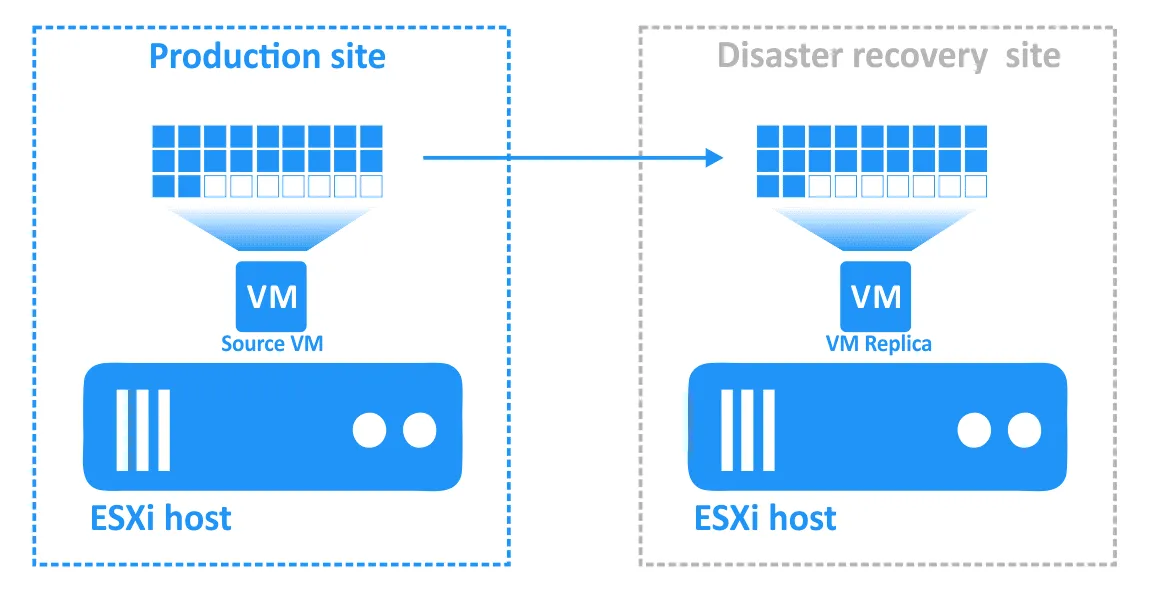
- Wszelkie zmiany w maszynie wirtualnej (na przykład transakcje dodane do bazy danych w wyniku zakupów internetowych dokonywanych przez klientów) są zapisywane na dysku wirtualnym repliki maszyny wirtualnej. Niektóre bloki są zapisywane, a inne usuwane. Dysk wirtualny źródłowej maszyny wirtualnej nie zawiera tych transakcji.
- Po rozwiązaniu incydentu i przywróceniu funkcji lokalizacji produkcyjnej obciążenia muszą zostać przeniesione z powrotem do lokalizacji produkcyjnej. Zaktualizowane dane repliki maszyny wirtualnej muszą zostać przeniesione z powrotem do maszyny źródłowej. Maszyny wirtualne muszą zostać ponownie zsynchronizowane za pomocą replikacji odwrotnej z wykorzystaniem funkcji powrotu po awarii.
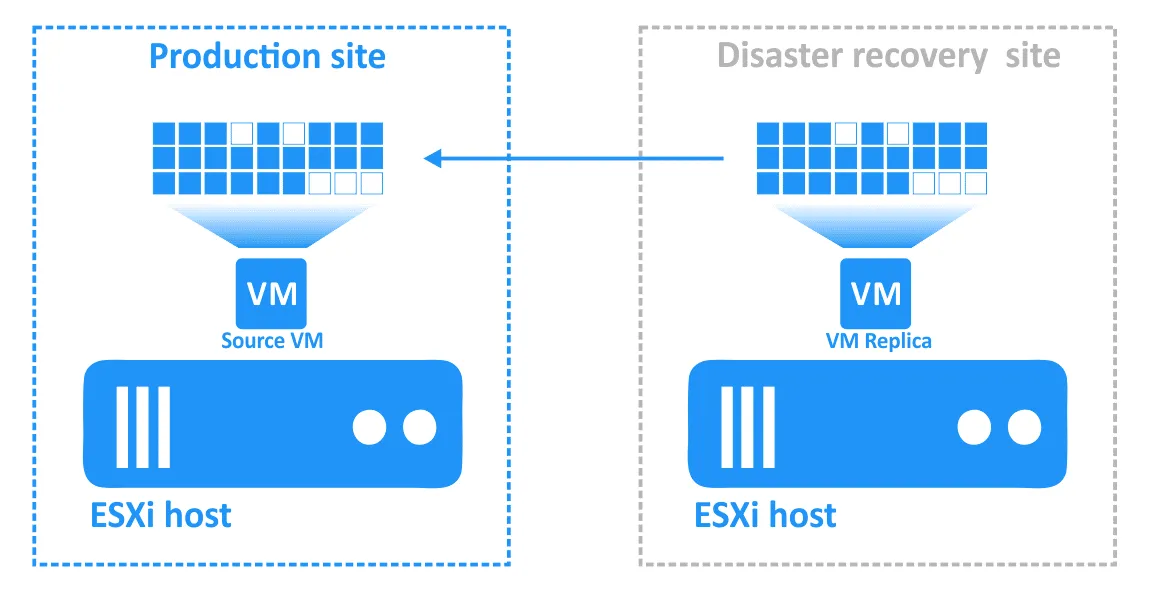
Konfiguracja powrotu po awarii w NAKIVO Backup & Replication
Powrót po awarii można przeprowadzić w trybie produkcyjnym lub testowym (gdy wszystkie zmiany w środowisku wirtualnym wprowadzone przez operację powrotu po awarii zostaną cofnięte do stanu sprzed powrotu po awarii po zakończeniu testu).
Przyjrzyjmy się szczegółowo, jak działa każdy z tych przypadków.
|
Production failback |
Test failback |
| 1 | Wyłączenie oryginalnej maszyny wirtualnej źródłowej (jeśli istnieje i jest włączona). | |
| 2 |
Utworzenie kopia zapasowa maszyny wirtualnej źródłowej (jeśli maszyna wirtualna źródłowa działa). Utworzenie tej migawki pozwala przywrócić stan maszyny wirtualnej źródłowej sprzed Trybu failover w przypadku, gdy nie uda się poprawnie przeprowadzić powrotu po awarii. |
|
| 3 | Uruchomienie replikacja przyrostowa (jeśli oryginalna maszyna wirtualna źródłowa jest online w lokalizacji produkcyjnej) lub pełnej replikacji (jeśli maszyna wirtualna jest odzyskiwana do nowej lokalizacji produkcyjnej). | |
| 4 | Wyłączenie repliki maszyny wirtualnej (opcjonalnie). | Replika maszyny wirtualnej służy do hostowania obciążeń i nie jest wyłączana. |
| 5 | Replikacja przyrostowa jest uruchamiana jeszcze raz z repliki maszyny wirtualnej do maszyny wirtualnej źródłowej. Różnica (dane, które uległy zmianie od czasu pierwszego uruchomienia replikacji) powinna być tym razem znacznie mniejsza. | Replikacja z repliki maszyny wirtualnej do oryginalnej maszyny źródłowej (lub nowej maszyny produkcyjnej) odbywa się tylko raz, ponieważ jest to wystarczające do celów testowych. |
| 6 | Podłączanie oryginalnej maszyny źródłowej do nowej sieci za pomocą mapowania sieci (opcjonalnie). | Podłączenie maszyny wirtualnej źródłowej do izolowanej sieci, tak aby nie doszło do żadnych zakłóceń w środowisku produkcyjnym (opcjonalnie). |
| 7 | Modyfikacja statycznego adresu IP oryginalnej maszyny wirtualnej źródłowej za pomocą funkcji Re-IP (opcjonalnie). | |
| 8 | Włączenie oryginalnej maszyny wirtualnej źródłowej. | |
| 9 | Cleanup after a successful failback. Po pomyślnym zakończeniu operacji powrotu po awarii zarówno maszyna wirtualna źródłowa, jak i jej replika znajdują się w normalnym stanie.
|
Cleanup if the source VM didn't exist before the test failback was run:
|
Przygotowanie do powrotu po awarii
Najpierw należy utworzyć zadanie Odzyskiwania lokacji, które obejmuje działania związane z Trybem failover. Proces ten został szczegółowo opisany wcześniej.
- Do wykonania działania Trybu failover wymagane jest zadanie replikacji oraz replika maszyny wirtualnej.
- Zadanie Odzyskiwania lokacji musi obejmować działanie Trybu failover, aby umożliwić powrót po awarii.
- Repliki maszyn wirtualnych muszą znajdować się w Trybie failover; w związku z tym powrót po awarii można wykonać dopiero po wykonaniu Trybu failover.
Uruchamianie powrotu po awarii
Przyjrzyjmy się przykładowi uruchamiania powrotu po awarii za pomocą NAKIVO Backup & Replication.
- Upewnij się, że Tryb failover został uruchomiony w ramach zadania Odzyskiwanie lokacji (powinno ono już istnieć).
- Utwórz nowe zadanie Odzyskiwanie lokacji — działania związane z powrotem po awarii można włączyć do tego zadania. Na stronie
JobskliknijCreate>Site recovery job.
Uruchomi się Kreator nowego zadania Odzyskiwanie lokacji .
1. Actions.
- W lewym panelu kliknij
Failback VMware VMs(dla innych środowisk użyjFailback Hyper-V VMslubFailback EC2 Instances).
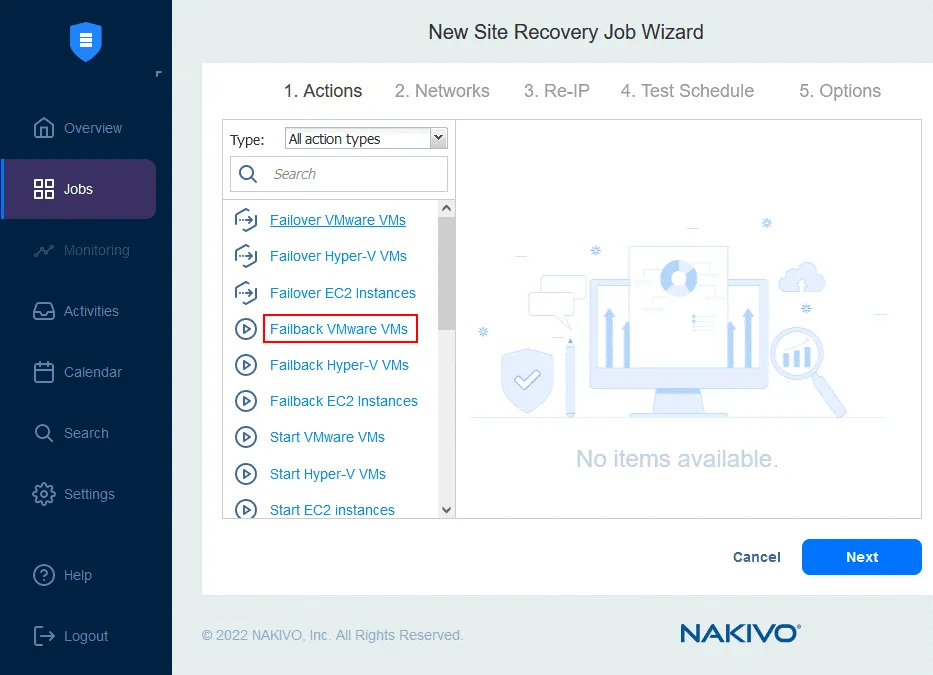
- Wybierz repliki maszyn wirtualnych, do których ma zostać zastosowana operacja Trybu failover. Kliknij
Next.
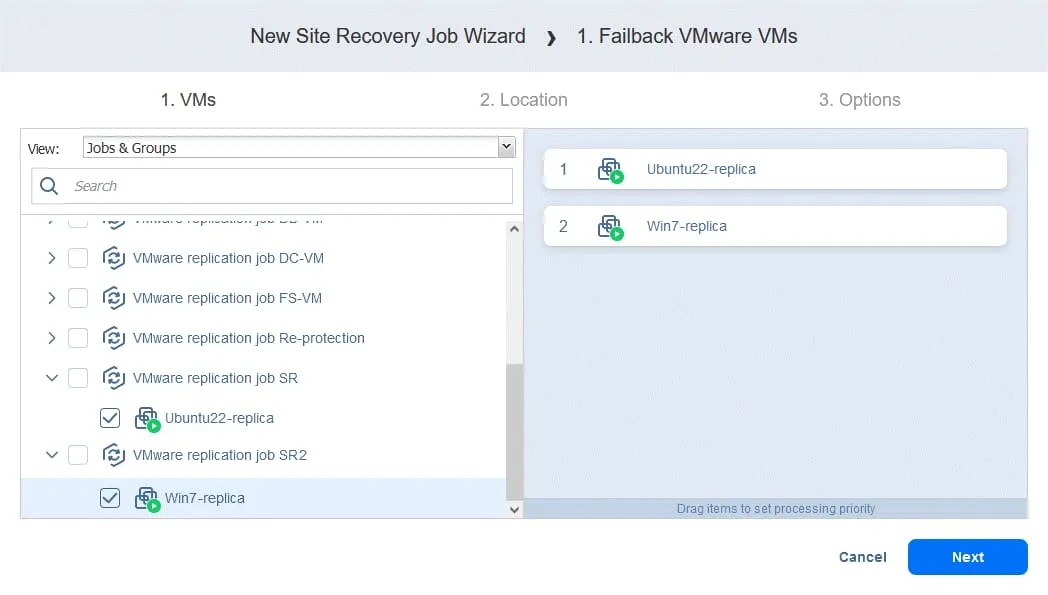
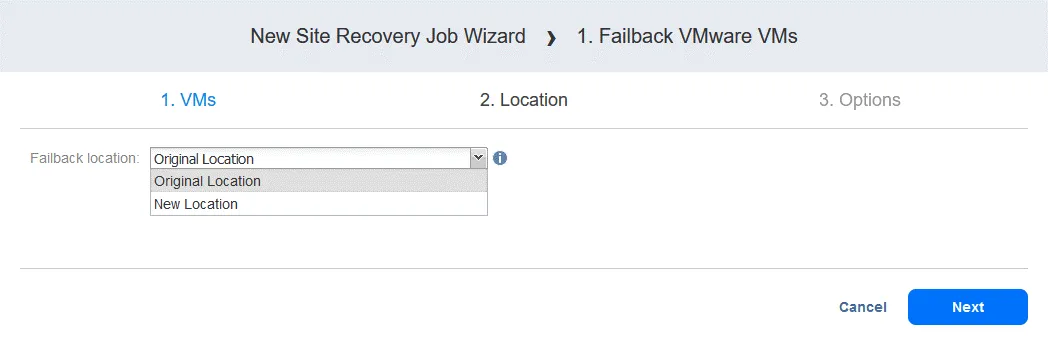
- Wybierz lokalizację powrotu po awarii — może to być pierwotna lokalizacja produkcyjna lub nowa lokalizacja. Kliknij
Next.
- Wybierz opcje zadania. W razie potrzeby wybierz
Power off replica VMs. KliknijSave, gdy będziesz gotowy do kontynuowania.
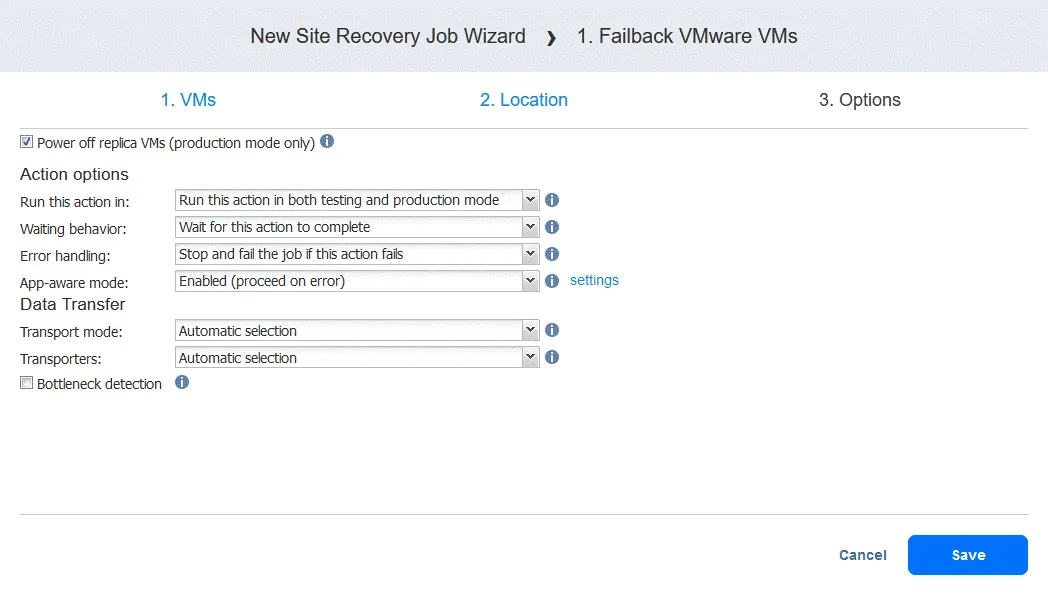
- Po dodaniu akcji powrotu po awarii zadanie Odzyskiwania lokacji wygląda tak, jak na poniższym zrzucie ekranu. Kliknij
Next.
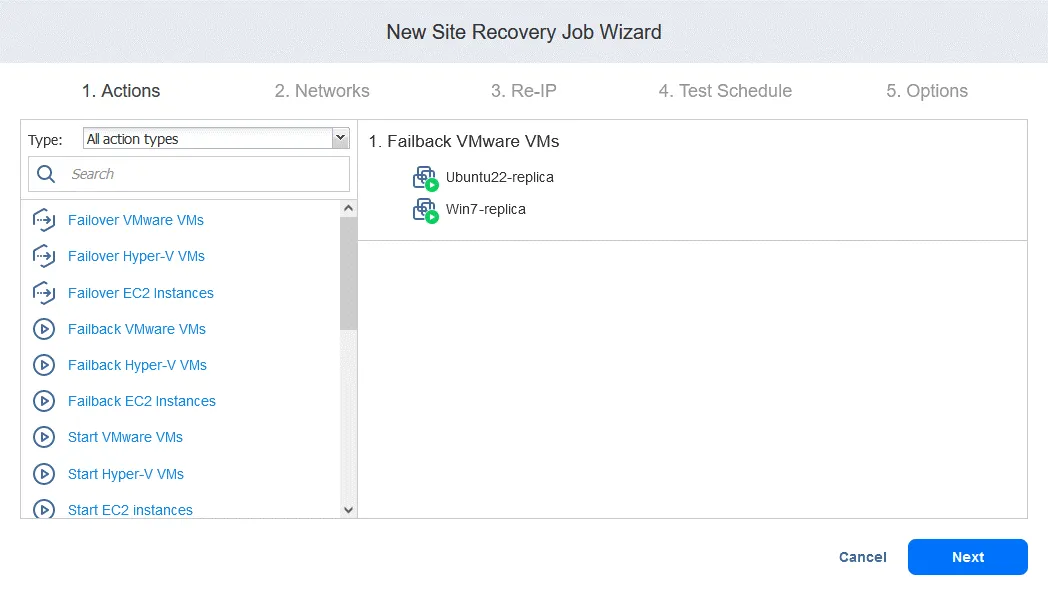
2. Networks. Wybierz tę opcję, jeśli chcesz włączyć mapowanie sieci dla tego zadania. Kliknij Next.
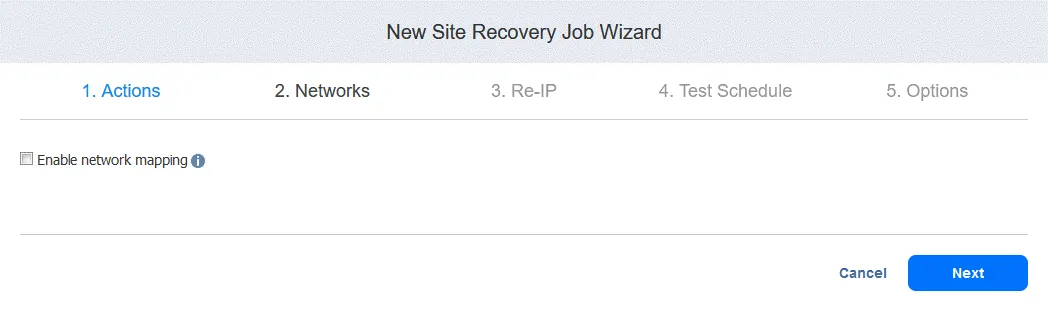
3. Re-IP. Wybierz tę opcję, jeśli chcesz włączyć funkcję Re-IP dla tego zadania. Kliknij Next.
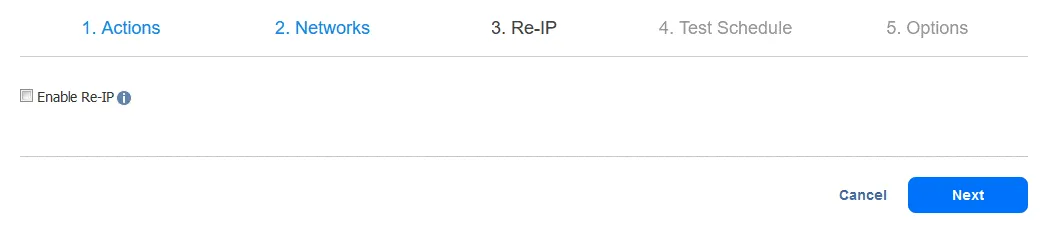
4. Test Schedule. Skonfiguruj opcje harmonogramu, a następnie kliknij Next.
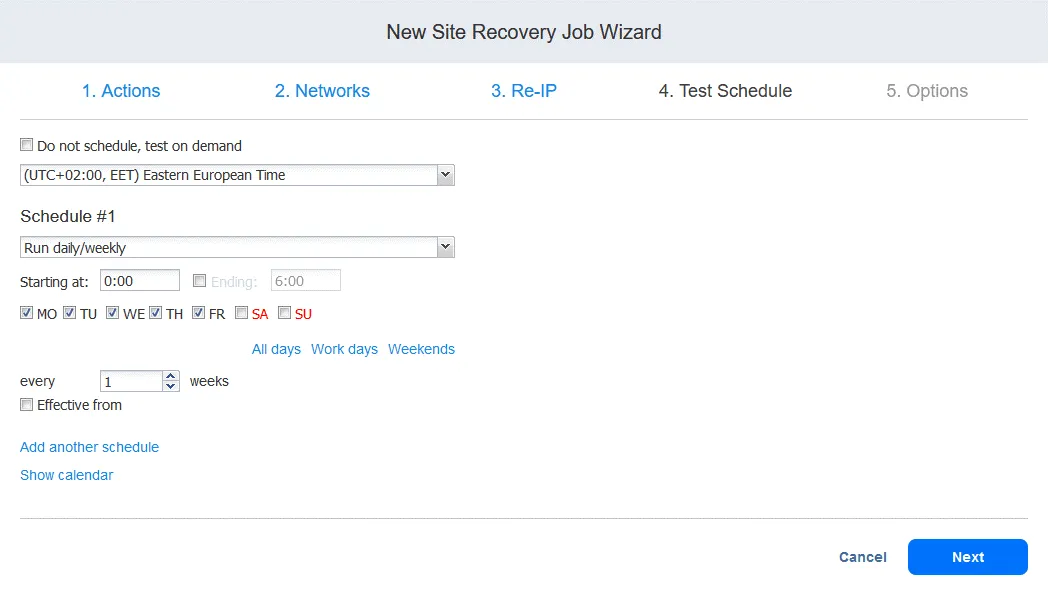
5. Options. Zdefiniuj opcje zadania Odzyskiwania lokacji i wprowadź nazwę zadania. Można ustawić wymagany czas RTO dla maszyny wirtualnej oraz podać adres e-mail, na który ma zostać wysłany raport z powrotu po awarii. Kliknij Finish , aby zakończyć tworzenie nowego zadania Odzyskiwania lokacji z opcją powrotu po awarii.
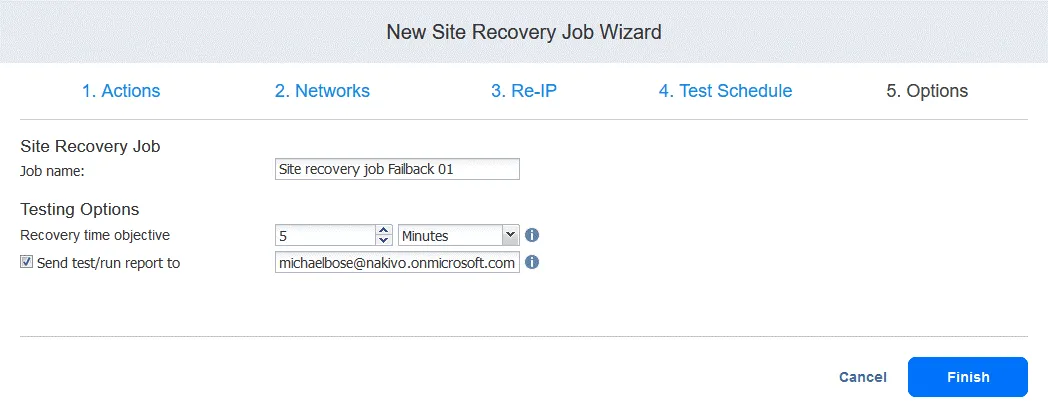
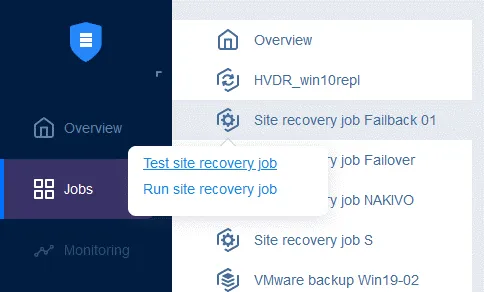
Teraz można uruchomić to zadanie Odzyskiwania lokacji w celu powrotu po awarii: wystarczy kliknąć prawym przyciskiem myszy nazwę zadania Odzyskiwania lokacji, wybrać opcję Run job, a następnie Test site recovery job lub Run site recovery job.
Krok 6. Przeprowadzanie testów odzyskiwania awaryjnego
Testy odzyskiwania awaryjnego pomagają upewnić się, że jesteś gotowy do odzyskania danych w razie awarii oraz że wszystkie wybrane komponenty mogą zostać pomyślnie odzyskane w wyznaczonych ramach czasowych.
Istnieją dwa główne powody dlaczego warto przeprowadzać testy odzyskiwania awaryjnego:
To make sure that everything can be recovered successfully. Gdy testujesz swój plan odzyskiwania awaryjnego i odkrywasz pewne nieprawidłowości, możesz naprawić te problemy, zanim spowodują one poważne kłopoty w rzeczywistej sytuacji kryzysowej.To make sure that RTO values can be met. Testy odzyskiwania awaryjnego pozwalają sprawdzić, czy obciążenia mogą zostać odzyskane w ramach odpowiednich RTO. Test odzyskiwania lokacji można uruchomić ręcznie na żądanie lub automatycznie zgodnie z harmonogramem, co sprawia, że proces ten jest bezproblemowy i pozwala zaoszczędzić czas.
Różnice między Trybem failover w trybie testowym a produkcyjnym
Mechanizm wykonywania Trybu failover różni się w zależności od tego, czy zadanie Odzyskiwania lokacji jest uruchamiane w trybie testowym, czy produkcyjnym. Zestawienie kroków dla każdego trybu przedstawiono w poniższej tabeli.
Production (emergency) failover |
Test failover |
|
| 1 | Wyłącz replikację z maszyny wirtualnej źródłowej do repliki | |
| 2 | Przywróć replikę maszyny wirtualnej do określonego punktu odzyskiwania (RP) (opcjonalnie, domyślnie używany jest ostatni punkt RP) | Uruchom jednorazową replikację przyrostową z maszyny wirtualnej źródłowej do repliki |
| 3 | Podłącz replikę maszyny wirtualnej do new sieci za pomocą mapowania sieci (opcjonalnie) |
Podłącz replikę maszyny wirtualnej do isolated sieci za pomocą mapowania sieci (opcjonalnie) |
| 4 | Zmodyfikuj statyczny adres IP repliki za pomocą funkcji Re-IP (opcjonalnie) | |
| 4A | Wyłącz maszynę wirtualną źródłową (opcjonalnie) | — |
| 5 | Włącz replikę | |
| 6 | Przełącz replikę do Trybu failover | |
Jak widać, drugi i trzeci punkt różnią się w przypadku przepływów pracy produkcyjnych i testowych. Replikację z maszyny wirtualnej źródłowej można uruchomić w trybie testowym, gdy maszyna ta jest uruchomiona. W większości przypadków w sytuacji awaryjnej maszyna źródłowa przestaje działać, co uniemożliwia przeprowadzenie replikacji. Sieci służące do połączenia maszyn wirtualnych można zdefiniować oddzielnie w opcjach mapowania sieci dla trybu produkcyjnego i testowego podczas konfigurowania zadania Odzyskiwania lokacji.
Po wykonaniu zadania Odzyskiwania lokacji w trybie testowym przeprowadzane jest czyszczenie w Trybie failover. Replika maszyny wirtualnej zostaje wyłączona i przywrócona do stanu sprzed Trybu failover za pomocą migawki (migawka repliki maszyny wirtualnej jest tworzona przed wykonaniem akcji Trybu failover). Następnie replika jest przełączana z Trybu failover do stanu normalnego, a replikacja z obiektu źródłowego do repliki jest ponownie włączana.
Funkcje testowania odzyskiwania awaryjnego w NAKIVO Odzyskiwanie lokacji
Przyjrzyjmy się pokrótce głównym punktom funkcji testowania w NAKIVO Odzyskiwanie lokacji.
1. Checking the actions included in testing
Przejrzyj logikę działań w zadaniu Odzyskiwanie lokacji. Sprawdź, czy działania są ułożone w odpowiedniej kolejności i upewnij się, że nie tworzą pętli nieskończonej. Opcje zadania Odzyskiwania lokacji można edytować, gdy zadanie nie jest uruchomione: w razie potrzeby można zmienić kolejność działań, dodać lub usunąć działania albo edytować opcje działań.
2. Checking networking
Sprawdź, czy sieć działa prawidłowo. Pomiędzy lokalizacją produkcyjną a lokalizacją odzyskiwania awaryjnego (DR) można wykorzystać połączenie VPN, jednak w normalnym stanie połączenie to nie może być okresowo rozłączane. Sieć w lokalizacji DR musi również działać bez zakłóceń. Sprawdź ustawienia mapowania sieci i zmiany adresów IP, których użyłeś do skonfigurowania Trybu failover i powrotu po awarii. Jeśli maszyna wirtualna jest skonfigurowana dla nieprawidłowej sieci, połączenie sieciowe może nie zostać nawiązane. To samo dotyczy ustawień IP.
3. Setting the test schedule
Testowanie zadania Odzyskiwanie lokacji można zaplanować w opcjach planowania zadań Odzyskiwanie lokacji. Otwórz interfejs internetowy swojej instancji NAKIVO Backup & Replication. W lewym panelu kliknij prawym przyciskiem myszy nazwę zadania i wybierz Edit z menu kontekstowego.
Zalety Odzyskiwania lokacji firmy NAKIVO
Comprehensive DR orchestration and automation. Odzyskiwanie lokacji pozwala wdrażać plany odzyskiwania awaryjnego z wysokim poziomem automatyzacji. Można zdefiniować kolejność odzyskiwania maszyn wirtualnych z uwzględnieniem ich zależności, tak aby w razie awarii odzyskiwanie przebiegało jak najskuteczniej.Flexibility to accommodate the needs of various businesses. Można tworzyć wiele zadań Odzyskiwania lokacji zgodnie z własnymi potrzebami. Zestaw działań, które można włączyć do zadań Odzyskiwania lokacji, pozwala tworzyć różne scenariusze odzyskiwania danych, dostosowane do konkretnych sytuacji.Built into the data protection solution. Odzyskiwanie lokacji to funkcja wchodząca w skład NAKIVO Backup & Replication i dostępna wraz z pozostałymi elementami kompleksowego zestawu funkcji produktu; nie ma potrzeby kupowania osobnej licencji na Odzyskiwanie lokacji. Dzięki temu rozwiązaniu wszystkie działania związane z ochroną danych i odzyskiwaniem po awarii są zarządzane z jednego panelu.Significant savings compared to other DR solutions. NAKIVO Backup & Replication, z wbudowanym narzędziem Odzyskiwanie lokacji, jest opłacalnym rozwiązaniem. Produkt nadal zadowala użytkowników przydatnymi nowymi funkcjami, zachowując jednocześnie te same przystępne ceny – zwłaszcza w porównaniu z konkurentami na rynku odzyskiwania awaryjnego.



