Replikacja danych w czasie rzeczywistym: wszystko, co musisz wiedzieć
Ochrona najważniejszych usług w centrum danych wymaga czegoś więcej niż tylko regularnych kopii zapasowych — konieczne jest stosowanie replikacji, aby w razie awarii zminimalizować utratę danych i przestoje. Maszyny wirtualne mają znaczną przewagę nad serwerami fizycznymi, ponieważ upraszczają ten proces. W tym wpisie na blogu omówimy zalety replikacji w czasie rzeczywistym dla maszyn wirtualnych, przedstawiając jej zasady działania, kluczowe przypadki użycia oraz sposoby skutecznej konfiguracji, ze szczególnym uwzględnieniem platformy VMware vSphere.

Czym jest replikacja w czasie rzeczywistym?
Replikacja danych w czasie rzeczywistym to proces powielania i synchronizacji danych w czasie rzeczywistym między wieloma systemami (maszynami wirtualnymi, bazami danych itp.) w celu zapewnienia wysokiej dostępności i odzyskiwania awaryjnego. Opóźnienie lub latencja między zmianami w danych źródłowych a ich replikacją może wynosić kilka sekund lub mniej, w zależności od ustawień i topologii zastosowanej w infrastrukturze.
Replikacja w czasie rzeczywistym jest zazwyczaj stosowana w celu ochrony danych krytycznych. W przypadku maszyn wirtualnych replikacja w czasie rzeczywistym służy do ochrony najbardziej krytycznych maszyn wirtualnych, które wymagają najsurowszych celów punktu odzyskiwania (RPO) i celów związanych z czasem odzyskiwania (RTO) (RPO i RTO). Jeśli tradycyjne kopie zapasowe i replikacja nie są w stanie spełnić wymagań dotyczących RPO i RTO, warto rozważyć skonfigurowanie replikacji w czasie rzeczywistym.
Kluczowe korzyści z replikacji danych w czasie rzeczywistym
Replikacja w czasie rzeczywistym zapewnia następujące korzyści:
- Zminimalizowane przestoje . Ponieważ zmiany danych są replikowane z systemu źródłowego do systemu docelowego w czasie rzeczywistym, Tryb failover maszyny wirtualnej można szybko wykonać na replice maszyny wirtualnej, która zawiera najnowsze zmiany. Pozwala to organizacjom na szybkie przywrócenie działania maszyn wirtualnych i usług, co skraca przestoje i poprawia ciągłość działania.
- Ciągłość działania . Replika maszyny wirtualnej zawierająca najnowszy zestaw danych może posłużyć do szybkiego odzyskania maszyny wirtualnej i wznowienia działalności biznesowej.
- Spójność danych . Replika maszyny wirtualnej utworzona przy użyciu replikacji w czasie rzeczywistym zawiera ten sam zestaw danych co oryginalna maszyna wirtualna. Po przeprowadzeniu Trybu failover i przywróceniu obciążeń za pomocą repliki maszyny wirtualnej nie ma potrzeby identyfikowania danych, które należy odtworzyć po ostatnim zadaniu replikacji, jak ma to miejsce w przypadku tradycyjnej replikacji maszyn wirtualnych.
- Skalowalność i wydajność . Repliki maszyn wirtualnych aktualizowane w czasie rzeczywistym mogą służyć do zapewnienia ciągłego i spójnego dostępu do zasobów dla wielu biur/centrów danych/lokalizacji w różnych lokalizacjach geograficznych.
Jak działa replikacja danych w czasie rzeczywistym
Replikacja w czasie rzeczywistym jest funkcją dostępną przy korzystaniu z wysokiej klasy systemów pamięci masowej, a zasada jej działania może się różnić w zależności od wdrożenia. Do replikacji danych maszyn wirtualnych w czasie rzeczywistym zazwyczaj wykorzystuje się następujące komponenty:
- Główna maszyna wirtualna: aktywna maszyna wirtualna, która przetwarza obciążenia.
- Replika maszyny wirtualnej: Stale aktualizowana kopia głównej maszyny wirtualnej, zazwyczaj znajdująca się na innym hoście lub w innym centrum danych.
- Menedżer replikacji: narzędzie lub usługa w ramach rozwiązania do ochrony danych, które koordynuje proces replikacji.
- Śledzenie zmian: śledzi i rejestruje zmiany w głównej maszynie wirtualnej, zapewniając, że replikowane są wyłącznie zmodyfikowane dane.
Replikacja synchroniczna a asynchroniczna: kluczowe różnice
Istnieją dwa rodzaje replikacji danych w zależności od zasady działania: synchroniczna i asynchroniczna. Każdy typ replikacji danych ma swoje cechy charakterystyczne, zalety i przypadki użycia i można go wybrać w zależności od scenariusza.
Replikacja synchroniczna polega na kopiowaniu danych z maszyny wirtualnej źródłowej do repliki maszyny wirtualnej w trakcie ich zapisu. Jest to najskuteczniejszy typ replikacji dla krytycznych obciążeń. Dane są replikowane z maszyny wirtualnej głównej do maszyny wirtualnej pomocniczej natychmiast lub niemal natychmiast, dzięki czemu obie kopie są zawsze spójne. Ten typ replikacji danych pozwala osiągnąć zerowy RPO.
- Gdy na maszynie wirtualnej głównej następuje operacja zapisu, zmiana jest wysyłana do repliki.
- Maszyna wirtualna główna czeka na potwierdzenie od repliki przed zakończeniem operacji zapisu.
Wymagania dotyczące konfiguracji replikacji synchronicznej są wysokie: aby uniknąć opóźnień, potrzebne są szybkie połączenia sieciowe o niskim opóźnieniu.
Wady:
- Może to wpłynąć na wydajność głównej maszyny wirtualnej, ponieważ potwierdzenie zmian przez replikę zajmuje trochę czasu.
- Ze względu na wymagania dotyczące opóźnień replikacja synchroniczna jest zazwyczaj ograniczona do lokalizacji położonych blisko siebie.
Replikacja asynchroniczna (replikacja punktowa) kopiuje zmiany z opóźnieniem. Zmiany danych wprowadzone na maszynie źródłowej są wysyłane do repliki w regularnych odstępach czasu skonfigurowanych w regułach harmonogramu. W rezultacie występuje opóźnienie między aktualizacjami repliki. Replikacja asynchroniczna może przebiegać niemal w czasie rzeczywistym, z odstępami wynoszącymi jedną lub kilka minut.
- Operacje zapisu na maszynie wirtualnej głównej są wykonywane natychmiast, bez oczekiwania na potwierdzenie od repliki.
- Aktualizacje repliki są wykonywane okresowo na podstawie zmian umieszczonych w kolejce lub zgromadzonych w partiach.
Wymagania dotyczące konfiguracji replikacji asynchronicznej są przystępne dla większości użytkowników i organizacji. Konieczne jest połączenie sieciowe między hostami wirtualizacji a komponentami rozwiązania do ochrony danych.
Replika może pozostawać w tyle względem głównej maszyny wirtualnej (replika maszyny wirtualnej może nie zawierać najnowszego zestawu danych), co w przypadku awarii może prowadzić do utraty danych i zapewnia jedynie spójność docelową. Jest to wada asynchronicznej replikacji danych. Na przykład, jeśli replikacja odbywa się co godzinę, a awaria ma miejsce o godz. 10:30, w replice maszyny wirtualnej zabraknie danych zapisanych w ciągu ostatnich 30 minut.
|
Aspekt |
Replikacja synchroniczna |
Replikacja asynchroniczna |
|
Spójność danych |
Natychmiastowa i spójna |
Ostateczna z możliwym opóźnieniem |
|
Wymagania sieciowe |
Duża przepustowość, małe opóźnienie |
Może działać w wolniejszych sieciach |
|
RPO (utrata danych) |
Bliskie zeru |
Zmienne, w zależności od częstotliwości replikacji |
|
Wpływ na wydajność |
Wyższe, ze względu na potwierdzenie zapisu |
Niższe, ponieważ zapisy są niezależne |
|
Lokalizacja geograficzna |
Krótkie odległości |
Odpowiednie dla dużych odległości |
|
Koszty sprzętu |
Wysokie |
Niskie do średnich |
|
Przypadki użycia (branże) |
Bankowość, opieka zdrowotna |
Odzyskiwanie awaryjne, analityka |
Korzystanie z replikacji w czasie rzeczywistym dla wszystkich maszyn wirtualnych może nie być konieczne, ponieważ wymagałoby to wysokiego budżetu. Nie wszystkie dane mają takie samo znaczenie dla organizacji, a replikacja w czasie rzeczywistym powinna być stosowana w przypadku danych o największym znaczeniu. Można wybrać optymalną metodę replikacji dla każdej maszyny wirtualnej w zależności od konkretnych czynników i scenariuszy. Wybierając metodę replikacji w celu ochrony maszyn wirtualnych, należy wyznaczyć precyzyjne cele i wziąć pod uwagę następujące kwestie:
- Ocena ryzyka . Przeanalizuj potencjalne zakłócenia i oszacuj negatywne konsekwencje dla Twojej organizacji w przypadku awarii maszyny wirtualnej.
- Krytyczność danych . Stwórz listę wszystkich systemów działających na maszynach wirtualnych i oszacuj znaczenie każdej maszyny wirtualnej w zależności od tolerancji na utratę danych i przestoje.
- Wymagania dotyczące zasobów . Oblicz, ile zasobów zużywa replika w czasie rzeczywistym dla danego systemu.
Wybór odpowiedniego rozwiązania do replikacji danych w czasie rzeczywistym
Ważne jest, aby wybrać skuteczne i niezawodne rozwiązanie do ochrony danych, które oferuje wsparcie dla replikacji danych w czasie rzeczywistym dla maszyn wirtualnych i jest w stanie spełnić Twoje wymagania.
Kluczowe funkcje, na które należy zwrócić uwagę w narzędziu do replikacji danych
Zaleca się, aby oprogramowanie do ochrony danych z narzędziami do replikacji danych zawierało następujące funkcje:
- Wsparcie dla wielu typów replikacji . Rozważ rozwiązanie do ochrony danych, które obsługuje replikację w czasie rzeczywistym oraz replikację asynchroniczną maszyn wirtualnych. W tym przypadku można skorzystać z ciągłej lub replikacji danych w czasie rzeczywistym, która wymaga wysokiej klasy sprzętu o niskim opóźnieniu dla krytycznych maszyn wirtualnych. Jednocześnie można obniżyć koszty i replikować zwykłe maszyny wirtualne o niższych wymaganiach dotyczących RPO, korzystając z replikacji asynchronicznej.
- Interfejs przyjazny dla użytkownika . Rozwiązanie przyjazne dla użytkownika jest wygodniejsze w konfiguracji i może zająć mniej czasu. Elastyczna konfiguracja zapewnia administratorom więcej korzyści w różnych przypadkach użycia.
- Wiele lokalizacji replikacji . Zaleca się, aby rozwiązanie do ochrony danych obsługiwało replikację do tej samej lokalizacji oraz do innej lokalizacji. W przypadku Replikacji maszyny wirtualnej VMware lepiej jest, gdy obsługiwana jest replikacja do tego samego vCenter oraz do innego vCenter. Sprawdź opcje maszyn wirtualnych Tryb failover i powrót po awarii .
- Spójność z aplikacją . Sprawdź, czy preferowane rozwiązanie obsługuje spójność z aplikacją , aby zapewnić spójność danych zapisywanych przez aplikacje w replikach maszyn wirtualnych.
- Wymagania . Rozwiązanie o przyjaznych wymaganiach może skrócić czas potrzebny na konfigurację.
- Koszty . Sprawdź ceny i licencje. Wybierz rozwiązanie, które najlepiej pasuje do Twojego budżetu.
Niezawodna replikacja danych w czasie rzeczywistym z NAKIVO
NAKIVO Backup & Replication to uniwersalne rozwiązanie do ochrony danych, które obsługuje replikację maszyn wirtualnych VMware, w tym replikację tradycyjną i replikację w czasie rzeczywistym. Rozwiązanie zapewnia następujące korzyści związane z replikacją maszyn wirtualnych w czasie rzeczywistym:
- RPO i RTO . Można skonfigurować RPO na poziomie zaledwie 1 sekundy, aby zapewnić synchronizację najnowszych zmian z repliką maszyny wirtualnej i uniknąć utraty danych w przypadku awarii maszyny wirtualnej. Odzyskiwanie maszyny wirtualnej (Tryb failover) można przeprowadzić w ciągu kilku sekund lub minut. Można osiągnąć niemal zerowe przestoje i niemal zerową utratę danych.
- Tryb failover na replikę . Czas przestoju jest bliski zeru dzięki szybkiemu przełączeniu awaryjnemu maszyny wirtualnej na replikę w celu wznowienia obciążeń. Automatyczny tryb failover pozwala na szybkie uruchomienie replik maszyn wirtualnych.
- Mapowanie sieci i zmiana adresu IP . Podczas przywracania repliki maszyny wirtualnej w innej lokalizacji może być konieczne użycie innej sieci maszyn wirtualnych i konfiguracji IP dla połączenia sieciowego maszyny wirtualnej. Mapowanie sieci pozwala łatwo wybrać nową sieć bez edytowania konfiguracji maszyny wirtualnej w interfejsie użytkownika VMware. Można tworzyć reguły mapowania sieci. Funkcja zmiany adresu IP pozwala ustawić nową konfigurację IP dla repliki maszyny wirtualnej bez edytowania ustawień sieciowych w systemie operacyjnym gościa.
- Interfejs użytkownika . Rozwiązanie NAKIVO zapewnia przyjazny dla użytkownika interfejs internetowy, który sprawia, że konfiguracja replikacji maszyny wirtualnej VMware w czasie rzeczywistym jest szybka i wygodna.
- Przystępna cena . NAKIVO Backup & Replication oferuje licencje bezterminowe i licencje subskrypcyjne z elastyczną polityką licencyjną. Pełną listę ceny i edycje można sprawdzić na stronie funkcji.
Rozwiązanie NAKIVO wykorzystuje filtr wejścia/wyjścia VMware w klastrze, aby zapewnić replikację w czasie rzeczywistym dla maszyn wirtualnych VMware. Filtry wejścia/wyjścia VMware zwiększają możliwości pamięci masowej VMware dla środowisk wirtualnych. Operacje wejścia/wyjścia między maszynami wirtualnymi a urządzeniami pamięci masowej są przechwytywane i przetwarzane przez filtry. Ponadto zoptymalizowana jest wydajność replikacji w czasie rzeczywistym.
Filtr I/O odpowiada za szyfrowanie danych w celu poprawy bezpieczeństwa oraz za sprawdzanie integralności danych podczas replikacji maszyn wirtualnych w czasie rzeczywistym. W związku z tym filtr I/O jest wymagany dla hosta źródłowego ESXi, a usługa Journal Service jest wymagana dla hosta docelowego. Usługa Journal Service odpowiada za śledzenie zmian i jest instalowana na komputerze, na którym działa docelowy Transporter. Dla każdego dysku maszyny wirtualnej tworzony jest dziennik, który służy do śledzenia zmian i rejestrowania operacji wejścia/wyjścia w celu zachowania punktów odzyskiwania.
Konfiguracja replikacji danych w czasie rzeczywistym za pomocą NAKIVO
Wyjaśnimy, jak skonfigurować replikację w czasie rzeczywistym dla maszyn wirtualnych w środowisku VMware vSphere przy użyciu NAKIVO Backup & Replication.
Wymagania
Przed rozpoczęciem konfiguracji replikacji w czasie rzeczywistym upewnij się, że Twoje środowisko spełnia główne wymagania, w tym:
- Źródłem musi być klaster zarządzany przez vCenter, a miejscem docelowym może być samodzielny serwer ESXi lub host ESXi dodany do tego samego vCenter.
- Magazyn danych docelowy powinien mieć co najmniej 5 GB.
- Host ESXi źródłowy powinien mieć co najmniej 16 GB pamięci RAM.
- Czas musi być zsynchronizowany na hostach ESXi i transporterach.
Zobacz pełna lista wymagań.
Nasze środowisko vSphere posiada serwer vCenter z dwoma centrami danych (źródłowym i docelowym).
DC_1jest centrum danych źródłowym z klastrem dwóch hostów wraz z źródłowym transporterem .DC_2jest centrum danych docelowym z pojedynczym serwerem ESXi i docelowym transporterem .- Celem centrum danych może być zarządzanie w ramach jednego lub dwóch vCenter, a nawet działanie jako samodzielny serwer ESXi, w zależności od konkretnych potrzeb infrastruktury.
Konfiguracja środowiska vSphere
To jest środowisko vSphere używane w przewodniku. Posiada vCenter Server z dwoma centrami danych (źródłowym i docelowym).
- Główne centrum danych z transporterem urządzenia wirtualnego źródłowego jest już zainstalowane.
- Zainstalowano dodatkowe centrum danych z transporterem urządzenia wirtualnego docelowego.
- Centrum danych docelowe może być zarządzane za pomocą jednego lub dwóch serwerów vCenter, a nawet działać jako samodzielny serwer ESXi, w zależności od konkretnych potrzeb infrastruktury.
- NAKIVO Director jest zainstalowany w docelowym centrum danych, które jest centrum danych rezerwowym. Taka konfiguracja pozwala na dostęp do Director w przypadku wystąpienia awarii i niedostępności głównego centrum danych.

Zmień poziom akceptacji źródłowego serwera ESXi na Community supported poziom. Musimy zmienić poziom akceptacji profilu obrazu hosta na każdym serwerze ESXi w centrum danych źródłowym na Community supported .
- Otwórz program VMware vSphere Client, kliknij kartę
Configurei przejdź doSecurity Profile. Następnie przejdź doHost Image Profile Acceptance Leveli kliknijEdit.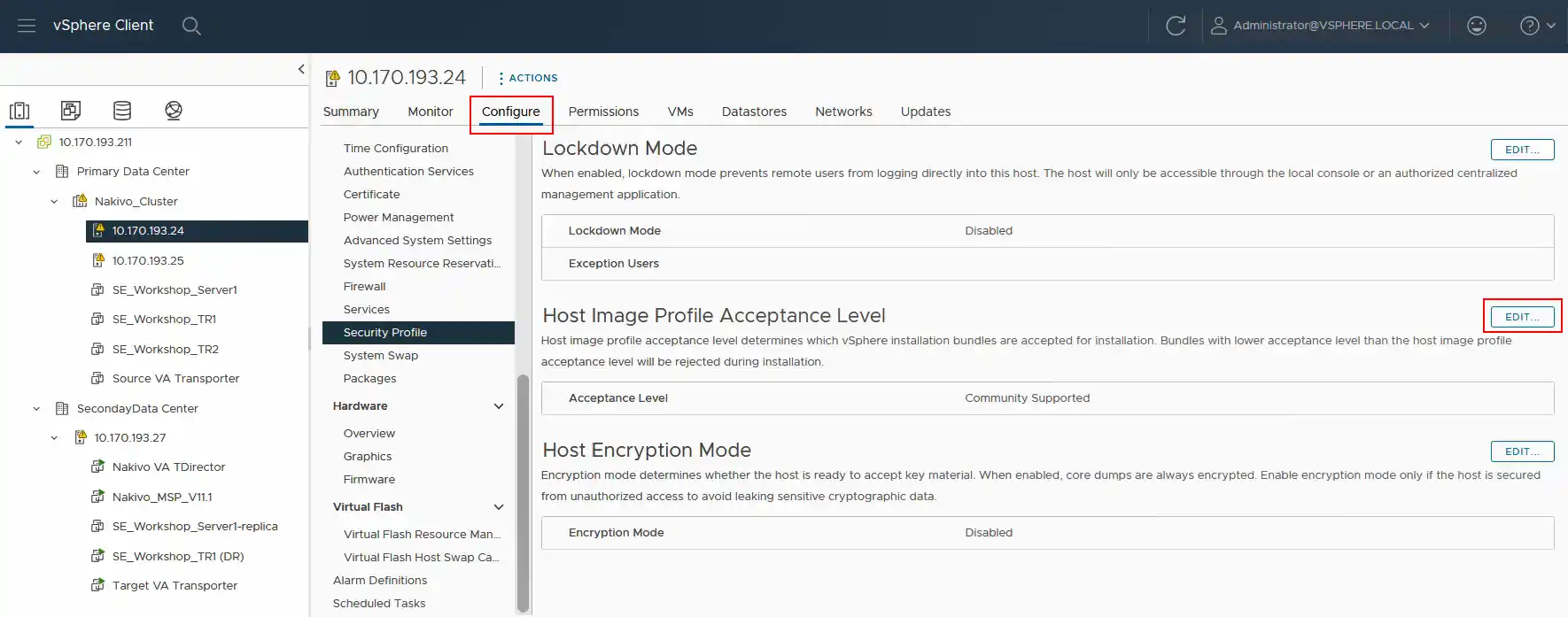
- Zmień poziom akceptacji na <
strong>Community Supported. KliknijOK, aby zapisać ustawienia.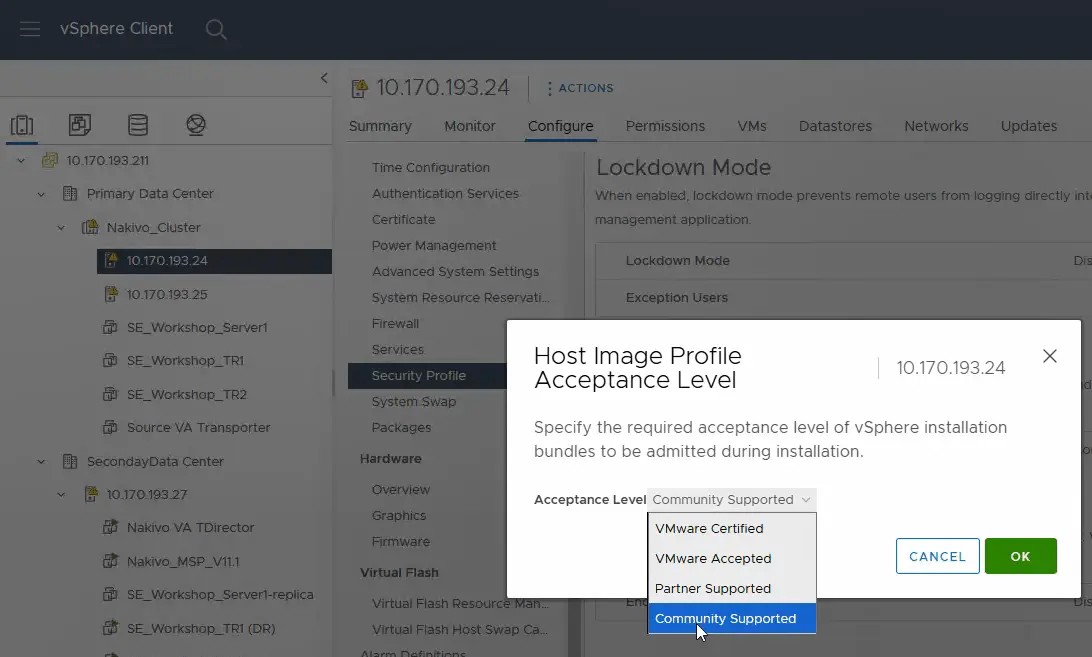
- Wykonaj te same czynności na drugim hoście ESXi w centrum danych źródłowym i ustaw poziom akceptacji na
Community Supported.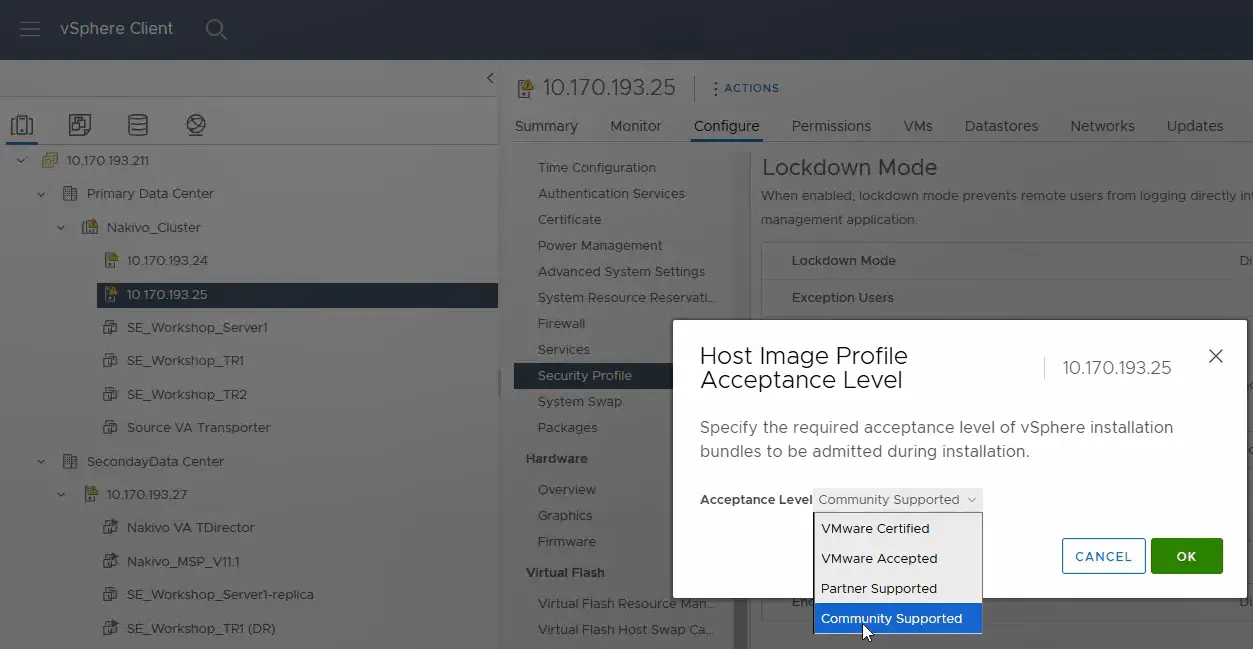
Konfiguracja zasobów
- Po edycji poziomu akceptacji profilu obrazu hosta otwórz interfejs internetowy NAKIVO Backup & Replication i przejdź do
Settings > Inventory, aby dodać źródłowy vCenter do zasobów. Kliknij ikonęPlus, aby dodać nowy element do zasobów.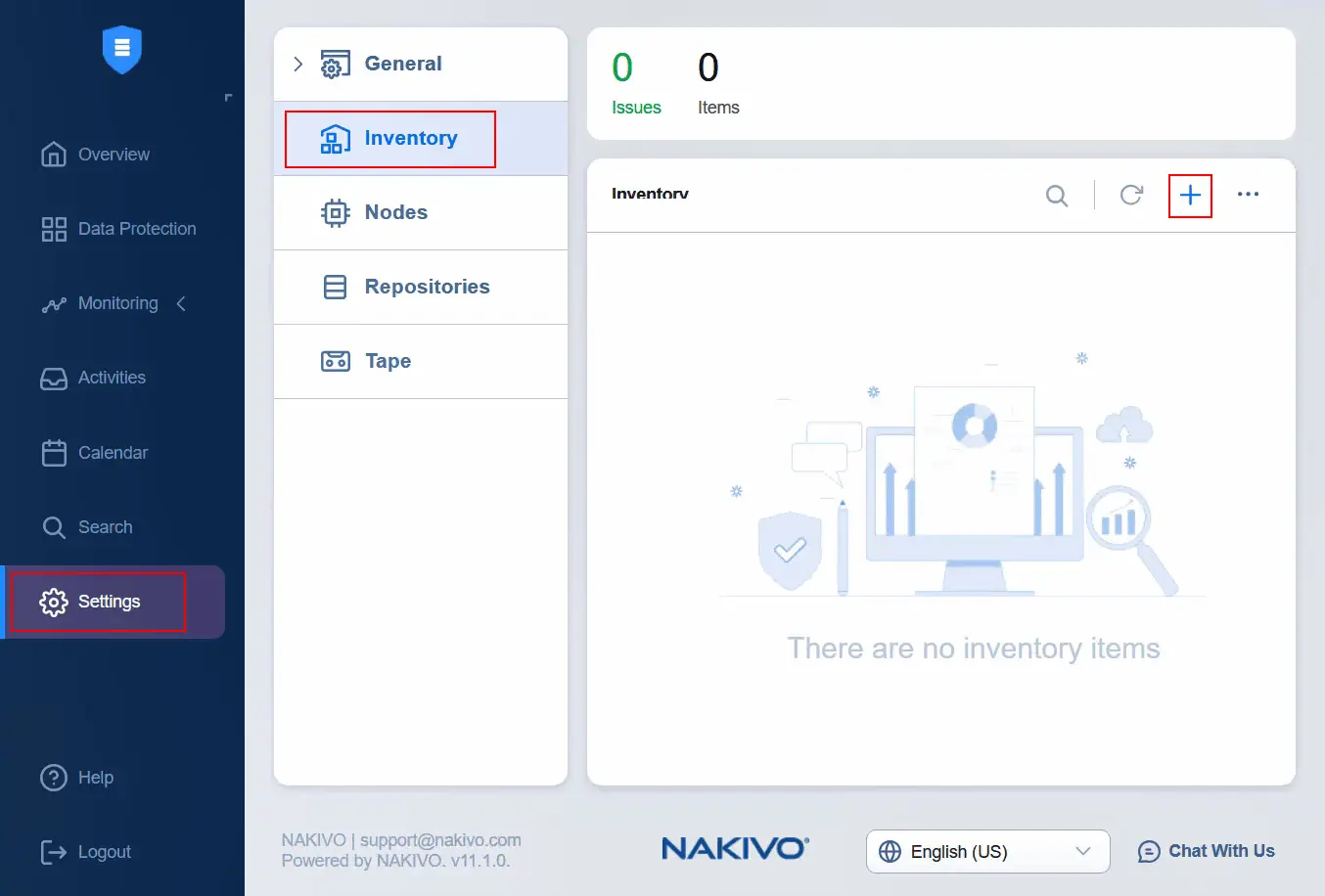
- Wybierz
Virtualjako platformę i kliknijNext.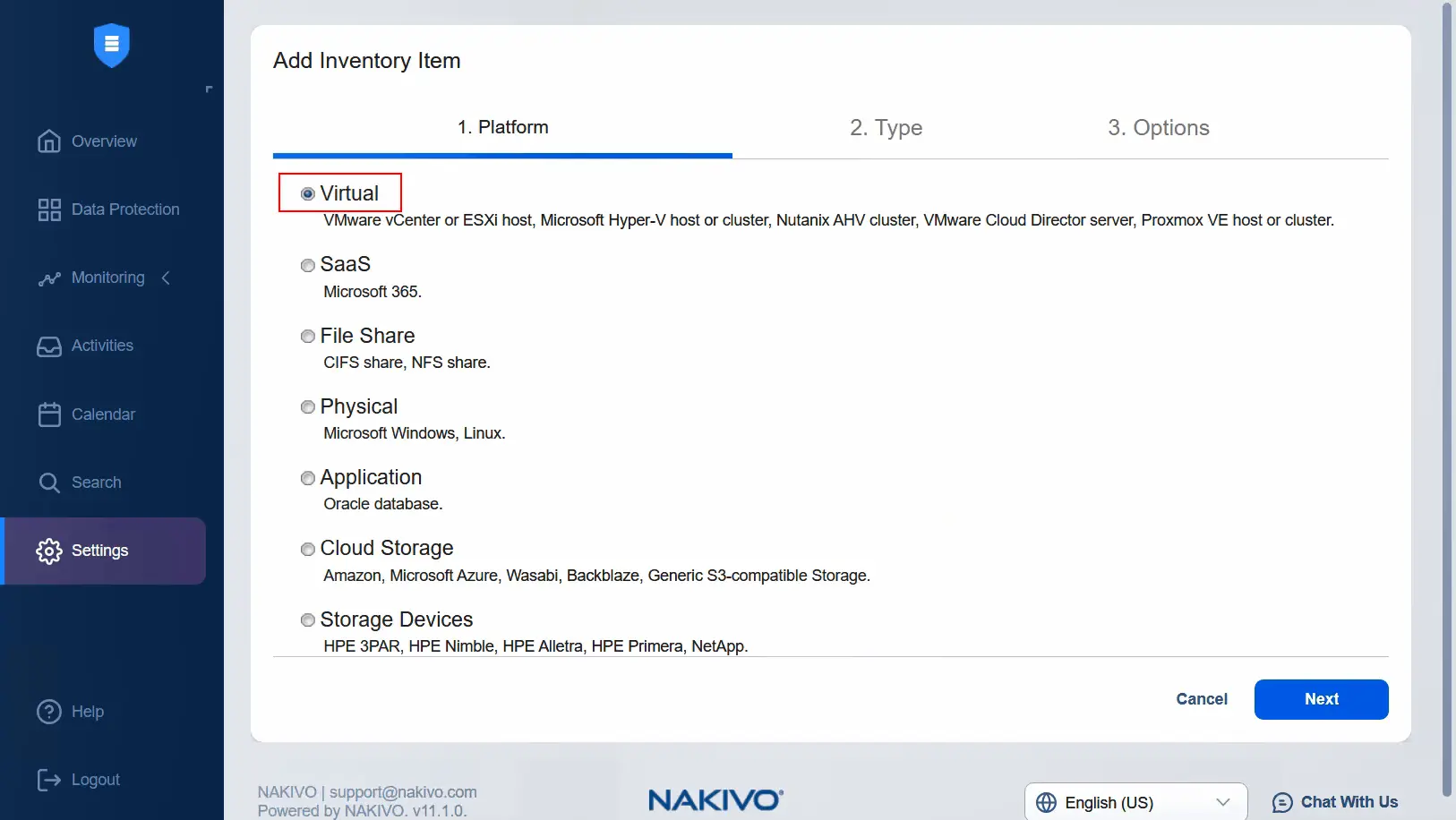
- Wybierz
VMware vCenterlubESXi hostjako typ. Następnie przejdź do kolejnego kroku.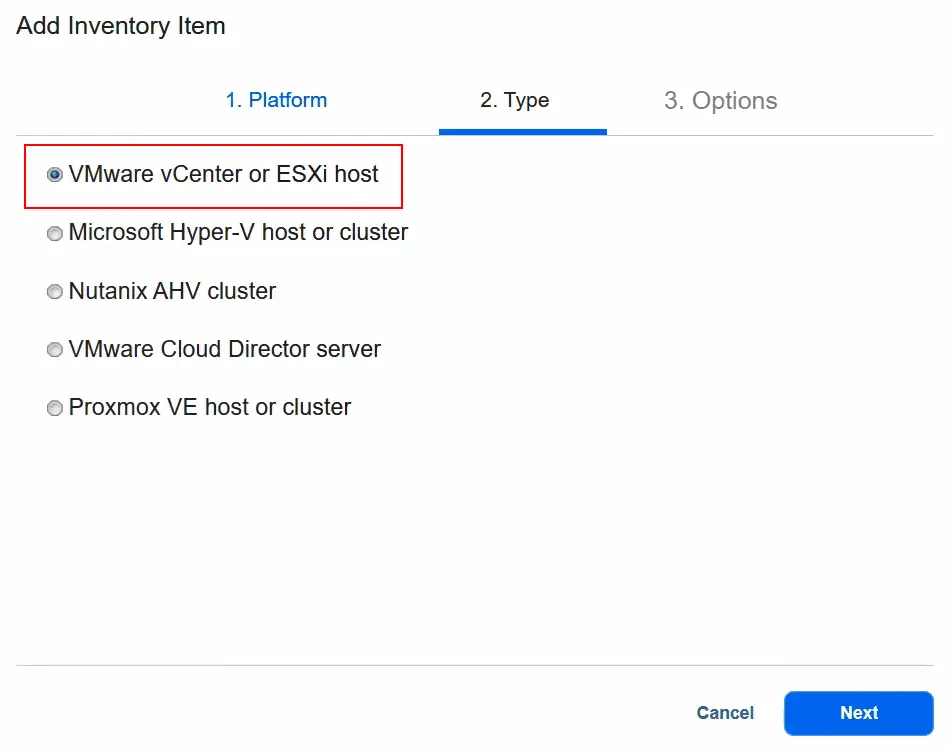
- W kroku
Optionswprowadź nazwę wyświetlaną, na przykładvCenter. Następnie wprowadź adres IP tego serwera vCenter, a także nazwę użytkownika i hasło, aby uzyskać do niego dostęp. KliknijFinish, aby zapisać ustawienia i dodać wybrany serwer vCenter do zasobów NAKIVO.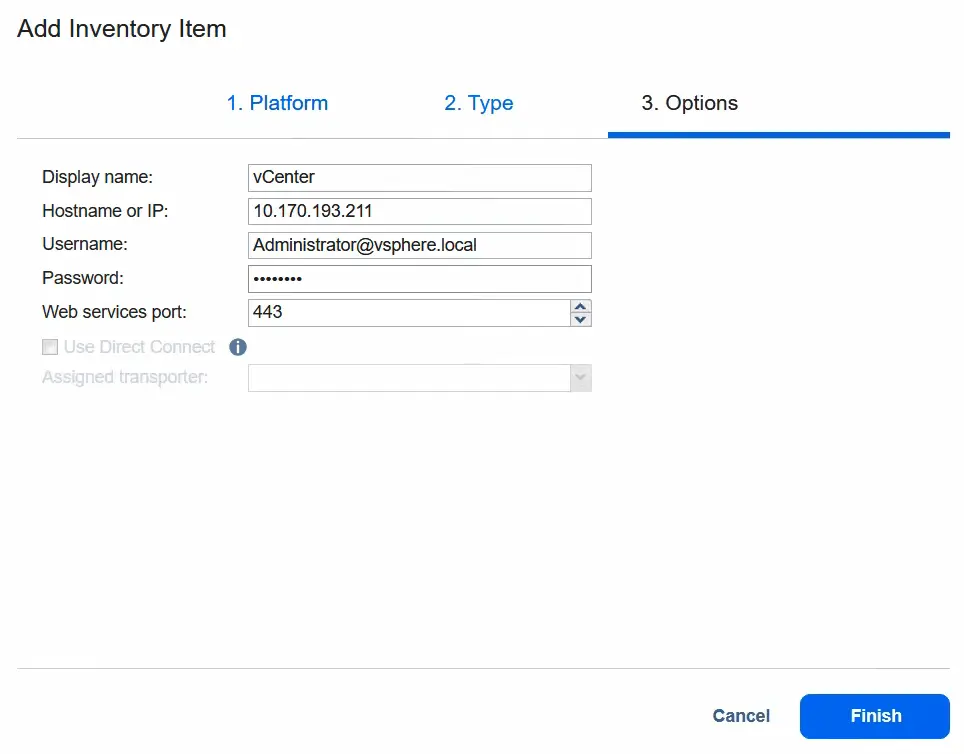
- Poczekaj, aż serwer vCenter zostanie dodany do zasobów. Po dodaniu, jeśli klikniemy pozycję vCenter, w zasobach NAKIVO zobaczymy główne i pomocnicze centra danych na tym samym serwerze vCenter.
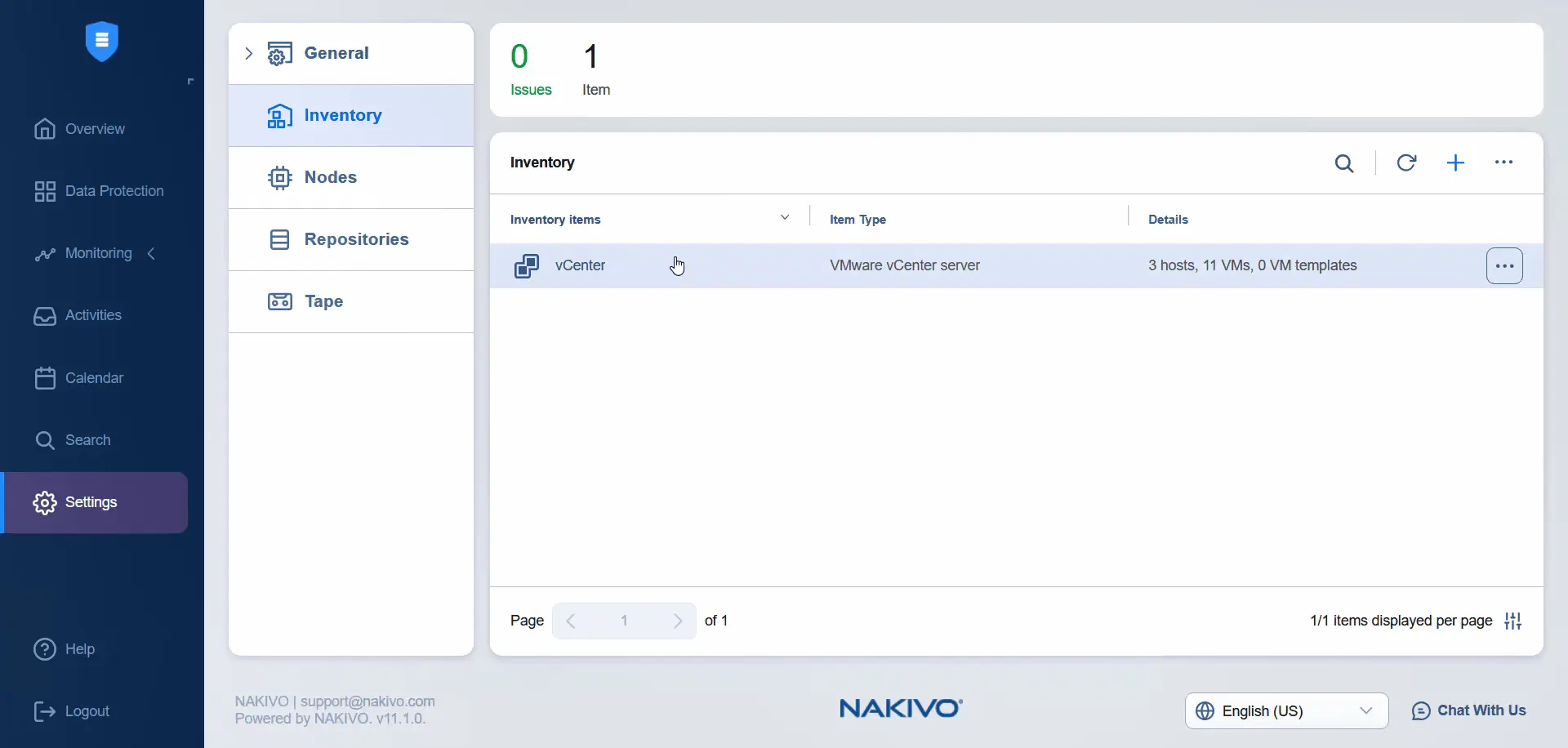
Instalacja filtra I/O
Następnie musimy zainstalować filtr I/O na każdym hoście ESXi po stronie źródłowej. Filtr I/O musi być zainstalowany w klastrze, aby umożliwić replikację danych w czasie rzeczywistym. Nie ma potrzeby instalowania filtra I/O po stronie docelowej.
- Kliknij
Nodes, kliknijGot It(jeśli odwiedzasz tę sekcję po raz pierwszy), kliknijPlusi naciśnijReal-Time Replication Service.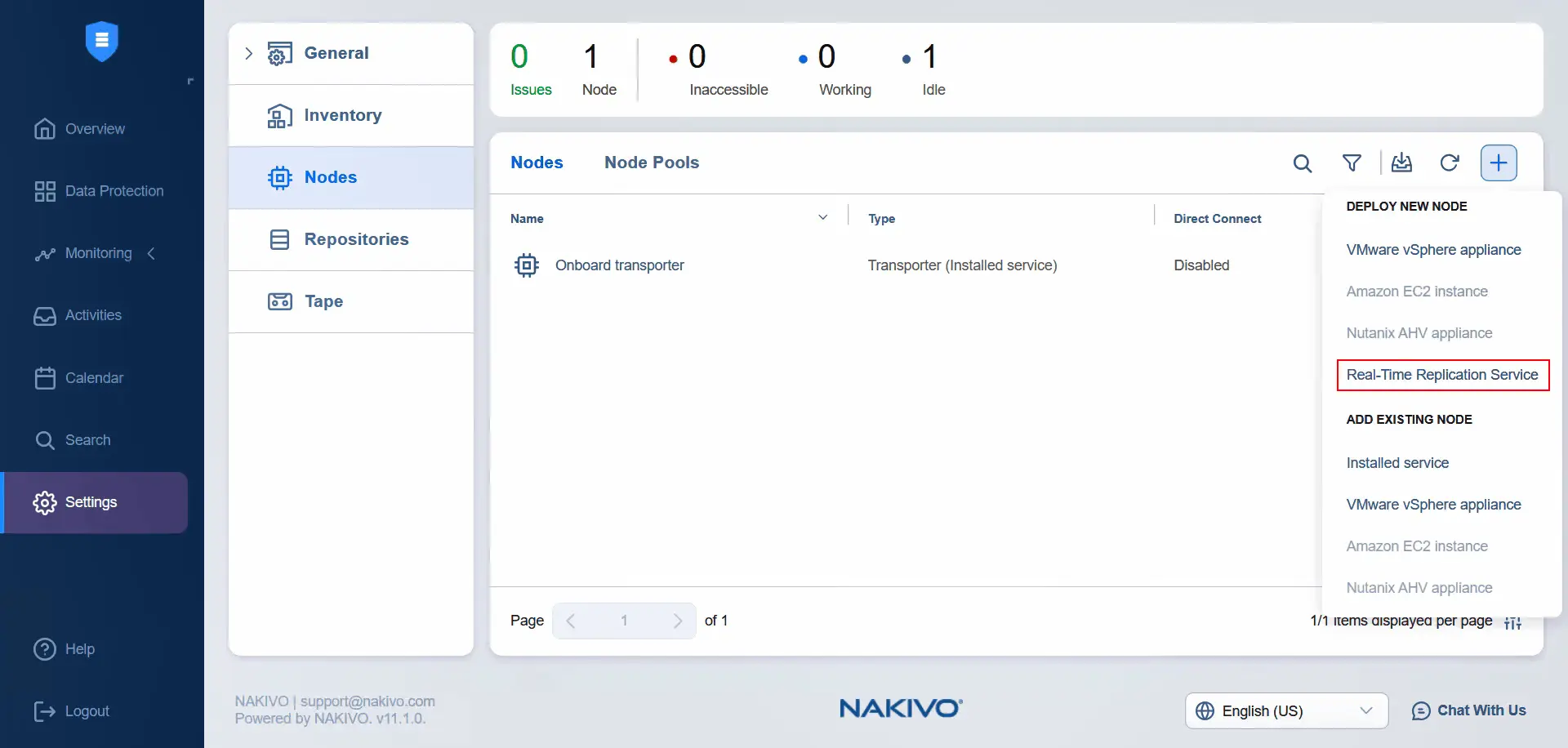
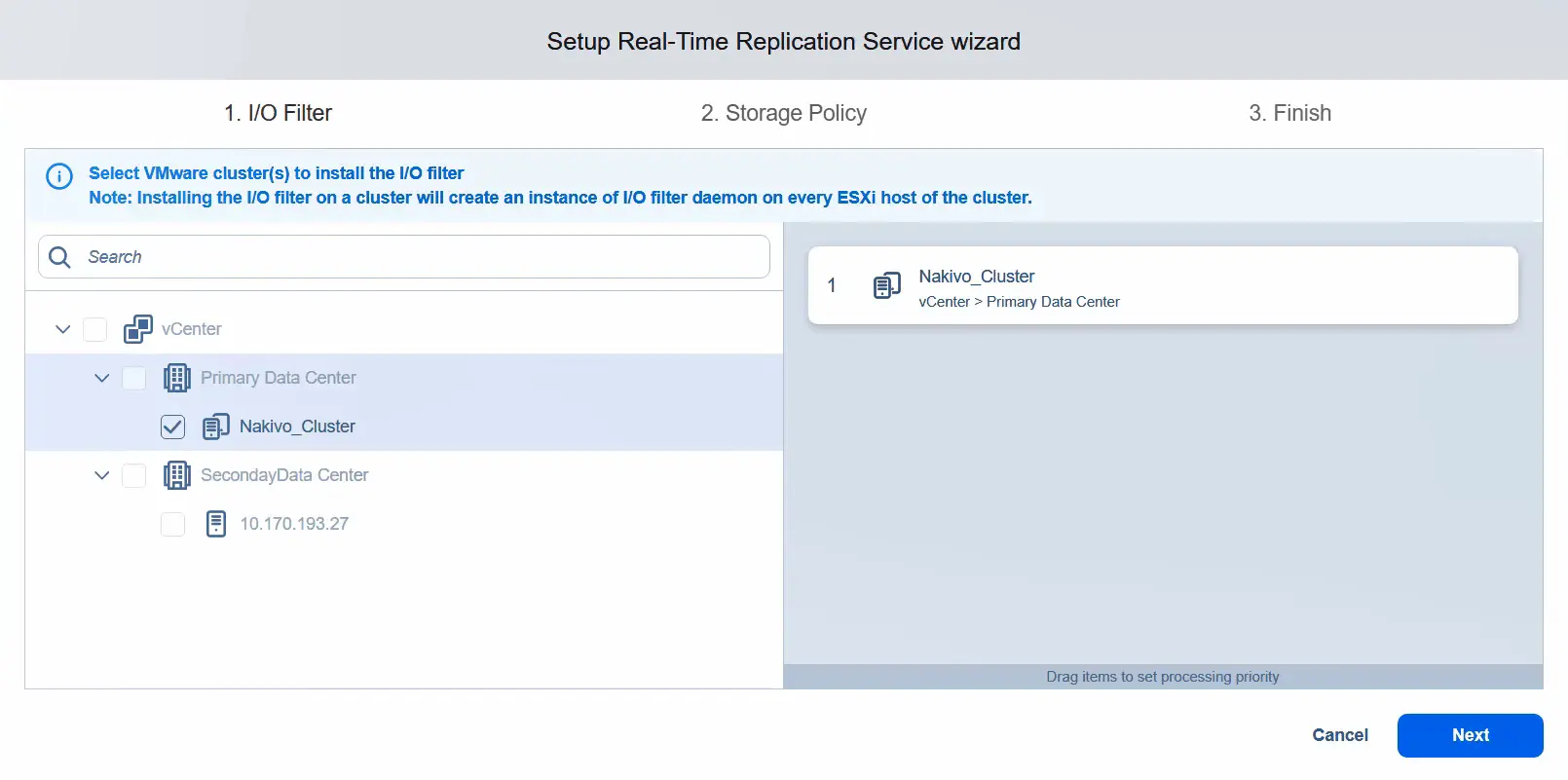
- Zainstaluj filtr I/O tylko w głównym centrum danych, które jest centrum danych źródłowym. Po wybraniu klastra w centrum danych przejdź do następnego kroku.
- Zastosuj zasadę pamięci masowej i przypisz ją do maszyn wirtualnych, których chcesz używać do replikacji w czasie rzeczywistym. W tym przykładzie stosujemy zasadę pamięci masowej tylko do jednej maszyny wirtualnej. Kliknij
Next.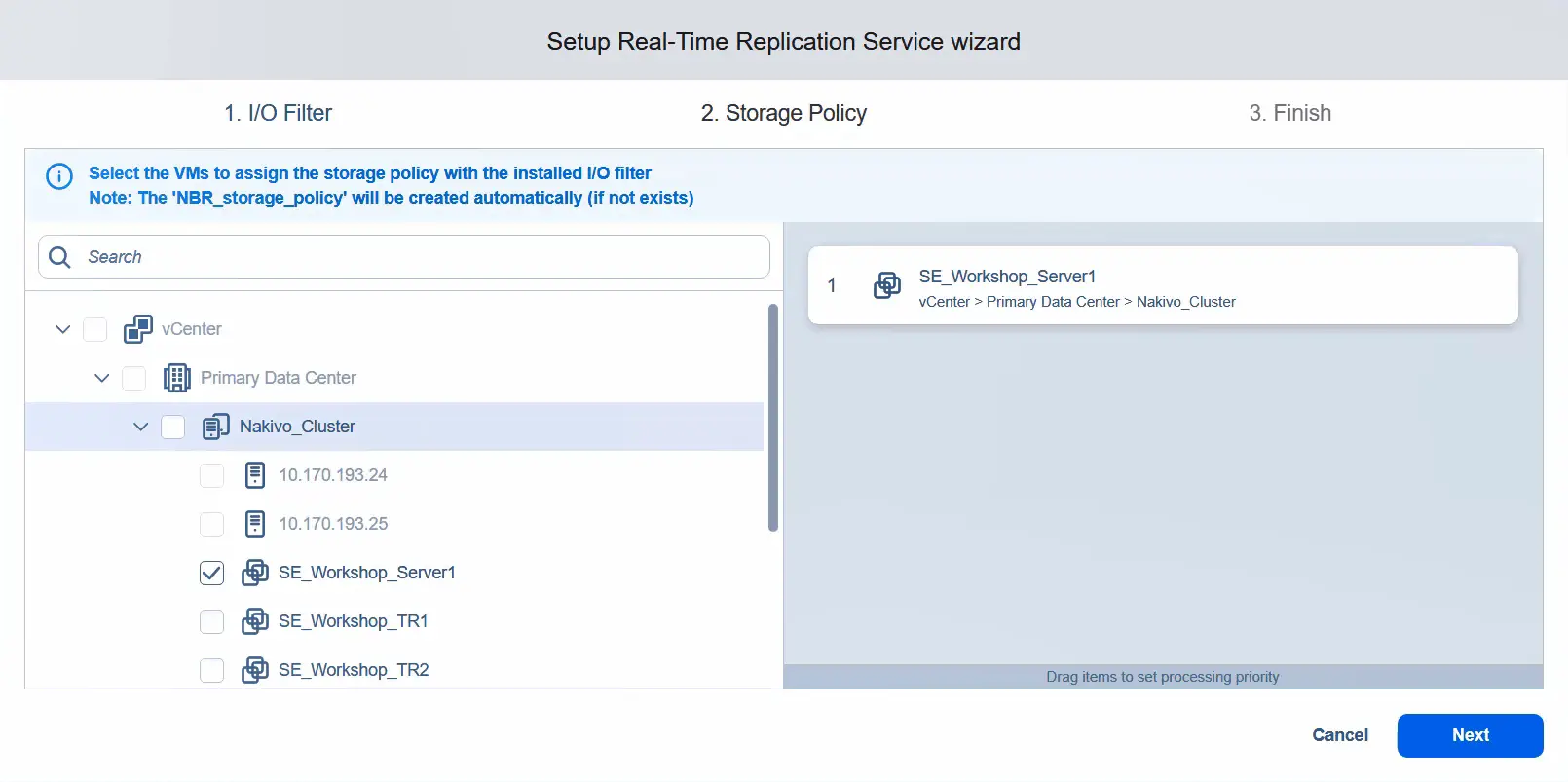
- Usługi replikacji w czasie rzeczywistym zostaną teraz zainstalowane.
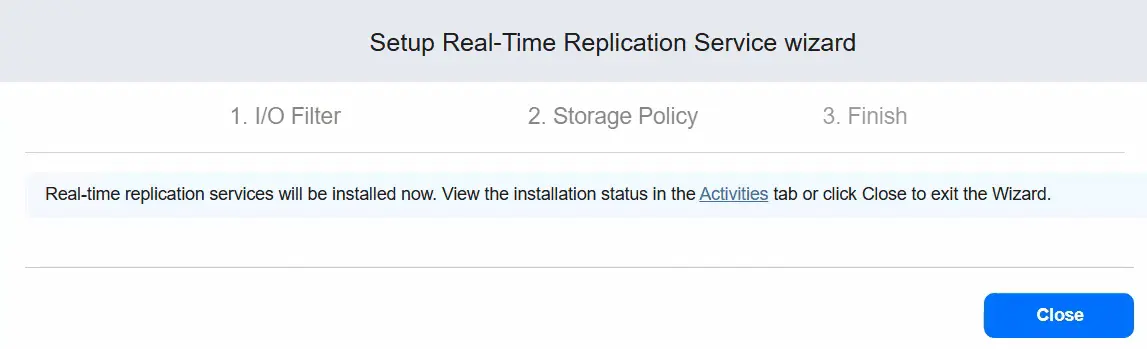
Podczas instalacji możemy śledzić jej status.
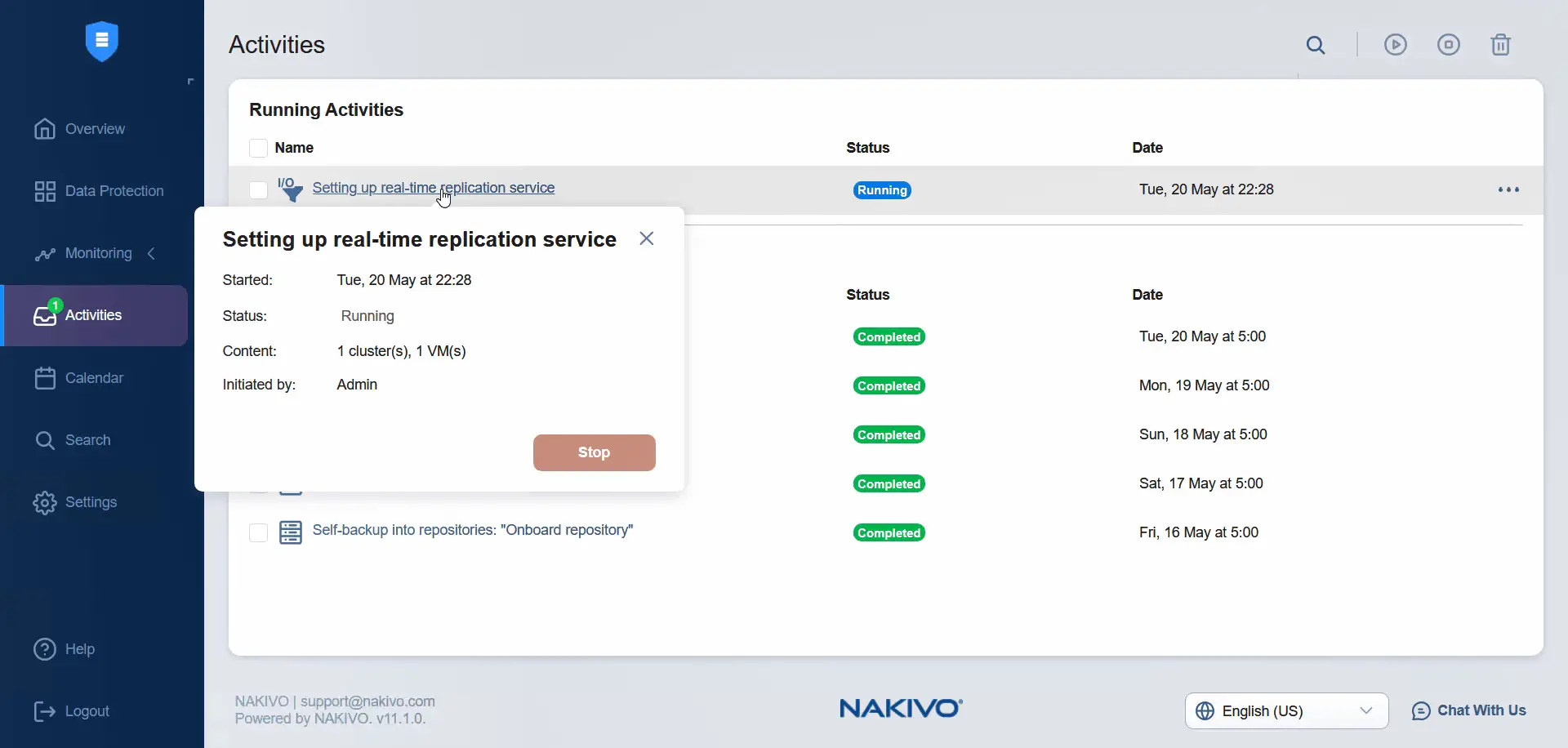
Postęp instalacji można sprawdzić w VMware vCenter. Rozpoczęło się zadanie instalacji filtra I/O. Musimy poczekać, aż filtr I/O zostanie zainstalowany na obu serwerach ESXi.
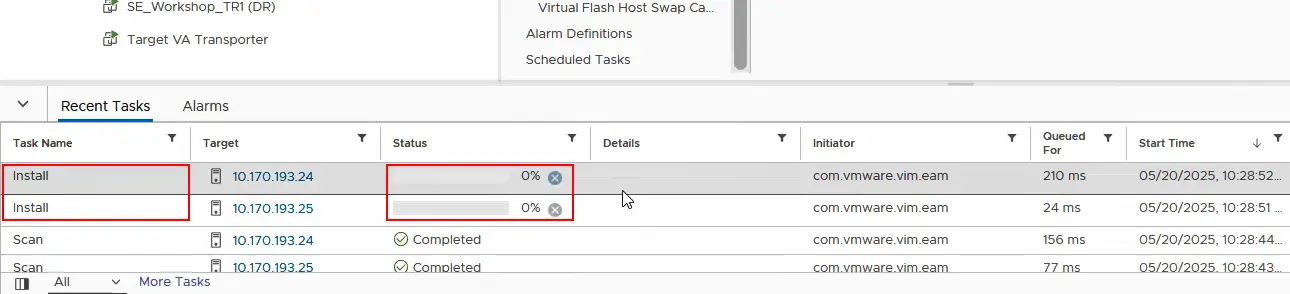
- Teraz musimy sprawdzić, czy filtr I/O został już zainstalowany na każdym serwerze ESXi w klastrze źródłowym. Wybierz host ESXi i kliknij
Configure > I/O Filters. Widzimy, żenakfilterjest już zainstalowany. Podobnie upewnij się, że filtr I/O jest zainstalowany na drugim hoście ESXi w klastrze.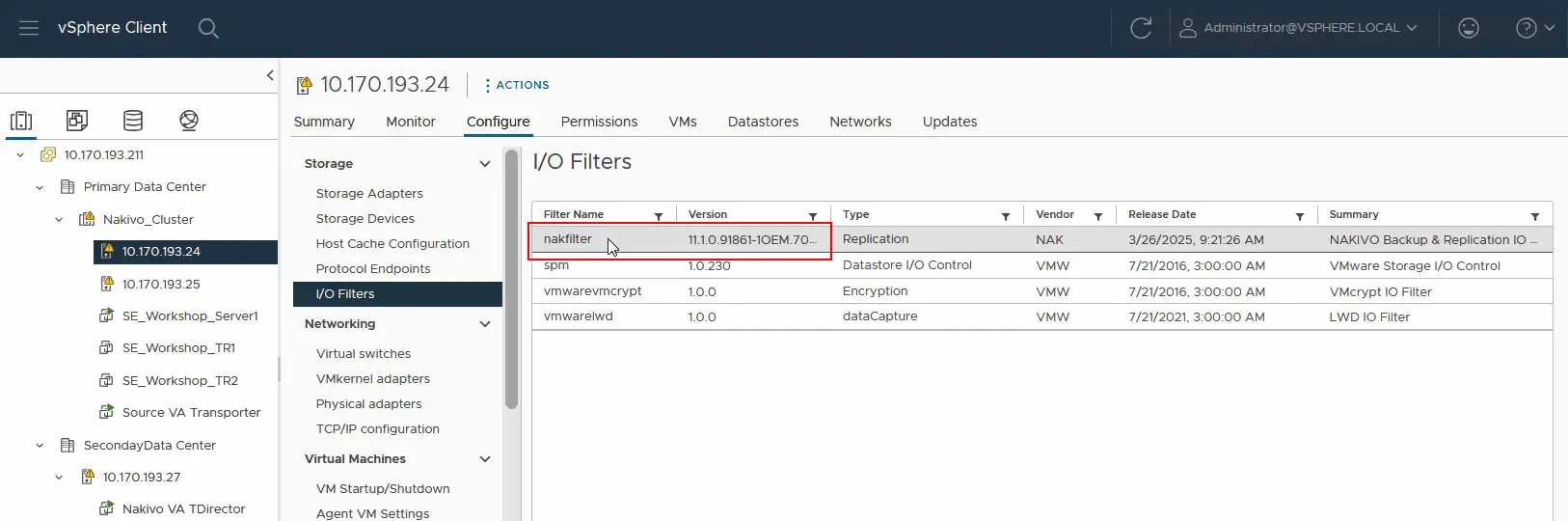
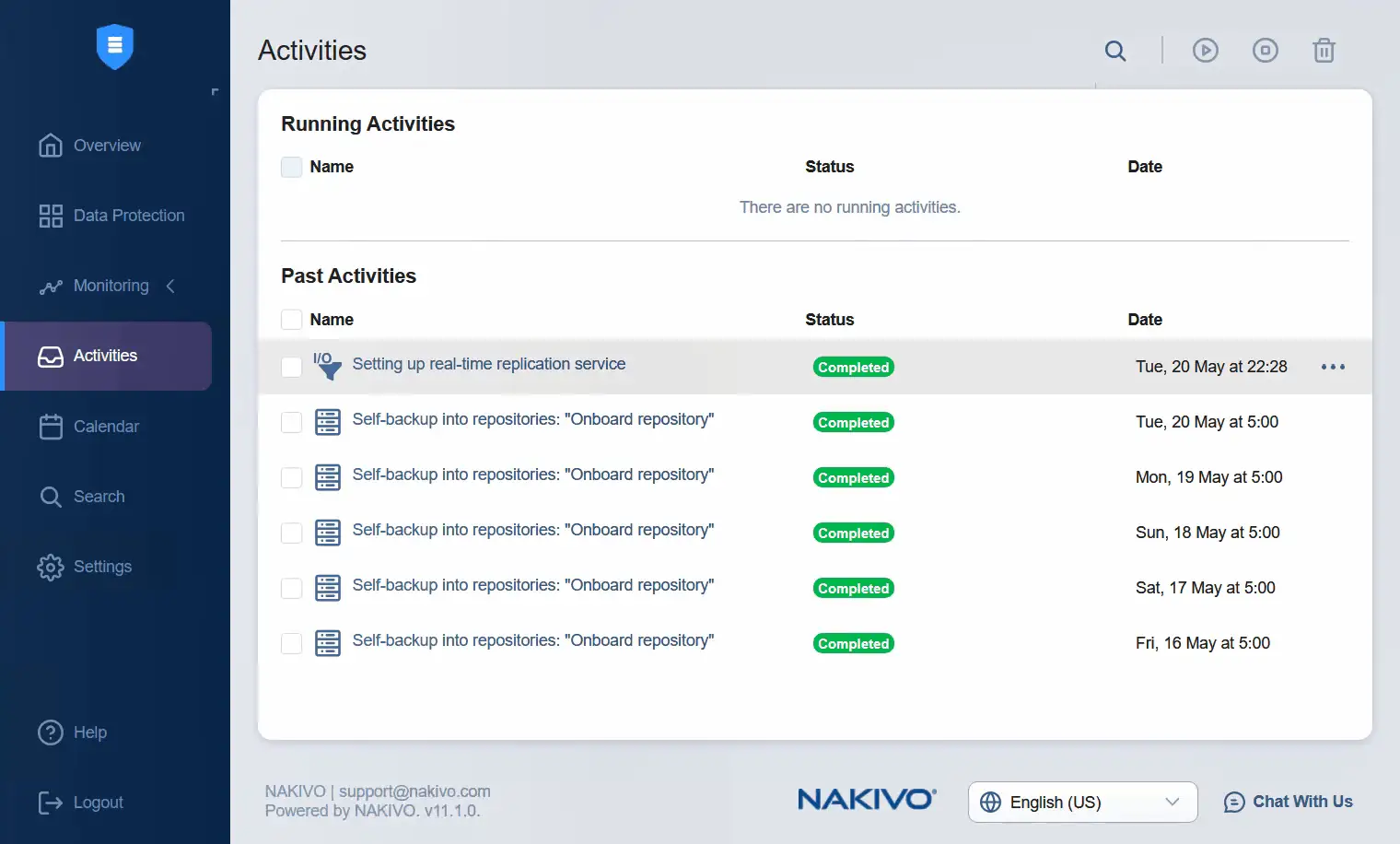
- Przejdź do interfejsu internetowego NAKIVO Backup & Replication, gdzie możesz sprawdzić aktywność. W tym przypadku konfiguracja usługi replikacji w czasie rzeczywistym została pomyślnie zakończona.
Dodawanie transportera
- Wróć do
Settings, aby dodać docelowy transporter doNodes. Zanim przejdziemy dalej, możemy sprawdzić status filtra I/O wyświetlany dla węzłów. W tym przypadku status jest dobry.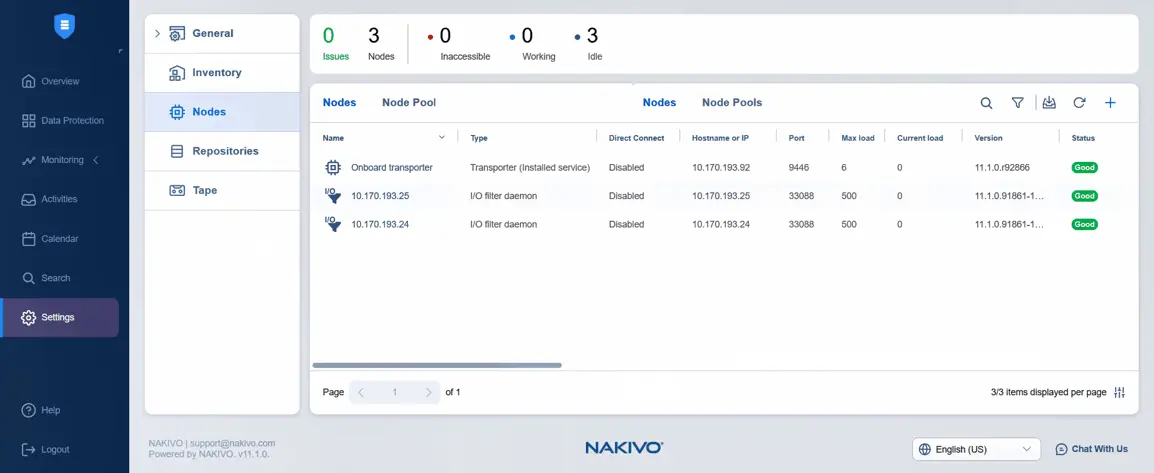
- W sekcji
SettingswybierzNodes, kliknijPlusi naciśnijVMware vSphere appliancew sekcjiAdd Existing Node. Urządzenie wirtualne zostało już zainstalowane podczas instalacji usługi I/O (automatycznie).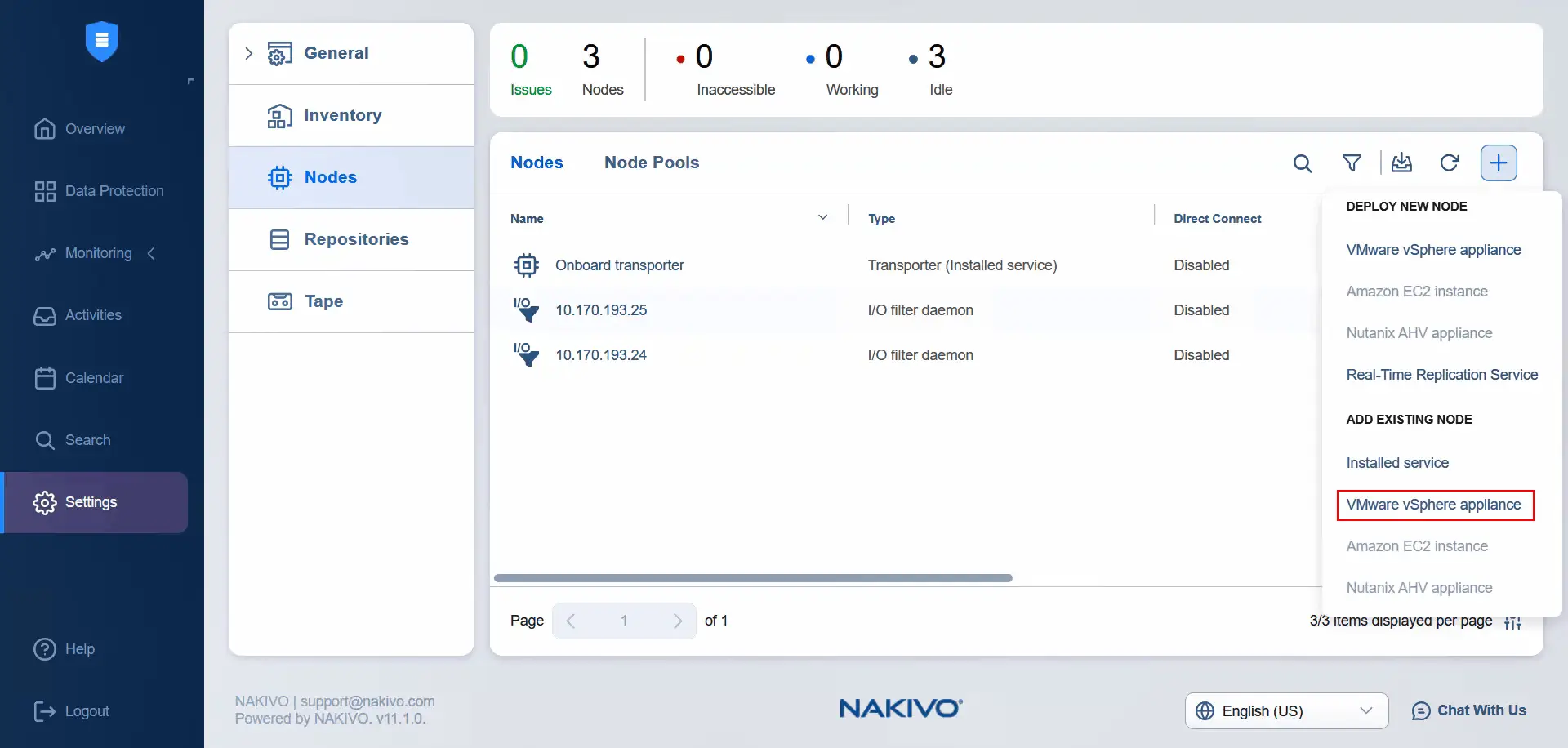
- Wybierz docelowy host ESXi i wybierz docelowe urządzenie wirtualne Transporter. Wprowadź nazwę użytkownika urządzenia wirtualnego Transporter oraz hasło dla tego użytkownika. W odpowiednim polu możesz wprowadzić nazwę transportera. Kliknij
Add.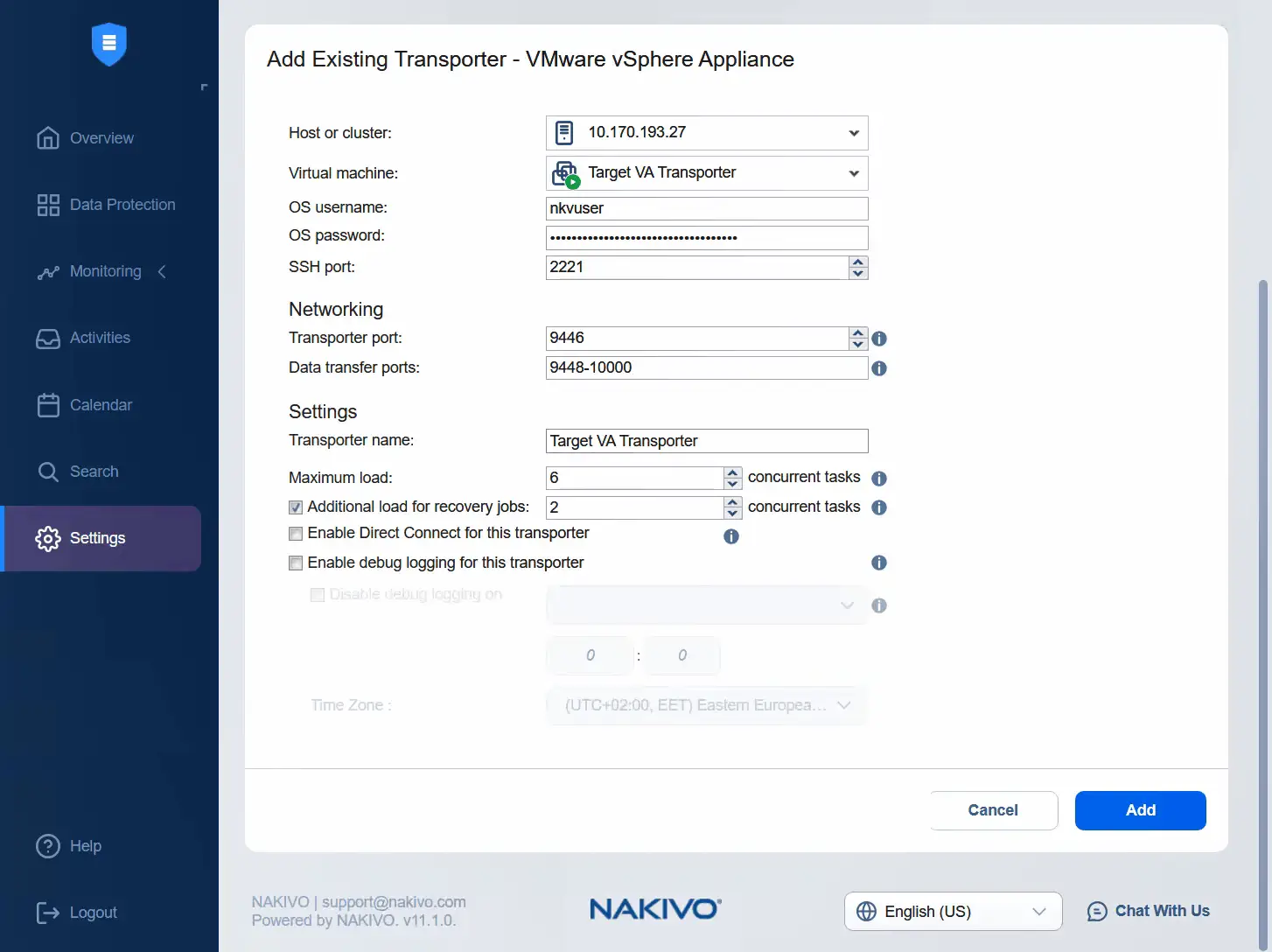
- Trwa dodawanie docelowego urządzenia Transporter. Możesz sprawdzić postęp tutaj lub monitorować status na liście węzłów. Teraz widzimy, że docelowe urządzenie wirtualne Transporter zostało pomyślnie dodane, a jego stan jest dobry.
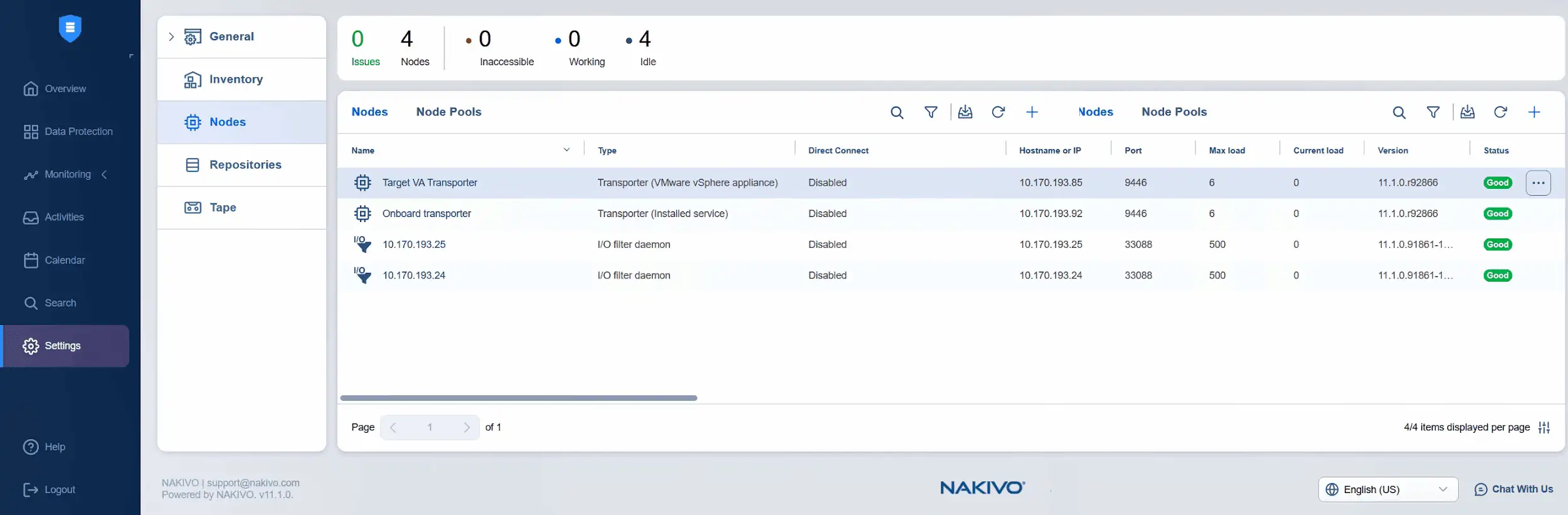
- Czas dodać źródłowe urządzenie wirtualne Transporter do węzłów. Kliknij
Plusi wybierzVMware vSphere Appliancew sekcjiAdd Existing Node.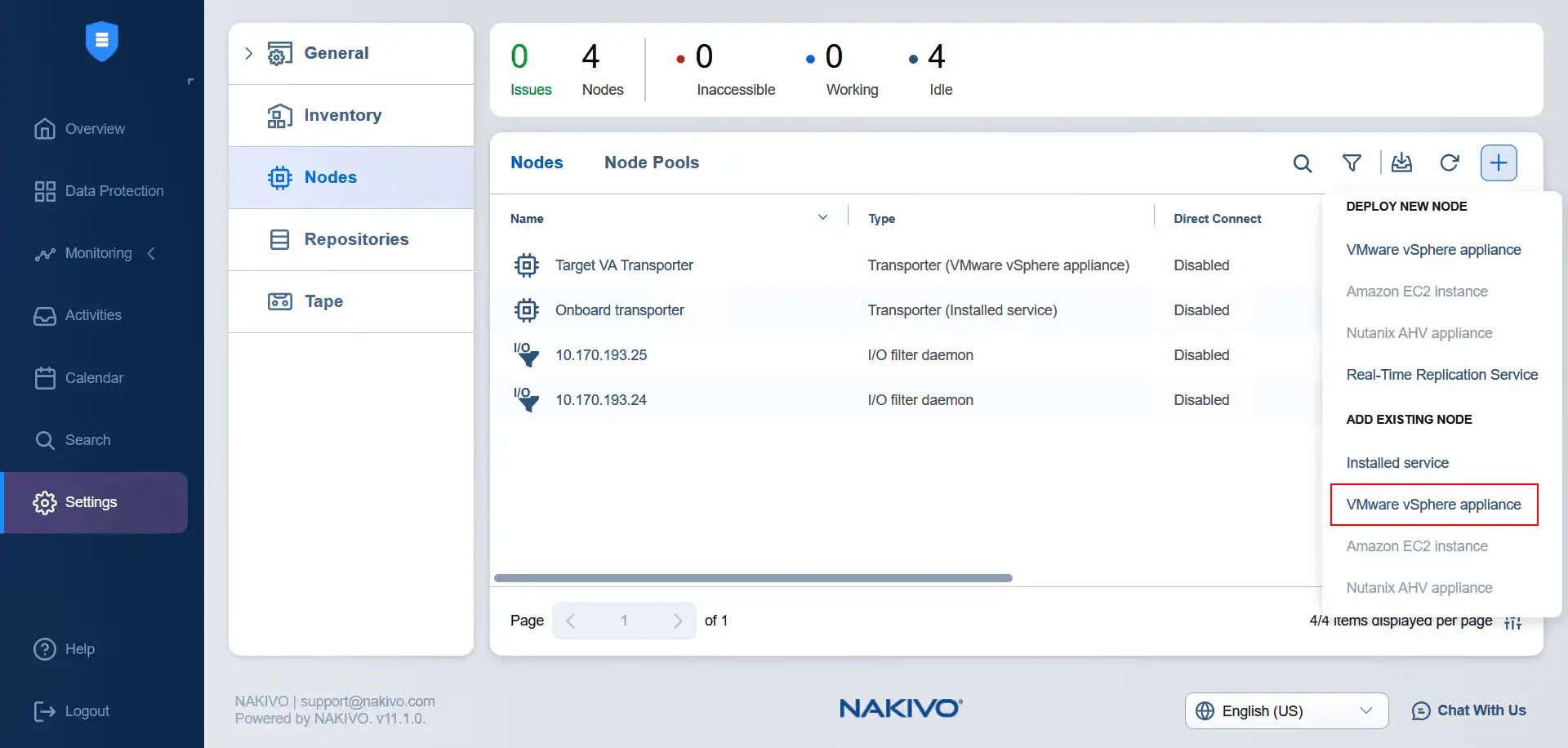
- Wybierz klaster jako źródło. Wybierz źródłowe urządzenie wirtualne Transporter. Wprowadź nazwę użytkownika i hasło wybranego urządzenia transportującego. Jeśli rozwiniesz więcej opcji, możesz wprowadzić nazwę urządzenia transportującego. Kliknij
Add.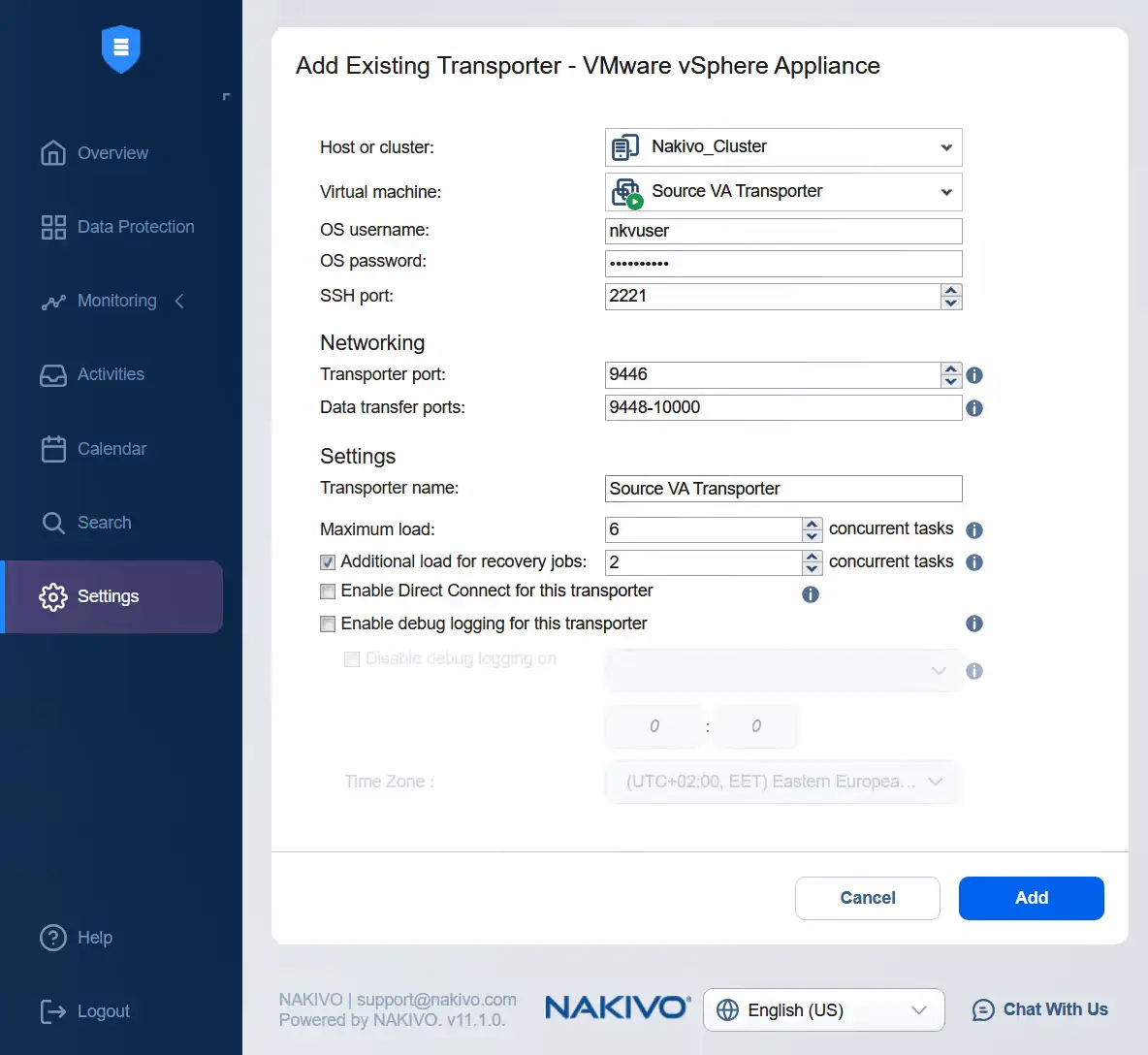
- Po chwili urządzenie wirtualne źródłowe Transporter zostanie pomyślnie dodane do węzłów.
Tworzenie zadania replikacji w czasie rzeczywistym
Przejdź na stronę Data Protection w celu utworzenia zadania replikacji w czasie rzeczywistym dla maszyny wirtualnej. Kliknij Plus i wybierz Real-time replication for VMware.
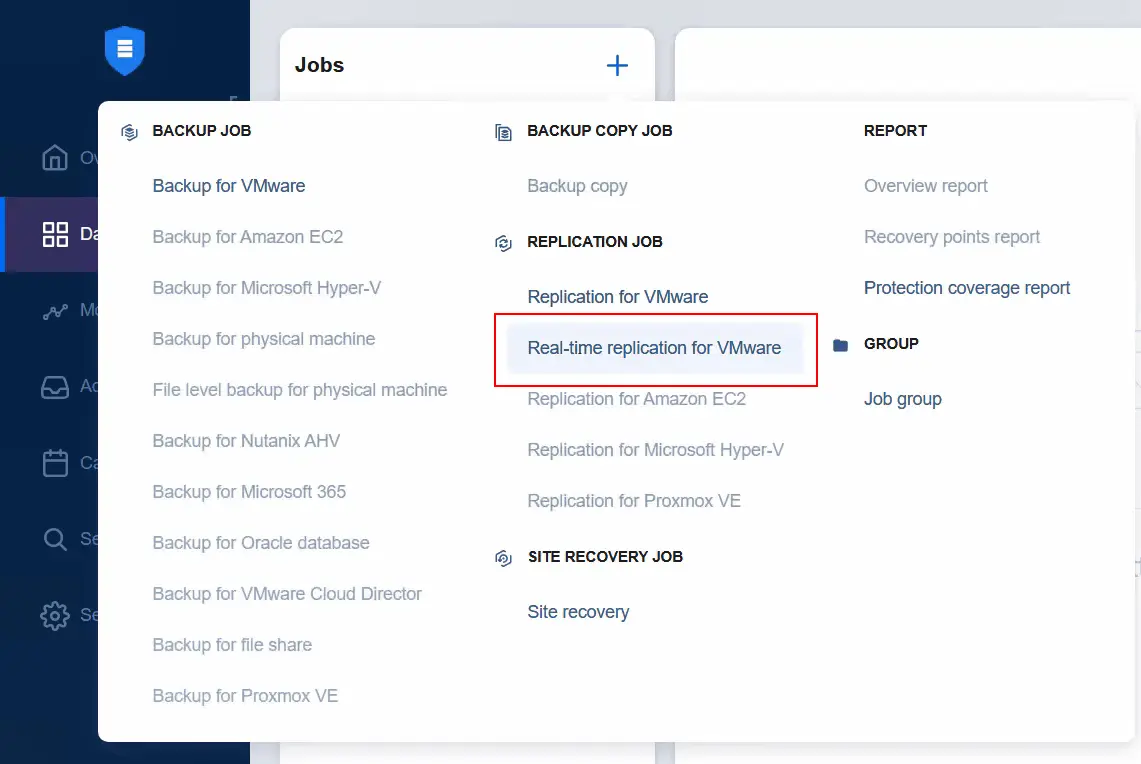
- Na etapie
Sourcew widokuHosts & Clustersw głównym centrum danych wybierz maszynę wirtualną, do której zastosowano zasady przechowywania danych dla maszyn wirtualnych. Należy pamiętać, że nie można wybrać innych maszyn wirtualnych, ponieważ zasady przechowywania danych dla maszyn wirtualnych nie zostały do nich zastosowane. KliknijNext, aby kontynuować.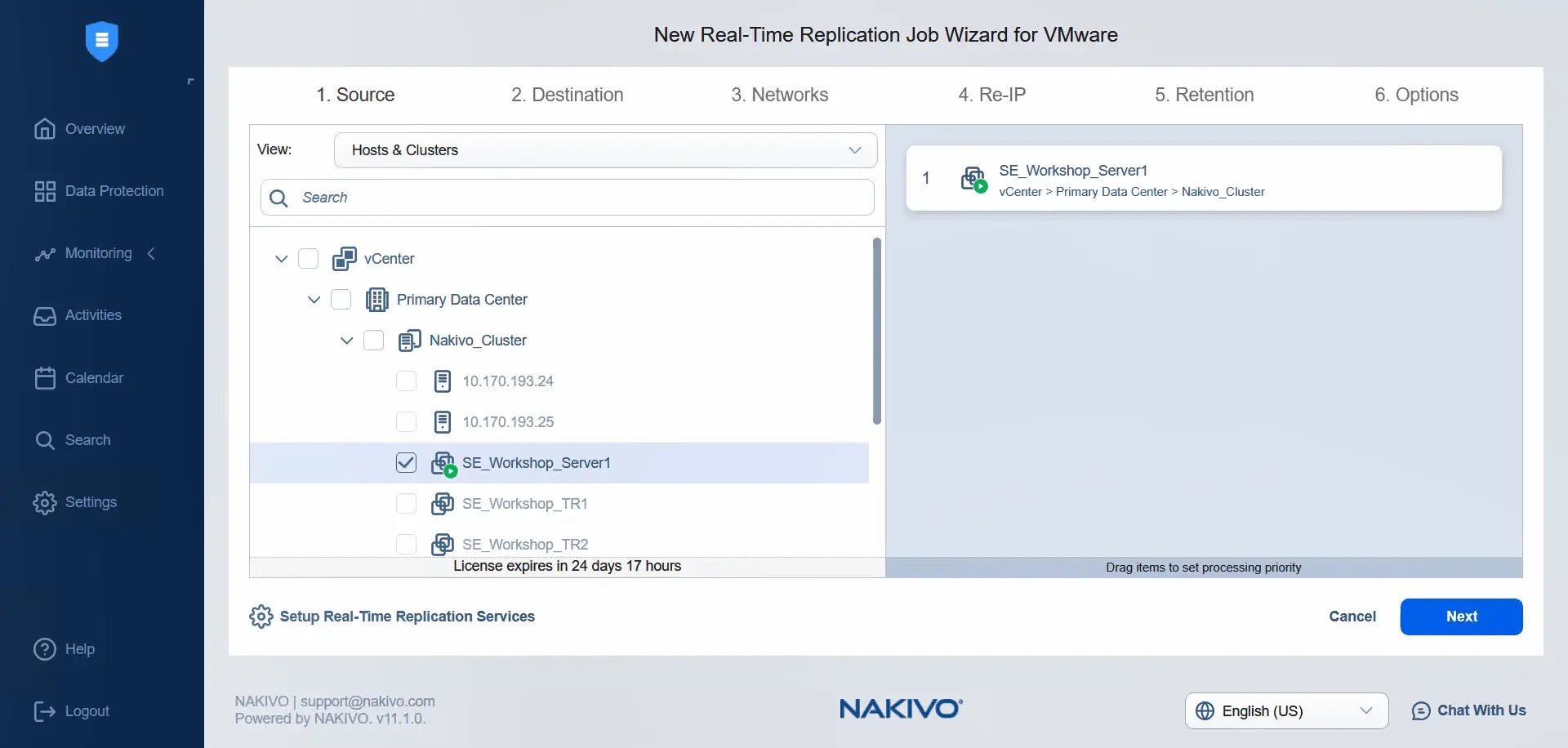
- W kroku
Destinationmożemy wybrać samodzielny host ESXi jako kontener docelowy. Wybierz magazyn danych podłączony do tego hosta ESXi. Przejdź do następnego kroku.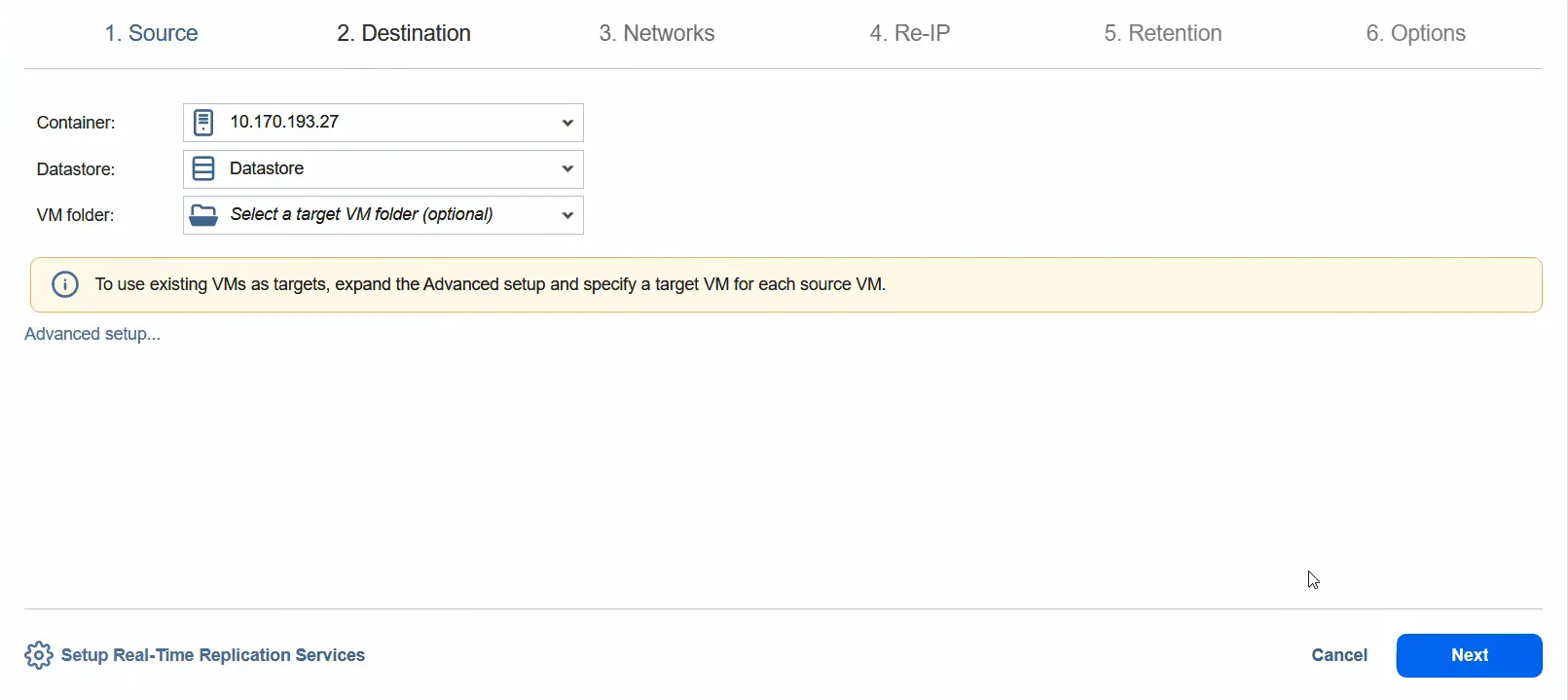
- Możesz włączyć mapowanie sieci, wybierając sieć źródłową i sieć docelową. Kliknij
Next.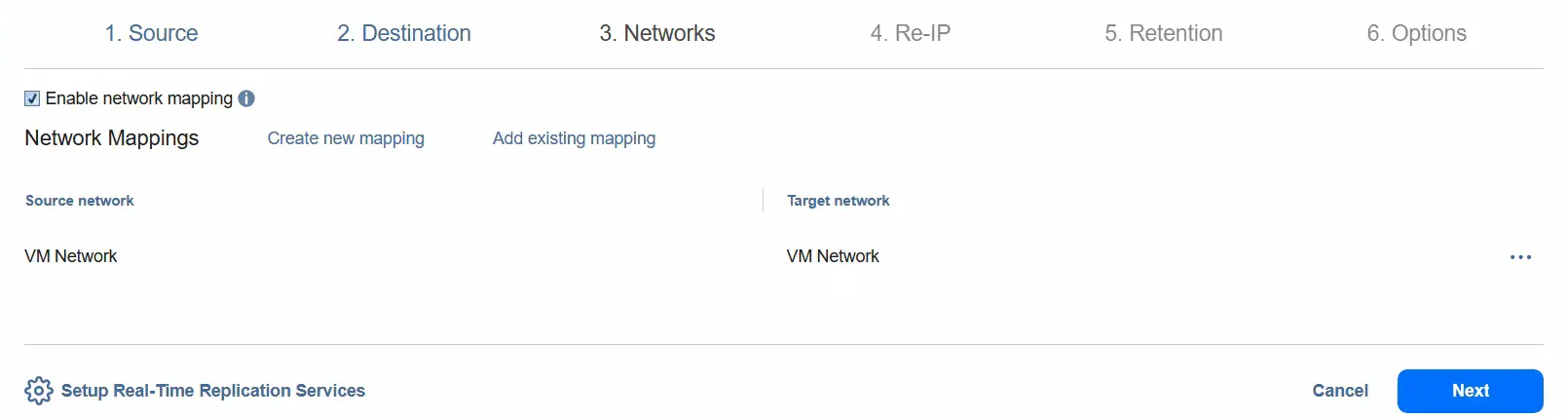
- Możesz włączyć opcję Re-IP, aby zmienić konfigurację adresu IP dla docelowej maszyny wirtualnej.
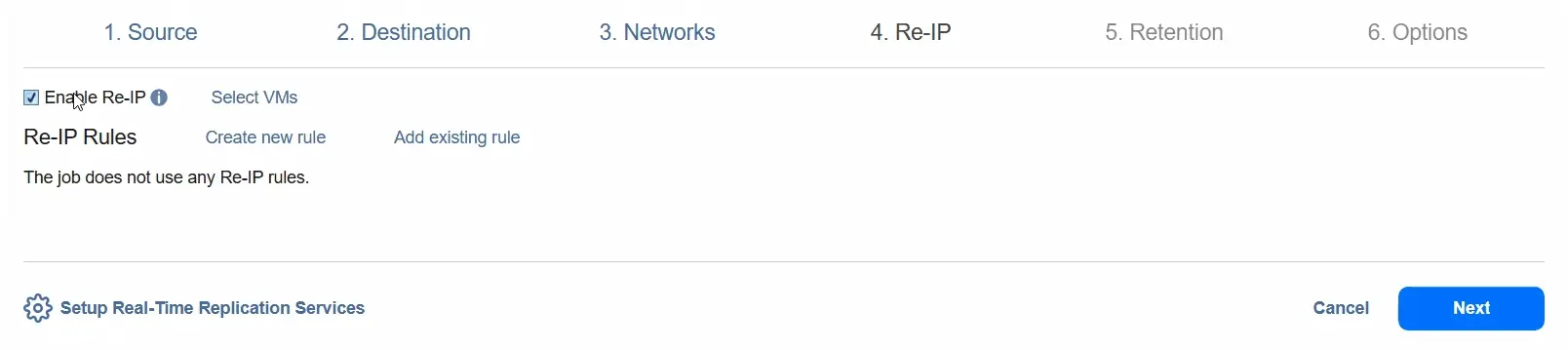
- W kroku
Retentionwybierz cel punktu odzyskiwania (RPO). Domyślnie wynosi on 1 minutę. Możemy zmniejszyć RPO do 1 sekundy lub zwiększyć do 60 minut (jest to wartość maksymalna). Można wybrać opcję „Przerwij replikację maszyny wirtualnej, jeśli RPO przekroczy określony czas”.Można wybrać tryb dziennika:
Roll forward journallubRollback journal.W przypadku opcji
Rollback journalnowe zmiany danych są zapisywane bezpośrednio w replice maszyny wirtualnej, a wszystkie dane w replice są zapisywane w dzienniku. Stare dane w dzienniku są usuwane zgodnie z ustawieniami dziennika.Przy włączonej opcji
Roll forward journalnowe zmiany danych są zapisywane w dzienniku, a stare dane są scalane z repliką zgodnie z ustawieniami dziennika. Na razie pozostawiamy ustawienie bez zmian i używamy opcjiRoll forward journal.Można wybrać opcję
Journal history limit, aby ustawić limit historii dziennika w zakresie od 1 godziny do 30 dni.Opcja
Journal size limitustawia limit rozmiaru dziennika. Wartość może wynosić od 1 gigabajta do 20 terabajtów. Na razie pozostawiamy tę opcję niezaznaczoną i przechodzimy do następnego kroku.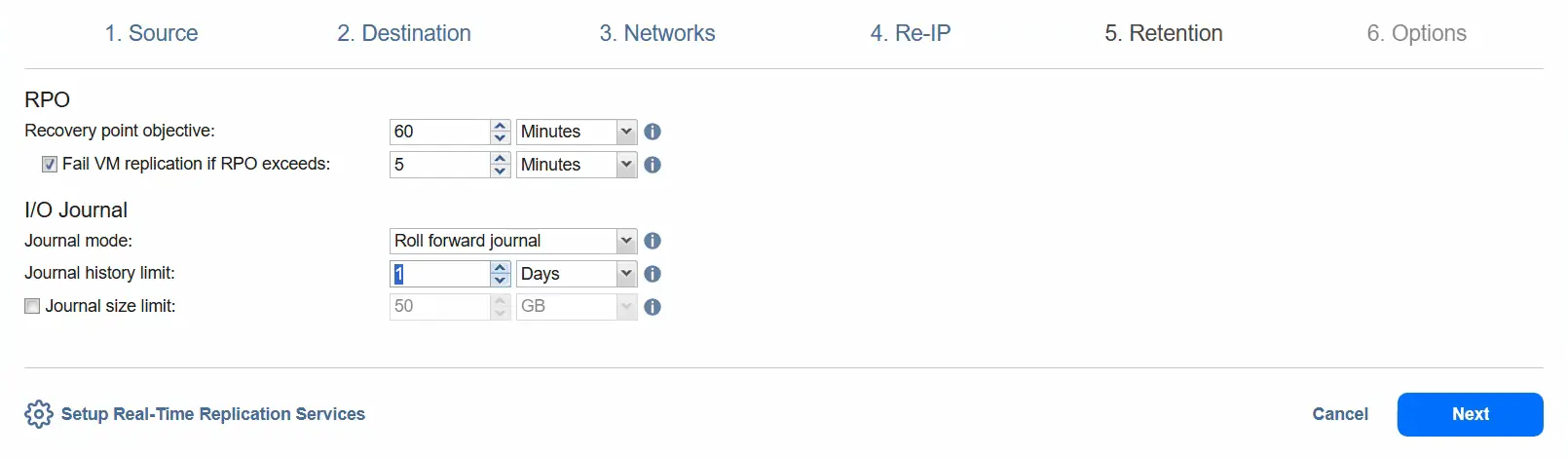
- W kroku
Optionszdefiniuj nazwę zadania dla replikacji w czasie rzeczywistym. W tym przykładzie pozostawiamy nazwę zadania bez zmian, a priorytet zadania ustawiamy na 5 . Możemy włączyć szyfrowanie sieciowe, aby szyfrować ruch między demonem filtru I/O a usługą dziennika przez port 63092. Szyfrowanie wykorzystuje certyfikat na transporcie, który ustanawia bezpieczne połączenie z usługą dziennika.Możemy ograniczyć pojemność magazynu na hoście źródłowym dla każdej maszyny wirtualnej do 10 gigabajtów oraz wykluczyć nieużywane bloki. W przypadku pozostałych opcji możemy zachować wartości domyślne.
Dla hosta źródłowego musimy wybrać transporter źródłowy, którym jest Source VA Transporter. Następnie wybieramy ten sam transporter dla hosta ESXi 24.
Dla hosta docelowego musimy wybrać transporter docelowy, którym jest odpowiedni transporter docelowego urządzenia wirtualnego.
Kliknij
Finish & Run, aby zapisać ustawienia zadania i uruchomić zadanie w czasie rzeczywistym Replikacja VMware . KliknijRun, a następnie kliknijRunponownie, gdy pojawi się komunikat potwierdzający.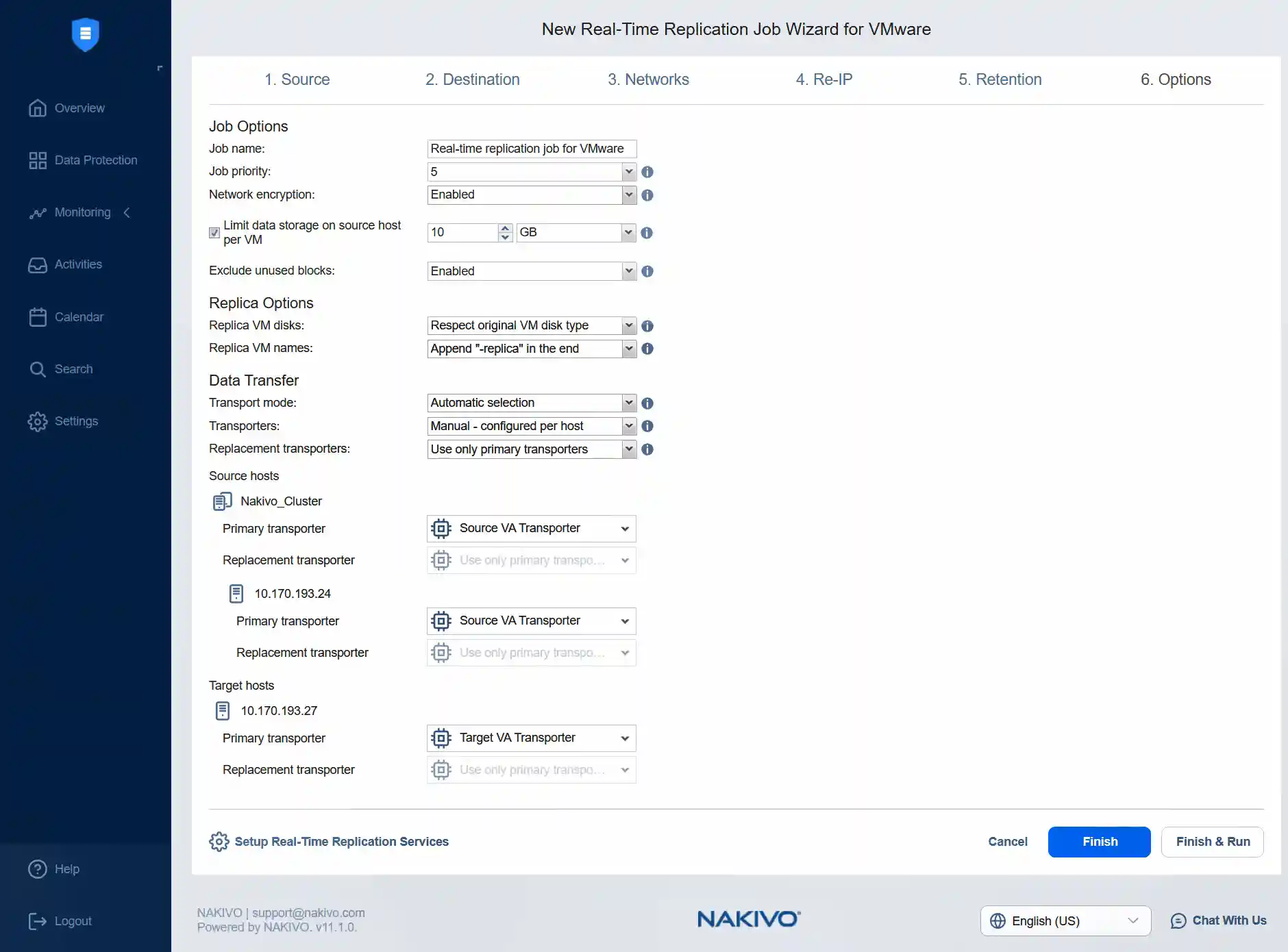
Wnioski
Replikacja danych w czasie rzeczywistym dla maszyn wirtualnych znacznie poprawia ciągłość działania, ograniczając przestoje i zapewniając możliwość jak najszybszego odzyskiwania maszyn wirtualnych. Funkcja ta powinna być stosowana w przypadku najbardziej krytycznych maszyn wirtualnych zawierających najważniejsze dane, podczas gdy tradycyjna replikacja asynchroniczna może być bardziej opłacalna w przypadku danych o mniejszym znaczeniu. Użyj NAKIVO Backup & Replication do replikacji w czasie rzeczywistym i replikacji asynchronicznej maszyn wirtualnych w VMware vSphere.



