Podstawy ochrony danych: Jak wykonać kopię zapasową zasobnika Amazon S3
Amazon S3 to niezawodny magazyn-chmura oferowany przez Amazon Web Services (AWS). Pliki są przechowywane jako obiekty w zasobnikach Amazon S3. Usługa ta jest powszechnie wykorzystywana do przechowywania kopii zapasowych danych ze względu na wysoką niezawodność Amazon S3. W przeciwieństwie do usługi Amazon Elastic Block Storage (EBS), w której dane redundantne są przechowywane w jednej strefie dostępności, w Amazon S3 dane redundantne są rozdzielane między wiele stref dostępności.
Jeśli centrum danych w jednej strefie stanie się niedostępne, można uzyskać dostęp do danych w innej strefie. W niektórych przypadkach może być konieczne wykonanie kopii zapasowej danych przechowywanych w zasobnikach Amazon S3, aby uniknąć utraty danych spowodowanej błędem ludzkim lub awarią oprogramowania. Dane mogą zostać usunięte lub uszkodzone, jeśli użytkownik mający dostęp do zasobnika S3 usunie dane lub uszkodzi je, wprowadzając niepożądane zmiany. Awaria oprogramowania może spowodować podobne skutki.

Przechowywanie wersji obiektów w Amazon S3
Przechowywanie wersji obiektów to skuteczna funkcja usługi Amazon S3, która chroni dane w zasobniku przed uszkodzeniem, wprowadzeniem niepożądanych zmian oraz usunięciem. Gdy wprowadzane są zmiany w pliku (przechowywanym jako obiekt w S3), tworzona jest nowa wersja tego obiektu. W zasobniku przechowywanych jest wiele wersji tego samego obiektu. Możesz uzyskać dostęp do poprzednich wersji obiektu i je przywrócić. Jeśli obiekt zostanie usunięty, zostanie do niego przypisany „znacznik usunięcia”, ale możesz cofnąć tę czynność i otworzyć poprzednią wersję obiektu sprzed usunięcia. Funkcję przechowywania wersji w usłudze Amazon S3 można wykorzystać bez dodatkowego oprogramowania do tworzenia kopii zapasowej S3.
Możesz użyć zasad cyklu życia, aby określić, jak długo wersje powinny być przechowywane w zasobniku S3, tworząc w ten sposób rodzaj kopii zapasowej Amazon S3. Dodatkowe koszty przechowywania kolejnych wersji nie powinny być wysokie, jeśli odpowiednio skonfigurujesz zasady cyklu życia, a nowe wersje zastępują najstarsze. Stare wersje można usunąć lub przenieść do bardziej ekonomicznego magazynu (na przykład do magazynu typu cold storage), aby zoptymalizować koszty.
Jak włączyć przechowywanie wersji w AWS S3
Zaloguj się do konsoli zarządzania AWS, korzystając z konta z odpowiednimi uprawnieniami. Kliknij Services , a następnie wybierz S3 w kategorii Magazyn .
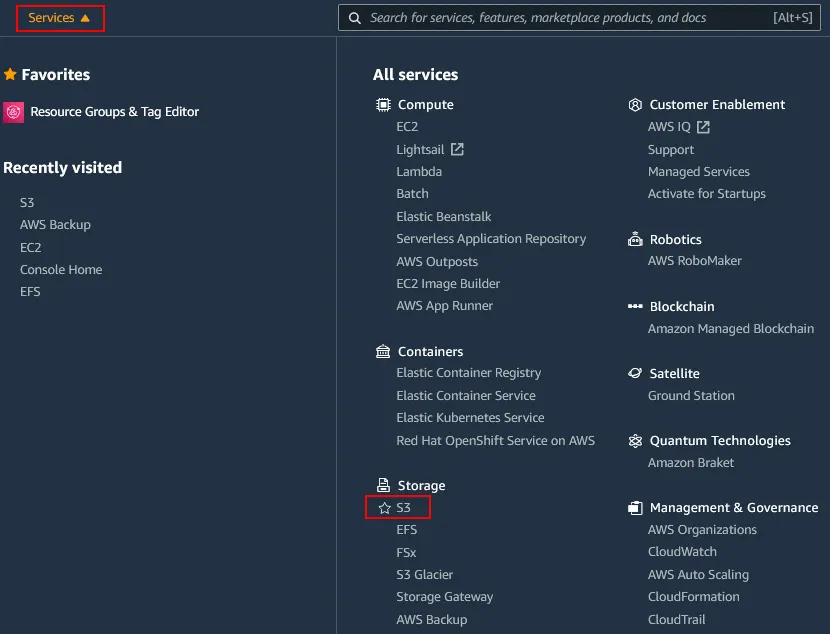
W panelu nawigacyjnym kliknij Buckets i wybierz żądany zasób S3, dla którego chcesz włączyć przechowywanie wersji. W tym przykładzie wybieram zasób o nazwie blog-bucket01 . Kliknij nazwę zasobu, aby otworzyć jego szczegóły.
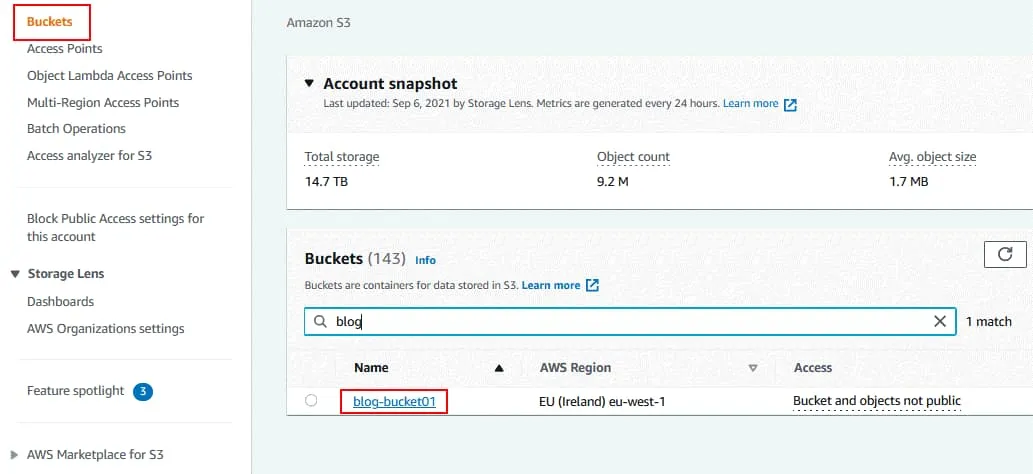
Otwórz kartę Properties dla wybranego zasobu.
W sekcji Bucket Versioning kliknij Edit.
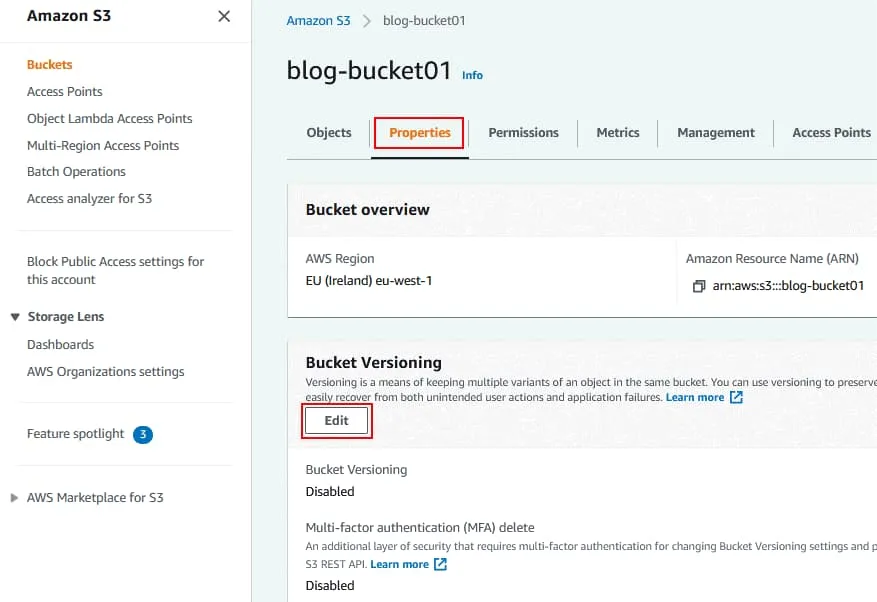
Przechowywanie wersji jest domyślnie wyłączone.
Kliknij Enable , aby włączyć przechowywanie wersji zasobnika.
Kliknij Save Changes.
Wyświetli się wskazówka, że może być konieczna aktualizacja reguł cyklu życia. To jest następny krok.
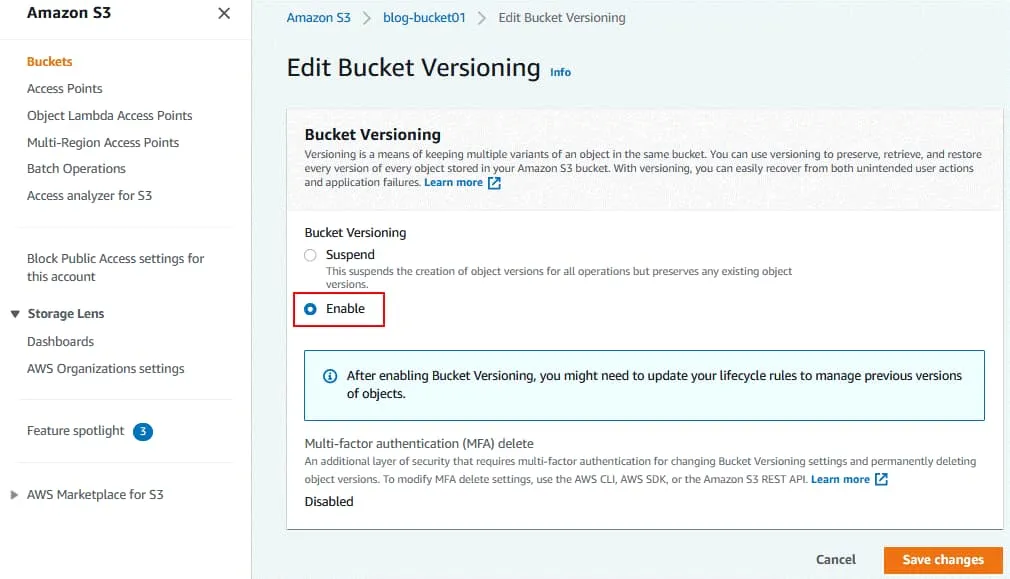
Jeśli zmiany konfiguracji zostały zastosowane, u góry strony wyświetli się komunikat: Pomyślnie edytowano przechowywanie wersji zasobnika .
Reguły cyklu życia
Aby skonfigurować reguły cyklu życia dla przechowywania wersji Amazon S3, przejdź do zakładki Management na stronie wybranego zasobnika. W sekcji Reguły cyklu życia kliknij Create lifecycle rule.
Otworzy się strona Utwórz regułę cyklu życia .
Lifecycle Rule configuration. Wprowadź nazwę reguły cyklu życia, na przykład Cykl życia bloga 01 .
Wybierz zakres reguły. Możesz zastosować filtry, aby zastosować reguły cyklu życia do określonych obiektów lub zastosować regułę do wszystkich obiektów w zasobniku. Zdefiniuj tagi obiektów, aby wskazać obiekty, do których mają być zastosowane działania związane z cyklem życia. Wprowadź klucz i wartość w odpowiednich polach, a następnie kliknij przycisk „ Add tag ”, aby dodać tag, lub przycisk „ Remove ”, aby go usunąć.

Lifecycle rule actions. Wybierz działania, które ma wykonywać ta reguła:
- Przeniesienie aktualnych wersje obiektów między klasami pamięci masowej
- Przeniesienie poprzednich wersje obiektów między klasami pamięci masowej
- Wygaszenie aktualnych wersje obiektów
- Trwałe usunięcie poprzednich wersje obiektów
- Usunięcie wygasłych znaczników usunięcia lub niekompletnych wieloczęściowych przesyłek

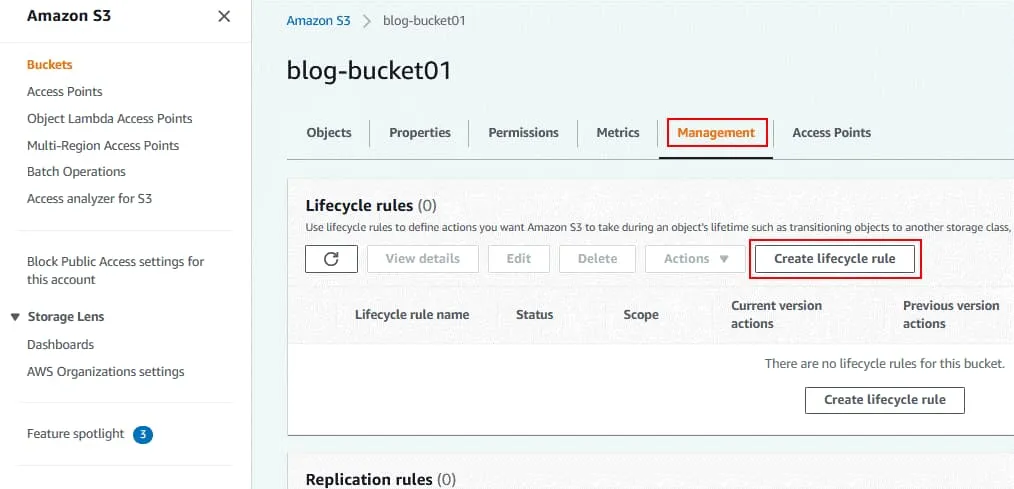
Transition noncurrent versions of objects between storage classes.
Wybierz przejścia między klasami pamięci masowej oraz liczbę dni, po upływie których obiekty przestają być aktualne.
W moim przykładzie obiekty są przenoszone z bieżącej klasy magazynu S3 do Standard-IA po 35 dniach.
Permanently delete previous versions of objects.
Wprowadź liczbę dni, po upływie których poprzednie wersje muszą zostać usunięte. Wartość ta musi być wyższa niż liczba dni, po upływie których obiekty stają się nieaktualne. W moim przykładzie obiekty są trwale usuwane po 40 dniach.
Kliknij Create Rule , aby utworzyć regułę cyklu życia.
Replikowanie zasobnika
Alternatywą dla automatycznej kopii zapasowej usługi Amazon S3 jest replikacja zasobnika między regionami. Należy utworzyć drugi zasobnik, który będzie zasobnikiem docelowym w innym regionie, oraz utworzyć regułę replikacji. Po utworzeniu reguły replikacji wszystkie zmiany wprowadzone w zasobniku źródłowym są automatycznie odzwierciedlane w zasobniku docelowym.
Znajdź sekcję Replication rules w zakładce Zarządzanie dla zasobnika źródłowego i kliknij Create replication rule.
Otworzy się strona Utwórz regułę replikacji .
Wprowadź nazwę reguły replikacji, na przykład Blog S3 bucket replication .
Zdefiniuj status reguły w momencie jej utworzenia (enabled lub disabled).
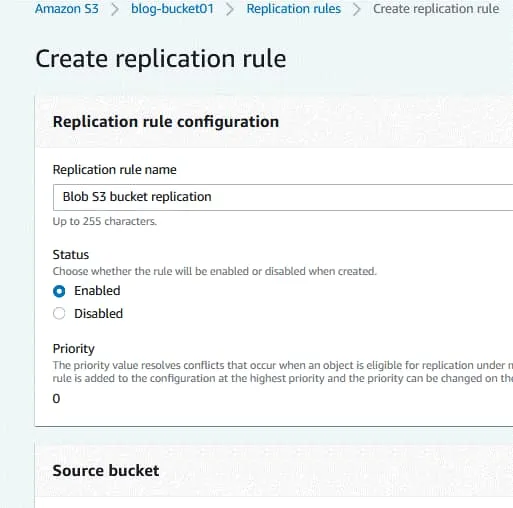
Zbiornik źródłowy. Zbiornik źródłowy został już wybrany ( blog-bucket01 ).
Wybierz zakres reguły. Możesz użyć reguły replikacji dla wszystkich obiektów w zbiorniku lub skonfigurować filtry i zastosować regułę do niestandardowych obiektów.
Miejsce docelowe. Wprowadź nazwę zasobnika docelowego lub kliknij Browse S3 i wybierz zasobnik z listy. Możesz wybrać zasobnik na tym koncie lub na innym koncie. Jeśli przechowywanie wersji AWS S3 jest włączone dla zasobnika źródłowego, przechowywanie wersji obiektów musi być również włączone dla zasobnika docelowego. Wyświetlany jest region docelowy dla wybranego zasobnika docelowego. 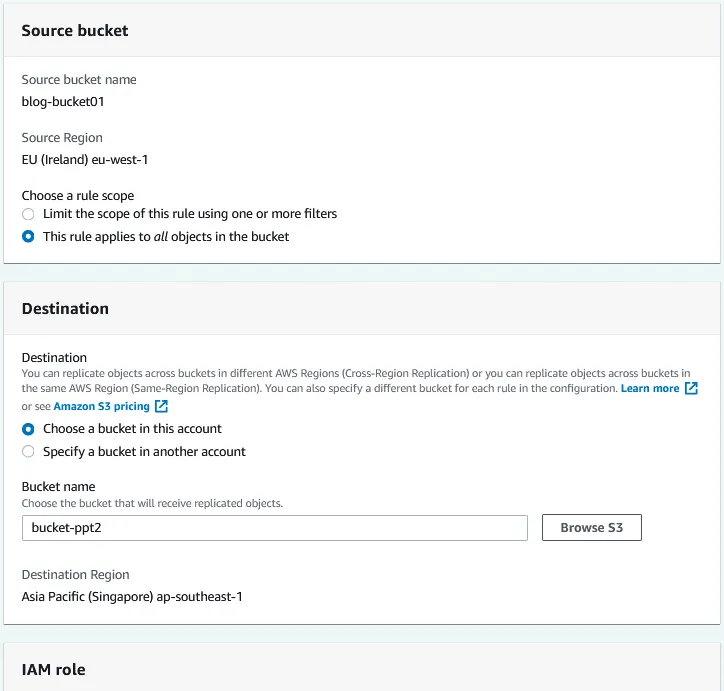
Skonfiguruj rolę w ramach systemu zarządzania tożsamością i dostępem (IAM), a następnie wybierz klasę pamięci masowej oraz dodatkowe opcje replikacji. Kliknij „ Save ”, aby zapisać konfigurację i utworzyć regułę replikacji dla zasobnika.
Kopia zapasowa AWS S3 w interfejsie CLI
AWS CLI to zaawansowany interfejs wiersza poleceń służący do pracy z różnymi usługami Amazon, w tym z Amazon S3. Dostępne jest przydatne polecenie sync, które pozwala wykonać kopię zapasową zasobników Amazon S3 na komputerze z systemem Linux poprzez kopiowanie plików z zasobnika do lokalnego katalogu w systemie Linux działającym na instancji EC2.
Funkcją charakterystyczną polecenia sync w AWS CLI jest to, że pliki w lokalnym systemie plików (miejscu docelowym kopii zapasowej Amazon S3) nie są usuwane, jeśli brakuje ich w źródłowym zasobniku S3 i odwrotnie. Jest to ważne w przypadku wykonywania kopii zapasowej AWS S3, ponieważ jeśli niektóre pliki zostały przypadkowo usunięte z zasobnika S3, istniejące pliki nie zostaną usunięte z lokalnego katalogu komputera z systemem Linux po synchronizacji.
Zalety:
- WSparcie dla dużych zasobników S3 i skalowalność
- Podczas synchronizacji obsługiwane jest wiele wątków
- Możliwość synchronizacji tylko nowych i zaktualizowanych plików
- Wysoka prędkość synchronizacji dzięki inteligentnym algorytmom
Wady:
- System Linux działający na instancji EC2 zużywa przestrzeń dyskową woluminów EBS. Koszty przechowywania danych na woluminach EBS są wyższe niż w przypadku zasobników S3.
W tym samouczku używane są polecenia dla serwera Ubuntu.
Najpierw należy zainstalować AWS CLI.
Zaktualizuj drzewo repozytorii:
sudo apt-get update
Zainstaluj AWS CLI:
sudo apt install awscli
lub
Zainstaluj unzip:
sudo apt install unzip
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip"
unzip awscli-exe-linux-x86_64.zip
sudo ./aws/install
Sprawdź poświadczenia AWS w systemie Linux działającym na instancji EC2.
aws configure list
Dodaj poświadczenia, aby uzyskać dostęp do AWS za pomocą AWS CLI z instancji Linux, jeśli poświadczenia nie zostały jeszcze ustawione:
aws configure
Wprowadź następujące parametry:
AWS Access Key ID
AWS Secret Access Key
Domyślna nazwa regionu
Domyślny format wyjściowy
Utwórz katalog do przechowywania kopii zapasowej do usługi Amazon S3. W moim przykładzie tworzę katalog ~/s3/ do przechowywania kopii zapasowych S3 oraz podkatalog o nazwie identycznej z nazwą zasobnika. Pliki przechowywane w zasobniku S3 powinny zostać skopiowane do tego lokalnego katalogu na komputerze z systemem Linux. ~ to katalog domowy użytkownika, który w moim przypadku to /home/ubuntu .
mkdir -p ~/s3/your_bucket_name
Zastąp your_bucket_name nazwą swojego zasobnika ( blog-bucket01 w naszym przykładzie). mkdir -p ~/s3/blog-bucket01
Zsynchronizuj zawartość zasobnika z lokalnym katalogiem na instancji EC2 z systemem Linux:
aws s3 sync s3:// blog-bucket01 /home/ubuntu/s3/ blog-bucket01/
Jeśli konfiguracja poświadczeń, nazwa zasobnika i ścieżka docelowa są poprawne, dane powinny zacząć się pobierać z zasobnika S3. Czas potrzebny do zakończenia operacji zależy od rozmiaru plików w zasobniku oraz prędkości połączenia internetowego.
Automatyczne tworzenie kopii zapasowych w Amazon S3
Możesz skonfigurować zadania automatycznego tworzenia kopii zapasowych w Amazon S3 za pomocą polecenia sync w AWS CLI. Utwórz plik skryptu sync.sh, aby wykonać kopię zapasową AWS S3 (zsynchronizuj pliki z zasobnika S3 do lokalnego katalogu na instancji systemu Linux), a następnie uruchom ten skrypt zgodnie z harmonogramem.
nano /home/ubuntu/s3/sync.sh
#!/bin/sh
# Display the current date and time
echo '-----------------------------'
date
echo '-----------------------------'
echo ''
# Display the script initialization message
echo 'Syncing remote S3 bucket...'
# Running the sync command
/usr/bin/aws s3 sync s3://{BUCKET_NAME} /home/ubuntu/s3/{BUCKET_NAME}/
# Echo "Script execution is completed"
echo 'Sync complete'
Zastąp {BUCKET_NAME} nazwą zasobnika S3, którego kopię zapasową chcesz wykonać.
Pełna ścieżka do aws (plik binarny AWS CLI) jest zdefiniowana, aby crontab poprawnie uruchamiał aplikację aws w środowisku powłoki używanej przez crontab.
Ustaw skrypt jako wykonywalny:
sudo chmod +x /home/ubuntu/s3/sync.sh
Uruchom skrypt, aby sprawdzić, czy działa:
/home/ubuntu/s3/sync.sh
Edytuj crontab (harmonogram w systemie Linux) bieżącego użytkownika, aby zaplanować uruchamianie skryptu wykonania kopii zapasowej do usługi Amazon S3.
crontab -e
Być może konieczne będzie wybranie edytora tekstu do edycji konfiguracji crontab.
Format crontab do planowania zadań jest następujący:
m h dom mon dow command
Gdzie: m – minuty; h – godziny; dom – dzień miesiąca; dow – dzień tygodnia.
Dodajmy wiersz konfiguracyjny dla zadania, aby synchronizacja była uruchamiana co godzinę, a wyniki kopii zapasowej AWS S3 były zapisywane w pliku dziennika. Dodaj ten wiersz na końcu konfiguracji crontab.
0 * * * * /home/ubuntu/s3/sync.sh > /home/ubuntu/s3/sync.log
Automatyczna kopia zapasowa Amazon S3 została skonfigurowana. Plik dziennika może służyć do sprawdzania wykonania zadań synchronizacji.
Wnioski
Istnieje wiele metod wykonywania kopii zapasowej do usługi Amazon S3, a dwie z nich zostały omówione w tym wpisie na blogu. Można włączyć przechowywanie wersji obiektów dla zasobnika, aby zachować poprzednie wersje obiektów, co pozwala na odzyskanie plików w przypadku wprowadzenia niepożądanych zmian. Replikacja Amazon S3 to kolejne natywne narzędzie służące do tworzenia kopii plików przechowywanych w zasobniku Amazon S3 jako obiekty. W tym przypadku obiekty są replikowane z jednego zasobnika do drugiego. Można również wykonać kopię zapasową zasobnika Amazon S3 za pomocą narzędzia synchronizacji w AWS CLI, które pozwala zsynchronizować pliki w zasobniku z lokalnym katalogiem na komputerze z systemem Linux działającym na instancji EC2. Automatyczne tworzenie kopii zapasowej w usłudze Amazon S3 można zaplanować za pomocą skryptu i crontabu.
Ogólnie rzecz biorąc, magazyn-chmura Amazon S3 jest bardzo niezawodny, a tworzenie kopii zapasowej do usługi Amazon S3 jest powszechną praktyką. Jeśli dysponujesz strategią ochrony danych oraz strategią tworzenia kopii zapasowych w AWS, powinieneś posiadać kopię zapasową. W takim przypadku zaleca się wykonanie kopii zapasowej danych zarówno w usłudze Amazon S3, jak i w innej lokalizacji docelowej. Użyj NAKIVO Backup & Replication, aby chronić swoje dane na maszynach fizycznych i wirtualnych. NAKIVO Backup & Replication to solidne oprogramowanie do tworzenia kopii zapasowych w środowisku wirtualnym, które może być używane do ochrony maszyn wirtualnych, a także instancji Amazon EC2 i maszyn fizycznych.



