Jak zainstalować Kubernetes w systemie Ubuntu
Ręczne wdrażanie kontenerów Docker na wielu serwerach może być bardzo czasochłonne i całkowicie pochłaniać czas administratora systemu odpowiedzialnego za to zadanie. We współczesnej branży IT popularność chmur, mikrousług i kontenerów stale rośnie, dlatego opracowano rozwiązania takie jak Kubernetes.
Kubernetes to otwarte oprogramowanie do zarządzania kontenerami i orkiestracji, które pozwala zbudować klaster ułatwiający wdrażanie kontenerów w środowiskach rozproszonych, a także zapewniający wysoką dostępność aplikacji w kontenerach. Celem tego wpisu na blogu jest omówienie sposobu instalacji Kubernetes na systemie Ubuntu w celu uruchamiania aplikacji w kontenerach Docker.

Wymagania i konfiguracja systemu do instalacji Kubernetes na Ubuntu
Klaster Kubernetes składa się z węzłów głównych i węzłów roboczych. Konfiguracja sprzętowa zależy od potrzeb użytkownika oraz aplikacji, które planuje on uruchamiać w kontenerach Docker. Minimalne wymagania sprzętowe do instalacji Kubernetes na Ubuntu to:
- Co najmniej 2-rdzeniowy Procesor x86/x64 (Central Processor Unit)
- 2 GB pamięci RAM (Random Access Memory) lub więcej
- Dostęp do Internetu
Porty, które muszą być otwarte w celu instalacji Kubernetes na Ubuntu:
| Protokół & zakres portów | Źródło | Cel | Kierunek |
| TCP 443 | Węzły robocze, użytkownicy końcowi, żądania API | Serwer API Kubernetes | Ruch przychodzący do węzła głównego |
| TCP 10250 | Węzły główne | Port sprawdzania stanu Kubelet w węźle roboczym | Ruch przychodzący do węzła roboczego |
| TCP 30000-32767 | Zewnętrzni klienci aplikacji | Domyślny zakres portów do świadczenia usług zewnętrznych | |
| UDP 8285 | Węzły robocze | Backend UDP sieci nakładkowej Flannel | |
| UDP 8472 | Węzły robocze | Backend VXLAN sieci nakładkowej Flannel | |
| TCP 179 | Węzły robocze | Wymagane tylko w przypadku korzystania z sieci Calico BGP | |
| TCP 2379-2380 | Węzły główne | API klienta serwera etcd | Ruch przychodzący do węzła etcd |
| TCP 2379-2380 | Węzły robocze | API klienta serwera etcd wymagane w przypadku korzystania z Flannel lub Calico |
Domyślnie w systemie Ubuntu zainstalowana jest zapora iptables, ale nie ma w niej żadnych gotowych reguł blokujących. Dlatego jeśli instalujesz system Ubuntu, aby wypróbować Kubernetes, nie musisz edytować reguł zapory. Kube-proxy umieszcza najpierw swoje łańcuchy iptables, a następnie wstawia dwie reguły iptables. Są to reguły KUBE-EXTERNAL-SERVICES i KUBE-FIREWALL, które są wstawiane na początku łańcucha INPUT.
Instalacja Kubernetes na Ubuntu może odbywać się zarówno na maszynach fizycznych, jak i wirtualnych. Ogólnym zaleceniem jest użycie najnowszej wersji 64-bitowego systemu Ubuntu Linux. W dzisiejszym wpisie na blogu wyjaśniono, jak zainstalować Kubernetes w systemie Ubuntu 18.04 LTS działającym na maszynach wirtualnych VMware. Pierwszy opisany typ wdrażania Kubernetes obejmuje jeden węzeł główny oraz dwa węzły robocze wykorzystywane w klastrze Kubernetes. W poniższej tabeli przedstawiono liczbę węzłów w zależności od warunków, role węzłów, nazwy hostów oraz adresy IP maszyn użytych w rozpatrywanym przykładzie.
| Nr | Rola węzła | Adres IP | Nazwa hosta |
| 1 | Master | 192.168.101.21 | docker-nakivo21 |
| 2 | Worker | 192.168.101.31 | docker-nakivo31 |
| 3 | Worker | 192.168.101.32 | docker-nakivo32 |
Możesz korzystać z maszyn wirtualnych działających na hostach ESXi, jeśli używasz VMware vSphere, lub możesz uruchamiać maszyny wirtualne na VMware stacji roboczej zainstalowanej na komputerze osobistym z systemem Linux lub Windows. W dzisiejszym przykładzie używamy maszyn wirtualnych działających na VMware Stacji Roboczej. Maszyny wirtualne korzystają z sieci NAT sieć z dostępem do Internetu, a jeśli wolisz VirtualBox od VMware, możesz z niej skorzystać.
Adres IP maszyny hosta: 10.10.10.53
Adres IP wirtualnej bramy dla sieci NAT (VMNet8): 192.168.101.2
Ten sam użytkownik systemu Linux istnieje na wszystkich maszynach z systemem Ubuntu: kubernetes-user
Konfiguracja maszyny wirtualnej: 2 procesory, 4 GB pamięci RAM, dysk wirtualny o pojemności 20 GB
Adresy IP sieci VMnet8 można zmienić, przechodząc do Edit > Virtual Network Editor w programie VMware stacja robocza.
Aby ułatwić zrozumienie, w dzisiejszym przykładzie wszystkie komponenty zostaną zainstalowane w systemie Linux ręcznie, bez użycia narzędzi do automatyzacji, takich jak Ansible.
Wdrażanie maszyny wirtualnej z systemem Ubuntu
Utwórz nową maszynę wirtualną o nazwie docker-nakivo21 .
Zainstaluj 64-bitową wersję systemu Ubuntu na pierwszej maszynie i ustaw nazwę hosta oraz nazwę użytkownika.
Nazwa maszyny wirtualnej: docker-nakivo21
Nazwa użytkownika: kubernetes-user

Zainstaluj VMware Tools po pierwszym zalogowaniu się do zainstalowanego systemu operacyjnego. Jeśli korzystasz z maszyn fizycznych, nie musisz używać VMware Tools i możesz pominąć ten krok.
Uwaga : Znak $ na początku oznacza, że polecenie jest uruchamiane jako zwykły użytkownik ( kubernetes-user w tym przypadku). Jeśli ciąg znaków zaczyna się od znaku # , polecenie musi zostać wykonane jako użytkownik główny . Polecenie `sudo` (wystarczy wpisać `sudo` lub ` sudo -i `, w zależności od tego, czy chcesz działać jako zwykły użytkownik, czy jako superużytkownik) pozwala na wykonywanie poleceń w imieniu innego użytkownika, w tym użytkownika root. Aby uzyskać uprawnienia root w konsoli, wpisz ` sudo apt-get install open-vm-tools `. Naciśnij klawisze Ctrl+D, aby wyjść z trybu root.
Narzędzia VMware Tools można zainstalować z obrazu ISO dostarczonego wraz z hiperwizorem VMware lub z repozytoriów systemu Linux (jak wyjaśniono poniżej).
$&
Jeśli potrzebujesz zaawansowanych funkcji pulpitu, takich jak wspólny schowek, przeciąganie i upuszczanie plików itp., uruchom:
$ sudo apt-get install open-vm-tools-desktop
Uruchom ponownie maszynę wirtualną.
$ init 6
Skonfiguruj maszynę z systemem Ubuntu przed instalacją Kubernetes
Przed instalacją Kubernetes na maszynach z systemem Ubuntu należy wykonać pewne przygotowania. Przede wszystkim należy skonfigurować statyczny adres IP i nazwę hosta dla każdego zwykłego serwera.
Ustaw statyczny adres IP
Podobnie jak w przypadku każdego innego typu klastra, zdecydowanie zaleca się stosowanie statycznych adresów IP na węzłach.
Przed ustawieniem adresu IP zainstaluj narzędzia sieciowe systemu Linux.
$ sudo apt-get install net-tools
Wpisz ifconfig , aby sprawdzić aktualny adres IP maszyny wirtualnej z systemem Ubuntu.
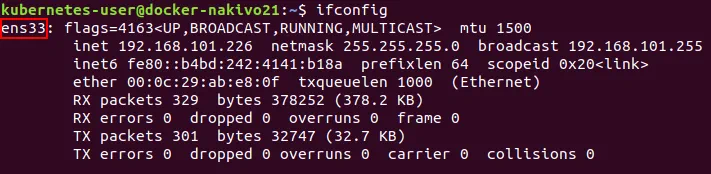
Można zauważyć, że adres IP jest uzyskiwany automatycznie za pośrednictwem protokołu DHCP. Zapamiętaj nazwę interfejsu sieciowego. W obecnym przykładzie nazwa ta to ens33 . Nazwa pierwszego interfejsu sieciowego Ethernet to zazwyczaj eth0 w przypadku maszyn fizycznych.
Do edycji plików konfiguracyjnych potrzebny jest edytor tekstu. Zainstaluj vim jako edytor tekstu.
$ sudo apt-get install vim
W najnowszych wersjach Ubuntu konfiguracja sieci jest ustawiana w pliku yaml. Otwórz plik yaml konfiguracji sieci w vim.
$ sudo vim /etc/netplan/01-network-manager-all.yaml
Domyślny widok pliku konfiguracyjnego to:

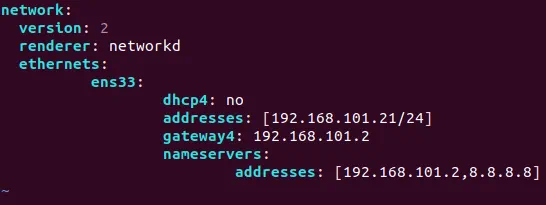
Edytuj ten plik konfiguracji sieci zgodnie z poniższym przykładem:
network:
version: 2
renderer: networkd
ethernets:
ens33:
dhcp4: no
addresses: [192.168.101.21/24]
gateway4: 192.168.101.2
nameservers:
addresses: [192.168.101.2,8.8.8.8]
Zapisz zmiany i zamknij plik.
:wq
$ sudo netplan try
Naciśnij klawisz ENTER, aby zaakceptować nową konfigurację.
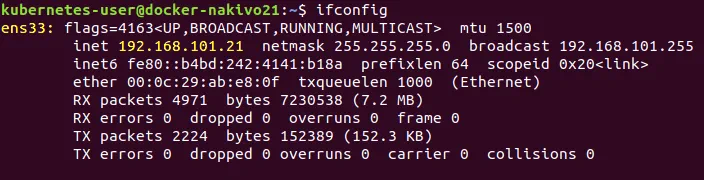
Sprawdź, czy konfiguracja sieci została zmieniona i spróbuj wykonać polecenie ping, na przykład do adresów: nakivo.com .
$ ifconfig
$ ping nakivo.com
Skonfiguruj nazwę hosta
Sprawdź aktualną nazwę hosta.
$ hostnamectl
Jak zapewne pamiętasz, nazwa hosta dla pierwszej maszyny wirtualnej, czyli docker-nakivo21 została już skonfigurowana podczas instalacji. Aby zmienić nazwę hosta, wykonaj następujące czynności (będzie to potrzebne do skonfigurowania drugiej i trzeciej maszyny wirtualnej po klonowaniu. Te dwie maszyny wirtualne mają być skonfigurowane jako węzły robocze):
Na przykład, jeśli chcesz zmienić nazwę hosta na docker-nakivo21 na pierwszej maszynie wirtualnej, uruchom: $ sudo hostnamectl set-hostname docker-nakivo21
Sprawdź, czy nowa nazwa hosta została zastosowana.
$ less /etc/hostname
Edytuj plik hosts .
$ sudo vim /etc/hosts
Zawartość pliku hosts musi wyglądać następująco:
127.0.0.1 localhost
127.0.1.1 docker-nakivo21
Uruchom ponownie maszynę.
$ init 6
Wyłącz plik wymiany
Korzystanie z pliku wymiany (partycji swap) nie jest obsługiwane przez Kubernetes, a wyłączenie swappiness jest konieczne do pomyślnej instalacji Kubernetes na Ubuntu.
Wyłącz plik wymiany, aby zapobiec wysokiemu zużyciu procesora przez kubelet.
$ sudo swapoff -a
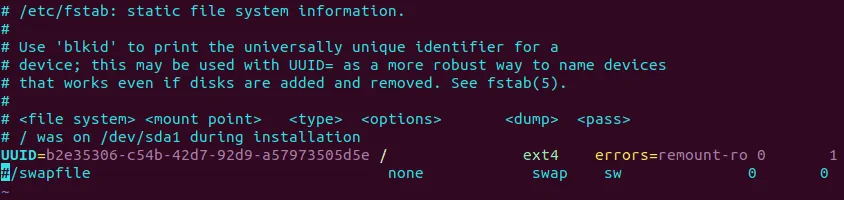
Edytuj /etc/fstab i skomentuj ciąg znaków za pomocą znaku # .
$ sudo vim /etc/fstab
#/swapfile none swap sw 0 0
Możesz zrobić to samo za pomocą sed za pomocą jednego polecenia:
$ sudo sed -i '/ swap / s/^(.*)$/#1/g' /etc/fstab
Wyłącz swap w sysctl.conf
$ sudo echo "vm.swappiness=0" | sudo tee --append /etc/sysctl.conf
Gdzie 0 to procent swapiness. W tym przypadku swap może być używany tylko wtedy, gdy zabraknie pamięci RAM (domyślnie swap jest używany, gdy ponad 60% pamięci RAM jest zapełnione).
Zastosuj zmiany konfiguracji bez restartu.
$ sudo sysctl -p
Uwaga : Jeśli partycja swap nie jest wyłączona, proces kswapd0 w systemie Ubuntu Linux z uruchomionym Kubernetes może zużywać duże ilości zasobów procesora na Twoim komputerze, powodując brak reakcji aplikacji i zawieszanie się systemu. Dzieje się tak, gdy systemowi operacyjnemu zabraknie pamięci, a stare strony pamięci są przenoszone do partycji swap przez proces systemowy jądra Linux. Z dziwnych powodów czasami coś idzie nie tak i pojawia się niekończąca się pętla, która zużywa wszystkie zasoby procesora. Na poniższym zrzucie ekranu widać wysokie zużycie procesora przez proces kswapd0 gdy Kubernetes jest zainstalowany na Ubuntu. Średnia wartość obciążenia jest nadmiernie wysoka.
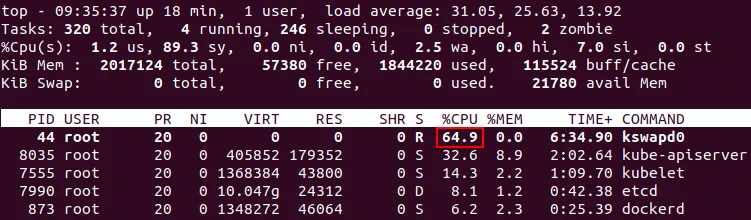
Jeśli kswapd0 nadal przeciąża Procesor, uruchom następujące polecenie, aby unieważnić wszystkie pamięci podręczne i zatrzymać kswapd0 (wykonaj jako root).
# echo 1 > /proc/sys/vm/drop_caches
Wyłącz maszynę wirtualną.
$ init 0
Ta częściowo skonfigurowana maszyna wirtualna ( docker-nakivo21 ) ma zostać użyta jako węzeł główny. Utwórz dwie maszyny, które będą służyć jako węzły robocze. Jeśli korzystasz z maszyn fizycznych, powtórz poprzednie kroki ręcznie (lub użyj narzędzi do automatyzacji, takich jak Ansible, do jednoczesnej konfiguracji wielu maszyn z systemem Linux przez SSH). Ponieważ w tym przykładzie używane są maszyny wirtualne, można je sklonować, aby zaoszczędzić czas podczas przygotowywania środowiska do instalacji Kubernetes na maszynach z systemem Ubuntu.
Sklonuj maszynę wirtualną
Sklonuj swoją pierwszą maszynę wirtualną. Jeśli korzystasz z VMware ESXi, możesz użyć wbudowanej funkcji klonowania. Więcej informacji na ten temat znajdziesz w naszym wpisie na blogu pod adresem klonowanie maszyn wirtualnych przy użyciu szablonów maszyn wirtualnych. Jeśli korzystasz z programu VMware Station, możesz również klonować maszyny wirtualne na dwa sposoby (za pomocą wbudowanego narzędzia do klonowania lub ręcznie). Kliknij VM > Manage > Clone , aby utworzyć klon powiązany. Stwórzmy pełny klon pierwszej maszyny wirtualnej i ręcznie skopiujmy pliki maszyny wirtualnej. W tym przypadku pliki są kopiowane z katalogu docker-nakivo21 do katalogu docker-nakivo31. Katalogi należy utworzyć ręcznie przed skopiowaniem plików maszyny wirtualnej.
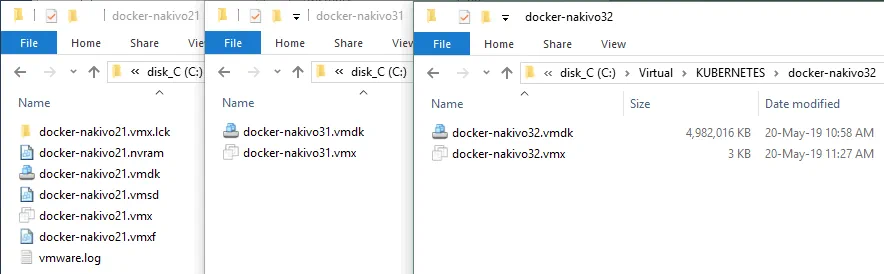
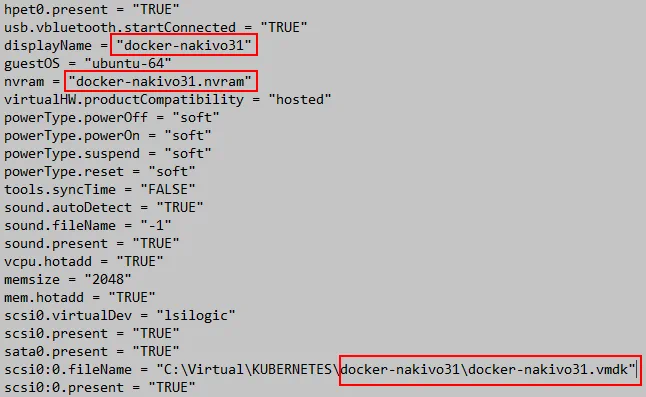
Edytuj plik VMX, ponieważ nazwa maszyny wirtualnej i ścieżka do pliku dysku wirtualnego uległy zmianie.
displayName = "docker-nakivo31"
scsi0:0.fileName = "C:VirtualKUBERNETESdocker-nakivo31docker-nakivo31.vmdk"
nvram = "docker-nakivo31.nvram"
Maszyna wirtualna, która będzie używana jako pierwszy węzeł roboczy, została utworzona. Sklonuj pierwszą maszynę wirtualną jeszcze raz, aby przygotować drugi węzeł roboczy klastra Kubernetes.
Edytuj plik VMX trzeciej maszyny wirtualnej (drugiego węzła roboczego), tak jak to zrobiłeś wcześniej.
displayName = "docker-nakivo32"
scsi0:0.fileName = "C:VirtualKUBERNETESdocker-nakivo31docker-nakivo32.vmdk"
nvram = "docker-nakivo32.nvram"
Otwórz klony maszyn wirtualnych w stacji roboczej VMware (File> Open i wybierz plik VMX maszyny wirtualnej) lub po prostu kliknij dwukrotnie plik VMX maszyny wirtualnej. Włącz trzy maszyny wirtualne (jedną maszynę źródłową i dwa klony). Kliknij I Copied It , gdy pojawi się monit.
Uwaga : Jeśli korzystasz z maszyn wirtualnych, edytuj adres IP i nazwę hosta na każdym klonie maszyny wirtualnej po sklonowaniu maszyn. Jeśli korzystasz z maszyn fizycznych, wykonaj wszystkie poprzednie kroki zgodnie z adresami IP i nazwami hostów dla każdej maszyny.
Konfigurowanie adresów IP i nazw hostów na maszynach wirtualnych
Zmień adres IP i nazwę hosta na docker-nakivo31 oraz docker-nakivo32 maszynach wirtualnych (jak pokazano powyżej).
Powtórz kroki opisane w powyższych sekcjach, aby skonfigurować statyczne adresy IP i nazwy hostów.
Adres IP musi brzmieć: 192.168.101.31 oraz 192.168.101.32 ; nazwy hostów muszą brzmieć odpowiednio docker-nakivo31 oraz docker-nakivo32 na węzłach roboczych.
Wszystkie maszyny muszą być skonfigurowane do rozpoznawania nazw hostów węzłów na adresy IP. Można skonfigurować serwer DNS lub ręcznie przeprowadzić edycję pliku hosts na każdej maszynie. Edytujmy plik hosts .
Dodaj następujące ciągi do pliku hosts na każdej maszynie ( docker-nakivo21 , docker-nakivo31 , docker-nakivo32 ).
$ sudo vim /etc/hosts
Dodaj te linie do pliku hosts :
192.168.101.21 docker-nakivo21
192.168.101.31 docker-nakivo31
192.168.101.32 docker-nakivo32

Wykonaj polecenie ping na inne hosty z każdego hosta, aby upewnić się, że nazwy hostów są rozpoznawane: $ ping docker-nakivo21
$ ping docker-nakivo31
$ ping docker-nakivo32
Konfiguracja dostępu SSH na wszystkich hostach (maszynach wirtualnych)
Skonfiguruj dostęp SSH na wszystkich hostach. Zainstaluj serwer OpenSSH, wykonując polecenia na każdej maszynie.
$ sudo apt-get install openssh-server
Przejdź do katalogu domowego kubernetes-user i wygeneruj parę kluczy SSH (zestaw kluczy kryptograficznych składający się z klucza prywatnego i klucza publicznego). Pary kluczy SSH mogą być używane do uzyskania dostępu do zdalnej konsoli Linuxa przez SSH bez użycia haseł. Klucz publiczny można skopiować na maszynę, z której chcesz się połączyć zdalnie, podczas gdy klucz prywatny jest ściśle tajny i musi być przechowywany na maszynie, z którą chcesz się połączyć.
$ ssh-keygen
Nie ma potrzeby wprowadzania hasła do generowania klucza (hasło jest opcjonalne).
Skopiuj klucze na inne maszyny z systemem Ubuntu:
$ ssh-copy-id kubernetes-user@192.168.101.31
$ ssh-copy-id kubernetes-user@192.168.101.32
Wprowadź hasło użytkownika, aby potwierdzić kopiowanie kluczy.
Spróbuj połączyć się z drugą maszyną ( docker-nakivo31 ) jako kubernetes-user (czyli zwykły użytkownik).
$ ssh 'kubernetes-user@192.168.101.31'
Następnie przetestuj połączenie z trzecią maszyną ( docker-nakivo32 ).
$ ssh 'kubernetes-user@192.168.101.32'
Po pomyślnym nawiązaniu połączenia w wierszu poleceń konsoli pojawi się nazwa maszyny zdalnej.

Naciśnij Ctrl+D, aby wyjść z konsoli zdalnej.
Jak skopiować klucz do łączenia się przez SSH jako użytkownik główny?
Ponieważ w Kubernetes będziesz potrzebować uprawnień użytkownika głównego, utwórzmy klucze do konfiguracji dostępu SSH dla użytkownika głównego. Wykonaj następujące polecenia na wszystkich maszynach (docker-nakivo21, docker-nakivo31 i docker-nakivo32), do których dostęp przez SSH jest wymagany jako użytkownik główny.
$ sudo -i
Edytuj plik konfiguracyjny serwera SSH.
# vim /etc/ssh/sshd_config
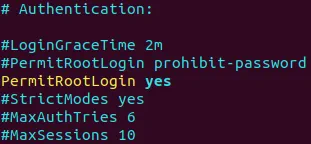
Dodaj/edytuj następujący ciąg znaków w tym pliku.
PermitRootLogin yes
Uruchom ponownie demona serwera SSH.
# /etc/init.d/ssh stop
# /etc/init.d/ssh start
Ustaw hasło root (hasło dla użytkownika głównego).
# passwd
$ cd /home/kubernetes-user/
$ sudo ssh-keygen -t rsa
Skopiuj klucz publiczny, aby móc logować się zdalnie przez SSH jako użytkownik główny (klucz jest przechowywany w katalogu domowym zwykłego użytkownika, ponieważ poprzednie polecenie zostało uruchomione z tego katalogu).
$ sudo ssh-copy-id -i /home/kubernetes-user/.ssh/id_rsa.pub 127.0.0.1
Jeśli klucz jest zapisany w katalogu domowym użytkownika głównego, skopiuj go za pomocą tego polecenia:
# ssh-copy-id -i /root/.ssh/id_rsa.pub 127.0.0.1
Potwierdź tę operację i wprowadź hasło.
Powtórz tę czynność, kopiując klucz z każdej maszyny na pozostałe. Na przykład na maszynie docker-nakivo21 wykonaj:
# ssh-copy-id -i /root/.ssh/id_rsa.pub 192.168.101.31
# ssh-copy-id -i /root/.ssh/id_rsa.pub 192.168.101.32
Autoryzuj klucz publiczny.
# cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys
Sprawdź, czy możesz zalogować się jako użytkownik główny przez SSH na maszynie lokalnej. $ sudo ssh root@127.0.0.1
Spróbuj nawiązać połączenie z/do zdalnej maszyny bez podawania hasła.
$ sudo ssh root@192.168.101.21
$ sudo ssh root@192.168.101.31
$ sudo ssh root@192.168.101.32
Uwaga : Łączenie się jako użytkownik główny może być niebezpieczne. Nie łącz się jako użytkownik główny, jeśli nie jest to konieczne — lepiej połączyć się przez SSH jako zwykły użytkownik i użyć polecenia sudo .
Instalacja Docker
Docker to najpopularniejsza platforma kontenerowa dla aplikacji Enterprise obsługiwana przez Kubernetes. Zainstaluj Docker na wszystkich maszynach. Wykonaj poniższe polecenia na docker-nakivo21 , docker-nakivo31 , docker-nakivo32 .
Nie ma jednak potrzeby się spieszyć. Na początek możesz po prostu zainstalować Docker, używając standardowego polecenia:
$ sudo apt-get install -y docker.io
Jednak w tym przypadku używana wersja Docker może nie być najnowsza. Naprawmy to, instalując najnowszą wersję Docker.
Najpierw zainstaluj wymagane pakiety.
$ sudo apt-get install apt-transport-https ca-certificates curl software-properties-common
Curl to uniwersalne, kompaktowe narzędzie zaprojektowane do przesyłania danych z/do hosta bez interakcji użytkownika przy użyciu jednego z obsługiwanych protokołów (HTTP, HTTPS, FTP, FTPS, SFTP, LDAP, LDAPS, IMAP, IMAPS, POP3, POP3S, SCP, SMB, SMTP, TELNET itp.).
Dodaj klucz GPG dla oficjalnego repozytorium Docker do swojego systemu Ubuntu:
$ curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
Wynik na konsoli powinien wyglądać następująco: OK.
Dodaj oficjalne repozytorium Docker do swojego menedżera pakietów apt:
$ sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu bionic stable"
Zaktualizuj bazę danych menedżera pakietów po wprowadzeniu ręcznych zmian za pomocą poprzedniego polecenia.
$ sudo apt-get update
Sprawdź wersję pakietu Docker dostępnego w oficjalnym repozytorium.
$ apt-cache policy docker-ce
Zainstaluj Docker.
$ sudo apt-get install docker-ce
Po instalacji możesz sprawdzić wersję Docker.
$ docker --version
W tym przypadku wynik to: Docker wersja 18.09.6, kompilacja 481bc77 .
Uruchom Docker i ustaw jego demona tak, aby ładował się automatycznie przy starcie systemu.
$ sudo systemctl start docker
$ sudo systemctl enable docker
Po zainstalowaniu Dockera na wszystkich maszynach możesz przejść bezpośrednio do etapu instalacji Kubernetes na Ubuntu.
Instalacja Kubernetes na Ubuntu i inicjalizacja klastra
Teraz nic nie stoi na przeszkodzie, aby zainstalować podstawowe komponenty Kubernetes.
Uruchom polecenia jako root na wszystkich maszynach, które mają zostać włączone do klastra Kubernetes.
$ sudo -i
Dodaj klucz GPG dla oficjalnego repozytorium Docker do systemu Ubuntu:
# curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add -
Dodaj oficjalne repozytorium Kubernetes do bazy dostępnych repozytoriów pakietów dla menedżera pakietów apt.
# cat <
deb http://apt.kubernetes.io/ kubernetes-xenial main
EOF
Alternatywnie możesz dodać repozytorium za pomocą tego polecenia: # echo 'deb http://apt.kubernetes.io/ kubernetes-xenial main' | sudo tee /etc/apt/sources.list.d/kubernetes.list
Gdzie tee to narzędzie, które odczytuje dane ze standardowego wejścia i zapisuje je na standardowym wyjściu oraz w określonych plikach.
Zaktualizuj listę pakietów dostępnych w repozytoriach w systemie Ubuntu.
# apt-get update

Zainstalowanie kubectl , kubeadm oraz kubectl ma kluczowe znaczenie dla instalacji Kubernetes na Ubuntu.
# apt-get install -y kubelet kubeadm kubectl
Zainstaluj keepalived.
# apt-get install keepalived
# systemctl enable keepalived && systemctl start keepalived
Sprawdź, czy wartość wynosi 1 dla prawidłowego działania Kubernetes zainstalowanego na Ubuntu.
# sysctl net.bridge.bridge-nf-call-iptables
Aby ustawić tę wartość na 1 uruchom polecenie:
sysctl net.bridge.bridge-nf-call-iptables=1
Edytuj plik konfiguracyjny kubeadm.
# vim /etc/systemd/system/kubelet.service.d/10-kubeadm.conf
Dodaj ciąg znaków po istniejącym ciągu Environment:
Environment=”cgroup-driver=systemd/cgroup-driver=cgroupfs”
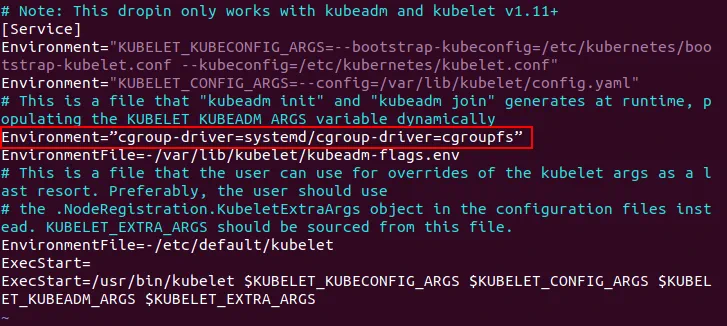
Cgroups to grupy kontrolne, które izolują wykorzystanie zasobów, takich jak procesor, pamięć, wejście/wyjście dysku, sieć.
Na węźle głównym ( docker-nakivo21 ) uruchom polecenie, aby zainicjować klaster Kubernetes w systemie Ubuntu.
# kubeadm init --pod-network-cidr=10.244.0.0/16 --apiserver-advertise-address=192.168.101.21
Gdzie
–pod-network-cidr jest wymagane przez sterownik Flannel. CIDR (Classless Inter-Domain Routing) definiuje adres sieci nakładkowej (takiej jak Flannel), która zostanie skonfigurowana później. Maska sieciowa określa również, ile podów może działać na jednym węźle. Adres sieciowy CIDR i adres sieciowy używany dla Flannel muszą być takie same.
–apiserver-advertise-address=192.168.101.21 określa adres IP, który będzie ogłaszany przez Kubernetes jako jego serwer API.

Przeczytaj wynik i zapisz polecenia wyświetlone na końcu tekstu. To ważna kwestia. Wygenerowany token jest wymagany do dodania węzłów roboczych do klastra Kubernetes.
Uruchom poniższe polecenia jako użytkownik, który uruchomił kubeadm init. W tym przypadku polecenia są wykonywane jako użytkownik główny.
# mkdir -p $HOME/.kube
# sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
# sudo chown $(id -u):$(id -g) $HOME/.kube/config
Jeśli nie uruchomisz tych poleceń, Kubernetes zwróci błąd: Połączenie z serwerem localhost:8080 zostało odrzucone — czy podałeś właściwy host lub port?
Kubernetes nie kopiuje automatycznie tego pliku konfiguracyjnego do katalogu użytkownika. Należy wykonać tę operację ręcznie.

Sprawdź węzły dodane do klastra
# kubectl get nodes

W klastrze Kubernetes instalowanym na Ubuntu widać jeden węzeł główny, który ma status NotReady . Wynika to z faktu, że sieć nakładkowa nie została skonfigurowana. Skonfiguruj Flannel, aby naprawić status NotReady węzła głównego Kubernetes. Utwórz katalog do przechowywania plików YAML dla Docker i Kubernetes, na przykład /home/kubernetes-user/kubernetes/
Język YAML (Yet Another Markup Language) zapewnia większą wygodę podczas tworzenia podów i wdrażania w Kubernetes. Wszystkie parametry kontenerów, które mają zostać wdrożone, można zdefiniować w pliku konfiguracyjnym YAML zamiast ręcznie uruchamiać każde polecenie w konsoli Linuksa. Pliki YAML są również nazywane plikami manifestowymi w kontekście Kubernetes.
Utwórz plik konfiguracyjny YAML o następującej treści:
Uruchom polecenie
# kubectl apply -f ./kube-flannel.yml
Alternatywnie możesz znaleźć gotowe, bezpłatne przykłady konfiguracji wdrażania YAML dla Kubernetes na GitHubie.
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/a70459be0084506e4ec919aa1c114638878db11b/Documentation/kube-flannel.yml
Sprawdź węzły dodane do klastra Kubernetes, który wdrażasz na Ubuntu:
# kubectl get nodes
Status węzła głównego to teraz Ready.

Upewnij się, że Flannel został poprawnie skonfigurowany:
# kubectl get pods --all-namespaces

Możesz zobaczyć, że pod Flannel działa. Ten pod składa się z dwóch kontenerów – demona Flannel oraz initContainer używanego do wdrażania konfiguracji CNI w lokalizacji dostępnej dla Kubernetes.
Czasami podczas instalacji Kubernetes na Ubuntu może wystąpić następujący błąd:
Nie można połączyć się z serwerem: net/http: przekroczono limit czasu uzgadniania TLS.
Jak można rozwiązać ten problem? Poczekaj kilka sekund i spróbuj ponownie — często to wystarczy.
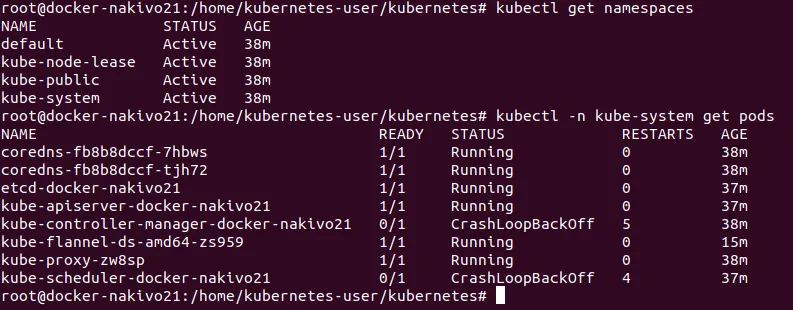
Przestrzenie nazw to logiczne jednostki w klastrze Kubernetes, które reprezentują zasoby klastra i mogą być traktowane jako wirtualne klastry. Jeden fizyczny klaster można logicznie podzielić na wiele wirtualnych klastrów. Domyślne przestrzenie nazw Kubernetes to Default , Kube-public oraz Kube-system . Możesz uzyskać listę przestrzeni nazw:
# kubectl get namespaces
Jak pamiętasz, podstawową jednostką wdrażania w Kubernetes jest pod, czyli zbiór kontenerów, które współdzielą przestrzeń nazw sieciową i montowania. Wszystkie kontenery w podzie są planowane na tym samym węźle Kubernetes. Sprawdź dostępne pody:
# kubectl -n kube-system get pods
Jeśli chcesz zresetować/zatrzymać klaster, uruchom:
# kubeadm reset
Na węźle głównym wszystko jest w porządku. Oznacza to, że możesz teraz kontynuować instalację Kubernetes na Ubuntu i przejść do dodawania węzłów roboczych do klastra.
Na węzłach roboczych ( docker-nakivo31 , docker-nakivo32 ) uruchom polecenie:
# kubeadm join 192.168.101.21:6443 --token d8mbzb.uulxu01jbty8yh4z
--discovery-token-ca-cert-hash sha256:65ace7a4ff6fff795abf086f18d5f0d97da71d4639a0d0a6b93f42bea4948a79
Token i hash zostały zanotowane po inicjalizacji klastra za pomocą polecenia kubeadm init , jak być może pamiętasz.
Na węźle głównym sprawdź ponownie status klastra. # kubectl get nodes

Teraz w klastrze Kubernetes działającym na maszynach z systemem Ubuntu widać jeden węzeł główny i dwa węzły robocze.
Możesz sprawdzić konfigurację Kubernetes:
# kubectl cluster-info

Wdrażanie poda w Kubernetes
Teraz możesz wdrożyć pod zawierający kontenery w swoim klastrze Kubernetes. Jak zapewne pamiętasz, w Kubernetes kontenery są zawarte w podach. Jeśli korzystasz z plików YAML, dla wygody utwórz katalog do przechowywania tych plików. Przejdź do tego katalogu i uruchom polecenia takie jak kubectl apply -f test.yaml
Taki katalog został już utworzony podczas konfiguracji Flannel – /home/kubernetes-user/kubernetes/
Czas wdrożyć nowy pod. Najpierw musisz utworzyć wdrażanie. Wdrażanie to koncepcja kontrolera używana do dostarczania deklaratywnych aktualizacji do podów i zestawów replik. Wdrażanie można utworzyć za pomocą pojedynczego polecenia lub plików YAML.
Przykład 1 – wdrażanie MySQL
W tym przykładzie utwórzmy plik YAML. Nazwa pliku to mysql-wdrażanie.yaml
Aby zapoznać się z konfiguracją, zajrzyj do załączonego pliku.
# vim mysql-deployment.yaml
Istnieją dwa popularne podejścia do zarządzania zasobami za pomocą kubectl . Jaka jest różnica między kubectl create a kubectl apply ? Korzystając z kubectl create , informujesz Kubernetes, co chcesz utworzyć, zastąpić lub usunąć; polecenie to nadpisuje wszystkie zmiany. Alternatywnie, kubectl apply wprowadza zmiany przyrostowe i to polecenie może być użyte do zapisania zmian zastosowanych do obiektu działającego.
Utwórz wdrażanie:
# kubectl apply -f ./mysql-deployment.yaml

Kubernetes może wyświetlać informacje o Twoim wdrażaniu.
# kubectl describe deployment mysql
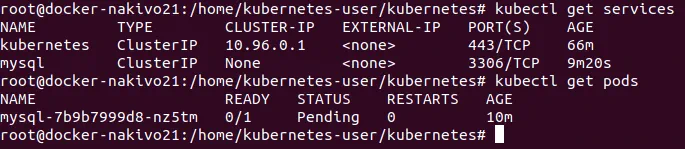
Sprawdź pody:
# kubectl get po
lub
# kubectl get pods
lub
# kubectl get pods -l app=mysql
Jeśli widzisz status „pending” dla poda, może to oznaczać, że brakuje zasobów obliczeniowych. Spróbuj dodać trochę procesorów i pamięci, aby naprawić status „pending” podu w Kubernetes.
W razie potrzeby możesz usunąć usługę:
# kubectl delete service
Możesz również usunąć pod:
# kubectl delete pod mysql-7b9b7999d8-nz5tm
Przykład 2 — Wdrażanie nginx
Wdróżmy nginx przy użyciu innej metody bez plików yaml.
Utwórz wdrażanie.
# kubectl create deployment nginx --image=nginx
Sprawdź, czy wdrażanie zostało utworzone.
# kubectl get deployments
Utwórz usługę.
# kubectl create service nodeport nginx --tcp=80:80
Usługę można utworzyć przy użyciu następujących typów usług – ClusterIP, NodePort, LoadBalance i ExternalName. Jeśli używany jest typ NodePort, do uzyskania dostępu do dostarczonych usług przydzielany jest losowy port z zakresu 30000–32767. Ruch kierowany na ten port jest przekazywany do odpowiedniej usługi.
Sprawdź, czy usługa została utworzona i nasłuchuje na zdefiniowanym porcie.
# kubectl get svc
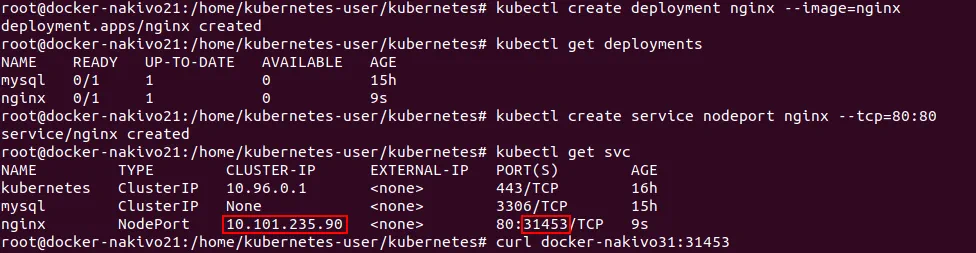
Zapamiętaj numer portu (w tym przypadku 31453).
Sprawdź, czy usługa została wdrożona i jest dostępna (w tym przykładzie polecenie jest uruchamiane na węźle głównym). Użyj nazwy hosta węzła i portu, które zapamiętałeś w poprzednim kroku.
# curl docker-nakivo31:31453
Możesz również sprawdzić, czy usługa jest dostępna w przeglądarce dowolnego węzła. W pasku adresu przeglądarki internetowej spróbuj odwiedzić strony:
http:// 10.101.235.90
lub
http://docker-nakivo31:31453
http://docker-nakivo32:31453
Jeśli wszystko jest w porządku, zobaczysz stronę powitalną nginx.

Możliwe jest również odwiedzenie strony testowej nginx z dowolnego komputera, który ma dostęp do sieci, z którą połączone są węzły Kubernetes — ( 192.168.101.0/24 ) w tym przypadku. Na przykład można odwiedzić strony internetowe za pomocą przeglądarki:
http://192.168.101.21:31453/
http://192.168.101.31:31453/
http://192.168.101.32:31453/
Skonfiguruj interfejs internetowy do monitorowania Kubernetes
Instalacja Kubernetes na Ubuntu jest prawie zakończona, ale dla większej wygody możesz również zainstalować pulpit nawigacyjny Kubernetes. Pulpit nawigacyjny Kubernetes to interfejs internetowy służący do zarządzania i monitorowania Kubernetes. Aby zainstalować pulpit nawigacyjny, utwórz plik kubernetes-dashboard.yaml , podobnie jak to zrobiłeś wcześniej przed wykonaniem poleceń.
# kubectl create -f ./kubernetes-dashboard.yaml
# kubectl apply -f ./kubernetes-dashboard.yaml
Sprawdź pody.
# kubectl get pods -o wide --all-namespaces
Uruchom proxy do serwera API Kubernetes.
# kubectl proxy

Aby wprowadzić kolejne polecenia w konsoli, otwórz kolejne okno konsoli. W przeciwnym razie proces zostanie zakończony.
W przeglądarce internetowej na węźle głównym przejdź do strony:
http://localhost:8001
Zobaczysz stronę testową.
Wpisz pełny adres w pasku adresu przeglądarki internetowej.
http://localhost:8001/api/v1/namespaces/kube-system/services/https:kubernetes-dashboard:/proxy/
Utwórz pulpit nawigacyjny z kontem serwisowym, wykonując polecenia w nowym oknie konsoli.
# kubectl create serviceaccount dashboard -n default
# kubectl create clusterrolebinding dashboard-admin -n default
--clusterrole=cluster-admin
--serviceaccount=default:dashboard
# kubectl get secret $(kubectl get serviceaccount dashboard -o jsonpath="{.secrets[0].name}") -o jsonpath="{.data.token}" | base64 –decode
Teraz możesz zobaczyć wygenerowany token:
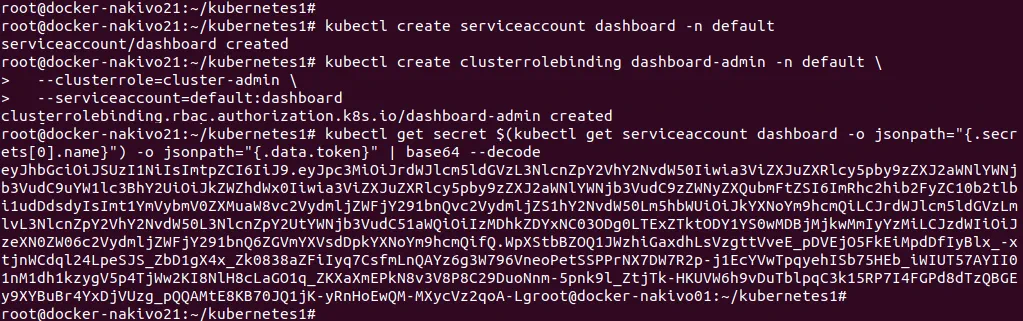
Skopiuj wygenerowany token i wklej go w sekcji tokenów interfejsu internetowego, aby zalogować się do pulpitu nawigacyjnego.
Na poniższym zrzucie ekranu widać interfejs internetowy pulpitu nawigacyjnego Kubernetes. Możesz sprawdzić status węzłów, wdrażaniach i podów, a także role, klasy pamięci masowej i inne komponenty. 
Konfiguracja narzędzia monitorującego Heapster
Zainstaluj Heapster, aby rozszerzyć możliwości monitorowania pulpitu nawigacyjnego Kubernetes o parametry dotyczące Procesora, pamięci i inne. Utwórz plik manifestu o nazwie heapster.yaml .
# vim heapster.yaml
W kolejnym kroku wdrażaj Heapster.
# kubectl create -f heapster.yaml
Edytuj rolę RBAC (kontrola dostępu na podstawie ról) Heapstera i dodaj uprawnienia do dostępu do statystyk węzłów.
# kubectl edit clusterrole system:heapster

Sprawdź, czy w konsoli można mierzyć wskaźniki dotyczące Procesora i pamięci.
# kubectl top node

Teraz możesz otworzyć interfejs internetowy pulpitu nawigacyjnego Kubernetes i zobaczyć, że dodano kilka sekcji, w tym wykresy wykorzystania Procesora i pamięci.
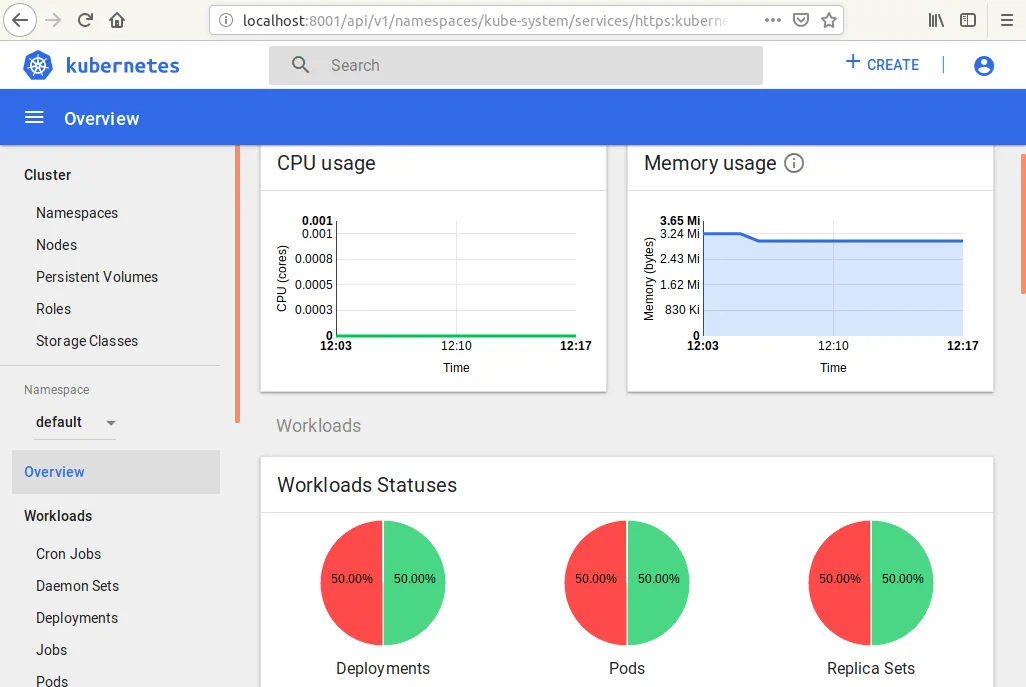
Twój klaster Kubernetes jest teraz skonfigurowany i gotowy do pracy.
Wdrażanie klastra Kubernetes o wysokiej dostępności z wieloma węzłami głównymi w systemie Ubuntu
Posiadanie klastra Kubernetes z jednym węzłem głównym i kilkoma węzłami roboczymi jest dobrym rozwiązaniem, ale czasami jedyny węzeł główny może ulec awarii z powodu problemów sprzętowych lub utraty zasilania. Aby zapewnić wyższą odporność na awarie klastra Kubernetes wdrożonego na węzłach Ubuntu, lepiej rozważyć wdrożenie klastra Kubernetes o wysokiej dostępności z wieloma węzłami głównymi. Wykorzystanie tego modelu wdrażania klastra Kubernetes pozwala uniknąć pojedynczego punktu awarii. Zaleca się stosowanie nieparzystej liczby węzłów głównych, a minimalna liczba węzłów głównych zapewniająca odporność na awarie to trzy. Jeśli używasz więcej niż trzech węzłów głównych, a liczba węzłów jest parzysta, odporność całego klastra na awarie nie wzrasta. W poniższej tabeli przedstawiono porównanie wartości odporności na awarie w zależności od liczby węzłów głównych w klastrze Kubernetes. Na przykład, jeśli klaster ma 5 węzłów głównych, może on przetrwać awarię 2 węzłów głównych, ponieważ trzy węzły główne pozostają sprawne (3 z 5 to ponad 50% i stanowi większość). Rozmiar klastra odnosi się do liczby węzłów głównych w klastrze.
| Rozmiar klastra | Większość | Odporność na awarie |
| 1 | 1 | 0 |
| 2 | 2 | 0 |
| 3 | 2 | 1 |
| 4 | 3 | 1 |
| 5 | 3 | 2 |
| 6 | 4 | 2 |
| 7 | 4 | 3 |
| 8 | 5 | 3 |
| 9 | 5 | 4 |
W tej części dzisiejszego wpisu na blogu omówiono sposób instalacji Kubernetes na węzłach z systemem Ubuntu w ramach wdrażania klastra Kubernetes o wysokiej dostępności (HA), serwera proxy HA oraz kilku węzłów roboczych. W poniższej tabeli można zobaczyć adresy IP, nazwy hostów i role hostów użytych do zainstalowania klastra Kubernetes HA na węzłach Ubuntu w laboratorium testowym opisanym w tym przykładzie.
| Nr | Rola węzła | Adres IP | Nazwa hosta |
| 1 | Master | 192.168.101.21 | docker-nakivo21 |
| 2 | Master | 192.168.101.22 | docker-nakivo22 |
| 3 | Master | 192.168.101.23 | docker-nakivo23 |
| 4 | HA Proxy | 192.168.101.19 | ha-proxy19 |
| 5 | Worker | 192.168.101.31 | docker-nakivo31 |
| 6 | Worker | 192.168.101.32 | docker-nakivo32 |
Niektóre polecenia są takie same jak podczas instalacji Kubernetes na Ubuntu przy użyciu modelu z jednym węzłem głównym. Z tego powodu komentarze do niektórych poleceń nie są powtarzane. Możesz przewinąć tę stronę w górę, aby przypomnieć sobie objaśnienia poleceń.
Przygotuj wszystkie maszyny (proxy HA, węzły główne i węzły robocze) do instalacji Kubernetes, wykonując następujące czynności:
- Skonfiguruj statyczne adresy IP.
- Ustaw nazwy hostów. Nazwy wszystkich hostów muszą być rozpoznane jako adresy IP.
- Dostęp SSH musi być włączony i skonfigurowany przy użyciu certyfikatów.
- Pamięć wymiany musi być wyłączona.
Te kroki należy wykonać przed rozpoczęciem instalacji Docker na każdej maszynie, podobnie jak w sekcji powyżej, gdzie wyjaśniono instalację Kubernetes na Ubuntu przy użyciu jednego węzła głównego. Po przygotowaniu wszystkich maszyn przejdź do ( 192.168.101.19 ).
Konfiguracja modułu równoważenia obciążenia HA Proxy
Moduł równoważenia obciążenia HA Proxy służy do rozdzielania ruchu przychodzącego między węzłami Kubernetes. Moduł ten jest wdrażany przed węzłami głównymi. Otwórz konsolę maszyny ha-proxy19 i wykonaj czynności przedstawione poniżej.
Zainstaluj cfssl
Cfssl (Cloud Flare SSL) to zestaw narzędzi służący do generowania różnych certyfikatów, w tym łańcuchów certyfikatów TLS/SSL.
Pobierz pliki binarne z oficjalnego repozytorium.
# wget https://pkg.cfssl.org/R1.2/cfssl_linux-amd64
# wget https://pkg.cfssl.org/R1.2/cfssljson_linux-amd64
Nadaj plikom binarnym uprawnienia do wykonywania.
# chmod +x cfssl*
Przenieś te pliki binarne do /usr/local/bin/
# mv cfssl_linux-amd64 /usr/local/bin/cfssl
# mv cfssljson_linux-amd64 /usr/local/bin/cfssljson
Sprawdź instalację, sprawdzając wersję zainstalowanego cfssl.
# cfssl version
Zaktualizuj drzewo repozytorium.
# apt-get update
Zainstaluj HA proxy.
# apt-get install haproxy
Utwórz i edytuj plik haproxy.cfg .
# vim /etc/haproxy/haproxy.cfg
Dodaj te linie na końcu tego pliku konfiguracyjnego.
frontend kubernetes
bind 192.168.101.19:6443
option tcplog
mode tcp
default_backend kubernetes-master-nodes
backend kubernetes-master-nodes
mode tcp
balance roundrobin
option tcp-check
server docker-nakivo21 192.168.101.21:6443 check fall 3 rise 2
server docker-nakivo22 192.168.101.22:6443 check fall 3 rise 2
server docker-nakivo23 192.168.101.23:6443 check fall 3 rise 2

Uruchom ponownie usługę.
# systemctl restart haproxy
Wygeneruj certyfikaty TSL
Możesz nadal korzystać z konsoli maszyny proxy HA. Utwórz plik konfiguracyjny urzędu certyfikacji o nazwie ca-config.json .
# vim ca-config.json
Dodaj następującą treść do tego pliku konfiguracyjnego:
{
"signing": {
"default": {
"expiry": "8760h"
},
"profiles": {
"kubernetes": {
"usages": ["signing", "key encipherment", "server auth", "client auth"],
"expiry": "8760h"
}
}
}
}
Utwórz plik konfiguracyjny żądania podpisania przez urząd certyfikacji.
# vim ca-csr.json
Dodaj do tego pliku treść pokazaną poniżej:
{
„CN”: „Kubernetes”,
„key”: {
„algo”: „rsa”,
„size”: 2048
},
„names”: [
{
„C”: „GB”,
„L”: „London”,
„O”: „Kubernetes”,
„OU”: „CA”,
„ST”: „Nakivo”
}
]
}
Gdzie:
C – kraj, na przykład GB (Wielka Brytania).
L – lokalizacja, taka jak miasto lub miejscowość.
O – organizacja.
OU – jednostka organizacyjna (na przykład dział zdefiniowany jako właściciel klucza).
ST – stan lub prowincja.
Teraz wygeneruj klucz publiczny i prywatny.
# cfssl gencert -initca ca-csr.json | cfssljson -bare ca
Sprawdź, czy klucze ca-key.pem oraz ca.pem zostały wygenerowane.
# ls -al
Tworzenie certyfikatu dla klastra Etcd
Etcd obsługuje komunikację między serwerami/klastrami przy użyciu uwierzytelniania za pomocą certyfikatów klienckich. Powinieneś posiadać certyfikat CA oraz podpisaną parę kluczy dla jednego z członków klastra.
Utwórz plik konfiguracyjny żądania podpisania certyfikatu.
# vim kubernetes-csr.json
{
"CN": "kubernetes",
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "GB",
"L": "London",
"O": "Kubernetes",
"OU": "Kubernetes",
"ST": "Nakivo"
}
]
}
Następnie wygeneruj certyfikat i klucz prywatny.
# cfssl gencert
-ca=ca.pem
-ca-key=ca-key.pem
-config=ca-config.json
-hostname=192.168.101.21,192.168.101.22,192.168.101.23,192.168.101.19,127.0.0.1,kubernetes.default
-profile=kubernetes kubernetes-csr.json |
cfssljson -bare kubernetes
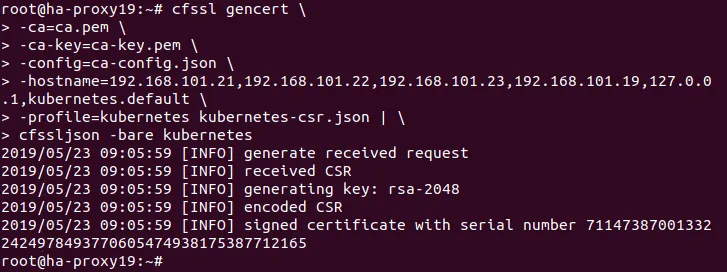
Wyświetl listę plików w katalogu, aby sprawdzić, czy kubernetes-key.pem oraz kubernetes.pem zostały wygenerowane.
# ls -al
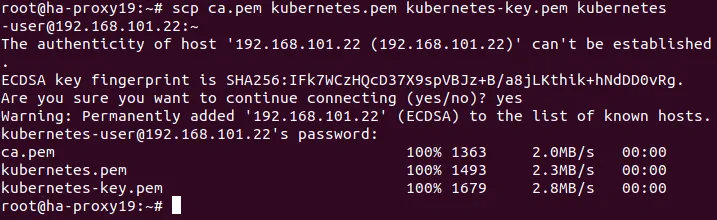
Skopiuj utworzony certyfikat do każdego węzła. # scp ca.pem kubernetes.pem kubernetes-key.pem kubernetes-user@192.168.101.21:~
# scp ca.pem kubernetes.pem kubernetes-key.pem kubernetes-user@192.168.101.22:~
# scp ca.pem kubernetes.pem kubernetes-key.pem kubernetes-user@192.168.101.23:~
# scp ca.pem kubernetes.pem kubernetes-key.pem kubernetes-user@192.168.101.31:~
# scp ca.pem kubernetes.pem kubernetes-key.pem kubernetes-user@192.168.101.32:~
# scp ca.pem kubernetes.pem kubernetes-key.pem kubernetes-user@192.168.101.33:~
Gdzie ~ to katalog domowy użytkownika kubernetes-user na hostach z systemem Ubuntu.
Przygotowanie węzłów Ubuntu do instalacji Kubernetes
Uruchom polecenia przedstawione w tej sekcji na wszystkich węzłach głównych i roboczych. Zainstaluj Docker, a następnie zainstaluj Kubernetes na maszynach z systemem Ubuntu, które zostaną włączone do klastra Kubernetes. Zacznijmy od przygotowania 192.168.101.21 węzła głównego.
Zainstaluj Docker.
# apt-get install apt-transport-https ca-certificates curl software-properties-common
# curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
# add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu bionic stable"
# apt-get update
# apt-get install docker-ce
Docker jest teraz zainstalowany. Cubeadm, kublet i cubectl to komponenty Kubernetes wymagane do zainstalowania Kubernetes na Ubuntu.
Zainstaluj komponenty Kubernetes — kubeadm, kubelet i kubectl.
# curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add -
# echo 'deb http://apt.kubernetes.io/ kubernetes-xenial main' | sudo tee /etc/apt/sources.list.d/kubernetes.list
# apt-get update
# apt-get install -y kubelet kubeadm kubectl
Po przygotowaniu wszystkich węzłów i zainstalowaniu Docker, kubelet, kubeadm oraz kubectl należy zainstalować i skonfigurować etcd na węzłach głównych.
Instalacja i konfiguracja etcd na węzłach głównych Ubuntu
Etcd to spójny i wysoce dostępny magazyn przeznaczony do przechowywania kluczy oraz wykonania kopii zapasowej wszystkich danych klastra. Klaster etcd musi zostać skonfigurowany przed skonfigurowaniem klastra HA Kubernetes z wieloma węzłami master. Zacznijmy od skonfigurowania 192.168.101.21 węzła master.
Installing and configuring etcd on the 192.168.101.21 machine.
Utwórz katalog konfiguracyjny dla etcd.
# mkdir /etc/etcd /var/lib/etcd
Przejdź do katalogu, do którego skopiowano certyfikaty. Jest to katalog domowy użytkownika kubernetes, w tym przypadku – /home/kubernetes-user/
Skopiuj certyfikaty do katalogu konfiguracyjnego etcd.
# cp ca.pem kubernetes.pem kubernetes-key.pem /etc/etcd
Sprawdź, czy pliki zostały skopiowane.
# ls -al /etc/etcd
Wróć do poprzedniego katalogu
# cd -
Pobierz pliki binarne etcd z repozytorium.
# wget https://github.com/coreos/etcd/releases/download/v3.3.9/etcd-v3.3.9-linux-amd64.tar.gz
Rozpakuj archiwum etcd.
# tar xvzf etcd-v3.3.9-linux-amd64.tar.gz
Teraz przenieś pliki binarne etcd do /usr/local/bin/
# mv etcd-v3.3.9-linux-amd64/etcd* /usr/local/bin/
Utwórz plik jednostki systemd dla etcd.
# vim /etc/systemd/system/etcd.service
Dodaj do tego pliku poniższe ciągi znaków.
[Unit]
Description=etcd
Documentation=https://github.com/coreos
[Service]
ExecStart=/usr/local/bin/etcd
--name 192.168.101.21
--cert-file=/etc/etcd/kubernetes.pem
--key-file=/etc/etcd/kubernetes-key.pem
--peer-cert-file=/etc/etcd/kubernetes.pem
--peer-key-file=/etc/etcd/kubernetes-key.pem
--trusted-ca-file=/etc/etcd/ca.pem
--peer-trusted-ca-file=/etc/etcd/ca.pem
--peer-client-cert-auth
--client-cert-auth
--initial-advertise-peer-urls https://192.168.101.21:2380
--listen-peer-urls https://192.168.101.21:2380
--listen-client-urls https://192.168.101.21:2379,http://127.0.0.1:2379
--advertise-client-urls https://192.168.101.21:2379
--initial-cluster-token etcd-cluster-0
--initial-cluster 192.168.101.21=https://192.168.101.21:2380,192.168.101.22=https://192.168.101.22:2380,192.168.101.23=https://192.168.101.23:2380
--initial-cluster-state new
--data-dir=/var/lib/etcd
Restart=on-failure
RestartSec=5
[Install]
WantedBy=multi-user.target
Przeładuj konfigurację menedżera systemd, aby pobrał zmienione konfiguracje z systemu plików i ponownie wygenerował drzewa zależności.
# systemctl daemon-reload
Spraw, aby etcd uruchamiał się podczas startu systemu.
# systemctl enable etcd
Uruchom etcd. # systemctl start etcd
Wykonaj te same czynności na drugim węźle głównym ( docker-nakivo22 – 192.168.101.21 oraz docker-nakivo23 – 192.168.101.22 ). Jedyna różnica w czynnościach wymaganych dla tych węzłów głównych polega na edycji pliku konfiguracyjnego etcd.service . Należy zdefiniować prawidłowe adresy IP dla każdego z pozostałych węzłów głównych. Na przykład plik konfiguracyjny etcd.service musi wyglądać następująco dla drugiego węzła głównego ( 192.168.101.22 ) w bieżącym laboratorium testowym Kubernetes.
[Unit]
Description=etcd
Documentation=https://github.com/coreos
[Service]
ExecStart=/usr/local/bin/etcd
--name 192.168.101.22
--cert-file=/etc/etcd/kubernetes.pem
--key-file=/etc/etcd/kubernetes-key.pem
--peer-cert-file=/etc/etcd/kubernetes.pem
--peer-key-file=/etc/etcd/kubernetes-key.pem
--trusted-ca-file=/etc/etcd/ca.pem
--peer-trusted-ca-file=/etc/etcd/ca.pem
--peer-client-cert-auth
--client-cert-auth
--initial-advertise-peer-urls https://192.168.101.22:2380
--listen-peer-urls https://192.168.101.22:2380
--listen-client-urls https://192.168.101.22:2379,http://127.0.0.1:2379
--advertise-client-urls https://192.168.101.22:2379
--initial-cluster-token etcd-cluster-0
--initial-cluster 192.168.101.21=https://192.168.101.21:2380,192.168.101.22=https://192.168.101.22:2380,192.168.101.23=https://192.168.101.23:2380
--initial-cluster-state new
--data-dir=/var/lib/etcd
Restart=on-failure
RestartSec=5
[Install]
WantedBy=multi-user.target
Inicjalizacja węzłów głównych w klastrze Kubernetes HA
Teraz można zainicjować węzły główne w klastrze Kubernetes HA zainstalowanym na maszynach z systemem Ubuntu.
Inicjalizacja węzła głównego 192.168.101.21
Na pierwszym węźle głównym należy wykonać czynności opisane poniżej.
Utwórz plik konfiguracyjny yaml dla kubeadm.
# vim config.yaml
Dodaj parametry konfiguracyjne do tego pliku:
apiVersion: kubeadm.k8s.io/v1alpha3
kind: ClusterConfiguration
kubernetesVersion: stable
apiServerCertSANs:
- 192.168.101.19
controlPlaneEndpoint: "192.168.101.19:6443"
etcd:
external:
endpoints:
- https://192.168.101.21:2379
- https://192.168.101.22:2379
- https://192.168.101.23:2379
caFile: /etc/etcd/ca.pem
certFile: /etc/etcd/kubernetes.pem
keyFile: /etc/etcd/kubernetes-key.pem
networking:
podSubnet: 10.244.0.0/16
apiServerExtraArgs:
apiserver-count: "3"
Sieć zdefiniowana jako podSubnet (10.244.0.0/16) musi być taka sama jak w kube-flannel.yml pliku.
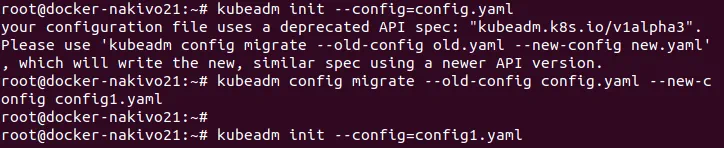
Zainicjuj maszynę Ubuntu jako węzeł główny.
# kubeadm init --config=config.yaml
Czasami może pojawić się ostrzeżenie dotyczące starej wersji pliku konfiguracyjnego:
Twój plik konfiguracyjny używa przestarzałej specyfikacji API: „kubeadm.k8s.io/v1alpha3”. Użyj polecenia „kubeadm config migrate –old-config old.yaml –new-config new.yaml”, które zapisze nową, podobną specyfikację przy użyciu nowszej wersji API.
Zaktualizuj wersję pliku konfiguracyjnego za pomocą polecenia:
# kubeadm config migrate --old-config config.yaml --new-config config1.yaml
Inny błąd może wystąpić podczas inicjalizacji węzła klastra Kubernetes z wieloma węzłami głównymi, jeśli etcd nie działa:
[ERROR ExternalEtcdVersion]: Pobierz https://192.168.101.21:2379/wersja: dial tcp 192.168.101.21:2379: connect: connection refused

Sprawdź, czy etcd działa. Możesz uruchomić etcd ręcznie:
# systemctl start etcd
Po pomyślnej inicjalizacji węzła głównego w klastrze Kubernetes działającym na systemie Ubuntu otrzymasz następujący komunikat, tak jak pokazano na zrzucie ekranu. 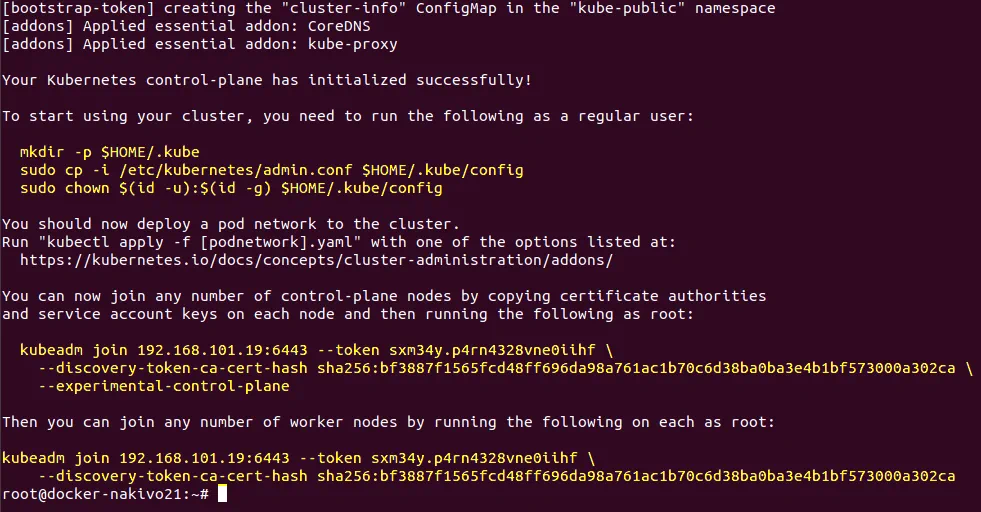
Wynik pomyślnego wykonania tego polecenia zawiera wskazówkę, jak rozpocząć korzystanie z klastra, a także polecenia zawierające token i skrót certyfikatu potrzebne do dołączenia węzłów do klastra. Zapisz te ważne ciągi znaków, ponieważ wkrótce będą Ci potrzebne. Na zrzucie ekranu są one zaznaczone na żółto i powtórzone poniżej.
Możesz teraz dołączyć dowolną liczbę węzłów płaszczyzny sterowania, kopiując certyfikaty
i klucze kont usługowych na każdy węzeł, a następnie uruchamiając jako root:
kubeadm join 192.168.101.19:6443 --token sxm34y.p4rn4328vne0iihf
--discovery-token-ca-cert-hash sha256:bf3887f1565fcd48ff696da98a761ac1b70c6d38ba0ba3e4b1bf573000a302ca
--experimental-control-plane
Następnie możesz dołączyć dowolną liczbę węzłów roboczych, uruchamiając na każdym z nich jako root:
kubeadm join 192.168.101.19:6443 --token sxm34y.p4rn4328vne0iihf
--discovery-token-ca-cert-hash sha256:bf3887f1565fcd48ff696da98a761ac1b70c6d38ba0ba3e4b1bf573000a302ca
Uruchom polecenia, aby rozpocząć korzystanie z zainicjowanego węzła w klastrze.
# mkdir -p $HOME/.kube
# sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
# sudo chown $(id -u):$(id -g) $HOME/.kube/config
Sprawdź węzły dodane do klastra.
# kubectl get nodes

Skopiuj certyfikaty do dwóch pozostałych węzłów głównych
# scp -r /etc/kubernetes/pki kubernetes-user@192.168.101.22:~
# scp -r /etc/kubernetes/pki kubernetes-user@192.168.101.23:~
Inicjowanie węzła głównego 192.168.101.22
Uruchom polecenia na drugim węźle głównym (192.168.101.22).
Usuń pliki apiserver.crt oraz apiserver.key znajdujące się w katalogu domowym (~) użytkownika kubernetes-user .
$ rm ~/pki/apiserver.*
Przenieś certyfikaty przechowywane w katalogu domowym do katalogu /etc/kubernetes/ .
$ sudo mv ~/pki /etc/kubernetes/
Utwórz plik konfiguracyjny yaml dla kubeadm.
# vim config.yaml
Zawartość tego pliku yaml jest taka sama jak dla pierwszego węzła głównego ( 192.168.101.21 ). Zobacz konfigurację inicjalizacji pierwszego węzła głównego powyżej. Możesz skopiować już utworzony plik używany na pierwszym węźle głównym klastra Kubernetes HA zainstalowanego na maszynach z systemem Ubuntu.
Zainicjuj drugi węzeł główny.
# kubeadm config migrate --old-config config.yaml --new-config config1.yaml
# kubeadm init --config=config1.yaml
Wynik jest taki sam, jak wynik wyświetlony po zainicjowaniu pierwszego węzła głównego w klastrze Kubernetes HA:
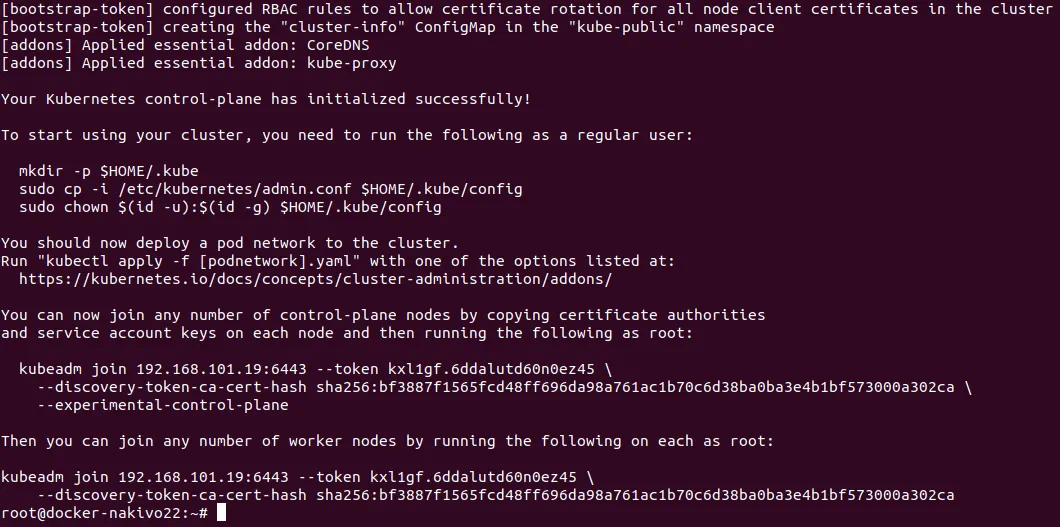
Podobnie, wykonaj polecenia, aby rozpocząć korzystanie ze zainicjowanego węzła w klastrze.
# mkdir -p $HOME/.kube
# sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
# sudo chown $(id -u):$(id -g) $HOME/.kube/config
Sprawdź węzły dodane do klastra.
# kubectl get nodes

Do klastra dodano dwa z trzech węzłów głównych. Pozostał jeszcze jeden węzeł główny do dodania.
Inicjalizacja trzeciego (192.168.101.23) węzła głównego
Powtórz te same kroki, które wykonałeś podczas inicjalizacji drugiego węzła (192.168.101.22) w klastrze. Nie zapomnij zanotować poleceń wraz z tokenami i skrótami służącymi do dodawania węzłów do klastra, które pojawiają się po zainicjowaniu węzła głównego.
Sprawdź, czy wszystkie trzy węzły główne zostały pomyślnie dodane do klastra.
# kubectl get nodes
Instalacja Flannel w celu usunięcia statusu NotReady węzłów głównych w Kubernetes
Zainstalujmy Flannel. W przeciwieństwie do pierwszego przykładu, w którym nauczyłeś się instalować Kubernetes na Ubuntu w celu utworzenia klastra z jednym węzłem głównym, w tym przykładzie Flannel zostanie zainstalowany przy użyciu pliku yaml.
Uruchom polecenie, aby zainstalować Flannel i naprawić NotReady status węzłów, który jest wyświetlany, ponieważ nie skonfigurowano jeszcze sieci nakładkowej. Utwórz plik kube-flannel.yaml za pomocą edytora tekstu vim, na przykład na pierwszym węźle głównym.
# kubectl apply -f kube-flannel.yml
Zapamiętaj adres podSubnet zdefiniowany w pliku config.yaml . Adres sieciowy musi być taki sam w pliku kube-flannel.yaml .
Sprawdź swoje węzły i ich status.
# kubectl get nodes
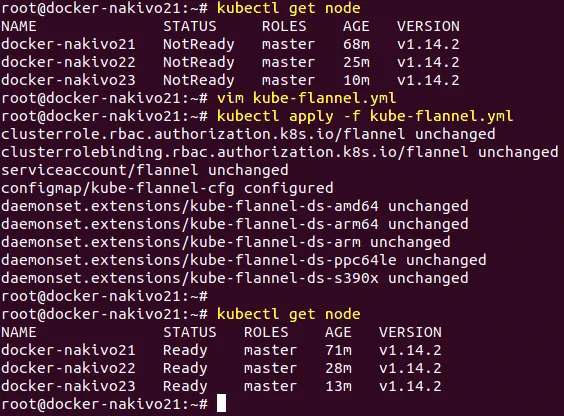
Teraz wszystkie węzły główne działają poprawnie.
Dodawanie węzłów roboczych do klastra
Po zainicjowaniu wszystkich węzłów głównych możesz dodać węzły robocze do swojego klastra Kubernetes. Dodajmy pierwszy węzeł roboczy ( 192.168.101.31 ) do klastra HA Kubernetes wdrożonego na maszynach z systemem Ubuntu. Użyj polecenia wyświetlonego po zainicjowaniu węzłów głównych (polecenia zawierającego token i hash), aby węzeł roboczy dołączył do klastra. Uruchom polecenie na maszynie 192.168.101.31 .
# kubeadm join 192.168.101.19:6443 --token kxl1gf.6ddalutd60n0ez45
--discovery-token-ca-cert-hash sha256:bf3887f1565fcd48ff696da98a761ac1b70c6d38ba0ba3e4b1bf573000a302ca
Sprawdź węzły klastra Kubernetes HA, aby upewnić się, że węzeł roboczy został dodany. Teraz na liście węzłów możesz również zobaczyć maszynę proxy HA.
# kubectl get nodes
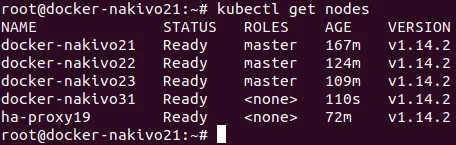
W podobny sposób dodaj inne węzły robocze do klastra Kubernetes High Availability zainstalowanego na maszynach z systemem Ubuntu. W zależności od potrzeb możesz w dowolnym momencie dodać więcej węzłów roboczych. Na tym kończy się dzisiejszy samouczek.
Wnioski
Wdrażanie Kubernetes na Ubuntu nie jest tak trudne, jak mogłoby się wydawać na pierwszy rzut oka. Wdrażanie klastra Kubernetes wymaga pewnego wysiłku, ale w rezultacie zyskujesz wiele korzyści, takich jak łatwiejsze, scentralizowane zarządzanie, wysoka skalowalność i równoważenie obciążenia. Najprostszym typem wdrażania Kubernetes jest wdrażanie z jednym serwerem głównym – należy zainstalować Kubernetes na węzłach Ubuntu, w tym na węzłach głównych i roboczych. Jeśli potrzebujesz bardziej niezawodnej infrastruktury do uruchamiania aplikacji kontenerowych, rozważ wdrażanie klastra Kubernetes z wieloma węzłami głównymi, znanego jako klaster Kubernetes o wysokiej dostępności. Tego typu wdrażanie Kubernetes eliminuje pojedynczy punkt awarii, a klaster może nadal funkcjonować nawet w przypadku awarii niektórych węzłów głównych.
W przypadku obu typów wdrażania musisz skonfigurować dostęp SSH, ustawić statyczne adresy IP i nazwy hostów, zainstalować Docker, wyłączyć korzystanie z partycji swap, a na koniec zainstalować komponenty Kubernetes, takie jak kubeadm, kubectl, kubelet, oraz skonfigurować Flannel do sieci nakładkowej. W przypadku wdrażania klastra Kubernetes HA musisz również skonfigurować proxy HA na samodzielnej maszynie, wygenerować certyfikaty i skonfigurować klaster etcd. Większość etapów konfiguracji Kubernetes, tworzenia wdrażania, a także uruchamiania podów można wykonać na dwa sposoby: ręcznie, uruchamiając polecenia udostępnione przez interfejs wiersza poleceń, oraz korzystając z plików konfiguracyjnych YAML. Korzystanie z plików YAML pozwala na tworzenie bardziej złożonych struktur i sprawia, że proces administracji jest wygodniejszy.
Kubernetes można zainstalować w systemie Ubuntu, działającym zarówno na maszynach fizycznych, jak i wirtualnych. Jeśli Kubernetes jest zainstalowany na maszynach wirtualnych działających w vSphere, można zapewnić dodatkową ochronę, korzystając z Klaster VMware High Availability z funkcją Fault Tolerance. Logika wdrażania Kubernetes omówiona w tym wpisie na blogu może być również wykorzystana do instalacji Kubernetes w innych dystrybucjach systemu Linux.



