Bewährte Best Practices für die Hyper-V-Disaster Recovery
& & In virtuellen Umgebungen sind die Erwartungen an die Verfügbarkeit von Diensten und die Geschäftskontinuität sehr hoch. Von Unternehmen wird heute erwartet, dass sie ihren Betrieb ohne Unterbrechungen aufrechterhalten und ihren Kunden Dienstleistungen anbieten.
Um die Verfügbarkeit trotz Störungen durch verschiedene Faktoren aufrechtzuerhalten, sollten Sie einen Disaster Recovery-Planerstellen und ständig aktualisieren. Mit einem solchen Plan können Sie das erforderliche Maß an Verfügbarkeit und Datenverlust-Ziele aufrechterhalten und eine schnelle Wiederherstellung mit minimalem Datenverlust sicherstellen. Dieser Blog enthält nützliche Tipps für die Hyper-V-Disaster Recovery.

Was ist VM-Disaster Recovery?
Disaster Recovery umfasst eine Reihe von Richtlinien, Verfahren und Tools, die darauf abzielen, Ausfallzeiten zu minimieren und Geschäftsfunktionen nach einem schwerwiegenden Vorfall so schnell wie möglich wiederherzustellen. Die Disaster Recovery (DR) für virtuelle Umgebungen, einschließlich der Hyper-V-Disaster Recovery, umfasst im Allgemeinen:
- Blockbasierte VM-Sicherung und -Replikation auf Image-Ebene
- Aufbewahrung von VM-Backups und -Replikaten an einem entfernten DR-Standort
- Failover zu VM-Replikaten im Katastrophenfall
- Verwendung von VM-Backups für die langfristige Speicherung und zuverlässige Wiederherstellung
VM-Disaster Recovery in einer Hyper-V-Umgebung
Microsoft Hyper-V umfasst eine Reihe integrierter Funktionen, die eine effiziente VM-Notfallwiederherstellung ermöglichen. Das Budget, die Infrastruktur und der Umfang Ihrer Geschäftsabläufe bestimmen, welche Funktionen in Ihrem Disaster Recovery-Plan enthalten sein sollten. Die VM-Disaster Recovery in einer Hyper-V-Umgebung basiert jedoch in der Regel auf Folgendem:
- DR-Standort. Ein Standort, an den ein Unternehmen seine Prozesse während eines Vorfalls verlagern kann, bis die Produktionsstandorte/Systeme wieder betriebsbereit sind.
- Alternative virtuelle Plattform- und Datenbankserver. Im Katastrophenfall müssen die Server und die Software der virtuellen Plattform am DR-Standort bereitstehen, um Virtuelle Maschinen zu hosten. So werden Ausfallzeiten minimiert und die Geschäftskontinuität gewährleistet.
- Virtuelle Backup- und Replikationssoftware für DR. Hyper-V verwendet die Volume Shadow Copy Service (VSS)-Technologie, die die Erstellung von Backups oder Schnappschüssen ermöglicht, selbst wenn diese in Gebrauch sind. Die Hyper-V-Replikation ermöglicht die Verwendung von Kopien (Replikaten) laufender VMs als Mittel zur Wiederherstellung der VM im Katastrophenfall. Moderne Softwarelösungen kombinieren Backup- und Replikationsfunktionen, um Sie bei der Disaster Recovery zu unterstützen.
Diese Maßnahmen können Unternehmen dabei helfen, einen VM-Disaster-Recovery-Plan in einer Hyper-V-Umgebung zu erstellen und erfolgreich umzusetzen.
Insider-Tipps für eine erfolgreiche Hyper-V-VM-Disaster Recovery
Hier finden Sie eine Liste mit Tipps für eine erfolgreiche Hyper-V-VM-Disaster Recovery:
- Führen Sie regelmäßig VM-Backups durch und testen Sie diese. Legen Sie den Plan für die VM-Backups entsprechend den Anforderungen und Prioritäten Ihres Unternehmens fest. Testen Sie regelmäßig die Gültigkeit und Integrität der erstellten Backups.
- Erstellen und testen Sie regelmäßig Replikate. Je nachdem, wie wichtig eine bestimmte Anwendung oder VM für die Geschäftskontinuität ist, können Sie eine Replikation einrichten, um eine nahezu sofortige Wiederherstellung zu gewährleisten. Testen Sie Ihre Replikate regelmäßig, um ihre Integrität und Verwendbarkeit zu überprüfen.
- Führen Sie Failover-Tests durch. Durch Tests können Sie überprüfen, ob kritische Vorgänge im Falle eines DR-Vorfalls auf einen DR-Standort übertragen werden können. Failover-Tests helfen dabei, Schwachstellen zu identifizieren, die den DR-Prozess potenziell beeinträchtigen könnten.
- Aktualisieren Sie Ihre Lösung für die Datensicherheit regelmäßig. Da Microsoft seine Produkte ständig aktualisiert, ist es wichtig, Ihre Lösung für Datensicherheit zu aktualisieren, um neue APIs und Hyper-V-Erweiterungen nutzen zu können.
- Speichern Sie Backups und Replikate an einem entfernten Standort. Durch die Speicherung dieser Daten an einem entfernten Standort können Sie das Risiko eines Single Point of Failure ausschließen.
- Wenden Sie Windows-Updates auf jede VM an, um Sicherheitslücken zu schließen. Hyper-V verändert sich und entwickelt sich rasant weiter, und Microsoft ist bemüht, seine Hyper-V-Integrationsdienste auf dem neuesten Stand zu behalten.
- Testen Sie auf Hardware- und Softwarefehler. Die Durchführung von RAM- und Festplattenüberprüfungstests sowie die Überprüfung auf Festplattenwarnungen sind unerlässlich, wenn Sie Systemausfälle und potenzielle Datenverluste vermeiden möchten.
- Sorgen Sie für ausreichend Speicherplatz auf Ihren physischen Maschinen und VMs. Freier Speicherplatz ermöglicht zuverlässige Backups und schnelle Replikationen, während viel RAM beim Neustart einer VM entscheidend ist. Um erfolgreiche Backups und Replikationen zu gewährleisten, ist es daher sinnvoll, eine Lösung für Datensicherheit zu installieren, die den Speicher verwaltet und Benachrichtigungen über den kritischen RAM-Stand sendet.
- Installieren und implementieren Sie eine Lösung für Datensicherheit, die VSS unterstützt. VSS überwacht die Leistung und den Status von VMs während Backup- und Replikationsaufträgen. Sie sollten VSS auch so konfigurieren, dass Backups und Replikate effektiv optimiert werden.
So schützen Sie Ihre Infrastruktur mit der DR-Lösung von NAKIVO
Da die Disaster Recovery von Hyper-V-VMs auf VM-Backups und Replikaten basiert, sollten beide Optionen bei der Auswahl einer Lösung für die Datensicherheit zur Umsetzung eines DR-Plans berücksichtigt werden. NAKIVO Backup & Replication ist eine Lösung, die umfassende Datensicherheit für Microsoft Hyper-V-VMs bietet und sowohl Backup- als auch Replikationsfunktionen umfasst.
- Microsoft Hyper-V-VM-Backup. Bei Verwendung einer modernen imagebasierten Lösung wie NAKIVO Backup & Replication wird eine Point-in-Time-Kopie der VM erstellt, die das Betriebssystem, Konfigurationen usw. enthält. Im Falle eines DR-Vorfalls kann eine VM aus dem Backup in demselben Zustand wiederhergestellt werden, in dem sie sich während des Backup-Prozesses befand. Sie können beispielsweise eine Hyper-V-VM sofort booten oder sie als VMware vSphere-VM wiederherstellen.
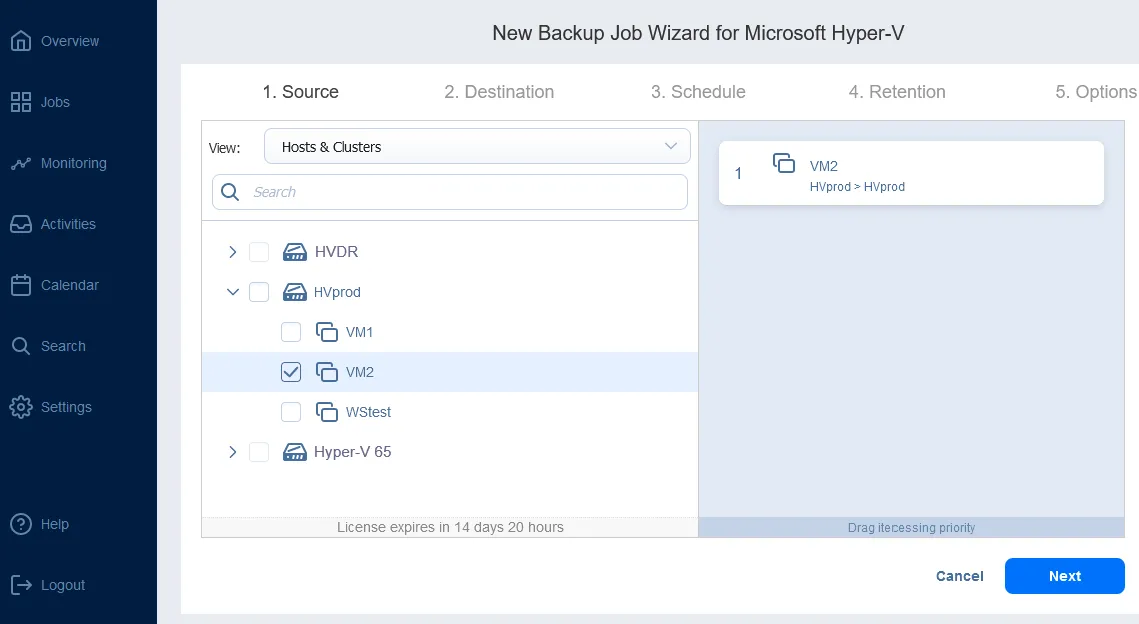
Sie können Hyper-V-VMs mit NAKIVO sichern, indem Sie nach dem Hinzufügen des Hyper-V-Hosts zum Lösungsinventar einen neuen Backupauftrag auf dem Hauptbildschirm erstellen.
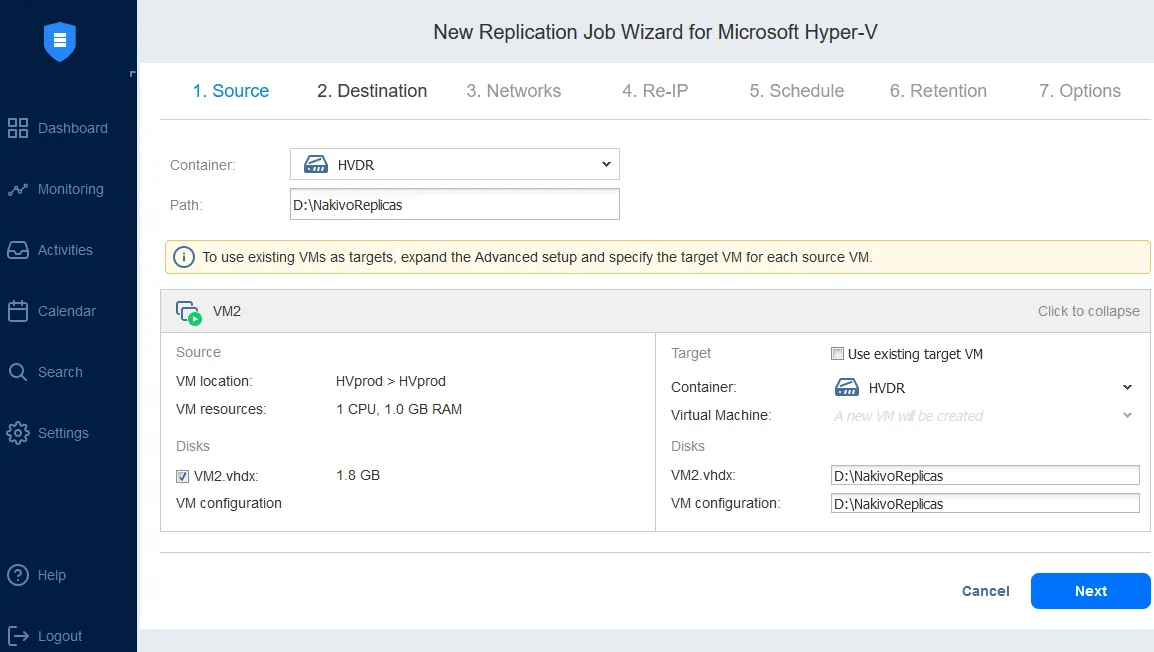
- Microsoft Hyper-V VM-Replikation. Mit Hyper-V VM-Replikationkönnen Sie eine identische Kopie einer primären VM erstellen, die als VM-Replik bezeichnet wird und im Falle eines DR-Ereignisses, bei dem eine sofortige Wiederherstellung erforderlich ist, einfach eingeschaltet werden kann. Das Auslagern von Workloads auf die Replik (d. h. das Verschieben von VMs und Systemen an den DR-Standort) zum Wiederherstellen des Betriebs am DR-Standort ist für die Aufrechterhaltung der Geschäftskontinuität und Hochverfügbarkeit von entscheidender Bedeutung.
Die Konfiguration eines Hyper-V-Replikationsauftrags mit NAKIVO ermöglicht Ihnen die Konfiguration von Netzwerkzuordnungen und Re-IP-Regeln.
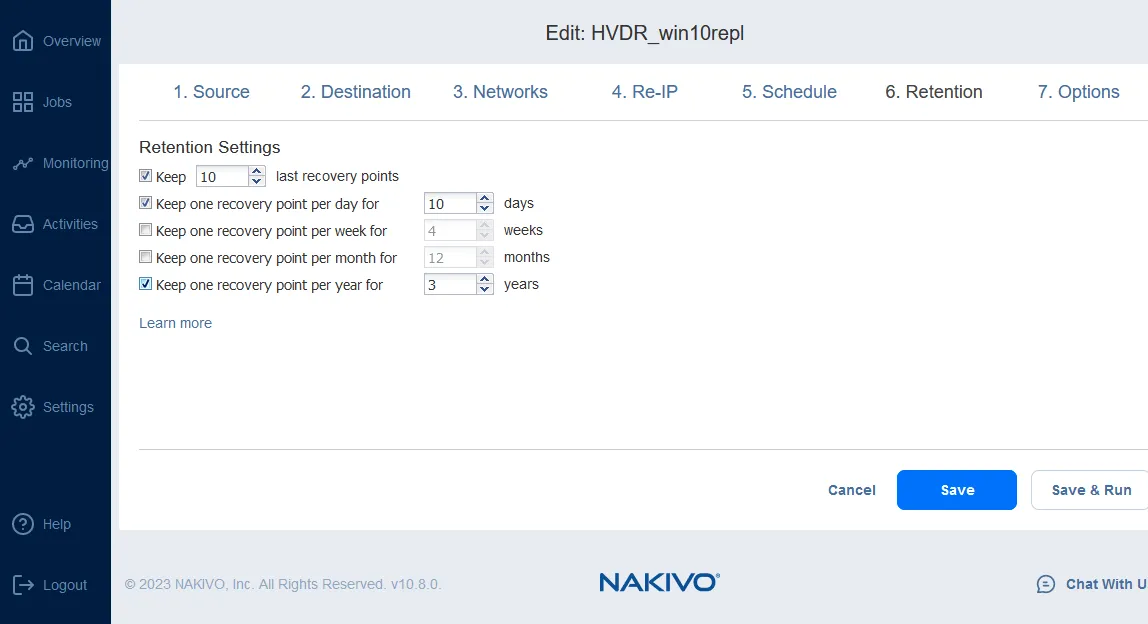
- RTO und RPO. Die Ziele der Wiederherstellungspunkte (RPO) und das Wiederherstellungszeit-Ziel (RTO) sind Schlüsselmesswerte, die bei der Planung der Disaster Recovery für Hyper-V-VMs festgelegt werden müssen. RPO und RTO sollten in Ihrem DR-Plan für die verschiedenen kritischen Workloads definiert werden und bestimmen die Häufigkeit der Sicherung/Replikation.
- RPO bezeichnet die Datenmenge, deren Verlust für ein Unternehmen ohne geschäftliche Beeinträchtigung verkraftbar ist (gemessen als Zeitintervall zwischen zwei Backupaufträgen).
- RTO ist der Zeitraum, innerhalb dessen der Geschäftsbetrieb nach einer Katastrophe wiederhergestellt werden muss, bevor sich der Vorfall negativ auf ein Unternehmen auswirkt. VM-Replikations- und Failover-Vorgänge ermöglichen wesentlich kürzere RTOs als die Wiederherstellung aus einem VM-Backup.
Sie können Aufbewahrungseinstellungen konfigurieren, indem Sie die Richtlinie „Grandfather-Father-Son”implementieren. Diese Einstellungen legen die Anzahl der VM-Replikate fest, die Sie behalten und für die Hyper-V-Disaster Recovery verwenden können.
Hyper-V Disaster Recovery mit NAKIVO
NAKIVO Backup & Replikation verfügt über eine Reihe von Funktionen, darunter die erweiterte Standortwiederherstellung Funktionalität, die VMware-, Hyper-V- und AWS EC2-Umgebungen unterstützt. Die Standortwiederherstellung umfasst eine Reihe von Aktionen und Verfahren, die auf bestimmte Weise angeordnet werden können, um einen VM-Disaster-Recovery-Workflow (Auftrag) zu erstellen. Standortwiederherstellungs-Workflows in NAKIVO Backup & Replikation ermöglicht die Orchestrierung und Automatisierung eines DR-Prozesses über mehrere Standorte hinweg.
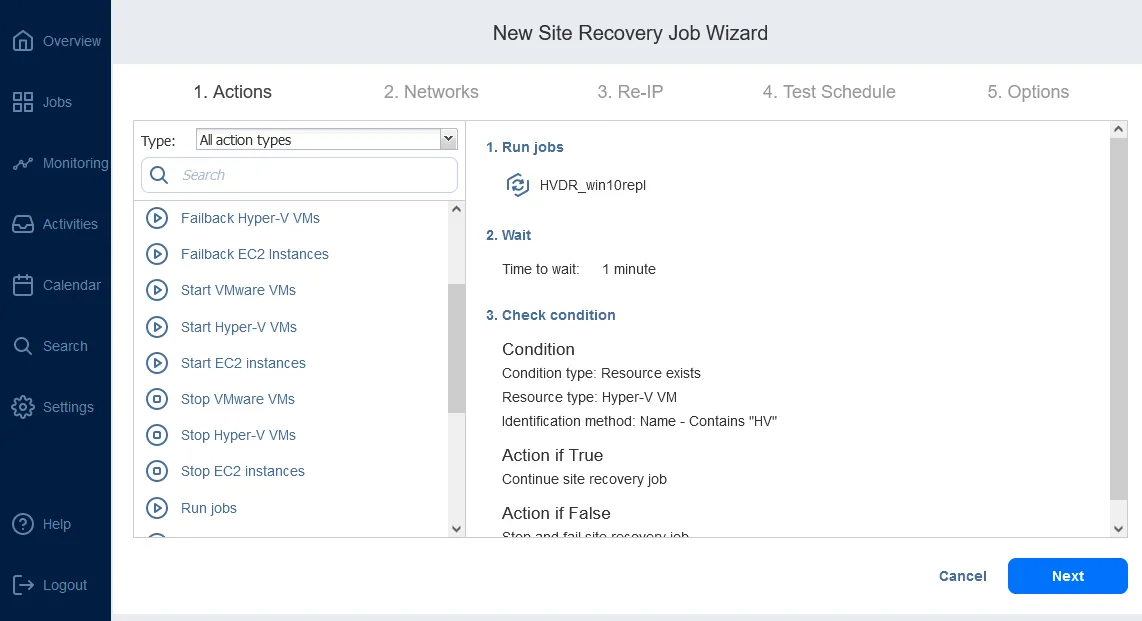
Standortwiederherstellungs-Aufträge können (neben anderen DR-Aktionen) ein automatisiertes Failover umfassen, das die Wiederherstellung eines gesamten Standorts mit nur wenigen Klicks ermöglicht. Darüber hinaus bietet NAKIVO Backup & Replikation & Replication zwei Arten von Failover: geplant und Notfall.
- Geplantes Failover wird in der Regel verwendet, um ein System vor einer bevorstehenden Katastrophe oder während Wartungsarbeiten am primären Standort zu schützen. In diesem Fall führt die Lösung eine letzte Datensynchronisierung durch und verschiebt dann die Arbeitslast vom primären Standort auf die VM-Replikate.
- Notfall-Failover wird aktiviert, wenn Ihr primärer Standort bereits von einem Vorfall betroffen ist. Die Lösung verlagert die Arbeitslast vom primären Standort auf die VM-Replik ohne Datensynchronisierung (um Zeit zu sparen) und reduziert Ausfallzeiten.
Darüber hinaus kann NAKIVO Backup & Replikation einen Auftrag für die Standortwiederherstellung im Testmodus (geplant oder ad hoc) ausführen. Dies ist eine ideale Möglichkeit, um herauszufinden, ob Ihre Wiederherstellungsworkflows wie geplant funktionieren und ob Ihre RTOs eingehalten werden können.
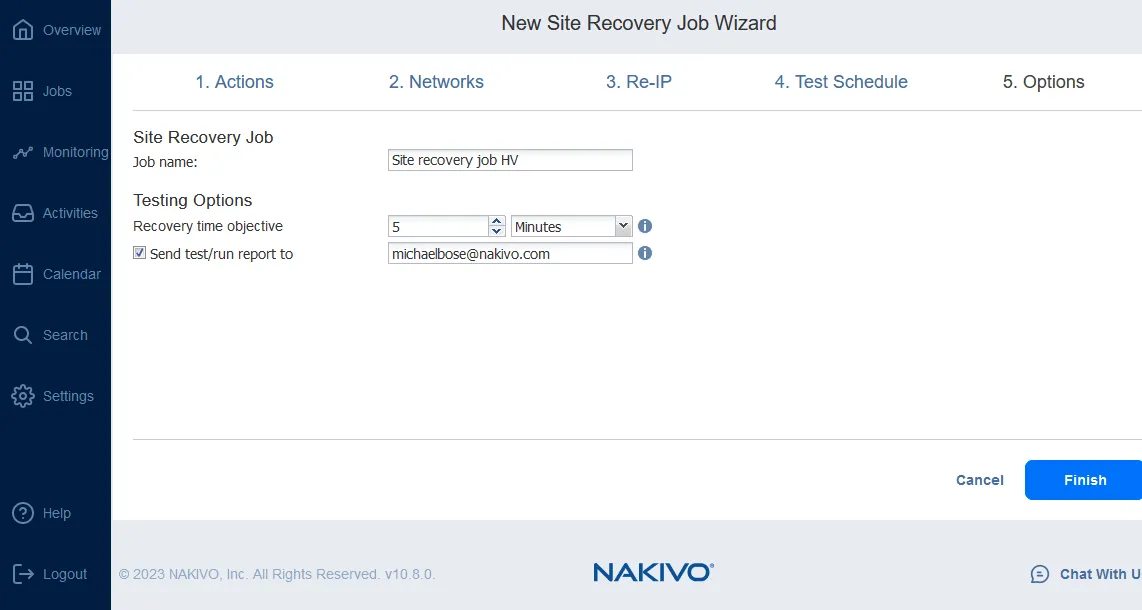
Die Möglichkeit, mit Hilfe von NAKIVO Backup & Replikation einen Workflow für die Standortwiederherstellung zu erstellen, bietet jedem Unternehmen einen erheblichen Vorteil. Sie können eine DR-Strategie erstellen, die Ihren spezifischen Geschäftsanforderungen entspricht, diese im Voraus einrichten und im Katastrophenfall mit nur wenigen Klicks ausführen. Darüber hinaus können Sie Ihre DR-Strategie ständig testen und optimieren, um die bestmöglichen Ergebnisse zu erzielen (keine Ausfallzeiten, kürzere RTOs, hohe Verfügbarkeit und geringere Kosten).



