Czym jest deduplikacja w magazynie danych dotyczących kopii zapasowych
Dzisiejsze rozbudowane infrastruktury wirtualne generują ogromne ilości danych. Prowadzi to do wzrostu ilości danych kopii zapasowych oraz wydatków na infrastrukturę pamięci masowej służącą do ich przechowywania, w tym na urządzenia pamięci masowej i ich konserwację. Z tego powodu administratorzy sieci poszukują sposobów na oszczędzanie miejsca na dyskach podczas tworzenia częstych kopii zapasowych kluczowych maszyn i aplikacji.
Jedną z powszechnie stosowanych technik jest deduplikacja kopii zapasowych. W tym wpisie na blogu omówiono, czym jest deduplikacja danych, jakie są jej rodzaje oraz przypadki użycia, ze szczególnym uwzględnieniem kopii zapasowych.

Czym jest deduplikacja?
Deduplikacja danych to technologia służąca do optymalizacji pojemności magazynu. Deduplikacja danych polega na odczytaniu danych źródłowych oraz danych już przechowywanych w magazynie, aby przesłać lub zapisać wyłącznie unikalne bloki danych. Zachowywane są odniesienia do zduplikowanych danych. Wykorzystując tę technologię do uniknięcia powielania danych na woluminie, można zaoszczędzić miejsce na dysku i zmniejszyć obciążenie magazynu.
Początki deduplikacji danych
Prekursorami deduplikacji danych są algorytmy kompresji LZ77 i LZ78 wprowadzone odpowiednio w 1977 i 1978 roku. Polegają one na zastępowaniu powtarzających się sekwencji danych odniesieniami do oryginalnych.
Koncepcja ta wpłynęła na inne popularne metody kompresji. Najbardziej znaną z nich jest DEFLATE, która jest stosowana w formatach obrazów PNG i plików ZIP. Przyjrzyjmy się teraz, jak działa deduplikacja w przypadku kopii zapasowych maszyn wirtualnych i w jaki sposób pomaga ona oszczędzać miejsce na dysku oraz koszty związane z infrastrukturą.
Czym jest deduplikacja w kopiach zapasowych?
Podczas tworzenia kopii zapasowej deduplikacja danych sprawdza, czy w pamięci źródłowej i docelowym repozytorium kopii zapasowych znajdują się identyczne bloki danych. Duplikaty nie są kopiowane, a zamiast tego tworzone jest odwołanie lub wskaźnik do istniejących bloków danych w docelowej pamięci kopii zapasowej.

Ile miejsca można zaoszczędzić dzięki deduplikacji danych?
Aby zrozumieć, ile miejsca na dysku można zyskać dzięki deduplikacji, rozważmy przykład. Minimalne wymagania systemowe do zainstalowania {4} to co najmniej 32 GB wolnego miejsca na dysku. Jeśli masz dziesięć maszyn wirtualnych z tym systemem operacyjnym, kopie zapasowe zajmą łącznie co najmniej 320 GB, a jest to tylko czysty system operacyjny bez żadnych aplikacji ani baz danych.
Jeśli musisz przeprowadzić wdrażanie więcej niż jednej maszyny wirtualnej ( maszyna wirtualna ) z tym samym systemem, prawdopodobnie użyjesz szablonu, co oznacza, że na początku będziesz mieć dziesięć identycznych maszyn. A to z kolei oznacza, że otrzymasz 10 zestawów zduplikowanych bloków danych. W tym przykładzie uzyskasz współczynnik oszczędności miejsca na dysku wynoszący 10:1. Ogólnie rzecz biorąc, oszczędności w zakresie od 5:1 do 10:1 są uważane za dobre.
Współczynnik deduplikacji danych
Współczynnik deduplikacji danych to wskaźnik służący do pomiaru stosunku rozmiaru danych pierwotnych do rozmiaru danych po usunięciu zbędnych fragmentów. Wskaźnik ten pozwala ocenić skuteczność procesu deduplikacji danych. Aby obliczyć tę wartość, należy podzielić ilość danych przed deduplikacją przez przestrzeń dyskową zajmowaną przez te dane po deduplikacji. Na przykład współczynnik deduplikacji wynoszący 5:1 oznacza, że w magazynie kopii zapasowej można zmieścić pięć razy więcej danych niż byłoby to konieczne w przypadku przechowywania tych samych danych bez deduplikacji.
Należy określić deduplication ratio oraz storage space reduction. Te dwa parametry są czasami mylone. Współczynniki deduplikacji nie zmieniają się proporcjonalnie do korzyści wynikających z redukcji danych, ponieważ po przekroczeniu pewnego punktu zaczyna obowiązywać prawo malejących przychodów. Zobacz wykres poniżej.

Oznacza to, że niższe współczynniki mogą przynieść większe oszczędności niż wyższe. Na przykład współczynnik deduplikacji 50:1 nie jest pięć razy lepszy niż współczynnik 10:1. Współczynnik 10:1 zapewnia 90% redukcję zajmowanej przestrzeni dyskowej, podczas gdy współczynnik 50:1 zwiększa tę wartość do 98%, biorąc pod uwagę, że większość nadmiarowości została już wyeliminowana. Więcej informacji na temat sposobu obliczania tych wartości procentowych można znaleźć na stronie {7} dokument dotyczący deduplikacji danych.
Czynniki wpływające na wydajność deduplikacji danych
Ze względu na kilka czynników trudno jest przewidzieć wydajność redukcji danych, dopóki dane nie zostaną faktycznie poddane deduplikacji. Poniżej przedstawiono niektóre czynniki, które mają wpływ na redukcję danych podczas stosowania deduplikacji:
- Rodzaje i zasady wykonywania kopii zapasowych danych . Deduplikacja w przypadku pełne kopie zapasowe jest bardziej skuteczna niż w przypadku kopii zapasowych przyrostowy lub różnicowy .
- Współczynnik zmian . Jeśli istnieje wiele zmian danych do wykonania kopii zapasowej, wówczas współczynnik deduplikacji jest niższy.
- Ustawienia przechowywania . Im dłużej przechowujesz kopie zapasowe danych w magazynie kopii zapasowych, tym skuteczniejsza może być deduplikacja danych w tym magazynie.
- Typ danych . Deduplikacja plików, w których dane zostały już skompresowane, takich jak
JPG, PNG, MPG, AVI, MP4, ZIP, RARitp., nie jest skuteczna. To samo dotyczy danych bogatych w metadane oraz danych zaszyfrowanych. Typy danych zawierające powtarzające się fragmenty lepiej nadają się do deduplikacji. - Zakres danych . Deduplikacja danych jest bardziej skuteczna w przypadku dużego zakresu danych. Globalna deduplikacja pozwala zaoszczędzić więcej miejsca na dysku w porównaniu z deduplikacją lokalną.
Uwaga: Deduplikacja lokalna działa na pojedynczym węźle/urządzeniu dyskowym. Globalna deduplikacja analizuje cały zestaw danych na wszystkich węzłach/urządzeniach dyskowych w celu wyeliminowania duplikatów danych. Jeśli masz wiele węzłów z włączoną deduplikacją lokalną na każdym z nich, deduplikacja nie będzie tak wydajna, jak w przypadku włączenia globalnej deduplikacji dla nich.
- Oprogramowanie i sprzęt. Połączenie rozwiązań programowych ze sprzętem do deduplikacji pozwala osiągnąć lepsze współczynniki deduplikacji niż w przypadku samego oprogramowania. Na przykład rozwiązanie do tworzenia kopii zapasowych firmy NAKIVO oferuje integracja z {9},
Dell EMC Data DomainorazNEC HYDRAstorurządzenia do deduplikacji, które zapewniają współczynniki deduplikacji sięgające nawet 17:1.
Techniki deduplikacji kopii zapasowej
Techniki deduplikacji kopii zapasowej można podzielić na następujące kategorie:
- Gdzie odbywa się deduplikacja danych
- Kiedy odbywa się deduplikacja
- Jak odbywa się deduplikacja
Gdzie odbywa się deduplikacja danych
Deduplikacja kopii zapasowej może odbywać się po stronie źródła lub po stronie docelowej, a techniki te nazywane są odpowiednio deduplikacją po stronie źródła i deduplikacją po stronie docelowej.
Deduplikacja po stronie źródła
Deduplikacja po stronie źródła zmniejsza obciążenie sieci, ponieważ podczas wykonywania kopii zapasowej przesyłana jest mniejsza ilość danych. Wymaga to jednak zainstalowania agenta deduplikacji na każdej maszynie wirtualnej lub na każdym hoście. Inną wadą jest to, że deduplikacja po stronie źródła może spowolnić maszyny wirtualne ze względu na obliczenia wymagane do identyfikacji zduplikowanych bloków danych.

Deduplikacja po stronie docelowej
Deduplikacja po stronie docelowej najpierw przesyła dane do repozytorium kopii zapasowych, a następnie przeprowadza deduplikację. Ciężkie zadania obliczeniowe są wykonywane przez oprogramowanie odpowiedzialne za deduplikację.
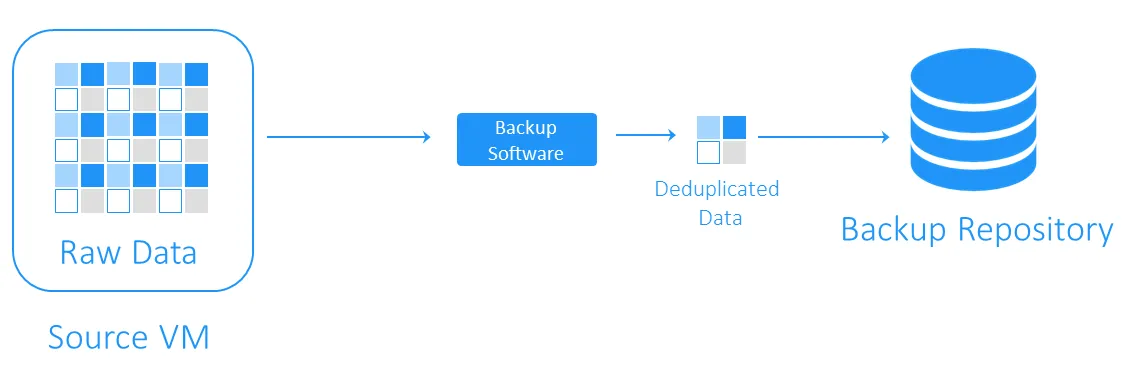
Po zakończeniu deduplikacji danych
Deduplikacja kopii zapasowych może być wykonywana w trybie inline lub post-processing.
- Deduplikacja inline sprawdza, czy dane są zduplikowane, zanim zostaną zapisane w repozytorium kopii zapasowej. Technika ta wymaga mniej miejsca w repozytorium kopii zapasowej, ponieważ usuwa nadmiarowości ze strumienia danych kopii zapasowej, ale powoduje wydłużenie czasu tworzenia kopii zapasowej, ponieważ deduplikacja inline odbywa się podczas zadania tworzenia kopii zapasowej.
- Deduplikacja po przetworzeniu przetwarza dane po ich zapisaniu w repozytorium kopii zapasowych. Oczywiście podejście to wymaga więcej wolnego miejsca w repozytorium, ale tworzenie kopii zapasowych przebiega szybciej, a wszystkie niezbędne operacje są wykonywane później. Deduplikacja po przetworzeniu jest również nazywana deduplikacją asynchroniczną.
Jak przebiega deduplikacja danych
Najpopularniejszymi metodami identyfikacji duplikatów są metody oparte na skrótach (hash) oraz zmodyfikowane metody oparte na skrótach.
- W przypadku metody opartej na skrótach oprogramowanie do deduplikacji dzieli dane na bloki o stałej lub zmiennej długości i oblicza dla każdego z nich skrót przy użyciu algorytmów kryptograficznych, takich jak
MD5, SHA-1,lubSHA-256. Każda z tych metod generuje unikalny „odcisk palca” bloków danych, więc bloki o podobnych skrótach są uznawane za identyczne. Wadą tej metody jest to, że może ona wymagać znacznych zasobów obliczeniowych, zwłaszcza w przypadku dużych kopii zapasowych. - Zmodyfikowana metoda oparta na skrótach wykorzystuje prostsze algorytmy generowania skrótów, takie jak
CRC, które generują tylko 16 bitów (w porównaniu z 256 bitami wSHA-256). Następnie, jeśli bloki mają podobne skróty, są porównywane bajt po bajcie. Jeśli są całkowicie podobne, bloki są uznawane za identyczne. Metoda ta jest nieco wolniejsza niż metoda oparta na skrótach, ale wymaga mniej zasobów obliczeniowych.
Wybór oprogramowania do deduplikacji kopii zapasowych
Deduplikacja kopii zapasowych jest jednym z najpopularniejszych przypadków użycia deduplikacji. Jednak do wdrożenia tej technologii redukcji danych konieczne jest posiadanie odpowiedniego oprogramowania oraz sprzętu do magazynu danych.
NAKIVO Backup & Replication to rozwiązanie do tworzenia kopii zapasowych, które obsługuje globalną deduplikację po przetworzeniu docelowym z modyfikowanym wykrywaniem duplikatów opartym na skrótach. Można również skorzystać z deduplikacji po stronie źródła, poprzez integrację z rozwiązaniem NAKIVO urządzenia deduplikacyjnego, takiego jak {16} z {17}, NEC HYDRAstor i HP StoreOnce z obsługą Catalyst.



