Bonnes pratiques en matière de reprise après sinistre Hyper-V
Dans les environnements virtuels, les attentes en matière de disponibilité des services et de continuité des activités sont très élevées. Aujourd’hui, les entreprises sont censées mener leurs opérations et fournir des services à leurs clients sans interruption.
Pour maintenir la disponibilité malgré les perturbations causées par différents facteurs, vous devez créer et mettre à jour en permanence un plan de reprise après sinistre. Un tel plan vous permet de maintenir le niveau de disponibilité requis et les cibles de prévention des pertes de données, ainsi que d’assurer une récupération rapide avec un minimum de pertes de données. Ce blog fournit des conseils utiles pour la reprise après sinistre Hyper-V.

Qu’est-ce que la reprise après sinistre VM ?
La reprise après sinistre est un ensemble de politiques, de procédures et d’outils visant à minimiser les temps d’arrêt et à assurer la récupération des fonctions commerciales le plus rapidement possible après un incident majeur. La reprise après sinistre (DR) pour les environnements virtuels, y compris la reprise après sinistre Hyper-V, comprend généralement :
- Sauvegarde et réplication de VM basées sur des images au niveau des blocs
- Conservation des sauvegardes et des réplicas de VM sur un site de reprise après sinistre distant
- Basculement vers des réplicas de machines virtuelles en cas de sinistre
- Utilisation des sauvegardes de machines virtuelles pour un stockage à long terme et une récupération fiable
Reprise après sinistre des machines virtuelles dans un environnement Hyper-V
Microsoft Hyper-V comprend un ensemble de fonctionnalités inhérentes qui activent une reprise après sinistre efficace des machines virtuelles. Le budget, l’infrastructure et l’échelle de vos opérations commerciales déterminent les fonctionnalités qui doivent être incluses dans votre plan de reprise après sinistre. Cependant, la reprise après sinistre des machines virtuelles dans un environnement Hyper-V repose généralement sur les éléments suivants :
- Site de reprise après sinistre. Emplacement vers lequel une organisation peut transférer ses processus pendant un incident jusqu’à ce que le site/les systèmes de production soient à nouveau opérationnels.
- Plateforme virtuelle et serveurs de base de données alternatifs. En cas de sinistre, les serveurs et les logiciels de plateforme virtuelle doivent être prêts sur le site de reprise après sinistre pour héberger les Virtuellen Maschinen. Ainsi, les temps d’arrêt sont minimisés et la continuité des activités est garantie.
- Logiciel de sauvegarde et de réplication virtuelles pour la reprise après sinistre. Hyper-V utilise la technologie Volume Shadow Copy Service (VSS), qui permet de créer des copies de sauvegarde ou des instantanés, même lorsqu’ils sont en cours d’utilisation. La réplication Hyper-V permet d’utiliser les copies (réplicas) des machines virtuelles en cours d’exécution pour restaurer la machine virtuelle en cas de sinistre. Les solutions logicielles modernes combinent des fonctionnalités de sauvegarde et de réplication pour vous aider à assurer la reprise après sinistre.
Cet ensemble de moyens peut aider les organisations à créer et à mettre en œuvre avec succès un plan de reprise après sinistre pour les machines virtuelles dans un environnement Hyper-V.
Conseils d’initiés pour une reprise après sinistre réussie des machines virtuelles Hyper-V
Voici une liste de conseils pour une reprise après sinistre réussie des machines virtuelles Hyper-V :
- Exécutez et testez régulièrement les sauvegardes des machines virtuelles. Définissez le calendrier des sauvegardes en fonction des besoins et des priorités de votre organisation. Testez régulièrement la validité et l’intégrité des sauvegardes créées.
- Créez et testez régulièrement des réplicas. En fonction de l’importance d’une application ou d’une machine virtuelle particulière pour la continuité des activités, vous pouvez configurer la réplication afin de garantir une récupération quasi instantanée. Testez régulièrement vos réplicas pour vérifier leur intégrité et leur utilisabilité.
- Effectuez des tests de basculement. Les tests vous permettent zu überprüfen, ob die kritischen Operationen auf einen Re-Rest-Server übertragen werden können, im Falle eines Ereignisses. Les tests de basculement permettent d’identifier les faiblesses susceptibles de compromettre le processus de reprise après sinistre.
- Mettez régulièrement à jour votre solution de protection des données. Étant donné que Microsoft met constamment à jour ses produits, il est important de mettre à jour votre solution de protection des données afin de pouvoir utiliser les nouvelles API et extensions Microsoft Hyper-V.
- Stockez les sauvegardes et les réplicas sur un site distant. En conservant ces données à distance, vous éliminez le risque de point de défaillance unique.
- Appliquez les mises à jour Windows à chaque machine virtuelle afin de corriger les failles de sécurité. Hyper-V évolue et se développe rapidement, et Microsoft s’efforce de maintenir à jour ses services d’intégration Hyper-V.
- Testez les erreurs matérielles et logicielles. Il est essentiel d’effectuer des tests de vérification de la RAM et du disque, ainsi que de vérifier les avertissements du disque, si vous souhaitez éviter une défaillance du système et une perte potentielle de données.
- Conservez un espace disque suffisant sur vos machines physiques et vos VMs. Un espace disque libre permet des sauvegardes fiables et une réplication rapide, tandis qu’une grande quantité de RAM est cruciale lors du redémarrage d’une VM. Ainsi, pour garantir la réussite des sauvegardes et des réplications, il est pratique d’installer une solution de protection des données capable de gérer l’espace de stockage et d’envoyer des notifications sur le niveau critique de RAM.
- Installez et mettez en œuvre une solution de protection des données qui prend en charge VSS. VSS surveille les performances et l’état des VMs pendant les tâches de sauvegarde et de réplication. Vous devez également configurer VSS pour optimiser efficacement les sauvegardes et les réplicas.
Comment protéger votre infrastructure avec la solution de reprise après sinistre de NAKIVO
Étant donné que la reprise après sinistre des machines virtuelles Hyper-V repose sur les sauvegardes et les réplicas des machines virtuelles, ces deux options doivent être prises en compte lors du choix d’une solution de protection des données pour mettre en œuvre un plan de reprise après sinistre. NAKIVO Backup & Réplication est une solution qui offre une protection complète des données pour les machines virtuelles Microsoft Hyper-V et qui inclut à la fois des fonctionnalités de sauvegarde et de réplication.
- Sauvegarde de machines virtuelles Microsoft Hyper-V. Si vous utilisez une solution moderne basée sur l’image telle que NAKIVO Backup & Replication, une copie ponctuelle de la VM est créée, qui comprend le système d’exploitation, les configurations, etc. En cas d’incident de reprise après sinistre, une VM peut être récupérée à partir de la sauvegarde dans le même état que celui dans lequel elle se trouvait lors du processus de sauvegarde. Vous pouvez, par exemple, effectuer l’amorçage instantané d’une machine virtuelle Hyper-V ou effectuer la récupération en tant que machine virtuelle VMware vSphere.
Vous pouvez sauvegarder les VMs Hyper-V avec NAKIVO en créant une nouvelle tâche de sauvegarde par l’écran principal après avoir ajouté l’hôte Hyper-V à l’inventaire de la solution.
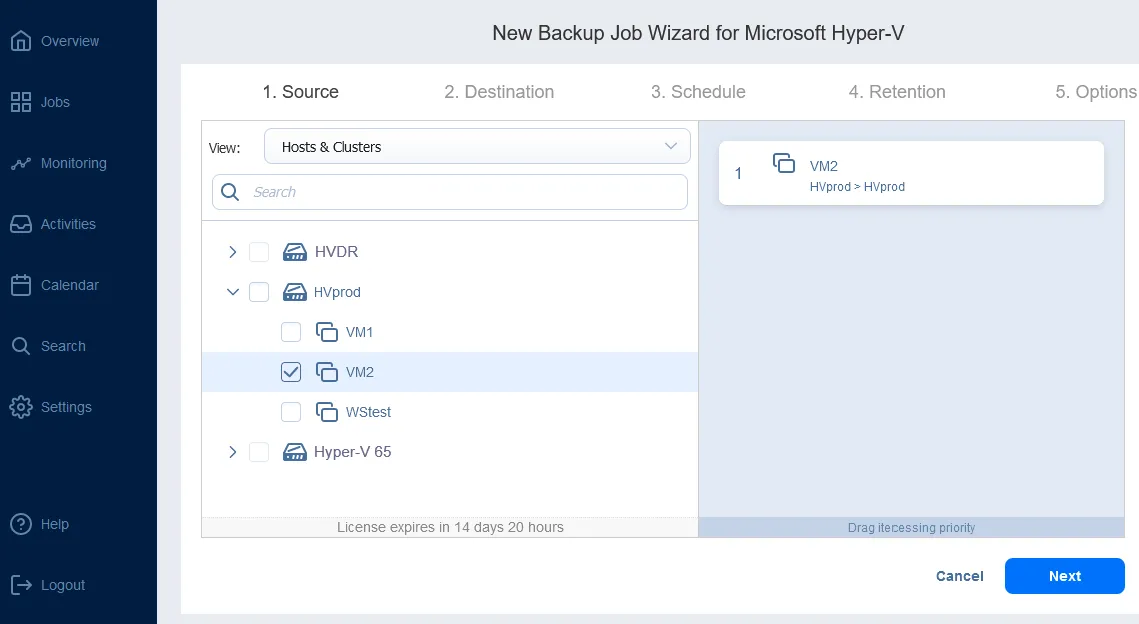
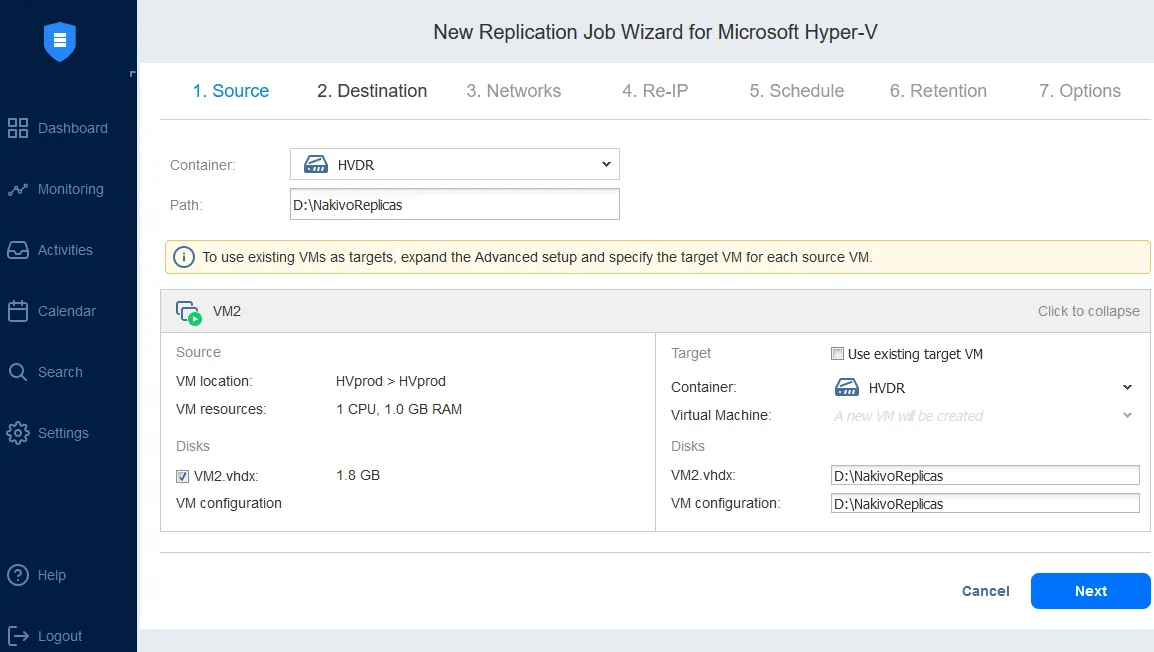
- Réplication de machines virtuelles Microsoft Hyper-V. En utilisant Réplication de machines virtuelles Hyper-V, vous pouvez créer une copie identique d’une machine virtuelle principale, appelée réplique de machine virtuelle, qui peut être simplement mise sous tension en cas d’événement de reprise après sinistre lorsqu’une récupération immédiate est nécessaire. Le basculement des workloads vers la réplique (c’est-à-dire le déplacement des VMs et des systèmes vers le site de reprise après sinistre) afin de réaliser la récupération des opérations sur ce site est essentiel pour maintenir la continuité des activités et la haute disponibilité.
La configuration d’une tâche de réplication Hyper-V avec NAKIVO vous permet de configurer le mappage réseau et les règles de réassignation d’adresses IP.
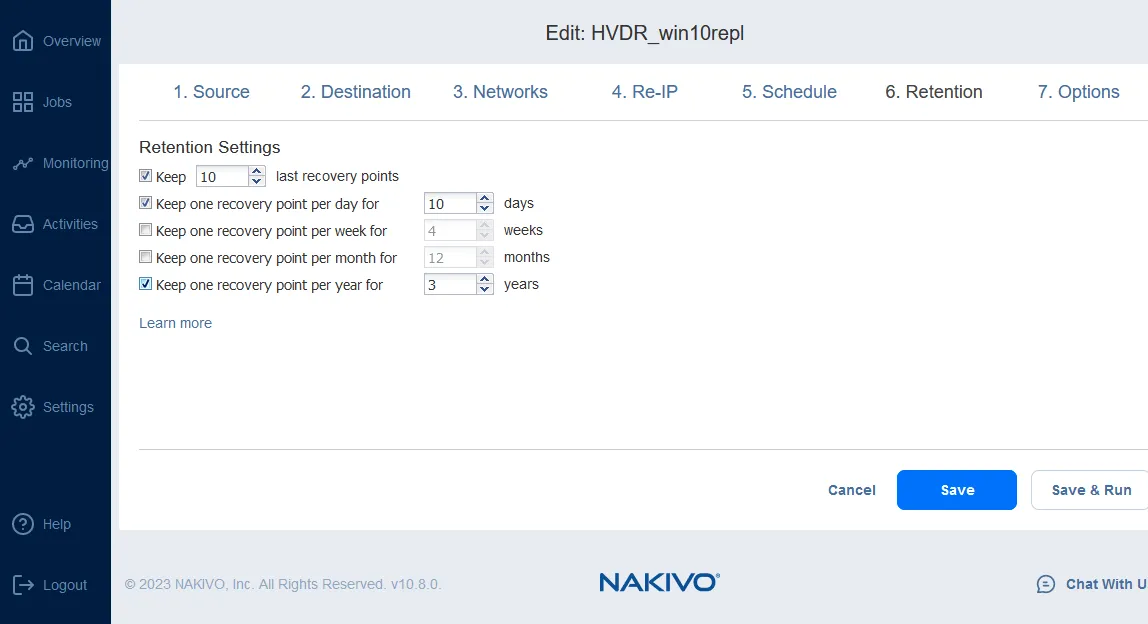
- RTO et RPO. L’objectif de point de récupération (RPO) et l’objectif de temps de récupération (RTO) sont des indicateurs clés à définir lors de la planification de la reprise après sinistre des machines virtuelles Hyper-V. RPO et RTO doivent être définis dans votre plan de reprise après sinistre pour les différentes charges de travail critiques et détermineront la fréquence des sauvegardes/réplications.
- Le RPO correspond à la quantité de données qu’une entreprise peut se permettre de perdre sans nuire à ses activités (mesurée comme l’intervalle de temps entre deux tâches de sauvegarde/réplication).
- Le RTO est le délai dans lequel les opérations commerciales doivent être rétablies après une catastrophe avant que l’incident n’ait un impact négatif sur une organisation. Les opérations de réplication et de basculement des machines virtuelles permettent des RTO beaucoup plus courts que la récupération à partir d’une sauvegarde de machine virtuelle.
Vous pouvez configurer les paramètres de conservation en mettant en œuvre la politique de conservation grand-père-père-fils. Ces paramètres déterminent le nombre de réplicas de machines virtuelles que vous conservez et que vous pouvez utiliser pour la reprise après sinistre Hyper-V.
Orchestration de la reprise après sinistre Hyper-V avec NAKIVO
NAKIVO Backup & Replication dispose d’un ensemble de fonctionnalités, notamment la fonctionnalité avancée Reprise après sinistre qui prend en charge les environnements VMware, Hyper-V et AWS EC2. La reprise après sinistre représente un ensemble d’actions et de procédures qui peuvent être organisées d’une manière particulière pour créer un workflow (tâche) de reprise après sinistre pour les machines virtuelles. Les workflows de reprise après sinistre dans NAKIVO Backup & Replication permettent l’orchestration et l’automatisation d’un processus de reprise après sinistre sur plusieurs sites.
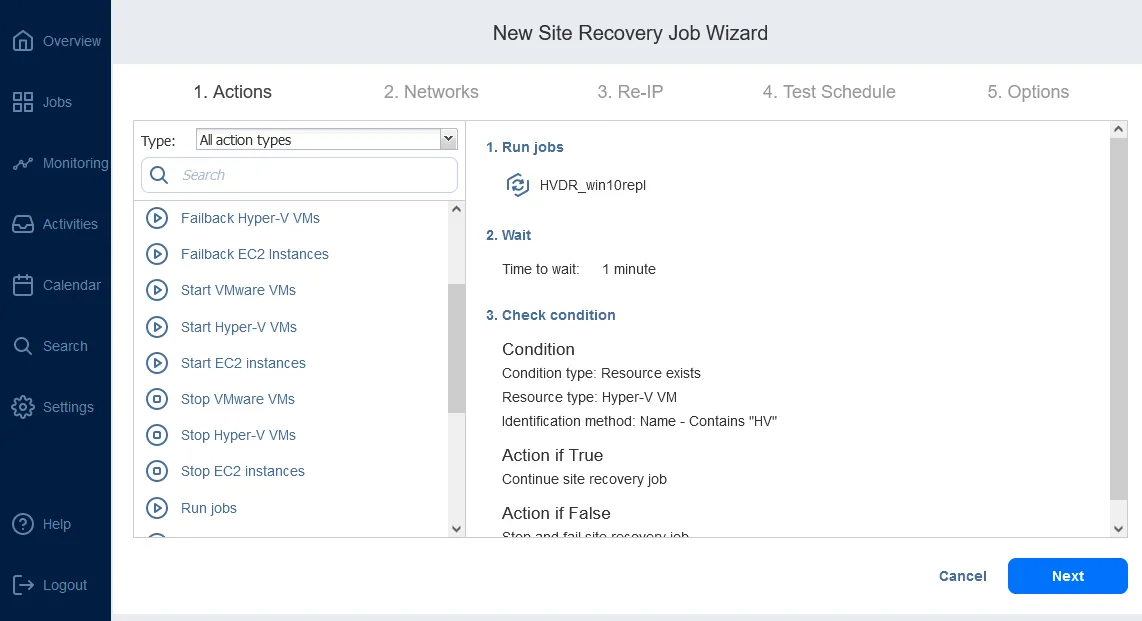
Les tâches de reprise après sinistre peuvent inclure (entre autres actions de reprise après sinistre) un basculement automatisé, qui permet la récupération de l’ensemble d’un site en quelques clics seulement. De plus, NAKIVO Backup & Replication propose deux types de basculement : planifié et d’urgence.
- Le basculement planifié est généralement utilisé pour protéger un système contre une catastrophe imminente ou pendant les opérations de maintenance sur le site principal. Dans ce cas, la solution effectue une dernière synchronisation des données, puis transfère la charge de travail du site principal vers les réplicas VM.
- Le basculement d’urgence est activé lorsque votre site principal a déjà été touché par un incident. La solution transfère la charge de travail du site principal vers la réplique VM sans synchronisation des données (pour gagner du temps) et réduit les temps d’arrêt.
De plus, NAKIVO Backup & Replication peut exécuter une tâche de reprise après sinistre en mode test (planifiée ou ad hoc), ce qui est un moyen idéal pour vérifier si vos workflows de reprise après sinistre fonctionnent comme prévu et si vos RTO peuvent être respectés.
La possibilité de créer un workflow de reprise après sinistre à l’aide de NAKIVO Backup & Replication & Replication offre un avantage significatif à toute entreprise. Vous pouvez créer une stratégie de reprise après sinistre qui correspond aux besoins spécifiques de votre entreprise, la configurer à l’avance et l’exécuter en quelques clics en cas de sinistre. De plus, vous pouvez tester et optimiser en permanence votre stratégie de reprise après sinistre afin d’obtenir les meilleurs résultats possibles (temps d’arrêt nul, RTO plus courts, haute disponibilité et coûts réduits).



