Disaster Recovery mit NAKIVO: Planung, Implementierung und Testen
Backup und Disaster Recovery sind die Grundlagen von Strategien zur Datensicherheit in Unternehmen und Branchen. Disaster Recovery ist der Prozess der Wiederherstellung virtueller Maschinen und der darauf ausgeführten Dienste an einem sekundären Standort (bekannt als Disaster Recovery-Standort), wenn der Produktionsstandort nicht mehr verfügbar ist. Diese sekundären DR-Standorte beherbergen redundante Server, Computer und Netzwerkgeräte mit der erforderlichen Software und können je nach Redundanzgrad unterschiedlicher Art sein .
NAKIVO Backup & Replication umfasst die Standortwiederherstellung, mit der Sie erweiterte Wiederherstellungssequenzen (mit vollständigem Standort-Failover) erstellen können, die mit einem Klick gestartet werden können, wenn Ihr primärer Standort ausfällt. In diesem Blogbeitrag erfahren Sie mehr über wichtige Komponenten der DR-Strategie wie die Planung der IT-Notfallwiederherstellung, das Testen und die Durchführung der Disaster Recovery mit der integrierten Lösung von NAKIVO.

Schritt 1. Planung der Disaster Recovery
Als wesentlicher Schritt für eine effektive Disaster Recovery sollte die Planung eine Bewertung der Wiederherstellungsanforderungen des Unternehmens und die Entwicklung eines umfassenden Verständnisses dafür umfassen, welche Komponenten, Schritte und Verfahren in einen Disaster-Recovery-Workflow aufgenommen werden sollten.
Planung der Disaster Recovery: Best Practices
1. Führen Sie eine Business Impact Analysis durch
Eine Business Impact Analysis (oder BIA) wird verwendet, um die potenziellen negativen Auswirkungen von größeren Vorfällen oder Naturkatastrophen auf den Geschäftsbetrieb zu ermitteln. Diese Analyse umfasst die Festlegung einer Prioritätsreihenfolge für verschiedene VMs, die Reihenfolge der Wiederherstellung und die verfügbare Zeit, bevor eine Störung den Geschäftsbetrieb erheblich beeinträchtigt. Beispielsweise kann der Ausfall einer VM zu Verzögerungen und Unannehmlichkeiten führen, während der Ausfall einer anderen VM zu einer vollständigen Unterbrechung geschäftskritischer Vorgänge führen kann.
2. Bewerten Sie die damit verbundenen Risiken
Stellen Sie vor der DR-Planung die relevanten Daten zu den Risiken für den Betrieb und die Geschäftskontinuität Ihres Unternehmens zusammen. In einigen Regionen sind langfristige Stromausfälle oder Virenangriffe wahrscheinlicher als Tornados, während in anderen Regionen Naturkatastrophen häufiger vorkommen. Eine Risikobewertung hilft Ihnen dabei, das angemessene Schutzniveau gegen bestimmte Bedrohungen zu bestimmen und Maßnahmen zur Minimierung der Risiken und zur Abmilderung der Folgen zu entwickeln. Auch wenn die Risiken nicht vollständig beseitigt werden können, sind Sie so besser auf die Katastrophenszenarien vorbereitet, mit denen Sie wahrscheinlich konfrontiert werden.
3. Entwickeln Sie eine Dokumentation zur Disaster Recovery
Sobald die Risiken und ihre potenziellen Auswirkungen auf Ihr Unternehmen identifiziert sind, haben Sie ein besseres Verständnis dafür, worauf Sie sich bei der Planung von Prozessen der Disaster Recovery konzentrieren sollten. Dokumentieren Sie Wiederherstellungsverfahren , beschreiben Sie alle wichtigen Schritte und DR-Maßnahmen im Detail und aktualisieren Sie die Dokumente regelmäßig, um Änderungen in der Umgebung widerzuspiegeln. Die Dokumentation sollte Folgendes enthalten:
- Umfang der Disaster Recovery. Bewerten Sie die Bedeutung jeder Hardware- und Softwarekomponente in Ihrer Infrastruktur und nehmen Sie diejenigen für geschäftskritische Vorgänge in Ihren Disaster-Recovery-Plan auf. VMs, die kritische Informationen, IT-Systeme und Anwendungen enthalten, deren Betrieb für die kontinuierliche Bereitstellung von Diensten unerlässlich ist, sollten bei der Wiederherstellung oberste Priorität haben.
- Reihenfolge der VM-Wiederherstellung. Bestimmte VMs können von der Software oder den Informationen einer anderen VM abhängig sein, was bedeutet, dass sie nicht separat betrieben oder willkürlich gestartet werden können. Sie sollten die Reihenfolge der Wiederherstellung festlegen, um die Wiederherstellung zu optimieren und das Risiko von Softwarekonflikten am DR-Standort zu vermeiden. Beispielsweise muss die VM, auf der der Active Directory-Domänencontroller ausgeführt wird, betriebsbereit sein, bevor Sie eine VM mit einem Dateiserver starten können, der die Active Directory-Authentifizierung verwendet.
Ein weiteres Beispiel sind Webdienste, die häufig auf Software angewiesen sind, die auf mehreren verschiedenen VMs installiert ist. Möglicherweise muss die folgende Reihenfolge implementiert werden:
- Die VM mit dem Datenbankserver sollte zuerst gestartet werden.
- Anschließend kann die VM mit dem Anwendungsserver gestartet werden.
- Erst dann kann die VM mit dem Webserver gestartet werden.
- RTO und RPO bei Disaster Recovery. Legen Sie die Wiederherstellungszeit-Ziele (RTO) und die Ziele der Wiederherstellungspunkte (RPO) für die verschiedenen priorisierten VMs im Disaster Recovery-Plan fest. Beispielsweise können VMs mit Finanzsystemen kürzere Ziele für die Wiederherstellung haben als solche, die zur Speicherung archivierter Dokumente verwendet werden.
- Abhängigkeiten. Bei der Festlegung der Abhängigkeitskette zwischen Mitarbeitern und IT-Komponenten sollten Sie mit Ihren Mitarbeitern zusammenarbeiten und diese berücksichtigen, um Schwachstellen zu vermeiden, die zu einem Fehlschlagen der Wiederherstellung führen können. Beispielsweise muss eine VM, die von der Buchhaltungsabteilung verwendet wird, möglicherweise zuerst wiederhergestellt werden, wenn Mitarbeiter anderer Abteilungen für ihre Arbeit auf diese Finanzvorgänge angewiesen sind.
- Mitarbeiter . Weisen Sie den Teammitgliedern, die an DR-Prozessen beteiligt sind, Rollen und Verantwortlichkeiten zu. Wenn sie am DR-Standort arbeiten werden, stellen Sie sicher, dass dort Arbeitsstationen mit allen erforderlichen Geräten, Büromöbeln und Hardware eingerichtet sind, damit sie ihre Arbeit mit minimalen Unterbrechungen fortsetzen können. Wenn Mitarbeiter während einer Katastrophe remote arbeiten können, konfigurieren Sie den VPN-Zugang und stellen Sie im Voraus VPN-Konten bereit.
- Hardwareanforderungen . Der Erfolg eines Disaster-Recovery-Plans hängt in hohem Maße von der Leistung und den Fähigkeiten der Hardware am DR-Standort ab. Dabei sind mehrere Faktoren zu berücksichtigen:
- Server müssen über ausreichend CPU-, Speicher- und Festplattenkapazität verfügen, um die übertragenen Workloads zu bewältigen. Eine geringe CPU-Leistung und unzureichender Arbeitsspeicher können die Geschwindigkeit Ihrer VMs beeinträchtigen, während eine unzureichende Festplattengeschwindigkeit zu einer schlechten VM-Leistung führt.
- Netzwerke müssen über ausreichend Bandbreite verfügen, damit die wiederhergestellten VMs miteinander, mit gemeinsam genutzten Speichern und bei Bedarf mit Benutzern interagieren können.
Schritt 2. Vorbereitung auf Disaster Recovery
Sobald Sie Ihre Dokumentation fertiggestellt haben, können Sie mit der Vorbereitung auf Disaster Recovery fortfahren, indem Sie den Standort für die Wiederherstellung vorbereiten und die Replikation kritischer Workloads auf diesen Standort einrichten. Die Replikation ist erforderlich, damit VM-Failover VM-Replikate erstellen kann, wenn die primäre Infrastruktur ausfällt.
Was ist VM-Replikation?
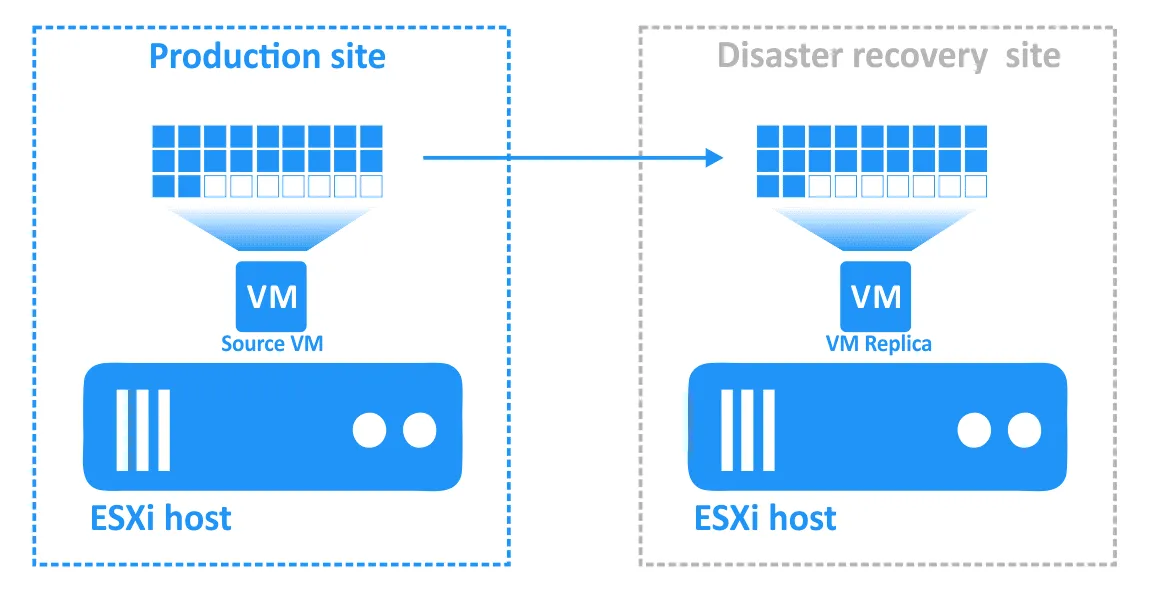
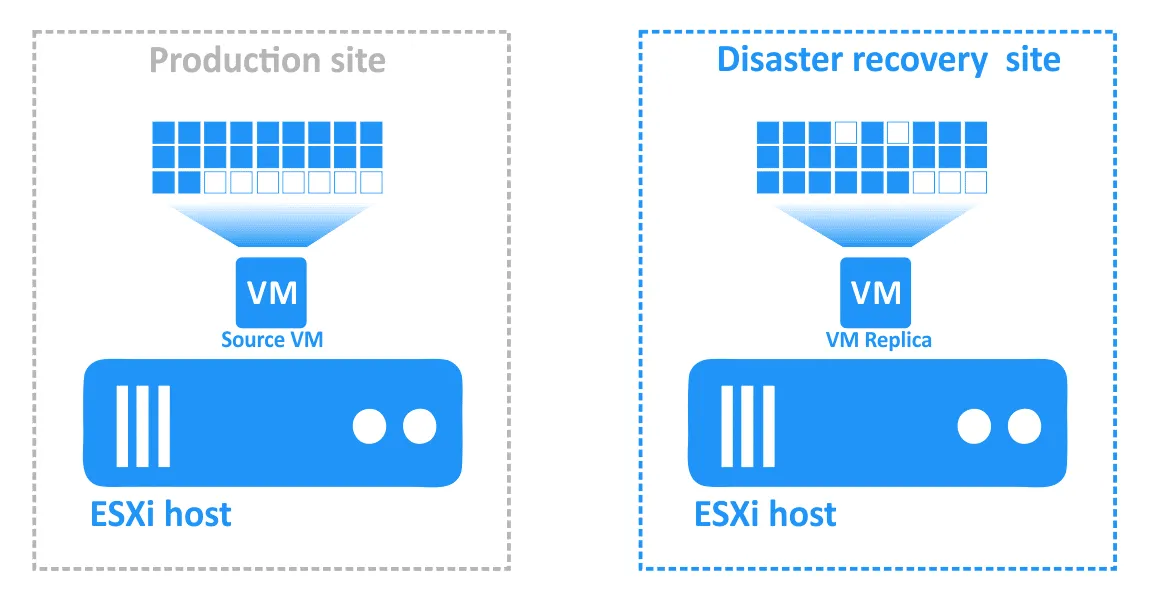
Bei der Replikation virtueller Maschinen wird eine identische Kopie einer Quelle-VM (als „VM-Replikat” bezeichnet) auf einem anderen Host (dem Zielhost) erstellt. Die VM-Replik ist eine normale VM, die ausgeschaltet bleibt, bis sie benötigt wird (zu diesem Zeitpunkt kann sie fast sofort auf ihrem Host gestartet werden).
Weitere Details zum Erstellen und Konfigurieren eines VMware-VM-Replikations-Auftrags in NAKIVO Backup & Replication finden Sie hier.
Der Prozess der Umschaltung von Workloads von einer Quelle (Produktions-VM) auf eine VM-Replik am DR-Standort zum Zweck der Aufrechterhaltung der Geschäftskontinuität und Hochverfügbarkeit wird als Failover bezeichnet.
Bewährte Best Practices für die VM-Replikation
Es gibt eine Vielzahl bewährter Best Practices für die Replikation , um eine bessere Zuverlässigkeit und Leistung des Prozesses zu gewährleisten. Hier konzentrieren wir uns auf zwei wichtige Punkte:
- Führen Sie die VM-Replikation auf Host-Ebene statt auf Gast-Ebene durch . Die Virtualisierungsschicht ist die Zwischenschicht zwischen der physischen Hardware und dem Gastbetriebssystem, das auf einer VM ausgeführt wird. Die auf Virtualisierungsebene durchgeführte Replikation wird als Host-Level-Replikation bezeichnet und ist effizienter als die Guest-Level-Replikation.
- Verwenden Sie Application-Aware Replikation, um Datenverluste zu vermeiden. Wenn ein für die Replikation erforderlicher VM-Schnappschuss erstellt wird, während diese Anwendungen ohne zusätzliche Maßnahmen ausgeführt werden, hätte dies ähnliche Auswirkungen wie ein unerwarteter Stromausfall und ein unerwartetes Herunterfahren, und die Daten könnten verloren gehen.
Bei Application-Aware Methoden werden die Anwendungen angehalten (quiesced) und der Speicher geleert, sodass vor der Erstellung des Schnappschusses keine Daten auf die Festplatte geschrieben werden können. Sobald der konsistente Snapshot erstellt wurde, kann eine VM-Replik erstellt werden. Solche VM-Replikate können erfolgreich wiederhergestellt werden, wobei die darin enthaltenen Anwendungen ordnungsgemäß ausgeführt werden.
NAKIVO Backup & Replication unterstützt Application-Aware Replikation auf Host-Ebene für VMware-VMs, Hyper-V-VMs und EC2-Instanzen mit spezieller Funktionalität für Microsoft SQL Server, Exchange Server und Active Directory Domain Controller.
Schritt 3. Erstellen eines Disaster-Recovery-Workflows
Um einen DR-Workflow zu erstellen, benötigen Sie eine spezielle Disaster-Recovery-Lösung wie NAKIVO Backup & Replication, die über eine integrierte Standortwiederherstellung verfügt, um DR-Sequenzen zu orchestrieren und zu automatisieren.
- Was ist ein Disaster-Recovery-Workflow?
- Verfügbare Aktionen für einen DR-Workflow
- So erstellen Sie einen Disaster-Recovery-Workflow
- NAKIVOs Standortwiederherstellung-Konfigurationsanleitung
Was ist ein Disaster-Recovery-Workflow?
Ein DR-Workflow ist eine Abfolge von Aktionen, die im Rahmen des Disaster Recovery-Prozesses ausgeführt werden, um Workloads sicher und schnell auf Replikate umzuschalten. Der Workflow organisiert den Failover-Prozess mit Aktionen in Bezug auf Quell-VMs, Ziel-VMs, zu erfüllende Bedingungen usw. Sie sollten festlegen, in welcher Reihenfolge die Aktionen ausgeführt werden sollen, da einige Disaster Recovery-Verfahren vom Ergebnis der Ausführung anderer Verfahren abhängen können.
Verfügbare Aktionen der Standortwiederherstellung
Mit der Funktionalität der Standortwiederherstellung können Sie komplexe DR-Sequenzen erstellen, indem Sie Aktionen und Bedingungen in einem einzigen Workflow kombinieren. Jede Aktion kann in NAKIVO Backup & Replication nur im Testmodus, nur im Produktionsmodus oder in beiden Modi (dies ist die Standardeinstellung) ausgeführt werden. Sie können eine oder alle der folgenden Aktionen in einer Sequenz einfügen:
- Failover – initiiert ein Failover zu replizierten VMware-VMs, Hyper-V-VMs oder EC2-Instanzen.
- Failback – gibt Workloads von den Replikaten der VM an die Quelle der VM zurück. Die seit dem Failover in den VM-Replikaten vorgenommenen Änderungen werden bei der Durchführung des Failback-Vorgangs in die Quelle geschrieben. Die VMs werden synchronisiert, und die Quelle befindet sich wieder im tatsächlichen Produktionszustand.
- Start – VMware-VMs starten, Hyper-V-VMs oder EC2-Instanzen starten.
- Stop – VMware-VMs stoppen, Hyper-V-VMs oder EC2-Instanzen stoppen.
- Job ausführen – Führt einen Backup-Job, Replikationsjob, Standortwiederherstellungsjob, Backupkopie-Job oder Flash-VM-Boot-Job aus.
- Aufträge stoppen – Stoppt einen Auftrag (einen der im vorherigen Punkt aufgeführten Aufträge).
- Skript ausführen – Führt ein Skript auf einem der folgenden Ziele aus: dem Server mit dem Director, einem Remote-Windows-Server, einem Remote-Linux-Server, einer VMware-VM, einer Hyper-V-VM oder einer EC2-Instanz.
- Repository anhängen – Hängt ein Backup-Repository an, das von NAKIVO Backup & Replication zum Speichern von Backups verwendet wird.
- Repository abtrennen – Trennt ein Backup-Repository.
- E-Mail senden – Sendet eine E-Mail mit der von Ihnen verfassten Nachricht an einen oder mehrere definierte Empfänger.
- Warten – Wartet die festgelegte Zeit, bevor mit der nächsten Aktion fortgefahren wird.
- Bedingung prüfen – prüft basierend auf Ihrer Eingabe (ganzer oder Teil eines Ressourcennamens) eine der folgenden Bedingungen:
- Die Ressource ist vorhanden
- Die Ressource wird ausgeführt
- IP/Hostname ist erreichbar
So erstellen Sie einen Standortwiederherstellungs-Workflow
Sehen wir uns ein Beispiel für die Erstellung eines Standortwiederherstellungs-Auftrags in NAKIVO Backup & Replication an.
Unsere Konfiguration
Hier ist die Konfiguration, die wir betrachten werden: ein primärer (Produktions-)Standort mit VMware vSphere-VMs und ein DR-Standort an einem entfernten Standort:
- DC-VM ist eine Windows-basierte VM, auf der Active Directory Domain Controller ausgeführt wird.
- FS-VM ist eine Windows-basierte VM mit einem Dateiserver (für die Dateifreigabe wird das SMB-Protokoll verwendet). Für die Benutzerauthentifizierung wird Active Directory verwendet. Oracle-Datenbank-Dumps werden auf dem Dateiserver gespeichert.
- Ora-DB ist die VM, auf der die Oracle-Datenbank ausgeführt wird.
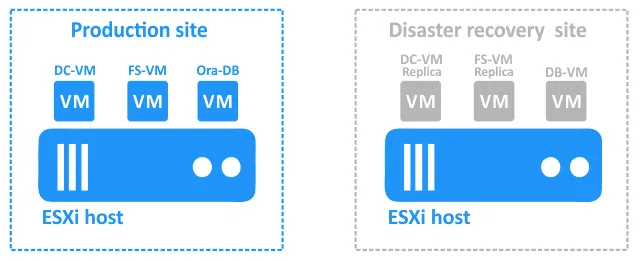
Der Disaster-Recovery-Standort enthält die folgenden VMs:
- DC-VM-replica und FS-VM-replica sind Replikate der Produktions-VMs. Sie können als Ziele für Failover verwendet werden.
- DB-VM ist eine Linux-basierte VM mit installierter Oracle-Datenbanksoftware enthält jedoch keine Datenbanken.
Die Datenbank wird mit NAKIVO Backup & Replication auf Datenbankebene auf FS-VM am Produktionsstandort gesichert (diese Oracle-Datenbank-Backup ist anwendungskonsistent). FS-VM und DC-VM werden mit der NAKIVO-Lösung auf Host-Ebene zum DR-Standort repliziert.
Reihenfolge der VM-Wiederherstellung
Bei einem Vorfall, der zum Ausfall des Produktionsstandorts führt, müssen die Komponenten am DR-Standort wie folgt wiederhergestellt werden:
- Failover von DC-VM zu DC-VM-Replik.
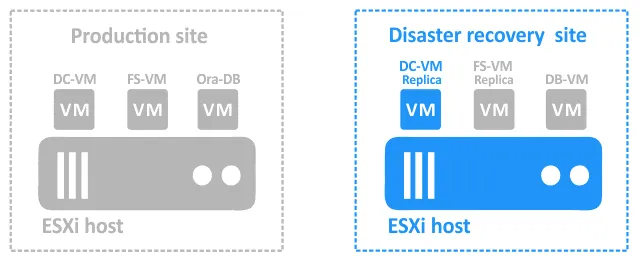
- Sobald DC-VM-Replik betriebsbereit ist, Failover von FS-VM zu FS-VM-Replik . Sie müssen in dieser Reihenfolge vorgehen, da FS-VM für die Benutzerauthentifizierung auf dem Dateiserver auf DC-VM angewiesen ist.
- Sobald diese beiden VMs ausgeführt werden, kann DB-VM auf das freigegebene Verzeichnis auf dem Dateiserver zugreifen, in dem der Speicherauszug gespeichert ist. Jetzt kann DB-VM gestartet werden.
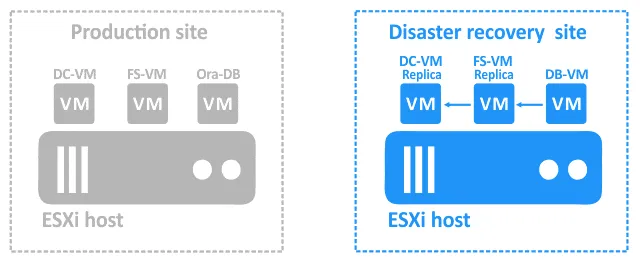
- Sobald DB-VM ausgeführt wird, führen Sie ein Skript aus, mit dem die Datenbank aus dem Speicherauszug auf dem Dateiserver wiederhergestellt werden kann. Die blauen Pfeile in den obigen Diagrammen zeigen die Abhängigkeiten.
Beachten Sie, dass es einige Zeit dauern kann, bis Dienste auf einer eingeschalteten VM-Replik nach dem Failover gestartet werden und bevor ein Failover auf das weitere Replikat oder die Wiederherstellung einer Anwendung oder Datenbank erfolgt. Diese Wartezeit sollte Teil der DR-Sequenz sein.
Für diese Reihenfolge des VM-Failovers müssen Sie einen Standortwiederherstellung-Auftrag in NAKIVO Backup & Replication mit der folgenden Logik erstellen:
- Aktion 1 : Failover von DC-VM . Warten Sie, bis diese Aktion abgeschlossen ist, bevor Sie mit dem nächsten Schritt fortfahren. Beenden Sie den Auftrag, wenn diese Aktion fehlschlägt.
- Aktion 2 . Warten Sie 3 Minuten lang.
- Aktion 3 . Prüfen Sie die Bedingung von DC-VM-Replik . Prüfen Sie, ob die Ressource ausgeführt wird. Wenn die Ressource ausgeführt wird, fahren Sie mit der nächsten Aktion im Auftrag für Standortwiederherstellung fort. Wenn nicht, beenden Sie den Auftrag und melden Sie einen Fehler.
- Aktion 4 . Failover von FS-VM . Warten Sie, bis dieser Auftrag abgeschlossen ist, bevor Sie zur nächsten Aktion weiterfahren. Beenden Sie den Auftrag, wenn diese Aktion fehlschlägt.
- Aktion 5 . Warten Sie 3 Minuten lang.
- Aktion 6 . Prüfen Sie die Bedingung von FS-VM-Replik . Wenn die Ressource ausgeführt wird, fahren Sie mit der nächsten Aktion des Site-Recovery-Auftrags fort. Ist dies nicht der Fall, stoppen Sie den Auftrag und melden Sie einen Fehler.
- Aktion 7 . Starten Sie DB-VM . Warten Sie, bis diese Aktion abgeschlossen ist, bevor Sie mit der nächsten Aktion fortfahren. Beenden Sie den Auftrag, wenn diese Aktion fehlschlägt.
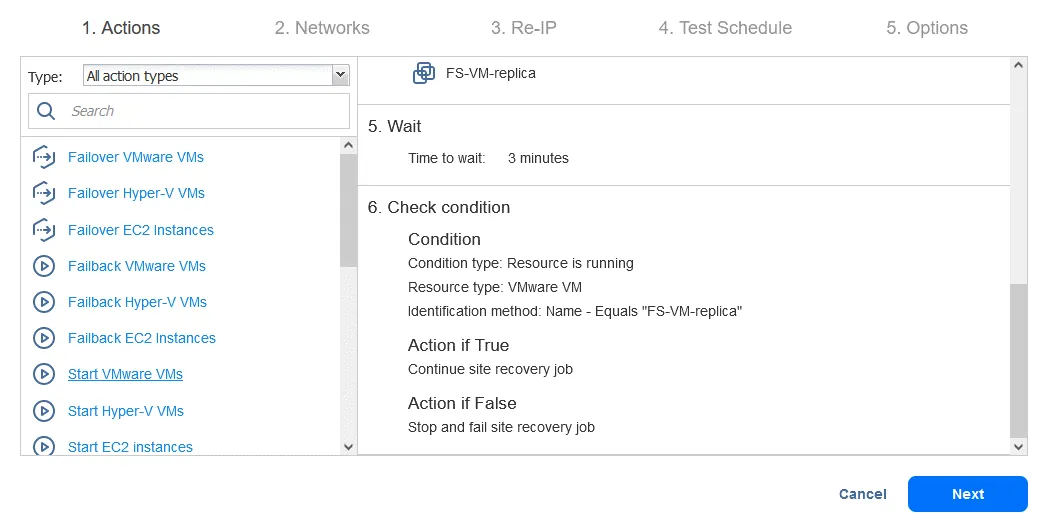
- Aktion 8 . Warten Sie 5 Minuten lang.
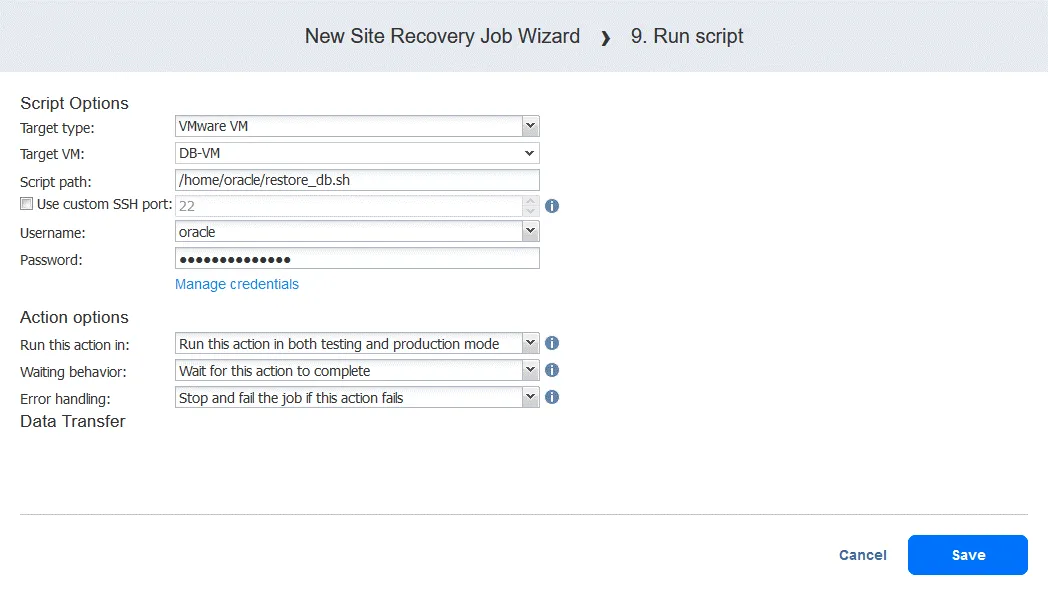
- Aktion 9 . Skript ausführen . Zieltyp: VMware VM. Ziel-VM: DB-VM. Skriptpfad: /home/oracle/restore_db.sh (wenn Sie diesen Schritt hinzufügen, müssen Sie den Benutzernamen und das Passwort eines Kontos mit ausreichenden Berechtigungen zum Ausführen des Skripts eingeben).
NAKIVO-Anleitung zur Standortwiederherstellung
Erstellen wir einen neuen Standortwiederherstellungs-Auftrag auf der Grundlage des oben skizzierten Plans. Klicken Sie auf der Seite Aufträge Ihrer NAKIVO Backup & Replication-Instanz auf Erstellen > Standortwiederherstellungs-Auftrag .
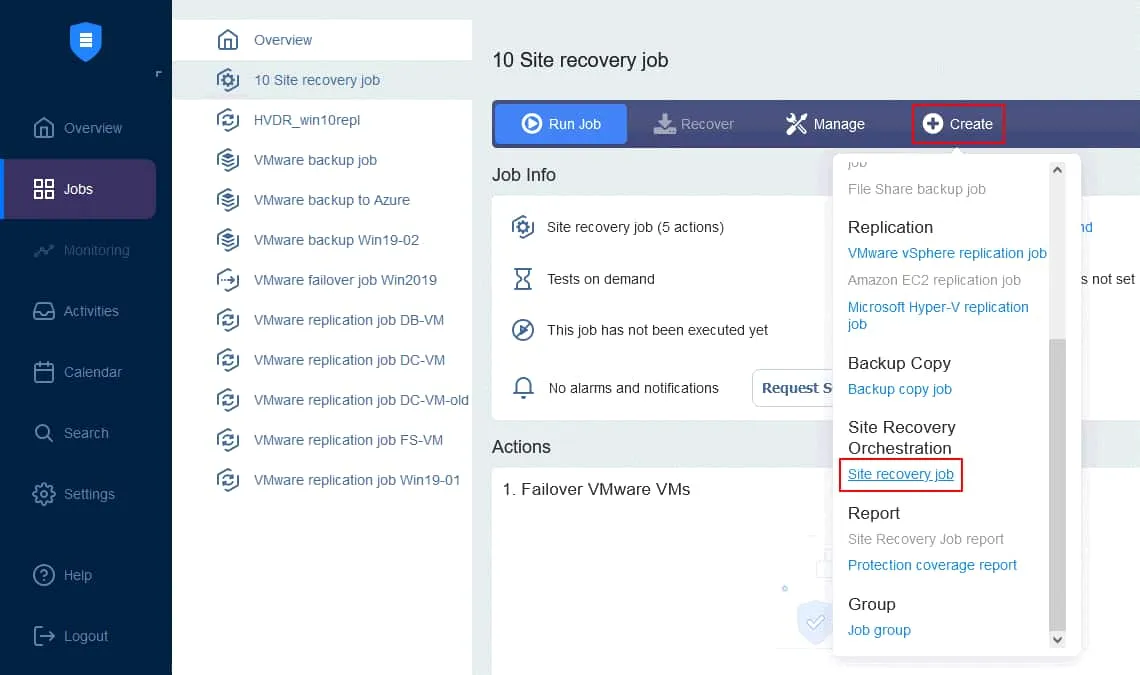
1. Aktionen
Der Assistent für neue Standortwiederherstellungs-Aufträge wird gestartet. Im linken Bereich finden Sie Aktionen, die dem Auftrag hinzugefügt werden können. Klicken Sie einfach auf eine Aktion, um sie zur Sequenz hinzuzufügen. Beachten Sie, dass Sie keine Aktionen für verschiedene Plattformen in einer Sequenz mischen können (wir erstellen einen Auftrag für VMware-VMs).
Aktion 1. Failover DC-VM
- Klicken Sie im linken Bereich auf Failover VMware-VMs .
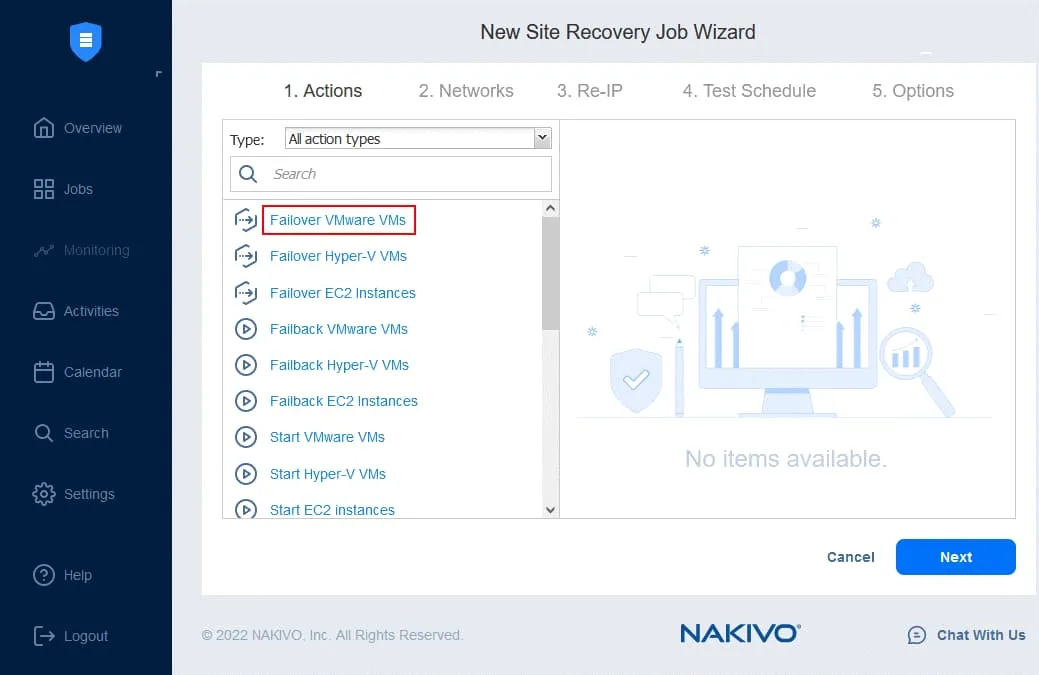
- Wählen Sie im linken Bereich die VM-Replik aus einem vorhandenen Replikationsauftrag aus. In unserem Workflow ist das Failover zu DC-VM-Replik die erste Aktion. Im rechten Fensterbereich können Sie einen Wiederherstellungspunkt auswählen. Standardmäßig wird der neueste Wiederherstellungspunkt verwendet.
Klicken Sie auf Weiter , um fortzufahren.
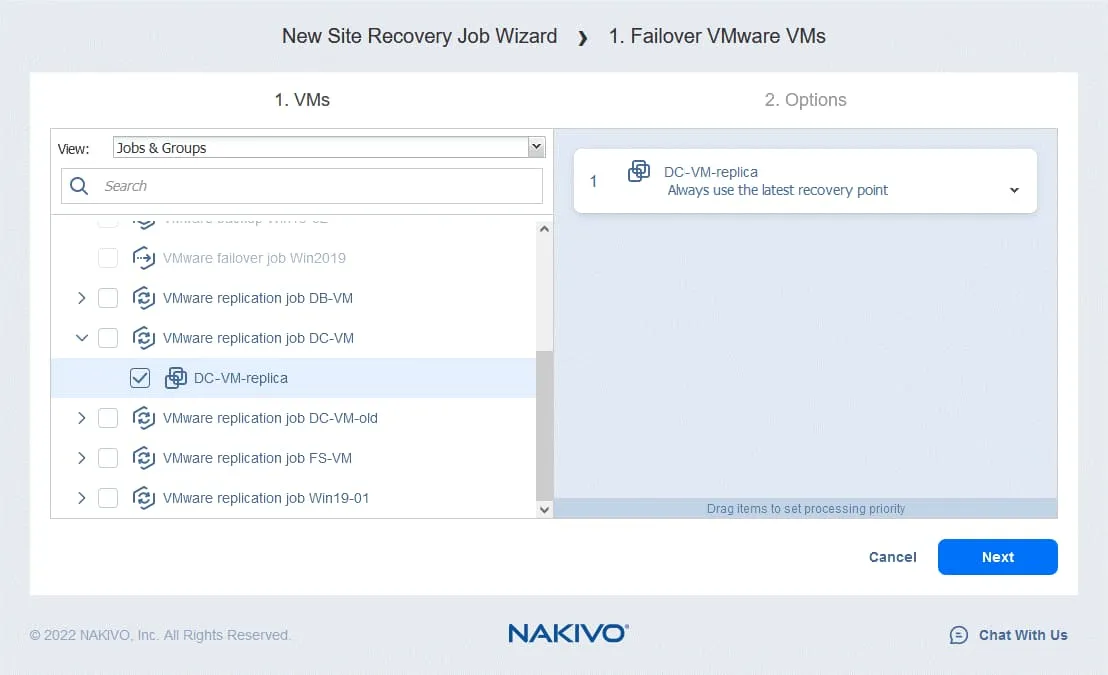
- Für die Optionen zur Disaster Recovery Failover können Sie die Option Quell-VMs ausschalten deaktivieren. Diese Option kann verwendet werden, um einen Konflikt zwischen IP-Adressen zu vermeiden, wenn die Quell-VMs und Replikate dieselben Netzwerke verwenden.
Basierend auf der oben beschriebenen Logik wählen wir die folgenden Optionen aus:
- Diese Aktion ausführen in: Diese Aktion sowohl im Test- als auch im Produktionsmodus ausführen
- Warteverhalten: Warten auf den Abschluss dieser Aktion
- Fehlerbehandlung: Stopp und Fehler beim Auftrag, wenn diese Aktion fehlschlägt
Klicken Sie auf Speichern , um die erstellte Aktion zu speichern.
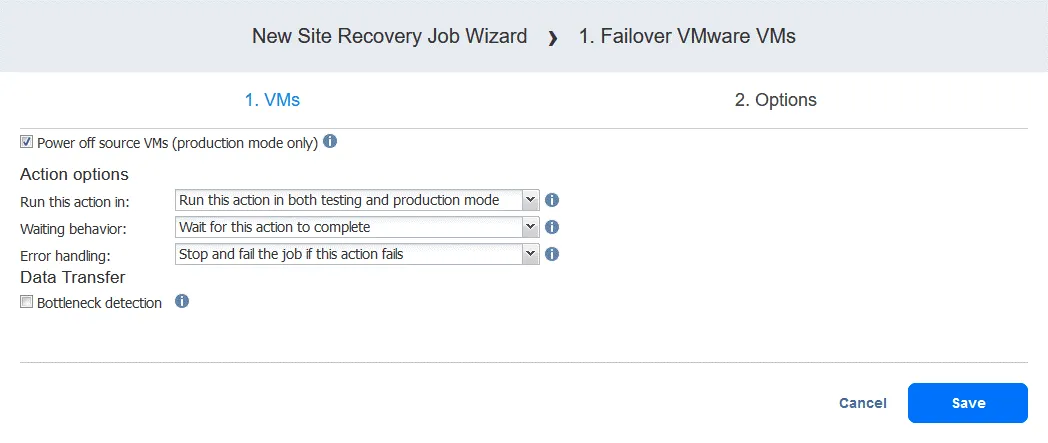
Aktion 2. 3 Minuten warten
Eine Warteaktion ist in diesem Fall nützlich, da die folgende Failover-Aktion im Workflow (Failover zu FS-VM-Replik ) erfordern würde, dass die DC-VM-Replik aktiv ist und bereits mit Active Directory-Domänendiensten ausgeführt wird.
- Klicken Sie im linken Bereich des Bildschirms „ “ (Aktionen) ( ) auf „ “ (Warten) ( ).
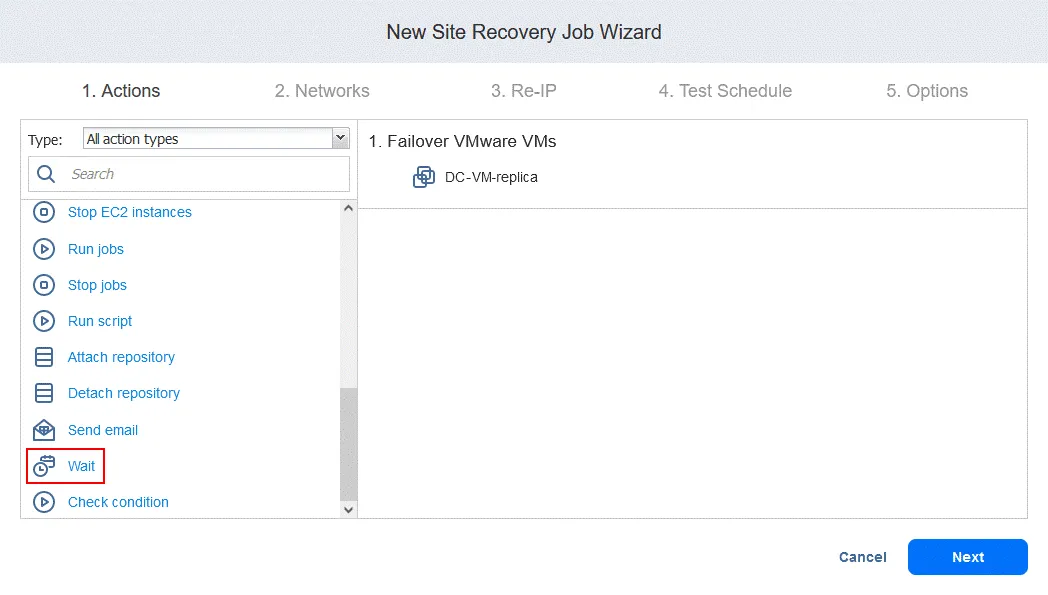
- Wählen Sie die Wartezeit aus (wir verwenden „ “ (3 Minuten) ( ).
Wählen Sie die Aktionsoptionen wie bei der ersten Aktion aus und klicken Sie auf „ “ (Save) ( ).
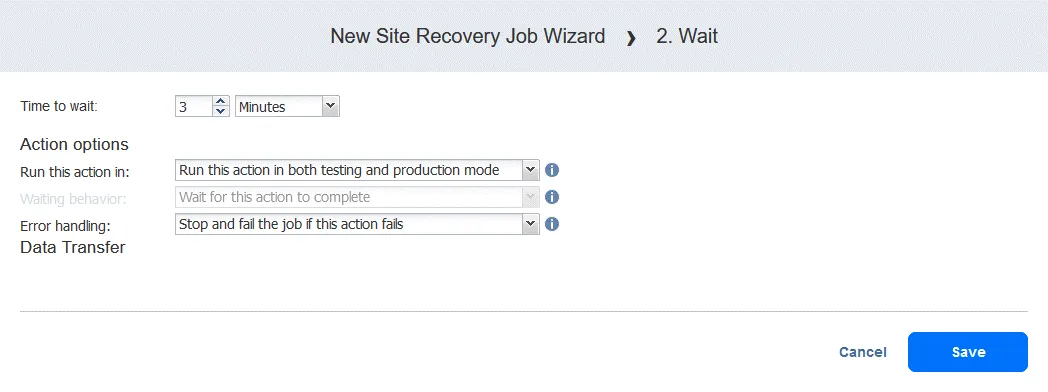
Die neue Aktion wird nach der vorherigen Aktion am Ende der Liste hinzugefügt. Sie können Aktionen neu anordnen, bearbeiten oder entfernen. Bewegen Sie einfach den Mauszeiger über eine Aktion, um die Optionen anzuzeigen.
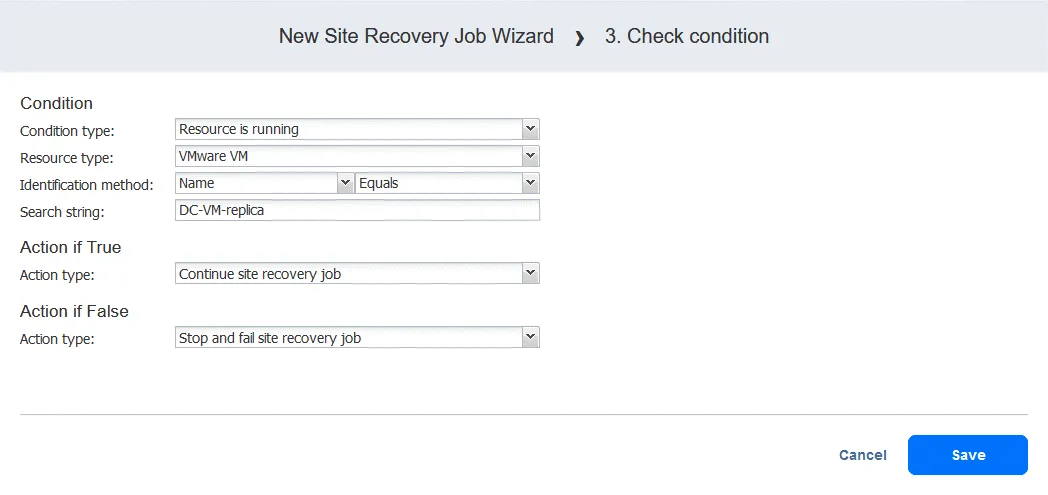
Aktion 3. Prüfen Sie die Bedingung von DC-VM-Replik
- Klicken Sie im linken Bereich des Bildschirms Aktionen auf Bedingung prüfen , um zu überprüfen, ob die VM, die in der ersten Aktion ausgefallen ist, ausgeführt wird.
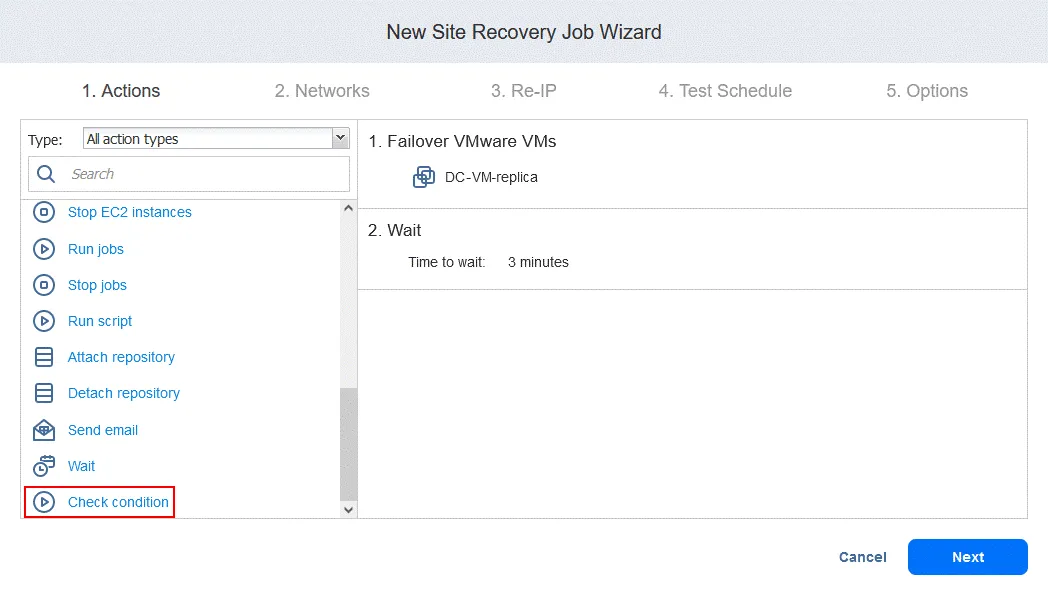
- Konfigurieren Sie diese Aktion wie folgt:
- Wählen Sie den Bedingungstyp aus: Ressource wird ausgeführt . Die anderen Optionen sind Ressource existiert oder IP/Hostname ist erreichbar.
- Wählen Sie den Ressourcentyp aus: VMware-VM .
- Identifikationsmethode auswählen: Name (die andere Option ist ID ), um die betreffende VM zu identifizieren. Sie können einen beliebigen Teil der Zeichenfolge der VM verwenden. Da wir hier den genauen Namen kennen, verwenden wir die Funktion Gleich .
- Suche definieren: DC-VM-replica .
Jetzt haben wir eine Aktion, die überprüft, ob die VMware-VM mit dem Namen DC-VM-replica ausgeführt wird. Klicken Sie auf Speichern , um fortzufahren.
Aktion 4. Failover FS-VM
- Wie bei Aktion 1 klicken Sie auf Failover VMware VMs .
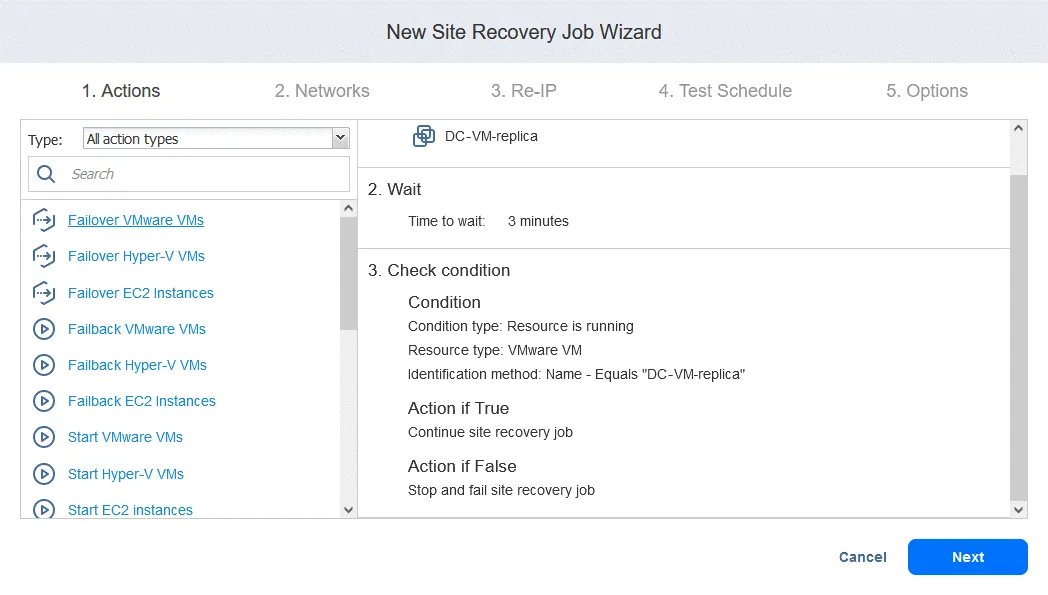
- In diesem Fall wählen wir FS-VM-Replikat aus. Klicken Sie auf Weiter und wählen Sie dann für die Failover-Aktion dieselben Optionen aus, die Sie in Aktion 1 ausgewählt haben, und klicken Sie auf Speichern .
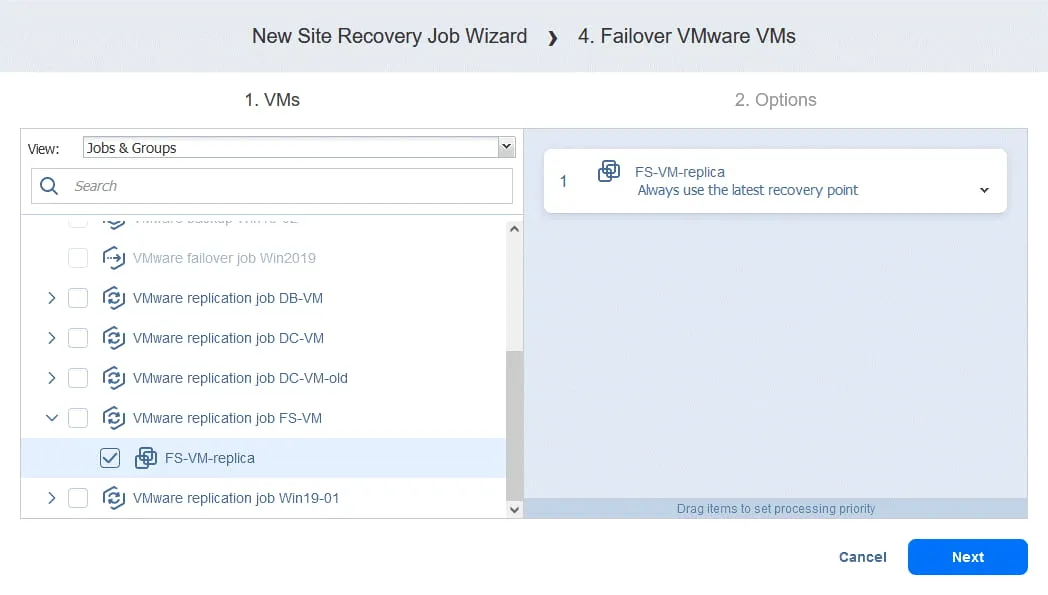
Aktion 5. Warten Sie 3 Minuten
Klicken Sie auf Warten und konfigurieren Sie diese Aktion wie in Aktion 2 . Die angegebene Zeit beträgt in unserem Fall erneut 3 Minuten .
Aktion 6. Prüfen Sie die Bedingung von FS-VM-Replica
Klicken Sie auf Prüfen Sie die Bedingung , um zu überprüfen, ob die VMware-VM FS-VM-Replica ausgeführt wird. Beziehen Sie sich auf die Aktion 2 und wählen Sie dieselben Optionen aus – außer natürlich den VM-Name.
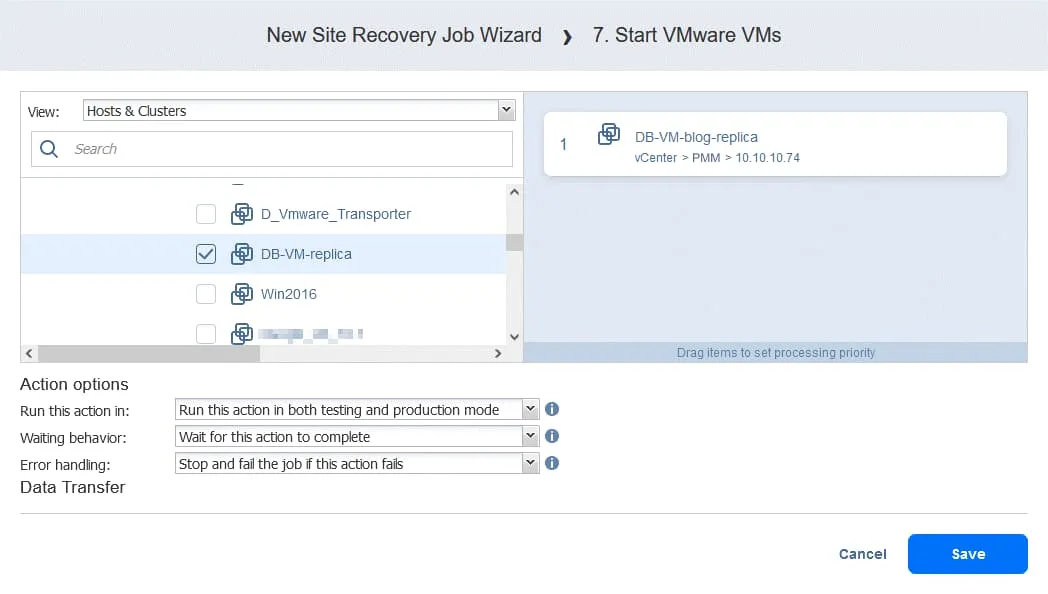
Aktion 7. Starten Sie DB-VM
- Klicken Sie auf VMware-VMs starten im linken Bereich des Bildschirms Aktionen .
- Wählen Sie DB-VM . Diese VM kann gestartet werden, sobald Sie sicher sind, dass die FS-VM-Replik läuft. Wählen Sie unten auf der Seite die gleichen Aktionsoptionen wie in den vorherigen Aktionen. Klicken Sie dann auf Speichern .
Aktion 8. Warten Sie 5 Minuten
Warten Sie 5 Minuten. Klicken Sie auf „ “ (Warten) „ “ (Warten) und konfigurieren Sie diese Aktion ähnlich wie für „ “ (Warten) Aktion 2 „ “ (Warten). Dies sollte ausreichend Zeit sein, um den Oracle-Dienst auf „ “ (Warten) DB-VM „ “ (Warten) zu starten. „
“ (Aktion 9. Skript ausführen) „
- “ (Warten) Klicken Sie auf dem Bildschirm „ “ (Aktion 1. Skript ausführen) „ “ (Aktion 1. Skript ausführen) „ “ (Warten) „Run script“ (Skript ausführen) „ “ (Warten). Denken Sie daran, dass dieses Skript dazu dient, die Oracle-Datenbank auf Datenbankebene aus einem auf „ “ (Warten) FS-VM-Replik „ “ (Warten) gespeicherten Dump wiederherzustellen. „
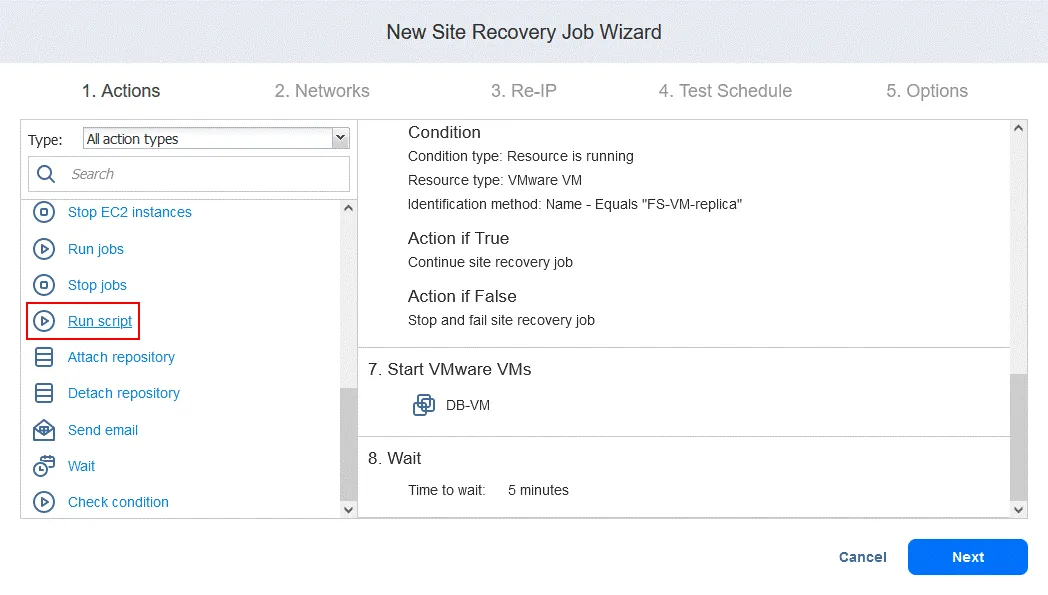
- “ (Aktion 10. Skript ausführen) Definieren Sie die Skriptoptionen. In unserem Fall:
- Zieltyp: VMware VM
- Ziel-VM: DB-VM
- Skriptpfad: /home/oracle/restore.db.sh
- Benutzername: oracle
- Passwort: (Passwort)
Ihr Skriptpfad, Benutzername und Passwort unterscheiden sich davon. Vergessen Sie nicht, sicherzustellen, dass die Skriptdatei ausführbar ist und dass der Benutzer über ausreichende Berechtigungen zum Ausführen des Skripts verfügt. Die Aktionsoptionen werden in diesem Beispiel wie gewohnt konfiguriert.
Klicken Sie auf Speichern , wenn Sie bereit sind, fortzufahren.
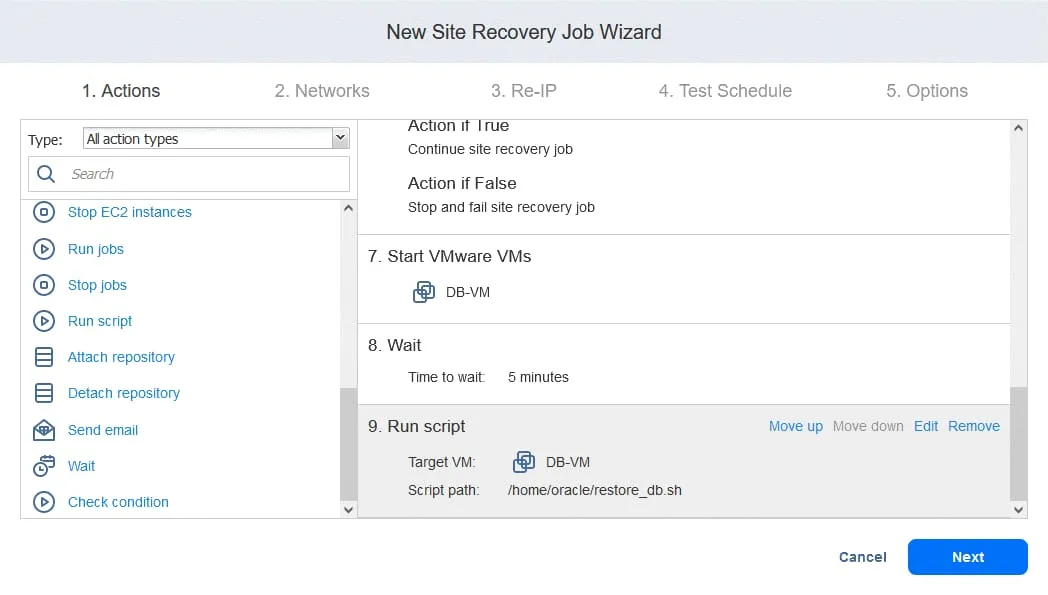
- Jetzt können Sie alle konfigurierten Aktionen sehen. Klicken Sie auf die Schaltfläche Weiter , um mit der Konfiguration des Standortwiederherstellungsauftrags gemäß Ihrem Disaster Recovery-Plan fortzufahren.
2.
Netzwerke
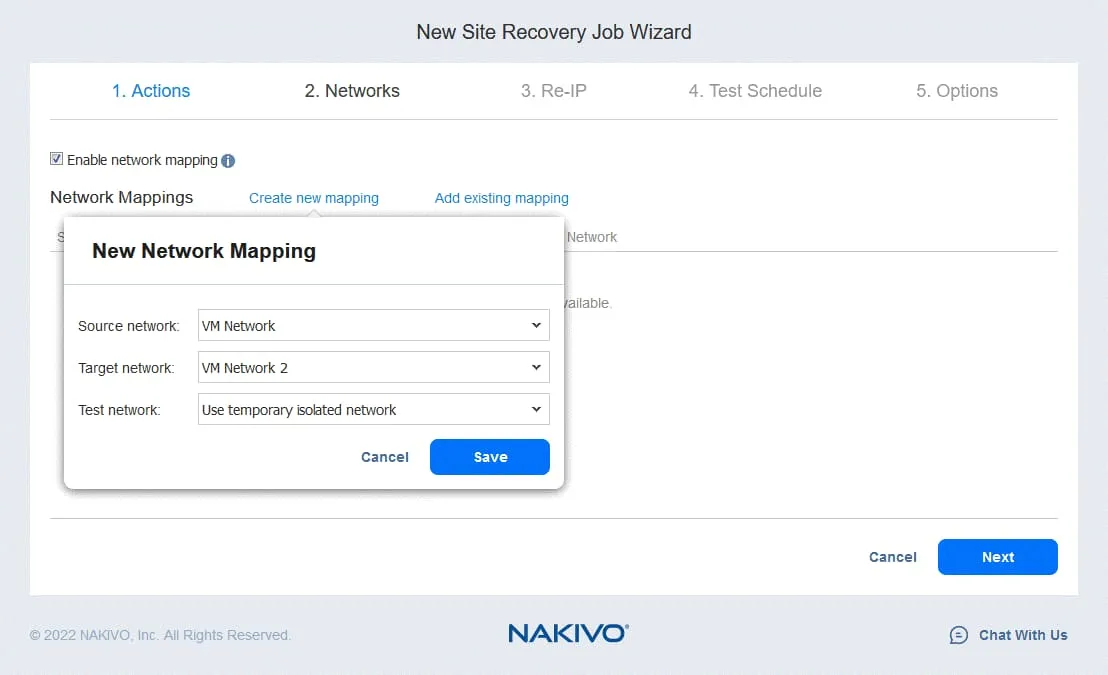
Wenn die VMs am Produktionsstandort und am DR-Standort mit unterschiedlichen Netzwerken verbunden sind , wählen Sie Netzwerkzuordnung aktivieren . Klicken Sie auf Neue Zuordnung erstellen und wählen Sie im Popup-Fenster ein Quellnetzwerk, ein Zielnetzwerk und ein Netzwerk für das Testen von Aufträgen für die Standortwiederherstellung aus.
Klicken Sie auf Speichern , um die Netzwerkzuordnungsregel zu speichern, und klicken Sie dann auf Weiter .
Hinweis : Sie können auch vorhandene Zuordnungsregeln verwenden, wenn Sie diese in anderen Replikations-, Failover- oder Standortwiederherstellung-Aufträgen konfiguriert haben.
3. Re-IP
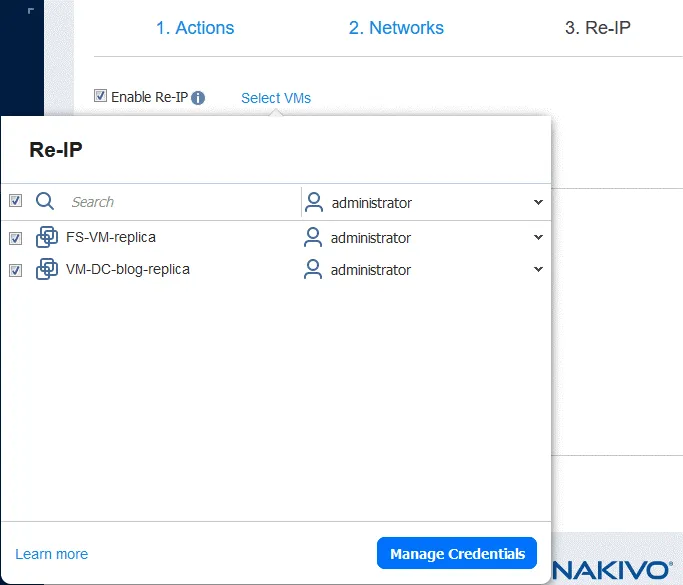
Wenn die für die VM-Verbindung am Quellstandort und am Zielstandort verwendeten Netzwerke unterschiedliche IP-Adressen haben, sollten Sie Re-IP aktivieren, indem Sie Re-IP aktivieren auswählen.
- Erstellen Sie eine neue Re-IP-Regel, indem Sie auf „ “ (Neue Regel erstellen) klicken. „ “ (Neue Regel erstellen) „ “ (Neue Regel erstellen) „ “ (Neue Regel erstellen) „Save“ (Speichern) „ “ (Neue Regel erstellen) „Save“ (Speichern) „ “ (Neue Regel erstellen) „Save“ (Speichern) „
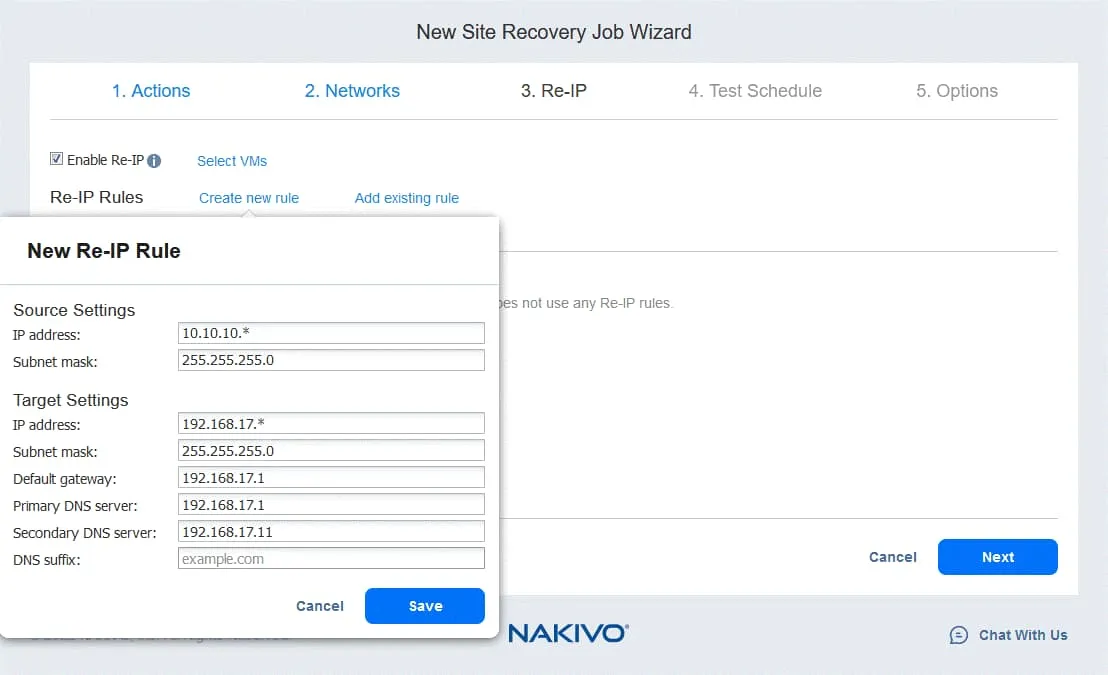
- “ (Neue Regel erstellen) „Click“ (Klicken) „ “ (Neue Regel erstellen) „Wählen Sie VMs aus“ (Wählen Sie VMs aus) „ “ (Neue Regel erstellen) „Wählen Sie VMs aus“ (Wählen Sie VMs aus) „Wählen Sie VMs aus“ (Wählen Sie VMs aus) „Wählen Sie VMs aus“ (Wählen Sie VMs aus) „Wählen Sie VMs aus“ (Wählen Sie VMs aus) „Wählen Sie VMs aus“ (Wählen Sie VMs aus) „Wählen Sie VMs aus“ (Wählen Sie VMs aus) „Wählen Sie VMs aus“ (Wählen Sie VMs aus) „Wählen Sie VMs aus“ (Wählen Sie VMs aus) „Wählen Sie VMs aus“ (Wählen Sie VMs aus) „Wählen Sie VMs aus“ (Wählen Sie VMs aus) „ 4. Plan testen
Sie können einen Plan speziell für die Ausführung von Site Recovery-Aufträgen im Testmodus und die Durchführung von Disaster Recovery-Tests erstellen. Auf diese Weise können Sie testen, ob der Auftrag innerhalb der erforderlichen Zeiträume erfolgreich ausgeführt werden kann. Wenn Sie fertig sind, klicken Sie auf „Weiter“.
Wir werden in Schritt 6 näher auf das Testen von Site Recovery-Aufträgen eingehen.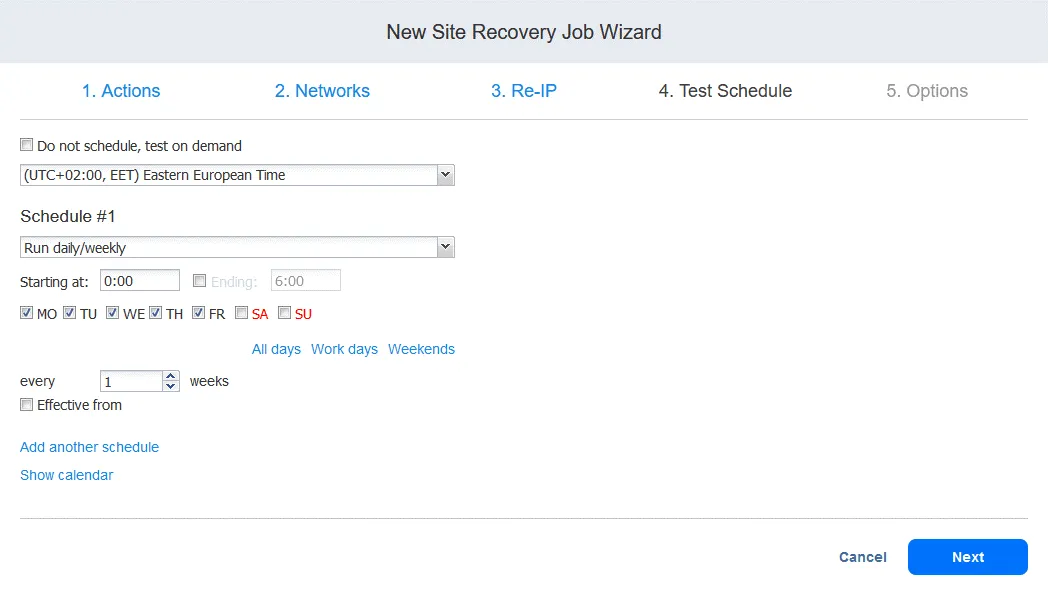
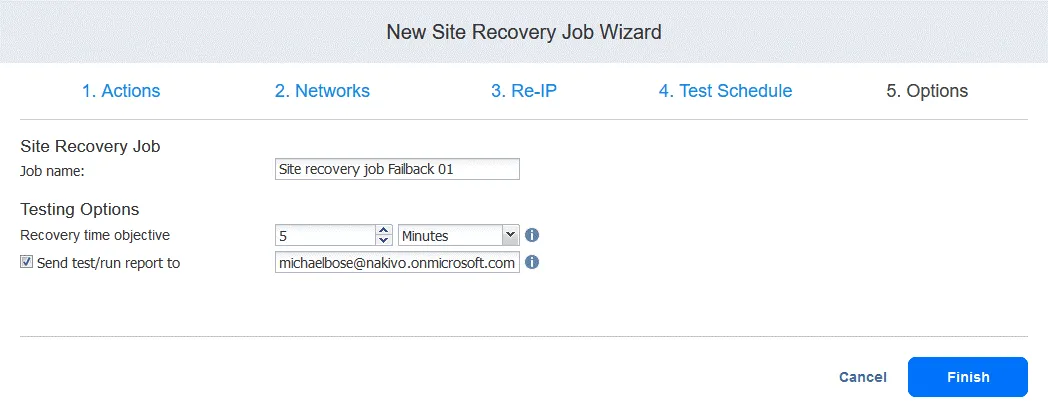
5. Optionen
Geben Sie den Auftrags-Name und das Wiederherstellungszeit-Ziel ein. Klicken Sie auf „ “ (Fertigstellen) „Finish“ (Fertigstellen) „ “ (Fertigstellen) „Finish“ (Fertigstellen), wenn die Konfiguration abgeschlossen ist. „
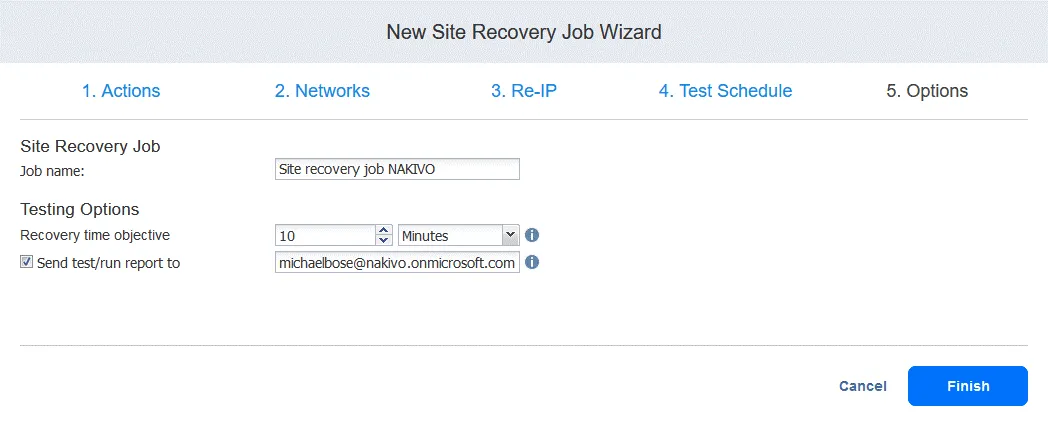
“ (Fertigstellen) „Step 4. Re-Protecting the Environment“ (Schritt 4. Erneuter Schutz der Umgebung) „
“ (Schritt 4. Erneuter Schutz der Umgebung) Nachdem die VMs ausgefallen sind und die Workloads zum DR-Standort migriert wurden, sind die ursprünglichen Produktions-VMs nun offline, und die Replikate am DR-Standort sind nun die einzigen funktionsfähigen Kopien. Wenn nun ein eingeschaltetes VM-Replikat ausfällt, haben Sie keine Möglichkeit, die Daten und Workloads schnell wiederherzustellen. „
“ (Schritt 4. Erneuter Schutz der Umgebung) Um die auf dem DR-Standort ausgeführten VMs zu schützen, sollten Sie diese VMs an einen anderen sicheren Ort replizieren. Auf diese Weise können Sie bei einem Ausfall der auf dem DR-Standort ausgeführten VM schnell auf die neue VM-Replik umschalten.
Mit der Funktionalität der Standortwiederherstellung können Sie eine automatische Replikation konfigurieren, sobald das VM-Failover abgeschlossen ist. Hier finden Sie ein Beispiel dafür, wie Sie VMs nach einem Failover mit einem Auftrag zur Standortwiederherstellung erneut schützen können.
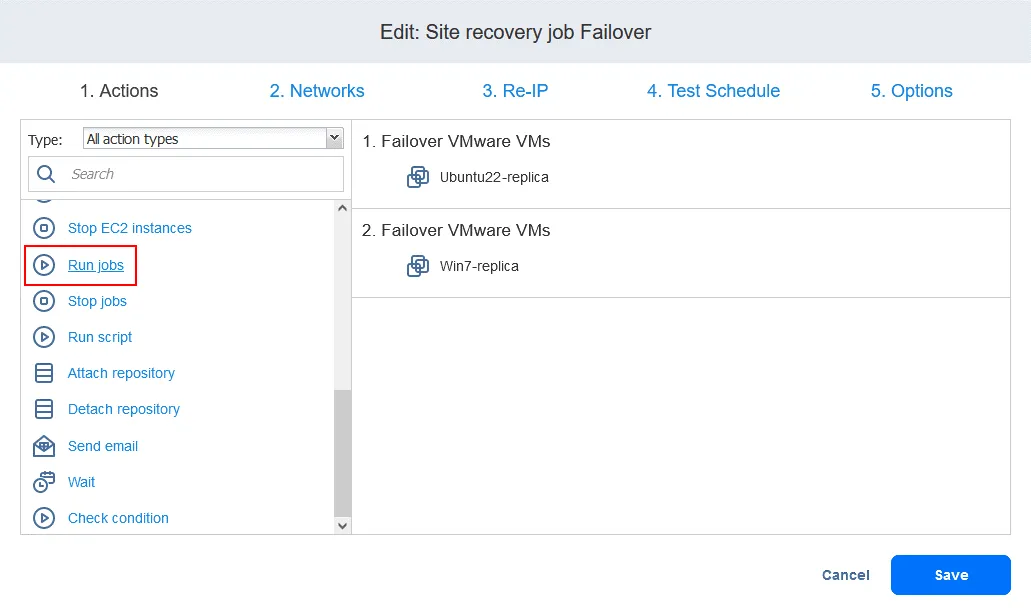
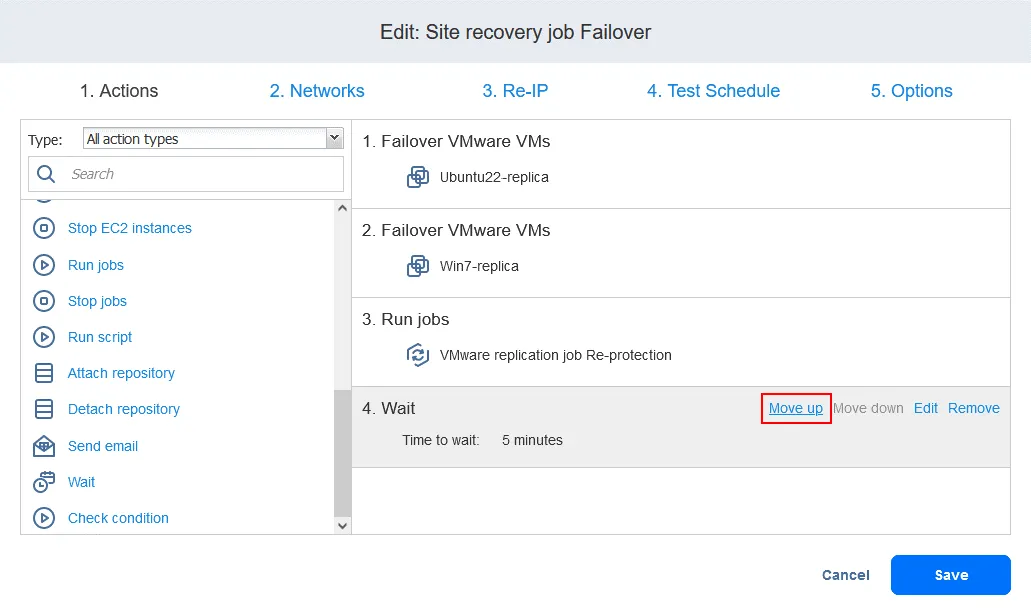
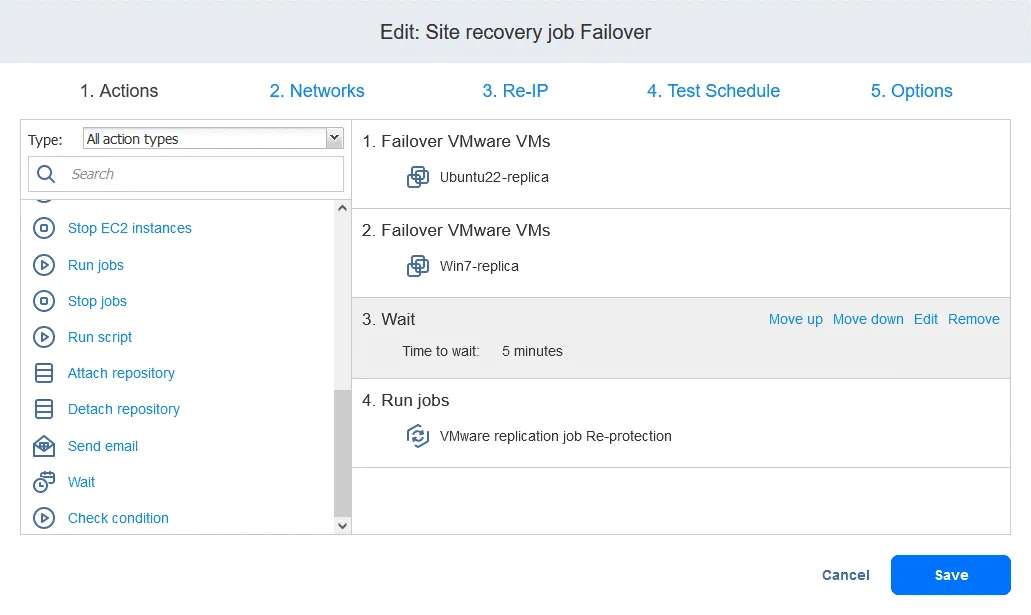
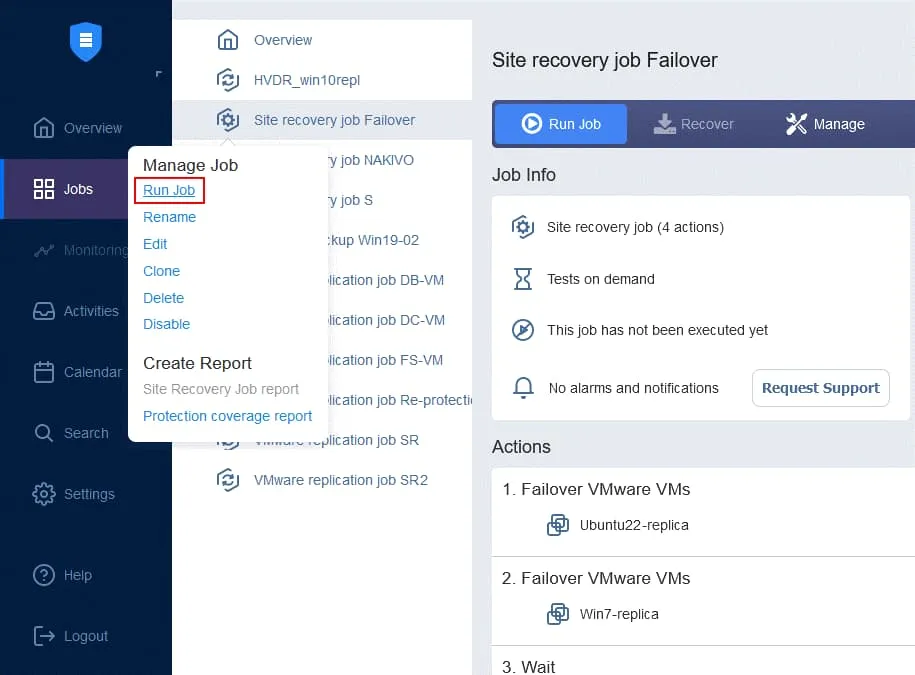
- Klicken Sie auf der Seite „ Aufträge “ mit der rechten Maustaste auf den Namen des kürzlich erstellten Site Recovery-Auftrags. Klicken Sie im Kontextmenü auf „ Bearbeiten “. Sie können Ihre zuvor zum Site Recovery-Auftrag hinzugefügten Failover-Aktionen sehen. Suchen Sie „ Aufträgeausführen “. Sie können Ihre zuvor zum Site Recovery-Auftrag hinzugefügten Failover-Aktionen sehen. Suchen Sie „ Aufträgeausführen “. Wählen Sie den Replikationsjob aus der Jobliste aus. Wählen Sie wie gewohnt die Aktionsoptionen aus und klicken Sie auf Speichern . Fügen Sie eine Warten Aktion zwischen der Failover-Aktion und dem Replikationsauftrag ein. Dadurch erhält die VM-Replik etwas Zeit, um zu starten und das Betriebssystem zu laden (Sie können keine ausgeschaltete VM replizieren). Klicken Sie in der Liste der Aktionen im linken Bereich auf Warten . Wählen Sie eine Wartezeit aus – 5 Minuten sollten ausreichen. Wählen Sie die Aktionsoptionen aus und klicken Sie auf „ “ (Aktionsreihenfolge bearbeiten) und „Save“ (Speichern) ( ). „ “ (Aktionsreihenfolge bearbeiten) Wenn Sie die Aktion hinzufügen, wird sie an das Ende der Aktionsliste angehängt. Klicken Sie auf „ “ (Aktionsreihenfolge bearbeiten) und „Move up“ (Nach oben verschieben) ( ) und verschieben Sie die Aktion „ “ (Warten) ( ) von der vierten Position an die dritte Position – sie muss vor der Replikation erfolgen. „ “ (Aktionsreihenfolge bearbeiten) Jetzt sind die Aktionen in der erforderlichen Reihenfolge angeordnet. „ “ (Aktionsreihenfolge bearbeiten) Schließlich ist der Standortwiederherstellungs-Auftrag bereit, für die Durchführung des VM-Failovers und die automatische erneute Sicherung der für das Failover verwendeten VM-Replikate verwendet zu werden. Klicken Sie mit der rechten Maustaste auf den Namen Ihres Standortwiederherstellungs-Auftrags auf der Startseite und klicken Sie im Kontextmenü auf „ “ („Auftrag ausführen“) „ “ („Auftrag ausführen“). Schritt 5. Failback Failback ist der Prozess der Wiederherstellung virtueller Maschinen in ihrem letzten Zustand vom DR-Standort zurück zum ursprünglichen oder einem neuen Produktionsstandort. Um zu verstehen, warum Sie den Failback benötigen, lassen Sie uns noch einmal zusammenfassen, wie der Failover funktioniert: Wenn eine Katastrophe eintritt (oder vorhergesagt wird), wird ein Failover auf ein Replikat der VM durchgeführt. Alle Änderungen an der VM (z. B. Transaktionen, die einer Datenbank hinzugefügt werden, wenn Kunden Online-Käufe tätigen) werden auf eine virtuelle Festplatte des Replikats der VM geschrieben. Einige Blöcke werden geschrieben, andere gelöscht.
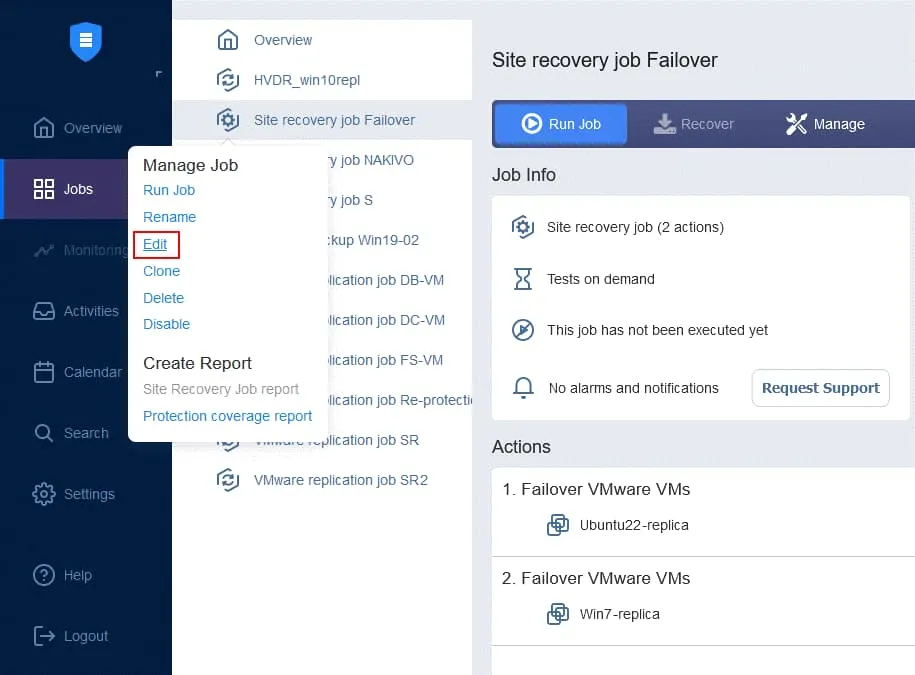
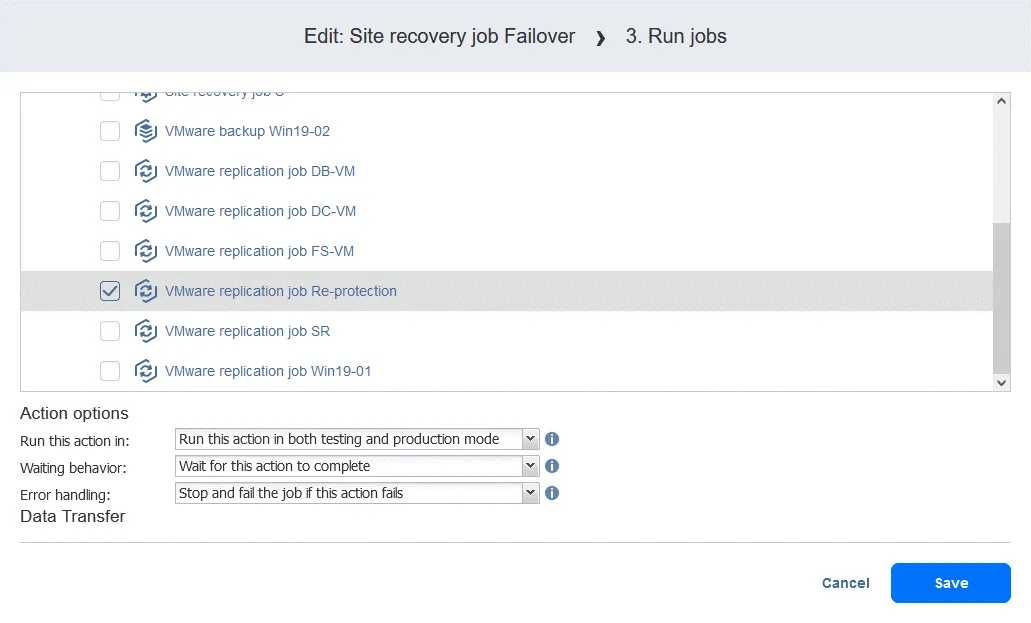
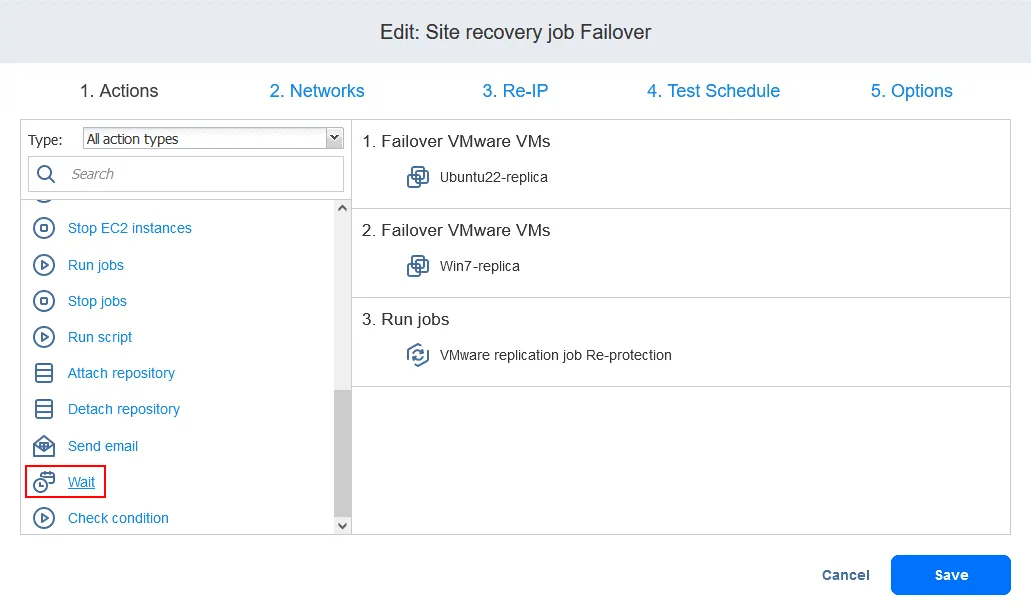
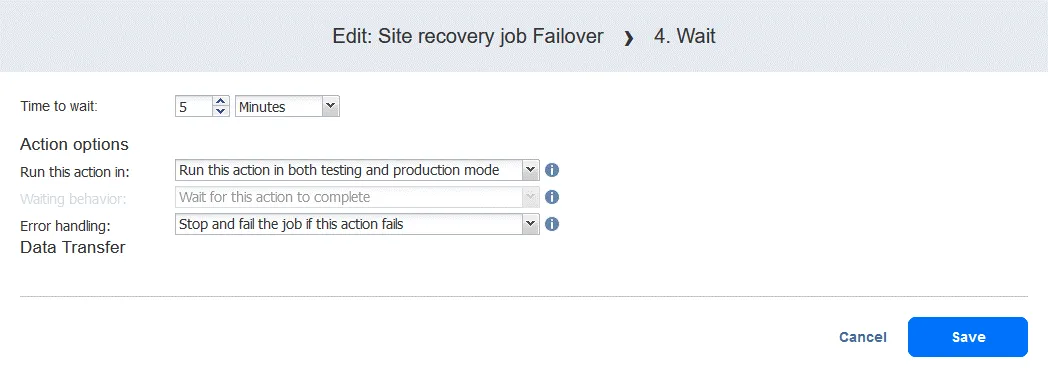
- Die virtuelle Festplatte der Quelle enthält diese Transaktionen nicht.
- Sobald der Vorfall behoben ist und die Produktionsumgebung wieder funktionsfähig ist, müssen die Workloads zurück in die Produktionsumgebung übertragen werden. Die aktualisierten Daten der VM-Replik müssen zurück auf die Quelle übertragen werden. Die VMs müssen mithilfe von Failback mit umgekehrter Replikation neu synchronisiert werden.
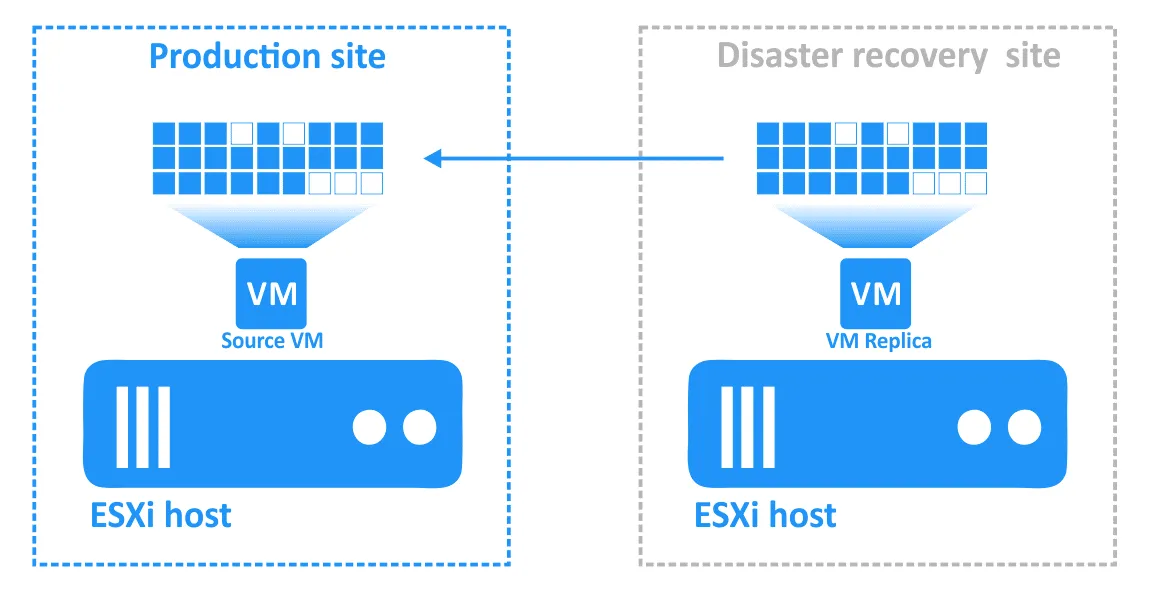
Konfigurieren von Failback in NAKIVO Backup & Replication
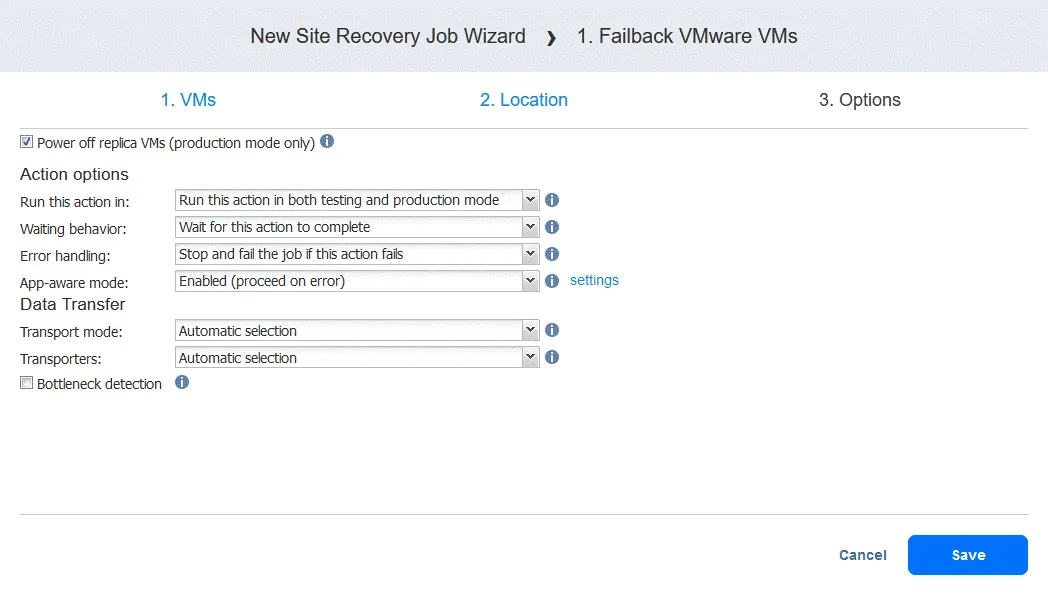
Failback kann entweder im Produktionsmodus oder im Testmodus durchgeführt werden (wenn alle durch die Failback-Aktion vorgenommenen Änderungen in Ihrer virtuellen Umgebung nach dem Test auf den Zustand vor dem Failback zurückgesetzt werden).
Betrachten wir nun im Detail, wie die einzelnen Fälle funktionieren.
Produktions-Failback Test-Failback 1 Ausschalten der ursprünglichen Quelle (sofern vorhanden und eingeschaltet). 2 Erstellen eines Schutz-Schnappschusses der Quelle (sofern die Quelle funktionsfähig ist).
Durch das Erstellen dieses Schnappschusses können Sie den Zustand der Quelle vor dem Failover wiederherstellen, falls das Failback nicht ordnungsgemäß durchgeführt werden kann.
3 Ausführen einer inkrementellen Replikation (wenn die ursprüngliche Quelle am Produktionsstandort online ist) oder einer vollständigen Replikation (wenn die VM an einem neuen Produktionsstandort wiederhergestellt wird). 4 Ausschalten der VM-Replik (optional). Die VM-Replik wird zum Hosten der Workloads verwendet und nicht ausgeschaltet. 5 Die inkrementelle Replikation wird noch einmal von der VM-Replik zur Quelle ausgeführt. Die Differenz (die Daten, die sich seit der ersten Replikation geändert haben) sollte diesmal viel kleiner sein. Die Replikation von einem VM-Replikat zur ursprünglichen Quell-VM (oder einer neuen Produktions-VM) wird nur einmal durchgeführt, da dies für Testzwecke ausreichend ist. 6 Verbinden der ursprünglichen Quell-VM mit ihrem neuen Netzwerk mithilfe der Netzwerkzuordnung (optional). Verbinden der Quell-VM mit einem isolierten Netzwerk, damit es zu keinerlei Störungen der Produktionsumgebung kommt (optional). 7 Ändern der statischen IP-Adresse der ursprünglichen Quell-VM mit Re-IP (optional). 8 Einschalten der ursprünglichen Quell-VM. 9 Aufräumen nach einem erfolgreichen Failback . Nach einem erfolgreichen Failback-Vorgang befinden sich sowohl die Quell-VM als auch die VM-Replik in ihrem regulären Zustand. - Der Schutz-Schnappschuss wird aus der ursprünglichen Quell-VM entfernt.
- Der Replikationsauftrag wird so konfiguriert, dass er die neu erstellte primäre (Quell-)VM anstelle der alten verwendet (optional; gilt, wenn Sie auf eine neue VM umgeschaltet haben).
- Umschalten der VM-Replik vom Failover-Zustand (Betriebszustand) in den normalen Zustand.
Bereinigung nach einem fehlgeschlagenen Failback :
- Zurücksetzen der Quell-VM auf den erstellten Schutz-Schnappschuss.
- Entfernen des Schutz-Schnappschusses aus der Quell-VM.
- Wieder einschalten der VM-Replik.
Bereinigung, wenn die Quell-VM vor der Ausführung des Test-Failbacks nicht vorhanden war: - Entfernen der Quell-VM.
Bereinigung, wenn die Quell-VM bereits vor der Ausführung des Test-Failbacks vorhanden war:
- Zurücksetzen der Quell-VM auf den Zustand zum Zeitpunkt der Erstellung des Schutz-Snapshots.
- Einschalten der Quell-VM (falls sie ausgeschaltet war).
- Entfernen des Schutz-Snapshots aus der Quell-VM.
Vorbereitung für den Failback
Zunächst sollten Sie einen Standortwiederherstellungs-Auftrag erstellen, der Failover-Aktionen enthält. Dieser Vorgang wurde zuvor ausführlich beschrieben.
- Für die Durchführung einer Failover-Aktion sind ein Replikationsjob und eine VM-Replik erforderlich.
- Ein Site Recovery-Auftrag muss eine Failover-Aktion enthalten, damit ein Failback durchgeführt werden kann.
- Die VM-Replikate müssen sich im Failover-Zustand befinden, daher können Sie ein Failback erst nach Durchführung eines Failovers durchführen.
Ausführen eines Failbacks
Sehen wir uns anhand eines Beispiels an, wie ein Failback mit NAKIVO Backup & Replication durchgeführt wird.
- Stellen Sie sicher, dass der Failover als Teil eines Site-Wiederherstellungs-Auftrags ausgeführt wurde (dieser sollte bereits erstellt worden sein).
- Erstellen Sie einen neuen Site-Wiederherstellungs-Auftrag – die Failback-Aktionen können in diesen Auftrag integriert werden. Klicken Sie auf der Seite Aufträge auf Erstellen > Standortwiederherstellungs-Auftrag .
Der Assistent für neuen Site-Wiederherstellungs-Auftrag wird gestartet.
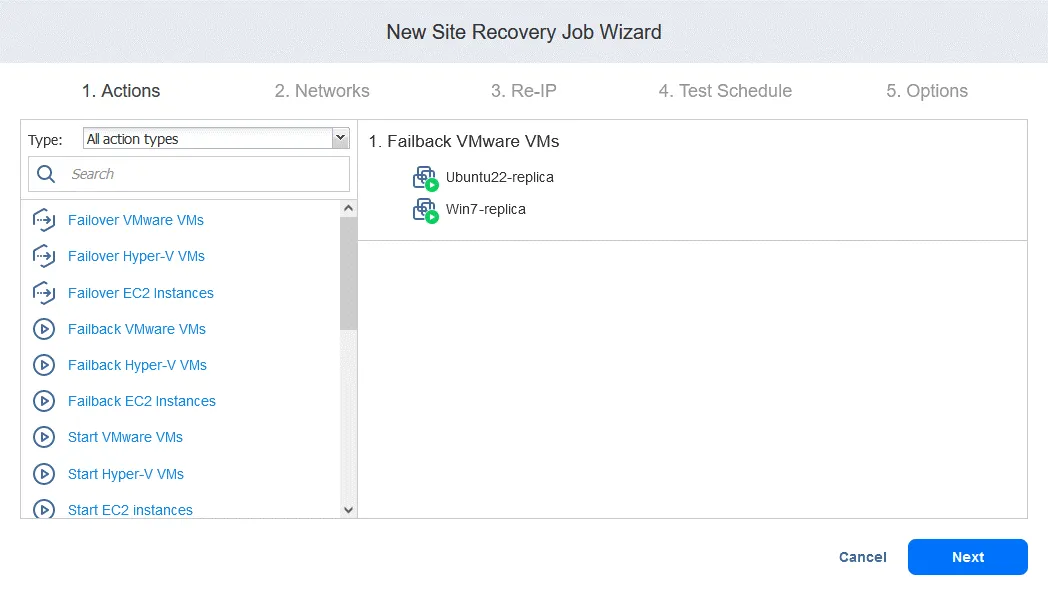
1. Aktionen .
-
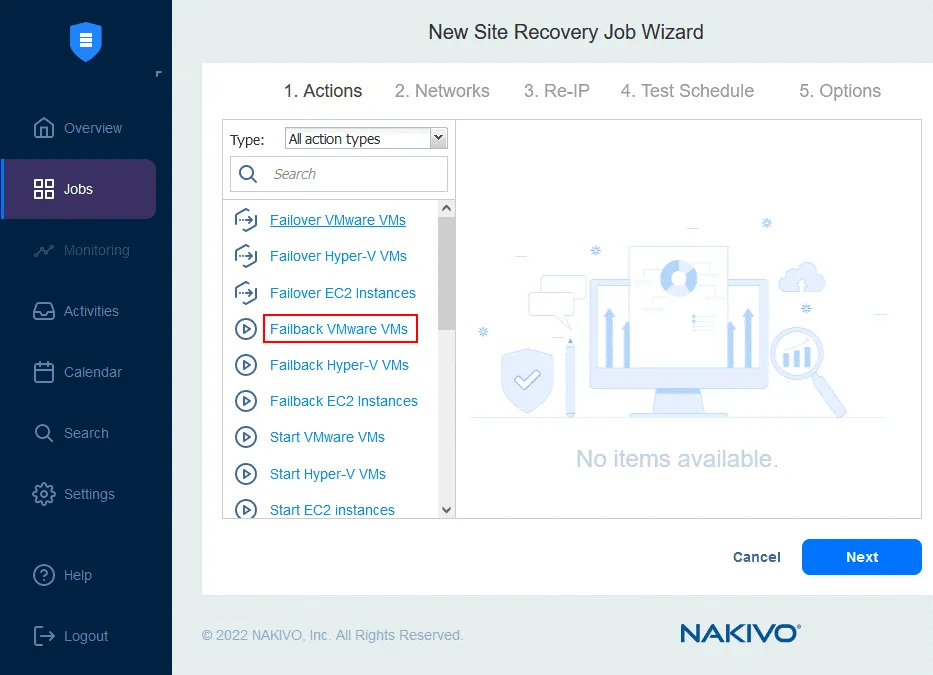
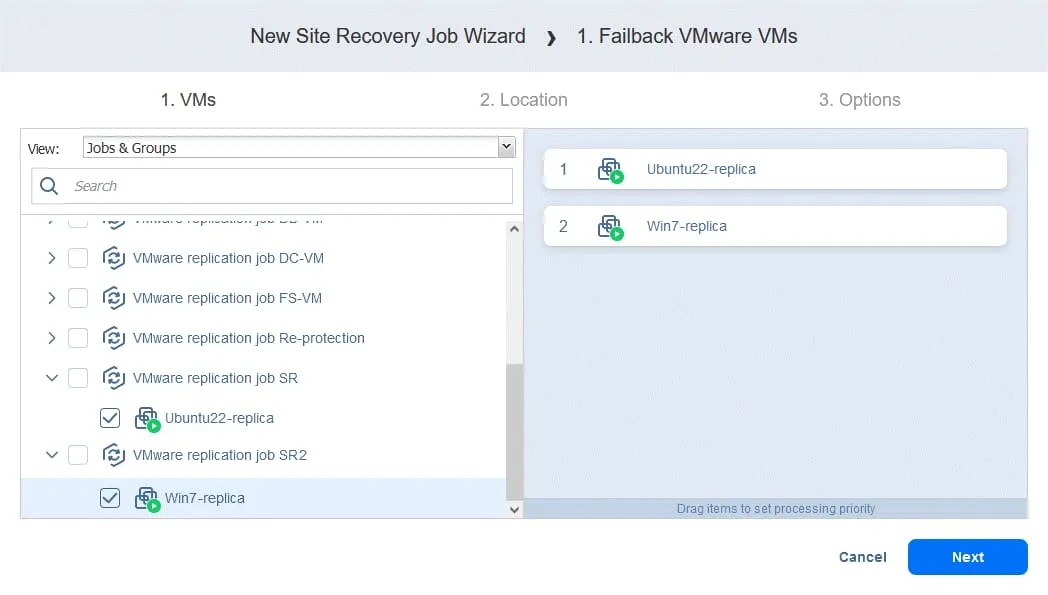
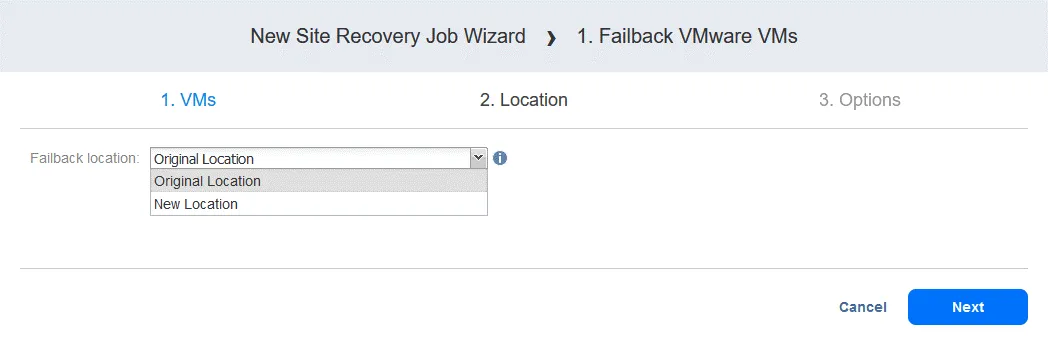
Klicken Sie im linken Fensterbereich auf „ “ (Failback von VMware-VMs) „ “ (für andere Umgebungen verwenden Sie „ “ (Failback von Hyper-V-VMs) „ “ oder „ “ (Failback von EC2-Instanzen) „ “). „ “ (Failback-Standort auswählen) Wählen Sie die VM-Replikate aus, auf die der Failover-Vorgang angewendet werden soll. Klicken Sie auf „ “ (Weiter) „ “ (Failback-Standort auswählen) „ “ (Failback-Standort auswählen) Wählen Sie einen Failback-Standort aus – dies kann der ursprüngliche Produktionsstandort oder ein neuer Standort sein. Klicken Sie auf „ “ (Weiter) „ “ (Failback-Standort auswählen) „ “ (Failback-Standort auswählen) Wählen Sie die Auftragsoptionen aus. Wählen Sie Replica-VMs ausschalten aus, falls erforderlich. Klicken Sie auf Speichern , wenn Sie bereit sind, fortzufahren. Nachdem Sie die Failback-Aktion hinzugefügt haben, sieht der Auftrag der Standortwiederherstellung wie im folgenden Screenshot aus. Klicken Sie auf Weiter . 2. Netzwerke . Wählen Sie diese Option aus, wenn Sie die Netzwerkkartierung für diesen Auftrag aktivieren müssen. Klicken Sie auf Weiter . 3. Re-IP . Wählen Sie diese Option aus, wenn Sie Re-IP für diesen Auftrag aktivieren müssen. Klicken Sie auf „ “ (Netzwerkzuordnung aktivieren) und dann auf „Weiter“ (Weiter) und „ “ (Netzwerkzuordnung aktivieren). Klicken Sie auf „ “ (Netzwerkzuordnung aktivieren) und dann auf „Weiter“ (Weiter) und „ “ (Zeitplan testen). Konfigurieren Sie Ihre Auftragsoptionen und klicken Sie dann auf „ “ (Auftragsoptionen konfigurieren) und „Weiter“ (Weiter) und „ “ (Auftragsoptionen konfigurieren). Klicken Sie auf „Zeitplan testen“ (Zeitplan testen) und dann auf „ “ (Zeitplan testen). Konfigurieren Sie Ihre Auftragsoptionen und klicken Sie dann auf „ “ (Auftragsoptionen konfigurieren) und „Weiter“ (Weiter) und „ “ (Auftragsoptionen konfigurieren). Klicken Sie auf „Optionen“ (Optionen) und dann auf „Auftrags-Name“ (Auftrags-Name). Definieren Sie die Auftragsoptionen für die Standortwiederherstellung und geben Sie den Auftrags-Name ein. Sie können die erforderliche RTO für die VM festlegen und die E-Mail-Adresse für den Failback-Bericht angeben. Klicken Sie auf „ “ (Auftrags-Name) und dann auf „Finish“ (Fertigstellen) und „ “ (Auftrags-Name festlegen), um die Erstellung dieses neuen Auftrags mit Standortwiederherstellung abzuschließen. Klicken Sie auf „ “ (Auftrags-Name festlegen) und dann auf „Finish“ (Fertigstellen) und „ Jetzt kannst du diesen Site Recovery-Auftrag ausführen, um ein VM-Failback durchzuführen: Klicke einfach mit der rechten Maustaste auf den Namen des Site Recovery-Auftrags, wähle „ “ (Auftrag ausführen) „ “ (Failback-Bericht) und wähle „ “ (Failback-Bericht) „Test site recovery job“ (Site Recovery-Auftrag testen) „ “ (Failback-Bericht) oder „ “ (Site Recovery-Auftrag ausführen) „ “ (Failback-Bericht). „ “ (Failback-Bericht) Schritt 6. Durchführen von Disaster Recovery-Tests „ “ (Disaster Recovery-Tests) Mit Disaster Recovery-Tests kannst du sicherstellen, dass du im Katastrophenfall für die Wiederherstellung bereit bist und dass alle ausgewählten Komponenten innerhalb der festgelegten Zeiträume erfolgreich wiederhergestellt werden können. „ “ (Disaster Recovery-Tests) Es gibt zwei Hauptgründe , warum Sie Disaster Recovery-Tests durchführen müssen : Um sicherzustellen, dass alles erfolgreich wiederhergestellt werden kann . Wenn Sie Ihren Disaster Recovery-Plan testen und dabei Probleme erkennen, können Sie diese beheben, bevor sie in einer realen Krisensituation zu ernsthaften Problemen führen. Um sicherzustellen, dass die RTO-Werte eingehalten werden können .
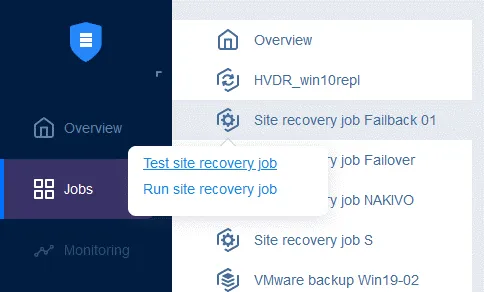
-
Mit Disaster Recovery-Tests können Sie überprüfen, ob Ihre Workloads innerhalb der relevanten RTOs wiederhergestellt werden können. Ein Standortwiederherstellungs-Test kann manuell auf Abruf oder automatisch nach einem festgelegten Zeitplan durchgeführt werden, was den Prozess vereinfacht und Ihnen Zeit spart. Unterschiede zwischen Test- und Produktions-Failover
Der Mechanismus zur Ausführung eines Failovers unterscheidet sich je nachdem, ob der Standortwiederherstellungs-Job im Test- oder im Produktionsmodus ausgeführt wird. Die folgenden Tabellen enthalten eine Übersicht über die einzelnen Schritte für jeden Modus.
Produktions-Failover (Notfall) Test-Failover 1 Deaktivieren Sie die Replikation von der Quell-VM zur Replik. 2 Rollen Sie das Replikat auf einen bestimmten Wiederherstellungspunkt (RP) zurück (optional, standardmäßig wird der letzte RP verwendet). Führen Sie einmalig eine inkrementelle Replikation von der Quell-VM zur Replik durch. 3 Verbinden Sie das Replikat über die Netzwerkzuordnung (optional) mit einem neuen Netzwerk. Verbinden Sie die VM-Replik mit einem isolierten Netzwerk mit Netzwerkzuordnung (optional) 4 Ändern Sie die statische IP-Adresse der Replik mit Re-IP (optional) 4A Schalten Sie die Quell-VM aus (optional) — 5 Schalten Sie die Replik ein 6 Versetzen Sie die Replik in den Status „Failover“ Wie Sie sehen können, unterscheiden sich der zweite und dritte Punkt zwischen dem Produktions- und dem Test-Workflow. Sie können die Replikation von einer Quell-VM im Testmodus ausführen, während die Quell-VM läuft. In den meisten Fällen funktioniert die Quell-VM bei einem Ausfall nicht mehr, sodass keine Replikation durchgeführt werden kann. Die Netzwerke für die VM-Verbindung können bei der Konfiguration eines Site Recovery-Auftrags separat in den Netzwerkzuordnungen für den Produktionsmodus und den Testmodus definiert werden.
Die Bereinigung des Failover-Tests wird nach der Ausführung eines Site Recovery-Auftrags im Testmodus durchgeführt. Die VM-Replik wird ausgeschaltet und über einen Schnappschuss (ein Schnappschuss einer VM-Replik wird vor der Durchführung einer Failover-Aktion erstellt) in den Zustand vor dem Failover zurückversetzt. Die Replik wird dann vom Failover-Zustand in den normalen Zustand versetzt, und die Replikation vom Quellobjekt zur Replik wird wieder aktiviert.
Funktionen zum Testen der Disaster Recovery in NAKIVO Site Recovery
Lassen Sie uns kurz die wichtigsten Punkte der Testfunktionen in NAKIVO Site Recovery durchgehen.
1. Überprüfen der im Test enthaltenen Aktionen
Überprüfen Sie die Logik der Aktionen im Standortwiederherstellungs-Auftrag. Überprüfen Sie, ob die Aktionen in der richtigen Reihenfolge angeordnet sind und stellen Sie sicher, dass sie keine Endlosschleife bilden. Sie können die Auftragsoptionen für den Site Recovery-Auftrag bearbeiten, wenn der Auftrag nicht ausgeführt wird: Ändern Sie die Reihenfolge der Aktionen, fügen Sie Aktionen hinzu, entfernen Sie Aktionen oder bearbeiten Sie die Aktionsoptionen nach Bedarf.
2. Überprüfen des Netzwerks
Überprüfen Sie, ob Ihr Netzwerk ordnungsgemäß funktioniert. Zwischen einem Produktionsstandort und einem Disaster Recovery (DR)-Standort kann eine VPN-Verbindung verwendet werden, diese Verbindung darf jedoch im Normalzustand nicht regelmäßig unterbrochen werden. Das Netzwerk am DR-Standort muss ebenfalls ohne Unterbrechungen funktionieren. Überprüfen Sie die Netzwerkzuordnungen und die Re-IP-Einstellungen, die Sie zur Konfiguration von Failover und Failback verwendet haben. Wenn eine VM für das falsche Netzwerk konfiguriert ist, kann möglicherweise keine Netzwerkverbindung hergestellt werden. Das Gleiche gilt für die IP-Einstellungen.
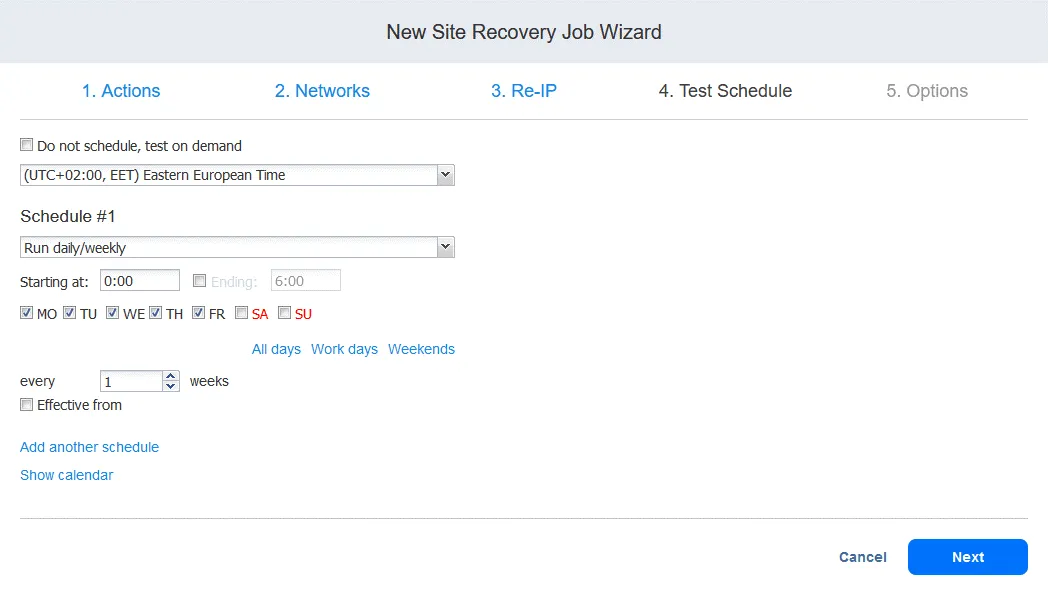
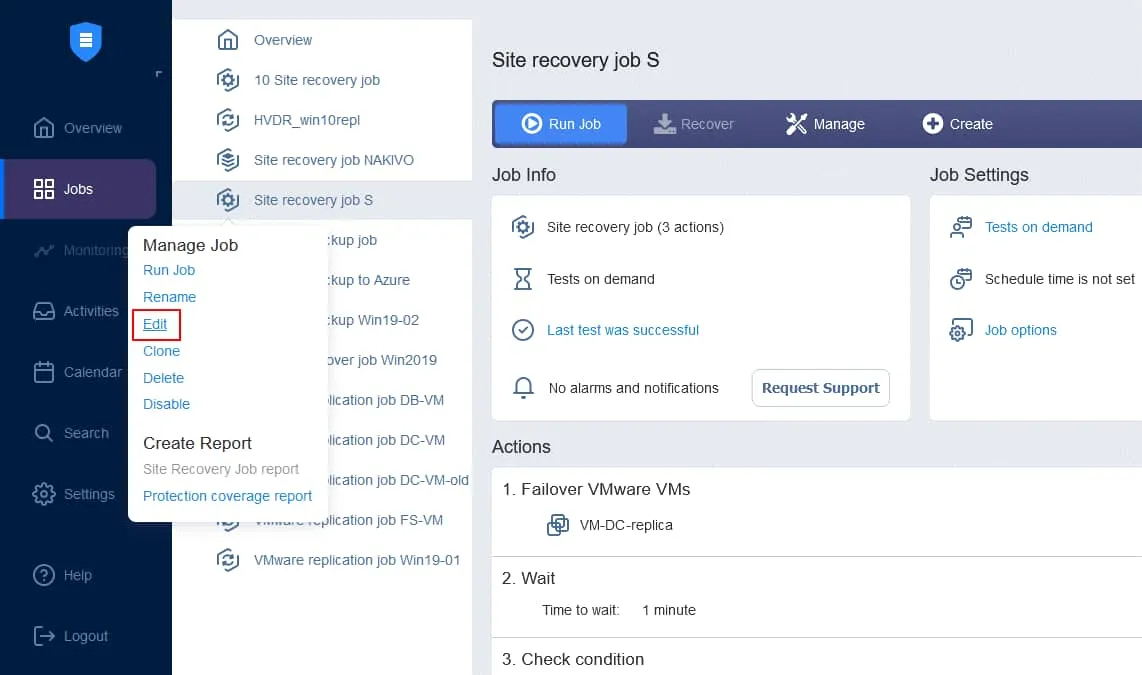
3. Zeitplan testen
Das Testen von Aufträgen für die Standortwiederherstellung kann in den Optionen für die Auftragsplanung der Standortwiederherstellung geplant werden. Öffnen Sie die Weboberfläche Ihrer NAKIVO Backup & Replication-Instanz. Klicken Sie im linken Bereich mit der rechten Maustaste auf den Namen Ihres Auftrags und klicken Sie im Kontextmenü auf „ “ (Bearbeiten) „ “ (Zeitplan für den Standortwiederherstellungs-Auftrag bearbeiten).
Die Vorteile von NAKIVO Standortwiederherstellung
- Umfassende Orchestrierung und Automatisierung der Standortwiederherstellung . Mit NAKIVO Standortwiederherstellung können Sie Disaster Recovery-Pläne mit einem hohen Automatisierungsgrad implementieren. Sie können die Reihenfolge der VM-Wiederherstellung unter Berücksichtigung der VM-Abhängigkeiten festlegen, damit die Wiederherstellung im Katastrophenfall so effizient wie möglich erfolgt.
- Flexibilität zur Anpassung an die Anforderungen verschiedener Unternehmen . Sie können je nach Bedarf mehrere Standortwiederherstellungs-Aufträge erstellen. Die für die Einbindung in Standortwiederherstellungs-Aufträge verfügbaren Aktionen ermöglichen die Erstellung verschiedener Wiederherstellungs-Workflows, die auf unterschiedliche Situationen zugeschnitten sind.
- In die Datensicherheit integriert . Standortwiederherstellung ist eine Funktion von NAKIVO Backup & Replication und zusammen mit den übrigen umfassenden Funktionen des Produkts verfügbar. Sie müssen keine separate Lizenz für Standortwiederherstellung erwerben. Mit dieser Lösung werden alle Aktivitäten zur Datensicherheit und zur Disaster Recovery über eine einzige Oberfläche verwaltet.
- Erhebliche Einsparungen im Vergleich zu anderen DR-Lösungen . NAKIVO Backup & Replication ist mit dem integrierten Tool für Standortwiederherstellung eine kostengünstige Lösung. Das Produkt überzeugt die Nutzer weiterhin mit nützlichen neuen Funktionen und bleibt dabei preislich attraktiv – insbesondere im Vergleich zu den Mitbewerbern auf dem Markt für Disaster Recovery.



