NAKIVO Backup- &-Replikationskomponente: Backup-Repository
& NAKIVO Backup & Replikation besteht aus drei Kernkomponenten: Director, Transporter und Backup-Repository. Während der Director dient zum Management aller Komponenten, während der Transporter für die Datenübertragung zwischen den Knoten zuständig ist. In diesem Leitfaden erklären wir, wie Sie ein Backup-Repository in der NAKIVO-Lösung erstellen und konfigurieren, und gehen auf die unterstützten Funktionen und Plattformen ein.
Was ist ein Backup-Repository?
Ein Backup-Repository ist eine Kernkomponente von NAKIVO Backup & Replikation & , in dem Backups (Wiederherstellungspunkte) gespeichert werden. Es handelt sich um einen speziellen Ordner, in dem Backups und von der Lösung generierte Backup-Metadaten gespeichert werden. Wenn Sie die Backup-Lösung auf einem unterstützten Betriebssystem bereitstellen, können Sie automatisch ein Verzeichnis für das standardmäßige integrierte Repository erstellen. Unter Windows heißt dieses Verzeichnis „NakivoBackup“ und unter Linux „repository“. Dieser Ordner kann dann als Repository für gesicherte Daten und Metadaten des Backup-Repositorys verwendet werden.
WICHTIG: Unter keinen Umständen dürfen Sie Dateien im Ordner „NakivoBackup“ manuell ändern oder löschen. Dies könnte zu einer dauerhaften Beschädigung des gesamten Backup-Repositorys führen, die nicht rückgängig gemacht werden kann, und zum Verlust von Backup-Daten.
HINWEIS: Um Störungen des Betriebs der NAKIVO-Lösung und mögliche Datenbeschädigungen zu vermeiden, sollten Sie die Anwendung zur Whitelist oder Ausschlussliste der Antivirensoftware hinzufügen, die auf dem Rechner läuft, auf dem das NAKIVO Backup-Repository bereitgestellt ist.
Nach der Installation der vollständigen Lösung (Director- und Transporter-Komponenten) wird automatisch ein Backup-Repository als Standardeinstellung erstellt. Dieses Standard-Backup-Repository erhält den Namen „Integriertes Repository“ (dieser Name wird in der Weboberfläche angezeigt).
Unterstützte Speichermedien und Plattformen
NAKIVO Backup & Replikation & Replikation unterstützt verschiedene Speichermedien und Plattformen für die Erstellung eines Backup-Repositorys:
- Lokaler Ordner, ein Verzeichnis im Dateisystem des Computers, auf dem ein Transporter installiert ist
- NFS und SMB-Freigaben
- Öffentliche Clouds (Amazon S3, Microsoft Azure, Wasabi, Backblaze B2) und andere S3-kompatible Speicher (Cloudian, MinIO, Ceph, C2 Object Storage, Lyve Cloud usw.)
- SaaS
Das SaaS-Repository ist ein spezieller Repository-Typ, der zum Speichern von Office 365-Backups. Dieser Repository-Typ wird in einem lokalen Verzeichnis für den zugewiesenen Transporter erstellt. Das Backup-Repository kann auf ext3-, ext4-, NTFS- und FAT32-Dateisystemen erstellt werden.
- Deduplizierungs-Geräte mit Support für native Protokolle
Arten von Backup-Repositorys
NAKIVO Backup & Replikation bietet zwei Arten von Backup-Repositorys für inkrementelle Backups:
- inkrementelle Backups mit vollständigen Backups. NAKIVO Backup & Replication erstellt bei der ersten Ausführung des Backupauftrags ein vollständiges Backup und ermöglicht Ihnen anschließend, je nach Bedarf vollständige und inkrementelle Wiederherstellungspunkte zu erstellen. Die Lösung ermöglicht es Ihnen, periodisch synthetische Vollbackups basierend auf den Auftragseinstellungen des Backupauftrags zu erstellen.
- Forever-inkrementelle Backups. Die Lösung erstellt nur beim ersten Ausführen des Backupauftrags ein vollständiges Backup. Bei allen nachfolgenden Auftragsausführungen werden nur geänderte Daten (Inkremente) an das Backup-Repository gesendet.
Ab Version 10.4 wird beim Erstellen eines neuen Backup-Repositorys standardmäßig die Einstellung „Inkrementell mit vollständiger Sicherung“ angewendet (anstelle der Erstellung eines Forever-Inkrementellen Backup-Repositorys, wie es vor Version 10.4 der Fall war). Der Speicher-Typ kann bei der Erstellung des Repositorys konfiguriert werden.
Größe des Backup-Repositorys
Es wird empfohlen, dass jedes Backup-Repository in NAKIVO Backup & Replikation & Replication nach Komprimierung und Deduplizierung bis zu 128 TB an Backup-Daten speichern kann. Sie können pro Lösungsinstallation bis zu 500 Backup-Repositorys erstellen.
Jedes neue Backup-Repository benötigt zusätzlich zu den 5 GB freien Speicherplatz, die für den erfolgreichen Betrieb eines bestehenden Backup-Repositorys erforderlich sind, mindestens 5 GB freien Speicherplatz. Die Lösung überprüft automatisch alle 1 Minute den freien Speicherplatz, wenn mehr als 10 GB freier Speicherplatz vorhanden sind. Wenn weniger als 10 GB freier Speicherplatz vorhanden sind, wird die Überprüfung alle 10 Sekunden durchgeführt, um Fehler aufgrund von unzureichendem Speicherplatz zu vermeiden.
Skalierbarkeit
Ein bestimmtes Backup-Repository wird von einem einzigen Transporter gesteuert, der als zugewiesener Transporter bezeichnet wird. Einfacher ausgedrückt: Nur ein Transporter ist berechtigt, Daten in einem bestimmten Backup-Repository zu lesen und zu schreiben. Der zugewiesene Transporter übernimmt die volle Verantwortung für alle Interaktionen im Zusammenhang mit seinem jeweiligen Backup-Repository. Ein einzelner Transporter kann mehreren Backup-Repositorys gleichzeitig zugewiesen werden und diese effektiv verwalten.
Ein einzelnes Backup-Repository kann nicht von mehr als einem Director/Tenant gleichzeitig verwendet werden.
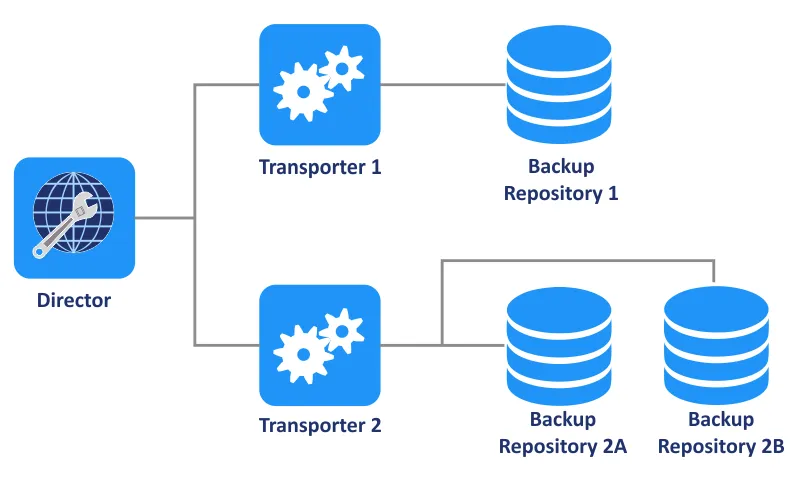
Funktionen des Backup-Repositorys
Ein Backup-Repository unterstützt viele nützliche Funktionen, darunter:
- Deduplizierung. Backup-Repositorys können so konfiguriert werden, dass sie die Globale Deduplizierung verwenden, um Backup-Daten auf Blockebene zu deduplizieren. Doppelte Datenblöcke werden unabhängig von der Quelle aus dem Backup ausgeschlossen, wodurch effektiv Speicher gespart wird. Beachten Sie, dass diese Funktion nur mit dem Forever-Incremental-Backup-Repository verwendet werden kann.
- Komprimierung. Daten in einem Backup-Repository können mit drei Kompressionsstufen von niedrig bis hoch komprimiert werden. So können Sie ein Gleichgewicht zwischen Speicherersparnis und Auslastung der CPU für die Datenkomprimierung herstellen. Die Komprimierung kann beim Erstellen eines neuen Backup-Repositorys konfiguriert werden.
- Verschlüsselung. Ein Backup-Repository (bei Installation unter Linux) kann verschlüsselt werden, um alle im Repository gespeicherten Backup-Daten mit einem Passwort zur Verschlüsselung zu schützen. Die Verschlüsselung hat Auswirkungen auf die Backup-Geschwindigkeit.
- Speicherplatzrückgewinnung. Die Rückgewinnung des Nicht verwendeten Speicherplatzes ermöglicht es Ihnen, die Größe eines Backup-Repositorys zu komprimieren und den Nicht verwendeten Speicherplatz zurückzugewinnen, wenn Sie einen forever incremental Backup-Speicher verwenden.
- Selbstheilungsfunktion des Backup-Repositorys. Diese Funktion überprüft Probleme, die durch Dateninkonsistenzen (einschließlich Metadaten) verursacht werden, überprüft die Datenintegrität und repariert Fehler, sofern dies möglich ist. Die Selbstheilungsfunktion des Backup-Repositorys kann automatisch, nach Plan oder manuell ausgeführt werden. Sie können auch eine vollständige Datenüberprüfung durchführen. Eine vollständige Datenüberprüfung in einem Backup-Repository wird unterstützt. Diese Funktion kann ein Repository vor Beschädigungen nach einem unerwarteten Herunterfahren des Computers schützen.
- Backup-Repositorys können angehängt und getrennt werden. Mit dieser Funktion können Sie die Daten in einem konsistenten Zustand erhalten, Repository-Dateien an einen anderen Standort kopieren usw. Dies kann manuell oder nach Plan erfolgen. Wenn ein Backup-Repository freigegeben wird, stellt die NAKIVO-Lösung die Interaktion mit diesem Repository und seinen Dateien ein.
- Ein verbundenes Backup-Repository wird von einem Transporter betrieben, gilt zu einem bestimmten Zeitpunkt als voll funktionsfähig und kann für Aufträge verwendet werden.
- Ein getrenntes Backup-Repository wird nicht von einem Transporter betrieben und kann nicht für Aufträge verwendet werden. Es kann getrennt bewegt oder getrennt werden.
Es ist nicht möglich, Wartungsarbeiten manuell oder nach Plan durchzuführen, wenn ein Repository getrennt ist.
Es wird empfohlen, Vorgänge, die CPU-Ressourcen beanspruchen (z. B. Speicherplatzrückgewinnung und Überprüfung des Backup-Repositorys), außerhalb der Geschäftszeiten, z. B. nachts oder am Wochenende, auszuführen. Für diese Vorgänge wird eine CPU auf dem Computer verwendet, dem ein Transporter für das entsprechende Backup-Repository zugewiesen ist.
Unveränderlichkeit von Wiederherstellungspunkten
Backup-Repositorys auf bestimmten Medien und Plattformen unterstützen die Unveränderlichkeit von Backups. Die Unveränderlichkeit verhindert unerwünschte Änderungen, Verschlüsselungen und Löschungen von Daten, wodurch Wiederherstellungspunkte gegen Ransomware und andere Cyberbedrohungen immun sind. Diese Technologie basiert auf der WORM-Technologie (Write Once Read Many).
Die Unveränderlichkeit sollte für ein Backup im Assistenten zur Erstellung von Aufträgen aktiviert werden. Sie kann für Wiederherstellungspunkte aktiviert werden, die in den folgenden unterstützten Backup-Repository-Typen gespeichert sind:
- Lokaler Ordner auf dem zugewiesenen Transporter für Backup-Repositorys unter Linux
- Repositorys in Amazon S3, Wasabi, Azure Blob Storage und Backblaze B2
- Andere S3-kompatible Speicherplattformen, die Object Lock und Unveränderlichkeit auf Versionsebene unterstützen
Bei Verwendung von Backup-Repositorys wie Amazon S3, Wasabi, Azure Blob Storage, Backblaze B2 Cloud Storage und anderen S3-kompatiblen Speicherplattformen sollten Sie Object Lock oder die Unterstützung der Unveränderbarkeit auf Versionsebene für den Bucket oder Blob-Container aktivieren, der für die Speicherung von Backups zuständig ist. Diese Unveränderbarkeitsfunktion stellt sicher, dass Daten selbst vom Root-Benutzer nicht geändert oder gelöscht werden können und dass sie nach der Aktivierung nicht verkürzt oder aufgehoben werden können.
Bei Verwendung des Lokaler Ordner Typs von Backup-Repository werden unveränderliche Wiederherstellungspunkte vor dem Überschreiben, Löschen oder Ändern durch andere Personen als den Root-Benutzer geschützt, bis der angegebene Zeitraum abgelaufen ist.
Nach der Bereitstellung des Lokaler Ordner als integraler Bestandteil von VMware vSphere (aus der OVA-Vorlage) oder einer vorkonfigurierten AMI in Amazon EC2 bereitgestellt wird, bietet NAKIVO Backup & Replikation einen verbesserten Schutz vor Ransomware. Dazu gehört die Option, die in diesem Repository gespeicherten Wiederherstellungspunkte unveränderlich zu machen, was bedeutet, dass sie nach Aktivierung der Unveränderlichkeitsfunktion von niemandem, auch nicht vom Root-Benutzer, geändert oder modifiziert werden können.
Backup-Repository-Struktur
Ein Backup-Repository hat eine spezielle Struktur zum Speichern von Backup-Daten, und Sie können keine herkömmlichen Dateien, wie z. B. virtuelle Festplatten, im Verzeichnis eines Backup-Repositorys (NakivoBackup) finden.
Wichtig: Ändern oder löschen Sie keine Dateien oder Ordner eines Backup-Repositorys manuell.
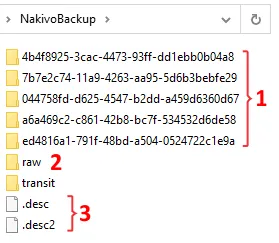
- Backup-Ordner: Jeder Ordner enthält die Wiederherstellungspunkte für einen bestimmten Backupauftrag.
- Raw-Ordner: Enthält Rohdatendateien (Chunk-Dateien). Format der Chunk-Dateien: index.variant(0000.001, 0001.002, 0002.00a, 0003.00b, …).
- Deskriptordateien: Speicherinformationen aller Chunk-Dateien im Repository:
- + RawBlockRecord (einschließlich Flags, Variante, Länge, Offset, Hash1, Hash2, Rcount): Die Informationen eines Blocks in der Deskriptordatei.
- + ShiftBlockRecord (variant_old, offset_old, variant_new, offset_new): Die Informationen eines Blocks, der von der alten Position zur neuen Position in den Rohdatendateien verschoben wurde.
- + ChunkMap: Speicherinformationen von Chunk-Dateien (gleicher Chunk-Index, unterschiedliche Variante) und die Deskriptordateien enthalten eine Liste von ChunkMap, die beim Initialisieren des Repositorys geladen wird.
Die Sperrdatei wird verwendet, um zu verhindern, dass ein Backup-Repository von zwei Transportern gleichzeitig verwendet wird.
Die logische Struktur des Backup-Repositorys ist wie folgt:
– Backup-Repository
- Backup 1
- Wiederherstellungspunkt 1
- Wiederherstellungspunkt 2
- Etc.
- Backup 2
- Wiederherstellungspunkt 1
- Wiederherstellungspunkt 2
- Etc.
Wiederherstellungspunkte werden automatisch gelöscht, wenn ihre Aufbewahrungsfrist abläuft (basierend auf den festgelegten Ablaufdaten oder der alten Aufbewahrungsmethode in den Versionen 10.7 und früher). Sie sollten keine Dateien manuell aus dem Verzeichnis des Backup-Repositorys löschen.
So erstellen Sie ein Backup-Repository
Sie können ein neues Backup-Repository in NAKIVO Backup & Replikation & erstellen. Replikation auf jeder der oben aufgeführten unterstützten Plattformen.
Erstellen wir ein neues Backup-Repository auf einem Rechner mit Ubuntu Linux. Die wichtigste Anforderung für die Erstellung eines neuen Backup-Repositorys auf einem Remote-Rechner ist die vorherige Installation eines Transporteurs auf diesem Linux-Rechner. Auf diesem Linux-Rechner ist bereits ein Transporter installiert.
In diesem Beispiel verwenden wir diese beiden Computer für die Bereitstellung und Konfiguration der NAKIVO-Lösung:
- NAKIVO Director (Komplettlösung): 192.168.101.209
- NAKIVO Transporter auf einem Linux-Rechner: 192.168.101.210
Wenn der Transporter installiert ist, führen Sie die folgenden Schritte aus, um ein neues Backup-Repository auf einem Linux-Rechner zu erstellen:
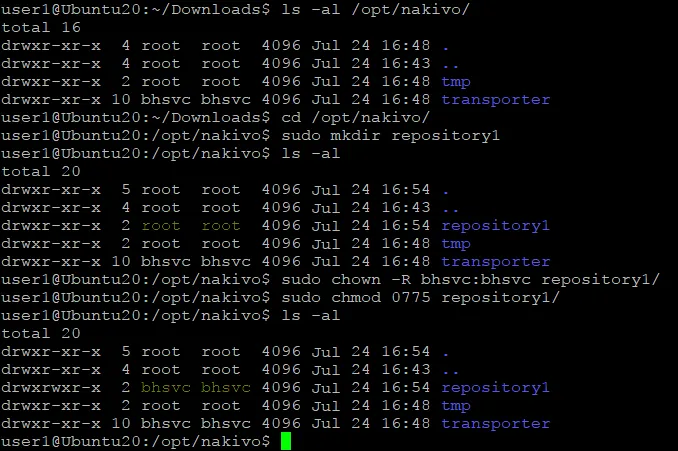
- Erstellen Sie ein Verzeichnis, das für das neue Backup-Repository zum Speichern von Backups verwendet wird. Wir erstellen ein Verzeichnis namens repository1 in /opt/NAKIVO/ und gehen Sie in der Linux-Konsole zu diesem Verzeichnis:
cd /opt/nakivo/sudo mkdir repository1 - Legen Sie den NAKIVO-Benutzer mit dem Namen bhsvc als Eigentümer dieses Verzeichnisses fest: repository1 (für diese Aktion benötigen Sie Root-Rechte):
sudo chown -R bhsvc:bhsvc repository1Hinweis: Wenn Sie ein Backup-Repository auf einem NAS erstellen, verwenden Sie folgenden Befehl, um den NAKIVO-Benutzer als Eigentümer des Repository-Verzeichnisses festzulegen:
sudo chown -R u_bhsvc:g_bhsvc repository1 - Legen Sie die richtigen Berechtigungen für dieses Verzeichnis fest, damit die NAKIVO-Lösung Daten zum Backup lesen und schreiben kann:
sudo chmod 0775 repository1 - Überprüfen Sie, ob der Eigentümer und die Berechtigungen festgelegt wurden, indem Sie den Inhalt von /opt/nakivo/:
ls -al
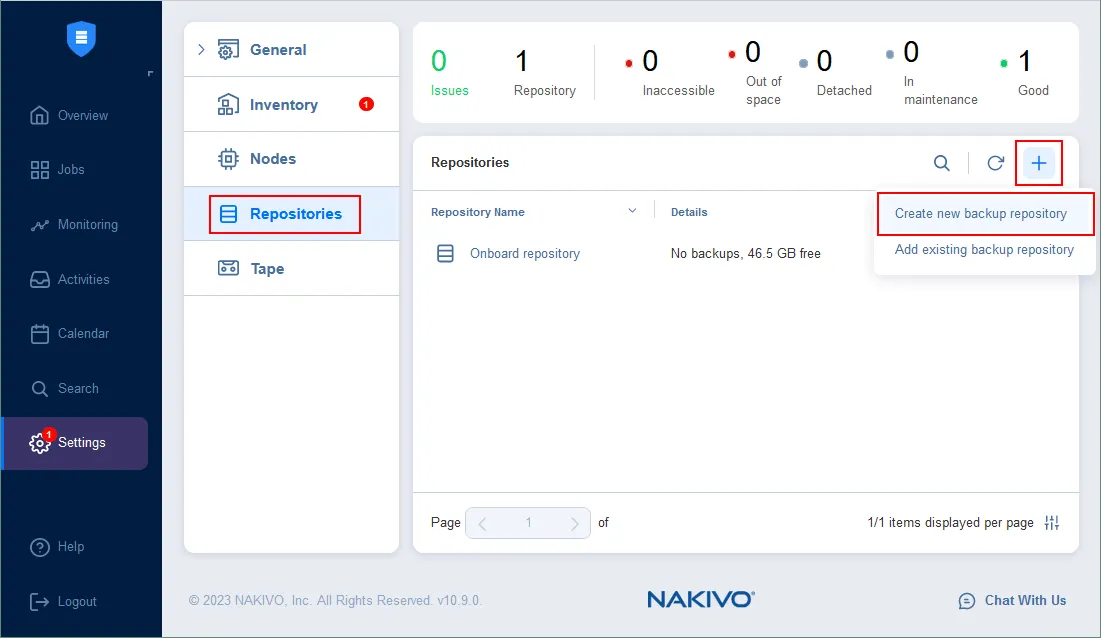
- Ein Verzeichnis wurde erstellt und konfiguriert. Öffnen Sie nun die Weboberfläche von NAKIVO Backup & Replikation & (bereitgestellt von der NAKIVO Director-Komponente). Der Link, den wir in unserem Webbrowser öffnen, lautet https://192.168.101.209:4443 in diesem Fall.
- Gehen Sie zu Einstellungen > Repositorys, klicken Sie auf +und klicken Sie auf Neues Backup-Repository erstellen.
- Der Assistent zum Erstellen eines neuen Backup-Repositorys wird geöffnet.
- Wählen Sie im ersten Schritt des Assistenten einen Backup-Repository-Typ aus. Da wir ein neues Backup-Repository auf einem Linux-Rechner erstellen, wählen wir Lokaler Ordner. Klicken Sie auf „ <“ (Weiter) >„Weiter“ (Weiter) , um fortzufahren. „<“ (Weiter) >
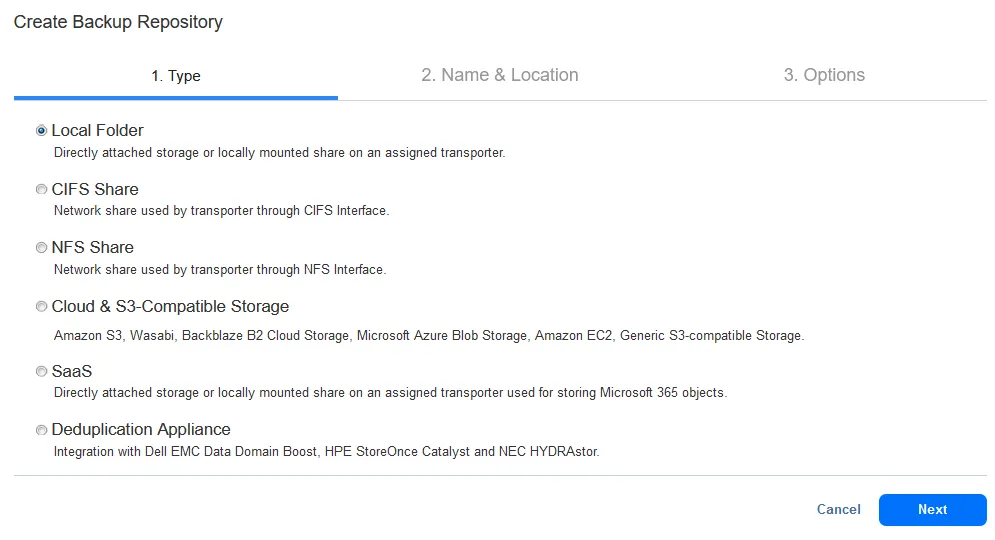
- Im zweiten Schritt müssen Sie einen Namen und einen Standort festlegen. Geben Sie einen Namen des Backup-Repositorys ein, zum Beispiel RepositoryL1.
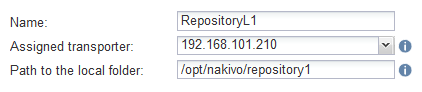
Wählen Sie den zugewiesenen Transporter für dieses Backup-Repository aus. Wir wählen den Transporter aus, der auf dem Remote-Linux-Rechner installiert ist (192.168.101.210).
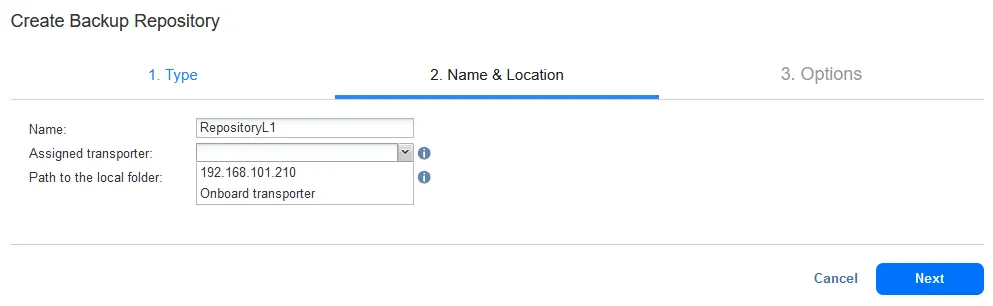
Geben Sie den Pfad zum lokalen Ordner auf dem Rechner ein, auf dem der Transporter installiert ist. Dieses Verzeichnis ist /opt/NAKIVO/repository1 in unserem Fall, das ist das Verzeichnis, das wir auf unserem Linux-Rechner erstellt haben.
Klicken Sie auf Weiter um fortzufahren.
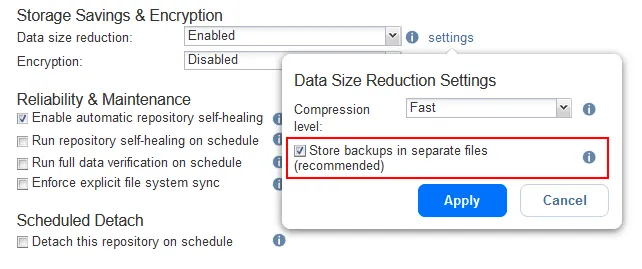
- Optionen konfigurieren. In diesem Schritt sollten Sie die Optionen für Speichereinsparungen, Verschlüsselung, Zuverlässigkeit und Wartung für das Backup-Repository konfigurieren. Wenn Sie Komprimierung verwenden möchten, legen Sie die Optionen zur Datenmengenreduzierung jetzt in diesem Schritt fest. Die Einstellungen für die Komprimierung eines Backup-Repositorys können nach seiner Erstellung nicht mehr geändert werden.

Wenn Sie ein Backup-Repository für fortlaufende inkrementelle Backups erstellen möchten, klicken Sie auf Einstellungen unter Datenmengenreduzierung und deaktivieren Sie das Kontrollkästchen Backups in separaten Dateien speichern (empfohlen) Aktivieren Sie das Kontrollkästchen. Klicken Sie auf Anwenden.
- Ein neues Backup-Repository wurde erstellt.
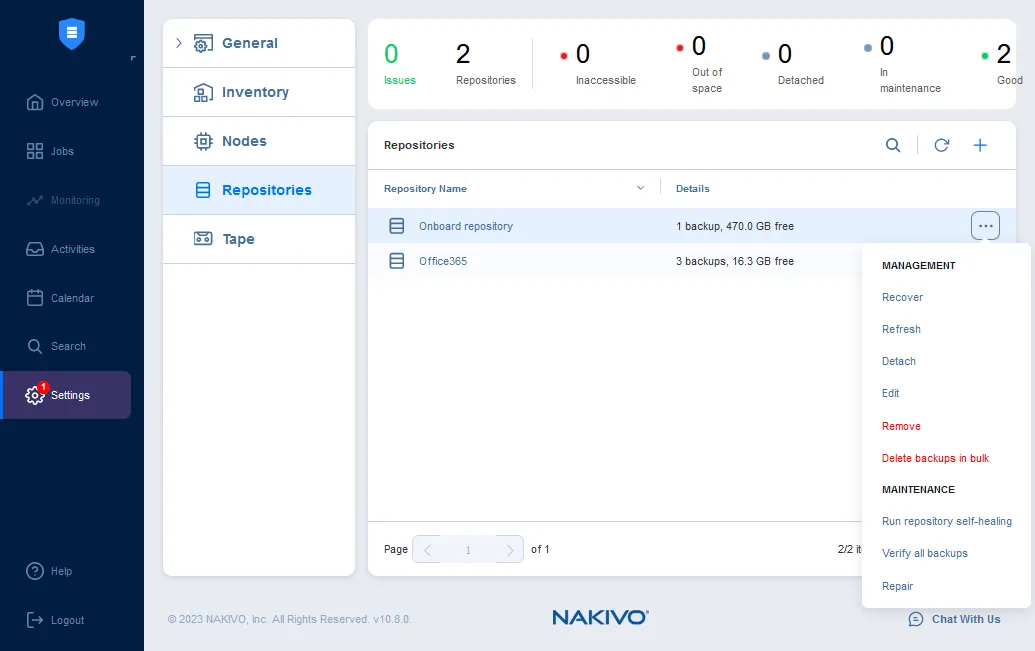
Sie können auf ein Backup-Repository klicken (die Liste der Repositorys befindet sich unter Einstellungen > Repositorys), um die belegte Größe, die freie Größe und andere Parameter des Backup-Repositorys anzusehen.
Sie können mit der Maus über den Namen des Backup-Repositorys fahren und auf das Symbol mit den drei Punkten klicken, um ein Menü mit Aktionen zu öffnen, die Sie mit dem ausgewählten Backup-Repository ausführen können. Sie können Daten wiederherstellen, einige Repository-Einstellungen bearbeiten, Backups überprüfen, ein Backup-Repository reparieren, die Repository-Selbstheilung durchführen usw.
Aktivieren der Unveränderlichkeit
Wenn Sie unveränderliche Wiederherstellungspunkte in einem Backup-Repository speichern möchten, sollten Sie die Unveränderlichkeit beim Erstellen eines neuen Backupauftrags aktivieren (klicken Sie auf Aufträge, klicken Sie auf + , um einen neuen Backupauftrag zu erstellen, und wählen Sie aus, was Sie sichern möchten). Ein auf einem Linux-Rechner erstelltes Backup-Repository (wie in unserem Fall) unterstützt Unveränderlichkeit.
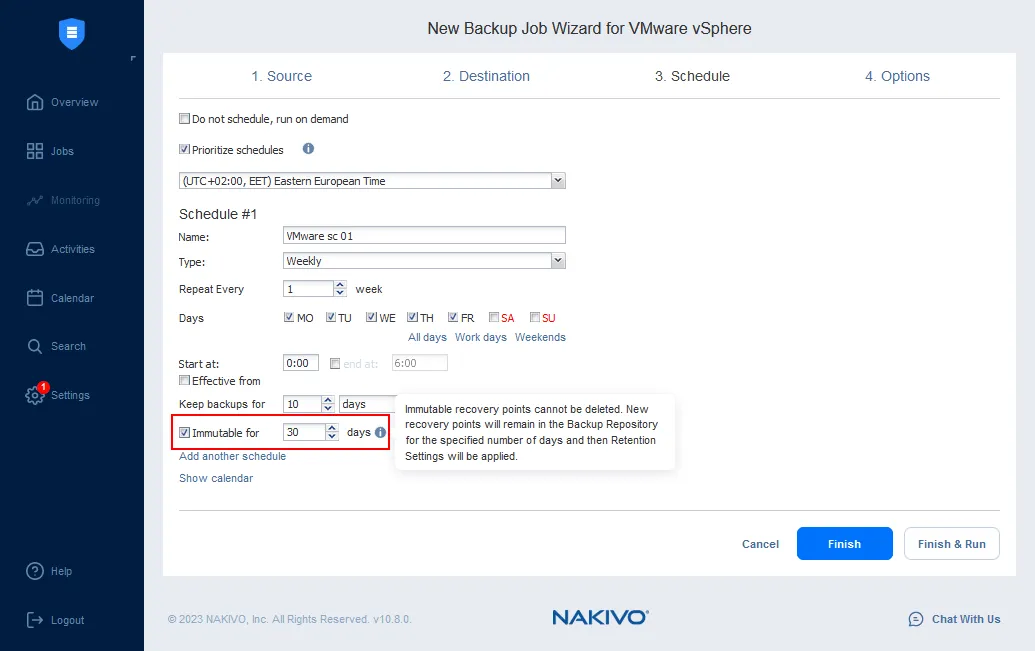
In Schritt 3 des Assistenten für neue Backupaufträge, in dem die Zeitplanungs- und Aufbewahrungseinstellungen für einen Backupauftrag konfiguriert werden, finden Sie die Einstellungen für die Unveränderlichkeit. Aktivieren Sie das entsprechende Kontrollkästchen und geben Sie die Anzahl der Tage ein, für die das Backup unveränderlich sein soll.



