Jak podłączyć Amazon S3 jako dysk w celu udzielenia udziału plików w chmurze
W usłudze Amazon S3 dane są przechowywane w „bucketach”, które stanowią podstawową jednostkę przechowywania danych. Uprawnienia użytkowników do dostępu do bucketów można skonfigurować za pośrednictwem interfejsu internetowego AWS. Jeśli chcesz, aby dostęp do AWS S3 był możliwy bez użycia przeglądarki internetowej, możesz zezwolić użytkownikom na korzystanie z interfejsu systemu operacyjnego, takiego jak Linux, Windows lub macOS.
Dostęp do magazynu-chmury Amazon S3 z wiersza poleceń może okazać się przydatny w wielu sytuacjach. Jest to szczególnie przydatne w przypadku systemów operacyjnych, które nie posiadają graficznego interfejsu użytkownika (GUI), w szczególności maszyn wirtualnych działających w chmurze publicznej, a także do automatyzacji zadań, takich jak kopiowanie plików lub tworzenie kopie zapasowe danych w chmurze.
Czytaj dalej, aby dowiedzieć się, jak zamontować zasobnik Amazon S3 jako system plików na komputerze z systemem Linux oraz jako dysk w lokalnym katalogu na komputerach z systemem Windows i macOS, aby móc korzystać z AWS S3 bez przeglądarki internetowej.

Jak zamontować zasób S3 jako system plików w systemie Linux
AWS udostępnia interfejs API umożliwiający pracę z zasobami Amazon S3 za pomocą aplikacji innych producentów. Można nawet stworzyć własną aplikację, która będzie współpracować z zasobami S3 przy użyciu interfejsu API Amazon. Można stworzyć aplikację, która wykorzystuje tę samą ścieżkę do przesyłania plików do magazynu-chmury Amazon S3 i udostępnia tę samą ścieżkę na każdym komputerze poprzez zamontowanie zasobu S3 w tym samym katalogu za pomocą S3FS. W tym samouczku używamy S3FS do zamontowania zasobnika Amazon S3 jako dysku w katalogu systemu Linux.
S3FS to specjalne rozwiązanie oparte na FUSE (system plików w przestrzeni użytkownika), opracowane w celu montowania zasobników S3 w katalogach systemów operacyjnych Linux, podobnie jak montuje się Udostępnianie CIFS/NFS jako dysk sieciowy. S3FS jest rozwiązaniem darmowym i open source.
Po zamontowaniu magazynu-chmury Amazon S3 za pomocą S3FS na komputerze z systemem Linux można używać cp , mv , rm oraz innych poleceń w konsoli systemu Linux do obsługi plików, tak jak w przypadku zamontowanych dysków lokalnych lub sieciowych.
Zamontujmy na przykład zasobnik Amazon S3 w katalogu systemu Linux z Ubuntu 18.04 LTS. W tym przewodniku używana jest świeża instalacja Ubuntu. Tę samą zasadę można zastosować w nowszych wersjach.
- Zaktualizuj drzewo repozytorium:
sudo apt-get update - Jeśli w systemie Linux jest zainstalowany jakikolwiek istniejący FUSE, usuń go przed skonfigurowaniem środowiska i zainstalowaniem fuse-f3fs, aby uniknąć konfliktów. Ponieważ korzystamy ze świeżej instalacji Ubuntu, nie uruchamiamy polecenia
sudo apt-get remove fusew celu usunięcia FUSE. - Zainstaluj s3fs z internetowych repozytoriów oprogramowania:
sudo apt-get install s3fs - Musisz wygenerować identyfikator klucza dostępu oraz tajny klucz dostępu w interfejsie internetowym AWS dla swojego konta (użytkownik IAM). Użytkownik IAM musi mieć pełny dostęp do S3. Możesz skorzystać z tego linku:
https://console.aws.amazon.com/iam/home?#/security_credentialsUWAGA: Zaleca się montowanie zasobników Amazon S3 jako zwykły użytkownik z ograniczonymi uprawnieniami, a użytkowników z uprawnieniami administracyjnymi używać wyłącznie do generowania kluczy.
- Klucze te są potrzebne do dostępu do API AWS. Aby wygenerować identyfikator klucza dostępu AWS i tajny klucz dostępu AWS, musisz posiadać uprawnienia administracyjne. Jeśli nie masz wystarczających uprawnień, poproś administratora systemu o wygenerowanie kluczy AWS za Ciebie. Administrator może wygenerować klucze AWS dla konta użytkownika w sekcji Użytkownicy konsoli AWS, w zakładce Dane uwierzytelniające , klikając przycisk Utwórz klucz dostępu
 .
. -
W wyskakującym oknie Utwórz klucz dostępu należy kliknąć Pobierz plik .csv lub kliknąć Pokaż pod nazwą wiersza Tajny klucz dostępu . Jest to jedyny przypadek, w którym tajny klucz dostępu jest widoczny w interfejsie internetowym AWS. Przechowaj identyfikator klucza dostępu AWS i tajny klucz dostępu w bezpiecznym miejscu.

- Pobierany plik CSV zawierający klucze dostępu można otworzyć na przykład w programie Microsoft Office 365 Excel.

- Wróć do konsoli Ubuntu, aby utworzyć plik konfiguracyjny do przechowywania klucza dostępu AWS i tajnego klucza dostępu potrzebnych do zamontowania zasobnika S3 za pomocą S3FS. Polecenie do tego celu brzmi:
echo ACCESS_KEY:SECRET_ACCESS_KEY > PATH_TO_FILEZmień ACCESS_KEY na swój klucz dostępu AWS oraz SECRET_ACCESS_KEY na swój tajny klucz dostępu.
W tym przykładzie plik konfiguracyjny z kluczami AWS zostanie zapisany w katalogu domowym naszego użytkownika. Upewnij się, że plik z kluczami jest przechowywany w bezpiecznym miejscu, niedostępnym dla osób nieuprawnionych.
echo AKIA4SK3HPQ9FLWO8AMB:esrhLH4m1Da+3fJoU5xet1/ivsZ+Pay73BcSnzP > ~/.passwd-s3fs - Sprawdź, czy klucze zostały zapisane w pliku:
cat ~/.passwd-s3fs - Ustaw prawidłowe uprawnienia dla passwd-s3fs pliku, w którym przechowywane są klucze dostępu:
chmod 600 ~/.passwd-s3fs - Utwórz katalog (punkt montowania), który będzie służył jako punkt montowania dla Twojego zasobnika S3. W tym przykładzie tworzymy katalog Amazon cloud drive S3 w katalogu domowym użytkownika.
mkdir ~/s3-bucketMożna również użyć istniejącego pustego katalogu.
- Nazwa zasobnika używanego w tym przewodniku to blog-bucket01 . Plik text1.txt jest przesyłany do naszego blog-bucket01 w Amazon S3 przed zamontowaniem zasobnika do katalogu w systemie Linux. Nie zaleca się używania kropki (.) w nazwach zasobników.

- Zamontujmy zasób. Użyj poniższego polecenia, aby ustawić nazwę zasobu, ścieżkę do katalogu używanego jako punkt montowania oraz plik zawierający klucz dostępu AWS i tajny klucz dostępu.
s3fs bucket-name /path/to/mountpoint -o passwd_file=/path/passwd-s3fsW naszym przypadku polecenie używane do zamontowania zasobu to:
s3fs blog-bucket01 ~/s3-bucket -o passwd_file=~/.passwd-s3fs - Zasób został zamontowany. Możemy uruchomić polecenia, aby sprawdzić, czy nasz zasób ( blog-bucket-01 ) został zamontowany w katalogu s3-bucket :
mount | grep bucketdf -h | grep bucket - Sprawdźmy zawartość katalogu, do którego zamontowano zasób S3:
ls -al ~/s3-bucketJak widać na poniższym zrzucie ekranu, plik test1.txt przesłany wcześniej za pośrednictwem interfejsu internetowego jest obecny i wyświetla się w konsoli.

- Teraz możesz spróbować utworzyć nowy plik na dysku twardym i skopiować go do zasobu S3 w konsoli systemu Linux.
echo test2 > test2.txtcp test2.txt ~/s3-bucket/ - Odśwież stronę internetową AWS, na której wyświetlane są pliki w zasobie. Powinieneś zobaczyć nowy test2.txt plik skopiowany do zasobnika S3 w konsoli Linuksa przy użyciu katalogu, do którego zamontowano zasobnik.




Jak zamontować zasobnik S3 przy uruchomieniu systemu Linux automatycznie
Jeśli chcesz skonfigurować automatyczne montowanie zasobnika S3 za pomocą S3FS na komputerze z systemem Linux, musisz utworzyć plik passwd-s3fs w /etc/passwd-s3fs , co jest standardową lokalizacją. Po utworzeniu tego pliku nie musisz używać klucza -o passwd_file do ręcznego ustawiania lokalizacji pliku z kluczami AWS.
- Utwórz plik /etc/passwd-s3fs :
vim /etc/passwd-s3fsUWAGA: Jeśli vim edytor tekstu nie został jeszcze zainstalowany w systemie Linux, uruchom polecenie
apt-get install vim. - Wprowadź swój klucz dostępu AWS i tajny klucz dostępu zgodnie z powyższym opisem.
AKIA4SK3HPQ9FLWO8AMB:esrhLH4m1Da+3fJoU5xet1/ivsZ+Pay73BcSnzcP
Alternatywnie możesz zapisać klucze w pliku /etc/passwd-s3fs za pomocą polecenia:
echo AKIA4SK3HPQ9FLWO8AMB:esrhLH4m1Da+3fJoU5xet1/ivsZ+Pay73BcSnzcP > /etc/passwd-s3fs - Ustaw wymagane uprawnienia dla pliku /etc/passwd-s3fs :
chmod 640 /etc/passwd-s3fs - Edytuj plik konfiguracyjny FUSE:
vim /etc/fuse.conf - Usuń komentarz z ciągu user_allow_other , jeśli chcesz zezwolić na korzystanie z Amazon S3 do udziału plików przez innych użytkowników (niebędących użytkownikami głównymi) na Twoim komputerze z systemem Linux.

- Otwórz /etc/fstab za pomocą edytora tekstowego:
vim /etc/fstab - Dodaj następujący wiersz na końcu pliku:
s3fs#blog-bucket01 /home/user1/s3-bucket/ fuse _netdev,allow_other,url=https://s3.amazonaws.com 0 0
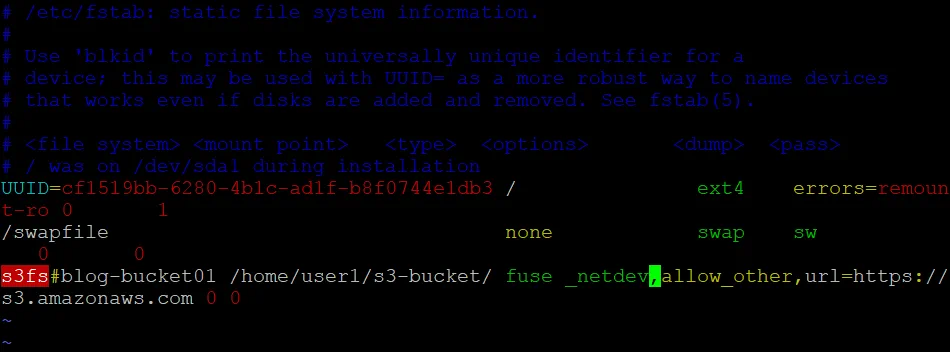
- Zapisz edytowany /etc/fstab plik i zamknij edytor tekstowy.
Uwaga: Jeśli chcesz ustawić właściciela i grupę, możesz użyć parametrów
-o uid=1001 -o gid=1001 -o mp_umask=002(zmień wartości liczbowe identyfikatora użytkownika, identyfikatora grupy i umask zgodnie z konfiguracją). Jeśli chcesz włączyć pamięć podręczną, użyj parametru-ouse_cache=/tmp(w razie potrzeby ustaw własny katalog zamiast /tmp/ ). Możesz ustawić liczbę prób ponownego zamontowania zasobnika, jeśli nie został on zamontowany przy pierwszym uruchomieniu, korzystając z parametru retries. Na przykładretries=5ustawia pięć prób. - Uruchom ponownie komputer z systemem Ubuntu, aby sprawdzić, czy zasobnik S3 jest montowany automatycznie podczas uruchamiania systemu:
init 6 - Poczekaj, aż komputer z systemem Linux się uruchomi.
- Możesz uruchomić polecenia, aby sprawdzić, czy zasób AWS S3 został automatycznie zamontowany w s3-bucket katalogu podczas uruchamiania systemu Ubuntu.
mount | grep bucket
df -h | grep bucket
ls -al /home/user1/s3-bucket/
W naszym przypadku dysk w chmurze Amazon S3 został automatycznie zamontowany w określonym katalogu systemu Linux podczas uruchamiania systemu Ubuntu (patrz zrzut ekranu poniżej). Konfiguracja została pomyślnie zastosowana.

S3FS obsługuje również pracę z rsync oraz buforowanie plików w celu zmniejszenia ruchu.
Montowanie magazynu w chmurze Amazon S3 w systemie Windows
Możesz wypróbować wins3fs , które jest rozwiązaniem równoważnym S3FS do montowania magazynu w chmurze Amazon S3 jako dysku sieciowego w systemie Windows. Jednak w tej sekcji będziemy używać rclone . Rclone to narzędzie wiersza poleceń, które można wykorzystać do montowania i synchronizacji magazynu-chmury, takich jak zasoby Amazon S3, Google Cloud Storage, Dysk Google, Microsoft OneDrive, DropBox i inne.
Rclone to darmowe narzędzie typu open source, które można pobrać z oficjalnej strony internetowej oraz z serwisu GitHub. Potrzebną wersję rclone można pobrać, korzystając z jednego z poniższych linków:
Skorzystajmy z bezpośredniego linku z oficjalnej strony:
Ten schemat postępowania można wykorzystać w przypadku nowszych wersji rclone po ich wydaniu. Poniższe czynności wykonuje się w interfejsie wiersza poleceń i mogą one być przydatne dla użytkowników korzystających z systemu Windows bez GUI na serwerach lub maszynach wirtualnych.
- Otwórz Windows PowerShell jako administrator .
- Utwórz katalog do pobrania i przechowywania rclone plików:
mkdir c:rclone - Przejdź do utworzonego katalogu:
cd c:rclone - Pobierz rclone korzystając z bezpośredniego linku podanego powyżej. Edytuj numer wersji w linku, jeśli pobierasz inną wersję.
Invoke-WebRequest -Uri "https://downloads.rclone.org/v1.51.0/rclone-v1.51.0-windows-amd64.zip" -OutFile "c:rclonerclone.zip" - Rozpakuj pliki z pobranego archiwum:
Expand-Archive -path 'c:rclonerclone.zip' -destinationpath '.' - Sprawdź zawartość katalogu:
dir
- W tym przypadku pliki zostały rozpakowane do katalogu C:rclonerclone-v1.51.0-windows-amd64 .
UWAGA: W tym przykładzie nazwa katalogu rclone po rozpakowaniu plików to rclone-v1.51.0-windows-amd64 . Nie zaleca się jednak używania kropek (.) w nazwach katalogów. Katalog można na przykład przemianować na rclone-v1-51-win64 .
- Skopiujmy rozpakowane pliki do C:rclone , aby uniknąć kropek w nazwie katalogu:
cp C:rclonerclone-v1.51.0-windows-amd64*.* C:rclone
- Uruchom rclone w trybie konfiguracji:
.rclone.exe config
- Konfigurator działa jak kreator w trybie wiersza poleceń. Na każdym etapie kreatora należy wybrać wymagane parametry.
- Wpisz
ni naciśnijEnteraby wybrać opcję „New remote” (Nowe zdalne).n/s/q >
n
- Wpisz nazwę swojego zasobnika S3:
name >
blog-bucket01 - Po wpisaniu nazwy wybierz typ magazynu-chmury do skonfigurowania. Wpisz
4aby wybrać magazyn-chmura Amazon S3.Storage >
4 - Wybierz dostawcę usług w chmurze. Wpisz
1, aby wybrać Amazon Web Services S3.provider >
1
- Pobierz poświadczenia AWS z środowiska uruchomieniowego (true lub false).
1(false) jest używane domyślnie. NaciśnijEnterbez wpisywania niczego, aby użyć wartości domyślnej.env_auth >
1 - Wprowadź swój klucz dostępu AWS:
access_key_id >
AKIA4SK3HPQ9FLWO8AMB - Wprowadź swój tajny klucz dostępu:
secret_access_key >
esrhLH4m1Da+3fJoU5xet1/ivsZ+Pay73BcSnzcP
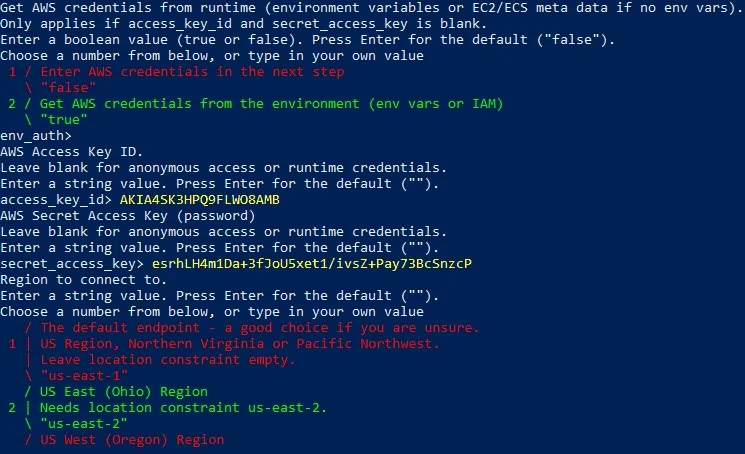
- Region, z którym chcesz się połączyć. UE (Irlandia) eu-west-1 jest używany dla naszego zasobnika w tym przykładzie i powinniśmy wpisać
6.region >
6

- Punkt końcowy dla API S3. Pozostaw puste, jeśli korzystasz z AWS, aby użyć domyślnego punktu końcowego dla regionu. Naciśnij
Enter.Punkt końcowy >
- Ograniczenie lokalizacji musi być ustawione tak, aby pasowało do regionu. Wpisz
6, aby wybrać region UE (Irlandia) „eu-west-1”.location_constraint >
6 - Gotowa lista ACL używana podczas tworzenia zasobników oraz przechowywania lub kopiowania obiektów. Naciśnij
Enter, aby użyć domyślnych parametrów.acl >
- Określ algorytm szyfrowania po stronie serwera używane podczas przechowywania tego obiektu w S3. W naszym przypadku szyfrowanie jest wyłączone i musimy wpisać 1 (Brak). server_side_encryption >
1

- W przypadku korzystania z identyfikatora KMS należy podać identyfikator ARN klucza. Ponieważ szyfrowanie nie jest stosowane, należy wpisać
1(Brak).sse_kms_key_id >
1 - Wybierz klasę magazynu, która ma być używana podczas zapisywania nowych obiektów w S3. Wprowadź wartość typu ciąg znaków. W naszym przypadku odpowiednia jest opcja standardowej klasy przechowywania (
2).storage_class >
2

- Edytować zaawansowaną konfigurację? (y/n)
y/n >
n - Sprawdź konfigurację i wpisz
y(tak), jeśli wszystko jest poprawne.t/e/d >
y

- Wpisz
q, aby zamknąć kreatora konfiguracji.e/n/d/r/c/s/q >
q - Rclone jest teraz skonfigurowany do pracy z magazynem-chmura Amazon S3. Upewnij się, że masz prawidłowe ustawienia daty i czasu na komputerze z systemem Windows. W przeciwnym razie może wystąpić błąd podczas montowania zasobnika S3 jako dysku sieciowego na komputerze z systemem Windows: Czas może być ustawiony nieprawidłowo. Różnica między czasem żądania a czasem bieżącym jest zbyt duża .
- Uruchom rclone w katalogu, w którym znajduje się
rclone.exei wyświetl listę zasobników dostępnych dla Twojego konta AWS:.rclone.exe lsd blog-bucket01:
- Możesz wprowadzić
c:rclonedo zmiennej środowiskowejPath. Pozwala to na uruchamianie rclone z dowolnego katalogu bez konieczności przechodzenia do katalogu, w którym przechowywany jest plik rclone.exe. - Jak widać na powyższym zrzucie ekranu, dostęp do magazynu-chmury Amazon S3 jest poprawnie skonfigurowany i wyświetlana jest lista zasobników (w tym blog-bucket01 używany w tym samouczku).
- Zainstaluj Chocolately , czyli menedżera pakietów dla systemu Windows, który służy do instalowania aplikacji z repozytoriów internetowych:
Set-ExecutionPolicy Bypass -Scope Process -Force; `iex ((New-Object System.Net.WebClient).DownloadString('https://chocolatey.org/install.ps1')) - WinFSP (Windows File System Proxy) to odpowiednik FUSE w systemie Linux dla systemu Windows. Jest szybki, stabilny i pozwala tworzyć systemy plików w trybie użytkownika.
Zainstaluj WinFSP z repozytoriów Chocolatey:
choco install winfsp -y
- Teraz możesz zamontować swój zasób Amazon S3 w systemie Windows jako dysk sieciowy. Zamontujmy blog-bucket01 jako S:
.rclone mount blog-bucket01:blog-bucket01/ S: --vfs-cache-mode fullGdzie pierwszy „blog-bucket” to nazwa zasobnika wprowadzona w pierwszym kroku kreatora konfiguracji rclone, a drugi „blog-bucket” zdefiniowany po „:” to nazwa zasobnika Amazon S3 ustawiona w interfejsie internetowym AWS.

- Wyświetl listę wszystkich podłączonych dysków i partycji:
gdr -PSProvider 'FileSystem' - Sprawdź zawartość zamapowanego dysku sieciowego:
ls S: - Zbiornik S3 jest teraz zamontowany jako dysk sieciowy (S:). Możesz wyświetlić trzy pliki txt przechowywane w blog-bucket01 w magazynie Amazon S3, korzystając z innej instancji programu Windows PowerShell lub wiersza poleceń systemu Windows.


Jeśli system Windows posiada graficzny interfejs użytkownika, można go użyć do pobierania i wysyłania plików do magazynu Amazon S3. Jeśli skopiujesz plik za pomocą interfejsu Windows (graficznego lub wiersza poleceń), dane zostaną zsynchronizowane w ciągu chwili i nowy plik będzie widoczny zarówno w interfejsie Windows, jak i w interfejsie internetowym AWS.

Jeśli naciśniesz Ctrl+C lub zamkniesz okno CMD lub PowerShell, w którym rclone jest uruchomiony (w tej instancji CMD lub PowerShell wyświetla się komunikat „Usługa clone została uruchomiona”), Twój zasób Amazon S3 zostanie odłączony od punktu montowania (w tym przypadku S:).
Jak zautomatyzować montowanie zasobu S3 podczas uruchamiania systemu Windows
Wygodne jest, gdy zasób jest montowany jako dysk sieciowy automatycznie podczas uruchamiania systemu Windows. Zobaczmy, jak skonfigurować automatyczne montowanie zasobnika S3 w systemie Windows.
- Utwórz plik rclone-S3.cmd w katalogu C:rclone .
- Dodaj ciąg znaków do pliku rclone-S3.cmd :
C:rclonerclone.exe mount blog-bucket01:blog-bucket01/ S: –vfs-cache-mode full
- Zapisz plik CMD. Możesz uruchomić ten plik CMD zamiast ręcznie wpisywać polecenie, aby zamontować zasób S3.
- Skopiuj plik rclone-S3.cmd do folderu autostartu dla wszystkich użytkowników:
C:ProgramDataMicrosoftWindowsStart MenuProgramsStartUp
- Alternatywnie możesz utworzyć skrót do C:WindowsSystem32cmd.exe i ustawić argumenty potrzebne do zamontowania zasobnika S3 we ustawieniach docelowych:
C:WindowsSystem32cmd.exe /k cd c:rclone & rclone mount blog-bucket01:blog-bucket01/ S: –vfs-cache-mode full

- Następnie dodaj edytowany skrót do folderu autostartu systemu Windows:
C:ProgramDataMicrosoftWindowsStart MenuProgramsStartUp
Jest jedna mała wada – po podłączeniu zasobnika S3 do komputera z systemem Windows jako dysku sieciowego wyświetla się okno wiersza poleceń z komunikatem „ Usługa rclone została uruchomiona ”. Możesz spróbować skonfigurować automatyczne montowanie zasobnika S3 za pomocą harmonogramu systemu Windows lub NSSM, czyli bezpłatnego narzędzia do tworzenia i konfigurowania usług systemu Windows oraz ich automatycznego uruchamiania.
Montowanie zasobnika S3 jako systemu plików w systemie macOS
Zasobnik Amazon S3 można zamontować w systemie macOS w taki sam sposób, jak w systemie Linux. Należy zainstalować S3FS ze strony macOS oraz ustawić uprawnienia i klucze Amazon.
W tym przykładzie wykorzystano system macOS 10.15 Catalina. Tę zasadę konfiguracji można zastosować również w nowszych wersjach. Nazwa zasobnika S3 to blog-bucket01 , nazwa użytkownika w systemie macOS to user1 , a katalog używany jako punkt montowania zasobnika to /Volumes/s3-bucket/.
Przyjrzyjmy się konfiguracji krok po kroku.
- Zainstaluj homebrew , czyli menedżera pakietów dla systemu macOS służącego do instalowania aplikacji z internetowych repozytoriów oprogramowania:
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install.sh)" - Zainstaluj osxfuse :
brew cask install osxfuse - Uruchom ponownie system:
sudo shutdown -r now - Zainstaluj S3FS:
brew install s3fs - Po zainstalowaniu S3FS ustaw klucz dostępu i tajny klucz dostępu dla swojego zasobnika Amazon S3. Możesz zdefiniować klucze dla bieżącej sesji, jeśli chcesz zamontować zasób tylko raz lub zamierzasz to robić rzadko:
export AWSACCESSKEYID=AKIA4SK3HPQ9FLWO8AMBexport AWSSECRETACCESSKEY=esrhLH4m1Da+3fJoU5xet1/ivsZ+Pay73BcSnzP - Jeśli zamierzasz regularnie korzystać z zamontowanego zasobu, ustaw klucze AWS w pliku konfiguracyjnym używanym przez S3FS dla swojego konta użytkownika w systemie macOS:
echo AKIA4SK3HPQ9FLWO8AMB:esrhLH4m1Da+3fJoU5xet1/ivsZ+Pay73BcSnzP > ~/.passwd-s3fs - Jeśli masz wiele zasobników i kluczy dostępu do nich, zdefiniuj je w formacie:
echo bucket-name:access-key:secret-key > ~/.passwd-s3fs - Ustaw odpowiednie uprawnienia, aby zezwolić na dostęp do odczytu i zapisu wyłącznie właścicielowi:
chmod 600 ~/.passwd-s3fs - Utwórz katalog, który będzie służył jako punkt montowania zasobnika Amazon S3:
sudo mkdir -p /Volumes/s3-bucket/ - Twoje konto użytkownika musi być ustawione jako właściciel utworzonego katalogu:
sudo chown user1 /Volumes/s3-bucket/

- Zamontuj zasobnik za pomocą S3FS:
s3fs blog-bucket01 /Volumes/s3-bucket/ - W oknie dialogowym wyświetli się ostrzeżenie dotyczące bezpieczeństwa systemu macOS. Kliknij
Open System Preferences, aby zezwolić aplikacji S3FS i powiązanym połączeniom.

- W oknie Security & Privacy kliknij kłódkę, aby wprowadzić zmiany, a następnie naciśnij przycisk
Allow.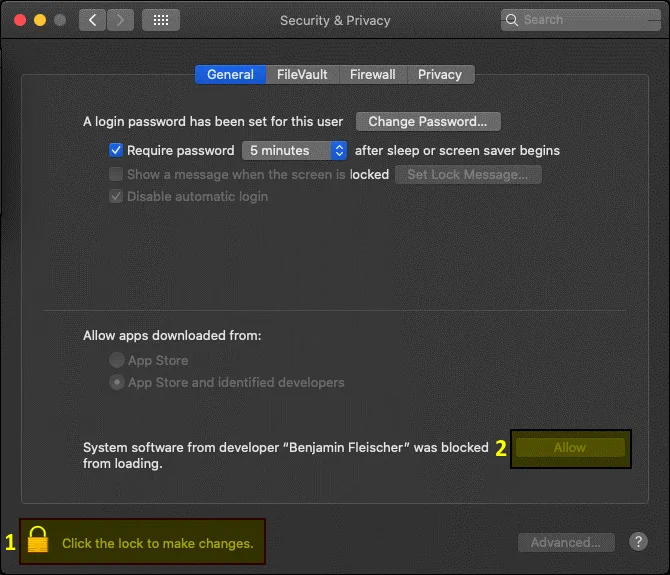
- Uruchom ponownie polecenie montowania:
s3fs blog-bucket01 /Volumes/s3-bucket/ - Wyświetli się wyskakujące okienko z ostrzeżeniem: Terminal chce uzyskać dostęp do plików na woluminie sieciowym .
Kliknij
OK, aby zezwolić na dostęp.

- Sprawdź, czy zasobnik został zamontowany:
mount | grep bucket - Sprawdź zawartość zasobnika:
ls -al /Volumes/s3-bucket/ - Zbiornik został pomyślnie zamontowany. Możesz przeglądać, kopiować i usuwać pliki w zbiorniku.

Możesz spróbować skonfigurować montowanie zbiornika S3 przy logowaniu użytkownika za pomocą launchd .
Wnioski
Gdy wiesz już, jak zamontować magazyn-chmura Amazon S3 jako system plików w najpopularniejszych systemach operacyjnych, udostępnianie plików za pośrednictwem Amazon S3 staje się wygodniejsze. Bucket Amazon S3 można zamontować za pomocą S3FS w systemach Linux i macOS oraz za pomocą rclone lub wins3fs w systemie Windows. Automatyzacja procesu kopiowania danych do bucketów Amazon S3 po zamontowaniu ich w lokalnych katalogach systemu operacyjnego jest wygodniejsza w porównaniu z korzystaniem z interfejsu internetowego.
Możesz skopiować swoje dane do Amazon S3 w celu utworzenia kopii zapasowej, korzystając z interfejsu swojego systemu operacyjnego. Można spróbować użyć dedykowanych aplikacji do tworzenia kopii zapasowych, które korzystają z interfejsów API AWS w celu uzyskania dostępu do zasobników S3. NAKIVO Backup & Replication to kompletne rozwiązanie do ochrony danych z wbudowanym wsparciem dla zasobników S3 jako miejsc docelowych dla kopii zapasowych. Rozwiązanie to można wykorzystać do wykonania kopii zapasowej danych w maszynach wirtualnych VMware, maszynach wirtualnych Hyper-V oraz instancjach EC2 do Amazon S3.


