Wprowadzenie do Amazon S3: Jak działa przechowywanie obiektów w chmurze
Amazon Simple Storage Service (S3) to popularna usługa magazynu-chmury, stanowiąca część platformy Amazon Web Services (AWS). Usługa Amazon S3 zapewnia wysoką niezawodność, elastyczność, skalowalność i dostępność. Liczba obiektów i ilość danych przechowywanych w Amazon S3 jest nieograniczona. Magazyn-chmura S3 jest atrakcyjny dla firm, ponieważ płaci się tylko za to, z czego się korzysta.
Jednak terminologia i metodologia mogą prowadzić do nieporozumień i trudności dla nowych użytkowników Amazon S3. Gdzie są przechowywane dane S3? Jak działa magazyn-chmura Amazon S3? Ten wpis na blogu wyjaśnia główne pojęcia i zasadę działania magazynu-chmury Amazon S3.

O usłudze Amazon S3 Storage
Amazon S3 była pierwszą usługą chmurową firmy AWS, uruchomioną w 2006 roku. Od tego czasu popularność tej usługi przechowywania danych stale rośnie. Obecnie Amazon oferuje szeroki wachlarz innych usług chmurowych, jednak usługa przechowywania danych Amazon S3 jest najczęściej wykorzystywana. Oprócz usługi Amazon S3, AWS oferuje woluminy Amazon EBS dla instancji EC2 oraz usługę Amazon Drive. Jednak te trzy usługi mają różne zastosowania i cele.
EBS (Elastic Block Storage) woluminy dla instancji EC2 (Elastic Compute Cloud) to dyski wirtualne dla maszyn wirtualnych znajdujących się w chmurze Amazon. Jak można wywnioskować z nazwy EBS, jest to pamięć blokowa w chmurze, która jest odpowiednikiem dysków twardych w komputerach fizycznych. System operacyjny można zainstalować na woluminie EBS podłączonym do instancji EC2 .
Amazon Drive (wcześniej znany jako Amazon Cloud Drive) jest odpowiednikiem Google Drive i Microsoft OneDrive. Amazon Drive ma mniejszy zakres funkcji niż Amazon S3. Amazon Drive jest pozycjonowany jako usługa przechowywania danych w chmurze służąca do wykonania kopii zapasowej zdjęć i innych danych użytkownika.
Amazon S3 magazyn-chmura to usługa oparta na obiektach. Nie można zainstalować systemu operacyjnego podczas korzystania z pamięci Amazon S3, ponieważ nie ma dostępu do danych na poziomie bloków, co jest wymagane przez system operacyjny. Jeśli chcesz zamontować pamięć Amazon S3 jako dysk sieciowy w swoim systemie operacyjnym, użyj systemu plików w przestrzeni użytkownika. Przeczytaj wpis na blogu dotyczący podłączenie magazynu-chmury S3 dla różnych systemów operacyjnych. Google Cloud jest odpowiednikiem magazynu-chmura Amazon S3.
Główne pojęcia związane z Amazon S3
Jeśli zamierzasz korzystać z Amazon S3 po raz pierwszy, niektóre pojęcia mogą wydawać się dla Ciebie nietypowe i nieznane. Metodologia przechowywania danych w chmurze S3 różni się od przechowywania danych na tradycyjnych dyskach twardych, dyskach półprzewodnikowych lub macierzach dyskowych. Poniżej znajduje się przegląd głównych pojęć i technologii wykorzystywanych do przechowywania danych oraz zarządzania nimi w chmurze Amazon S3.
W jaki sposób S3 przechowuje pliki?
Jak wyjaśniono powyżej, dane w Amazon S3 są przechowywane jako obiekty. Takie podejście zapewnia wysoce skalowalną pamięć masową w chmurze. Obiekty mogą znajdować się na różnych fizycznych dyskach rozproszonych w centrum danych. W centrach danych Amazon wykorzystywany jest specjalny sprzęt, oprogramowanie oraz rozproszone systemy plików, aby zapewnić wysoką skalowalność. Nadmiarowość i przechowywanie wersji to funkcje wdrożone przy użyciu podejścia opartego na pamięci blokowej. Gdy plik jest przechowywany w Amazon S3 jako obiekt, domyślnie jest on przechowywany w wielu miejscach (takich jak dyski, centra danych lub strefy dostępności) jednocześnie. Usługa Amazon S3 regularnie sprawdza spójność danych poprzez weryfikację kontrolnych sum kontrolnych. W przypadku wykrycia uszkodzenia danych obiekt jest odtwarzany przy użyciu danych redundantnych. Obiekty są przechowywane w magazynach Amazon S3. Domyślnie dostęp do obiektów w pamięci masowej Amazon S3 oraz zarządzanie nimi odbywa się za pośrednictwem interfejsu internetowego.
Czym jest pamięć obiektowa S3?
Magazyn obiektów to rodzaj pamięci masowej, w której dane są przechowywane jako obiekty, a nie jako bloki. Koncepcja ta jest przydatna w przypadku danych kopia zapasowa, archiwizacji oraz skalowalności w środowiskach o dużym obciążeniu.
Objects są podstawowymi jednostkami przechowywania danych w zasobnikach Amazon S3. Obiekt składa się z trzech głównych elementów – treści obiektu (dane przechowywane w obiekcie, takie jak plik lub katalog), unikalnego identyfikatora obiektu (ID) oraz metadanych. Metadane są przechowywane jako pary klucz-wartość i zawierają informacje, takie jak nazwa, rozmiar, data, atrybuty bezpieczeństwa, typ zawartości i adres URL.
Każdy obiekt posiada listę kontroli dostępu (ACL), która pozwala skonfigurować, kto ma prawo dostępu do obiektu. Magazyn obiektowy Amazon S3 pozwala uniknąć wąskich gardeł w sieci w godzinach szczytu, kiedy ruch do obiektów przechowywanych w magazynie-chmurze S3 znacznie wzrasta. Amazon zapewnia elastyczną przepustowość sieci, ale pobiera opłaty za dostęp do przechowywanych obiektów. Pamięć obiektowa sprawdza się, gdy duża liczba klientów musi uzyskać dostęp do danych (wysoka częstotliwość odczytu). W modelu pamięci obiektowej wyszukiwanie w metadanych przebiega szybciej.
Przeczytaj również o Szyfrowanie w usłudze Amazon S3 , które może pomóc w ochronie danych przechowywanych w magazynie Amazon S3 i zwiększeniu bezpieczeństwa.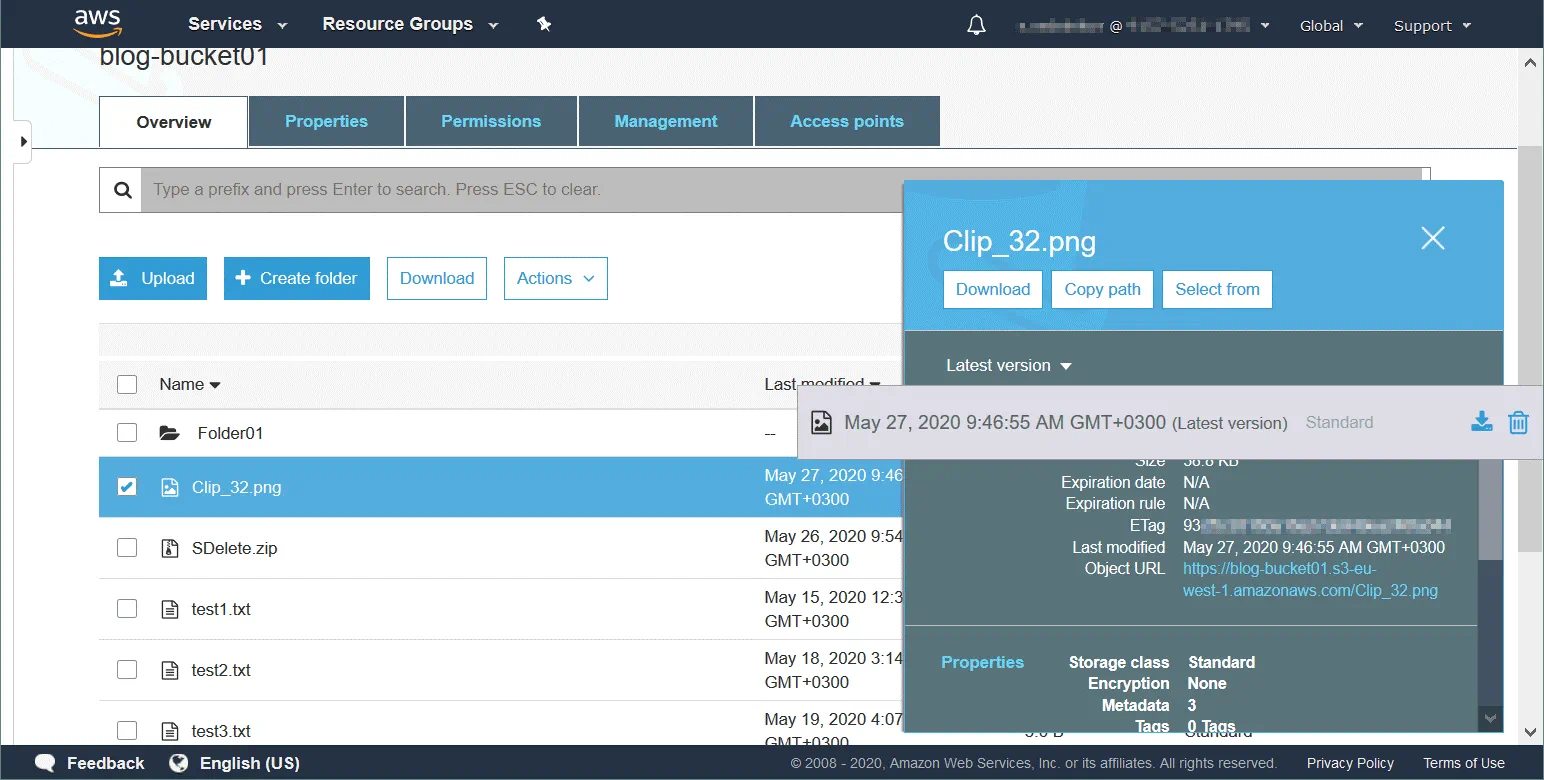
Zbiorniki
A bucket to podstawowe logiczne kontenery, w których przechowywane są dane w pamięci Amazon S3. W zasobniku można przechowywać nieskończoną ilość danych i nieograniczoną liczbę obiektów. Każdy obiekt S3 jest przechowywany w zasobniku. Obowiązuje ograniczenie wielkości jednego obiektu przechowywanego w zasobniku do 5 TB. Zasobniki służą do organizowania przestrzeni nazw na najwyższym poziomie oraz do kontroli dostępu.
Klucze
Obiekt posiada unique key po przesłaniu do zasobnika. Klucz ten jest ciągiem znaków, który naśladuje hierarchię katalogów. Znajomość klucza umożliwia dostęp do obiektu w zasobniku. Zasobnik, klucz i identyfikator wersji jednoznacznie identyfikują obiekt. Na przykład, jeśli nazwa zasobnika to blog-bucket01 , region, w którym znajdują się centra danych przechowujące dane, to s3-eu-west-1 , a nazwa obiektu to test1.txt (plik tekstowy), adres URL do potrzebnego pliku przechowywanego jako obiekt w zasobniku to: https://blog-bucket01.s3-eu-west-1.amazonaws.com/test1.txt
Jeśli chcesz udostępniać obiekty innym użytkownikom, musisz skonfigurować uprawnienia poprzez edycję atrybutów obiektu. Podobnie można utworzyć TextFiles folder i zapisać plik tekstowy w tym folderze:
https://blog-bucket01.s3-eu-west-1.amazonaws.com/TextFiles/test1.txt
Istnieją dwa typy adresów URL, które można wykorzystać:
- bucketname.s3.amazonaws.com/objectname
- s3.amazon.aws.com/bucketname/objectname
Regiony AWS
Amazon posiada centra danych w różnych regionach na całym świecie, w tym w USA, Irlandii, RPA, Indiach, Japonii, Chinach, Korei, Kanadzie, Niemczech, Włoszech i Wielkiej Brytanii. Podczas tworzenia zasobnika można wybrać żądany region. Zaleca się wybranie regionu, który znajduje się najbliżej użytkownika lub jego klientów, aby zapewnić mniejsze opóźnienia w połączeniu sieciowym lub zminimalizować koszty (ponieważ cena przechowywania danych różni się w zależności od regionu). Dane przechowywane w danym regionie AWS nigdy nie opuszczają centrów danych tego regionu, dopóki użytkownik nie przeniesie ich ręcznie. Regiony AWS są odizolowane od siebie, aby zapewnić odporność na awarie i stabilność.
Każdy region zawiera strefy dostępności, które są odizolowanymi lokalizacjami w obrębie regionu AWS. W każdym regionie dostępne są co najmniej trzy strefy dostępności, aby zapobiec awariom spowodowanym katastrofami, takimi jak pożary, tajfuny, huragany, powodzie itp.
Model spójności danych
W przypadku obiektów przechowywanych w magazynie Amazon S3 przeprowadzana jest kontrola spójności typu „odczyt po zapisie”. Amazon S3 replikuje dane na serwerach i w centrach danych w obrębie wybranego regionu, aby zapewnić wysoką dostępność. Po pomyślnym wykonaniu żądania PUT zmienione dane muszą zostać zreplikowane na serwerach. Proces ten może zająć trochę czasu. W takim przypadku użytkownik może uzyskać stare dane lub zaktualizowane dane, ale nie dane uszkodzone. Dotyczy to również usuniętych obiektów i zasobników. Blokowanie obiektów nie jest wykonywane, gdy nowe obiekty są wysyłane do zasobników S3. Jeśli jednocześnie wykonywanych jest wiele żądań PUT, pierwszeństwo ma ostatnie żądanie PUT. Możesz stworzyć własną aplikację z mechanizmem blokowania, który działa z obiektami przechowywanymi w magazynie Amazon S3.
Funkcje Amazon S3
Koncepcja pamięci obiektowej pozwala Amazon zapewnić przydatne funkcje i dużą elastyczność w zakresie przechowywania danych w magazynie Amazon S3 oraz zarządzania nimi. Przyjrzyjmy się tym funkcjom.
Przechowywanie wersji
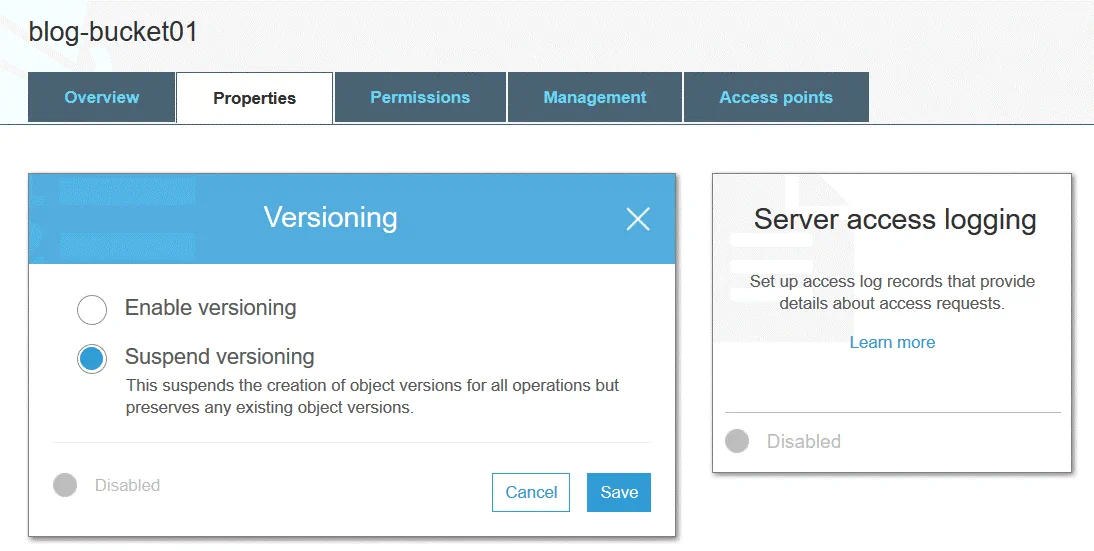
Przechowywanie wersji obiektów pozwala na przechowywanie wielu wersji jednego obiektu w jednym zasobniku. Funkcja ta chroni obiekty przechowywane w usłudze Amazon S3 przed niezamierzoną edycją, nadpisaniem lub usunięciem. Po zmianie lub usunięciu obiektu można przywrócić jedną z jego poprzednich wersji. Przechowywanie wersji jest realizowane dzięki zastosowaniu modelu przechowywania obiektowego. Można używać przechowywania wersji do celów archiwizacji. Przechowywanie wersji jest domyślnie wyłączone.
Identyfikator wersji jest przypisywany do każdego obiektu S3, nawet jeśli przechowywanie wersji nie jest włączone (w tym przypadku wartość identyfikatora wersji jest ustawiona na null). Jeśli przechowywanie wersji jest włączone, nowa wartość identyfikatora wersji jest przypisywana do nowej wersji obiektu po zapisaniu zmian. Przechowywanie wersji można włączyć na poziomie zasobnika. Wartość identyfikatora wersji pierwszej wersji obiektu pozostaje taka sama. Po usunięciu obiektu z zasobnika S3 (z włączonym przechowywaniem wersji) znacznik usunięcia jest nakładany na najnowszą wersję obiektu.
Klasy przechowywania
Klasy przechowywania Amazon S3 definiują przeznaczenie pamięci wybranej do przechowywania danych. Klasę przechowywania można ustawić na poziomie obiektu. Można jednak ustawić domyślną klasę przechowywania dla obiektów, które będą tworzone na poziomie zasobnika.
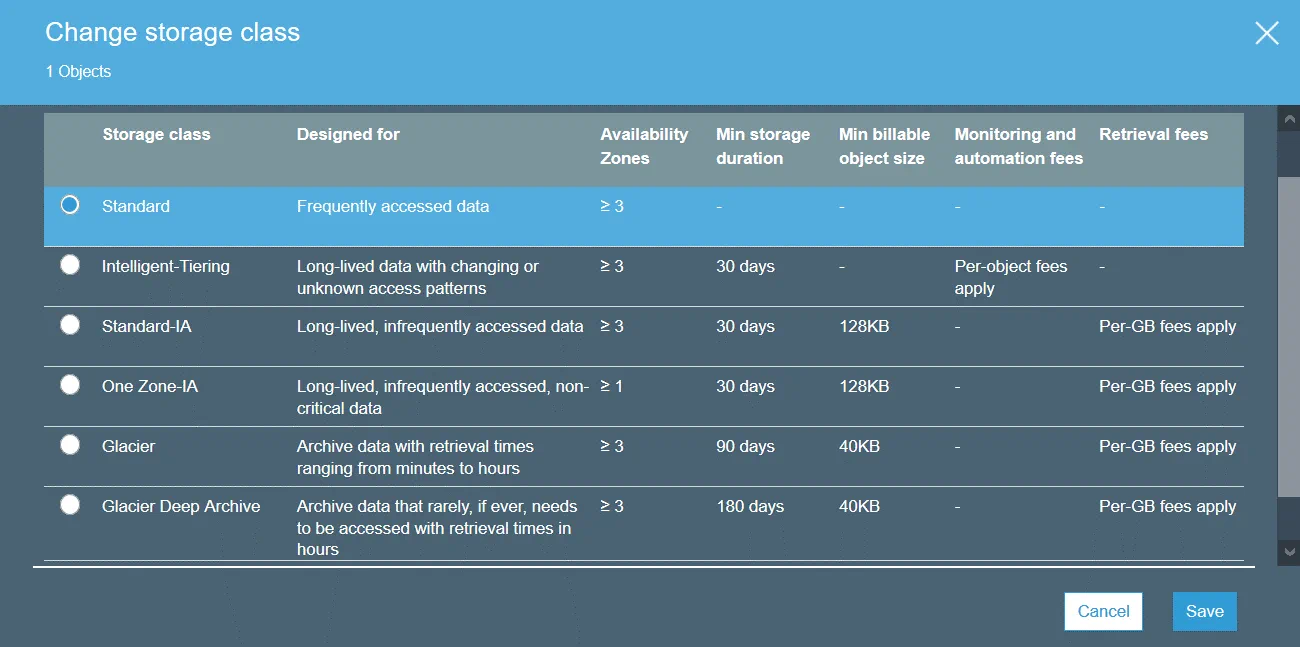
S3 Standard jest domyślną klasą przechowywania. Ta klasa służy do przechowywania danych aktywnych i jest odpowiednia dla danych często używanych. Klasy magazynowania Standard należy używać do hostowania stron internetowych, dystrybucji treści, tworzenia aplikacji w chmurze itp. Funkcje tej klasy magazynowania to wysokie koszty magazynowania, niskie koszty przywracania oraz szybki dostęp do danych.
S3 Standard-IA (rzadki dostęp) może służyć do przechowywania danych, do których dostęp jest rzadszy niż w przypadku klasy S3 Standard. Klasa S3 Standard-IA jest zoptymalizowana pod kątem dłuższego okresu magazynowania. Pobieranie danych przechowywanych w klasie magazynu S3 Standard-IA jest płatne. Ponadto zarówno w S3 Standard jak i S3 Standard-IA należy uiścić opłatę za żądania dotyczące danych (PUT, COPY, POST, LIST, GET, SELECT).
S3 One Zone-IA jest przeznaczona dla danych, do których dostęp jest rzadki. Dane są przechowywane tylko w jednej strefie dostępności (w przypadku S3 Standard dane są przechowywane w trzech strefach dostępności), co skutkuje niższym poziomem nadmiarowości i odporności. Deklarowany poziom dostępności wynosi 99,5%, czyli mniej niż w przypadku pozostałych dwóch klas magazynów. S3 One Zone-IA charakteryzuje się niższymi kosztami przechowywania, wyższymi kosztami przywracania oraz koniecznością płacenia za pobieranie danych w oparciu o liczbę GB. Można rozważyć wykorzystanie tej klasy magazynu jako ekonomicznego rozwiązania do przechowywania danych typu „ kopia zapasowa ” lub kopii danych utworzonych za pomocą replikacji międzyregionowej Amazon S3. W przeciwieństwie do innych klas magazynów,
S3 Glacier nie zapewnia natychmiastowego dostępu do przechowywanych danych. S3 Glacier może służyć do przechowywania danych w ramach długoterminowej archiwizacji przy niskich kosztach. Nie ma gwarancji nieprzerwanego działania. Aby odzyskać dane, trzeba poczekać od kilku minut do kilku godzin. Można przenieść stare dane z magazynu o wyższej klasie (na przykład z S3 Standard) do S3 Glacier, korzystając z zasad cyklu życia S3, i w ten sposób obniżyć koszty przechowywania.
S3 Glacier Deep Archive jest podobna do S3 Glacier, ale czas potrzebny na odzyskanie danych wynosi około 12–48 godzin. Cena jest niższa niż w przypadku S3 Glacier. Klasa pamięci masowej S3 Glacier Deep Archive może służyć do przechowywania kopii zapasowych i danych archiwalnych firm, które muszą spełniać wymagania regulacyjne dotyczące archiwizacji danych (finanse, opieka zdrowotna). To dobra alternatywa dla kaset taśmowych.
S3 Intelligent-Tiering to specjalna klasa pamięci masowej, która korzysta z innych klas pamięci masowej. S3 Intelligent-Tiering ma na celu automatyczny wybór lepszej klasy pamięci masowej do przechowywania danych, gdy nie wiesz, jak często będziesz potrzebować dostępu do tych danych. Amazon S3 może monitorować wzorce dostępu do danych podczas korzystania z obsługi warstw S3, a następnie przechowywać obiekty w jednej z dwóch wybranych klas przechowywania (jedna przeznaczona jest dla danych, do których dostęp jest częsty, a druga dla danych, do których dostęp jest rzadki). Takie podejście zapewnia optymalną opłacalność bez utraty wydajności.
Na przykład, jeśli uzyskasz dostęp do obiektu przechowywanego w klasie przechowywania dla danych, do których dostęp jest rzadki, obiekt ten zostanie automatycznie przeniesiony do klasy przechowywania dla danych, do których dostęp jest częsty. W przeciwnym razie, jeśli obiekt nie był używany przez dłuższy czas, zostanie przeniesiony do klasy magazynu przeznaczonej dla rzadko używanych danych. Obiekty mogą znajdować się w tym samym zasobniku, a zmiana klasy magazynu następuje na poziomie obiektu S3.
Listy kontroli dostępu
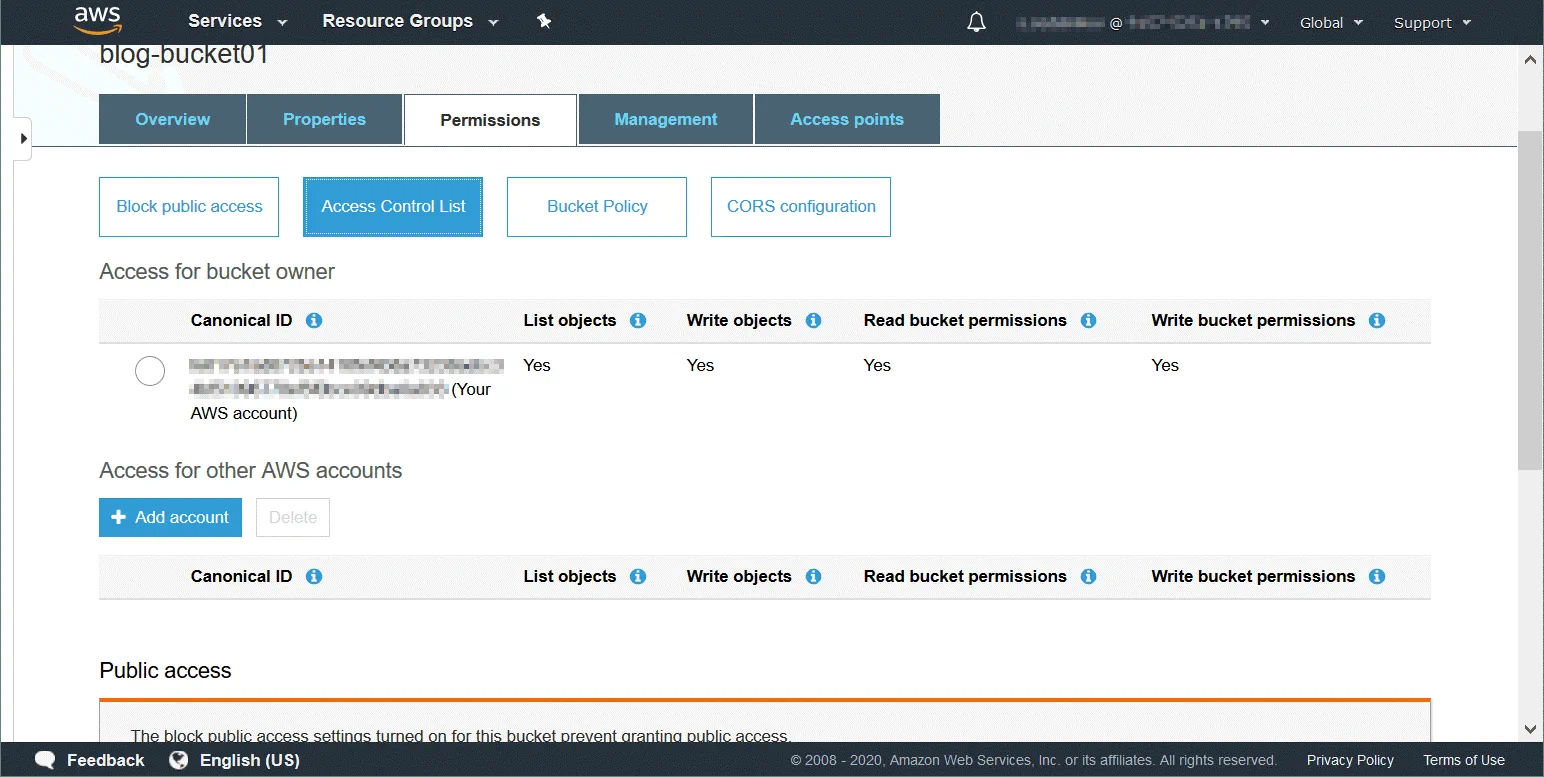
Lista kontroli dostępu (ACL) to funkcja służąca do zarządzania i kontroli dostępu do obiektów i zasobników. Listy kontroli dostępu to oparte na zasobach zasady, które są dołączane do każdego zasobnika i obiektu w celu zdefiniowania użytkowników i grup posiadających uprawnienia dostępu do zasobnika i obiektu. Domyślnie właściciel zasobu ma pełny dostęp do zasobnika lub obiektu po utworzeniu zasobu. Uprawnienia dostępu do zasobnika określają, kto może uzyskać dostęp do obiektów w zasobniku. Uprawnienia dostępu do obiektów określają, którzy użytkownicy mogą uzyskać dostęp do obiektów oraz jaki rodzaj dostępu im przysługuje. Można na przykład ustawić uprawnienia tylko do odczytu dla jednego użytkownika, a uprawnienia do odczytu i zapisu dla innego.
Pełna lista użytkowników, którym można przyznać uprawnienia (użytkownik posiadający uprawnienia nazywany jest beneficjentem):
Owner – użytkownik, który tworzy zasobnik/obiekt.
Authenticated Users – wszyscy użytkownicy posiadający konto AWS.
All Users – wszyscy użytkownicy, w tym użytkownicy anonimowi (użytkownicy, którzy nie posiadają konta AWS).
User by Email/Id – określony użytkownik posiadający konto AWS. Aby przyznać dostęp temu użytkownikowi, należy podać jego e-mail lub identyfikator AWS.
Dostępne typy uprawnień:
Full Control – ten typ uprawnień zapewnia uprawnienia do odczytu, zapisu, odczytu (ACP) oraz zapisu ACP.
Read – pozwala wyświetlić zawartość zasobnika, gdy jest stosowane na poziomie zasobnika. Pozwala na odczyt danych obiektu i metadanych, gdy jest stosowane na poziomie obiektu.
Write – może być stosowane tylko na poziomie zasobnika i pozwala na tworzenie, usuwanie i nadpisywanie dowolnego obiektu w zasobniku.
Read Permissions (READ ACP) – użytkownik może odczytywać uprawnienia dla określonego obiektu lub zasobnika.
Write Permissions (WRITE ACP) – użytkownik może nadpisywać uprawnienia dla określonego obiektu lub zasobnika. Włączenie tego typu uprawnień dla użytkownika jest równoznaczne z ustawieniem uprawnień pełnej kontroli, ponieważ użytkownik może ustawić dowolne uprawnienia dla swojego konta. Uprawnienie to jest domyślnie dostępne dla właściciela zasobnika.
Zasady zasobników
Zasady zasobników to oparte na zasobach zasady zarządzania tożsamością i dostępem AWS, które służą do tworzenia reguł warunkowych przyznawania uprawnień dostępu kontom i użytkownikom AWS podczas uzyskiwania dostępu do zasobników i obiektów w zasobnikach. Możesz używać zasad dotyczących zasobników do definiowania reguł bezpieczeństwa dla więcej niż jednego obiektu w zasobniku.
Zasada dotycząca zasobnika jest zdefiniowana jako plik JSON. Tekst konfiguracji zasady dotyczącej zasobnika musi spełniać wymagania formatu JSON, aby był ważny. Zasada dotycząca zasobnika może być dołączona tylko na poziomie zasobnika i jest dziedziczona przez wszystkie obiekty w zasobniku. Możesz przyznać dostęp użytkownikom łączącym się z określonych adresów IP, użytkownikom określonych kont AWS i tak dalej.
Poniżej znajduje się przykład polityki, która przyznaje pełny dostęp wszystkim użytkownikom jednego konta oraz dostęp tylko do odczytu wszystkim użytkownikom innego konta. {
"Statement": [
{
"Effect": "Allow",
"Principal": {
"SGWS": "95381782731015222837"
},
"Action": "s3:*",
"Resource": [
"urn:sgws:s3:::blog-bucket01",
"urn:sgws:s3:::blog-bucket01/*"
]
},
{
"Effect": "Allow",
"Principal": {
"SGWS": "30284200178239526177"
},
"Action": "s3:GetObject",
"Resource": "urn:sgws:s3:::blog-bucket01/shared/*"
},
{
"Effect": "Allow",
"Principal": {
"SGWS": "30284200178239526177"
},
"Action": "s3:ListBucket",
"Resource": "urn:sgws:s3:::blog-bucket01",
"Condition": {
"StringLike": {
"s3:prefix": "shared/*"
}
}
}
]
}
Użytkownicy mogą uzyskać dostęp do pamięci masowej Amazon S3 za pomocą kluczy dostępu (Access Key ID i Secret Access Key) bez konieczności podawania nazwy użytkownika i hasła. Takie podejście pozwala zwiększyć bezpieczeństwo i jest wykorzystywane do tworzenia aplikacji korzystających z interfejsów API w celu uzyskania dostępu do pamięci masowej w chmurze Amazon S3.
Interfejsy API dla Amazon S3
Amazon udostępnia interfejsy programowania aplikacji (API) umożliwiające korzystanie z funkcji S3 oraz tworzenie własnych aplikacji, które muszą współpracować z pamięcią masową Amazon S3. Amazon udostępnia interfejsy REST i SOAP. Interfejs REST wykorzystuje standardowe żądania HTTP do obsługi zasobników i obiektów. Interfejs API REST korzysta ze standardowych nagłówków HTTP. Kolejnym dostępnym interfejsem jest SOAP. Korzystanie z SOAP przez HTTP jest przestarzałe, ale nadal można używać SOAP przez HTTPS.
Model rozliczeniowy
Amazon S3 oferuje model „płać tylko za to, z czego korzystasz”. Nie jest wymagana opłata minimalna – nie musisz płacić za z góry określoną ilość miejsca w magazynie i transfer sieciowy. Istnieją kategorie użytkowania, za które należy zapłacić:
Storage. Płać za obiekty przechowywane w Amazon S3. Kwota do zapłaty zależy od wykorzystanej przestrzeni dyskowej, czasu przechowywania obiektów w magazynie Amazon S3 (w ciągu miesiąca) oraz klasy przechowywania używanej przez przechowywane obiekty.
Requests and data retrieval. Musisz zapłacić za żądania wysłane w celu pobrania danych przechowywanych w magazynie-chmura Amazon S3.
Data transfer. Należy uiścić opłatę za całą wykorzystaną przepustowość (ruch przychodzący i wychodzący) z wyjątkiem danych przychodzących z Internetu; danych wychodzących, które są przesyłane do instancji Amazon EC2 znajdujących się w tym samym regionie AWS co źródłowy zasobnik S3; danych wychodzących z zasobnika S3 do CloudFront.
Management and replication. Należy uiścić opłatę za korzystanie z funkcji zarządzania pamięcią masową, takich jak analityka i oznaczanie obiektów. Amazon pobiera opłaty za replikację międzyregionową i replikację w tym samym regionie.
Skorzystaj z Kalkulator Amazon S3 , aby oszacować swoje płatności.



