Ripristino di emergenza con NAKIVO: pianificazione, implementazione e test
Il backup e il ripristino di emergenza sono alla base delle strategie di protezione dei dati in tutte le organizzazioni e in tutti i settori. Il ripristino di emergenza è il processo di ripristino delle VM e dei servizi in esecuzione su di esse in un sito secondario (noto come sito di ripristino di emergenza) quando il sito di produzione non è disponibile. Questi siti di ripristino di emergenza, che ospitano server, computer e apparecchiature di rete ridondanti con il software necessario, possono essere di diversi tipi a seconda del livello di ridondanza.
NAKIVO Backup & Replication include la funzionalità di ripristino dell’ambiente che consente di creare sequenze di ripristino avanzate (con failover completo del sito) che possono essere avviate con un solo clic quando il sito primario non è disponibile. Leggi questo post sul blog per conoscere i componenti chiave della strategia di DR, come la pianificazione del ripristino di emergenza IT, il test e l’esecuzione del ripristino di emergenza con la soluzione integrata di NAKIVO.

Fase 1. Pianificazione del ripristino di emergenza
Come fase essenziale per un ripristino di emergenza efficace, la pianificazione dovrebbe includere una valutazione delle esigenze di ripristino dell’organizzazione e lo sviluppo di una comprensione completa di quali componenti, fasi e procedure dovrebbero essere inclusi in un flusso di lavoro di ripristino di emergenza.
Pianificazione del ripristino di emergenza: procedure consigliate
1. Condurre un’analisi dell’impatto sul business
Un’analisi dell’impatto sul business (o BIA) viene utilizzata per determinare il potenziale impatto negativo di incidenti gravi o disastri naturali sulle operazioni aziendali. Questa analisi comporta l’assegnazione di un ordine di priorità alle diverse VM, la sequenza di ripristino e il tempo disponibile prima che un’interruzione abbia un impatto significativo sulle operazioni aziendali. Ad esempio, il guasto di una VM potrebbe causare ritardi e inconvenienti, mentre il guasto di un’altra VM può portare alla completa interruzione delle operazioni critiche per l’azienda.
2. Valutare i rischi coinvolti
Prima di pianificare il DR, raccogliere i dati rilevanti sui rischi per le operazioni e la continuità operativa della vostra organizzazione. In alcune aree, un’interruzione di corrente a lungo termine o un attacco di virus sono più probabili di un tornado, ma in altre le catastrofi naturali sono un evento comune. Una valutazione dei rischi aiuta a determinare il livello appropriato di protezione contro determinate minacce e a elaborare misure per ridurre al minimo i rischi e mitigarne le conseguenze. Anche se i rischi non possono essere completamente eliminati, sarete meglio preparati per gli scenari di catastrofe che potreste dover affrontare.
3. Sviluppare la documentazione relativa al ripristino di emergenza
Una volta identificati i rischi e il loro potenziale impatto sulla vostra attività, avrete una migliore comprensione di dove concentrare i vostri sforzi per pianificare i processi di ripristino di emergenza. Documentare le procedure di ripristino , descrivendo in dettagli tutti i passaggi fondamentali e le misure di ripristino di emergenza, e aggiornare regolarmente i documenti per riflettere i cambiamenti apportati all’ambiente. La documentazione dovrebbe includere:
- Ambito del ripristino di emergenza. Valutate l’importanza di ciascun componente hardware e software nella vostra infrastruttura e includete quelli per le operazioni mission-critical nel vostro piano di ripristino di emergenza. Le VM che ospitano informazioni critiche, sistemi IT e applicazioni il cui funzionamento è essenziale per garantire la continuità dei servizi dovrebbero essere la vostra priorità assoluta per il ripristino.
- Ordine di ripristino delle VM. Alcune VM possono dipendere dal software o dalle informazioni ospitate in un’altra VM, il che significa che non possono funzionare separatamente o essere avviate in modo casuale. È necessario specificare l’ordine di ripristino per semplificare il ripristino ed eliminare il rischio di conflitti software nel sito DR. Ad esempio, la VM che esegue Active Directory Domain Controller deve essere attiva e funzionante prima di poter avviare una VM con un file server che utilizza l’autenticazione Active Directory.
Un altro esempio sono i servizi web, che spesso si basano su software installato su diverse VM. Potrebbe essere necessario implementare la seguente sequenza:
- La VM con il server di database deve essere avviata per prima.
- È quindi possibile avviare la VM con il server delle applicazioni.
- Solo a questo punto è possibile avviare la VM con il server web.
- RTO e RPO nel ripristino di emergenza. Impostare l’ obiettivo di tempo di ripristino (RTO) e il obiettivo di punto di ripristino (RPO) per le diverse VM prioritarie nel piano di ripristino di emergenza. Ad esempio, le VM con sistemi finanziari potrebbero avere obiettivi di ripristino più brevi rispetto a quelle utilizzate per l’archiviazione dei documenti.
- Dipendenze. Quando si determina la catena di dipendenze tra il personale e i componenti IT, collaborare con il personale e tenerne conto per evitare collegamenti deboli che possono portare al fallimento del ripristino. Ad esempio, una VM utilizzata dal reparto contabilità potrebbe dover essere ripristinata per prima se i lavoratori di altri reparti dipendono da tali operazioni finanziarie per svolgere il proprio lavoro.
- Personale . Assegnare ruoli e responsabilità ai membri del team che partecipano ai processi di DR. Se lavoreranno presso il sito DR, assicurarsi che vi siano estazioni di lavoro dotate di tutte le attrezzature, gli arredi per ufficio e l’hardware necessari, in modo che possano continuare il loro lavoro con interruzioni minime. Se i dipendenti possono lavorare in remoto durante un disastro, configurare l’accesso VPN e fornire account VPN in anticipo.
- Requisiti hardware . Il successo di un piano di ripristino di emergenza dipende in larga misura dalle prestazioni e dalle capacità dell’hardware situato nel sito di ripristino. È necessario tenere conto di diversi fattori:
- I server devono disporre di CPU, memoria e capacità disco sufficienti per sostenere i carichi di lavoro trasferiti. Prestazioni della CPU basse e memoria insufficiente possono influire sulla velocità delle VM, mentre una velocità del disco insufficiente comporta prestazioni scadenti delle VM.
- Le reti devono fornire una larghezza di banda sufficiente affinché le VM ripristinate possano interagire tra loro, con lo storage condiviso e con gli utenti, se necessario.
Passaggio 2. Preparazione al Ripristino di emergenza
Una volta ottenuta la documentazione, è possibile procedere alla preparazione al Ripristino di emergenza preparando il sito di Ripristino di emergenza e configurando la replica dei carichi di lavoro critici su tale sito. La replica è obbligatoria per il failover delle VM per replicare le VM quando l’infrastruttura primaria non è disponibile.
Che cos’è la replica delle VM?
La replica delle VM è il processo di creazione di una copia identica di una VM di origine (denominata “replica della VM”) su un host diverso (l’host di destinazione). La replica VM è una VM normale che rimane spenta fino al momento in cui è necessaria (a quel punto può essere avviata e resa operativa sul proprio host quasi istantaneamente).
Per ulteriori dettagli, verificare come creare e configurare un processo di replica VMware in NAKIVO Backup & Replication.
Il processo di trasferimento dei carichi di lavoro da una VM di origine (produzione) a una replica VM nel sito DR allo scopo di mantenere la continuità operativa e l’alta disponibilità è noto come failover.
Procedure consigliate per la replica delle VM
Esistono una serie di procedure consigliate per la replica volte a garantire una maggiore affidabilità ed efficacia del processo. In questa sede ci concentreremo su due punti chiave:
- Eseguire la replica delle VM a livello di host anziché a livello di guest . Il livello di virtualizzazione è il livello intermedio tra l’hardware fisico e il sistema operativo guest in esecuzione su una VM. La replica eseguita a livello di virtualizzazione è denominata replica a livello di host ed è più efficiente rispetto alla replica a livello di guest.
- Utilizzare la replica coerente con le applicazioni per evitare la perdita di dati. Se uno snapshot della VM necessario per la replica viene acquisito mentre queste applicazioni sono in esecuzione senza alcuna azione aggiuntiva, l’effetto sarebbe simile a un’interruzione di corrente e uno spegnimento imprevisti e i dati potrebbero andare persi.
Con i metodi coerenti con le applicazioni, le applicazioni vengono congelate (messe in pausa) e la memoria viene svuotata, e i dati non possono essere scritti sul disco prima che venga acquisito uno snapshot. Una volta acquisita la snapshot coerente, è possibile creare una replica della VM. Tali repliche della VM possono essere ripristinate correttamente con le applicazioni al loro interno in esecuzione.
NAKIVO Backup & Replication supporta la replica a livello di host coerente con le applicazioni per VM VMware, VM Hyper-V e istanze di EC2 con funzionalità speciali per Microsoft SQL Server, Exchange Server e Active Directory Domain Controller.
Passaggio 3. Creazione di un flusso di lavoro di ripristino di emergenza
Per creare un flusso di lavoro di ripristino di emergenza, è necessaria una soluzione di ripristino di emergenza specializzata come NAKIVO Backup & Replication, che fornisce una funzionalità di ripristino dell’ambiente integrata per effettuare l’orchestrazione e l’automatizzazione delle sequenze di ripristino di emergenza.
- Che cos’è un flusso di lavoro di ripristino di emergenza?
- Azioni disponibili per un flusso di lavoro di ripristino di emergenza
- Come creare un flusso di lavoro di ripristino di emergenza
- Guida alla configurazione di Site Recovery di NAKIVO
Che cos’è un flusso di lavoro di ripristino di emergenza?
Un flusso di lavoro di ripristino di emergenza è una sequenza di azioni eseguite come parte del processo di ripristino di emergenza per il failover sicuro e rapido dei carichi di lavoro alle repliche. Il flusso di lavoro organizza il processo di failover con azioni relative alle VM di origine, alle VM di destinazione, alle condizioni da soddisfare, ecc. È necessario definire l’ordine in cui le azioni devono essere eseguite, poiché alcune procedure di ripristino di emergenza possono dipendere dal risultato dell’esecuzione di altre.
Azioni di ripristino dell’ambiente disponibili
La funzionalità di ripristino dell’ambiente consente di creare sequenze DR complesse combinando azioni e condizioni in un unico flusso di lavoro. Ogni azione può essere eseguita solo in modalità di test, solo in modalità di produzione o in entrambe le modalità (impostazione predefinita) in NAKIVO Backup & Replication. È possibile includere una o tutte le seguenti azioni in una sequenza:
- Failover – avvia il failover alle VM VMware, Hyper-V o alle istanze di EC2 replicate.
- Failback – riporta i carichi di lavoro dalla replica della VM all’origine della VM. Le modifiche apportate alla replica della VM dal momento del failover vengono scritte nella VM di origine quando viene eseguita l’operazione di failback. Le VM vengono sincronizzate e la VM di origine torna allo stato di produzione effettivo.
- Avvio – avvia VM VMware, VM Hyper-V o istanze di EC2.
- Arresto – arresta VM VMware, VM Hyper-V e istanze di EC2 in esecuzione.
- Esegui processo – esegue un processo di backup, replica, ripristino del sito, copia di backup o avvio flash delle VM.
- Arresta lavori – arresta un lavoro (uno qualsiasi dei lavori elencati nel punto precedente).
- Esegui script – esegue uno script su uno dei seguenti target: il server con Director, un Server Windows remoto, un Server Linux remoto, una macchina virtuale VMware, una macchina virtuale Hyper-V o un’istanza di EC2.
- Collega repository – collega un repository di backup utilizzato da NAKIVO Backup & Replication per archiviare i backup.
- Scollega repository – scollega un repository di backup.
- Invia e-mail – invia un’e-mail con il messaggio composto a uno o più destinatari definiti.
- Attendi – attende il periodo di tempo designato prima di procedere all’azione successiva.
- Controlla condizione – in base all’input fornito (tutto o parte del nome di una risorsa), verifica una delle seguenti condizioni:
- La risorsa esiste
- La risorsa è in esecuzione
- L’IP/nome host è raggiungibile
Come creare un flusso di lavoro di ripristino dell’ambiente
Vediamo un esempio di come creare un lavoro di ripristino dell’ambiente in NAKIVO Backup & Replication.
La nostra configurazione
Ecco la configurazione che prenderemo in considerazione: un sito primario (di produzione) con macchine virtuali VMware vSphere e un sito di DR in una posizione remota:
- DC-VM è una macchina virtuale basata su Windows che esegue Active Directory Domain Controller.
- FS-VM è una macchina virtuale basata su Windows con un file server in esecuzione (il protocollo SMB viene utilizzato per la condivisione file). Active Directory viene utilizzato per l’autenticazione degli utenti. I dump del database Oracle sono memorizzati sul file server.
- Ora-DB è la VM su cui è in esecuzione il database Oracle.
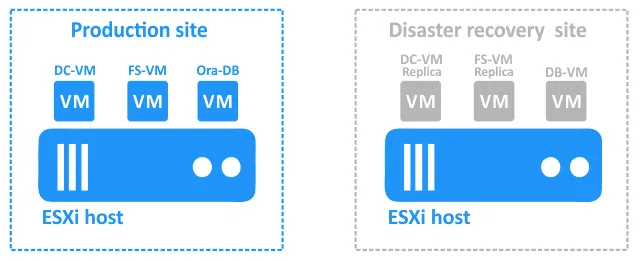
Il sito di ripristino di emergenza contiene le seguenti VM:
- DC-VM-replica e FS-VM-replica sono repliche delle VM di produzione. Possono essere utilizzate come destinazioni per il failover.
- DB-VM è una VM basata su Linux con software Oracle Database installato ma non contiene database.
Il database viene sottoposto a backup con NAKIVO Backup & Replication a livello di database su FS-VM sul sito di produzione (questo backup del database Oracle è coerente con l’applicazione). FS-VM e DC-VM vengono replicati a livello di host sul sito DR con la soluzione NAKIVO.
Ordine di ripristino delle VM
Durante un incidente che causa il blocco del sito di produzione, i componenti devono essere ripristinati sul sito DR come segue:
- Failover di DC-VM a DC-VM-replica.
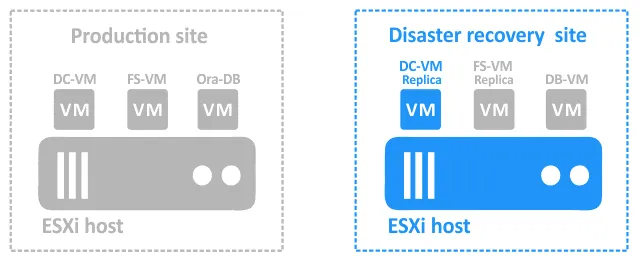
- Una volta che DC-VM-replica è attivo, failover di FS-VM a FS-VM-replica . È necessario operare in questo ordine perché FS-VM si affida a DC-VM per l’autenticazione degli utenti sul file server.
- Una volta che queste due VM sono in esecuzione, DB-VM può accedere alla directory condivisa sul file server in cui è memorizzato il dump. Ora è possibile avviare DB-VM .
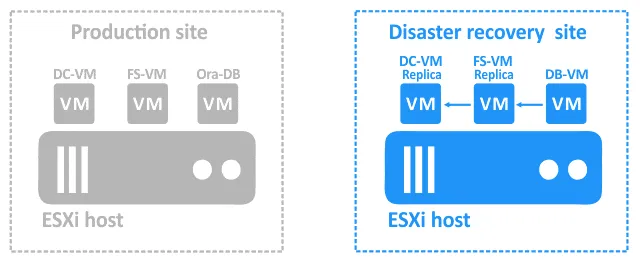
- Una volta che DB-VM è in esecuzione, eseguire uno script in grado di ripristinare il database dal dump situato sul file server. Le frecce blu nei diagrammi sopra riportati mostrano le dipendenze.
Si noti che potrebbe essere necessario un po’ di tempo per l’avvio dei servizi su una replica VM accesa dopo l’azione di failover e prima di eseguire il failover alla replica successiva o di ripristinare un’applicazione o un database. Questo tempo di attesa dovrebbe essere parte della sequenza DR.
Per questo ordine di failover VM, è necessario creare un lavoro di ripristino dell’ambiente in NAKIVO Backup & Replication con la seguente logica:
- Azione 1 : Eseguire il failover di DC-VM . Attendere il completamento di questa azione prima di procedere al passaggio successivo. Interrompere il lavoro se questa azione non va a buon fine.
- Azione 2 . Attendere per 3 minuti.
- Azione 3 . Controlla condizione di DC-VM-replica . Controlla se la risorsa è in esecuzione. Se la risorsa è in esecuzione, procedere con l’azione successiva nel lavoro di ripristino dell’ambiente. In caso contrario, interrompere e indicare come non riuscito il lavoro.
- Azione 4 . Eseguire il failover di FS-VM . Attendi il completamento di questa azione prima di procedere con l’azione successiva. Interrompere il processo se questa azione non va a buon fine.
- Azione 5 . Attendere per 3 minuti.
- Azione 6 . Controlla condizione di FS-VM-replica . Se la risorsa è in esecuzione, procede con l’azione successiva del processo di ripristino dell’ambiente. In caso contrario, arresta e indica come non riuscito il lavoro di ripristino dell’ambiente.
- Azione 7 . Avviare DB-VM . Attendi il completamento di questa azione prima di procedere con l’azione successiva. Interrompere il processo se questa azione non va a buon fine.
- Azione 8 . Attendere per 5 minuti.
- Azione 9 . Esegui script . Tipo di destinazione: VM VMware. VM di destinazione: DB-VM. Percorso dello script: /home/oracle/restore_db.sh (quando si aggiunge questo passaggio, è necessario inserire il nome utente e la password di un account con autorizzazioni sufficienti per eseguire lo script).
Procedura guidata di NAKIVO Site Recovery
Creiamo un nuovo lavoro di ripristino dell’ambiente basato sul piano sopra descritto. Nella pagina Lavori dell’istanza NAKIVO Backup & Replication, fare clic su Crea > Lavoro di ripristino dell’ambiente .
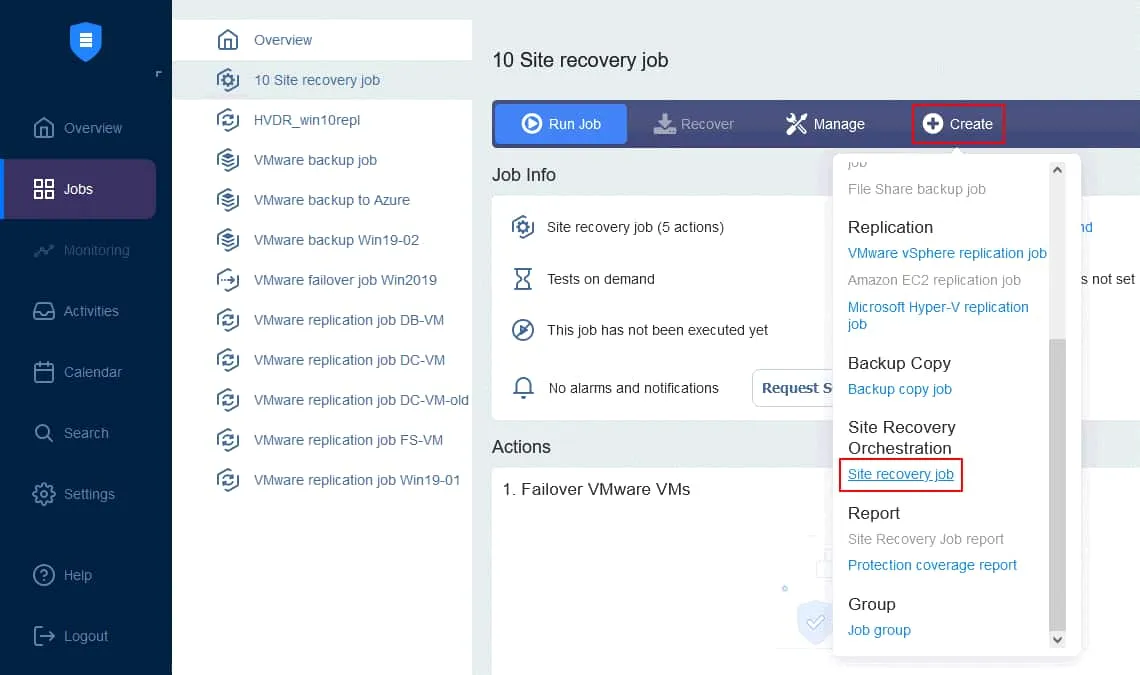
1. Azioni
Viene avviata la procedura guidata Nuovo lavoro di ripristino dell’ambiente . Nel pannello di sinistra sono disponibili le azioni che possono essere aggiunte al lavoro. È sufficiente fare clic su un’azione per aggiungerla alla sequenza. Si noti che non è possibile combinare azioni per piattaforme diverse in un’unica sequenza (stiamo creando un lavoro per macchine virtuali VMware).
Azione 1. Failover DC-VM
- Nel riquadro sinistro, fare clic su Failover VMware VMs .
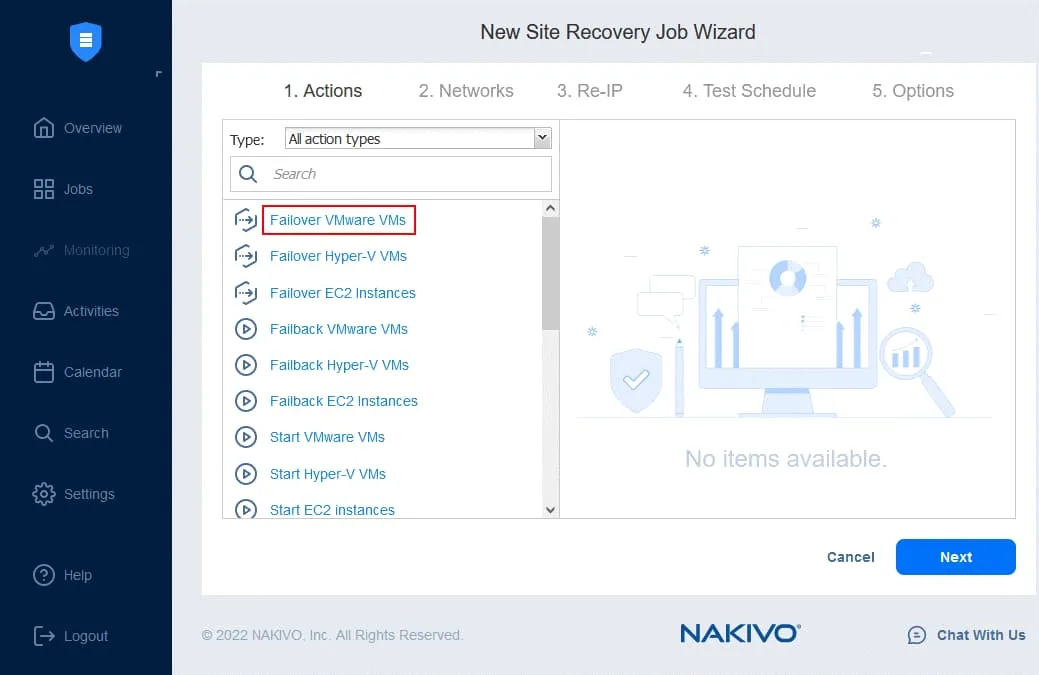
- Nel riquadro sinistro, selezionare la replica della macchina virtuale da un lavoro di replica esistente. Nel nostro flusso di lavoro, il failover a DC-VM-replica è la prima azione. Nel riquadro destro è possibile selezionare un punto di ripristino. Per impostazione predefinita viene utilizzato l’ultimo punto di ripristino.
Fare clic su Avanti per continuare.
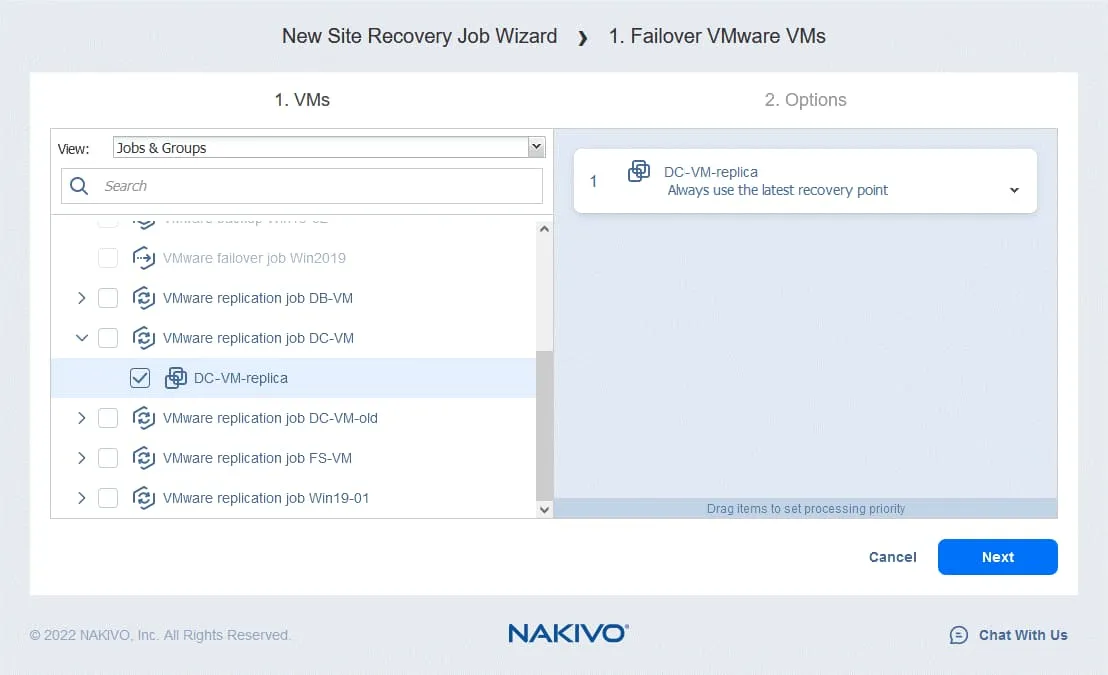
- Per le opzioni di failover del ripristino di emergenza è possibile deselezionare Spegni le VM di origine – questa opzione può essere utilizzata per evitare un conflitto di indirizzi IP se le VM di origine e le repliche utilizzano le stesse reti.
In base alla logica sopra descritta, selezioniamo le seguenti opzioni:
- Esegui questa azione in: Esegui questa azione sia in modalità di test che in modalità di produzione
- Comportamento dell’attesa: Attendi il completamento di questa azione
- Gestione degli errori: Arresta e indica come non riuscito il lavoro se questa azione non riesce
Fai clic su Salva per salvare l’azione creata.
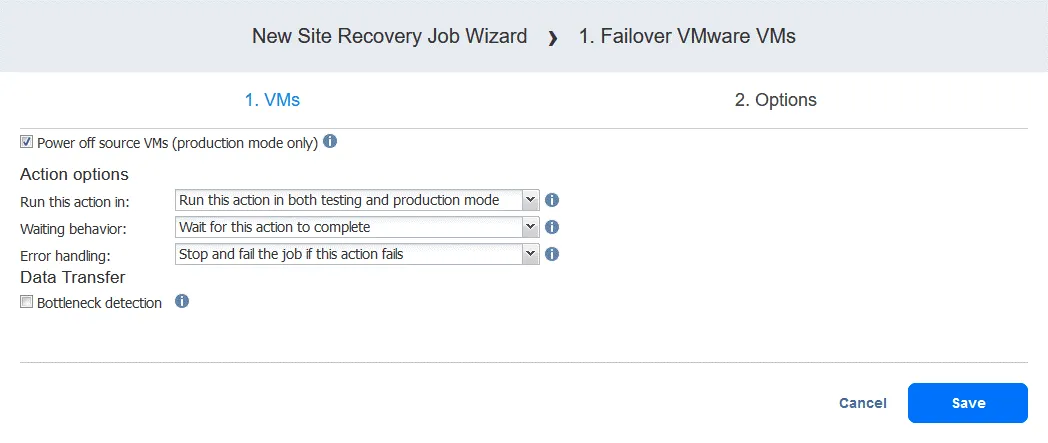
Azione 2. Attendere 3 minuti
A wait azione è utile in questo caso perché la seguente azione di failover nel flusso di lavoro (failover a FS-VM-replica ) richiederebbe che DC-VM-replica fosse attivo e già in esecuzione con Active Directory Domain Services.
- Nel riquadro sinistro della schermata Azioni fare clic su Attesa .
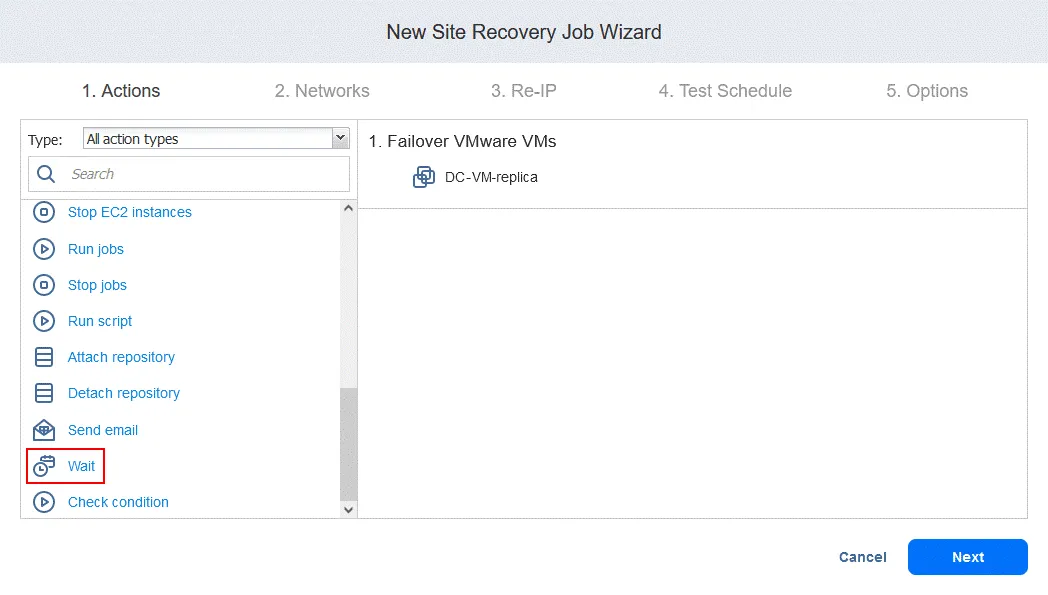
- Selezionare il Tempo di attesa (in questo caso 3 minuti ).
Selezionare le opzioni di azione come fatto per la prima azione e fare clic su Salva .
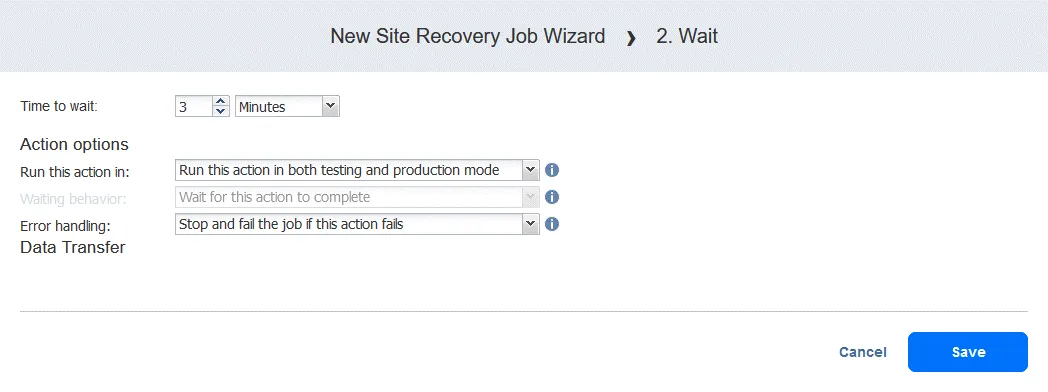
La nuova azione viene aggiunta dopo l’azione precedente, in fondo all’elenco. È possibile riordinare, modificare o rimuovere le azioni. È sufficiente posizionare il mouse su un’azione per visualizzare le opzioni.
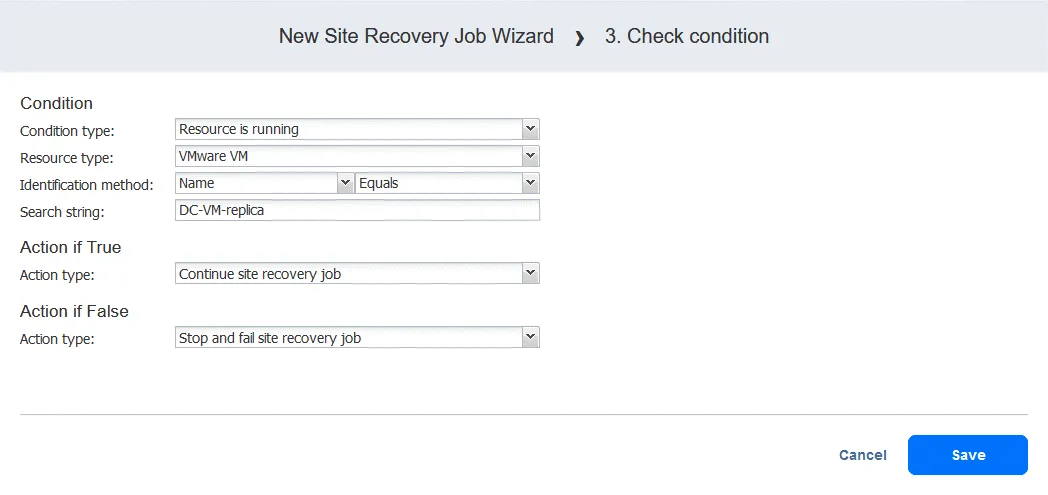
Azione 3. Controlla condizione di DC-VM-replica
- Nel riquadro sinistro della schermata Azioni fare clic su Controlla condizione per verificare se la VM sottoposta a failover nella prima azione è in esecuzione.
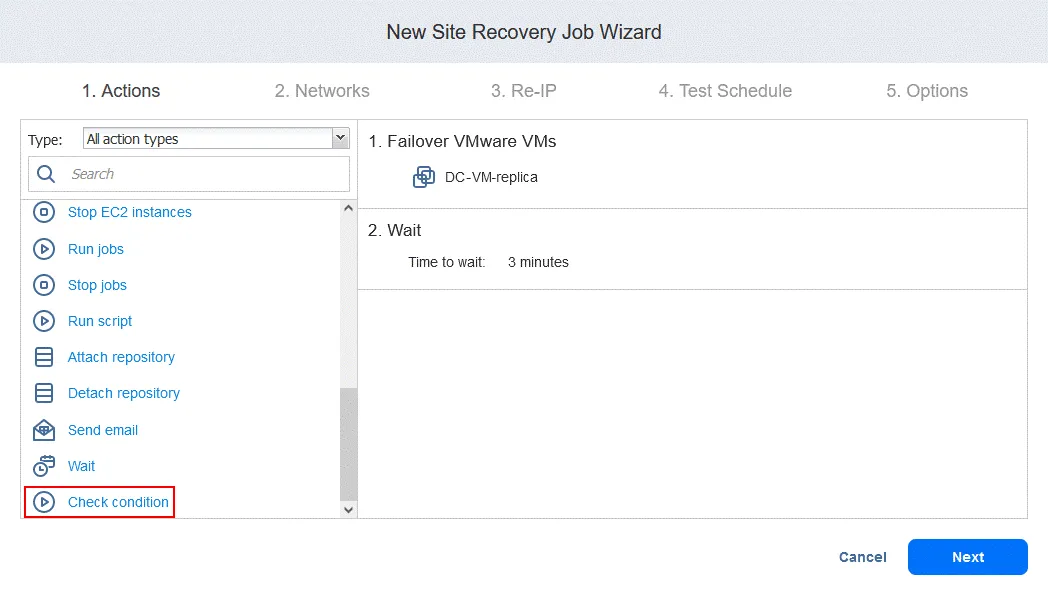
- Configurare questa azione come segue:
- Selezionare il tipo di condizione: Risorsa in esecuzione . Le altre opzioni sono risorsa esistente o IP/nome host raggiungibile.
- Selezionare il tipo di risorsa: VMware VM .
- Selezionare il metodo di identificazione: Nome (l’altra opzione è ID ) per identificare la VM in questione. È possibile utilizzare qualsiasi parte della stringa della VM. In questo caso, conosciamo il nome esatto, quindi utilizziamo la funzione Equals .
- Definire la stringa di ricerca: DC-VM-replica .
Ora abbiamo un’azione che verifica se la VM VMware denominata DC-VM-replica è in esecuzione. Fare clic su Salva per procedere.
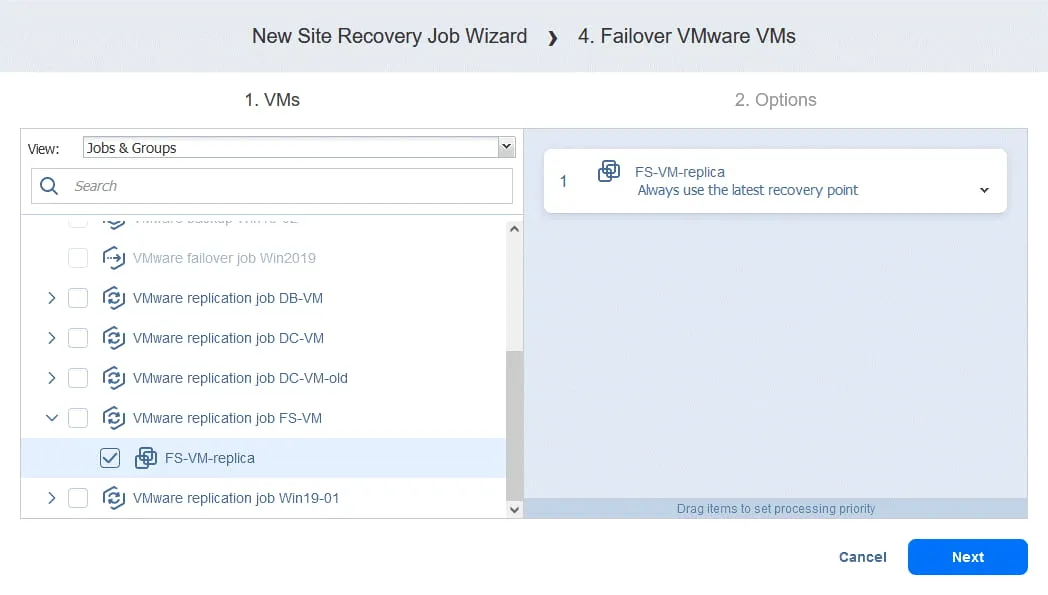
Azione 4. Failover FS-VM
- Come per Azione 1 , fare clic su Failover VMware VM .
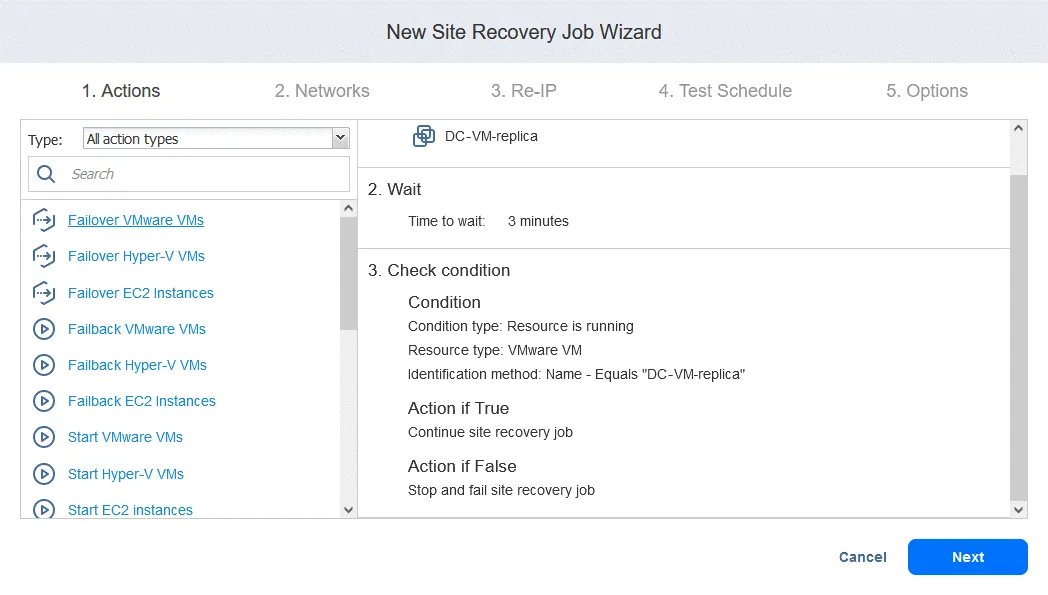
- In questo caso selezioniamo FS-VM-replica . Fare clic su Avanti , quindi selezionare le stesse opzioni per l’azione di failover come fatto in Azione 1 e fare clic su Salva .
Azione 5. Attendere 3 minuti
Fare clic su Attendere e configurare questa azione come fatto per azione 2 . Il tempo specificato è ancora 3 minuti nel nostro caso.
Azione 6. Controlla condizione di FS-VM-replica
Fare clic su Controlla condizione per verificare se la VM VMware FS-VM-replica è in esecuzione. Fare riferimento all’azione 2 e selezionare le stesse opzioni, tranne, ovviamente, il nome della VM.
Azione 7. Avvia DB-VM
- Fare clic su Avvia VM VMware nel riquadro sinistro della schermata Azioni .
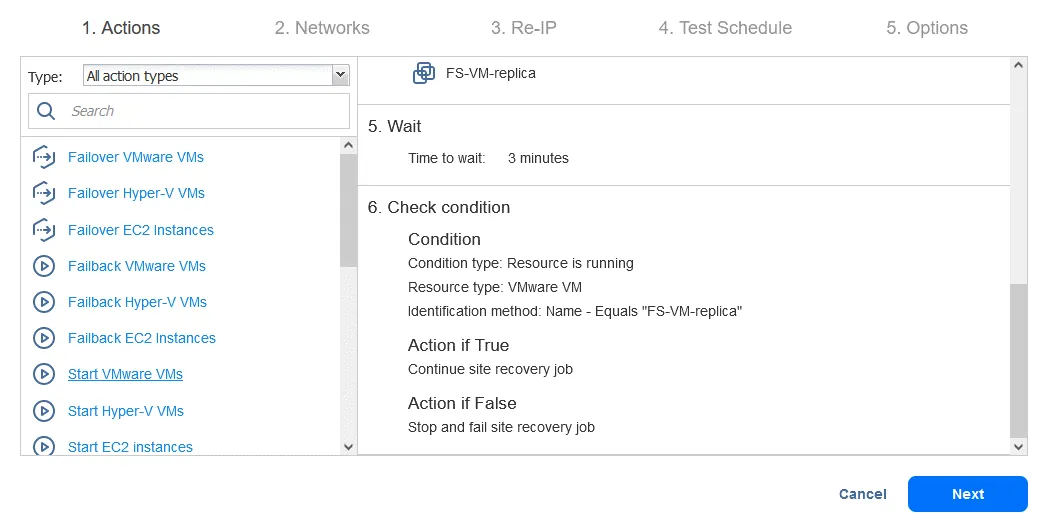
- Selezionare DB-VM . Questa VM può essere avviata una volta che si è certi che FS-VM-replica sia in esecuzione. Nella parte inferiore della pagina, selezionare le stesse opzioni di azione mostrate nelle azioni precedenti. Quindi fare clic su Salva .
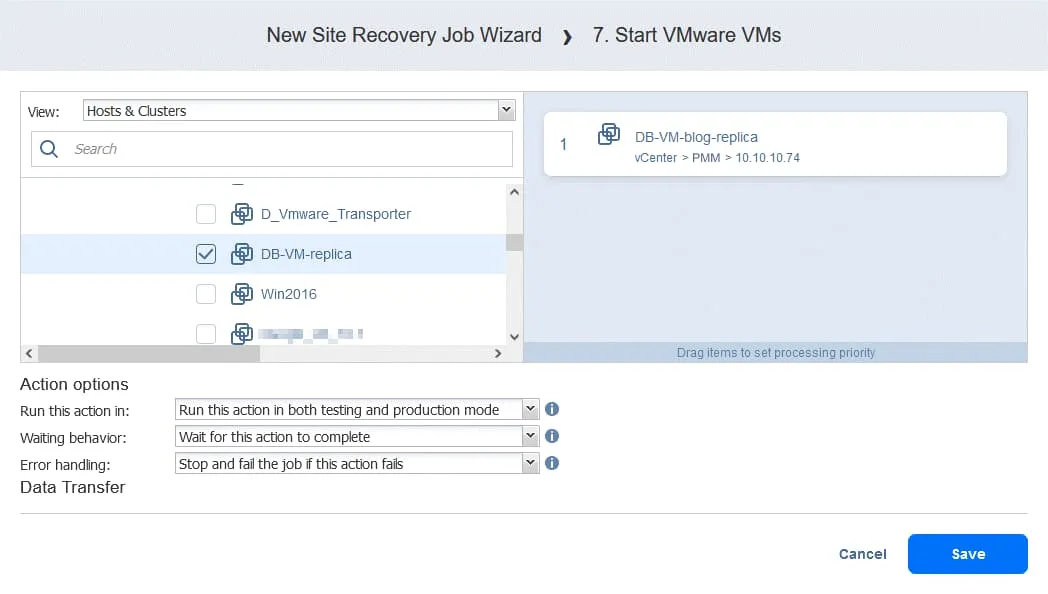
Azione 8. Attendere 5 minuti
Attendere 5 minuti. Fare clic su Attendere e configurare questa azione in modo simile all’azione azione 2 . Questo dovrebbe essere un tempo sufficiente per avviare il servizio Oracle su DB-VM .
Azione 9. Esegui script
- Nella schermata Azioni fare clic su Esegui script . Ricordare che questo script ha lo scopo di ripristinare l’Oracle Database a livello di database da un dump memorizzato su FS-VM-replica .
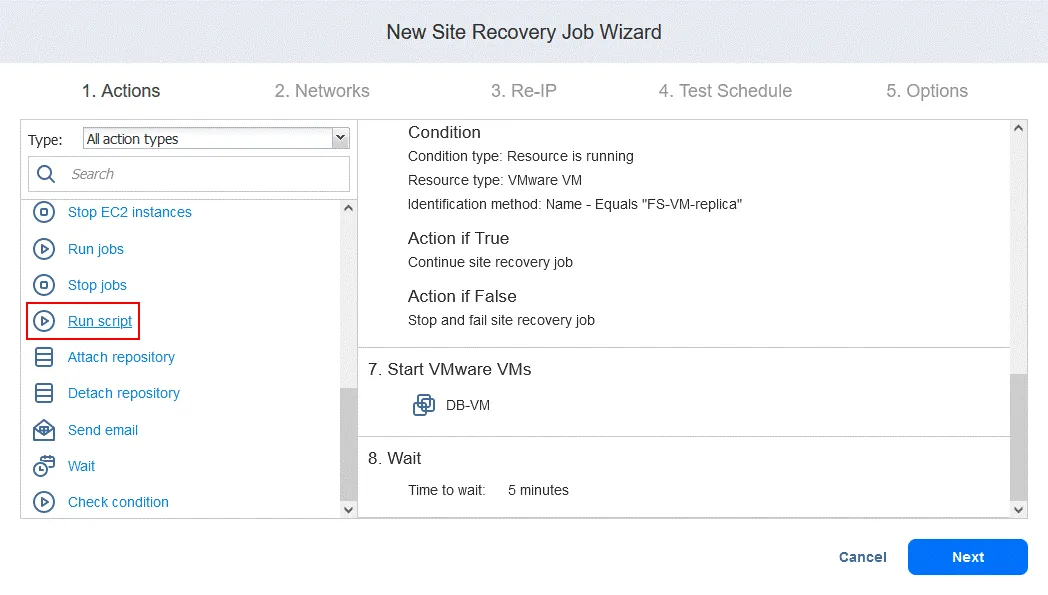
- Definire le opzioni di script. Nel nostro caso:
- Tipo di destinazione: VMware VM
- VM di destinazione: DB-VM
- Percorso dello script: /home/oracle/restore.db.sh
- Nome utente: oracle
- Password: (password)
Il percorso dello script, il nome utente e la password saranno diversi. Assicurarsi che il file dello script sia eseguibile e che l’utente disponga dei permessi sufficienti per eseguire lo script. In questo esempio, le opzioni di azione sono configurate come di consueto.
Fare clic su Salva quando si è pronti a continuare.
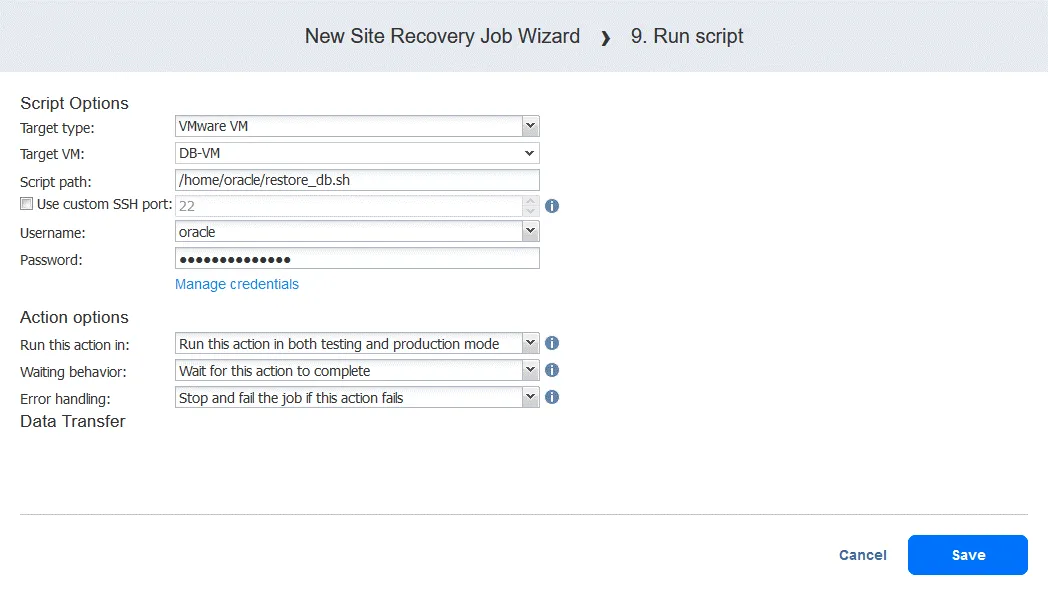
- Ora è possibile visualizzare tutte le azioni configurate. Fare clic sul pulsante Avanti per continuare la configurazione del processo di ripristino dell’ambiente in base al piano di ripristino di emergenza.
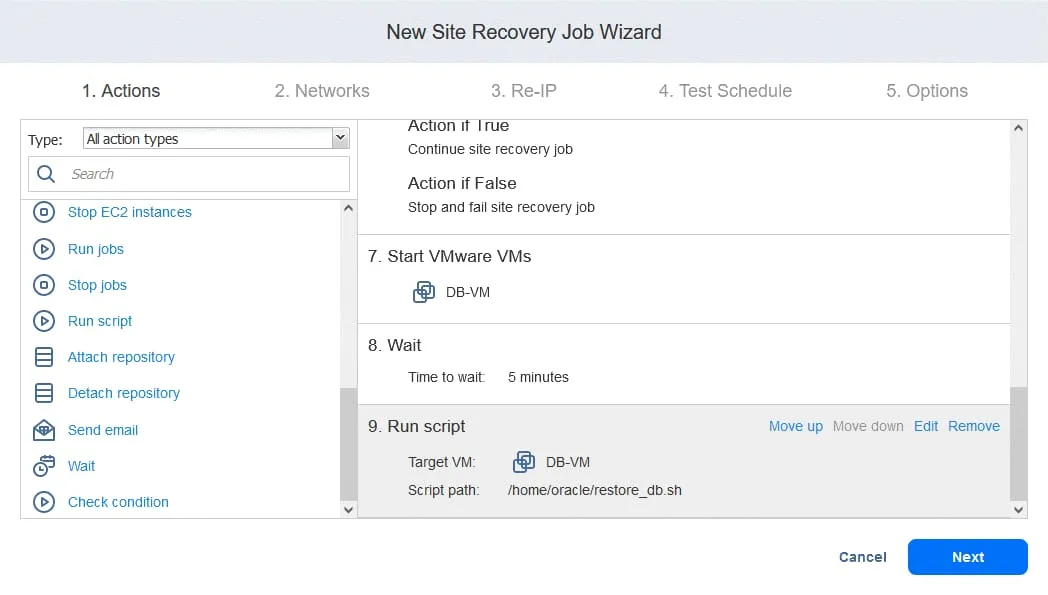
2. Reti
Se le macchine virtuali nel sito di produzione e nel sito di DR sono collegate a reti diverse , selezionare Abilita mapping di rete . Fare clic su Crea nuovo mapping , nelle finestre popup selezionare una rete di origine, una rete di destinazione e una rete da utilizzare per il test del processo di ripristino dell’ambiente.
Fare clic su Salva per salvare la regola di mapping di rete, quindi fare clic su Avanti .
Nota : è anche possibile utilizzare regole di mapping di rete esistenti se sono state configurate in altri lavori di replica, failover o Site Recovery.
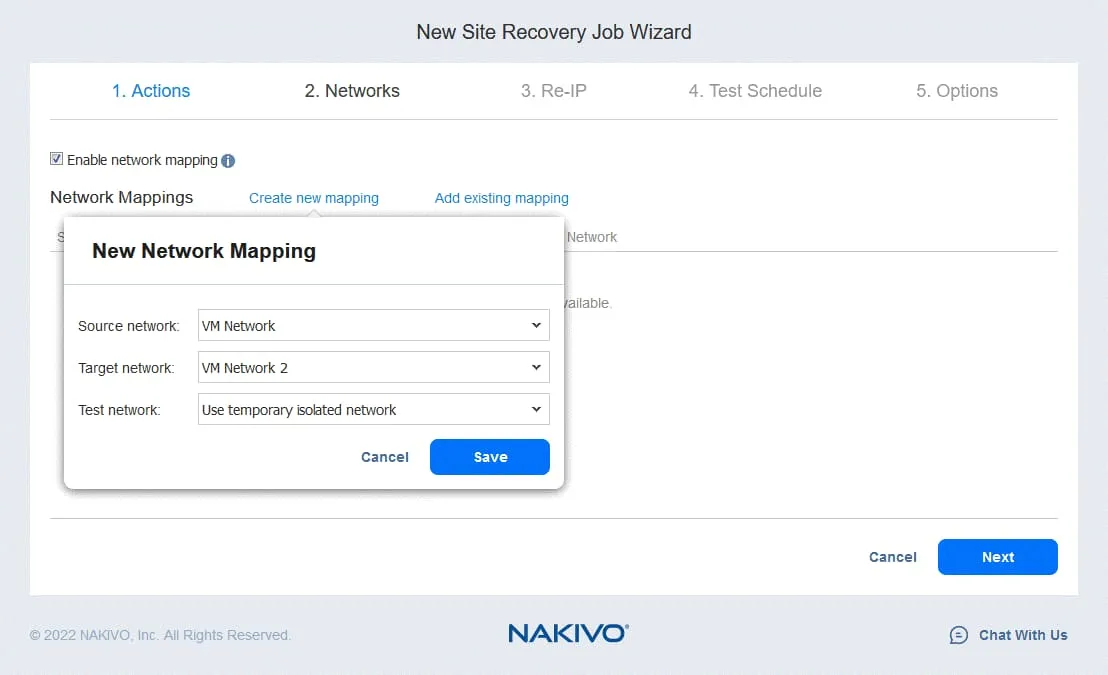
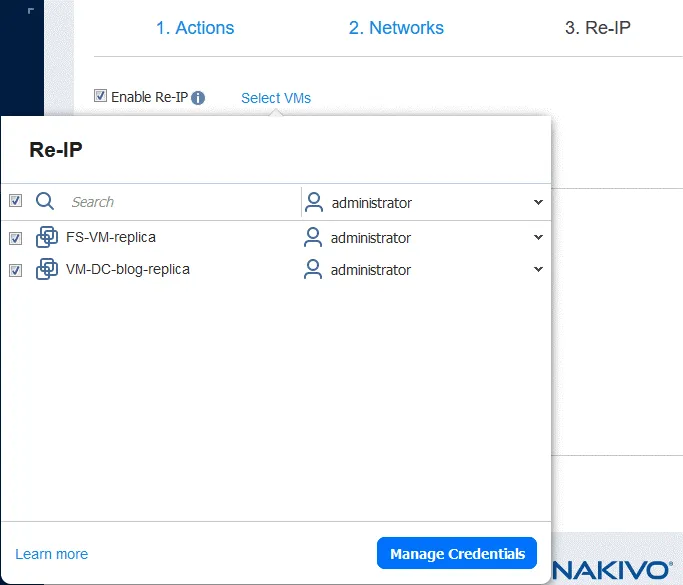
3. Ridefinizione IP
Se le reti utilizzate per la connessione delle macchine virtuali nel sito di origine e nel sito di destinazione hanno indirizzi diversi, è necessario abilitare la ridefinizione IP selezionando Abilita ridefinizione IP .
- Creare una nuova regola di ridefinizione IP facendo clic su Crea nuova regola . Definire le impostazioni di origine e di destinazione, quindi fare clic su Salva .
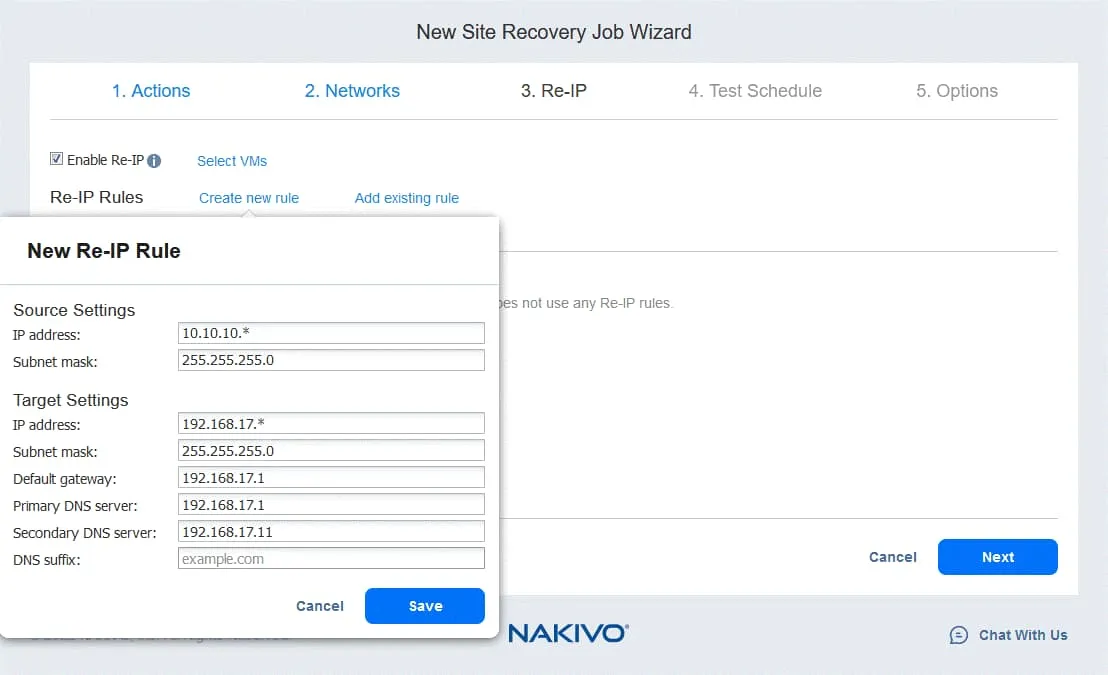
- Fare clic su Seleziona le VM e seleziona le VM per le quali si desidera utilizzare la regola di ridefinizione IP. È necessario fornire le credenziali di un utente con autorizzazioni sufficienti per modificare le impostazioni di rete nel sistema operativo guest della VM.
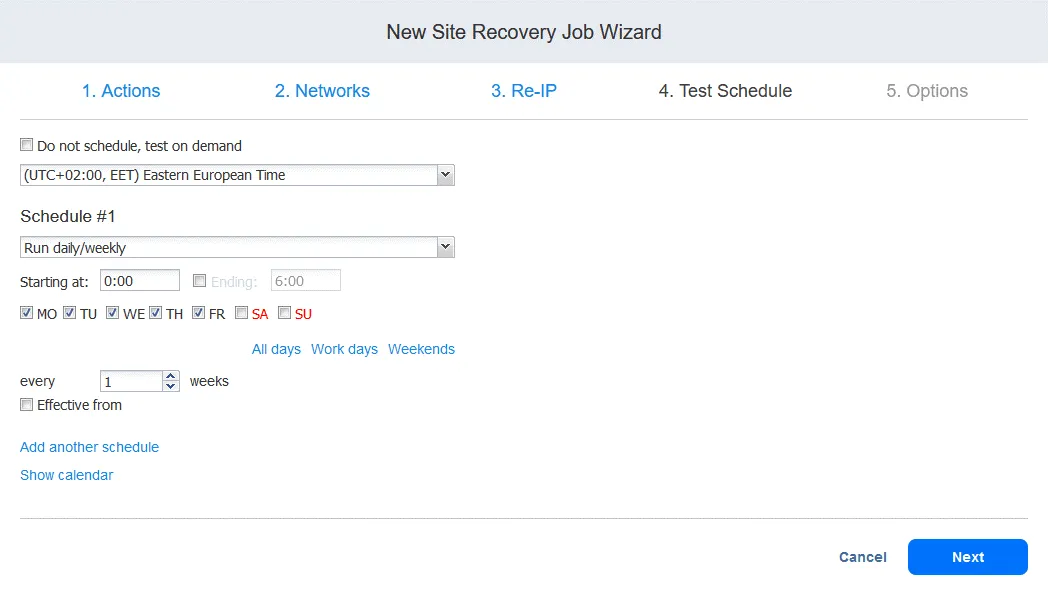
4. Pianificazione dei test
È possibile creare una pianificazione specifica per l’esecuzione di processi di Site Recovery in modalità test e per l’esecuzione di test di ripristino di emergenza. Ciò consente di verificare se il processo può essere eseguito correttamente entro i tempi richiesti. Al termine, fare clic su Avanti.
Il test dei processi di Site Recovery verrà descritto in modo più dettagliato al punto 6.
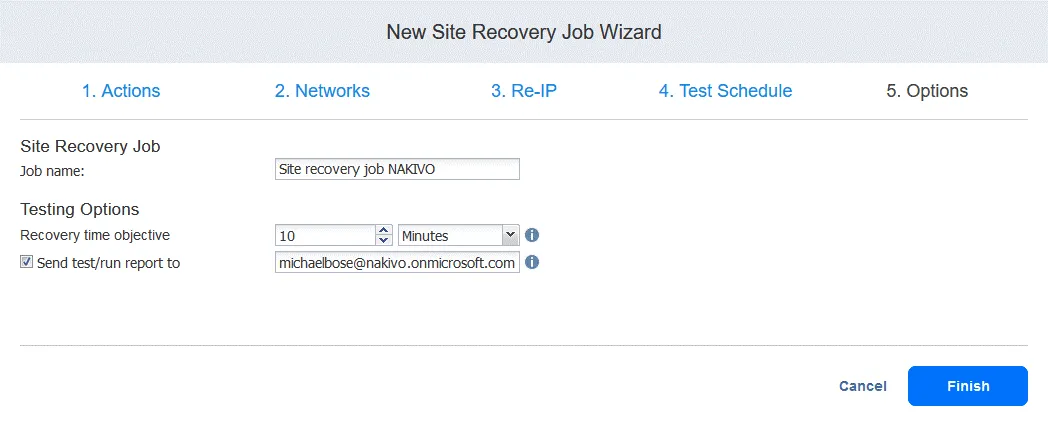
5. Opzioni
Digitare il nome del lavoro e l’obiettivo di tempo di ripristino. Fare clic su Termina al termine della configurazione.
Passaggio 4. Protezione dell’ambiente
Una volta eseguito il failover delle VM e migrati i carichi di lavoro al sito di DR, le VM di produzione originali sono ora offline e le repliche nel sito di DR sono le uniche copie funzionanti. Se una replica della VM accesa dovesse ora guastarsi, non sarebbe possibile ripristinare rapidamente i dati e i carichi di lavoro.
Per proteggere le VM in esecuzione nel sito di DR, è necessario replicarle in un altro luogo sicuro. In questo modo, se la VM in esecuzione nel sito di DR si guasta, è possibile eseguire rapidamente il failover sulla nuova replica della VM.
La funzionalità di ripristino dell’ambiente consente di configurare la replica automatizzata non appena il failover della VM è completato. Di seguito è riportato un esempio dettagliato di come proteggere nuovamente le VM con un lavoro di ripristino dell’ambiente dopo un failover.
- Nella pagina Lavori , fare clic con il pulsante destro del mouse sul nome del lavoro di ripristino dell’ambiente creato di recente. Fare clic su Modifica nel menu contestuale.
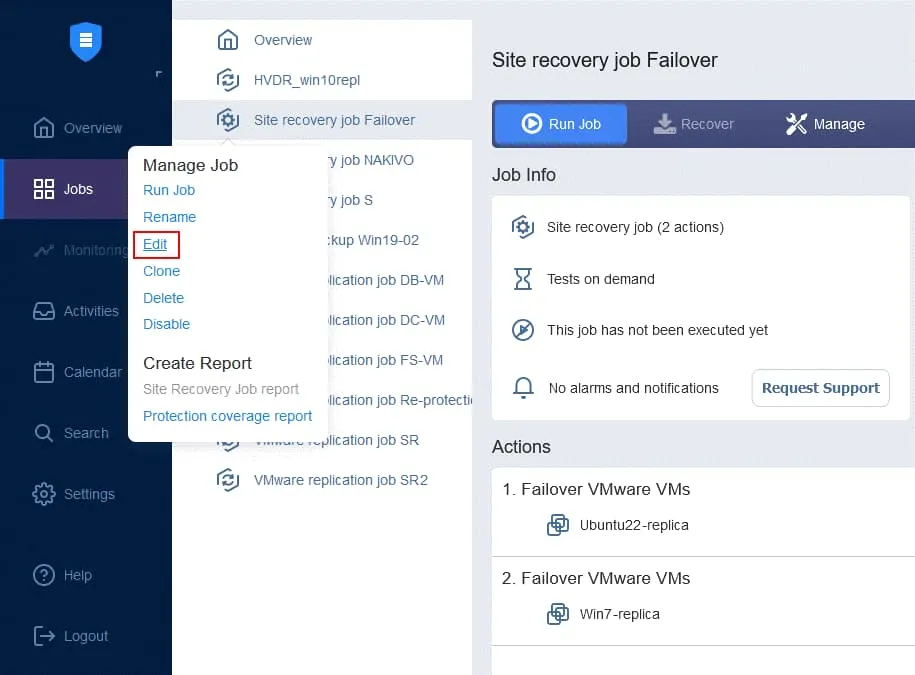
- È possibile visualizzare le azioni di failover aggiunte in precedenza al lavoro di ripristino dell’ambiente. Individuare e fare clic su Esegui lavori nell’elenco delle azioni situato nel pannello sinistro della schermata di ripristino dell’ambiente Azioni .
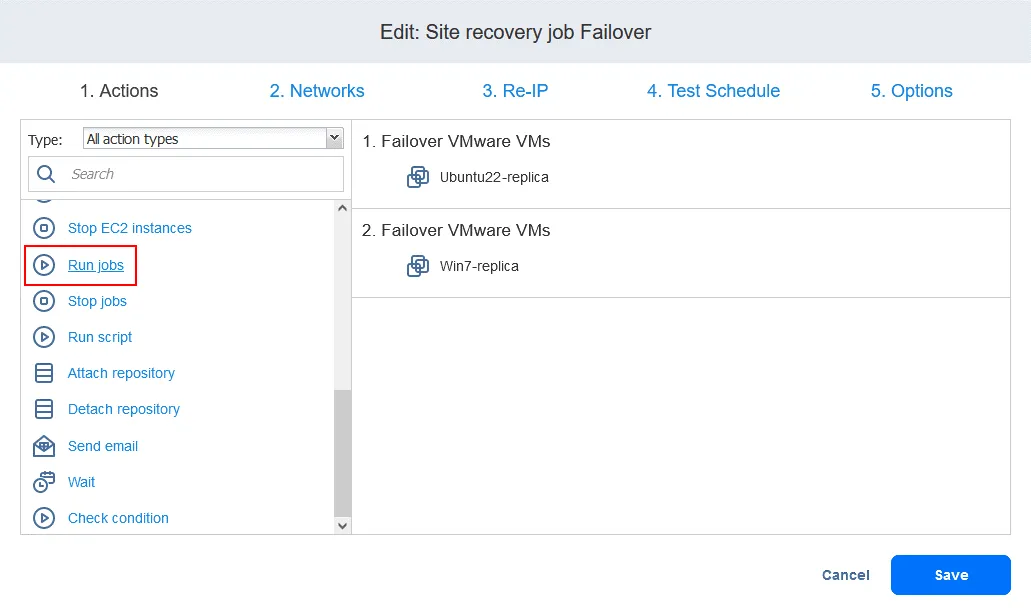
- Selezionare il lavoro di replica dall’elenco dei lavori. Selezionare le opzioni di azione come di consueto e fare clic su Salva .
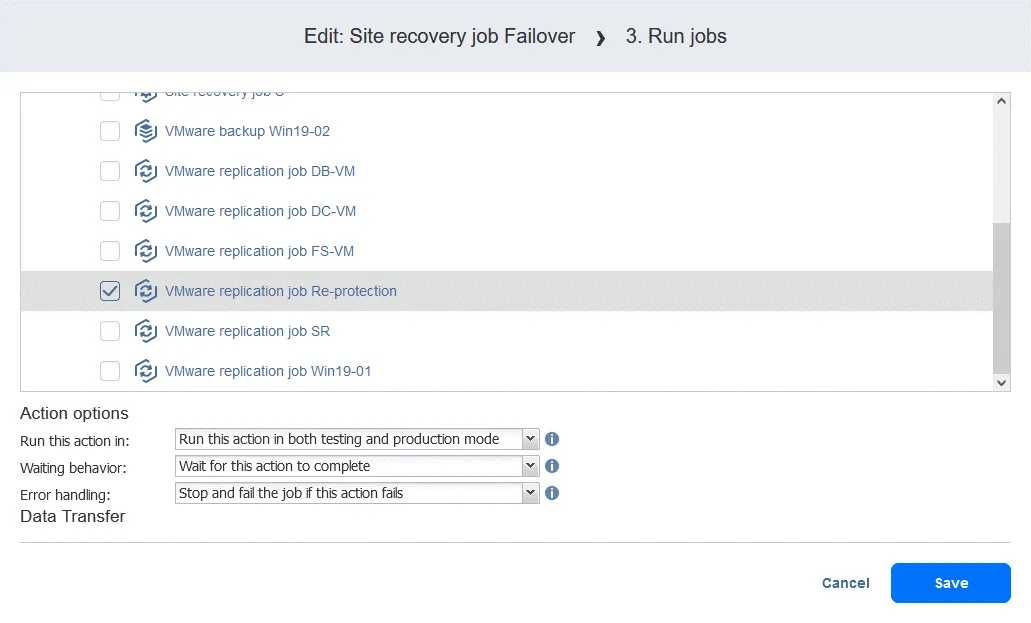
- Aggiungere un’azione Attesa tra l’azione di failover e il processo di replica. Ciò consente alla replica della VM di avviarsi e caricare il sistema operativo (non è possibile replicare una VM spenta). Nell’elenco Azioni nel riquadro sinistro, fare clic su Attesa .
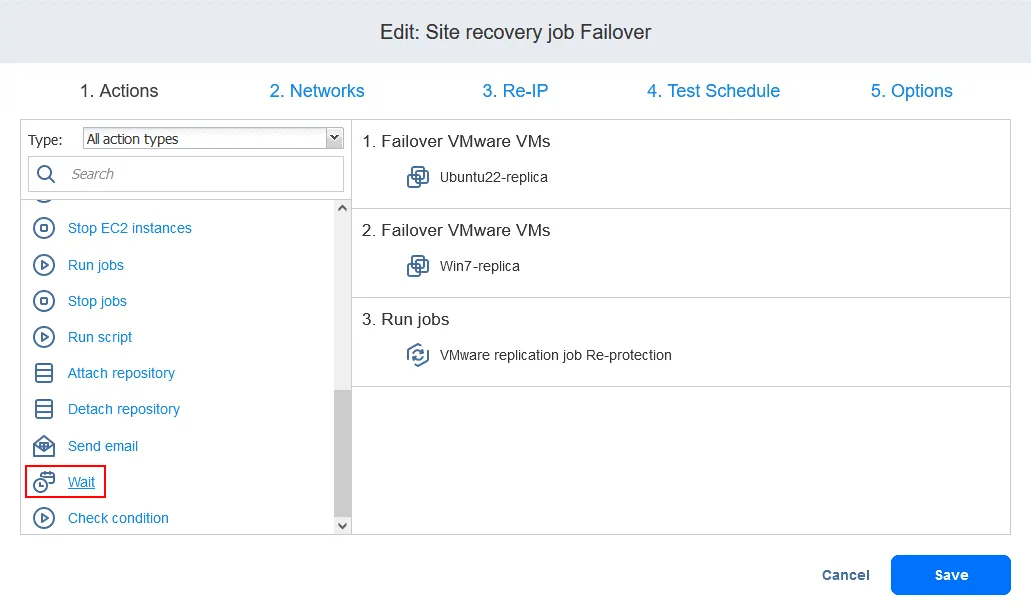
- Selezionare un tempo di attesa: 5 minuti dovrebbero essere sufficienti. Selezionare le opzioni di azione e fare clic su Save .
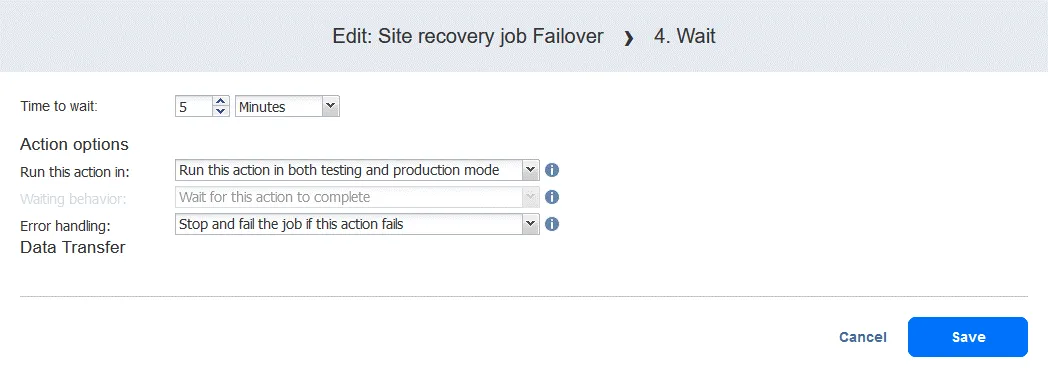
- Quando si aggiunge l’azione, questa viene aggiunta alla fine dell’elenco delle azioni. Fare clic su Move up e spostare l’azione Wait dalla quarta posizione alla terza posizione: deve essere eseguita prima della replica.
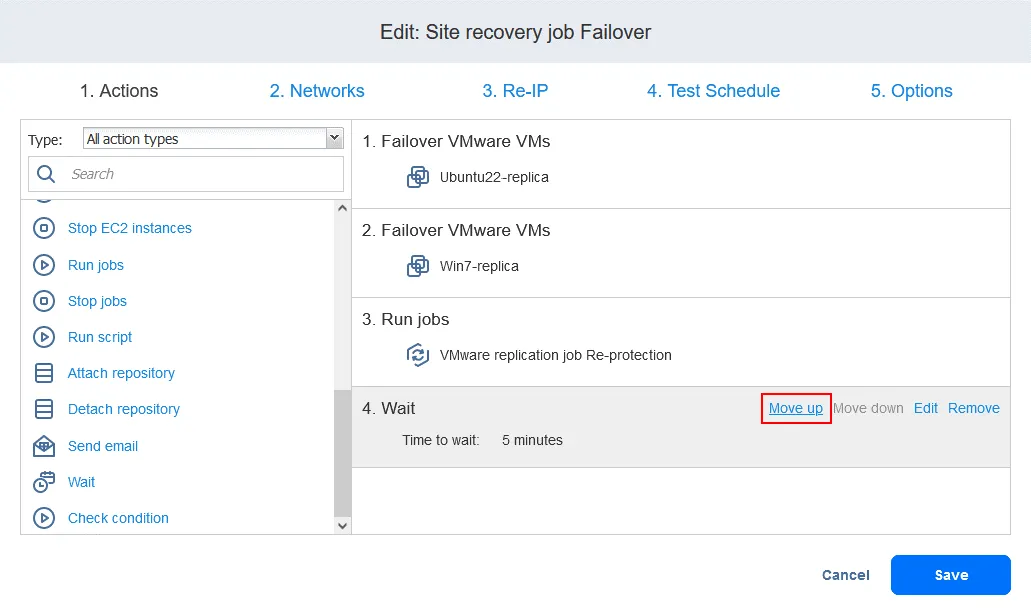
Ora le azioni sono disposte nell’ordine richiesto.
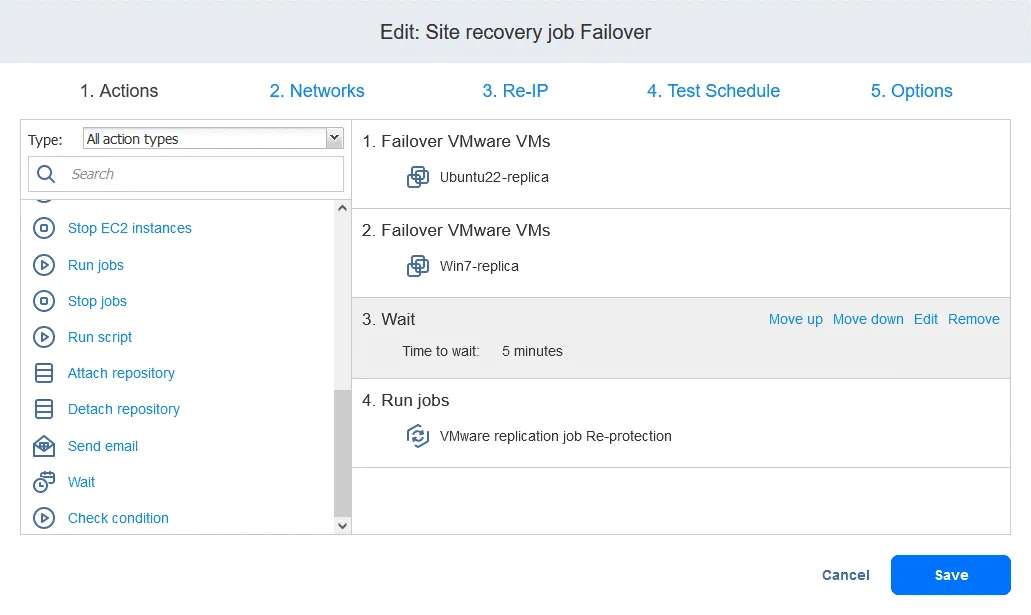
- Infine, il lavoro di ripristino dell’ambiente è pronto per essere utilizzato per eseguire il failover della VM e la riprotezione automatica delle repliche della VM utilizzate per il failover. Fare clic con il pulsante destro del mouse sul nome del lavoro di ripristino dell’ambiente Site Recovery nella pagina iniziale e fare clic su Esegui lavoro nel menu contestuale.
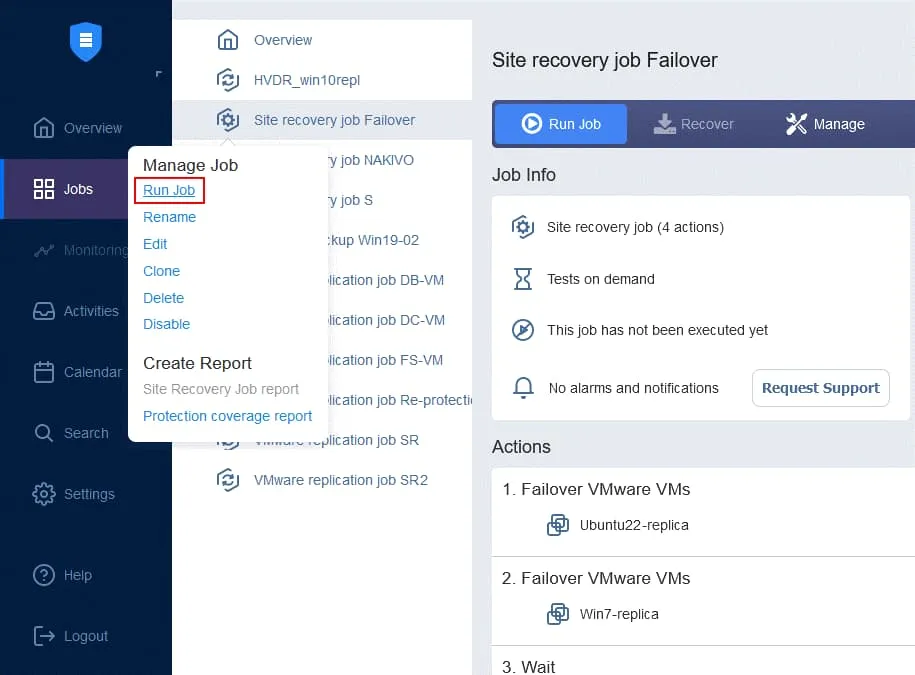
Passaggio 5. Failback
Il failback è il processo di ripristino delle VM nel loro stato più recente dal sito DR al sito di produzione originale o a uno nuovo. Per comprendere perché è necessario il failback, ricapitoliamo come funziona il failover:
- Quando si verifica un disastro (o se ne prevede il verificarsi), viene eseguito il failover su una replica della macchina virtuale.
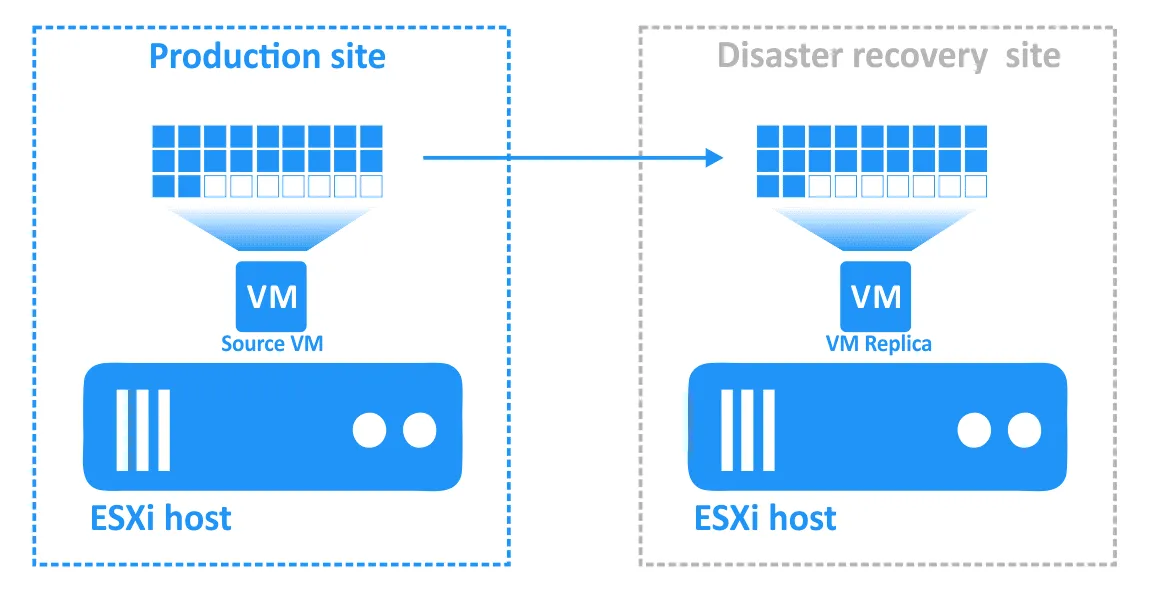
- Qualsiasi modifica alla macchina virtuale (ad esempio, transazioni aggiunte a un database quando i clienti effettuano acquisti online) viene scritta su un disco virtuale della replica della macchina virtuale. Alcuni blocchi vengono scritti, altri vengono cancellati. Il disco virtuale della VM di origine non contiene tali transazioni.
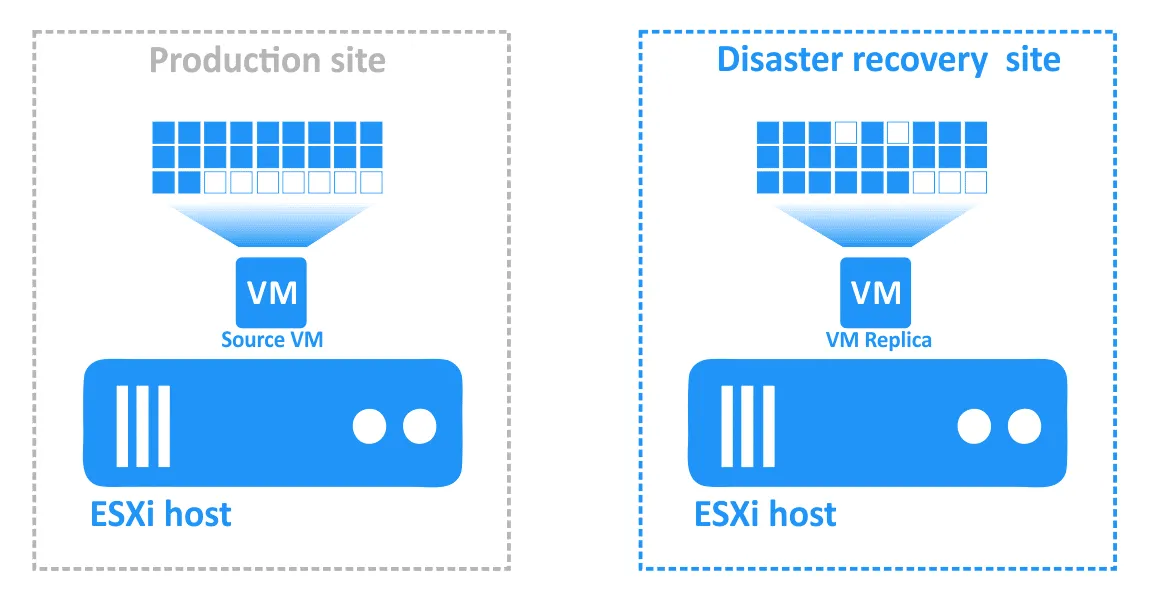
- Una volta risolto l’incidente e ripristinata la funzionalità del sito di produzione, è necessario riportare i carichi di lavoro sul sito di produzione. I dati aggiornati della replica della VM devono essere trasferiti nuovamente alla VM di origine. Le VM devono essere risincronizzate con la replica inversa utilizzando il failback.
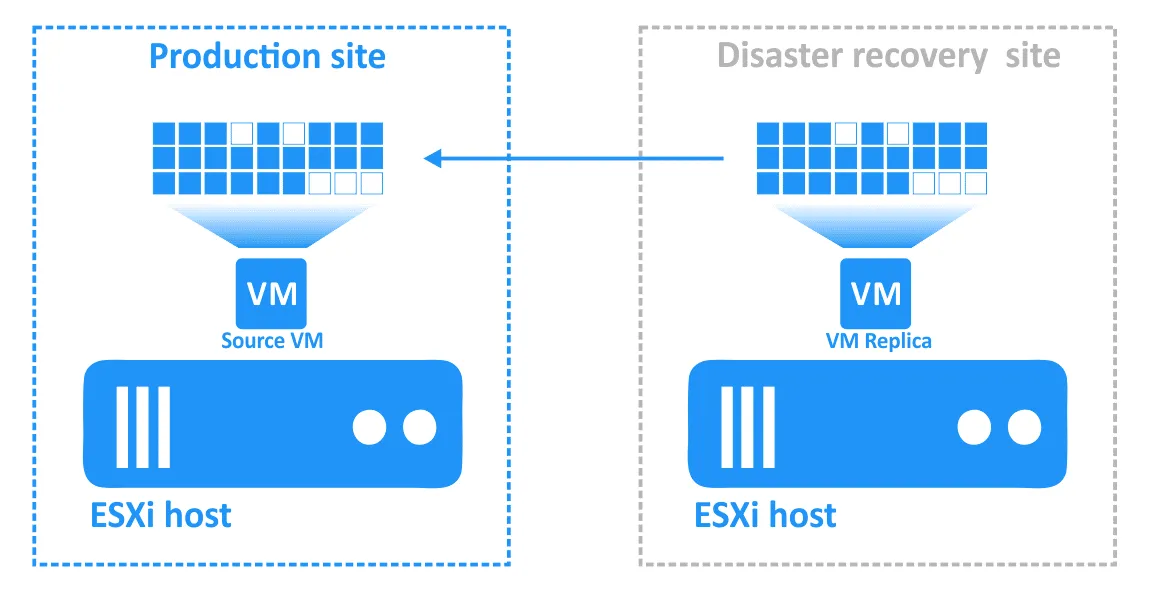
Configurazione del failback in NAKIVO Backup & Replication
Il failback può essere eseguito sia in modalità di produzione che in modalità di test (quando tutte le modifiche apportate all’ambiente virtuale dall’azione di failback vengono ripristinate allo stato precedente al failback dopo il test).
Consideriamo in dettaglio come funziona ciascun caso.
| Failback di produzione | Failback di test | |
| 1 | Spegnimento della VM di origine originale (se esiste ed è accesa). | |
| 2 |
Creazione di uno snapshot protettivo della VM di origine (se la VM di origine è funzionante). La creazione di questo snapshot consente di ripristinare lo stato precedente al failover della VM di origine nel caso in cui il failback non possa essere eseguito correttamente. |
|
| 3 | Esecuzione della replica incrementale (se la VM di origine originale è online nel sito di produzione) o della replica completa (se la VM viene ripristinata in un nuovo sito di produzione). | |
| 4 | Spegnimento della replica della VM (facoltativo). | La replica della VM viene utilizzata per ospitare i carichi di lavoro e non viene spenta. |
| 5 | La replica incrementale viene eseguita ancora una volta dalla replica della VM alla VM di origine. Il delta (i dati che sono cambiati dalla prima esecuzione della replica) dovrebbe essere molto più piccolo questa volta. | La replica da una replica VM alla VM di origine originale (o a una nuova VM di produzione) viene eseguita una sola volta perché è sufficiente ai fini del test. |
| 6 | Collegamento della VM di origine originale alla sua nuova rete con il mapping di rete (facoltativo). | Collegamento della VM di origine a una rete isolata in modo che non vi siano interruzioni dell’ambiente di produzione (opzionale). |
| 7 | Modifica dell’indirizzo IP statico della VM di origine originale con ridefinizione dell’IP (opzionale). | |
| 8 | Accensione della VM di origine originale. | |
| 9 | Pulizia dopo un failback riuscito . Dopo un’operazione di failback riuscita, sia la VM di origine che la replica della VM esistono nei loro stati normali.
Pulizia dopo un failback non riuscito :
|
Pulizia se la VM di origine non esisteva prima dell’esecuzione del test di failback:
Pulizia se la VM di origine esisteva già prima dell’esecuzione del failback di prova:
|
Preparazione per il failback
Innanzitutto, è necessario creare un lavoro di ripristino dell’ambiente che includa azioni di failover. Questo processo è stato descritto in dettagli in precedenza.
- Per eseguire un’azione di failover sono obbligatori un processo di replica e una replica della VM.
- Un lavoro di ripristino dell’ambiente deve includere un’azione di failover per poter eseguire il failback.
- Le repliche della VM devono essere in stato di failover; pertanto, è possibile eseguire il failback solo dopo aver eseguito il failover.
Esecuzione del failback
Vediamo un esempio di come eseguire il failback con NAKIVO Backup & Replication.
- Assicurarsi che il failover sia stato eseguito come parte di un processo di ripristino dell’ambiente (che dovrebbe essere già stato creato).
- Creare un nuovo lavoro di ripristino dell’ambiente: le azioni di failback possono essere incorporate in questo lavoro. Nella pagina Lavori fare clic su Crea > Lavoro di ripristino dell’ambiente .
Viene avviata la procedura guidata Nuovo lavoro di ripristino dell’ambiente Nuovo lavoro di ripristino dell’ambiente .
1. Azioni .
- Nel riquadro sinistro, fare clic su Failback VMware VMs (per altri ambienti, utilizzare Failback Hyper-V VMs o Failback istanze di EC2 ).
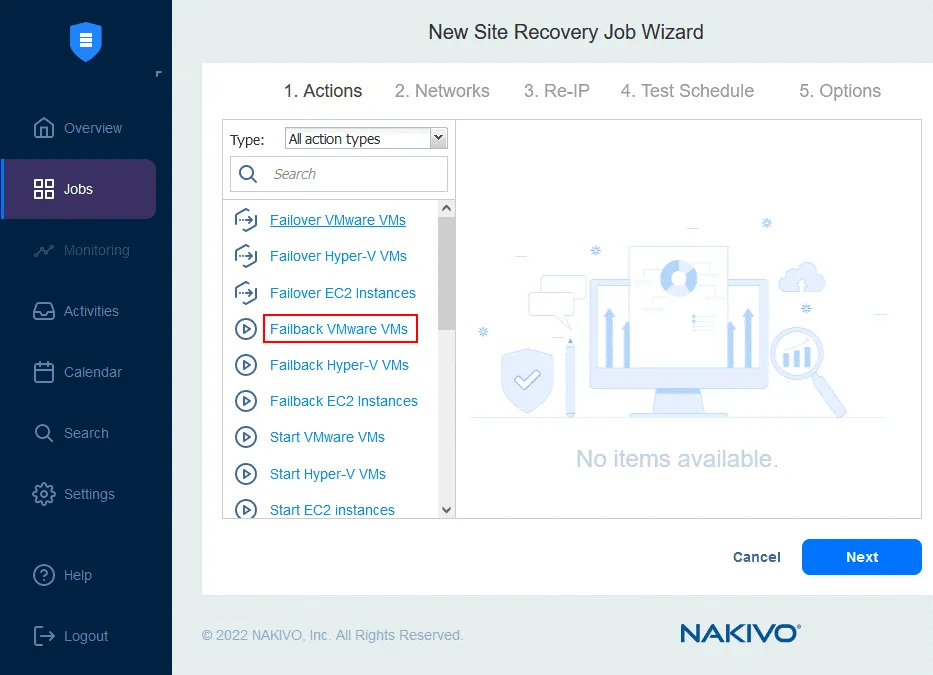
- Selezionare le repliche VM a cui applicare l’operazione di failover. Fare clic su Avanti .
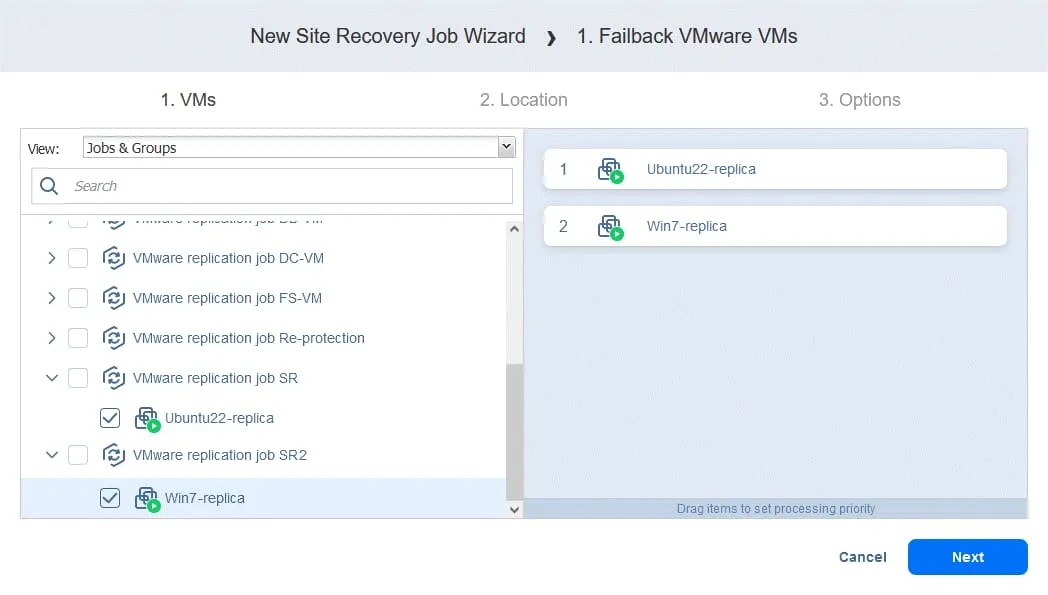
- Selezionare una ubicazione di failback, che può essere il sito di produzione originale o una nuova ubicazione. Fare clic su Avanti .
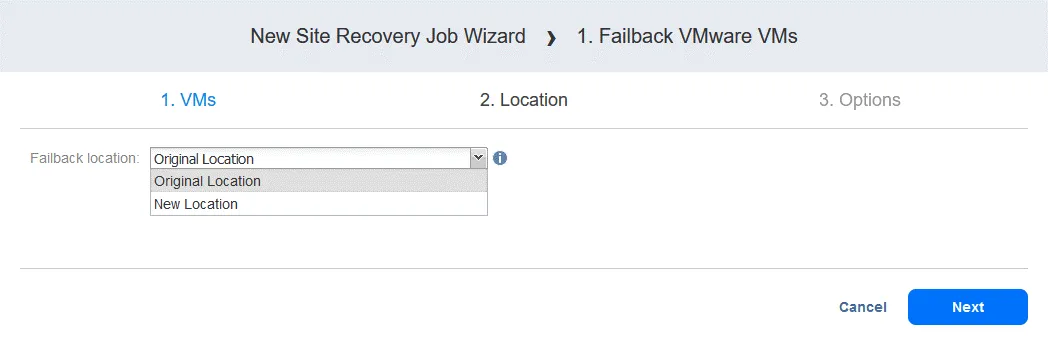
- Selezionare le opzioni del lavoro. Selezionare Spegnere le macchine virtuali replica se necessario. Fare clic su Salva quando si è pronti a procedere.
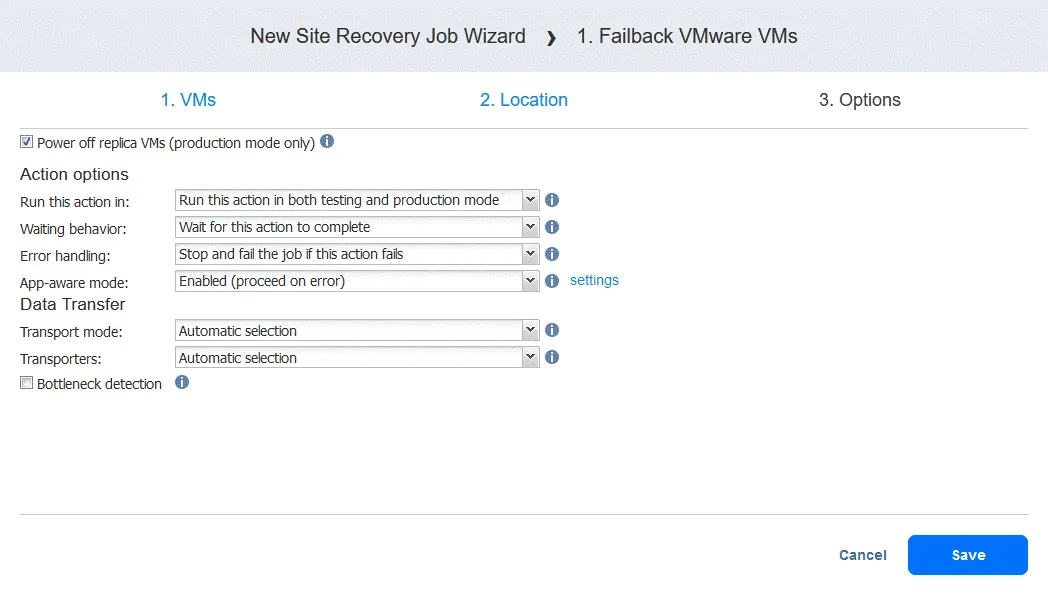
- Dopo aver aggiunto l’azione di failback, il processo di Site Recovery apparirà come nella schermata sottostante. Fare clic su Avanti .
2. Reti . Selezionare questa opzione se è necessario abilitare il mapping di rete per questo processo. Fare clic su Avanti .
3. Ridefinizione IP . Selezionare questa opzione se è necessario abilitare la ridefinizione IP per questo processo. Fare clic su Avanti .
4. Pianificazione dei test . Configurare le opzioni di pianificazione, quindi fare clic su Avanti .
5. Opzioni del lavoro . Definire le opzioni del lavoro Site Recovery e immettere il nome del lavoro. È possibile impostare l’RTO necessario per la VM e specificare l’indirizzo e-mail per il report di failback. Fare clic su Termina per completare la creazione di questo nuovo lavoro Site Recovery con failback.
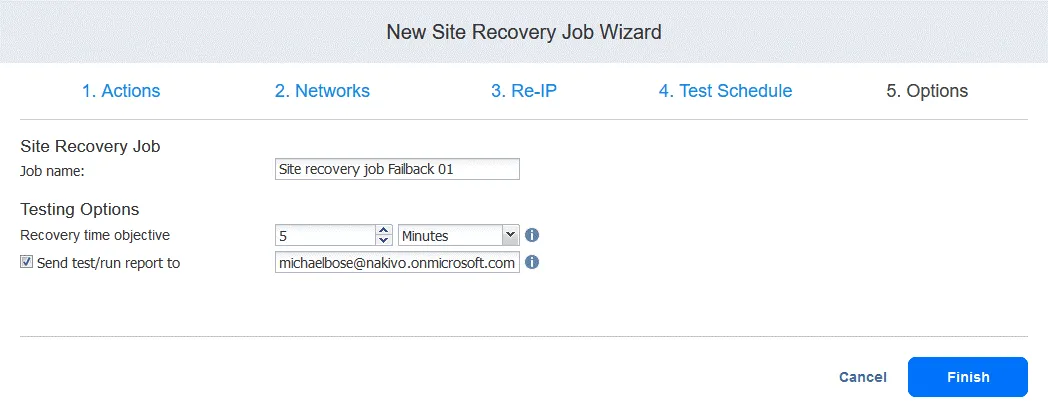
Ora è possibile eseguire questo processo di ripristino del sito per eseguire il failback della VM: è sufficiente fare clic con il pulsante destro del mouse sul nome del processo di ripristino del sito, selezionare Esegui processo e selezionare Prova processo di ripristino del sito o Esegui processo di ripristino del sito .
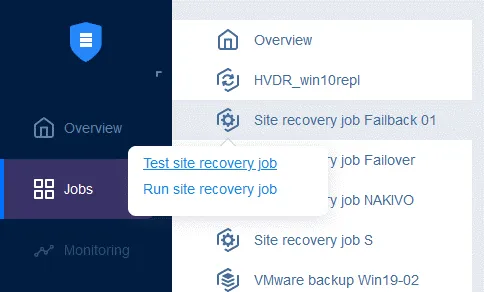
Passaggio 6. Esecuzione del test di ripristino di emergenza
Il test di ripristino di emergenza consente di assicurarsi di essere pronti per il ripristino in caso di emergenza e che tutti i componenti selezionati possano essere ripristinati correttamente entro i tempi previsti.
Ci sono due motivi principali per cui è necessario eseguire test di ripristino di emergenza :
- Per assicurarsi che tutto possa essere ripristinato correttamente . Quando si testa il piano di ripristino di emergenza e si rilevano alcuni problemi, è possibile risolverli prima che causino gravi problemi in uno scenario di crisi reale.
- Per assicurarsi che i valori RTO possano essere rispettati . I test di ripristino di emergenza consentono di verificare se i carichi di lavoro possono essere ripristinati entro i tempi di ripristino previsti (RTO). Un test di ripristino del sito può essere eseguito manualmente su richiesta o automaticamente in base alla pianificazione, il che rende il processo semplice e consente di risparmiare tempo.
Differenze tra failover di test e di produzione
Il meccanismo di esecuzione di un failover varia a seconda che il lavoro di ripristino dell’ambiente venga eseguito in modalità di test o di produzione. La tabella seguente riporta una descrizione dettagliata delle fasi per ciascuna modalità.
| Failover di produzione (emergenza) | Failover di test | |
| 1 | Disabilitare la replica dalla VM di origine alla replica | |
| 2 | Riportare la replica della VM a un determinato punto di ripristino (RP) (facoltativo, per impostazione predefinita viene utilizzato l’ultimo RP) | Eseguire una volta la replica incrementale dalla VM di origine alla replica |
| 3 | Connettere la replica della VM a una nuova rete con il mapping di rete (facoltativo) | Collegare la replica della VM a una rete isolata con mapping di rete (opzionale) |
| 4 | Modificare l’indirizzo IP statico della replica con ridefinizione dell’IP (opzionale) | |
| 4A | Spegnere la VM di origine (opzionale) | — |
| 5 | Accendere la replica | |
| 6 | Passare la replica allo stato “Failover” | |
Come si può vedere, il secondo e il terzo punto differiscono tra il flusso di lavoro di produzione e quello di test. È possibile eseguire la replica da una VM di origine in modalità di test mentre la VM di origine è in esecuzione. Nella maggior parte dei casi, quando si verifica un disastro, la VM di origine non funziona più e quindi non è possibile eseguire la replica. Le reti per la connessione delle VM possono essere definite separatamente nelle opzioni di mapping di rete per la modalità di produzione e la modalità di test durante la configurazione di un processo di ripristino del sito.
La pulizia del failover viene eseguita dopo l’esecuzione di un processo di ripristino del sito in modalità di test. La replica della VM viene spenta e riportata allo stato precedente al failover tramite snapshot (prima di eseguire un’azione di failover viene acquisita una snapshot della replica della VM). La replica viene quindi commutata dallo stato di failover allo stato normale e la replica dall’oggetto di origine alla replica viene riattivata.
Funzionalità di test per il ripristino di emergenza in Site Recovery di NAKIVO
Esaminiamo rapidamente i punti principali della funzionalità di test in Site Recovery di NAKIVO.
1. Verifica delle azioni incluse nel test
Esaminare la logica delle azioni nel lavoro di ripristino dell’ambiente di Site Recovery. Verificare che le azioni siano disposte nell’ordine corretto e assicurarsi che non formino un ciclo infinito. È possibile modificare le opzioni del lavoro Site Recovery quando il lavoro non è in esecuzione: cambiare l’ordine delle azioni, aggiungere azioni, rimuovere azioni o modificare le opzioni di azione secondo necessità.
2. Verifica della rete
Verificare che la rete funzioni correttamente. È possibile utilizzare una connessione VPN tra un sito di produzione e un sito di ripristino di emergenza (DR), ma questa connessione non può essere disconnessa periodicamente in condizioni normali. Anche la rete del sito di ripristino di emergenza (DR) deve funzionare senza interruzioni. Controllare le impostazioni di mapping di rete e Re-IP utilizzate per configurare il failover e il failback. Se una VM è configurata per una rete errata, potrebbe non essere possibile stabilire una connessione di rete. Lo stesso vale per le impostazioni IP.
3. Pianificazione dei test
I test dei processi di Site Recovery possono essere pianificati nelle opzioni di pianificazione dei processi di Site Recovery. Aprire l’interfaccia web dell’istanza di NAKIVO Backup & Replication. Nel riquadro sinistro, fare clic con il pulsante destro del mouse sul nome del lavoro e selezionare Modifica nel menu contestuale.
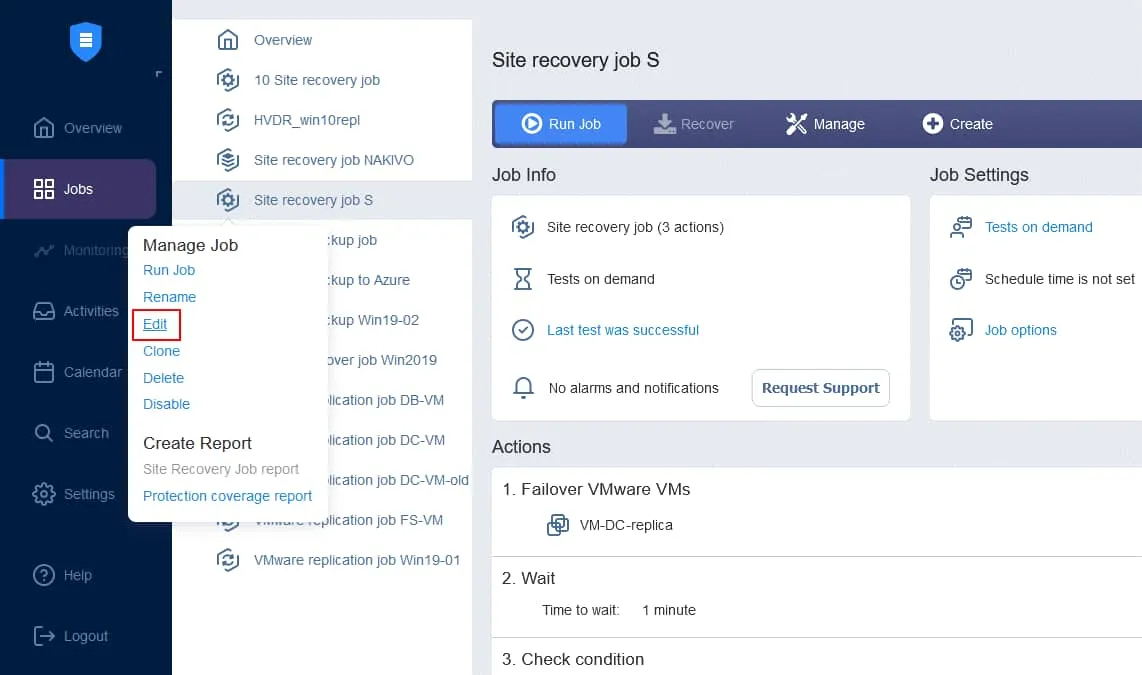
I vantaggi di Site Recovery di NAKIVO
- Orchestrazione e automazione complete del DR . Site Recovery consente di implementare piani di ripristino di emergenza con elevati livelli di automazione. È possibile definire l’ordine di ripristino delle VM tenendo conto delle dipendenze delle VM, in modo che, in caso di disastro, il ripristino sia il più efficiente possibile.
- Flessibilità per soddisfare le esigenze di diverse aziende . È possibile creare più lavori di ripristino dell’ambiente in base alle proprie esigenze. L’insieme di azioni disponibili da incorporare nei lavori di ripristino dell’ambiente consente di creare diversi flussi di lavoro di ripristino personalizzati in base alle diverse situazioni.
- Integrato nella soluzione di protezione dei dati . Il ripristino dell’ambiente è una funzione inclusa in NAKIVO Backup & Replication e disponibile insieme al resto delle funzioni complete del prodotto; non è necessario acquistare una licenza separata per il ripristino dell’ambiente. Con questa soluzione, tutte le attività di protezione dei dati e di ripristino di emergenza sono gestite da un unico pannello di controllo.
- Risparmi significativi rispetto ad altre soluzioni di ripristino di emergenza . NAKIVO Backup & Replication, con lo strumento di ripristino dell’ambiente integrato, è una soluzione conveniente. Il prodotto continua a soddisfare gli utenti con nuove utili funzioni, mantenendo gli stessi prezzi accessibili, soprattutto se confrontato con i concorrenti sul mercato del ripristino di emergenza.



