Reprise après sinistre avec NAKIVO : planification, mise en œuvre et tests
La sauvegarde et la reprise après sinistre constituent les fondements des stratégies de protection des données dans toutes les organisations et tous les secteurs. Reprise après sinistre est le processus qui consiste à restaurer les machines virtuelles et les services qui y sont exécutés sur un site secondaire (appelé site de reprise après sinistre) lorsque le site de production est indisponible. Hébergeant des serveurs, des ordinateurs et des équipements réseau redondants avec les logiciels nécessaires, ces Les sites DR secondaires peuvent être de différents types. en fonction du niveau de redondance.
NAKIVO Backup & Replication inclut la fonctionnalité Reprise après sinistre qui vous permet de créer des séquences de récupération avancées (avec basculement complet du site) pouvant être lancées d’un simple clic lorsque votre site principal tombe en panne. Lisez cet article de blog pour en savoir plus sur les éléments clés d’une stratégie de reprise après sinistre, tels que la planification de la reprise après sinistre informatique, les tests et la mise en œuvre de la reprise après sinistre avec la solution intégrée de NAKIVO.

Étape 1. Planification de la reprise après sinistre
Étape essentielle pour une reprise après sinistre efficace, la planification doit inclure une évaluation des besoins de l’organisation en matière de reprise et une compréhension approfondie des composants, étapes et procédures à inclure dans un workflow de reprise après sinistre.
Planification de la reprise après sinistre : bonnes pratiques
1. Réalisez une analyse d’impact sur l’activité
Une analyse d’impact sur les activités (ou AIA) est utilisée pour déterminer l’impact négatif potentiel d’incidents majeurs ou de catastrophes naturelles sur les opérations commerciales. Cette analyse consiste à attribuer un ordre de priorité aux différentes VMs, à définir la séquence de récupération et le temps disponible avant qu’une interruption n’ait un impact significatif sur les opérations commerciales. Par exemple, la défaillance d’une VM peut entraîner des retards et des désagréments, tandis que la défaillance d’une autre VM peut entraîner une interruption complète des opérations critiques pour l’entreprise.
2. Évaluer les risques encourus
Avant de planifier la récupération après sinistre, compilez les données pertinentes sur les risques pesant sur les opérations et la continuité des activités de votre organisation. Dans certaines régions, une panne de courant prolongée ou une attaque virale sont plus probables qu’une tornade, mais les catastrophes naturelles sont fréquentes dans d’autres. Une évaluation des risques vous aide à déterminer le niveau de protection approprié contre certaines menaces et à mettre en place des mesures pour minimiser les risques et atténuer les conséquences. Même si les risques ne peuvent être complètement éliminés, vous serez mieux préparé aux scénarios de catastrophe auxquels vous êtes susceptible d’être confronté.
3. Élaborez une documentation relative à la reprise après sinistre
Une fois les risques et leur impact potentiel sur votre entreprise identifiés, vous comprenez mieux où concentrer vos efforts pour planifier les processus de reprise après sinistre. Procédures de récupération de documents, décrivant en détail toutes les étapes essentielles et les mesures de reprise après sinistre, et mettez régulièrement à jour les documents afin de refléter les changements apportés à l’environnement. La documentation doit inclure :
- Portée de la reprise après sinistre. Évaluez l’importance de chaque composant matériel et logiciel de votre infrastructure et incluez ceux qui sont essentiels à vos opérations dans votre plan de reprise après sinistre. Les VMs hébergeant des informations critiques, les systèmes informatiques et les applications dont le fonctionnement est essentiel pour assurer la continuité des services doivent être votre priorité absolue en matière de récupération.
- Ordre de récupération des VMs. Certaines VMs peuvent dépendre des logiciels ou des informations hébergés dans une autre Vm, ce qui signifie qu’elles ne peuvent pas fonctionner séparément ou être démarrées de manière aléatoire. Vous devez spécifier l’ordre de reprise afin de rationaliser la reprise après sinistre et d’éliminer le risque de conflits logiciels sur le site de reprise après sinistre. Par exemple, la machine virtuelle exécutant le contrôleur de domaine Active Directory doit être opérationnelle avant que vous puissiez démarrer une machine virtuelle avec un serveur de fichiers qui utilise l’authentification Active Directory.
Les services Web, qui dépendent souvent de logiciels installés sur plusieurs VMs différentes, constituent un autre exemple. La séquence suivante peut devoir être mise en œuvre :
- La machine virtuelle avec le serveur de base de données doit être démarrée en premier.
- La machine virtuelle avec le serveur d’applications peut alors être démarrée.
- Ce n’est qu’ensuite que la machine virtuelle avec le serveur web peut être démarrée.
- RTO et RPO dans la reprise après sinistre. Définissez le d’objectif de délai de récupération (RTO) et le d’objectif de point de récupération (RPO) pour les différentes VMs prioritaires dans le plan de reprise après sinistre. Par exemple, les VMs avec des systèmes financiers peuvent avoir des objectifs de reprise plus courts que celles utilisées pour stocker des documents archivés.
- Dépendances. Lorsque vous déterminez la chaîne de dépendance entre le personnel et les composants informatiques, travaillez avec votre personnel et tenez-en compte afin d’éviter les maillons faibles qui peuvent entraîner l’échec de la récupération. Par exemple, une machine virtuelle utilisée par le service comptable peut devoir être réalisée en premier si les employés d’autres services dépendent de ces opérations financières pour effectuer leur travail.
- Personnel . Attribuez des rôles et des responsabilités aux membres de l’équipe qui participent aux processus de récupération après sinistre. S’ils doivent travailler sur le site de reprise après sinistre, assurez-vous que des postes de travail y sont installés avec tout l’équipement, le mobilier de bureau et le matériel nécessaires, afin qu’ils puissent poursuivre leur travail avec un minimum d’interruptions. Si les employés peuvent travailler à distance en cas de sinistre, configurez l’accès VPN et fournissez des comptes VPN à l’avance.
- Conditions à remplir pour l’installation du matériel . La réussite d’un plan de reprise après sinistre dépend fortement des performances et des capacités du matériel situé sur le site de reprise après sinistre. Plusieurs facteurs doivent être pris en compte :
- Les serveurs doivent disposer d’une capacité suffisante en termes de processeurs, de mémoire et de disque pour supporter les Workloads transférés. Une faible performance du processeur et une mémoire insuffisante peuvent affecter la vitesse de vos VMs, tandis qu’une vitesse de disque insuffisante entraîne de mauvaises performances des VMs.
- Les Réseaux doivent fournir une bande passante suffisante pour que les VMs en cours de récupération puissent interagir entre elles, avec stockage partagéet avec les utilisateurs si nécessaire.
Étape 2. Préparation à la reprise après sinistre
Une fois que vous disposez de votre documentation, vous pouvez passer à la préparation de la reprise après sinistre en préparant le site de reprise après sinistre et en configurant la réplication des Workloads critiques vers ce site. La réplication est nécessaire pour que Basculement de VM puisse répliquer les VMs lorsque l’infrastructure principale tombe en panne.
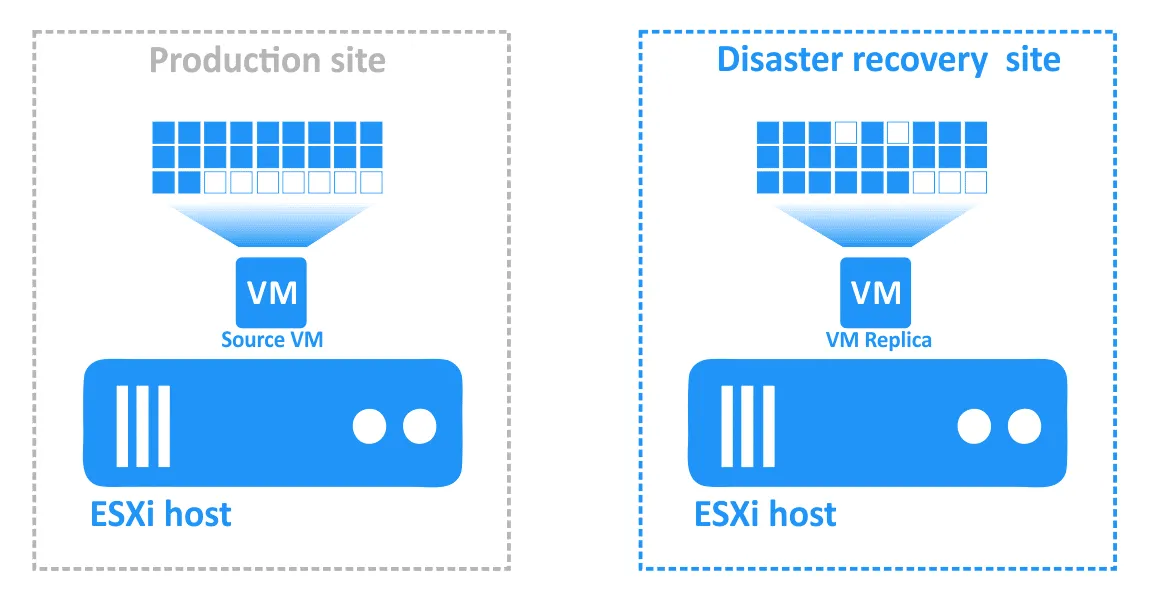
Qu’est-ce que la réplication de VMs ?
La réplication de VMs est le processus qui consiste à créer une copie identique d’une machine virtuelle source (appelée « réplique de machine virtuelle ») sur un hôte différent (l’hôte cible). La réplique de VM est une VM normale qui reste à l’état éteint jusqu’à ce qu’elle soit nécessaire (à ce moment-là, elle peut être mise en service et fonctionner sur son hôte presque instantanément).
Pour plus de détails, consultez la procédure de création et de Configurer une tâche de réplication VMware dans NAKIVO Backup & Replication.
Le processus de transfert des Workloads d’une VM source (de production) vers une réplique de VM sur le site de reprise après sinistre dans le but de maintenir la continuité des activités et la haute disponibilité est appelé « basculement ».
Bonnes pratiques en matière de réplication de VM
Il existe une variété de bonnes pratiques en matière de réplication pour garantir une meilleure fiabilité et efficacité du processus. Nous nous concentrerons ici sur deux points clés :
- Effectuez la réplication de VM au niveau de la niveau hôte plutôt que niveau invité . La couche de virtualisation est la couche intermédiaire entre le matériel physique et le système d’exploitation invité s’exécutant sur une VM. La réplication effectuée au niveau de la virtualisation est appelée réplication au niveau de l’hôte et est plus efficace que la réplication au niveau de l’invité.
- Utilisez la réplication cohérente avec les applications pour éviter la perte de données. Si un instantané de VM nécessaire à la réplication est pris pendant que ces applications sont en cours d’exécution sans aucune action supplémentaire, l’effet serait similaire à une coupure de courant et un arrêt inattendus, et les données pourraient être perdues.
Avec les méthodes cohérentes avec les applications, les applications sont gelées (mis en veille) et la mémoire est vidée, et les données ne peuvent pas être écrites sur le disque avant la prise d’un instantané. Une fois l’instantané cohérent pris, une réplique de VM peut être créée. Ces répliques de VM peuvent être restaurées avec succès, les applications qu’elles contiennent fonctionnant correctement.
NAKIVO Backup & Replication prend en charge la réplication au niveau de l’hôte cohérente avec les applications pour les VMs VMware, les VMs Hyper-V et les instances EC2 avec des fonctionnalités spéciales pour Microsoft SQL Server, Exchange Server et Active Directory Domain Controller.
Étape 3. Création d’un workflow de reprise après sinistre
Pour créer un workflow de reprise après sinistre, vous avez besoin d’une solution spécialisée telle que NAKIVO Backup & Replication, qui fournit une fonctionnalité intégrée de reprise après sinistre pour orchestrer et automatiser les séquences de reprise après sinistre.
- Qu’est-ce qu’un workflow de reprise après sinistre ?
- Actions disponibles pour un workflow DR
- Comment créer un workflow de reprise après sinistre
- Présentation de la configuration de Reprise après sinistre de NAKIVO
Qu’est-ce qu’un workflow de reprise après sinistre ?
Un workflow de reprise après sinistre est une séquence d’actions exécutées dans le cadre du processus de reprise après sinistre afin d’assurer un basculement sûr et rapide des Workloads vers des réplicas. Le workflow organise le processus de basculement avec des actions liées aux VMs sources, aux VMs cibles, aux conditions à remplir, etc. Vous devez définir l’ordre dans lequel les actions doivent être exécutées, car certaines procédures de reprise après sinistre peuvent dépendre du résultat de l’exécution d’autres procédures.
Actions de Reprise après sinistre disponibles
La fonctionnalité Reprise après sinistre vous permet de créer des séquences de reprise après sinistre complexes en combinant des actions et des conditions dans un seul workflow. Chaque action peut être exécutée uniquement en mode test, uniquement en mode production ou dans les deux modes (ce qui est utilisé par défaut) dans NAKIVO Backup & Replication.
Vous pouvez inclure tout ou partie des actions suivantes dans une séquence :
- Basculement – lance le basculement vers des réplicas de VMs VMware, Hyper-V ou des instances EC2.
- Restauration automatique – renvoie les Workloads de la réplique de la machine virtuelle vers la machine virtuelle source. Les modifications apportées à la réplique de la machine virtuelle depuis le point de basculement sont écrites dans la machine virtuelle source lors de la restauration automatique. Les machines virtuelles sont synchronisées et la machine virtuelle source est à nouveau dans son état de production réel.
- Démarrer – démarre les machines virtuelles VMware, les machines virtuelles Hyper-V ou les instances EC2.
- Arrêter – arrête les machines virtuelles VMware, les machines virtuelles Hyper-V et les instances EC2 en cours d’exécution.
- Exécuter une tâche – exécute une tâche de sauvegarde, de réplication, de reprise après sinistre, de copie de sauvegarde ou de démarrage instantané de machines virtuelles.
- Arrêter les tâches – arrête une tâche (l’une des tâches répertoriées dans la liste précédente).
- Exécuter le script – exécute un script sur l’une des cibles suivantes : le serveur avec le Director, un Serveur Windows distant, un Serveur Linux distant, une machine virtuelle VMware, une machine virtuelle Hyper-V ou une instance EC2.
- Joindre le référentiel – joint un référentiel de sauvegarde utilisé par NAKIVO Backup & Replication pour stocker les sauvegardes.
- Détacher le référentiel – détache un référentiel de sauvegarde.
- Envoyer un e-mail – envoie un e-mail avec le message que vous rédigez à un ou plusieurs destinataires définis.
- Warten – attend pendant la période désignée avant de passer à l’action suivante.
- Vérifier l’état – en fonction de votre saisie (tout ou partie d’un nom de ressource), vérifie l’une des conditions suivantes :
- La ressource existe
- La ressource est en cours d’exécution
- L’adresse IP/le nom d’hôte est accessible
Comment créer un workflow de reprise après sinistre
Voyons un exemple de création d’une tâche de reprise après sinistre dans NAKIVO Backup & Replication.
Notre configuration
Voici la configuration que nous allons examiner : un site principal (production) avec des VMs VMware vSphere et un site de reprise après sinistre à distance :
- DC-VM est une machine virtuelle Windows exécutant Active Directory Domain Controller.
- FS-VM est une machine virtuelle Windows avec un serveur de fichiers en cours d’exécution (le protocole SMB est utilisé pour le partage de fichiers). Active Directory est utilisé pour l’authentification des utilisateurs. Les sauvegardes de la base de données Oracle sont stockées sur le serveur de fichiers.
- Ora-DB est la machine virtuelle sur laquelle la base de données Oracle est exécutée.
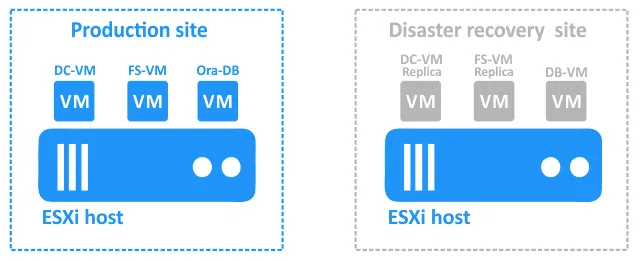
Le site de reprise après sinistre contient les VMs suivantes :
- DC-VM-replica et FS-VM-replica sont des réplicas des VMs de production. Ils peuvent être utilisés comme cibles pour le basculement.
- DB-VM est une machine virtuelle basée sur Linux avec Logiciel de base de données Oracle installé mais ne contient aucune base de données.
La base de données est sauvergardée avec NAKIVO Backup & Replication au niveau de la base de données vers FS-VM sur le site de production (ce Sauvegarde de la base de données Oracle est cohérent avec l’application). FS-VM et DC-VM sont répliqués au niveau de l’hôte vers le site de reprise après sinistre avec la solution NAKIVO.
Ordre de récupération des VM
Lors d’un incident entraînant la mise hors service du site de production, les composants doivent être récupérés sur le site de reprise après sinistre comme suit :
- Basculement de DC-VM vers DC-VM-replica.
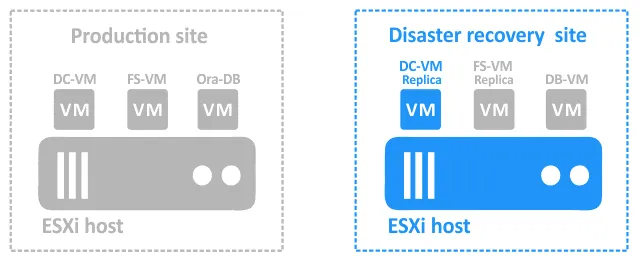
- Une fois que DC-VM-replica est opérationnel, basculement de FS-VM vers FS-VM-replica . Vous devez procéder dans cet ordre, car FS-VM dépend de DC-VM pour l’authentification des utilisateurs sur le serveur de fichiers.
- Une fois ces deux VMs en cours d’exécution, DB-VM peut accéder au répertoire partagé sur le serveur de fichiers où le dump est stocké. Vous pouvez maintenant démarrer DB-VM .
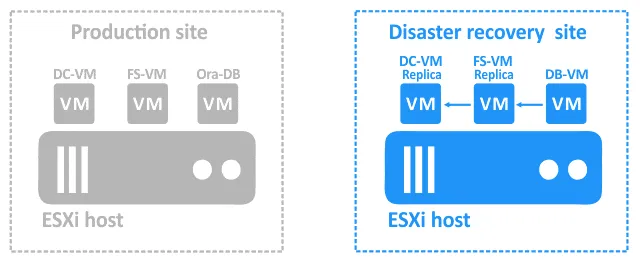
- Une fois que DB-VM est en cours d’exécution, exécutez le script qui peut restaurer la base de données à partir du dump situé sur le serveur de fichiers. Les flèches bleues dans les schémas ci-dessus indiquent les dépendances.
Notez qu’un certain temps peut être nécessaire pour que les services démarrent sur une réplique de VM sous tension après l’action de basculement et avant de basculer vers la réplique suivante ou de récupérer une application ou une base de données. Ce temps d’attente doit faire partie de la séquence de reprise après sinistre.
Pour cet ordre de basculement de VM, vous devez créer une tâche de reprise après sinistre dans NAKIVO Backup & Replication avec la logique suivante :
- Action 1 : Basculez DC-VM . Warten auf den Abschluss dieser Aktion bevor Sie zur nächsten étape übergehen. Arrêtez la tâche wenn diese Aktion fehlschlägt.
- Action 2 . Warten auf 3 Minuten.
- Action 3 . Vérifiez l’état de DC-VM-replica . Vérifiez si la ressource est en cours d’exécution. Si la ressource est en cours d’exécution, passez à l’action suivante dans la tâche de reprise après sinistre. Sinon, arrêtez et faites échouer la tâche.
- Action 4 . Basculez FS-VM . Attendez que cette action soit terminée avant de passer à l’action suivante. Arrêtez la tâche si cette action échoue.
- Action 5 . Warten auf den Abschluss dieser Aktion für 3 Minuten.
- Action 6 . Vérifiez l’état de FS-VM-replica . Si la ressource est en cours d’exécution, passez à l’action suivante de la tâche de reprise après sinistre. Sinon, arrêtez et faites échouer la tâche.
- Action 7 . Démarrer DB-VM . Attendez que cette action soit terminée avant de passer à l’action suivante. Arrêtez la tâche si cette action échoue.
- Action 8 . Attendez pendant 5 minutes.
- Action 9 . Exécuter le script . Type de cible : VMware VM. VM cible : DB-VM. Chemin d’accès au script : /home/oracle/restore_db.sh (lorsque vous ajoutez cette étape, vous devez saisir le nom d’utilisateur et le mot de passe d’un compte disposant des autorisations suffisantes pour exécuter le script).
Présentation de la reprise après sinistre de NAKIVO
Créons une nouvelle tâche de reprise après sinistre basée sur le plan décrit ci-dessus. Sur la page Jobs de votre instance NAKIVO Backup & Replication, cliquez sur Create > Tâche de reprise après sinistre .
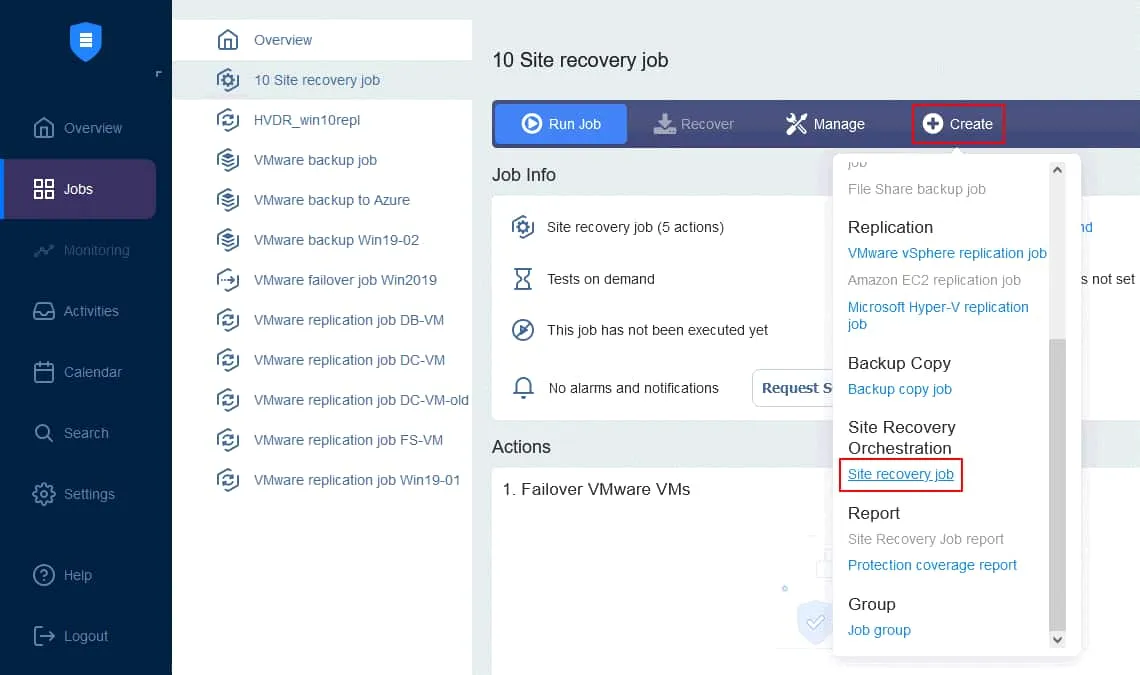
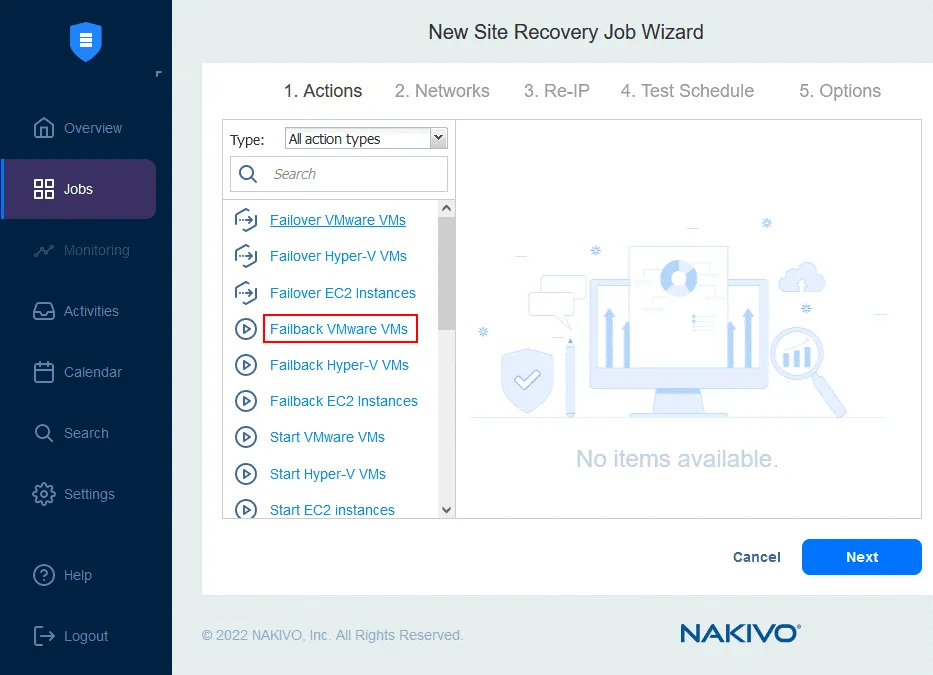
1. Actions
L’assistant de nouvelle tâche de reprise après sinistre est lancé. Dans le panneau de gauche, vous trouverez les actions qui peuvent être ajoutées à la tâche. Il suffit de cliquer sur une action pour l’ajouter à la séquence. Notez que vous ne pouvez pas mélanger des actions pour différentes plateformes dans une même séquence (nous créons une tâche pour les VMs VMware).
Action 1. Basculement DC-VM
- Dans le volet gauche, cliquez sur Basculement des machines virtuelles VMware .
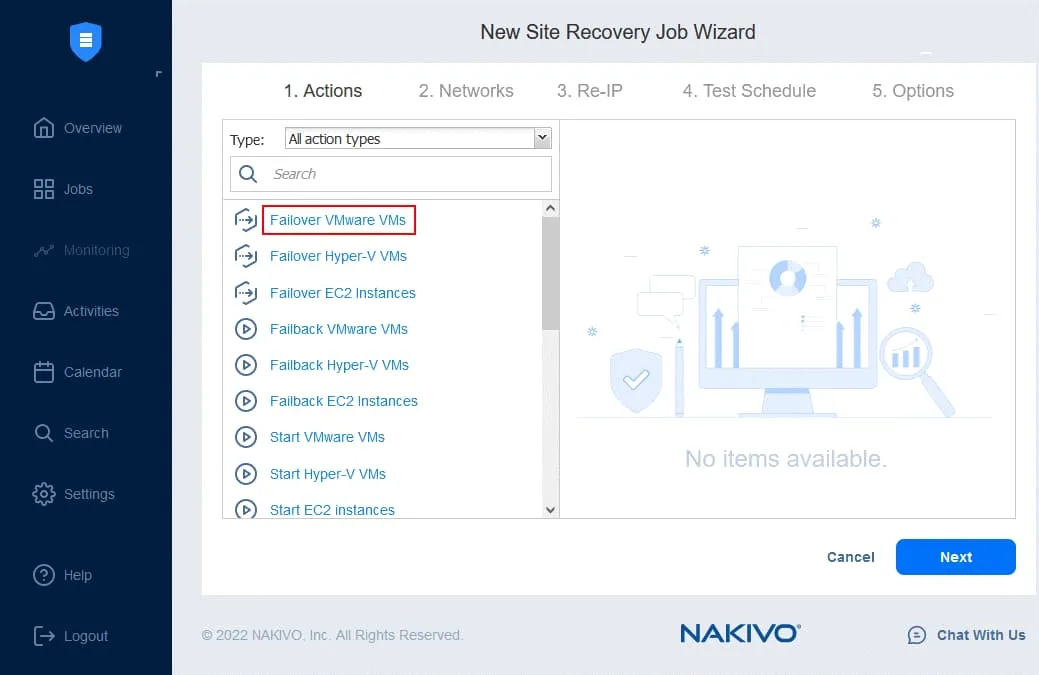
- Dans le volet gauche, sélectionnez la réplique de machine virtuelle à partir d’une tâche de réplication existante. Dans notre flux de travail, le basculement vers DC-VM-replica est la première action. Dans le volet droit, vous pouvez sélectionner un point de récupération. Le dernier point de récupération est utilisé par défaut.
Cliquez sur Suivant pour continuer.
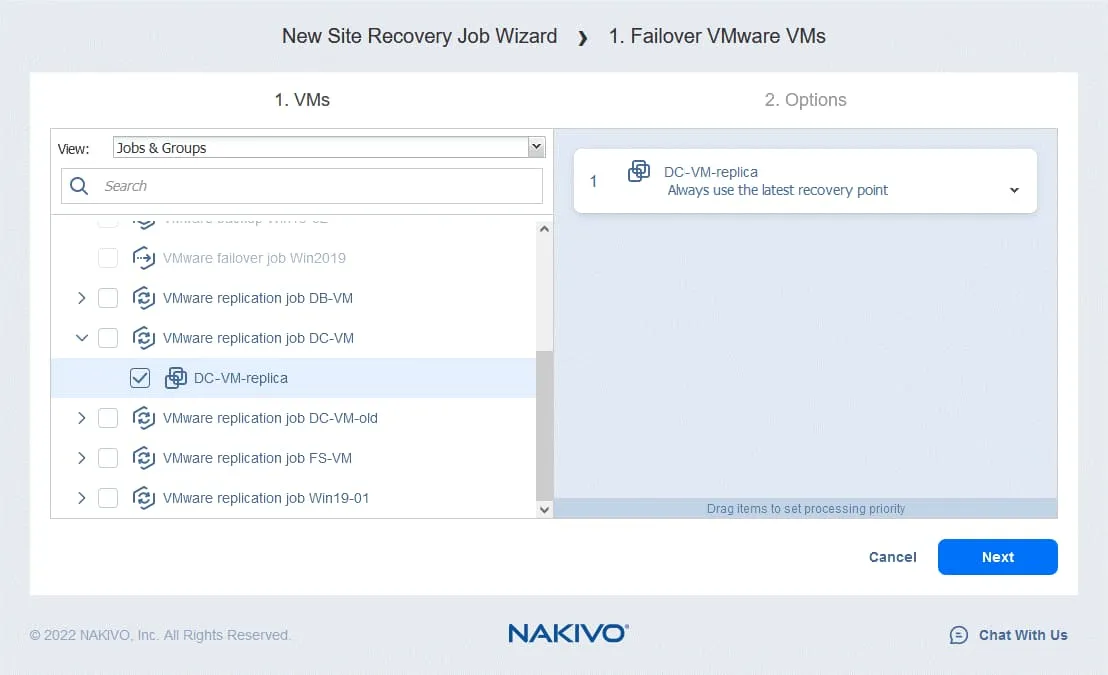
- Pour les options de reprise après sinistre basculement , vous pouvez désélectionner Éteindre les machines virtuelles sources – cette option peut être utilisée pour éviter un conflit d’adresses IP si les machines virtuelles sources et les réplicas utilisent les mêmes réseaux.
Sur la base de la logique décrite ci-dessus, nous sélectionnons les options suivantes :
- Exécutez cette action dans : Exécutez cette action en mode test et en mode production
- Comportement d’attente : Warten auf den Abschluss dieser Aktion
- Gestion des erreurs : Arrêter et faire échouer la tâche si cette action échoue
Cliquez sur Enregistrer pour enregistrer l’action créée.
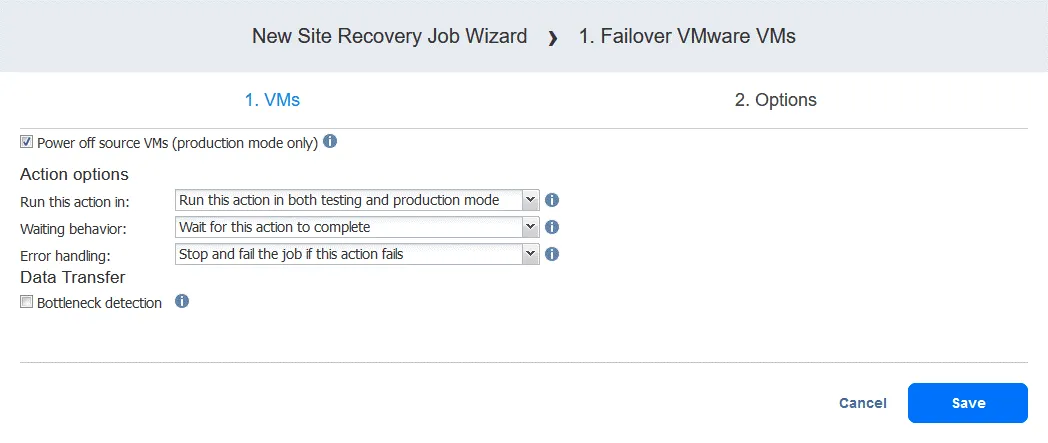
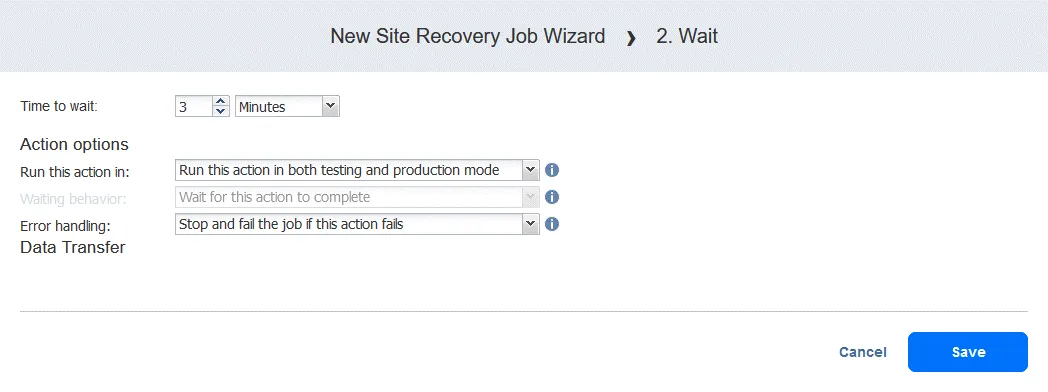
Action 2. Attendez 3 minutes
A wait action est utile dans ce cas, car l’action de basculement suivante dans le flux de travail (basculement vers FS-VM-replica ) nécessiterait que DC-VM-replica soit opérationnel et déjà en cours d’exécution avec les services de domaine Active Directory.
- Dans le volet gauche de l’écran Actions , cliquez sur Warten .
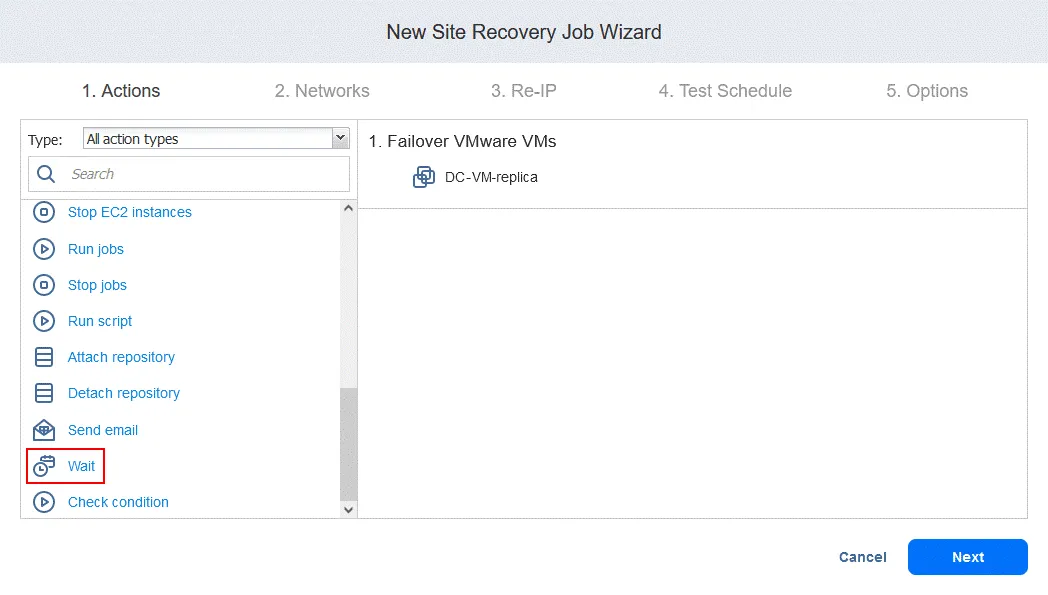
- Sélectionnez le temps d’attente (nous utilisons 3 minutes ).
Sélectionnez les options d’action comme vous l’avez fait pour la première action, puis cliquez sur Enregistrer .
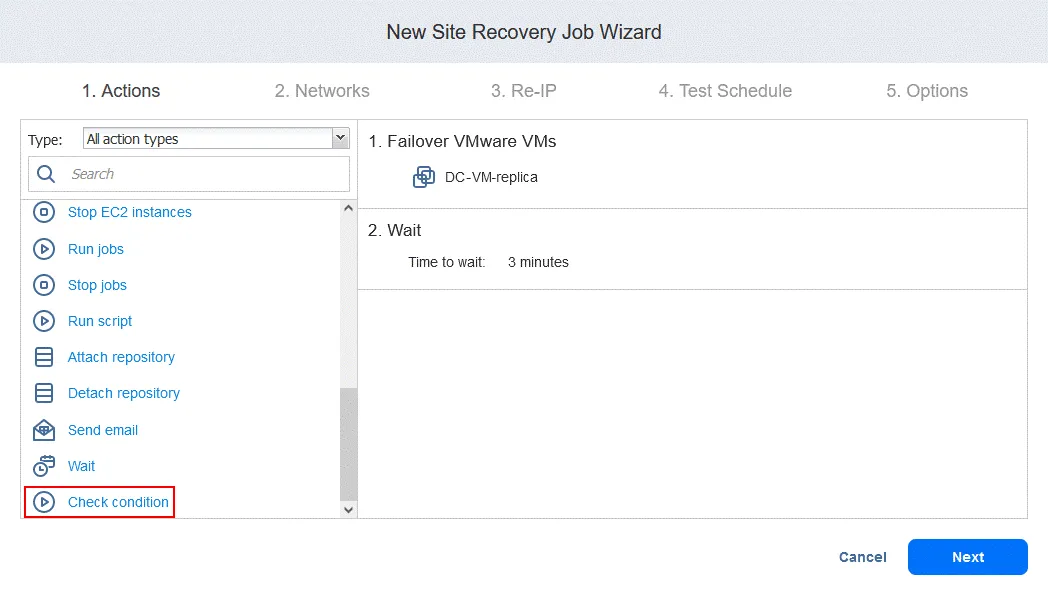
La nouvelle action est ajoutée après l’action précédente, en bas de la liste. Vous pouvez réorganiser, modifier ou enlever des actions. Il suffit de passer votre souris sur une action pour voir les options.
Action 3. Vérifier l’état de DC-VM-replica
- Dans le volet gauche de l’écran Actions , cliquez sur Vérifier l’état pour vérifier si la machine virtuelle qui a été basculée lors de la première action est en cours d’exécution.
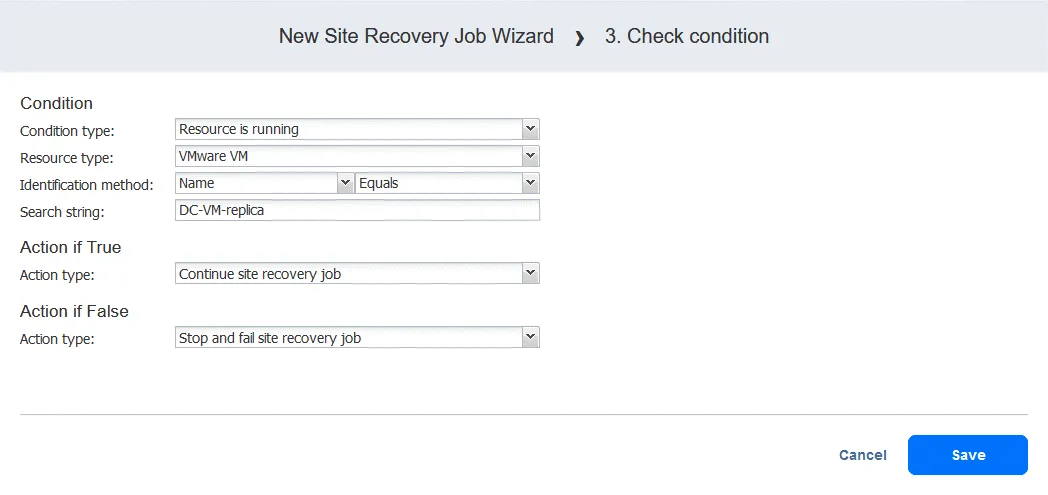
- Configurez cette action comme suit :
- Sélectionnez le type de condition : La ressource est en cours d’exécution . Les autres options sont la ressource existe ou l’adresse IP/le nom d’hôte est accessible.
- Sélectionnez le type de ressource : VMware VM .
- Sélectionnez la méthode d’identification : Nom (l’autre option est ID ) pour identifier la VM en question. Vous pouvez utiliser n’importe quelle partie de la chaîne de la VM. Ici, nous connaissons le nom exact, nous utilisons donc la fonction Est égal à .
- Définissez la chaîne de recherche : DC-VM-replica .
Nous avons maintenant une action qui vérifie si la VM VMware nommée DC-VM-replica est en cours d’exécution. Cliquez sur Enregistrer pour continuer.
Action 4. Basculement FS-VM
- Comme pour Action 1 , cliquez sur Basculement des machines virtuelles VMware .
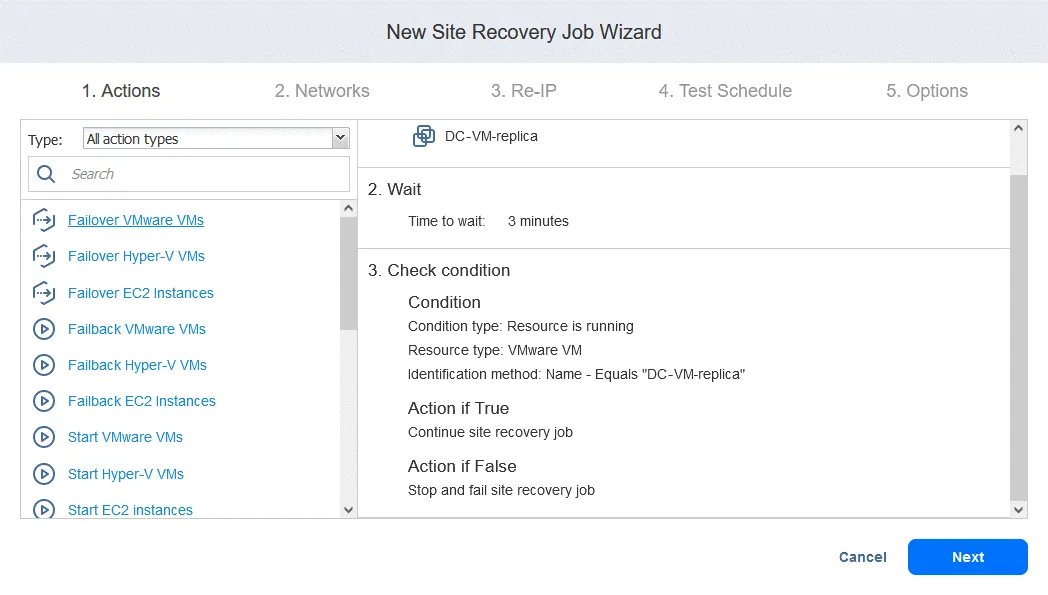
- Dans ce cas, nous sélectionnons FS-VM-replica . Cliquez sur Suivant , puis sélectionnez les mêmes options pour l’action de basculement que celles que vous avez utilisées dans Action 1 et cliquez sur Enregistrer .
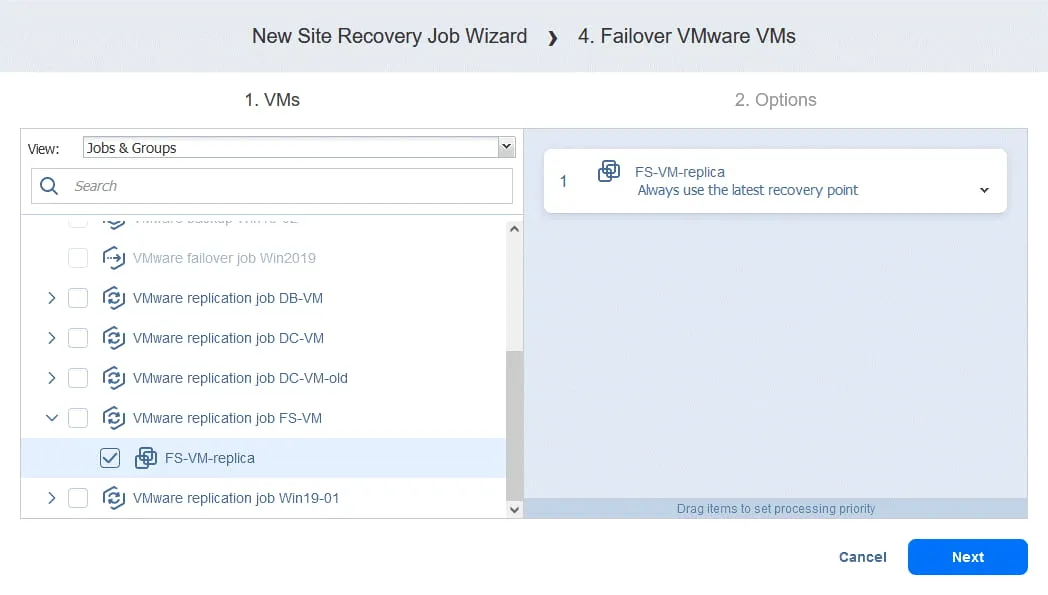
Action 5. Attendez 3 minutes
Cliquez sur Attendez et configurez cette action comme vous l’avez fait pour action 2 . Le temps spécifié est à nouveau 3 minutes dans notre cas.
Action 6. Vérifiez l’état de FS-VM-replica
Cliquez sur Vérifiez l’état afin de vérifier si la machine virtuelle VMware FS-VM-replica est en cours d’exécution. Reportez-vous à l’action 2 et sélectionnez les mêmes options, à l’exception, bien sûr, du VM-Name.
Action 7. Démarrer DB-VM
- Cliquez sur Démarrer les machines virtuelles VMware dans le volet gauche de l’écran Actions .
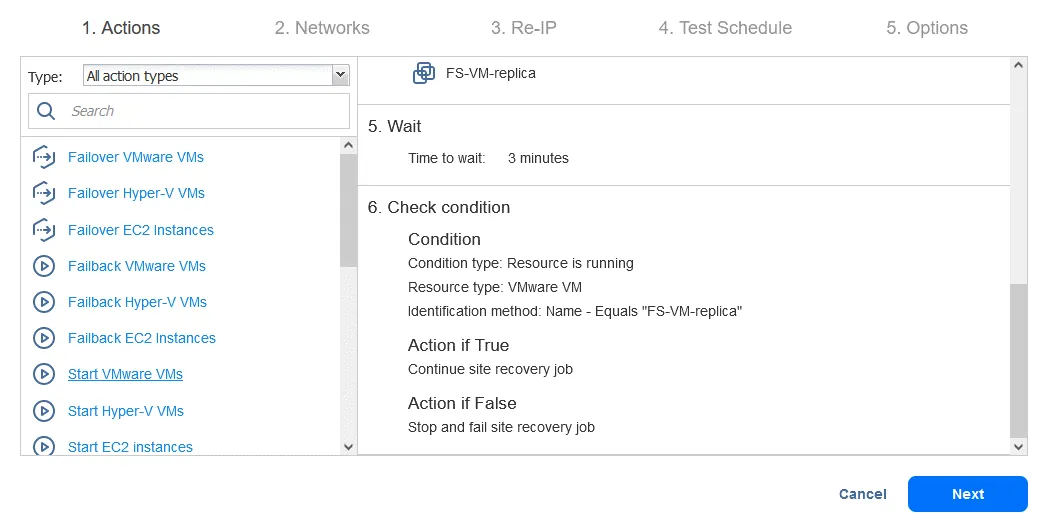
- Sélectionnez DB-VM . Cette VM peut être démarrée une fois que vous êtes sûr que FS-VM-replica est en cours d’exécution. Au bas de la page, sélectionnez les mêmes options d’action que celles indiquées dans les actions précédentes. Cliquez ensuite sur Enregistrer .
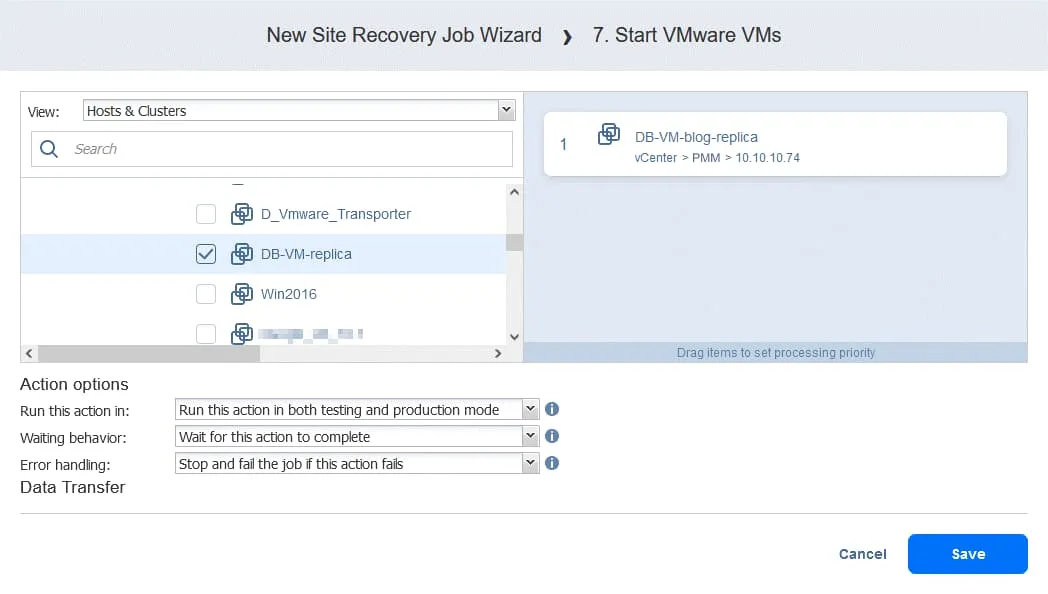
Action 8. Attendez 5 minutes
Attendez 5 minutes. Cliquez sur Warten et configurez cette action de la même manière que pour action 2 . Cela devrait suffire pour démarrer le service Oracle sur DB-VM .
Action 9. Exécuter le script
- Sur l’écran Actions cliquez sur Exécuter le script . Rappelez-vous que ce script est destiné à réaliser la récupération de la base de données Oracle au niveau de la base de données à partir d’un dump stocké sur FS-VM-replica .
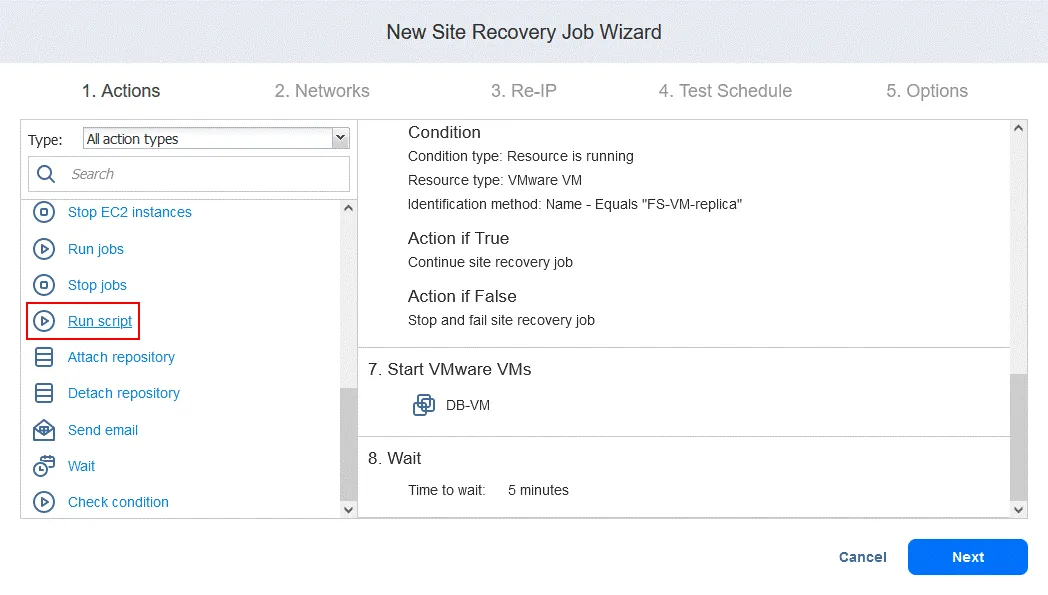
- Définissez les options de script. Dans notre cas :
- Type de cible : VMware VM
- VM cible : DB-VM
- Chemin d’accès au script : /home/oracle/restore.db.sh
- Nom d’utilisateur : oracle
- Mot de passe : (mot de passe)
Votre chemin d’accès au script, votre nom d’utilisateur et votre mot de passe seront différents. N’oubliez pas de vous assurer que le fichier script est exécutable et que l’utilisateur dispose des autorisations suffisantes pour exécuter le script. Les options d’action sont configurées comme d’habitude dans cet exemple.
Cliquez sur Enregistrer lorsque vous êtes prêt à continuer.
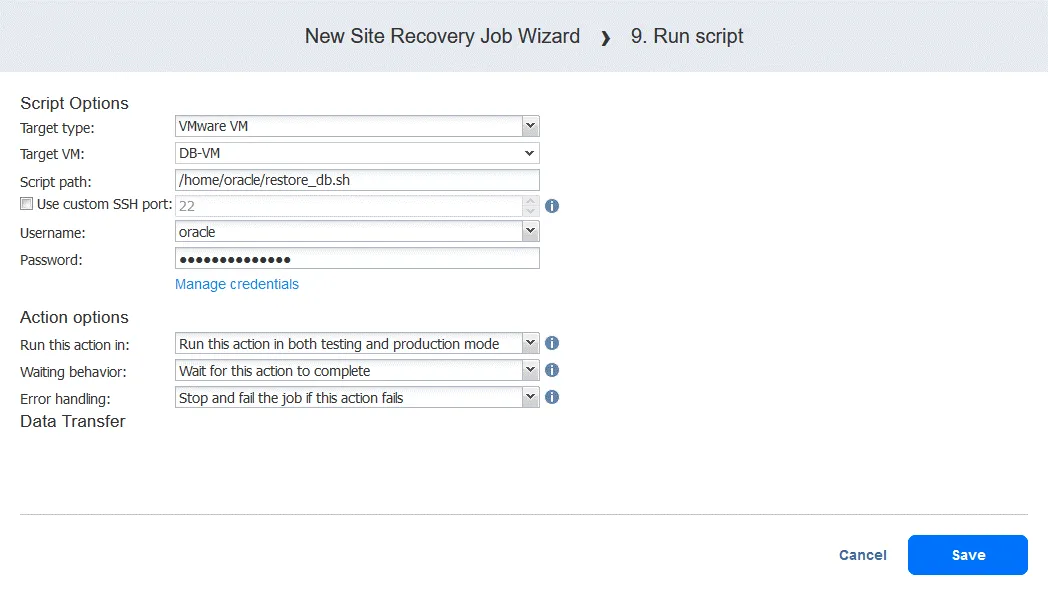
- Vous pouvez désormais voir toutes les actions configurées. Cliquez sur le bouton Suivant pour continuer la configuration de la tâche de reprise après sinistre en fonction de votre plan de reprise après sinistre.
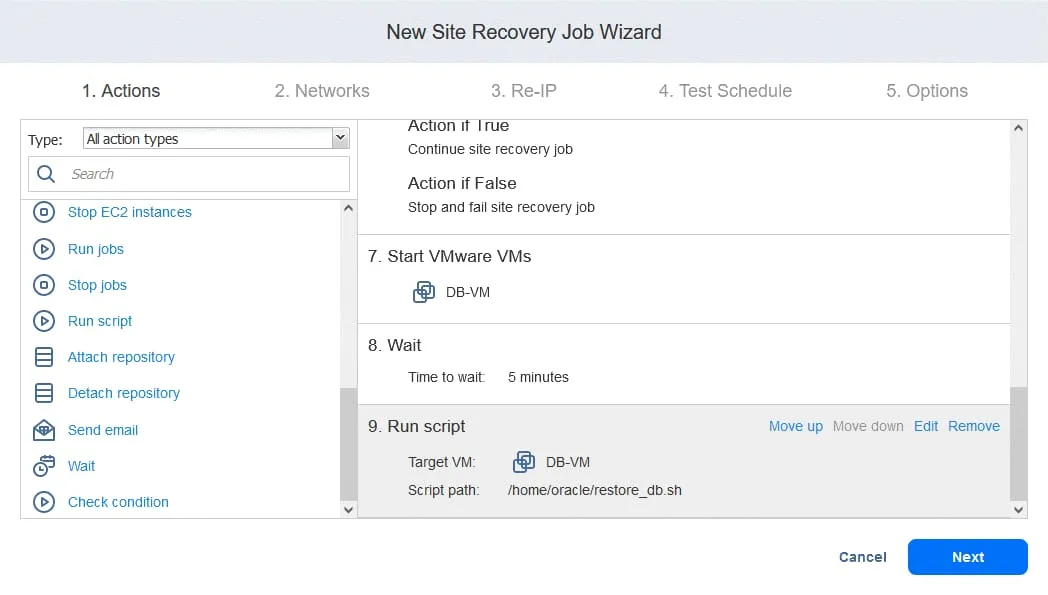
2. Réseaux
Si les machines virtuelles du site de production et du site de reprise après sinistre sont connecté à différents réseaux, sélectionnez Activer le mappage réseau . Cliquez sur Créer un nouveau mappage , dans les fenêtres contextuelles, sélectionnez un réseau source, un réseau de destination et un réseau à utiliser pour tester la tâche de reprise après sinistre.
Cliquez sur Enregistrer pour enregistrer la règle de mappage réseau, puis cliquez sur Suivant .
Remarque : vous pouvez également utiliser des règles de mappage existantes si vous les avez configurées dans d’autres tâches de réplication, de basculement ou de reprise après sinistre.
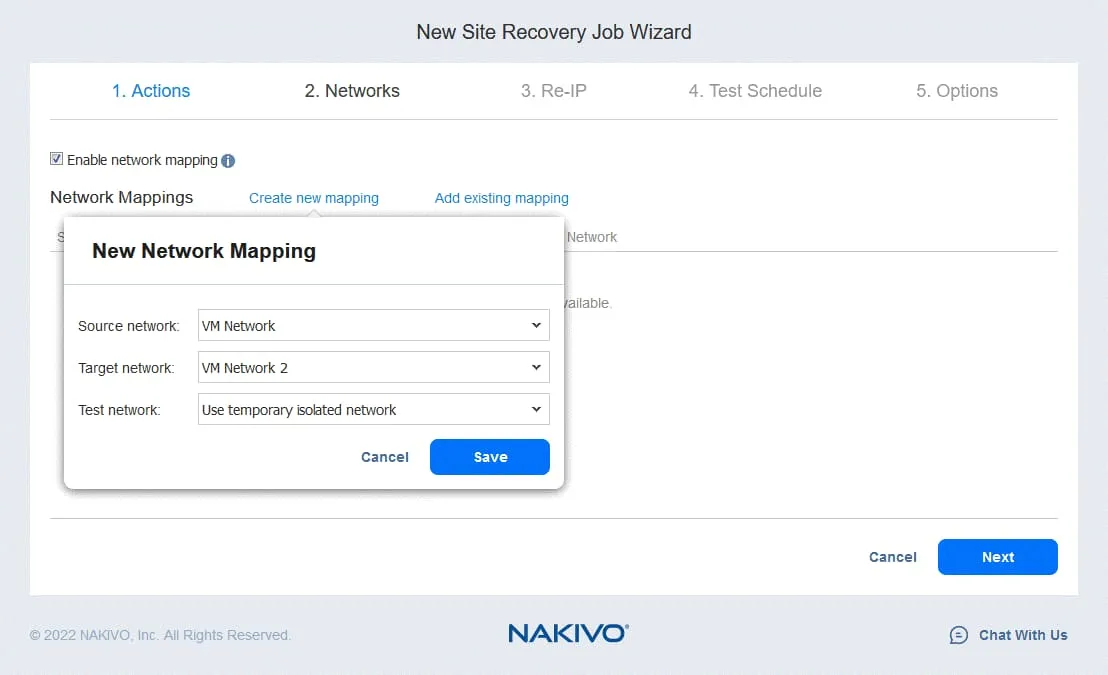
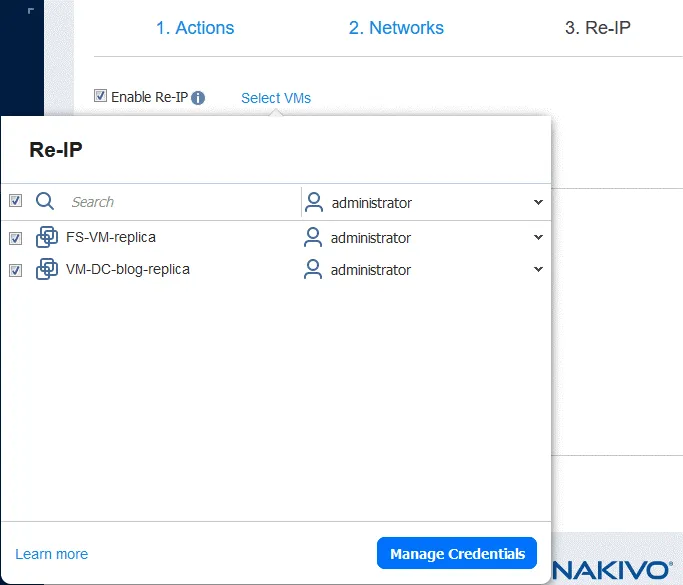
3. Re-IP
Si les réseaux utilisés pour la connexion VM sur le site source et le site cible ont des adresses différentes, vous devez activer la Réassignation d’adresses IP en sélectionnant Activer la Réassignation d’adresses IP .
- Créez une nouvelle règle de réassignation d’adresses IP en cliquant sur Créer une nouvelle règle . Définissez les paramètres de la source et les paramètres de la cible, puis cliquez sur Enregistrer .
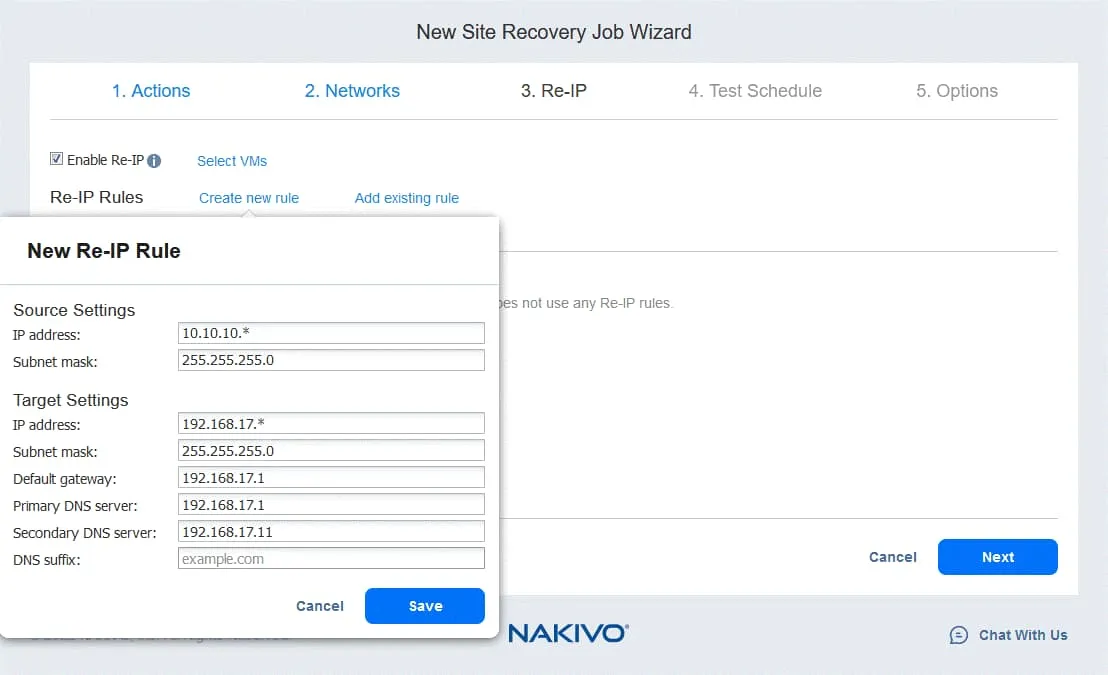
- Cliquez sur Sélectionner les VM et sélectionnez les VM pour lesquelles la Réassignation d’adresses IP doit être utilisée. Vous devez fournir les identifiants de connexion d’un utilisateur disposant des autorisations suffisantes pour modifier les paramètres de réseau dans le système d’exploitation invité de la machine virtuelle.
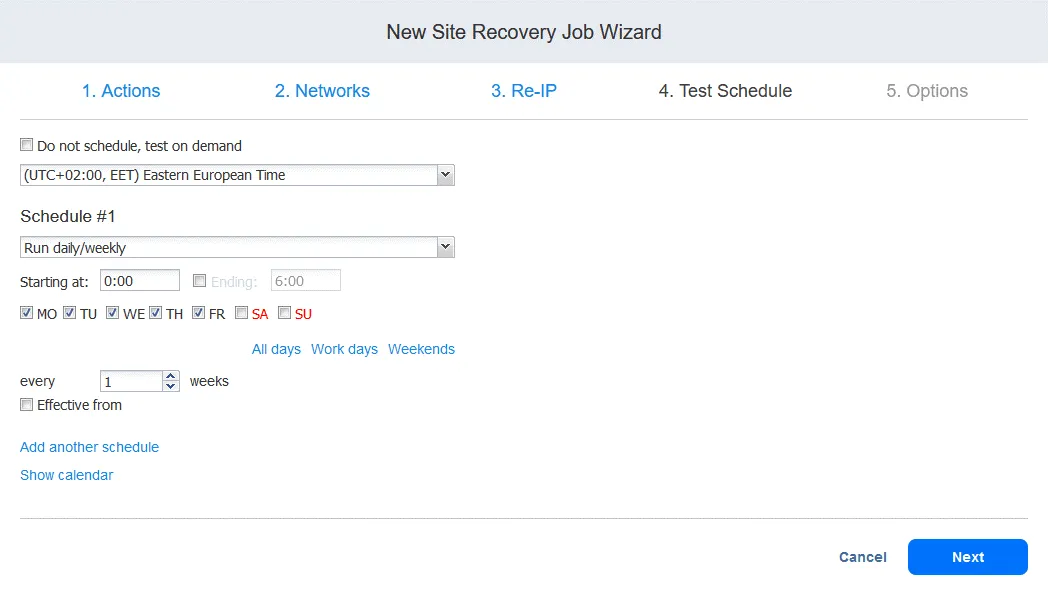
4. Calendrier des tests
Vous pouvez créer un calendrier spécialement destiné à exécuter des tâches de Reprise après sinistre en mode test et à effectuer des tests de reprise après sinistre. Cela vous permet de vérifier si la tâche peut être exécutée avec succès dans les délais requis. Une fois terminé, cliquez sur Suivant.
Nous aborderons plus en détail les tests des tâches de Reprise après sinistre à l’étape 6.
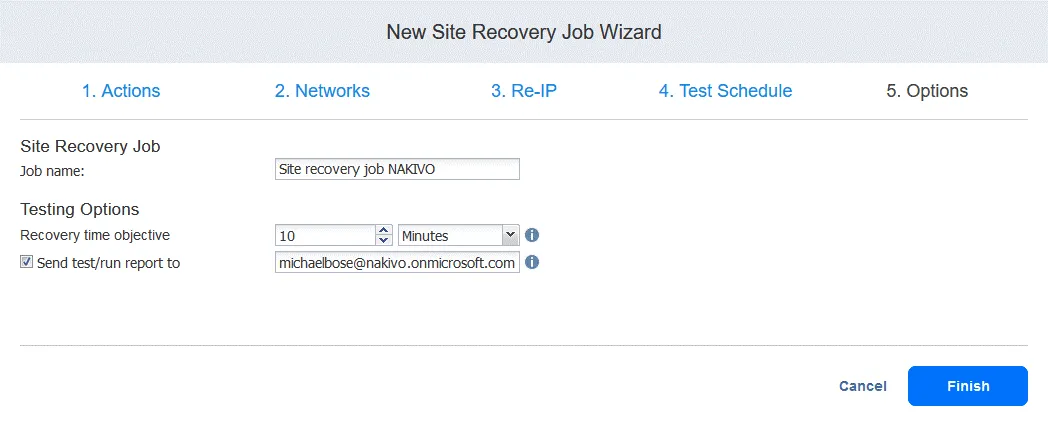
5. Options
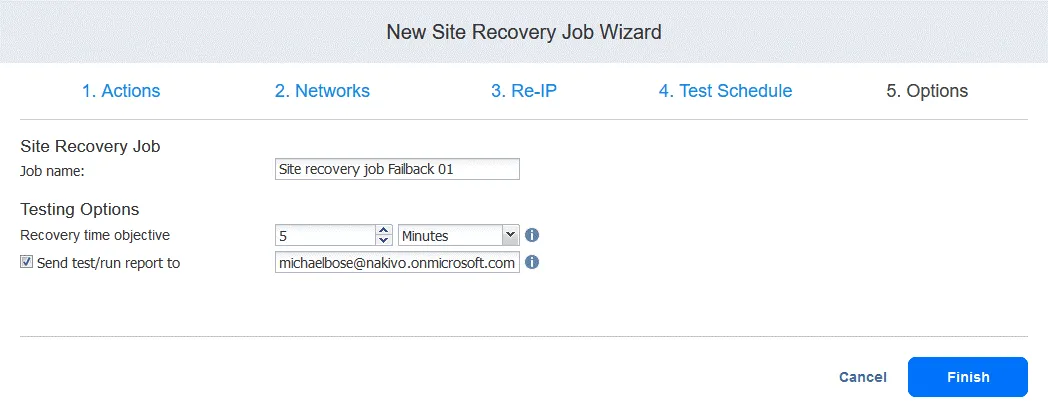
Saisissez le nom de la tâche et les objectifs de temps de récupération. Cliquez sur Terminer une fois la configuration terminée.
Étape 4. Protéger à nouveau l’environnement
Une fois les VMs basculées et les Workloads migrés vers le site de reprise après sinistre, les VMs de production d’origine sont désormais hors ligne et les réplicas du site de reprise après sinistre sont désormais les seules copies fonctionnelles. Si une réplica de VM sous tension tombe en panne, vous ne serez pas en mesure de restaurer rapidement les données et les Workloads.
Afin de protéger les VMs exécutées sur le site de reprise après sinistre, vous devez les répliquer vers un autre emplacement sûr. Ainsi, si la machine virtuelle exécutée sur le site de reprise après sinistre tombe en panne, vous pouvez rapidement basculer vers la nouvelle réplique de machine virtuelle.
La fonctionnalité Reprise après sinistre vous permet de configurer la réplication automatisée dès que le basculement de la machine virtuelle est terminé. Voici un exemple détaillé de la manière de protéger à nouveau les VMs à l’aide d’une tâche Reprise après sinistre après un basculement.
- Dans la page Jobs , cliquez avec le bouton droit sur le nom de la tâche de Reprise après sinistre que vous venez de créer. Cliquez sur Modifier dans le menu contextuel.
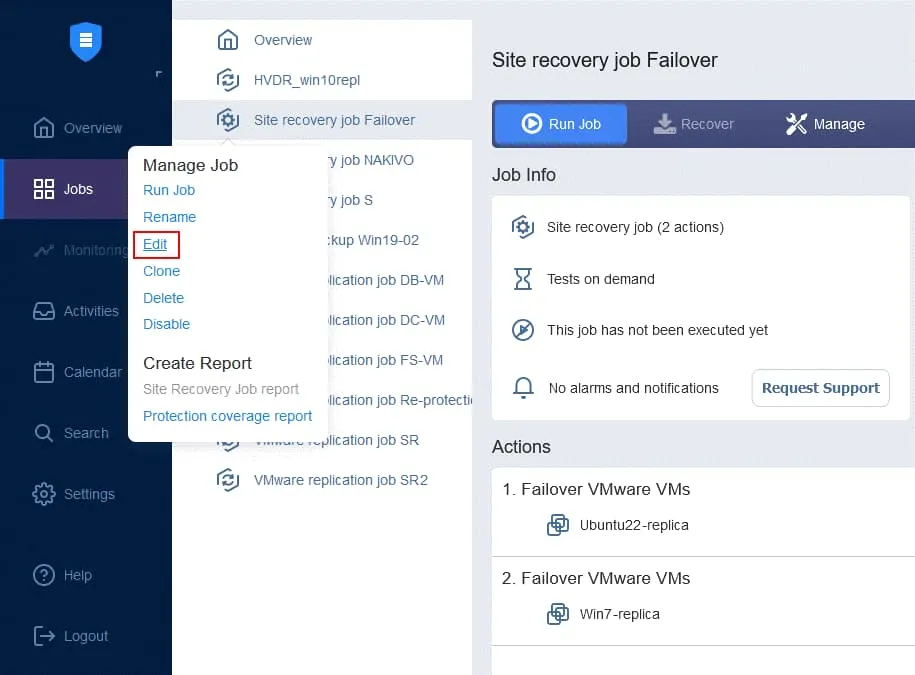
- Vous pouvez voir vos actions de basculement ajoutées à la tâche de Reprise après sinistre précédemment. Recherchez et cliquez sur Exécuter des tâches dans la liste des actions située dans le panneau gauche de l’écran de Reprise après sinistre Actions .
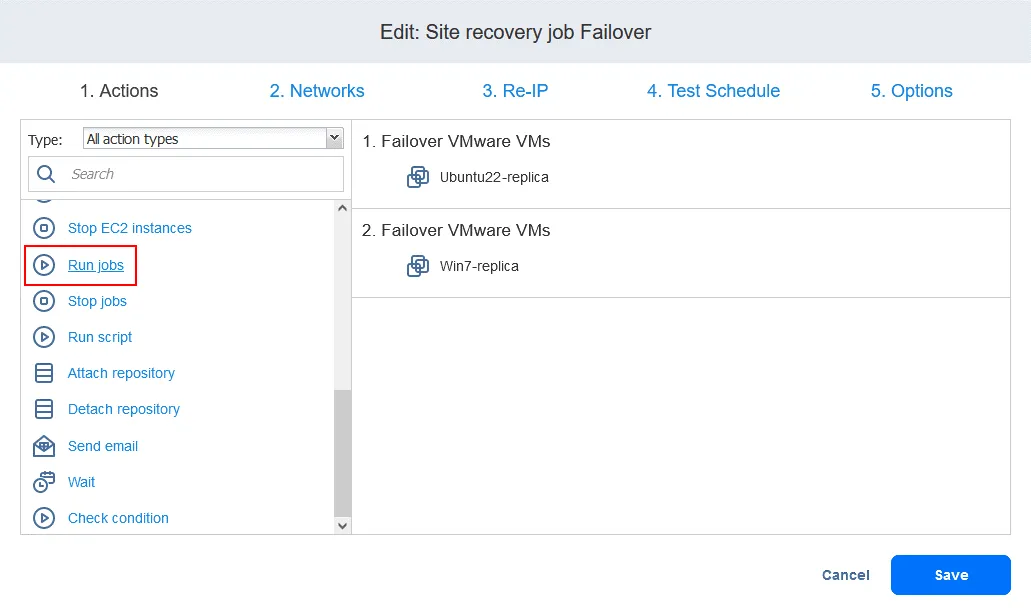
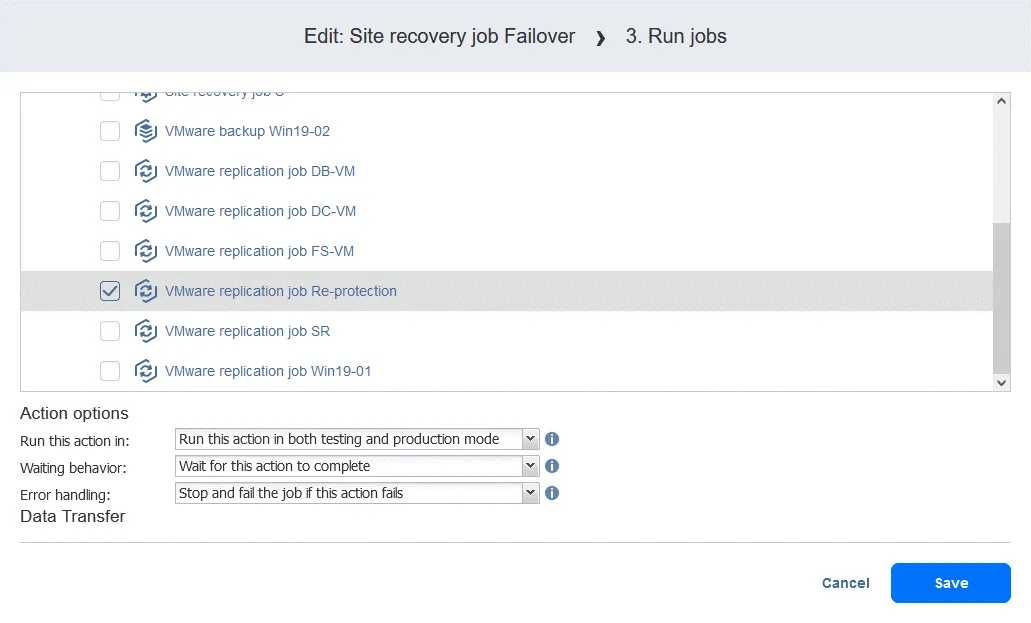
- Sélectionnez la tâche de réplication dans la liste des tâches. Sélectionnez les options d’action comme d’habitude et cliquez sur Enregistrer .
- Ajoutez une action Warten entre l’action de basculement et la tâche de réplication. Cela donne à la réplique de la machine virtuelle le temps de démarrer et de charger le système d’exploitation (vous ne pouvez pas répliquer une machine virtuelle éteinte). Dans la liste Actions du volet gauche, cliquez sur Warten .
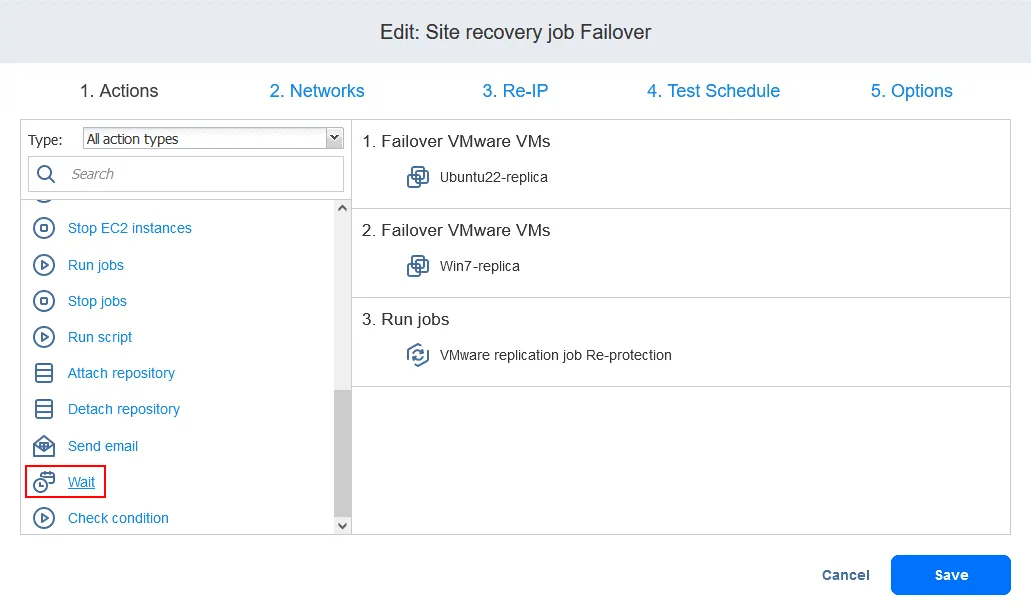
- Sélectionnez un temps d’attente – 5 minutes devraient suffire. Sélectionnez les options d’action et cliquez sur « » (Définir l’action). «Save» (Enregistrer). « » (Définir l’action). «
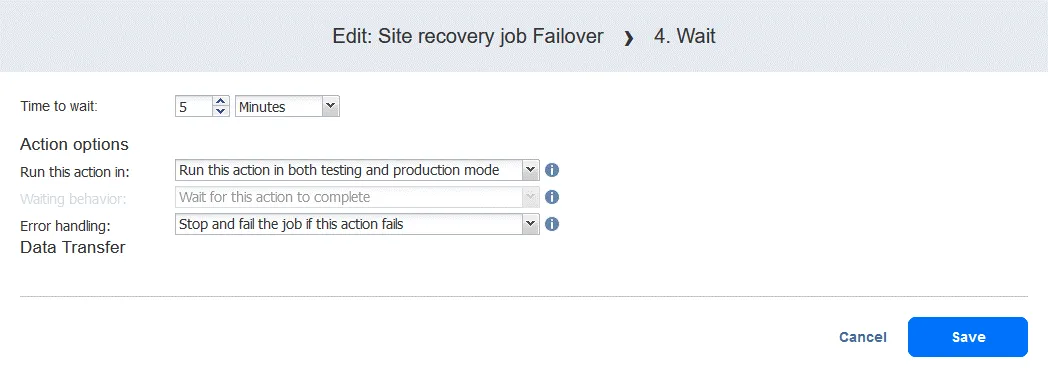
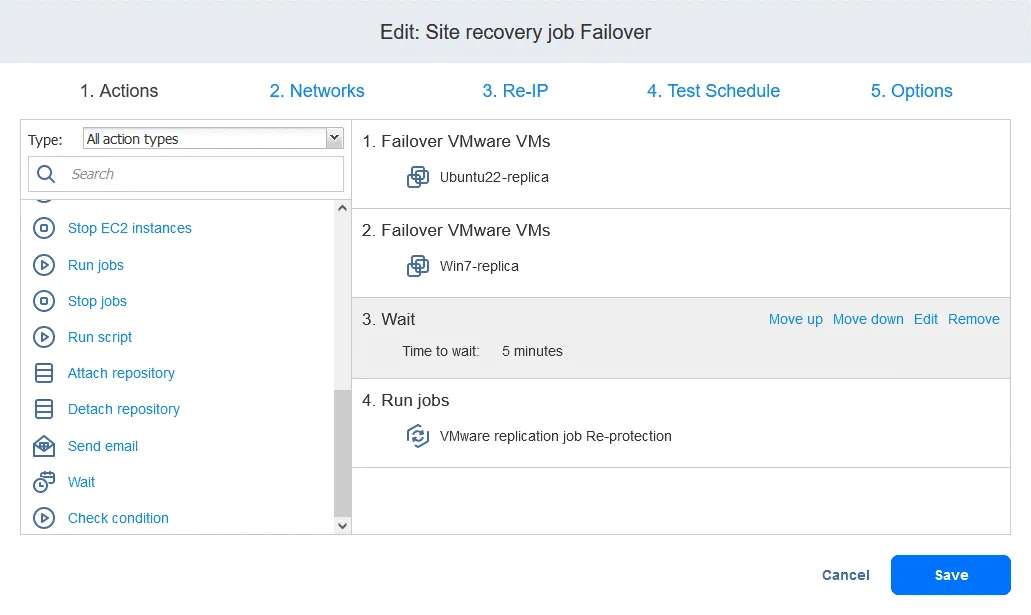
- » (Définir l’action). Lorsque vous ajoutez l’action, elle est ajoutée à la fin de la liste des actions. Cliquez sur « » (Définir l’action). «Move up» (Déplacer vers le haut). « » (Déplacer vers le haut). Déplacez l’action « » (Définir l’action). «Warten» (Attendre). « » (Définir l’action). de la quatrième position à la troisième position. Elle doit avoir lieu avant la réplication. «
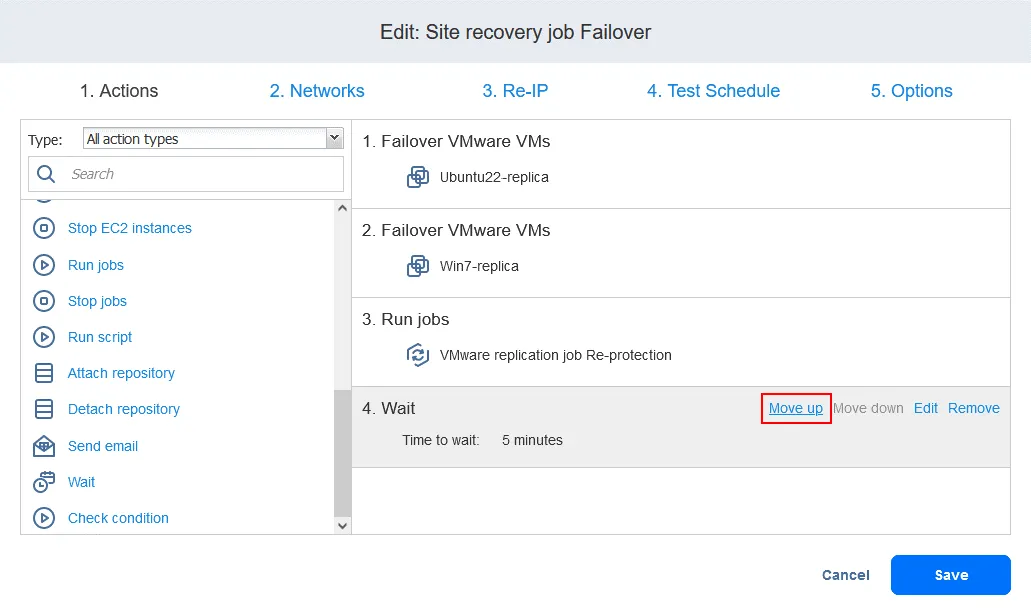
» (Définir l’action). Les actions sont désormais classées dans l’ordre requis. «
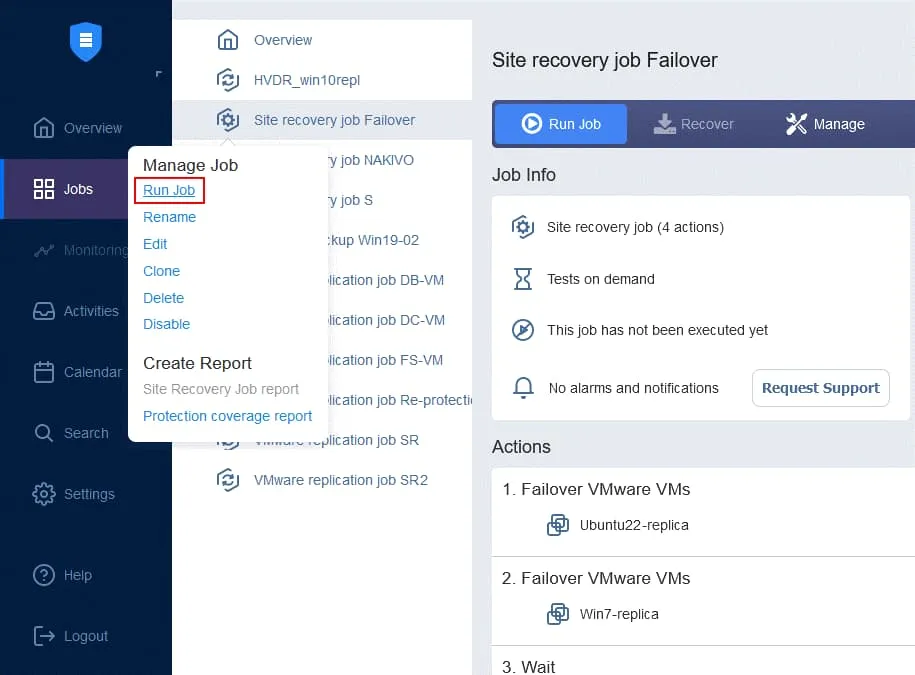
- » (Définir l’action). Enfin, la tâche Reprise après sinistre est prête à être utilisée pour effectuer le basculement de la machine virtuelle et la reprotection automatique des réplicas de machines virtuelles utilisés pour le basculement. Cliquez avec le bouton droit sur le nom de votre tâche de reprise après sinistre sur la page d’accueil, puis cliquez sur Exécuter la tâche dans le menu contextuel.
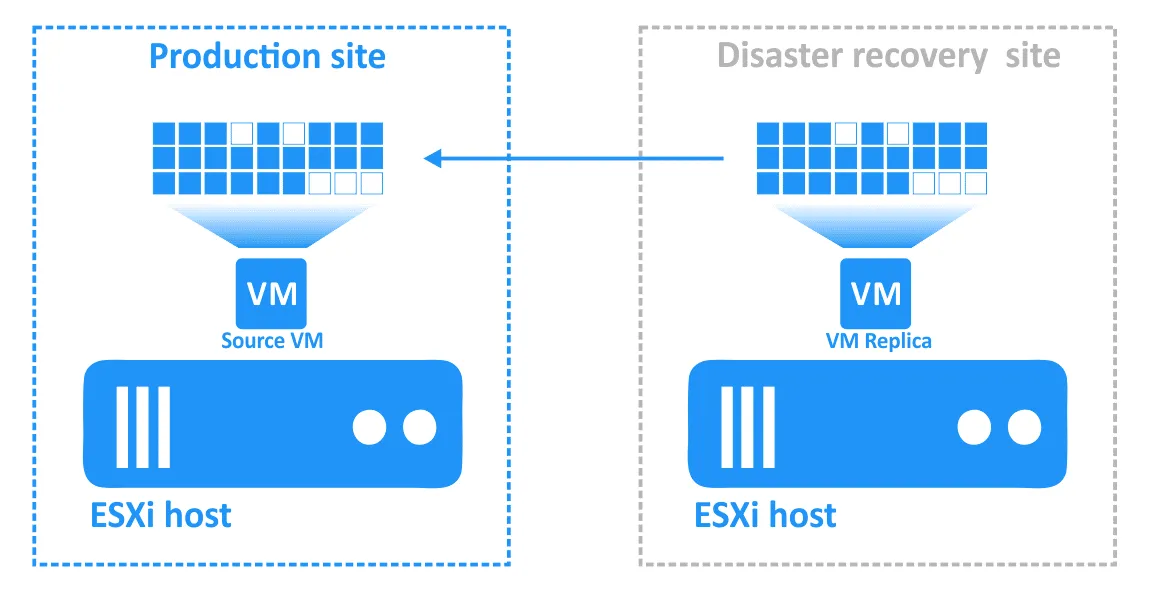
Étape 5. Restauration automatique
La restauration automatique est le processus qui consiste à restaurer les machines virtuelles dans leur état le plus récent depuis le site de reprise après sinistre vers le site de production d’origine ou un nouveau site de production. Pour comprendre pourquoi vous avez besoin de la restauration automatique, récapitulons le fonctionnement du basculement :
- Lorsqu’une catastrophe survient (ou est prévue), le basculement vers une réplique de VM est effectué.
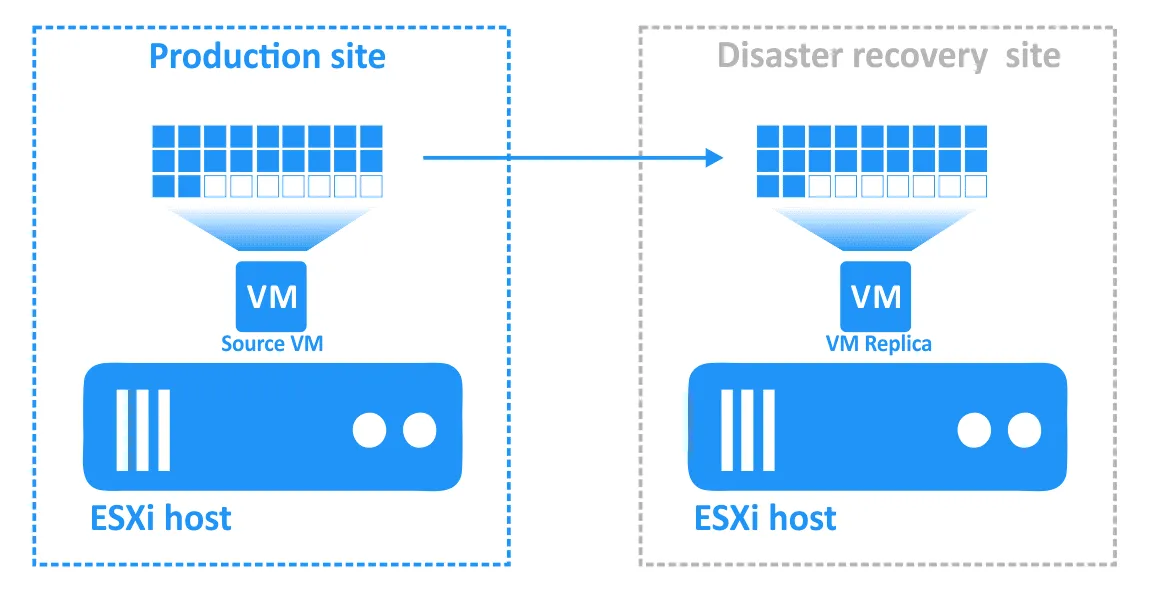
- Toutes les modifications apportées à la VM (par exemple, les transactions ajoutées à une base de données lorsque les clients effectuent des achats en ligne) sont écrites sur un disque virtuel de la réplique de VM. Certains blocs sont écrits, d’autres sont effacés. Le disque virtuel de la VM source ne contient pas ces transactions.
- Une fois l’incident résolu et le site de production à nouveau opérationnel, les Workloads doivent être transférés vers le site de production. Les données mises à jour de la réplique de la VM doivent être transférées vers la VM source. Les VMs doivent être resynchronisées avec une réplication inverse à l’aide d’une restauration automatique.
Configuration de la restauration automatique dans NAKIVO Backup & Replication
La restauration automatique peut être effectuée soit en mode production, soit en mode test (lorsque toutes les modifications apportées à votre environnement virtuel par l’action de restauration automatique sont rétablies à leur état antérieur à la restauration automatique après le test).
Examinons en détail le fonctionnement de chaque cas.
| Restauration automatique après défaillance de production | Test de restauration automatique après défaillance | |
| 1 | Mise hors tension de la machine virtuelle source d’origine (si elle existe et est sous tension). | |
| 2 |
Création d’un instantané de protection de la machine virtuelle source (si celle-ci est fonctionnelle). La création de cet instantané vous permet de restaurer l’état de la machine virtuelle source avant le basculement en cas d’échec de la restauration automatique après défaillance. |
|
| 3 | Exécution de réplication incrémentielle (si la VM source d’origine est en ligne sur le site de production) ou réplication complète (si la VM est en cours de procédure de récupération vers un nouveau site de production). | |
| 4 | Mise hors tension de la réplique de la VM (facultatif). | La réplique de la VM est utilisée pour héberger les Workloads et n’est pas mise hors tension. |
| 5 | La réplication incrémentielle est exécutée une fois de plus à partir de la réplique de la VM vers la VM source. Le delta (les données qui ont changé depuis la première exécution de la réplication) devrait être beaucoup plus petit cette fois-ci. | La réplication depuis une réplique de VM vers la VM source d’origine (ou une nouvelle VM de production) n’est effectuée qu’une seule fois, car cela suffit à des fins de test. |
| 6 | Connexion de la VM source d’origine à son nouveau réseau à l’aide du mappage réseau (facultatif). | Connexion de la VM source à un réseau isolé afin qu’il n’y ait aucune perturbation de l’environnement de production (facultatif). |
| 7 | Modification de l’adresse IP statique de la VM source d’origine avec la réassignation d’adresses IP (facultatif). | |
| 8 | Mise sous tension de la VM source d’origine. | |
| 9 | Nettoyage après une restauration automatique réussie . Après une opération de restauration automatique réussie, la VM source et la réplique de VM existent toutes deux dans leur état normal.
Nettoyage après une restauration automatique échouée :
|
|
- >
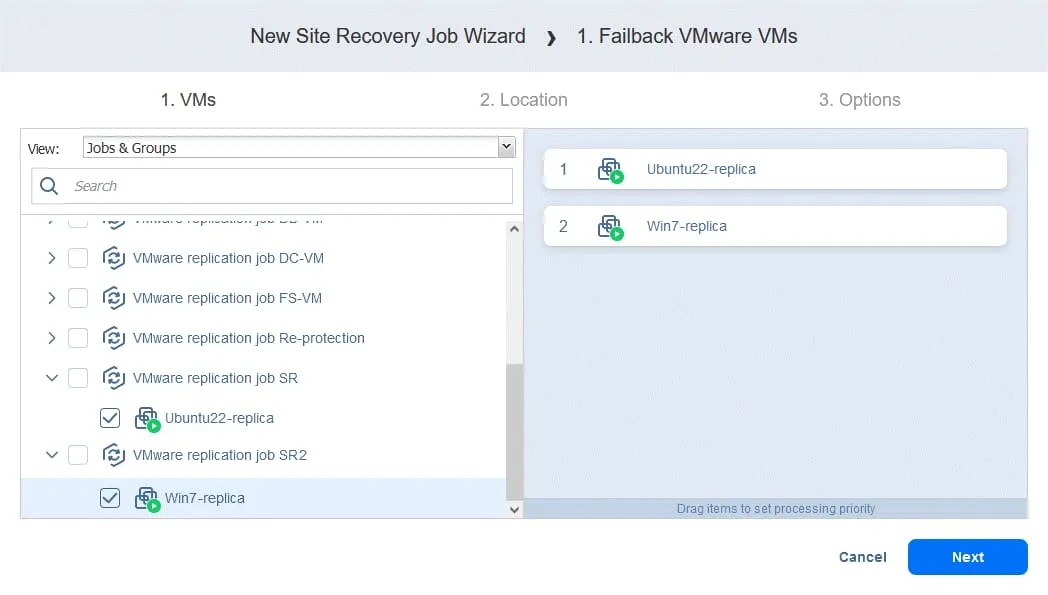
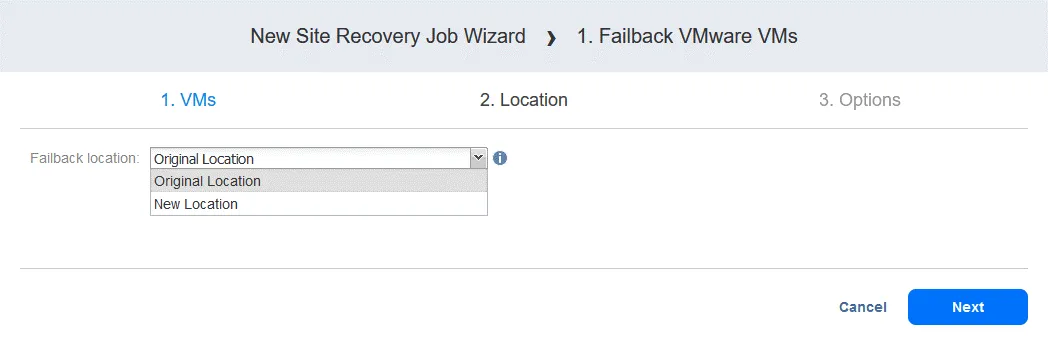
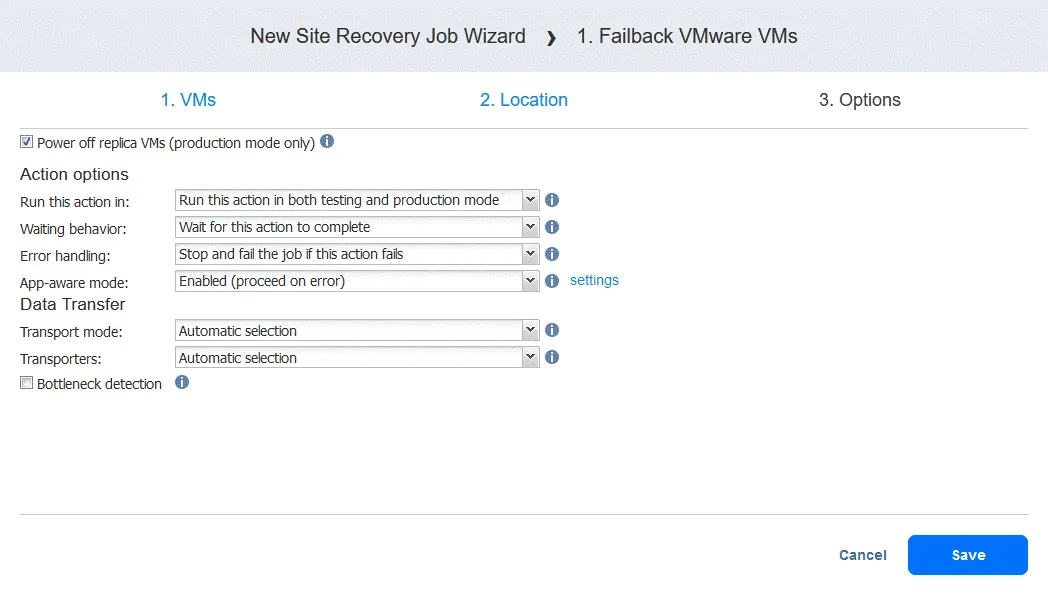
- Cliquez sur Suivant .
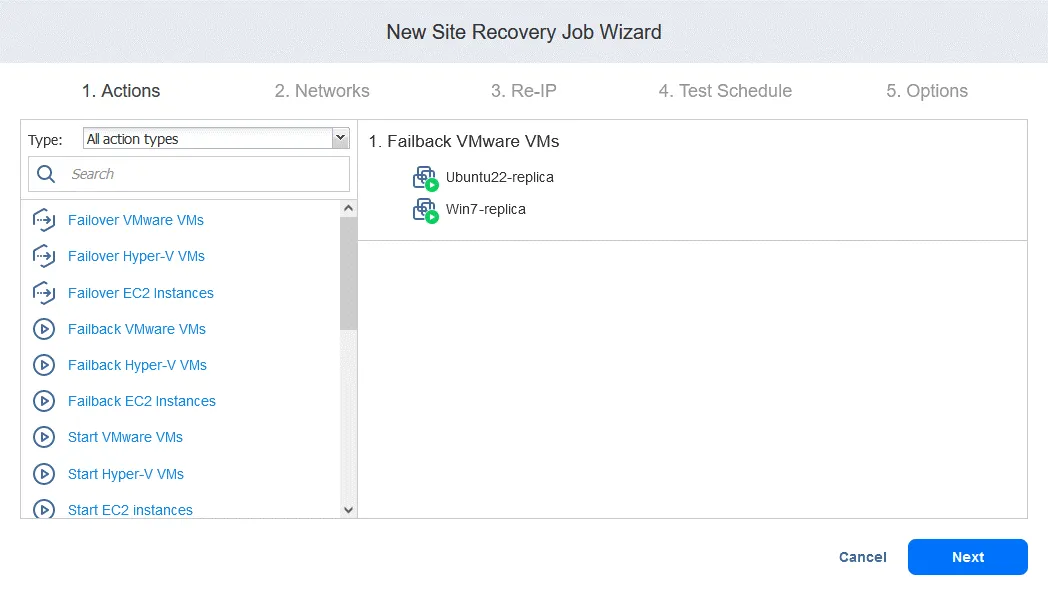
2. Réseaux . Sélectionnez cette option si vous devez activer le mappage réseau pour cette tâche. Cliquez sur Suivant .
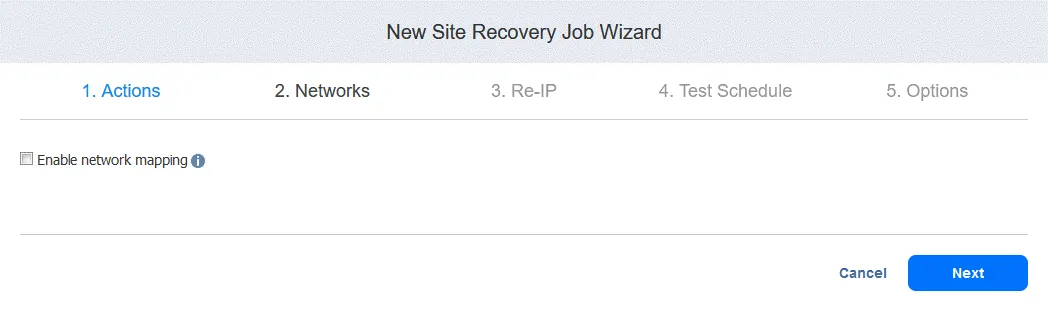
3. Réassignation d’adresses IP . Sélectionnez cette option si vous devez activer la Réassignation d’adresses IP pour cette tâche. Cliquez sur Suivant .
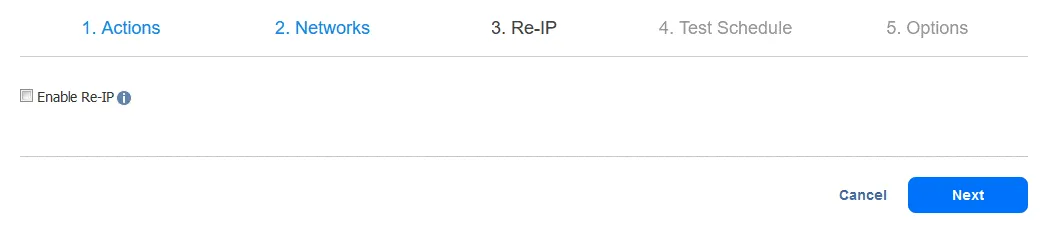
4. Calendrier des tests . Configurez vos options de planification, puis cliquez sur Suivant .
5. Options . Définissez les options de la tâche de Reprise après sinistre et entrez le nom de la tâche. Vous pouvez définir le RTO requis pour la machine virtuelle et spécifier l’adresse e-mail pour le rapport de restauration automatique. Cliquez sur Finish pour finaliser la création de cette nouvelle tâche de Reprise après sinistre avec restauration automatique.
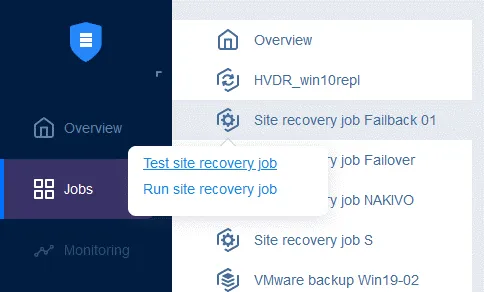
Vous pouvez désormais exécuter cette tâche de Reprise après sinistre pour effectuer la restauration automatique de la machine virtuelle : il suffit de cliquer avec le bouton droit sur le nom de la tâche de Reprise après sinistre, de sélectionner Run job , puis de sélectionner Test site recovery job ou Run site recovery job .
Étape 6. Exécution d’un test de reprise après sinistre
Les tests de reprise après sinistre vous aident à vous assurer que vous êtes prêt à effectuer une reprise en cas de sinistre et que tous les composants sélectionnés peuvent être récupérés avec succès dans les délais impartis.
Il existe deux raisons principales Pourquoi vous avez besoin de tests de reprise après sinistre:
- Pour vous assurer que tout peut être récupéré avec succès . Lorsque vous testez votre plan de reprise après sinistre et que vous découvrez des problèmes, vous pouvez corriger les problèmes avant qu’ils ne causent de graves difficultés dans un scénario de crise réel.
- Pour vous assurer que les valeurs RTO peuvent être respectées . Les tests de reprise après sinistre vous permettent de vérifier si vos charges de travail peuvent être récupérées dans les délais RTO pertinents. Un test de reprise de site peut être exécuté manuellement à la demande ou automatiquement selon un calendrier planifié, ce qui facilite le processus et vous fait gagner du temps.
Différences entre le basculement en mode test et en mode production
Le mécanisme d’exécution d’un basculement diffère selon que la tâche de reprise de site est exécutée en mode test ou en mode production. Le tableau ci-dessous présente les différentes étapes pour chaque mode.
| Basculement de production (urgence) | Tester le basculement | |
| 1 | Désactiver la réplication depuis la machine virtuelle source vers la réplique | |
| 2 | Restaurer la réplique de la machine virtuelle à un certain point de récupération (RP) (facultatif, le dernier RP est utilisé par défaut) | Exécuter une réplication incrémentielle depuis la machine virtuelle source vers la réplique une fois |
| 3 | Connecter la réplique de la machine virtuelle à un nouveau réseau avec le mappage réseau (facultatif) | Connectez la réplique de la VM à un réseau isolé à l’aide du mappage réseau (facultatif) |
| 4 | Modifiez l’adresse IP statique de la réplique à l’aide de la Réassignation d’adresses IP (facultatif) | |
| 4A | Éteignez la VM source (facultatif) | — |
| 5 | Allumez la réplique | |
| 6 | Passez la réplique à l’état de basculement (Failover) | |
Comme vous pouvez le constater, les deuxième et troisième points diffèrent entre les workflows de production et de test. Vous pouvez exécuter la réplication à partir d’une machine virtuelle source en mode test pendant que la machine virtuelle source est en cours d’exécution. Dans la plupart des cas, lorsqu’une catastrophe survient, la machine virtuelle source ne fonctionne plus et la réplication ne peut donc pas être effectuée. Les réseaux pour la connexion des machines virtuelles peuvent être définis séparément dans les options de mappage réseau pour le mode production et le mode test lors de la configuration d’une tâche de reprise après sinistre.
Le nettoyage du test de basculement est effectué après l’exécution d’une tâche de reprise après sinistre en mode test. La réplique de la machine virtuelle est mise hors tension et rétablit son état antérieur au basculement via un instantané (un instantané de la réplique de la machine virtuelle est pris avant d’effectuer une action de basculement). La réplique passe alors de l’état de basculement à son état normal, et la réplication de l’objet source vers la réplique est activée.
Fonctionnalités de test de reprise après sinistre dans Site Recovery de NAKIVO
Passons rapidement en revue les principaux points des fonctionnalités de test dans Site Recovery de NAKIVO.
1. Vérification des actions incluses dans le test
Vérifiez la logique des actions dans la tâche de reprise après sinistre. Vérifiez si les actions sont classées dans l’ordre approprié et assurez-vous qu’elles ne forment pas une boucle infinie. Vous pouvez modifier les options de la tâche de reprise après sinistre lorsque celle-ci n’est pas en cours d’exécution : modifiez l’ordre des actions, ajoutez des actions, enlevez des actions ou modifiez les options d’action si nécessaire.
2. Vérification de la mise en réseau
Vérifiez que votre réseau fonctionne correctement. Une connexion VPN peut être utilisée entre un site de production et un site de reprise après sinistre (DR), mais cette connexion ne peut pas être déconnectée périodiquement en état normal. Le réseau du site DR doit également fonctionner sans interruption. Vérifiez les paramètres de mappage réseau et de réassignation d’adresses IP que vous avez utilisés pour configurer le basculement et la restauration automatique. Si une machine virtuelle est configurée pour un réseau incorrect, la connexion réseau peut ne pas être établie. Il en va de même pour les paramètres IP.
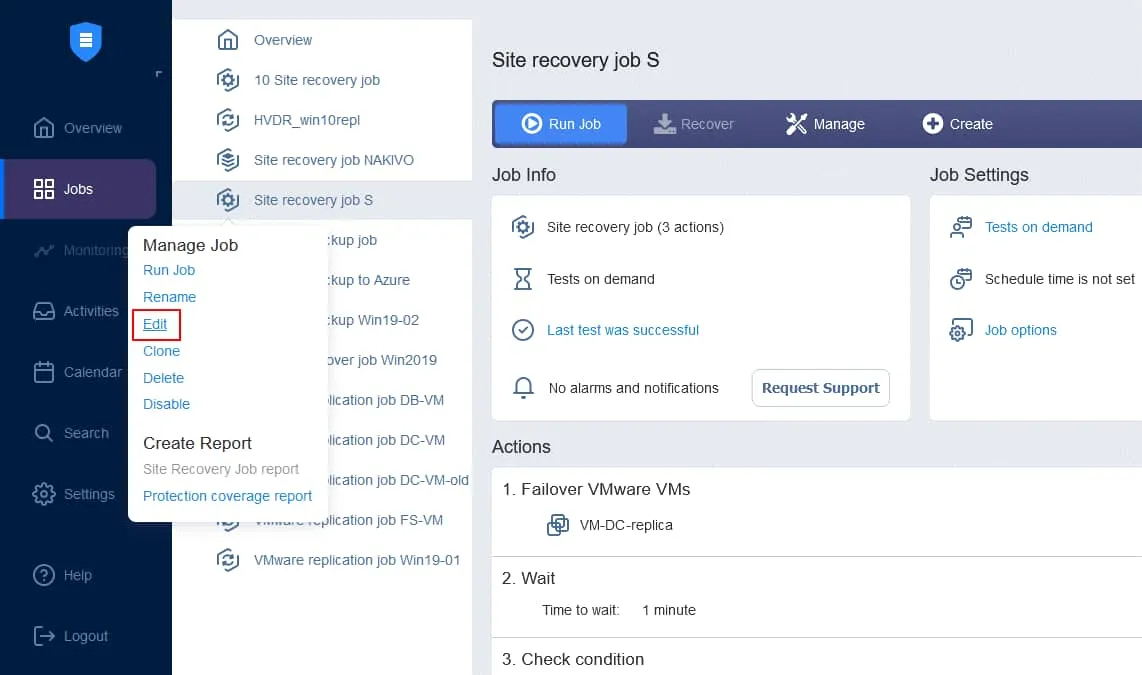
3. Définition du calendrier des tests
Les tests des tâches de Reprise après sinistre peuvent être planifiés dans les options de planification des tâches de Reprise après sinistre. Ouvrez l’interface Web de votre instance de NAKIVO Backup & Replication. Dans le volet gauche, cliquez avec le bouton droit sur le nom de votre tâche et cliquez sur Modifier dans le menu contextuel.
Les avantages de Site Recovery de NAKIVO
- Orchestration et automatisation complètes de la reprise après sinistre . Site Recovery vous permet de mettre en œuvre des plans de reprise après sinistre avec un haut niveau d’automatisation. Vous pouvez définir l’ordre de récupération des machines virtuelles en tenant compte de leurs dépendances afin que, en cas de sinistre, la récupération soit aussi efficace que possible.
- Flexibilité pour répondre aux besoins de diverses entreprises . Vous pouvez créer plusieurs tâches de reprise après sinistre en fonction de vos besoins. L’ensemble des actions disponibles pour être intégrées dans les tâches de reprise après sinistre permet de créer différents workflows de reprise sur mesure pour différentes situations.
- Intégré à la solution de protection des données . Site Recovery est une fonctionnalité incluse dans NAKIVO Backup & Replication et disponible avec le reste de l’ensemble complet de fonctionnalités du produit ; vous n’avez pas besoin d’acheter une licence distincte pour Site Recovery. Avec cette solution, toutes les activités de protection des données et de reprise après sinistre sont gérées à partir d’un seul et même écran.
- Économies significatives par rapport aux autres solutions de reprise après sinistre . NAKIVO Backup & Replication, avec l’outil Reprise après sinistre intégré, est une solution rentable. Le produit continue de satisfaire les utilisateurs avec de nouvelles fonctionnalités utiles tout en conservant les mêmes prix abordables, en particulier par rapport à ses concurrents sur le marché de la reprise après sinistre.



