Was ist Deduplizierung im Speicher für Backups?
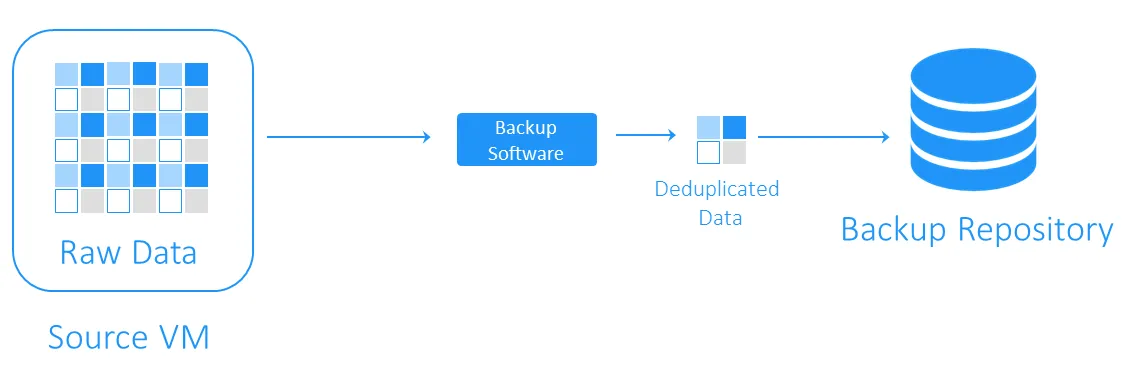
Datendeduplizierung ist eine Technologie zur Optimierung der Speicherkapazität. Bei der Datendeduplizierung werden die Daten aus der Quelle und die bereits gespeicherten Daten gelesen, um nur eindeutige Datenblöcke zu übertragen oder zu speichern. Verweise auf die doppelten Daten bleiben erhalten. Durch den Einsatz dieser Technologie zur Vermeidung von Duplikaten auf einer Festplatte können Sie Speicher sparen und den Speicheraufwand reduzieren. Die Vorläufer der Datendeduplizierung sind die 1977 bzw. 1978 eingeführten Komprimierungsalgorithmen LZ77 und LZ78. Dabei werden wiederholte Datensequenzen durch Verweise auf die ursprünglichen Daten ersetzt. Dieses Konzept beeinflusste andere beliebte Komprimierungsmethoden. Die bekannteste davon ist DEFLATE, die in PNG-Bild- und ZIP-Dateiformaten verwendet wird. Sehen wir uns nun an, wie Deduplizierung bei VM-Backups funktioniert und wie genau sie dazu beiträgt, Speicherplatz und Kosten für die Infrastruktur zu sparen. Bei einem Backup überprüft die Datendeduplizierung, ob identische Datenblöcke zwischen dem Quellspeicher und dem Ziel-Backup-Repository vorhanden sind. Duplikate werden nicht kopiert, sondern es wird ein Verweis oder Zeiger auf die vorhandenen Datenblöcke im Zielspeicher für das Backup erstellt. Um zu verstehen, wie viel Speicherplatz durch Deduplizierung gewonnen werden kann, betrachten wir ein Beispiel. Die Mindestsystemanforderungen für die Installation von Windows Server 2016 betragen mindestens 32 GB freier Festplattenspeicher. Wenn Sie zehn VMs mit diesem Betriebssystem haben, belaufen sich die Backups auf insgesamt mindestens 320 GB, und das ist nur ein sauberes Betriebssystem ohne Anwendungen oder Datenbanken. Wenn Sie mehr als eine Virtuelle Maschine (VM) mit demselben System bereitstellen müssen, werden Sie wahrscheinlich eine Vorlage verwenden, was bedeutet, dass Sie zunächst zehn identische Maschinen haben. Das bedeutet auch, dass Sie 10 Sätze doppelter Datenblöcke erhalten. In diesem Beispiel haben Sie eine Platzersparnis von 10:1. Im Allgemeinen gelten Einsparungen im Bereich von 5:1 bis 10:1 als gut. Die Daten-Deduplizierungsrate ist eine Kennzahl, mit der die ursprüngliche Größe der Daten im Vergleich zur Größe der Daten nach Entfernung redundanter Teile gemessen wird. Anhand dieser Kennzahl können Sie die Effektivität des Daten-Deduplizierungsprozesses bewerten. Um den Wert zu berechnen, müssen Sie die Datenmenge vor der Deduplizierung durch den Speicherplatz dividieren, den diese Daten nach der Deduplizierung belegen. Ein Deduplizierungsverhältnis von 5:1 bedeutet beispielsweise, dass Sie fünfmal mehr gesicherte Daten in Ihrem Backup-Speicher ablegen können, als ohne Deduplizierung erforderlich wäre. Sie sollten das Deduplizierungsverhältnis und die Speicherplatzreduzierungbestimmen. Diese beiden Parameter werden manchmal verwechselt. Deduplizierungsverhältnisse ändern sich nicht proportional zu den Vorteilen der Datenreduzierung, da ab einem bestimmten Punkt das Gesetz des abnehmenden Ertrags zum Tragen kommt. Siehe die folgende Grafik. Das bedeutet, dass niedrigere Verhältnisse zu größeren Einsparungen führen können als höhere. Beispielsweise ist ein Deduplizierungsverhältnis von 50:1 nicht fünfmal besser als ein Verhältnis von 10:1. Das Verhältnis von 10:1 sorgt für eine Reduzierung des belegten Speichers um 90 %, während das Verhältnis von 50:1 diesen Wert auf 98 % erhöht, da der größte Teil der Redundanz bereits beseitigt wurde. Weitere Informationen zur Berechnung dieser Prozentsätze finden Sie unter Dokument der Storage Networking Industry Association (SNIA) zur Datendeduplizierung. Aufgrund verschiedener Faktoren ist es schwierig, die Effizienz der Datenreduzierung vorherzusagen, bevor die Daten tatsächlich dedupliziert wurden. Im Folgenden sind einige der Faktoren aufgeführt, die sich bei der Verwendung der Deduplizierung auf die Datenreduktion auswirken: Hinweis: Die lokale Deduplizierung funktioniert auf einem einzelnen Knoten/Festplattengerät. Die globale Deduplizierung analysiert den gesamten Datensatz auf allen Knoten/Festplattengeräten, um Datenduplikate zu eliminieren. Wenn Sie mehrere Knoten haben, auf denen jeweils die lokale Deduplizierung aktiviert ist, ist die Deduplizierung nicht so effizient wie bei einer globalen Deduplizierung. Die Techniken zum Backup und zur Deduplizierung lassen sich anhand der folgenden Kriterien kategorisieren: Die Backup-Deduplizierung kann auf der Quelle oder auf der Zielseite erfolgen, wobei diese Techniken als quellenseitige Deduplizierung bzw. zielseitige Deduplizierung bezeichnet werden. Die quellseitige Deduplizierung verringert die Netzwerkbelastung, da während des Backups weniger Daten übertragen werden. Allerdings muss dafür auf jeder VM oder jedem Host ein Deduplizierungsagent installiert werden. Ein weiterer Nachteil ist, dass die Quellseite die Deduplizierung durchführt und dies die VMs verlangsamen kann , da für die Identifizierung doppelter Datenblöcke Berechnungen erforderlich sind. > Bei der zielseitigen Deduplizierung werden die Daten zunächst in das Backup-Repository übertragen und anschließend dedupliziert. Die rechenintensiven Aufgaben werden von der für die Deduplizierung zuständigen Software ausgeführt. Die Backup-Deduplizierung kann inline oder nachträglich erfolgen. Die gängigsten Methoden zur Identifizierung von Duplikaten sind die hashbasierte und die modifizierte hashbasierte Methode. Die Backup-Deduplizierung ist einer der beliebtesten Verwendungsfälle für Deduplizierung. Dennoch benötigen Sie die geeignete Softwarelösung und Hardware für den Speicher, um diese Datenreduktionstechnologie zu implementieren. NAKIVO Backup & Replication ist eine Backup-Lösung, die die Verwendung der globalen Ziel-Nachbearbeitungs-Deduplizierung mit modifizierter Hash-basierter Duplikaterkennung unterstützt. Sie können auch die Vorteile der quellseitigen Deduplizierung nutzen, indem Sie ein Deduplizierungs-Gerät wie EMC Daten-Domäne mit DD Boost, NEC HYDRAstor und HP StoreOnce mit Catalyst-Support in die NAKIVO-Lösung integrieren.
Was ist Deduplizierung?
Ursprünge der Datendeduplizierung
Was ist Deduplizierung bei Backups?

Wie viel Speicherplatz können Sie durch Datendeduplizierung einsparen?
Daten-Deduplizierungsrate

Faktoren, die die Effizienz der Datendeduplizierung beeinflussen
Techniken zur Backup-Deduplizierung
Wo die Datendeduplizierung erfolgt
Quellseitige Deduplizierung

Zielseitige Deduplizierung
Wenn die Datendeduplizierung abgeschlossen ist
Wie die Datendeduplizierung durchgeführt wird
Auswahl einer Software zur Backup-Deduplizierung



