Replica dei dati in tempo reale: tutto quello che c’è da sapere
Proteggere i servizi più critici in un data center richiede molto più di semplici backup regolari: è necessaria la replica per garantire una perdita di dati e tempi di inattività minimi in caso di guasto. Le VM offrono un vantaggio significativo rispetto ai server fisici semplificando questo processo. In questo post del blog esploreremo i vantaggi della replica in tempo reale per le VM, illustrandone i principi, i casi d’uso principali e come configurarla in modo efficace, con particolare attenzione a VMware vSphere.

Che cos’è la replica in tempo reale?
La replica dei dati in tempo reale è il processo di duplicazione e sincronizzazione dei dati in tempo reale su più sistemi (VM, database, ecc.) ai fini dell’alta disponibilità e del ripristino di emergenza. Il ritardo o la latenza dei dati tra le modifiche ai dati originali e la replica dei dati può essere misurato in secondi o meno, a seconda delle impostazioni e della topologia utilizzate nell’infrastruttura.
La replica in tempo reale viene solitamente utilizzata per proteggere i dati critici. Nel caso delle VM, la replica in tempo reale viene utilizzata per proteggere le VM più critiche che richiedono obiettivi rigorosi di punto di ripristino (RPO) e obiettivi di tempo di ripristino (RTO) ( RPO e RTO ). Se il backup e la replica tradizionali non sono in grado di soddisfare i requisiti RPO e RTO, è consigliabile configurare la replica in tempo reale.
Vantaggi principali della replica dei dati in tempo reale
La replica in tempo reale offre i seguenti vantaggi:
- Riduzione al minimo dei tempi di inattività . Poiché le modifiche ai dati vengono replicate dal sistema di origine al sistema di destinazione in tempo reale, è possibile eseguire rapidamente un failover della VM sulla replica della VM, che contiene le modifiche più recenti. Ciò consente alle organizzazioni di ripristinare rapidamente il funzionamento della VM e i servizi, riducendo i tempi di inattività e migliorando la continuità operativa .
- Continuità operativa . Una replica della VM che contiene l’ultimo set di dati può essere utilizzata per ripristinare rapidamente una VM e riprendere le operazioni aziendali.
- Coerenza dei dati . Una replica della VM creata con la replica in tempo reale contiene lo stesso set di dati della VM originale. Dopo aver eseguito un failover e ripristinato i carichi di lavoro con una replica VM, non è necessario identificare quali dati devono essere ricreati dopo l’ultimo processo di replica, come invece avviene con la replica VM tradizionale.
- Scalabilità e prestazioni . Le repliche VM aggiornate in tempo reale possono essere utilizzate per rendere le risorse accessibili in modo continuo e coerente per più uffici/data center/siti in diverse ubicazioni geografiche.
Come funziona la replica dei dati in tempo reale
La replica in tempo reale è una funzione disponibile quando si utilizzano sistemi di storage di fascia alta e il principio di funzionamento può variare a seconda dell’implementazione. I seguenti componenti sono generalmente utilizzati per eseguire la replica dei dati in tempo reale per le VM:
- VM primaria: La VM attiva che elabora i carichi di lavoro.
- VM replica: una copia continuamente aggiornata della VM primaria, che in genere risiede su un host o un data center diverso.
- Gestore della replica: uno strumento o un servizio nella soluzione di protezione dei dati che coordina il processo di replica.
- Tracciamento delle modifiche: traccia e registra le modifiche nella VM primaria, assicurando che vengano replicati solo i dati modificati.
Replica sincrona vs asincrona: differenze chiave
Esistono due tipi di replica dei dati in base al loro principio di funzionamento: sincrona e asincrona. Ciascun tipo di replica dei dati ha caratteristiche, vantaggi e casi d’uso propri e può essere scelto a seconda dello scenario.
Replica sincrona comporta la copia dei dati dalla VM di origine alla replica della VM mentre vengono scritti. È il tipo di replica più efficace per i carichi di lavoro critici. I dati vengono replicati dalla VM primaria alla VM secondaria istantaneamente o quasi istantaneamente e, di conseguenza, entrambe le copie sono sempre coerenti. Questo tipo di replica dei dati consente di ottenere un RPO pari a zero.
- Quando si verifica un’operazione di scrittura sulla VM primaria, la modifica viene inviata alla replica.
- La VM primaria attende un riconoscimento dalla replica prima di completare l’operazione di scrittura.
I requisiti per configurare la replica sincrona sono elevati: sono necessarie connessioni di rete ad alta velocità e bassa latenza per evitare ritardi.
Svantaggi:
- Le prestazioni della VM primaria potrebbero risentirne, poiché la replica impiega tempo per confermare le modifiche.
- A causa dei requisiti di latenza, la replica sincrona è solitamente limitata a ubicazioni geograficamente vicine.
La replica asincrona (replica point-in-time) copia le modifiche in un secondo momento. Le modifiche ai dati apportate sulla VM di origine vengono inviate alla replica della VM a intervalli regolari configurati nelle regole di pianificazione. Di conseguenza, si verifica un ritardo tra gli aggiornamenti della replica. La replica asincrona può essere quasi in tempo reale con intervalli di uno o più minuti.
- Le operazioni di scrittura sulla VM primaria vengono completate immediatamente senza attendere la conferma dalla replica.
- Gli aggiornamenti della replica vengono eseguiti periodicamente in base alle modifiche in coda o in batch.
I requisiti per configurare la replica asincrona sono accessibili per la maggior parte degli utenti e delle organizzazioni. È necessaria una connessione di rete tra gli host di virtualizzazione e i componenti della soluzione di protezione dei dati.
La replica potrebbe rimanere indietro rispetto alla VM primaria (una replica della VM potrebbe non contenere l’ultimo set di dati), causando una potenziale perdita di dati in caso di guasto e fornendo una coerenza finale. Questo è lo svantaggio della replica asincrona dei dati. Ad esempio, se la replica viene eseguita ogni ora e si verifica un disastro alle 10:30, i dati scritti negli ultimi 30 minuti non saranno presenti nella replica della VM.
|
Aspetto |
Replica sincrona |
Replica asincrona |
|
Coerenza dei dati |
Immediata e coerente |
Eventuale con possibile ritardo |
|
Requisiti di rete |
Elevata larghezza di banda, bassa latenza |
Può funzionare con reti più lente |
|
RPO (perdita di dati) |
Quasi zero |
Variabile, in base all’intervallo di replica |
|
Impatto sulle prestazioni |
Maggiore, a causa del riconoscimento di scrittura |
Minore, poiché le scritture sono indipendenti |
|
Ubicazione geografica |
Brevi distanze |
Adatto per lunghe distanze |
|
Costi per l’hardware |
Elevati |
Da bassi a medi |
|
Esempi di casi d’uso (settori) |
Settore bancario, sanitario |
Ripristino di emergenza, analisi |
Potrebbe non essere necessario utilizzare la replica in tempo reale per tutte le VM, poiché ciò richiederebbe un budget elevato. Non tutti i dati hanno la stessa importanza per un’organizzazione e la replica in tempo reale dovrebbe essere utilizzata per i dati più critici. È possibile scegliere il metodo di replica ottimale per ogni VM in base a fattori e scenari specifici. Quando si seleziona un metodo di replica per proteggere le VM, è necessario definire obiettivi precisi e considerare i seguenti punti:
- Valutazione del rischio . Analizzare le potenziali interruzioni e stimare le conseguenze negative per l’organizzazione in caso di guasto di una VM.
- Criticità dei dati . Crea un elenco di tutti i sistemi in esecuzione sulle VM e valuta l’importanza di ciascuna VM in base alla perdita di dati e alla tolleranza ai tempi di inattività.
- Requisiti di risorse . Calcolare quante risorse consuma una replica in tempo reale per il sistema appropriato.
Scegliere la soluzione giusta per la replica dei dati in tempo reale
È importante scegliere una soluzione di protezione dei dati efficace e affidabile che supporti la replica dei dati in tempo reale per le VM e sia in grado di soddisfare i requisiti.
Funzioni chiave da ricercare in uno strumento di replica dei dati
Si raccomanda che il software di protezione dei dati con strumenti di replica dei dati includa le seguenti funzioni:
- Supporto per più tipi di replica . Prendete in considerazione una soluzione di protezione dei dati che supporti la replica in tempo reale e la replica asincrona delle VM. In questo caso, è possibile utilizzare la replica continua o in tempo reale dei dati che richiede hardware di fascia alta con bassa latenza per le VM critiche. Allo stesso tempo, è possibile risparmiare sui costi e replicare le VM regolari con requisiti RPO inferiori utilizzando la replica asincrona.
- Interfaccia intuitiva . Una soluzione intuitiva è più comoda da configurare e può richiedere meno tempo. La configurazione flessibile offre maggiori vantaggi agli amministratori per diversi casi d’uso.
- Ubicazioni di replica multiple . Si consiglia che la soluzione di protezione dei dati supporti la replica nello stesso sito e in un altro sito. In caso di replica di VM VMware, è preferibile che sia supportata la replica nello stesso vCenter e in un altro vCenter. Verificare le opzioni di failover e failback delle VM.
- Coerenza con le applicazioni . Verificare se la soluzione preferita supporta la coerenza con le applicazioni per garantire che i dati scritti dalle applicazioni siano coerenti nelle repliche delle VM.
- Requisiti . Una soluzione con requisiti di facile utilizzo può ridurre il tempo necessario per la configurazione.
- Costi . Controllare i prezzi e le licenze. Scegli la soluzione più adatta al tuo budget.
Replica affidabile dei dati in tempo reale con NAKIVO
NAKIVO Backup & Replication & Replication è una soluzione universale per la protezione dei dati che supporta la replica per le VM VMware, compresa la replica tradizionale e la replica in tempo reale. La soluzione offre i seguenti vantaggi di replica delle VM in tempo reale:
- RPO e RTO . È possibile configurare un RPO di appena 1 secondo per garantire che le ultime modifiche siano sincronizzate con la replica della VM e non si perdano dati in caso di guasto della VM. Il ripristino della VM (failover) può essere eseguito in pochi secondi o minuti. È possibile ottenere tempi di inattività e perdite di dati prossimi allo zero.
- Failover alla replica . I tempi di inattività sono prossimi allo zero grazie al rapido failover della VM alla replica per riprendere i carichi di lavoro. Il failover automatizzato consente di avviare rapidamente le repliche delle VM.
- Mappatura di rete e Ridefinizione IP . Quando si ripristina una replica di una VM in un’altra ubicazione, potrebbe essere necessario utilizzare un’altra rete VM e una configurazione IP per la connessione di rete della VM. La mappatura di rete consente di selezionare facilmente una nuova rete senza modificare la configurazione della VM nell’interfaccia utente VMware. È possibile creare regole di mappatura di rete. Re-IP consente di impostare la nuova configurazione IP per la replica della VM senza modificare le impostazioni di rete nel sistema operativo guest.
- Interfaccia utente . La soluzione NAKIVO offre un’interfaccia web intuitiva che rende la configurazione della replica in tempo reale VMware veloce e conveniente.
- Prezzo accessibile . NAKIVO Backup & Replication offre licenze perpetue e in abbonamento con una politica di licenze flessibile. È possibile consultare l’elenco completo dei prezzi e delle edizioni nella pagina delle funzioni.
La soluzione NAKIVO utilizza un filtro I/O VMware in un cluster per garantire la replica in tempo reale delle macchine virtuali VMware. I filtri I/O VMware migliorano le capacità di storage di VMware per gli ambienti virtuali. Le operazioni di input/output tra VM e dispositivi di storage vengono intercettate e manipolate dai filtri. Inoltre, le prestazioni della replica in tempo reale vengono ottimizzate.
Il filtro I/O è responsabile della crittografia dei dati per migliorare la sicurezza e i controlli di integrità dei dati per la replica delle VM in tempo reale. Pertanto, il filtro I/O è obbligatorio per l’host ESXi di origine e il Servizio di journaling è obbligatorio per l’host di destinazione. Il servizio Journal è responsabile del tracciamento delle modifiche ed è installato su una macchina in cui è in esecuzione il Transporter di destinazione. Il journal viene creato per ogni disco VM per tracciare le modifiche e registrare le operazioni I/O al fine di conservare i punti di ripristino di riferimento.
Configurazione della replica dei dati in tempo reale con NAKIVO
Spieghiamo come configurare la replica in tempo reale per le macchine virtuali in VMware vSphere con NAKIVO Backup & Replication.
Requisiti
Prima di iniziare a configurare la replica in tempo reale, assicurarsi che l’ambiente soddisfi i requisiti principali, tra cui:
- L’origine deve essere un cluster gestito da vCenter, mentre la destinazione può essere un server ESXi autonomo oppure l’host ESXi può essere aggiunto allo stesso vCenter.
- L’archivio dati di destinazione deve avere almeno 5 GB.
- L’host ESXi di origine deve avere almeno 16 GB di RAM.
- L’ora deve essere sincronizzata sugli host ESXi e sui Transporter.
Vedere l’elenco completo dei requisiti .
Il nostro ambiente vSphere dispone di un vCenter Server con due data center (origine e destinazione).
- DC_1 è il data center di origine con un cluster di due host e un Transporter di origine .
- DC_2 è il datacenter di destinazione con un singolo server ESXi e un Transporter di destinazione .
- Il datacenter di destinazione può essere gestito da uno o due vCenter o persino funzionare come server ESXi autonomo, a seconda delle esigenze specifiche dell’Infrastruttura.
Configurazione dell’ambiente vSphere
Questo è l’ambiente vSphere utilizzato nella procedura guidata. Dispone di un vCenter Server con due data center (di origine e di destinazione).
- Il data center primario con il Transporter dell’appliance virtuale di origine è già installato.
- Il data center secondario con il Transporter dell’appliance virtuale di destinazione è installato.
- Il data center di destinazione può essere gestito con uno o due server vCenter o persino utilizzato come server ESXi autonomo, a seconda delle esigenze specifiche dell’infrastruttura.
- NAKIVO Director è installato nel data center di destinazione, che è il data center secondario. Questa configurazione consente di accedere a Director in caso di disastro e di indisponibilità del data center primario.

Modificare il livello di accettazione del server ESXi di origine al livello supportato dalla community . È necessario modificare il livello di accettazione del profilo immagine host su ciascun server ESXi sull’origine al livello Supportato dalla comunità .
- Apri VMware vSphere Client, fai clic sulla scheda Configura e vai su Profilo di sicurezza . Quindi, passare a Livello di accettazione del profilo immagine host e fare clic su Modifica .
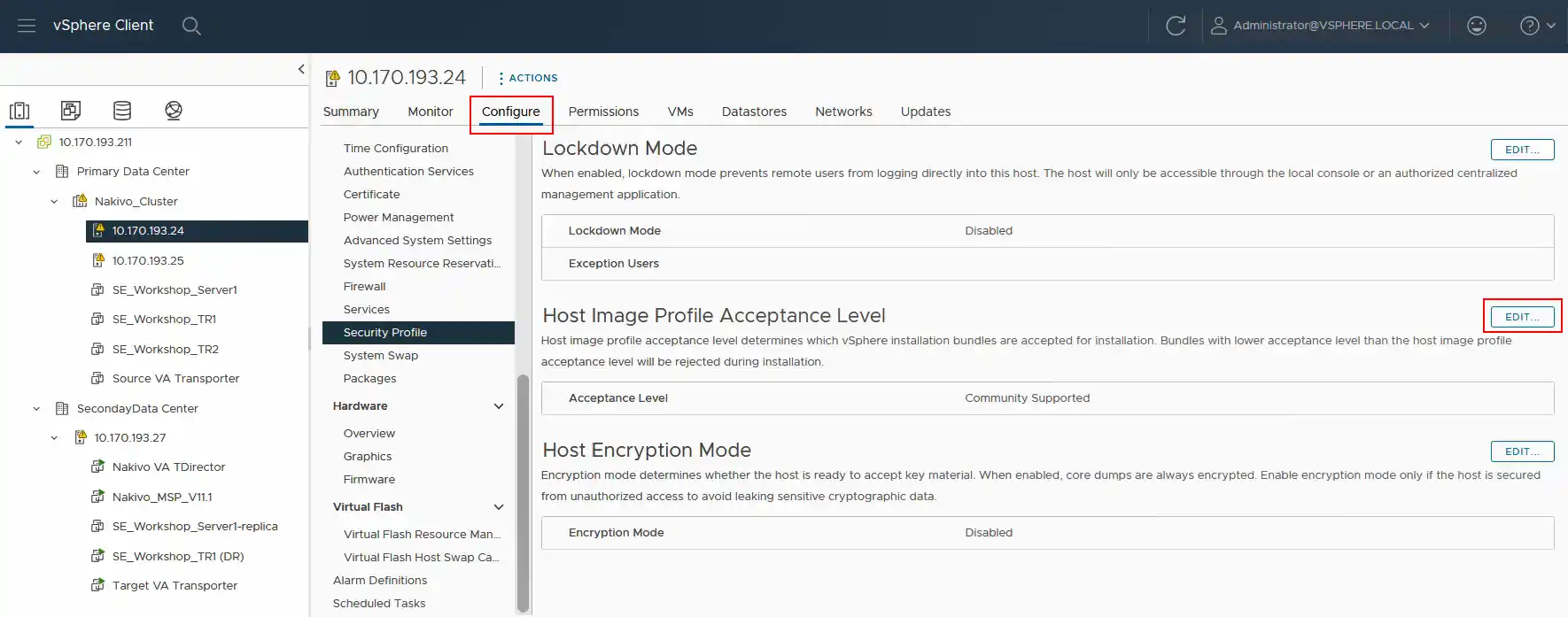
- Modificare il livello di accettazione in Supportato dalla comunità . Fare clic su OK per salvare le impostazioni.
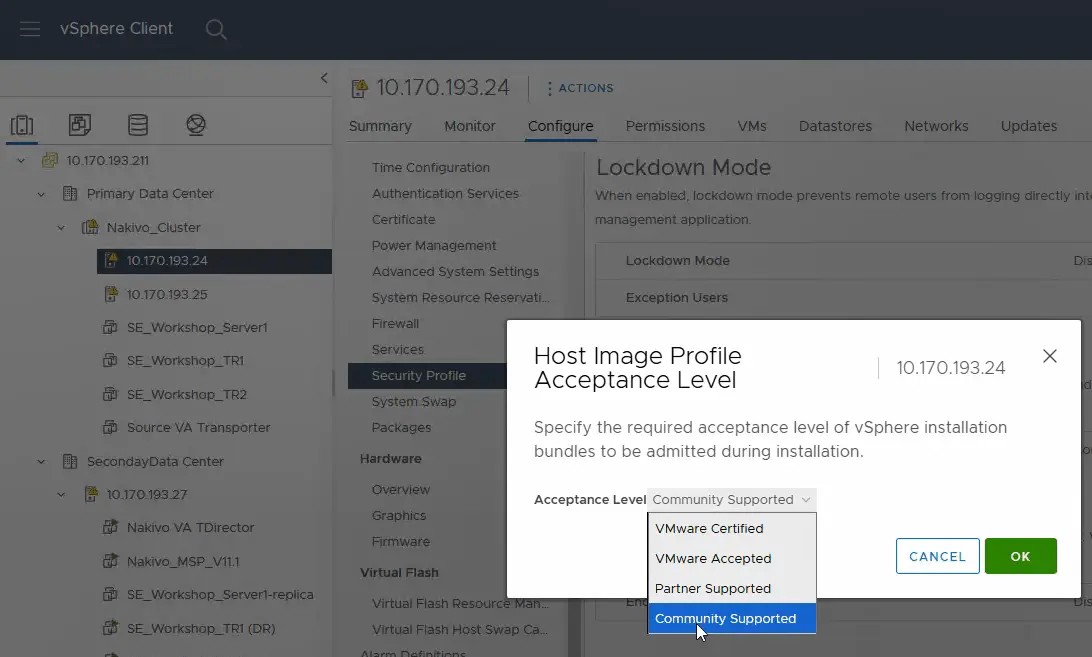
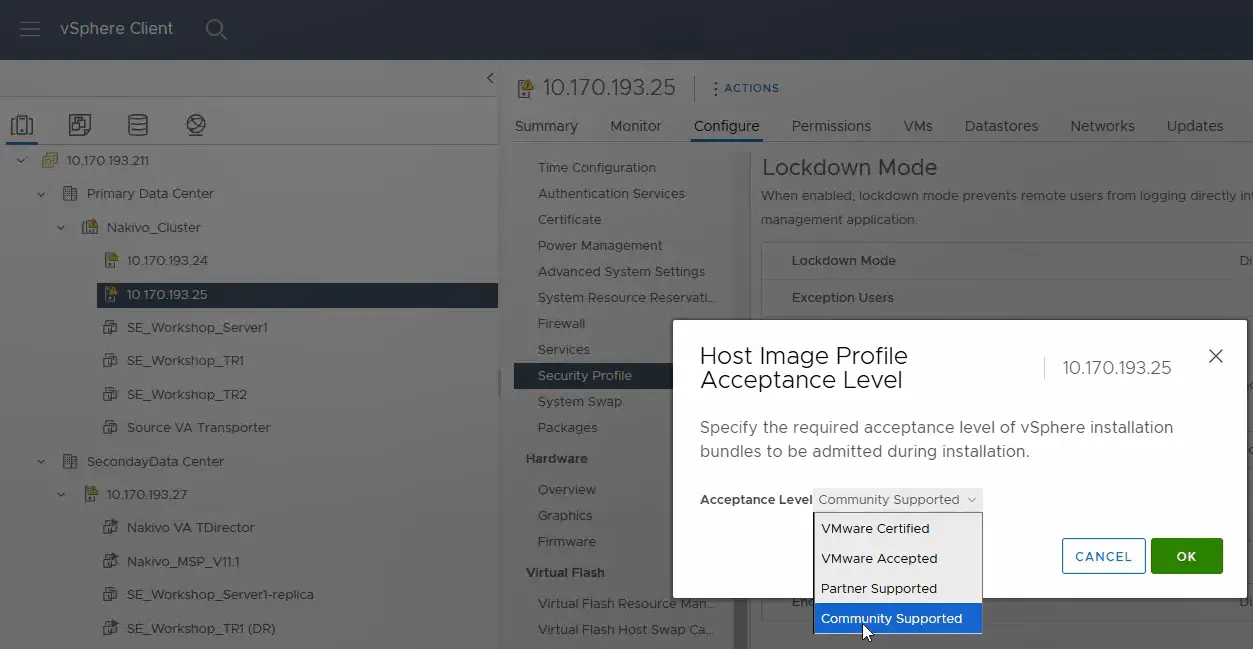
- Eseguire la stessa operazione sul secondo host ESXi nel data center di origine e impostare il livello di accettazione su Supportato dalla community .
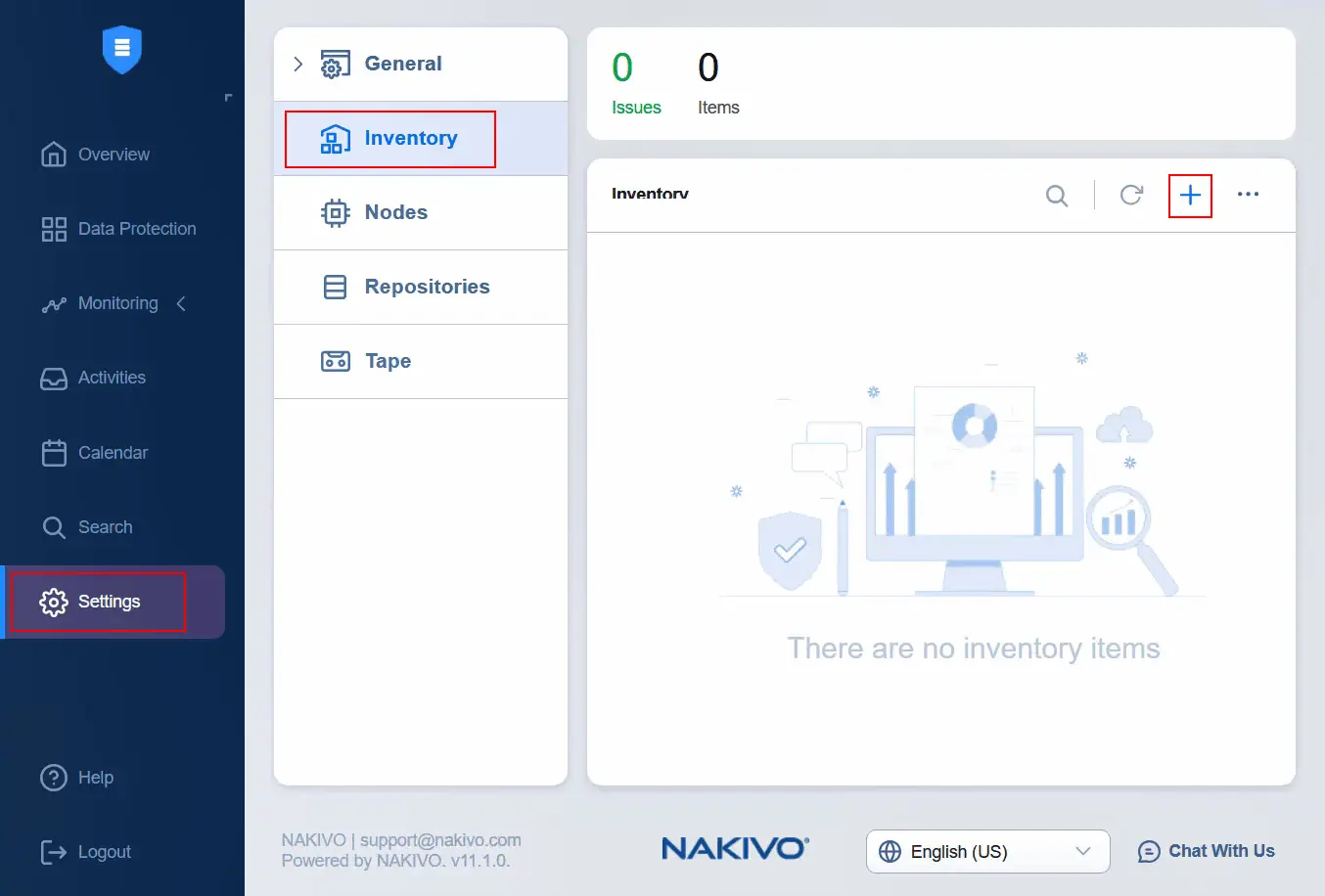
Configurazione dell’inventario
- Dopo aver modificato il livello di accettazione del profilo immagine dell’host, aprire l’interfaccia web di NAKIVO Backup & Replication e andare su Impostazioni > Inventario per aggiungere il vCenter di origine all’inventario. Fare clic sull’icona Più per aggiungere un nuovo elemento all’inventario.
- Selezionare Virtuale come Piattaforma e fare clic su Avanti .
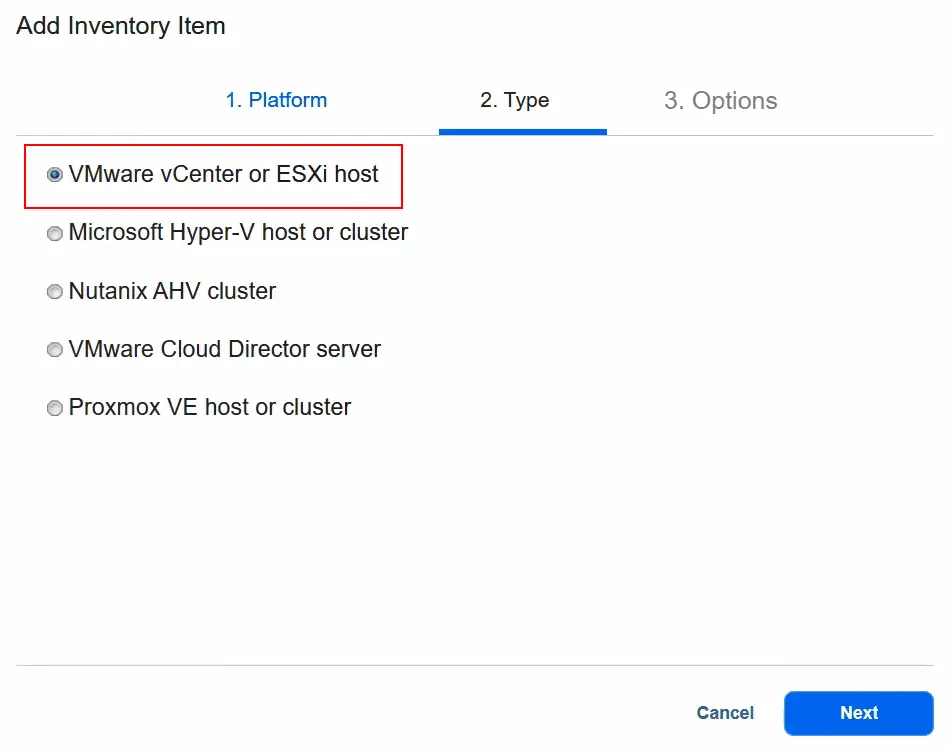
- Selezionare VMware vCenter oppure host ESXi come tipo. Quindi, andare avanti al passaggio successivo.
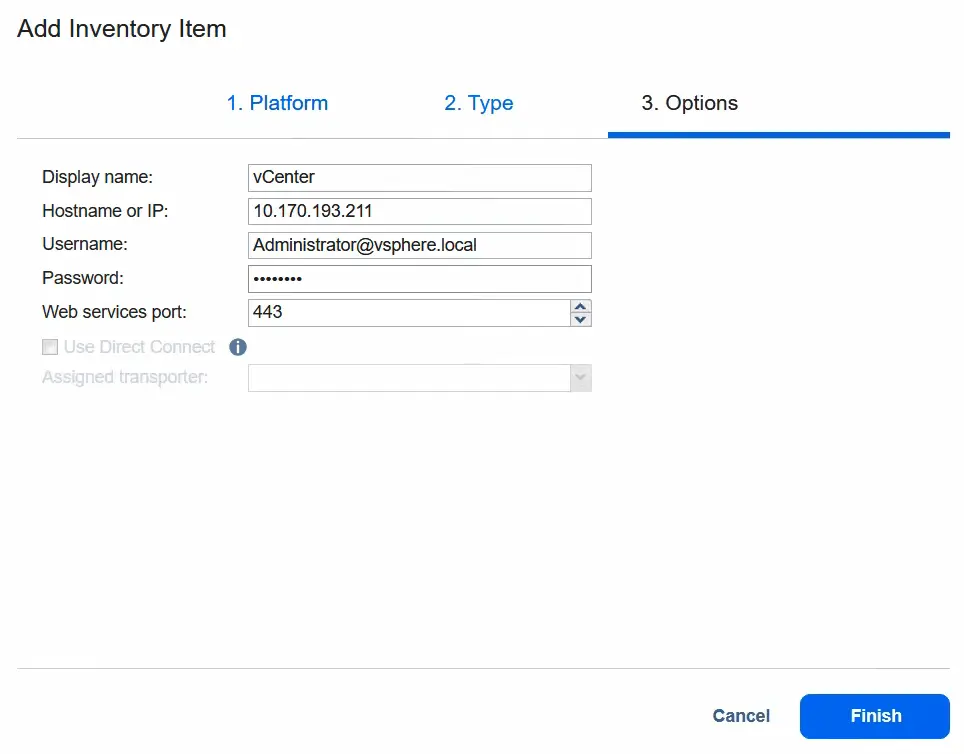
- Nel passaggio Opzioni , inserire il nome di visualizzazione, ad esempio vCenter . Quindi, inserisci l’indirizzo IP di questo vCenter Server, nonché il nome utente e la password per accedervi. Fai clic su Termina per salvare le impostazioni e aggiungere il vCenter selezionato all’inventario NAKIVO.
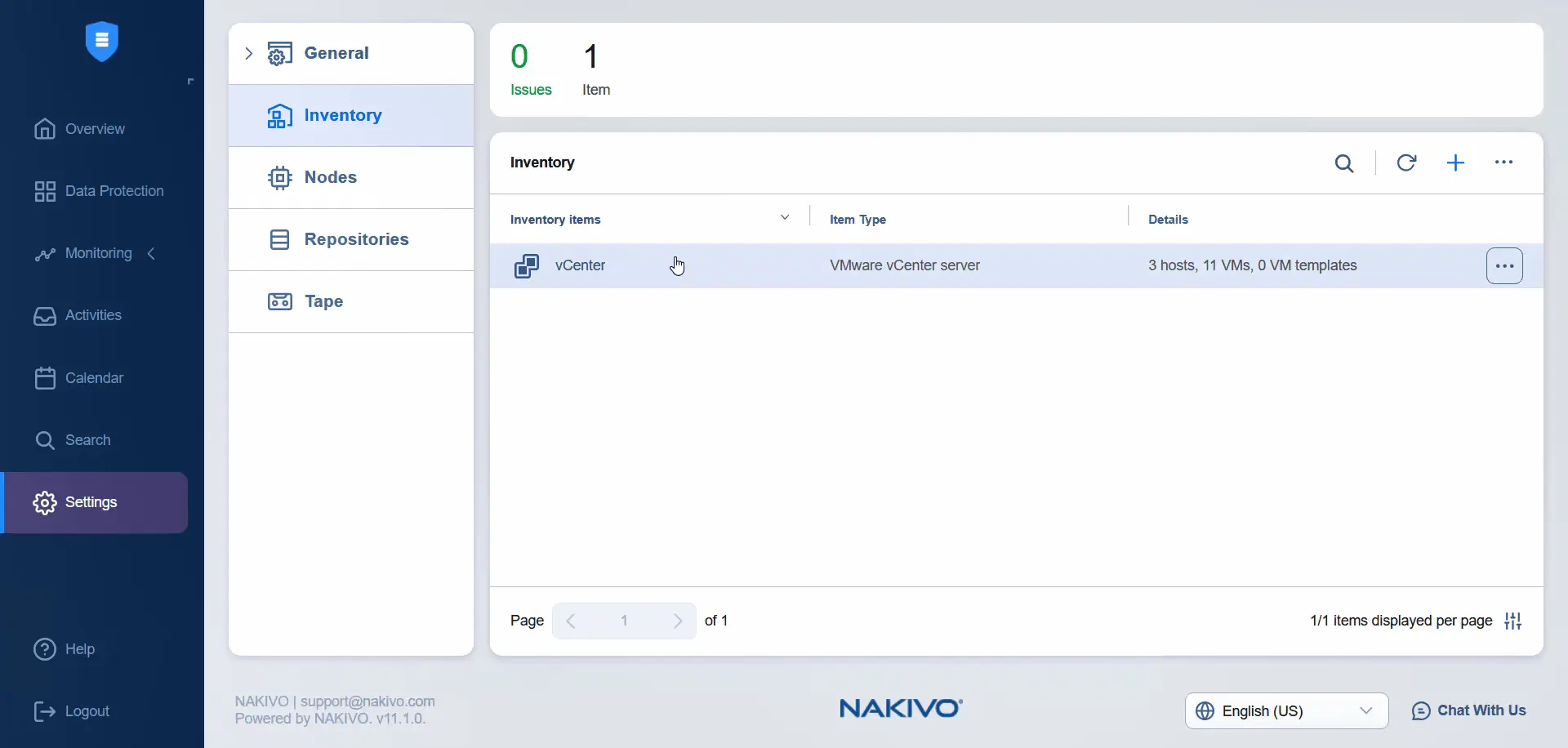
- Attendere fino a quando vCenter non viene aggiunto all’inventario. Una volta aggiunto, è possibile visualizzare i data center primario e secondario sullo stesso vCenter nell’inventario NAKIVO facendo clic sulla voce vCenter.
Installazione del filtro I/O
Avanti, è necessario installare il filtro I/O su ciascun host ESXi sul lato di origine. Il filtro I/O deve essere installato in un cluster per la replica in tempo reale. Non è necessario installare il filtro I/O sul lato di destinazione.
- Fare clic su Nodi , fare clic su Got It (se si visita questa sezione per la prima volta), fare clic su Plus e premere Real-Time Replication Service .
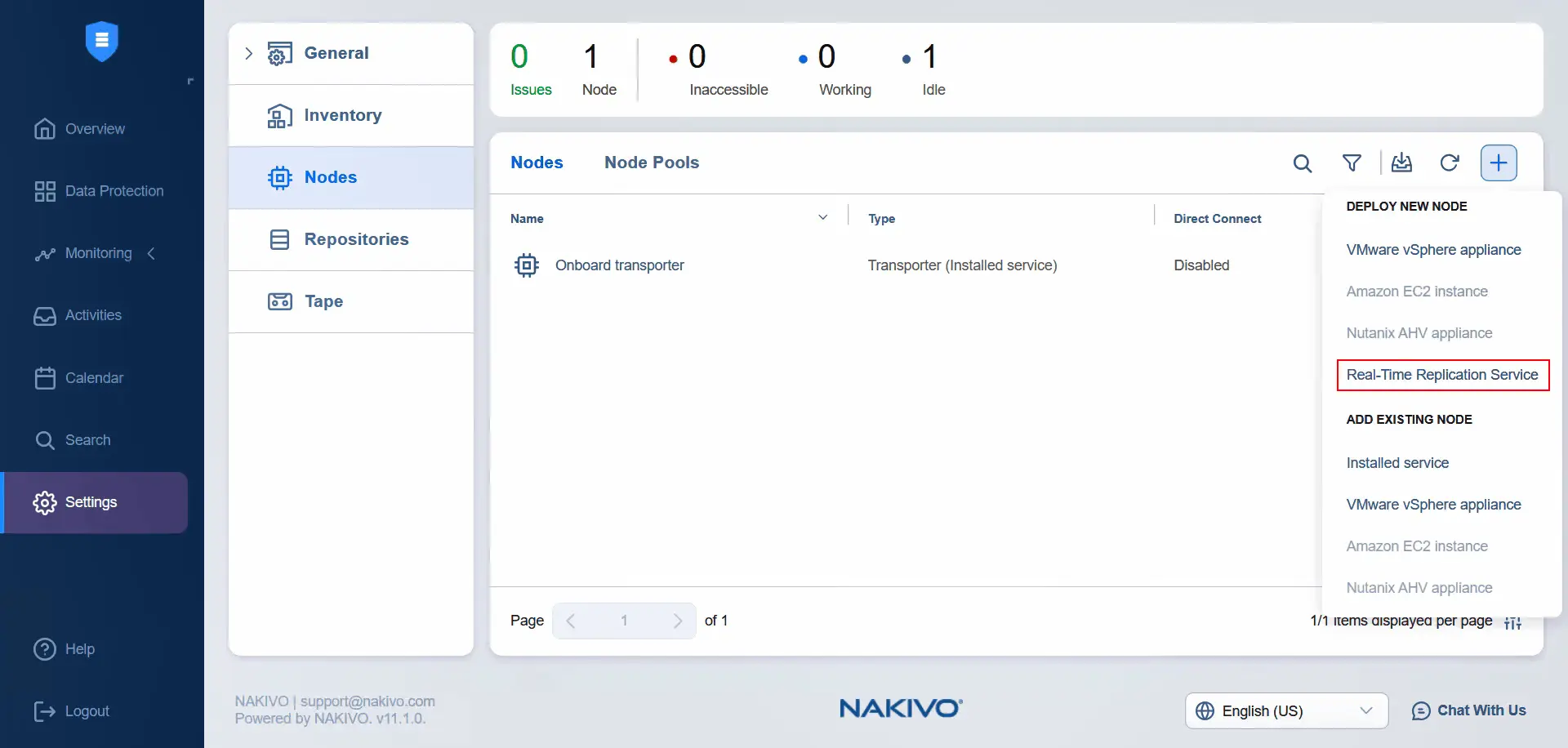
- Installa il filtro I/O solo sul data center primario, che è il data center di origine. Una volta selezionato un cluster nel data center, procedi al passaggio avanti.
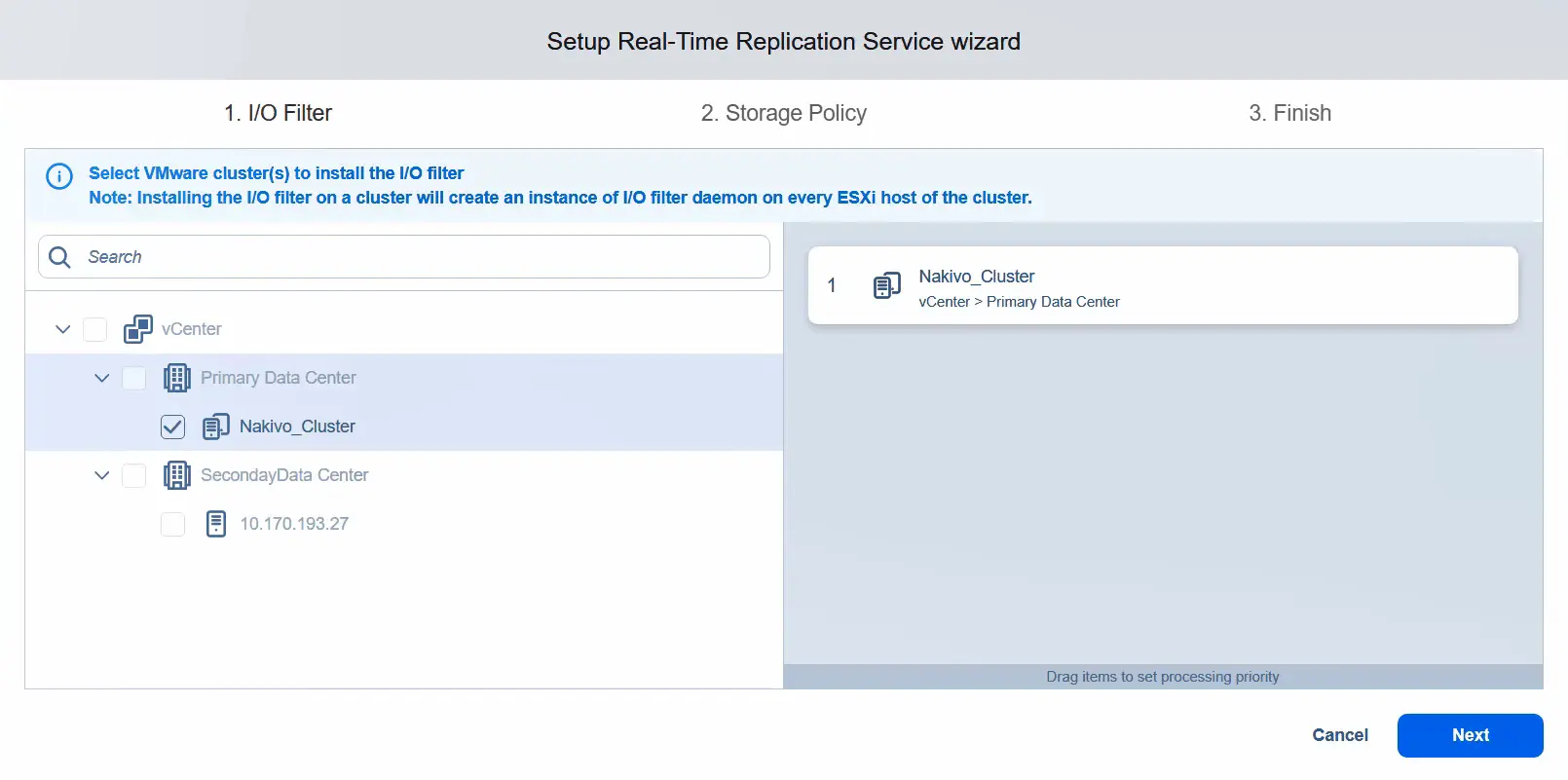
- Applica la politica di archiviazione e assegnala alle VM che si desidera utilizzare per la replica in tempo reale. In questo esempio, applichiamo la politica di archiviazione solo a una VM. Fare clic su Avanti .
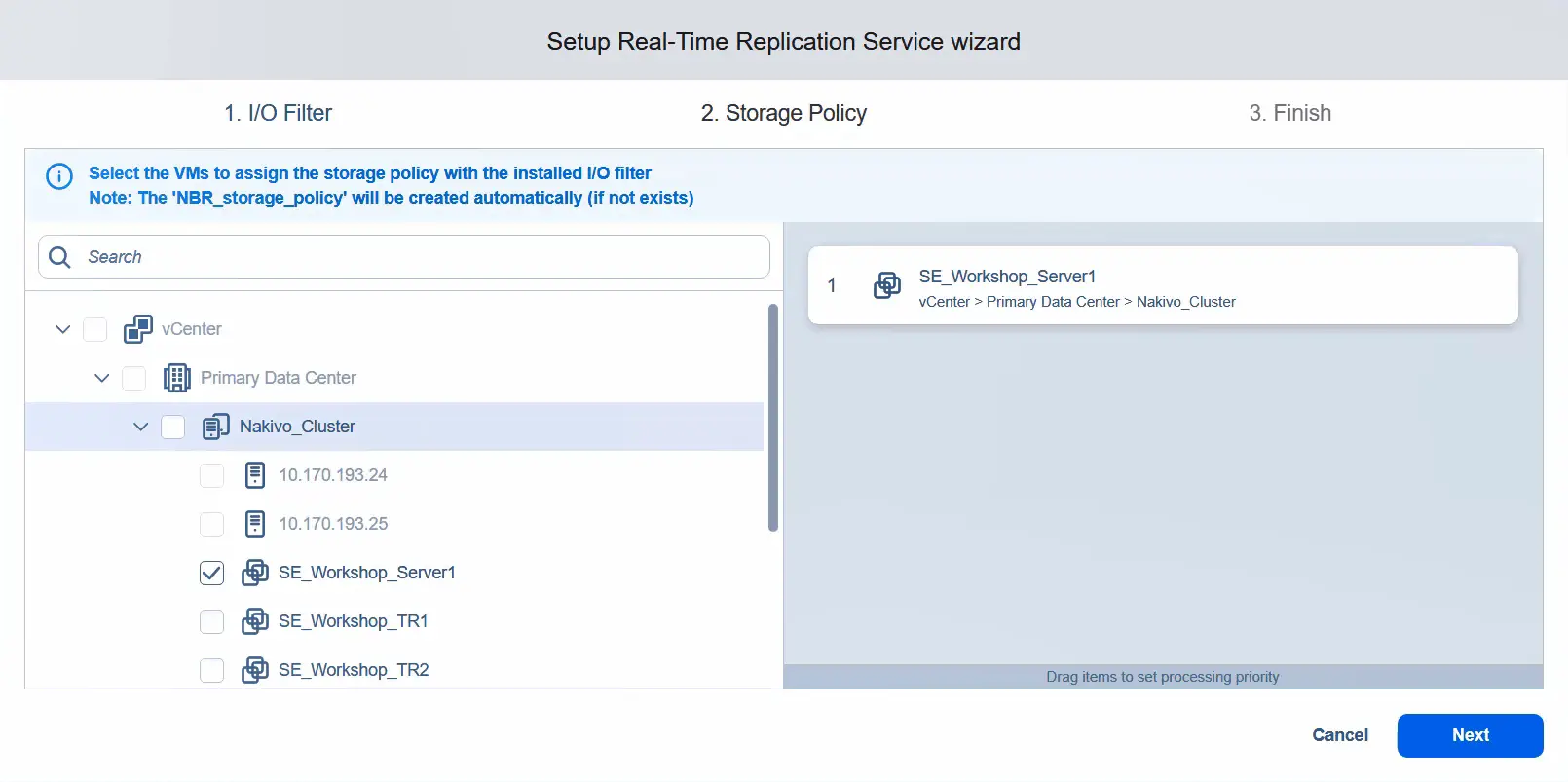
- I servizi di replica in tempo reale verranno installati ora.
È possibile visualizzare lo stato dell’attività mentre l’installazione è in corso.
È possibile controllare lo stato di avanzamento in VMware vCenter. L’installazione del filtro I/O è stata avviata. Dobbiamo attendere fino a quando il filtro I/O non sarà installato su entrambi i server ESXi.
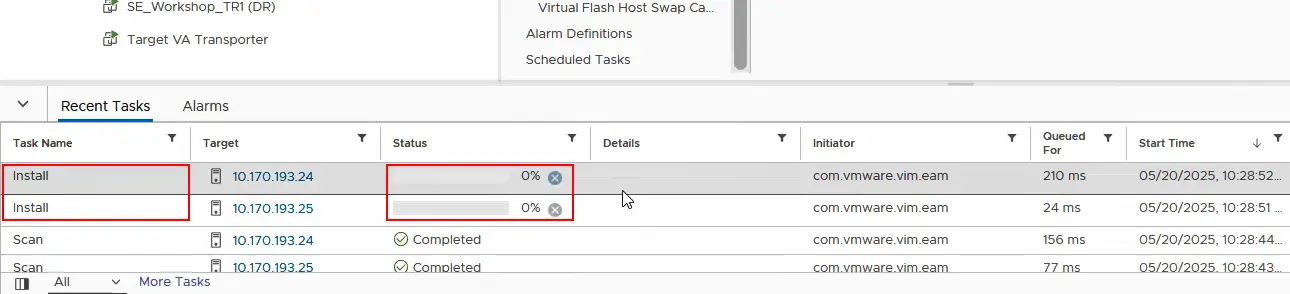
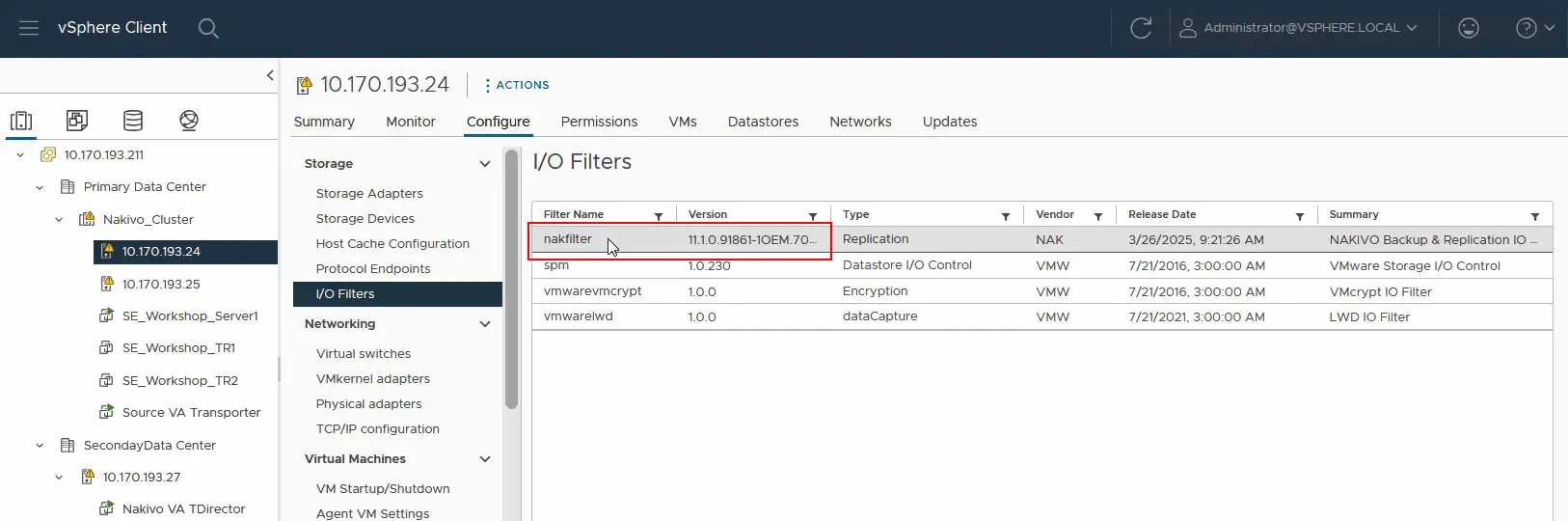
- Ora dobbiamo verificare se il filtro I/O è già stato installato su ciascun server ESXi nel cluster di origine. Selezionare l’host ESXi e fare clic su Configura > Filtri I/O . È possibile vedere che nakfilter è già installato. Allo stesso modo, assicurarsi che il filtro I/O sia installato sul secondo host ESXi nel cluster.
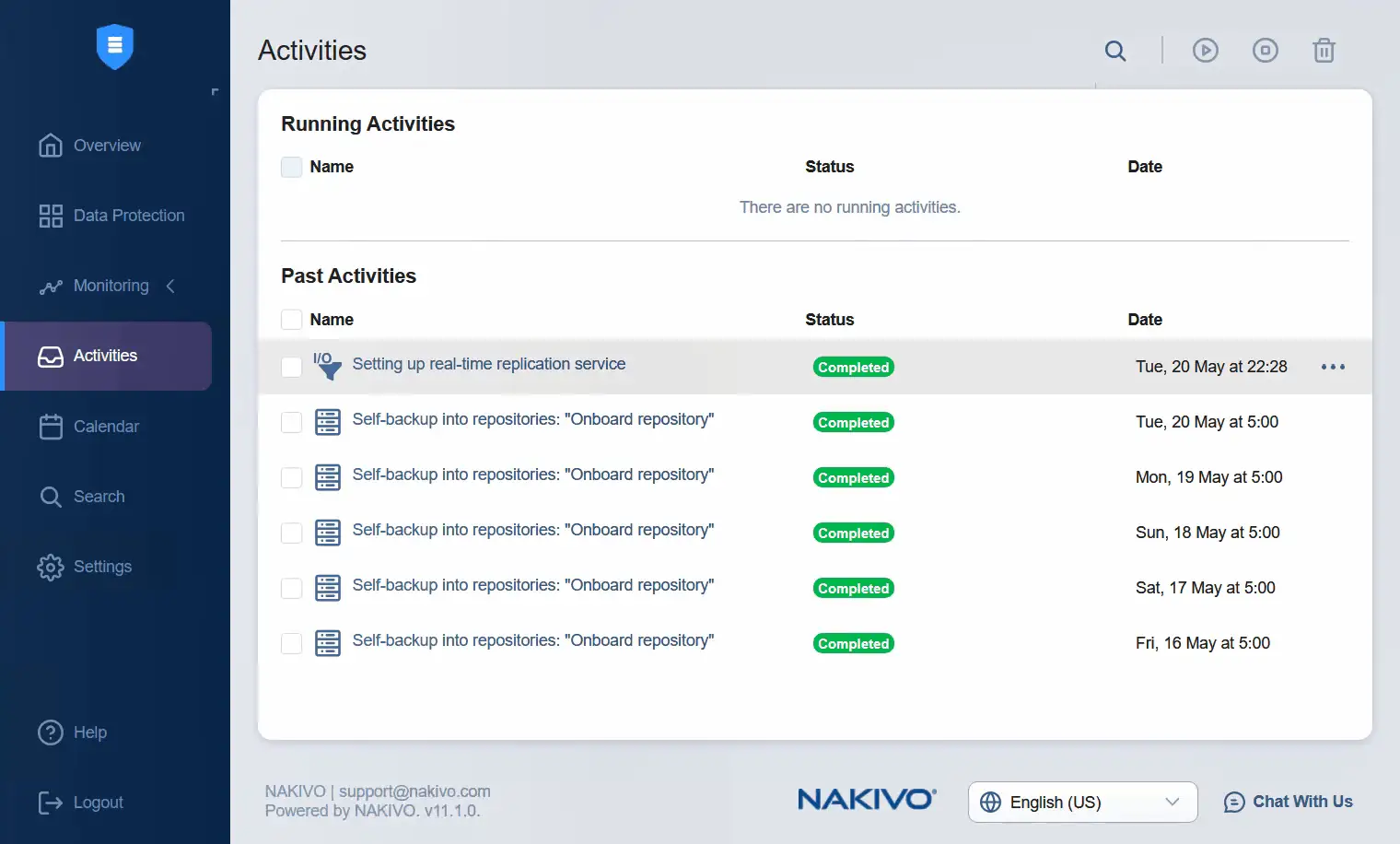
- Passare all’interfaccia web NAKIVO Backup & Replication, dove è possibile controllare le attività. In questo caso, la configurazione del servizio di replica in tempo reale è stata completata con successo.
Aggiunta del Transporter
- Torna a Impostazioni per aggiungere il Transporter di destinazione a Nodi . Prima di continuare, è possibile controllare lo stato del filtro I/O visualizzato per i nodi. In questo caso lo stato è in buono stato.
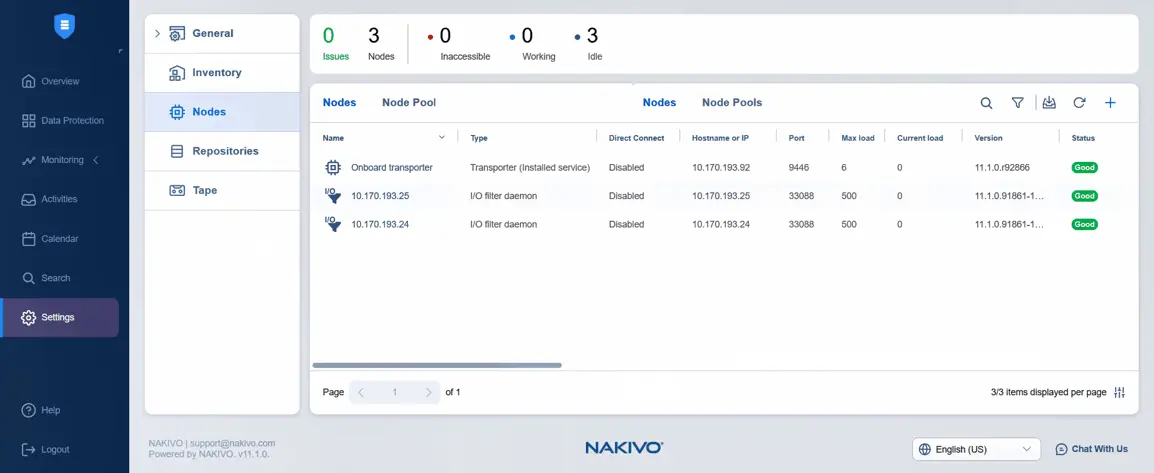
- In Impostazioni , selezionare Nodi , fare clic su Più e premere Appliance VMware vSphere sotto Aggiungi nodo esistente . Abbiamo già installato l’appliance virtuale quando è stato installato il servizio I/O (automaticamente).
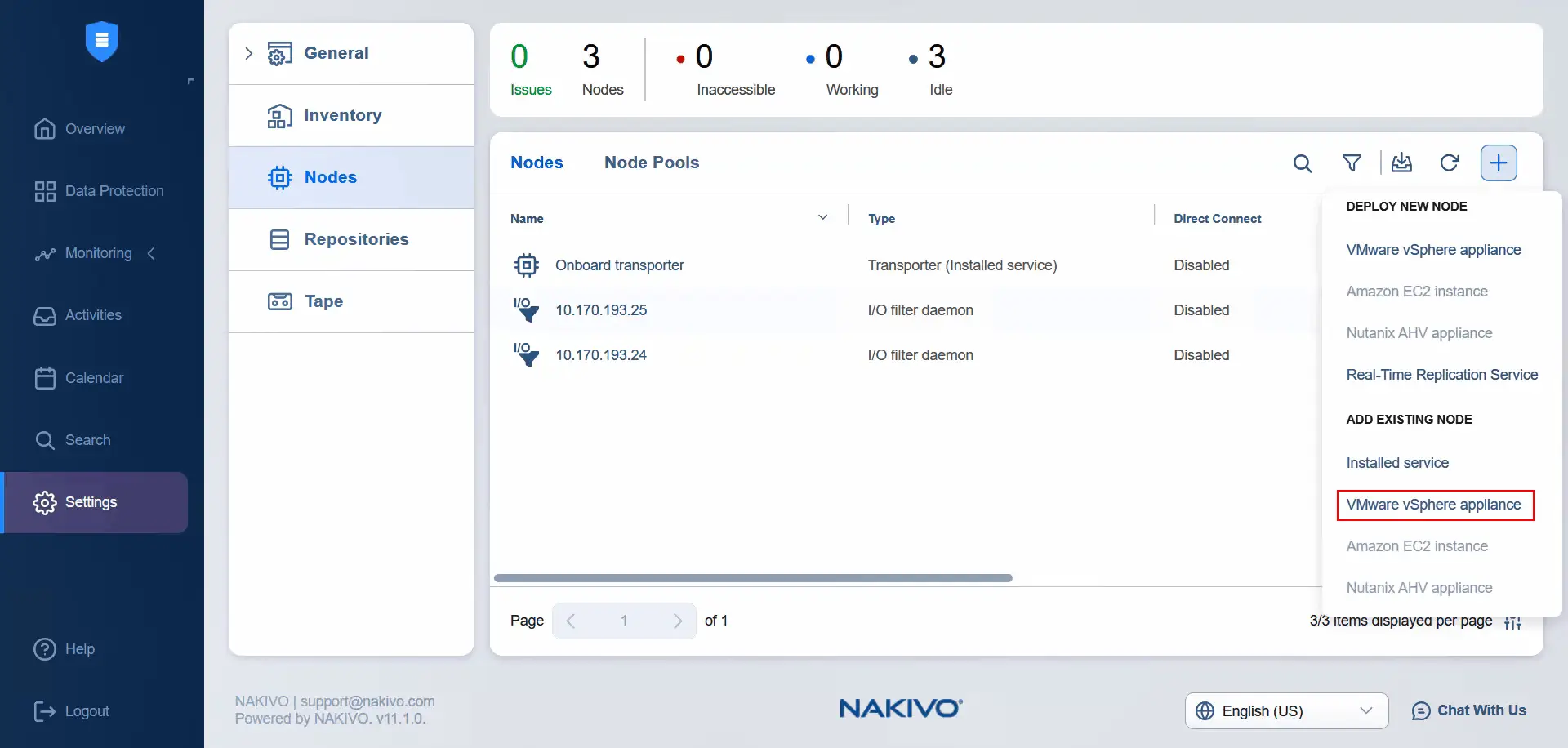
- Selezionare l’host ESXi di destinazione e selezionare l’appliance virtuale Transporter di destinazione. Immettere il nome utente dell’appliance virtuale Transporter e la password per questo utente. È possibile immettere il nome del Transporter nel campo appropriato. Fare clic su Aggiungi .
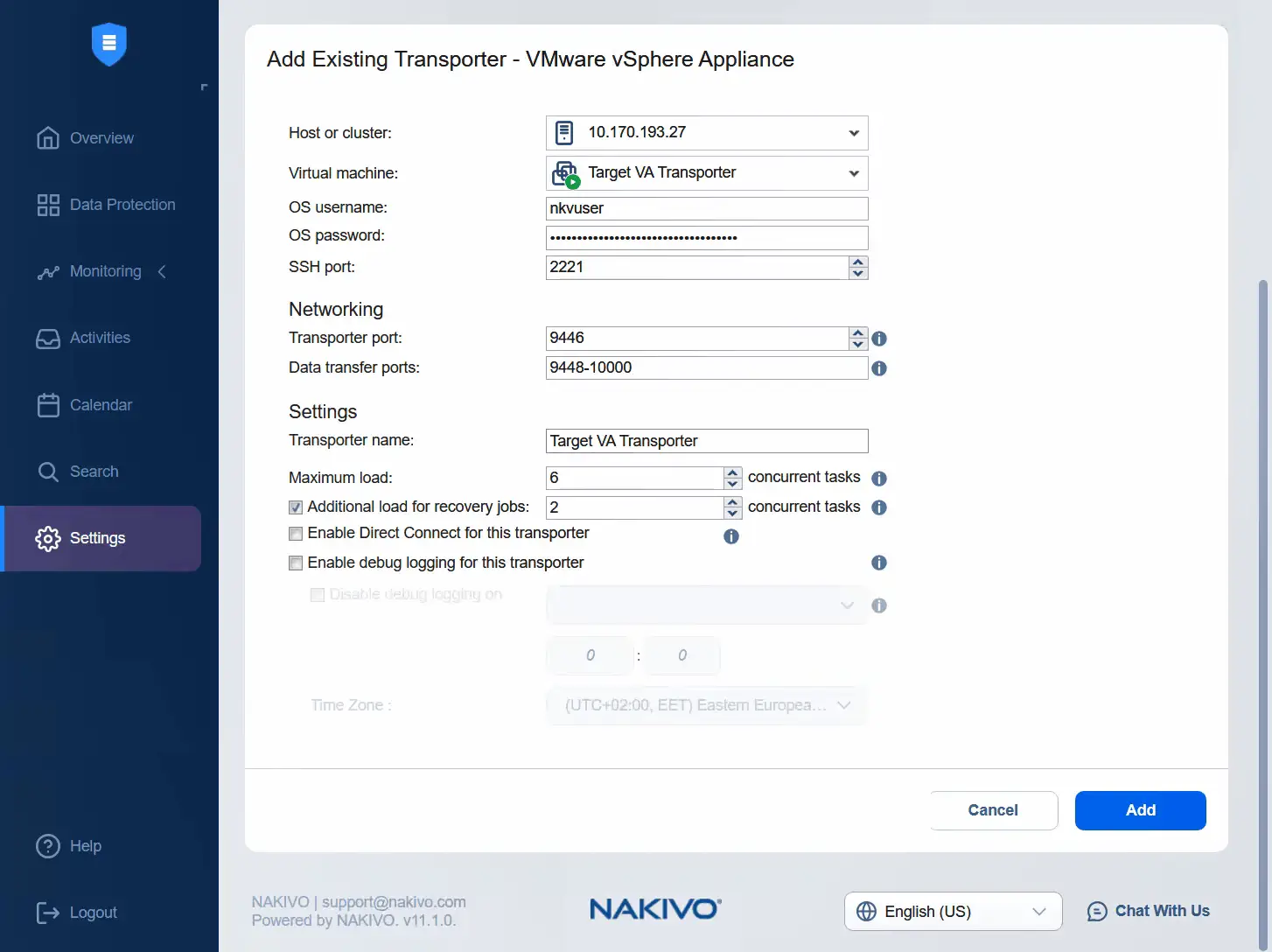
- L’aggiunta del Transporter di destinazione è in corso. È possibile controllare lo stato di avanzamento qui o monitorare lo stato nell’elenco dei nodi. Ora possiamo vedere che l’appliance virtuale Transporter di destinazione è stata aggiunta correttamente e che il suo stato è in buono stato.
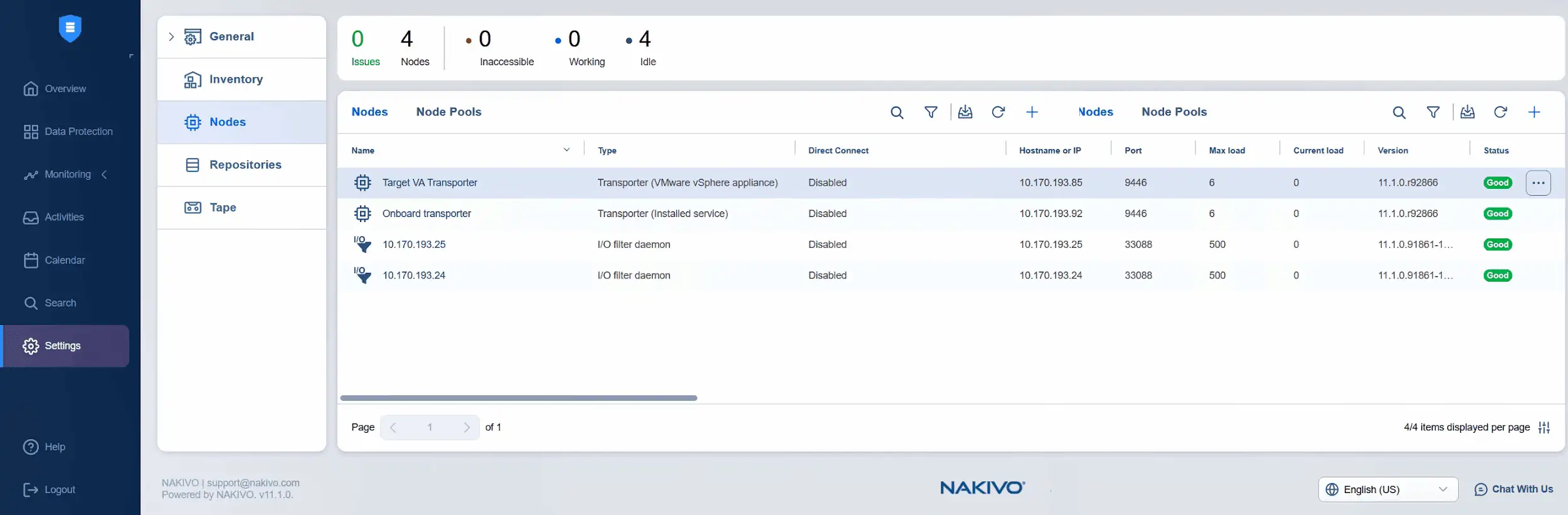
- È ora di aggiungere l’appliance virtuale Transporter di origine ai nodi. Fare clic su Più e selezionare Appliance VMware vSphere in Aggiungi nodo esistente .
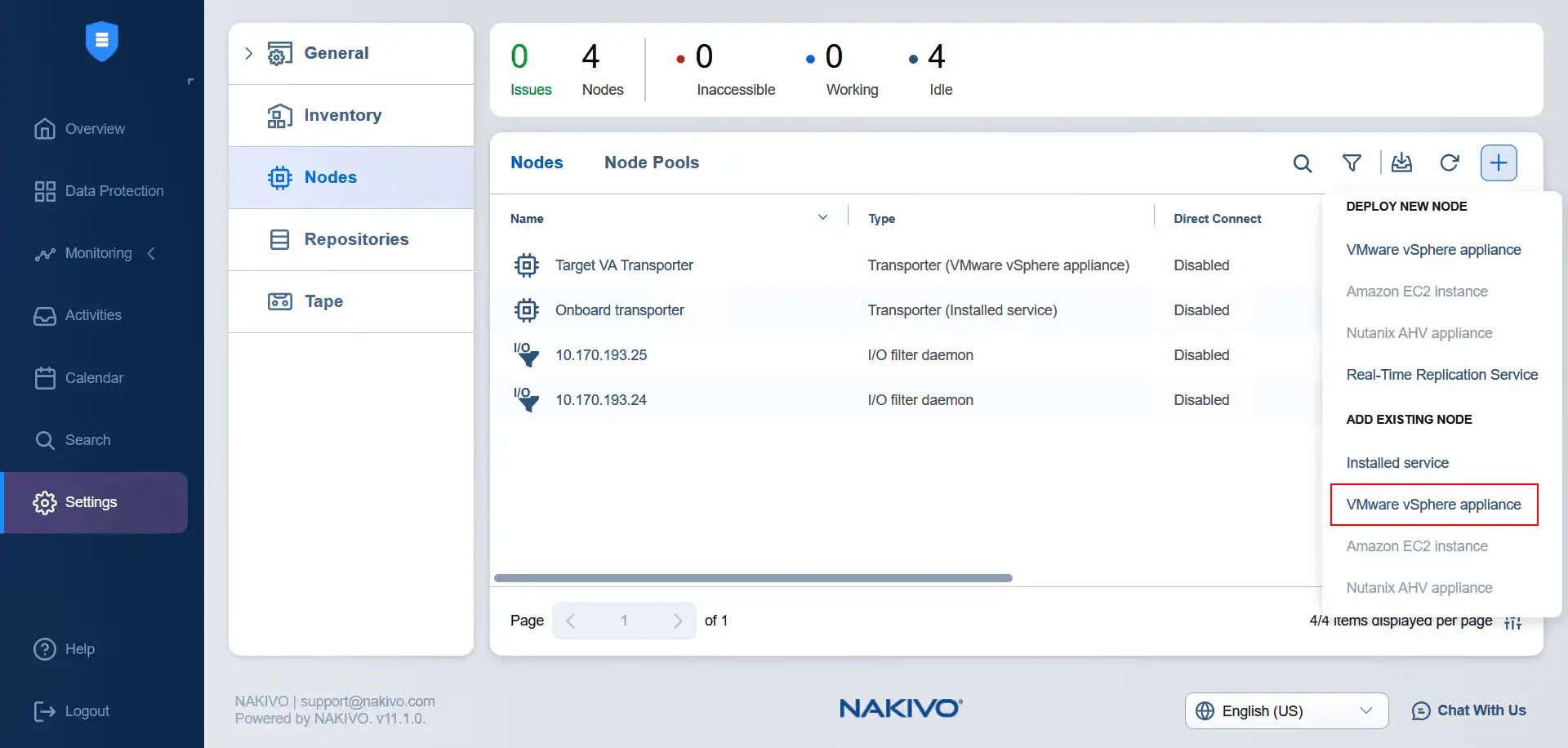
- Selezionare un cluster come origine. Selezionare il trasportatore dell’appliance virtuale di origine. Immettere il nome utente e la password dell’appliance del trasportatore selezionato. Se si espandono altre opzioni, è possibile immettere il nome del Transporter. Fare clic su Aggiungi .
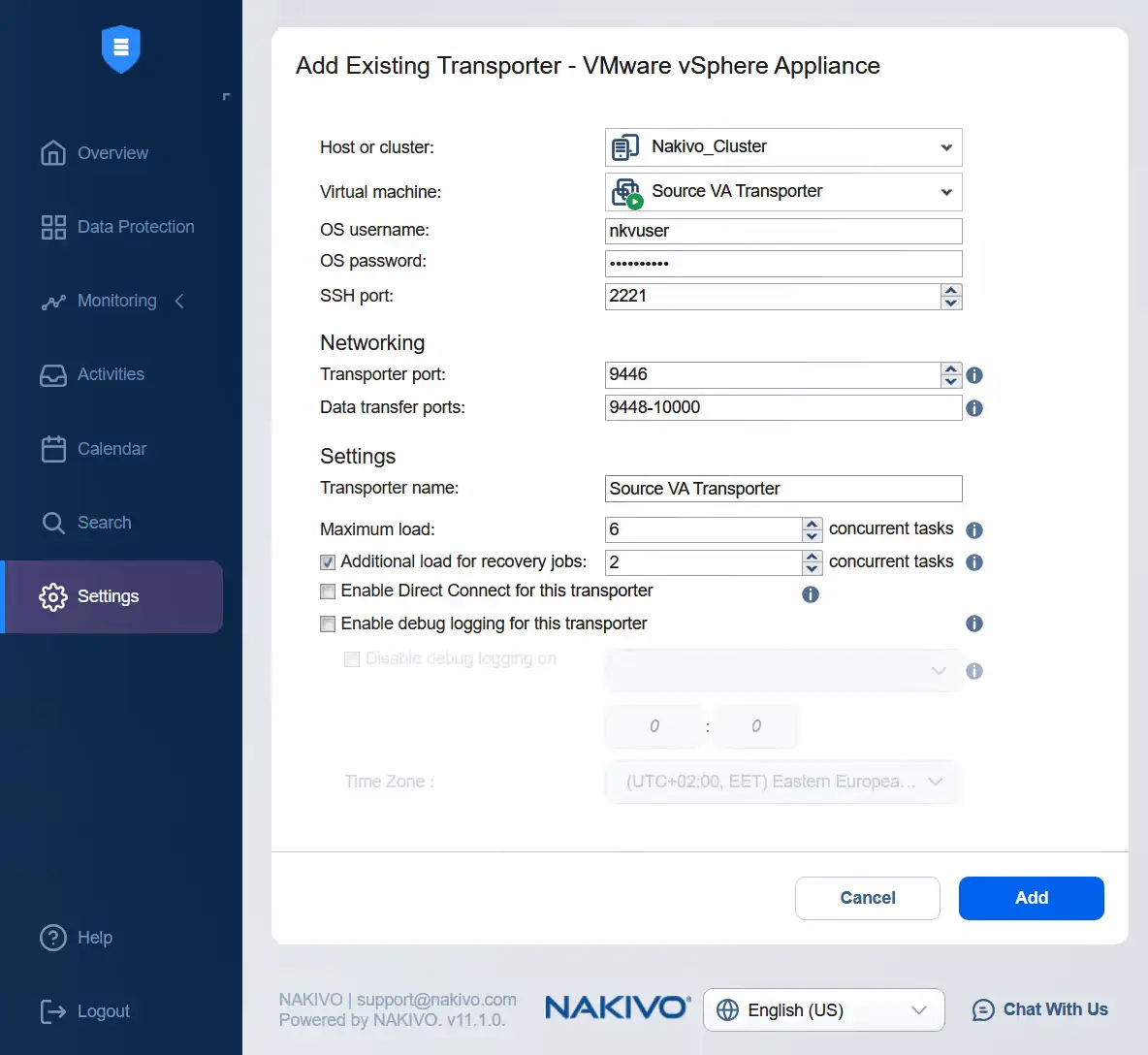
- Dopo qualche istante, il Transporter dell’appliance virtuale di origine viene aggiunto correttamente ai nodi.
Creazione di un processo di replica in tempo reale
Vai a Protezione dei dati per creare un processo di replica in tempo reale per la VM. Clicca su Più e premi Replica in tempo reale per VMware .
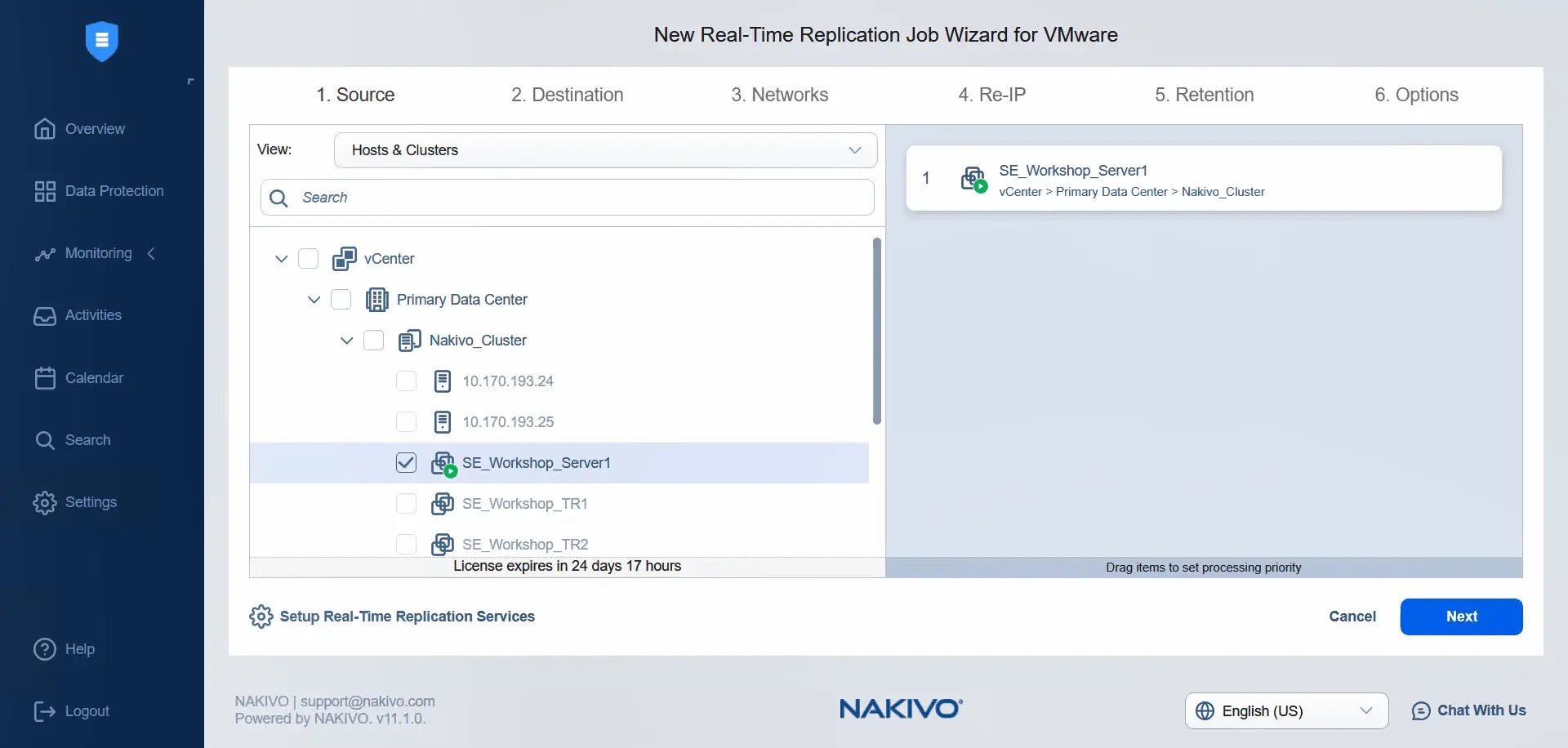
- Al passaggio Origine , utilizzando la vista Host & Cluster nel data center primario, selezionare la VM con il criterio di storage VM applicato. Si noti che non è possibile selezionare altre VM perché il criterio di storage VM non è applicato ad esse. Fare clic su Avanti per continuare.
- Al passaggio Destinazione , è possibile selezionare un host ESXi autonomo come contenitore di destinazione. Selezionare un archivio dati collegato a questo host ESXi. Passare alla fase successiva.
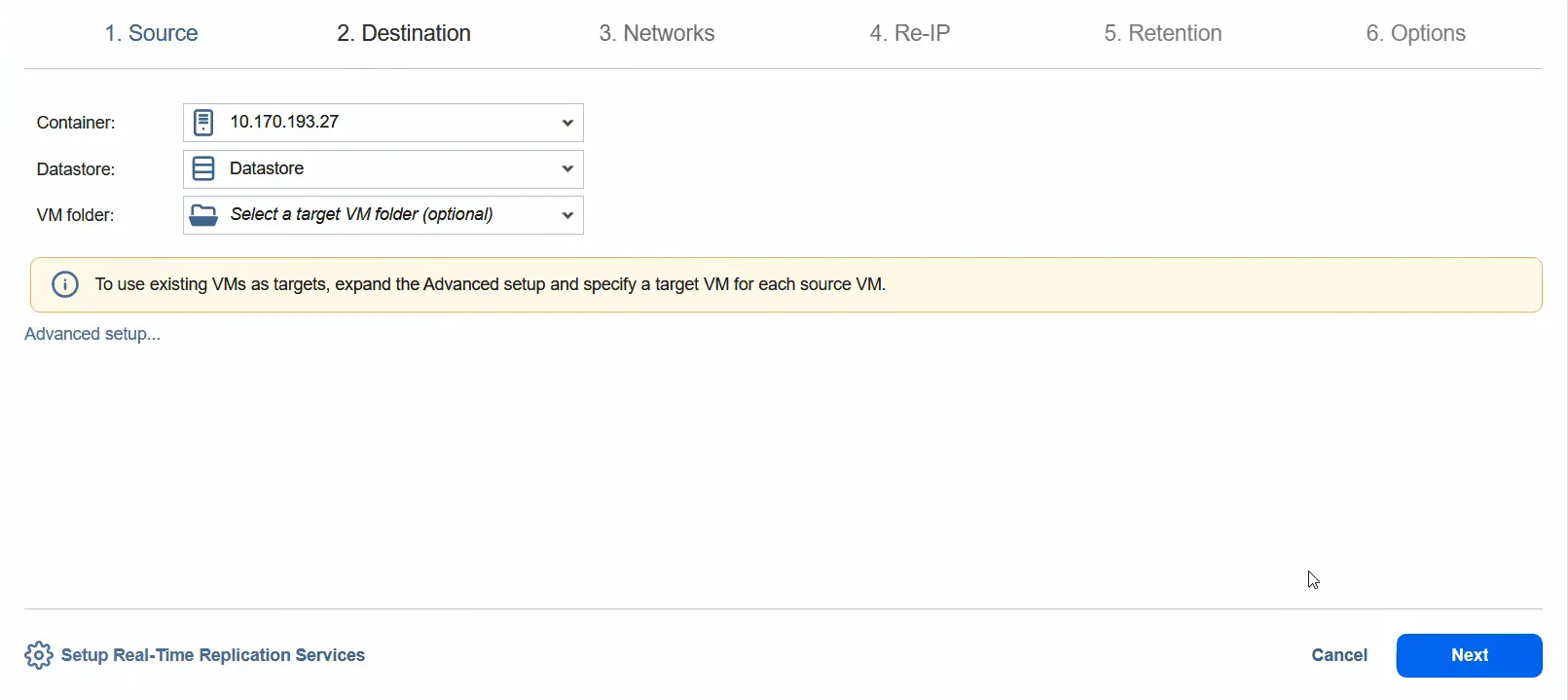
- È possibile abilitare il mapping di rete selezionando la rete di origine e la rete di destinazione. Fare clic su Avanti .
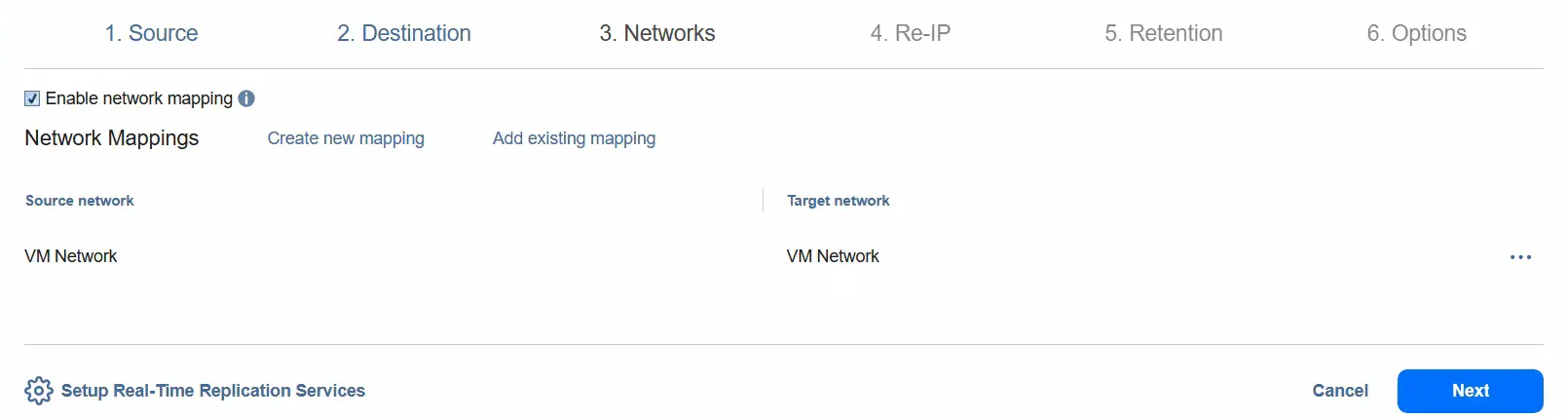
- È possibile abilitare la ridefinizione IP per modificare la configurazione dell’indirizzo IP per la VM di destinazione.
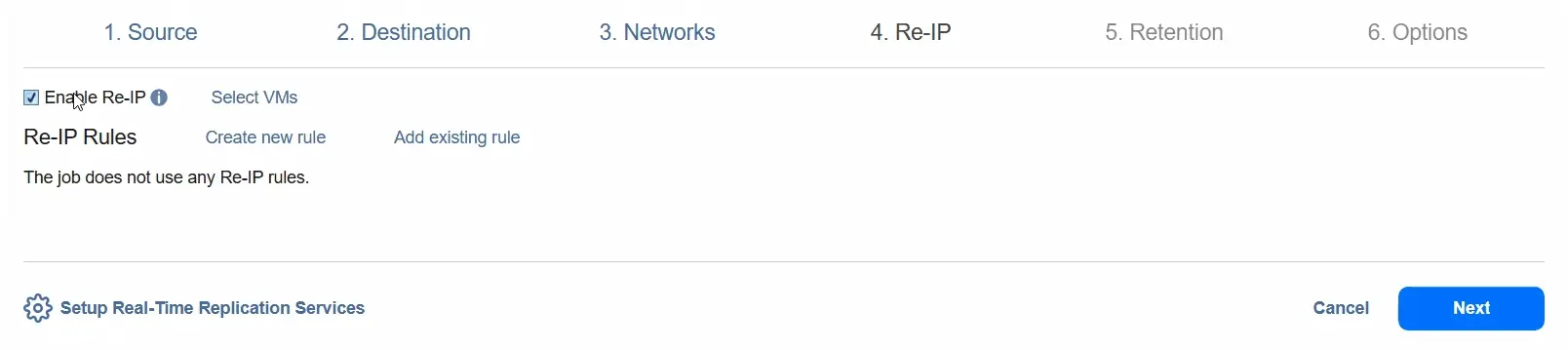
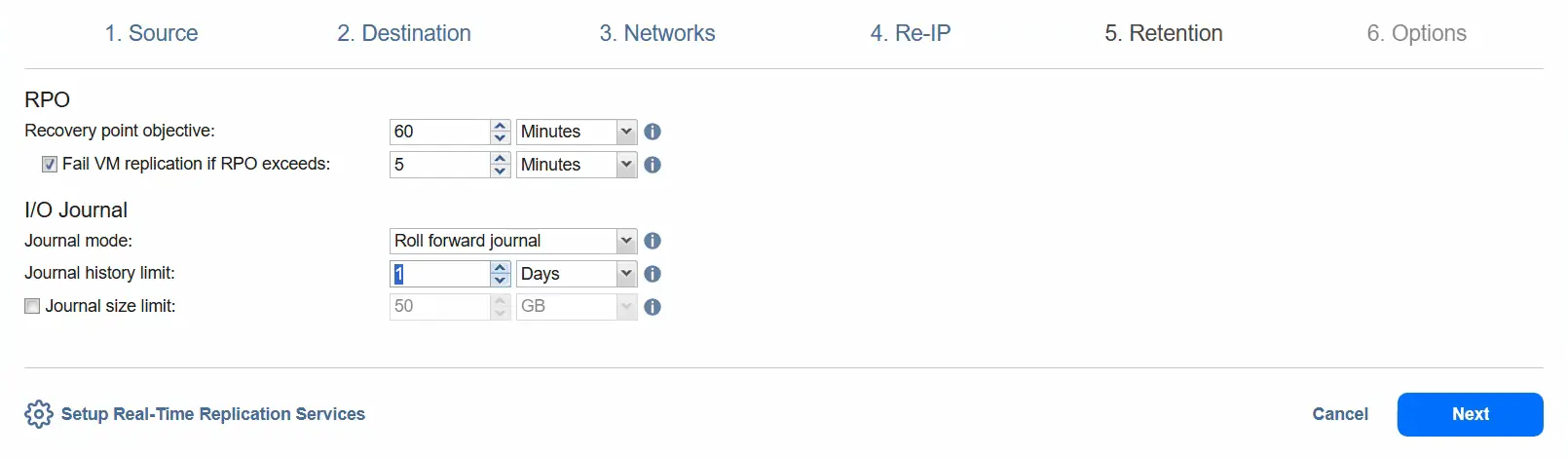
- Nel passaggio Conservazione , selezionare l’obiettivo di punto di ripristino (RPO). Per impostazione predefinita, è 1 minuto. È possibile ridurre l’RPO a 1 secondo o aumentarlo a 60 minuti (il valore massimo). È possibile selezionare l’opzione Fallimento della replica VM se l’RPO supera il tempo specificato.
È possibile selezionare la modalità del journal: Giornale roll forward o Giornale rollback .
Con l’opzione Rollback journal , le nuove modifiche ai dati vengono salvate direttamente nella replica della VM e tutti i dati nella replica vengono salvati nel journal. I vecchi dati nel journal vengono rimossi in base alle impostazioni del journal.
Con l’opzione Roll forward journal , le nuove modifiche ai dati vengono salvate nel journal e i vecchi dati vengono uniti alla replica in base alle impostazioni del journal. Per ora, manteniamo le impostazioni così com’è e utilizziamo l’opzione Roll forward journal .
È possibile selezionare l’opzione Journal history limit per impostare un limite per la cronologia del journal compreso tra 1 ora e 30 giorni.
L’opzione Limite dimensione journal imposta un limite per la dimensione del journal. Il valore può essere compreso tra 1 Gigabyte e 20 Terabyte. Per ora, lasciamo questa opzione deselezionata e passiamo al passaggio avanti.
- Nel passaggio Opzioni del lavoro , definire il nome del lavoro per la replica in tempo reale. In questo esempio, manteniamo il nome del lavoro così com’è e manteniamo la priorità del lavoro come 5 . Possiamo abilitare la crittografia di rete per crittografare il traffico tra il demone del filtro I/O e il servizio di journaling sulla porta 63092. La crittografia utilizza un certificato sul Transporter, che stabilisce una connessione sicura al servizio di journal.
Possiamo limitare l’archiviazione dei dati sull’host di origine per VM a 10 gigabyte ed escludere i blocchi inutilizzati. È possibile mantenere i valori predefiniti per le opzioni avanti.
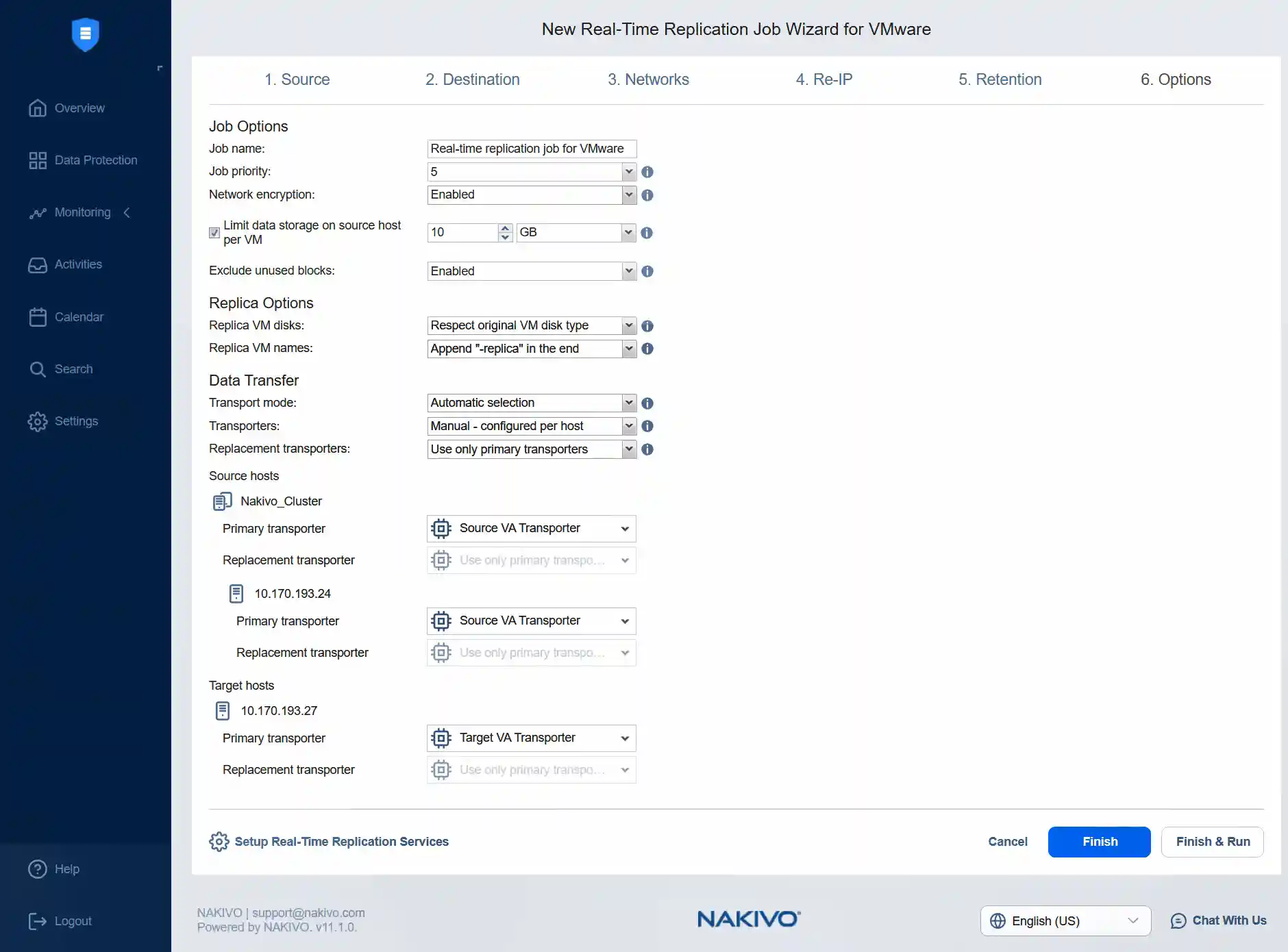
Per l’host di origine, è necessario selezionare il Transporter di origine, ovvero Source VA Transporter. Quindi, selezionare lo stesso Transporter per l’host ESXi 24.
Per l’host di destinazione, è necessario selezionare il Transporter di destinazione, ovvero il Transporter dell’appliance virtuale di destinazione appropriato.
Fare clic su Termina ed esegui & Run per salvare le impostazioni del lavoro ed eseguire il processo di replica VMware in tempo reale. Fare clic su Run , quindi fare clic nuovamente su Run quando viene visualizzato il messaggio di conferma.
Conclusione
La replica dei dati in tempo reale per le VM migliora significativamente la continuità operativa riducendo i tempi di inattività e offrendo la possibilità di eseguire il ripristino delle VM il più rapidamente possibile. Questa funzione dovrebbe essere utilizzata per le VM più critiche con i dati più importanti, mentre la replica asincrona tradizionale può essere più conveniente per i dati meno critici. Utilizzate NAKIVO Backup & Replication per la replica in tempo reale e la replica asincrona delle VM in VMware vSphere.



