NAKIVO Backup & Componente di replica: Repository di backup
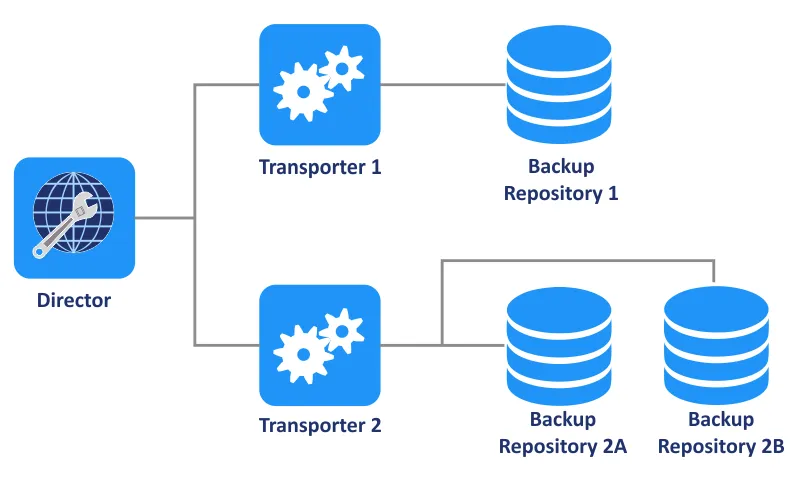
& & NAKIVO Backup & Replication ha tre componenti principali: Director, Transporter e repository di backup. Mentre il Director viene utilizzato per la gestione di tutto, il Transporter viene utilizzato per il trasferimento dei dati tra i nodi. In questa guida spieghiamo come creare e configurare un repository di backup nella soluzione NAKIVO e illustriamo le funzioni e le piattaforme supportate.
Che cos’è un repository di backup?
Un repository di backup è un componente fondamentale di NAKIVO Backup & Replication in cui vengono archiviati i backup (punti di ripristino). Si tratta di una cartella designata per l’archiviazione dei backup e dei metadati di backup generati dalla soluzione. Quando si distribuisce la soluzione di backup su un sistema operativo supportato, è possibile creare automaticamente una directory per il repository onboard predefinito. In Windows, questa directory si chiama “NakivoBackup” e in Linux si chiama “repository“. Questa cartella può quindi essere utilizzata come repository per i dati di backup e i metadati del repository di backup.
IMPORTANTE: In nessun caso è consentito modificare o eliminare manualmente i file presenti nella cartella “NakivoBackup“. Ciò potrebbe causare danni permanenti all’intero repository di backup, irreversibili, e la perdita dei dati di backup.
NOTA: Per evitare qualsiasi interruzione delle operazioni nella soluzione NAKIVO e potenziali danni ai dati, è necessario aggiungere l’applicazione alla whitelist o all’elenco delle esclusioni del software antivirus in esecuzione sul computer in cui è implementato il repository di backup NAKIVO.
Dopo aver installato la soluzione completa (componenti Director e Transporter), viene creato automaticamente un repository di backup come impostazione predefinita. A questo repository di backup predefinito viene assegnato il nome “Repository onboard” (questo nome viene visualizzato nell’interfaccia web).
Supporti di archiviazione e piattaforme supportati
NAKIVO Backup & Replication supporta diversi supporti di archiviazione e piattaforme per la creazione di un repository di backup:
- Cartella locale, ovvero una directory nel file system del computer su cui è installato Transporter
- NFS e Condivisioni SMB
- Cloud pubblici (Amazon S3, Microsoft Azure, Wasabi, Backblaze B2) e altri storage compatibili con S3 (Cloudian, MinIO, Ceph, C2 Object Storage, Lyve Cloud, ecc.)
- SaaS
Il repository SaaS è un tipo di repository speciale utilizzato per archiviare i backup di Office 365. Questo tipo di repository viene creato in una directory locale per il Transporter assegnato. L’archivio di backup può essere creato su file system ext3, ext4, NTFS e FAT32.
- Appliance di deduplicazione con supporto per protocolli nativi
Tipi di repository di backup
NAKIVO Backup & Replication offre due tipi di storage per i dati di backup per backup incrementale:
- Incrementale con backup completi. NAKIVO Backup & Replication crea un backup completo al primo avvio del lavoro di backup e successivamente consente di creare punti di ripristino completi e incrementali in base alle proprie esigenze. La soluzione consente di creare periodicamente backup completi sintetici in base alle impostazioni del lavoro di backup.
- Backup incrementali permanenti. La soluzione crea un backup completo solo al primo lavoro di backup. Tutte le esecuzioni successive invieranno solo i dati modificati (incrementi) al repository di backup.
A partire dalla versione 10.4, l’impostazione incrementale con backup completo viene applicata per impostazione predefinita durante la creazione di un nuovo repository di backup (anziché creare un repository di backup incrementale permanente come avveniva prima della versione 10.4). Il tipo di storage può essere configurato durante la creazione dell’archivio.
Dimensione dell’archivio di backup
Si consiglia che ogni repository di backup in NAKIVO Backup & Replication contenga fino a 128 TB di dati di backup dopo la compressione e la deduplicazione. È possibile creare fino a 500 repository di backup per ogni installazione della soluzione.
Ogni nuovo repository di backup richiede almeno 5 GB di spazio libero oltre ai 5 GB di spazio libero necessari per il corretto funzionamento di un repository di backup esistente. La soluzione controlla automaticamente lo spazio libero ogni minuto se è disponibile più di 10 GB di spazio libero. Se lo spazio libero è inferiore a 10 GB, il processo di controllo viene eseguito ogni 10 secondi per evitare errori causati dalla mancanza di spazio su disco.
Scalabilità
Un repository di backup specifico è controllato da un singolo Transporter assegnato. In termini più semplici, solo un Transporter è autorizzato a leggere e scrivere dati in un repository di backup specifico. Il Transporter assegnato si assume la piena responsabilità di tutte le interazioni relative al rispettivo repository di backup. Un singolo Transporter può essere assegnato a più repository di backup e gestirli efficacemente contemporaneamente.
Un singolo repository di backup non può essere utilizzato da più di un Director/Tenant alla volta.
Funzioni del repository di backup
Un repository di backup supporta molte funzioni utili, tra cui:
- Deduplicazione. I repository di backup possono essere configurati per utilizzare la funzione di deduplicazione globale per deduplicare i dati di backup a livello di blocco. I blocchi di dati duplicati vengono esclusi dal backup indipendentemente dall’origine dei dati, consentendo un risparmio effettivo di spazio di storage. Si noti che questa funzione può essere utilizzata solo con il repository di backup incrementale permanente.
- Compressione. I dati in un repository di backup possono essere compressi utilizzando tre livelli di compressione, da basso ad alto. In questo modo è possibile trovare un equilibrio tra il risparmio di spazio di archiviazione e il carico della CPU per comprimere i dati. La compressione può essere configurata durante la creazione di un nuovo repository di backup.
- Crittografia. Un repository di backup (se installato su Linux) può essere crittografato per proteggere tutti i dati di backup memorizzati nel repository utilizzando una password di crittografia. La crittografia influisce sulla velocità di backup.
- Recupero dello spazio. Il recupero dello spazio inutilizzato consente di compattare le dimensioni del repository di backup e recuperare lo spazio inutilizzato quando si utilizza un tipo di archiviazione di backup incrementale permanente .
- Riparazione automatica del repository di backup. Questa funzione verifica i problemi causati dall’incoerenza dei dati (compresi i metadati), controlla l’integrità dei dati e ripara gli errori quando possibile. La riparazione automatica del repository di backup può essere eseguita automaticamente, in base alla pianificazione o manualmente. È inoltre possibile eseguire una verifica completa dei dati. È supportata la verifica completa dei dati in un repository di backup. Questa funzione può proteggere un repository dal danneggiamento in seguito a uno spegnimento imprevisto del computer.
- I repository di backup possono essere collegati e scollegati. Questa funzione consente di conservare i dati in uno stato coerente, copiare i file del repository in un’altra posizione, ecc. Può essere eseguita manualmente o in base a una pianificazione. Quando un repository di backup viene scollegato, la soluzione NAKIVO interrompe l’interazione con questo repository e i suoi file.
- Un repository di backup allegato è gestito da un Transporter, è considerato pienamente funzionante in un dato momento e può essere utilizzato dai lavori.
- Un repository di backup scollegato non è gestito da un Transporter e non può essere utilizzato dai lavori. Può essere spostato o scollegato mentre è scollegato.
Quando un repository è scollegato, è impossibile eseguire la manutenzione manualmente o in base alla pianificazione.
Si consiglia di eseguire le operazioni che consumano risorse della CPU (ad esempio, il recupero dello spazio e la verifica del repository di backup) durante le ore non lavorative, ad esempio di notte o nei fine settimana. Per queste operazioni viene utilizzata una CPU del computer con un Transporter assegnato al repository di backup appropriato.
Immutabilità del punto di ripristino
Gli archivi di backup su determinati supporti e piattaforme supportano l’immutabilità per i backup. L’immutabilità impedisce modifiche indesiderate, crittografia e cancellazione dei dati, rendendo i punti di ripristino immuni da ransomware e altre minacce informatiche. Questa tecnologia si basa sulla tecnologia WORM (Write Once Read Many).
L’immutabilità deve essere abilitata per un backup nella procedura guidata di creazione del processo. Può essere abilitata per i punti di ripristino memorizzati nei seguenti tipi di repository di backup supportati:
- Cartella locale sul Transporter assegnato per i repository di backup su Linux
- Repository in Amazon S3, Wasabi, Archiviazione BLOB di Azure e Backblaze B2
- Altre piattaforme di archiviazione compatibili con S3 che supportano Object Lock e l’immutabilità a livello di versione
Quando si utilizzano repository di backup come Amazon S3, Wasabi, Archiviazione BLOB di Azure, Backblaze B2 Cloud Storage e altre piattaforme di archiviazione compatibili con S3, è necessario abilitare Object Lock o il supporto dell’immutabilità a livello di versione per il bucket o il contenitore blob responsabile dell’archiviazione dei backup. Questa funzione di immutabilità garantisce che i dati non possano essere modificati o eliminati, nemmeno dall’utente root, e che non possa essere abbreviata o revocata una volta abilitata.
Quando si utilizza il Cartella locale tipo di repository di backup, i punti di ripristino immutabili sono protetti dalla sovrascrittura, dall’eliminazione o dalla modifica da parte di chiunque non sia l’utente root fino al termine del periodo specificato.
Dopo l’implementazione del Cartella locale tipo di repository di backup come parte integrante di VMware vSphere (dal modello OVA) o un’AMI preconfigurata in Amazon EC2, NAKIVO Backup & Replication offre un livello avanzato di protezione dal ransomware. Ciò comporta la possibilità di rendere immutabili i punti di ripristino memorizzati all’interno di questo repository, il che significa che non possono essere alterati o modificati da nessuno, compreso l’utente root, una volta abilitata la funzione di immutabilità.
Struttura del repository di backup
Un repository di backup ha una struttura speciale per archiviare i dati di backup e non è possibile trovare file tradizionali, come i dischi virtuali, nella directory di un repository di backup (NakivoBackup).
Importante: Non modificare o eliminare manualmente alcun file o cartella di un repository di backup.
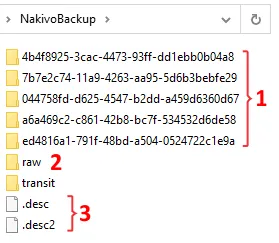
- Cartelle di backup: Ogni cartella contiene i punti di ripristino per ogni lavoro di backup.
- Cartella Raw: Contiene file di dati grezzi (file chunk). Formato dei file chunk: index.variant(0000.001, 0001.002, 0002.00a, 0003.00b, …).
- File descrittori: Informazioni di storage di tutti i file Chunk nel repository:
- + RawBlockRecord (include flag, variante, lunghezza, offset, hash1, hash2, rcount): Informazioni relative a un blocco nel file descrittore.
- + ShiftBlockRecord (variant_old, offset_old, variant_new, offset_new): Informazioni relative a un blocco che è stato spostato dalla vecchia posizione alla nuova posizione nei file di dati grezzi.
- + ChunkMap: informazioni di storage dei file chunk (stesso indice chunk, variante diversa) e i file descrittori conterranno un elenco di ChunkMap, che viene caricato durante l’inizializzazione del repository.
Il file di blocco viene utilizzato per impedire l’utilizzo simultaneo di un repository di backup da parte di due Transporter.
La struttura logica del repository di backup è la seguente:
– Repository di backup
- Backup 1
- Punto di ripristino 1
- Punto di ripristino 2
- Ecc.
- Backup 2
- Punto di ripristino 1
- Punto di ripristino 2
- Ecc.
I punti di ripristino vengono eliminati automaticamente alla scadenza del periodo di conservazione (in base alle date di scadenza impostate o al metodo di conservazione legacy nelle versioni 10.7 e precedenti). Non è consigliabile eliminare manualmente alcun file dalla directory del repository di backup.
Come creare un repository di backup
È possibile creare un nuovo repository di backup in NAKIVO Backup & Replication su una qualsiasi delle piattaforme supportate elencate sopra.
Creiamo un nuovo repository di backup su un computer con Ubuntu Linux installato. Il requisito principale per creare un nuovo repository di backup su un computer remoto è che Transporter sia già installato su quel computer Linux. Abbiamo già installato Transporter su questo computer Linux.
In questo esempio utilizziamo questi due computer per l’implementazione e la configurazione della soluzione NAKIVO:
- NAKIVO Director (soluzione completa): 192.168.101.209
- NAKIVO Transporter su una macchina Linux: 192.168.101.210
Se Transporter è installato, eseguire i seguenti passaggi per creare un nuovo repository di backup su una macchina Linux:
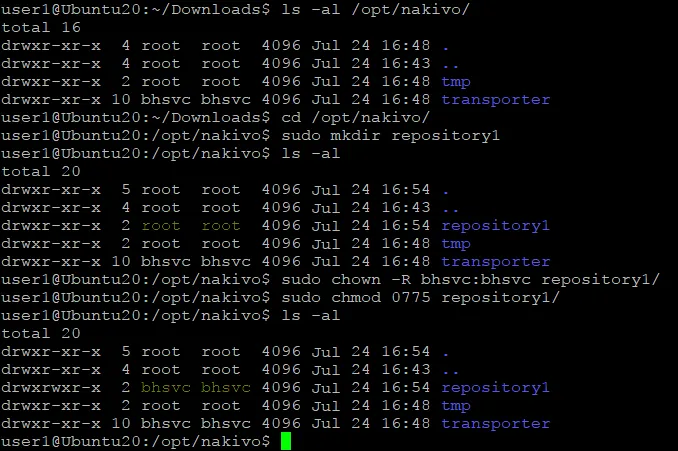
- Creare una directory che verrà utilizzata per il nuovo repository di backup per archiviare i backup. Creiamo una directory chiamata repository1 in /opt/NAKIVO/ e vai a questa directory nella console Linux:
cd /opt/nakivo/sudo mkdir repository1 - Impostare l’utente NAKIVO, denominato bhsvc come proprietario di questa repository1 directory (per eseguire questa operazione sono necessari i privilegi di root):
sudo chown -R bhsvc:bhsvc repository1Nota: Se si crea un repository di backup su NAS, per impostare l’utente NAKIVO come proprietario della directory del repository, utilizzare:
sudo chown -R u_bhsvc:g_bhsvc repository1 - Impostare le autorizzazioni corrette per questa directory in modo da consentire la lettura e la scrittura dei dati di backup da parte della soluzione NAKIVO:
sudo chmod 0775 repository1 - Verificare che il proprietario e le autorizzazioni siano stati impostati controllando il contenuto di /opt/NAKIVO/:
ls -al
- Una directory è stata creata e configurata. Ora apri l’interfaccia web di NAKIVO Backup & Replication & Replication (fornita dal componente NAKIVO Director). Il link che apriamo nel nostro browser web è https://192.168.101.209:4443 in questo caso.
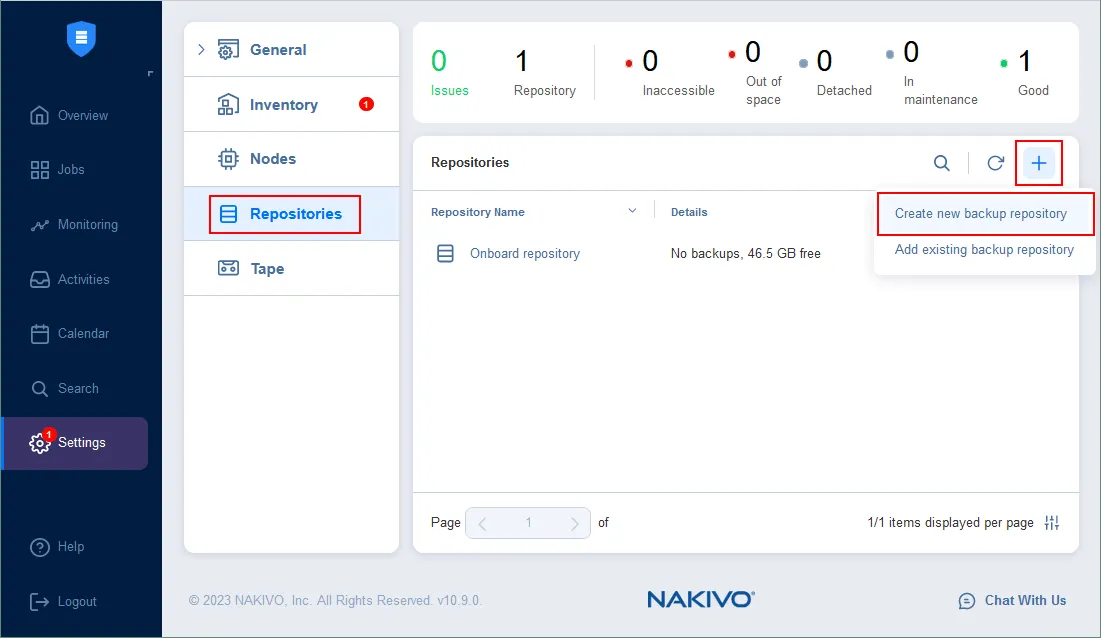
- Vai a Impostazioni > Repository, clicca su +, e clicca su Crea un nuovo repository di backup.
- Si apre la finestra di dialogo New Backup Repository Wizard (Procedura guidata Nuovo repository di backup) .
- Selezionare un tipo di repository di backup nel primo passaggio della procedura guidata. Poiché stiamo creando un nuovo repository di backup su un computer Linux, selezioniamo Cartella locale (Cartella locale). Premere Avanti per continuare.
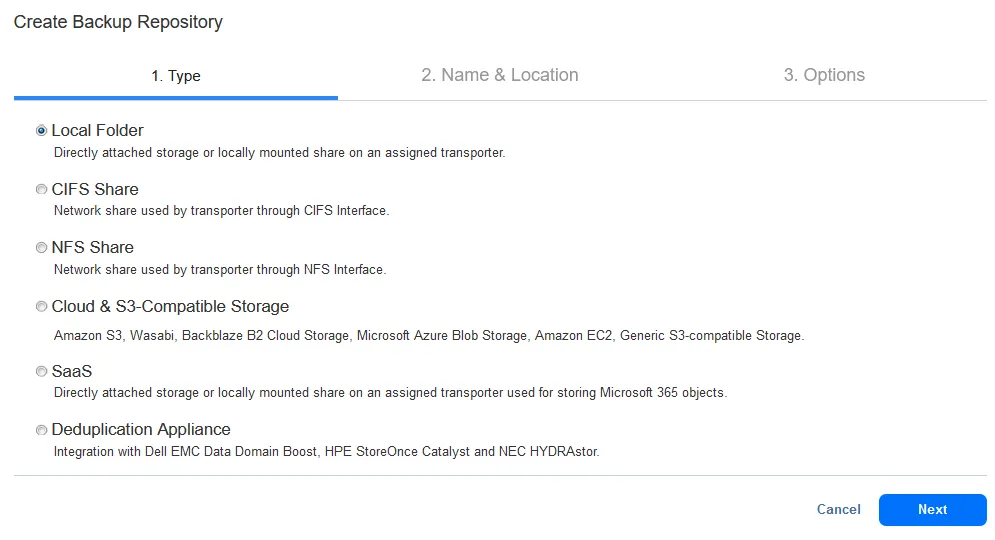
- Il secondo passaggio richiede l’impostazione di un nome e di una ubicazione. Immettere un nome per il repository di backup, ad esempio RepositoryL1.
Selezionare il Transporter assegnato a questo repository di backup. Selezioniamo il Transporter installato sulla macchina Linux remota (192.168.101.210).
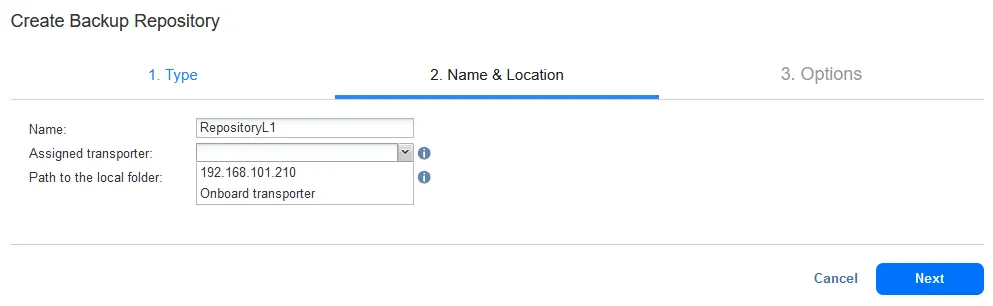
Inserisci il percorso alla cartella locale sulla macchina in cui è installato il Transporter. Questa directory è /opt/NAKIVO/repository1 nel nostro caso, che è la directory che abbiamo creato sul nostro computer Linux.
Fare clic su Avanti per continuare.
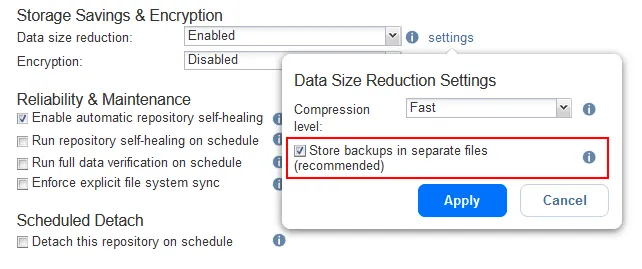
- Configurare le opzioni. In questa fase è necessario configurare le opzioni di risparmio di spazio di archiviazione, crittografia, affidabilità e manutenzione per il repository di backup. Se si desidera utilizzare la compressione, impostare le opzioni di riduzione della dimensione dei dati in questa fase. Non è possibile modificare le impostazioni di compressione per un repository di backup dopo che il repository è stato creato.

Se si desidera creare un repository di backup incrementale permanente, fare clic su Impostazioni alla voce Riduzione della dimensione dei dati e deseleziona la casella Archivia i backup in file separati (consigliato) . Fare clic su Applica.
- È stato creato un nuovo repository di backup.
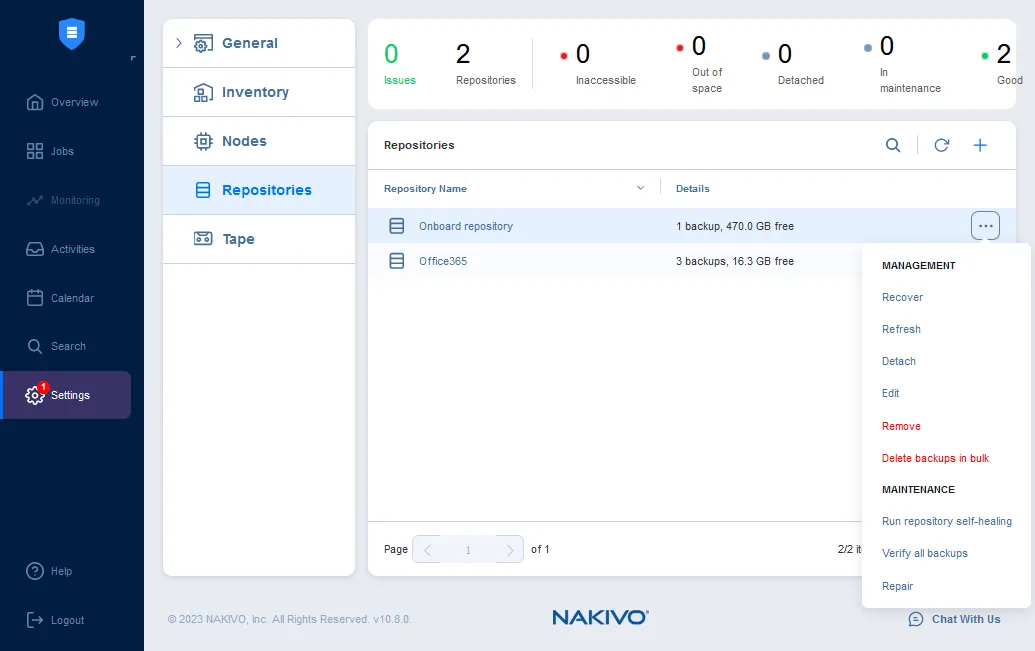
È possibile fare clic su un repository di backup (l’elenco dei repository si trova in Impostazioni > Repositories) per visualizzare la dimensione utilizzata, la dimensione libera e altri parametri del repository di backup.
È possibile passare il mouse sul nome del repository di backup e fare clic sull’icona con i tre puntini per aprire un menu con le azioni che è possibile eseguire con il repository di backup selezionato. È possibile ripristinare i dati, modificare alcune impostazioni del repository, verificare i backup, riparare un repository di backup, eseguire l’autoriparazione del repository, ecc.
Abilitazione dell’immutabilità
Se si desidera archiviare punti di ripristino immutabili in un repository di backup, è necessario abilitare l’immutabilità durante la creazione di un nuovo lavoro di backup (fare clic su Lavori, premere + per creare un nuovo lavoro di backup e selezionare ciò che si desidera sottoporre a backup). Un repository di backup creato su una macchina Linux (come nel nostro caso) supporta l’immutabilità.
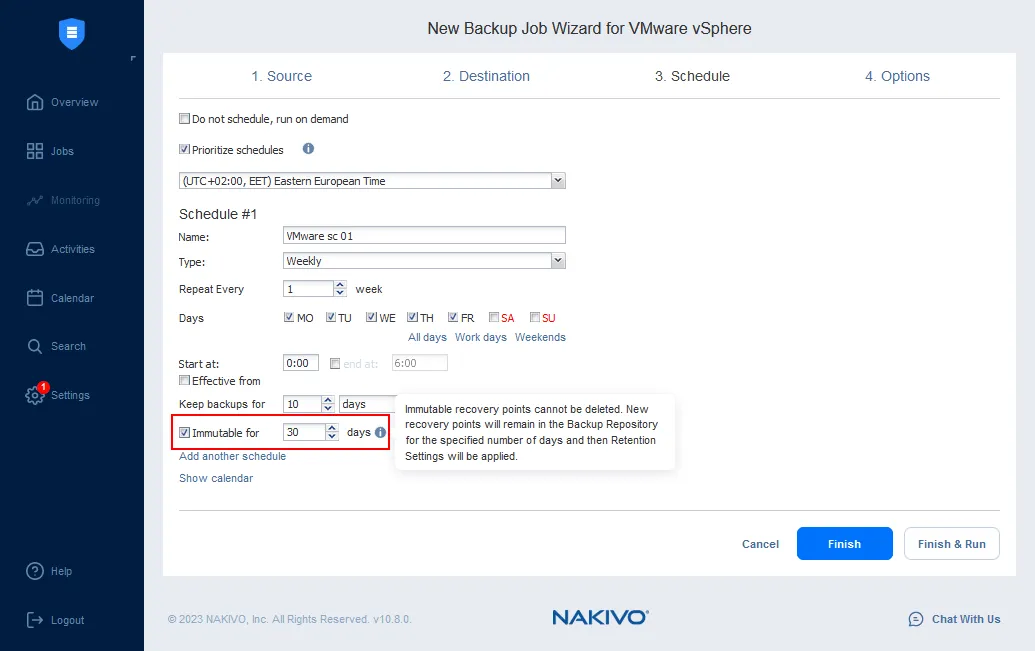
Al passaggio 3 della procedura guidata per la creazione di un nuovo lavoro di backup, in cui vengono configurate le impostazioni di pianificazione e di conservazione per un lavoro di backup, è possibile trovare le impostazioni di immutabilità. Selezionare la casella di controllo appropriata e il numero di giorni per rendere il backup immutabile per quel numero di giorni.



