Che cos’è la deduplicazione nell’storage dei dati di backup
<
La deduplicazione dei dati è una tecnologia di ottimizzazione della capacità di storage. La deduplicazione dei dati comporta la lettura dei dati di origine e dei dati già archiviati per trasferire o salvare solo i blocchi di dati unici. I riferimenti ai dati duplicati vengono mantenuti. Utilizzando questa tecnologia per evitare duplicati su un volume, è possibile risparmiare spazio su disco e ridurre il sovraccarico di storage. I predecessori della deduplicazione dei dati sono gli algoritmi di compressione LZ77 e LZ78 introdotti rispettivamente nel 1977 e nel 1978. Essi prevedono la sostituzione di sequenze di dati ripetute con riferimenti a quelle originali. Questo concetto ha influenzato altri metodi di compressione diffusi. Il più noto di questi è DEFLATE, utilizzato nei formati di immagine PNG e nei file ZIP. Ora vediamo come funziona la deduplicazione con i backup delle VM e in che modo contribuisce a risparmiare spazio di archiviazione e costi di infrastruttura. Durante un backup, la deduplicazione dei dati verifica la presenza di blocchi di dati identici tra l’archivio di origine e il repository di backup di destinazione. I duplicati non vengono copiati e viene creato un riferimento, o puntatore, ai blocchi di dati esistenti nell’archivio di backup di destinazione. Per capire quanto spazio di storage è possibile guadagnare con la deduplicazione, consideriamo un esempio. I requisiti minimi di sistema per l’installazione di Windows Server 2016 sono almeno 32 GB di spazio libero su disco. Se si dispone di dieci VM che eseguono questo sistema operativo, i backup occuperanno almeno 320 GB, e questo è solo un sistema operativo pulito senza applicazioni o database. È probabile che, se dovete effettuare l’implementazione di più di una Il rapporto di deduplicazione dei dati è una metrica utilizzata per misurare la dimensione dei dati originali rispetto alla dimensione dei dati dopo la rimozione delle parti ridondanti. Questa metrica consente di valutare l’efficacia del processo di deduplicazione dei dati. Per calcolare il valore, è necessario dividere la quantità di dati prima della deduplicazione per lo spazio di storage consumato da questi dati dopo la deduplicazione. Ad esempio, un rapporto di deduplicazione di 5:1 significa che è possibile archiviare cinque volte più dati di backup nell’archivio di backup rispetto a quanto richiesto per archiviare gli stessi dati senza deduplicazione. È necessario determinare il rapporto di deduplicazione e la riduzione dello storage . Questi due parametri vengono talvolta confusi. I rapporti di deduplicazione non cambiano in modo proporzionale ai vantaggi della riduzione dei dati, poiché oltre un certo punto entra in gioco la legge dei rendimenti decrescenti. Vedi il grafico sottostante. Ciò significa che i rapporti più bassi possono portare a risparmi più significativi rispetto a quelli più alti. Ad esempio, un rapporto di deduplicazione di 50:1 non è cinque volte migliore di un rapporto di 10:1. Il rapporto 10:1 offre una riduzione del 90% dello spazio di storage consumato, mentre il rapporto 50:1 aumenta questo valore al 98%, dato che la maggior parte della ridondanza è già stata eliminata. Per ulteriori informazioni su come vengono calcolate queste percentuali, è possibile consultare il documento della Storage Networking Industry Association (SNIA) sulla deduplicazione dei dati. È difficile prevedere l’efficienza della riduzione dei dati fino a quando questi non vengono effettivamente deduplicati a causa di diversi fattori. Di seguito sono riportati alcuni dei fattori che influiscono sulla riduzione dei dati quando si utilizza la deduplicazione: Nota: La deduplicazione locale funziona su un singolo nodo/dispositivo disco. La deduplicazione globale analizza l’intero set di dati su tutti i nodi/dispositivi disco per eliminare i dati duplicati. Se si dispone di più nodi con deduplicazione locale abilitata su ciascuno di essi, la deduplicazione non sarà efficiente come con la deduplicazione globale abilitata per essi. Le tecniche di deduplicazione dei backup possono essere classificate in base ai seguenti criteri: La deduplicazione del backup può essere eseguita sul lato sorgente o sul lato destinazione e tali tecniche sono denominate rispettivamente deduplicazione sul lato sorgente e deduplicazione sul lato destinazione. La deduplicazione lato sorgente riduce il carico di rete perché durante il backup vengono trasferiti meno dati. Tuttavia, è obbligatoria l’installazione di un agente di deduplicazione su ogni VM o su ogni host. L’altro svantaggio è che la deduplicazione lato origine può rallentare le VM a causa dei calcoli obbligatori per l’identificazione dei blocchi di dati duplicati. > La deduplicazione lato destinazione trasferisce prima i dati al repository di backup e poi esegue la deduplicazione. Le attività di calcolo più complesse vengono eseguite dal software responsabile della deduplicazione. La deduplicazione del backup può essere in linea o in post-elaborazione. I metodi più comuni per identificare i duplicati sono quelli basati su hash e quelli basati su hash modificato. La deduplicazione dei backup è uno dei casi d’uso più diffusi della deduplicazione. Tuttavia, per implementare questa tecnologia di riduzione dei dati è necessario disporre della soluzione software e dell’hardware di storage adeguati. NAKIVO Backup & Replication è una soluzione di backup che supporta l’utilizzo della deduplicazione post-elaborazione globale con rilevamento dei duplicati basato su hash modificato. È inoltre possibile sfruttare la deduplicazione lato sorgente integrando un’appliance di deduplicazione come DELL EMC Data Domain con DD Boost, NEC HYDRAstor e HP StoreOnce con supporto Catalyst con la soluzione NAKIVO.
Che cos’è la deduplicazione?
Origini della deduplicazione dei dati
Che cos’è la deduplicazione nel backup?

Quanto spazio è possibile risparmiare con la deduplicazione dei dati?
Rapporto di deduplicazione dei dati

Fattori che influenzano l’efficienza della deduplicazione dei dati
Tecniche di deduplicazione dei backup
Dove viene eseguita la deduplicazione dei dati
Deduplicazione lato sorgente

Deduplicazione lato destinazione
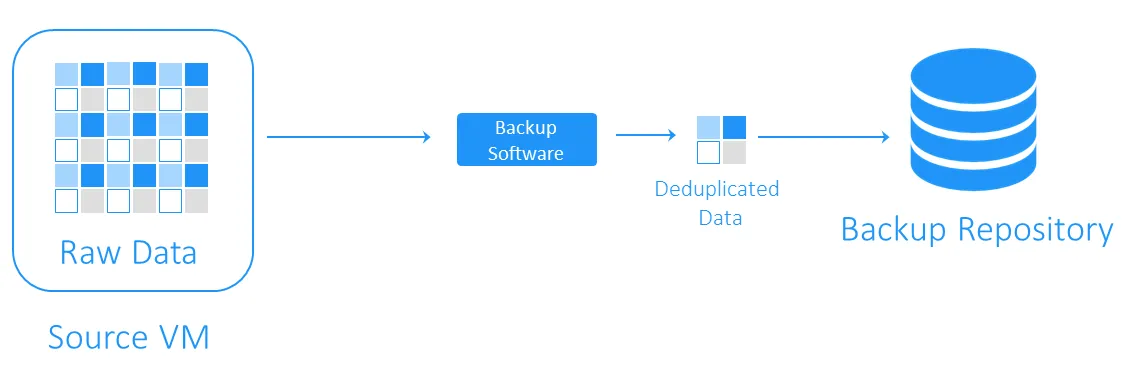
Una volta completata la deduplicazione dei dati
Come viene eseguita la deduplicazione dei dati
Scelta del software di deduplicazione dei backup


