Comment configurer la réplication MS SQL Server
Microsoft SQL Server est un logiciel de gestion de bases de données qui peut être installé sur les systèmes d’exploitation Windows Server. Les bases de données sont utilisées par les entreprises de tous les secteurs, et de nombreuses solutions logicielles utilisent des bases de données, qu’elles soient centralisées ou distribuées. La disponibilité des bases de données et la cohérence des données sont essentielles pour les entreprises, ce qui rend la sauvegarde et la réplication des bases de données indispensables.Découvrez les types de réplication SQL Server, le fonctionnement de la réplication dans SQL Server et comment effectuer une réplication SQL Server.
Qu’est-ce que la réplication SQL Server ?
La réplication MS SQL Server est le processus qui consiste à copier des données d’une base de données vers une autre, y compris des objets de base de données spécifiques, et à maintenir une copie synchronisée de ces données entre la base de données source et la base de données cible. Grâce à la réplication dans SQL Server, vous pouvez créer une copie identique de votre base de données principale et synchroniser les modifications entre les deux bases de données tout en conservant la cohérence et l’intégrité des données.
Terminologie utilisée pour la réplication MS SQL Server
Avant d’aborder la configuration et la mise en place de la réplication MS SQL Server, passons d’abord brièvement en revue les principaux termes et les modèles de réplication.Articles sont les unités de base à reproduire, telles que les tables, les procédures, les fonctions et les vues. Les articles peuvent être dotés d’une évolutivité verticale ou horizontale grâce à des filtres. Plusieurs articles peuvent être créés pour le même objet.Une publication est un ensemble logique d’articles. Il s’agit de l’ensemble final d’entités issues de la base de données destinées à être répliquées.Un filtre est un ensemble de conditions pour un article. La réplication MS SQL Server vous permet d’utiliser des filtres et de sélectionner des entités personnalisées pour la réplication, ce qui réduit le trafic, la redondance et la quantité de données stockées dans une réplique de base de données. Par exemple, vous pouvez sélectionner uniquement les tables et les champs les plus critiques par l’intermédiaire de filtres, puis répliquer uniquement ces données.Agents sont des composants MS SQL Server qui peuvent agir comme services d’arrière-plan pour les systèmes de gestion de bases de données relationnelles et qui sont utilisés pour planifier l’exécution automatisée de tâches, telles que la sauvegarde et la réplication de bases de données MS SQL. Il existe cinq types d’agents : Snapshot Agent, Log Reader Agent, Distribution Agent, Merge Agent et Queue Reader Agent.Métadonnées sont les données utilisées pour décrire les entités de la base de données. Il existe un large éventail de fonctions de métadonnées intégrées qui vous permettent de renvoyer des informations sur l’instance MS SQL Server, les instances de base de données et les entités de base de données.
Rôles dans la réplication de bases de données SQL
Il existe trois rôles principaux dans la réplication de base de données MS SQL : distributeur, éditeur et abonné.
- Un distributeur est une instance de base de données MS SQL configurée pour collecter les transactions provenant des publications et les distribuer aux abonnés. Un distributeur sert de base de données pour stocker les transactions répliquées.
Une base de données de distribution peut être considérée à la fois comme l’éditeur et le distributeur. Dans le modèle de distribution locale, une seule instance MS SQL Server exécute à la fois l’éditeur et le distributeur. Un modèle de distribution à distance peut être utilisé lorsque vous souhaitez que les abonnés soient configurés pour utiliser une seule instance MS SQL Server afin d’obtenir différentes publications (distribution centralisée). Dans ce modèle, l’éditeur et le distributeur s’exécutent sur des serveurs différents.
- Un éditeur est la copie principale de la base de données sur laquelle la publication est configurée, mettant les données à la disposition d’autres serveurs MS SQL configurés pour être utilisés dans le processus de réplication. L’éditeur peut avoir plusieurs publications.
- Un abonné est une base de données qui reçoit les données répliquées à partir d’une publication. Un abonné peut recevoir des données provenant de plusieurs éditeurs et publications. Un modèle à abonné unique est utilisé lorsqu’il n’y a qu’un seul abonné. Un modèle à abonnés multiples est utilisé lorsque plusieurs abonnés sont connectés à une seule publication.
Abonnement est une demande de copie d’une publication qui doit être livrée à l’abonné. L’abonnement sert à définir les données de publication qui doivent être reçues, ainsi que le lieu et le moment où ces données seront reçues. Il existe deux types d’abonnements :
- Abonnement Push: Les données modifiées sont transmises de manière forcée depuis un distributeur vers une base de données d’abonnés. Aucune demande de la part de l’abonné n’est nécessaire.
- Tirer l’abonnement: Les données modifiées sur l’éditeur sont demandées par un abonné. L’agent s’exécute du côté de l’abonné.
Une base de données d’abonnement est une base de données cible dans le modèle de réplication MS SQL.

Dans le plusieurs éditeurs – plusieurs abonnés modèle, l’éditeur peut agir en tant qu’abonné sur l’un des serveurs MS SQL. Veillez à éviter tout conflit de mise à jour potentiel lorsque vous utilisez ce modèle de réplication MS SQL Server.
Types de réplication MS SQL Server
La réplication MS SQL Server est une technologie permettant de copier et de synchroniser des données entre des bases de données de manière continue ou régulière, à intervalles planifiés. En ce qui concerne le sens de la réplication, la réplication MS SQL Server peut être unidirectionnelle, un-à-plusieurs, bidirectionnelle et plusieurs-à-un. Il existe quatre types de réplication MS SQL Server : la réplication instantanée, la réplication transactionnelle, la réplication peer-to-peer et la réplication par fusion.
Réplication instantanée
Réplication instantanée est utilisé pour répliquer les données exactement telles qu’elles apparaissent au moment où l’instantané de la base de données est créé. Ce type de réplication convient aux données qui ne changent pas fréquemment, lorsqu’il n’est pas critique que la réplique de la base de données soit plus ancienne que la base de données principale, ou lorsqu’un grand nombre de modifications sont apportées en peu de temps. Le suivi des modifications n’est pas utilisé avec la réplication par instantané.Par exemple, la réplication par instantané peut être utilisée lorsque les taux de change ou les listes de prix sont mis à jour une fois par jour et doivent être distribués du serveur principal aux serveurs des succursales.
Réplication transactionnelle
Réplication transactionnelle Il s’agit d’une réplication automatisée périodique lorsque les données sont distribuées depuis une base de données principale vers une réplique de base de données en temps réel (ou quasi réel). La réplication transactionnelle est plus complexe que la réplication par instantané. Toutes les transactions effectuées ainsi que l’état final de la base de données sont répliqués, ce qui permet de surveiller l’historique complet des transactions sur la réplique.Au début du processus de réplication transactionnelle, un instantané est appliqué à l’abonné, puis les données sont transférées en continu de la base de données principale vers une réplique de la base de données à mesure que des modifications sont apportées à ces données. La réplication transactionnelle est largement utilisée comme réplication unidirectionnelle. Cas d’utilisation de la réplication transactionnelle :
Cas d’utilisation de la réplication transactionnelle :
- Création d’un serveur de base de données avec une réplique de base de données à utiliser en cas de basculement si le serveur de base de données principal tombe en panne.
- Réception de rapports sur les opérations effectuées dans les succursales par plusieurs éditeurs dans les succursales et par un seul abonné au siège social.
- Répliquer les modifications dès qu’elles surviennent.
- Les données de la base de données Source changent fréquemment.
Réplication peer-to-peer
Réplication peer-to-peer est utilisé pour répliquer les données d’une base de données vers plusieurs abonnés simultanément. Ce type de réplication MS SQL Server peut être utilisé lorsque vos serveurs de bases de données sont répartis à travers le monde. Les modifications peuvent être apportées sur n’importe quel serveur de base de données. Elles sont ensuite propagées à tous les serveurs de bases de données. La réplication peer-to-peer peut aider à améliorer l’évolutivité d’une application qui utilise une base de données. Son principe de fonctionnement repose principalement sur la réplication transactionnelle. Vous trouverez ci-dessous un exemple d’utilisation de la réplication peer-to-peer MS SQL Server entre des serveurs de bases de données répartis à travers le monde.
Vous trouverez ci-dessous un exemple d’utilisation de la réplication peer-to-peer MS SQL Server entre des serveurs de bases de données répartis à travers le monde.
Réplication fusionnée
Réplication fusionnée est un type de réplication bidirectionnelle généralement utilisé dans les environnements serveur-client pour synchroniser les données entre les serveurs de bases de données lorsqu’ils ne peuvent pas être connectés en permanence. Lorsque la connexion réseau est établie entre les deux serveurs de bases de données, les agents de réplication de fusion détectent les modifications apportées aux deux bases de données et modifient les bases de données pour synchroniser et mettre à jour leur état. La réplication de fusion est similaire à la réplication transactionnelle, mais les données sont répliquées de l’éditeur vers l’abonné et inversement. Ce type de réplication de base de données est le plus complexe de tous les types de réplication MS SQL Server et est rarement utilisé. Par exemple, la réplication par fusion peut être utilisée par plusieurs magasins pairs qui travaillent avec un entrepôt partagé. Chaque magasin est autorisé à modifier les informations contenues dans la base de données de l’entrepôt et, dans le même temps, tous les magasins doivent disposer de l’état mis à jour de leurs bases de données après l’expédition des marchandises ou la livraison des fournitures à l’entrepôt. La réplication par fusion peut être utilisée dans les cas où les informations mises à jour doivent être disponibles simultanément pour la base de données principale (ou centrale) et les bases de données des succursales.
Ce type de réplication de base de données est le plus complexe de tous les types de réplication MS SQL Server et est rarement utilisé. Par exemple, la réplication par fusion peut être utilisée par plusieurs magasins pairs qui travaillent avec un entrepôt partagé. Chaque magasin est autorisé à modifier les informations contenues dans la base de données de l’entrepôt et, dans le même temps, tous les magasins doivent disposer de l’état mis à jour de leurs bases de données après l’expédition des marchandises ou la livraison des fournitures à l’entrepôt. La réplication par fusion peut être utilisée dans les cas où les informations mises à jour doivent être disponibles simultanément pour la base de données principale (ou centrale) et les bases de données des succursales.
Conditions à remplir pour la réplication MS SQL Server
Les ports suivants doivent être ouverts pour le trafic entrant :
- TCP 1433, 1434, 2383, 2382, 135, 80, 443
- UDP 1434
Veillez à configurer le pare-feu Windows et à activer les ports appropriés pour le trafic entrant sur chaque hôte avant d’installer MS SQL Server. Les hôtes participant à la réplication MS SQL doivent se résoudre mutuellement par un nom d’hôte.Avant de configurer la réplication MS SQL Server, les logiciels suivants doivent être installés pour MS SQL Server :
- .NET Framework – un ensemble de bibliothèques
- MS SQL Server – le logiciel serveur de base de données
- MS SQL Server Management Studio (SSMS) – logiciel permettant de gérer les bases de données MS SQL à l’aide d’une interface graphique (GUI).
REMARQUE : MS SQL Server 2016 est utilisé pour la configuration dans cet article. Vous pouvez utiliser le même principe pour configurer la réplication dans les versions plus récentes de SQL Server.N’oubliez pas que si vous installez MS SQL Server 2016 sur la première machine où se trouve la base de données source, vous devez également installer MS SQL Server 2016 sur la deuxième machine pour que la base de données fonctionne correctement.Par exemple, si vous souhaitez configurer la réplication transactionnelle MS SQL, vous pouvez utiliser le deuxième serveur de base de données (où le souscripteur est configuré) d’une version comprise entre deux versions du serveur de base de données source sur lequel l’éditeur est configuré. Si la version de l’éditeur sur MS SQL Server est 2016, le distributeur peut être configuré sur les versions 2016, 2017, 2019 et 2022, et l’abonné peut être configuré sur MS SQL Server 2012, 2014, 2016, 2017 et 2019. La version du distributeur ne peut pas être inférieure à celle de l’éditeur. La réplication ne fonctionnera pas si vous installez MS SQL Server 2008 sur la deuxième machine, par exemple.
Recommandations de base pour la réplication de bases de données MS SQL
Avant de configurer l’environnement pour MS SQL Server, voici quelques facteurs à prendre en compte :
- Il existe des limitations concernant les champs d’identité et les déclencheurs.
- Les publications ne peuvent contenir que des tables avec la clé primaire.
- Il est recommandé de ne pas planifier la création d’instantanés pour les bases de données volumineuses afin d’éviter d’utiliser une grande quantité de ressources informatiques.
- Soyez prudent lorsque vous modifiez des données dans la réplique de base de données résidant sur l’abonné. Lorsqu’une transaction modifiant des données est en cours et que ces données ont été modifiées ou supprimées, la réplication peut s’arrêter jusqu’à ce que ce problème soit résolu.
Configuration de l’environnement
Lorsque vous configurez la réplication MS SQL pour la première fois, il est recommandé de le faire d’abord dans un environnement de test. Par exemple, nous configurons la réplication dans des serveurs SQL fonctionnant sur des machines virtuelles. Deux hôtes fonctionnant sous Windows Server 2016 et MS SQL Server 2016 sont utilisés dans ce tutoriel pour expliquer la réplication MS SQL Server.Examinons la configuration de l’environnement de test utilisé pour rédiger cet article de blog afin de mieux comprendre la configuration de la réplication MS SQL Server.Hôte 1
- Adresse IP : 192.168.101.101
- Nom d’hôte : MSSQL01
- ID d’instance MS SQL Server : MSSQLSERVER1
Hôte 2
- Adresse IP : 192.168.101.102
- Nom d’hôte : MSSQL02
- ID d’instance MS SQL Server : MSSQLSERVER2
Les deux machines ont un disque C: et un disque D: dans leur configuration de disque.Vous pouvez désactiver temporairement le pare-feu Windows lorsque vous installez MS SQL Server afin de vous entraîner à configurer la réplication MS SQL Server.Cet article de blog ne traite pas de l’installation de MS SQL Server, car ce tutoriel se concentre sur la configuration de la réplication MS SQL Server. Dans cet exemple, les deux serveurs MS SQL sont installés sans PolyBase.Vérifiez que vous avez installé les fonctionnalités requises pour la réplication MS SQL Server une fois l’installation de MS SQL Server terminée. Notez que les services du moteur de base de données, tels que la réplication SQL Server et R-Services, doivent être sélectionnés lors de l’installation de MS SQL Server. Le chemin d’installation par défaut est utilisé dans cet exemple (C:Program FilesMicrosoft SQL Server). Autres paramètres :
Autres paramètres :
- Mode d’authentification mixte (authentification Windows et authentification MS SQL Server)
- Répertoire racine des données : D:MSSQL_Server
- Répertoire de la base de données système : D:MSSQL_ServerMSSQL13.MSSQLSERVER1MSSQLData
- Répertoire de la base de données utilisateur : D:MSSQL_ServerMSSQL13.MSSQLSERVER1MSSQLData
- Répertoire du journal de la base de données utilisateur : D:MSSQL_ServerMSSQL13.MSSQLSERVER1MSSQLData
- Répertoire de sauvegarde : D:MSSQL_ServerMSSQL13.MSSQLSERVER1MSSQLBackup
Une fois MS SQL Server 2016 et SQL Server Management Studio installés sur les machines, vous pouvez préparer vos serveurs MS SQL pour la réplication de bases de données.
Préparation à la réplication MS SQL Server
Vous devez configurer les serveurs avant de pouvoir démarrer la réplication de la base de données. Dans notre exemple, un compte Windows sera utilisé pour les agents de réplication MS SQL Server.
- Créer le mssql utilisateur sur les deux serveurs et définissez le même mot de passe.
- Le mssql Dans cet exemple, l’utilisateur est membre des groupes suivants :
- Administrateurs (administrateurs locaux sur des machines locales, pas administrateurs de domaine)
- Groupe d’utilisateurs SQL MSSQLSERVER1
- SQLServer2005SQLBrowserUtilisateur$MSSQL01
- Vous pouvez modifier les utilisateurs et les groupes par pression Win+R, ouverture CMD, et exécuter le
lusrmgr.msccommande.
Les deux machines Windows Server utilisées dans cet exemple ne font pas partie d’Active Directory. Si vous utilisez Active Directory, vous pouvez créer le mssql utilisateur sur le contrôleur de domaine.
Connexion à MS SQL Server
- Exécutez SQL Server Management Studio pour la gestion.
- Connectez-vous (voir capture d’écran) en tant que sa par l’authentification SQL Server.
- MSSQL01MSSQLSERVER1 est le nom d’hôte et le nom de l’instance MS SQL sur le premier serveur.
- MSSQL02MSSQLSERVER2 est le nom d’hôte et le nom de l’instance MS SQL sur le deuxième serveur.

De même, vous pouvez vous connecter sur le deuxième serveur (MSSQL02) à la deuxième instance MS SQL Server (MSSQLSERVER2). Vous pouvez également vous connecter à la deuxième instance MS SQL Server (MSSQLSERVER2) par le premier MS SQL Server (MSSQL01) en saisissant les identifiants de connexion dans SQL Server Management Studio. Vous pouvez vous connecter aux deux instances MS SQL Server (MSSQL01 et MSSQL02) dans une seule instance de SQL Server Management Studio.Pour ce faire, dans l’Explorateur d’objets, cliquez sur Connecter > Moteur de base de donnéesDans ce tutoriel, nous allons nous connecter à MSSQLSERVER1 depuis MSSQL01 et à MSSQLSERVER2 depuis MSSQL02 par l’intermédiaire de SQL Server Management Studio pour configurer les serveurs MS SQL.
Démarrer l’agent
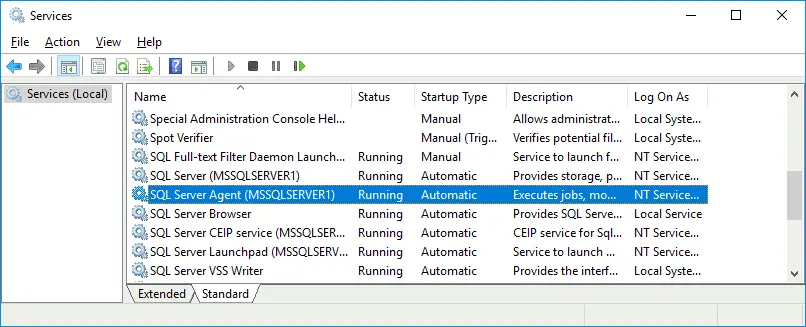
Une fois connecté à l’instance MS SQL Server, vous constaterez que l’agent ne fonctionne pas. Par défaut, SQL Server Agent ne démarre pas automatiquement. Vous pouvez démarrer ce service manuellement, mais il est préférable de le configurer pour qu’il démarre automatiquement après l’amorçage de Windows. Pour configurer le service Agent afin qu’il démarre automatiquement :
Pour configurer le service Agent afin qu’il démarre automatiquement :
- Presse Win+R, exécuter cmd, et exécutez le
services.msccommande. - Ouvrez les paramètres du service SQL Server Agent et définissez Startup Tapez pour Automatique.
Configuration des utilisateurs pour MS SQL Server
Après nous être connectés à l’instance MSSQLSERVER1 dans SQL Server Management Studio, nous devons configurer les utilisateurs :
- Aller à Explorateur d’objets et ouvrir La sécurité > Connexions.
- Clic droit Connexions et sélectionnez Nouvelle connexion. Sélectionner Authentification Windows.
- Entrez le nom d’utilisateur mssql dans le Général section.
- Cliquez Rechercher, puis appuyez sur Vérifier les noms pour confirmer, puis cliquez sur OK deux fois pour enregistrer les paramètres.

- Maintenant, le MSSQL01mssql L’utilisateur Windows est ajouté à la liste des utilisateurs pouvant se connecter à la base de données (de même, ajoutez le mssql utilisateur à connexions sur la deuxième machine MSSQL02 dans SQL Server Management Studio).
- Ajouter le mssql utilisateur au administrateurs système rôles de serveur dans le La sécurité configuration de la base de données dans SQL Server Management Studio.
- Aller à MSSQL01MSSQLSERVER1 > Rôles du serveur, cliquez avec le bouton droit de la souris administrateur système, et ouvrir Propriétés.
- Dans le Membres page, cliquez sur Ajouter, entrez le nom de votre utilisateur mssql, et cliquez Vérifier les noms.
- Cochez la case du nom d’utilisateur. MSSQL01mssql et cliquez OK.

- Effectuez la même configuration sur votre deuxième machine (MSSQL02 dans ce cas).
- Redémarrez les deux machines.
Vous pouvez désormais vous connecter par l’authentification Windows sur les deux serveurs.

Importation d’une base de données à partir d’une sauvegarde
Importons un exemple de base de données à partir d’une sauvegarde, puis répliquons la base de données de la première machine vers la deuxième machine. Le AdventureWorks2016 La base de données est utilisée comme exemple dans cet exemple.
- Copiez le AdventureWorks2016.bak fichier de sauvegarde de la base de données dans votre répertoire de sauvegarde MSSQL. Dans notre cas, ce répertoire sur le premier serveur est D:MSSQL_ServerMSSQL13.MSSQLSERVER1MSSQLBackup
- Importez un exemple de base de données. Sur le premier ordinateur dans SQL Server Management Studio, accédez à MSSQL01MSSQLSERVER1, cliquez avec le bouton droit de la souris Bases de données, et sélectionnez Restaurer la base de données dans le menu contextuel.

- Dans le Restaurer la base de données fenêtre, sélectionnez les paramètres nécessaires :
- Source: Appareil.
- Cliquez sur le trois points pour parcourir le fichier de sauvegarde de la base de données.
- Dans le Sélectionner les appliances de sauvegarde fenêtre, sélectionnez le type de support de sauvegarde : fichier.
- Cliquez Ajouter.
- Sélectionnez le nécessaire .bak fichier – D:MSSQL_ServerMSSQL13.MSSQLSERVER1MSSQLSauvegardesAdventureWorks2016.bak
- Frapper OK, puis appuyez sur OK encore une fois.
- Le AdventureWorks2016 La base de données a été restaurée avec succès.

Vous pouvez importer la base de données à partir d’une sauvegarde sur la deuxième machine, où la réplique de la base de données sera exécutée. Cette approche vous permet de réduire le trafic réseau, car la réplication commencera par copier les modifications apportées depuis la création de la sauvegarde, sans copier l’intégralité des données de la base de données vers une base de données vide.Restaurez la base de données à partir d’une sauvegarde sur le deuxième serveur et renommez la base de données en AdventureWorks2016r, où « r » signifie « réplique ».Enfin, nous avons :
| Nom d’hôteNom de l’instance MSSQL | Nom de la base de données |
| MSSQL01MSSQLSERVER1 | AdventureWorks2016 |
| MSSQL02MSSQLSERVER2 | AdventureWorks2016r |
Après avoir importé la base de données, vous devez effectuer quelques réglages pour préparer vos serveurs MS SQL.
- Sur le MSSQL01 machine, allez à MSSQL01MSSQLSERVER1 > La sécurité > Connexions, sélectionner MSSQL01mssql. Cliquez avec le bouton droit (ou double-cliquez) mssql utilisateur et sélectionner Propriétés.
- Dans Rôles du serveur, cochez la case suivante dbcreator rôle.

- Sur le Mappage des utilisateurs page, sélectionnez les utilisateurs associés à cette connexion et cochez la case AdventureWorks2016 case à cocher de la base de données (sélectionner AdventureWorks2016r sur le deuxième serveur en conséquence).
- Dans le appartenance à un rôle de base de données section, cochez la case db_owner case à cocher.

- Cliquez OK pour enregistrer les paramètres.
Effectuez la même configuration sur la machine MSSQL02. Vous pouvez ensuite configurer les composants MS SQL Server nécessaires à la réplication de la base de données.
Configuration de la réplication de base de données
La configuration de la réplication en mode graphique est la méthode la plus pratique. La configuration suivante est effectuée dans SQL Server Management Studio. La réplication de base de données transactionnelle est expliquée dans cet exemple, car il s’agit de l’un des types de réplication MS SQL Server les plus utilisés.La vue sur le serveur de base de données principal (MSSQL01MSSQLSERVER1) et la vue sur le deuxième serveur (MSSQL02MSSQLSERVER2) dans SQL Server Management Studio sont illustrées dans la capture d’écran ci-dessous.
Configuration de la distribution
La distribution peut être utilisée pour plusieurs éditeurs et abonnés. Dans cet exemple, la distribution est configurée sur le serveur principal sur lequel la base de données Source est stockée. Sur le serveur principal (MSSQL01MSSQLSERVER1), cliquez avec le bouton droit de la souris La réplication et, dans le menu contextuel, sélectionnez Configurer la distribution. Le Configurer l’assistant de distribution s’ouvre.
Le Configurer l’assistant de distribution s’ouvre.
- Distributeur. Sélectionnez l’instance de base de données actuelle s’exécutant sur le serveur principal (MSSQL01MSSQLSERVER1) pour qu’elle serve de distributeur dans cet exemple. Cliquez sur Suivant chaque fois pour passer à l’étape suivante de l’assistant.
- Démarrage de SQL Server Agent. Si vous n’avez pas configuré MS SQL Server Agent pour qu’il démarre automatiquement, comme expliqué ci-dessus, le message suivant s’affichera. Sélectionnez Oui, configurez le service SQL Server Agent pour qu’il démarre automatiquement..

- Dossier instantané. Vous pouvez conserver le chemin d’accès par défaut. Un instantané est nécessaire pour initialiser la réplication. Assurez-vous qu’il y a suffisamment d’espace libre sur le disque où se trouve votre répertoire d’instantanés. L’espace libre doit correspondre au moins à la taille de la base de données répliquée.
- Base de données de distribution. Entrez le nom de la base de données de distribution. Vous pouvez conserver le nom par défaut (distribution) et des dossiers pour le fichier de base de données de distribution et le fichier journal.

- Éditeurs. Définissez les éditeurs de réplication MS SQL Server qui peuvent accéder au distributeur. Cochez la case à côté du nom de la base de données de distribution sur l’instance MS SQL Server principale (qui héberge une base de données source qui sera répliquée). Dans cet exemple, il s’agit de l’instance MSSQL01MSSQLSERVER1, et le nom de la base de données de distribution est distribution.
- Actions du sorcier. Sélectionner Configurer la distribution pour configurer la distribution lors de la dernière étape de l’assistant. Dans cet exemple, nous ne générerons pas de fichier script à exécuter ultérieurement.

- Terminer l’assistant. Vérifiez le résumé de la configuration de la distribution et cliquez sur Terminer pour créer le distributeur.

- Le Succès Le statut doit apparaître si le distributeur a été créé et configuré avec succès.

Si vous constatez qu’une erreur s’est produite lors de la configuration de SQL Server Agent pour qu’il démarre automatiquement, accédez à la configuration des services et vérifiez le mode de démarrage de SQL Server Agent (voir comment configurer le démarrage de l’agent ci-dessus dans cet article de blog).Vous pouvez également ouvrir les propriétés de SQL Server Agent dans SQL Server Management Studio et vérifier l’état du service et les options de redémarrage. Cliquez avec le bouton droit de la souris. Agent SQL Server à la fin de la liste dans Explorateur d’objets et frapper Propriétés pour afficher ou modifier les propriétés de l’agent.
Configuration de l’éditeur
Une fois la distribution configurée, vous pouvez configurer l’éditeur. L’éditeur doit être configuré sur le serveur principal (MSSQL01MSSQLSERVER1) où est stockée la base de données maître à répliquer. Sélectionnez La réplication, cliquez avec le bouton droit de la souris Publications locales et, dans le menu contextuel, sélectionnez Nouvelle publication. Le Assistant de nouvelle publication s’ouvre.
Le Assistant de nouvelle publication s’ouvre.
- Base de données des publications. Sélectionnez la base de données que vous souhaitez répliquer (AdventureWorks2016 dans ce cas). Appuyez sur Suivant à chaque étape de l’assistant pour continuer.

- Type de publication. Pour cette étape, vous pouvez sélectionner les types de réplication MS SQL Server pour une base de données. Sélectionnons une publication transactionnelle, qui est un type de réplication largement utilisé.
- ArticlesSélectionnez les objets nécessaires, tels que les tables, les procédures, les vues, les vues indexées et les fonctions définies par l’utilisateur, à publier en tant qu’articles. Il est possible de sélectionner la réplication des champs personnalisés dans les tables et de sélectionner les propriétés des articles si nécessaire. Dans cet exemple, certaines tables sont sélectionnées.
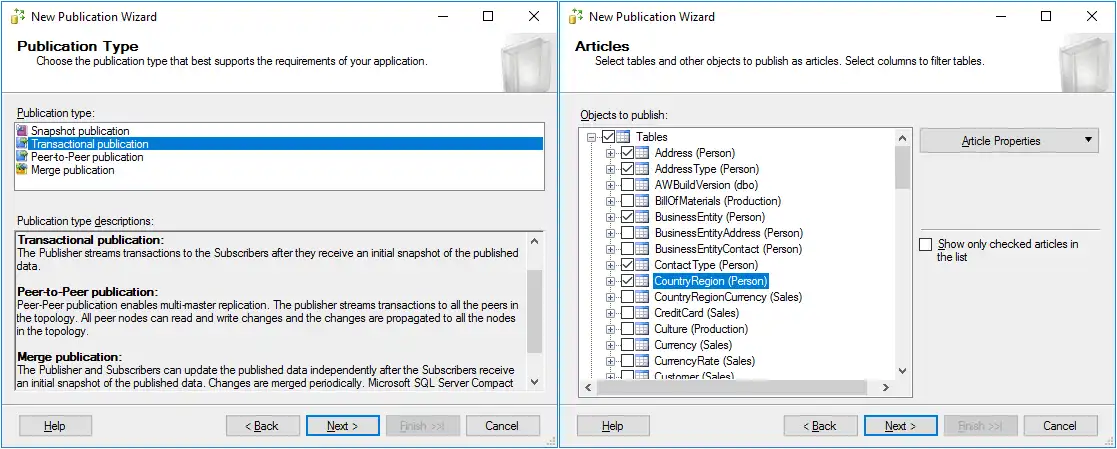
- Filtrer les lignes du tableau. Aucun filtre n’est ajouté dans cet exemple (il s’agit de la configuration par défaut des filtres). Vous pouvez ajouter des filtres si nécessaire.
- Agent instantané. Indiquez quand exécuter l’agent instantané. Configurons l’agent pour qu’il s’exécute immédiatement. Sélectionnez Créer immédiatement un instantané et le conserver disponible pour initialiser les abonnements..
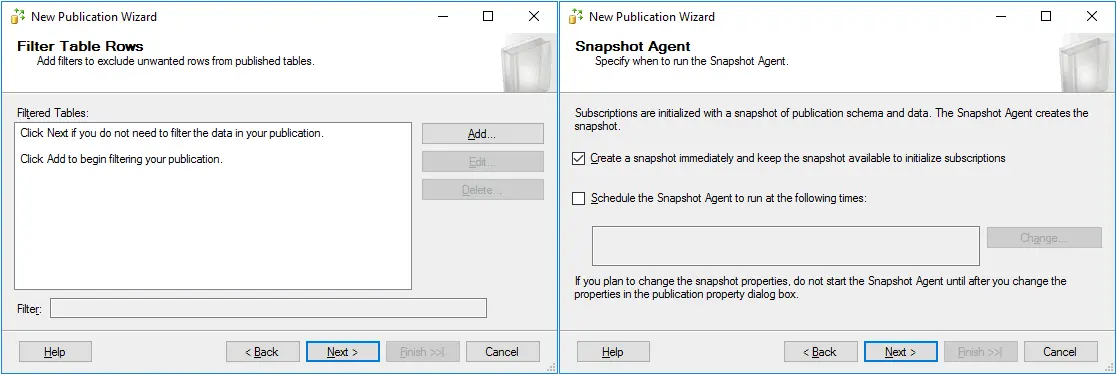
- Sécurité des agents. Sélectionner Utilisez les paramètres de sécurité de l’agent instantané.. Cliquez sur le Paramètres de sécurité pour sélectionner le compte sous lequel l’agent sera exécuté.
Dans le Sécurité de l’agent instantané fenêtre qui s’ouvre, entrez les identifiants de connexion du mssql Utilisateur Windows que vous avez créé précédemment. Sélectionnez « Se connecter à l’éditeur ». Par usurpation de l’identité du compte de processus. Cliquez sur OK pour enregistrer les paramètres et revenir à l’assistant.

Après avoir défini l’utilisateur requis, vous pouvez voir cet utilisateur dans le Agent instantané et Agent de lecture de journaux sections.

- Actions du sorcier. Cochez la case supérieure pour créer la publication lors de la dernière étape de l’assistant.
- Terminer l’assistant. Vérifiez la configuration de votre publication et cliquez sur Terminer pour créer une nouvelle publication.

Dans le Création d’une publication fenêtre, vous pouvez suivre la progression de la création d’une nouvelle publication. Patientez quelques instants et vous devriez voir s’afficher le statut « Réussi » si tout s’est déroulé correctement. La publication est désormais créée et vous pouvez la voir dans l’Explorateur d’objets en allant dans La réplication > Publications locales.
La publication est désormais créée et vous pouvez la voir dans l’Explorateur d’objets en allant dans La réplication > Publications locales.
Configuration de l’abonné
Comme vous vous en souvenez, la réplication MS SQL Server peut être soit une réplication pull, soit une réplication push. Si vous configurez une réplication push, vous devez configurer l’abonné pour qu’il exécute des agents sur le serveur de base de données principal (MSSQL01 dans ce cas). Si vous configurez une réplication pull, l’abonné doit être configuré pour exécuter des agents sur la deuxième machine (MSSQL02), c’est-à-dire la machine sur laquelle la réplique de la base de données sera créée.Configurons la réplication push et créons un nouvel abonnement sur le premier serveur MS SQL Server (MSSQL01MSSQLSERVER1) où réside la base de données maître.Dans l’Explorateur d’objets, accédez à La réplication, cliquez avec le bouton droit de la souris Abonnements locaux et, dans le menu contextuel, sélectionnez Nouveaux abonnements. Le Assistant de nouvel abonnement s’ouvre.
Le Assistant de nouvel abonnement s’ouvre.
- Publication. Sélectionnez la publication pour laquelle vous souhaitez créer un nouvel abonnement. Dans notre exemple, le nom de l’éditeur est MSSQL01MSSQLSERVER1 et le nom de la publication (créée précédemment) est AdvWorks_Pub. Cliquez Suivant à chaque étape de l’assistant pour continuer.
- Emplacement de l’agent de distribution. Sélectionnez le type de réplication en choisissant entre l’abonnement push et l’abonnement pull. Dans notre exemple, nous voulons que tous les agents s’exécutent côté serveur source, c’est pourquoi nous sélectionnons la première option pour créer un abonnement push. Cela vous permet de gérer la réplication MS SQL Server de manière centralisée.

- Abonnés. Par défaut, le serveur sur lequel vous exécutez l’assistant (MSSQL01MSSQLSERVER1 dans ce cas) s’affiche en tant qu’abonné, et la base de données d’abonnement n’est pas définie. Ajoutons un nouvel abonné et sélectionnons une base de données d’abonnement située sur le deuxième serveur de base de données (MSSQL01MSSQLSERVER2). Cliquez sur Ajouter un abonné et, dans le menu contextuel, sélectionnez Ajouter un abonné SQL Server.
- Dans la fenêtre contextuelle, entrez les identifiants de connexion pour la deuxième instance MSSQL Server (MSSQL01MSSQLSERVER2 dans notre cas) et cliquez sur Connecter.

- Cochez la case correspondant à votre deuxième serveur sur lequel votre réplique de base de données sera stockée (MSSQL02MSSQLSERVER2) et, dans le champ Base de données d’abonnement Dans le menu déroulant, sélectionnez une nouvelle base de données ou une base de données existante restaurée à partir d’une sauvegarde pour l’utiliser comme réplique de base de données.
Dans notre exemple, le AdventureWorks2016r a été créé sur le deuxième serveur par restauration du serveur principal (Source) AdventureWorks2016 base de données à partir d’une sauvegarde pour démarrer la réplication. La réplication est lancée en répliquant uniquement les nouvelles données, et non par la copie de l’intégralité de la base de données après le démarrage du processus de réplication. Ainsi, AdventureWorks2016r est sélectionnée comme base de données d’abonnement dans l’exemple actuel.

- Dans la fenêtre contextuelle, entrez les identifiants de connexion pour la deuxième instance MSSQL Server (MSSQL01MSSQLSERVER2 dans notre cas) et cliquez sur Connecter.
- Sécurité des agents de distribution. Cliquez sur le bouton avec trois points (…), puis sélectionnez l’utilisateur et les autres options de sécurité pour l’agent de distribution.
Dans le Sécurité des agents de distribution fenêtre qui s’ouvre, configurez l’agent de distribution pour qu’il s’exécute sur le MSSQL01 héberger sous le mssql compte utilisateur. Entrez le mot de passe pour le mssql Utilisateur Windows. Sélectionnez Connectez-vous au distributeur par l’intermédiaire du compte du processus. et sélectionnez Se connecter à l’abonné par usurpation d’identité du compte de processus. Frapper OK pour enregistrer les paramètres.

Vos propriétés d’abonnement sont désormais configurées.

- Planifier le calendrier de synchronisation. Sélectionnez l’agent qui se trouve sur le distributeur pour Fonctionner en continu pour l’abonné actuel.
- Initialiser les abonnements. Sélectionnez le Initialiser Cochez la case et sélectionnez dans le menu déroulant Immédiatement pour savoir quand initialiser l’abonnement. Vous pouvez également sélectionner l’option Mémoire optimisée option si nécessaire.

- Actions du sorcier. Cochez la case supérieure pour créer le ou les abonnements à la fin de l’assistant.
- Terminer l’assistant. Vous pouvez vérifier vos paramètres d’abonnement et cliquer sur Terminer pour créer l’abonnement.

- Warten bis zum Erstellen des Abonnements. Wenn Sie den Text sehen, Succès Statut, cela signifie que l’abonnement a été créé avec succès.

- Après avoir configuré la réplication dans SQL Server, trois tâches s’affichent dans l’Explorateur d’objets. Vous pouvez les consulter en accédant à Agent SQL Server > Tâches.

Finalisation de la configuration de la réplication
Une fois que vous avez configuré le distributeur, l’éditeur et l’abonné, vous pouvez vérifier le statut de la réplication MS SQL Server.
- Sur le premier serveur (MSSQL01MSSQLSERVER1), lancez le moniteur de réplication pour voir le statut de la réplication MS SQL Server. Dans SQL Server Management Studio, sélectionnez votre instance MS SQL Server (MSSQLSERVER1), allez dans La réplication, cliquez avec le bouton droit de la souris Publications locales et, dans le menu contextuel, sélectionnez Lancer le moniteur de surveillance de la réplication.

- Il existe un Agent de lecture de journaux erreur dans notre cas. Pour afficher les détails de l’erreur, sélectionnez la base de données Source (l’éditeur) dans le volet gauche, sélectionnez l’onglet Agents onglet dans le volet droit, puis double-cliquez sur le nom de l’erreur.

- Dans la fenêtre qui s’ouvre, vous pouvez voir l’historique de l’agent et les messages d’erreur. Les messages d’erreur sont les suivants :
- Le processus n’a pas pu exécuter sp_replcmds sur MSSQL01MSSQLSERVER1. Source : MSSQl_REPL. Numéro d’erreur : MSSQL_REPL20011).
- Impossible d’exécuter en tant que principal de la base de données car le principal « dbo » n’existe pas, ce type de principal ne peut pas être imité ou vous ne disposez pas des autorisations nécessaires. (Source : MSSQLServer, numéro d’erreur : 15517).

Le deuxième message d’erreur suggère qu’une autorisation quelconque est manquante. Corrigeons cette erreur.
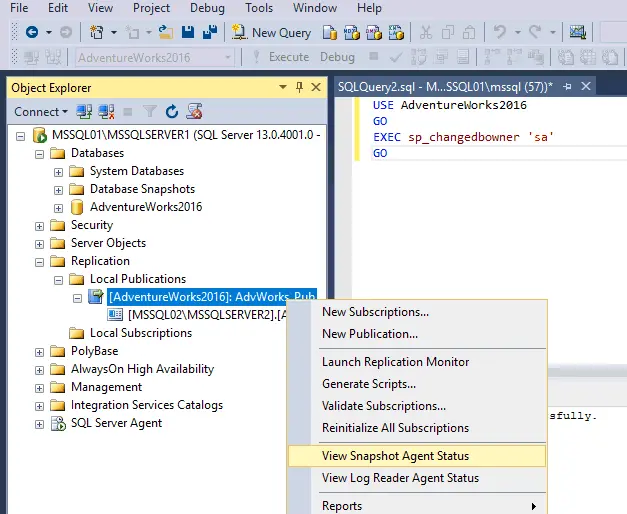
- Créez une nouvelle requête dans MS SQL Management Studio et exécutez cette requête. Dans la fenêtre principale, cliquez sur le bouton Nouvelle requête bouton.
- Dans la section Requête SQL de la fenêtre principale, entrez la requête suivante :
USE AdventureWorks2016GOEXEC sp_changedbowner 'sa'GOCliquez sur le Exécuter bouton.
Commande(s) exécutée(s) avec succès.
- Suivant, rendez-vous sur MSSQL01MSSQLSERVER1 > La réplication > Publications locales > [AdventureWorks2016]: AdvWorks_Pub. Cliquez avec le bouton droit sur le nom de la publication et, dans le menu contextuel, sélectionnez Afficher le statut de l’agent Snapshot. Vous pouvez cliquer sur Action > Rafraîchir rafraîchir le statut et Réinitialiser tous les abonnements appliquer un instantané à chaque abonné.
Tout est désormais résolu, aucune erreur n’est affichée et la réplication MS SQL Server devrait fonctionner.

Vérification du fonctionnement de la réplication
Voyons comment fonctionne la réplication MS SQL Server. Affichez le contenu d’un tableau du AdventureWorks2016 base de données stockée sur le premier serveur MS SQL (MSSQL01MSQLSERVER1). Dans notre exemple, nous allons sélectionner toutes les données de la Personne.Type d’adresse table. Pour ce faire, exécutez la requête suivante :USE AdventureWorks2016;GOSELECT *FROM Person.AddressType;Le résultat de l’exécution de la requête est affiché dans la capture d’écran ci-dessous : Exécutez une requête similaire sur le deuxième serveur pour afficher toutes les données du Personne.Type d’adresse du AdventureWorks2016r base de données stockée sur MSSQL02MSSQLSERVER2.
Exécutez une requête similaire sur le deuxième serveur pour afficher toutes les données du Personne.Type d’adresse du AdventureWorks2016r base de données stockée sur MSSQL02MSSQLSERVER2.USE AdventureWorks2016r;GOSELECT *FROM Person.AddressType;Si vous comparez les captures d’écran ci-dessus et ci-dessous, le contenu du Personne.Type d’adresse sont identiques dans les deux bases de données (une base de données Source sur le premier serveur et la base de données cible qui est une réplique de la base de données sur le deuxième serveur).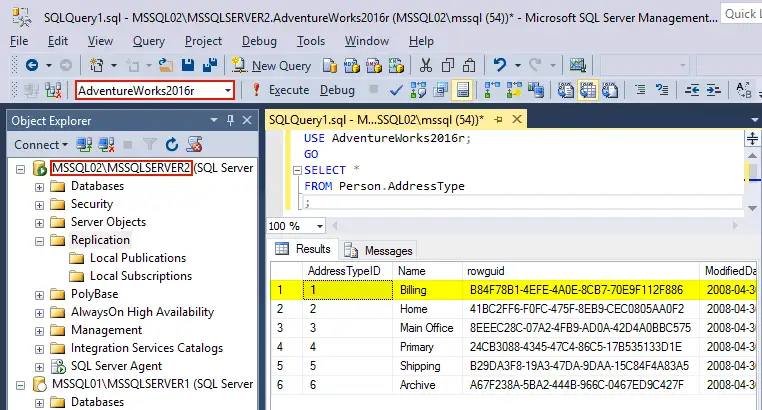 Supprimons une ligne dans le fichier Type d’adresse de la personne tableau provenant du AdventureWorks2016 base de données (source) sur le premier serveur (MSSQL01MSSQLSERVER1). Exécutez la requête pour supprimer une ligne qui contient « Facturation » au nom et pour afficher le contenu du tableau après cela :
Supprimons une ligne dans le fichier Type d’adresse de la personne tableau provenant du AdventureWorks2016 base de données (source) sur le premier serveur (MSSQL01MSSQLSERVER1). Exécutez la requête pour supprimer une ligne qui contient « Facturation » au nom et pour afficher le contenu du tableau après cela :DELETE FROM Person.AddressType WHERE Name='Billing';SELECT * FROM Person.AddressType; Comme vous pouvez le voir, la première ligne avec le IDTypeAdresse 1 et nom « Facturation » a été supprimé du Personne.Type d’adresse table dans le AdventureWorks2016 base de données sur le MSSQL01 machine.La réplication transactionnelle est en cours d’exécution. Vérifions le contenu du fichier Personne.Type d’adresse table dans le AdventureWorks2016r base de données sur le MSSQL02 machine. Exécutez à nouveau une requête similaire à celle ci-dessus pour voir le contenu de la table :
Comme vous pouvez le voir, la première ligne avec le IDTypeAdresse 1 et nom « Facturation » a été supprimé du Personne.Type d’adresse table dans le AdventureWorks2016 base de données sur le MSSQL01 machine.La réplication transactionnelle est en cours d’exécution. Vérifions le contenu du fichier Personne.Type d’adresse table dans le AdventureWorks2016r base de données sur le MSSQL02 machine. Exécutez à nouveau une requête similaire à celle ci-dessus pour voir le contenu de la table :USE AdventureWorks2016r;GOSELECT *FROM Person.AddressType;À la suite de la réplication, la première ligne a également été supprimée du fichier Personne.Type d’adresse table dans la base de données secondaire qui sert de réplique de la base de données (AdventureWorks2016r). Vous pouvez voir les résultats dans la capture d’écran ci-dessous.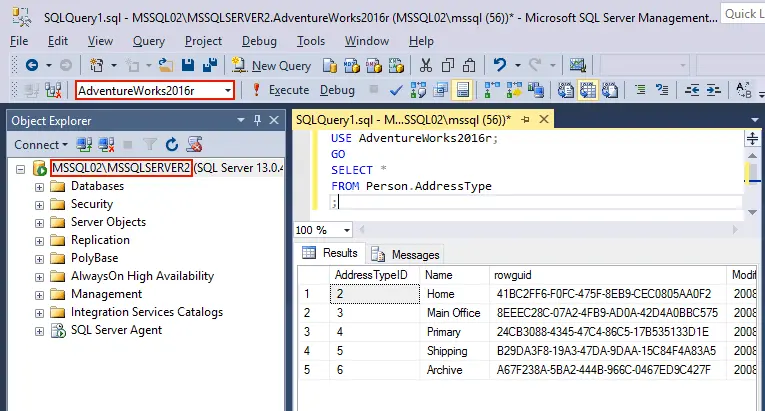 La réplication de base de données dans SQL Server travaille correctement.
La réplication de base de données dans SQL Server travaille correctement.
Conclusion
Il existe quatre types de réplication MS SQL Server : réplication instantanée, transactionnelle, peer-to-peer et fusion. La réplication transactionnelle étant largement utilisée, nous avons configuré ce type de réplication MS SQL Server dans cet article de blog. Le distributeur, l’éditeur et l’abonné doivent être configurés pour que la réplication de la base de données fonctionne. L’abonné peut être configuré sur un serveur source (réplication push) et un serveur cible (réplication pull).Cependant, vous devriez envisager d’utiliser à la fois la réplication et sauvegardes des bases de données MS SQL pour augmenter les chances de réussite récupération des données de la base de données.

