Haute disponibilité vs tolérance aux pannes vs reprise après sinistre : vue d’ensemble
Lorsqu’il s’agit de maintenir l’infrastructure informatique d’une organisation opérationnelle 24 heures sur 24, 7 jours sur 7, il semble encore y avoir une certaine confusion entre les trois termes clés utilisés : haute disponibilité (HA), tolérance aux pannes (FT) et reprise après sinistre (DR). Ces trois termes impliquent le maintien de la continuité des activités et l’accès aux systèmes informatiques. Cependant, chaque terme a sa propre définition, ses propres méthodologies et ses propres cas d’utilisation. Dans cet article, nous allons définir ce que sont la haute disponibilité, la tolérance aux pannes et la reprise après sinistre dans la pratique, et explorer comment ces termes se recoupent et pourquoi il est important de les mettre en œuvre. 
Qu’est-ce que la haute disponibilité ?
La haute disponibilité est la capacité d’un système à fonctionner (temps de fonctionnement) et à être accessible aux utilisateurs pendant une période donnée sans subir de panne. Le temps de disponibilité est la durée pendant laquelle un serveur fonctionne sans redémarrage imprévu ni mise hors tension. La haute disponibilité (HA) est calculée comme le pourcentage de temps pendant lequel un système est opérationnel pendant des périodes déterminées, sans compter les maintenances et les arrêts planifiés. HA n’est pas censé garantir une disponibilité à 100 %, ce qui est difficile et irréalisable. Un temps d’arrêt maximal de 5 minutes et 26 secondes par an est considéré comme acceptable, ce qui correspond à un temps de fonctionnement de 99,999 %. Cependant, même cette valeur peut ne pas constituer une cible raisonnable pour de nombreuses organisations. Selon l’organisation, le secteur d’activité et les ressources disponibles, la valeur HA requise peut être inférieure.
Comment fonctionne la haute disponibilité ?
L’objectif de haute disponibilité d’une organisation est atteint par l’élimination d’un point de défaillance unique dans un système, en utilisant des composants redondants et de basculement. Cela signifie qu’il faut s’assurer que la défaillance d’un seul composant n’entraîne pas l’indisponibilité de l’ensemble du système. Dans le domaine de la virtualisation, la haute disponibilité peut être conçue à l’aide de technologies de clustering. Par exemple, lorsqu’un de vos hôtes ou l’une de vos machines virtuelles (VM) au sein d’un cluster tombe en panne, une autre VM prend le relais (basculement) et maintient les performances adéquates du système. Bien que la redondance des composants soit la condition sine qua non pour garantir une haute disponibilité, ces composants ne suffisent pas à eux seuls pour que le système soit considéré comme hautement disponible. Un système hautement disponible est un système qui comprend à la fois des composants redondants et des mécanismes de détection des pannes et de redirection automatique de la charge de travail. Il peut s’agir d’équilibreurs de charge ou d’hyperviseurs. Le DRS dans VMware vSphere est un exemple de répartiteur de charge.
Quand la haute disponibilité est-elle importante ?
Une architecture à haute disponibilité est nécessaire pour toutes les charges de travail critiques qui ne peuvent se permettre aucun temps d’arrêt. Si la défaillance d’un système ou d’applications compromet la survie de l’entreprise, la haute disponibilité peut être utilisée pour minimiser les temps d’arrêt. Selon Statista, le coût d’une heure d’indisponibilité se situait entre 300 000 et 400 000 dollars américains pour 25 % des entreprises en 2020. Cela signifie que même un taux de disponibilité très élevé de 99,999 % (soit 5 minutes et 26 secondes d’indisponibilité par an) peut coûter environ 35 000 dollars américains à certaines entreprises. Outre des pertes financières importantes, les temps d’arrêt peuvent avoir d’autres conséquences graves, telles que la perte de productivité, l’incapacité à fournir des services en temps voulu, l’atteinte à la réputation de l’entreprise, etc. Les systèmes hautement disponibles permettent d’éviter de tels scénarios en gérant les pannes automatiquement et en temps opportun.
Qu’est-ce que la tolérance aux pannes ?
La tolérance aux pannes est la capacité d’un système à continuer de fonctionner correctement sans interruption en cas d’événements de défaillance d’un ou plusieurs de ses composants. Un système tolérant aux pannes comprend deux composants étroitement couplés qui se reflètent mutuellement afin d’assurer la redondance. De cette manière, si le composant principal tombe en panne, le composant secondaire est immédiatement prêt à prendre le relais.
Comment fonctionne la tolérance aux pannes ?
La tolérance aux pannes, tout comme la haute disponibilité, repose sur la redondance pour garantir la disponibilité. Cette redondance peut être obtenue en exécutant simultanément une application sur deux serveurs, ce qui active l’un des serveurs pour qu’il prenne instantanément le relais de l’autre en cas de défaillance du serveur principal. Dans les environnements virtualisés, la redondance pour la tolérance aux pannes est obtenue en conservant et en exécutant des copies identiques d’une machine virtuelle donnée sur des hôtes distincts. Toute modification ou entrée effectuée sur la VM principale est dupliquée sur la VM secondaire. De cette manière, en cas de corruption de la VM principale, la tolérance aux pannes est assurée grâce au transfert instantané des charges de travail d’une VM vers sa copie.
Quand la tolérance aux pannes est-elle importante ?
La conception tolérante aux pannes est cruciale pour les systèmes qui ne peuvent tolérer aucun temps d’arrêt (temps d’arrêt nul). Si vous disposez d’applications critiques et que le moindre temps d’arrêt entraîne des pertes irrémédiables, vous devriez envisager de configurer vos composants informatiques en tenant compte de la tolérance aux pannes.
Tolérance aux pannes vs haute disponibilité
Lorsque l’on compare HA et FT, la tolérance aux pannes est une solution plus coûteuse. Mais la tolérance aux pannes et la haute disponibilité diffèrent également sur deux points principaux :
- La tolérance aux pannes est une version plus stricte de la haute disponibilité. La haute disponibilité vise à réduire au minimum les temps d’arrêt, tandis que la tolérance aux pannes va plus loin en garantissant un temps d’arrêt nul.
- Cependant, dans le modèle tolérant aux pannes, la capacité d’un système à fournir des performances élevées en cas d’événements de défaillance n’est pas la priorité absolue. En revanche, on s’attend à ce qu’un système puisse maintenir ses performances opérationnelles, même à un niveau réduit.
Qu’est-ce que la reprise après sinistre ?
La reprise après sinistre est un processus utilisé par les organisations pour répondre aux incidents qui affectent les systèmes et pour effectuer rapidement la récupération de la fonctionnalité de l’infrastructure informatique. La reprise après sinistre comprend un plan de reprise après sinistre, une équipe de reprise après sinistre, une solution dédiée à la reprise après sinistre, un site de reprise, etc. Cette approche consiste à utiliser des sites chauds, tièdes ou froids en fonction de la valeur RTO définie dans le plan de reprise après sinistre et des ressources disponibles. Les deux principaux indicateurs de la reprise après sinistre sont les objectifs de temps de récupération (RTO) et les objectifs de point de récupération (RPO), qui visent respectivement à minimiser les temps d’arrêt et les pertes de données.
Comment fonctionne la reprise après sinistre ?
La reprise après sinistre nécessite de disposer d’un site secondaire où vous pouvez restaurer vos données et charges de travail critiques (en totalité ou en partie) afin de reprendre une activité suffisante après un événement perturbateur. Pour transférer les charges de travail vers un site distant, il est nécessaire de mettre en place une solution de reprise après sinistre appropriée. Une telle solution peut prendre en charge l’opération de basculement en temps opportun et avec peu d’intervention de votre part, ce qui vous permet d’atteindre vos RTO désignés.
Quels sont les éléments constitutifs de la reprise après sinistre ?
La reprise après sinistre est un concept beaucoup plus large et complexe que la haute disponibilité et la tolérance aux pannes. Il s’agit d’une stratégie comprenant un ensemble complet d’éléments, notamment : l’évaluation des risques, la planification, l’analyse des dépendances, la configuration des sites distants, la formation du personnel, les tests, la mise en place de l’automatisation, etc. Un autre aspect de la DR qui va au-delà de la haute disponibilité et de la tolérance aux pannes est son indépendance vis-à-vis du site de production.
Quand la reprise après sinistre est-elle importante ?
Le terme « catastrophe » ne désigne pas uniquement une catastrophe naturelle, mais tout type d’incident perturbateur qui touche l’ensemble du site de production et entraîne un temps d’arrêt important, notamment les cyberattaques, les coupures de courant, les erreurs humaines, les défaillances logicielles, etc. Cela signifie qu’un tel incident peut se produire à tout moment de manière inattendue. Dans la plupart des cas, les catastrophes sont impossibles à prévoir ou à éviter, et les organisations doivent prendre des mesures pour renforcer leur préparation à la reprise après sinistre, ainsi qu’optimiser régulièrement leurs stratégies de reprise après sinistre.
Reprise après sinistre vs haute disponibilité
La reprise après sinistre, contrairement à la haute disponibilité et à la tolérance aux pannes, offre des conséquences catastrophiques qui rendent indisponibles des infrastructures informatiques entières plutôt que des défaillances de composants individuels. Étant donné que la reprise après sinistre est axée à la fois sur les données et sur la technologie, son objectif principal est de récupérer les données et de remettre en état de fonctionnement les composants de l’infrastructure dans les plus brefs délais après un incident imprévu. En ce qui concerne la différence entre la haute disponibilité et la reprise après sinistre, la haute disponibilité et la tolérance aux pannes ne peuvent pas vous aider à récupérer des données en cas de sinistre et de perte de données causés par un incident imprévu. C’est dans ce scénario que la reprise après sinistre peut vous fournir une infrastructure DR indépendante et des copies ponctuelles de vos données (points de récupération) afin de minimiser les temps d’arrêt et d’éviter la perte de données. Notez toutefois les différences entre la reprise après sinistre et à sauvegarder.
Utilisation de NAKIVO Backup & Replication pour la reprise après sinistre
NAKIVO Backup & Replication est une solution rapide, fiable et abordable. Il combine des fonctionnalités haut de gamme de protection des données et de reprise après sinistre (la fonctionnalité Reprise après sinistre) conçues pour simplifier et automatiser les opérations de reprise après sinistre. 
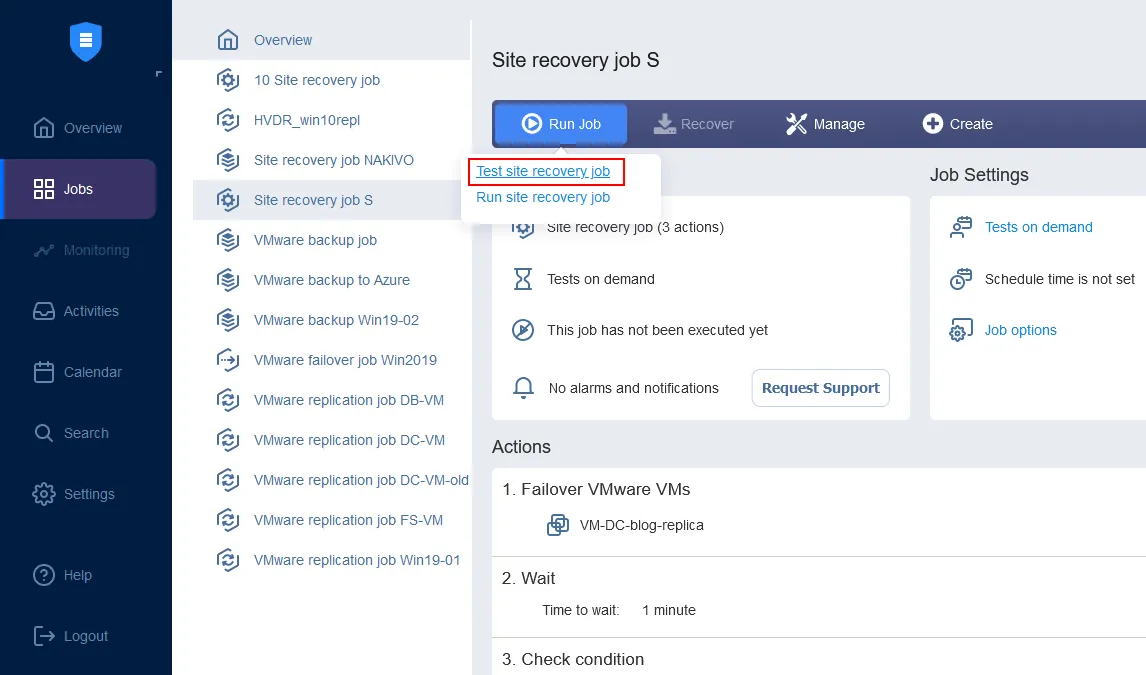
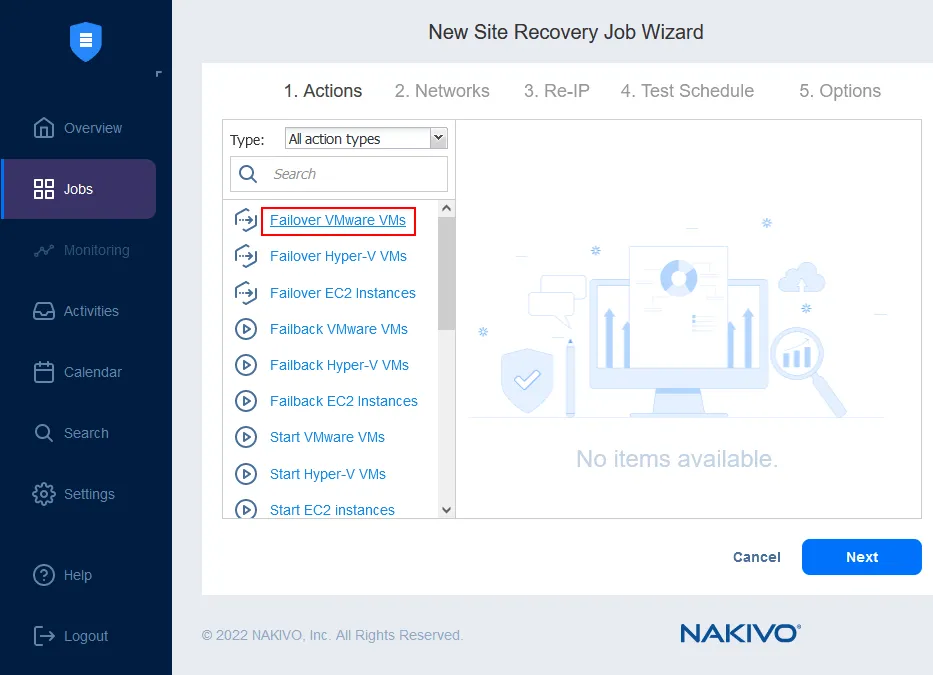 Vous pouvez combiner jusqu’à 200 actions dans un seul workflow (tâche) afin de vous adapter à différents scénarios de catastrophe et de répondre à différents objectifs, notamment : surveillance, migration de centre de données, basculement d’urgence, basculement planifié, restauration automatique, etc. En cas de sinistre, tous les workflows créés peuvent être mis en œuvre immédiatement, d’un simple clic, ce qui permet aux entreprises d’atteindre le délai de reprise le plus court possible. Grâce à la reprise après sinistre, vous pouvez effectuer des tests automatisés de reprise après sinistre non perturbateurs. De cette manière, vous pouvez vous assurer que vos workflows de reprise après sinistre sont valides, qu’ils reflètent toutes les modifications récentes apportées à votre infrastructure informatique et qu’il n’y a pas de faiblesses avant qu’une catastrophe ne se produise réellement.
Vous pouvez combiner jusqu’à 200 actions dans un seul workflow (tâche) afin de vous adapter à différents scénarios de catastrophe et de répondre à différents objectifs, notamment : surveillance, migration de centre de données, basculement d’urgence, basculement planifié, restauration automatique, etc. En cas de sinistre, tous les workflows créés peuvent être mis en œuvre immédiatement, d’un simple clic, ce qui permet aux entreprises d’atteindre le délai de reprise le plus court possible. Grâce à la reprise après sinistre, vous pouvez effectuer des tests automatisés de reprise après sinistre non perturbateurs. De cette manière, vous pouvez vous assurer que vos workflows de reprise après sinistre sont valides, qu’ils reflètent toutes les modifications récentes apportées à votre infrastructure informatique et qu’il n’y a pas de faiblesses avant qu’une catastrophe ne se produise réellement.