Qu’est-ce que la déduplication dans le stockage des données de sauvegarde ?
Les grandes infrastructures virtuelles actuelles génèrent une quantité considérable de données. Cela entraîne une augmentation des données de sauvegarde et des dépenses liées à l’infrastructure de stockage de sauvegarde, qui comprend les appliances de stockage et leur maintenance. C’est pourquoi les administrateurs réseau recherchent des moyens d’économiser de l’espace de stockage lorsqu’ils effectuent des sauvegardes fréquentes des machines et applications critiques.
L’une des techniques les plus couramment utilisées est la déduplication des sauvegardes. Cet article de blog explique ce qu’est la déduplication des données, les types de déduplication et les cas d’utilisation, en mettant l’accent sur les sauvegardes.

Qu’est-ce que la déduplication ?
La déduplication des données est une technologie d’optimisation du stockage. La déduplication des données consiste à lire les données source et les données déjà stockées afin de transférer ou d’enregistrer uniquement les blocs de données uniques. Les références aux données dupliquées sont conservées. Par l’utilisation de cette technologie pour éviter les doublons sur un volume, vous pouvez économiser de l’espace disque et réduire les frais de stockage.
Origines de la déduplication des données
Les prédécesseurs de la déduplication des données sont les algorithmes de compression LZ77 et LZ78, introduits respectivement en 1977 et 1978. Ils consistent à remplacer les séquences de données répétées par des références aux données d’origine.
Ce concept a influencé d’autres méthodes de compression courantes. La plus connue d’entre elles est DEFLATE, qui est utilisée dans les formats d’image PNG et de fichier ZIP. Voyons maintenant comment fonctionne la déduplication avec les sauvegardes de machines virtuelles et comment elle permet précisément d’économiser de l’espace de stockage et des coûts d’infrastructure.
Qu’est-ce que la déduplication dans la sauvegarde ?
Lors d’une sauvegarde, la déduplication des données vérifie s’il existe des blocs de données identiques entre le stockage source et le référentiel de sauvegarde cible. Les doublons ne sont pas copiés et une référence, ou un pointeur, vers les blocs de données existants dans le stockage de sauvegarde de la cible est créée.

Combien d’espace la déduplication des données peut-elle vous faire gagner ?
Pour comprendre combien d’espace de stockage peut être gagné grâce à la déduplication, prenons un exemple. La configuration minimale à remplir pour installer Windows Server 2016 est d’au moins 32 Go d’espace disque libre. Si vous avez dix VMs exécutant ce système d’exploitation, les sauvegardes totaliseront au moins 320 Go, et il s’agit là uniquement d’un système d’exploitation propre, sans aucune application ni base de données.
Si vous devez réaliser un déploiement impliquant plusieurs
Taux de déduplication des données
Le taux de déduplication des données est une mesure utilisée pour comparer la taille des données d’origine à la taille des données après suppression des parties redondantes. Cette mesure vous permet d’évaluer l’efficacité du processus de déduplication des données. Pour calculer cette valeur, vous devez diviser la quantité de données avant déduplication par l’espace de stockage consommé par ces données après déduplication.
Par exemple, un taux de déduplication de 5:1 signifie que vous pouvez stocker cinq fois plus de données sauvegardées dans votre espace de stockage de sauvegarde que ce qui serait nécessaire pour stocker les mêmes données sans déduplication.
Vous devez déterminer le taux de déduplication et la réduction de l’espace de stockage. Ces deux paramètres sont parfois confondus. Les taux de déduplication ne changent pas proportionnellement aux avantages de la réduction des données, car la loi des rendements décroissants entre en jeu au-delà d’un certain point. Voir le graphique ci-dessous.

Cela signifie que les ratios les plus bas peuvent apporter des économies plus importantes que les ratios les plus élevés. Par exemple, un ratio de déduplication de 50:1 n’est pas cinq fois meilleur qu’un ratio de 10:1. Le ratio 10:1 permet une réduction de 90 % de l’espace de stockage consommé, tandis que le ratio 50:1 augmente cette valeur à 98 %, étant donné que la plupart des redondances ont déjà été éliminées. Pour plus d’informations sur le calcul de ces pourcentages, vous pouvez consulter le document de la Storage Networking Industry Association (SNIA) sur la déduplication des données.
les facteurs qui influent sur l’efficacité de la déduplication des données
Il est difficile de prédire l’efficacité de la réduction des données avant que celles-ci ne soient effectivement dédupliquées, en raison de plusieurs facteurs. Voici quelques-uns des facteurs qui ont une incidence sur la réduction des données lors de l’utilisation de la déduplication :
- Types et politiques de sauvegarde des données. La déduplication pour les sauvegardes complètes est plus efficace que pour les sauvegardes incrémentielles ou les sauvegardes différentielles .
- Taux de modification. Si les données à sauvergarder ont subi de nombreuses modifications, le taux de déduplication est plus faible.
- Paramètres de conservation. Plus vous conservez longtemps les sauvegardes de données dans le stockage de sauvegarde, plus la déduplication des données sur ce stockage peut être efficace.
- Type de données. La déduplication n’est pas efficace pour les fichiers dont les données ont déjà été compressées, tels que les fichiers JPG, PNG, MPG, AVI, MP4, ZIP, RAR, etc. Il en va de même pour les données riches en métadonnées et les données cryptées. Les types de données contenant des parties répétitives se prêtent mieux à la déduplication.
- Portée des données. La déduplication des données est plus efficace pour un large éventail de données. La déduplication globale permet d’économiser plus d’espace de stockage que la déduplication locale.
Remarque : La déduplication locale fonctionne sur un seul nœud/disque. La déduplication globale analyse l’ensemble des données sur tous les nœuds/disques afin d’éliminer les doublons. Si vous disposez de plusieurs nœuds sur lesquels la déduplication locale est activée, celle-ci ne sera pas aussi efficace que si vous activiez la déduplication globale pour tous ces nœuds.
- Logiciel et matériel. La combinaison de solutions logicielles et de matériel de déduplication peut offrir de meilleurs taux de déduplication que le logiciel seul. Par exemple, la solution de sauvegarde de NAKIVO offre une intégration avec les appliances de déduplication HP StoreOnce, EMC Data Domain et NEC HYDRAstor pour des taux de déduplication pouvant atteindre 17:1.
Techniques de déduplication des sauvegardes
Les techniques de déduplication des sauvegardes peuvent être classées selon les critères suivants :
- Où la déduplication des données est effectuée
- Lorsque la déduplication est effectuée
- Comment la déduplication est effectuée
Où la déduplication des données est effectuée
La déduplication des sauvegardes peut être effectuée côté source ou côté cible, ces techniques étant respectivement appelées déduplication côté source et déduplication côté cible.
Déduplication côté source
La déduplication côté source réduit la charge réseau, car moins de données sont transférées lors de la sauvegarde à sauvegarder. Cependant, elle nécessite l’installation d’un agent de déduplication sur chaque machine virtuelle ou chaque hôte. L’autre inconvénient est que la déduplication côté source peut ralentir les VMs en raison des calculs nécessaires à l’identification des blocs de données en double.

Déduplication côté cible
La déduplication côté cible transfère d’abord les données vers le référentiel de sauvegarde, puis effectue la déduplication. Les tâches informatiques lourdes sont effectuées par le logiciel chargé de la déduplication.
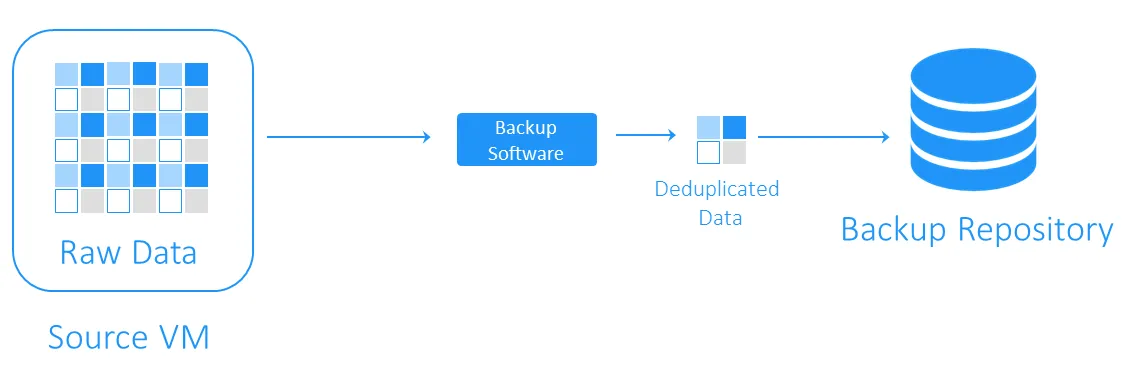
Une fois la déduplication des données effectuée
La déduplication des sauvegardes peut être effectuée en ligne ou en post-traitement.
- La déduplication en ligne vérifie les doublons avant que les données ne soient écrites dans un référentiel de sauvegarde. Cette technique nécessite moins d’espace de stockage dans un référentiel de sauvegarde, car elle supprime les redondances du flux de données de sauvegarde, mais elle allonge la durée de la sauvegarde, car la déduplication en ligne s’effectue pendant la tâche de sauvegarde.
- Déduplication post-traitement traite les données après leur écriture dans le référentiel de sauvegarde. Cette approche nécessite évidemment plus d’espace libre dans le référentiel, mais les sauvegardes s’exécutent plus rapidement et toutes les opérations nécessaires sont effectuées après coup. La déduplication post-traitement est également appelée déduplication asynchrone.
Comment la déduplication des données est-elle effectuée ?
Les méthodes les plus courantes pour identifier les doublons sont celles basées sur le hachage et celles basées sur le hachage modifié.
- Avec la méthode basée sur le hachage , le logiciel de déduplication divise les données en blocs de longueur fixe ou variable et calcule un hachage pour chacun d’eux à l’aide d’algorithmes cryptographiques tels que MD5, SHA-1 ou SHA-256. Chacune de ces méthodes produit une empreinte digitale unique des blocs de données, de sorte que les blocs ayant des hachages similaires sont considérés comme identiques. L’inconvénient de cette méthode est qu’elle peut nécessiter d’importantes ressources informatiques, en particulier dans le cas de sauvegardes volumineuses.
- La méthode modifiée basée sur les hachages utilise des algorithmes de génération de hachages plus simples, tels que CRC, qui ne produisent que 16 bits (contre 256 bits pour SHA-256). Ensuite, si les blocs ont des hachages similaires, ils sont comparés octet par octet. S’ils sont complètement similaires, les blocs sont considérés comme identiques. Cette méthode est un peu plus lente que celle basée sur le hachage, mais elle nécessite moins de ressources informatiques.
Choisir un logiciel de déduplication des sauvegardes
La déduplication des sauvegardes est l’un des cas d’utilisation les plus courants de la déduplication. Cependant, vous devez disposer d’une solution logicielle et d’un matériel de stockage appropriés pour mettre en œuvre cette technologie de réduction des données.
NAKIVO Backup & Replication est une solution de sauvegarde qui prend en charge l’utilisation de la déduplication globale post-traitement avec détection des doublons basée sur un hachage modifié. Vous pouvez également tirer parti de la déduplication côté source en intégrant une appliance de déduplication telle que DELL EMC Data Domain avec DD Boost, NEC HYDRAstor et HP StoreOnce avec prise en charge Catalyst à la solution NAKIVO.



