Echtzeit-Datenreplikation: Alles, was Sie wissen müssen
Der Schutz Ihrer wichtigsten Dienste in einem Rechenzentrum erfordert mehr als nur regelmäßige Backups – es ist eine Replikation erforderlich, um im Falle eines Ausfalls Datenverluste und Ausfallzeiten auf ein Minimum zu reduzieren. Virtuelle Maschinen bieten gegenüber physischen Servern einen erheblichen Vorteil, da sie diesen Prozess vereinfachen. In diesem Blogbeitrag untersuchen wir die Vorteile der Echtzeit-Replikation für virtuelle Maschinen und behandeln dabei ihre Prinzipien, wichtige Anwendungsfälle und die effektive Konfiguration mit Schwerpunkt auf VMware vSphere.

Was ist Echtzeit-Replikation?
Echtzeit-Datenreplikation ist der Prozess der Datenduplizierung und -synchronisierung in Echtzeit über mehrere Systeme (VMs, Datenbanken usw.) hinweg zum Zwecke der Hochverfügbarkeit und Disaster Recovery. Die Zeitverzögerung oder Datenlatenz zwischen den ursprünglichen Datenänderungen und der Datenreplikation kann je nach den in der Infrastruktur verwendeten Einstellungen und der Topologie in Sekunden oder weniger gemessen werden.
Echtzeit-Replikation wird in der Regel zum Schutz kritischer Daten verwendet. Bei virtuellen Maschinen wird die Echtzeitreplikation zum Schutz der kritischsten VMs verwendet, die die strengsten Ziele der Wiederherstellungspunkte und der Wiederherstellungszeit-Ziele ( RPO und RTO ) erfordern. Wenn herkömmliche Backups und Replikationen Ihre RPO- und RTO-Anforderungen nicht erfüllen können, sollten Sie die Konfiguration einer Echtzeitreplikation in Betracht ziehen.
Wesentliche Vorteile der Echtzeit-Datenreplikation
Die Echtzeitreplikation bietet die folgenden Vorteile:
- Minimierte Ausfallzeiten . Da Datenänderungen in Echtzeit vom Quellsystem auf das Zielsystem repliziert werden, kann ein VM-Failover schnell auf das Replikat der VM durchgeführt werden, das die neuesten Änderungen enthält. Dadurch können Unternehmen den VM-Betrieb und die Dienste schnell wiederherstellen, wodurch Ausfallzeiten reduziert und die Geschäftskontinuität verbessert werden.
- Geschäftskontinuität . Ein VM-Replikat, das den neuesten Datensatz enthält, kann verwendet werden, um eine VM schnell wiederherzustellen und den Geschäftsbetrieb wieder aufzunehmen.
- Datenkonsistenz . Eine mit Echtzeitreplikation erstellte VM-Replik enthält denselben Datensatz wie die ursprüngliche VM. Nach der Durchführung eines Failovers und der Wiederherstellung von Workloads mit einer VM-Replik muss nicht wie bei der herkömmlichen VM-Replikation ermittelt werden, welche Daten nach dem letzten Replikationsauftrag neu erstellt werden müssen.
- Skalierbarkeit und Leistung . In Echtzeit aktualisierte VM-Replikate können verwendet werden, um Ressourcen für mehrere Büros/Rechenzentren/Standorte an verschiedenen geografischen Standorten kontinuierlich und konsistent zugänglich zu machen.
So funktioniert die Echtzeit-Datenreplikation
Die Echtzeit-Replikation ist eine Funktion, die bei der Verwendung von High-End-Speichern verfügbar ist. Die Funktionsweise kann je nach Implementierung variieren. Die folgenden Komponenten werden im Allgemeinen für die Echtzeit-Datenreplikation für VMs verwendet:
- Primäre VM: Die aktive virtuelle Maschine, die Workloads verarbeitet.
- Replikat-VM: Eine kontinuierlich aktualisierte Kopie der primären VM, die sich in der Regel auf einem anderen Host oder in einem anderen Rechenzentrum befindet.
- Replikationsmanager: Ein Tool oder Dienst in der Lösung für Datensicherheit, der den Replikationsprozess koordiniert.
- Verfolgung ändern: Verfolgt und protokolliert Änderungen in der primären VM und stellt sicher, dass nur geänderte Daten repliziert werden.
Synchrone vs. asynchrone Replikation: Wesentliche Unterschiede
Es gibt zwei Arten der Datenreplikation, die sich in ihrer Funktionsweise unterscheiden: synchron und asynchron. Jede Art der Datenreplikation hat ihre eigenen Merkmale, Vorteile und Verwendungsfälle und kann je nach Szenario ausgewählt werden.
Bei der synchronen Replikation werden Daten während des Schreibvorgangs von der Quelle auf das Replikat der Quelle kopiert. Dies ist die effektivste Art der Replikation für kritische Workloads. Die Daten werden sofort oder nahezu sofort von der primären VM auf die sekundäre VM repliziert, sodass beide Kopien immer konsistent sind. Mit dieser Art der Datenreplikation können Sie einen RPO von Null erreichen.
- Wenn ein Schreibvorgang auf der primären VM stattfindet, wird die Änderung an das Replikat gesendet.
- Die primäre VM wartet auf eine Bestätigung von der Replik, bevor sie den Schreibvorgang abschließt.
Die Anforderungen für die Konfiguration einer synchronen Replikation sind hoch: Es sind schnelle Netzwerkverbindungen mit geringer Latenz erforderlich, um Verzögerungen zu vermeiden.
Nachteile:
- Die Leistung der primären VM kann beeinträchtigt werden, da es einige Zeit dauert, bis die Replikate Änderungen bestätigen.
- Aufgrund der Latenzanforderungen ist die synchrone Replikation in der Regel auf geografisch nahe gelegene Standorte beschränkt.
Bei der asynchronen Replikation (Point-in-Time-Replikation) werden die Änderungen nachträglich kopiert. Datenänderungen, die auf der Quelle vorgenommen werden, werden in regelmäßigen Abständen, die in Regeln konfiguriert sind, an die VM-Replik gesendet. Daher kommt es zu einer Verzögerung zwischen den Replik-Aktualisierungen. Die asynchrone Replikation kann nahezu in Echtzeit mit Intervallen von einer oder mehreren Minuten erfolgen.
- Schreibvorgänge auf der primären VM werden sofort ausgeführt, ohne auf eine Bestätigung von der Replik zu warten.
- Die Replik-Aktualisierungen werden periodisch auf der Grundlage der in der Warteschlange oder im Stapel gespeicherten Änderungen durchgeführt.
Die Anforderungen für die Konfiguration der asynchronen Replikation sind für die meisten Benutzer und Organisationen erschwinglich. Eine Netzwerkverbindung zwischen Virtualisierungshosts und Komponenten der Datensicherheit ist erforderlich.
Die Replik kann hinter der primären VM zurückbleiben (eine VM-Replik enthält möglicherweise nicht den neuesten Datensatz), was zu potenziellen Datenverlusten im Falle eines Ausfalls führen kann und eine eventuelle Konsistenz gewährleistet. Dies ist der Nachteil der asynchronen Datenreplikation. Wenn beispielsweise die Replikation jeden Tag einmal durchgeführt wird und um 10:30 Uhr eine Katastrophe eintritt, würden die in den letzten 30 Minuten geschriebenen Daten auf dem VM-Replikat fehlen.
|
Aspekt |
Synchrone Replikation |
Asynchrone Replikation |
|
Datenkonsistenz |
Sofortig und konsistent |
Eventuell mit möglicher Verzögerung |
|
Netzwerkanforderungen |
Hohe Bandbreite, geringe Latenz |
Kann mit langsameren Netzwerken arbeiten |
|
RPO (Datenverlust) |
Nahe Null |
Variabel, basierend auf dem Replikationsintervall |
|
Auswirkungen auf die Leistung |
Höher aufgrund der Schreibbestätigung |
Niedriger, da Schreibvorgänge unabhängig sind |
|
Geografische Lage |
Kurze Entfernungen |
Geeignet für lange Entfernungen |
|
Kosten für Hardware |
Hoch |
Niedrig bis mittel |
|
Verwendungsfälle (Branchen) |
Bankwesen, Gesundheitswesen |
Disaster Recovery, Analytik |
Die Verwendung von Echtzeit-Replikation für alle VMs ist möglicherweise nicht erforderlich, da dies ein hohes Budget erfordern würde. Nicht alle Daten sind für ein Unternehmen gleich wichtig, daher sollte die Echtzeit-Replikation nur für die kritischsten Daten verwendet werden. Sie können die optimale Replikationsmethode für jede VM in Abhängigkeit von bestimmten Faktoren und Szenarien auswählen. Legen Sie bei der Auswahl einer Replikationsmethode zum Schutz Ihrer VMs genaue Ziele fest und berücksichtigen Sie die folgenden Punkte:
- Risikobewertung . Analysieren Sie potenzielle Störungen und schätzen Sie die negativen Folgen für Ihr Unternehmen im Falle eines VM-Ausfalls ab.
- Datenkritikalität . Erstellen Sie eine Liste aller Systeme, die auf Virtuellen Maschinen laufen, und schätzen Sie die Bedeutung jeder Virtuellen Maschine in Abhängigkeit von Datenverlust und Ausfalltoleranz ein.
- Anforderungen an die Ressourcen . Ermitteln Sie, wie viele Ressourcen eine Echtzeit-Replik für das entsprechende System verbraucht.
Auswahl der richtigen Lösung für die Echtzeit-Datenreplikation
Es ist wichtig, eine effektive und zuverlässige Lösung für die Datensicherheit zu wählen, die Support für die Echtzeit-Datenreplikation für Virtuelle Maschinen bietet und Ihren Anforderungen entspricht.
Wichtige Funktionen, auf die Sie bei einem Datenreplikationstool achten sollten
Es wird empfohlen, dass Software für Datensicherheit mit Datenreplikationstools die folgenden Funktionen umfasst:
- Support für mehrere Replikationstypen . Ziehen Sie eine Lösung für die Datensicherheit in Betracht, die Echtzeit-Replikation und asynchrone Replikation von Virtuellen Maschinen unterstützt. In diesem Fall können Sie für kritische VMs eine kontinuierliche oder Echtzeit-Datenreplikation verwenden, die High-End-Hardware mit geringer Latenz erfordert. Gleichzeitig können Sie Kosten sparen und reguläre VMs mit geringeren RPO-Anforderungen mithilfe der asynchronen Replikation replizieren.
- Benutzerfreundliche Oberfläche . Eine benutzerfreundliche Lösung ist bequemer zu konfigurieren und erfordert möglicherweise weniger Zeit. Die flexible Konfiguration bietet Administratoren mehr Vorteile für verschiedene Verwendungsfälle.
- Mehrere Replikationsstandorte . Es wird empfohlen, dass die Lösung für die Datensicherheit die Replikation zum selben Standort und zu einem anderen Standort unterstützt. Im Falle einer VMware VM-Replikation ist es besser, wenn die Replikation zum selben vCenter und zu einem anderen vCenter unterstützt wird. Überprüfen Sie die Optionen für VM-Failover und Failback.
- Application-Awareness. Überprüfen Sie, ob die bevorzugte Lösung Application-Awareness unterstützt, um sicherzustellen, dass die von Anwendungen geschriebenen Daten in VM-Replikaten konsistent sind.
- Anforderungen . Eine Lösung mit benutzerfreundlichen Anforderungen kann die Zeit für die Konfiguration reduzieren.
- Kosten . Überprüfen Sie die Preise und die Lizenzierung. Wählen Sie die Lösung, die am besten zu Ihrem Budget passt.
Zuverlässige Echtzeit-Datenreplikation mit NAKIVO
NAKIVO Backup & Replication & Replication ist eine universelle Lösung für die Datensicherheit, die die Replikation für VMware-VMs unterstützt, einschließlich traditioneller Replikation und Echtzeit-Replikation. Die Lösung bietet die folgenden Vorteile der Echtzeit-VM-Replikation:
- RPO und RTO . Sie können einen RPO von nur 1 Sekunde konfigurieren, um sicherzustellen, dass die neuesten Änderungen mit dem VM-Replikat synchronisiert werden und Sie im Falle eines VM-Ausfalls keine Daten verlieren. Die Wiederherstellung der VM (Failover) kann in wenigen Sekunden bis Minuten erfolgen. Sie können eine Nahezu-null-Ausfallzeit und einen Nahezu-null-Datenverlust erreichen.
- Failover zur Replik . Die Ausfallzeit ist nahezu null, da ein schnelles VM-Failover zur Replik erfolgt, um die Workloads wieder aufzunehmen. Durch automatisiertes Failover können Sie VM-Replikate schnell starten.
- Netzwerkzuordnungen und Re-IP . Wenn Sie ein VM-Replikat an einem anderen Standort wiederherstellen, müssen Sie möglicherweise ein anderes VM-Netzwerk und eine andere IP-Konfiguration für die Netzwerkverbindung der VM verwenden. Mit der Netzwerkzuordnung können Sie ganz einfach ein neues Netzwerk auswählen, ohne die VM-Konfiguration in der VMware-Benutzeroberfläche bearbeiten zu müssen. Sie können Regeln für die Netzwerkzuordnung erstellen. Mit Re-IP können Sie die neue IP-Konfiguration für das VM-Replikat festlegen, ohne die Netzwerkeinstellungen im Gastbetriebssystem bearbeiten zu müssen.
- Benutzeroberfläche . Die NAKIVO-Lösung bietet eine benutzerfreundliche Weboberfläche, die die Konfiguration der VMware-Echtzeitreplikation schnell und bequem macht.
- Erschwinglicher Preis . NAKIVO Backup & Replication bietet permanente Lizenzen und Abonnementlizenzen mit einer flexiblen Lizenzierungsrichtlinie. Die vollständige Liste der Preise und Ausgaben finden Sie auf der Seite der Funktion.
Die NAKIVO-Lösung verwendet einen VMware-I/O-Filter in einem Cluster, um die Echtzeit-Replikation für VMware-VMs sicherzustellen. VMware-I/O-Filter verbessern die VMware-Speicherkapazitäten für virtuelle Umgebungen. Eingabe-/Ausgabevorgänge zwischen virtuellen Maschinen und Speichergeräten werden von den Filtern abgefangen und bearbeitet. Darüber hinaus wird die Leistung der Echtzeit-Replikation optimiert.
Der I/O-Filter ist für die Verschlüsselung der Daten verantwortlich, um die Sicherheit und Datenintegritätsprüfungen für die Echtzeit-VM-Replikation zu verbessern. Daher ist der I/O-Filter für den Quell-ESXi-Host und der Journal-Dienst für den Zielhost erforderlich. Der Journal-Dienst ist für die Verfolgung der Änderungen zuständig und wird auf einem Rechner installiert, auf dem der Ziel- Transporter läuft. Das Journal wird für jede VM-Festplatte erstellt, um Änderungen zu verfolgen und E/A-Vorgänge aufzuzeichnen, um Referenzwiederherstellungspunkte zu behalten.
Einrichten der Echtzeit-Datenreplikation mit NAKIVO
Im Folgenden wird erläutert, wie Sie die Echtzeitreplikation für virtuelle Maschinen in VMware vSphere mit NAKIVO Backup & Replication konfigurieren.
Anforderungen
Bevor Sie mit der Konfiguration der Echtzeit-Replikation beginnen, stellen Sie sicher, dass Ihre Umgebung die wichtigsten Anforderungen erfüllt, darunter:
- Die Quelle muss ein von vCenter verwalteter Cluster sein, und das Ziel kann ein eigenständiger ESXi-Server sein oder der ESXi-Host kann zum selben vCenter hinzugefügt werden.
- Der Ziel-Datenspeicher sollte mindestens 5 GB groß sein.
- Der Quell-ESXi-Host sollte über mindestens 16 GB RAM verfügen.
- Die Zeit muss auf ESXi-Hosts und Transportern synchronisiert sein.
Siehe die vollständige Liste der Anforderungen .
Unsere vSphere-Umgebung verfügt über einen vCenter Server mit zwei Rechenzentren (Quelle und Ziel).
- DC_1 ist das Rechenzentrum der Quelle mit einem Cluster aus zwei Hosts und einem Transporter .
- DC_2 ist das Zielrechenzentrum mit einem einzelnen ESXi-Server und einem Ziel-Transporter .
- Das Ziel-Rechenzentrum kann je nach den spezifischen Anforderungen Ihrer Infrastruktur unter einem oder zwei vCentern verwaltet werden oder sogar als eigenständiger ESXi-Server betrieben werden.
Konfigurieren der vSphere-Umgebung
Dies ist die vSphere-Umgebung, die in der Anleitung verwendet wird. Sie verfügt über einen vCenter Server mit zwei Rechenzentren (Quelle und Ziel).
- Das primäre Rechenzentrum mit dem virtuellen Transporter für die Quelle ist bereits installiert.
- Das sekundäre Rechenzentrum mit dem virtuellen Transporter für das Ziel ist installiert.
- Das Ziel-Rechenzentrum kann je nach den spezifischen Anforderungen Ihrer Infrastruktur mit einem oder zwei vCenter-Servern verwaltet oder sogar als eigenständiger ESXi-Server betrieben werden.
- Der NAKIVO Director ist im Ziel-Rechenzentrum installiert, das das sekundäre Rechenzentrum ist. Diese Konfiguration ermöglicht Ihnen den Zugriff auf den Director, wenn eine Katastrophe eintritt und das primäre Rechenzentrum nicht verfügbar ist.

Ändern Sie die Akzeptanzstufe des Quell-ESXi-Servers auf die Stufe Community-unterstützt . Wir müssen die Akzeptanzstufe des Host-Image-Profils auf jedem ESXi-Server auf der Quelle auf den Support-Level Community-unterstützt ändern.
- Öffnen Sie VMware vSphere Client, klicken Sie auf die Registerkarte Konfigurieren und gehen Sie zu Sicherheitsprofil . Navigieren Sie dann zu „Host-Image-Profil-Akzeptanzstufe“ und klicken Sie auf „Bearbeiten“.
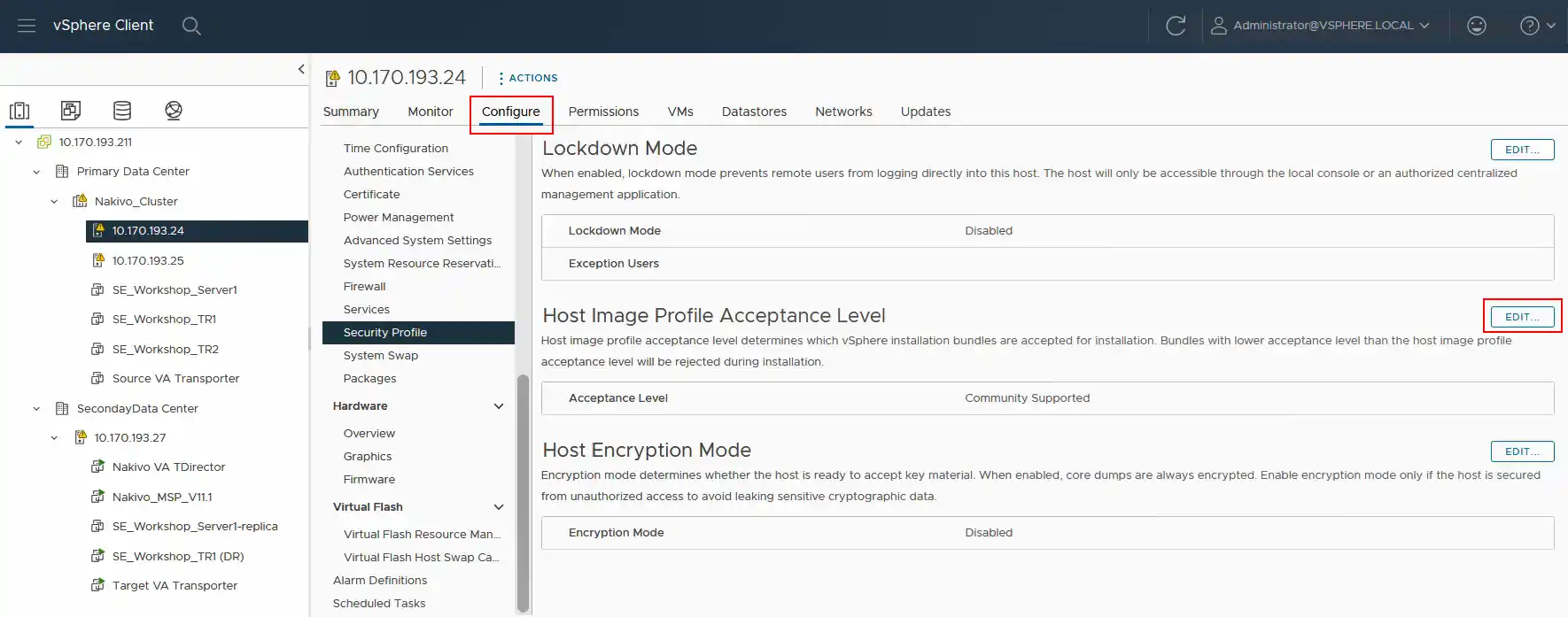
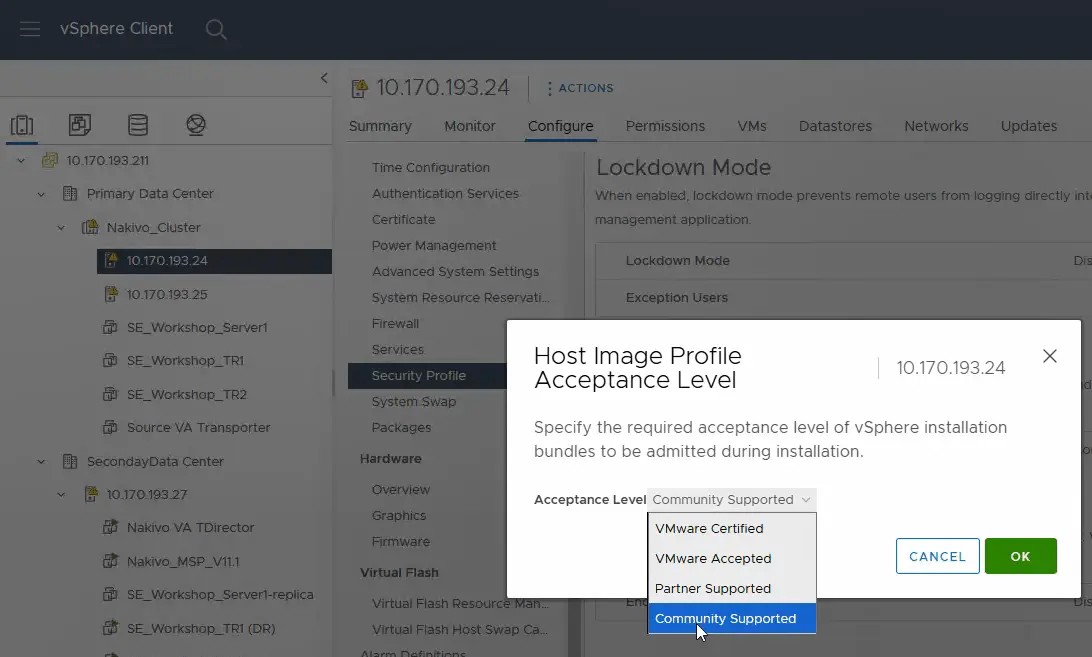
- Ändern Sie das Support-Level in Community Supported . Klicken Sie auf OK , um die Einstellungen zu speichern.
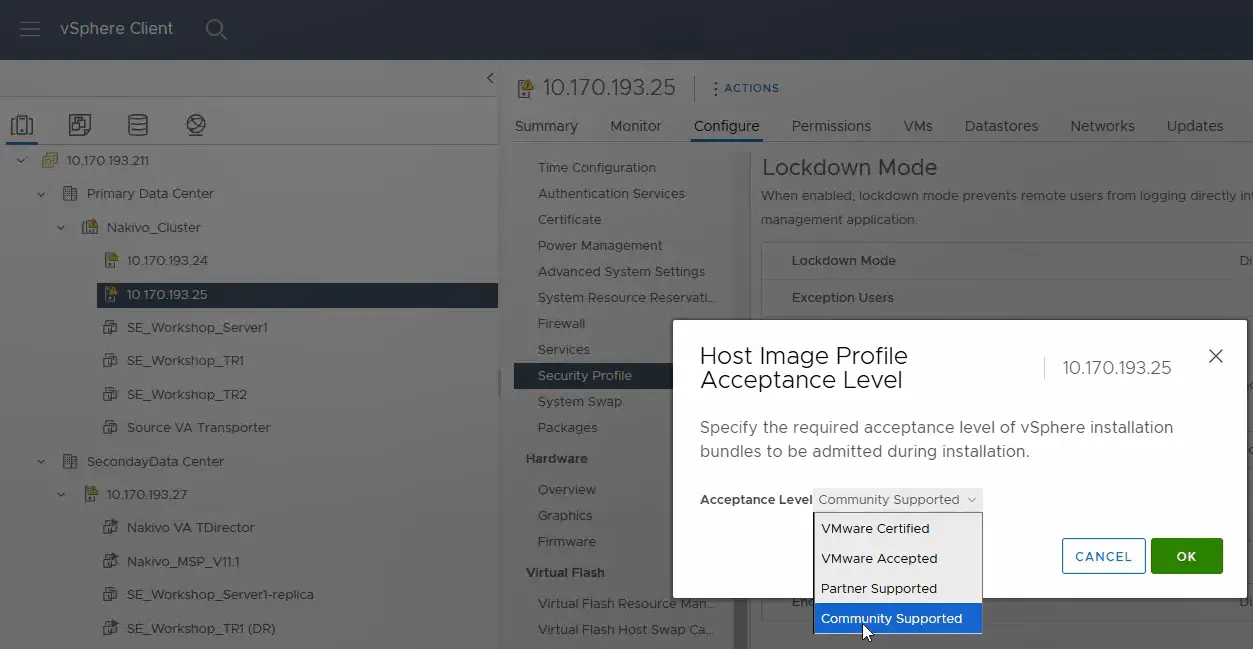
- Führen Sie denselben Vorgang auf dem zweiten ESXi-Host im Quell-Rechenzentrum durch und setzen Sie den Support-Level auf Community Supported .
Konfigurieren des Inventars
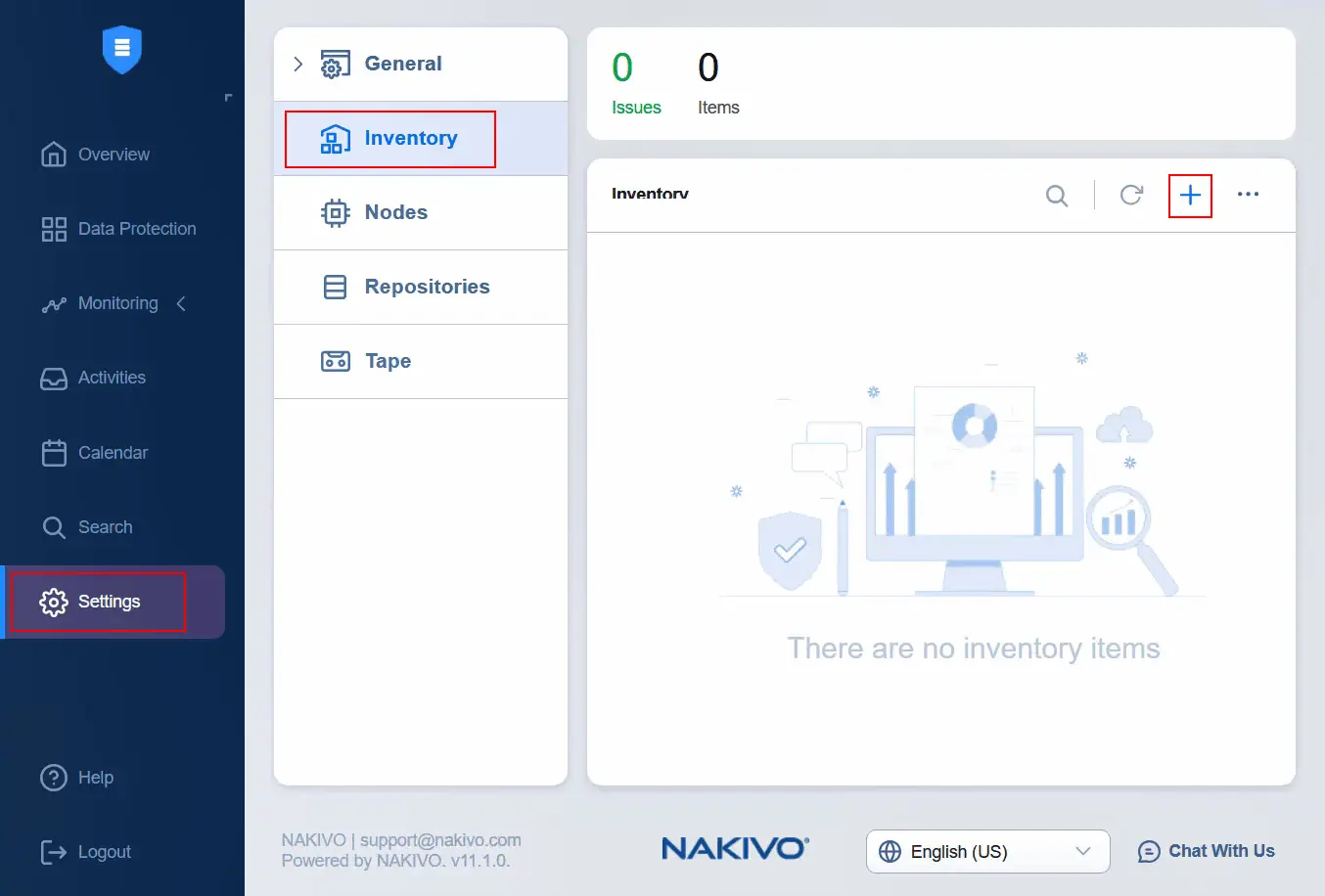
- Nach dem Bearbeiten der Akzeptanzstufe für das Host-Image-Profil, öffnen Sie die NAKIVO Backup & Replication-Weboberfläche und gehen Sie zu Einstellungen > Inventar , um das Quell-vCenter zum Inventar hinzuzufügen. Klicken Sie auf das Symbol Plus , um dem Inventar einen neuen Eintrag hinzuzufügen.
- Wählen Sie Virtuell als Plattform aus und klicken Sie auf Weiter .
- Wählen Sie VMware vCenter oder ESXi-Host als Typ aus. Fahren Sie dann mit dem weiteren Schritt fort.
- Geben Sie im Schritt Optionen den Anzeigenamen ein, zum Beispiel vCenter . Geben Sie anschließend die IP-Adresse dieses vCenter-Servers sowie den Benutzernamen und das passwort für den Zugriff ein. Klicken Sie auf Fertigstellen , um die Einstellungen zu speichern und das ausgewählte vCenter zum NAKIVO-Inventar hinzuzufügen.
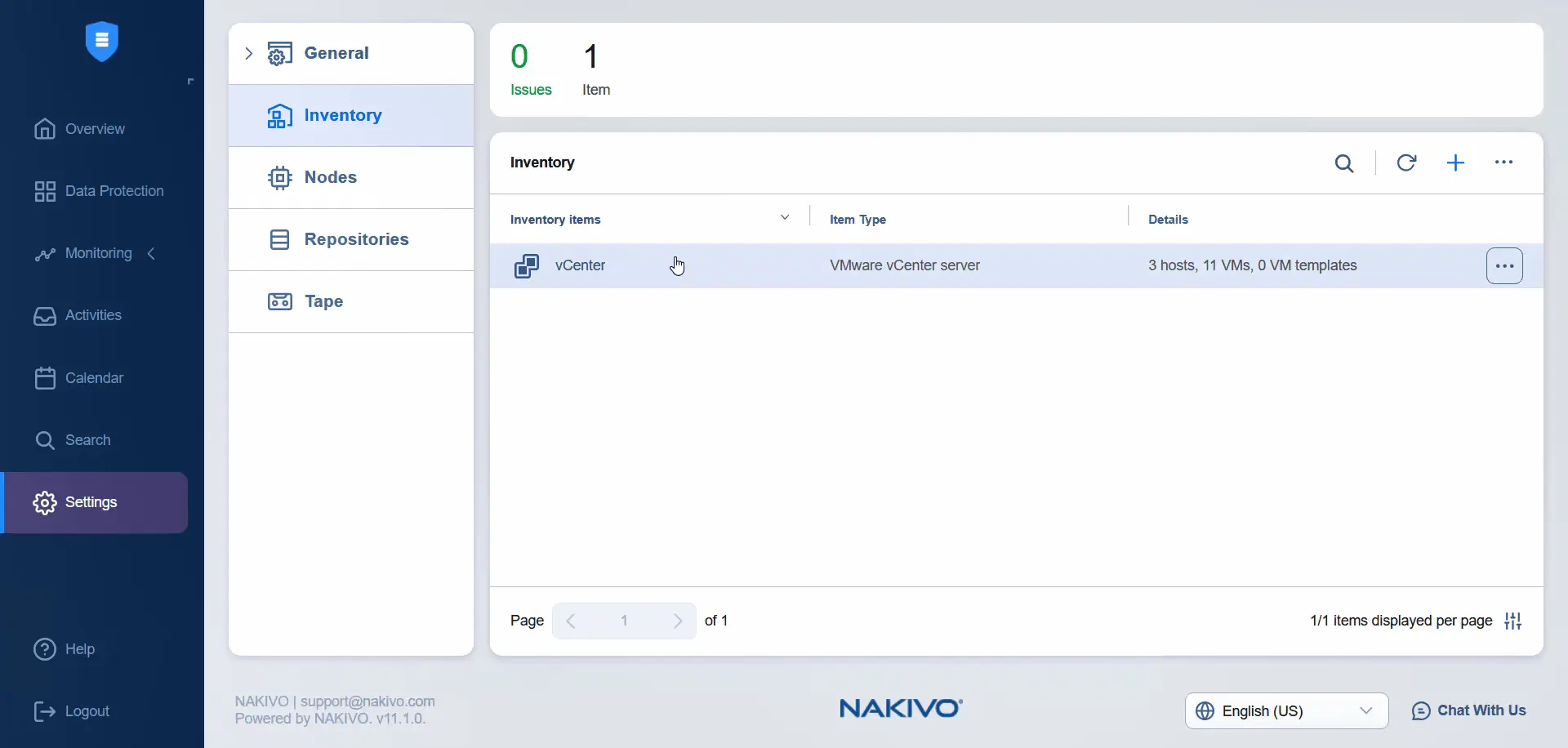
- Warten Sie, bis vCenter zum Inventar hinzugefügt wurde. Nach dem Hinzufügen können wir die primären und sekundären Rechenzentren auf demselben vCenter im NAKIVO-Inventar sehen, wenn wir auf das vCenter-Element klicken.
Installation des I/O-Filters
Weiter müssen wir den I/O-Filter auf jedem ESXi-Host auf der Quelle installieren. Der I/O-Filter muss in einem Cluster installiert werden, um eine Echtzeit-Replikation zu ermöglichen. Auf der Zielseite muss der I/O-Filter nicht installiert werden.
- Klicken Sie auf Knoten , klicken Sie auf Verstanden (wenn Sie diesen Abschnitt zum ersten Mal besuchen), klicken Sie auf Plus und drücken Sie Echtzeit-Replikation Dienst .
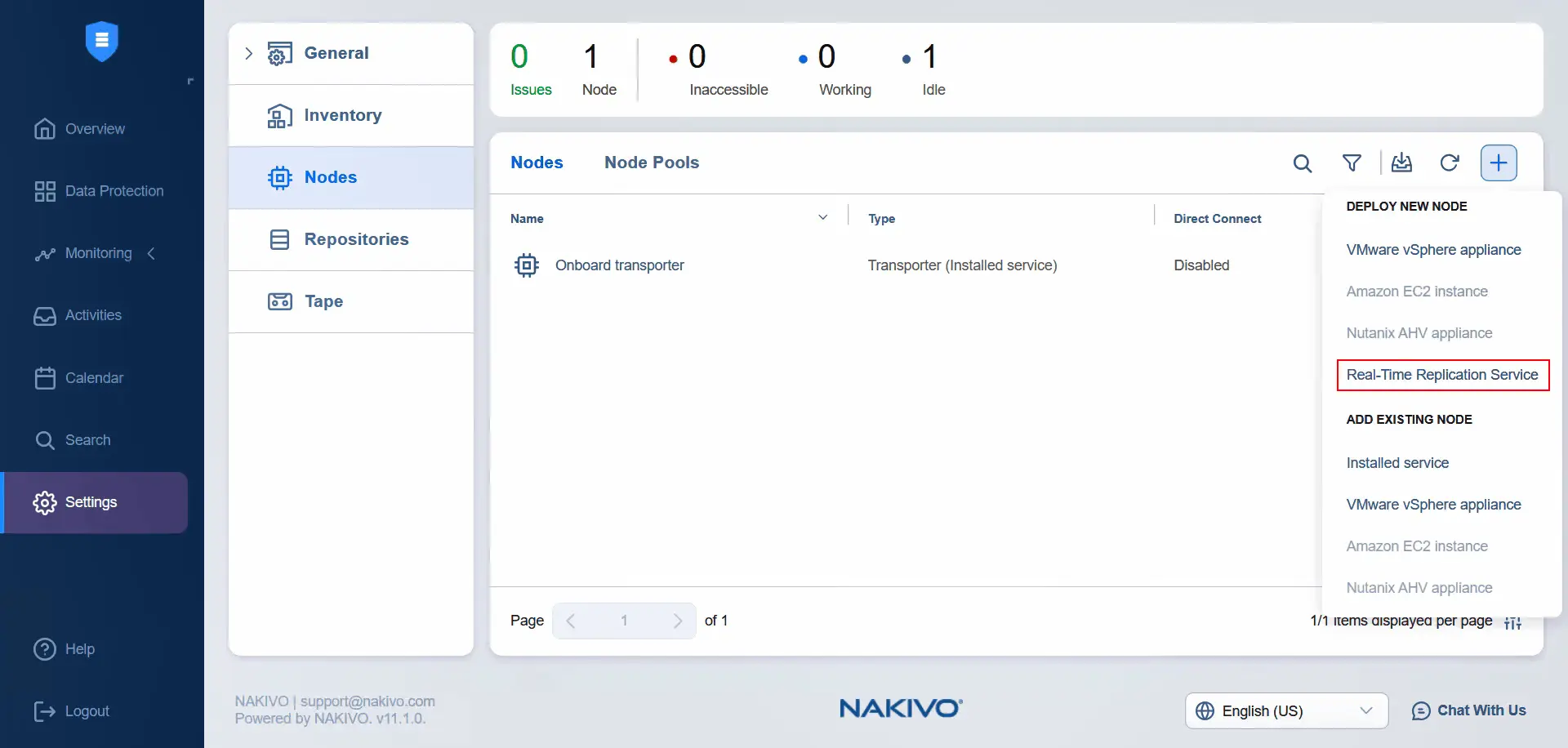
- Installieren Sie den E/A-Filter nur im primären Rechenzentrum, das die Quelle ist. Sobald ein Cluster im Rechenzentrum ausgewählt wurde, fahren Sie mit dem weiteren Schritt fort.
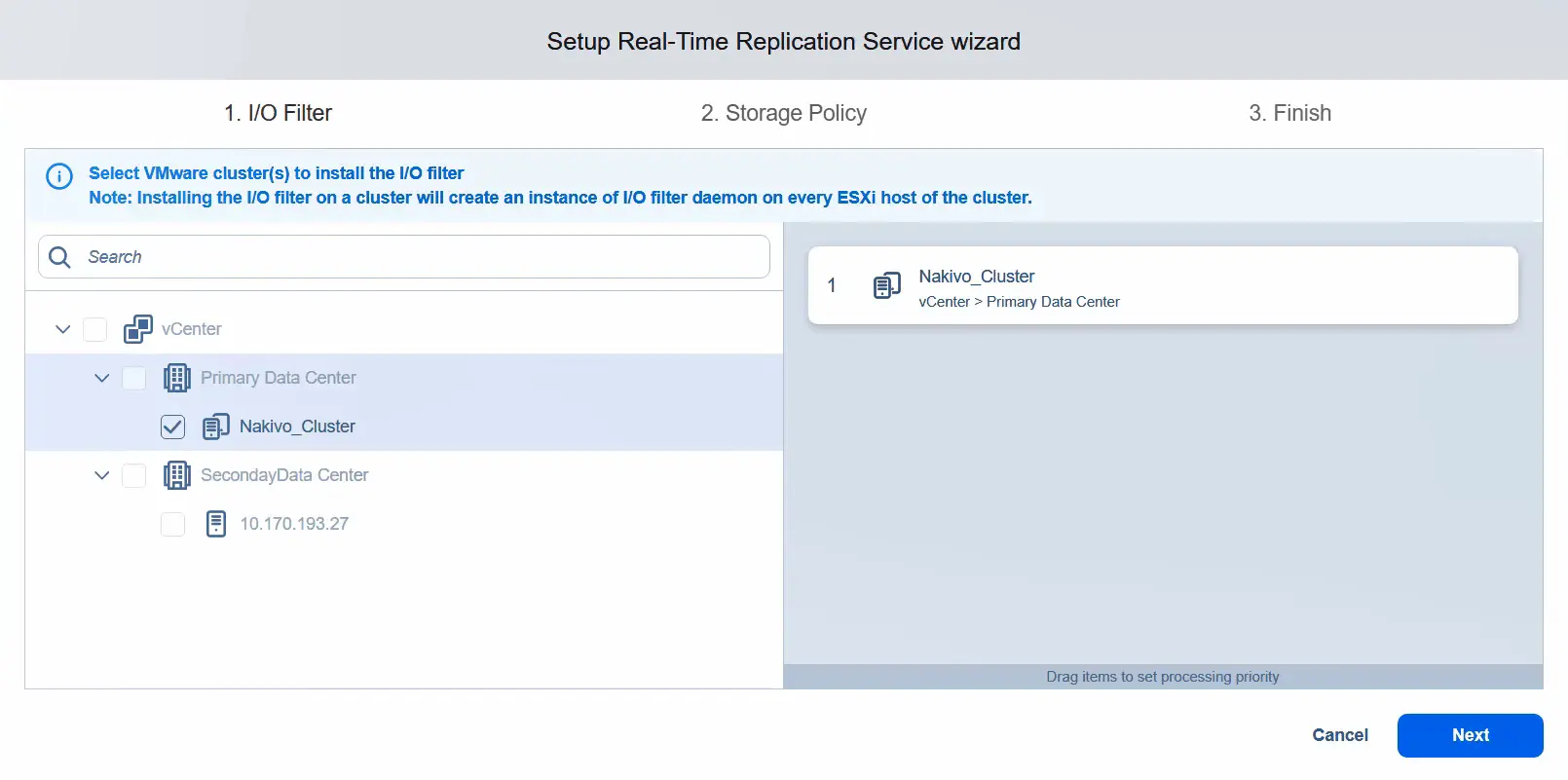
- Anwenden Sie die Speicher-Richtlinie und weisen Sie sie den Virtuellen Maschinen zu, die Sie für die Echtzeitreplikation verwenden möchten. In diesem Beispiel wenden wir die Speicher-Richtlinie nur auf eine Virtuelle Maschine an. Klicken Sie auf Weiter .
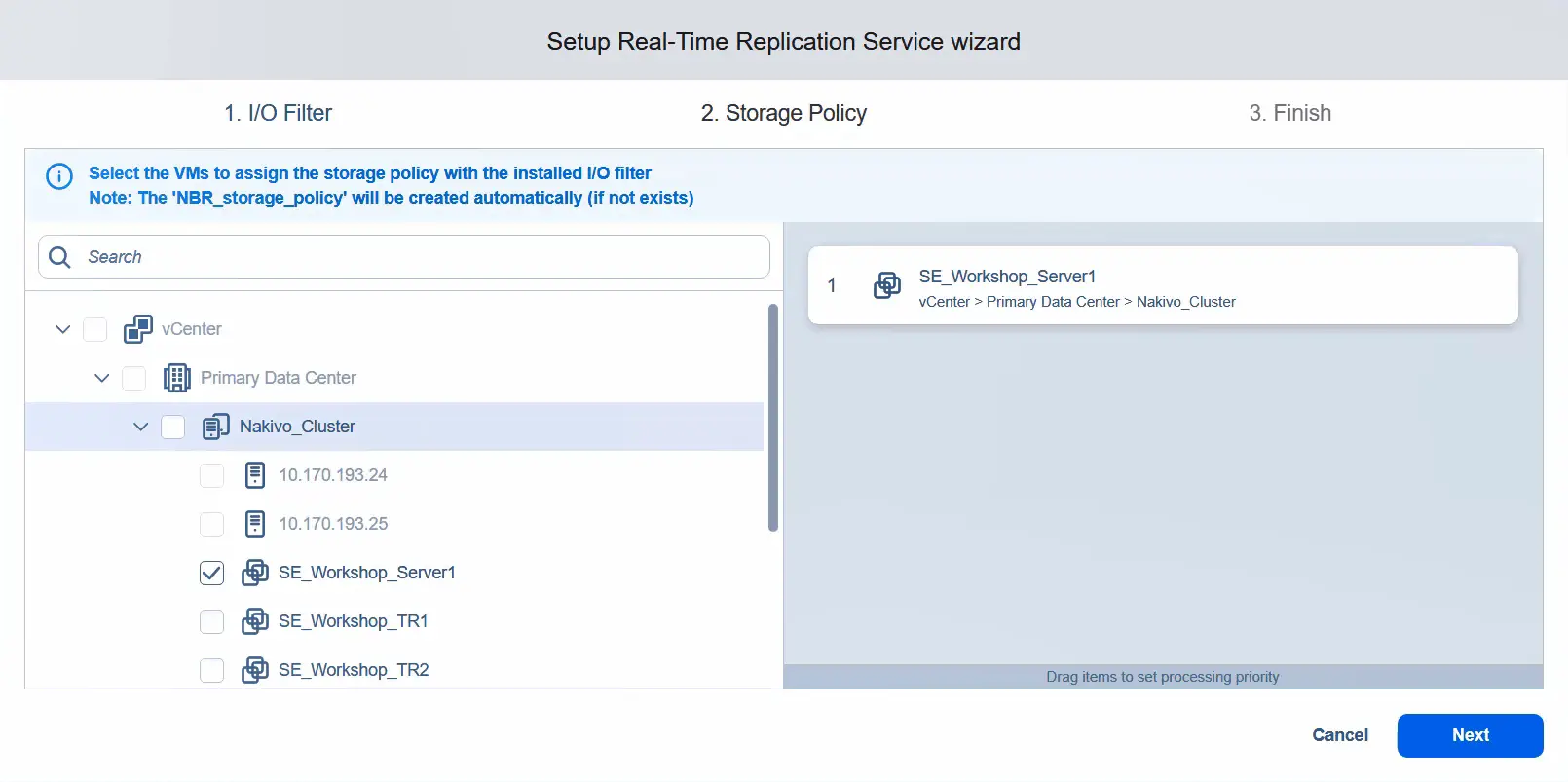
- Die Echtzeit-Replikationsdienste werden nun installiert.
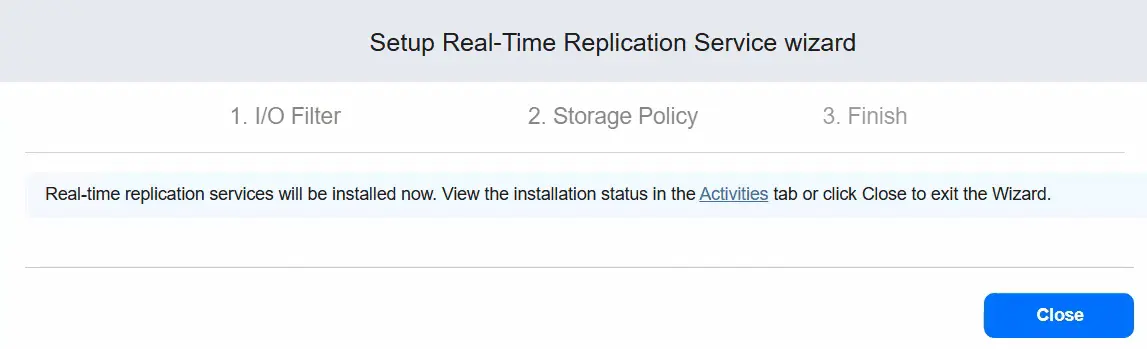
Während der Installation wird der Status angezeigt.
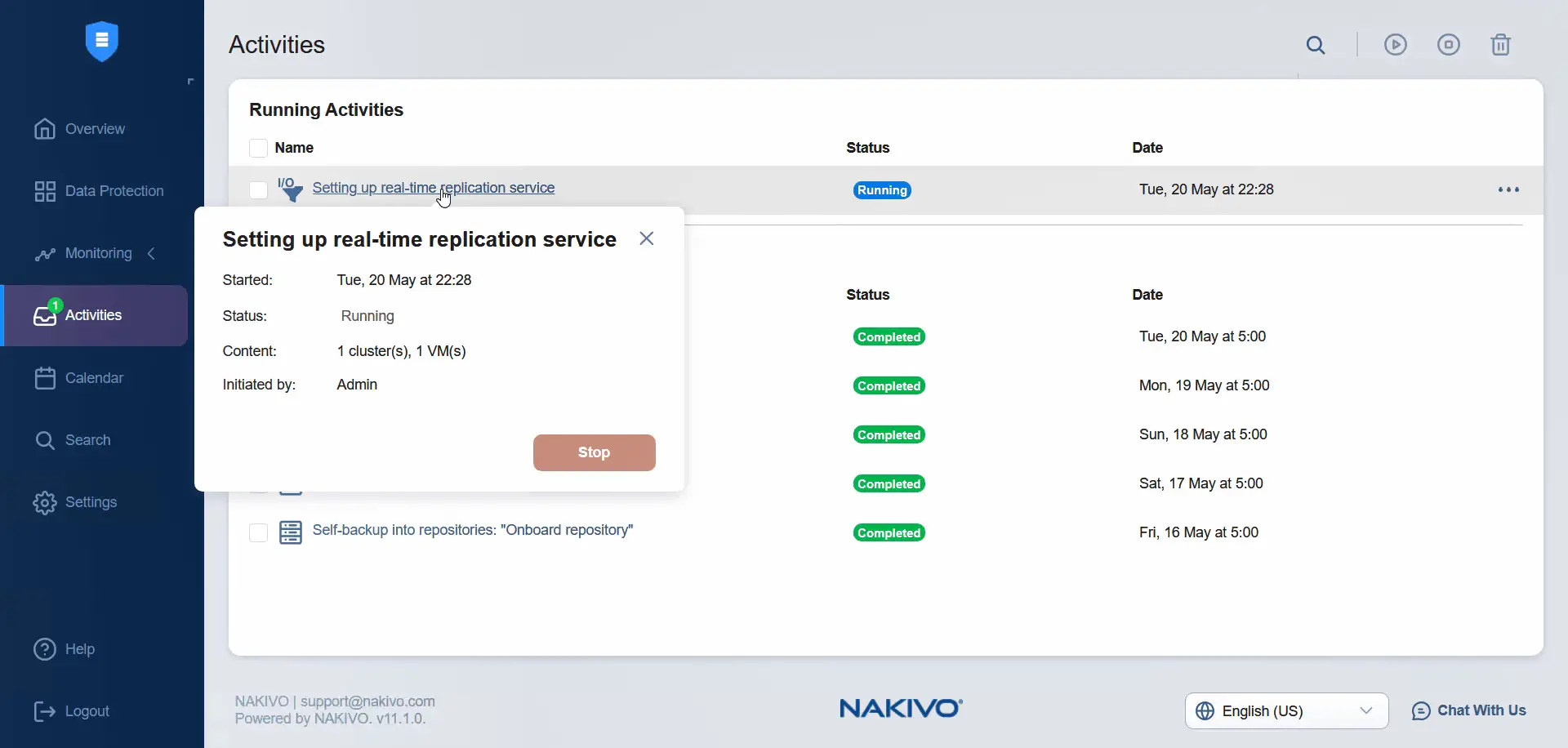
Wir können den Fortschritt in VMware vCenter überprüfen. Die Installation des E/A-Filters hat begonnen. Wir müssen warten, bis der E/A-Filter auf beiden ESXi-Servern installiert ist.
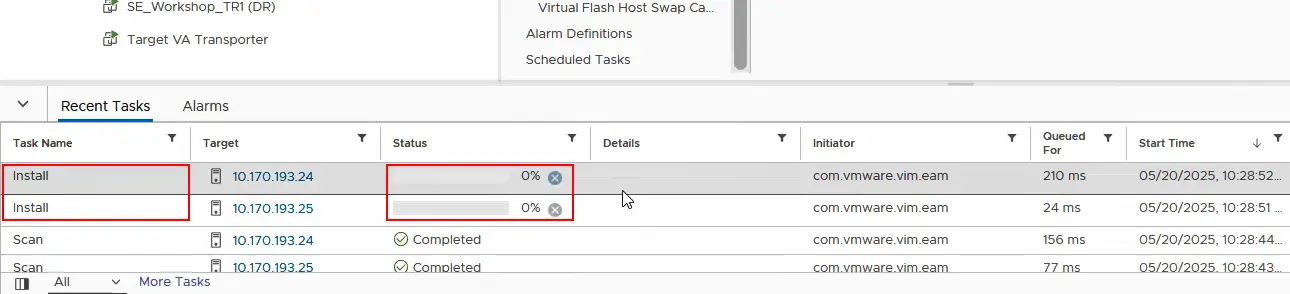
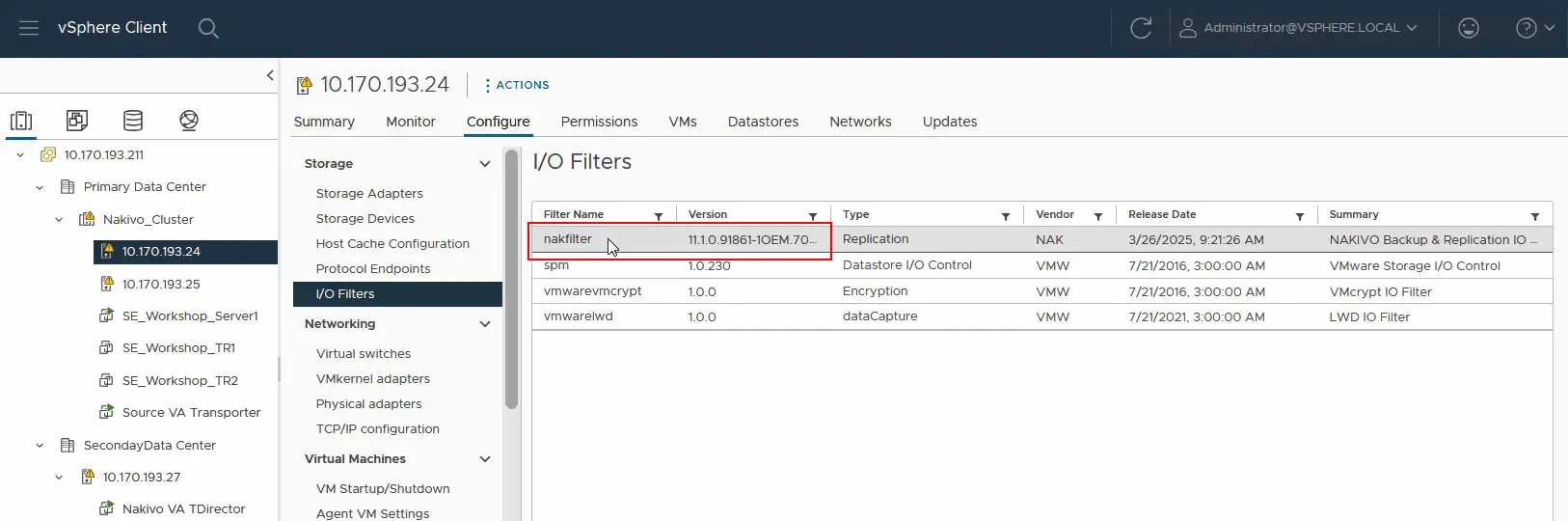
- Jetzt müssen wir überprüfen, ob der E/A-Filter bereits auf jedem ESXi-Server im Cluster der Quelle installiert wurde. Wählen Sie den ESXi-Host aus und klicken Sie auf „ > -E/A-Filter konfigurieren“ . Wir sehen, dass nakfilter bereits installiert ist. Stellen Sie ebenfalls sicher, dass der E/A-Filter auf dem zweiten ESXi-Host im Cluster installiert ist.
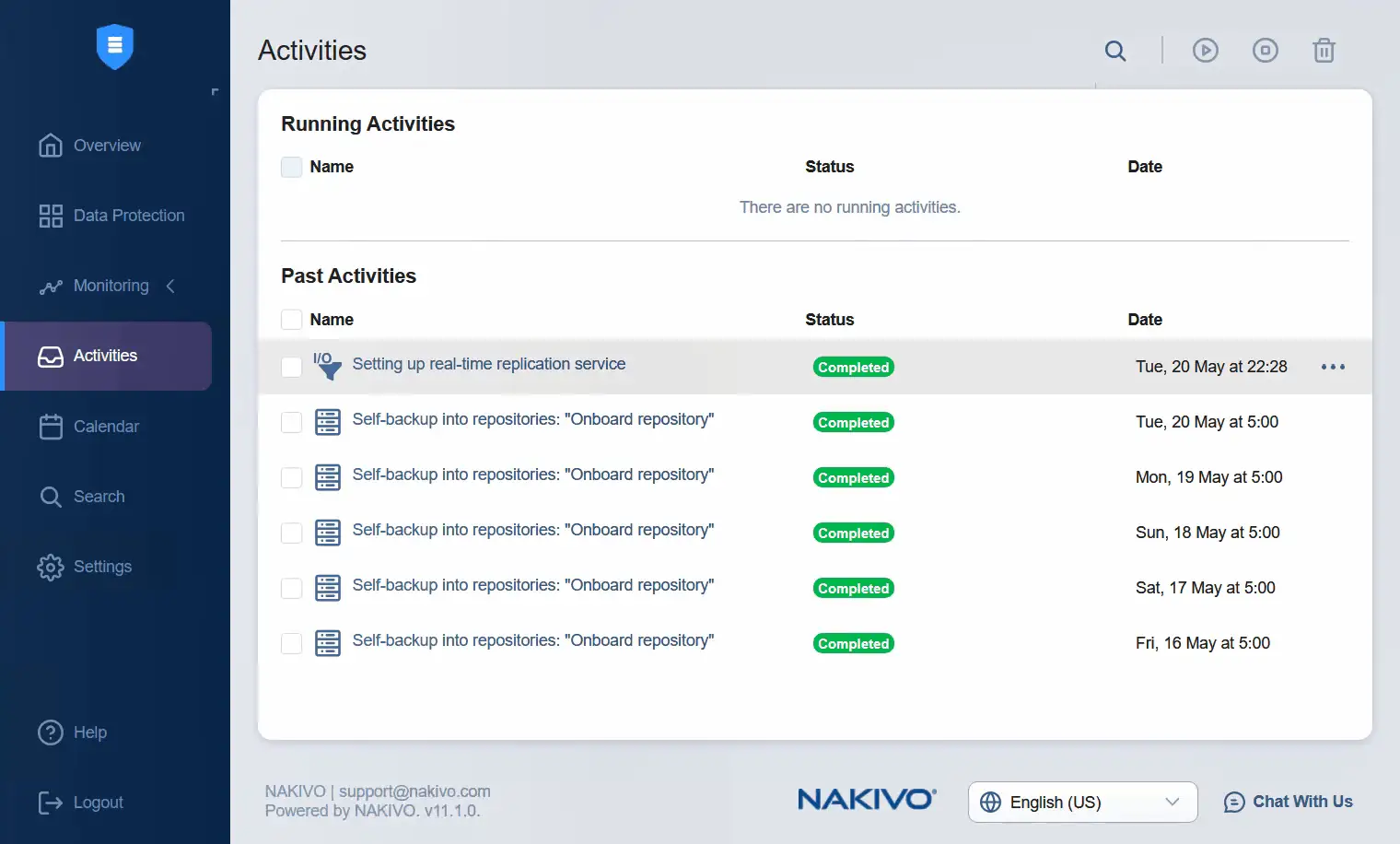
- Wechseln Sie zur Weboberfläche von NAKIVO Backup & Replication, wo Sie die Aktivitäten überprüfen können. In diesem Fall wurde die Einrichtung des Echtzeit-Replikationsdienstes erfolgreich abgeschlossen.
Hinzufügen des Transporteurs
- Kehren Sie zu Einstellungen zurück, um den Ziel-Transporter hinzuzufügen Knoten hinzuzufügen. Bevor wir fortfahren, können wir den Status der Anzeige des für die Knoten angezeigten E/A-Filters überprüfen. Der Status ist in diesem Fall gut.
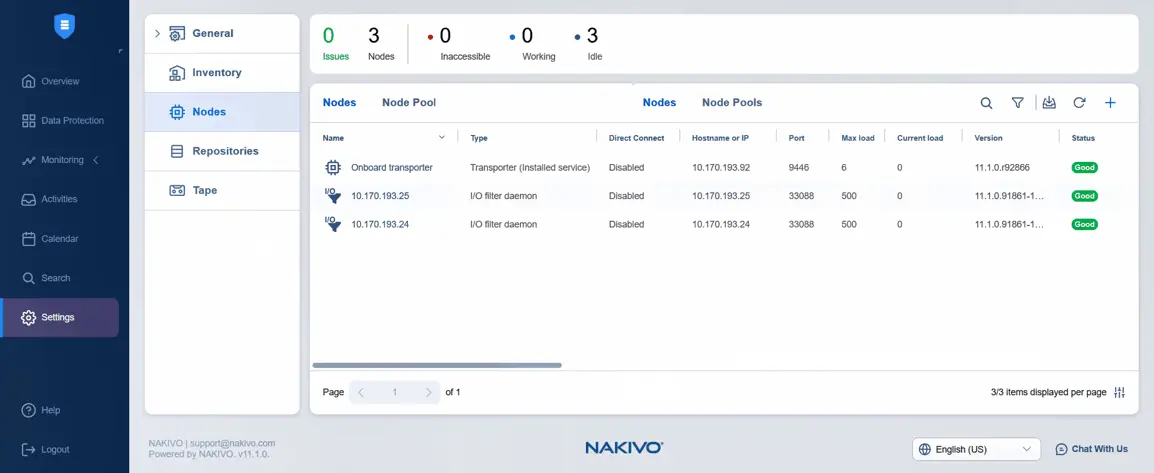
- Wählen Sie unter Einstellungen die Option Knoten , klicken Sie auf Plus und drücken Sie VMware vSphere-Appliance unter Vorhandenen Knoten hinzufügen . Wir haben die Virtuelle Appliance bereits installiert, als der I/O-Dienst installiert wurde (automatisch).
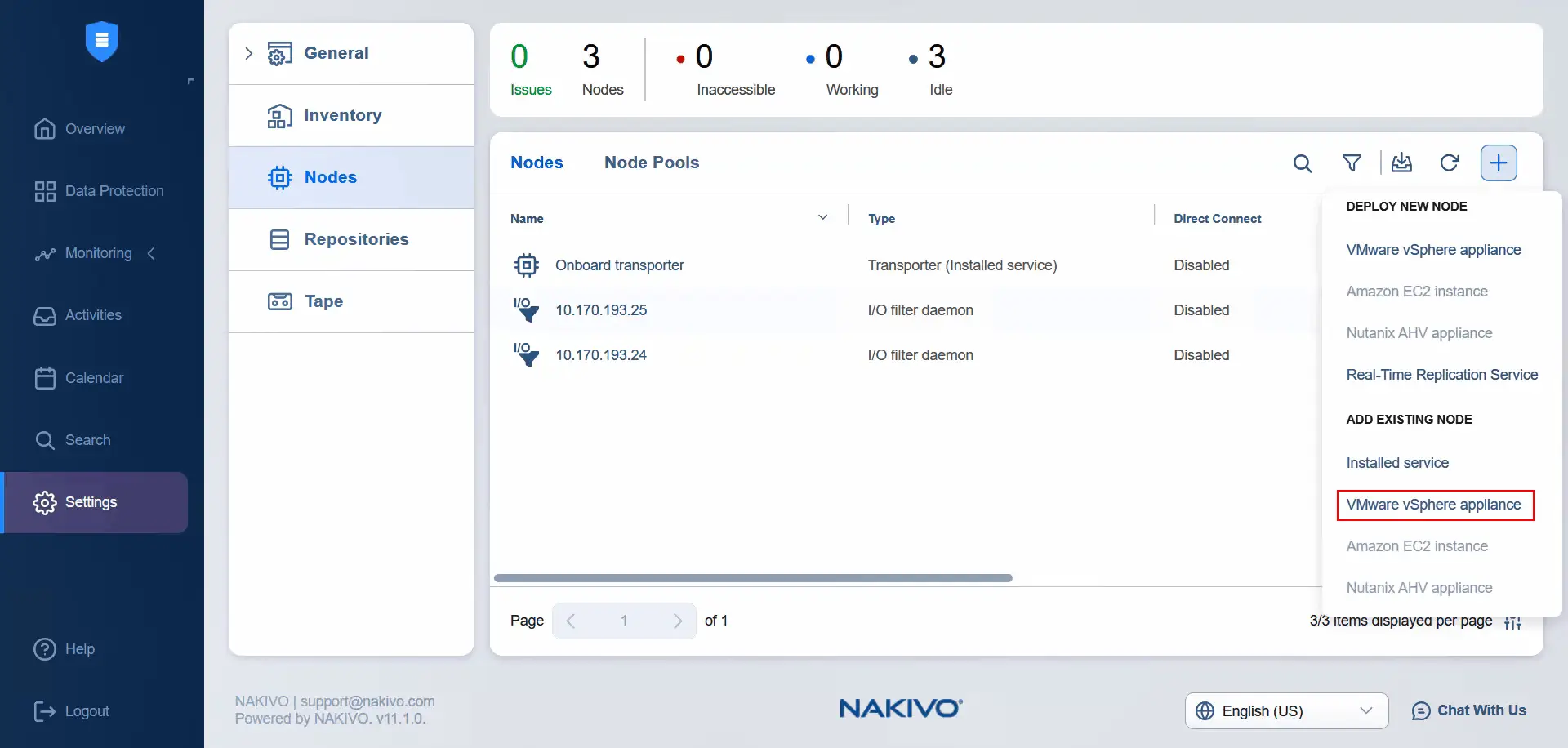
- Wählen Sie den Ziel-ESXi-Host und die Ziel-Virtuelle Appliance Transporter aus. Geben Sie den Benutzernamen der Transporter-Virtuellen Appliance und das Passwort für diesen Benutzer ein. Sie können den Transporter-Name in das entsprechende Feld eingeben. Klicken Sie auf Hinzufügen .
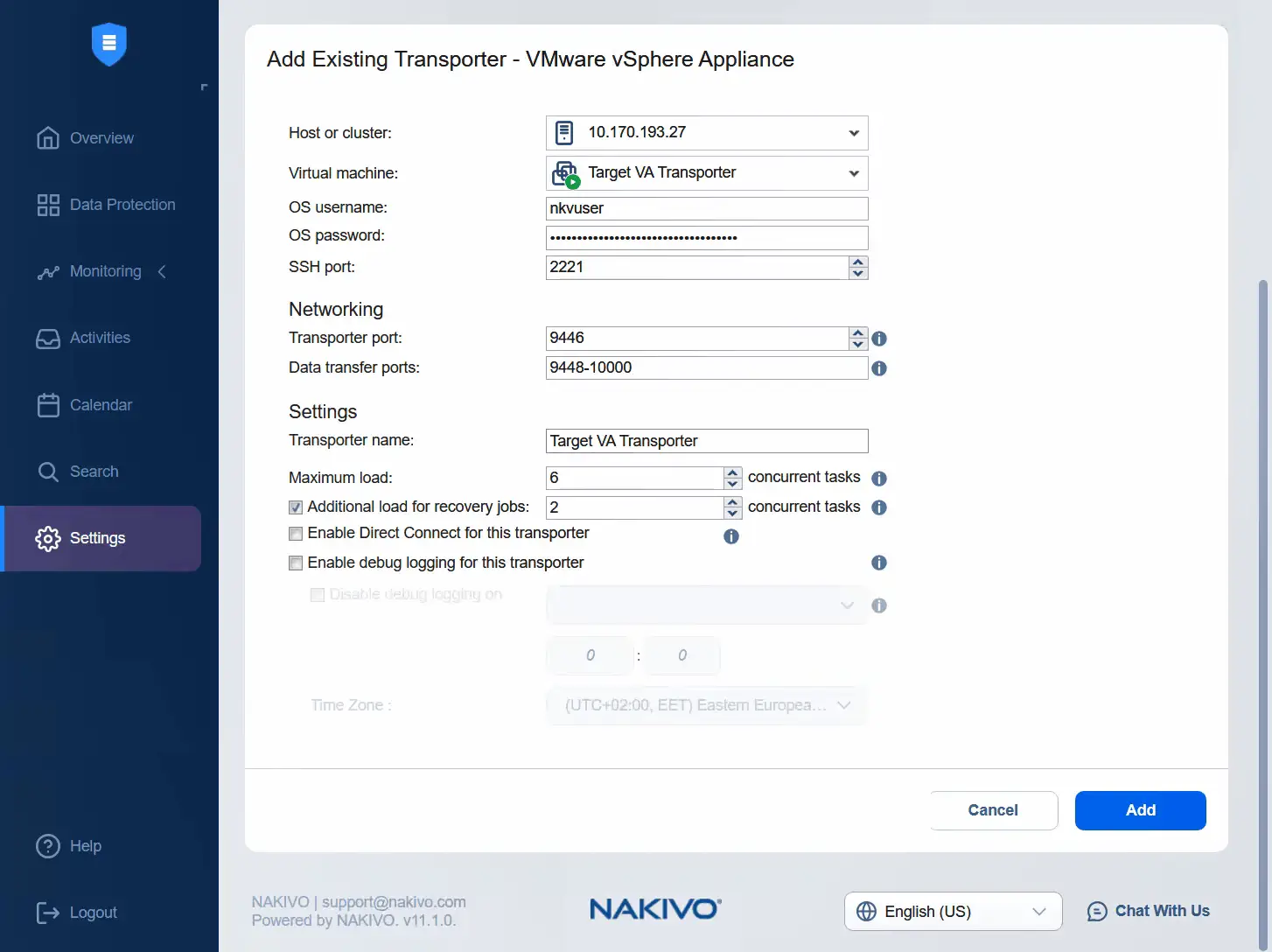
- Das Hinzufügen des Ziel-Transporteurs wird ausgeführt. Sie können den Fortschritt hier überprüfen oder den Status in der Liste der Knoten überwachen. Nun sehen wir, dass die virtuelle Ziel-Appliance Transporter erfolgreich hinzugefügt wurde und ihr Status gut ist.
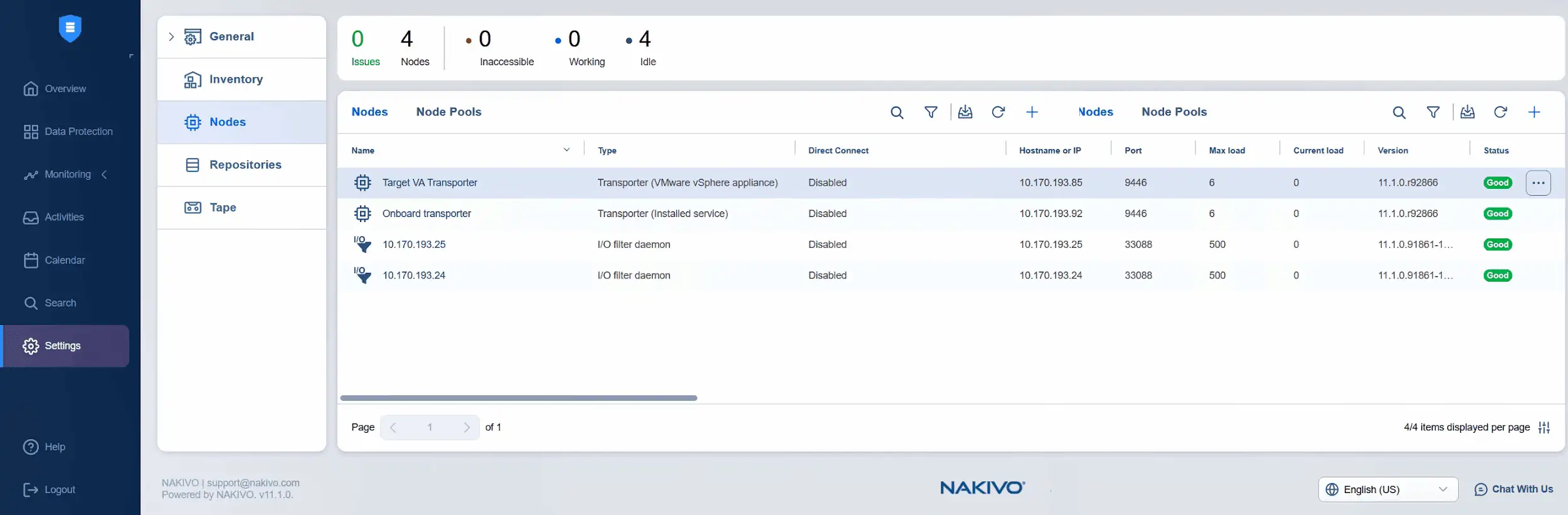
- Nun ist es an der Zeit, die virtuelle Quell-Appliance Transporter zu den Knoten hinzuzufügen. Klicken Sie auf Plus und dann auf VMware vSphere-Appliance unter Vorhandenen Knoten hinzufügen .
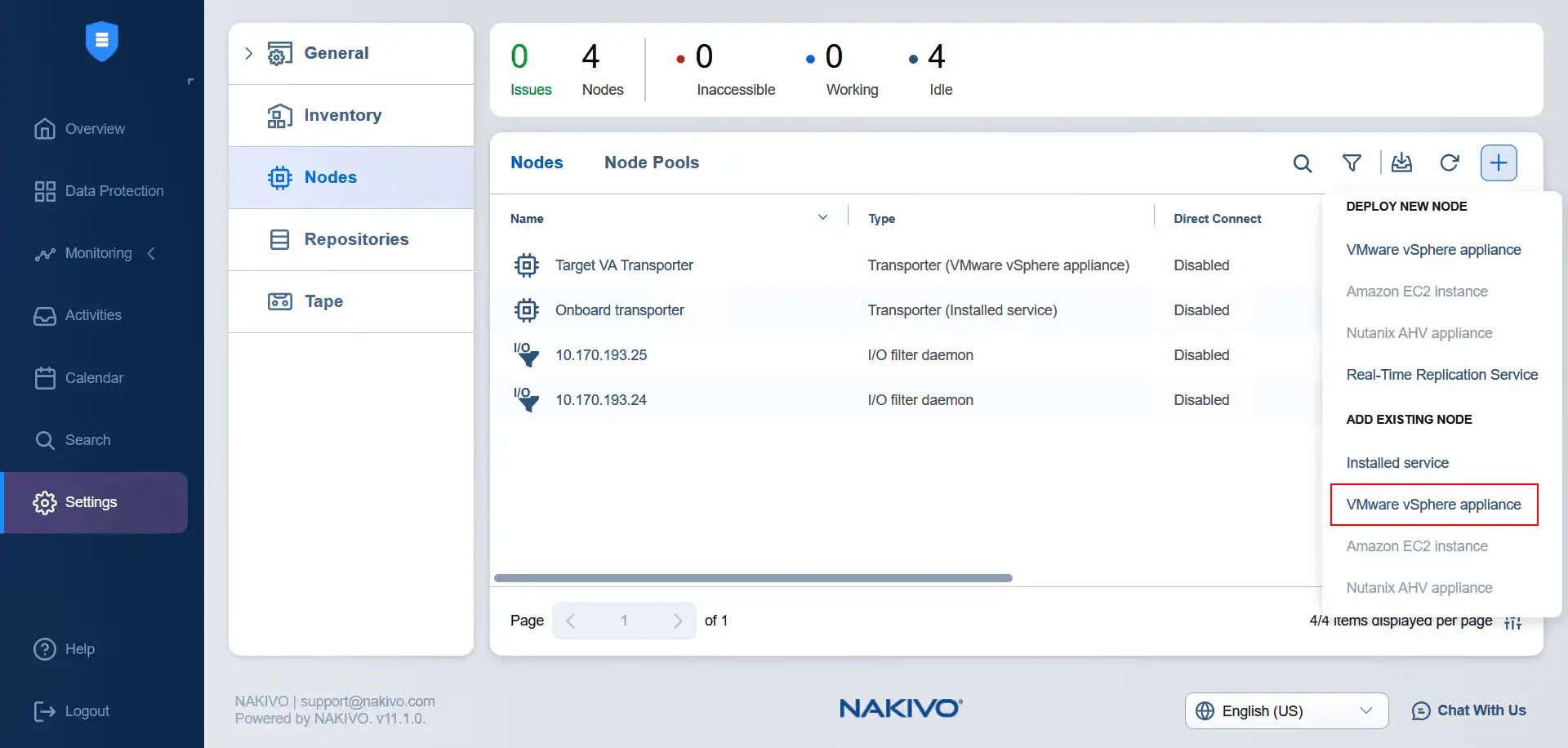
- Wählen Sie einen Cluster als Quelle aus. Wählen Sie den Quell-Transporter für Virtuelle Appliances aus. Geben Sie den Benutzernamen und das Passwort der ausgewählten Transporter-Appliance ein. Wenn Sie weitere Optionen erweitern, können Sie den Transporter-Name eingeben. Klicken Sie auf Hinzufügen .
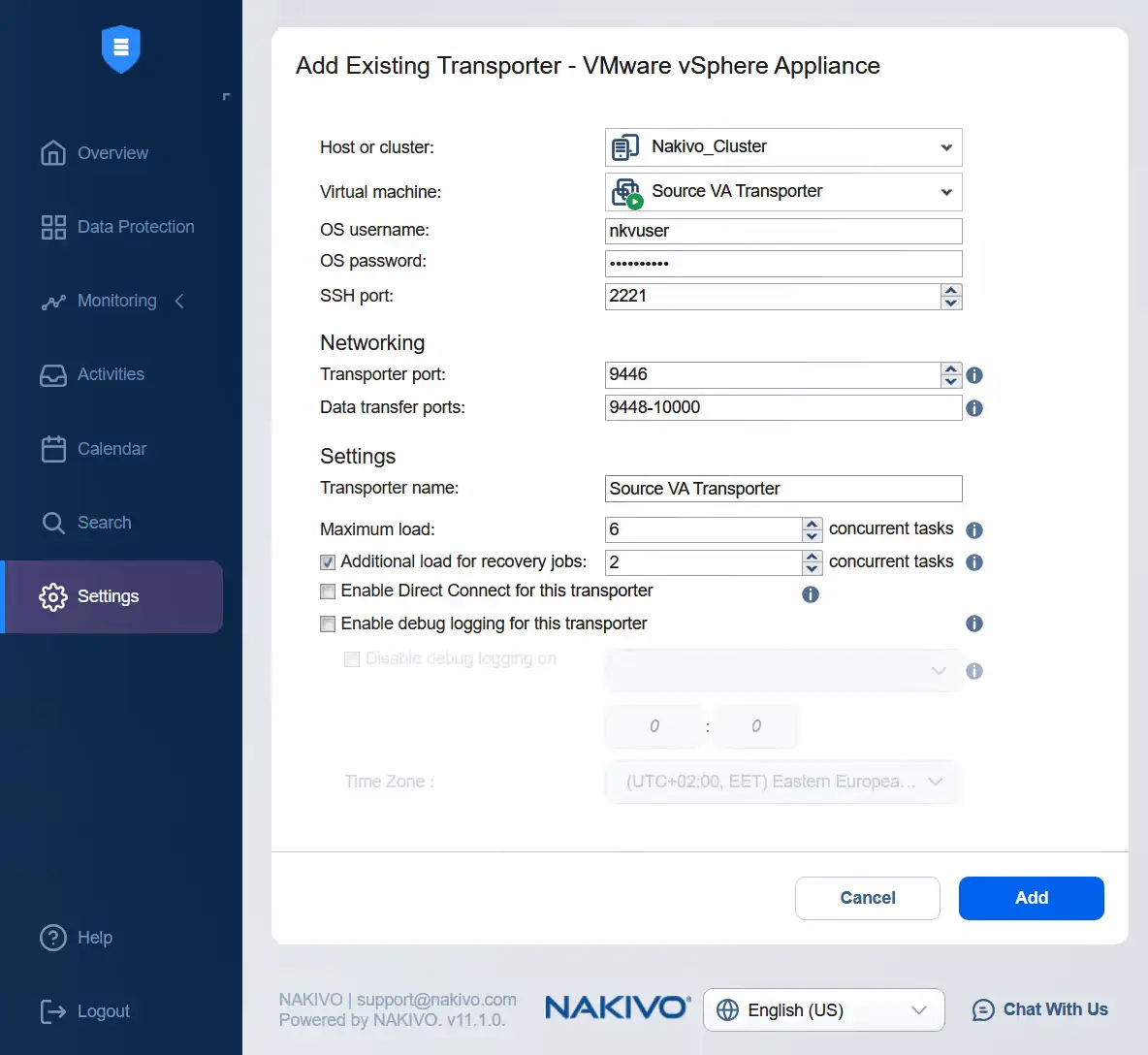
- Nach einiger Zeit wird der Quell-Transporter für Virtuelle Appliances erfolgreich zu den Knoten hinzugefügt.
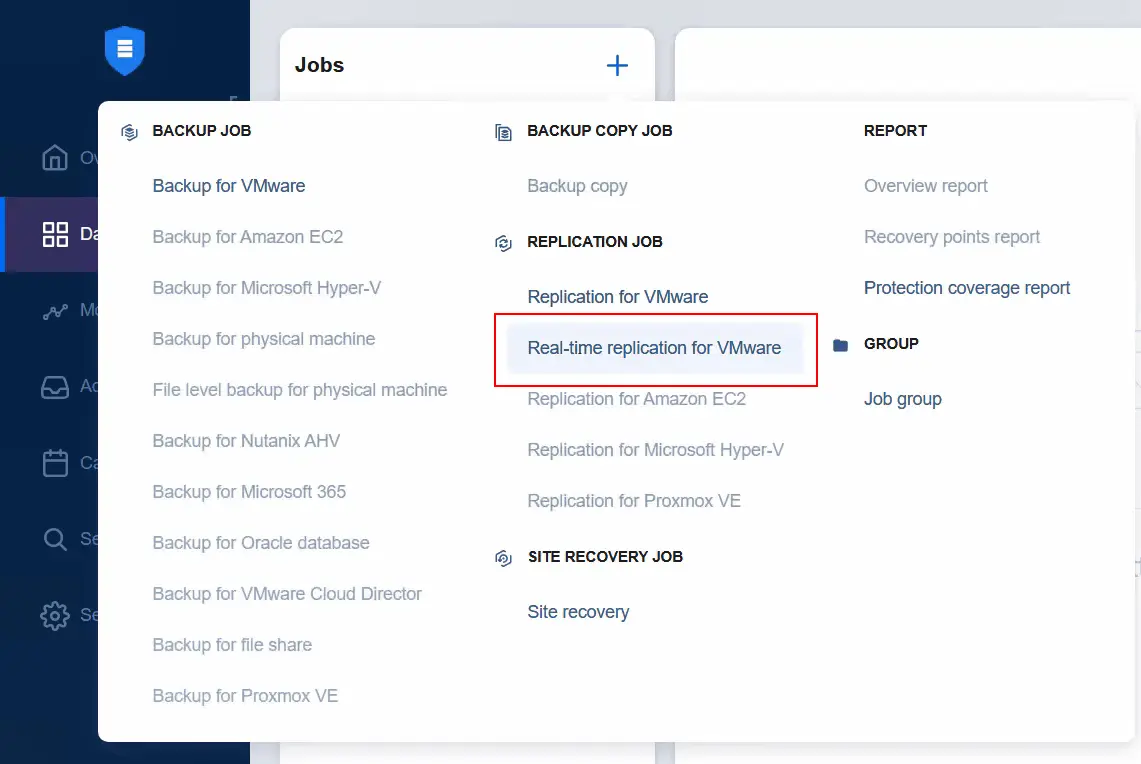
Erstellen eines Echtzeit-Replikationsauftrags
Gehen Sie zu Datensicherheit , um einen Echtzeit-Replikationsauftrag für die VM zu erstellen. Klicken Sie auf Plus und drücken Sie Echtzeit-Replikation für VMware .
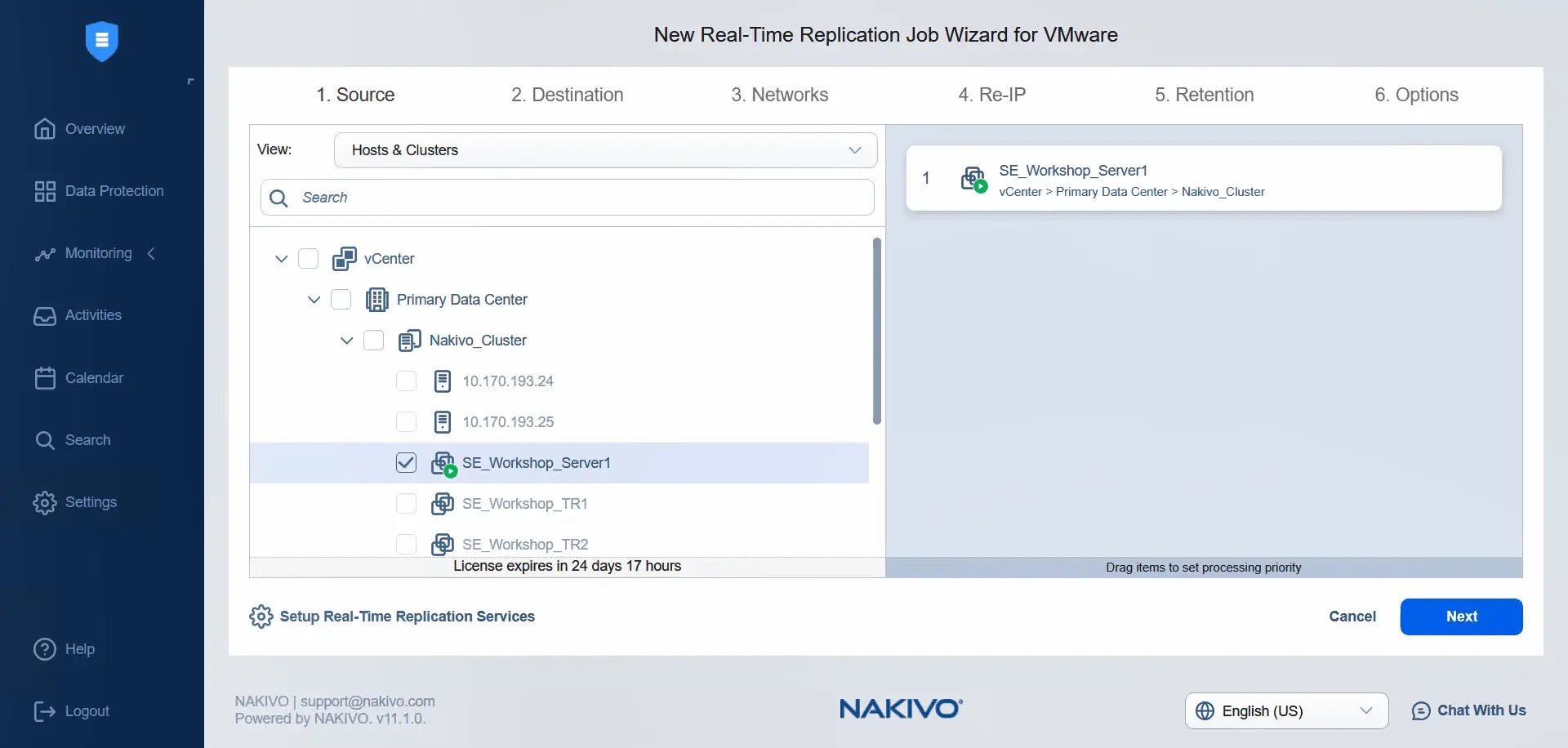
- Im Schritt Quelle wählen Sie in der Ansicht Hosts & Cluster im primären Rechenzentrum die virtuelle Maschine mit der angewendeten VM-Speicher-Richtlinie aus. Beachten Sie, dass wir keine anderen virtuellen Maschinen auswählen können, da die VM-Speicher-Richtlinie nicht auf diese angewendet wird. Klicken Sie auf Weiter , um fortzufahren.
- Im Schritt Ziel können wir einen eigenständigen ESXi-Host als Ziel-Container auswählen. Wählen Sie einen an diesen ESXi-Host angehängten Datenspeicher aus. Fahren Sie mit dem nächsten Schritt weiter.
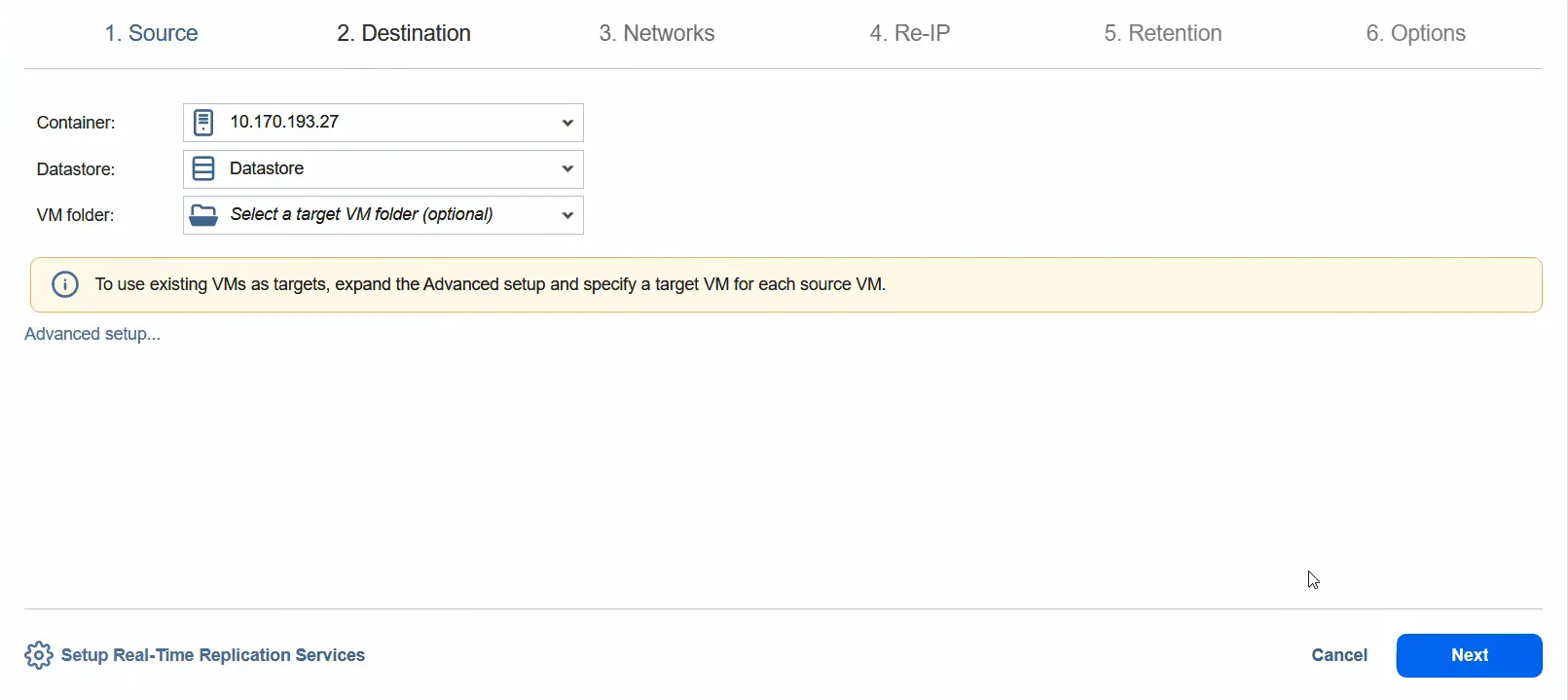
- Sie können die Netzwerkzuordnung aktivieren, indem Sie das Quellnetzwerk und das Zielnetzwerk auswählen. Klicken Sie auf Weiter .
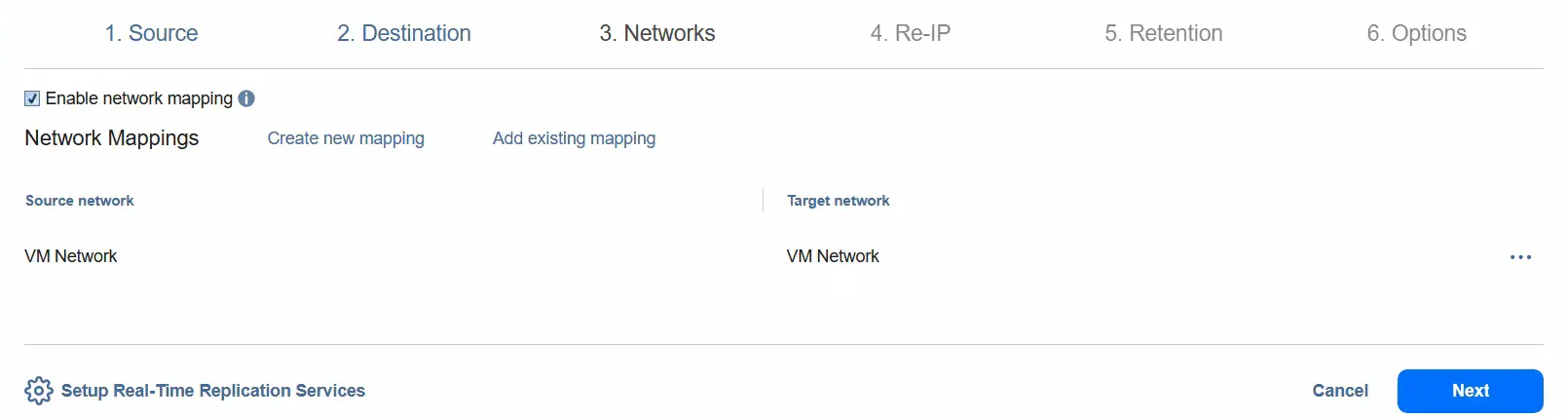
- Sie können Re-IP aktivieren, um die IP-Adresse für die Ziel-VM zu ändern.
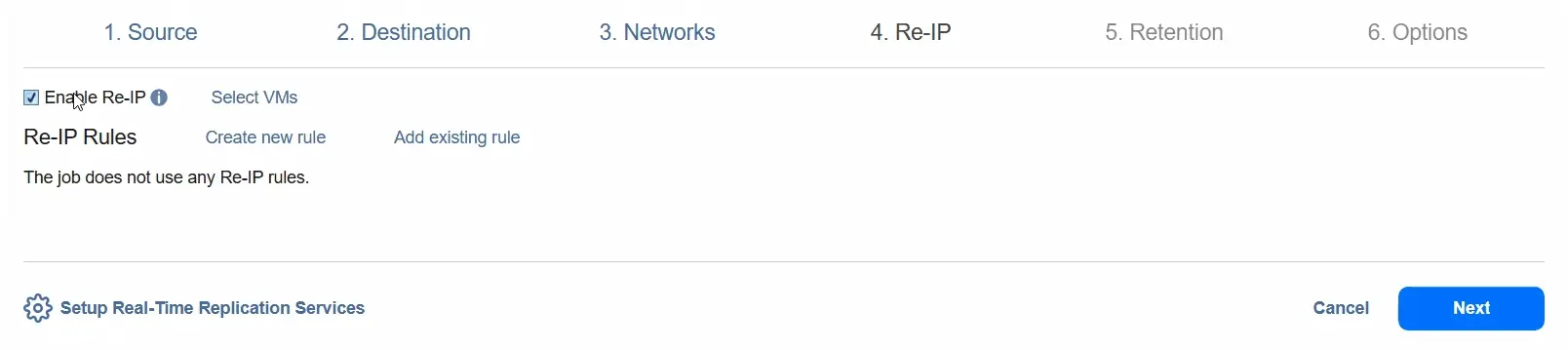
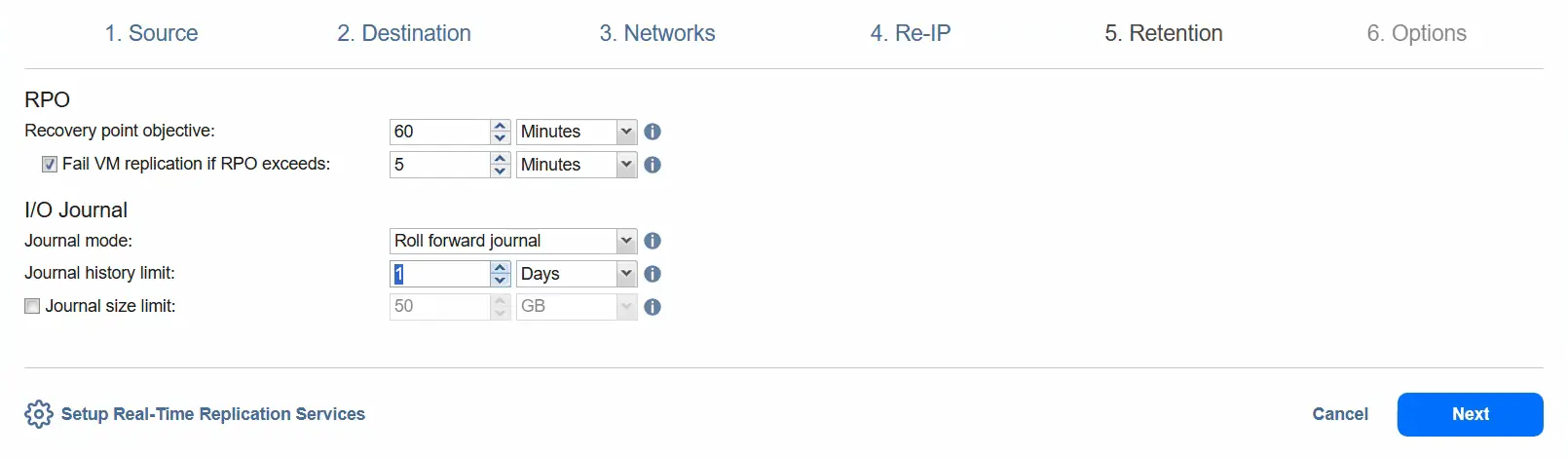
- Wählen Sie im Schritt Aufbewahrung das Ziel der Wiederherstellungspunkte (RPO) aus. Standardmäßig beträgt es 1 Minute. Wir können den RPO auf 1 Sekunde verringern oder auf 60 Minuten erhöhen (dies ist der Maximalwert). Sie können die Option „ VM-Replikation fehlschlagen lassen, wenn RPO die angegebene Zeit überschreitet“ auswählen.
Sie können den Journalmodus auswählen: Rollforward-Journal oder Rollback-Journal .
Mit der Option Rollback-Journal werden neue Datenänderungen direkt in dem VM-Replikat gespeichert und alle Daten in dem Replikat werden im Journal gespeichert. Alte Daten im Journal werden basierend auf den Journal-Einstellungen entfernt.
Mit der Option Rollforward-Journal werden die neuen Datenänderungen im Journal gespeichert und die alten Daten basierend auf den Journal-Einstellungen in die Replik integriert. Vorerst behalten wir die Einstellungen bei und verwenden die Option „ Rollforward-Journal “.
Mit der Option „ Begrenzung des Journalverlaufs “ können Sie eine Begrenzung für den Journalverlauf zwischen 1 Stunde und 30 Tagen festlegen.
Mit der Option Journal size limit legen Sie ein Limit für die Größe des Journals fest. Der Wert kann zwischen 1 Gigabyte und 20 Terabyte liegen. Vorerst behalten wir diese Option deaktiviert und fahren mit dem weiteren Schritt fort.
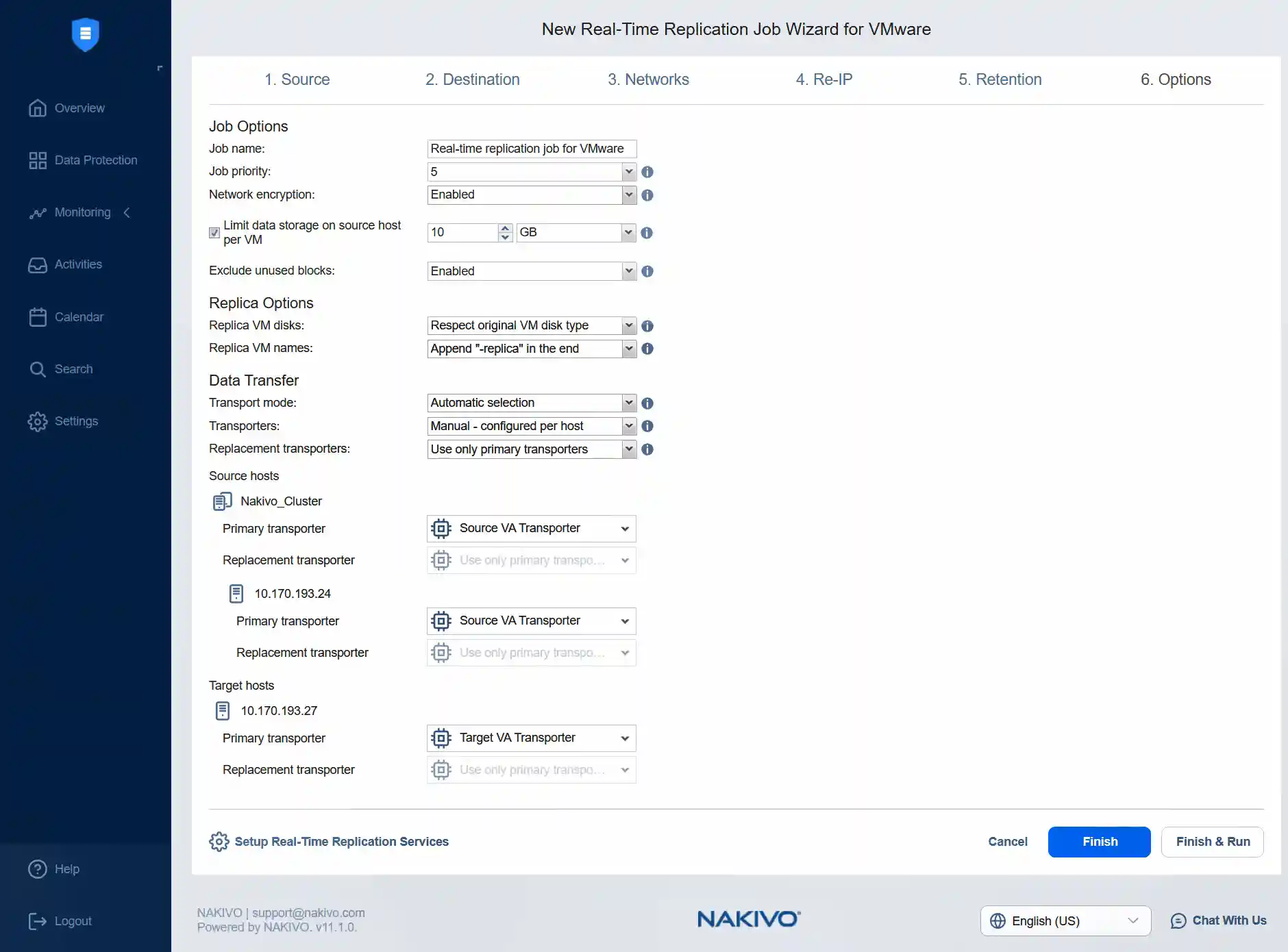
- Im Schritt Optionen legen Sie den Auftrags-Name für die Echtzeit-Replikation fest. In diesem Beispiel behalten wir den Auftrags-Name unverändert bei und behalten die Auftragspriorität als 5 bei. Wir können die Netzwerkverschlüsselung aktivieren, um den Datenverkehr zwischen dem I/O-Filter-Daemon und dem Journal-Dienst über Port 63092 zu verschlüsseln. Die Verschlüsselung verwendet ein Zertifikat auf dem Transporter, das eine sichere Verbindung zum Journal-Dienst herstellt.
Wir können den Speicher auf dem Quellhost pro VM auf 10 Gigabyte begrenzen und Ungenutzte Blöcke ausschließen. Wir können die Standardwerte für die weiteren Optionen behalten.
Für den Quellhost müssen wir den Quelltransporter auswählen, nämlich den Source VA Transporter. Anschließend wählen wir denselben Transporter für den ESXi-Host 24 aus.
Für den Zielhost müssen wir den Zieltransporter auswählen, nämlich den entsprechenden Ziel-Virtuellen-Appliance-Transporter.
Klicken Sie auf „Fertigstellen“ (Fertigstellen) & „Run“ (Ausführen) , um die Auftragseinstellungen zu speichern und den Echtzeit-VMware-Replikationsauftrag auszuführen. Klicken Sie auf „Run“ (Ausführen) und dann erneut auf „Run“ (Ausführen) , wenn die Bestätigungsmeldung angezeigt wird.
Fazit
Die Echtzeit-Datenreplikation für virtuelle Maschinen verbessert die Geschäftskontinuität erheblich, indem sie Ausfallzeiten reduziert und die Möglichkeit bietet, die Wiederherstellung von VMs so schnell wie möglich durchzuführen. Diese Funktion sollte für die kritischsten VMs mit den wichtigsten Daten verwendet werden, während die herkömmliche asynchrone Replikation für weniger kritische Daten kostengünstiger sein kann. Verwenden Sie NAKIVO Backup & Replication für die Echtzeit-Replikation und asynchrone Replikation von Virtuellen Maschinen in VMware vSphere.


