Hochverfügbarkeit vs. Fehlertoleranz vs. Disaster Recovery: Ein Überblick
<>Wenn es darum geht, die IT-Infrastruktur eines Unternehmens rund um die Uhr betriebsbereit zu halten, scheint es immer noch einige Verwirrung zwischen den drei verwendeten Kernbegriffen zu geben: Hochverfügbarkeit (HA), Fehlertoleranz (FT) und Disaster Recovery (DR). Alle drei Begriffe beziehen sich auf die Aufrechterhaltung der Geschäftskontinuität und den Zugriff auf IT-Systeme. Jeder Begriff hat jedoch seine eigene spezifische Definition, Methodik und Verwendungsfälle.
In diesem Blogbeitrag definieren wir, was Hochverfügbarkeit, Fehlertoleranz und Disaster Recovery in der Praxis bedeuten, und untersuchen, wie sich die Begriffe überschneiden und warum ihre Umsetzung wichtig ist.

Was ist Hochverfügbarkeit?
Hochverfügbarkeit ist die Fähigkeit eines Systems, über einen bestimmten Zeitraum hinweg ohne Ausfälle zu arbeiten (Betriebszeit) und für Benutzer zugänglich zu sein. Die Betriebszeit ist die Zeit, während der ein Server ohne ungeplante Neustarts oder Abschaltungen betriebsbereit ist.
Die Hochverfügbarkeit (HA) wird als Prozentsatz der Zeit berechnet, in der ein System während festgelegter Zeiten betriebsbereit ist, ohne geplante Wartungsarbeiten und Abschaltungen zu berücksichtigen. Von HA wird keine 100-prozentige Betriebszeit erwartet, da dies schwierig und unpraktisch zu erreichen ist. Eine Ausfallzeit von bis zu 5 Minuten und 26 Sekunden pro Jahr gilt als akzeptabel, was einer Betriebsverfügbarkeit von 99,999 % entspricht. Allerdings ist selbst dieser Wert für viele Unternehmen möglicherweise kein realistisches Ziel. Je nach Unternehmen, Branche und Ressourcen kann der erforderliche HA-Wert niedriger sein.
Wie funktioniert Hochverfügbarkeit?
Das Ziel der Hochverfügbarkeit für ein Unternehmen wird durch die Beseitigung eines Single Point of Failure in einem System mithilfe von Redundanz- und Failover-Komponenten erreicht. Das bedeutet, dass sichergestellt wird, dass der Ausfall einer einzelnen Komponente nicht zur Nichtverfügbarkeit des gesamten Systems führt.
In der Virtualisierung kann Hochverfügbarkeit mit Hilfe von Clustering-Technologienerreicht werden. Wenn beispielsweise einer Ihrer Hosts oder Ihre Virtuellen Maschinen (VM) innerhalb eines Clusters ausfällt, übernimmt eine andere VM (Failover) und sorgt für die Aufrechterhaltung der ordnungsgemäßen Leistung des Systems.
Redundante Komponenten sind zwar die ultimative Bedingung für die Gewährleistung von Hochverfügbarkeit, aber diese Komponenten allein reichen nicht aus, um das System als hochverfügbar zu bezeichnen. Ein hochverfügbares System umfasst sowohl redundante Komponenten als auch Mechanismen zur Fehlererkennung und automatischen Umleitung der Workloads. Dies können Load Balancer oder Hypervisoren sein. DRS in VMware vSphere ist ein Beispiel für einen Load Balancer.
Wann ist Hochverfügbarkeit wichtig?
Eine hochverfügbare Architektur ist für alle kritischen Workloads erforderlich, bei denen Ausfallzeiten nicht toleriert werden können. Wenn der Ausfall eines Systems oder einer Anwendung das Überleben des Unternehmens gefährdet, kann HA eingesetzt werden, um Ausfallzeiten zu minimieren. Laut Statistabeliefen sich die Kosten für eine Stunde Ausfallzeit im Jahr 2020 für 25 % der Unternehmen auf 300.000 bis 400.000 US-Dollar. Das bedeutet, dass selbst die sehr hohe Verfügbarkeit von 99,999 % – 5 Minuten und 26 Sekunden Ausfallzeit pro Jahr – einige Unternehmen rund 35.000 US-Dollar kosten kann.
Neben erheblichen finanziellen Verlusten kann eine Ausfallzeit auch andere schwerwiegende Folgen haben, wie z. B. Produktivitätsverluste, die Unfähigkeit, Dienstleistungen rechtzeitig zu erbringen, eine Schädigung des Unternehmensrufes und so weiter. Hochverfügbare Systeme helfen, solche Szenarien zu vermeiden, indem sie Ausfälle automatisch und zeitnah beheben.
Was ist Fehlertoleranz?
Fehlertoleranz ist die Fähigkeit eines Systems, im Falle des Ausfalls einer oder mehrerer seiner Komponenten ohne Ausfallzeit weiter ordnungsgemäß zu funktionieren. Ein fehlertolerantes System umfasst zwei eng gekoppelte Komponenten, die sich gegenseitig spiegeln, um Redundanz zu gewährleisten. Auf diese Weise kann die sekundäre Komponente sofort einspringen, wenn die primäre Komponente ausfällt.
Wie funktioniert Fehlertoleranz?
Fehlertoleranz basiert ebenso wie Hochverfügbarkeit auf Redundanz, um die Betriebszeit sicherzustellen. Eine solche Redundanz kann durch die gleichzeitige Ausführung einer Anwendung auf zwei Servern erreicht werden, wodurch ein Server sofort den anderen übernehmen kann, wenn der primäre Server ausfällt.
In virtualisierten Umgebungen wird Redundanz für Fehlertoleranz durch die Pflege und Ausführung identischer Kopien einer bestimmten virtuellen Maschine auf separaten Hosts erreicht. Jede Änderung oder Eingabe, die auf der primären VM vorgenommen wird, wird auf der sekundären VM dupliziert. Auf diese Weise wird im Falle einer Beschädigung der primären VM die Fehlertoleranz durch die sofortige Übertragung der Workloads von einer VM auf ihr Duplikat gewährleistet.
Wann ist Fehlertoleranz wichtig?
Ein fehlertolerantes Design ist entscheidend für Systeme, die keine Ausfallzeiten tolerieren können (Null-Ausfallzeit). Wenn es geschäftskritische Anwendungen gibt und selbst die geringste Ausfallzeit zu unwiderruflichen Verlusten führt, sollten Sie Ihre IT-Komponenten unter Berücksichtigung der Fehlertoleranz konfigurieren.
Fehlertoleranz vs. Hochverfügbarkeit
Im Vergleich zwischen HA und FT ist Fehlertoleranz die kostspieligere Lösung. Fehlertoleranz und Hochverfügbarkeit unterscheiden sich jedoch auch in zwei wesentlichen Punkten:
- Fehlertoleranz ist eine strengere Version der Hochverfügbarkeit. Hochverfügbarkeit konzentriert sich auf minimale Ausfallzeiten, während Fehlertoleranz noch einen Schritt weiter geht und null Ausfallzeiten bietet.
- Im fehlertoleranten Modell hat jedoch die Fähigkeit eines Systems, im Falle eines Ausfalls eine hohe Leistung zu erbringen, nicht oberste Priorität. Stattdessen wird erwartet, dass ein System seine Leistung aufrechterhalten kann, wenn auch auf einem reduzierten Niveau.
Was ist Disaster Recovery?
Disaster Recovery ist ein Prozess, mit dem Unternehmen auf Vorfälle reagieren, die sich auf Systeme auswirken, und die Funktionalität der IT-Infrastruktur schnell wiederherstellen können. Disaster Recovery umfasst einen Disaster-Recovery-Plan, ein Disaster-Recovery-Team, eine dedizierte Disaster-Recovery-Lösung, einen Wiederherstellungsstandort usw. Dieser Ansatz beinhaltet die Verwendung von Hot-, Warm- oder Cold-Standorten abhängig vom RTO-Wert, der im Disaster-Recovery-Plan definiert ist, und den verfügbaren Ressourcen.
Die beiden wichtigsten Kennzahlen der DR sind Wiederherstellungszeit-Ziele (RTOs) und Ziele der Wiederherstellungspunkte (RPOs), um Ausfallzeiten bzw. Datenverluste zu minimieren.
Wie funktioniert Disaster Recovery?
Disaster Recovery erfordert einen sekundären Standort, an dem Sie Ihre kritischen Daten und Workloads (ganz oder teilweise) wiederherstellen können, um nach einem Störfall den Geschäftsbetrieb in ausreichendem Umfang wieder aufzunehmen.
Um die Workloads an einen entfernten Standort zu übertragen, muss eine geeignete Disaster-Recovery-Lösung integriert werden. Eine solche Lösung kann die Failover- Operation zeitnah und mit geringem Aufwand Ihrerseits übernehmen, sodass Sie Ihre festgelegten RTOs erreichen können.
Was sind die Komponenten der Disaster Recovery?
Disaster Recovery ist ein viel umfassenderes und komplexeres Konzept als Hochverfügbarkeit und Fehlertoleranz. Es bezieht sich auf eine Strategie mit einer umfassenden Reihe von Komponenten, darunter: Risikobewertung, Planung, Abhängigkeitsanalyse, Konfiguration von Remote-Standorten, Mitarbeiterschulungen, Tests, Automatisierungseinrichtung und so weiter. Ein weiterer Aspekt der DR, der über Hochverfügbarkeit und Fehlertoleranz hinausgeht, ist ihre Unabhängigkeit vom Produktionsstandort.
Wann ist Disaster Recovery wichtig?
Disaster bezieht sich nicht nur auf Naturkatastrophen, sondern auf jede Art von Störungsereignis, das den gesamten Produktionsstandort trifft und zu erheblichen Ausfallzeiten führt, darunter Cyberangriffe, Stromausfälle, menschliches Versagen, Softwarefehler und andere. Das bedeutet, dass solche Vorfälle jederzeit unerwartet auftreten können. In den meisten Fällen sind Katastrophen unvorhersehbar und unvermeidbar, weshalb Unternehmen Maßnahmen ergreifen sollten, um ihre Notfallvorsorge zu verbessern und ihre DR-Strategien regelmäßig zu optimieren.
Disaster Recovery vs. Hochverfügbarkeit
Im Gegensatz zu Hochverfügbarkeit und Fehlertoleranz befasst sich Disaster Recovery mit katastrophalen Folgen, die zur Nichtverfügbarkeit der gesamten IT-Infrastruktur führen, und nicht mit Ausfällen einzelner Komponenten. Da DR sowohl daten- als auch technologieorientiert ist, besteht sein Hauptziel darin, Daten wiederherzustellen und Infrastrukturkomponenten nach einem ungeplanten Vorfall innerhalb kürzester Zeit wieder betriebsbereit zu machen.
Was den Unterschied zwischen Hochverfügbarkeit und Disaster Recovery betrifft, so können Hochverfügbarkeit und Fehlertoleranz Ihnen nicht dabei helfen, Daten im Falle einer Katastrophe und eines Datenverlusts aufgrund eines unvorhergesehenen Vorfalls wiederherzustellen. In diesem Szenario kann Disaster Recovery Ihnen eine unabhängige DR-Infrastruktur und Point-in-Time-Kopien Ihrer Daten (Wiederherstellungspunkte) zur Verfügung stellen, um Ausfallzeiten zu minimieren und Datenverluste zu vermeiden. Beachten Sie jedoch die Unterschiede zwischen Disaster Recovery und Backup.
Verwendung von NAKIVO Backup & Replication für Disaster Recovery
NAKIVO Backup & Replikation ist eine schnelle, zuverlässige und kostengünstige Lösung. Sie kombiniert hochwertige Datensicherheit und Disaster-Recovery-Funktionalität – die Standortwiederherstellung –, die DR-Vorgänge vereinfachen und automatisieren soll.

Wenn Sie einen Remote-Standort konfiguriert haben, wie es die DR-Best Practices vorschreiben, ist die Lösung einfach zu bedienen und zu konfigurieren und ermöglicht Ihnen gleichzeitig die Erstellung komplexer Wiederherstellungs-Workflows.
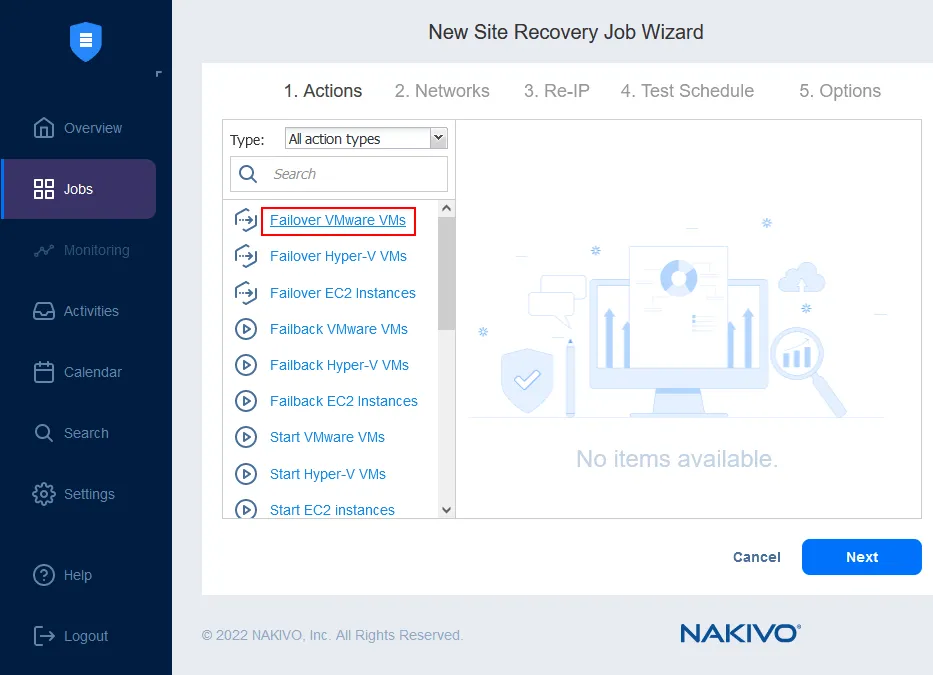
Sie können bis zu 200 Aktionen in einem Auftrag (Job) kombinieren, um verschiedenen Katastrophenszenarien gerecht zu werden und unterschiedliche Zwecke zu erfüllen, darunter: Überwachte Workloads, Migration von Rechenzentren, Notfall-Failover, geplantes Failover, Failback usw. Im Katastrophenfall kann jeder der erstellten Workflows mit einem einzigen Klick sofort in die Tat umgesetzt werden, sodass Unternehmen die kürzeste Zeit für die Wiederherstellung erreichen können.
Mit der Standortwiederherstellung können Sie automatisierte, nicht störende Disaster-Recovery-Tests durchführen. Auf diese Weise können Sie sicherstellen, dass Ihre Standortwiederherstellung-Workflows gültig sind, dass sie alle aktuellen Änderungen in Ihrer IT-Infrastruktur widerspiegeln und dass keine Schwachstellen vorhanden sind, bevor eine tatsächliche Katastrophe eintritt.