Procedure consigliate per lo storage Hyper-V
Lo storage è uno dei componenti più importanti dei server, compresi i server di virtualizzazione con hypervisor installato e VM in esecuzione. Lo storage può determinare prestazioni elevate o basse, nonché garantire un’affidabilità elevata o bassa nella conservazione dei dati delle VM e dei dischi virtuali. Nell’ambiente virtuale Hyper-V è possibile utilizzare diversi tipi di storage e l’amministratore deve effettuare la scelta giusta prima di configurare un server o effettuare l’implementazione di VM.
Questo post del blog ha lo scopo di aiutarti a esplorare diversi tipi di opzioni di storage al fine di scegliere quello più adatto al tuo ambiente e quindi in grado di soddisfare in modo efficiente i tuoi requisiti.

Raccomandazioni per l’archiviazione Hyper-V
L’archiviazione che può essere montata sul server Hyper-V può essere di due tipi: archiviazione locale o archiviazione remota.
Archiviazione locale consiste in diversi dischi collegati localmente al server. Tali dischi sono solitamente collegati con interfaccia SAS (Serial Attached SCSI) a un controller RAID (Redundant Array of Independent Disks) all’interno dello chassis del server. L’uso di dischi SAS è preferibile rispetto ai dischi SATA (nonostante la compatibilità – i dischi SATA possono essere collegati a porte SAS ma non viceversa) a causa del maggiore livello di affidabilità dei dischi SAS. Lo storage locale può essere più conveniente rispetto allo storage remoto. Se non si prevede di effettuare l’implementazione di un cluster Hyper-V, è possibile utilizzare lo storage locale.
Lo storage remoto ha una ubicazione separata dal server Hyper-V ed è collegato al server tramite i protocolli iSCSI, Fibre Channel o SMB 3.0. Fibre Channel e iSCSI forniscono archiviazione a livello di blocco, mentre SMB 3.0 è archiviazione a livello di file. Fibre Channel richiede un’interfaccia fisica speciale per collegare i server all’archiviazione, come SAN (Storage Area Network). FCoE (Fibre Channel over Ethernet) può essere utilizzato per collegare l’archiviazione tramite reti Ethernet. Il protocollo iSCSI può essere utilizzato per collegare un server a SAN o NAS (Network Attached Storage). Il dispositivo NAS assomiglia a un mini server dotato di un controller RAID con slot per unità disco all’interno e diverse porte per la connessione alla rete esterna. Anche un server autonomo può essere configurato per essere utilizzato come NAS. SAN e NAS possono garantire la ridondanza dei dati per una maggiore affidabilità.
Quando si effettua l’implementazione di un cluster di failover, è necessario utilizzare uno storage remoto condiviso con tutti i nodi all’interno del cluster. In questo caso, tale storage è denominato storage condiviso.
Utilizzare RAID 1 o RAID 10
RAID è l’acronimo di Redundant Array of Independent Disks (matrice ridondante di dischi indipendenti). La ridondanza dei dati sull’storage consente di proteggere i dati in caso di guasto del disco. Esistono diversi tipi di RAID.
RAID 0 non è ridondante ed è chiamato disk striping. Non c’è tolleranza ai guasti: il guasto di un disco causa il guasto dell’intero array. L’aumento delle prestazioni può essere citato come caso d’uso (ad esempio, la memorizzazione nella cache di streaming live per l’industria televisiva). Per creare questo tipo di RAID è obbligatorio avere almeno 2 dischi.
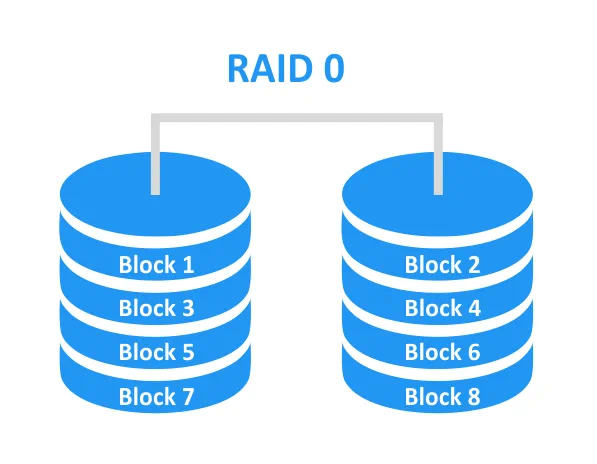
RAID 1 è ridondante. Tutti i blocchi su un disco vengono replicati su un altro disco, ottenendo così una ridondanza del 100%. Se uno dei dischi si guasta, è possibile accedere ai dati sul secondo disco e utilizzarli per ricostruire l’array. La probabilità di una ricostruzione dell’array riuscita è elevata. RAID 1 può essere utilizzato per lo storage di failover. È obbligatorio avere almeno 2 dischi per costruire questo tipo di RAID.
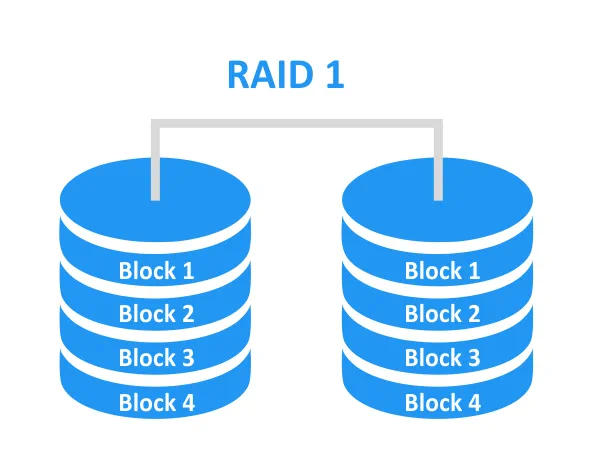
RAID 10 è una combinazione di RAID 0 e RAID 1. Vengono sfruttati i vantaggi di entrambi i tipi di array, ottenendo così un array tollerante ai guasti con prestazioni più elevate. I dischi mirrorati vengono combinati in uno stripe. Per creare questo tipo di RAID sono obbligatori almeno 4 dischi. Se il RAID 10 è composto da 4 dischi, la protezione dei dati può essere garantita in caso di guasto di un singolo disco. Inoltre, l’array a 4 dischi può sopravvivere se due dischi di mirror diversi si guastano.

RAID 5 fornisce uno striping con parità. I blocchi sono distribuiti su più dischi, ma anche le informazioni di parità utilizzabili per il ripristino sono memorizzate su più dischi. Lo spazio occupato dalle informazioni di parità è pari alla capacità di un disco. Ad esempio, le informazioni di parità occupano circa il 25% dello spazio di un array a 4 dischi. Non è ridondante al 100% come il RAID 1. In teoria, il RAID 5 può sopravvivere se uno dei dischi si guasta. Per costruire questo tipo di RAID è obbligatorio avere almeno 3 dischi.

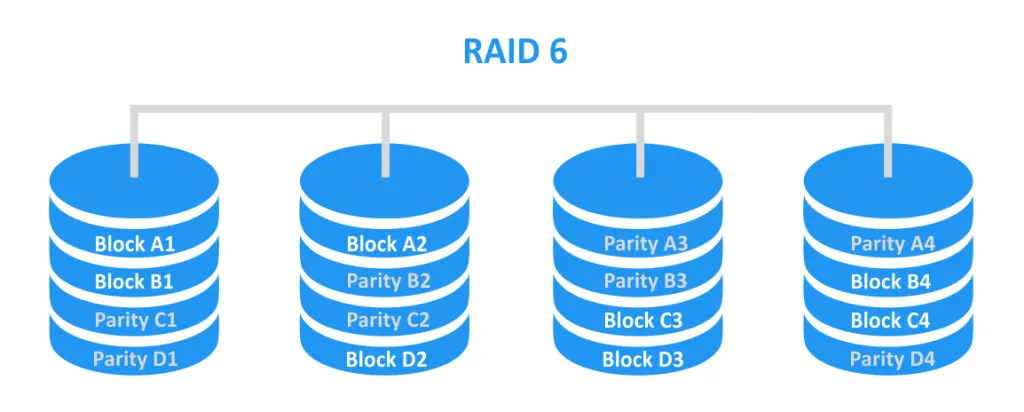
RAID 6 fornisce uno striping con doppia parità. È simile al concetto di RAID 5, ma le informazioni di parità sono memorizzate su due dischi invece che su uno solo. RAID 6 può sopravvivere in caso di guasto di un massimo di due dischi. Per creare questo tipo di RAID è obbligatoria la presenza di almeno 4 dischi.
A prima vista, RAID 5 e RAID 6 sembrano interessanti, ma diamo un’occhiata più da vicino. RAID 5 è stato sviluppato decine di anni fa, quando la capacità dei dischi era piuttosto ridotta. Nel mondo moderno, la capacità dei dischi rigidi cresce più rapidamente della velocità dei dischi; di conseguenza, se un disco si guasta, la ricostruzione del RAID 5 può richiedere molto tempo. Il carico di lavoro di ciascun disco nel RAID 5 aumenta in modo significativo durante la ricostruzione, soprattutto se il server utilizza intensivamente lo storage per eseguire contemporaneamente attività regolari. Sui dischi appartenenti al RAID 5 potrebbero esserci dati utilizzati raramente e non è possibile essere certi che tali dati possano essere letti correttamente. Ciò aumenta la probabilità di errore. Se si verifica un errore durante la ricostruzione dell’array, l’intero array potrebbe non funzionare. Quando RAID 5 ha un disco guasto, questo array funziona come RAID 0 e i dati sono a rischio.
RAID 6 ha il doppio dei dati di parità che possono essere utilizzati per il ripristino rispetto a RAID 5. Di conseguenza, la probabilità di sopravvivere al guasto di un disco e la probabilità di una ricostruzione riuscita sono più elevate. Il RAID 6 presenta un altro problema: le sue prestazioni sono le più basse rispetto al RAID 10 e al RAID 5. I problemi di prestazioni sono particolarmente evidenti durante la ricostruzione.
Come si può vedere, il RAID 1 e il RAID 10 offrono la massima affidabilità, motivo per cui sono consigliati per l’uso con lo storage Hyper-V. Il RAID hardware può essere configurato su un server fisico o su un dispositivo NAS.
Utilizzo dello storage ad alta velocità
Le prestazioni di input/output dello storage hanno un impatto significativo sulla fornitura di prestazioni VM sufficienti. Per archiviare le VM è necessario utilizzare i dischi rigidi (HDD) più veloci. Esiste un’ampia gamma di dischi rigidi moderni con prestazioni ad alte prestazioni, che offrono velocità elevate a un prezzo accessibile per gigabyte. Se la velocità di un disco rigido non è sufficiente per le VM, è possibile utilizzare un’unità a stato solido (SSD). A differenza dei classici HDD rotanti, gli SSD non hanno parti mobili, quindi garantiscono una velocità maggiore, ma sono più costosi. Il prezzo per gigabyte di un SSD è più alto e la sua capacità complessiva è solitamente inferiore a quella di un HDD. Utilizzando i dischi con le prestazioni più elevate per l’storage Hyper-V, le VM sono in grado di funzionare senza ritardi.
Utilizza un volume dedicato per archiviare le VM
Evita di archiviare le VM sui volumi di sistema. Il volume di sistema è solitamente occupato dalla lettura o dalla scrittura dei file di sistema utilizzati dal sistema operativo (C: è sempre un volume di sistema per impostazione predefinita). Pertanto, l’archiviazione dei file delle macchine virtuali sul volume di sistema può ridurre le prestazioni delle macchine virtuali. Un altro problema che può verificarsi è quello dello spazio libero insufficiente sul volume. Questa situazione può verificarsi quando i file di sistema occupano tutto lo spazio libero sul disco o quando i file delle macchine virtuali, come i file del disco virtuale, occupano tutto lo spazio sul disco. Di conseguenza, le VM su cui sono archiviati i file all’interno di un volume di sistema sono a rischio di guasto. Inoltre, anche l’host Hyper-V potrebbe non funzionare correttamente senza spazio libero sufficiente per la scrittura dei file di sistema. Utilizza volumi separati per l’archiviazione dei sistemi operativi e delle VM. Inoltre, evita di archiviare file di sistema, come i file di swap, su unità utilizzate per i dati delle VM.
Archiviare i file delle VM in un’unica ubicazione
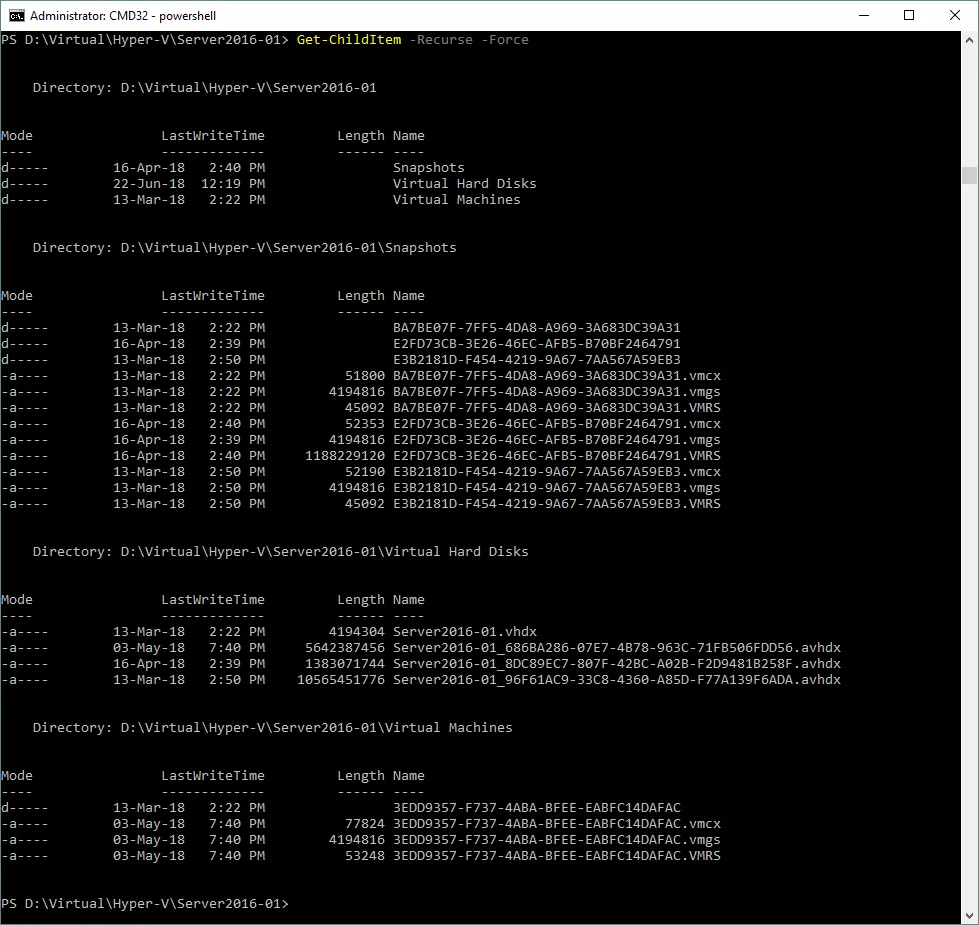
Alcuni dei file principali della VM Hyper-V sono: VHDX (VHD) – file del disco virtuale, AVHDX – file del disco virtuale differenziale, VMCX – file di configurazione e VMRS – file dello stato di runtime. I file della VM potrebbero essere archiviati in diverse ubicazioni predefinite che non sono convenienti per gli amministratori. Per evitare ciò, specificare una singola directory per l’archiviazione di tutti i file appartenenti alla VM corrente. Nella schermata sottostante è possibile vedere che tutti i file appartenenti a una VM denominata Server2016-01 sono archiviati in sottodirectory di una directory denominata Server2016-01.
Lasciare spazio per i file BIN (VMRS)
I file BIN consumano spazio su disco per archiviare lo stato della memoria. A tal fine, è necessario lasciare uno spazio riservato sui volumi in cui sono archiviati i file VM. A partire da Hyper-V 2016, l’estensione di questo tipo di file è stata modificata da BIN a VMRS. Questo tipo di file occupa il secondo posto in termini di consumo di spazio su disco dopo i file VHDX del disco virtuale. La dimensione di un file BIN (VMRS) è pari alla dimensione della memoria virtuale della VM. Ad esempio, se la VM ha un disco virtuale da 30 GB e 8 GB di memoria virtuale, è necessario riservare almeno 38 GB sullo storage. Se la memoria virtuale dinamica è configurata per una VM, la dimensione del file BIN (VMRS) sarà pari alla quantità di memoria provisionata in quel momento.
Quale file system utilizzare: NTFS o ReFS?
NTFS (New Technology File System) è un file system creato da Microsoft nel 1993 e ampiamente utilizzato negli ambienti Windows odierni.
ReFS (Resilient File System) è il più recente file system di Microsoft rilasciato con Windows Server 2012, che presenta miglioramenti quali:
- Protezione dei dati contro il danneggiamento tramite l’uso di checksum per metadati e file
- Integrazione con gli spazi di archiviazione
- Controllo automatico dell’integrità dei dati e correzione degli errori (se si verifica un errore)
- Tecnologia di clonazione dei blocchi (utile quando si clonano le VM)
- Maggiore tolleranza alle interruzioni di corrente
- Supporto per la crittografia con BitLocker
- Aumento della dimensione massima dei file e della lunghezza dei nomi dei file
- Aumento del volume massimo
- Creazione più rapida di dischi virtuali fissi
Come si può vedere, il file system ReFS presenta una lunga lista di vantaggi ed è progettato per soddisfare in modo più efficiente i requisiti di storage del server. Tuttavia, presenta anche alcuni svantaggi:
- Windows non può essere caricato dal volume ReFS
- La compressione dei dati, la deduplicazione basata su file di Windows, la crittografia dei file, i collegamenti fisici, gli attributi estesi e le quote disco non sono supportati
- Non può essere utilizzato per volumi condivisi in cluster
- Non fornisce supporto per i nomi di file legacy 8.3
Infine, la scelta del file system spetta all’amministratore. Si consiglia di utilizzare ReFS per l’archiviazione Hyper-V se le limitazioni di ReFS non sono rilevanti per il sistema.
Utilizzare una rete di storage ad alta velocità
Quando si utilizza l’archiviazione remota, la connessione di rete è un fattore cruciale. Se si dispone di dischi ad alta velocità nel NAS o nella SAN ma la connessione di rete è lenta, le prestazioni complessive del sistema di storage risulteranno compromesse. Per questo motivo si consiglia di utilizzare una rete dedicata ad alta velocità con bassa latenza. Si consiglia una connessione di rete a 10 Gbit per garantire una velocità accettabile. È utile anche l’utilizzo del teaming NIC per l’aggregazione della larghezza di banda.
Evitare di archiviare la VM con il controller di dominio su condivisione SMB3
Per il corretto funzionamento della condivisione SMB 3.0 è obbligatorio accedere a un controller di dominio. Se un host con condivisione SMB 3.0 o un host Hyper-V non è in grado di accedere al controller di dominio, l’autenticazione non può essere superata e non è possibile stabilire una connessione. In questa situazione, un server Hyper-V non è in grado di avviare una VM con controller di dominio che si trova su una condivisione SMB 3.0. Per evitare questo problema, conservare una VM con controller di dominio nell’archivio locale dell’host Hyper-V.
Utilizzare i volumi condivisi del cluster per l’archiviazione del cluster
Quando si effettua l’implementazione di un cluster, è necessario configurare l’archiviazione condivisa. Quando si utilizza uno storage tradizionale senza CSV, solo un nodo (host Hyper-V) alla volta può accedere allo stesso disco/LUN. I volumi condivisi in cluster (CSV) possono risolvere questo problema fornendo accesso simultaneo allo storage per più nodi senza rimontare i volumi e modificare la proprietà con le autorizzazioni. Con CSV è possibile avere un file system clusterizzato sovrapposto a NTFS o ReFS per Hyper-V.
Evitare l’uso di dischi pass-through
Un disco pass-through è un disco fisico (LUN) collegato a una VM. Questo tipo di disco viene utilizzato come dispositivo di storage ed è collegato direttamente al controller del disco di una VM. Nelle prime versioni di Hyper-V, l’utilizzo dei dischi pass-through contribuiva ad aumentare le prestazioni. Oggi i formati dei dischi virtuali sono sufficientemente avanzati, quindi includere le prestazioni e utilizzare i dischi pass-through non ha senso a causa dei problemi che possono verificarsi durante il loro utilizzo. Non è possibile spostare facilmente un disco pass-through con una VM e il software di backup non può eseguire il backup di una VM con questo tipo di disco a livello di host.
Quale tipo di disco virtuale preferire: VHD o VHDX?
VHD è un formato legacy di dischi virtuali per VM introdotto nel 2003. VHDX è un formato più avanzato (rilasciato con Windows Server 2012) che ha un limite di capacità più elevato per i dischi virtuali (fino a 64 TB), supporta blocchi da 4 KB, consente il ridimensionamento in tempo reale dei dischi virtuali e dispone di un aggiornamento continuo della struttura dei metadati che riduce la probabilità di danneggiamento dei dati causato da interruzioni di corrente. Per questo motivo, è preferibile utilizzare dischi virtuali VHDX nell’ambiente Hyper-V.
L’uso di dischi virtuali fissi e ad espansione dinamica
A disco virtuale fisso è un file VHDX (VHD) che consuma tutto lo spazio preallocato sullo storage, indipendentemente dalla quantità di spazio utilizzato all’interno del disco virtuale. I vantaggi dell’utilizzo di un disco virtuale fisso sono che funzionano più velocemente, non causano problemi di over-provisioning e la frammentazione del file VHDX rimane la stessa dopo la creazione. Gli svantaggi dell’utilizzo di un disco virtuale fisso sono che la loro creazione può richiedere più tempo sui volumi NTFS e che è necessario più spazio di storage per la creazione del disco.
Il disco virtuale ad espansione dinamica inizia con una dimensione ridotta di pochi kilobyte dopo la pre-allocazione, che cresce dopo la scrittura dei file all’interno del disco virtuale fino a raggiungere la dimensione massima pre-allocata durante la creazione del disco. Un disco dinamico non può essere ridotto automaticamente quando i dati su un disco di questo tipo vengono eliminati. I vantaggi dell’utilizzo di dischi dinamici sono che consentono di risparmiare spazio, sono veloci da creare e includono l’over-provisioning. Gli svantaggi sono che i dischi dinamici sono più lenti dei dischi fissi, comportano una maggiore frammentazione e l’over-provisioning potrebbe causare uno spazio libero insufficiente sull’storage dopo la crescita dei dischi dinamici.
È possibile utilizzare sia dischi virtuali fissi che dinamici a seconda delle esigenze.
Dischi rigidi virtuali differenziali
Un disco rigido virtuale differenziale è un file di disco virtuale (AVHDX o AVHD) creato nella directory della VM con dischi virtuali dopo la creazione di un punto di controllo. Lo scopo della differenziazione del disco virtuale è quello di memorizzare le modifiche scritte su un disco virtuale padre di una VM dopo la creazione di un punto di controllo. Un disco virtuale padre può essere un disco fisso, dinamico o differenziale. Quando un punto di controllo viene eliminato, il disco virtuale differenziale creato con questo punto di controllo viene unito al disco virtuale padre. Il disco virtuale differenziale può anche essere creato con la nuova procedura guidata per i dischi rigidi virtuali di Hyper-V. È importante notare che la creazione di un numero elevato di punti di controllo comporta la creazione di dischi virtuali differenziali sempre più grandi, con conseguente diminuzione delle prestazioni.
Monitoraggio dello stato di salute e delle prestazioni del disco
Il monitoraggio regolare dello stato di salute del disco può prevenire eventuali danni al disco che potrebbero causare il danneggiamento dei dati. Utilizza le utility in grado di effettuare il monitoraggio dei dati S.M.A.R.T. (Self-Monitoring, Analysis, and Reporting Technology) delle unità disco, compresi i dischi appartenenti al RAID. Quanto prima identifichi un disco con problemi, tanto maggiore sarà la probabilità che i tuoi dati siano al sicuro. È inoltre necessario monitorare le prestazioni del disco per identificare quali dischi possono essere sovraccarichi. Ciò può aiutare a decidere di ridistribuire le VM con operazioni che richiedono un uso intensivo del disco tra altri dispositivi di storage, al fine di ottimizzare le prestazioni complessive.
Conclusione
L’storage è una componente fondamentale per i server, poiché i dati in esso contenuti sono particolarmente importanti per la maggior parte delle aziende IT. Il post del blog di oggi ha trattato le procedure consigliate per l’archiviazione per Hyper-V, che possono aiutare a ottimizzare le prestazioni delle VM e garantire un’elevata affidabilità dell’archiviazione. Tra tutti i consigli elencati sopra, scegliete quelli più adatti al vostro ambiente.
Anche se disponete di un’archiviazione di prima classe, è importante eseguire correttamente il backup dei dati delle VM Hyper-V. NAKIVO Backup & Replication può aiutarvi a eseguire il backup delle VM Hyper-V nel modo più efficiente.



