Einführung in Amazon S3: So funktioniert Objektspeicherung in der Cloud
Amazon Simple Storage Service (S3) ist ein beliebter Cloud-Speicher, der Teil der Amazon Web Services (AWS) ist. Der Cloud-Speicher Amazon S3 bietet hohe Zuverlässigkeit, Flexibilität, Skalierbarkeit und Zugänglichkeit. Die Anzahl der Objekte und die Menge der in Amazon S3 gespeicherten Daten sind unbegrenzt. Der S3-Cloud-Speicher ist für Unternehmen attraktiv, da Sie nur für das bezahlen, was Sie tatsächlich nutzen.
Allerdings können die Terminologie und Methodik für neue Amazon S3-Nutzer zu Missverständnissen und Schwierigkeiten führen. Wo werden S3-Daten gespeichert? Wie funktioniert der Amazon S3-Speicher? Dieser Blogbeitrag erklärt die wichtigsten Konzepte und Funktionsprinzipien des Amazon S3 Cloud-Speichers.

Über Amazon S3 Storage
Amazon S3 war der erste Cloud-Dienst von AWS und wurde 2006 eingeführt. Seitdem hat die Popularität dieses Speicherdienstes stetig zugenommen. Mittlerweile bietet Amazon eine Vielzahl weiterer Cloud-Dienste an, aber der Cloud-Speicher Amazon S3 ist nach wie vor der am weitesten verbreitete. Zusätzlich zum Amazon S3-Speicher bietet AWS Amazon EBS-Volumes für EC2 und Amazon Drive an. Die drei Dienste haben jedoch unterschiedliche Verwendungszwecke und Ziele.
EBS (Elastic Block Storage) Volumes für EC2 (Elastic Compute Cloud) Instanzen sind virtuelle Festplatten für virtuelle Maschinen, die sich in der Amazon Cloud befinden. Wie der Name EBS schon sagt, handelt es sich um einen Blockspeicher in der Cloud, der den Festplatten in physischen Computern entspricht. Ein Betriebssystem kann auf einem EBS-Volume installiert werden, das an eine EC2- Instanz angeschlossen ist.
Amazon Drive (früher bekannt als Amazon Cloud Drive) ist das Pendant zu Google Drive und Microsoft OneDrive. Amazon Drive hat einen geringeren Bereich an Funktionen als Amazon S3. Amazon Drive ist als Cloud-Speicherdienst zum Sichern von Fotos und anderen Benutzerdaten positioniert.
Amazon S3 Cloud-Speicher ist ein objektbasierter Speicherdienst. Bei der Verwendung von Amazon S3-Speicher können Sie kein Betriebssystem installieren, da auf die Daten nicht auf Blockebene zugegriffen werden kann, wie es für ein Betriebssystem erforderlich ist. Wenn Sie Amazon S3-Speicher als Netzlaufwerk in Ihrem Betriebssystem einbinden müssen, verwenden Sie ein Dateisystem im Userspace. Lesen Sie den Blogbeitrag über die Einbindung von S3-Cloud-Speicher in verschiedene Betriebssysteme. Google Cloud ist das Pendant zu Amazon S3-Cloud-Speicher.
Amazon S3 Hauptkonzepte
Wenn Sie Amazon S3 zum ersten Mal verwenden, sind Ihnen einige Konzepte möglicherweise ungewohnt und unbekannt. Die Methodik der Datenspeicherung in der S3-Cloud unterscheidet sich von der Datenspeicherung auf herkömmlichen Festplatten, Solid-State-Laufwerken oder Festplatten-Arrays. Im Folgenden finden Sie eine Übersicht über die wichtigsten Konzepte und Technologien, die zum Speichern und Verwalten von Daten im Amazon S3-Cloud-Speicher verwendet werden.
Wie speichert S3 Dateien?
Wie oben erläutert, werden Daten in Amazon S3 als Objekte gespeichert. Dieser Ansatz ermöglicht eine hoch skalierbare Speicherung in der Cloud. Objekte können an verschiedenen physischen Festplatten mit Standorten in einem Rechenzentrum verteilt sein. In den Rechenzentren von Amazon werden spezielle Hardware, Software und verteilte Dateisysteme verwendet, um eine hohe Skalierbarkeit zu gewährleisten. Redundanz und Versionierung sind Funktionen, die mithilfe des Blockspeicheransatzes implementiert werden. Wenn eine Datei in Amazon S3 als Objekt gespeichert wird, wird sie standardmäßig an mehreren Orten (z. B. auf Festplatten, in Rechenzentren oder Verfügbarkeitszonen) gleichzeitig gespeichert. Der Amazon S3-Dienst überprüft regelmäßig die Datenkonsistenz, indem er Kontroll-Hash-Summen überprüft. Wenn eine Datenbeschädigung festgestellt wird, wird das Objekt von den redundanten Daten wiederhergestellt. Objekte werden in Amazon S3-Buckets gespeichert. Standardmäßig kann über die Webschnittstelle auf Objekte im Amazon S3-Speicher zugegriffen und diese verwaltet werden.
Was ist S3-Objektspeicher?
Objektspeicher ist eine Art von Speicher, bei dem Daten als Objekte statt als Blöcke gespeichert werden. Dieses Konzept ist nützlich für Daten Backups, Archivierung und Skalierbarkeit für Umgebungen mit hoher Auslastung.
Objekte sind die grundlegenden Einheiten des Speichers in Amazon S3-Buckets. Ein Objekt besteht aus drei Hauptkomponenten: dem Inhalt des Objekts (in dem Objekt gespeicherte Daten wie Dateien oder Verzeichnisse), der eindeutigen Objektkennung (ID) und Metadaten. Metadaten werden als Schlüssel-Wert-Paare gespeichert und enthalten Informationen wie Name, Größe, Datum, Sicherheitsattribute, Inhaltstyp und URL.
Jedes Objekt verfügt über eine Zugriffskontrollliste (ACL), um zu konfigurieren, wer auf das Objekt zugreifen darf. Mit dem Amazon S3-Objektspeicher können Sie Netzwerkengpässe während der Stoßzeiten vermeiden, wenn der Datenverkehr zu Ihren in der S3-Cloud-Speicher gespeicherten Objekten erheblich zunimmt. Amazon bietet eine flexible Netzwerkbandbreite, berechnet jedoch Gebühren für den Netzwerkzugriff auf die gespeicherten Objekte. Der Objektspeicher eignet sich gut, wenn eine große Anzahl von Clients auf die Daten zugreifen muss (hohe Lesefrequenz). Die Suche über Metadaten ist beim Objektspeichermodell schneller.
Lesen Sie auch mehr über Amazon S3-Verschlüsselung , die Ihnen helfen kann, die im Amazon S3-Cloud-Speicher gespeicherten Daten zu schützen und die Sicherheit zu erhöhen.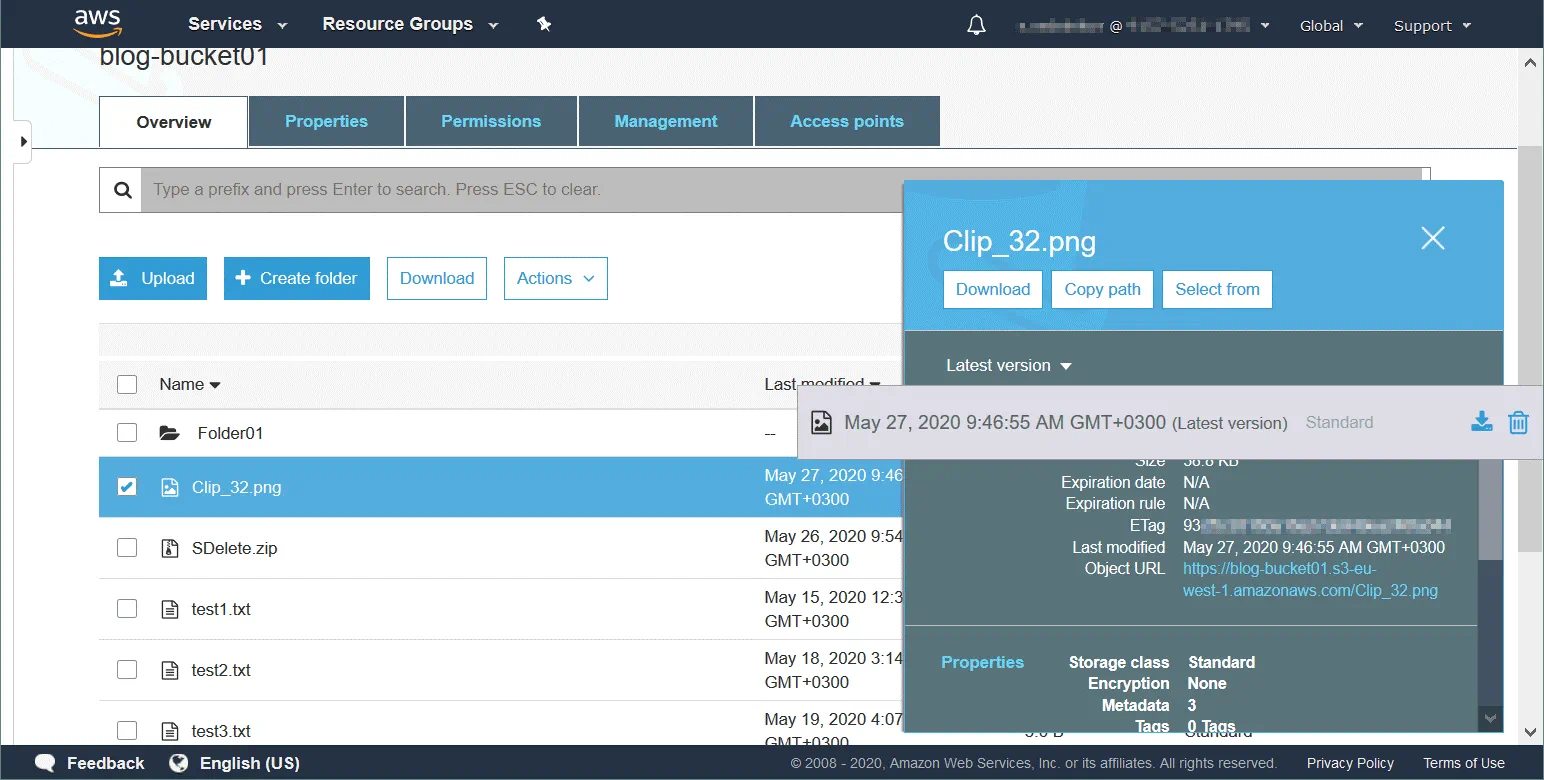
Buckets
Ein Bucket ist ein grundlegender logischer Container, in dem Daten im Amazon S3-Speicher abgelegt werden. In einem Bucket können Sie unbegrenzt viele Daten und Objekte speichern. Jedes S3-Objekt wird in einem Bucket gespeichert. Die Größe eines in einem Bucket gespeicherten Objekts ist auf 5 TB begrenzt. Buckets werden verwendet, um den Namespace auf höchster Ebene zu organisieren und dienen der Zugriffskontrolle.
Schlüssel
Ein Objekt hat einen eindeutigen Schlüssel , nach dem es in einen Bucket hochgeladen wurde. Dieser Schlüssel ist eine Zeichenfolge, die eine Verzeichnisstruktur nachahmt. Wenn Sie den Schlüssel kennen, können Sie auf das Objekt im Bucket zugreifen. Ein Bucket, ein Schlüssel und eine Version-ID identifizieren ein Objekt eindeutig. Wenn beispielsweise ein Bucket-Name blog-bucket01lautet, befindet sich der Standort, an dem die Rechenzentren Ihre Daten speichern, unter s3-eu-west-1 und der Objektname lautet test1.txt (eine Textdatei), lautet die URL zu der benötigten Datei, die als Objekt im Bucket gespeichert ist:
https://blog-bucket01.s3-eu-west-1.amazonaws.com/test1.txt
Wenn Sie Objekte mit anderen Benutzern teilen möchten, müssen Sie die Berechtigungen von den Objektattributen aus konfigurieren. Ebenso können Sie einen Ordner „ <“ erstellen und die Textdatei in diesem Ordner speichern: >TextFiles Ordner erstellen und die Textdatei in diesem Ordner speichern:
https://blog-bucket01.s3-eu-west-1.amazonaws.com/TextFiles/test1.txt
Es gibt zwei Arten von URLs, die verwendet werden können:
- bucketname.s3.amazonaws.com/objectname
- s3.amazon.aws.com/bucketname/objectname
AWS-Regionen
Amazon verfügt über Rechenzentren in verschiedenen Regionen weltweit, darunter in den USA, Irland, Südafrika, Indien, Japan, China, Korea, Kanada, Deutschland, Italien und Großbritannien. Sie können bei der Erstellung eines Buckets die gewünschte Region auswählen. Es wird empfohlen, eine Region auszuwählen, die Ihnen oder Ihren Kunden am nächsten liegt, um eine geringere Latenz für die Netzwerkverbindung zu erzielen oder die Kosten zu minimieren (da die Preise für die Datenspeicherung je nach Region unterschiedlich sind). In einer bestimmten AWS-Region gespeicherte Daten verlassen niemals die Rechenzentren dieser Region, bis Sie die Daten manuell migrieren. AWS-Regionen sind voneinander isoliert, um Fehlertoleranz und Stabilität zu gewährleisten.
Jede Region enthält Verfügbarkeitszonen, bei denen es sich um isolierte Standorte innerhalb einer AWS-Region handelt. Für jede Region stehen mindestens drei Verfügbarkeitszonen zur Verfügung, um Ausfälle aufgrund von Katastrophen wie Bränden, Taifunen, Hurrikanen, Überschwemmungen usw. zu verhindern.
Das Datenkonsistenzmodell
Die Konsistenzprüfung „Read-After-Write” wird für Objekte durchgeführt, die im Amazon S3-Speicher gespeichert sind. Amazon S3 repliziert Daten über Server und Rechenzentren innerhalb einer ausgewählten Region, um eine hohe Verfügbarkeit zu erreichen. Nach einer erfolgreichen PUT-Anfrage müssen die geänderten Daten über die Server repliziert werden. Dieser Vorgang kann einige Zeit in Anspruch nehmen. In diesem Fall kann ein Benutzer die alten oder aktualisierten Daten abrufen, jedoch nicht die beschädigten Daten. Dies gilt auch für gelöschte Objekte und Buckets. Beim Senden neuer Objekte an S3-Buckets wird keine Objektsperre durchgeführt. Wenn mehrere PUT-Anfragen gleichzeitig ausgeführt werden, hat die letzte PUT-Anfrage Vorrang. Sie können Ihre eigene Anwendung mit einem Sperrmechanismus erstellen, der mit in Amazon S3-Speichern gespeicherten Objekten arbeitet.
Amazon S3-Funktionen
Das Konzept der objektbasierten Speicherung ermöglicht es Amazon, nützliche Funktionen und eine hohe Flexibilität für die Speicherung und das Management von Daten in Amazon S3-Speichern bereitzustellen. Sehen wir uns diese Funktionen einmal genauer an.
Versionierung
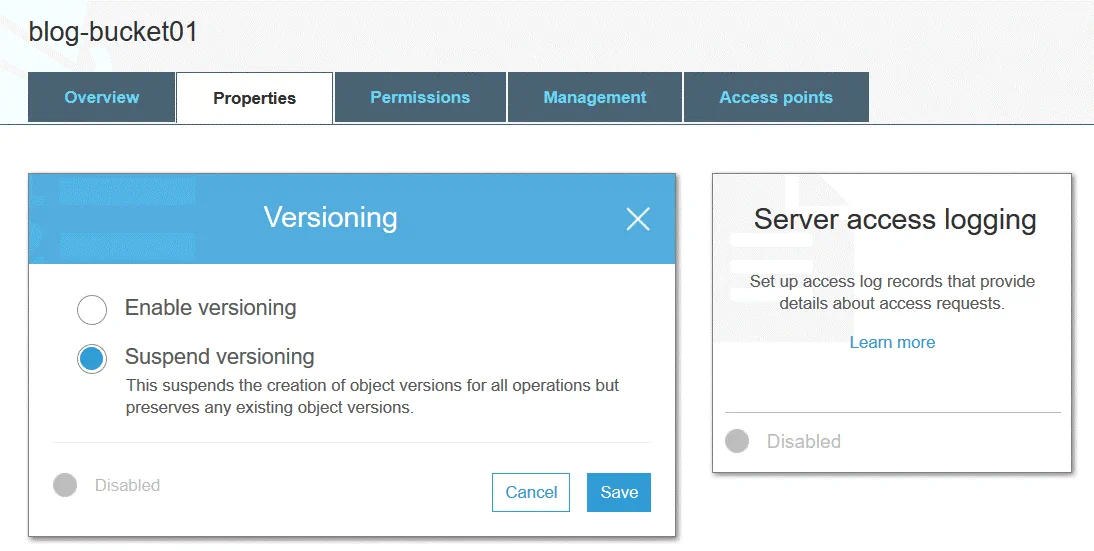
Die Objektversionierung ermöglicht es Ihnen, mehrere Versionen eines Objekts in einem Bucket zu speichern. Diese Funktion schützt Objekte, die im Amazon S3-Speicher gespeichert sind, vor unbeabsichtigten Änderungen, Überschreibungen oder Löschungen. Nach dem Ändern oder Löschen eines Objekts können Sie eine der vorherigen Versionen dieses Objekts wiederherstellen. Die Versionierung wird durch die Verwendung des Objektspeicheransatzes implementiert. Sie können die Versionierung zu Archivierungszwecken verwenden. Die Versionierung ist standardmäßig deaktiviert.
Jedem S3-Objekt wird eine Versions-ID zugewiesen, auch wenn die Versionierung nicht aktiviert ist (in diesem Fall wird der Wert der Versions-ID auf null gesetzt). Wenn die Versionierung aktiviert ist, wird einer neuen Version des Objekts nach dem Schreiben von Änderungen ein neuer Versions-ID-Wert zugewiesen. Die Versionierung kann auf Bucket-Ebene aktiviert werden. Der Versions-ID-Wert der ersten Version des Objekts bleibt unverändert. Wenn Sie ein Objekt aus einem S3-Bucket löschen (bei aktivierter Versionierung), wird die Löschmarkierung auf die neueste Version des Objekts angewendet.
Speicherklassen
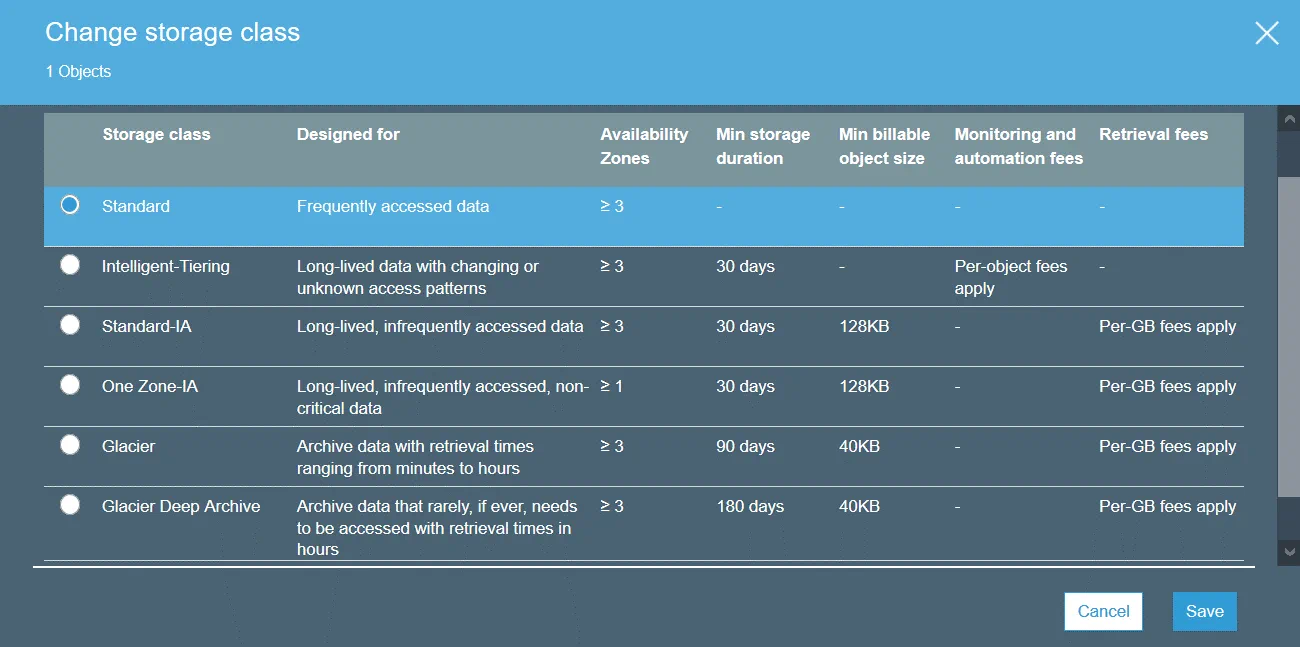
Amazon S3-Speicherklassen definieren den Zweck des für die Speicherung von Daten ausgewählten Speichers. Eine Speicherklasse kann auf Objektebene festgelegt werden. Sie können jedoch die Standard-Speicherklasse für Objekte festlegen, die auf Bucket-Ebene erstellt werden.
S3 Standard ist die Standard-Speicherklasse. Diese Klasse ist ein Hot-Data-Speicher und eignet sich für häufig verwendete Daten. Verwenden Sie die Standard-Speicherklasse zum Hosten von Websites, zum Verteilen von Inhalten, zum Entwickeln von Cloud-Anwendungen usw. Hohe Speicherkosten, niedrige Wiederherstellungskosten und schneller Zugriff auf die Daten sind die Funktionen dieser Speicherklasse.
S3 Standard-IA (seltener Zugriff) kann zum Speichern von Daten verwendet werden, auf die weniger häufig zugegriffen wird als in S3 Standard. S3 Standard-IA ist für eine längere Speicherdauer optimiert. Für das Abrufen von Daten, die in der Speicherklasse S3 Standard-IA gespeichert sind, fallen Gebühren an. Darüber hinaus müssen Sie sowohl bei S3 Standard als auch bei S3 Standard-IA für Datenanfragen (PUT, COPY, POST, LIST, GET, SELECT) bezahlen.
S3 One Zone-IA ist für selten abgerufene Daten konzipiert. Die Daten werden nur in einer Verfügbarkeitszone gespeichert (bei S3 Standard werden die Daten in drei Verfügbarkeitszonen gespeichert), wodurch wird ein geringeres Maß an Redundanz und Resilienz geboten. Die angegebene Verfügbarkeit beträgt 99,5 % und ist damit geringer als bei den beiden anderen Speicherklassen. S3 One Zone-IA hat geringere Speicherkosten, höhere Wiederherstellungskosten und Sie müssen für das Abrufen von Daten pro GB bezahlen. Sie können diese Speicherklasse als kostengünstige Lösung für die Speicherung von Backupkopien oder Backupkopien von Daten in Betracht ziehen, die mit der regionenübergreifenden Replikation von Amazon S3 erstellt wurden.
S3 Glacier bietet im Gegensatz zu den anderen Speicherklassen keinen sofortigen Zugriff auf gespeicherte Daten. S3 Glacier kann zur kostengünstigen Langzeitarchivierung von Daten verwendet werden. Es gibt keine Garantie für einen unterbrechungsfreien Betrieb. Sie müssen einige Minuten bis einige Stunden warten, um die Daten abzurufen. Sie können alte Daten von einem Speicher einer höheren Klasse (z. B. von S3 Standard) mithilfe von S3-Lebenszyklus-Richtlinien in S3 Glacier übertragen und so die Speicherkosten senken.
S3 Glacier Deep Archive ähnelt S3 Glacier, jedoch beträgt die Zeit für den Abruf der Daten etwa 12 bis 48 Stunden. Der Preis ist niedriger als der Preis für S3 Glacier. Die Speicherklasse S3 Glacier Deep Archive kann zur Speicherung von Backups und Archivdaten von Unternehmen verwendet werden, die gesetzliche Anforderungen für die Datenarchivierung erfüllen (Finanzwesen, Gesundheitswesen). Dies ist eine gute Alternative zu Bandkassetten.
S3 Intelligent-Tiering ist eine spezielle Speicherklasse, die andere Speicherklassen nutzt. S3 Intelligent-Tiering soll automatisch eine bessere Speicherklasse für die Speicherung von Daten auswählen, wenn Sie nicht wissen, wie oft Sie auf diese Daten zugreifen müssen. Amazon S3 kann bei Verwendung von S3 Tiering Zugriffsmuster auf Daten überwachen und die Objekte dann in einer von zwei ausgewählten Speicherklassen speichern (eine für häufig aufgerufene Daten und eine für selten aufgerufene Daten). Dieser Ansatz bietet Ihnen optimale Kosteneffizienz ohne Leistungseinbußen.
Wenn Sie beispielsweise auf ein Objekt zugreifen, das in einer Speicherklasse für selten aufgerufene Daten gespeichert ist, wird dieses Objekt automatisch in eine Speicherklasse für häufig aufgerufene Daten verschoben. Andernfalls, wenn ein Objekt längere Zeit nicht aufgerufen wurde, wird es in die Speicherklasse für selten verwendete Daten verschoben. Objekte können sich im selben Bucket befinden, und die Speicherklasse wird auf S3-Objektebene geändert.
Zugriffskontrolllisten
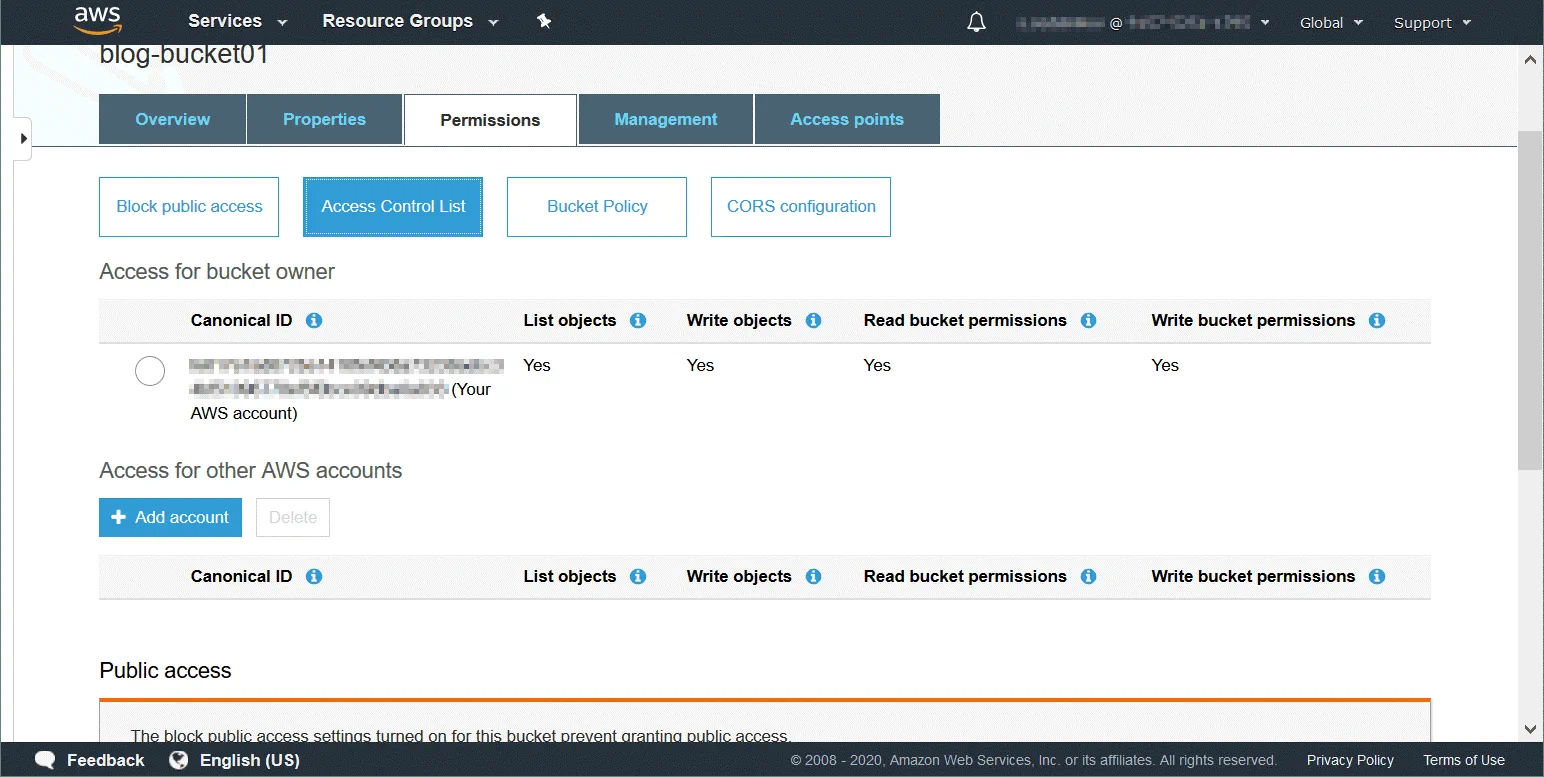
Eine Zugriffskontrollliste (ACL) ist eine Funktion, mit der der Zugriff auf Objekte und Buckets verwaltet und kontrolliert wird. Zugriffskontrolllisten sind ressourcenbasierte Richtlinien, die jedem Bucket und Objekt zugeordnet sind, um Benutzer und Gruppen zu definieren, die über Berechtigungen für den Zugriff auf den Bucket und das Objekt verfügen. Standardmäßig hat der Ressourcenbesitzer nach dem Erstellen der Ressource vollen Zugriff auf einen Bucket oder ein Objekt. Bucket-Zugriffsberechtigungen legen fest, wer auf Objekte im Bucket zugreifen darf. Objektzugriffsberechtigungen legen fest, welche Benutzer auf Objekte zugreifen dürfen und welche Zugriffsart sie haben. Sie können beispielsweise für einen Benutzer nur Lesezugriffsrechte und für einen anderen Benutzer Lese- und Schreibzugriffsrechte festlegen.
Die vollständige Liste der Benutzer, die über Berechtigungen verfügen können (ein Benutzer mit Berechtigungen wird als Berechtigungsempfänger bezeichnet):
Eigentümer – ein Benutzer, der einen Bucket/ein Objekt erstellt.
Authentifizierte Benutzer – alle Benutzer, die über ein AWS-Konto verfügen.
Alle Benutzer – alle Benutzer, einschließlich anonymer Benutzer (Benutzer, die kein AWS-Konto haben).
Benutzer von E-Mail/ID – ein bestimmter Benutzer, der über ein AWS-Konto verfügt. Die E-Mail-Adresse oder AWS-ID eines Benutzers muss angegeben werden, um diesem Benutzer Zugriff zu gewähren.
Verfügbare Berechtigungstypen:
Vollzugriff – Dieser Berechtigungstyp umfasst die Berechtigungen „Lesen”, „Schreiben”, „Lesen (ACP)” und „Schreiben (ACP)”.
Lesen – Ermöglicht die Auflistung des Bucket-Inhalts, wenn diese Berechtigung auf Bucket-Ebene angewendet wird. Ermöglicht das Lesen der Objektdaten und Metadaten, wenn sie auf Objektebene angewendet werden.
Schreiben – kann nur auf Bucket-Ebene angewendet werden und ermöglicht das Erstellen, Löschen und Überschreiben beliebiger Objekte im Bucket.
Leseberechtigungen (READ ACP) – Ein Benutzer kann Berechtigungen für das angegebene Objekt oder den angegebenen Bucket lesen.
Schreibberechtigungen (WRITE ACP) – Ein Benutzer kann Berechtigungen für das angegebene Objekt oder den angegebenen Bucket überschreiben. Das Aktivieren dieses Berechtigungstyps für einen Benutzer entspricht dem Festlegen von Vollzugriffsberechtigungen, da der Benutzer beliebige Berechtigungen für sein Konto festlegen kann. Diese Berechtigung ist standardmäßig für den Bucket-Besitzer verfügbar.
Bucket-Richtlinien
Bucket-Richtlinien sind ressourcenbasierte AWS-Identitäten und Zugriffsverwaltungsrichtlinien, die zum Erstellen bedingter Regeln für die Gewährung von Zugriffsberechtigungen für AWS-Konten und Benutzer beim Zugriff auf Buckets und Objekte in Buckets verwendet werden. Mit Bucket-Richtlinien können Sie Sicherheitsregeln für mehrere Objekte in einem Bucket definieren.
Die Bucket-Richtlinie wird als JSON-Datei definiert. Der Konfigurationstext der Bucket-Richtlinie muss den Anforderungen des JSON-Formats entsprechen, um gültig zu sein. Die Bucket-Richtlinie kann nur auf Bucket-Ebene angehängt werden und wird an alle Objekte im Bucket vererbt. Sie können Benutzern, die sich von bestimmten IP-Adressen aus verbinden, Benutzern bestimmter AWS-Konten usw. Zugriff gewähren.
Nachfolgend sehen Sie ein Beispiel für eine Richtlinie, die allen Benutzern eines Kontos Vollzugriff und allen Benutzern eines anderen Kontos Lesezugriff gewährt.
{
"Statement": [
{
"Effect": "Allow",
"Principal": {
"SGWS": "95381782731015222837"
},
"Action": "s3:*",
"Resource": [
"urn:sgws:s3:::blog-bucket01",
"urn:sgws:s3:::blog-bucket01/*"
]
},
{
"Effect": "Allow",
"Principal": {
"SGWS": "30284200178239526177"
},
"Action": "s3:GetObject",
"Resource": "urn:sgws:s3:::blog-bucket01/shared/*"
},
{
"Effect": "Allow",
"Principal": {
"SGWS": "30284200178239526177"
},
"Action": "s3:ListBucket",
"Resource": "urn:sgws:s3:::blog-bucket01",
"Condition": {
"StringLike": {
"s3:prefix": "shared/*"
}
}
}
]
}
Benutzer können von Zugriffsschlüsseln (Zugriffsschlüssel-ID und geheimer Zugriffsschlüssel) auf den Amazon S3-Speicher zugreifen, ohne den Benutzername und das Passwort eingeben zu müssen. Dieser Ansatz ermöglicht Ihnen eine Verbesserung der Sicherheit und wird zur Erstellung von Anwendungen verwendet, die APIs für den Zugriff auf den Amazon S3-Cloud-Speicher nutzen.
APIs für Amazon S3
Amazon bietet Anwendungsprogrammierschnittstellen (APIs) für den Zugriff auf die S3-Funktionalität und die Entwicklung eigener Anwendungen, die mit Amazon S3-Speicher kompatibel sein müssen. Amazon stellt REST- und SOAP-Schnittstellen zur Verfügung. Die REST-Schnittstelle verwendet Standard-HTTP-Anfragen für die Arbeit mit Buckets und Objekten. Die REST-API verwendet Standard-HTTP-Header. Die SOAP-Schnittstelle ist eine weitere verfügbare Schnittstelle. Die Verwendung von SOAP über HTTP ist veraltet, aber Sie können weiterhin SOAP über HTTPS verwenden.
Das Zahlungsmodell
Amazon S3 bietet das Modell „Sie zahlen nur für das, was Sie nutzen”. Es gibt keine Mindestgebühr – Sie müssen nicht für eine festgelegte Menge an Speicher und Netzwerkverkehr bezahlen. Es gibt verschiedene Nutzungskategorien, für die Sie bezahlen müssen:
Speicher. Bezahlen Sie für Objekte, die in Amazon S3 gespeichert sind. Der zu zahlende Betrag hängt vom genutzten Speicherplatz, der Zeit der Speicherung der Objekte im Amazon S3-Speicher (während des Monats) und der von den gespeicherten Objekten verwendeten Speicherklasse ab.
Anfragen und Datenabruf. Sie müssen für Anfragen zum Abrufen von Daten bezahlen, die im Amazon S3-Cloud-Speicher gespeichert sind.
Datenübertragung. Sie müssen für die gesamte genutzte Bandbreite (eingehender und ausgehender Datenverkehr) bezahlen, mit Ausnahme von eingehenden Daten aus dem Internet, ausgehenden Daten, die an Amazon EC2-Instanzen übertragen werden, die sich in derselben AWS-Region wie der Quell-S3-Bucket befinden, sowie Daten, die von einem S3-Bucket an CloudFront übertragen werden.
MANAGEMENT und Replikation. Sie müssen für die Nutzung von Speicherverwaltungsfunktionen wie Analysen und Objekt-Tagging bezahlen. Amazon berechnet Gebühren für die regionenübergreifende Replikation und die Replikation innerhalb derselben Region.
Verwenden Sie den Amazon S3-Rechner , um Ihre Zahlungen zu schätzen.


