Usprawnij monitorowanie IT dzięki NAKIVO: wyjaśnienie działania alertów i raportów
Wdrożenie monitorowania IT w infrastrukturze organizacji może zwiększyć jej niezawodność oraz pomóc w zapobieganiu poważnym problemom, awariom i przestojom. Istnieją różne sposoby wdrażania monitorowania IT – można skorzystać z dedykowanych narzędzi lub z wbudowanych funkcji. Niezależnie od wybranego podejścia, w razie potrzeby można przeglądać dane z monitorowania lub skonfigurować automatyczne powiadomienia i raporty, aby otrzymywać informacje o ważnych zdarzeniach. W tym wpisie na blogu wyjaśniamy, jak usprawnić strategię monitorowania IT za pomocą alarmów i raportów.
Znaczenie monitorowania IT i raportowania dla przedsiębiorstw
Monitorowanie IT ma kluczowe znaczenie dla organizacji, ponieważ pomaga zapewnić prawidłowe i niezawodne działanie infrastruktury informatycznej.
Maximizing uptime and reliability. Kluczowe systemy biznesowe zazwyczaj wymagają działania przez całą dobę, siedem dni w tygodniu. Systemy takie są wykorzystywane w branżach takich jak opieka zdrowotna, finanse oraz przez innych dostawców usług, gdzie przestoje mogą prowadzić do poważnych konsekwencji. Na szczęście można zapobiec takim problemom, wdrażając i odpowiednio konfigurując system monitorowania IT.Proaktywne wykrywanie problemów pomaga administratorom na czas wykrywać potencjalne problemy, takie jak przeciążenia serwerów, błędy aplikacji, problemy sprzętowe i spadek wydajności, zanim doprowadzą one do poważnych awarii. To proaktywne podejście pozwala administratorom reagować i podejmować działania naprawcze, zanim pojawią się negatywne skutki dla serwerów, maszyn wirtualnych (VM), operacji biznesowych i użytkowników końcowych. Otrzymywanie raportów wskazujących na potencjalne problemy sprawia, że monitorowanie i administracja IT stają się bardziej wydajne.
Enhancing security. Monitorowanie IT służy do wykrywania nieautoryzowanych prób dostępu, nietypowego ruchu sieciowego i innych podejrzanych działań, które mogą wskazywać na cyberatak. Takie podejście pozwala administratorom na czas wykrywać zagrożenia bezpieczeństwa. Niektóre branże muszą spełniać wymagania regulacyjne, które wymagają ciągłego monitorowania systemów IT w celu uniknięcia kar.Improving performance and efficiency. Administratorzy mogą zoptymalizować wykorzystanie zasobów na serwerach, maszynach wirtualnych i sprzęcie sieciowym poprzez konfigurację monitorowania IT i alertów. Skonfigurowanie narzędzi do monitorowania IT w celu śledzenia wykorzystania Procesora, pamięci i przepustowości w celu dalszej analizy tych danych pozwala lepiej zrozumieć, co należy poprawić. W rezultacie organizacje mogą zoptymalizować swoje zasoby i ograniczyć marnotrawstwo, aby osiągnąć wysoką wydajność swoich systemów IT. Pomaga to również administratorom w identyfikacji wąskich gardeł i poprawie wydajności.Improving business continuity and disaster recovery. Wczesne wykrywanie awarii jest jednym z głównych powodów, dla których administratorzy organizacji powinni skonfigurować systemy monitorowania IT z powiadomieniami. Takie podejście pozwala wcześnie wykrywać oznaki uszkodzenia danych, awarie aplikacji i awarie sprzętu, aby zapobiec utracie danych. Zapobieganie utracie danych jest niezbędne do utrzymania ciągłość działania. Korzystając z narzędzi monitorujących z skonfigurowanymi powiadomieniami, administratorzy mogą zapewnić, że systemy kopii zapasowych i plany odzyskiwania awaryjnego są testowane i działają poprawnie. Może to stanowić gwarancję, że firma będzie w stanie szybko odzyskać dane i przywrócić działanie systemów w razie awarii.Improving customer experience. Klienci oczekują, że usługi będą dostępne o każdej porze. Skonfigurowanie systemów monitorowania IT w celu nadzorowania serwerów, maszyn wirtualnych, sprzętu sieciowego oraz aplikacji związanych z działaniem stron internetowych pomaga zapewnić, że strony i usługi są zawsze dostępne dla klientów. Monitorowana jest nie tylko dostępność zasobów, ale także wydajność, co pozwala osiągnąć najwyższą jakość usług.Otrzymywanie raportów zawierających informacje o problemach może prowadzić do ich szybkiego rozwiązania. Raporty zawierają informacje potrzebne administratorom do jak najszybszego rozwiązania problemów. Działania te minimalizują negatywny wpływ na klientów, a w rezultacie zapewniają im pozytywne doświadczenia.
Cost management. Skonfigurowanie proaktywnego monitorowania może zapobiec przestojom. Nieplanowane przestoje mogą być kosztowne, ponieważ organizacja traci przychody i musi przeznaczyć zasoby na odzyskanie danych oraz przywrócenie infrastruktury. Monitorowanie z powiadomieniami o alertach pozwala administratorom jak najszybciej naprawić problem i zmniejszyć ryzyko przestoju.
Zrozumienie alarmów w monitorowaniu IT
Skonfigurowanie alarmów dla systemów monitorowania IT poprawia czas reakcji administratorów, umożliwiając im szybsze wykrycie problemu i jego naprawę. Jeśli skonfigurowane są tylko zasoby takie jak strony internetowe z wykresami i statystykami, administrator systemu może zauważyć problemy dopiero podczas sprawdzania strony internetowej z informacjami o monitorowaniu. Administratorzy mają szeroki zakres różnych zadań i zazwyczaj nie mogą w sposób ciągły monitorować strony internetowej przedstawiającej stan infrastruktury IT.
Po skonfigurowaniu alarmów administratorzy otrzymują jak najszybciej powiadomienie o problemie, potencjalnym problemie, awarii lub innych krytycznych lub podejrzanych zdarzeniach. Zazwyczaj można skonfigurować interwał czasowy, na przykład wiadomość może zostać wysłana w ciągu 1 minuty lub 5 minut po wykryciu problemu przez system monitorowania.
W rezultacie administrator systemu może szybciej zauważyć problem i zareagować, aby go naprawić i uniknąć negatywnych konsekwencji. W zależności od oprogramowania do monitorowania IT można stosować różne metody powiadamiania, takie jak powiadomienia przez e-mail, SMS-owe, przez Skype itp.
Czym są alarmy i dlaczego mają znaczenie?
Alarmy to powiadomienia uruchamiane w momencie wystąpienia określonego zdarzenia oraz spełnienia odpowiednich warunków lub przekroczenia progów w systemie IT. Warunki te mogą opierać się na różnych zdarzeniach, w tym:
Performance issues:Wysokie obciążenie Procesora, wyczerpanie pamięci, długi czas reakcjiResource thresholds:Brak miejsca na dysku, przeciążenie przepustowości sieciSystem failures:Awarie serwera, błędy aplikacji, przerwy w działaniu usługSecurity incidents:Próby nieautoryzowanego dostępu, wykrycie złośliwego oprogramowania, nietypowy ruch sieciowyOperational events:Błędy wykonania kopii zapasowej, ponowne uruchomienie usług, zmiany w konfiguracji
Gdy uruchamia się alarm, system monitorowania generuje powiadomienie, które jest wysyłane do odpowiedniego użytkownika, głównie administratora IT, za pośrednictwem różnych kanałów. Powiadomienia te zawierają informacje o problemie, w tym jego ważność, system lub komponent, którego dotyczy, oraz zalecane działania.
Kluczowe metryki do monitorowania
CPU utilization. Monitorowanie wykorzystania procesora jest potrzebne, aby zapewnić wystarczające zasoby dla serwerów i systemów pod względem mocy obliczeniowej. Jest to ważne dla obsługi obciążeń bez przeciążania systemu. Wysokie wykorzystanie procesora może być sygnałem, że system jest przeciążony. Niskie wykorzystanie Procesora wskazuje, że zasoby są wystarczające lub że zasoby Procesora są niewykorzystane.
Memory (RAM) usage. Aplikacje i usługi potrzebują wystarczającej ilości pamięci do płynnego działania, a parametr pamięci ma w tym kontekście kluczowe znaczenie. Administratorzy powinni monitorować wykorzystanie pamięci RAM, aby zapobiegać wąskim gardłom pamięci, które mogą powodować spadek wydajności, a nawet awarie systemu. Należy zwracać uwagę na nadmierne wykorzystanie pamięci, niewystarczający przydział pamięci oraz wycieki pamięci.
Disk usage and I/O performance. Miejsce na dysku oraz wydajność operacji wejścia/wyjścia (I/O) to kluczowe wskaźniki dla przechowywania danych. Zaleca się monitorowanie tych parametrów, aby zapobiegać problemom związanym z pamięcią masową, w tym problemom z wydajnością. Zwracaj uwagę na wysokie zużycie dysku, szybki wzrost wykorzystanej przestrzeni dyskowej, duże opóźnienia podczas odczytu/zapisu danych oraz częste czasy oczekiwania na operacje wejścia/wyjścia. Nieprawidłowe zachowanie tych parametrów może wskazywać na potencjalne problemy z pamięcią masową.
Network bandwidth and latency. Wydajność sieci wpływa na wszystkie operacje w biurze lub centrum danych, ponieważ komputery, serwery i maszyny wirtualne są połączone ze sobą za pośrednictwem sieci. Wydajność sieci ma kluczowe znaczenie dla usług świadczonych klientom. Monitorowanie przepustowości sieci i opóźnień pozwala wykrywać wąskie gardła i inne problemy oraz naprawiać je na czas, aby efektywnie wykorzystywać zasoby sieciowe. Zwracaj uwagę na wysokie wykorzystanie sieci, utratę pakietów i duże opóźnienia, ponieważ wskaźniki te są oznakami niskiej wydajności i problemów z łącznością sieciową.
Service and process availability. Ważne procesy działają w systemach operacyjnych na serwerach lub maszynach wirtualnych i muszą być dostępne, aby zaspokoić potrzeby biznesowe. Monitorowanie usług i ich dostępności gwarantuje, że kluczowe usługi działają bez zakłóceń. Aby zapewnić dostępność usług, administratorzy powinni monitorować czas sprawności, częstotliwość ponownego uruchamiania usług oraz awarie procesów.
Database performance. Bazy danych często stanowią część bardziej złożonych rozwiązań, w tym aplikacji internetowych. Ponadto większość rozwiązań programowych do użytku wewnętrznego w organizacjach wymaga baz danych. Z tych powodów ważne jest monitorowanie wydajności i dostępności baz danych. Monitorowanie baz danych zapewnia dostępność danych i płynne działanie powiązanych operacji. Podczas monitorowania bazy danych należy skupić się na czasach odpowiedzi na zapytania, wolno działających zapytaniach, blokadach baz danych i wykorzystaniu puli połączeń, ponieważ wskaźniki te mają kluczowe znaczenie dla kondycji bazy danych.
Raportowanie w monitorowaniu IT
Raportowanie służy do dostarczania uporządkowanych, praktycznych wniosków na podstawie ogromnej ilości danych zebranych przez narzędzia monitorujące. Raportowanie przekształca surowe dane w informacje, które są czytelne i zrozumiałe dla osób pracujących w organizacji, a przede wszystkim dla osób odpowiedzialnych za administrację IT. Po zapoznaniu się z raportami administratorzy i kierownictwo mogą podejmować świadome decyzje. Pozwala to zespołom IT na optymalizację wydajności, zapobieganie problemom i poprawę ciągłości działania.
Raporty mogą wskazywać na anomalie, które nie są zauważalne podczas sprawdzania alarmów. Dane w raportach są agregowane dla większej wygody, aby uniknąć konieczności ręcznego wyszukiwania kluczowych metryk i porządkowania zebranych danych. W rezultacie administratorzy mają ogólny przegląd całej infrastruktury i najważniejszych komponentów. Posiadanie informacji o warunkach prowadzących do incydentu może zostać wykorzystane przez administratorów do szybkiego reagowania na incydenty i podejmowania działań zapobiegawczych.
Monitorowanie za pomocą NAKIVO Backup & Replication
NAKIVO Backup & Replication może pomóc w monitorowaniu elementów infrastruktury IT. Przejdź do sekcji Monitoring w interfejsie internetowym, dodaj monitorowane elementy i sprawdź wykresy przedstawiające obsługiwane wskaźniki infrastruktury VMware vSphere .

Możesz wybrać elementy do monitorowania, takie jak hosty ESXi lub klastry, maszyny wirtualne VMware oraz magazyny danych w Monitoring > Metrics. 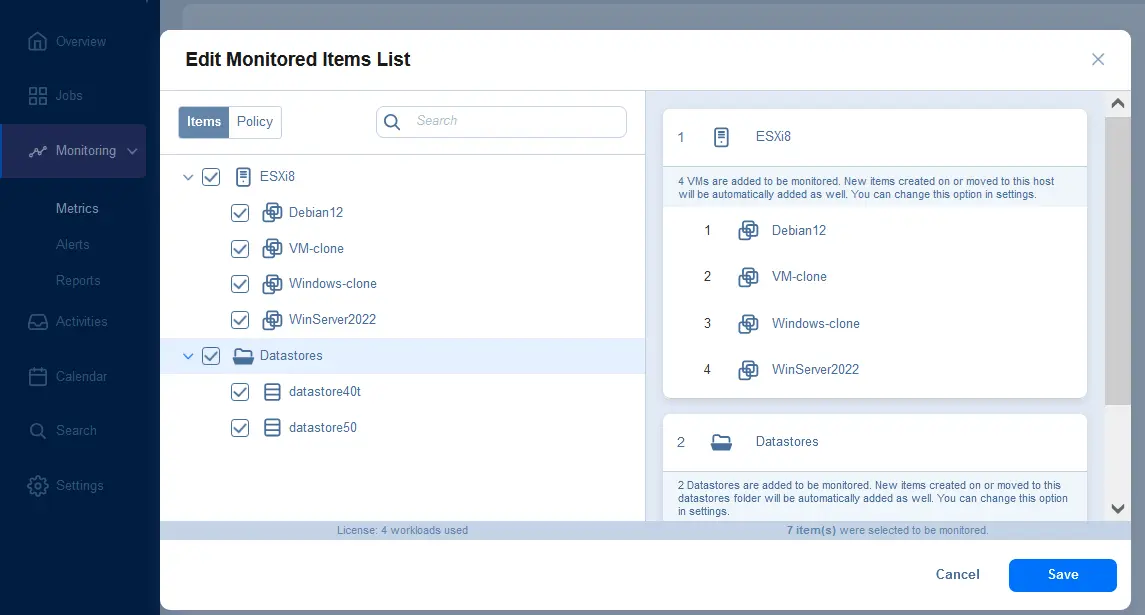
Konfiguracja alertów w rozwiązaniu NAKIVO
W rozwiązaniu NAKIVO można skonfigurować alerty, aby jak najszybciej otrzymywać powiadomienia o potencjalnych problemach, co pozwala szybko je rozwiązać, zanim doprowadzą do poważnych konsekwencji.
- Przejdź do
Monitoring>Alerts, wybierz zakładkęAlert Template Managementi kliknij+, aby dodać alerty dla określonych elementów.
- Wybierz monitorowane elementy, dla których ma być wyzwalany alert. Można wybrać hosty ESXi, maszyny wirtualne (VM) lub magazyny danych. Naciśnij
Next, aby kontynuować.
- Skonfiguruj reguły dla nowego szablonu alertu. Kliknij
+i wybierz warunek reguły. Na przykład można ustawić szablon reguły alertu, który musi zostać uruchomiony, jeśli średnie wykorzystanie pamięci hosta przekroczy 90% przez 1 godzinę. Do jednego szablonu alertu można dodać wiele reguł.
- Skonfiguruj ustawienia szablonu alertu. Wprowadź nazwę i opis alertu oraz wybierz poziom ważności. Możesz zaznaczyć pole wyboru, aby
send an email notification when this alert is triggeredi wprowadzić wiele adresów e-mail odbiorców, którzy powinni otrzymywać powiadomienia o alertach. KliknijFinish.
Konfigurowanie raportów w rozwiązaniu NAKIVO
- Aby skonfigurować raporty, przejdź do
Monitoring>Reports, kliknij+i naciśnijReport.
- Możesz wybrać jeden z obsługiwanych typów źródeł:
- Przegląd infrastruktury – informacje o serwerach vCenter, hostach ESXi zarządzanych przez vCenter oraz samodzielnych hostach ESXi
- Wydajność maszyn wirtualnych
- Pojemność magazynu danych
- Wydajność hosta
- Raport ochrony
Po wybraniu typu źródła wybierz elementy, które mają zostać uwzględnione w raporcie. Na poniższym zrzucie ekranu widać, że w liście rozwijanej zaznaczono opcję
Infrastructure Overvieworaz wybrano hosta ESXi do uwzględnienia w raporcie. KliknijNext, aby kontynuować.
- Skonfiguruj zakresy czasu i dat dla raportu. Możesz na przykład utworzyć raport obejmujący ostatnie 30 dni.

- Skonfiguruj ustawienia raportu. Wprowadź wyświetlaną nazwę raportu i opis. Opcjonalnie, w sekcji
Notificationszaznacz pole wyboru, aby wysłać raport na określone adresy e-mail. Wprowadź adres e-mail i naciśnijEnter, aby zastosować ten adres e-mail. Możesz wprowadzić wiele adresów e-mail. NaciśnijFinish, aby zapisać ustawienia tworzenia raportu.
- Możesz eksportować raporty do pliku. Wejdź na stronę
Monitoring>Reportsi zaznacz raporty, które chcesz wyeksportować (zaznacz pola wyboru). Kliknij przycisk…(więcej opcji), kliknijExport, a następnie w oknie dialogowym wybierz format pliku (PDF lub CSV). KliknijExport.
Wnioski
Monitorowanie infrastruktury IT może poprawić wydajność administracji, zapewnić ciągłość działania oraz obniżyć koszty. Zaleca się skonfigurowanie narzędzi do monitorowania IT tak, aby wysyłały alerty i raporty umożliwiające wczesną reakcję na incydenty, co pozwoli zapobiegać potencjalnym problemom i jak najszybciej naprawiać istniejące. Użyj NAKIVO Backup & Replication do ochrony danych, w tym maszyn wirtualnych VMware, a także do monitorowania infrastruktury vSphere i zadań związanych z ochroną danych.



