VMware vSphere HA と DRS の比較と解説
VMwareハイパーバイザーを使用すると、単一のサーバー上で仮想マシンを実行できます。スタンドアロンのESXiホスト上で複数の仮想マシンを実行したり、複数のホストを展開してさらに多くの仮想マシンを実行したりすることができます。ネットワーク経由で接続された複数のESXiホストがある場合、仮想マシンをあるホストから別のホストへ移行することができます。
ネットワーク経由で接続された複数のホストを使用して仮想マシンを実行しても、ビジネスニーズを満たせない場合があります。例えば、1つのホストに障害が発生すると、そのホスト上に存在するすべての仮想マシンも停止してしまいます。また、ESXiホスト上の仮想マシンのワークロードに不均衡が生じたり、ホスト間で手動で仮想マシンを移行したりすることが日常的に発生したりします。これらの問題に対処するため、VMwareは次のようなクラスタリング機能を提供しています。 VMware High Availability (HA) そして Distributed Resource Scheduler (DRS). vSphereのクラスタリング機能を利用することで、仮想マシンのダウンタイムを短縮し、ハードウェアリソースを効率的に活用できます。このブログ記事では、VMwareについて解説します HA そして DRS および各クラスタリング機能のユースケース。

vSphereクラスターとは何ですか?
vSphereクラスターとは、プロセッサ、メモリ、ストレージなどのハードウェアリソースを共有する、相互に接続されたESXiホストの集合体です。VMware vSphereクラスターは、 vCenterクラスタのリソースはリソースプールに集約されるため、ホストを クラスターこれにより、ホストのリソースはクラスタ全体のリソースの一部となります。クラスタのメンバーである ESXi ホストは、クラスタノードとも呼ばれます。vSphere クラスタには 2 種類あります: vSphere High Availability そして Distributed Resource Scheduler (VMware HA そして DRS).
VMwareクラスタの要件
VMwareを展開するには HA そして DRS, 以下のクラスタ要件を満たす必要があります:
- 2つ以上 ESXi 設定が同一のホスト(同じファミリーのプロセッサ(ESXiのバージョンやパッチレベルなど)を使用する必要があります。たとえば、同じファミリーのIntelプロセッサを搭載した2台のサーバーを使用することも可能です(または
AMD(プロセッサ)およびESXi 7.0 Update 3サーバーにインストールされています。セキュリティとパフォーマンスを向上させるため、少なくとも3つのホストを使用することをお勧めします。 - 管理ネットワーク、ストレージネットワーク、およびvMotionネットワーク用の高速ネットワーク接続。冗長化されたネットワーク接続が必要です。
- クラスタ内のすべてのESXiホストからアクセス可能な共有データストア。ストレージエリアネットワーク(SAN)、ネットワーク接続ストレージ(NAS)、および VMware vSAN 共有データストアとして使用できます。共有データストア上のデータにアクセスするには、NFSおよびiSCSIプロトコルがサポートされています。VMファイルは、共有データストアに保存する必要があります。
VMware vCenter ServerホストにインストールされているESXiのバージョンと互換性があるもの。
とは異なり、 Hyper-V Failover Clusterまた、定足数は必要なく、複雑なネットワーク名を使用する必要もありません。
とは VMware HA vSphereでは?
VMware vSphere High Availability (HA) これは、障害発生時に仮想マシン(VM)を自動的に再起動するように設計されたクラスタリング機能です。 VMware vSphere High Availability これにより、組織はvSphereクラスタ内で実行されているVMおよびそれらのVM上で動作するアプリケーションに対し、(実行中のアプリケーションに依存することなく)高可用性を確保できます。 VMware HA ESXiホストの障害からシステムを保護することができ、障害が発生したVMは正常なホスト上で再起動されます。その結果、ダウンタイムを大幅に短縮できます。
要件 vSphere HA
要件 vSphere HA vSphereクラスタの一般的な要件と併せて考慮する必要があります。設定を行うには VMware vSphere High Availability, 以下の条件を満たしている必要があります:
- A
VMware vSphere Standardライセンス - 各ホストで最低4 GBのRAM
- ping可能なゲートウェイ
vSphereはどのように機能するのでしょうか HA 仕事?
VMware vSphere High Availability ESXiホストをチェックして、ホストの障害を検出します。 ホスト障害が検出された場合(そのホスト上で実行中のVMも障害状態となる)、障害発生したVMはクラスタ内の正常なESXiホストへ移行されます。移行後、VMは新しいホストに登録され、その後起動されます。VMファイル(VMX、VMDK、その他のファイル)は、移行後も共有データストアという同じリソース上に配置されます。VMファイル自体は移行されません。 移行後、新しいESXiホストから提供されるのは、障害発生したVMが利用していたCPU、メモリ、およびネットワークコンポーネントのみです。
ダウンタイムは、別のホスト上でVMを再起動するのに必要な時間と同等です。ただし、オペレーティングシステムの起動や、VM上で必要なアプリケーションのロードに要する時間も考慮する必要があります。VMware HAはVMレイヤーで動作するソリューションであり、アプリケーションにネイティブな高可用性機能がない場合にも利用できます。 VMware vSphere High Availability これは、VMにインストールされているゲストOSには依存しません。
のワークフローは、 vSphere HA クラスタの構成は、以下の図に示されています。この例では、3台のESXiホストからなるクラスタがあります。すべてのホスト上でVMが実行されています。VMとファイル間の接続は点線で示されています。
1. クラスタの通常動作。すべてのVMは、それぞれのネイティブホスト上で実行されています。
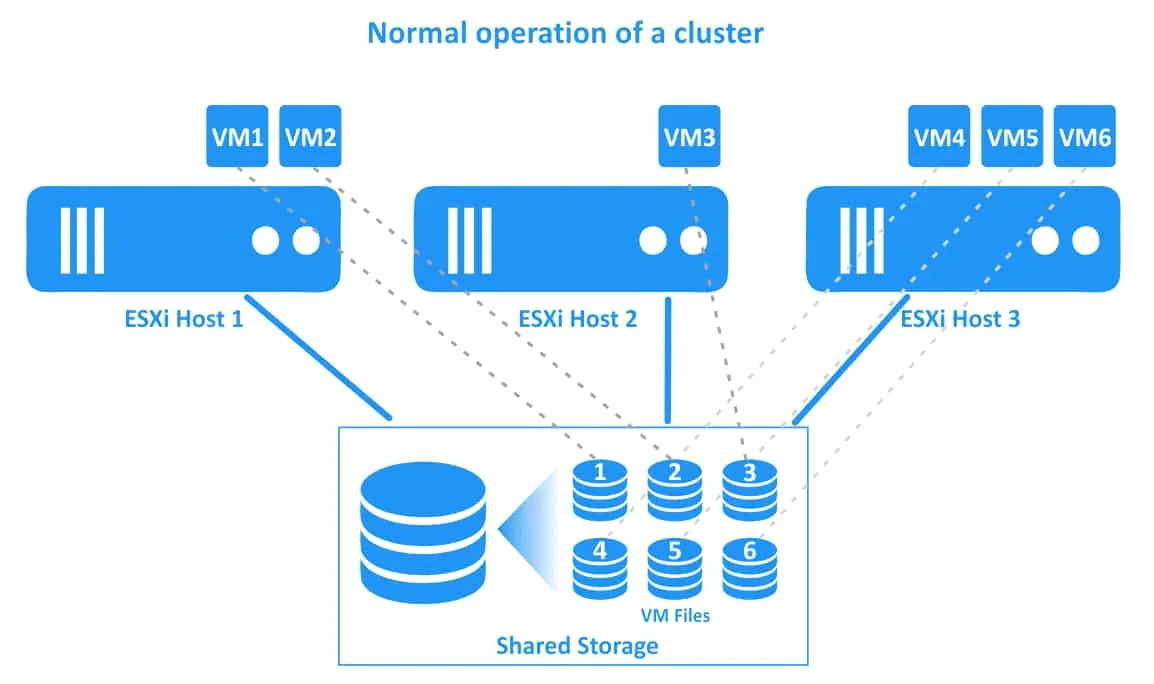
2. ESXiホスト1が障害を起こします。ESXiホスト1上に存在するVM(VM1およびVM2)は障害状態になります(これらのVMは電源がオフになります)。vSphere HA クラスターは、正常に動作している他のESXiホスト上でVMの再起動を開始します。
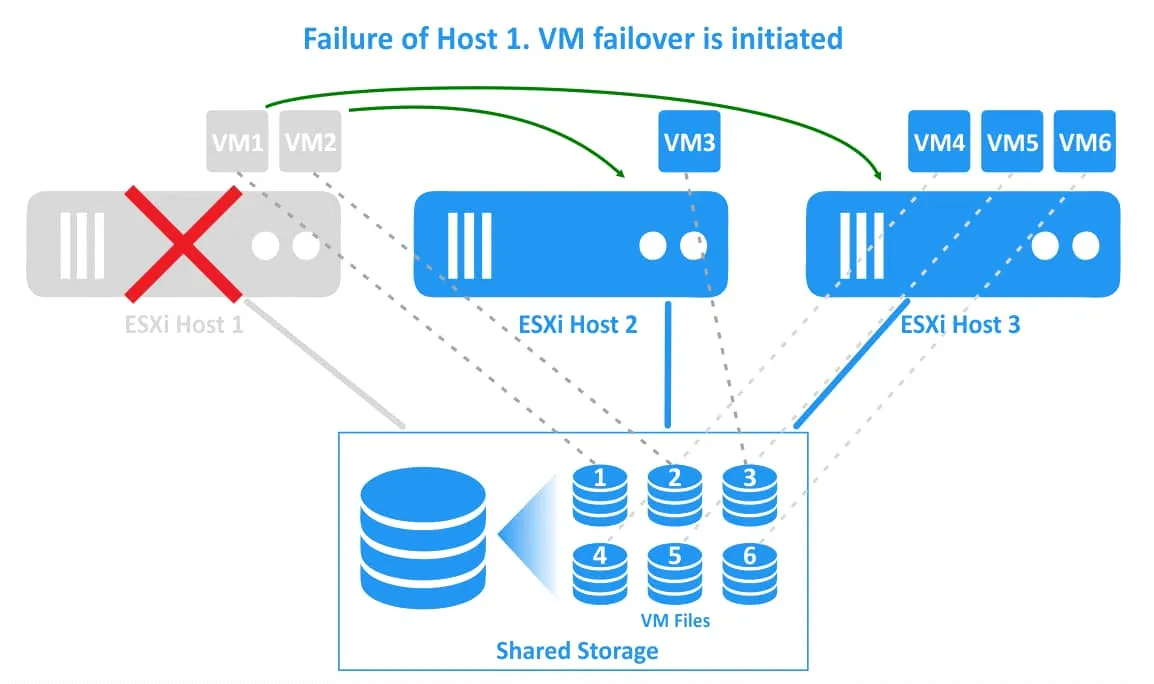
3. 仮想マシンは正常なホストへ移行され、再起動されました。VM1はESXiホスト2へ、VM2はESXiホスト3へ移行されました。仮想マシンのファイルは、vSphereクラスタのすべてのESXiホストに接続されている共有ストレージ上の同じ場所に配置されています。
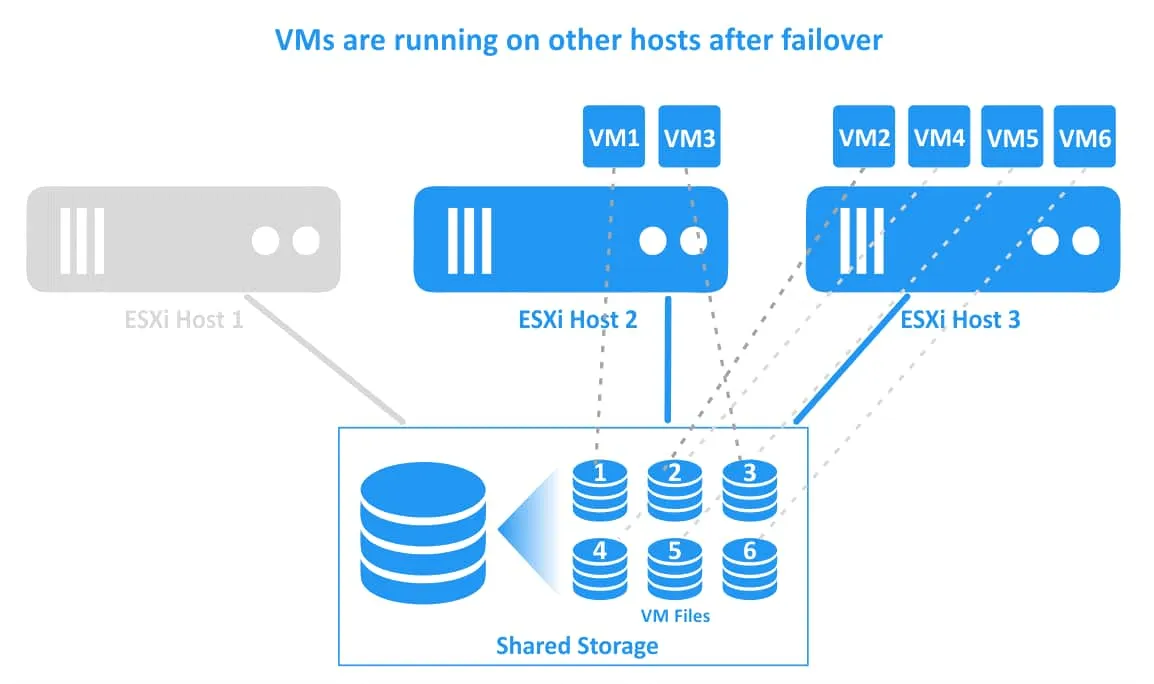
HA 上司と部下
その後 vSphere High Availability クラスタで有効になっている場合、1台のESXiホストが HA マスター。その他のESXiホストはサブホスト(スレーブ)となります。マスターはサブホストの状態を監視し、ホストの障害を速やかに検知して、障害が発生したVMの再起動を開始します。また、マスターホストはクラスタノード上の仮想マシンの電源状態も監視します。VMの障害が検知された場合、マスターはVMの再起動を開始します(マスターは、障害が発生したVMを再起動する前に最適なホストを選択します)。 HA マスターは、以下の情報について送信します HA クラスタの状態をvCenterに送信します。VMware vCenterは、が提供するインターフェースを使用してクラスタを管理します。 HA マスターホスト。
マスターは、クラスタ内の他のホストと同様に仮想マシンを実行できます。マスターホストに障害が発生した場合、別のマスターホストが選出されます。プライマリ ESXi ホストの選出においては、最も多くのデータストアに接続されているホストが優先されます。メンテナンスモードになっていないホストは、プライマリホストの選出に参加します。
サブホストは、仮想マシンを実行し、仮想マシンの状態を監視し、仮想マシンの状態に関する最新情報を HA マスターホスト。
Fault Domain Manager (FDM) は、物理サーバーの稼働状況を監視するために使用されるエージェントの名前です。 FDM エージェントは、その中の各ESXiホスト上で動作します HA クラスター。
ホストの障害の種類
ESXiホストの障害には、次の3つの種類があります:
失敗。 何らかの理由で、ESXiホストが動作しなくなりました。
孤立。 ESXiホストおよびそのホスト上の仮想マシンは正常に動作し続けていますが、ネットワークの問題により、そのホストはクラスタ内の他のホストから切り離された状態になっています。
パーティション。 プライマリホストとのネットワーク接続が切断されました。
障害の検知方法
vSphereの障害を検出するために、ハートビートが交換されます HA クラスタ。プライマリホストは、1秒ごとにセカンダリホストからハートビートを受信することで、セカンダリホストの状態を監視します。プライマリホストは ICMP セカンダリホストにpingを送信し、応答を待ちます。プライマリホストがセカンダリホストのエージェントと直接通信できない場合、セカンダリホストは正常に動作しているか、あるいは障害が発生しているもののネットワーク経由ではアクセスできない状態である可能性があります。
プライマリホストがハートビートを受信しない場合、プライマリホストは以下の方法でそのホストの状態を確認します。 Datastore Heartbeating. 通常動作時、あるネットワーク内の各ホストは HAクラスタは、共有データストアとハートビートをやり取りします。プライマリ ESXi ホストは、問題のあるホストへの ping 送信に加え、そのホストとの間でデータストアのハートビートが正常にやり取りされているかを確認します。問題のあるホストとの間でデータストアのハートビートがやり取りされておらず、かつそのホストから ICMP リクエストが返ってこない場合、そのホストは障害発生ホストとして指定されます。
注: 特別 .vSphere-HA ディレクトリは、ハートビート通信および保護対象のVMリストの特定のために、共有データストアのルートに作成されます。vSANデータストアはデータストアのハートビート通信には使用できない点に注意してください。
プライマリホストがセカンダリホストのエージェントに接続できない場合でも、セカンダリホストが共有データストアとハートビートを交換している場合、プライマリホストはそのホストを"ネットワーク隔離ホスト"としてマークします。 プライマリホストが、セカンダリホストがネットワークから隔離されたセグメントで実行されていると判断した場合、プライマリホストはその隔離されたホスト上のVMの監視を継続します。隔離されたホスト上のVMが電源オフ状態の場合、プライマリホストは別のESXiホスト上でこれらのVMの再起動を開始します。ESXiホストがネットワークから隔離された場合のvSphere HAクラスタの対応を構成できます。
個々のVMの監視。 VMware vSphere High Availability 個々のVMを監視し、特定のVMに障害が発生したかどうかを検知する機能を備えています。 VMware Tools ゲストOSにインストールされたソフトウェアは、仮想マシンの状態を判断するために使用されます。 VMware Tools ゲストOSのハートビートをESXiホストに送信します。
ハートビートおよび入出力(I/O)によって生成されたアクティビティ VMware Tools は、VM監視サービスによって監視されています。もし、 HA クラスターは、 VMware Tools 保護されたVM上のプロセスが応答しておらず、かつ I/O アクティビティが発生すると、ホストがVMの再起動を開始します。VMの監視 I/O このアクティビティでは、 HA 不要なVMのリセットを避けるためにクラスターを VMware Tools 何らかの理由でハートビートが送信されないものの、VMは正常に動作しています。監視の感度を設定することで、ゲストOSによって生成されるハートビートが VMware Tools ESXiホストに受信されません。VMware vSphere HA 単一のVMに障害が発生した場合、同じESXiホスト上でそのVMを再起動します。
VMware Tools 心拍データは hostd ネットワークスタックを経由するのではなく、ハイパーバイザーレベル(ESXi)で行われます。その後、ESXiホストは受信した情報をvCenterに送信します。 VMware Tools 仮想マシンがネットワークから切断されている場合、あるいは仮想マシンに接続された仮想ネットワークアダプタが存在しない場合でも、ESXiホストはハートビートを受信することができます。
VMおよびアプリケーションの監視。 次の方法をご利用いただけます SDK サードパーティ製ベンダーのツールを使用して、VMにインストールされた特定のアプリケーションに障害が発生していないかを監視します。別の方法として、VMware Application Monitoringをすでにサポートしているアプリケーションを使用することもできます。vSphere上で実行されているVMware VMのアプリケーション監視には、アプリケーションのハートビートが使用されます HA クラスター。
主要なパラメータ HA クラスタ構成
HAクラスタの設定を開始する前に、いくつかの重要なパラメータを定義する必要があります。
隔離対応 これは、ESXiホストがハートビート信号を受信しなかった場合の動作を定義するパラメータです。オプションは以下の通りです。 Leave powered on, Power off (デフォルト)、および Shutdown.
Reservation は、クラスタ内で最もリソースを消費するVMの最大特性に基づいて計算されるパラメータです。このパラメータは、フェイルオーバー容量の推定に使用されます。 HA クラスターは、Reservation パラメータの値を使用して予約スロットを作成します。
フェイルオーバー容量。 このパラメータは整数で指定され、ワークロードに悪影響を及ぼすことなくクラスタ内で許容される最大サーバー障害数を定義します(この数のESXiホストが障害を起こしても、クラスタおよびすべてのVMは引き続き動作します)。
許容されるホスト障害の回数。 このパラメータは、クラスタの稼働を維持するために許容されるホストの障害発生数を設定するために、システム管理者が定義するものです。 フェイルオーバー容量 このパラメータの値を設定する際には、この点が考慮されます。
Admission Control これは、ESXiホストに障害が発生した後にVMを復旧するために、十分なリソースが確保されるようにするためのパラメータです。このパラメータは管理者が設定し、ESXiホストの障害後にVMを起動するための空きスロットが不足している場合のVMの動作を定義します。 Admission Control フェイルオーバー容量、すなわちvSphereにおいて許容可能なリソース低下の割合を定義します HA フェイルオーバー後のクラスタ。
Restart Priority これは、クラスタノードのフェイルオーバー後にVMを起動する順序を定義するために、管理者が設定するものです。管理者はvSphereを設定できます HA 重要な仮想マシンを先に起動し、その後、他の仮想マシンを起動する。
フェイルオーバー容量とホスト障害
2つのケースを見てみましょう。いずれもESXiホストが3台ありますが、フェイルオーバー容量の値が異なります。1つ目のケースでは、1台のESXiホストが障害を起こしてもHAクラスタは動作し続けます(下の図の左側を参照)。2つ目のケースでは、 HA このクラスタは、2台のESXiホストの障害に耐えることができます(図の右側を参照)。
1. 各ESXiホストには4つのスロットがあります。クラスタ内には6台のVMがあります。1台のESXiホスト(例えば3台目のホスト)が障害を起こした場合、3台のVM(VM4、VM5、およびVM6)は残りの2台のESXiホストへ移行できます。 この例では、これら3つのVMは2番目のESXiホストへ移行しています。もしもう1台のESXiホストが障害を起こした場合、他のVMを移行して実行するための空きスロットはなくなります。
2. 各ESXiホストには4つのスロットがあります。VMware vSphereでは4つのVMが実行されています HA クラスタ。この場合、2台のESXiホストが障害を起こしても、クラスタ内のすべてのVMを実行するのに十分なスロットが確保されています。
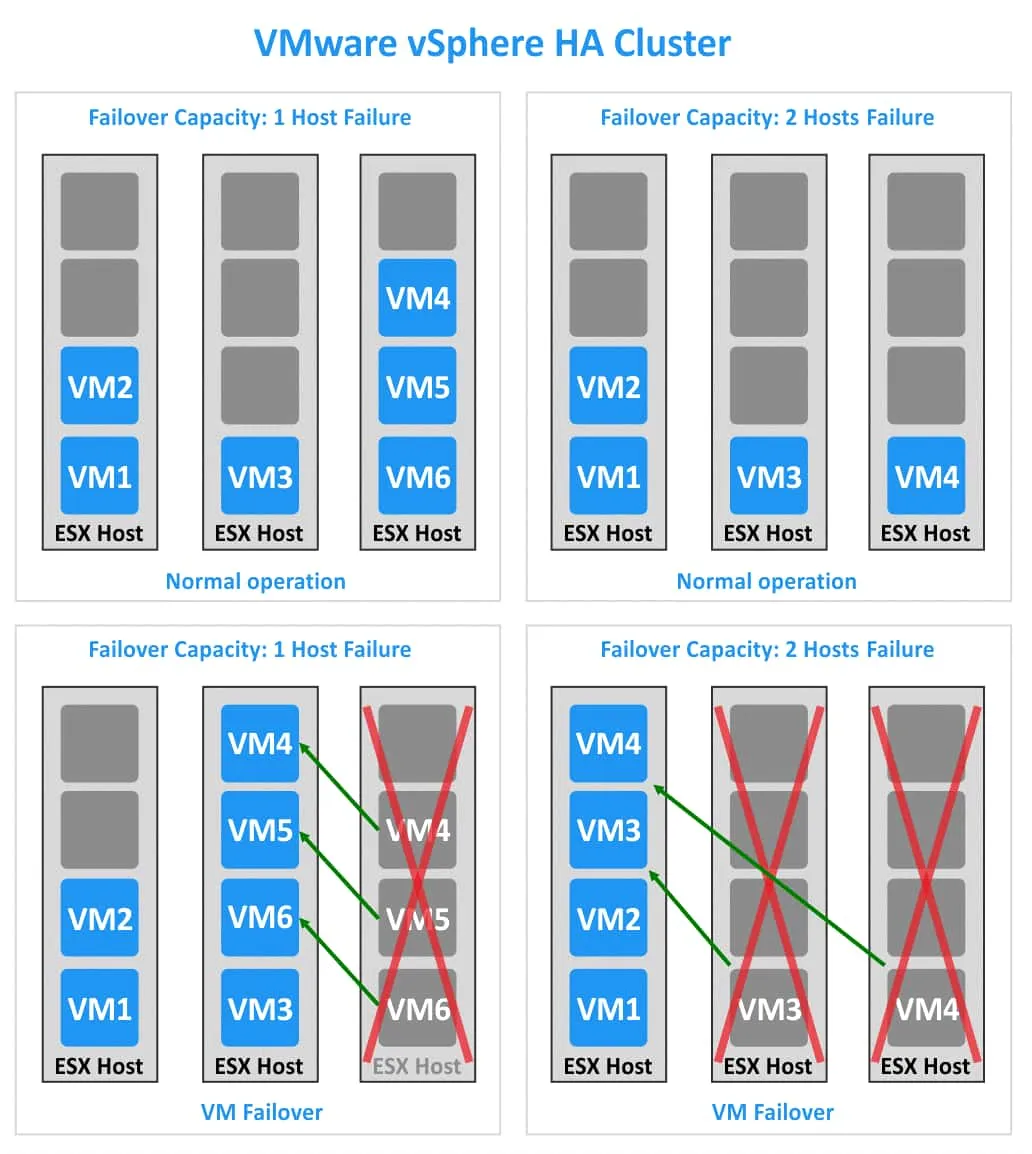
計算するために Failover Capacity, 以下の手順を実行します。クラスタ内の全ノード数から、クラスタ内のVM数と1ノードあたりのスロット数の比率を引きます。その結果が整数でない場合は、最も近い下位の整数に切り下げます。計算してみましょう Failover Capacity これら2つの例について。
例 1:
3–6/4=1.5
1.5を1に四捨五入する。ある HA クラスターは、もし~であれば存続できる 1 ESXiホストに障害が発生しました。
例 2:
3–4/4=2
2は整数であるため、切り捨てる必要はありません。以下の条件を満たせば、すべてのVMは動作を継続できます。 2 ESXiホストは障害を起こすことがあります。
入館管理
前述の通り、アドミッション・コントロールは、クラスタ内のホストに障害が発生した後も、VM を実行するのに十分なリソースを確保するために必要なパラメータです。また、 Admission Control State 利便性を高めるためのパラメータ。 Admission Control State は、以下の比率として計算される Failover Capacity ~へ 許容されるホスト障害の数 (NHF).
もし Failover Capacity より大きい NHF、そして HA クラスタが正しく設定されています。そうでない場合は、設定を行う必要があります。 Admission Control 手動で設定します。以下の2つのオプションが利用可能です:
1. 可用性制約に違反する場合、仮想マシンを起動しない(ハードウェアリソースが不足している場合はVMを起動しない)。
2. 可用性制約に違反する場合でも、仮想マシンの起動を許可する(ハードウェアリソースが不足していてもVMを起動する)。
環境に適したオプションを選択してください。 vSphere High Availability クラスタのユースケースに最適です。もし目的が HA クラスタでは、最初のオプションを選択してください(Do not power on VMs)。もし、すべてのVMを稼働させることが最優先事項であるなら、2番目のオプションを選択してください(Allow VMs to be started)。なお、後者の場合、クラスタの挙動が予測不能になる可能性があることに注意してください。最悪の場合、HAクラスタが機能しなくなる恐れがあります。
VMのオーバーライド
VMによる上書き(または HA ~の場合のオーバーライド HA (クラスタ)を無効にできるオプション HA で実行中の特定のVMについて HA クラスタ。vSphere を設定できます HA このオプションをクラスタレベルで有効にすることで、より詳細なレベルでクラスタを管理できます。
フォールトトレランス
VMwareはvSphere向けに機能を提供しています HA ESXiホストに障害が発生した場合でもダウンタイムをゼロに抑えることができるクラスタです。この機能は Fault Tolerance. 標準構成では、 vSphere High Availability 失敗した場合はVMの再起動が必要となります、 Fault Tolerance これにより、VMが登録されているプライマリESXiホストに障害が発生した場合でも、VMの稼働を継続できます。 Fault Tolerance 重要なアプリケーションを実行するミッションクリティカルなVMに使用できます。
最高レベルの事業継続性を実現し、ダウンタイムをゼロにするには、保護対象のVMの稼働インスタンスが2つ存在するため、一定のオーバーヘッドが発生します。 Fault Tolerance2つ目のゴーストVMは2番目のESXiホスト上で実行されており、元のVMに対するすべての変更(CPU、RAM、ネットワークの状態)は、最初のESXiホストから2番目のESXiホストへレプリケートされます。保護対象のVMはプライマリVMと呼ばれ、複製されたVMはセカンダリVMと呼ばれます。 ESXiホストの障害に対する保護を確保するため、プライマリVMとセカンダリVMは異なるESXiホスト上に配置する必要があります。
2つのVM(プライマリVMとセカンダリVM)は同時に実行されており、両方のESXiホスト上でCPU、RAM、およびネットワークリソースを消費します(したがって、フォールトトレランス機能で保護されたVMは、vSphere上で2倍のリソースを消費します)。 HA (クラスタ)。これらのVMはリアルタイムで継続的に同期されます。ユーザーはプライマリ(元の)VMでのみ作業が可能であり、セカンダリ(ゴースト)VMはユーザーからは見えません。
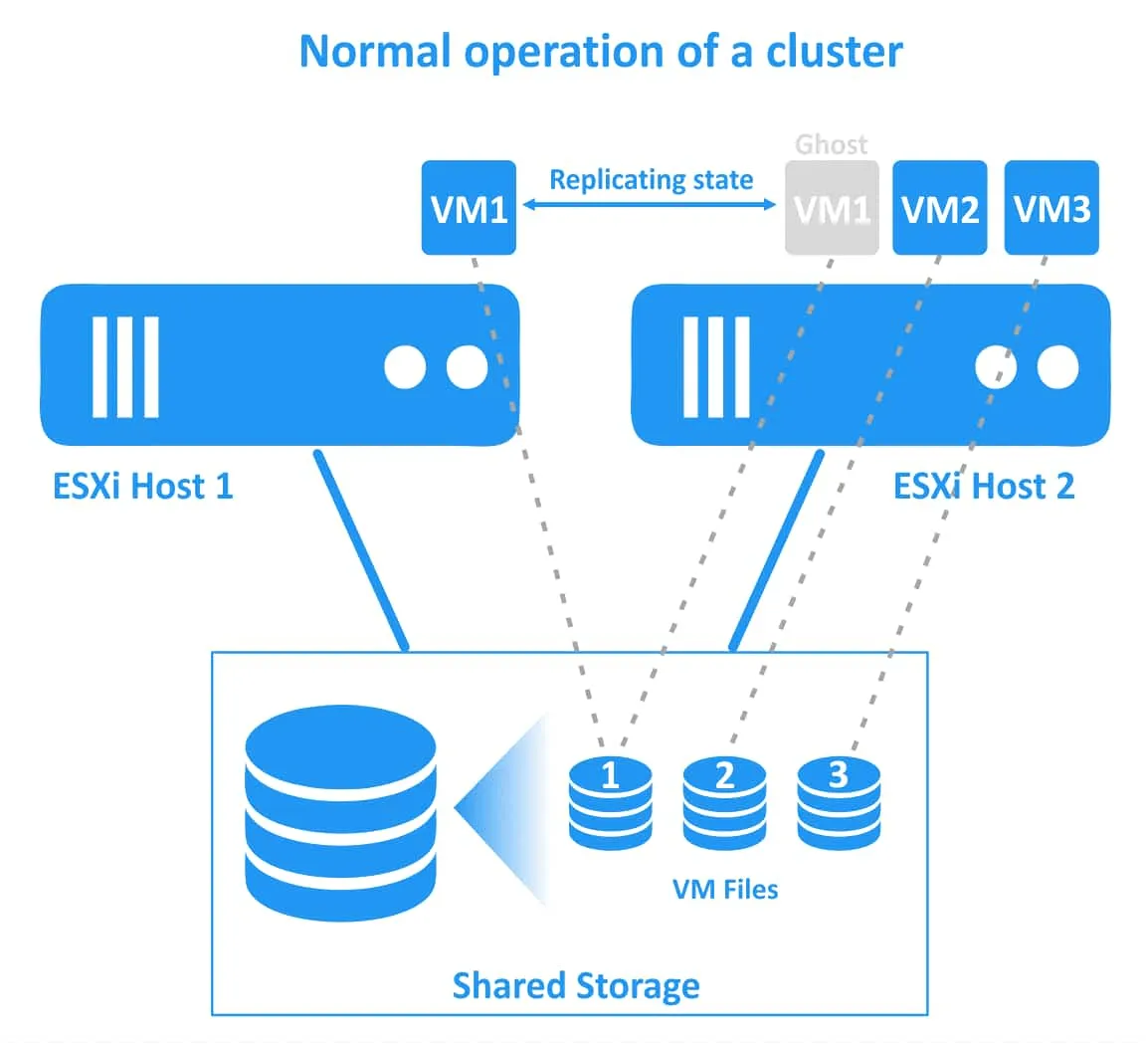
最初のESXiホスト(プライマリVMが稼働しているホスト)に障害が発生した場合、ワークロードは2番目のESXiホスト上で稼働しているセカンダリVM(VMクローンまたはゴーストVM)に移行されます。セカンダリVMは瞬時にアクティブ状態となり、アクセス可能になります。透過的なフェイルオーバーが行われている間、ユーザーはわずかなネットワーク遅延を感じる場合があります。 フェイルオーバー中にサービスの中断やデータの損失は発生しません。フェイルオーバーが正常に完了した後、冗長性を確保し、ESXiホストの障害に対するVM保護を継続するために、別の正常なESXiホスト上に新しいゴーストVMが作成されます。
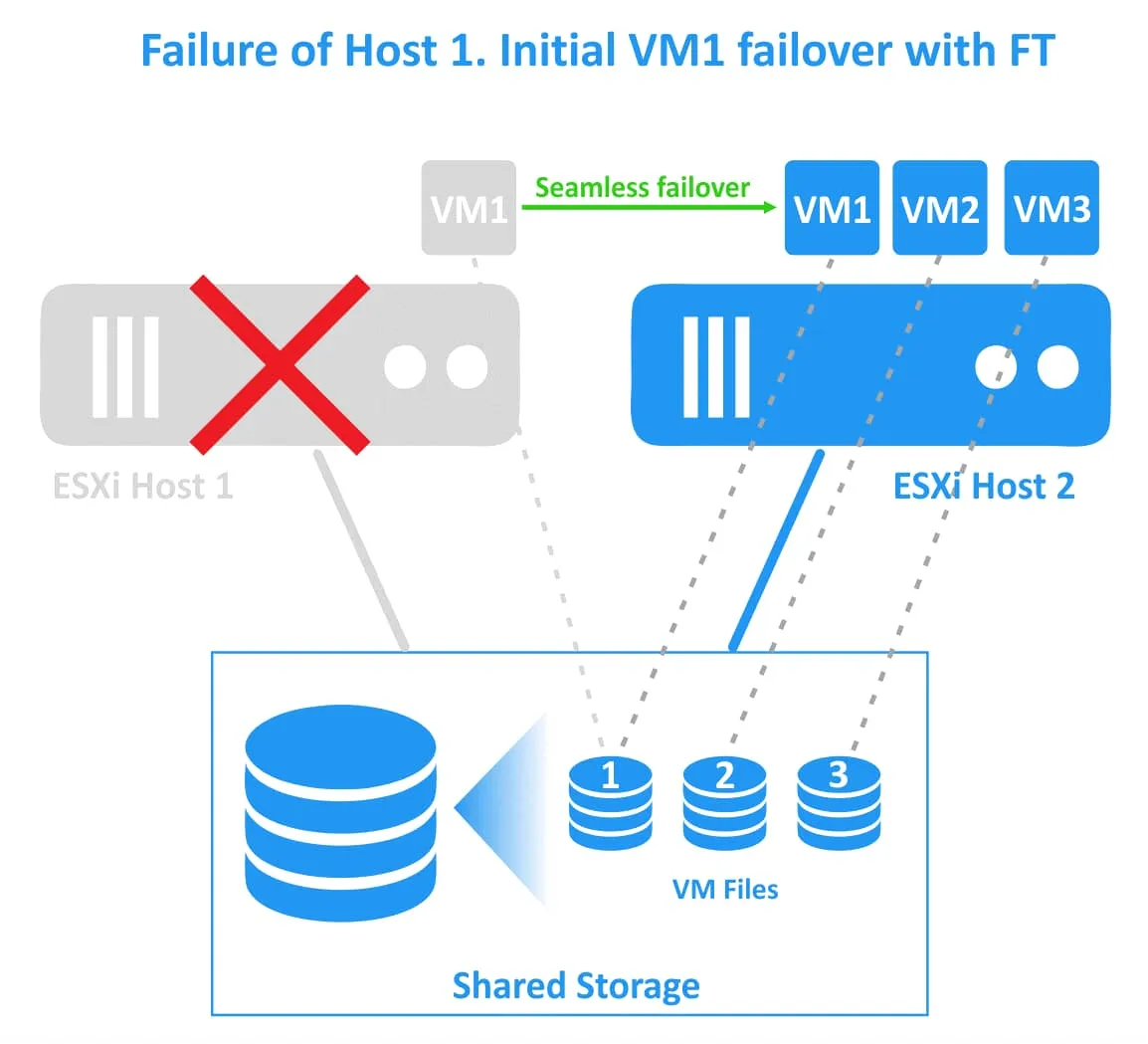
Fault Tolerance フェイルオーバーの調整のために共有ストレージ上でファイルロック機構が機能するため、スプリットブレイン(保護対象のVMの2つのアクティブなコピーが同時に実行される状態)を回避します。しかし、 Fault Tolerance VM内部のソフトウェア障害(ゲストOSの障害や特定のアプリケーションの障害など)に対しては保護されません。プライマリVMが障害を起こした場合、セカンダリVMも同様に障害を起こします。
要件 Fault Tolerance
- vSphere
HA少なくとも2台のESXiホストで構成されるクラスター。 vMotionそしてFT logging.- ハードウェアアクセラレーションに対応した互換性のあるCPU
MMU仮想化。
専用の Fault Tolerance vSphere 内のネットワーク HA クラスターの使用が推奨されます。
~のライセンス Fault Tolerance
- ESXiホストを使用するには、ライセンスが必要です
Fault Tolerance. - vSphere
StandardそしてEnterprise1台のVMにつき最大2つのvCPUをサポートします。 - vSphere
Enterprise Plus1台のVMにつき最大8つのvCPUを使用できます。
Fault Tolerance 制限
使用にはいくつかの制限があります VMware Fault Tolerance vSphere において。vSphere の以下の機能は、 FT:
- VMのスナップショット。保護対象のVMにはスナップショットが存在してはなりません。
- 連結クローン
- VMware
vVolデータストア
対応していないデバイス:
Raw device mappingデバイス- 物理CD-ROMや、仮想マシンに仮想デバイスとして接続されているサーバーのその他のデバイス
- オーディオ機器とUSB機器
- サイズが2 TBを超えるVMDK仮想ディスク
- 3Dグラフィックス対応のビデオデバイス
- パラレルポートとシリアルポート
Hot-plugデバイスNIC (network interface controller)パススルーStorage vMotion(VMファイルを別のストレージに移行するには、一時的に無効にする必要があります)
とは DRS VMware vSphereでは?
Distributed Resource Scheduler (DRS) これは、クラスタ内で実行されている仮想マシンの負荷分散を可能にする、VMware vSphereのクラスタリング機能です。 DRS vSphereクラスター内のVMの負荷およびESXiサーバーの負荷を確認します。もし DRS 過負荷状態にあるホストまたはVMを検出した場合、 DRS VMを、サービス品質を確保するために十分な空きハードウェアリソースを持つESXiホストに移行します(QoS). DRS クラスタ内で新しいVMを作成する際、そのVMに最適なESXiホストを選択できます。
VMware DRS これにより、バランスのとれたクラスタ内で仮想マシンを実行でき、過負荷や、仮想マシンおよび仮想マシン上で動作するアプリケーションが正常に動作するために必要なハードウェアリソースが不足する状況を回避できます(この場合、クラスタ全体として十分なリソースが確保されている必要があります)。
DRS 要件
の要件 DRSvSphereクラスタの一般的な要件に加え、以下の要件があります:
- vSphere
Enterpriseまたは vSphereEnterprise Plusライセンス - CPUを搭載した
Enhanced vMotion CompatibilityVMのライブマイグレーションにはvMotion - 専用の
vMotionネットワーク
設定済みのVMware vMotion を操作するには、 DRS クラスターは、~とは異なり、 HA クラスタ。vMotionが必要となるのは、以下の場合のみです。 Fault Toleranceまた、VMwareに必要なvSphereライセンス DRS は、使用許諾よりも高い vSphere High Availability.
の役割 vMotion
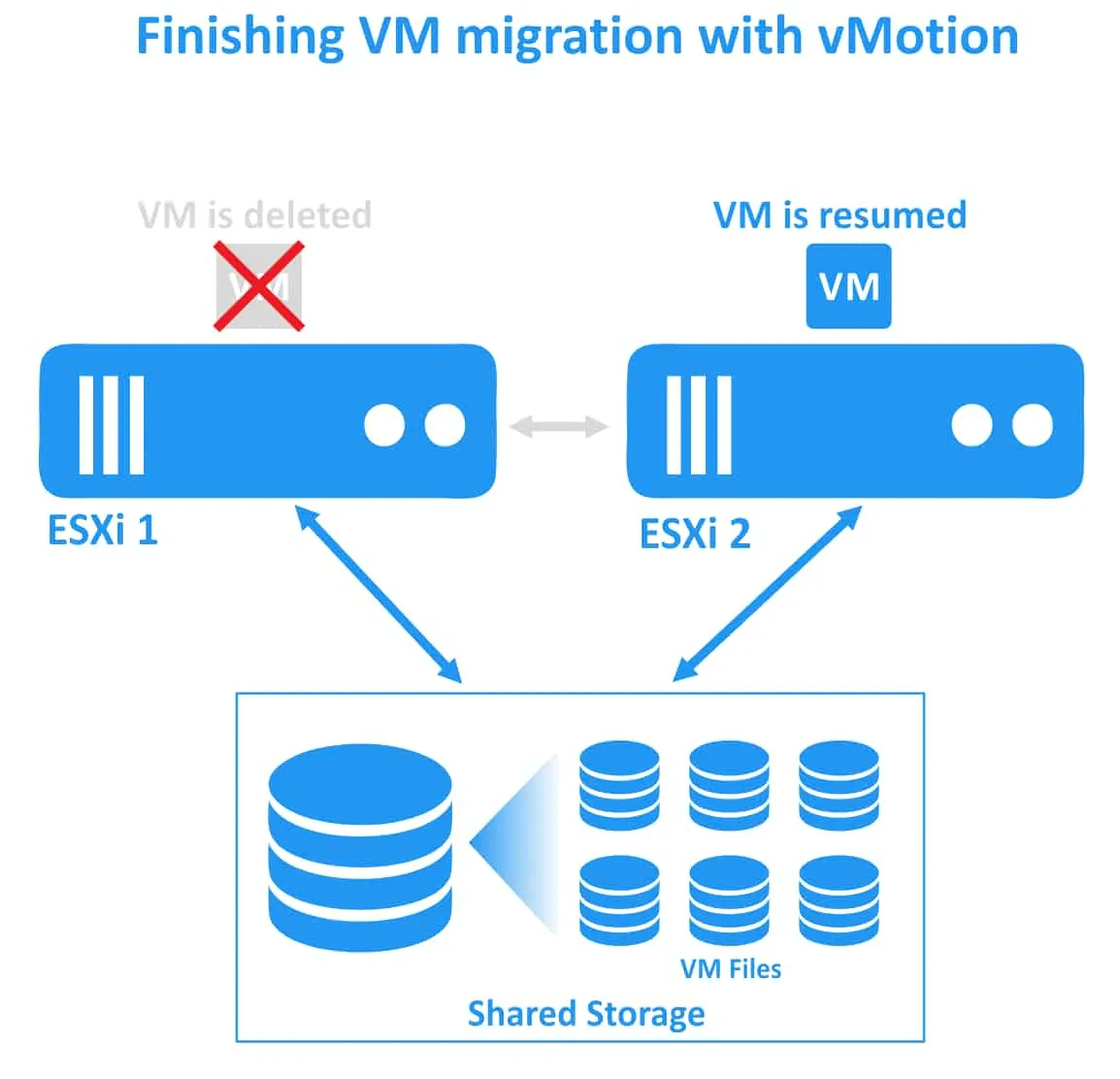
以下の手順で、VMをあるESXiホストから別のESXiホストへ移行します vMotion(これは、……の説明の際に触れた通り) Fault Tolerance 動作します。VMware を使用する場合 vMotion、VMの移行(CPU、メモリ、ネットワークの状態)は、実行中のVMを中断することなく行われます(ダウンタイムは発生しません)。VMware vMotionは、正常な動作に不可欠な機能です。 DRS.
vMotionの操作における主な手順を見てみましょう:
1. vMotion 移行先のESXiホスト上にシャドウVMを作成します。移行先のESXiホストは、移行対象のVMに必要なリソースを事前に確保します。VMは中間状態となり、移行中はVMの設定を変更することはできません。

2. プリコピー処理。各VMメモリページは、 vMotion ネットワーク。
3. VMの動作中にメモリページが変更されるため、ソースから宛先へのメモリページのコピーが次のパスで実行されます。これは、変更されたメモリページがなくなるまで繰り返される反復処理です。変更されたメモリページは"ダーティページ"と呼ばれます。VMの移行には、 vMotion VM上でメモリを大量に消費する操作が行われると、変更されるメモリページが増えるため。

4. ソース側のESXiホストでVMが停止され、宛先ホストで再開されます。この瞬間、移行されたVM内部で約1秒間、ごくわずかなネットワーク遅延が生じることがあります。
の動作原理 DRS VMware内で
VMware DRS デフォルトの間隔である5分ごとに、CPUとRAMの負荷を確認してvSphereクラスタの負荷バランスを判定します。VMware DRS クラスタのリソースプール内のすべてのリソース(VMが消費しているリソースや、クラスタ内の各ESXiホストがVMの実行に提供可能なリソースを含む)をチェックします。リソースチェックは、設定されたポリシーに従って実行されます。
また、VMの需要(チェック時点においてVMの実行に必要なハードウェアリソース)も考慮されます。メモリのVM需要を計算する際には、以下の式が使用されます:
VMメモリ要求量 = 関数(使用中のアクティブメモリ、スワップ済みメモリ、共有メモリ) + 25% (アイドル時のメモリ消費量)
CPU使用率は、仮想マシン(VM)が現在消費しているプロセッサリソースの数に基づいて計算されます。前回のチェック時に収集されたVMのCPU最大値および平均値は、 DRS 特定のVMのリソース使用状況の傾向を把握するため。vSphereの場合 DRS クラスタ内の不均衡を検出し、一部のESXiホストに過負荷がかかっていることが判明した場合、 DRS 過負荷状態のホスト上で実行中のVMを、空きリソースのあるホストへライブマイグレーションします。
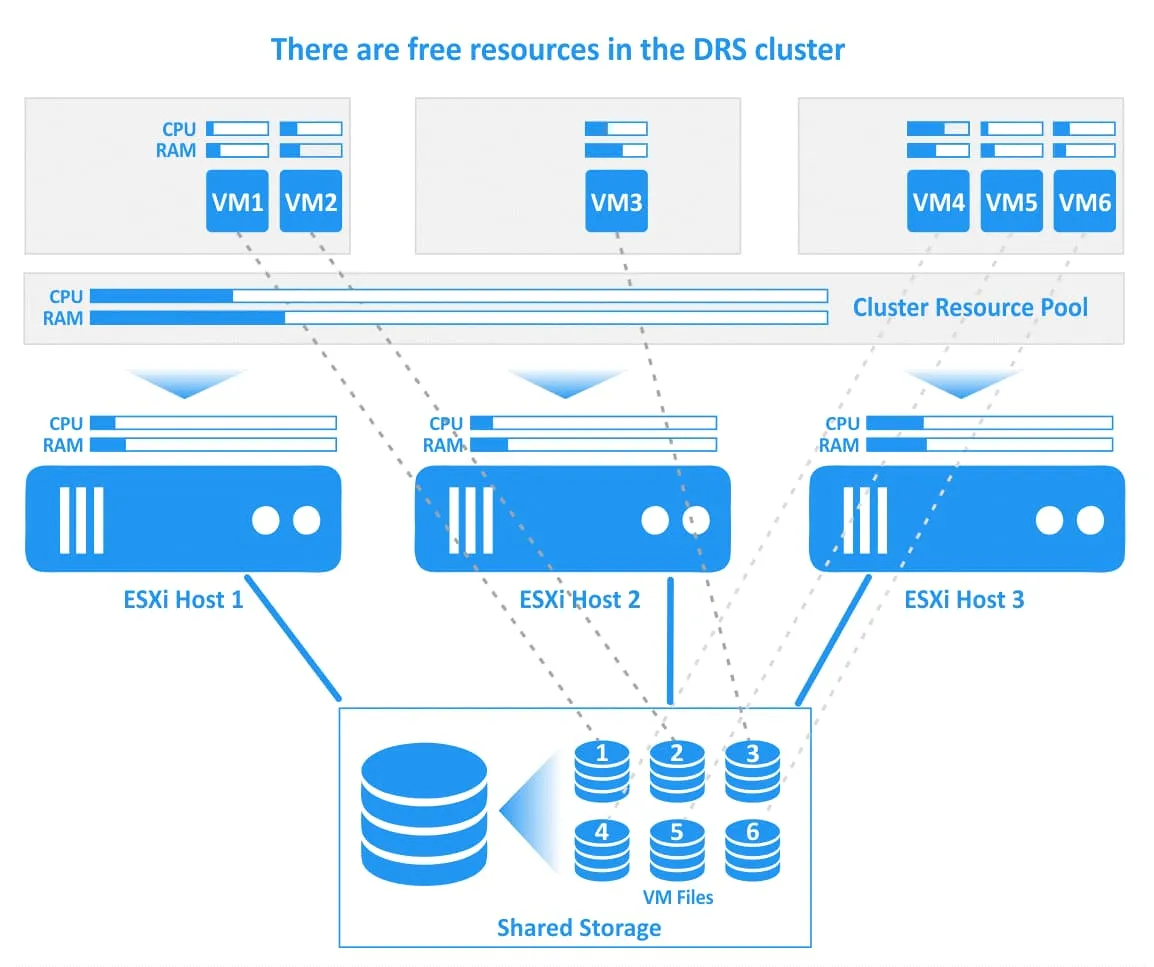
vSphereの仕組みを見てみましょう DRS 図解を交えた例を用いて、VMwareでの動作を解説します。下の図では、 DRS ESXiホスト3台で構成されるクラスター。すべてのホストは、VMファイルが格納されている共有ストレージに接続されています。1台目のホストは負荷が非常に高く、2台目のホストにはCPUとメモリのリソースに余裕があり、3台目のホストは負荷が高くなっています。1台目(VM1)および3台目(VM4、VM5)のESXiホスト上のいくつかのVMが、割り当てられたCPUおよびメモリリソースのほぼすべてを消費しています。この場合、これらのVMのパフォーマンスが低下する可能性があります。

VMware DRS 負荷の高いVM2を、リソースが逼迫しているESXiホスト1から、十分な空きリソースを持つESXiホスト2へ移行し、VM4をESXiホスト3からESXiホスト2へ移行することが合理的な措置であると判断する。もし DRS 自動モードで動作するように設定されている場合、実行中のVMは vMotion (この操作は、下の画像で緑色の矢印で示されています)。仮想ディスクを含むVMファイル(VMDK)、設定ファイル(VMX)、およびその他のファイルは、VMの移行中および移行後も共有ストレージ上の同じ場所に配置されます(図中のVMとそのファイルの関係は点線で示されています)。
選択したVMの移行が完了すると、 DRS クラスタの負荷が均等化されます。クラスタ内の各ESXiホストには、VMを効率的に実行し、高いパフォーマンスを確保するための空きリソースがあります。

VMのワークロードのばらつきによって状況が変化し、クラスタのバランスが再び崩れる可能性があります。その場合、 DRS クラスター内の使用済みリソースと空きリソースを確認し、VMの移行を再度開始します。
vSphere の主要なパラメータ DRS 設定
VMware vSphere DRS これは、さまざまな状況においてDRSをより効率的に活用できるようにする、高度にカスタマイズ可能なクラスタリング機能です。その動作に影響を与える主なパラメータを見てみましょう。 DRS vSphereクラスター内で。
VMware DRS 自動化のレベル
いつ DRS vSphereクラスタの負荷が不均衡であることを検出した場合、 DRS VMの配置および移行に関する推奨事項を提供します vMotionこの推奨事項は、以下の3つの自動化レベルのうちいずれかを使用して実装できます:
Fully automated. 仮想マシンの初期配置と vMotion 推奨事項は自動的に適用されます DRS (ユーザーによる操作は不要です)。
Partially automated. 新しいVMの初期配置に関する推奨事項のみが自動的に適用されます。その他の推奨事項については、手動で適用を開始して適用することも、無視することも可能です。
Manual. DRS 仮想マシンの初期配置および移行に関する推奨事項を提供しますが、これらの推奨事項を適用するにはユーザーの操作が必要です。また、提供された推奨事項を無視することも可能です。 DRS.
DRS 攻撃性のレベル(移動の閾値)
DRS 攻撃レベルや移動閾値とは、ある対象に対して許容される最大不均衡レベルを制御するオプションのことです。 DRS クラスタ。しきい値は、最も保守的な"1"から最も積極的な"5"までの5段階があります。
積極的な設定では、VMの配置によるメリットがわずかであってもVMの移行が開始されます。保守的な設定では、VMの移行後に大きなメリットが得られる場合でも、VMの移行は開始されません。中程度の積極性を持つレベル3がデフォルトで選択されており、これが推奨設定です。
VMwareにおけるアフィニティルール DRS
アフィニティおよびアンチアフィニティのルールは、特定のVMを特定のESXiホストに配置する必要がある場合に役立ちます。たとえば、クラスタ内の1つのESXiホスト上で特定のVMをまとめて実行する必要がある場合や、その逆の場合(2つ以上のVMを異なるESXiホストにのみ配置し、特定のホストには配置しないようにする必要がある場合)などが挙げられます。具体的な使用例としては、次のようなものがあります:
- 1つのホストに障害が発生した場合でも両方のVMが停止しないよう、仮想ドメインコントローラーVM(プライマリドメインコントローラーとセカンダリドメインコントローラー)を別々のホストに配置してください。この場合、これらのVMを単一のESXiホスト上で同時に実行してはなりません。
- 適切なハードウェア上で実行するライセンスが付与されたソフトウェアを実行している仮想マシンで、ライセンス上の制限により他の物理コンピュータでは実行できないもの(例:Oracle Database)。
アフィニティ規則は、次のように分類されます:
- VM間アフィニティルール(個々のVM向け)
- VMとホストの親和性ルール(ホストのグループとVMのグループ間の関係)
VMホストルールには、推奨ルール(VMは…すべき)と必須ルール(VMは…しなければならない)があります。必須ルールは、たとえ DRS が無効になっているため、vMotion を使用して該当する VM を手動で移行することはできません。この仕組みは、vCenter が一時的に利用できない場合や障害が発生した場合でも、ESXi ホスト上で実行されている VM に適用されるルールが破られないようにするためのものです。
には 4 つのオプションがあります。 DRS 親和性のルール:
仮想マシンはまとめて配置してください。 選択したVMは、単一のESXiホスト上で一緒に実行されている必要があります(VMの移行が必要な場合は、これらのVMをすべてまとめて移行する必要があります)。このルールは、選択したVM間のネットワークトラフィックを局所化したい場合(VMが大量のネットワークトラフィックを生成することでESXiホスト間のネットワークに過負荷がかかるのを防ぐため)に利用できます。また、複数のVMにインストールされた(相互に依存する)コンポーネントを使用する複雑なアプリケーションを実行する場合や、 vApp. これには、例えば、データベースサーバーやアプリケーションサーバーなどが含まれる。
仮想マシンを分離する。 選択したVMは、単一のESXiホスト上で実行されてはなりません。このオプションは、高可用性を確保するために使用されます。
仮想マシンからホストへ。 VMグループに追加されたVMは、指定されたESXiホストまたはホストグループ上で実行される必要があります。設定を行う必要があります DRS グループ(VM/ホストグループ)。A DRS グループには複数のVMまたはESXiホストが含まれています。
仮想マシンから仮想マシンへ。 このルールは、あるVMグループを起動した後、別の(依存する)VMグループを起動したい場合に、VM同士を関連付けるために選択できます。このオプションは、VMwareで HA そして DRS クラスタ内で一緒に構成されます。
ルールが競合する場合、古い方のルールが優先されます。
VMware 向け VM オーバーライド DRS
vSphere での VM オーバーライドの使用と同様に HA クラスタでは、VMのオーバーライドは、より詳細な設定を行うために使用されます。 DRS VMware vSphere 内で、で設定されたグローバル設定を上書きできるようにします DRS クラスタレベルで設定を行い、個々のVMに対して具体的な設定を定義します。特定のVMに対してVMのオーバーライドが適用されても、クラスタ内の他のVMには影響しません。
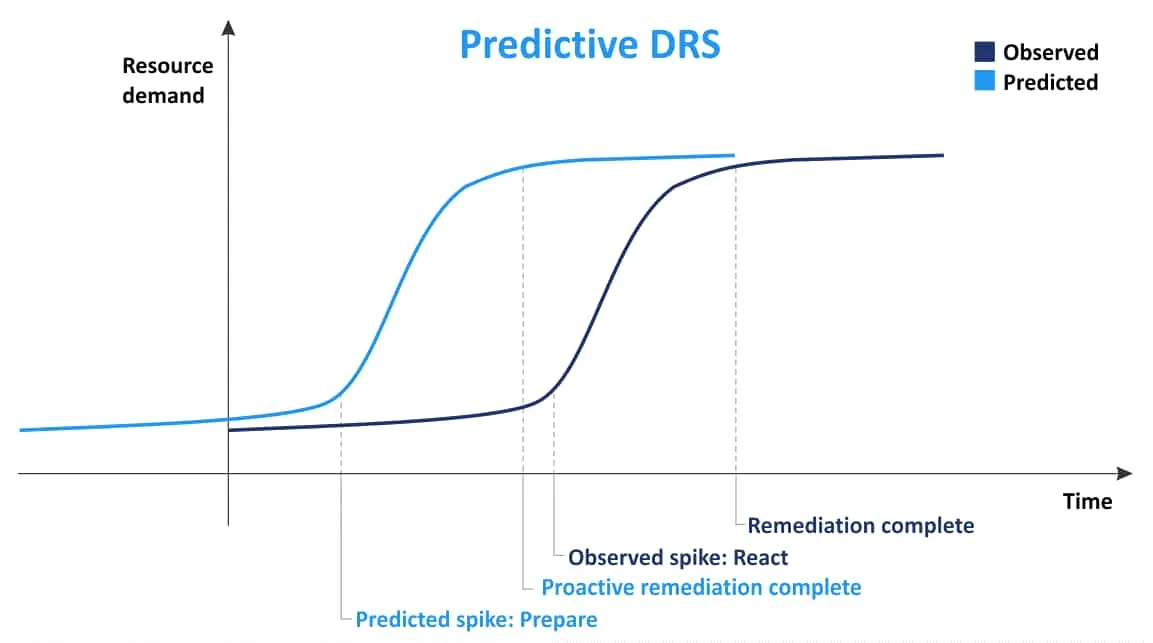
Predictive DRS
の主なコンセプトは Predictive DRS VMの配置に関する情報を収集し、その情報を基に、リソース使用率が急増する時期と場所を予測することです。この情報を活用して、 Predictive DRS ESXiサーバーが過負荷になり、VMがリソース不足に陥る前に、ホスト間でVMを移動させて負荷分散を改善することができます。この機能は、クラスター内のVMに対する需要が時間帯によって変動する場合に役立ちます。 Predictive DRS デフォルトでは無効になっています。 VMware vRealize Operations Manager Power DRSを使用するには、これが必要です。
Distributed Power Manager
Distributed Power Manager (DPM) これは、クラスタ内に十分な空きリソースがあり、ESXiホストをシャットダウン(ホストをスタンバイモードにする)し、クラスタ内の残りのESXiホスト上でVMを実行できる場合に、VMを移行するために使用される機能です(残りのホストは、必要なVMを実行するのに十分なリソースを提供できる必要があります)。
クラスタ内で仮想マシンを実行するために、より多くのリソースが必要になった場合、 DPM 停止していたサーバーを起動し、通常モードで動作させる。サポートされている電源管理プロトコルのいずれかを使用して、ネットワーク経由でホストの電源を入れる。これらのプロトコルには、インテリジェント Platform Management Interface (IPMI), Hewlett-Packard Integrated Lights-Out (iLO)、または Wake-On-LAN (WOL). それから DRS ワークロードを分散させ、クラスタの負荷を均等化するために、一部のVMをこのサーバーに移行します。デフォルトでは、 Distributed Power Management 無効になっています。 DPM 推奨事項は、自動または手動で適用できます。

Storage DRS
一方で DRS CPUおよびRAMの計算リソースに基づいてVMを移行し、 Storage DRS データストアの使用状況(たとえば、空きディスク容量など)に基づいて、仮想マシンファイルをあるデータストアから別のデータストアへ移行します。アフィニティおよびアンチアフィニティのルールを使用すると、 Storage DRS VMの仮想ディスクファイルは、すべて同じデータストアに保存する必要があります。たとえば、特定の処理を実行するVMのVMDKファイルを保存するように、アンチアフィニティルールを設定できます。 I/O 異なるデータストアでの集中的な操作。これは、VMおよび初期のVMデータストアのパフォーマンス低下を防ぐために行います(I/O (アンチアフィニティ・ルールを使用する場合、ディスク・ワークロードは複数のデータストアに分散されます)。
Storage DRS これは、仮想マシン(VM)を使用する際に便利です シンプロビジョニング オーバープロビジョニングの場合のディスク。 Storage DRS これにより、薄いディスクのサイズが肥大化し、その結果、データストアに空き領域がなくなるという事態を回避できます。空き領域が不足すると、そのデータストアに仮想ディスクを保存している仮想マシンが動作しなくなります。仮想マシンのディスクファイルは、次のコマンドを使用して、あるデータストアから別のデータストアへ移行できます。 Storage vMotion 仮想マシンが実行中の間。
CPUおよびメモリ使用量の監視
VMwareでは、Webインターフェース上でリソースの使用状況を監視する機能を提供しています。 VMware vSphere Clientクラスター内のCPU使用率は、以下の手順で監視できます。 Settings > Monitor > vSphere DRS > CPU Utilization. 個別のESXiホストのメモリとストレージ容量を監視するための他のオプションもあります。VMwareの監視は NAKIVO Backup & Replication 10.5. インフラストラクチャの監視に関する詳細は、 ブログ記事.
VMwareの使用 HA そして DRS 一緒に
VMware HA そして DRS これらは競合する技術ではありません。互いに補完し合う関係にあり、VMwareの両方を併用することができます DRS そして HA vSphereクラスタ内で、VMの再起動時に高可用性を確保し、ワークロードの負荷分散を行うために HA 他のESXiホスト上で。本番環境で稼働しているvSphereクラスタでは、自動フェイルオーバーと負荷分散のために、両方の技術を使用することを推奨します。
ESXiホストに障害が発生した場合、 VMのフェイルオーバー はによって開始される HA、そしてVMは他のホスト上で再起動されます。この状況における最優先事項は、VMを利用可能な状態にすることです。しかし、VMの移行後、一部のESXiホストに過負荷がかかり、それらのホスト上で実行されているVMに悪影響を及ぼす可能性があります。VMware DRS クラスタ内の各ホストのリソース使用状況を確認し、フェイルオーバー後のVMの最適な配置に関する推奨事項を提供します。その結果、フェイルオーバー後もVMがワークロードを適切なパフォーマンスで実行するのに十分なリソースが確保されていることを常に確認できます。VMware DRS そして HA これを有効にすると、クラスタの効率が向上します。
結論
VMwareは、最も要求の厳しいvSphereのお客様のニーズに応えるため、vSphereにおいてクラスタの強力な機能を提供しています。当社はVMwareの認定を受けています DRS そして HA また、これらのクラスタリング機能それぞれの動作原理と主要なパラメータについて説明しました。VMware DRS そして HA 互いに補完し合い、クラスタ利用の最終的な成果を向上させます。
VMwareを使用する場合でも DRS そして HA、vSphere上のVMware仮想マシンのバックアップを忘れないでください。ダウンロード NAKIVO Backup & Replication 無料版(対象:) VMwareのバックアップ お客様の環境において。



