Come convertire una macchina fisica Linux in una VM Hyper-V
<
Casi d’uso per il ripristino P2V
Il ripristino di una macchina fisica su una VM è chiamato anche ripristino P2V. Esistono due casi d’uso principali per il ripristino P2V: il ripristino P2V temporaneo e la migrazione P2V permanente.
Ripristino P2V temporaneo. Si tratta del ripristino di una macchina fisica su una VM dal backup fino a quando la macchina fisica danneggiata non viene riparata, riconfigurata o sostituita. Questo approccio comporta tempi di inattività minimi. Se un server fisico o una stazione di lavoro si disconnettono, è possibile ripristinare quella macchina su una VM da backup. Fino a quando la macchina fisica non viene riparata o sostituita, la VM ripristinata funziona al posto del server fisico o della stazione di lavoro danneggiati. In caso di ripristino P2V di una stazione di lavoro, un utente può connettersi a una VM ripristinata in remoto da qualsiasi computer disponibile. Quando la macchina fisica danneggiata viene riparata, tutti i dati necessari devono essere trasferiti alla macchina riparata. Successivamente, è possibile eliminare la VM temporanea, che era in funzione durante la riparazione della macchina fisica, e trasferire tutto il carico di lavoro alla macchina fisica riparata.
È necessario eseguire regolarmente il backup delle macchine fisiche. In questo modo, anche se il computer si guasta inaspettatamente, è possibile essere certi che i dati siano al sicuro e possano essere utilizzati per il ripristino. L’illustrazione seguente mostra i vantaggi del ripristino P2V temporaneo che contribuisce a ridurre i tempi di inattività.
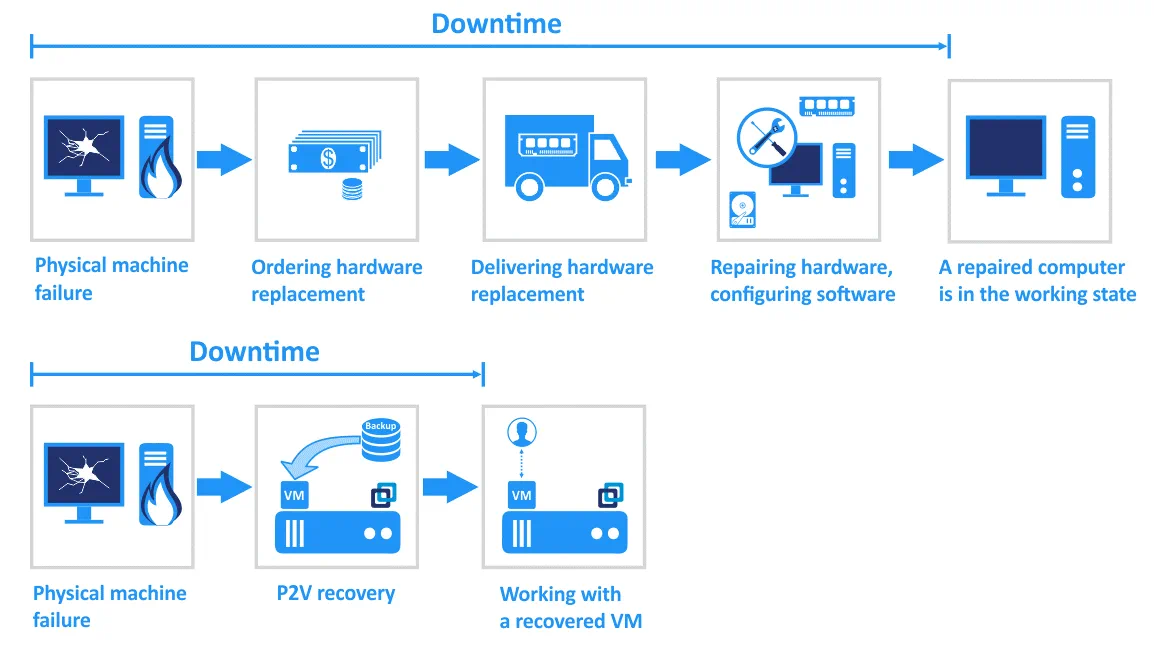
Migrazione P2V permanente. Questa opzione viene spesso utilizzata quando si modifica l’infrastruttura IT e si convertono macchine fisiche in VM per un utilizzo permanente. Ad esempio, se si acquista un nuovo server per eseguire un hypervisor, è possibile scegliere di convertire un server Linux fisico in una VM VMware (VM) o convertire un server Windows fisico in una VM Hyper-V (a seconda dell’ambiente virtuale). NAKIVO Backup & Replication & >Come funziona il backup del server Linux
Questo post del blog descrive il processo di ripristino P2V delle macchine Linux. Tuttavia, non sarà possibile ripristinare i dati senza prima eseguire il backup. Diamo un’occhiata a come funziona Linux Server Backup in NAKIVO Backup & Replication.
Quando un server Linux fisico viene aggiunto all’inventario in NAKIVO Backup & Replication, un agente di macchina fisica che comunica con NAKIVO Backup & Replication Director e Transporter viene distribuito sulla macchina Linux. Il file di installazione inst.sh viene caricato sulla macchina Linux di destinazione tramite SSH. Avanti, il certificato (certificate.pem) e il token bhsvc.id (ID + chiave pre-condivisa) vengono caricati per garantire una comunicazione sicura tra l’agente e il Director, dopodiché l’agente viene installato in modo silenzioso. L’agente viene eseguito come servizio dopo l’installazione e si avvia automaticamente (se non si tratta di una implementazione dell’agente una tantum). L’agente per macchine fisiche non può essere installato su macchine che dispongono già di Transporter. Le macchine fisiche Linux saranno visibili nell’inventario di NAKIVO Backup & Replication dopo la corretta installazione dell’agente. È possibile creare ed eseguire processi di backup per macchine fisiche dopo averle aggiunte all’inventario, in modo simile a come si eseguono i processi per le macchine virtuali VMware e Hyper-V.
Funzionalità dell’agente per macchine fisiche:
- Supporta snapshot LVM (gestione dei volumi logici).
- Funziona in modalità sicura utilizzando un certificato e una chiave pre-condivisa.
- Se si aggiorna NAKIVO Backup & Replication & , gli agenti di macchina fisica associati verranno aggiornati automaticamente.
- È supportato il ripristino dei file all’origine.
- È supportato il backup incrementale con metodo proprietario di tracciamento delle modifiche.
Requisiti
Il server Linux fisico di cui si desidera eseguire il backup deve soddisfare i seguenti requisiti.
Requisiti hardware:
CPU a 32 bit o 64 bit (architettura x86 / x86-64)
Minimo 1 GB di RAM
La dimensione massima del disco supportata è 64 TB
Tabella delle partizioni MBR o GPT
Requisiti di storage:
Tipi di disco e file system supportati su un server Linux fisico di origine: Ext2, Ext3, Ext4, XFS, ReiserFS, NTFS, FAT32, Linux SWAP
Tipi LVM supportati: Lineare, RAID 0, RAID 1
Distribuzioni Linux ufficialmente supportate:
Ubuntu 16 – Ubuntu 18 LTS, 64 bit
SLES (SUSE Linux Enterprise Server) v12.0-12.4, 64 bit
CentOS v6.6-7.6, 64 bit
Red Hat Enterprise Linux v6.3-7.5, 64 bit
Requisiti di rete:
Il server SSH deve essere in esecuzione sul server Linux (il pacchetto openssh-server deve essere installato).
Le seguenti porte TCP devono essere aperte sul server Linux fisico di destinazione:
- TCP 22 deve essere aperto per stabilire connessioni SSH (accessi sicuri e trasferimento di file tramite SCP e SFTP).
- TCP 9446 è utilizzato da NAKIVO Backup & Replication per comunicare con la macchina.
Per l’implementazione dell’agente sono necessari i privilegi di root. È possibile abilitare l’accesso dell’utente root tramite SSH sul computer Linux, ma non è l’opzione migliore in termini di sicurezza. Se l’utente non è root, assicurarsi che possa connettersi a un computer Linux fisico tramite SSH ed eseguire il comando sudo per ottenere i privilegi di root. L’autenticazione tramite password deve essere abilitata sul server SSH.
L’algoritmo per il ripristino P2V per server Linux
Ecco la sequenza di azioni per il ripristino P2V per server Linux:
- Eseguire il backup del server Linux fisico nel repository di backup
- Esportare i dati dal backup al disco virtuale nel formato appropriato (VMDK, VHD o VHDX)
- Copiare i file del disco virtuale nell’archivio dati accessibile da un hypervisor
- Creare una nuova VM e impostarla per utilizzare il disco esportato
- Avviare una VM su una macchina fisica che esegue un hypervisor
Flusso di lavoro di ripristino P2V
Esaminiamo l’intero processo di ripristino P2V di un server Linux fisico su una VM VMware utilizzando un esempio. Il server Linux di origine esegue Ubuntu 18.04 LTS, mentre l’host ESXi di destinazione esegue ESXi 6.5 ed è gestito da vCenter Server (versione 6.5). L’account utilizzato sul server Linux è user1 con sudo abilitato. In questo caso non vengono utilizzati convertitori P2V aggiuntivi. Il server fisico Linux viene convertito in una VM dal backup utilizzando NAKIVO Backup & Replication.
Aggiunta di una macchina fisica Linux all’inventario
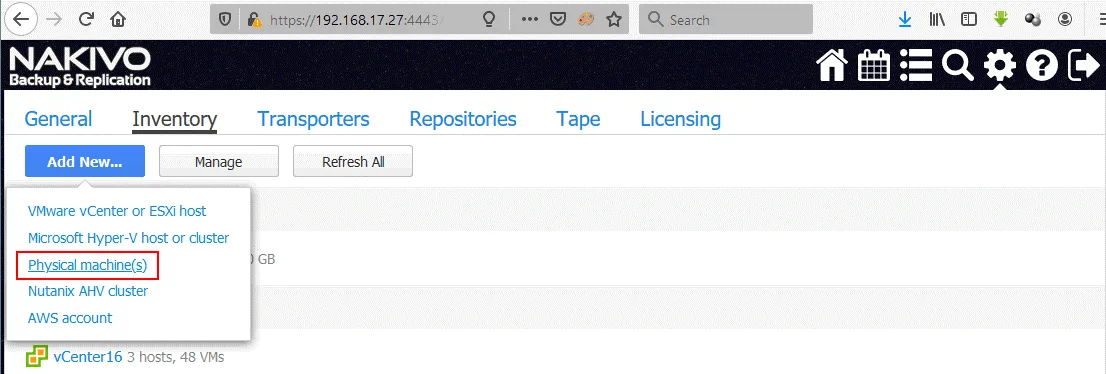
- Per prima cosa è necessario aggiungere il server Linux fisico all’inventario in NAKIVO Backup & Replication. Accedere a NAKIVO Backup & Replication, andare su Configurazione > Inventario. Fare clic su Aggiungi nuovo e selezionare Macchine fisiche.
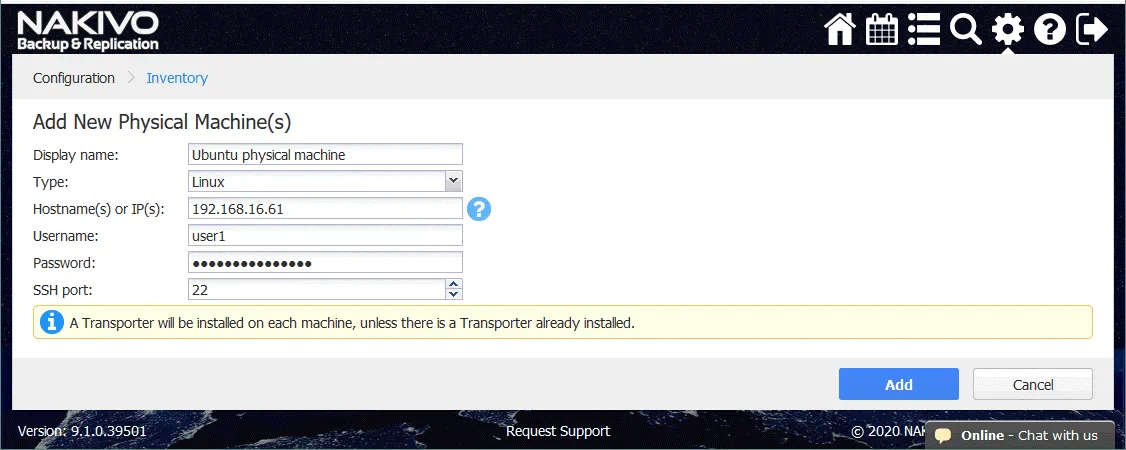
- Nella pagina Aggiungi nuove macchine fisiche, impostare i parametri obbligatori.
Nome di visualizzazione: Macchina fisica Ubuntu
Tipo: Linux
Nome host o IP: 192.168.16.61
Nome utente: user1
Password: ********
Porta SSH: 22
PL’agente di macchina fisica verrà installato sulla tua macchina Linux fisica. - Clicca su Aggiungi.
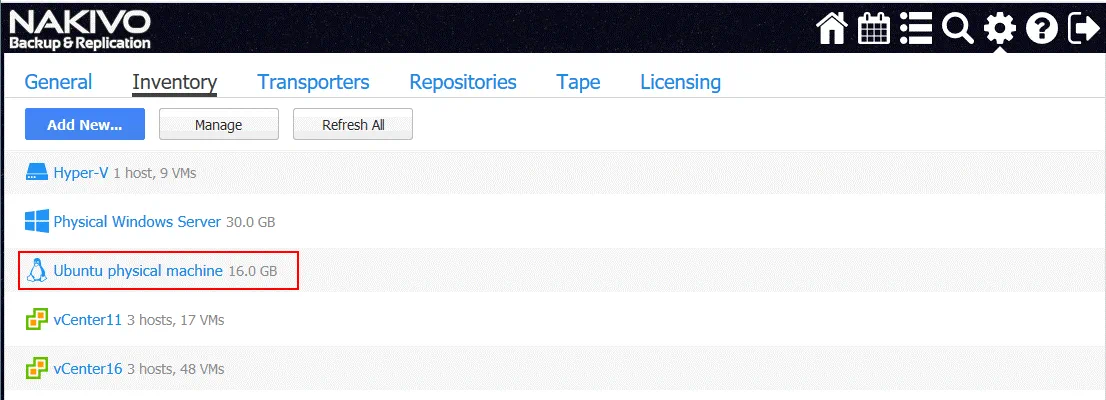
- Ora puoi vedere il tuo server Linux fisico nell’inventario.
Creazione di un backup di un server Linux fisico
Creare un nuovo Lavoro di backup della macchina fisica in NAKIVO Backup & Replication. Nella pagina iniziale, fare clic su Creare > Lavoro di backup della macchina fisica.
Si apre la procedura guidata Nuovo lavoro di backup per la macchina fisica.
1. Macchine. Selezionare la macchina desiderata dall’elenco delle macchine fisiche disponibili. Le macchine Linux e Windows sono ordinate in categorie separate. In questo esempio è stata selezionata la macchina fisica Ubuntu . Premere Avanti per continuare con ogni passaggio della procedura guidata.
2. Destinazione. Seleziona un repository di backup. In questo esempio, il repository di backup CIFS viene utilizzato per archiviare un backup di macchine fisiche di Linux. È possibile espandere le opzioni facendo clic sul nome del server Linux (macchina fisica Ubuntu in questo caso) e selezionando i dischi e le partizioni personalizzati di cui eseguire il backup.
3. Pianificazione. Questo è il passaggio standard per i lavori di backup in NAKIVO Backup & Replica. Selezionare le opzioni di pianificazione obbligatorie.
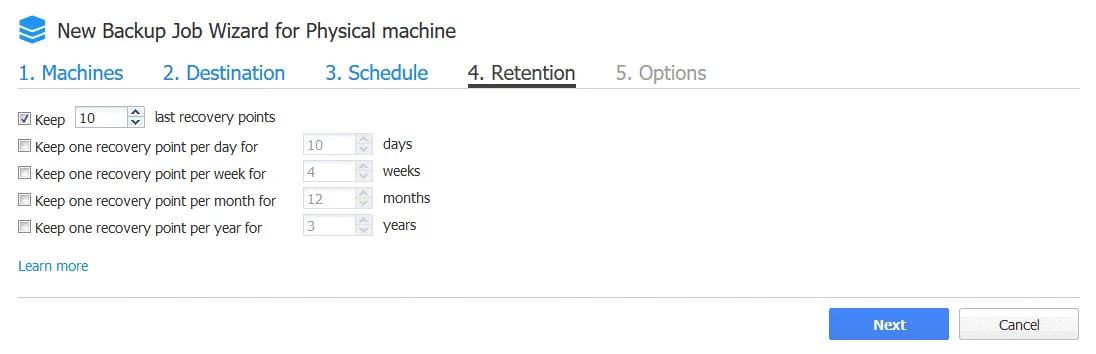
4. Ritenzione.
Impostare le impostazioni di conservazione necessarie.
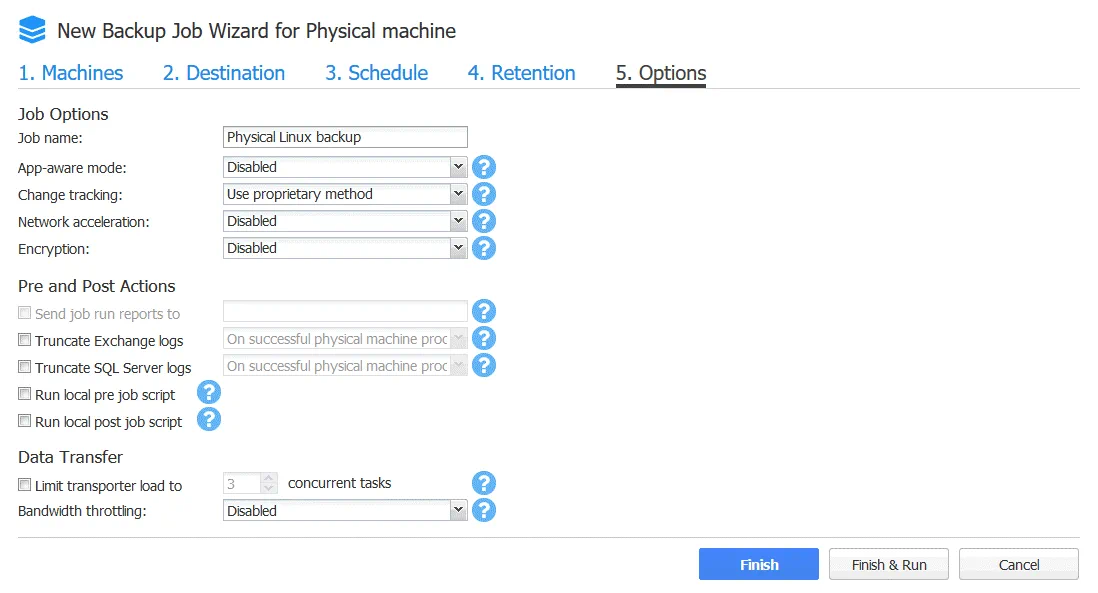
5. Opzioni. Qui è possibile impostare il nome del lavoro, abilitare o disabilitare la modalità coerente con le applicazioni, selezionare il metodo di tracciamento delle modifiche e impostare l’accelerazione di rete e la crittografia. Tenere presente che è possibile utilizzare solo il metodo proprietario NAKIVO per il tracciamento delle modifiche, a differenza dei lavori per le macchine virtuali VMware e Hyper-V. Questo perché si sta eseguendo il backup di una macchina fisica e non di una VM su un livello host.
Dopo aver configurato tutte le opzioni del lavoro, premere Fine per completare la creazione del lavoro, oppure premere Finish & Run per salvare le impostazioni del lavoro ed eseguirlo.
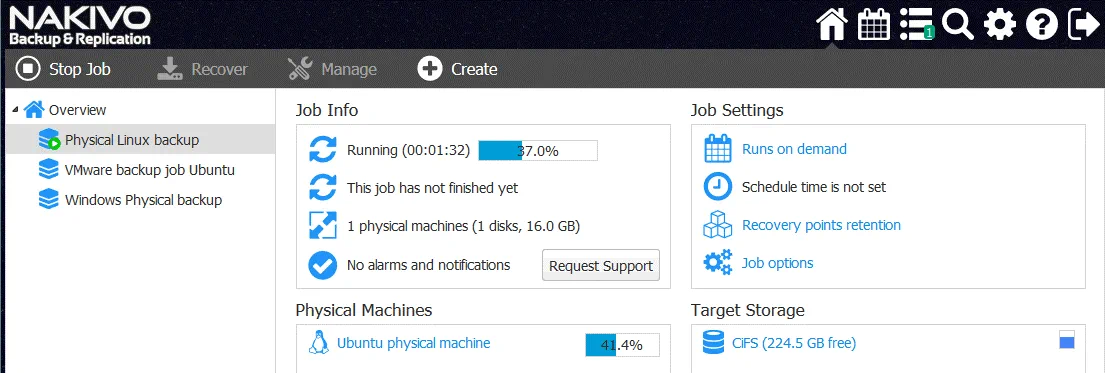
Attendere fino al completamento del backup del server Linux fisico. L’avanzamento del backup viene visualizzato nell’interfaccia web di NAKIVO Backup & Replication & Replication.
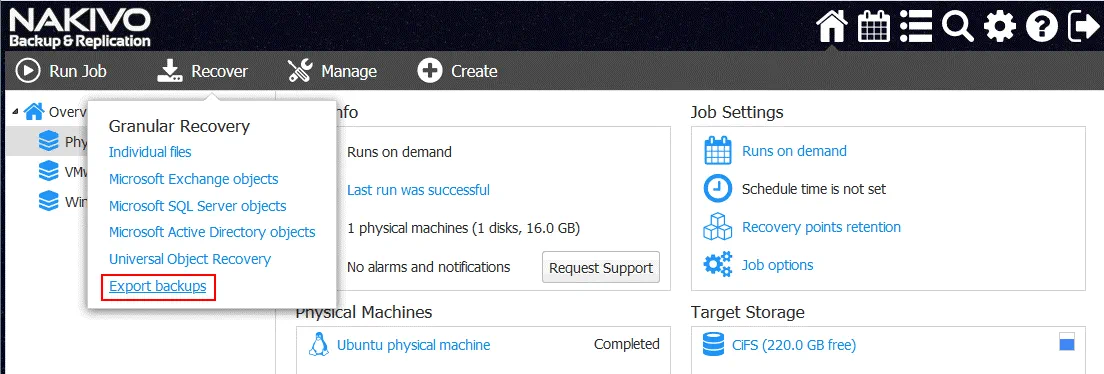
Esportazione del backup
Una volta eseguito il backup del server Linux fisico, è possibile eseguire il ripristino della macchina e la conversione in VM Hyper-V o VMware con NAKIVO Backup & Replica di VM Hyper-V o VMware utilizzando l’esportazione del backup.
Nella pagina iniziale, fare clic su Ripristina > Esporta backup per esportare i dati da backup al disco virtuale nel formato appropriato.
Si apre la procedura guidata di esportazione del backup.
1. Backup. Selezionare il backup del server Linux fisico e il punto di ripristino necessario. Per impostazione predefinita, viene selezionato il punto di ripristino più recente. Fare clic su Avanti per ogni passaggio per continuare.
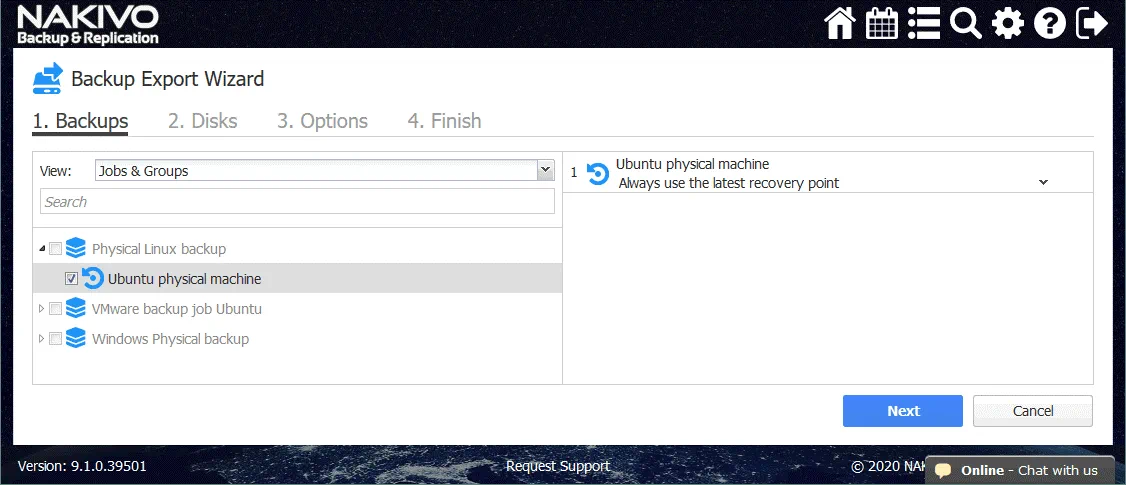
2. Dischi. Seleziona i dischi richiesti da un backup. Per impostazione predefinita, sono selezionati tutti i dischi esistenti.
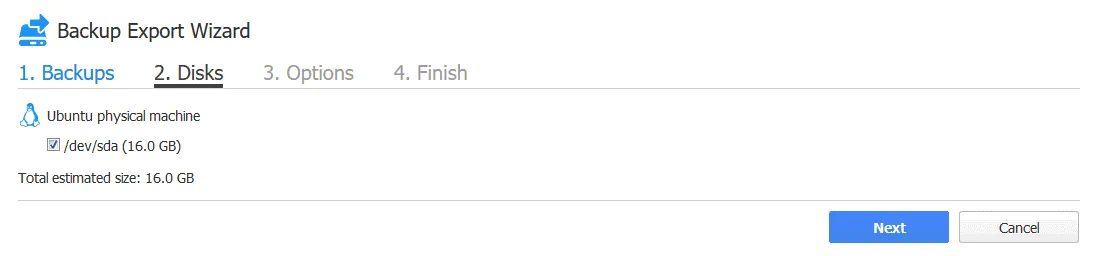
3. Opzioni. Selezionare le opzioni di esportazione del backup.
Formato di esportazione: VMDK
Ubicazione di esportazione: Condivisione CIFS
Percorso della condivisione: FILESERVERShare07
Nome utente: backupuser
Password: ********
Fare clic su Esegui test della connessione per verificare di aver inserito le credenziali corrette con autorizzazioni di lettura/scrittura sufficienti.
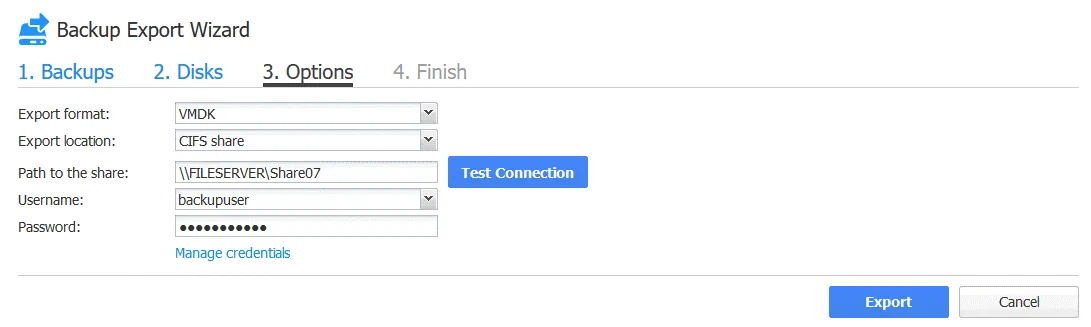
Una volta verificata la connessione, fare clic sul pulsante Export per avviare il processo di esportazione del backup.
4. Termina. Quando l’esportazione del backup ha inizio, è possibile passare alla scheda Attività e monitorare lo stato di avanzamento del processo di esportazione del backup in esecuzione.
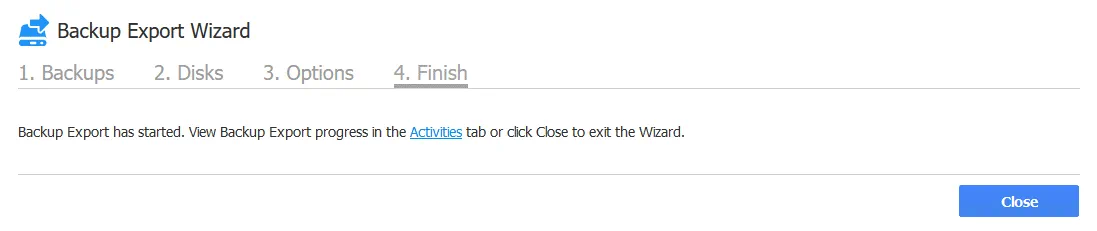
Attendere il completamento del lavoro di esportazione del backup.
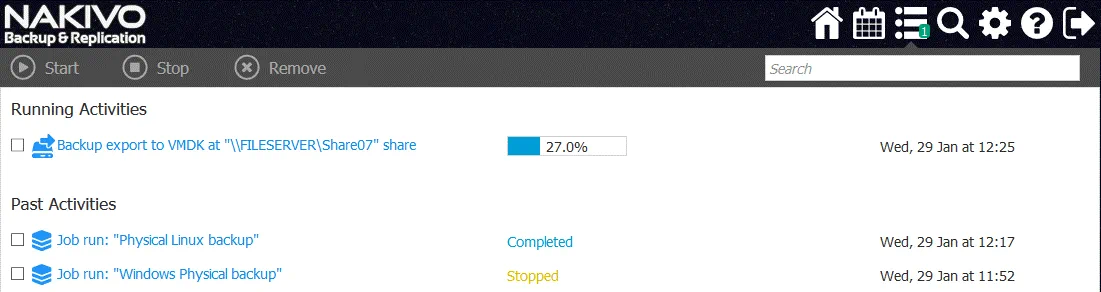
Copia dei dischi esportati nell’archivio dati ESXi
Al termine del lavoro di backup, è possibile visualizzare i file del disco virtuale nella posizione definita. Nel nostro caso, si tratta di una cartella condivisa in cui sono memorizzati due file del disco virtuale in formato VMware ESXi:
Ubuntu-physical-machine_Disk1_Wed–29-Jan-2020-at-10-17-30-(UTC-+00-00).vmdk
Ubuntu-physical-machine_Disk1_Wed–29-Jan-2020-at-10-17-30-(UTC-+00-00)-flat.vmdk
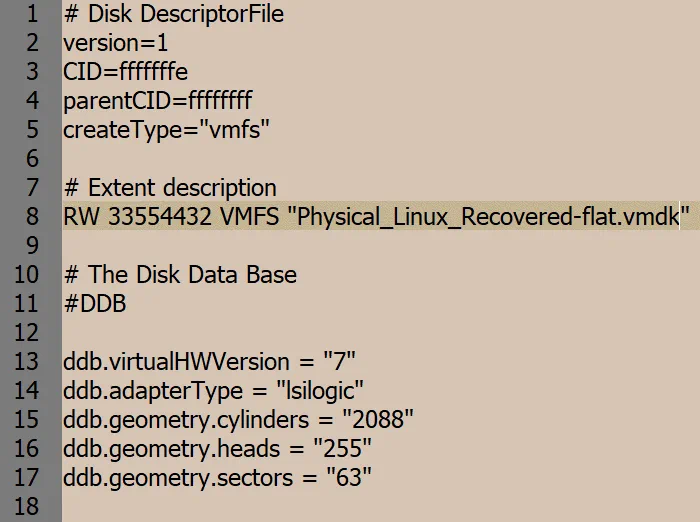
Il formato ESXi di un disco virtuale richiede due file: un file descrittore del disco (.vmdk) e un file che contiene i dati grezzi (-flat.vmdk). I nomi dei file esportati contengono il nome della macchina fisica definita in Inventario, il numero del disco, il giorno della settimana, la data, l’ora e il fuso orario.

Per comodità, rinominiamo i file del disco virtuale con nomi più brevi prima di caricarli in un archivio dati collegato a un host ESXi.
Physical_Linux_Recovered.vmdk
Physical_Linux_Recovered-flat.vmdk

Copiare i file del disco virtuale nell’archivio dati. In questo esempio, VMware vSphere Client viene utilizzato per connettersi a vCenter e configurare l’host ESXi gestito da vCenter.
In VMware vSphere Client, andare su Archivi dati e selezionare l’archivio dati connesso all’host ESXi che si desidera utilizzare per eseguire il server Linux ripristinato. In questo esempio, il nome dell’archivio dati selezionato è SSD2. Avanti, aprire la scheda File e fare clic su Nuova cartella per creare una nuova directory nell’archivio dati selezionato.
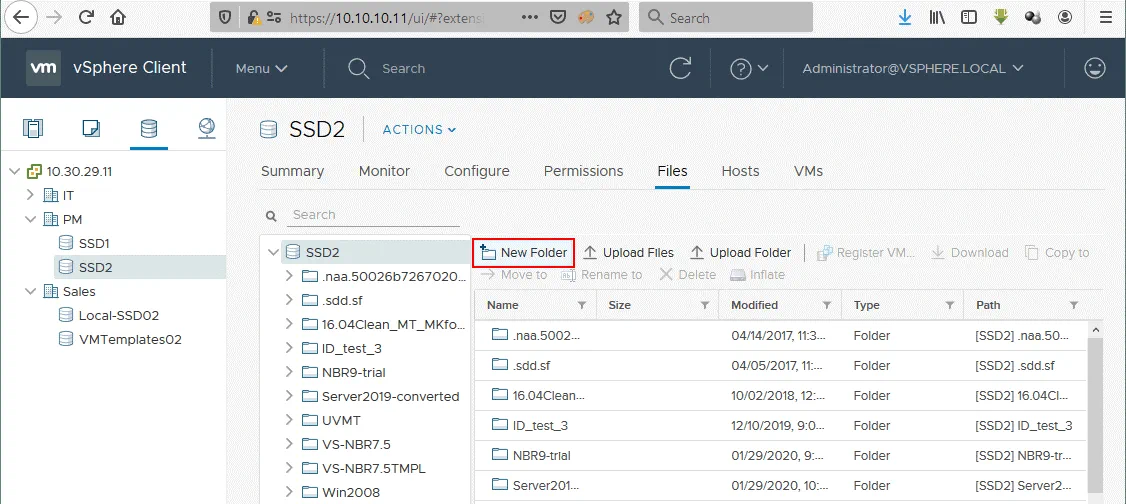
Definire il nome della nuova directory, ad esempio Physical_Linux_recovered.
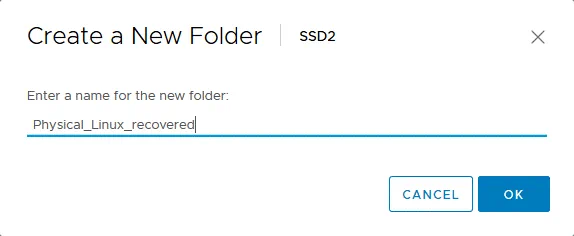
La directory Physical_Linux_Recovered viene creata nella directory SSD2 archivio dati.
Aprire la directory creata, fare clic su Carica file, e selezionare i due file esportati e rinominati (.vmdk e -flat.vmdk) da caricare.
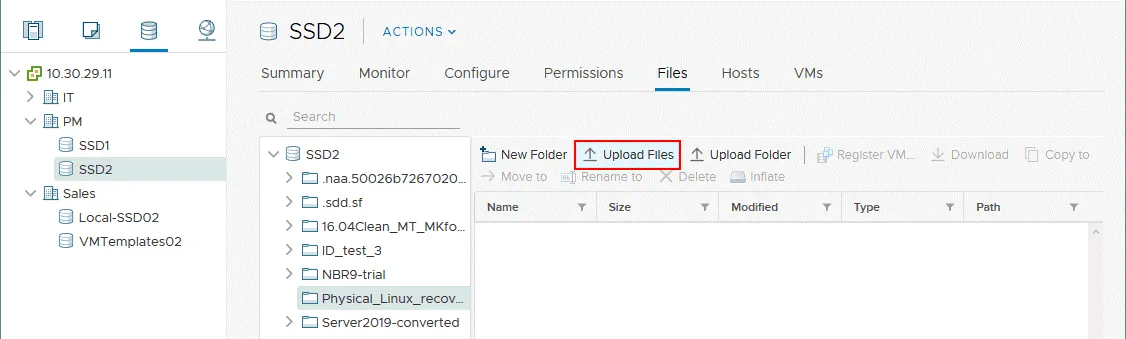
Una volta caricati i due file (.vmdk e -flat.vmdk), sarà visibile solo un file del disco virtuale anche se l’archivio dati contiene due file caricati. È possibile verificare la presenza di due file collegandosi all’host ESXi tramite SSH e controllando il contenuto della directory in cui sono stati caricati questi file.
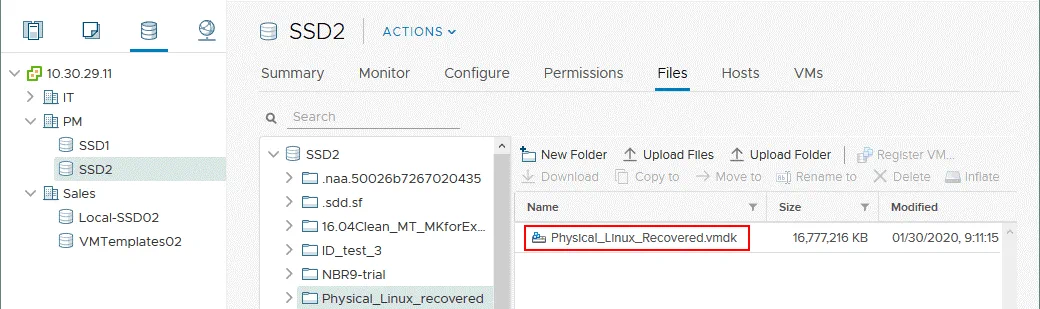
Nella console sono visibili due file del disco virtuale.

Creazione di una nuova VM di destinazione su ESXi
Ora è necessario creare una nuova VM e impostarla in modo che utilizzi il disco virtuale esportato. In VMware vSphere Client, andare su Host e cluster e selezionare l’host VMware ESXi su cui è stato caricato l’archivio dati contenente i file del disco virtuale esportato. Fare clic con il pulsante destro del mouse sull’host VMware ESXi e, nel menu contestuale, selezionare New VM per creare una nuova VM.
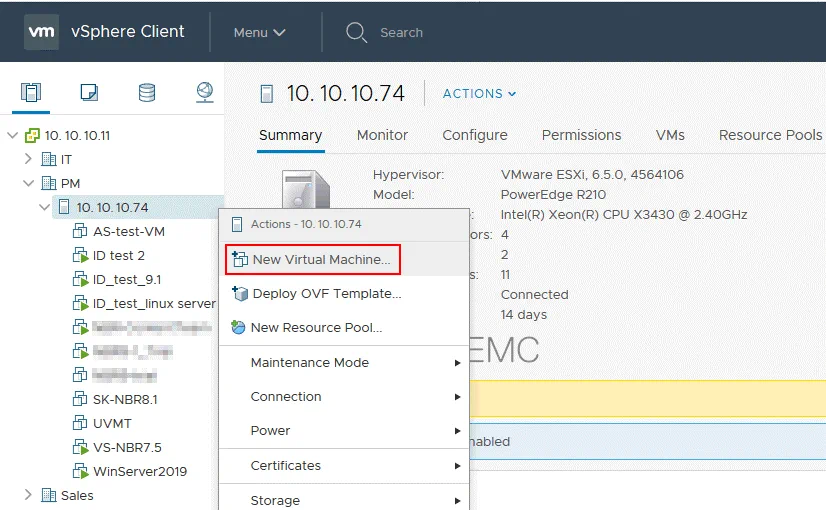
Si apre la procedura guidata New VM.
1. Selezionare un tipo di creazione. Selezionare Creare una nuova VM. Fare clic su Avanti per ogni fase della procedura guidata per continuare.
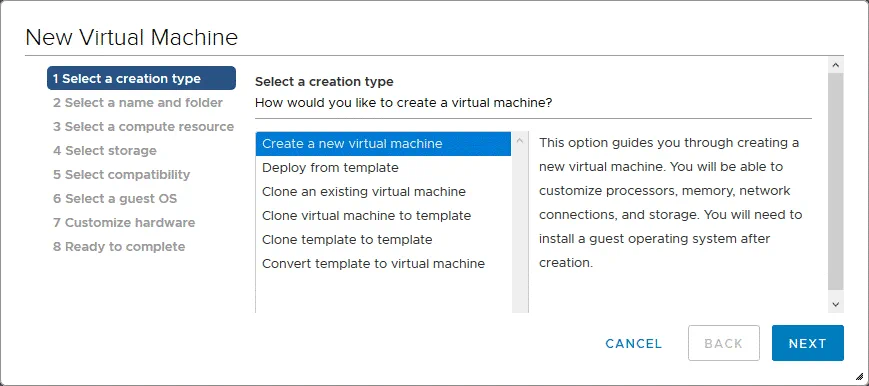
2. Selezionare un nome e una cartella. È necessario specificare un nome univoco per la VM e selezionare una posizione di destinazione. In questo esempio, il nome della nuova VM è Physical_Liniux_Recovered, mentre il nome del datacenter di destinazione gestito da vCenter è PM.
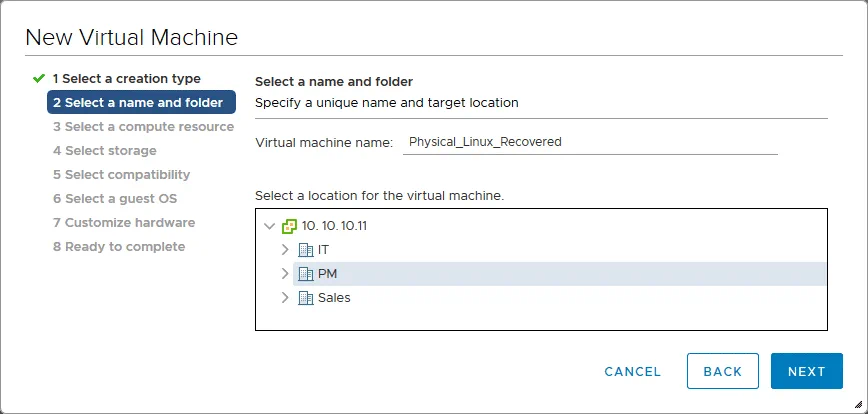
3. Selezionare una risorsa di calcolo. Durante questo passaggio, è necessario selezionare un host ESXi a cui è collegato l’archivio dati che contiene i file del disco virtuale caricati. La risorsa di calcolo di questo host ESXi verrà utilizzata per eseguire la VM. In questo esempio, viene creata una VM sull’host ESXi con l’indirizzo IP 10.10.10.74.
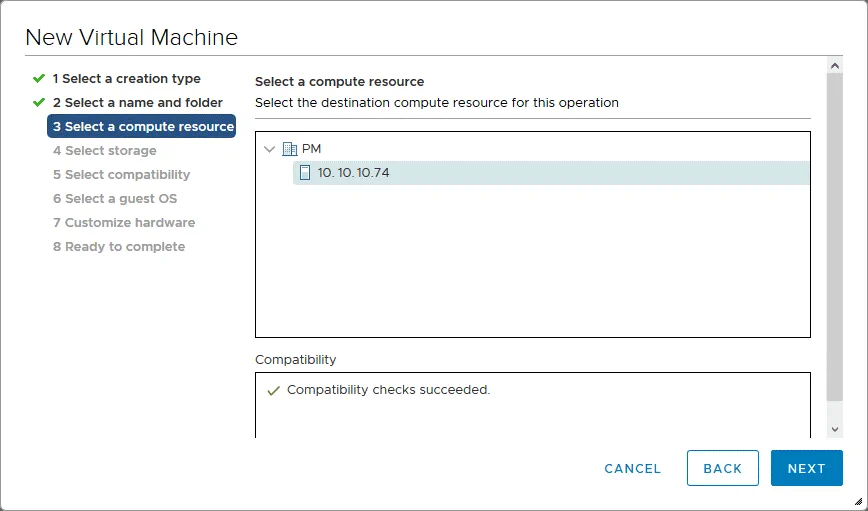
4. Selezionare lo storage. Selezionare l’archivio dati in cui sono stati collocati i file del disco virtuale esportati per ripristinare un server Linux fisico su una VM VMware. In questo esempio, tali file sono archiviati nel SSD2 archivio dati e tale archivio dati è selezionato.
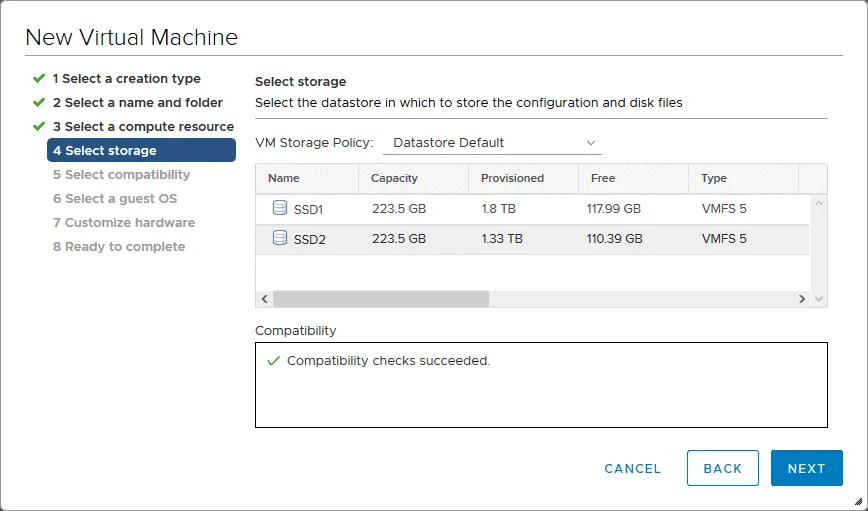
5. Selezionare la compatibilità. Selezionare la compatibilità hardware della VM (versione hardware VM). Se si prevede di migrare la VM su altri host ESXi di versioni precedenti, selezionare la versione ESXi più bassa in questo passaggio. ESXi 6.5 e versioni successive è selezionato nel nostro caso.
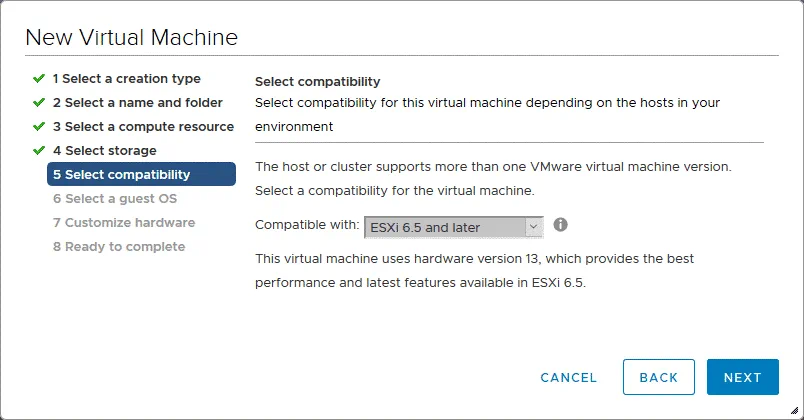
6. Selezionare un sistema operativo guest. Selezionare una famiglia e una versione del sistema operativo (OS) guest. Poiché è disponibile un disco virtuale con una macchina Linux (Ubuntu 18 x64) installata, dobbiamo selezionare Linux e Ubuntu Linux (64 bit).
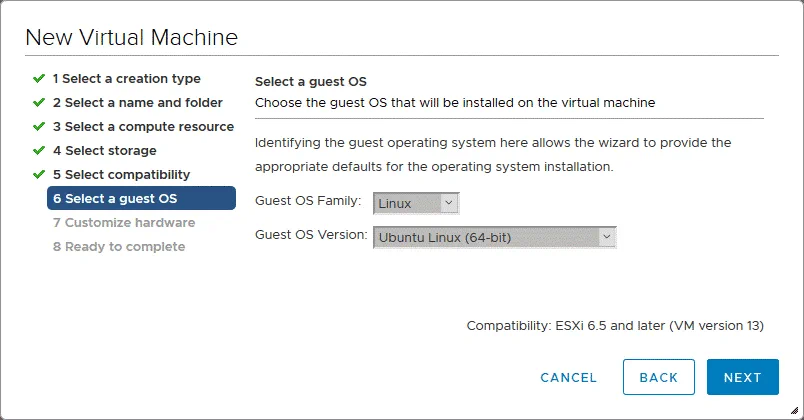
7. Personalizza l’hardware. Questo è il passaggio più interessante della procedura guidata Nuova VM necessaria per importare un disco virtuale esportato dal server Linux fisico di cui è stato eseguito il backup. Per impostazione predefinita, la procedura guidata suggerisce di creare un nuovo disco virtuale vuoto. Selezionare questo disco virtuale e fare clic sull’icona x (contrassegnata nella schermata sottostante).
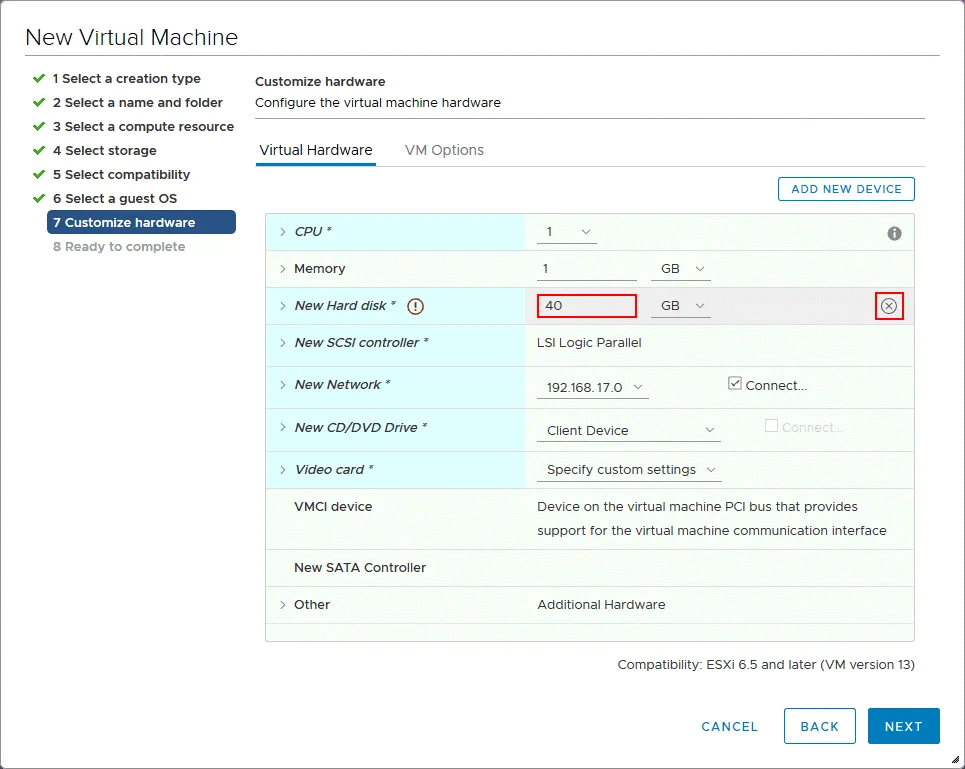
Avanti, fare clic sul pulsante Aggiungi nuovo dispositivo e selezionare Disco rigido esistente.
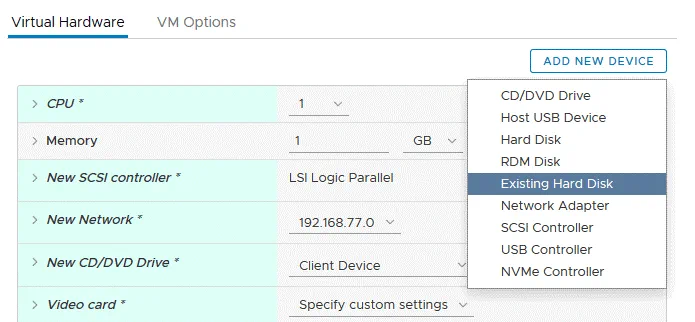
In Seleziona file finestra pop-up, seleziona la directory in cui hai caricato i file del disco virtuale esportati e seleziona il file del disco virtuale. Nel nostro caso, un file di dati del disco virtuale (-flat.vmdk) e un file descrittore del disco virtuale (.vmdk) sono memorizzati nel SSD2 archivio dati nella Physical_Linux_recovered Come indicato sopra, due file del disco virtuale vengono caricati nell’archivio dati, ma solo uno viene visualizzato in VMware vSphere Client. Premere OK per applicare la selezione dei file.
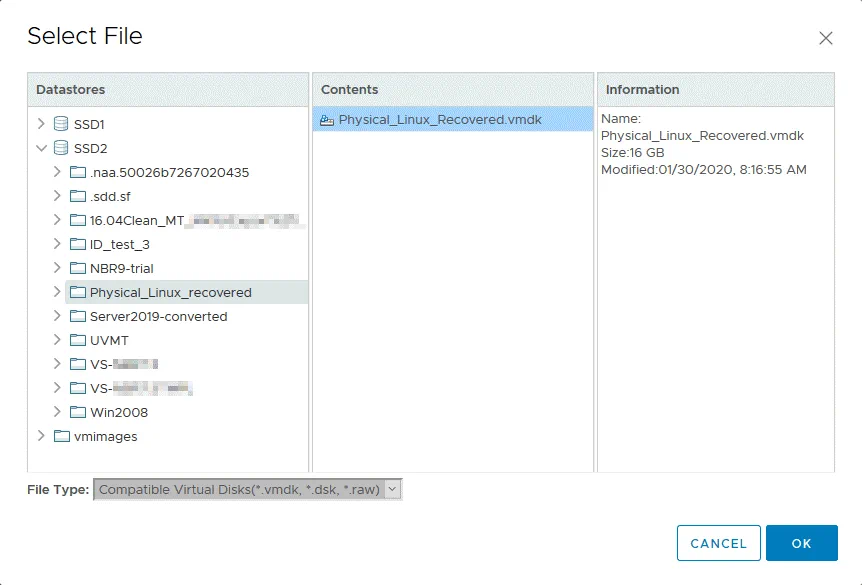
Ora puoi vedere che il disco virtuale esportato è stato aggiunto al nuovo hardware virtuale della VM.
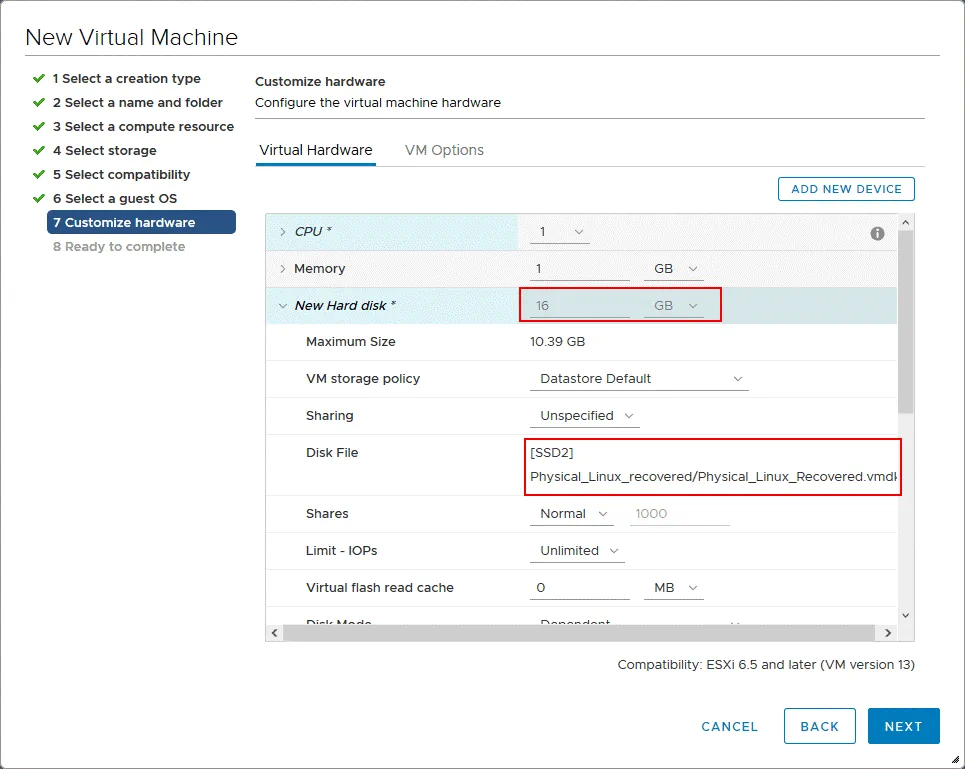
8. Pronto per il completamento. Controlla il riepilogo della nuova configurazione della VM e premi Termina per completare la creazione della nuova VM.
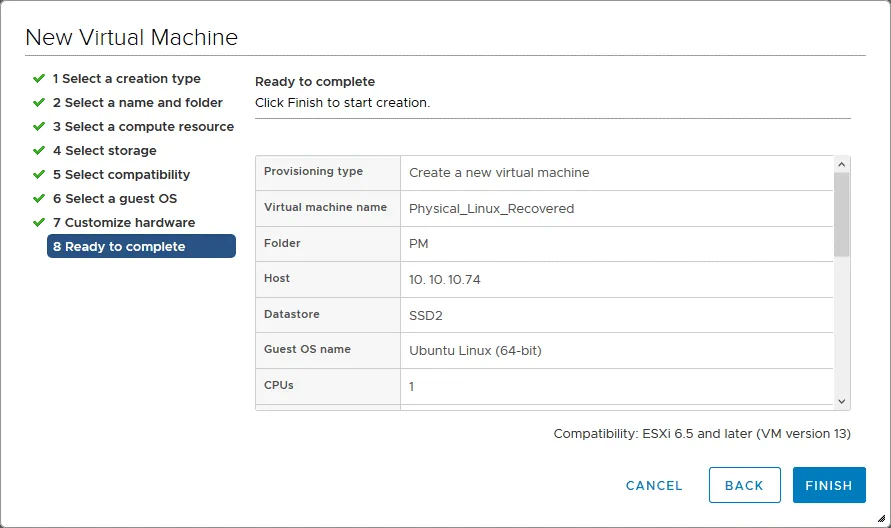
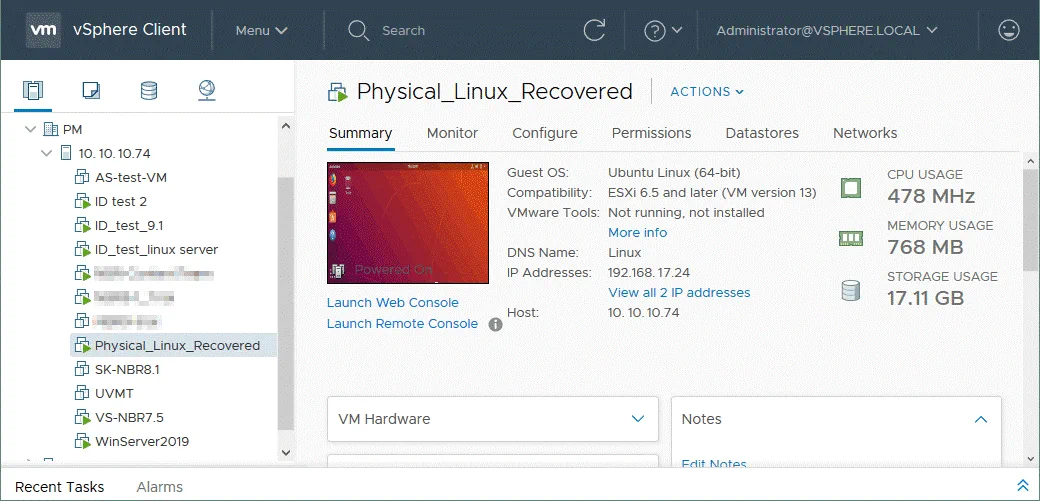
Vai a Host e cluster, seleziona la VM appena creata sull’host ESXi appropriato (Physical_Linux_Recovered su 10.10.10.74), quindi fare clic su Azioni > Alimentazione > Accendi per avviare la VM.
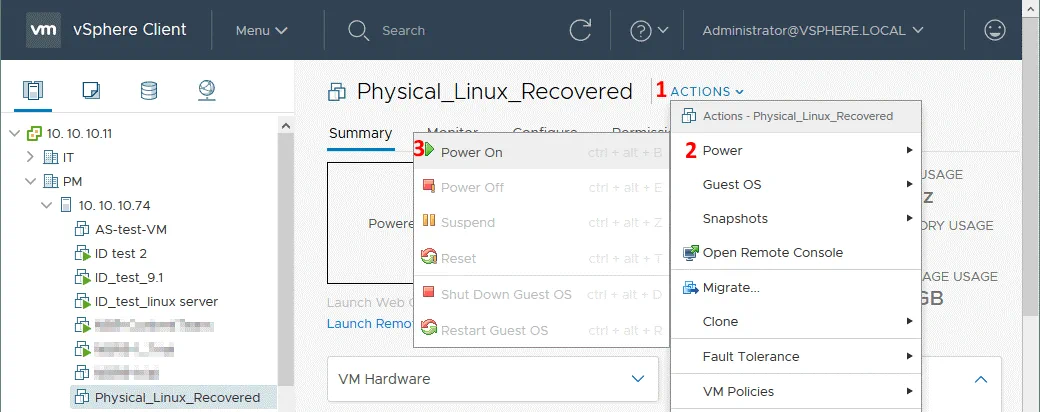
Dopo l’avvio della VM, non dimenticare di installare VMware Tools. Ora un server Linux fisico è stato ripristinato su una VM VMware dal backup utilizzando NAKIVO Backup & Replication & . Nello screenshot qui sotto, è possibile vedere che la conversione P2V di Linux (ripristino P2V) è stata completata con successo.
Conclusione
Il ripristino di macchine fisiche su macchine virtuali può essere utile in alcuni casi e può aiutarti a ridurre i tempi di inattività. NAKIVO Backup & Replication è una soluzione universale per la protezione dei dati che offre un supporto migliorato per le macchine fisiche, consentendoti di eseguire il backup e il ripristino di server fisici Linux e Windows, nonché di workstation Windows. NAKIVO Backup & Replication con Physical Machine Backup e Backup Export le funzioni possono essere utilizzate come convertitore P2V senza la necessità di scaricare alcun altro convertitore P2V.
Pertanto, è possibile convertire una macchina fisica in una VM con NAKIVO Backup & Replication dopo aver eseguito un backup. È sufficiente importare un disco virtuale in una nuova VM dopo la conversione. Questo post del blog ha utilizzato un esempio per illustrare la conversione di un server Linux fisico in una VM VMware ESXi, dimostrando che si tratta di un processo semplice.


