Alta disponibilità, tolleranza ai guasti e Ripristino di emergenza: una panoramica
<>Quando si tratta di mantenere l’infrastruttura IT di un’organizzazione attiva e funzionante 24 ore su 24, 7 giorni su 7, sembra esserci ancora una certa confusione tra i tre termini fondamentali utilizzati: alta disponibilità (HA), tolleranza ai guasti (FT) e ripristino di emergenza (DR). I tre termini riguardano il mantenimento della continuità operativa e l’accesso ai sistemi IT. Tuttavia, ogni termine ha una sua definizione specifica, metodologie e casi d’uso.
In questo post del blog definiremo cosa sono in pratica l’alta disponibilità, la tolleranza ai guasti e il ripristino di emergenza ed esploreremo come i termini si sovrappongono e perché è importante implementarli.

Che cos’è l’alta disponibilità?
L’alta disponibilità è la capacità di un sistema di funzionare (uptime) e di essere accessibile agli utenti per un determinato periodo di tempo senza subire interruzioni. Il tempo di attività è il tempo durante il quale un server è operativo senza riavvii imprevisti o spegnimenti.
L’alta disponibilità (HA) è calcolata come la percentuale di tempo in cui un sistema è operativo durante periodi di tempo prestabiliti, senza contare la manutenzione programmata e gli arresti. Non ci si aspetta che l’HA garantisca un tempo di attività del 100%, che è difficile e poco pratico da raggiungere. Un tempo di inattività fino a 5 minuti e 26 secondi all’anno è considerato accettabile, il che si traduce in un tempo di attività operativo del 99,999%. Tuttavia, anche questo valore potrebbe non essere un obiettivo ragionevole per molte organizzazioni. A seconda dell’organizzazione, del settore e delle risorse, il valore HA obbligatorio può essere inferiore.
Come funziona l’alta disponibilità?
L’obiettivo di alta disponibilità per un’organizzazione viene raggiunto attraverso l’eliminazione di un singolo punto di errore in un sistema utilizzando componenti di ridondanza e failover. Ciò significa garantire che il guasto di un singolo componente non comporti l’indisponibilità dell’intero sistema.
Nella virtualizzazione, l’alta disponibilità può essere progettata con l’aiuto di tecnologie di clustering. Ad esempio, quando uno degli host o delle VM all’interno di un cluster si guasta, un’altra VM subentra (failover) e mantiene le prestazioni adeguate del sistema.
Sebbene la presenza di componenti di ridondanza sia la condizione fondamentale per garantire l’alta disponibilità, questi componenti da soli non sono sufficienti affinché il sistema possa essere considerato altamente disponibile. Un sistema altamente disponibile è un sistema che include sia componenti ridondanti che meccanismi per il rilevamento dei guasti e il reindirizzamento automatico del carico di lavoro. Questi possono essere bilanciatori di carico o hypervisor. DRS in VMware vSphere è un esempio di bilanciatore di carico.
Quando è importante l’alta disponibilità?
Un’architettura ad alta disponibilità è necessaria per qualsiasi carico di lavoro critico che non può permettersi tempi di inattività. Se il guasto di un sistema o di un’applicazione mette a rischio la sopravvivenza dell’azienda, l’HA può essere utilizzato per ridurre al minimo i tempi di inattività. Secondo Statista, nel 2020 il costo di un’ora di inattività era compreso tra 300.000 e 400.000 dollari per il 25% delle aziende. Ciò significa che anche un valore di disponibilità molto elevato, pari al 99,999% (5 minuti e 26 secondi di downtime all’anno), può costare ad alcune aziende circa 35.000 dollari.
Oltre a significative perdite finanziarie, il downtime può avere altre gravi implicazioni, come la perdita di produttività, l’incapacità di fornire servizi in modo tempestivo, il danneggiamento della reputazione aziendale e così via. I sistemi ad alta disponibilità aiutano a evitare tali scenari gestendo i guasti in modo automatico e tempestivo.
Che cos’è la tolleranza ai guasti?
La tolleranza ai guasti è la capacità di un sistema di continuare a funzionare correttamente senza tempi di inattività in caso di guasto di uno o più dei suoi componenti. Un sistema tollerante ai guasti include due componenti strettamente accoppiati che si rispecchiano a vicenda per fornire ridondanza. In questo modo, se il componente primario si guasta, quello secondario è immediatamente pronto a subentrare.
Come funziona la tolleranza ai guasti?
La tolleranza ai guasti, come l’alta disponibilità, si basa sulla ridondanza per garantire l’operatività. Tale ridondanza può essere ottenuta eseguendo contemporaneamente un’applicazione su due server, il che consente a un server di subentrare immediatamente all’altro quando quello primario si guasta.
Negli ambienti virtualizzati, la ridondanza per la tolleranza ai guasti si ottiene mantenendo ed eseguendo copie identiche di una determinata VM su host separati. Qualsiasi modifica o input che avviene sulla VM primaria viene duplicato sulla VM secondaria. In questo modo, nel caso in cui la VM primaria venga danneggiata, la tolleranza ai guasti è garantita dal trasferimento istantaneo dei carichi di lavoro da una VM alla sua duplicata.
Quando è importante la tolleranza ai guasti?
La progettazione tollerante ai guasti è fondamentale per i sistemi che non possono tollerare alcun tempo di inattività (zero downtime). Se sono presenti applicazioni mission-critical e anche il minimo downtime si traduce in perdite irrevocabili, è opportuno considerare la configurazione dei componenti IT tenendo conto della tolleranza ai guasti.
Tolleranza ai guasti vs alta disponibilità
Confrontando HA e FT, la tolleranza ai guasti è una soluzione più costosa. Ma la tolleranza ai guasti e l’alta disponibilità differiscono anche sotto due aspetti principali:
- La tolleranza ai guasti è una versione più rigorosa dell’alta disponibilità. L’alta disponibilità si concentra sulla riduzione al minimo dei tempi di inattività, mentre la tolleranza ai guasti va oltre, garantendo zero dowmtime.
- Tuttavia, nel modello di tolleranza ai guasti, la capacità di un sistema di fornire prestazioni elevate in caso di guasto non è la priorità assoluta. Al contrario, ci si aspetta che un sistema sia in grado di mantenere le prestazioni operative, anche se a un livello ridotto.
Che cos’è il ripristino di emergenza?
Il ripristino di emergenza è un processo utilizzato dalle organizzazioni per rispondere agli incidenti che colpiscono i sistemi e ripristinare rapidamente la funzionalità dell’infrastruttura IT. Il ripristino di emergenza comprende un piano di ripristino di emergenza, un team di ripristino di emergenza, una soluzione dedicata al ripristino di emergenza, un sito di ripristino, ecc. Questo approccio prevede l’utilizzo di siti hot, warm o cold a seconda del valore RTO definito nel piano di ripristino di emergenza e delle risorse disponibili.
Le due metriche principali del DR sono gli obiettivi di tempo di ripristino (RTO) e gli obiettivi di punto di ripristino (RPO) per ridurre al minimo rispettivamente i tempi di inattività e la perdita di dati.
Come funziona il ripristino di emergenza?
Il ripristino di emergenza richiede una ubicazione secondaria in cui ripristinare i dati e le carghe di lavoro critici (in modo totale o parziale) al fine di riprendere un’operatività aziendale sufficiente a seguito di un evento dirompente.
Per trasferire le carghe di lavoro in una ubicazione remota, è obbligatorio integrare una soluzione di ripristino di emergenza adeguata. Tale soluzione può occuparsi del failover in modo tempestivo e con un intervento minimo da parte vostra, consentendovi di raggiungere gli RTO designati.
Quali sono i componenti del ripristino di emergenza?
Il ripristino di emergenza è un concetto molto più ampio e complesso rispetto all’alta disponibilità e alla tolleranza ai guasti. Si riferisce a una strategia con una serie completa di componenti che includono: valutazione dei rischi, pianificazione, analisi delle dipendenze, configurazione del sito remoto, formazione del personale, test, impostazione dell’automazione e così via. Un altro aspetto del DR che va oltre l’alta disponibilità e la tolleranza ai guasti è la sua indipendenza dal sito di produzione.
Quando è importante il ripristino di emergenza?
Il ripristino di emergenza non si riferisce solo a una catastrofe naturale, ma a qualsiasi tipo di incidente dirompente che colpisce l’intero sito di produzione e porta a un significativo tempo di inattività, inclusi attacchi informatici, interruzioni di corrente, errori umani, guasti software e altro. Ciò significa che tali incidenti possono verificarsi in qualsiasi momento in modo imprevisto. Nella maggior parte dei casi i disastri sono impossibili da prevedere o evitare e le organizzazioni dovrebbero adottare misure per rafforzare la loro preparazione al ripristino di emergenza, nonché ottimizzare regolarmente le loro strategie di ripristino di emergenza.
Ripristino di emergenza vs alta disponibilità
Il ripristino di emergenza, a differenza dell’alta disponibilità e della tolleranza ai guasti, si occupa delle conseguenze catastrofiche che rendono indisponibili intere infrastrutture IT piuttosto che dei guasti di singoli componenti. Poiché il DR è incentrato sia sui dati che sulla tecnologia, il suo obiettivo principale è quello di ripristinare i dati e di rimettere in funzione i componenti dell’Infrastruttura nel più breve tempo possibile dopo un incidente imprevisto.
Per quanto riguarda la differenza tra alta disponibilità e ripristino di emergenza, l’alta disponibilità e la tolleranza ai guasti non possono aiutare a ripristinare i dati in caso di disastri e perdite di dati causati da un incidente imprevisto. Questo è lo scenario in cui il ripristino di emergenza può fornire un’infrastruttura DR indipendente e copie puntuali dei dati (punti di ripristino) per ridurre al minimo i tempi di inattività ed evitare la perdita di dati. Si noti tuttavia le differenze tra ripristino di emergenza e backup.
Utilizzo di NAKIVO Backup & Replication per il ripristino di emergenza
NAKIVO Backup & Replication è una soluzione veloce, affidabile e conveniente. Combina protezione dei dati di alto livello e funzionalità di ripristino di emergenza – la funzione di ripristino dell’ambiente – progettata per semplificare e automatizzare le operazioni di ripristino di emergenza.

Se si dispone di un sito remoto configurato, come obbligatorio per le procedure consigliate di ripristino di emergenza, è facile da usare e configurare, consentendo al contempo di creare flussi di lavoro di ripristino complessi.
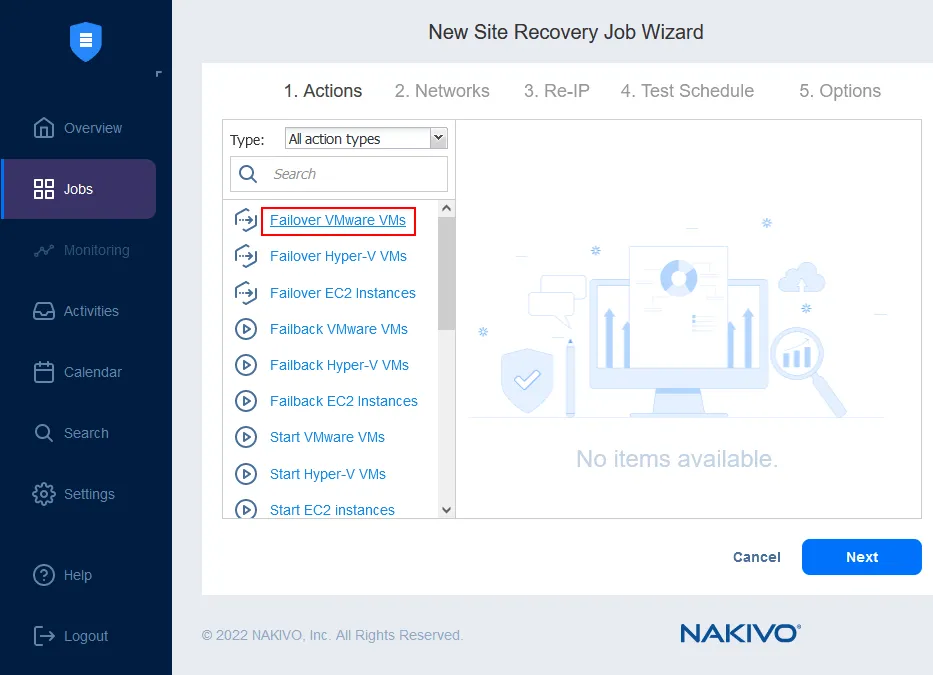
È possibile combinare fino a 200 azioni in un unico flusso di lavoro (lavoro) per adattarsi a diversi scenari di emergenza e servire diversi scopi, tra cui: monitoraggio, migrazione del data center, failover di emergenza, failover pianificato, failback, ecc. In caso di emergenza, qualsiasi flusso di lavoro creato può essere attivato immediatamente con un solo clic, consentendo alle aziende di ottenere tempi di ripristino minimi.
Con il ripristino dell’ambiente è possibile eseguire test di ripristino di emergenza automatizzati e senza interruzioni. In questo modo, è possibile assicurarsi che i flussi di lavoro del ripristino dell’ambiente siano validi, che riflettano tutte le recenti modifiche apportate all’infrastruttura IT e che non presentino punti deboli prima che si verifichi un disastro reale.