Introduzione ad Amazon S3: come funziona l’archiviazione degli oggetti sul cloud
Amazon Simple Storage Service (S3) è un popolare servizio di storage sul cloud che fa parte di Amazon Web Services (AWS). L’storage sul cloud Amazon S3 offre elevata affidabilità, flessibilità, scalabilità e accessibilità. Il numero di oggetti e la quantità di dati archiviati in Amazon S3 sono illimitati. L’storage sul cloud S3 è interessante per le aziende perché si paga solo ciò che si utilizza.
Tuttavia, la terminologia e la metodologia possono causare incomprensioni e difficoltà ai nuovi utenti di Amazon S3. Dove vengono archiviati i dati S3? Come funziona l’archiviazione Amazon S3? Questo post del blog spiega i concetti principali e il principio di funzionamento dell’archiviazione sul cloud Amazon S3.

Informazioni sull’archiviazione Amazon S3
Amazon S3 è stato il primo servizio di storage sul cloud di AWS ed è stato lanciato nel 2006. Da allora, la popolarità di questo servizio di storage sul cloud è cresciuta costantemente. Oggi Amazon offre un’ampia gamma di altri servizi cloud, ma Amazon S3 è quello più utilizzato. Oltre ad Amazon S3, AWS offre Amazon EBS per EC2 e Amazon Drive. Tuttavia, questi tre servizi hanno usi e scopi diversi.
EBS (Elastic Block Storage) per EC2 (Elastic Compute Cloud) sono dischi virtuali per VM che risiedono nel cloud Amazon. Come si può intuire dal nome EBS, si tratta di un’archiviazione a blocchi nel cloud che è l’analogo dei dischi rigidi nei computer fisici. È possibile installare un sistema operativo su un volume EBS collegato a un’istanza di Amazon EC2 .
Amazon Drive (precedentemente noto come Amazon Cloud Drive) è l’analogo di Google Drive e Microsoft OneDrive. Amazon Drive ha una gamma di funzioni più ridotta rispetto ad Amazon S3. Amazon Drive è posizionato come servizio di storage sul cloud per il backup di foto e altri dati utente.
Amazon S3 storage sul cloud è un servizio di storage basato su oggetti. Non è possibile installare un sistema operativo quando si utilizza l’archiviazione Amazon S3 perché non è possibile accedere ai dati a livello di blocco come obbligatorio per un sistema operativo. Se è necessario montare l’archiviazione Amazon S3 come unità di rete sul sistema operativo, utilizzare un file system nello spazio utente. Leggi il post sul blog relativo al montaggio dell’archiviazione sul cloud S3 su diversi sistemi operativi. Google Cloud è l’analogo dell’storage sul cloud Amazon S3.
Concetti principali di Amazon S3
Se è la prima volta che utilizza Amazon S3, alcuni concetti potrebbero risultare insoliti e poco familiari. La metodologia di archiviazione dei dati nel cloud S3 è diversa dall’archiviazione dei dati su dischi rigidi tradizionali, unità a stato solido o array di dischi. Di seguito è riportata una panoramica dei principali concetti e tecnologie utilizzati per archiviare e gestire i dati nel storage sul cloud Amazon S3.
Come archivia i file S3?
Come spiegato sopra, i dati in Amazon S3 sono archiviati come oggetti. Questo approccio fornisce uno storage altamente scalabile sul cloud. Gli oggetti possono avere diverse ubicazioni su diversi dischi fisici distribuiti in un data center. Nei data center Amazon vengono utilizzati hardware, software e file system distribuiti speciali per garantire un’elevata scalabilità. La ridondanza e il controllo delle versioni sono funzioni implementate utilizzando l’approccio di storage a blocchi. Quando un file viene archiviato in Amazon S3 come oggetto, viene archiviato in più posizioni (ad esempio su dischi, in data center o zone di disponibilità) contemporaneamente per impostazione predefinita. Il servizio Amazon S3 verifica regolarmente la coerenza dei dati controllando le somme di controllo hash. Se viene rilevato un danneggiamento dei dati, l’oggetto viene ripristinato utilizzando i dati ridondanti. Gli oggetti sono archiviati nei bucket Amazon S3. Per impostazione predefinita, è possibile accedere agli oggetti nell’archiviazione Amazon S3 e gestirli tramite l’interfaccia web.
Che cos’è l’archiviazione di oggetti S3?
L’archiviazione oggetti è un tipo di storage in cui i dati vengono memorizzati come oggetti anziché come blocchi. Questo concetto è utile per il backup dei dati , l’archiviazione e la scalabilità per ambienti ad alto carico.
Gli oggetti sono le entità fondamentali dell’archiviazione dei dati nei bucket Amazon S3. Un oggetto è composto da tre elementi principali: il contenuto dell’oggetto (dati memorizzati nell’oggetto, come un file o una directory), l’identificatore univoco dell’oggetto (ID) e i metadati. I metadati sono archiviati come valori di coppie di chiavi e contengono informazioni quali nome, dimensione, data, attributi di sicurezza, tipo di contenuto e URL.
Ogni oggetto dispone di un elenco di controllo degli accessi (ACL) per configurare chi è autorizzato ad accedere all’oggetto. L’archiviazione di oggetti Amazon S3 consente di evitare colli di bottiglia nella rete durante le ore di punta, quando il traffico verso gli oggetti archiviati sul storage sul cloud S3 aumenta in modo significativo. Amazon fornisce una larghezza di banda di rete flessibile, ma addebita i costi per l’accesso alla rete agli oggetti archiviati. L’archiviazione di oggetti è utile quando un numero elevato di client deve accedere ai dati (alta frequenza di lettura). La ricerca tramite metadati è più veloce per il modello di archiviazione di oggetti.
Leggi anche Crittografia Amazon S3 che può aiutarti a proteggere i dati archiviati nel storage sul cloud Amazon S3 e a migliorare la sicurezza.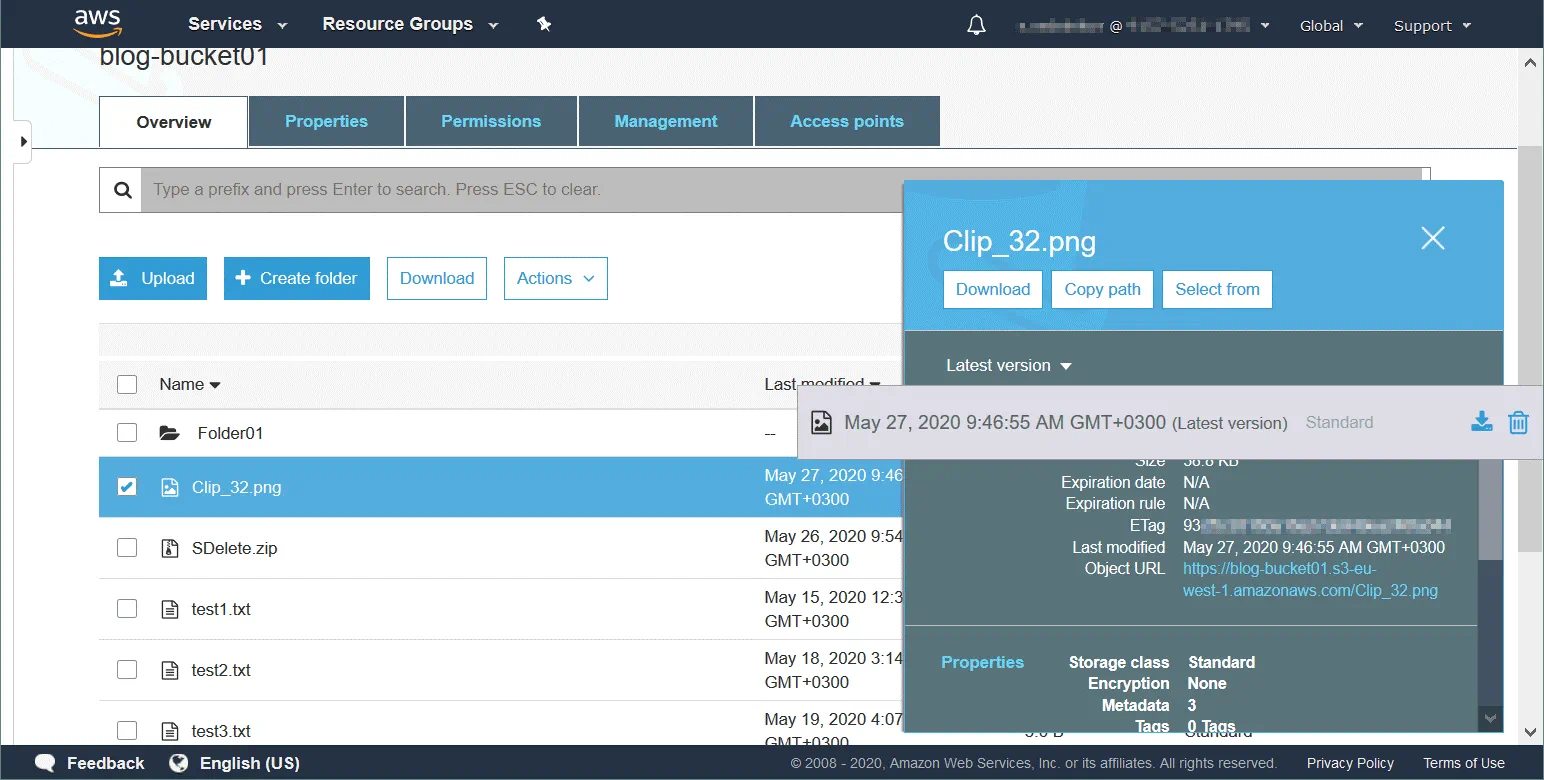
Bucket
Un bucket è un contenitore logico fondamentale in cui vengono archiviati i dati nell’archivio Amazon S3. È possibile archiviare una quantità infinita di dati e un numero illimitato di oggetti in un bucket. Ogni oggetto S3 è archiviato in un bucket. Esiste un limite di 5 TB per la dimensione di un oggetto archiviato in un bucket. I bucket vengono utilizzati per organizzare lo spazio dei nomi al livello più alto e per il controllo degli accessi.
Chiavi
Un oggetto ha una chiave univoca dopo essere stato caricato in un bucket. Questa chiave è una stringa che imita una gerarchia di directory. Conoscere la chiave consente di accedere all’oggetto nel bucket. Un bucket, una chiave e un ID versione identificano un oggetto in modo univoco. Ad esempio, se il nome di un bucket è blog-bucket01, l’ubicazione dei data center che archiviano i dati è s3-eu-west-1 e il nome dell’oggetto è test1.txt (un file di testo), l’URL del file necessario archiviato come oggetto nel bucket è:
https://blog-bucket01.s3-eu-west-1.amazonaws.com/test1.txt
Se desideri condividere oggetti con altri utenti, devi configurare le autorizzazioni modificando gli attributi degli oggetti. Allo stesso modo, è possibile creare una cartella TextFiles e memorizzare il file di testo in tale cartella:
https://blog-bucket01.s3-eu-west-1.amazonaws.com/TextFiles/test1.txt
Esistono due tipi di URL che possono essere utilizzati:
- bucketname.s3.amazonaws.com/objectname
- s3.amazon.aws.com/bucketname/objectname
Regioni AWS
Amazon dispone di data center in diverse regioni del mondo, tra cui Stati Uniti, Irlanda, Sudafrica, India, Giappone, Cina, Corea, Canada, Germania, Italia e Gran Bretagna. È possibile selezionare la regione desiderata durante la creazione di un bucket. Si consiglia di selezionare la regione più vicina a te o ai tuoi clienti per garantire una minore latenza della connessione di rete o ridurre al minimo i costi (poiché il prezzo per l’archiviazione dei dati varia a seconda della regione). I dati archiviati in una determinata regione AWS non lasciano mai i data center di quella regione fino a quando non li migri manualmente. Le regioni AWS sono isolate l’una dall’altra per garantire tolleranza ai guasti e stabilità.
Ogni regione contiene zone di disponibilità che sono ubicazioni isolate all’interno di una regione AWS. Sono disponibili almeno tre zone di disponibilità per ogni regione per prevenire guasti causati da disastri quali incendi, tifoni, uragani, inondazioni e così via.
Il modello di coerenza dei dati
Il controllo di coerenza read-after-write viene eseguito per gli oggetti archiviati nello storage Amazon S3. Amazon S3 replica i dati su server e data center all’interno di una regione selezionata per garantire un’elevata disponibilità. Dopo una richiesta PUT riuscita, i dati modificati devono essere replicati su tutti i server. Questo processo può richiedere del tempo. In questo caso, un utente può ottenere i dati precedenti o quelli aggiornati, ma non quelli danneggiati. Ciò vale anche per gli oggetti e i bucket eliminati. Il blocco degli oggetti non viene eseguito quando nuovi oggetti vengono inviati ai bucket S3. Se vengono eseguite più richieste PUT contemporaneamente, prevale l’ultima richiesta PUT. È possibile creare una propria applicazione con un meccanismo di blocco che funziona con gli oggetti archiviati nel storage Amazon S3.
Funzioni di Amazon S3
Il concetto di archiviazione basata su oggetti consente ad Amazon di fornire funzioni utili e un’elevata flessibilità per l’archiviazione dei dati nell’archiviazione e nella gestione di Amazon S3. Esaminiamo queste funzioni.
Controllo delle versioni
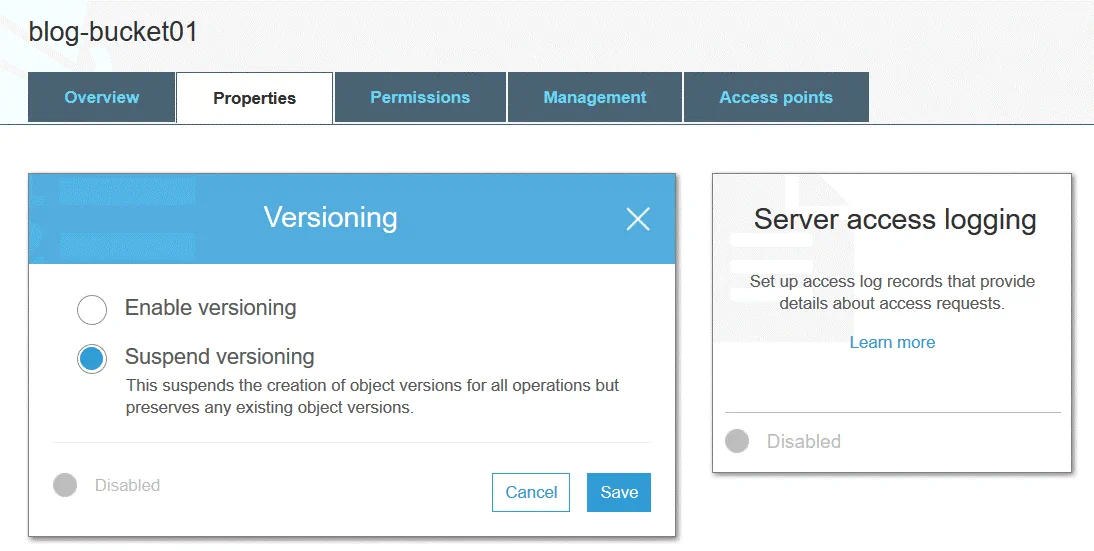
Il controllo delle versioni degli oggetti consente di archiviare più versioni di un oggetto in un unico bucket. Questa funzione protegge gli oggetti archiviati in Amazon S3 da modifiche, sovrascritture o cancellazioni involontarie. Dopo aver modificato o eliminato un oggetto, è possibile ripristinare una delle versioni precedenti dello stesso. Il controllo delle versioni è implementato grazie all’utilizzo dell’approccio di archiviazione degli oggetti. È possibile utilizzare il controllo delle versioni a fini di archiviazione. Il controllo delle versioni è disabilitato per impostazione predefinita.
A ogni oggetto S3 viene assegnato un ID versione anche se il controllo delle versioni non è abilitato (in questo caso il valore dell’ID versione è impostato su null). Se il controllo delle versioni è abilitato, dopo la scrittura delle modifiche viene assegnato un nuovo valore ID versione alla nuova versione dell’oggetto. Il controllo delle versioni può essere abilitato a livello di bucket. Il valore dell’ID versione della prima versione dell’oggetto rimane lo stesso. Quando si elimina un oggetto da un bucket S3 (con il controllo delle versioni abilitato), il marcatore di eliminazione viene applicato all’ultima versione dell’oggetto.
Classi di storage
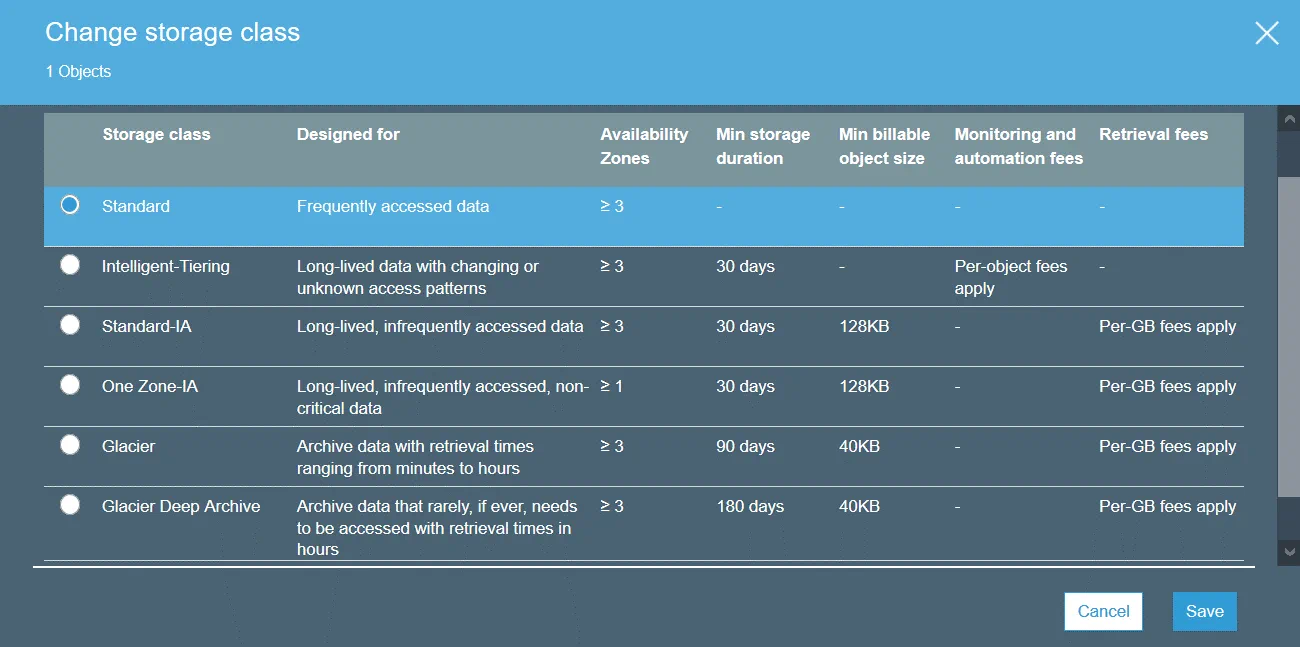
Le classi di storage Amazon S3 definiscono lo scopo dell’storage selezionato per la conservazione dei dati. Una classe di storage può essere impostata a livello di oggetto. Tuttavia, è possibile impostare la classe di storage predefinita per gli oggetti che verranno creati a livello di bucket.
S3 Standard è la classe di storage predefinita. Questa classe è dedicata all’archiviazione dei dati più utilizzati ed è ideale per i dati di uso frequente. Utilizza la classe di archiviazione Standard per ospitare siti web, distribuire contenuti, sviluppare applicazioni sul cloud e così via. I costi di archiviazione elevati, i costi di ripristino contenuti e l’accesso rapido ai dati sono le funzioni di questa classe di archiviazione.
S3 Standard-IA (accesso non frequente) può essere utilizzato per archiviare dati a cui si accede meno frequentemente rispetto a S3 Standard. S3 Standard-IA è ottimizzato per un periodo di storage più lungo. Il recupero dei dati archiviati nella classe di storage S3 Standard-IA è a pagamento. Inoltre, sia in S3 Standard che in S3 Standard-IA è necessario pagare per le richieste di dati (PUT, COPY, POST, LIST, GET, SELECT).
S3 One Zone-IA è progettato per dati a cui si accede raramente. I dati vengono archiviati solo in una zona di disponibilità (i dati vengono archiviati in tre zone di disponibilità per S3 Standard) e, di conseguenza, viene fornito un livello di ridondanza e resilienza inferiore. Il livello di disponibilità dichiarato è del 99,5%, inferiore a quello delle altre due classi di storage. S3 One Zone-IA ha costi di storage inferiori, costi di ripristino più elevati e il recupero dei dati viene addebitato in base al GB. È possibile considerare l’utilizzo di questa classe di storage come conveniente per archiviare copie di backup o copie di dati create con la replica interregionale di Amazon S3.
S3 Glacier non offre accesso immediato ai dati archiviati, a differenza delle altre classi di storage. S3 Glacier può essere utilizzato per archiviare dati a lungo termine a basso costo. Non vi è alcuna garanzia di funzionamento ininterrotto. È necessario attendere da pochi minuti a qualche ora per recuperare i dati. È possibile trasferire i dati obsoleti da un’archiviazione di classe superiore (ad esempio, da S3 Standard) a S3 Glacier utilizzando i criteri del ciclo di vita S3 e ridurre i costi di storage.
S3 Glacier Deep Archive è simile a S3 Glacier, ma il tempo necessario per recuperare i dati è di circa 12-48 ore. Il prezzo è inferiore a quello di S3 Glacier. La classe di archiviazione S3 Glacier Deep Archive può essere utilizzata per archiviare backup e dati di archiviazione di aziende che seguono i requisiti normativi per l’archiviazione dei dati (finanziari, sanitari). Si tratta di una valida alternativa alle cartucce a nastro.
S3 Intelligent-Tiering è una classe di archiviazione speciale che utilizza altre classi di archiviazione. S3 Intelligent-Tiering ha lo scopo di effettuare una selezione automatica della classe di storage migliore per archiviare i dati quando non si conosce la frequenza con cui sarà necessario accedervi. Amazon S3 è in grado di effettuare il monitoraggio dei modelli di accesso ai dati quando si utilizza S3 con la funzione di suddivisione in livelli, quindi archivia gli oggetti in una delle due classi di storage selezionate (una per i dati a cui si accede frequentemente e l’altra per i dati a cui si accede raramente). Questo approccio offre un rapporto costo-efficacia ottimale senza compromettere le prestazioni.
Ad esempio, se si accede a un oggetto archiviato in una classe di storage per dati a cui si accede raramente, tale oggetto viene spostato automaticamente in una classe di storage per dati a cui si accede frequentemente. Altrimenti, se un oggetto non è stato consultato per un lungo periodo di tempo, viene spostato nella classe di storage per dati utilizzati raramente. Gli oggetti possono essere collocati nello stesso bucket e la classe di storage viene modificata a livello di oggetto S3.
Elenchi di controllo degli accessi
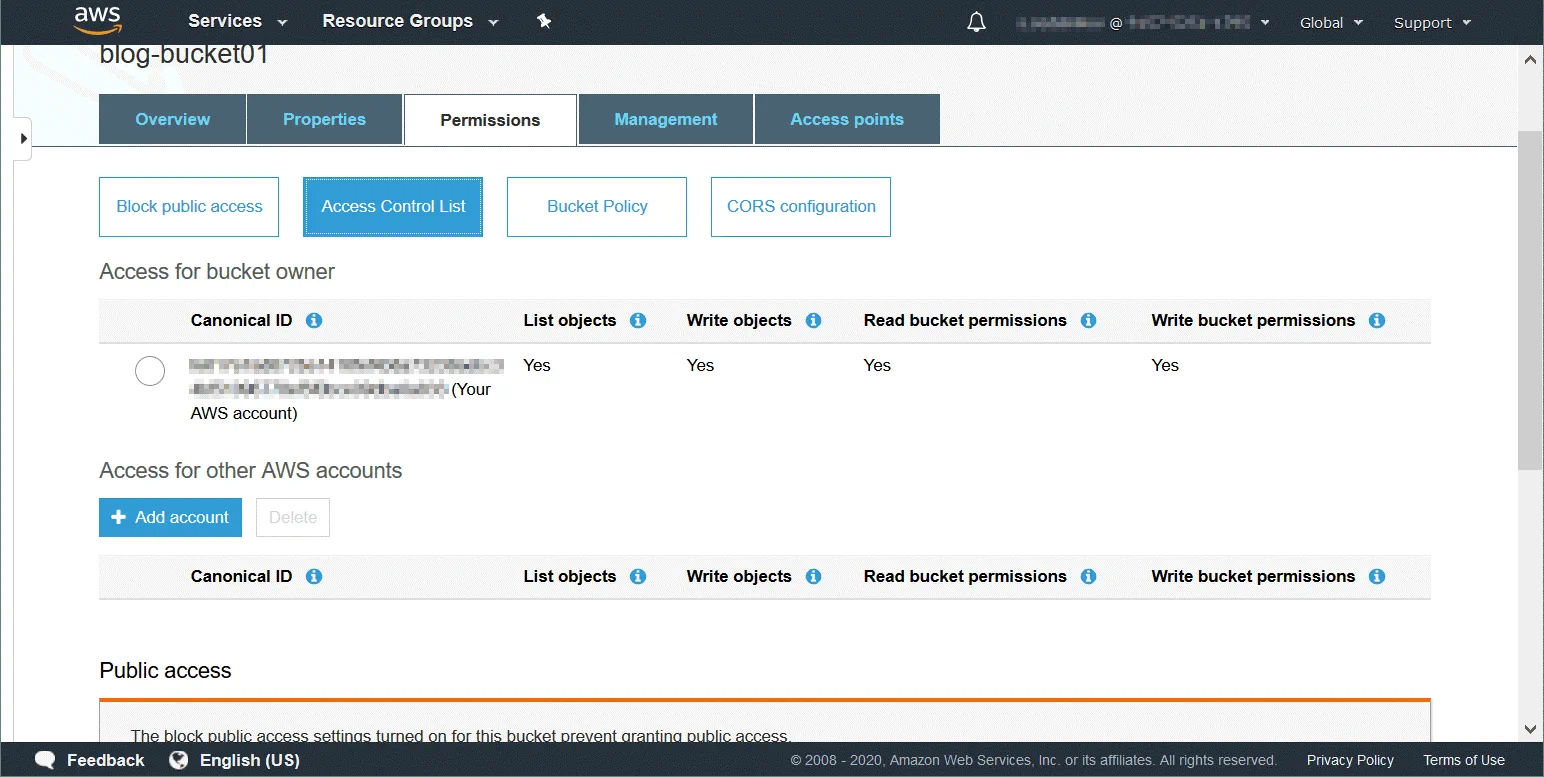
Un elenco di controllo degli accessi (ACL) è una funzione utilizzata per gestire e controllare l’accesso agli oggetti e ai bucket. Gli elenchi di controllo degli accessi sono criteri basati sulle risorse che vengono allegati a ciascun bucket e oggetto per definire gli utenti e i gruppi che dispongono delle autorizzazioni per accedere al bucket e all’oggetto. Per impostazione predefinita, il proprietario della risorsa ha pieno accesso a un bucket o a un oggetto dopo aver creato la risorsa. Le autorizzazioni di accesso al bucket definiscono chi può accedere agli oggetti nel bucket. Le autorizzazioni di accesso agli oggetti definiscono gli utenti che sono autorizzati ad accedere agli oggetti e il tipo di accesso. È possibile impostare autorizzazioni di sola lettura per un utente e autorizzazioni di lettura e scrittura per un altro utente, ad esempio.
L’elenco completo degli utenti che possono avere autorizzazioni (un utente che ha autorizzazioni è chiamato beneficiario):
Proprietario – un utente che crea un bucket/oggetto.
Utenti autenticati – qualsiasi utente che disponga di un account AWS.
Tutti gli utenti – qualsiasi utente, compresi gli utenti anonimi (utenti che non dispongono di un account AWS).
Utente per e-mail/ID – un utente specificato che dispone di un account AWS. È necessario specificare l’indirizzo e-mail o l’ID AWS di un utente per concedere l’accesso a tale utente.
Tipi di autorizzazioni disponibili:
Controllo completo – questo tipo di autorizzazione fornisce le autorizzazioni di lettura, scrittura, lettura (ACP) e scrittura ACP.
Lettura – consente di elencare il contenuto del bucket quando applicato a livello di bucket. Consente di leggere i dati e i metadati dell’oggetto quando applicato a livello di oggetto.
Scrittura – può essere applicato solo a livello di bucket e consente di creare, eliminare e sovrascrivere qualsiasi oggetto nel bucket.
Autorizzazioni di lettura (READ ACP) – un utente può leggere i permessi per l’oggetto o il bucket specificato.
Permessi di scrittura (WRITE ACP) – un utente può sovrascrivere i permessi per l’oggetto o il bucket specificato. Abilitare questo tipo di autorizzazione per un utente equivale a impostare le autorizzazioni di controllo completo, poiché l’utente può impostare qualsiasi autorizzazione per il proprio account. Questa autorizzazione è disponibile per il proprietario del bucket per impostazione predefinita.
Politiche dei bucket
Le politiche dei bucket sono politiche di gestione delle identità e degli accessi AWS basate sulle risorse che vengono utilizzate per creare regole condizionali per la concessione di autorizzazioni di accesso agli account AWS e agli utenti quando accedono ai bucket e agli oggetti nei bucket. È possibile utilizzare le politiche dei bucket per definire regole di sicurezza per più di un oggetto in un bucket.
La politica del bucket è definita come un file JSON. Il testo di configurazione della politica del bucket deve soddisfare i requisiti del formato JSON per essere valido. La politica del bucket può essere allegata solo a livello di bucket e viene ereditata da tutti gli oggetti nel bucket. È possibile concedere l’accesso agli utenti che si connettono da indirizzi IP specificati, agli utenti di account AWS specificati e così via.
Di seguito è riportato un esempio di criterio che concede l’accesso completo a tutti gli utenti di un account e l’accesso in sola lettura a tutti gli utenti di un altro account.
{
"Statement": [
{
"Effect": "Allow",
"Principal": {
"SGWS": "95381782731015222837"
},
"Action": "s3:*",
"Resource": [
"urn:sgws:s3:::blog-bucket01",
"urn:sgws:s3:::blog-bucket01/*"
]
},
{
"Effect": "Allow",
"Principal": {
"SGWS": "30284200178239526177"
},
"Action": "s3:GetObject",
"Resource": "urn:sgws:s3:::blog-bucket01/shared/*"
},
{
"Effect": "Allow",
"Principal": {
"SGWS": "30284200178239526177"
},
"Action": "s3:ListBucket",
"Resource": "urn:sgws:s3:::blog-bucket01",
"Condition": {
"StringLike": {
"s3:prefix": "shared/*"
}
}
}
]
}
Gli utenti possono accedere allo storage Amazon S3 utilizzando le chiavi di accesso (ID chiave di accesso e chiave di accesso segreta) senza inserire il nome utente e la password. Questo approccio consente di migliorare la sicurezza e viene utilizzato per creare applicazioni che utilizzano API per accedere allo storage sul cloud Amazon S3.
API per Amazon S3
Amazon fornisce interfacce di programmazione delle applicazioni (API) per accedere alle funzionalità di S3 e sviluppare applicazioni proprie che devono funzionare con l’archiviazione Amazon S3. Amazon fornisce interfacce REST e SOAP. L’interfaccia REST utilizza richieste HTTP standard per lavorare con bucket e oggetti. L’API REST utilizza intestazioni HTTP standard. L’interfaccia SOAP è un’altra interfaccia disponibile. L’uso di SOAP su HTTP è deprecato, ma è ancora possibile utilizzare SOAP su HTTPS.
Il modello di pagamento
Amazon S3 offre il modello “paghi solo quello che usi”. Non è obbligatoria una tariffa minima: non è necessario pagare per una quantità predeterminata di spazio di storage e traffico di rete. Esistono diverse categorie di utilizzo per cui è necessario pagare:
Storage. Pagamento per gli oggetti archiviati in Amazon S3. L’importo da pagare dipende dallo spazio di storage utilizzato, dal tempo di archiviazione degli oggetti nell’archiviazione Amazon S3 (durante il mese) e dalla classe di storage utilizzata dagli oggetti archiviati.
Richieste e recupero dei dati. È necessario pagare per le richieste effettuate per recuperare i dati archiviati nell’storage sul cloud Amazon S3.
Trasferimento dati. È necessario pagare per tutta la larghezza di banda utilizzata (traffico in entrata e in uscita) ad eccezione dei dati in entrata da Internet, dei dati in uscita trasferiti alle istanze di Amazon EC2 che si trovano nella stessa regione AWS del bucket S3 di origine e dei dati in uscita da un bucket S3 a CloudFront.
Gestione e replica. È necessario pagare per l’utilizzo delle funzioni di gestione dello storage come l’analisi e l’etichettatura degli oggetti. Amazon addebita costi per la replica tra regioni e la replica nella stessa regione.
Utilizza il calcolatore Amazon S3 per stimare i tuoi pagamenti.



