Grundlagen der Datensicherheit: So führen Sie ein Backup eines Amazon S3-Buckets durch
Amazon S3 ist ein zuverlässiger Cloud-Speicher, der von Amazon Web Services (AWS) bereitgestellt wird. Dateien werden als Objekte in Amazon S3-Buckets gespeichert. Dieser Speicher wird aufgrund der hohen Zuverlässigkeit von Amazon S3 häufig zum Speichern von Backups verwendet. Im Gegensatz zu Amazon Elastic Block Storage (EBS), wo redundante Daten in einer Verfügbarkeitszone gespeichert werden, werden redundante Daten in Amazon S3 über mehrere Verfügbarkeitszonen verteilt.
Wenn ein Rechenzentrum in einer Zone nicht mehr verfügbar ist, können Sie auf Daten in einer anderen Zone zugreifen. In einigen Fällen müssen Sie möglicherweise in Amazon S3-Buckets gespeicherte Daten sichern, um Datenverluste aufgrund menschlicher Fehler oder Softwareausfälle zu vermeiden. Daten können gelöscht oder beschädigt werden, wenn ein Benutzer, der Zugriff auf einen S3-Bucket hat, Daten löscht oder von unerwünschten Änderungen beschädigt. Softwarefehler können zu ähnlichen Ergebnissen führen.

Amazon S3 Versionierung
Die Objekt-Versionierung ist eine effektive Funktion in Amazon S3, die Ihre Daten in einem Bucket vor Beschädigung, unerwünschten Änderungen und Löschen schützt. Wenn Änderungen an einer Datei (die als Objekt in S3 gespeichert ist) vorgenommen werden, wird eine neue Version des Objekts erstellt. Mehrere Versionen desselben Objekts werden in einem Bucket gespeichert. Sie können auf frühere Versionen des Objekts zugreifen und diese wiederherstellen. Wenn das Objekt gelöscht wird, wird die „Löschmarkierung“ auf das Objekt angewendet, aber Sie können diese Aktion rückgängig machen und eine frühere Version des Objekts vor dem Löschen öffnen. Die Amazon S3-Versionierung kann ohne zusätzliche S3-Backup-Software verwendet werden.
Mit der Lebenszyklus-Richtlinie können Sie festlegen, wie lange Versionen in einem S3-Bucket gespeichert werden sollen, um eine Art Backup in Amazon S3 zu erhalten. Die zusätzlichen Kosten für die Speicherung weiterer Versionen sollten nicht hoch sein, wenn Sie die Lebenszyklus-Richtlinie richtig konfigurieren und neue Versionen die ältesten ersetzen. Die alten Versionen können gelöscht oder in einen kostengünstigeren Speicher (z. B. Cold Storage) verschoben werden, um die Kosten zu optimieren.
So aktivieren Sie die AWS S3-Versionierung
Melden Sie sich mit einem Konto mit ausreichenden Berechtigungen bei der AWS Management Console an. Klicken Sie auf Services und wählen Sie dann S3 in der Kategorie Speicher aus.
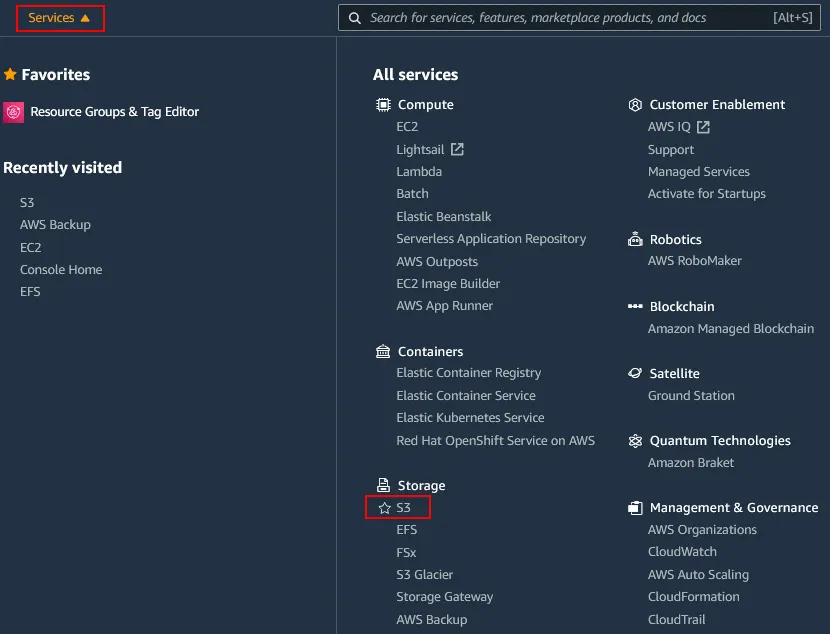
Klicken Sie im Navigationsbereich auf Buckets und wählen Sie den gewünschten S3-Bucket aus, für den Sie die Versionierung aktivieren möchten. In diesem Beispiel wähle ich den Bucket mit dem Namen blog-bucket01. Klicken Sie auf den Bucket-Name, um die Details des Buckets zu öffnen.
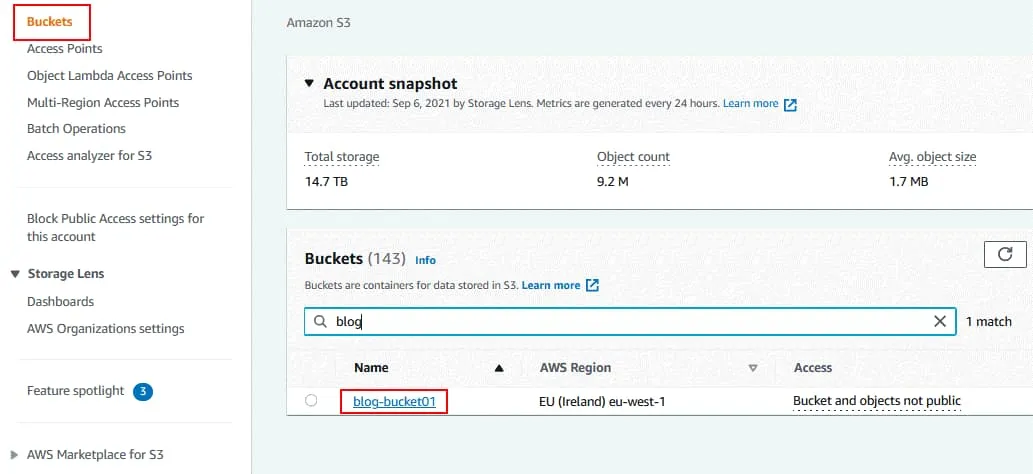
Öffnen Sie die Registerkarte Eigenschaften für den ausgewählten Bucket.
Klicken Sie im Abschnitt „ <“ >Bucket-Versionierung auf „ <“ >Bearbeiten.
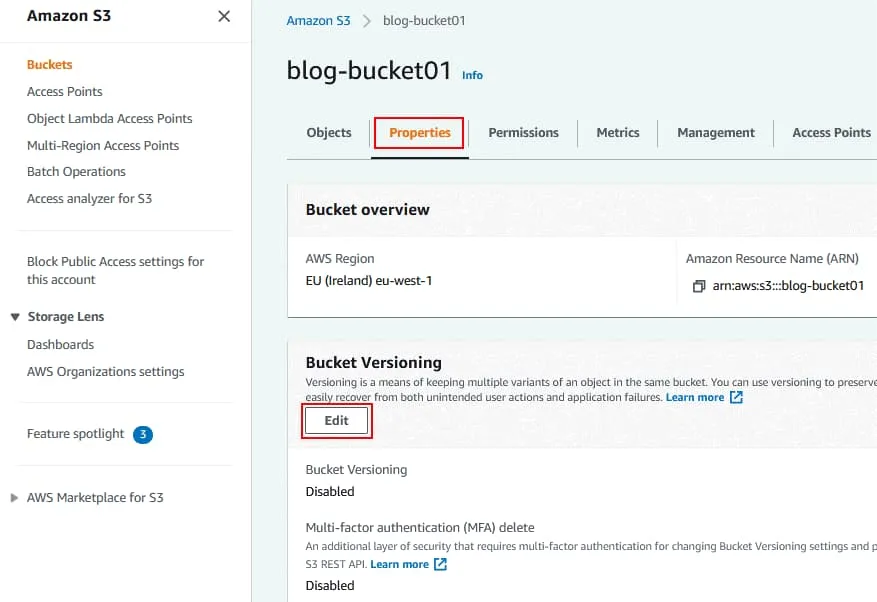
Die Bucket-Versionierung ist standardmäßig deaktiviert.
Klicken Sie auf Aktivieren Sie , um die Bucket-Versionierung zu aktivieren.
Klicken Sie auf Speichern Sie die Änderungen.
Es wird eine Anzeige angezeigt, dass Sie möglicherweise Ihre Lebenszyklusregeln aktualisieren müssen. Dies ist der weitere Schritt.
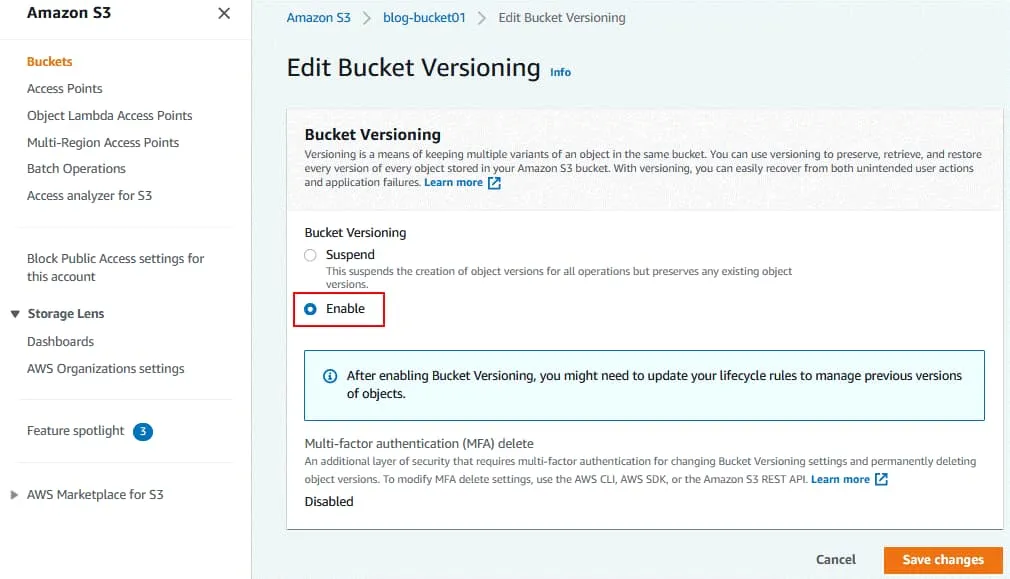
Die Meldung wird oben auf der Seite angezeigt, wenn Konfigurationsänderungen angewendet wurden: Bucket-Versionierung erfolgreich bearbeitet.
Lebenszyklusregeln
Um Lebenszyklusregeln für die Amazon S3-Versionierung zu konfigurieren, gehen Sie zur Registerkarte Management auf der Seite des ausgewählten Buckets. Klicken Sie im Abschnitt „ Lebenszyklusregeln auf „ Lebenszyklusregel erstellen.
Die Seite „ Lebenszyklusregel erstellen wird geöffnet.
Konfiguration der Lebenszyklusregel. Geben Sie den Namen der Lebenszyklusregel ein, zum Beispiel Blog-Lebenszyklus 01.
Wählen Sie den Regelbereich aus. Sie können Filter anwenden, um Lebenszyklusregeln auf bestimmte Objekte anzuwenden, oder die Regel auf alle Objekte im Bucket anzuwenden.
Definieren Sie Objekt-Tags, um Objekte zu kennzeichnen, für die Lebenszyklusaktionen angewendet werden müssen. Geben Sie einen Schlüssel und einen Wert in die entsprechenden Felder ein und klicken Sie auf die Schaltfläche Tag hinzufügen , um das Tag hinzuzufügen, oder auf die Schaltfläche Entfernen Schaltfläche zum Entfernen des Tags.

Aktionen für Lebenszyklusregeln. Wählen Sie die Aktionen aus, die diese Regel ausführen soll:
- Übergang aktuelle Versionen von Objekten zwischen Speicherklassen
- Übergang vorherige Versionen von Objekten zwischen Speicherklassen
- Ablaufen lassen aktuelle Versionen von Objekten
- Dauerhaft löschen vorherige Versionen von Objekten
- Löschen abgelaufener Löschmarkierungen oder unvollständiger mehrteiliger Uploads

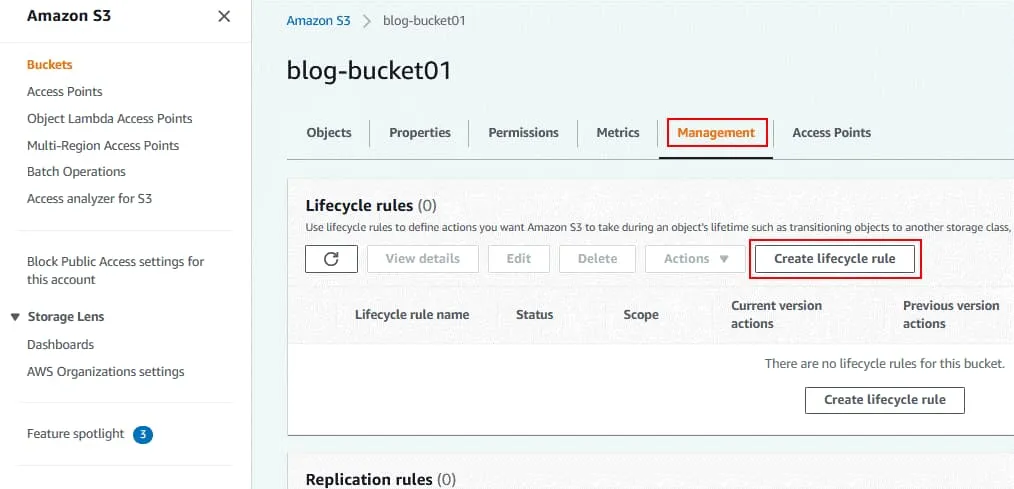
Übertragen nicht aktueller Versionen von Objekten zwischen Speicherklassen.
Wählen Sie Speicherklassenübergänge und die Anzahl der Tage, nach denen Objekte als nicht aktuell gelten.
In meinem Beispiel werden die Objekte nach 35 Tagen von der aktuellen S3-Speicherklasse in Standard-IA verschoben.
Löschen Sie frühere Versionen von Objekten dauerhaft.
Geben Sie die Anzahl der Tage ein, nach denen frühere Versionen gelöscht werden müssen. Der Wert muss höher sein als die Anzahl der Tage, nach denen Objekte veraltet sind. In meinem Beispiel werden Objekte nach 40 Tagen dauerhaft gelöscht.
Klicken Sie auf Regel erstellen um eine Lebenszyklusregel zu erstellen.
Replizieren des Buckets
Als Alternative zum automatischen Backup in Amazon S3 können Sie den Bucket über Regionen hinweg replizieren. Sie müssen einen zweiten Bucket erstellen, der als Ziel-Bucket in einer anderen Region dient, und eine Replikationsregel erstellen. Nach dem Erstellen der Replikationsregel werden alle Änderungen, die im Quell-Bucket vorgenommen werden, automatisch im Ziel-Bucket übernommen.
Suchen Sie den Abschnitt „ <“ (Replikationsregeln) >Replication rules im Bereich „ <“ (Quell-Bucket) >Management Registerkarte für Ihren Quell-Bucket und klicken Sie auf Replikationsregel erstellen.
Die Seite Replikationsregel erstellen wird geöffnet.
Geben Sie einen Namen für die Replikationsregel ein, zum Beispiel Blog S3-Bucket-Replikation.
Legen Sie den Status der Regel fest, wenn die Regel erstellt wird (aktiviert oder deaktiviert).
Quelle. Der Quell-Bucket wurde bereits ausgewählt (blog-bucket01).
Wählen Sie einen Regelbereich aus. Sie können die Replikationsregel für alle Objekte im Bucket verwenden oder Filter konfigurieren und die Regel auf benutzerdefinierte Objekte anwenden.
Ziel. Geben Sie den Namen des Ziel-Buckets ein oder klicken Sie auf S3 Durchsuchen und wählen Sie einen Bucket aus der Liste aus. Sie können einen Bucket in diesem Konto oder in einem anderen Konto auswählen. Wenn AWS S3-Versionierung für den Quell-Bucket aktiviert ist, muss die Objektversionierung auch für den Ziel-Bucket aktiviert sein. Für den ausgewählten Ziel-Bucket wird eine Zielregion angezeigt.
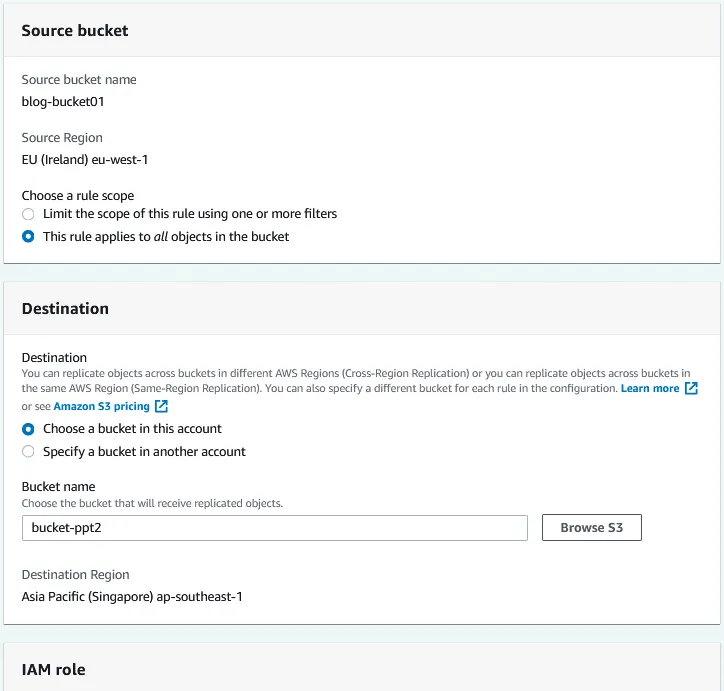
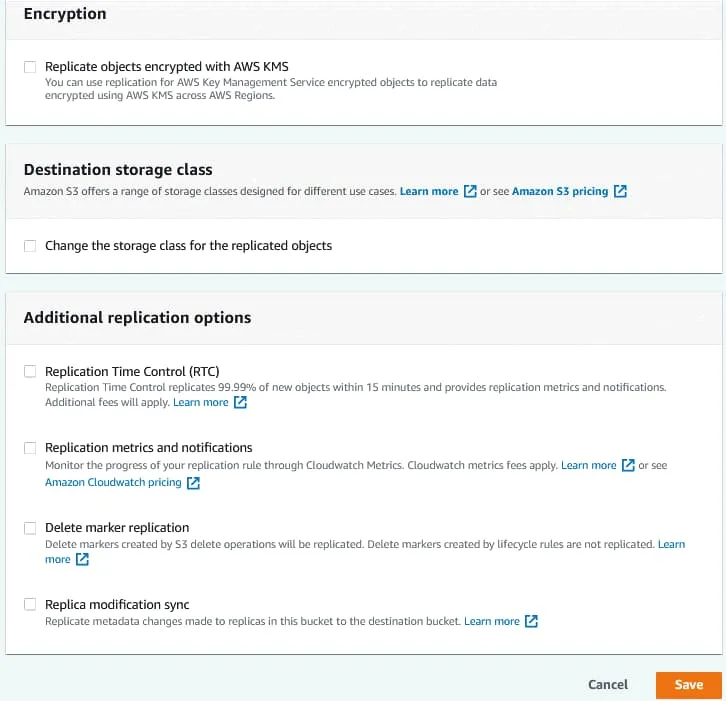
Konfigurieren Sie die IAM-Rolle (Identity and Access Management) und wählen Sie dann eine Speicherklasse und zusätzliche Replikationsoptionen aus. Klicken Sie auf Speichern Sie , um die Konfiguration zu speichern und eine Replikationsregel für den Bucket zu erstellen.
AWS S3-Backup in der CLI
AWS CLI ist die leistungsstarke Befehlszeilenschnittstelle für die Arbeit mit verschiedenen Amazon-Diensten, darunter Amazon S3. Es gibt einen nützlichen Synchronisierungsbefehl, mit dem Sie Amazon S3-Buckets auf einem Linux-Rechner sichern können, indem Sie Dateien aus dem Bucket in ein lokales Verzeichnis unter Linux kopieren, das auf einer Amazon EC2-Instanz ausgeführt wird.
Eine Funktion des Befehls „sync“ in AWS CLI ist, dass Dateien in einem lokalen Dateisystem (Amazon S3-Ziel) nicht gelöscht werden, wenn diese Dateien in der Quelle des S3-Buckets fehlen, und umgekehrt. Dies ist für die AWS S3-Sicherung wichtig, da bei versehentlichem Löschen einiger Dateien im S3-Bucket die vorhandenen Dateien nach der Synchronisierung nicht aus dem lokalen Verzeichnis eines Linux-Rechners gelöscht werden.
Vorteile:
- Unterstützung großer S3-Buckets und Skalierbarkeit
- Unterstützung mehrerer Threads während der Synchronisierung
- Die Möglichkeit, nur neue und aktualisierte Dateien zu synchronisieren
- Hohe Synchronisationsgeschwindigkeit dank intelligenter Algorithmen
Nachteile:
- Linux, das auf einer EC2-Instanz läuft, verbraucht den Speicher von EBS-Volumes. Die Speicherkosten für EBS-Volumes sind höher als für S3-Buckets.
In diesem Tutorial werden Befehle für Ubuntu Server verwendet.
Zunächst müssen Sie AWS CLI installieren.
Aktualisieren Sie den Baum der Repositorys:
sudo apt-get update
Installieren Sie AWS CLI:
sudo apt install awscli
oder
Installieren Sie unzip:
sudo apt install unzip
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip"
unzip awscli-exe-linux-x86_64.zip
sudo ./aws/install
Überprüfen Sie die AWS-Anmeldeinformationen in Linux, das auf Ihrer EC2-Instanz ausgeführt wird.
aws configure list
Fügen Sie Anmeldeinformationen hinzu, um mit AWS CLI von der Linux-Instanz aus auf AWS zuzugreifen, falls noch keine Anmeldeinformationen festgelegt wurden:
aws configure
Geben Sie die folgenden Parameter ein:
AWS-Zugriffsschlüssel-ID
AWS Secret Access Key
Standardregionsname
Standardausgabeformat
Erstellen Sie ein Verzeichnis zum Speichern Ihres Backups in Amazon S3. In meinem Beispiel erstelle ich das Verzeichnis ~/s3/ zum Speichern von S3-Backups und ein Unterverzeichnis mit einem Namen, der mit dem Namen des Buckets identisch ist. Die im S3-Bucket gespeicherten Dateien sollten in dieses lokale Verzeichnis auf dem Linux-Rechner kopiert werden. ~ ist das Home-Verzeichnis eines Benutzers, in meinem Fall /home/ubuntu .
mkdir -p ~/s3/your_bucket_name
Ersetzen Sie your_bucket_name durch den Namen Ihres Buckets (blog-bucket01 in unserem Beispiel).
mkdir -p ~/s3/blog-bucket01
Synchronisieren Sie den Inhalt des Buckets mit Ihrem lokalen Verzeichnis auf der EC2-Instanz unter Linux:
aws s3 sync s3:// blog-bucket01 /home/ubuntu/s3/ blog-bucket01/
Wenn die Konfiguration der Anmeldeinformationen, der Name des Buckets und der Zielpfad korrekt sind, sollte das Herunterladen der Daten aus dem S3-Bucket beginnen. Die Zeit, die zum Fertigstellen des Vorgangs benötigt wird, hängt von der Größe der Dateien im Bucket und Ihrer Internetverbindungsgeschwindigkeit ab.
Automatische Sicherung mit Amazon S3
Sie können automatische Backupaufträge mit Amazon S3 mit AWS CLI sync konfigurieren. Erstellen Sie eine Skriptdatei „sync.sh“, um die AWS S3-Sicherung zum Backup auszuführen (Dateien von einem S3-Bucket mit einem lokalen Verzeichnis auf Ihrer Linux-Instanz synchronisieren), und führen Sie dieses Skript dann nach Plan aus.
nano /home/ubuntu/s3/sync.sh
#!/bin/sh
# Display the current date and time
echo '-----------------------------'
date
echo '-----------------------------'
echo ''
# Display the script initialization message
echo 'Syncing remote S3 bucket...'
# Running the sync command
/usr/bin/aws s3 sync s3://{BUCKET_NAME} /home/ubuntu/s3/{BUCKET_NAME}/
# Echo "Script execution is completed"
echo 'Sync complete'
Ersetzen Sie {BUCKET_NAME} durch den Namen des S3-Buckets, den Sie sichern möchten.
Der vollständige Pfad zu aws (AWS CLI-Binärdatei) wird definiert, damit crontab die Anwendung aws in der von crontab verwendeten Shell-Umgebung korrekt ausführt.
Machen Sie das Skript ausführbar:
sudo chmod +x /home/ubuntu/s3/sync.sh
Führen Sie das Skript aus, um zu überprüfen, ob es funktioniert:
/home/ubuntu/s3/sync.sh
Bearbeiten Sie crontab (ein Scheduler in Linux) des aktuellen Benutzers, um die Ausführung des Skripts zum Backup in Amazon S3 zu planen.
crontab -e
Möglicherweise müssen Sie einen Texteditor auswählen, um die crontab-Konfiguration zu bearbeiten.
Das Format von crontab für die Planung von Aufgaben lautet wie folgt:
m h dom mon dow command
Dabei steht m für Minuten, h für Stunden, dom für den Tag des Monats und dow für den Tag der Woche.
Fügen wir eine Konfigurationszeile für die Aufgabe hinzu, um die Synchronisierung stündlich auszuführen und die AWS S3-Backup-Ergebnisse in der Protokolldatei zu speichern. Fügen Sie diese Zeile am Ende der crontab-Konfiguration hinzu.
0 * * * * /home/ubuntu/s3/sync.sh > /home/ubuntu/s3/sync.log
Das automatische Backup in Amazon S3 ist konfiguriert. Anhand der Protokolldatei können Sie die Ausführung der Synchronisierungsaufgaben überprüfen.
Fazit
Es gibt mehrere Methoden zum Backup in Amazon S3, von denen zwei in diesem Blogbeitrag behandelt wurden. Sie können die Objekt-Versionierung für einen Bucket aktivieren, um frühere Versionen von Objekten zu speichern. So können Sie Dateien wiederherstellen, wenn unerwünschte Änderungen an den Dateien vorgenommen wurden. Die Amazon S3-Replikation ist ein weiteres natives Tool, mit dem Sie eine Kopie der in einem Amazon S3-Bucket als Objekte gespeicherten Dateien erstellen können. In diesem Fall werden Objekte von einem Bucket in einen anderen repliziert. Sie können auch ein Backup eines Amazon S3-Buckets mit dem Synchronisierungstool in AWS CLI erstellen, mit dem Sie Dateien in einem Bucket mit einem lokalen Verzeichnis eines Linux-Rechners synchronisieren können, der auf einer EC2-Instanz läuft. Die automatische Sicherung von Amazon S3 kann mithilfe eines Skripts und crontab geplant werden.
Im Allgemeinen ist der Cloud-Speicher Amazon S3 sehr zuverlässig, und das Backup in Amazon S3 ist gängige Praxis. Wenn Sie über eine starke Strategie zur Datensicherheit und eine AWS-Sicherungsstrategie verfügen, sollten Sie eine Backupkopie haben. In diesem Fall wird empfohlen, Daten auf Amazon S3 und an einem weiteren Standort zu sichern. Verwenden Sie NAKIVO Backup & Replication, um Ihre Daten auf physischen und virtuellen Maschinen zu schützen. NAKIVO Backup & Replication ist eine robuste Virtualisierungs-Backup-Software, die zum Schutz von VMs sowie Amazon EC2-Instanzen und physischen Maschinen verwendet werden kann.


