高可用性、フォールトトレランス、災害復旧:概要
組織のITインフラを24時間365日稼働させ続けるという点において、"高可用性(HA)""フォールトトレランス(FT)""ディザスタリカバリ(DR)"という3つの主要な用語の間には、依然として混同が見られるようです。 これら3つの用語はいずれも、事業継続性とITシステムへのアクセス維持に関わっています。しかし、それぞれの用語には固有の定義、手法、および適用事例があります。
本ブログ記事では、高可用性、フォールトトレランス、およびディザスタリカバリが実務上どのようなものかを定義し、これらの用語がどのように重なり合っているか、またなぜそれらを実装することが重要なのかを探っていきます。

高可用性とは何か?
高可用性とは、システムがダウンすることなく、所定の期間にわたって稼働(アップタイム)し、ユーザーがアクセスできる状態を維持する能力のことです。アップタイムとは、予期せぬ再起動や電源切断が発生することなく、サーバーが稼働している時間のことを指します。
高可用性(HA)は、計画的なメンテナンスやシャットダウンを除き、設定された時間帯においてシステムが稼働している時間の割合として算出されます。 HAは100%の稼働率を実現することを期待されていません。これは達成が困難であり、現実的ではないからです。年間最大5分26秒のダウンタイムは許容範囲と見なされ、これは99.999%の稼働率に相当します。しかし、多くの組織にとって、この数値でさえも妥当な目標とは言えない場合があります。組織、業界、リソースによっては、求められるHAの値はこれよりも低くなることもあります。
高可用性はどのように機能するのでしょうか?
組織における高可用性の目標は、冗長性とフェイルオーバー機能を活用してシステム内の単一障害点を排除することで達成されます。つまり、単一のコンポーネントが故障しても、システム全体が利用不能になることがないよう確保することを意味します。
仮想化環境では、以下の機能を活用することで高可用性を設計することができます。 クラスタリング技術例えば、クラスタ内のホストまたは仮想マシン(VM)の1つに障害が発生した場合、別のVMが引き継ぎ(フェイルオーバー)、システムの適切なパフォーマンスを維持します。
冗長性コンポーネントを備えることは高可用性を確保するための究極の条件ですが、これらのコンポーネントだけでは、システムが高可用性であると見なすには不十分です。 高可用性システムとは、冗長化コンポーネントに加え、障害検知およびワークロードの自動リダイレクトを行うメカニズムを備えたシステムを指します。これには、ロードバランサーやハイパーバイザーなどが含まれます。 VMware vSphere における DRS はロードバランサーの一例です。
高可用性はどのような場合に重要なのでしょうか?
ダウンタイムが許されない重要なワークロードには、高可用性アーキテクチャが不可欠です。システムやアプリケーションの障害がビジネスの存続を脅かす場合、HAを活用することでダウンタイムを最小限に抑えることができます。 Statistaによると2020年には、企業の25%において、1時間のダウンタイムによるコストは30万~40万米ドルに上りました。これは、99.999%という極めて高い可用性(年間ダウンタイム5分26秒)であっても、一部の企業にとっては約3万5000米ドルのコストが発生し得ることを意味します。
多額の金銭的損失に加え、ダウンタイムは生産性の低下、サービスの適時提供の不能、企業の評判の失墜など、その他の深刻な影響をもたらす可能性があります。高可用性システムは、障害を自動的かつ迅速に処理することで、こうした事態を回避するのに役立ちます。
フォールトトレランスとは何か?
フォールトトレランスとは、システムを構成する1つ以上のコンポーネントに障害が発生した場合でも、ダウンタイムを生じさせることなく正常に動作し続ける能力のことです。フォールトトレラントなシステムには、冗長性を確保するために互いをミラーリングする2つの密接に連携したコンポーネントが含まれます。これにより、プライマリコンポーネントがダウンしても、セカンダリコンポーネントが直ちにその役割を引き継ぐ準備が整っています。
フォールトトレランスはどのように機能するのでしょうか?
フォールトトレランスは、高可用性と同様に、稼働時間を確保するために冗長性に依存しています。このような冗長性は、1つのアプリケーションを2台のサーバーで同時に実行することで実現でき、これにより、プライマリサーバーに障害が発生した場合でも、もう一方のサーバーが即座にその役割を引き継ぐことが可能になります。
仮想化環境では、フォールトトレランスのための冗長性は、特定の仮想マシンの同一のコピーを別々のホスト上で維持・実行することで実現されます。 プライマリVMで行われる変更や入力は、セカンダリVMにも複製されます。これにより、プライマリVMが破損した場合でも、ワークロードを一方のVMからその複製へ瞬時に移行することで、フォールトトレランスが確保されます。
フォールトトレランスはどのような場合に重要となるのでしょうか?
ダウンタイムを一切許容できない(ゼロダウンタイム)システムにおいては、フォールトトレラント設計が不可欠です。ミッションクリティカルなアプリケーションがあり、わずかなダウンタイムでも取り返しのつかない損失につながる場合は、フォールトトレラント性を考慮してITコンポーネントを構成することを検討すべきです。
フォールトトレランスと高可用性
HAとFTを比較すると、フォールトトレランスの方がコストがかかるソリューションです。しかし、フォールトトレランスと高可用性には、主に2つの点で違いがあります:
- フォールトトレランスは、高可用性のより厳格な形態です。高可用性はダウンタイムを最小限に抑えることに重点を置いていますが、フォールトトレランスはさらに一歩進んで、 ゼロ ダウンタイム。
- しかし、フォールトトレラントモデルにおいては、障害発生時にシステムが高いパフォーマンスを発揮できるかどうかは最優先事項ではない。それどころか、たとえパフォーマンスが低下したとしても、システムが稼働状態を維持できることが求められる。
ディザスタリカバリとは?
ディザスタリカバリとは、システムに影響を及ぼすインシデントに対応し、ITインフラの機能を迅速に復旧させるために組織が実施するプロセスです。ディザスタリカバリには、DR計画、DRチーム、専用のディザスタリカバリソリューション、復旧サイトなどが含まれます。このアプローチでは、以下のものを活用します 高温、常温、または低温の場所 で定義されたRTO値に応じて 災害復旧計画 および利用可能なリソース。
DRの2つの主要な指標は 復旧時間目標 (RTO)および復旧時点目標(RPO)を設定し、それぞれダウンタイムとデータ損失を最小限に抑える。
災害復旧はどのように行われるのでしょうか?
災害復旧には、障害発生後に十分な業務運営を再開できるよう、重要なデータやワークロードを(完全または部分的に)復元できるセカンダリサイトが必要です。
ワークロードを遠隔地に移行するには、適切な災害復旧ソリューションを導入する必要があります。このようなソリューションにより、以下の対応が可能となります。 フェイルオーバー 迅速かつ最小限の作業負担で運用が可能となり、これにより、設定されたRTOを達成することができます。
災害復旧にはどのような要素がありますか?
災害復旧(DR)は、高可用性やフォールトトレランスよりもはるかに広範かつ複雑な概念です。これは、リスク評価、計画策定、依存関係分析、リモートサイトの構成、スタッフ研修、テスト、自動化設定など、包括的な要素から成る戦略を指します。また、高可用性やフォールトトレランスを超えたDRのもう一つの特徴は、本番サイトからの独立性にあります。
災害復旧はどのような場合に重要なのでしょうか?
災害 これは自然災害だけでなく、生産拠点全体に影響を及ぼし、大幅な稼働停止につながるあらゆる種類の障害事象を指します。これには、サイバー攻撃、停電、人的ミス、ソフトウェアの障害などが含まれます。つまり、こうした事象はいつ予期せず発生するかわかりません。多くの場合、災害を予測したり回避したりすることは不可能であるため、組織は災害復旧(DR)体制を強化する措置を講じるとともに、DR戦略を定期的に見直して最適化すべきです。
災害復旧と高可用性
ディザスタリカバリは、高可用性やフォールトトレランスとは異なり、単一のコンポーネントの障害ではなく、ITインフラ全体が利用不能になるような壊滅的な事態に対処するものです。DRはデータと技術の両方を重視しているため、その主な目的は、予期せぬインシデント発生後、最短時間でデータを復旧させるとともに、インフラコンポーネントを稼働させることにあります。
高可用性とディザスタリカバリの違いについて言えば、高可用性やフォールトトレランスでは、予期せぬインシデントによる災害やデータ損失が発生した場合、データの復旧には役立ちません。このようなシナリオにおいて、ディザスタリカバリは独立したDRインフラストラクチャとデータの特定時点のコピー(リカバリポイント)を提供し、ダウンタイムを最小限に抑え、データ損失を防ぐことができます。ただし、 災害復旧とバックアップの違い.
使用 NAKIVO Backup & Replication 災害復旧用
NAKIVO Backup & Replication 高速で信頼性が高く、手頃な価格のソリューションです。ハイエンドなデータ保護機能と 災害復旧機能 – サイトリカバリ機能 – DR運用を簡素化・自動化するために設計されています。

DRのベストプラクティスに従ってリモートサイトを設定している場合、そのサイトは使いやすく設定も簡単でありながら、複雑な復旧ワークフローを構築することも可能です。
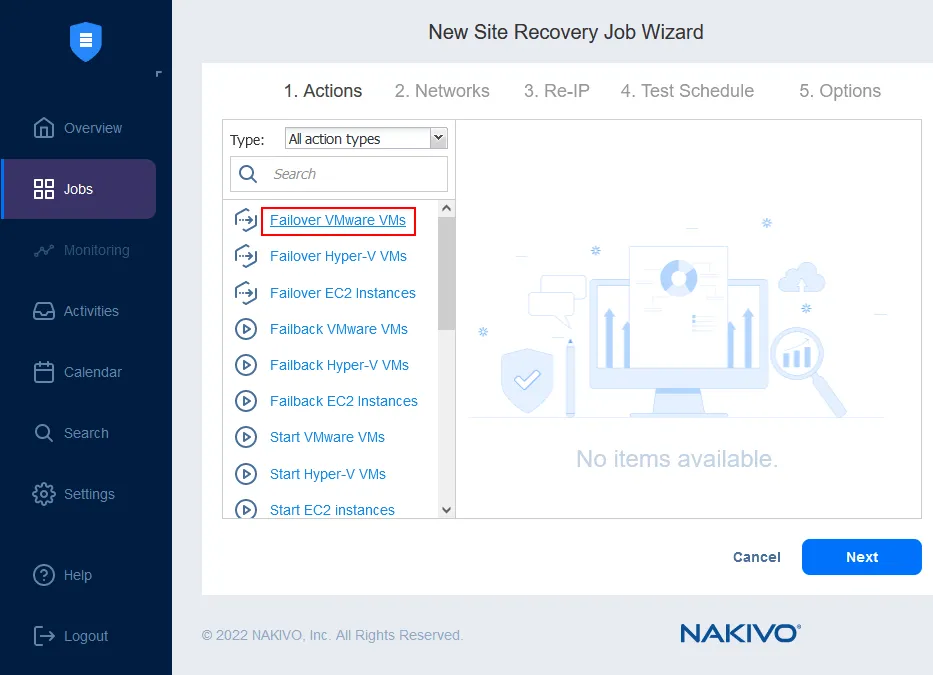
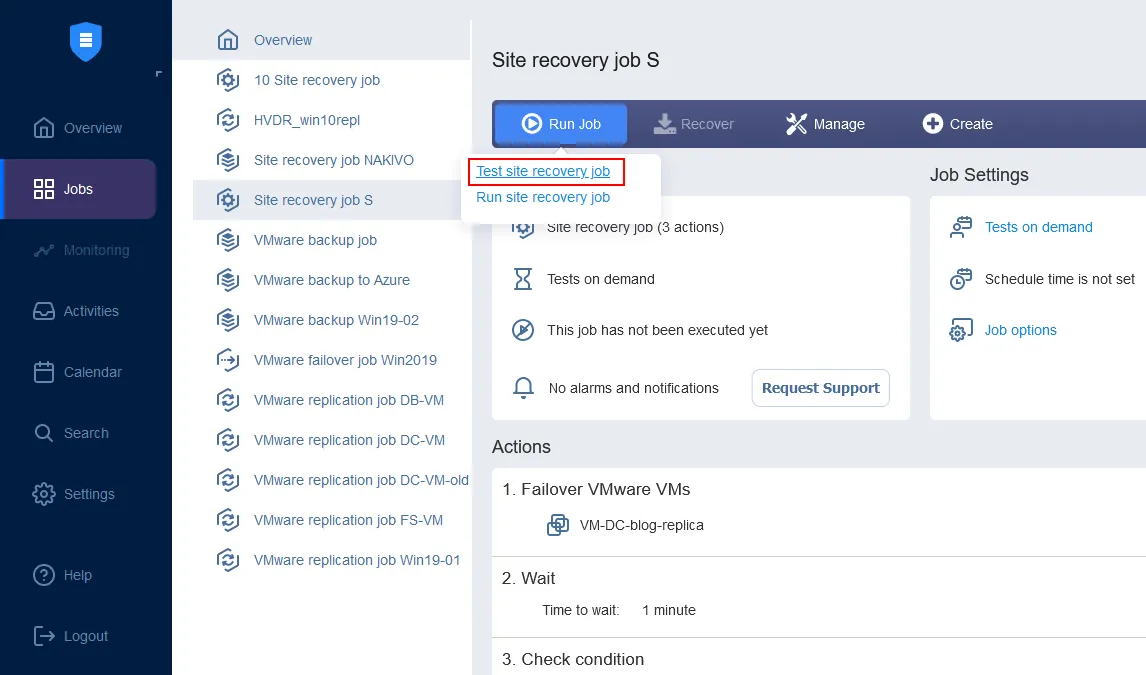
1つのワークフロー(ジョブ)には最大200個のアクションを組み合わせることができ、監視、データセンターの移行、緊急フェイルオーバー、計画的なフェイルオーバー、フェイルバックなど、さまざまな災害シナリオや目的に対応できます。災害発生時には、作成済みのワークフローをワンクリックですぐに実行できるため、企業は最短の復旧時間を実現できます。
Site Recoveryを導入することで、業務を中断することなく、自動化された災害復旧テストを実行できます。これにより、 サイト復旧ワークフロー それらが有効であり、ITインフラストラクチャで最近行われたすべての変更が反映されており、実際に災害が発生する前に脆弱性が存在しないことを確認する必要があります。