NAKIVO による災害復旧:計画、導入、およびテスト
バックアップと災害復旧は、あらゆる組織や業界におけるデータ保護戦略の基盤となっています。 災害復旧 これは、本番サイトが利用不能になった際に、セカンダリサイト(災害復旧サイトと呼ばれる)において、仮想マシンおよびそこで実行されているサービスを復旧させるプロセスです。必要なソフトウェアを備えた冗長化されたサーバー、コンピュータ、ネットワーク機器を収容し、これら セカンダリDRサイトには、さまざまな種類があります 冗長性のレベルに応じて。
NAKIVO Backup & Replication プライマリサイトがダウンした際にワンクリックで開始できる、高度な復旧シーケンス(サイト全体のフェイルオーバーを含む)を作成できる"Site Recovery"機能が含まれています。このブログ記事では、IT災害復旧計画、テスト、およびNAKIVOの統合ソリューションを用いた災害復旧の実行など、災害復旧戦略の主要な構成要素について解説しています。

ステップ1. 災害復旧計画
効果的な災害復旧を実現するための重要なステップとして、計画策定においては、組織の復旧ニーズを評価するとともに、災害復旧ワークフローにどのような構成要素、手順、およびプロセスを含めるべきかについて、包括的な理解を深める必要があります。
災害復旧の計画:ベストプラクティス
1. 事業影響度分析を実施する
A ビジネス影響分析(BIA) これは、重大なインシデントや自然災害が事業運営に及ぼす潜在的な悪影響を特定するために使用されます。この分析では、さまざまな仮想マシン(VM)の優先順位付け、復旧手順、および障害が事業運営に重大な影響を及ぼすまでの許容時間を決定します。例えば、あるVMの障害は遅延や不便を招くだけかもしれませんが、別のVMの障害は事業に不可欠な業務の完全な停止につながる可能性があります。
2. 関連するリスクを評価する
災害復旧(DR)計画を策定する前に、組織の業務および事業継続に対するリスクに関する関連データを収集してください。地域によっては、竜巻よりも長期の停電やウイルス攻撃の方が発生しやすい場合もありますが、自然災害が頻繁に発生する地域もあります。 リスク評価を行うことで、特定の脅威に対する適切な保護レベルを判断し、リスクを最小限に抑え、影響を軽減するための対策を講じることができます。リスクを完全に排除することはできませんが、直面する可能性の高い災害シナリオに対して、より万全な備えができるようになります。
3. 災害復旧に関する文書を作成する
リスクとその事業への潜在的な影響を特定できれば、災害復旧プロセスの策定において、どこに注力すべきかがより明確になります。 文書の復旧手順、すべての重要な手順と災害復旧(DR)対策を詳細に記述し、環境の変化を反映させるために文書を定期的に更新する。文書には以下を含めるべきである:
Disaster recovery scope.インフラストラクチャ内の各ハードウェアおよびソフトウェアコンポーネントの重要度を評価し、業務に不可欠な運用に関連するものを災害復旧計画に組み込んでください。重要な情報を格納する仮想マシン(VM)、ITシステム、およびサービスの継続的な提供を確保するために不可欠なアプリケーションは、復旧の最優先対象とすべきです。VM recovery order.特定のVMは、別のVMに格納されているソフトウェアや情報に依存している場合があり、そのため単独で動作させたり、任意の順序で起動させたりすることはできません。復旧作業を効率化し、DRサイトでのソフトウェア間の競合リスクを排除するために、復旧順序を明確に指定する必要があります。例えば、Active Directory認証を使用するファイルサーバーのVMを起動するには、Active Directoryドメインコントローラーを実行しているVMが起動して稼働している必要があります。
もう一つの例として、複数の異なるVMにインストールされたソフトウェアに依存することが多いWebサービスが挙げられます。次のような処理を実装する必要があるかもしれません:
- データベースサーバーが動作するVMを最初に起動する必要があります。
- これで、アプリケーションサーバーが動作するVMを起動できます。
- そうして初めて、Webサーバーが動作するVMを起動できます。
RTO and RPO in disaster recovery.設定する 目標回復時間 (RTO) および 復旧時点目標 (RPO)を、災害復旧計画における優先度の異なるVMごとに設定します。例えば、財務システムを実行するVMは、アーカイブされた文書を保存するために使用されるVMよりも、復旧目標時間が短くなる場合があります。Dependencies.スタッフとITコンポーネント間の依存関係を確認する際は、スタッフと連携し、彼らの業務状況を考慮に入れることで、復旧の失敗につながるような脆弱な部分が生じないようにしてください。例えば、他の部門の従業員が業務を行う上で経理部門の財務処理に依存している場合、経理部門が使用する仮想マシン(VM)を最優先で復旧させる必要があるかもしれません。Staff. 災害復旧(DR)プロセスに関与するチームメンバーに役割と責任を割り当ててください。DRサイトでの勤務となる場合は、必要な機器、オフィス家具、ハードウェアがすべて整ったワークステーションを現地に設置し、業務の中断を最小限に抑えて業務を継続できるようにしてください。災害発生時に従業員がリモートワークを行うことができる場合は、事前にVPNアクセスを設定し、VPNアカウントを提供してください。Hardware requirements. 災害復旧計画の成否は、DRサイトに設置されたハードウェアの性能と機能に大きく左右されます。以下の点を考慮する必要があります:- サーバーには、移行されたワークロードを維持するのに十分なCPU、メモリ、およびディスク容量が必要です。CPUの性能が低かったりメモリが不足していたりすると、仮想マシンの動作速度に影響を及ぼす可能性があります。また、ディスクの速度が不十分だと、仮想マシンのパフォーマンスが低下します。
- ネットワークは、復旧したVM同士が相互に通信できるよう、十分な帯域幅を確保する必要があります。 共有ストレージ、および必要に応じてユーザーとも。
ステップ2. 災害復旧の準備
ドキュメントが揃ったら、災害復旧サイトの準備を行い、重要なワークロードのレプリケーションを設定することで、災害復旧の準備を進めることができます。レプリケーションは、以下のために必要です。 VMのフェイルオーバー プライマリインフラストラクチャがダウンした際に、レプリカVMへ切り替える。
VMレプリケーションとは何ですか?
仮想マシンのレプリケーションとは、ソースVMの完全な複製("VMレプリカ"と呼ばれる)を別のホスト(ターゲットホスト)上に作成するプロセスです。VMレプリカは通常の仮想マシンであり、必要になるまでは電源オフの状態を維持しますが、必要になった時点で、そのホスト上でほぼ瞬時に起動して稼働を開始することができます。
作成方法を確認し、 VMwareのレプリケーションジョブを設定する で NAKIVO Backup & Replication 詳細については。
事業継続性と高可用性を維持するために、ソース(本番)VMからDRサイトのVMレプリカへワークロードを切り替えるプロセスは、フェイルオーバーと呼ばれます。
VMレプリケーションのベストプラクティス
次のようなものがあります 複製に関するさまざまなベストプラクティス プロセスの信頼性と有効性を高めるために。ここでは、次の2つの重要な点に焦点を当てます:
Perform VM replication at thehost level rather than the guest level. 仮想化レイヤーとは、物理ハードウェアとVM上で動作するゲストOSとの間の仲介層のことです。仮想化レベルで行われるレプリケーションは"ホストレベル"と呼ばれ、ゲストレベルでのレプリケーションよりも効率的です。Use application-aware replication to avoid data loss.レプリケーションに必要なVMのスナップショットを、これらのアプリケーションが実行中の状態で何らかの追加操作を行わずに取得した場合、予期せぬ停電やシャットダウンが発生したのと同様の影響が生じ、データが失われる可能性があります。
アプリケーション対応の手法では、アプリケーションが一時停止(クワイエスド)され、メモリがフラッシュされるため、スナップショットが取得されるまではディスクへの書き込みが行われません。一貫性のあるスナップショットが取得されると、VMのレプリカを作成できます。このようなVMレプリカは、その中のアプリケーションが正常に動作した状態で、正常に復元することができます。
NAKIVO Backup & Replication VMware VM、Hyper-V VM、およびEC2インスタンス向けのアプリケーション認識型ホストレベルレプリケーションをサポートしており、Microsoft SQL Server、Exchange Server、およびActive Directoryドメインコントローラー向けの特別な機能を備えています。
ステップ3. 災害復旧ワークフローの作成
DRワークフローを作成するには、次のような専用の災害復旧ソリューションが必要です。 NAKIVO Backup & Replication…には、DRプロセスを調整・自動化する組み込みのSite Recovery機能が備わっています。
災害復旧ワークフローとは何ですか?
DRワークフローとは、ワークロードをレプリカへ安全かつ迅速にフェイルオーバーさせるための災害復旧プロセスの一環として実行される一連のアクションのことです。このワークフローでは、ソースVM、ターゲットVM、満たすべき条件などに関連するアクションを用いて、フェイルオーバープロセスを体系化します。一部の災害復旧手順は他の手順の実行結果に依存する場合があるため、アクションの実行順序を定義する必要があります。
利用可能なサイト復旧アクション
Site Recovery 機能を使用すると、単一のワークフロー内でアクションと条件を組み合わせて、複雑な DR シーケンスを作成できます。各アクションは、テストモードのみ、本番モードのみ、または両方のモード(これがデフォルト設定です)で実行できます。 NAKIVO Backup & Replication.
シーケンスには、以下のアクションを1つでもすべてでも含めることができます:
Failover– レプリカのVMware VM、Hyper-V VM、またはEC2インスタンスへのフェイルオーバーを開始します。Failback– VMレプリカからソースVMへワークロードを戻します。フェイルオーバー以降にVMレプリカで行われた変更は、フェイルバック操作の実行時にソースVMに書き込まれます。これによりVMが同期され、ソースVMは再び本番環境の状態に戻ります。Start– VMware VM、Hyper-V VM、またはEC2インスタンスを起動します。Stop– 実行中のVMware VM、Hyper-V VM、およびEC2インスタンスを停止します。Run job– バックアップジョブ、レプリケーションジョブ、サイトリカバリジョブ、バックアップコピージョブ、またはFlash VM Bootジョブを実行します。Stop jobs– ジョブを停止します(前の項目に挙げたジョブのいずれか)。Run script– 以下のいずれかの対象(Directorがインストールされたサーバー、リモートWindowsサーバー、リモートLinuxサーバー、VMware VM、Hyper-V VM、またはEC2インスタンス)でスクリプトを実行します。Attach repository– で使用されるバックアップリポジトリを関連付けます NAKIVO Backup & Replication バックアップを保存するため。Detach repository– バックアップリポジトリを切り離します。Send email– 作成したメッセージを、指定した1人または複数の受信者にメールとして送信します。Wait– 指定された時間が経過するまで待機し、その後次のアクションに進みます。Check condition– 入力内容(リソース名の全部または一部)に基づき、以下の条件のいずれかをチェックします:- そのリソースは存在します
- リソースが実行中です
- IPアドレスまたはホスト名に接続可能
Site Recovery ワークフローの構築方法
では、Site Recoveryジョブを作成する方法の例を見てみましょう。 NAKIVO Backup & Replication.
当社の構成
ここでは、VMware vSphere 仮想マシンを稼働させるプライマリ(本番)サイトと、遠隔地に設置されたDRサイトという構成について検討します:
- DC-VM Active Directory ドメイン コントローラーを実行している Windows ベースの仮想マシンです。
- FS-VM これは、ファイルサーバーが稼働しているWindowsベースの仮想マシンです(ファイル共有にはSMBプロトコルが使用されています)。ユーザー認証にはActive Directoryが使用されています。Oracleデータベースのダンプファイルは、このファイルサーバーに保存されています。
- Ora-DB Oracleデータベースが実行されている仮想マシンです。
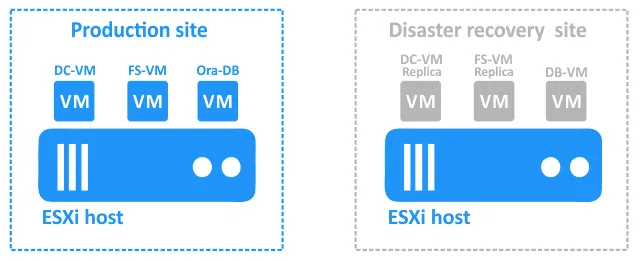
災害復旧サイトには、以下の仮想マシンが含まれています:
- DC-VM-レプリカ そして FS-VM-レプリカ これらは本番用VMのレプリカです。フェイルオーバーのターゲットとして使用できます。
- DB-VM は、Linuxベースの仮想マシンであり、 Oracle Database ソフトウェアがインストールされています ただし、データベースは含まれていません。
データベースは以下の方法でバックアップされます NAKIVO Backup & Replication データベースレベルで FS-VM 生産現場で(この Oracleデータベースのバックアップ (アプリケーションとの整合性が保たれている)。 FS-VM そして DC-VM NAKIVOソリューションにより、ホストレベルでDRサイトへレプリケーションされます。
VMの復旧手順
本番サイトが停止する事態が発生した場合、DRサイトにおいて以下の手順でコンポーネントを復旧する必要があります:
- フェイルオーバー DC-VM ~へ DC-VM-レプリカ。
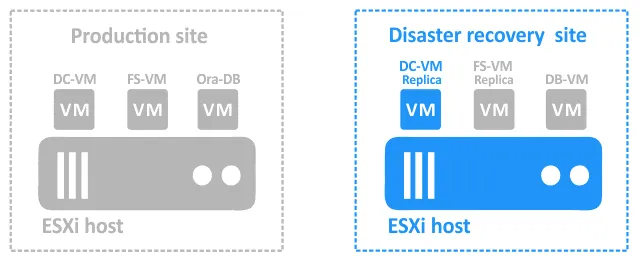
- かつて DC-VM-レプリカ が稼働中、フェイルオーバーは FS-VM ~へ FS-VM-レプリカ. この順序で操作する必要があるのは、 FS-VM ~に依存している DC-VM ファイルサーバーでのユーザー認証のために。
- これら2つのVMが起動したら、 DB-VM ダンプが保存されているファイルサーバー上の共有ディレクトリにアクセスできます。さて DB-VM を開始できます。
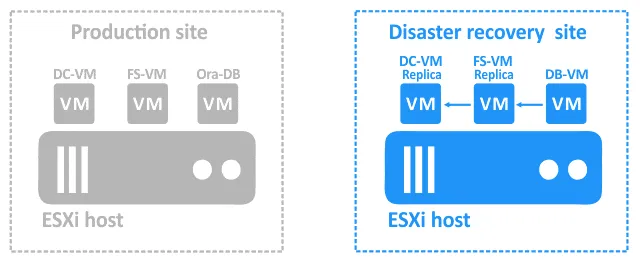
- かつて DB-VM が実行されている場合は、ファイルサーバーにあるダンプからデータベースを復元できるスクリプトを実行してください。上の図の青い矢印は、依存関係を示しています。
フェイルオーバー処理が完了した後、電源が投入されたVMレプリカ上でサービスが起動し、次のレプリカへのフェイルオーバーやアプリケーション・データベースの復旧が行われるまでには、ある程度の時間がかかる場合があることに注意してください。この待機時間は、DR手順の一部として考慮する必要があります。
このVMフェイルオーバーの手順では、 NAKIVO Backup & Replication 以下のロジックに基づき:
Action 1: DC-VMのフェイルオーバー. この処理が完了するまで待ってから、次の手順に進んでください。この処理が失敗した場合は、ジョブを停止してください。Action 2. 待って 3分間。Action 3. 状態を確認する の DC-VM-レプリカ. リソースが実行中かどうかを確認します。リソースが実行中の場合は、Site Recovery ジョブの次のアクションに進みます。実行中でない場合は、ジョブを停止し、失敗として処理します。Action 4. FS-VMのフェイルオーバー. 次の処理に進む前に、この処理が完了するまで待機してください。この処理が失敗した場合は、ジョブを停止してください。Action 5. 待って 3分間。Action 6. 状態を確認する の FS-VM-レプリカ. リソースが実行中の場合は、Site Recovery ジョブの次のアクションに進みます。実行中でない場合は、ジョブを停止し、失敗として処理します。Action 7. DB-VM を起動する. 次の処理に進む前に、この処理が完了するまで待機してください。この処理が失敗した場合は、ジョブを停止してください。Action 8. 待って 5分間。Action 9. スクリプトを実行する. 対象タイプ:VMware VM。対象VM:DB-VM。スクリプトのパス:/home/oracle/restore_db.sh(このステップを追加する際は、スクリプトを実行するための十分な権限を持つアカウントのユーザー名とパスワードを入力する必要があります)。
NAKIVOのSite Recovery 操作ガイド
上記の計画に基づいて、新しい Site Recovery ジョブを作成しましょう。 Jobs あなたの NAKIVO Backup & Replication 例えば、[クリック] Create > Site recovery job.
1. アクション
その 新しいサイト復旧ジョブウィザード が起動します。左側のパネルには、ジョブに追加できるアクションが表示されます。アクションをクリックするだけで、シーケンスに追加できます。なお、1つのシーケンス内で異なるプラットフォーム向けのアクションを混在させることはできません(ここではVMware VM用のジョブを作成しています)。
アクション 1. DC-VM のフェイルオーバー
- 左側のペインで、[クリック]
Failover VMware VMs.
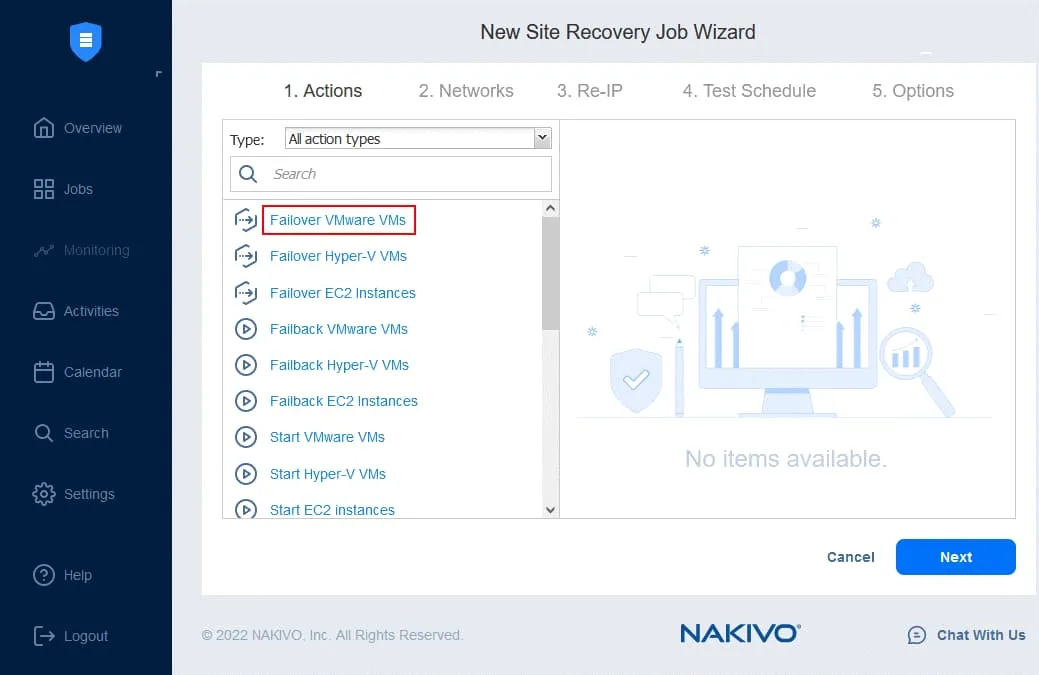
- 左ペインで、既存のレプリケーションジョブからVMレプリカを選択します。このワークフローでは、フェイルオーバー先として DC-VM-レプリカ これが最初の操作です。右側のペインで、リカバリポイントを選択できます。デフォルトでは、最新のリカバリポイントが使用されます。
クリック Next 続きを読む。
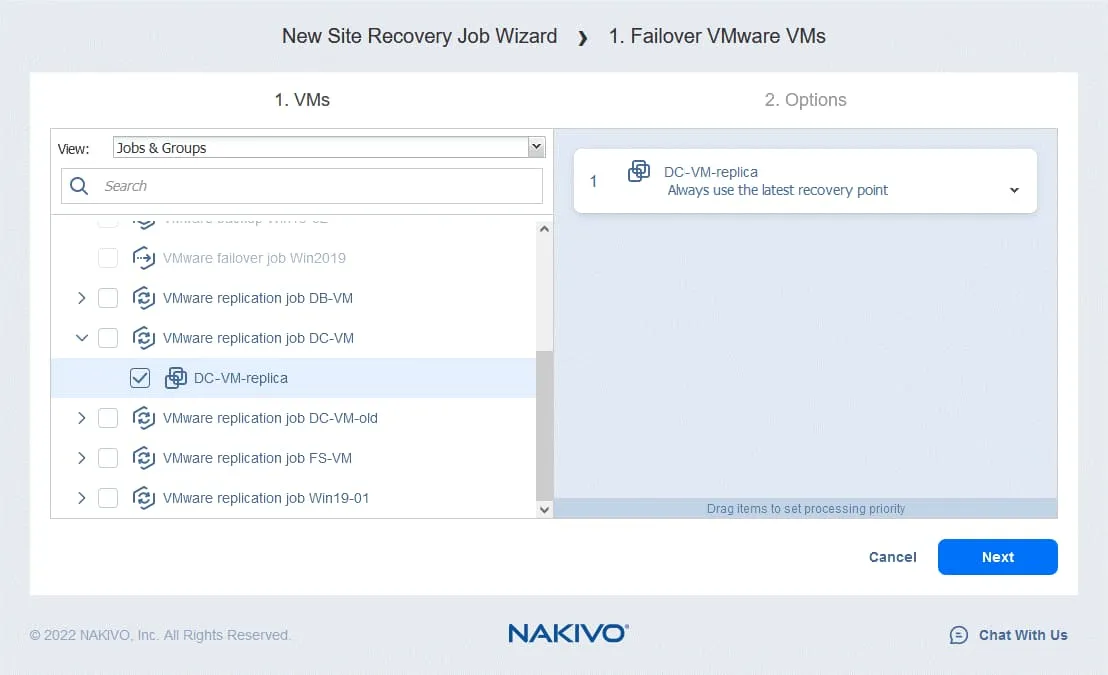
- 災害復旧のために フェイルオーバー オプションでは、選択を解除できます
Power off source VMs– このオプションは、ソースVMとレプリカが同じネットワークを使用している場合に、IPアドレスの競合を防ぐために使用できます。
上記の論理に基づき、以下の選択肢を選定します:
- このアクションを実行する場所:
Run this action in both testing and production mode - 待機時の挙動:
Wait for this action to complete - エラー処理:
Stop and fail the job if this action fails
クリック Save 作成したアクションを保存するには。
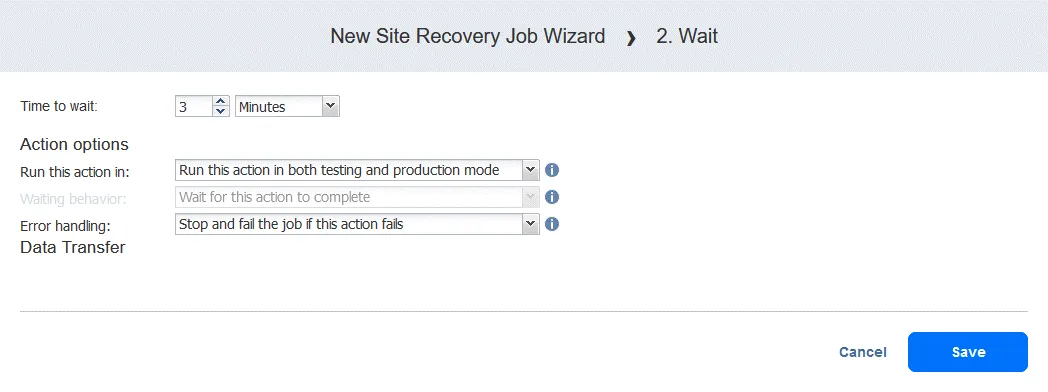
手順 2. 3分間待つ
A 待って このケースでは、このアクションが有用です。なぜなら、ワークフロー内の次のフェイルオーバーアクション(フェイルオーバー先: FS-VM-レプリカ) には、 DC-VM-レプリカ Active Directory ドメイン サービスがすでに稼働している状態であること。
- の左ペインで アクション 画面上でクリック
Wait.
- 待機時間を選択してください(ここでは 3分).
最初のアクション時と同様にアクションのオプションを選択し、クリックしてください Save.
新しいアクションは、リストの一番下にある前のアクションの後に追加されます。アクションの順序変更、編集、削除が可能です。アクションにマウスを合わせると、オプションが表示されます。
アクション3. の状態を確認する DC-VM-レプリカ
- の左ペインで アクション 画面上でクリック
Check condition最初のアクションでフェイルオーバーされたVMが実行中かどうかを確認する。
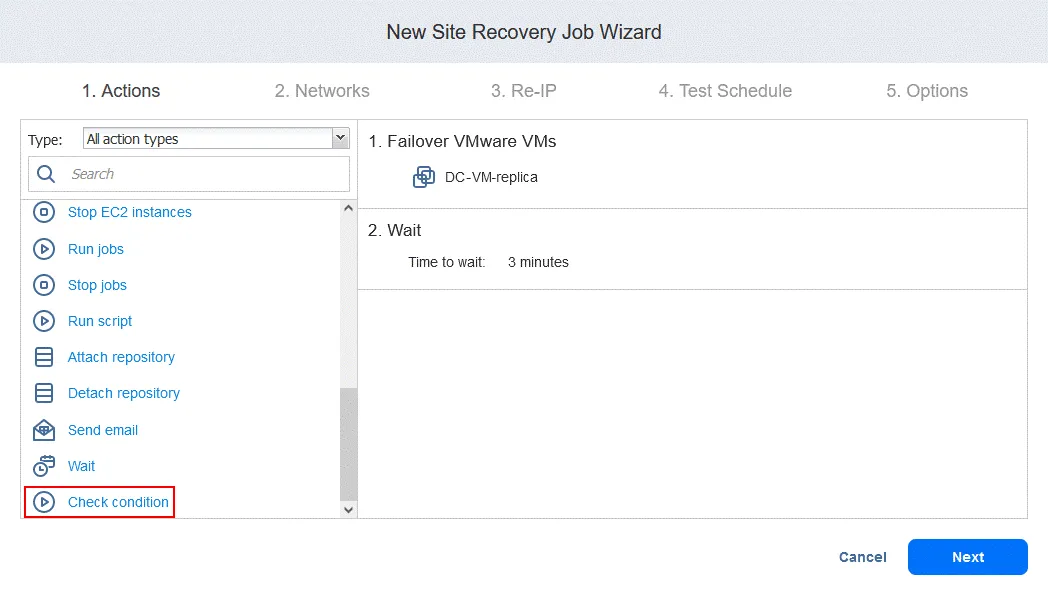
- このアクションを次のように設定してください:
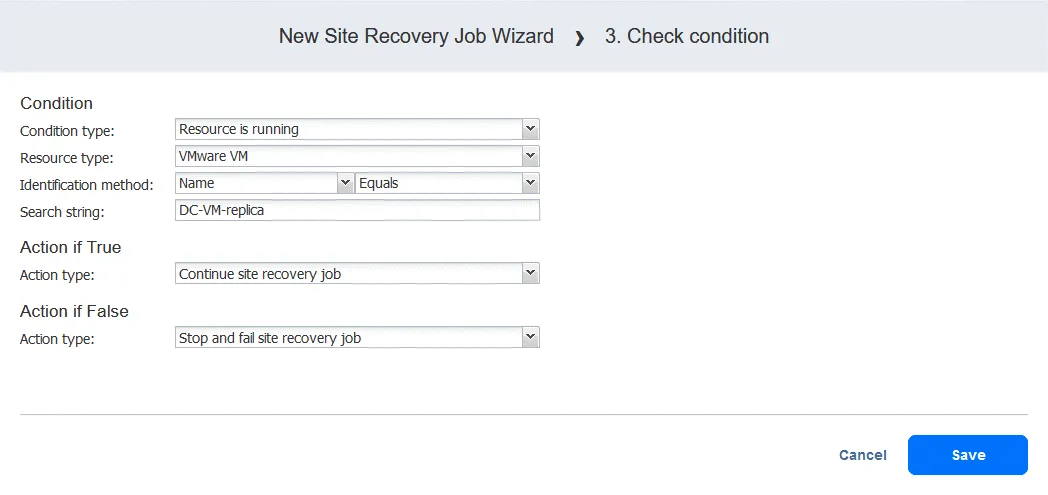
- 条件タイプを選択してください:
Resource is runningその他の選択肢は リソースが存在します または IPアドレス/ホスト名 アクセス可能です。 - リソースの種類を選択してください:
VMware VM. - 認証方法を選択してください:
Name(もう一つの選択肢は ID) を使用して、対象のVMを特定します。VMの文字列の任意の部分を使用できます。ここでは正確な名前がわかっているため、Equals関数。 - 検索文字列を指定してください:
DC-VM-replica.
これで、名前が DC-VM-レプリカ 実行中です。クリック Save 続行するには。
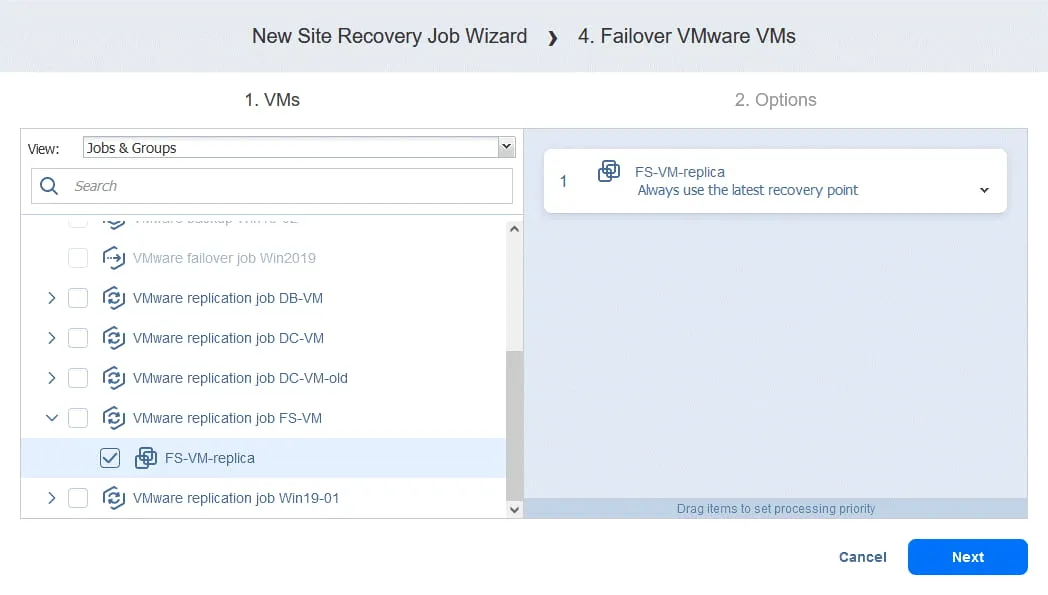
アクション 4. FS-VM のフェイルオーバー
- 前述の アクション1、クリック
Failover VMware VMs.
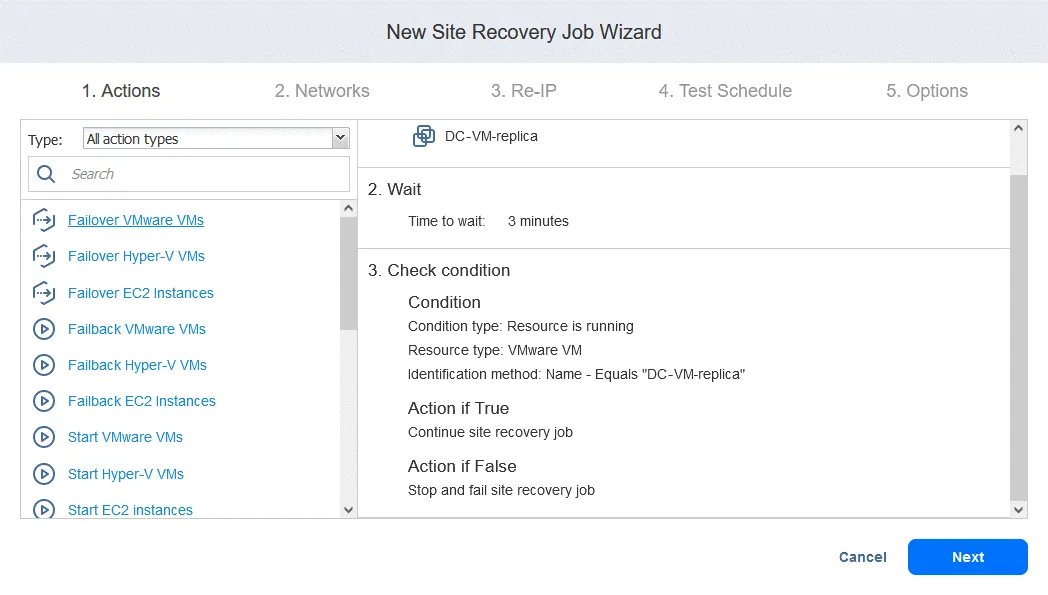
- 私たちは選定します FS-VM-レプリカ この場合は、クリックしてください
Next、次にフェイルオーバーアクションについて、 アクション1 をクリックしてSave.
手順5. 3分間待つ
クリック Wait そして、このアクションを、先ほど行ったのと同じように設定します アクション2指定された時間は、やはり 3分 私たちの場合。
アクション6. の状態を確認する FS-VM-レプリカ
クリック Check condition VMwareの仮想マシンが FS-VM-レプリカ が実行中です。詳しくは アクション2 そして、VM名以外は同じオプションを選択します。
アクション7. 開始 DB-VM
- クリック
Start VMware VMsの左ペインで アクション 画面。
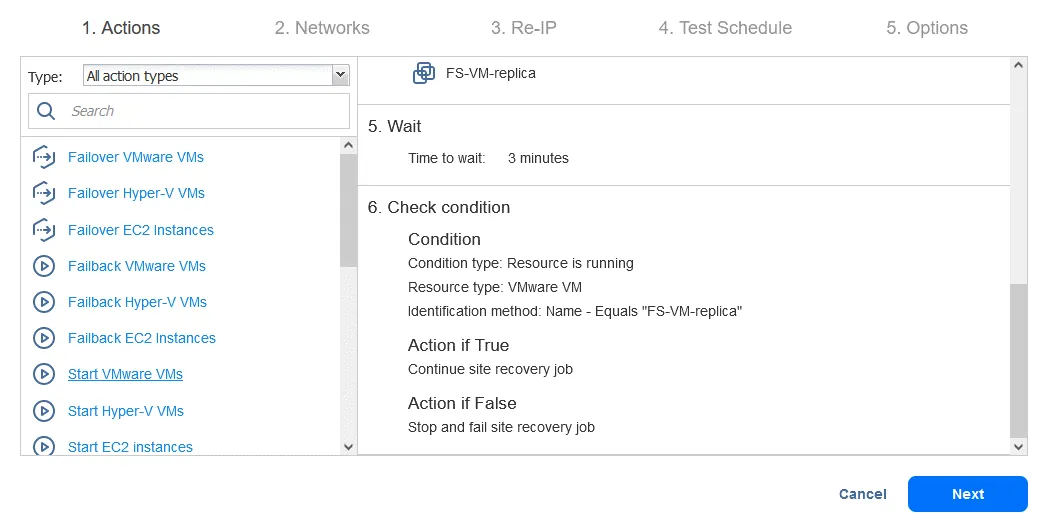
- 選択 DB-VM. 以下の点を確認し終えたら、このVMを起動できます。 FS-VM-レプリカ が実行中です。ページの下部で、前の操作と同じアクションオプションを選択してください。その後、クリックしてください
Save.
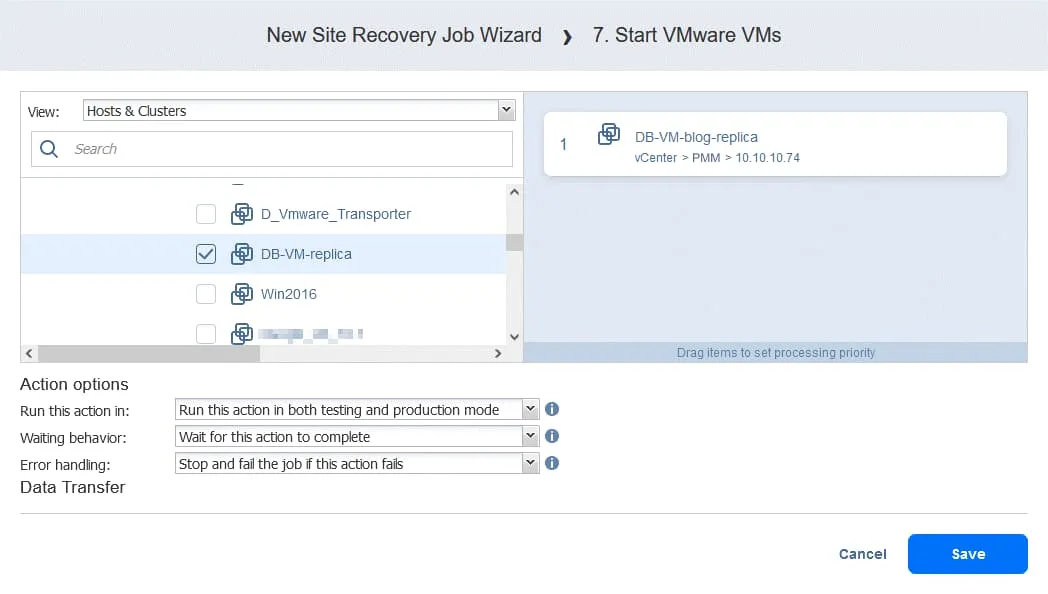
手順8. 5分間待つ
5分間お待ちください。クリックしてください Wait そして、このアクションを次のように設定します アクション2これで、Oracle サービスを起動するには十分な時間があるはずです。 DB-VM.
アクション 9. スクリプトを実行する
- ~について アクション 画面をクリック
Run scriptなお、このスクリプトは、に保存されたダンプから、データベースレベルでOracleデータベースを復元することを目的としている。 FS-VM-レプリカ.
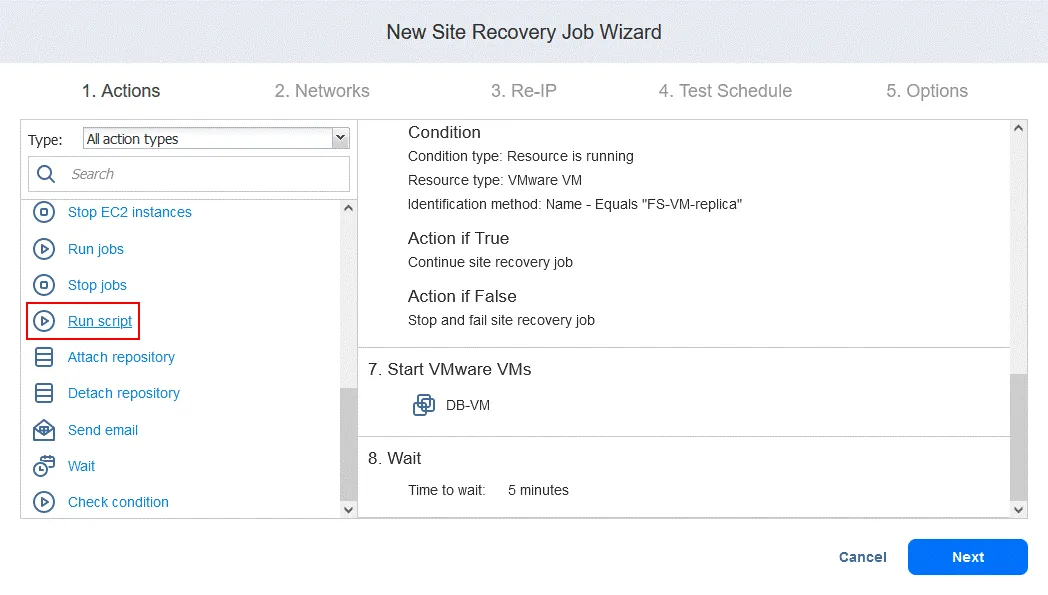
- スクリプトのオプションを定義します。今回の場合は:
- 対象タイプ: VMware仮想マシン
- 対象VM: DB-VM
- スクリプトのパス: /home/oracle/restore.db.sh
- ユーザー名: オラクル
- パスワード:(パスワード)
スクリプトのパス、ユーザー名、パスワードは環境によって異なります。スクリプトファイルが実行可能であること、およびユーザーがスクリプトを実行するための十分な権限を持っていることを必ず確認してください。この例では、アクションのオプションは通常通り設定されています。
クリック Save 準備ができたら、続けてください。
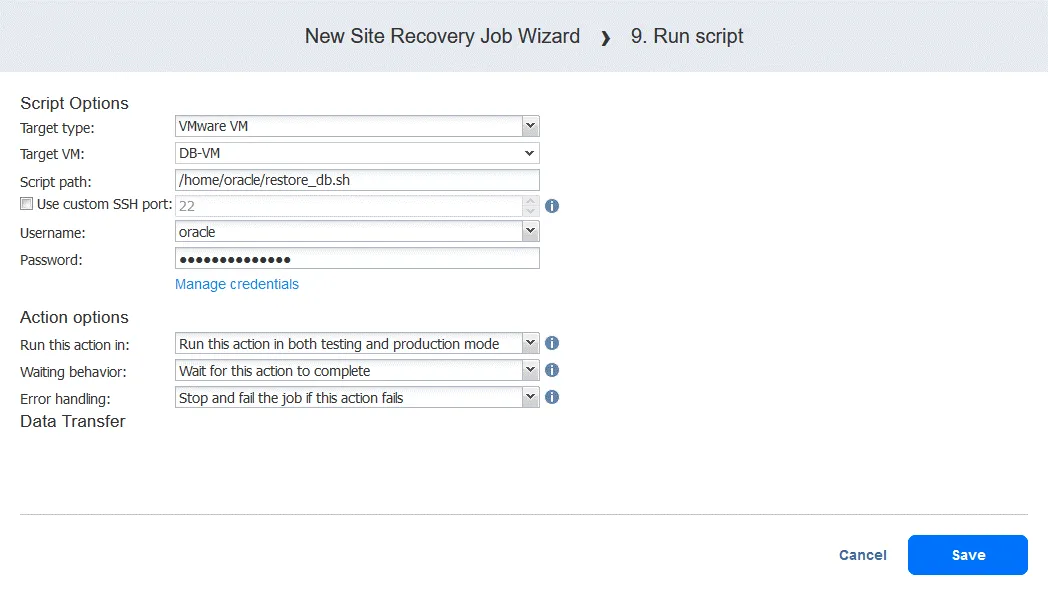
- これで、設定済みのすべてのアクションを確認できます。[]をクリックしてください。
Nextボタンをクリックして、災害復旧計画に基づいてSite Recoveryジョブの設定を続行してください。
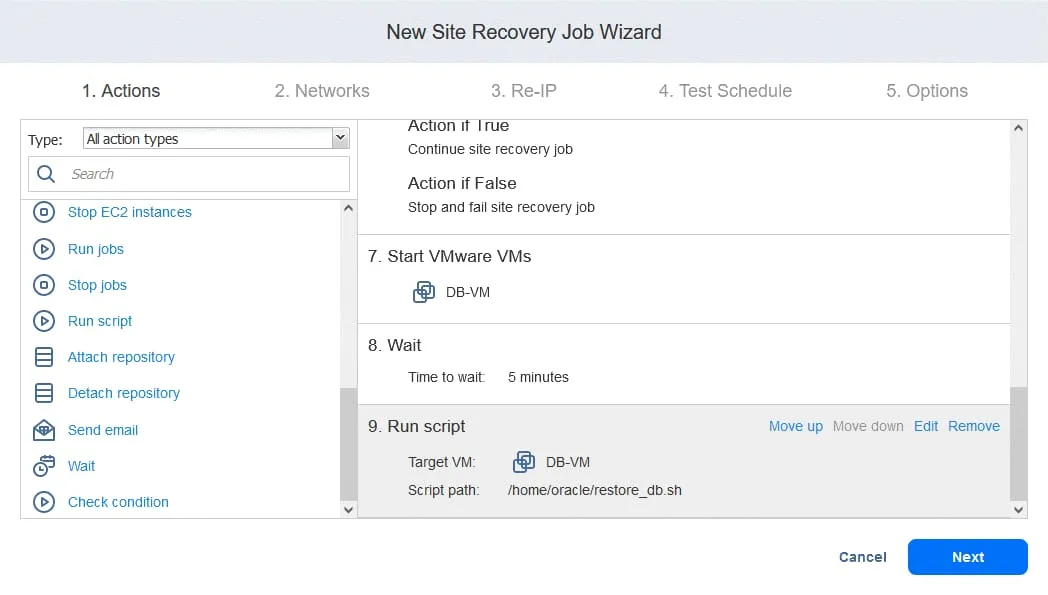
2. ネットワーク
本番サイトとDRサイトのVMが 異なるネットワークに接続されている、選択 Enable network mapping. クリック Create new mappingポップアップウィンドウで、ソースネットワーク、宛先ネットワーク、およびSite Recoveryジョブのテストに使用するネットワークを選択します。
クリック Save ネットワークマッピングルールを保存するには、[] をクリックします Next.
注: 他のレプリケーション、フェイルオーバー、または Site Recovery ジョブでマッピング規則を設定済みの場合は、それらを利用することもできます。
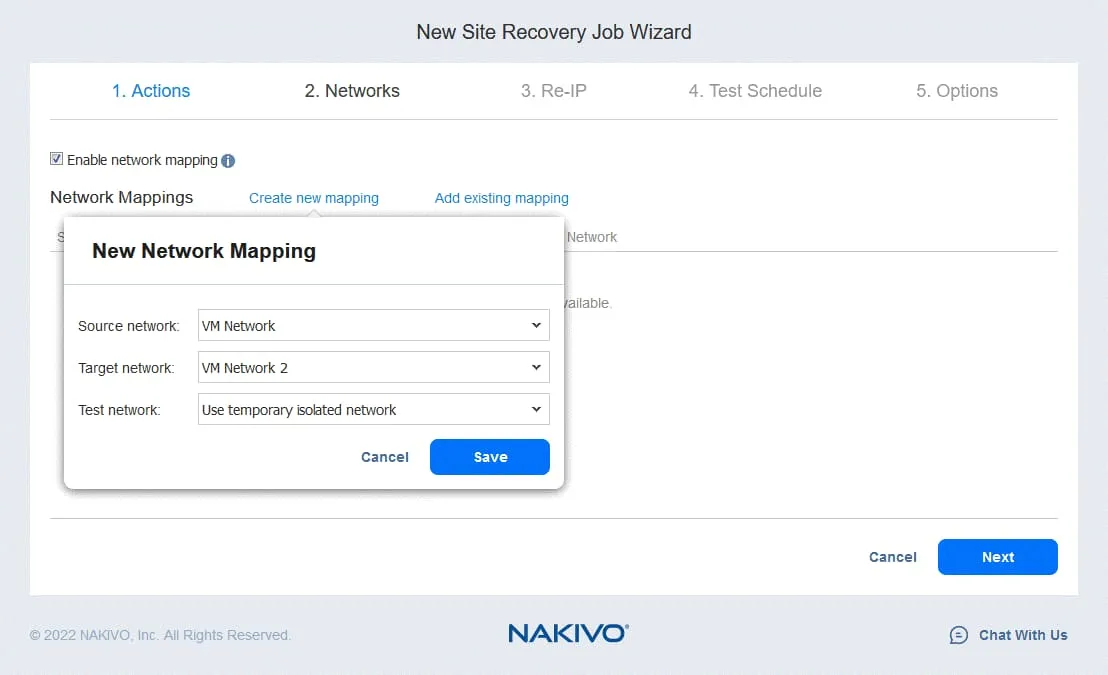
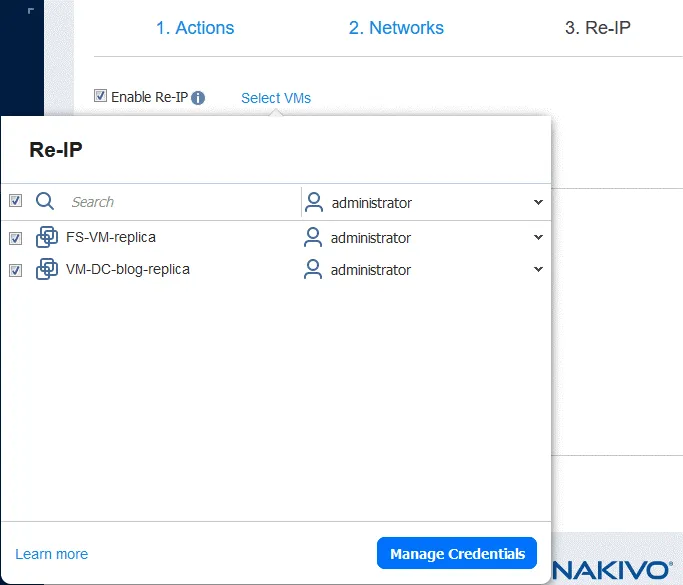
3. Re-IP
ソースサイトとターゲットサイトでVM接続に使用するネットワークのアドレスが異なる場合は、[Re-IP] を選択して有効にする必要があります。 Enable Re-IP.
- をクリックして、新しいRe-IPルールを作成します
Create new rule. ソース設定とターゲット設定を定義し、[クリック] をクリックしますSave.
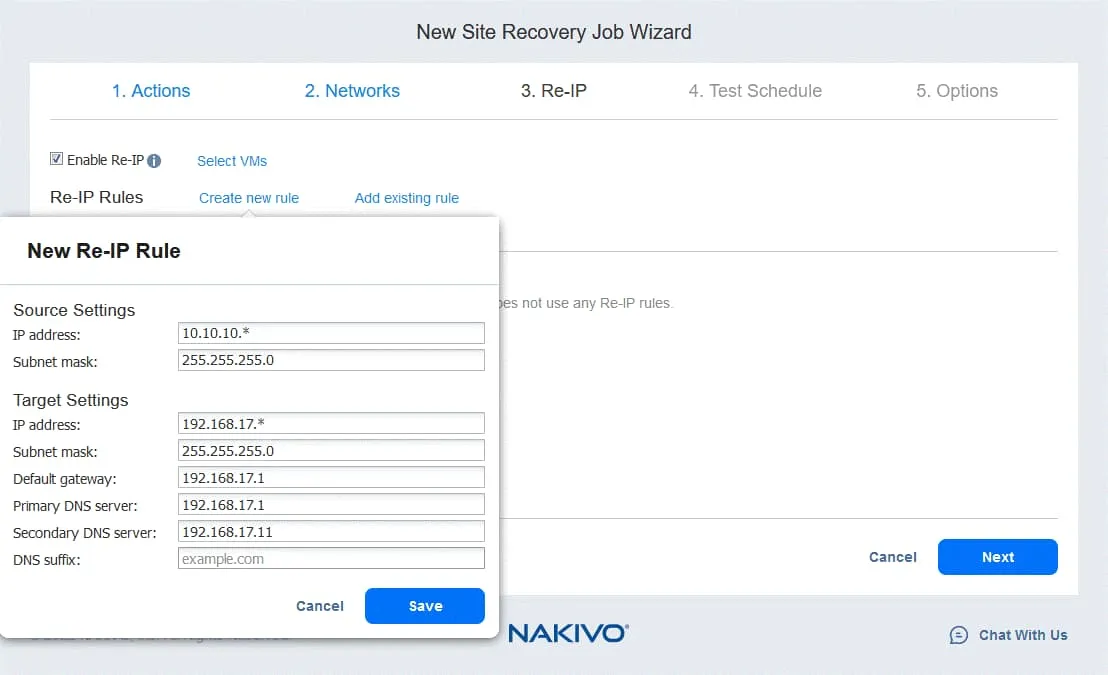
- クリック
Select VMsそして、Re-IP を使用する仮想マシンを選択してください。VM のゲスト OS でネットワーク設定を変更できる十分な権限を持つユーザーの認証情報を入力する必要があります。
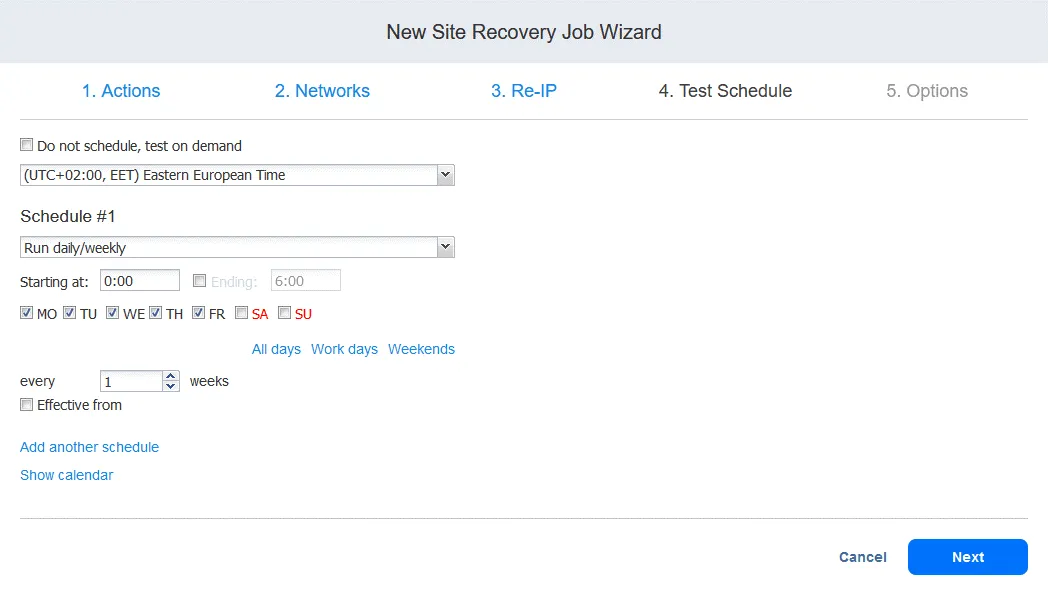
4. 試験スケジュール
テストモードで Site Recovery ジョブを実行し、災害復旧テストを行うことを目的としたスケジュールを作成できます。これにより、必要な時間枠内でジョブが正常に実行できるかどうかをテストできます。完了したら、[次へ] をクリックします。
Site Recovery ジョブのテストについては、手順 6 で詳しく説明します。
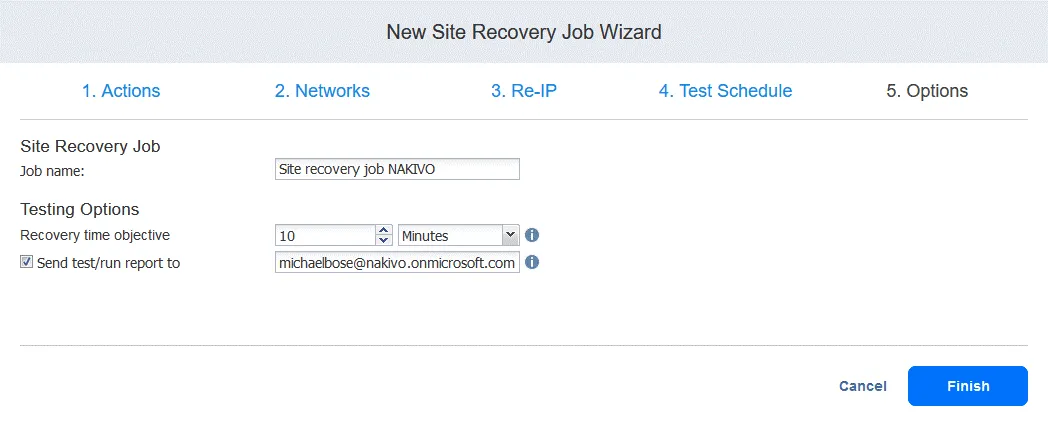
5. オプション
ジョブ名と復旧時間目標を入力します。クリックします Finish 設定が完了したら。
ステップ4. 環境の再保護
VMのフェイルオーバーが完了し、ワークロードがDRサイトに移行されると、元の本番環境のVMはオフライン状態となり、DRサイトにあるレプリカだけが稼働可能なコピーとなります。この状態で、電源が入ったVMレプリカが障害を起こした場合、データやワークロードを迅速に復旧することはできなくなります。
DRサイトで実行中のVMを保護するには、これらのVMを別の安全な場所にレプリケートする必要があります。そうすることで、DRサイトで実行中のVMに障害が発生した場合でも、新しいVMレプリカへ迅速にフェイルオーバーできます。
Site Recovery機能を使用すると、VMのフェイルオーバーが完了次第、自動レプリケーションを設定できます。以下に、フェイルオーバー後にSite Recoveryジョブを使用してVMを再保護する手順の例を示します。
- ~について
Jobsページで、先ほど作成した Site Recovery ジョブの名前を右クリックします。[クリック]Editコンテキストメニューで。
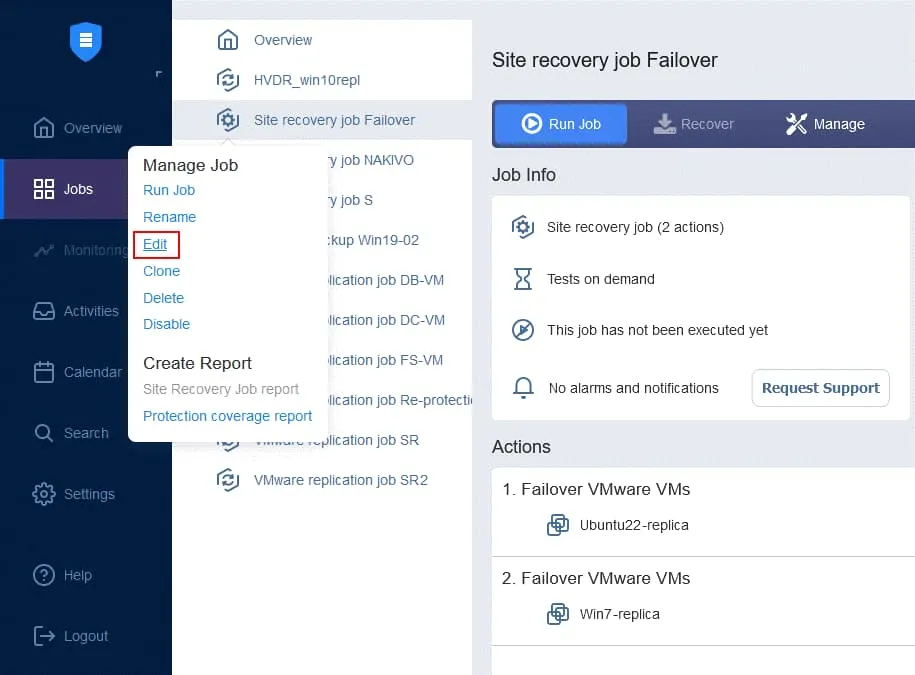
- 先ほどSite Recoveryジョブに追加したフェイルオーバー操作を確認できます。それを見つけてクリックしてください
Run jobsSite Recoveryの左パネルにあるアクション一覧からActions画面。
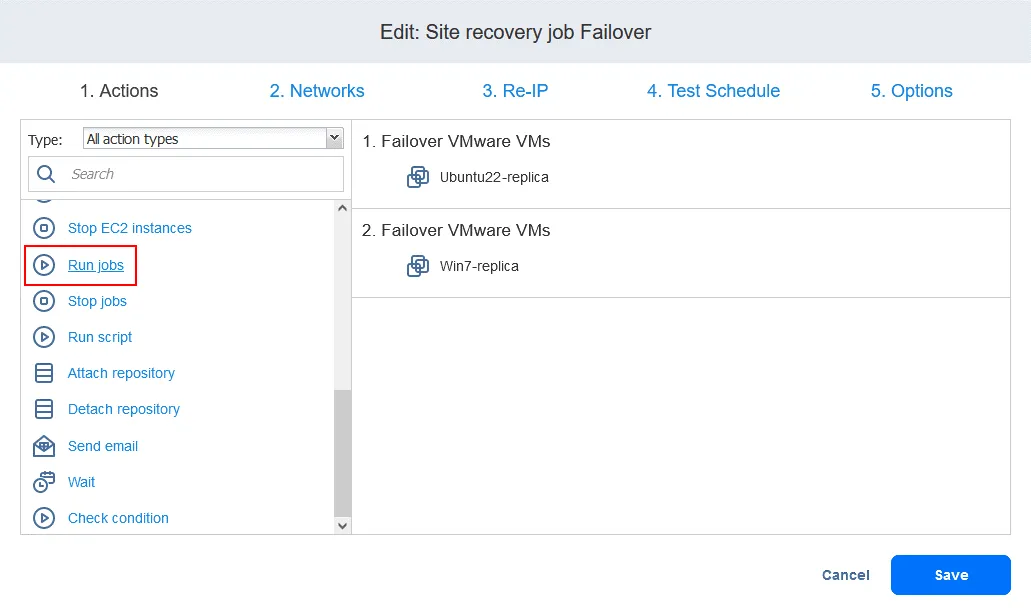
- ジョブ一覧からレプリケーション・ジョブを選択します。通常どおりアクション・オプションを選択し、[クリック] をクリックします。
Save.
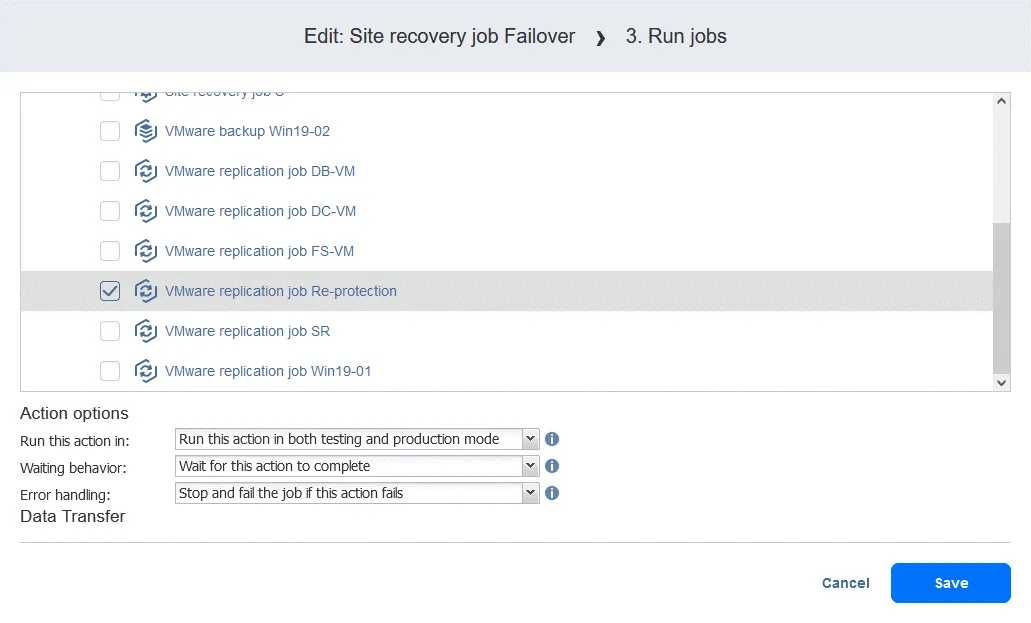
- [追加] 待って フェイルオーバー操作とレプリケーションジョブの間に行う操作です。これにより、VMレプリカが起動し、オペレーティングシステムを読み込むための時間が確保されます(電源がオフのVMはレプリケートできません)。左ペインの"アクション"リストで、[
Wait.
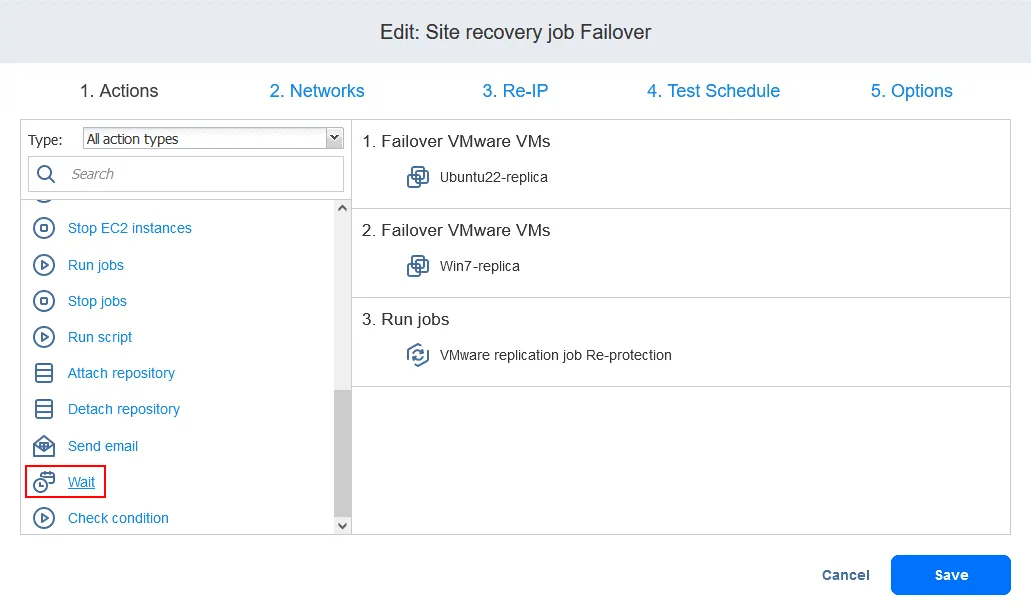
- 待機時間を選択してください。5分あれば十分です。アクションオプションを選択してクリックしてください
Save.
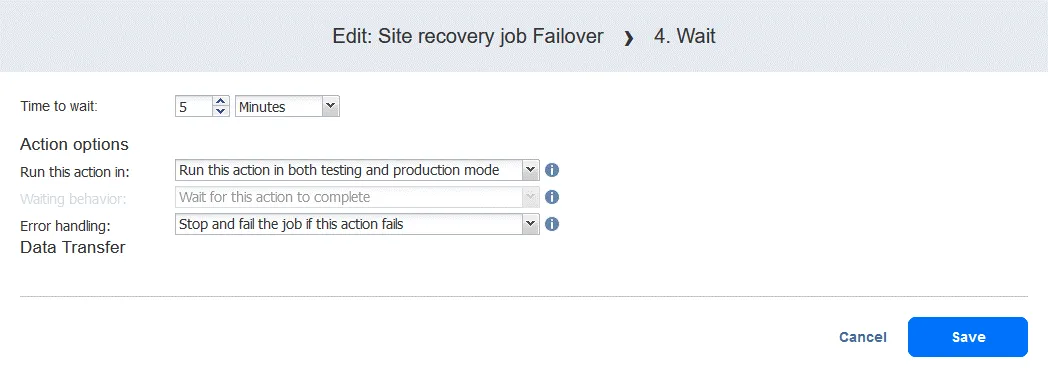
- アクションを追加すると、アクションリストの最後に追加されます。クリック
Move upそして、 待って 4番目の位置から3番目の位置への移動は、レプリケーションが行われる前に完了している必要があります。
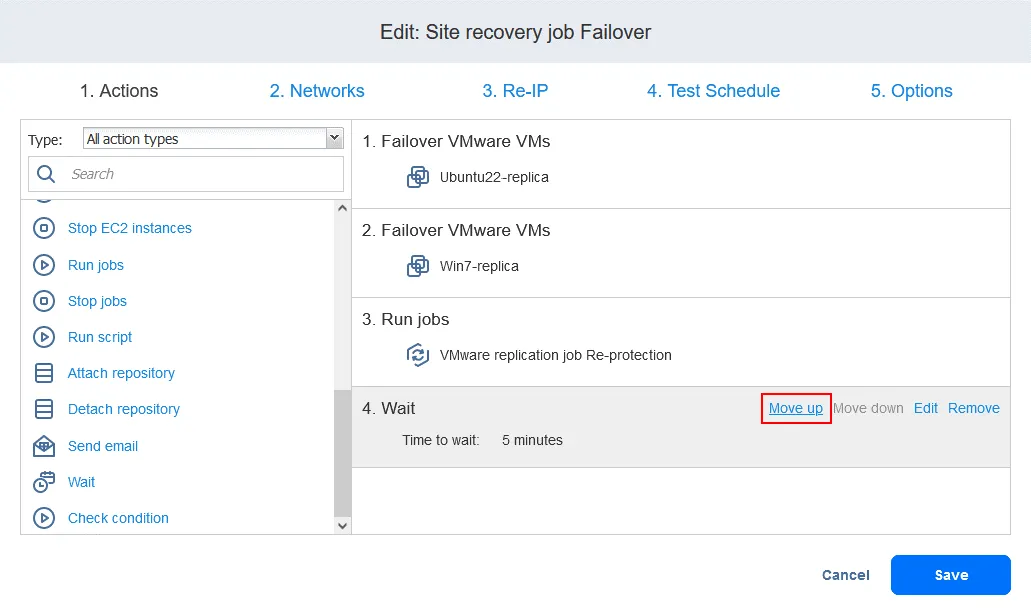
これで、アクションが必要な順序で並べ替えられました。
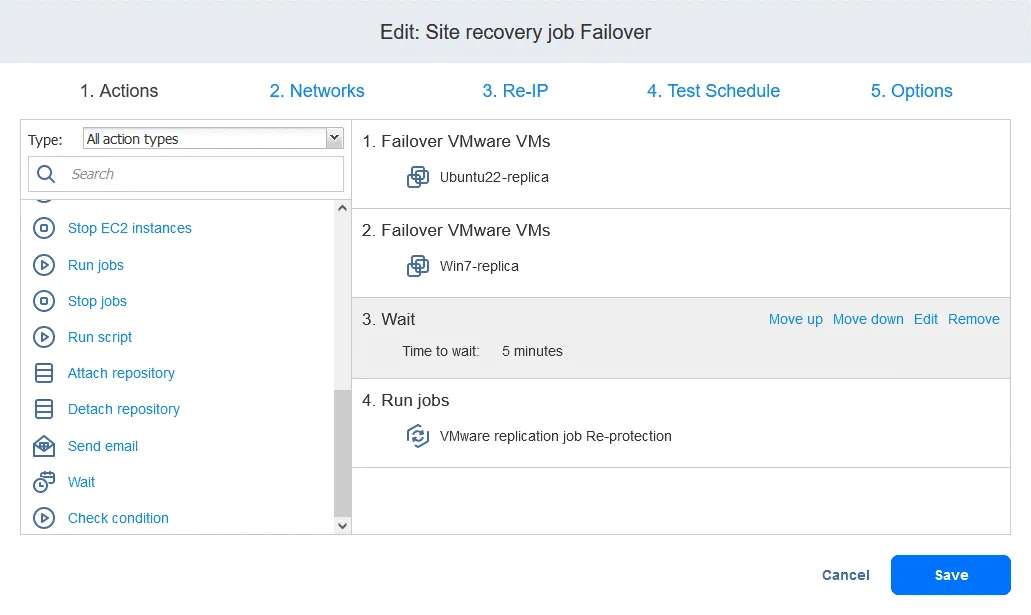
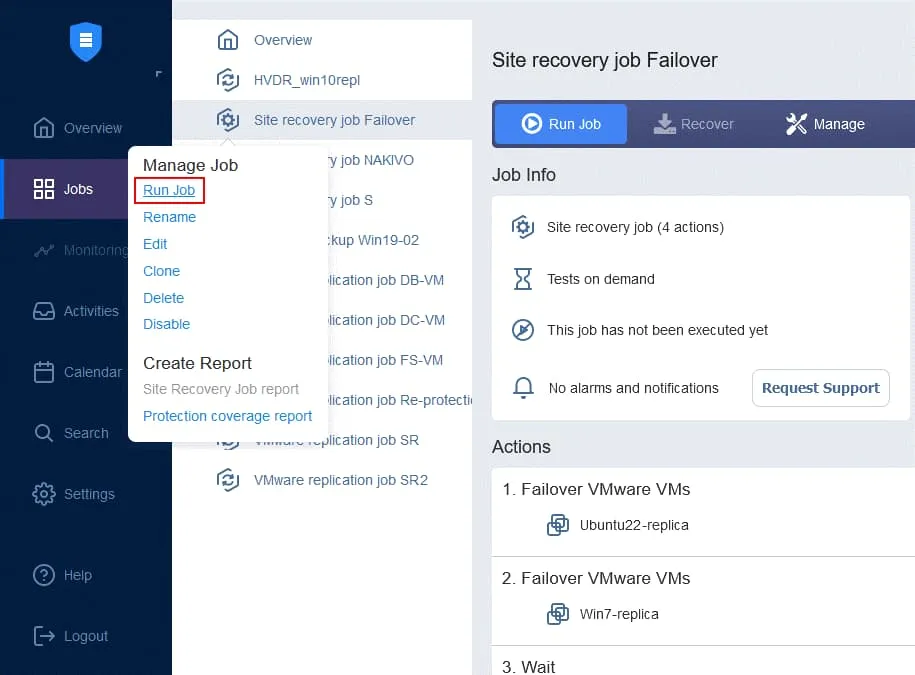
- これで、Site Recoveryジョブを使用してVMのフェイルオーバーを実行し、フェイルオーバーに使用されたVMレプリカの保護を自動的に再設定する準備が整いました。ホームページでSite Recoveryジョブの名前を右クリックし、[
Run jobコンテキストメニューで。
ステップ5. フェイルバック
フェイルバックとは、DRサイトにある仮想マシンを最新の状態で復元し、元の本番サイトまたは新しい本番サイトに戻すプロセスのことです。フェイルバックが必要な理由を理解するために、まずフェイルオーバーの仕組みを振り返ってみましょう:
- 災害が発生した場合(または発生が予測される場合)、VMのレプリカへのフェイルオーバーが実行されます。
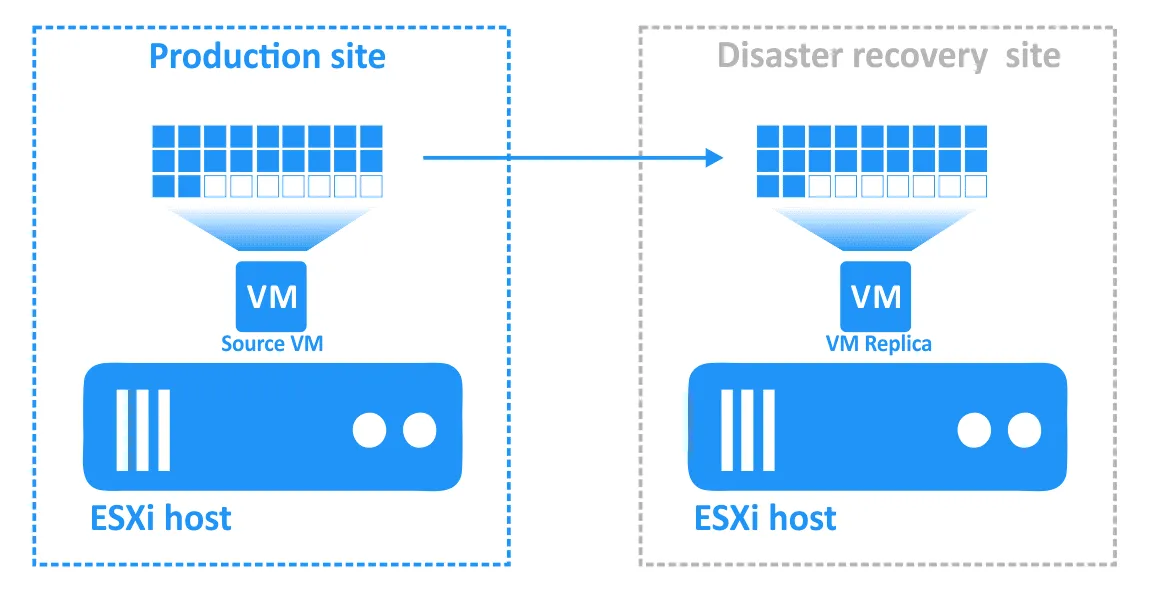
- VMへの変更(たとえば、顧客がオンラインで購入を行う際にデータベースに追加されるトランザクションなど)は、VMレプリカの仮想ディスクに書き込まれます。一部のブロックは書き込まれ、他のブロックは消去されます。ソースVMの仮想ディスクには、これらのトランザクションは存在しません。
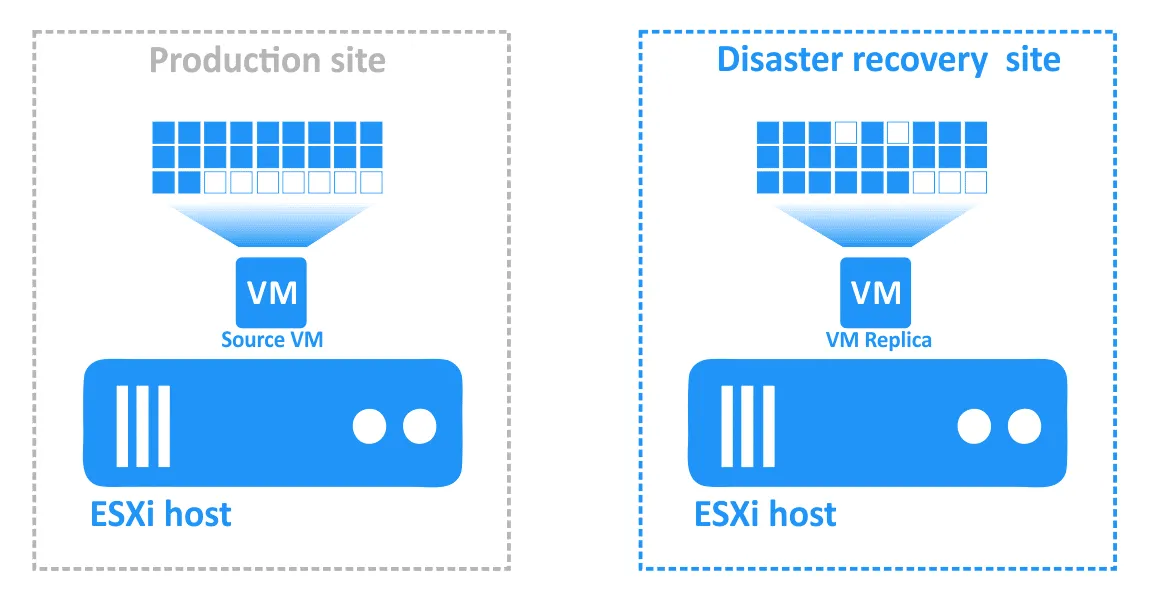
- インシデントが解決し、本番サイトが復旧したら、ワークロードを本番サイトに戻す必要があります。VMレプリカの更新されたデータをソースVMに転送する必要があります。フェイルバックを使用して、逆レプリケーションによりVMを再同期させる必要があります。
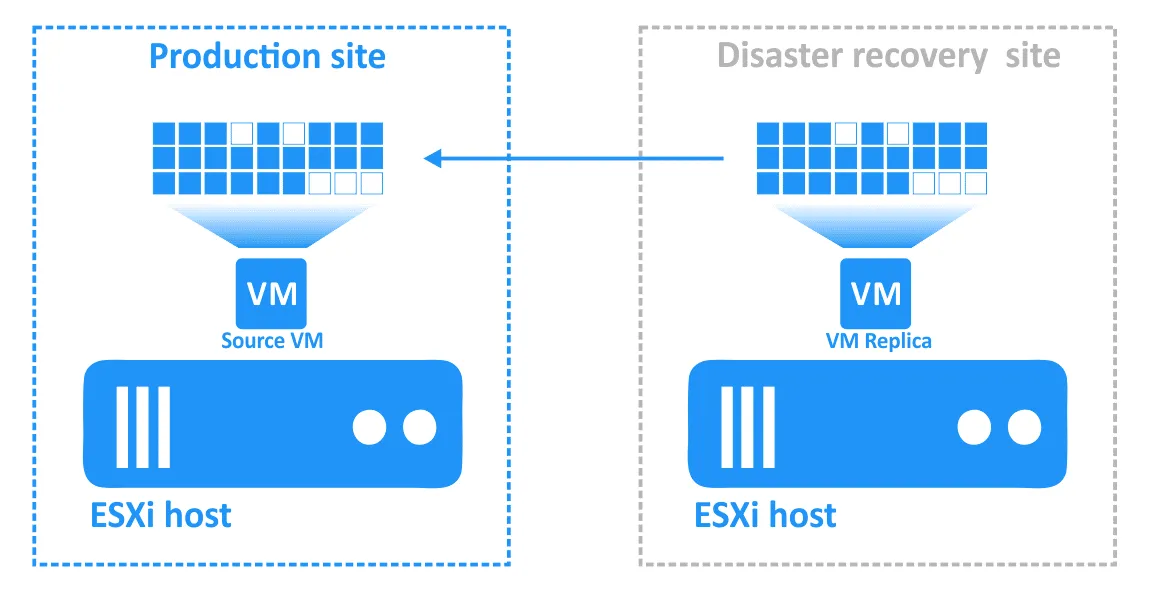
フェイルバックの設定 NAKIVO Backup & Replication
フェイルバックは、本番モードまたはテストモード(テスト終了後、フェイルバック操作によって仮想環境に加えられたすべての変更がフェイルバック前の状態に戻されるモード)のいずれかで実行できます。
それぞれのケースがどのように機能するかを詳しく見ていきましょう。
|
Production failback |
Test failback |
| 1 | 元のソースVMが存在し、電源が入っている場合は、その電源を切ります。 | |
| 2 |
作成する 保護用スナップショット ソースVMの(ソースVMが正常に動作している場合)。 このスナップショットを作成しておくと、フェイルバックが正常に実行できない場合に、ソースVMのフェイルオーバー前の状態を復元することができます。 |
|
| 3 | ランニング 増分レプリケーション (元のソースVMが本番環境で稼働している場合)または完全レプリケーション(VMを新しい本番環境に復旧する場合)。 | |
| 4 | VMレプリカの電源を切ります(任意)。 | VMレプリカはワークロードを実行するために使用され、電源は切られません。 |
| 5 | 増分レプリケーションが、VMレプリカからソースVMに向けてもう一度実行されます。今回の差分(最初のレプリケーション実行以降に変更されたデータ)は、前回よりもはるかに少なくなっているはずです。 | VMのレプリカから元のソースVM(または新しい本番用VM)へのレプリケーションは、テスト目的にはこれで十分であるため、1回のみ行われます。 |
| 6 | ネットワークマッピングを使用して、元のソースVMを新しいネットワークに接続します(オプション)。 | 本番環境に一切の影響を与えないよう、ソースVMを隔離されたネットワークに接続します(任意)。 |
| 7 | Re-IP を使用して、元のソース VM の静的 IP アドレスを変更します(オプション)。 | |
| 8 | 元のソースVMの電源を入れています。 | |
| 9 | Cleanup after a successful failbackフェイルバックが正常に完了すると、ソースVMとVMレプリカの両方が通常の状態に戻ります。
|
Cleanup if the source VM didn't exist before the test failback was run:
|
フェイルバックの準備
まず、フェイルオーバー操作を含む Site Recovery ジョブを作成する必要があります。この手順については、すでに詳しく説明しました。
- フェイルオーバーを実行するには、レプリケーションジョブとVMレプリカが必要です。
- フェイルバックを実行するには、サイト復旧ジョブにフェイルオーバー操作を含める必要があります。
- VMレプリカはフェイルオーバー状態である必要があります。したがって、フェイルオーバーを実行した後にのみ、フェイルバックを実行できます。
フェイルバックの実行
フェイルバックを実行する方法について、例を挙げて説明しましょう。 NAKIVO Backup & Replication.
- フェイルオーバーが Site Recovery ジョブの一部として実行されていることを確認してください(このジョブはすでに作成されているはずです)。
- 新しい Site Recovery ジョブを作成します。フェイルバックのアクションはこのジョブに組み込むことができます。
Jobsページで、[クリック]Create>Site recovery job.
その 新しいサイト復旧ジョブウィザード がリリースされました。
1. Actions.
- 左側のペインで、[ ] をクリックします
Failback VMware VMs(その他の環境では、Failback Hyper-V VMsまたはFailback EC2 Instances).
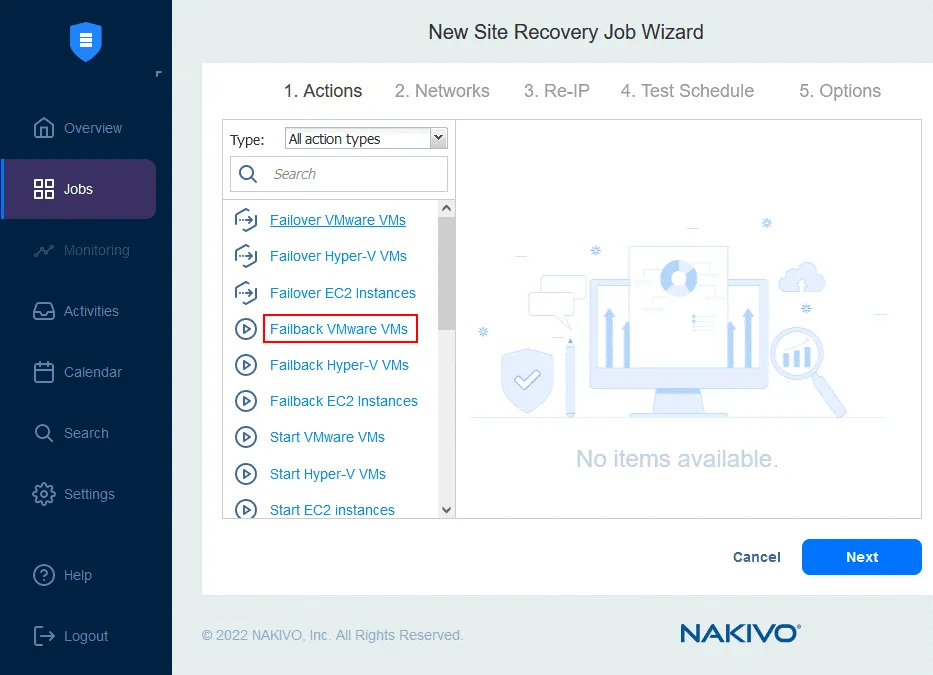
- フェイルオーバー操作を適用するVMレプリカを選択します。[クリック]
Next.
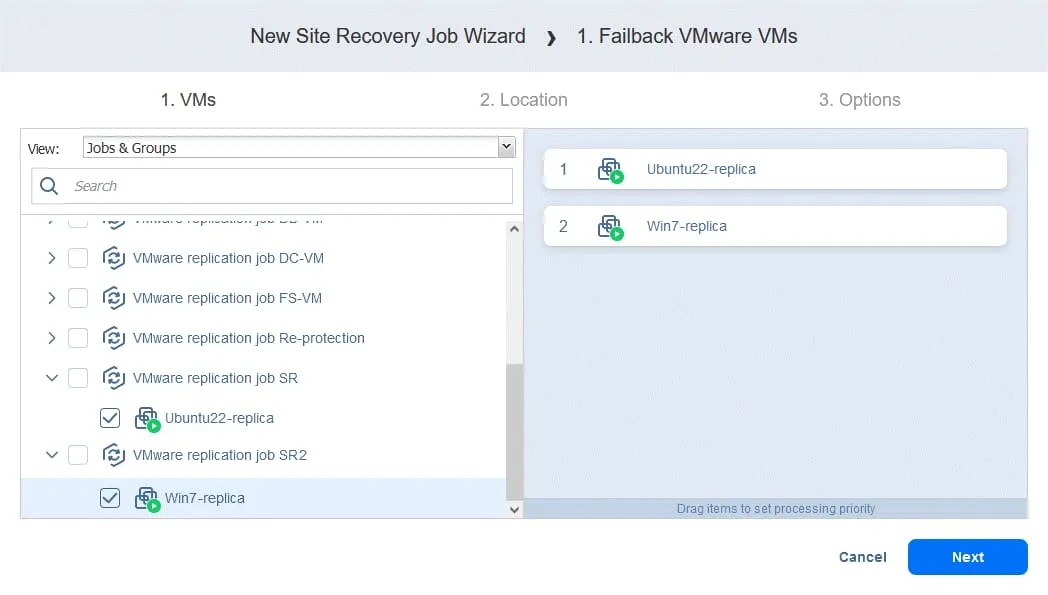
- フェイルバック先を選択してください。元の本番サイトでも、新しい場所でも構いません。クリックしてください
Next.
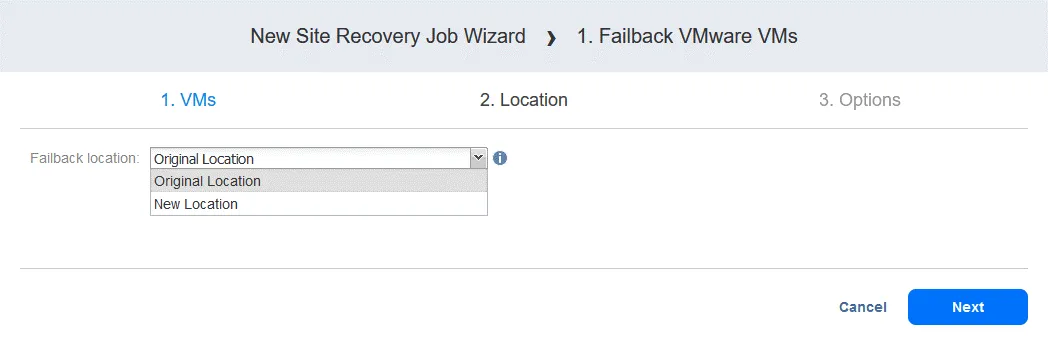
- ジョブオプションを選択します。選択
Power off replica VMs必要に応じて、クリックしてくださいSave準備が整いましたら、次へ進んでください。
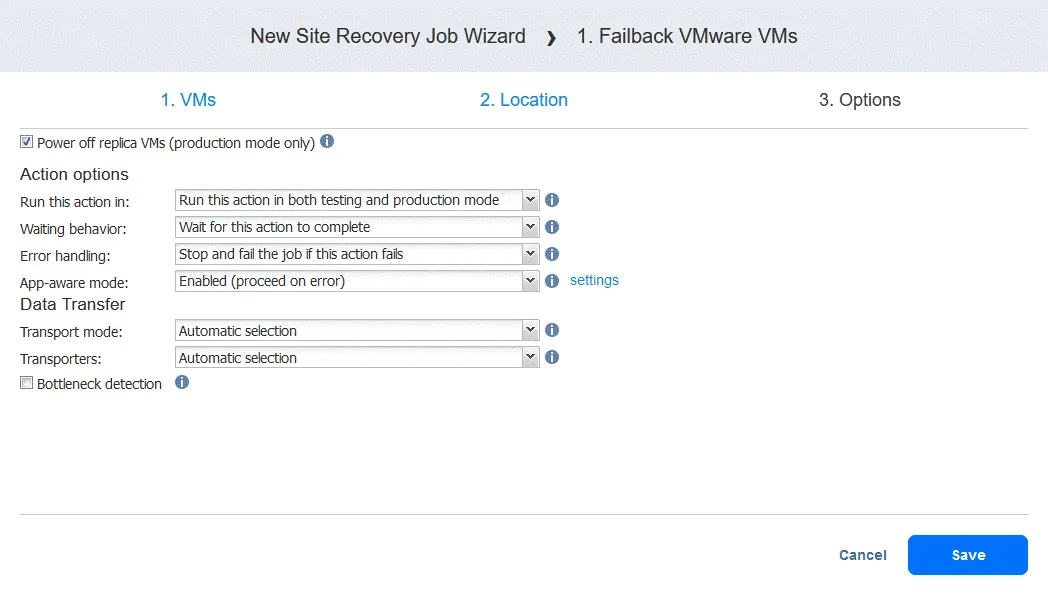
- フェイルバック操作を追加すると、Site Recoveryジョブは下のスクリーンショットのような表示になります。[クリック]
Next.
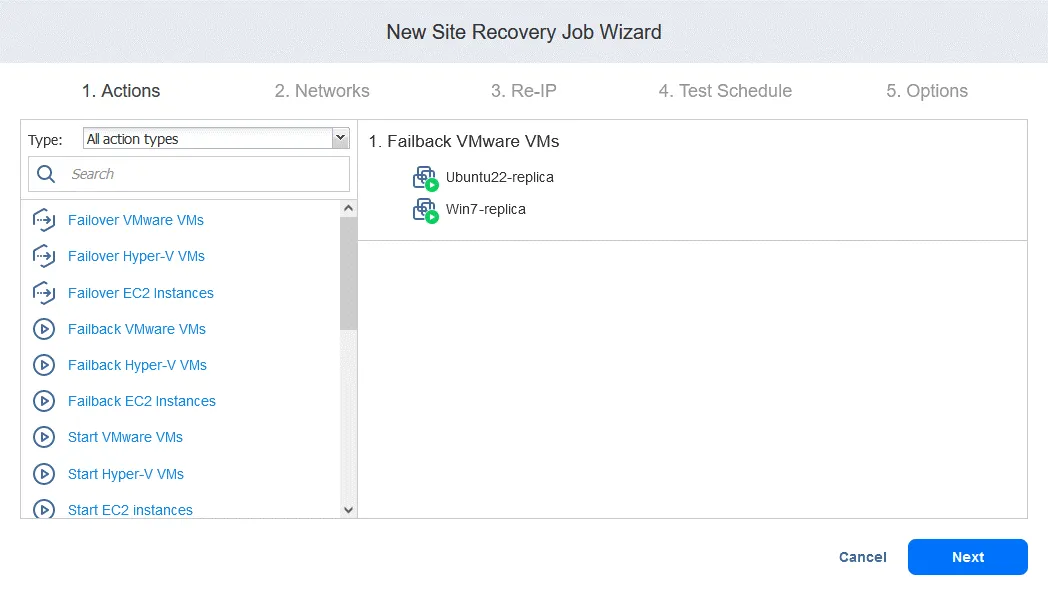
2. Networksこのジョブでネットワークマッピングを有効にする必要がある場合は、このオプションを選択してください。[クリック] Next.
3. Re-IPこのジョブでRe-IPを有効にする必要がある場合は、このオプションを選択してください。[クリック] Next.
4. Test Schedule. スケジュール設定を行い、[クリック] をクリックします Next.
5. Options. Site Recovery ジョブのオプションを定義し、ジョブ名を入力します。VM に必要な RTO を設定したり、フェイルバック レポートの受信先メールアドレスを指定したりできます。[クリック] Finish フェイルバック機能を含むこの新しいSite Recoveryジョブの作成を完了します。
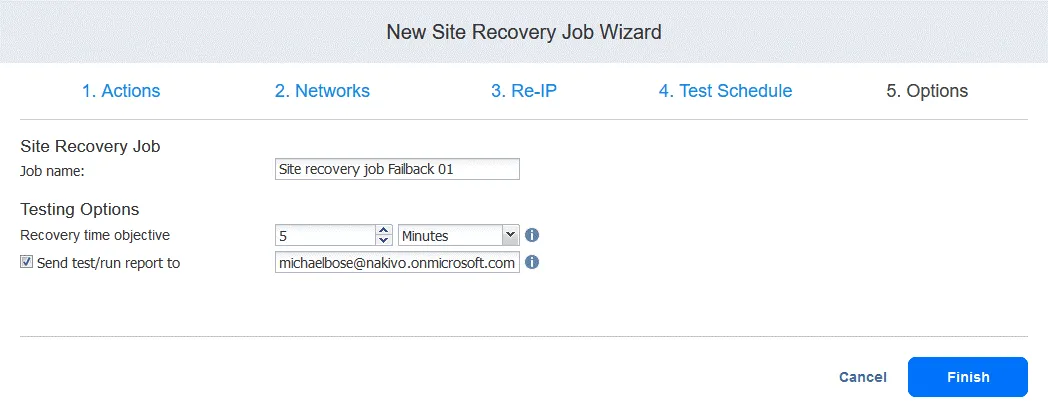
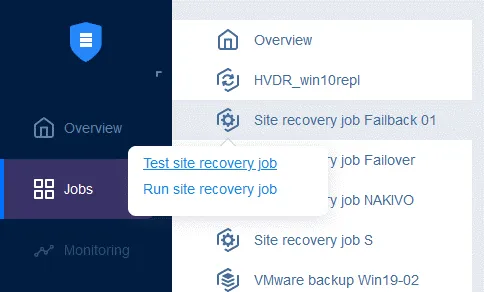
これで、この Site Recovery ジョブを実行して VM のフェイルバックを行うことができます。Site Recovery ジョブの名前を右クリックし、[ Run job、そして選択して Test site recovery job または Run site recovery job.
ステップ6. 災害復旧テストの実施
災害復旧テストを実施することで、災害発生時に復旧体制が整っていることを確認し、選定されたすべてのコンポーネントが設定された時間枠内で正常に復旧できることを保証できます。
主な理由は2つあります 災害復旧テストが必要な理由:
To make sure that everything can be recovered successfully. 災害復旧計画をテストして問題点が見つかった場合、実際の危機的状況で深刻な問題を引き起こす前に、その問題を修正することができます。To make sure that RTO values can be met. 災害復旧テストを実施することで、ワークロードが所定のRTO(復旧目標時間)内に復旧できるかどうかを確認できます。サイト復旧テストは、必要に応じて手動で実行することも、スケジュールに基づいて自動的に実行することも可能であり、これによりプロセスがスムーズになり、時間を節約できます。
テスト環境と本番環境のフェイルオーバーの違い
フェイルオーバーの実行メカニズムは、Site Recovery ジョブがテストモードで実行されるか、本番モードで実行されるかによって異なります。各モードの手順の概要を以下の表に示します。
Production (emergency) failover |
Test failover |
|
| 1 | ソースVMからレプリカへのレプリケーションを無効にする | |
| 2 | VMのレプリカを特定のリカバリポイント(RP)までロールバックする(オプション。デフォルトでは最後のRPが使用されます) | ソースVMからレプリカへの増分レプリケーションを1回実行する |
| 3 | VMのレプリカを new ネットワークとネットワークマッピング(オプション) |
VMのレプリカを isolated ネットワークとネットワークマッピング(オプション) |
| 4 | Re-IP を使用してレプリカの静的 IP アドレスを変更する(任意) | |
| 4A | ソースVMの電源を切る(任意) | — |
| 5 | レプリカの電源を入れる | |
| 6 | レプリカを"フェイルオーバー"状態に切り替える | |
ご覧のとおり、2番目と3番目の点は本番環境とテスト環境のワークフローで異なります。テストモードでは、ソースVMが稼働している状態で、そのVMからのレプリケーションを実行できます。一方、災害が発生した場合、ほとんどの場合、ソースVMは動作しなくなるため、レプリケーションを実行できなくなります。Site Recoveryジョブを設定する際、本番モードとテストモードの"ネットワークマッピング"オプションで、VM接続用のネットワークを個別に定義することができます。
フェイルオーバーテストのクリーンアップは、テストモードでSite Recoveryジョブを実行した後に実行されます。VMレプリカは電源が切られ、スナップショットを使用してフェイルオーバー前の状態に戻されます(フェイルオーバー操作を実行する前に、VMレプリカのスナップショットが作成されます)。その後、レプリカはフェイルオーバー状態から通常状態に切り替えられ、ソースオブジェクトからレプリカへのレプリケーションが再度有効化されます。
NAKIVO Site Recoveryの災害復旧テスト機能
NAKIVOのSite Recoveryにおけるテスト機能の主なポイントについて、簡単に確認していきましょう。
1. Checking the actions included in testing
Site Recoveryジョブ内のアクションのロジックを確認してください。アクションが適切な順序で配置されているかを確認し、無限ループになっていないことを確認してください。ジョブが実行されていないときは、Site Recoveryジョブのオプションを編集できます。必要に応じて、アクションの順序を変更したり、アクションを追加・削除したり、アクションのオプションを編集したりできます。
2. Checking networking
ネットワークが正常に動作していることを確認してください。本番サイトと災害復旧(DR)サイトの間ではVPN接続を使用できますが、通常時はこの接続を定期的に切断することはできません。また、DRサイトのネットワークも中断なく動作している必要があります。フェイルオーバーおよびフェイルバックの設定に使用したネットワークマッピングとIP再割り当ての設定を確認してください。VMが誤ったネットワークに設定されている場合、ネットワーク接続が確立されない可能性があります。IP設定についても同様です。
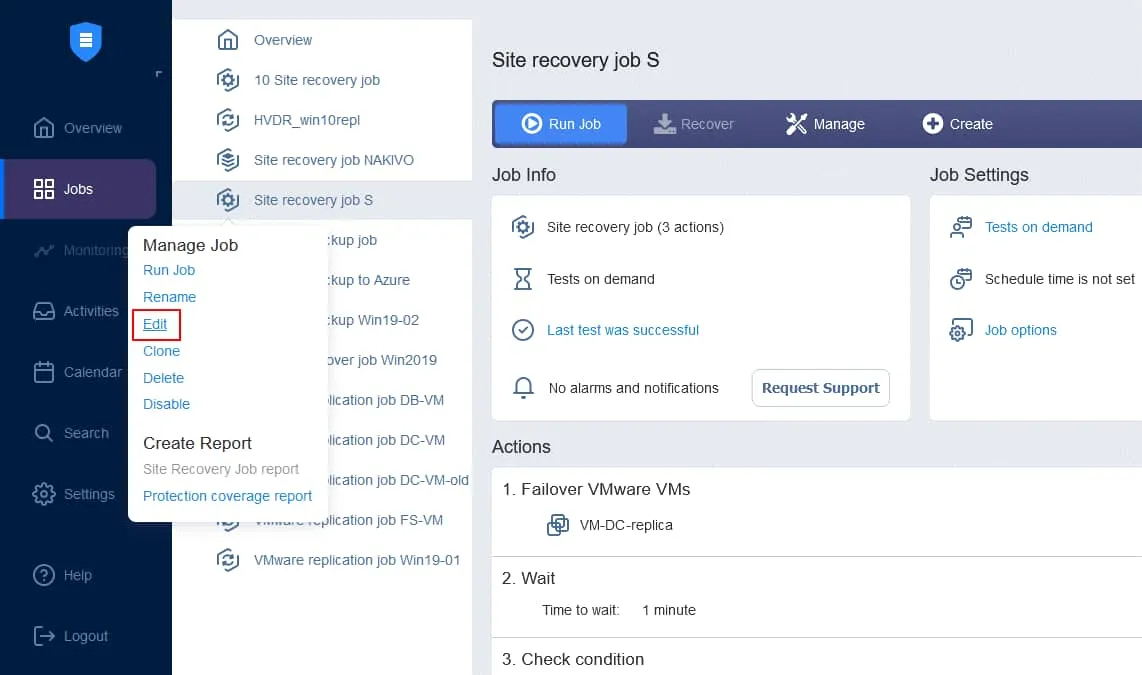
3. Setting the test schedule
Site Recovery ジョブのテストは、Site Recovery ジョブのスケジュール設定オプションでスケジュールできます。インスタンスの Web インターフェースを開き、 NAKIVO Backup & Replication. 左ペインで、ジョブの名前を右クリックし、[ Edit コンテキストメニューで。
NAKIVOのSite Recoveryのメリット
Comprehensive DR orchestration and automation. Site Recovery を使用すると、高度な自動化機能を備えたディザスタリカバリ計画を実施できます。VM の依存関係を考慮してリカバリ順序を定義できるため、災害発生時にも可能な限り効率的なリカバリを実現できます。Flexibility to accommodate the needs of various businesses必要に応じて、複数のSite Recoveryジョブを作成できます。Site Recoveryジョブに組み込むことができる一連のアクションを活用することで、さまざまな状況に合わせてカスタマイズされた、独自の復旧ワークフローを作成することが可能です。Built into the data protection solution. Site Recoveryは 機能 に含まれる NAKIVO Backup & Replication また、本製品のその他の包括的な機能セットと併せて利用可能です。Site Recovery用に別途ライセンスを購入する必要はありません。このソリューションにより、すべてのデータ保護および災害復旧業務を一元的に管理できます。Significant savings compared to other DR solutions. NAKIVO Backup & Replication…に組み込まれたSite Recoveryツールは、コストパフォーマンスに優れたソリューションです。この製品は、特にディザスタリカバリ市場の競合他社と比較しても、手頃な価格を維持しつつ、便利な新機能を次々と追加することで、ユーザーから高い評価を得続けています。



