災害復旧とバックアップ:主な違い
今日のビジネス環境において、データ損失やセキュリティ侵害はますます頻繁に発生しており、 2021年のサイバー攻撃件数が過去最高を記録組織のシステムやデータは、常に利用可能な状態であることが求められるため、しっかりと保護されなければなりません。 だからこそ、バックアップの重要性はいくら強調してもしすぎることはありません。しかし、重要なデータのバックアップはあらゆる企業のIT戦略において不可欠な要素である一方で、バックアップがあることと災害復旧計画があることは同じではありません。
ここで、データバックアップと災害復旧の違いについて考えてみましょう。これらの概念は、しばしば混同されて使われがちです。その違いを説明するために、まずそれぞれの概念を個別に検討し、その後、ユースケースや特徴を比較してみましょう。

バックアップとは何ですか?
バックアップ 元のデータが失われたり利用できなくなったりした場合に備えて、復旧用に作成されるデータのコピーです。バックアップとは、そのようなコピーを作成するプロセスを指すこともあります。
A 予備案 これは、スケジュールや組織の復旧目標に基づき、手動または自動で環境をバックアップするために実施される戦略です。
バックアップ計画には、理想的には、遠隔地の別のデータセンターを含む異なる場所に保存された複数のバックアップに加え、異なるメディア(ディスク、テープ、クラウドなど)に保存されたバックアップを含めるべきです。この手法は、"3-2-1のバックアップルール"に基づいています。
"3-2-1のルール"とは何ですか?
"3-2-1"バックアップのルール これは、あらゆるバックアップおよび復旧計画の根幹をなすものです。これによれば、以下のものを用意すべきであるとされています:
- データのコピーを少なくとも3部
- そのうち2つは、異なる媒体に保存しておく必要があります
- 1部は社外に保管してください。
なお、"3-2-1"のバックアップルールは、ランサムウェア攻撃後の復旧に備えて、不変ストレージに1つのコピーを保存するように拡張することも可能です。
しかし、単純なバックアップだけでは、業務を中断することなく顧客へのサービス提供を継続するには不十分です。ダウンタイムは収益の損失、顧客の離反、そして評判の低下につながることから、いかなる災害や予期せぬ事態に直面しても事業継続性を維持することは必須です。そこで必要となるのが、災害復旧(ディザスタリカバリ)です。
ディザスタリカバリとは?
災害復旧(DR) これは、システム障害、自然災害、またはランサムウェア攻撃が発生した場合に、データ、アプリケーション、およびシステムを別の拠点へ迅速に復旧させるための一連の対策です。これらの対策により、組織はデータの損失を防ぐと同時に、重要な業務用ITシステムやインフラへの可用性とアクセスを維持することができます。 災害復旧 また、予期せぬ障害の解消後に主要拠点での通常業務を再開するための措置も含まれています。
A 災害復旧計画 これは、災害復旧(DR)対策を、それぞれの優先順位と責任者を定めて実行に移すための文書化された手順です。
災害復旧は、事業継続(BC)の不可欠な要素です。事業継続とは、災害発生時にも通常通り事業運営を継続するための対策を包括する、より広範な概念です。顧客やパートナーへのサービス提供を継続するための包括的な対策として、 事業継続計画 これには、従業員、事業所、サプライヤー、および中核的な事業機能を維持するために必要なその他すべての事項に関する措置が含まれます。
災害復旧の実施
仮想化環境における災害復旧は、通常、専用のバックアップおよび災害復旧ソリューションに依存しています。この種のソフトウェアを使用すると、以下のことが可能になります:
- 業務に不可欠なVMのレプリカを作成する
- 障害発生時に、ITインフラのワークロードを別のDR拠点にあるレプリカに移行する(これをフェイルオーバーという)
- 障害が解消されたら、ワークロードをプライマリサイトに戻す(フェイルバックと呼ばれる)
これらのソリューションは、フェイルオーバー時にネットワーク設定を再構成するため、VMのレプリカはほぼ即座に稼働を開始できます。さらに、多くのソリューションでは、復旧を迅速化するために、複数の処理を自動化およびオーケストレーションすることが可能です。
ディザスタリカバリとバックアップの違いは何ですか?
ディザスタリカバリとバックアップは同義ではありません。リソースやニーズに応じて、組織はデータバックアップのみを利用する場合もあれば、包括的なディザスタリカバリ戦略と組み合わせて利用する場合もあります。ディザスタリカバリにはレプリケーション、フェイルオーバー、フェイルバックなどのプロセスが含まれるため、データバックアップとディザスタリカバリを単純に比較・対比することはできません。この文脈において、バックアップは運用上の復旧(詳細は後述)のために使用されます。
本稿における災害復旧とバックアップの比較では、使用シナリオ、実装に必要なリソース、および復旧目標の観点から、バックアップとレプリカの違いに焦点を当てます。
ユースケース
バックアップは、メールサーバー上のメールメッセージやPowerPointプレゼンテーション、その他のアプリケーションオブジェクトなど、紛失または破損したファイルやオブジェクトを復元するために使用されます。また、バックアップは、長期的なデータのアーカイブやデータ保持(例えば、コンプライアンス目的など)にもよく利用されます。
基本的に、バックアップは日々の業務において、特定の時点から単一のファイルや仮想マシン(VM)全体を迅速に復元するために、非常に頻繁に役立ちます。 これは"運用復旧"として知られており、ITインフラのリソースへのアクセスを失った従業員からの要請により、実行されることがよくあります。
一方、レプリカは、予期せぬ事象発生直後にシステムやマシンを復旧させ、中核となる業務が中断されないようにするために、災害復旧(DR)シナリオで使用されます。
DRサイトとDRソリューションの両方が整っていれば、フェイルオーバーを実行するだけで、ワークロードをDR拠点にあるVMレプリカに移行できます。 これにより、本番サイトが利用できない場合でも、組織は通常通り業務を継続できます。プライマリサイトでの障害が解消され次第、フェイルバックを実行できます。
復旧目標
定義する 復旧時間目標(RTO)および復旧時点目標(RPO) これは、バックアップおよび災害復旧計画における重要なステップの一つです。
- RTOとは、障害発生後、組織に重大な影響が生じる前に、データや業務を復旧させるために組織が許容できる時間のことです。
- RPOとは、深刻な影響が生じる前に組織が許容できる最大データ損失量のことです。RPOは、バックアップ/レプリケーションの頻度および保存ポリシーによって決定されます。
運用復旧と災害復旧では、RTO(復旧目標時間)とRPO(復旧時点目標)の値が異なります。ファイルが1つ欠けても必ずしも業務が停止するわけではないため、バックアップではRTOやRPOを長めに設定することができます。
一方、プライマリサイトや重要なマシンに障害が発生すると、従業員が重要なシステムにアクセスできなくなったり、顧客の不満を招いたりする可能性があります。そのため、特にミッションクリティカルなワークロードにおいては、災害復旧(DR)でははるかに短いRTOとRPOが求められます。
導入のためのリソース
バックアップおよびレプリカ/DR(災害復旧)のためのリソースには、ストレージと施設(データセンター)という2つの側面があります。
バックアップは、ローカルディスク、NAS、エンタープライズグレードの重複排除アプライアンス、パブリッククラウド、テープなど、さまざまな種類のストレージに保存できます。現在、最先端のバックアップソリューションには、バックアップのサイズを縮小し、それによって必要なストレージ容量を削減するための多くの機能が備わっています。これには、圧縮、重複排除、変更追跡技術などが含まれます。
メディアによっては、追加コストがほとんどかからないか、あるいは全くかからず、最初のバックアップから数年経っても復元が可能です(例えばテープを参照)。パブリッククラウドをバックアップ先として使用する場合、物理的な施設は不要です。 要するに、バックアップのコストは主にストレージメディアとメンテナンスに関連します。
一方、ディザスタリカバリ(DR)には、ディザスタリカバリ環境として使用する別のサイトと、プライマリサイトと並行して使用する冗長なハードウェア(DRサーバーやストレージシステムなど)が必要です。DRには、そのサイトを維持するために必要な光熱費や人件費も含まれます。
このDRサイトは通常、いつでもフェイルオーバーに対応できる、完全に稼働可能なITインフラストラクチャです。 これは"ホットサイト"とも呼ばれ、災害発生直後に業務を移行するために必要なすべてのハードウェア(サーバー)、ソフトウェア、ネットワークが含まれています。その他、より予算に優しい選択肢としては、MSP(マネージドサービスプロバイダー)へのアウトソーシングによる災害復旧サービス(DRaaS)の利用や、"コールドサイト"の維持などが挙げられます。
包括的な計画策定プロセス
バックアップのプロセスは、DR(災害復旧)計画ほど複雑ではありません。通常、単一障害点を回避するために、保存期間ポリシー、バックアップの頻度、およびバックアップ先を複数設定する必要があります。しかし、災害復旧となると、事態はたちまち複雑になります:
- 優先順位付け ビジネスアプリケーションの重要性を評価し、それらのアプリケーションを実行しているVMの復旧順序を優先順位付けするためです。例えば、CRMデータを格納しているVMは、人事データを格納しているVMよりも重要度が高いと考えられます。
- DRサイトの準備と保守 レプリカを収容し、万が一のフェイルオーバーに備えて稼働できるようにするため。
- 担当者の割り当て また、災害復旧の際、担当者が業務を遂行するために必要なアクセス権と権限を確保すること。さらに、災害復旧を開始する決定を下す責任者を特定すること。
- 徹底的なテスト. 包括的なDR計画には、綿密なテストが不可欠です。なぜなら、実際の災害発生時に計画が実行されなければ、深刻な結果を招く恐れがあるからです。
どのような災害復旧ソリューションを選ぶべきか?
簡単に言えば、バックアップと災害復旧計画の両方をデータ保護戦略に組み込むべきです。現代のビジネス環境では"常時稼働"の原則が重視されており、これは組織がどのような状況であっても、いつでも顧客にサービスや商品を提供できる態勢を整えておく必要があることを意味します。
バックアップは、主に業務復旧や長期保存の目的で使用されるべきです。ビジネスに不可欠なシステムやアプリケーションが稼働する仮想マシン(VM)については、災害復旧計画の一部として位置づけ、別のサイトへレプリケーションを行う必要があります。これら両方のアプローチを組み合わせた包括的なデータ保護戦略により、組織のデータを保護し、データコンプライアンスを維持しながら、事業継続性を確保することができます。
NAKIVOのソリューションによるバックアップと災害復旧
組織のバックアップおよび災害復旧計画への投資を検討されているのであれば、まずは適切なソリューションの選定を検討されることをお勧めします。そのようなソリューションは、信頼性が高いだけでなく、柔軟性も備えている必要があります。そうすることで、多様なテストオプションに対応できるほか、あらゆる規模の仮想化インフラストラクチャにも対応可能となります。
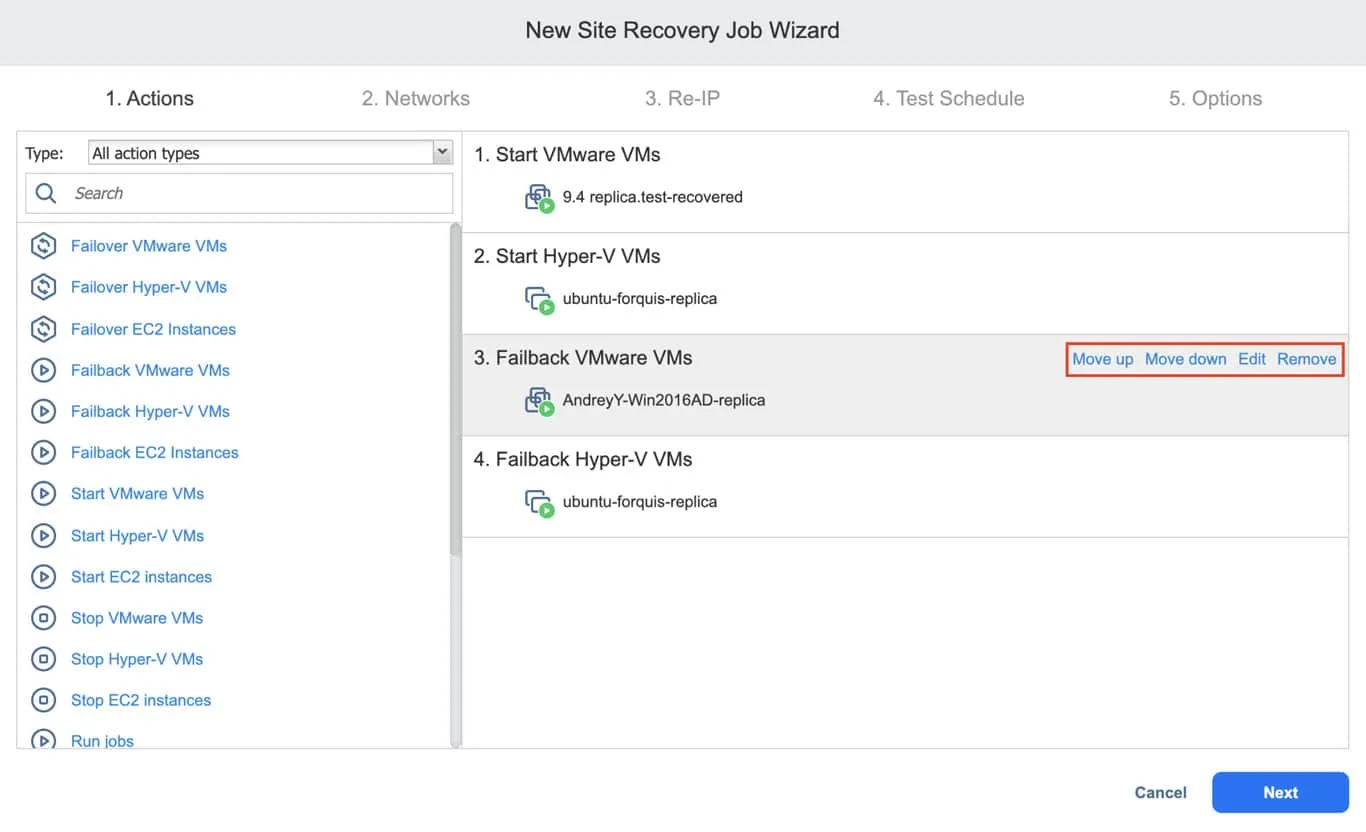
NAKIVO Backup & Replication 内蔵の サイト復旧 どのような複雑さの復旧ワークフローでも作成できる機能を備え、柔軟なテストスケジュール機能により、災害発生時にも環境が常に稼働可能な状態を維持します。
Site Recovery を使用すると、特定の仮想マシンの停止や起動、フェイルオーバーの実行、スクリプトの実行など、特定のアクションを組み合わせたシーケンスを構築できます。これらのアクションを活用することで、仮想環境のフェイルオーバーを実行するシンプルなワークフローから、特定のジョブを起動したり、プロセス内で他の Site Recovery ワークフローを利用したりする多層的で複雑なワークフローまで、自由に作成できます。
結論
定期的なバックアップを行うことと、災害復旧計画を策定しておくことは別物です。VMのバックアップとは、データの保存や長期的なアーカイブを目的としてデータを複製することを意味します。 災害復旧計画の策定は、事業継続戦略の一環であり、災害やその他の予期せぬ事態が発生した後、あるいは発生中においても、重要なシステムが稼働し続けることを保証するものです。バックアップポリシーに加えて災害復旧計画を実施することが推奨されますが、最終的には、自社にとってそれが本当に必要かどうか、またそれに投資するリソースがあるかどうかによって判断されることになるでしょう。
NAKIVO Backup & Replication バックアップおよび災害復旧ソリューションのすべてを、単一の管理画面から提供します。機能満載の無料トライアル版をダウンロードして、ご自身の環境で本ソリューションをお試しください!



