Introduction à Amazon S3 : comment fonctionne le stockage d’objets dans le cloud
Amazon Simple Storage Service (S3) est un service de stockage dans le cloud très populaire qui fait partie des services Amazon Web Services (AWS). Le stockage dans le cloud Amazon S3 offre une fiabilité, une flexibilité, une évolutivité et une accessibilité élevées. Le nombre d’objets et la quantité de données stockées dans Amazon S3 sont illimités. Le stockage dans le cloud S3 est intéressant pour les entreprises, car vous ne payez que ce que vous utilisez.
Cependant, la terminologie et la méthodologie peuvent entraîner des malentendus et des difficultés pour les nouveaux utilisateurs d’Amazon S3. Où sont stockées les données S3 ? Comment fonctionne le stockage Amazon S3 ? Cet article de blog explique les principaux concepts et le principe de fonctionnement du stockage dans le cloud Amazon S3.

À propos du stockage Amazon S3
Amazon S3 a été le premier service de stockage dans le cloud d’AWS et a été lancé en 2006. Depuis lors, la popularité de ce service de stockage dans le cloud n’a cessé de croître. Aujourd’hui, Amazon propose une large gamme d’autres services cloud, mais le stockage dans le cloud Amazon S3 reste le plus utilisé. Outre le stockage Amazon S3, AWS propose des volumes Amazon EBS pour EC2 et Amazon Drive. Mais ces trois services ont des utilisations et des objectifs différents.
Les volumes EBS (Elastic Block Storage) pour les instances EC2 (Elastic Compute Cloud) sont des disques virtuels pour les machines virtuelles résidant dans le cloud Amazon. Comme le nom EBS l’indique, il s’agit d’un stockage en bloc dans le cloud qui est l’équivalent des disques durs dans les ordinateurs physiques. Un système d’exploitation peut être installé sur un volume EBS attaché à une instance EC2 .
Amazon Drive (anciennement connu sous le nom d’Amazon Cloud Drive) est l’équivalent de Google Drive et Microsoft OneDrive. Amazon Drive offre moins de fonctionnalités qu’Amazon S3. Amazon Drive se positionne comme un service de stockage dans le cloud pour sauvegarder des photos et d’autres données utilisateur.
Amazon S3 est un service de stockage dans le cloud basé sur des objets. Vous ne pouvez pas installer de système d’exploitation lorsque vous utilisez le stockage Amazon S3, car les données ne sont pas accessibles au niveau des blocs, comme l’exige un système d’exploitation. Si vous devez monter le stockage Amazon S3 en tant que lecteur réseau sur votre système d’exploitation, utilisez un système de fichiers dans l’espace utilisateur. Lisez l’article de blog sur le montage du stockage dans le cloud S3 sur différents systèmes d’exploitation. Google Cloud est l’équivalent du stockage dans le cloud Amazon S3.
Concepts principaux d’Amazon S3
Si vous utilisez Amazon S3 pour la première fois, certains concepts peuvent vous sembler inhabituels et peu familiers. La méthodologie de stockage des données dans le cloud S3 est différente de celle utilisée pour les disques durs traditionnels, les disques SSD ou les baies de disques. Vous trouverez ci-dessous un aperçu des principaux concepts et technologies utilisés pour stocker et gérer les données dans le stockage dans le cloud Amazon S3.
Comment S3 stocke-t-il les fichiers ?
Comme expliqué ci-dessus, les données dans Amazon S3 sont stockées sous forme d’objets. Cette approche offre un stockage hautement évolutif dans le cloud. Les objets peuvent avoir différents emplacements sur des disques physiques répartis dans un centre de données. Du matériel, des logiciels et des systèmes de fichiers distribués spéciaux sont utilisés dans les centres de données Amazon pour offrir une grande évolutivité. La redondance et le versionnage sont des fonctionnalités mises en œuvre à l’aide de l’approche de stockage en blocs. Lorsqu’un fichier est stocké dans Amazon S3 en tant qu’objet, il est stocké simultanément à plusieurs endroits (tels que sur des disques, dans des centres de données ou des zones de disponibilité) par défaut. Le service Amazon S3 vérifie régulièrement la cohérence des données en contrôlant les sommes de contrôle. Si une corruption des données est détectée, l’objet est réalisé par la récupération des données redondantes. Les objets sont stockés dans des compartiments Amazon S3. Par défaut, les objets stockés dans Amazon S3 sont accessibles et gérables via l’interface web.
Qu’est-ce que le stockage d’objets S3 ?
Le stockage d’objets est un type de stockage dans lequel les données sont stockées sous forme d’objets plutôt que de blocs. Ce concept est utile pour la sauvegarde des données , l’archivage et l’évolutivité dans les environnements à forte charge.
Les objets sont les entités fondamentales du stockage de données dans les compartiments Amazon S3. Un objet comprend trois composants principaux : le contenu de l’objet (données stockées dans l’objet, telles qu’un fichier ou un répertoire), l’identifiant unique de l’objet (ID) et les métadonnées. Les métadonnées sont stockées sous forme de valeurs de paire de clés et contiennent des informations telles que le nom, la taille, la date, les attributs de sécurité, le type de contenu et l’URL.
Chaque objet dispose d’une liste de contrôle d’accès (ACL) permettant de configurer les personnes autorisées à y accéder. Le stockage d’objets Amazon S3 vous permet d’éviter les goulots d’étranglement réseau pendant les heures de pointe, lorsque le trafic vers vos objets stockés sur le stockage dans le cloud S3 augmente considérablement. Amazon fournit une bande passante réseau flexible, mais facture l’accès réseau aux objets stockés. Le stockage d’objets est satisfaisant lorsqu’un grand nombre de clients doivent accéder aux données (fréquence de lecture élevée). La recherche dans les métadonnées est plus rapide pour le modèle de stockage d’objets.
Lisez également les articles suivants : Amazon S3 chiffrement qui peuvent vous aider à protéger les données stockées dans le stockage dans le cloud Amazon S3 et à renforcer la sécurité.
Buckets
Un compartiment est un conteneur logique fondamental dans lequel les données sont stockées dans le stockage Amazon S3. Vous pouvez stocker une quantité infinie de données et un nombre illimité d’objets dans un compartiment. Chaque objet S3 est stocké dans un compartiment. La taille d’un objet stocké dans un compartiment est limitée à 5 To. Les buckets sont utilisés pour organiser l’espace de noms au plus haut niveau et pour contrôler l’accès.
Clés
Un objet possède une clé unique après avoir été téléchargé dans un bucket. Cette clé est une chaîne qui imite une hiérarchie de répertoires. Connaître la clé vous permet d’accéder à l’objet dans le compartiment. Un compartiment, une clé et un ID de version identifient un objet de manière unique. Par exemple, si le nom d’un compartiment est blog-bucket01, l’emplacement où les centres de données stockent vos données est s3-eu-west-1 et le nom de l’objet est test1.txt (un fichier texte), l’URL du fichier requis stocké en tant qu’objet dans le compartiment est :
https://blog-bucket01.s3-eu-west-1.amazonaws.com/test1.txt
Les autorisations doivent être configurées en modifiant les attributs de l’objet si vous souhaitez partager des objets avec d’autres utilisateurs. De même, vous pouvez créer un dossier TextFiles et stocker le fichier texte dans ce dossier :
https://blog-bucket01.s3-eu-west-1.amazonaws.com/TextFiles/test1.txt
Il existe deux types d’URL pouvant être utilisés :
- bucketname.s3.amazonaws.com/objectname
- s3.amazon.aws.com/bucketname/objectname
Régions AWS
Amazon dispose de centres de données dans différentes régions du monde, notamment aux États-Unis, en Irlande, en Afrique du Sud, en Inde, au Japon, en Chine, en Corée, au Canada, en Allemagne, en Italie et en Grande-Bretagne. Vous pouvez sélectionner la région de votre choix lors de la création d’un compartiment. Il est recommandé de sélectionner la région la plus proche de vous ou de vos clients afin de réduire la latence de la connexion réseau ou de minimiser les coûts (car le prix du stockage des données varie selon les régions). Les données stockées dans une région AWS donnée ne quittent jamais les centres de données de cette région, sauf si vous les migrez manuellement. Les régions AWS sont isolées les unes des autres afin d’assurer la tolérance aux pannes et la stabilité.
Chaque région contient des zones de disponibilité qui sont des emplacements isolés au sein d’une région AWS. Au moins trois zones de disponibilité sont disponibles pour chaque région afin d’éviter les pannes causées par des catastrophes telles que des incendies, des typhons, des ouragans, des inondations, etc.
Le modèle de cohérence des données
La vérification de la cohérence après écriture est effectuée pour les objets stockés dans le stockage Amazon S3. Amazon S3 réplique les données sur les serveurs et les centres de données d’une région sélectionnée afin d’assurer une haute disponibilité. Après une requête PUT réussie, les données modifiées doivent être répliquées sur les serveurs. Ce processus peut prendre un certain temps. Dans ce cas, l’utilisateur peut obtenir les anciennes données ou les données mises à jour, mais pas les données corrompues. Cela vaut également pour les objets et les compartiments supprimés. Le verrouillage des objets n’est pas effectué lorsque de nouveaux objets sont envoyés vers des compartiments S3. La dernière requête PUT l’emporte si plusieurs requêtes PUT sont effectuées simultanément. Vous pouvez créer votre propre application avec un mécanisme de verrouillage qui fonctionne avec les objets stockés dans le stockage Amazon S3.
Fonctionnalités d’Amazon S3
Le concept de stockage basé sur les objets permet à Amazon d’offrir des fonctionnalités utiles et une grande flexibilité pour le stockage et la gestion des données dans Amazon S3. Passons en revue ces fonctionnalités.
Gestion des versions
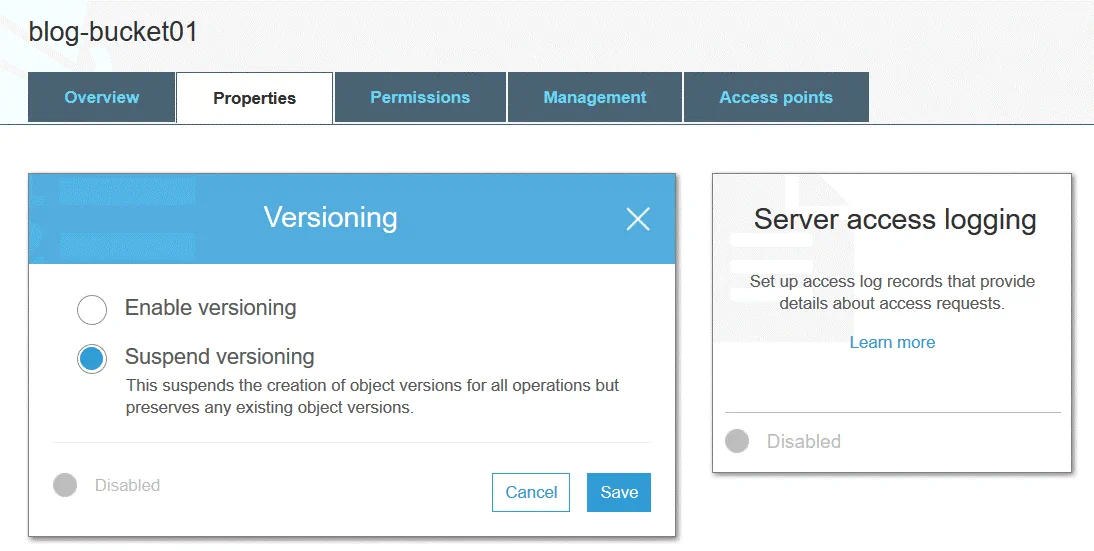
La gestion des versions d’objets vous permet de stocker plusieurs versions d’un objet dans un seul compartiment. Cette fonctionnalité permet de protéger les objets stockés dans le stockage Amazon S3 contre les modifications, les écrasements ou les suppressions involontaires. Après avoir modifié ou supprimé un objet, vous pouvez restaurer l’une des versions précédentes de cet objet. La gestion des versions est mise en œuvre grâce à l’utilisation de l’approche de stockage d’objets. Vous pouvez utiliser le versionnage à des fins d’archivage. Le versionnage est désactivé par défaut.
Un ID de version est attribué à chaque objet S3, même si le versionnage n’est pas activé (dans ce cas, la valeur de l’ID de version est définie sur null). Si le versionnage est activé, une nouvelle valeur d’ID de version est attribuée à une nouvelle version de l’objet après l’écriture des modifications. Le versionnage peut être activé au niveau du compartiment. La valeur de l’ID de version de la première version de l’objet reste la même. Lorsque vous supprimez un objet d’un compartiment S3 (avec le contrôle de version activé), le marqueur de suppression est appliqué à la dernière version de l’objet.
Classes de stockage
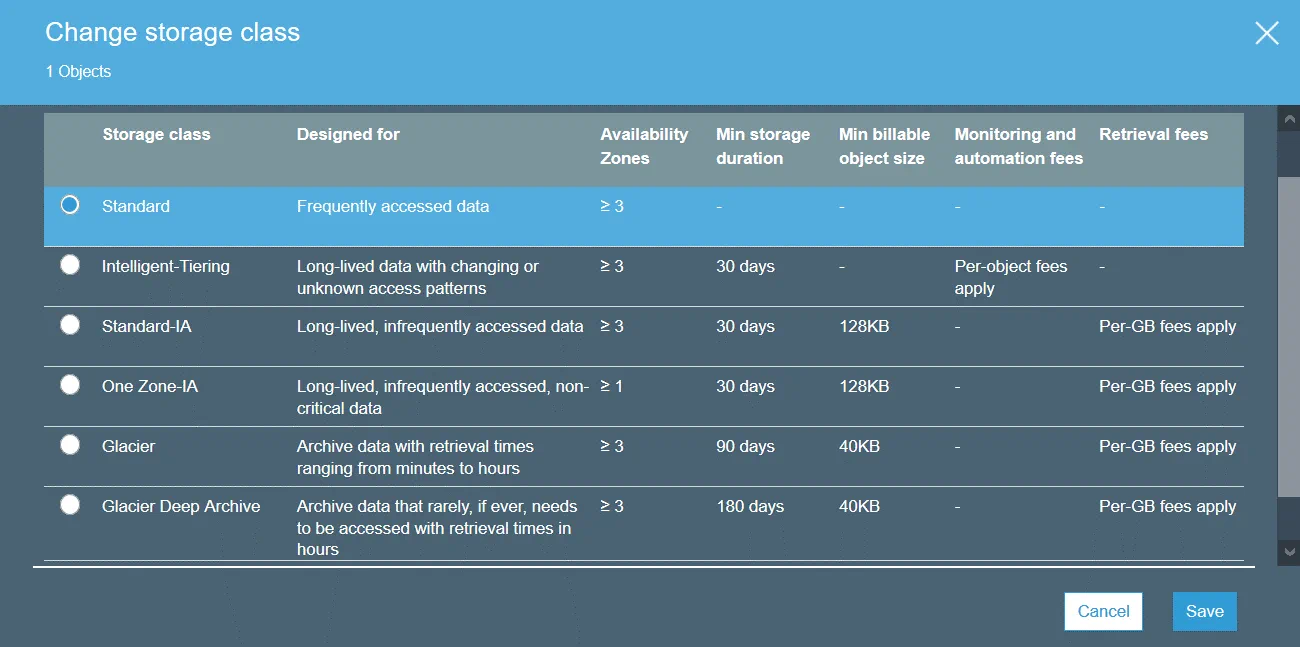
Les classes de stockage Amazon S3 définissent l’objectif du stockage sélectionné pour conserver les données. Une classe de stockage peut être définie au niveau de l’objet. Cependant, vous pouvez définir la classe de stockage par défaut pour les objets qui seront créés au niveau du compartiment.
S3 Standard est la classe de stockage par défaut. Cette classe est un stockage de données actives et convient aux données fréquemment utilisées. Utilisez la classe de stockage Standard pour héberger des sites Web, distribuer du contenu, développer des applications cloud, etc. Cette classe de stockage présente les fonctionnalités suivantes : des coûts de stockage élevés, des coûts de restauration faibles et un accès rapide aux données.
S3 Standard-IA (accès peu fréquent) peut être utilisé pour stocker des données auxquelles on accède moins fréquemment que dans S3 Standard. S3 Standard-IA est optimisé pour une durée de stockage plus longue. La récupération des données stockées dans la classe de stockage S3 Standard-IA est payante. De plus, dans les deux cas S3 Standard et S3 Standard-IA vous devez payer pour les requêtes de données (PUT, COPY, POST, LIST, GET, SELECT).
S3 One Zone-IA est conçu pour les données rarement consultées. Les données sont stockées dans une seule zone de disponibilité (les données sont stockées dans trois zones de disponibilité pour S3 Standard) et, par conséquent, le niveau de redondance et de résilience est moins élevé. Le niveau de disponibilité déclaré est de 99,5 %, ce qui est inférieur à celui des deux autres classes de stockage. S3 One Zone-IA présente des coûts de stockage moins élevés, des coûts de restauration plus élevés et vous devez payer pour la récupération des données au prix par Go. Vous pouvez envisager d’utiliser cette classe de stockage comme une solution rentable pour stocker des copies de sauvegarde ou des copies de données créées avec la réplication interrégionale Amazon S3.
S3 Glacier n’offre pas d’accès instantané aux données stockées, contrairement aux autres classes de stockage. S3 Glacier peut être utilisé pour stocker des données à long terme à faible coût. Il n’y a aucune garantie de fonctionnement ininterrompu. Vous devez attendre de quelques minutes à quelques heures pour récupérer les données. Vous pouvez transférer d’anciennes données depuis un stockage de classe supérieure (par exemple, depuis S3 Standard) vers S3 Glacier par l’intermédiaire des politiques de cycle de vie S3 et réduire ainsi les coûts de stockage.
S3 Glacier Deep Archive est similaire à S3 Glacier, mais le temps nécessaire pour récupérer les données est d’environ 12 à 48 heures. Son prix est inférieur à celui de S3 Glacier. La classe de stockage S3 Glacier Deep Archive peut être utilisée pour stocker les sauvegardes et les données d’archivage des entreprises qui respectent les conditions à remplir en matière d’archivage des données (finance, santé). Il s’agit d’une bonne alternative aux cartouches de bande.
S3 Intelligent-Tiering est une classe de stockage spéciale qui utilise d’autres classes de stockage. S3 Intelligent-Tiering est destiné à sélectionner automatiquement une meilleure classe de stockage pour stocker les données lorsque vous ne savez pas à quelle fréquence vous aurez besoin d’accéder à ces données. Amazon S3 peut effectuer la surveillance des modèles d’accès aux données lors de l’utilisation de S3 Intelligent-Hiérarchisation, puis stocker les objets dans l’une des deux classes de stockage sélectionnées (l’une pour les données fréquemment consultées et l’autre pour les données rarement consultées). Cette approche vous offre un rapport coût-efficacité optimal sans compromettre les performances.
Par exemple, si vous accédez à un objet stocké dans une classe de stockage pour les données rarement consultées, cet objet est automatiquement déplacé vers une classe de stockage pour les données fréquemment consultées. À l’inverse, si un objet n’a pas été consulté depuis longtemps, il est déplacé vers la classe de stockage pour les données rarement utilisées. Les objets peuvent être situés dans le même compartiment et la classe de stockage est modifiée au niveau de l’objet S3.
Listes de contrôle d’accès
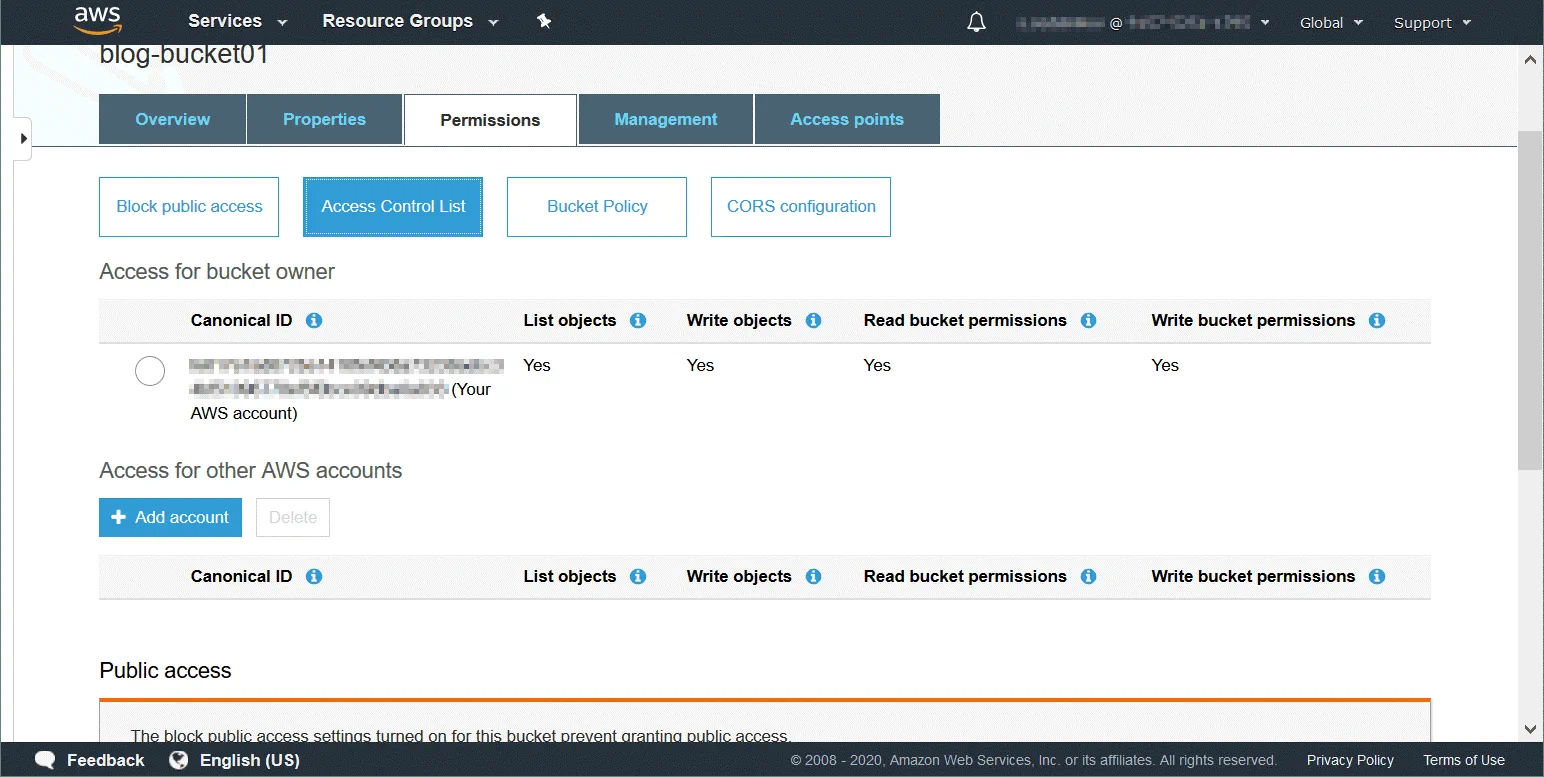
Une liste de contrôle d’accès (ACL) est une fonctionnalité utilisée pour gérer et contrôler l’accès aux objets et aux compartiments. Les listes de contrôle d’accès sont des politiques basées sur les ressources qui sont associées à chaque compartiment et objet afin de définir les utilisateurs et les groupes autorisés à accéder au compartiment et à l’objet. Par défaut, le propriétaire de la ressource dispose d’un accès complet à un compartiment ou à un objet après avoir créé la ressource. Les autorisations d’accès au compartiment définissent qui peut accéder aux objets dans le compartiment. Les autorisations d’accès aux objets définissent les utilisateurs autorisés à accéder aux objets et le type d’accès. Vous pouvez par exemple définir des autorisations en lecture seule pour un utilisateur et des autorisations en lecture-écriture pour un autre utilisateur.
Liste complète des utilisateurs pouvant disposer d’autorisations (un utilisateur disposant d’autorisations est appelé « bénéficiaire ») :
Propriétaire – utilisateur qui crée un compartiment/objet.
Utilisateurs authentifiés – tout utilisateur disposant d’un compte AWS.
Tous les utilisateurs – tous les utilisateurs, y compris les utilisateurs anonymes (utilisateurs qui n’ont pas de compte AWS).
Utilisateur par adresse e-mail/ID – un utilisateur spécifique qui possède un compte AWS. L’adresse e-mail ou l’ID AWS d’un utilisateur doit être spécifié pour lui accorder l’accès.
Types d’autorisations disponibles :
Contrôle total – ce type d’autorisation fournit les autorisations Lecture, Écriture, Lecture (ACP) et Écriture ACP.
Lecture – permet de répertorier le contenu du compartiment lorsqu’il est appliqué au niveau du compartiment. Permet de lire les données et métadonnées de l’objet lorsqu’elle est appliquée au niveau de l’objet.
Écriture – ne peut être appliqué qu’au niveau du compartiment et permet de créer, supprimer et écraser n’importe quel objet dans le compartiment.
Autorisations de lecture (READ ACP) – un utilisateur peut lire les autorisations pour l’objet ou le compartiment spécifié.
Autorisations d’écriture (WRITE ACP) – un utilisateur peut remplacer les autorisations pour l’objet ou le compartiment spécifié. Activer ce type d’autorisation pour un utilisateur est égal à définir des autorisations de contrôle total, car l’utilisateur peut définir toutes les autorisations pour son compte. Cette autorisation est disponible par défaut pour le propriétaire du compartiment.
Politiques de compartiment
Les politiques de compartiment sont des identités AWS basées sur les ressourcesbasées sur les identités AWS et les politiques de gestion des accès qui sont utilisées pour créer des règles conditionnelles afin d’accorder des autorisations d’accès aux comptes AWS et aux utilisateurs lorsqu’ils accèdent à des compartiments et à des objets dans des compartiments. Vous pouvez utiliser les politiques de compartiment pour définir des règles de sécurité pour plusieurs objets dans un compartiment.
La politique de compartiment est définie sous forme de fichier JSON. Le texte de configuration de la politique de compartiment doit respecter les conditions à remplir pour être valide. La politique de compartiment ne peut être jointe qu’au niveau du compartiment et est héritée par tous les objets du compartiment. Vous pouvez accorder l’accès aux utilisateurs qui se connectent à partir d’adresses IP spécifiées, aux utilisateurs de comptes AWS spécifiés, etc.
Vous trouverez ci-dessous un exemple de politique qui accorde un accès complet à tous les utilisateurs d’un compte et un accès en lecture seule à chaque utilisateur d’un autre compte.
{
"Statement": [
{
"Effect": "Allow",
"Principal": {
"SGWS": "95381782731015222837"
},
"Action": "s3:*",
"Resource": [
"urn:sgws:s3:::blog-bucket01",
"urn:sgws:s3:::blog-bucket01/*"
]
},
{
"Effect": "Allow",
"Principal": {
"SGWS": "30284200178239526177"
},
"Action": "s3:GetObject",
"Resource": "urn:sgws:s3:::blog-bucket01/shared/*"
},
{
"Effect": "Allow",
"Principal": {
"SGWS": "30284200178239526177"
},
"Action": "s3:ListBucket",
"Resource": "urn:sgws:s3:::blog-bucket01",
"Condition": {
"StringLike": {
"s3:prefix": "shared/*"
}
}
}
]
}
Les utilisateurs peuvent accéder au stockage Amazon S3 par l’intermédiaire de clés d’accès (ID de clé d’accès et clé d’accès secrète) sans avoir à saisir leur Nom d’utilisateur et leur mot de passe. Cette approche vous permet de renforcer la sécurité et est utilisée pour créer des applications qui utilisent des API pour accéder au stockage dans le cloud Amazon S3.
API pour Amazon S3
Amazon fournit des interfaces de programmation d’applications (API) pour accéder aux fonctionnalités S3 et développer vos propres applications qui doivent fonctionner avec le stockage Amazon S3. Amazon fournit des interfaces REST et SOAP. L’interface REST utilise des requêtes HTTP standard pour travailler avec les compartiments et les objets. Les en-têtes HTTP standard sont utilisés par l’API REST. L’interface SOAP est une autre interface disponible. L’utilisation de SOAP sur HTTP est obsolète, mais vous pouvez toujours utiliser SOAP sur HTTPS.
Le modèle de paiement
Amazon S3 propose un modèle de paiement à l’utilisation. Aucun frais minimum n’est requis : vous n’avez pas à payer pour une quantité prédéterminée de stockage et de trafic de mise en réseau. Il existe différentes catégories d’utilisation pour lesquelles vous devez payer :
Stockage. Payez pour les objets stockés dans Amazon S3. Le montant que vous devez payer dépend de l’espace de stockage utilisé, du temps de stockage des objets dans Amazon S3 (au cours du mois) et de la classe de stockage utilisée par les objets stockés.
Requêtes et récupération de données. Vous devez payer pour les requêtes effectuées afin de récupérer les données stockées dans le stockage dans le cloud Amazon S3.
Transfert de données. Vous devez payer pour toute la bande passante utilisée (trafic entrant et sortant), à l’exception des données entrantes provenant d’Internet, des données sortantes transférées vers des instances Amazon EC2 situées dans la même région AWS que le compartiment S3 source et des données sortantes d’un compartiment S3 vers CloudFront.
GESTION et réplication. Vous devez payer pour l’utilisation des fonctionnalités de gestion du stockage telles que l’analyse et le balisage des objets. Amazon facture la réplication interrégionale et la réplication intra-régionale.
Utilisez le calculateur Amazon S3 pour estimer vos paiements.



