So sánh và giải thích về VMware vSphere HA và DRS
Trình ảo hóa VMware cho phép bạn chạy các máy ảo trên một máy chủ duy nhất. Bạn có thể chạy nhiều máy ảo trên một máy chủ ESXi độc lập và triển khai nhiều máy chủ để chạy thêm máy ảo. Nếu bạn có nhiều máy chủ ESXi được kết nối qua mạng, bạn có thể di chuyển các máy ảo từ máy chủ này sang máy chủ khác.
Đôi khi, việc sử dụng nhiều máy chủ được kết nối qua mạng để chạy máy ảo là không đủ để đáp ứng nhu cầu kinh doanh. Ví dụ: trong trường hợp một máy chủ gặp sự cố, tất cả các máy ảo nằm trên máy chủ đó cũng sẽ gặp sự cố. Ngoài ra, tải công việc của các máy ảo trên các máy chủ ESXi có thể không cân bằng, và việc di chuyển máy ảo thủ công giữa các máy chủ là việc thường xuyên. Để giải quyết các vấn đề này, VMware cung cấp các tính năng cụm như VMware High Availability (HA) và Distributed Resource Scheduler (DRS). Sử dụng cụm vSphere cho phép bạn giảm thời gian ngừng hoạt động của máy ảo và sử dụng tài nguyên phần cứng một cách hợp lý. Bài viết blog này đề cập đến VMware HA và DRS cũng như các trường hợp sử dụng cho từng tính năng cụm.

Cụm vSphere là gì?
Cụm vSphere là một tập hợp các máy chủ ESXi được kết nối với nhau và chia sẻ các tài nguyên phần cứng như bộ xử lý, bộ nhớ và bộ lưu trữ. Các cụm VMware vSphere được quản lý tập trung tại vCenter. Các tài nguyên của cụm được gộp lại thành một nhóm tài nguyên, do đó khi bạn thêm một máy chủ vào cụm, các tài nguyên của máy chủ đó sẽ trở thành một phần của tài nguyên toàn bộ cụm. Các máy chủ ESXi là thành viên của cụm cũng được gọi là nút cụm. Có hai loại cụm vSphere: vSphere High Availability và Distributed Resource Scheduler (VMware HA và DRS).
Yêu cầu cụm VMware
Để triển khai VMware HA và DRS, cần đáp ứng một số yêu cầu cụm:
- Phải sử dụng hai hoặc nhiều máy chủ ESXi có cấu hình giống hệt nhau (các bộ xử lý cùng dòng, phiên bản ESXi và mức bản vá, v.v.). Ví dụ, bạn có thể sử dụng hai máy chủ có bộ xử lý Intel cùng dòng (hoặc
AMDbộ xử lý) và {12} được cài đặt trên các máy chủ. Nên sử dụng ít nhất ba máy chủ để đảm bảo bảo mật và hiệu suất tốt hơn. - Kết nối mạng tốc độ cao cho mạng quản lý, mạng lưu trữ và mạng vMotion. Yêu cầu kết nối mạng dự phòng.
- Một kho dữ liệu chung có thể truy cập được cho tất cả các máy chủ ESXi trong cụm. Mạng Lưu trữ Khu vực (SAN), Lưu trữ Kết nối Mạng (NAS) và VMware vSAN có thể được sử dụng làm kho dữ liệu chung. Các giao thức NFS và iSCSI được hỗ trợ để truy cập dữ liệu trên kho dữ liệu chung. Các tệp máy ảo phải được lưu trữ trên kho dữ liệu chung.
VMware vCenter Servertương thích với phiên bản ESXi được cài đặt trên các máy chủ.
Khác với Hyper-V Failover Cluster, không yêu cầu quorum và bạn không cần sử dụng các tên mạng phức tạp.
VMware HA trong vSphere là gì?
VMware vSphere High Availability (HA) là tính năng cụm được thiết kế để tự động khởi động lại máy ảo (VM) trong trường hợp xảy ra sự cố. VMware vSphere High Availability cho phép các tổ chức đảm bảo tính sẵn sàng cao cho các VM và ứng dụng đang chạy trên các VM trong cụm vSphere (không phụ thuộc vào ứng dụng đang chạy). VMware HA có thể cung cấp bảo vệ chống lại sự cố của máy chủ ESXi – VM bị lỗi sẽ được khởi động lại trên một máy chủ khỏe mạnh. Kết quả là, bạn có thể giảm đáng kể thời gian ngừng hoạt động.
Yêu cầu đối với vSphere HA
Yêu cầu đối với vSphere HA phải được xem xét cùng với các yêu cầu chung của cụm vSphere. Để thiết lập VMware vSphere High Availability, bạn phải có:
- A
VMware vSphere Standardgiấy phép - Tối thiểu 4 GB RAM trên mỗi máy chủ
- Một cổng có thể ping được
vSphere hoạt động như thế nào? HA
VMware vSphere High Availability kiểm tra các máy chủ ESXi để phát hiện sự cố máy chủ. Nếu phát hiện sự cố máy chủ (các máy ảo đang chạy trên máy chủ đó cũng bị lỗi), các máy ảo bị lỗi sẽ được di chuyển sang các máy chủ ESXi hoạt động bình thường trong cụm. Sau khi di chuyển, các máy ảo được đăng ký trên các máy chủ mới, sau đó các máy ảo này được khởi động. Các tệp máy ảo (VMX, VMDK và các tệp khác) được đặt trên cùng một tài nguyên, đó là kho dữ liệu chia sẻ, sau khi di chuyển. Các tệp máy ảo không được di chuyển. Chỉ các thành phần CPU, bộ nhớ và mạng được sử dụng bởi các máy ảo bị lỗi mới được cung cấp bởi máy chủ ESXi mới sau khi di chuyển.
Thời gian ngừng hoạt động bằng với thời gian cần thiết để khởi động lại một máy ảo trên một máy chủ khác. Tuy nhiên, hãy lưu ý rằng còn có thời gian cần thiết để hệ điều hành khởi động và tải các ứng dụng cần thiết trên máy ảo. VMware HA là giải pháp hoạt động ở lớp máy ảo và có thể được sử dụng ngay cả khi các ứng dụng không có tính năng sẵn có về khả năng sẵn sàng cao. VMware vSphere High Availability không phụ thuộc vào hệ điều hành khách được cài đặt trên máy ảo.
Quy trình làm việc của một cụm vSphere HA được minh họa trong sơ đồ bên dưới. Trong ví dụ này, có một cụm gồm ba máy chủ ESXi. Các máy ảo (VM) đang chạy trên tất cả các máy chủ. Các kết nối của các máy ảo và tệp tin của chúng được minh họa bằng các đường chấm.
1. Hoạt động bình thường của cụm. Tất cả các máy ảo đang chạy trên các máy chủ gốc của chúng.
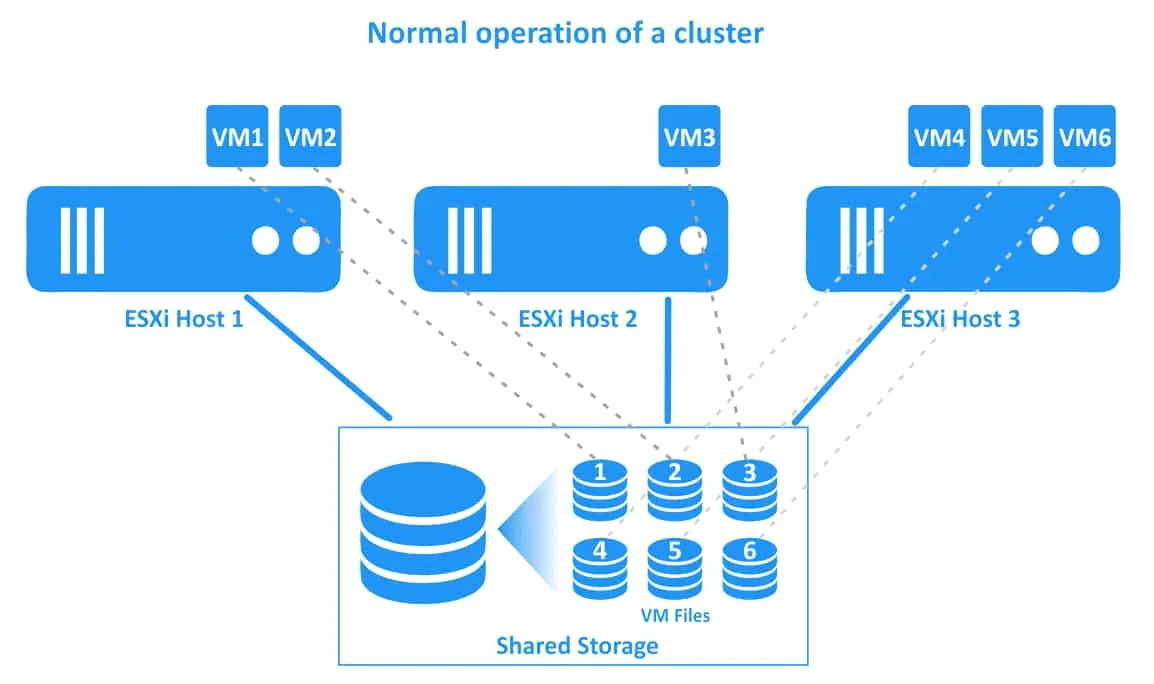
2. Máy chủ ESXi 1 gặp sự cố. Các máy ảo nằm trên máy chủ ESXi 1 (VM1 và VM2) bị ngừng hoạt động (các máy ảo này đã tắt nguồn). Cụm vSphere HA khởi động lại các máy ảo trên các máy chủ ESXi khỏe mạnh khác.
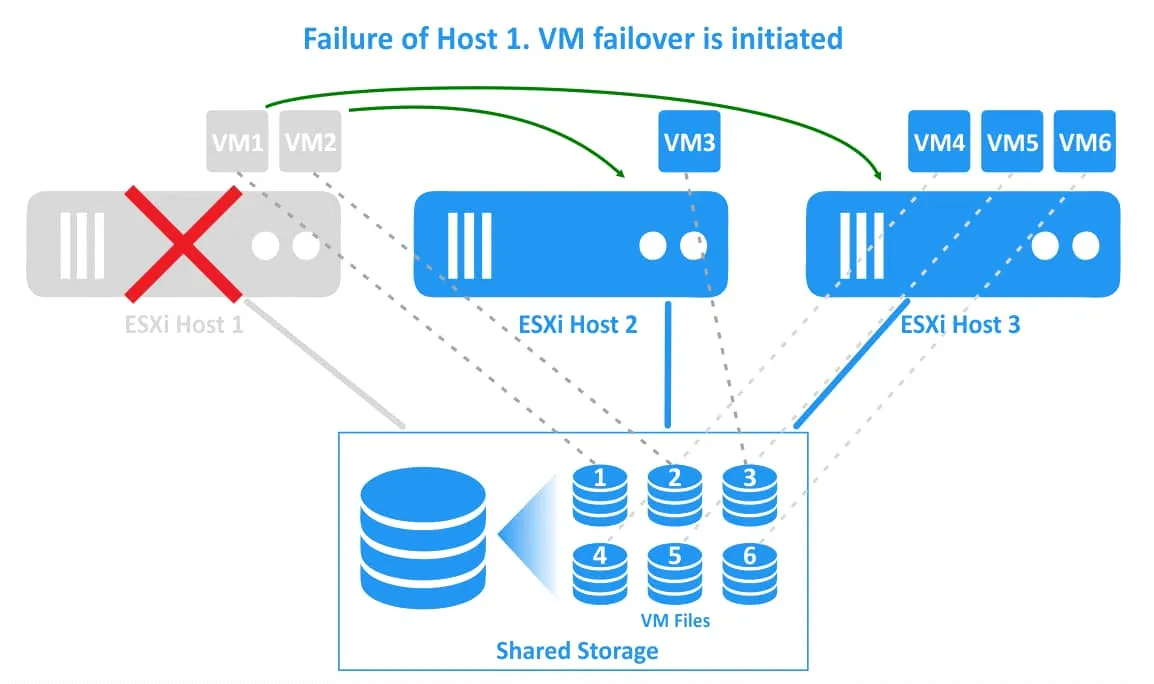
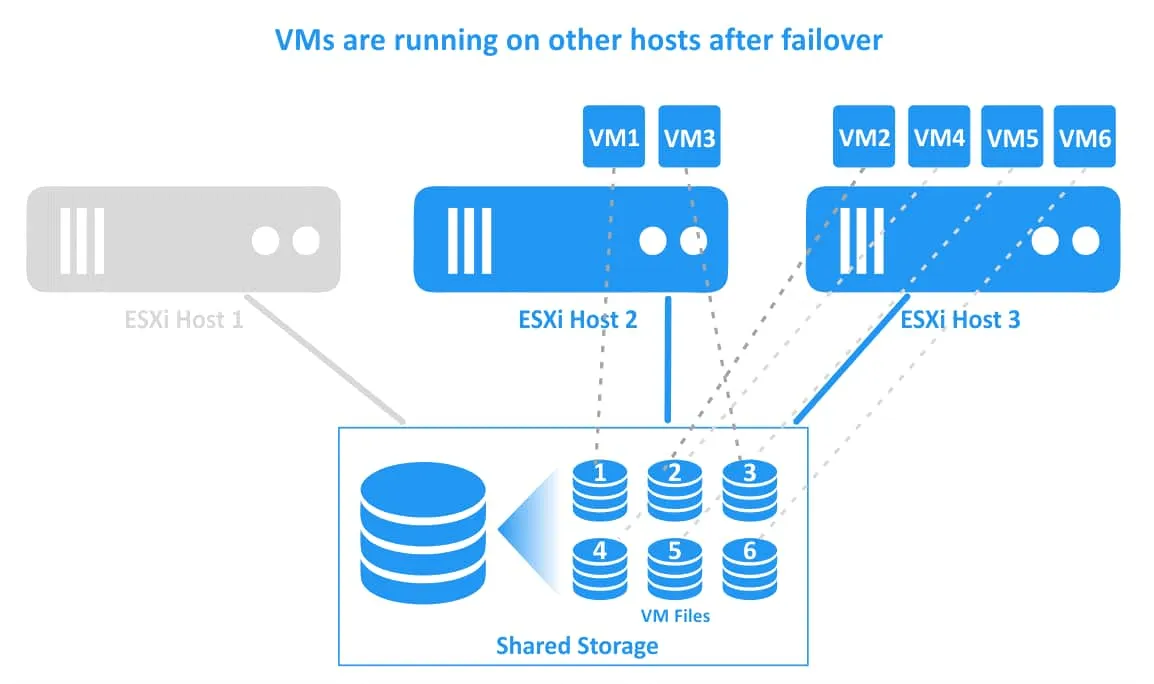
3. Các máy ảo đã được di chuyển và khởi động lại trên các máy chủ khỏe mạnh. VM1 đã được di chuyển sang máy chủ ESXi 2, và VM2 đã được di chuyển sang máy chủ ESXi 3. Các tệp máy ảo được lưu trữ tại cùng một vị trí trên bộ lưu trữ chia sẻ được kết nối với tất cả các máy chủ ESXi trong cụm vSphere.
HA máy chủ chính và máy chủ phụ
Sau khi vSphere High Availability được kích hoạt trong cụm, một máy chủ ESXi sẽ được chọn làm HA máy chủ chính. Các máy chủ ESXi khác là máy chủ phụ (máy chủ phụ). Máy chủ chính giám sát trạng thái của các máy chủ phụ để phát hiện sự cố máy chủ kịp thời và khởi động lại các máy ảo bị lỗi. Máy chủ chính cũng giám sát trạng thái nguồn của các máy ảo trên các nút cụm. Nếu phát hiện sự cố máy ảo, máy chủ chính sẽ khởi động lại máy ảo (máy chủ chính sẽ chọn máy chủ tối ưu trước khi khởi động lại máy ảo bị lỗi). Máy chủ chính của HA gửi thông tin về tình trạng hoạt động của cụm HA đến vCenter. VMware vCenter quản lý cụm bằng cách sử dụng giao diện do máy chủ chính HA cung cấp.
Máy chủ chính có thể chạy các máy ảo (VM) giống như các máy chủ khác trong cụm. Nếu một máy chủ chính gặp sự cố, một máy chủ chính khác sẽ được chọn. Máy chủ kết nối với số lượng kho dữ liệu (datastore) nhiều nhất sẽ có lợi thế trong việc bầu chọn máy chủ ESXi chính. Các máy chủ không ở chế độ bảo trì sẽ tham gia vào quá trình bầu chọn máy chủ chính.
Các máy chủ phụ có thể chạy máy ảo, theo dõi trạng thái của các máy ảo và báo cáo thông tin cập nhật về trạng thái máy ảo cho máy chủ chính HA .
Fault Domain Manager (FDM) là tên của trình đại lý (agent) được sử dụng để theo dõi tính khả dụng của các máy chủ vật lý. Trình đại lý FDM hoạt động trên mỗi máy chủ ESXi trong cụm HA .
Các loại sự cố máy chủ ESXi
Có ba loại sự cố máy chủ ESXi:
Sự cố. Máy chủ ESXi đã ngừng hoạt động vì một lý do nào đó.
Cách ly. Máy chủ ESXi và các máy ảo trên máy chủ này tiếp tục hoạt động, nhưng máy chủ bị cách ly khỏi các máy chủ khác trong cụm do vấn đề mạng.
Phân vùng. Kết nối mạng với máy chủ chính bị mất.
Cách phát hiện sự cố
Các tín hiệu kiểm tra (heartbeats) được trao đổi để phát hiện sự cố trong cụm vSphere HA . Máy chủ chính theo dõi trạng thái của các máy chủ phụ bằng cách nhận tín hiệu kiểm tra từ các máy chủ phụ mỗi giây. Máy chủ chính gửi ICMP các gói ping đến máy chủ phụ và chờ phản hồi. Nếu máy chủ chính không thể giao tiếp trực tiếp với trình đại lý (agent) của máy chủ phụ, máy chủ phụ có thể đang hoạt động bình thường hoặc đã gặp sự cố nhưng không thể truy cập qua mạng.
Nếu máy chủ chính không nhận được tín hiệu kiểm tra trạng thái, máy chủ chính sẽ kiểm tra máy chủ nghi ngờ thông qua Datastore Heartbeating. Trong quá trình hoạt động bình thường, mỗi máy chủ trong cụm HA trao đổi tín hiệu kiểm tra trạng thái với kho dữ liệu chung. Máy chủ ESXi chính kiểm tra xem tín hiệu kiểm tra trạng thái của kho dữ liệu đã được trao đổi với máy chủ nghi ngờ hay chưa, ngoài việc gửi các yêu cầu kiểm tra trạng thái đến máy chủ đó. Nếu không có trao đổi tín hiệu kiểm tra trạng thái (heartbeat) của kho dữ liệu với máy chủ đáng ngờ và máy chủ đó không gửi yêu cầu ICMP , thì máy chủ đó sẽ được đánh dấu là máy chủ bị lỗi.
Lưu ý: Một thư mục đặc biệt .vSphere-HA được tạo tại thư mục gốc của kho dữ liệu chia sẻ để thực hiện kiểm tra trạng thái và xác định danh sách các máy ảo được bảo vệ. Lưu ý rằng các kho dữ liệu vSAN không thể được sử dụng cho chức năng kiểm tra trạng thái của kho dữ liệu. Nếu máy chủ chính không thể kết nối với trình đại lý của máy chủ phụ, nhưng máy chủ phụ vẫn trao đổi tín hiệu kiểm tra trạng thái với kho dữ liệu chung, thì máy chủ chính sẽ đánh dấu máy chủ nghi ngờ đó là máy chủ bị cô lập mạng. Nếu máy chủ chính xác định rằng máy chủ phụ đang chạy trong một phân đoạn mạng bị cô lập, máy chủ chính sẽ tiếp tục giám sát các máy ảo trên máy chủ bị cô lập đó. Nếu các máy ảo (VM) trên máy chủ bị cách ly bị tắt nguồn, máy chủ chính sẽ khởi động lại các máy ảo này trên một máy chủ ESXi khác. Bạn có thể cấu hình phản ứng của cụm vSphere HA khi một máy chủ ESXi bị cách ly mạng.
Giám sát các máy ảo riêng lẻ. VMware vSphere High Availability có cơ chế để giám sát các máy ảo riêng lẻ và phát hiện xem một máy ảo cụ thể có bị lỗi hay không. {45} được cài đặt trên hệ điều hành khách (OS) được sử dụng để xác định trạng thái của máy ảo. VMware Tools gửi tín hiệu kiểm tra trạng thái (heartbeat) của hệ điều hành khách đến máy chủ ESXi.
Tín hiệu kiểm tra trạng thái và hoạt động đầu vào/đầu ra (I/O) do VMware Tools tạo ra được dịch vụ giám sát máy ảo theo dõi. Nếu máy chủ ESXi chính trong cụm HA phát hiện rằng VMware Tools trên máy ảo được bảo vệ không phản hồi và không có hoạt động I/O , máy chủ sẽ khởi động lại máy ảo. Việc giám sát hoạt động của VM I/O cho phép cụm HA tránh việc khởi động lại VM không cần thiết nếu VMware Tools không gửi tín hiệu kiểm tra (heartbeat) vì một lý do nào đó nhưng VM vẫn đang chạy. Bạn có thể thiết lập độ nhạy giám sát để cấu hình khoảng thời gian sau đó VM phải được khởi động lại nếu máy chủ ESXi không nhận được tín hiệu kiểm tra (heartbeat) của hệ điều hành khách được tạo bởi VMware Tools . VMware vSphere HA sẽ khởi động lại máy ảo trên cùng một máy chủ ESXi trong trường hợp một máy ảo bị lỗi.
VMware Tools tín hiệu kiểm tra trạng thái được gửi đến hostd ở cấp độ hypervisor (ESXi), không thông qua ngăn xếp mạng. Sau đó, máy chủ ESXi gửi thông tin nhận được đến vCenter. VMware Tools tín hiệu kiểm tra trạng thái có thể được máy chủ ESXi nhận được ngay cả khi máy ảo bị ngắt kết nối khỏi mạng và thậm chí khi không có bộ điều hợp mạng ảo nào được kết nối với máy ảo.
Giám sát máy ảo và ứng dụng. Bạn có thể sử dụng SDK từ nhà cung cấp bên thứ ba để giám sát xem một ứng dụng cụ thể được cài đặt trên máy ảo có bị lỗi hay không. Tùy chọn thay thế là sử dụng một ứng dụng đã hỗ trợ Giám sát Ứng dụng VMware. Các tín hiệu kiểm tra trạng thái ứng dụng được sử dụng để giám sát ứng dụng trên các máy ảo VMware chạy trong cụm vSphere HA
Các thông số chính cho HA Cấu hình cụm
Trước khi bắt đầu cấu hình cụm HA, bạn cần xác định một số thông số chính. Phản ứng cách ly là tham số xác định cách máy chủ ESXi hoạt động khi không nhận được tín hiệu nhịp tim. Các tùy chọn bao gồm Leave powered on, Power off (mặc định) và Shutdown.
Reservation là tham số được tính toán dựa trên các thông số tối đa của máy ảo (VM) tiêu tốn nhiều tài nguyên nhất trong cụm. Tham số này được sử dụng để ước tính Khả năng chuyển đổi dự phòng. Một cụm HA tạo các khe đặt chỗ bằng cách sử dụng giá trị của tham số Reservation.
Khả năng chuyển đổi dự phòng. Tham số này được đo bằng số nguyên và xác định số lượng máy chủ tối đa có thể bị lỗi trong cụm mà không ảnh hưởng tiêu cực đến khối lượng công việc (cụm và tất cả các VM vẫn có thể hoạt động sau khi số lượng máy chủ ESXi này bị lỗi).
Số lượng máy chủ bị lỗi được phép. Tham số này được quản trị viên hệ thống định nghĩa để thiết lập số lượng máy chủ có thể bị lỗi mà cụm vẫn tiếp tục hoạt động. Khả năng chuyển đổi dự phòng được tính đến khi thiết lập giá trị cho tham số này.
Admission Control là tham số được sử dụng để đảm bảo có đủ tài nguyên được dành riêng để khôi phục các máy ảo sau khi máy chủ ESXi bị lỗi. Tham số này được quản trị viên thiết lập và xác định hành vi của các máy ảo nếu không có đủ khe trống để khởi động máy ảo sau khi máy chủ ESXi gặp sự cố. Admission Control xác định khả năng chuyển đổi dự phòng, tức là tỷ lệ suy giảm tài nguyên có thể chấp nhận được trong cụm vSphere HA sau khi chuyển đổi dự phòng.
Restart Priority được quản trị viên thiết lập để xác định thứ tự khởi động máy ảo sau khi một nút cụm chuyển đổi dự phòng. Quản trị viên có thể cấu hình vSphere HA để khởi động các máy ảo quan trọng trước, sau đó mới khởi động các máy ảo khác.
Khả năng chuyển đổi dự phòng và sự cố máy chủ
Hãy xem xét hai trường hợp, mỗi trường hợp có ba máy chủ ESXi nhưng với các giá trị khả năng chuyển đổi dự phòng khác nhau. Trong trường hợp đầu tiên, cụm HA có thể hoạt động sau khi một máy chủ ESXi gặp sự cố (xem phía bên trái của hình ảnh bên dưới). Trong trường hợp thứ hai, cụm HA có thể chịu được sự cố của hai máy chủ ESXi (xem phía bên phải của hình ảnh).
1. Mỗi máy chủ ESXi có 4 khe cắm. Có 6 máy ảo trong cụm. Nếu một máy chủ ESXi bị sự cố (ví dụ: máy chủ thứ ba), thì ba máy ảo (VM4, VM5 và VM6) có thể di chuyển sang hai máy chủ ESXi còn lại. Trong ví dụ của tôi, ba máy ảo này đang di chuyển sang máy chủ ESXi thứ hai. Nếu có thêm một máy chủ ESXi bị lỗi, thì sẽ không còn khe trống để di chuyển và chạy các máy ảo khác.
2. Mỗi máy chủ ESXi có 4 khe cắm. Có 4 máy ảo (VM) đang chạy trong cụm VMware vSphere HA . Trong trường hợp này, có đủ khe cắm để chạy tất cả các máy ảo trong cụm nếu hai máy chủ ESXi bị lỗi.
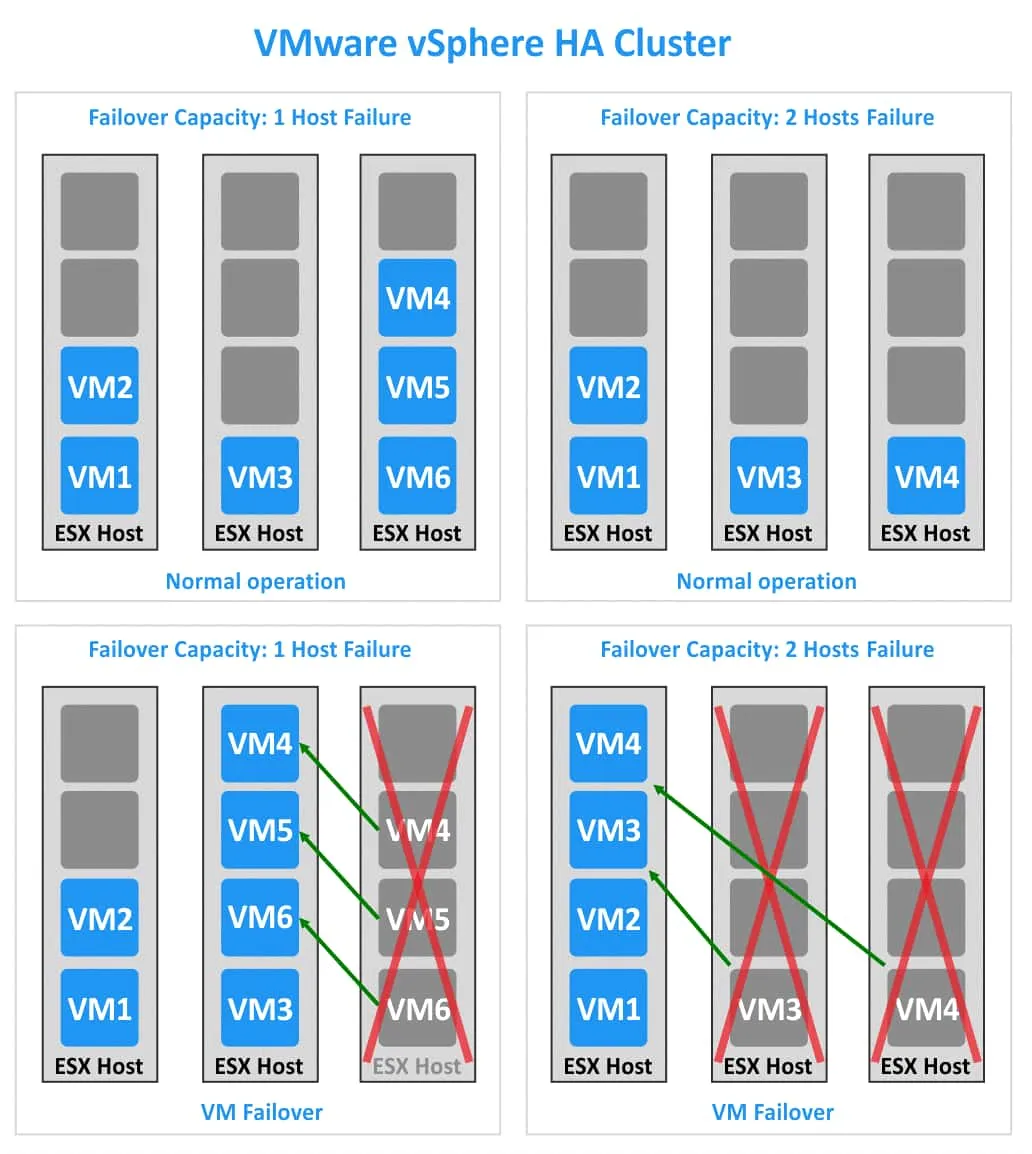
Để tính toán Failover Capacity, hãy thực hiện như sau: Từ tổng số nút trong cụm, trừ đi tỷ lệ giữa số lượng máy ảo trong cụm và số lượng khe cắm trên một nút. Nếu kết quả là một số không nguyên (một số không phải là số nguyên), hãy làm tròn số đó xuống số nguyên gần nhất. Hãy tính toán Failover Capacity cho hai ví dụ sau.
Ví dụ 1:
3–6/4=1.5
Làm tròn 1.5 xuống 1. Tất cả các máy ảo (VM) trong cụm HA có thể tiếp tục hoạt động nếu 1 máy chủ ESXi bị hỏng.
Ví dụ 2:
3–4/4=2
Không cần làm tròn xuống, vì 2 là số nguyên. Tất cả các máy ảo (VM) có thể tiếp tục hoạt động nếu 2 máy chủ ESXi bị hỏng.
Kiểm soát truy cập
Như đã đề cập ở trên, kiểm soát truy cập là tham số cần thiết để đảm bảo có đủ tài nguyên để chạy các máy ảo sau khi một máy chủ trong cụm gặp sự cố. Bạn cũng có thể định nghĩa tham số Admission Control State để thuận tiện hơn. Admission Control State được tính bằng tỷ lệ giữa Failover Capacity và Số lượng sự cố máy chủ được phép (NHF).
Nếu Failover Capacity lớn hơn NHF, thì cụm HA được cấu hình đúng cách. Ngược lại, bạn cần thiết lập Admission Control thủ công. Có hai tùy chọn sẵn có:
1. Không khởi động các máy ảo nếu chúng vi phạm các ràng buộc về tính sẵn sàng (không khởi động các máy ảo nếu không đủ tài nguyên phần cứng).
2. Cho phép khởi động các máy ảo ngay cả khi chúng vi phạm tính sẵn sàng (khởi động các máy ảo mặc dù thiếu tài nguyên phần cứng).
Chọn tùy chọn phù hợp nhất với trường hợp sử dụng cụm vSphere High Availability của bạn. Nếu mục tiêu của bạn là độ tin cậy của cụm HA , hãy chọn tùy chọn đầu tiên (Do not power on VMs). Nếu điều quan trọng nhất đối với bạn là chạy tất cả các máy ảo (VM), hãy chọn tùy chọn thứ hai (Allow VMs to be started). Lưu ý rằng trong trường hợp thứ hai, hành vi của cụm có thể không thể dự đoán được. Trong trường hợp xấu nhất, cụm HA có thể trở nên vô dụng.
VM overrides
VM overrides (hoặc HA overrides trong trường hợp cụm HA ) là tùy chọn cho phép bạn vô hiệu hóa HA cho một máy ảo (VM) cụ thể đang chạy trong cụm HA . Bạn có thể cấu hình cụm vSphere HA của mình ở mức chi tiết hơn với tùy chọn này ở cấp độ cụm.
Khả năng chịu lỗi
VMware cung cấp một tính năng cho cụm vSphere HA cho phép bạn đạt được thời gian ngừng hoạt động bằng không trong trường hợp máy chủ ESXi gặp sự cố. Tính năng này được gọi là Fault Tolerance. Trong khi cấu hình tiêu chuẩn của vSphere High Availability yêu cầu khởi động lại máy ảo (VM) trong trường hợp xảy ra sự cố, thì Fault Tolerance cho phép các máy ảo tiếp tục hoạt động nếu máy chủ ESXi chính mà các máy ảo này được đăng ký gặp sự cố. Fault Tolerance có thể được sử dụng cho các máy ảo quan trọng (mission-critical) chạy các ứng dụng then chốt.
Có chi phí hệ thống để đạt được thời gian ngừng hoạt động bằng không cho mức độ liên tục kinh doanh cao nhất vì có hai bản sao đang chạy của một máy ảo được bảo vệ bằng Fault Tolerance. Máy ảo “bóng ma” thứ hai chạy trên máy chủ ESXi thứ hai, và tất cả các thay đổi đối với máy ảo gốc (CPU, RAM, trạng thái mạng) được sao chép từ máy chủ ESXi ban đầu sang máy chủ ESXi thứ hai. Máy ảo được bảo vệ được gọi là máy ảo chính và máy ảo sao chép được gọi là máy ảo phụ. VM chính và VM phụ phải nằm trên các máy chủ ESXi khác nhau để đảm bảo bảo vệ chống lại sự cố máy chủ ESXi.
Hai VM (VM chính và VM phụ) chạy đồng thời và tiêu thụ tài nguyên CPU, RAM và mạng trên cả hai máy chủ ESXi (do đó, một VM được bảo vệ bằng tính năng Fault Tolerance tiêu thụ gấp đôi tài nguyên trong cụm vSphere HA ). Các VM này được đồng bộ hóa liên tục theo thời gian thực. Người dùng chỉ có thể làm việc với máy ảo chính (ban đầu) và máy ảo phụ (ghost) là vô hình đối với họ.
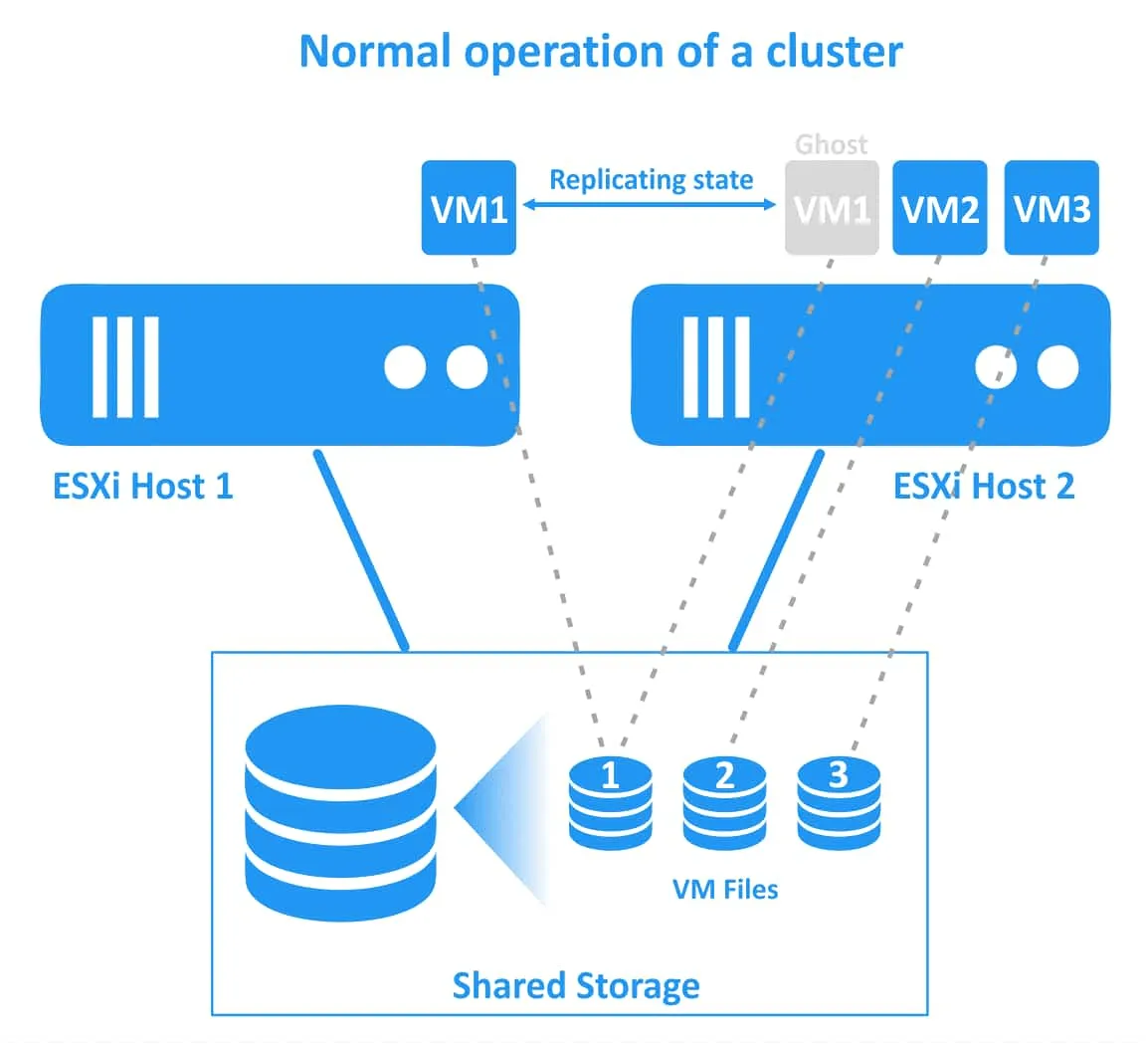
Nếu máy chủ ESXi đầu tiên gặp sự cố (máy chủ chứa máy ảo chính), các tải công việc sẽ được di chuyển sang máy ảo phụ (tức là bản sao máy ảo hoặc máy ảo ghost) đang chạy trên máy chủ ESXi thứ hai. Máy ảo phụ sẽ trở nên hoạt động và có thể truy cập ngay lập tức. Người dùng có thể nhận thấy độ trễ mạng nhẹ trong quá trình chuyển đổi dự phòng trong suốt. Không có gián đoạn dịch vụ hoặc mất dữ liệu trong quá trình chuyển đổi dự phòng. Sau khi chuyển đổi dự phòng thành công, một máy ảo “ghost” mới được tạo trên máy chủ ESXi dự phòng khỏe mạnh để đảm bảo dự phòng và tiếp tục bảo vệ máy ảo khỏi sự cố máy chủ ESXi.
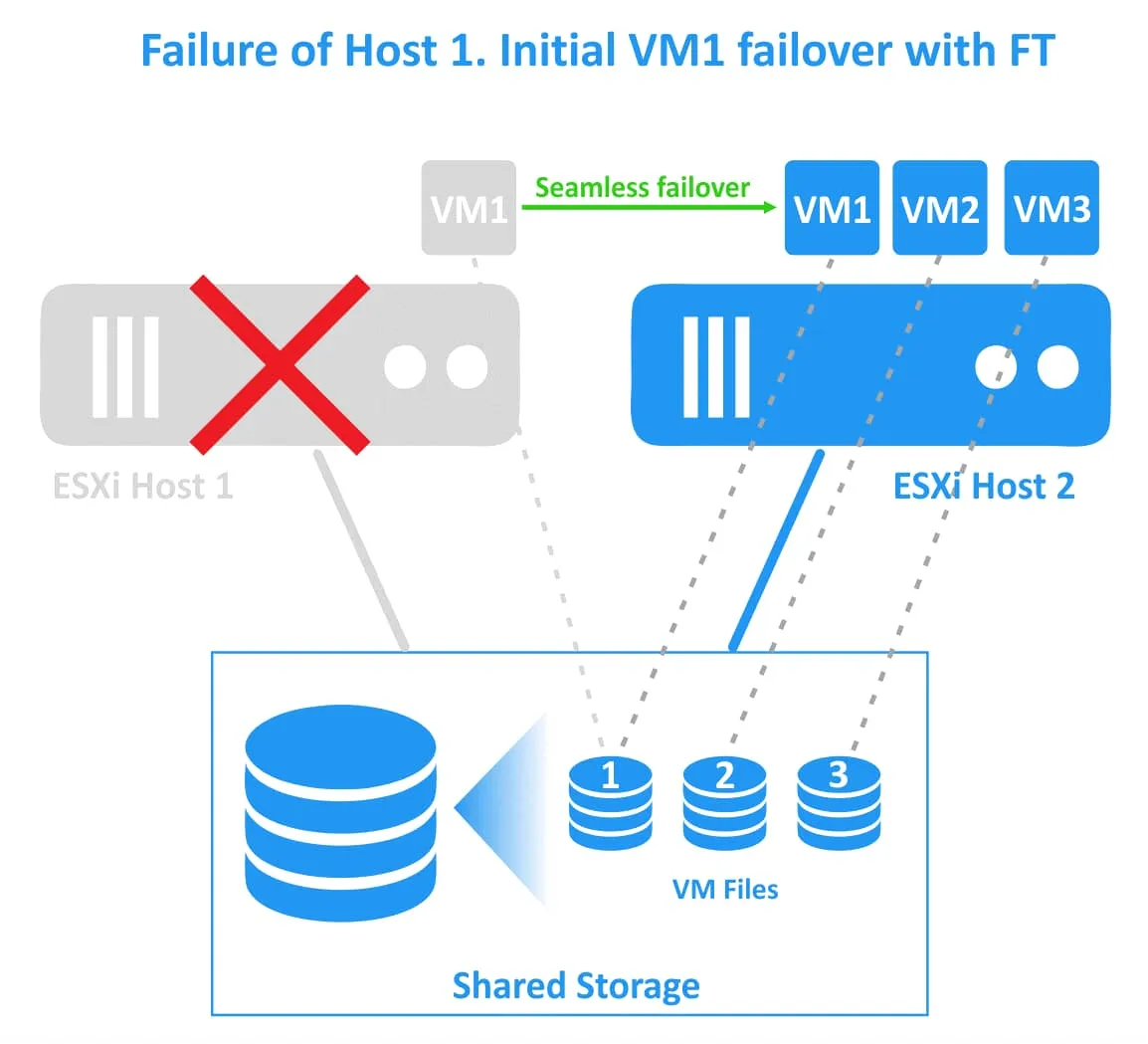
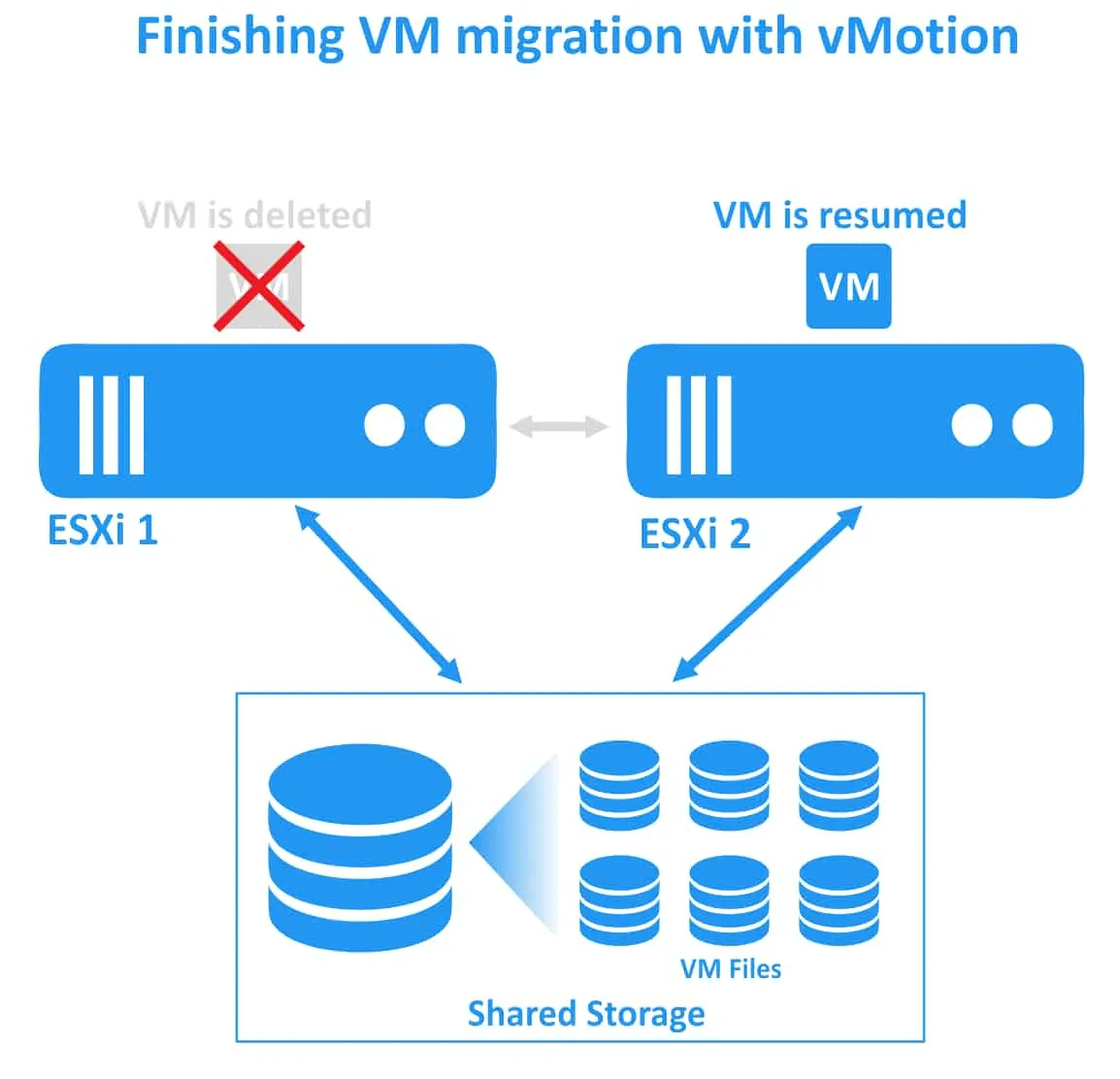
Fault Tolerance tránh các tình huống “split-brain” (khi hai bản sao hoạt động của máy ảo được bảo vệ chạy đồng thời) nhờ cơ chế khóa tệp trên lưu trữ chia sẻ để phối hợp chuyển đổi dự phòng. Tuy nhiên, Fault Tolerance không bảo vệ chống lại các sự cố phần mềm bên trong máy ảo (chẳng hạn như sự cố hệ điều hành khách hoặc sự cố của các ứng dụng cụ thể). Nếu máy ảo chính gặp sự cố, máy ảo phụ cũng sẽ gặp sự cố. Yêu cầu đối với Fault Tolerance
- Một cụm vSphere
HAvới tối thiểu hai máy chủ ESXi. vMotionvàFT logging.- Một CPU tương thích hỗ trợ ảo hóa có sự hỗ trợ của phần cứng
MMU.
Nên sử dụng một mạng chuyên dụng Fault Tolerance trong cụm vSphere HA .
Giấy phép cho Fault Tolerance
- máy chủ ESXi phải được cấp phép để sử dụng
Fault Tolerance. - vSphere
StandardvàEnterprisehỗ trợ tối đa 2 vCPU cho một máy ảo (VM). - vSphere
Enterprise Pluscho phép sử dụng tối đa 8 vCPU cho mỗi VM.
Fault Tolerance hạn chế
Có một số hạn chế khi sử dụng VMware Fault Tolerance trong vSphere. Các tính năng của VMware vSphere không tương thích với FT:
- bản sao lưu VM. Một VM được bảo vệ không được có bản sao lưu.
- Bản sao liên kết
- VMware {118} kho dữ liệu
Các thiết bị không được hỗ trợ:
Raw device mappingthiết bị- Đĩa CD-ROM vật lý và các thiết bị khác của máy chủ được kết nối với VM dưới dạng thiết bị ảo
- Thiết bị âm thanh và thiết bị USB
- Đĩa ảo VMDK có kích thước lớn hơn 2 TB
- Thiết bị video có đồ họa 3D
- Cổng song song và cổng nối tiếp
Hot-plugthiết bịNIC (network interface controller)chuyển tiếpStorage vMotion(phải được tắt tạm thời để di chuyển tệp VM sang bộ lưu trữ khác)
DRS là gì trong VMware vSphere?
Distributed Resource Scheduler (DRS) là một tính năng cụm VMware vSphere cho phép bạn cân bằng tải các máy ảo đang chạy trong cụm. DRS kiểm tra tải của máy ảo và tải của các máy chủ ESXi trong cụm vSphere. Nếu DRS phát hiện có máy chủ hoặc máy ảo bị quá tải, DRS sẽ di chuyển máy ảo sang một máy chủ ESXi có đủ tài nguyên phần cứng trống để đảm bảo chất lượng dịch vụ (QoS). DRS có thể chọn máy chủ ESXi tối ưu cho một máy ảo khi bạn tạo máy ảo mới trong cụm.
VMware DRS cho phép bạn chạy các máy ảo trong một cụm cân bằng và tránh tình trạng quá tải cũng như các tình huống không có đủ tài nguyên phần cứng cho các máy ảo và ứng dụng chạy trên máy ảo để hoạt động bình thường (trong trường hợp này, phải có đủ tài nguyên trong toàn bộ cụm).
DRS Yêu cầu
Các yêu cầu đối với DRS, cùng với các yêu cầu chung đối với cụm vSphere, bao gồm:
- Giấy phép vSphere
Enterprisehoặc vSphereEnterprise Plus - Một CPU có
Enhanced vMotion Compatibilityđể di chuyển trực tiếp máy ảo (VM) vớivMotion - Một máy chủ chuyên dụng
vMotionmạng
Cần có một máy chủ VMware đã được cấu hình vMotion để vận hành cụm DRS , khác với cụm HA , nơi vMotion chỉ được yêu cầu nếu sử dụng Fault Tolerance. Ngoài ra, giấy phép vSphere cần thiết cho VMware DRS cao hơn so với giấy phép để sử dụng vSphere High Availability.
Vai trò của vMotion
Di chuyển máy ảo (VM) từ một máy chủ ESXi sang máy chủ khác bằng vMotion, điều mà chúng tôi đã đề cập khi giải thích cách Fault Tolerance hoạt động. Với VMware vMotion, việc di chuyển máy ảo (CPU, bộ nhớ, trạng thái mạng) diễn ra mà không làm gián đoạn các máy ảo đang chạy (không có thời gian ngừng hoạt động). VMware vMotion là tính năng chính để đảm bảo hoạt động đúng đắn của DRS.
Hãy xem các bước chính của quá trình vMotion:
1. vMotion tạo một máy ảo bóng trên máy chủ ESXi đích. Máy chủ ESXi đích phân bổ trước đủ tài nguyên cho máy ảo cần di chuyển. VM được đặt vào trạng thái trung gian và cấu hình VM không thể thay đổi trong quá trình di chuyển.

2. Quá trình sao chép trước. Mỗi trang bộ nhớ VM được sao chép từ nguồn sang đích bằng cách sử dụng mạng vMotion .
3. Lần sao chép tiếp theo các trang bộ nhớ từ nguồn sang đích được thực hiện, vì các trang bộ nhớ đang bị thay đổi trong quá trình hoạt động của VM. Đây là quá trình lặp lại được thực hiện cho đến khi không còn trang bộ nhớ nào bị thay đổi. Các trang bộ nhớ bị thay đổi được gọi là trang bẩn. Quá trình di chuyển VM với vMotion sẽ mất nhiều thời gian hơn nếu các tác vụ tiêu tốn nhiều bộ nhớ được thực hiện trên VM vì có nhiều trang bộ nhớ bị thay đổi.

4. Máy ảo (VM) được dừng trên máy chủ ESXi nguồn và khởi động lại trên máy chủ đích. Lúc này, có thể nhận thấy độ trễ mạng không đáng kể bên trong VM đã được di chuyển trong khoảng một giây.
Nguyên lý hoạt động của DRS trong VMware
VMware DRS kiểm tra tải công việc từ góc độ CPU và RAM để xác định sự cân bằng của cụm vSphere mỗi 5 phút, đây là khoảng thời gian mặc định. VMware DRS kiểm tra tất cả tài nguyên trong nhóm tài nguyên của cụm, bao gồm tài nguyên được các VM sử dụng và tài nguyên của từng máy chủ ESXi trong cụm có thể cung cấp để chạy VM. Việc kiểm tra tài nguyên được thực hiện theo các chính sách đã cấu hình.
Nhu cầu của các máy ảo cũng được tính đến (các tài nguyên phần cứng mà máy ảo cần để chạy tại thời điểm kiểm tra). Công thức được sử dụng để tính toán nhu cầu bộ nhớ của máy ảo: Nhu cầu bộ nhớ của máy ảo (VM) = Hàm(Bộ nhớ đang sử dụng, Bộ nhớ đã hoán đổi, Bộ nhớ chia sẻ) + 25% (bộ nhớ tiêu thụ khi nhàn rỗi)
Nhu cầu CPU của máy ảo được tính toán dựa trên số lượng tài nguyên bộ xử lý hiện đang được máy ảo sử dụng. Các giá trị tối đa và giá trị trung bình của CPU máy ảo được thu thập trong lần kiểm tra gần nhất giúp DRS xác định xu hướng sử dụng tài nguyên của một máy ảo cụ thể. Nếu vSphere DRS phát hiện sự mất cân bằng trong cụm và một số máy chủ ESXi bị quá tải, thì DRS sẽ khởi động quá trình di chuyển trực tiếp các VM đang chạy trên máy chủ quá tải sang một máy chủ có tài nguyên trống.
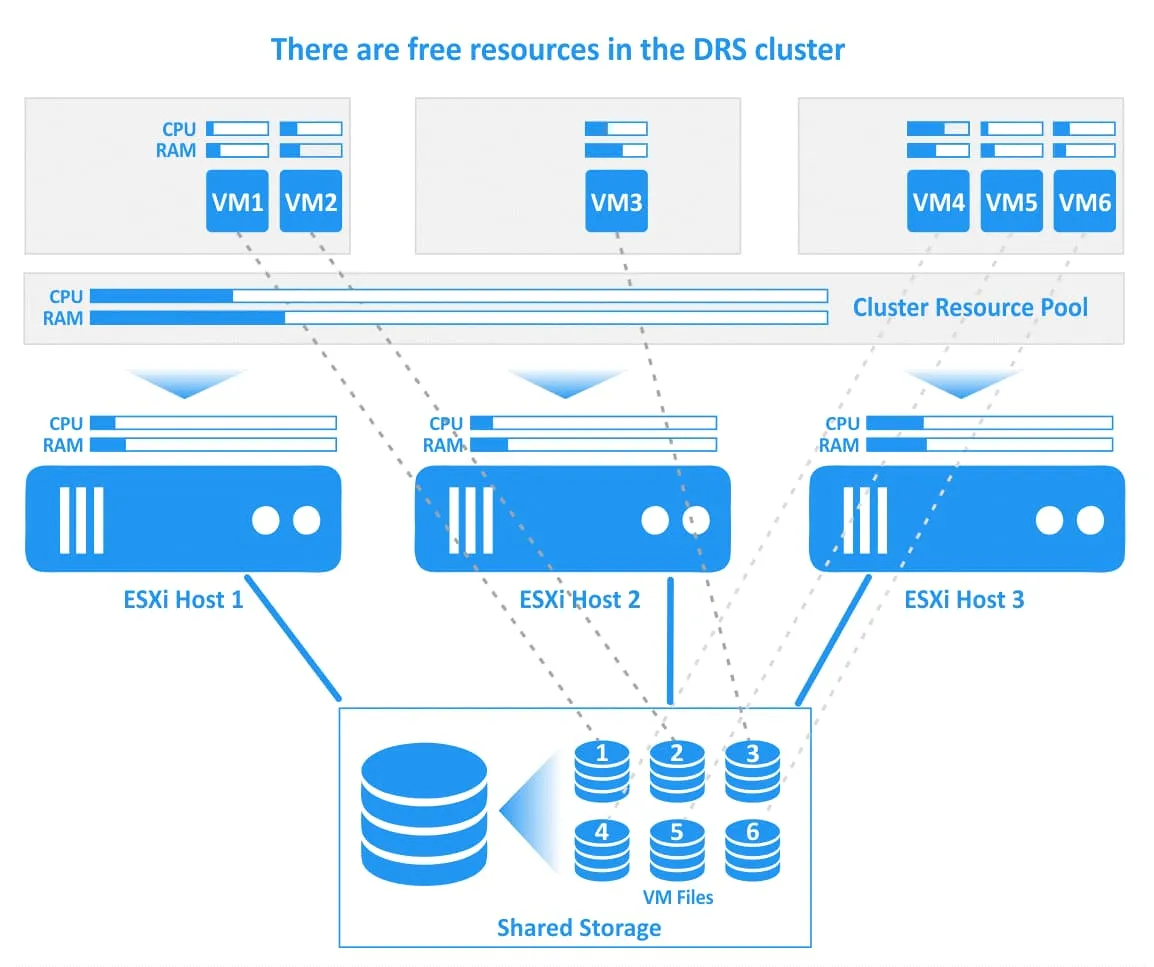
Hãy xem cách vSphere DRS hoạt động trong VMware thông qua một ví dụ kèm sơ đồ. Trong sơ đồ bên dưới, bạn có thể thấy một cụm DRS với 3 máy chủ ESXi. Tất cả các máy chủ đều được kết nối với bộ lưu trữ chung, nơi chứa các tệp máy ảo. Máy chủ đầu tiên đang quá tải, máy chủ thứ hai có tài nguyên CPU và bộ nhớ trống, còn máy chủ thứ ba đang hoạt động nặng. Một số máy ảo trên máy chủ ESXi đầu tiên (VM1) và thứ ba (VM4, VM5) đang tiêu thụ gần như toàn bộ tài nguyên CPU và bộ nhớ được phân bổ. Trong trường hợp này, hiệu suất của các máy ảo này có thể bị suy giảm.

VMware DRS xác định rằng hành động hợp lý là di chuyển VM2 đang quá tải từ máy chủ ESXi 1 sang máy chủ ESXi 2, nơi có đủ tài nguyên trống, và di chuyển VM4 từ máy chủ ESXi 3 sang máy chủ ESXi 2. Nếu DRS được cấu hình để hoạt động ở chế độ tự động, thì các VM đang chạy sẽ được di chuyển bằng vMotion (hành động này được minh họa bằng các mũi tên xanh trong hình bên dưới). Các tệp máy ảo bao gồm đĩa ảo (VMDK), tệp cấu hình (VMX) và các tệp khác được lưu trữ tại cùng một vị trí trên lưu trữ chia sẻ trong quá trình di chuyển máy ảo và sau khi di chuyển (các kết nối giữa máy ảo và tệp của chúng được minh họa bằng các đường chấm trong hình).
Sau khi các máy ảo được chọn đã được di chuyển, cụm DRS sẽ trở nên cân bằng. Mỗi máy chủ ESXi trong cụm đều có tài nguyên trống để chạy máy ảo hiệu quả và đảm bảo hiệu suất cao.

Tình huống có thể thay đổi do tải công việc của các máy ảo không đồng đều, và cụm có thể trở nên mất cân bằng trở lại. Trong trường hợp này, DRS sẽ kiểm tra tài nguyên đã sử dụng và tài nguyên trống trong cụm để khởi động quá trình di chuyển máy ảo một lần nữa.
Các thông số chính cho cấu hình vSphere DRS
VMware vSphere DRS là tính năng cụm có khả năng tùy chỉnh cao, cho phép bạn sử dụng DRS với hiệu quả cao hơn trong các tình huống khác nhau. Hãy cùng xem xét các tham số chính ảnh hưởng đến hành vi của DRS trong một cụm vSphere.
VMware DRS các mức độ tự động hóa
Khi DRS phát hiện một cụm vSphere bị mất cân bằng, DRS sẽ đưa ra các đề xuất về việc bố trí và di chuyển máy ảo (VM) thông qua vMotion. Các đề xuất này có thể được triển khai bằng cách sử dụng một trong ba mức độ tự động hóa:
Fully automated. Việc bố trí ban đầu cho máy ảo và vMotion các đề xuất sẽ được áp dụng tự động bởi DRS (không cần sự can thiệp của người dùng).
Partially automated. Các đề xuất về vị trí ban đầu của các VM mới là những đề xuất duy nhất được áp dụng tự động. Các đề xuất khác có thể được khởi tạo và áp dụng thủ công hoặc bỏ qua.
Manual. DRS cung cấp các đề xuất về vị trí ban đầu của VM và di chuyển VM, nhưng cần sự tương tác của người dùng để áp dụng các đề xuất này. Bạn cũng có thể bỏ qua các đề xuất do DRScung cấp.
DRS các mức độ tích cực (ngưỡng di chuyển)
DRS các mức độ tích cực hoặc ngưỡng di chuyển là tùy chọn để kiểm soát mức độ mất cân bằng tối đa có thể chấp nhận được cho một DRS cluster. Có năm giá trị ngưỡng từ 1 (thận trọng nhất) đến 5 (tích cực nhất).
Cài đặt tích cực sẽ khởi động di chuyển VM ngay cả khi lợi ích của việc đặt VM là rất nhỏ. Cài đặt thận trọng sẽ không khởi động di chuyển VM ngay cả khi có thể đạt được lợi ích đáng kể sau khi di chuyển. Mức 3, mức độ tích cực trung bình, được chọn mặc định và đây là cài đặt được khuyến nghị.
Quy tắc Affinity trong VMware DRS
Quy tắc Affinity và anti-affinity hữu ích khi bạn cần đặt các VM cụ thể trên các máy chủ ESXi cụ thể. Ví dụ, bạn có thể cần chạy một số VM cùng nhau trên một máy chủ ESXi trong cụm, hoặc ngược lại (bạn cần hai hoặc nhiều VM được đặt trên các máy chủ ESXi khác nhau, và các VM không được đặt trên cùng một máy chủ). Các trường hợp sử dụng có thể bao gồm:
- Các máy ảo điều khiển miền ảo (một máy chủ miền chính và máy chủ miền bổ sung) trên các máy chủ khác nhau để tránh cả hai máy ảo bị hỏng nếu một máy chủ bị hỏng. Trong trường hợp này, các máy ảo này không được chạy cùng nhau trên một máy chủ ESXi duy nhất.
- Các máy ảo chạy phần mềm được cấp phép để chạy trên phần cứng phù hợp và không thể chạy trên các máy tính vật lý khác do hạn chế về giấy phép (ví dụ: Oracle Database).
Các quy tắc tương thích được chia thành:
- Quy tắc tương thích giữa các máy ảo (cho từng máy ảo riêng lẻ)
- Quy tắc tương thích giữa máy ảo và máy chủ (mối quan hệ giữa các nhóm máy chủ và các nhóm máy ảo)
Các quy tắc tương thích giữa máy ảo và máy chủ có thể là ưu tiên (các máy ảo nên…) và bắt buộc (máy ảo phải…). Các quy tắc bắt buộc vẫn tiếp tục hoạt động ngay cả khi tùy chọn “ DRS ” bị tắt, điều này không cho phép bạn di chuyển các máy ảo (VM) tương ứng bằng vMotion theo cách thủ công. Nguyên tắc này được áp dụng để tránh vi phạm quy tắc được áp dụng cho các máy ảo đang chạy trên các máy chủ ESXi trong trường hợp vCenter tạm thời không khả dụng hoặc gặp sự cố.
Có bốn tùy chọn cho các quy tắc liên kết (affinity) của “ DRS ”:
Giữ các máy ảo ở cùng nhau. Các máy ảo được chọn phải chạy cùng nhau trên một máy chủ ESXi duy nhất (nếu cần di chuyển máy ảo, tất cả các máy ảo này phải được di chuyển cùng nhau). Quy tắc này có thể được sử dụng khi bạn muốn tập trung lưu lượng mạng giữa các máy ảo được chọn (để tránh quá tải mạng giữa các máy chủ ESXi nếu các máy ảo tạo ra lưu lượng mạng đáng kể). Một trường hợp sử dụng khác là chạy một ứng dụng phức tạp sử dụng các thành phần (phụ thuộc lẫn nhau) được cài đặt trên nhiều máy ảo hoặc chạy một vApp. Điều này có thể bao gồm, ví dụ, một máy chủ cơ sở dữ liệu và một máy chủ ứng dụng.
Các máy ảo riêng biệt. Các máy ảo được chọn không được chạy trên một máy chủ ESXi duy nhất. Tùy chọn này được sử dụng cho mục đích tính sẵn sàng cao.
Máy ảo đến máy chủ. Các máy ảo được thêm vào một nhóm máy ảo phải chạy trên máy chủ ESXi hoặc nhóm máy chủ được chỉ định. Bạn cần cấu hình DRS các nhóm (nhóm VM/máy chủ). Một DRS nhóm chứa nhiều máy ảo hoặc máy chủ ESXi.
Máy ảo với máy ảo. Quy tắc này có thể được chọn để liên kết các máy ảo với nhau khi bạn muốn bật nguồn cho một nhóm máy ảo và sau đó bật nguồn cho một nhóm máy ảo khác (phụ thuộc). Tùy chọn này được sử dụng khi VMware HA và DRS được cấu hình cùng nhau trong cụm.
Nếu có xung đột quy tắc, thì quy tắc cũ hơn sẽ được ưu tiên.
Ghi đè máy ảo (VM Override) cho VMware DRS
Tương tự như việc sử dụng ghi đè máy ảo trong cụm vSphere HA , ghi đè máy ảo được sử dụng để cấu hình chi tiết hơn cho DRS trong VMware vSphere và cho phép bạn ghi đè các thiết lập toàn cục được đặt ở cấp độ cụm DRS và định nghĩa các thiết lập cụ thể cho một máy ảo riêng lẻ. Các máy ảo khác trong cụm không bị ảnh hưởng khi ghi đè máy ảo được áp dụng cho một máy ảo cụ thể.
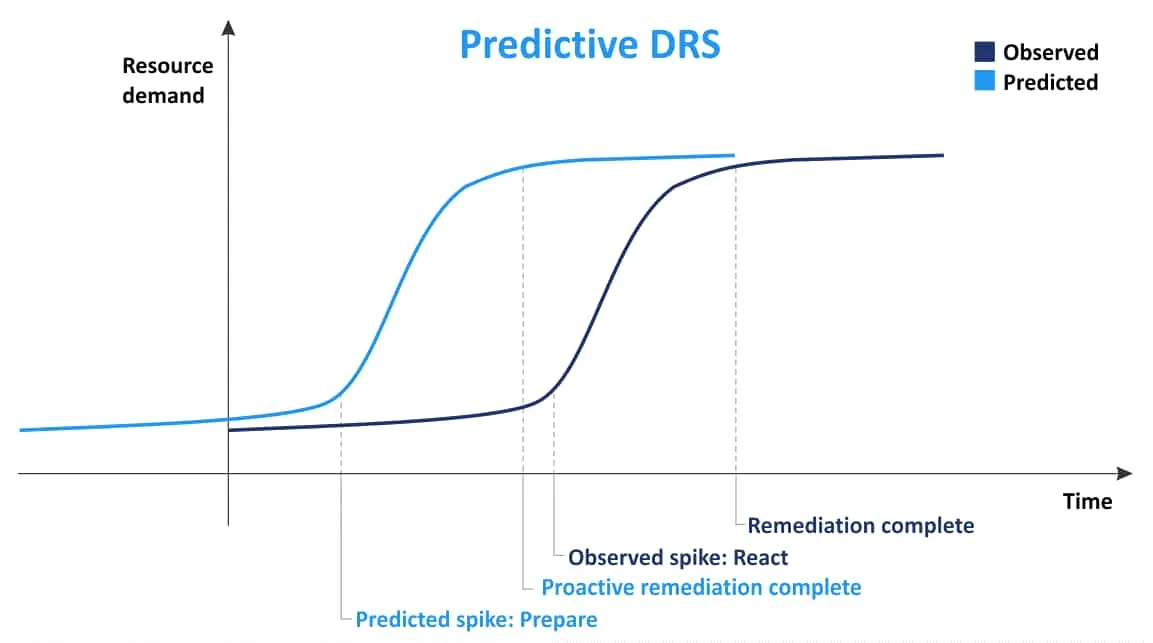
Predictive DRS
Khái niệm chính của Predictive DRS là thu thập thông tin về vị trí của máy ảo (VM) và sau đó, dựa trên thông tin đã thu thập trước đó, dự đoán thời điểm và vị trí xảy ra tình trạng sử dụng tài nguyên cao. Sử dụng thông tin này, Predictive DRS có thể di chuyển các máy ảo (VM) giữa các máy chủ để cân bằng tải tốt hơn trước khi máy chủ ESXi bị quá tải và các máy ảo (VM) thiếu tài nguyên. Tính năng này có thể hữu ích khi có sự thay đổi nhu cầu theo thời gian đối với các máy ảo (VM) trong cụm. Predictive DRS bị tắt theo mặc định. VMware vRealize Operations Manager là yêu cầu bắt buộc để sử dụng Power DRS.
Distributed Power Manager
Distributed Power Manager (DPM) là tính năng được sử dụng để di chuyển các máy ảo (VM) nếu có đủ tài nguyên trống trong cụm để tắt một máy chủ ESXi (đưa máy chủ vào chế độ chờ) và chạy các máy ảo trên các máy chủ ESXi còn lại trong cụm (các máy chủ còn lại phải cung cấp đủ tài nguyên để chạy các máy ảo cần thiết).
Khi cần thêm tài nguyên trong cụm để chạy các máy ảo, DPM sẽ khởi động lại một máy chủ đã tắt để nó hoạt động trở lại ở chế độ bình thường. Một trong các giao thức quản lý nguồn được hỗ trợ sẽ được sử dụng để bật nguồn cho máy chủ qua mạng. Các giao thức này bao gồm Intelligent Platform Management Interface (IPMI), Hewlett-Packard Integrated Lights-Out (iLO), hoặc Wake-On-LAN (WOL). Sau đó, DRS sẽ di chuyển một số máy ảo sang máy chủ này để phân phối tải công việc và cân bằng cụm. Theo mặc định, Distributed Power Management bị tắt. DPM các đề xuất có thể được áp dụng tự động hoặc thủ công.

Storage DRS
Trong khi DRS di chuyển các máy ảo dựa trên tài nguyên tính toán CPU và RAM, Storage DRS di chuyển các tệp máy ảo từ kho dữ liệu này sang kho dữ liệu khác dựa trên mức sử dụng kho dữ liệu, ví dụ như dung lượng đĩa trống. Các quy tắc tương thích và chống tương thích cho phép bạn định cấu hình xem Storage DRS có phải lưu trữ các tệp đĩa ảo của một máy ảo cùng nhau trên cùng một kho dữ liệu hay không. Ví dụ, bạn có thể cấu hình quy tắc chống tương thích để lưu trữ các tệp VMDK của một máy ảo thực hiện các hoạt động I/O trên các kho dữ liệu khác nhau. Bạn làm điều này để tránh suy giảm hiệu suất của máy ảo và kho dữ liệu ban đầu của máy ảo (các tải công việc đĩaI/O sẽ được phân phối trên nhiều kho dữ liệu khi sử dụng quy tắc chống tương thích).
Storage DRS hữu ích khi sử dụng các máy ảo có đĩa cung cấp theo nhu cầu trong trường hợp cấp phát quá mức. Storage DRS giúp tránh các tình huống khi kích thước của đĩa mỏng tăng lên, và do đó, không còn dung lượng trống trên kho dữ liệu. Thiếu dung lượng trống khiến các máy ảo lưu trữ đĩa ảo trên kho dữ liệu đó bị lỗi. Các tệp đĩa máy ảo có thể được di chuyển từ kho dữ liệu này sang kho dữ liệu khác với Storage vMotion trong khi máy ảo đang chạy.
Giám sát mức tiêu thụ CPU và bộ nhớ
VMware cung cấp khả năng giám sát việc sử dụng tài nguyên trong giao diện web của VMware vSphere Client. Bạn có thể giám sát mức sử dụng CPU trong cụm bằng cách truy cập Settings > Monitor > vSphere DRS > CPU Utilization. Ngoài ra còn có các tùy chọn khác để giám sát bộ nhớ và dung lượng lưu trữ cho các máy chủ ESXi riêng lẻ. Tính năng giám sát VMware được hỗ trợ trong NAKIVO Backup & Replication 10.5. Đọc thêm về giám sát cơ sở hạ tầng tại bài viết trên blog.
Sử dụng VMware HA và DRS cùng nhau
VMware HA và DRS không phải là các công nghệ cạnh tranh. Chúng bổ sung cho nhau, và bạn có thể sử dụng cả VMware DRS và HA trong một cụm vSphere để đảm bảo tính sẵn sàng cao cho các máy ảo (VM) và cân bằng tải công việc nếu các máy ảo được khởi động lại bởi HA trên các máy chủ ESXi khác. Nên sử dụng cả hai công nghệ này trong các cụm vSphere đang hoạt động trong môi trường sản xuất để thực hiện chuyển đổi dự phòng tự động và cân bằng tải.
Khi một máy chủ ESXi gặp sự cố, Chuyển đổi dự phòng máy ảo sẽ được kích hoạt bởi HA, và các máy ảo sẽ được khởi động lại trên các máy chủ khác. Ưu tiên hàng đầu trong tình huống này là đảm bảo các máy ảo (VM) có thể truy cập được. Tuy nhiên, sau khi di chuyển máy ảo, một số máy chủ ESXi có thể bị quá tải, điều này sẽ ảnh hưởng tiêu cực đến các máy ảo đang chạy trên những máy chủ đó. VMware DRS kiểm tra việc sử dụng tài nguyên trên từng máy chủ trong cụm và đưa ra các đề xuất về vị trí đặt máy ảo hợp lý nhất sau khi chuyển đổi dự phòng. Nhờ đó, bạn luôn có thể đảm bảo rằng có đủ tài nguyên cho các máy ảo sau khi chuyển đổi dự phòng để chạy các tải công việc với hiệu suất phù hợp. Khi cả VMware DRS và HA được kích hoạt, bạn có thể có một cụm hiệu quả hơn.
Kết luận
VMware cung cấp các tính năng mạnh mẽ của cụm trong vSphere để đáp ứng nhu cầu của những khách hàng vSphere khó tính nhất. Chúng tôi đã đề cập đến VMware DRS và HA và giải thích nguyên lý hoạt động cũng như các thông số chính của từng tính năng cụm này. VMware DRS và HA bổ sung cho nhau và giúp kết quả cuối cùng khi sử dụng cụm tốt hơn.
Ngay cả khi bạn sử dụng VMware DRS và HA, đừng quên sao lưu các máy ảo VMware trong vSphere. Tải xuống NAKIVO Backup & Replication Free Edition tại Sao lưu VMware cho môi trường của bạn.



