バックアップデータストレージにおける重複排除とは
今日の大規模な仮想インフラストラクチャでは、膨大な量のデータが生成されています。その結果、バックアップデータの量が増加し、ストレージアプライアンスやその保守を含むバックアップ用ストレージインフラへのコストも膨らんでいます。そのため、ネットワーク管理者は、重要なマシンやアプリケーションのバックアップを頻繁に作成する際、ストレージ容量を節約する方法を模索しています。
広く利用されている手法の一つが、バックアップの重複排除です。本ブログ記事では、データ重複排除とは何か、その種類、そしてバックアップに焦点を当てた活用事例について解説します。

重複排除とは何ですか?
データ重複排除は、ストレージ容量を最適化する技術です。データ重複排除では、ソースデータとストレージ内にすでに存在するデータを読み取り、重複しないデータブロックのみを転送または保存します。重複データへの参照情報は保持されます。この技術を用いてボリューム上の重複を排除することで、ディスク容量を節約し、ストレージのオーバーヘッドを削減できます。
データ重複排除の起源
データ重複排除の先駆けとなったのは、 LZ77 そして LZ78 1977年と1978年にそれぞれ導入された圧縮アルゴリズムです。これらは、繰り返し出現するデータ列を、元のデータへの参照に置き換えるという仕組みを採用しています。
この概念は、他の一般的な圧縮手法にも影響を与えました。その中でも最もよく知られているのは DEFLATEこれは、PNG画像やZIPファイル形式で使用されています。それでは、VMバックアップにおける重複排除の仕組みと、それがストレージ容量やインフラコストの削減に具体的にどのように役立つのかを見ていきましょう。
バックアップにおける重複排除とは?
バックアップ実行中、データ重複排除機能は、ソースストレージとターゲットのバックアップリポジトリの間で同一のデータブロックがないかを確認します。重複するデータはコピーされず、ターゲットのバックアップストレージ内の既存のデータブロックへの参照(ポインタ)が作成されます。

データ重複排除によって、どれだけの容量を節約できるでしょうか?
重複排除によってどれだけのストレージ容量を確保できるかを理解するために、例を挙げてみましょう。インストールに必要な最小システム要件は Windows Server 2016 少なくとも32 GBの空きディスク容量が必要です。このOSを実行する仮想マシンを10台稼働させると、バックアップの合計容量は少なくとも320 GBになります。これは、アプリケーションやデータベースが一切インストールされていない、クリーンなOSの状態での数値です。
複数の仮想マシンを展開する必要がある場合、 仮想マシン (VM)を同じシステムで作成する場合、テンプレートを使用することになります。つまり、最初は10台の同一のマシンが作成されることになります。また、これは10セットの重複データブロックが生じることを意味します。この例では、ストレージ容量の節約率は10:1となります。一般的に、5:1から10:1の範囲の節約率は良好と見なされます。
データ重複排除率
データ重複排除率は、元のデータサイズと、重複部分を削除した後のデータサイズを比較して測定する指標です。この指標により、データ重複排除プロセスの有効性を評価することができます。この値を算出するには、重複排除前のデータ量を、重複排除後にそのデータが占有するストレージ容量で割ります。
たとえば、5:1の重複排除率は、重複排除を行わない場合と比較して、バックアップストレージに5倍のバックアップデータを保存できることを意味します。
以下の点を決定する必要があります。 deduplication ratio そして storage space reduction. これら2つの指標は、混同されがちです。データ削減効果に対して重複排除率は比例して向上するわけではありません。なぜなら、ある一定の水準を超えると、限界効用の逓減の法則が作用してくるためです。下のグラフをご覧ください。

つまり、重複排除の比率が低いほど、高い比率の場合よりも大幅な容量削減効果が得られるということです。例えば、50:1の重複排除比率は、10:1の比率の5倍優れているわけではありません。10:1の比率では使用ストレージ容量が90%削減されますが、50:1の比率では、すでに冗長性の大部分が排除されているため、この値は98%にまで向上します。 これらの数値の算出方法に関する詳細については、以下をご覧ください。 Storage Networking Industry Association’s (SNIA) データ重複排除に関する資料.
データ重複排除の効率に影響を与える要因
いくつかの要因により、実際にデータの重複排除が行われるまでは、データ削減率を予測することは困難です。以下に、重複排除を使用する際にデータ削減率に影響を与える要因の一部を挙げます。
- データバックアップの種類とポリシー. 重複排除 完全バックアップ は~よりも効果的である 段階的な または 微分 バックアップ。
- 変動率バックアップ対象のデータ変更が多い場合、重複排除率は低くなります。
- 保持設定データのバックアップをバックアップストレージに保存する期間が長ければ長いほど、そのストレージ上のデータに対する重複排除の効果は高まります。
- データ型. すでに圧縮されているファイル(例:
JPG, PNG, MPG, AVI, MP4, ZIP, RARなどでは効果が期待できません。メタデータが豊富なデータや暗号化されたデータについても同様です。重複する部分を含むデータタイプの方が、重複排除には適しています。 - データの範囲データ重複排除は、データ量が多いほど効果的です。グローバル重複排除は、ローカル重複排除に比べてより多くのストレージ容量を節約できます。
注: ローカル重複排除は、単一のノードまたはディスクデバイス上で機能します。グローバル重複排除は、すべてのノードおよびディスクデバイス上のデータセット全体を分析し、重複データを排除します。複数のノードがあり、それぞれでローカル重複排除が有効になっている場合、グローバル重複排除を有効にした場合ほど効率的ではありません。
- ソフトウェアとハードウェア。 ソフトウェアソリューションと重複排除ハードウェアを組み合わせることで、ソフトウェア単独の場合よりも高い重複排除率を実現できます。例えば、NAKIVOのバックアップソリューションでは との連携
HP StoreOnce,Dell EMC Data Domain、およびNEC HYDRAstor最大17:1の重複排除率を実現する重複排除アプライアンス。
バックアップの重複排除技術
バックアップの重複排除技術は、以下の基準に基づいて分類することができます:
- データ重複排除が行われる場所
- 重複排除が完了したら
- 重複排除の仕組み
データ重複排除が行われる場所
バックアップの重複排除は、ソース側またはターゲット側で行うことができ、これらの手法はそれぞれ"ソースサイド重複排除"および"ターゲットサイド重複排除"と呼ばれます。
ソース側重複排除
ソースサイド重複排除は、バックアップ時のデータ転送量が減少するため、ネットワーク負荷を軽減します。ただし、各VMまたは各ホストに重複排除エージェントをインストールする必要があります。もう1つの欠点は、ソースサイド重複排除では 仮想マシンの動作を遅くする 重複するデータブロックの特定に必要な計算のため。

ターゲット側重複排除
ターゲット側重複排除では、まずデータをバックアップリポジトリに転送し、その後、重複排除を実行します。負荷の高い演算処理は、重複排除を担当するソフトウェアによって行われます。
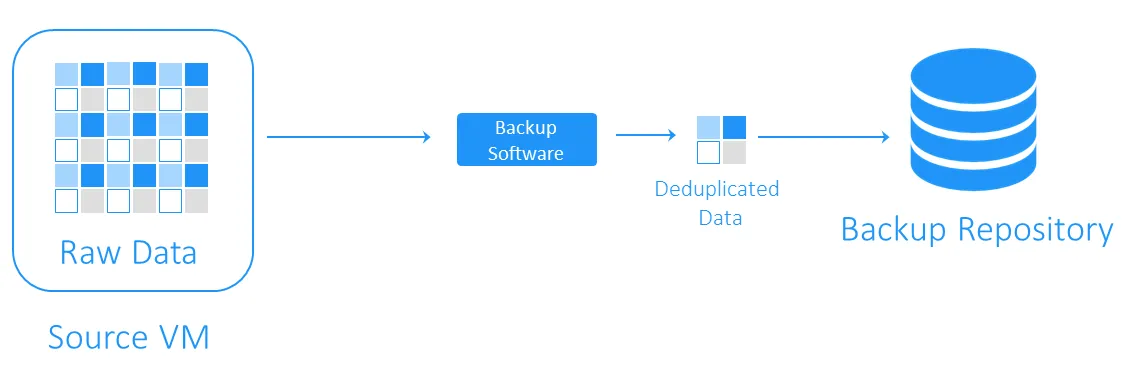
データ重複排除が完了したとき
バックアップの重複排除は、インライン方式または後処理方式で行うことができます。
- インライン重複排除 バックアップリポジトリへの書き込み前にデータの重複をチェックします。この手法では、バックアップデータストリームから冗長性を排除するため、バックアップリポジトリに必要なストレージ容量を削減できますが、インライン重複排除がバックアップジョブの実行中に実行されるため、バックアップにかかる時間が長くなります。
- 後処理による重複排除 バックアップリポジトリへの書き込み完了後にデータを処理します。当然ながら、このアプローチではリポジトリ内の空き容量をより多く必要としますが、バックアップの実行速度は向上し、必要なすべての処理はその後に行われます。後処理型重複排除は、非同期重複排除とも呼ばれます。
データ重複排除の仕組み
重複を特定する最も一般的な手法は、ハッシュベースの手法と、改良型ハッシュベースの手法である。
- ~とともに ハッシュベースの手法、重複排除ソフトウェアはデータを固定長または可変長のブロックに分割し、次のような暗号アルゴリズムを用いて各ブロックのハッシュ値を計算します。
MD5, SHA-1,またはSHA-256. これらの各手法はデータブロックごとに固有のフィンガープリントを生成するため、ハッシュ値が類似しているブロックは同一であるとみなされます。この手法の欠点は、特に大規模なバックアップの場合、多大な計算リソースを必要とする可能性があることです。 - その 修正されたハッシュベースの手法 次のような、より単純なハッシュ生成アルゴリズムを使用します
CRC、これはわずか16ビットしか生成しない(一方、SHA-256)。その後、ブロックのハッシュ値が類似している場合、バイト単位で比較されます。完全に一致すれば、それらのブロックは同一であるとみなされます。この方法はハッシュベースの手法よりも若干処理速度は遅くなりますが、必要な計算リソースは少なくて済みます。
バックアップ重複排除ソフトウェアの選定
バックアップの重複排除は、重複排除技術の中でも最も一般的な活用例の一つです。とはいえ、このデータ削減技術を実装するには、適切なソフトウェアソリューションとストレージ用ハードウェアが必要です。
NAKIVO Backup & Replication は、ハッシュベースの重複検出機能を改良したグローバルターゲット後処理重複排除をサポートするバックアップソリューションです。また、次のような重複排除アプライアンスを統合することで、ソースサイドの重複排除機能を活用することも可能です。 DELL EMC Data Domain ~とともに DD Boost, NEC HYDRAstor そして HP StoreOnce ~とともに Catalyst NAKIVOソリューションに関するサポート



