Nozioni fondamentali sulla protezione dei dati: come eseguire il backup di un bucket Amazon S3
Amazon S3 è un servizio di storage sul cloud affidabile fornito da Amazon Web Services (AWS). I file vengono archiviati come oggetti nei bucket Amazon S3. Questo servizio di storage sul cloud è ampiamente utilizzato per archiviare i backup dei dati grazie all’elevata affidabilità di Amazon S3. A differenza di Amazon Elastic Block Storage (EBS), dove i dati ridondanti vengono archiviati in un’unica zona di disponibilità, in Amazon S3 i dati ridondanti vengono distribuiti su più zone di disponibilità.
Se un data center in una zona diventa non disponibile, è possibile accedere ai dati in un’altra zona. In alcuni casi, potrebbe essere necessario eseguire il backup dei dati archiviati nei bucket Amazon S3 per evitare la perdita di dati causata da errori umani o guasti del software. I dati possono essere eliminati o danneggiati se un utente che ha accesso a un bucket S3 elimina i dati o li danneggia scrivendo modifiche indesiderate. Anche un guasto del software può causare risultati simili.

Amazon S3 Controllo delle versioni
Il controllo delle versioni degli oggetti è una funzione efficace di Amazon S3 che protegge i dati in un bucket da danneggiamenti, modifiche indesiderate e cancellazioni. Quando vengono apportate modifiche a un file (memorizzato come oggetto in S3), viene creata una nuova versione dell’oggetto. In un bucket vengono memorizzate più versioni dello stesso oggetto. È possibile accedere e ripristinare le versioni precedenti dell’oggetto. Se l’oggetto viene eliminato, viene applicato il “marcatore di eliminazione”, ma è possibile annullare questa azione e aprire una versione precedente dell’oggetto prima dell’eliminazione. Il controllo delle versioni di Amazon S3 può essere utilizzato senza software di backup S3 aggiuntivo.
È possibile utilizzare il criterio del ciclo di vita per definire per quanto tempo le versioni devono essere archiviate in un bucket S3 per avere una forma di backup in Amazon S3. I costi aggiuntivi per l’archiviazione di versioni aggiuntive non dovrebbero essere elevati se si configura correttamente il criterio del ciclo di vita e le nuove versioni sostituiscono quelle più vecchie. Le versioni precedenti possono essere eliminate o spostate in uno storage più economico (ad esempio, un archivio freddo) per ottimizzare i costi.
Come abilitare il controllo delle versioni di AWS S3
Accedi alla console di gestione AWS utilizzando un account con autorizzazioni sufficienti. Fai clic su Servizi e quindi seleziona S3 nella categoria Storage .
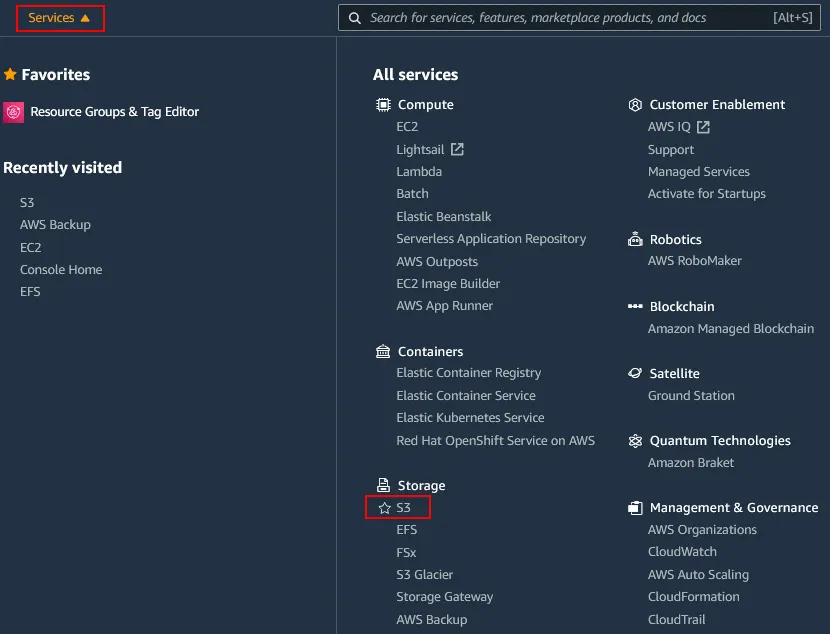
Nel riquadro di navigazione, fare clic su Bucket e selezionare il bucket S3 per cui si desidera abilitare il controllo delle versioni. In questo esempio, seleziono il bucket con il nome blog-bucket01. Fai clic sul nome del bucket per aprire i dettagli del bucket.
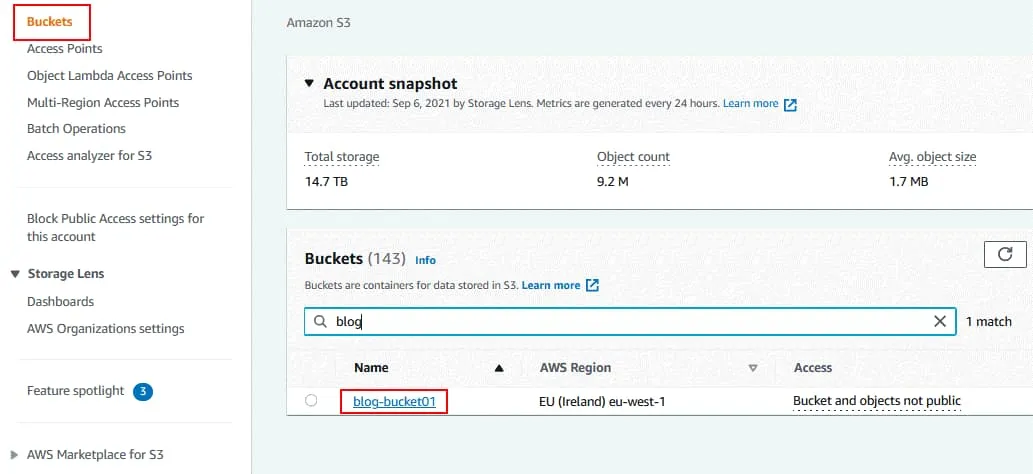
Apri la scheda Proprietà per il bucket selezionato.
Nella sezione Bucket Versioning , fare clic su Modifica.
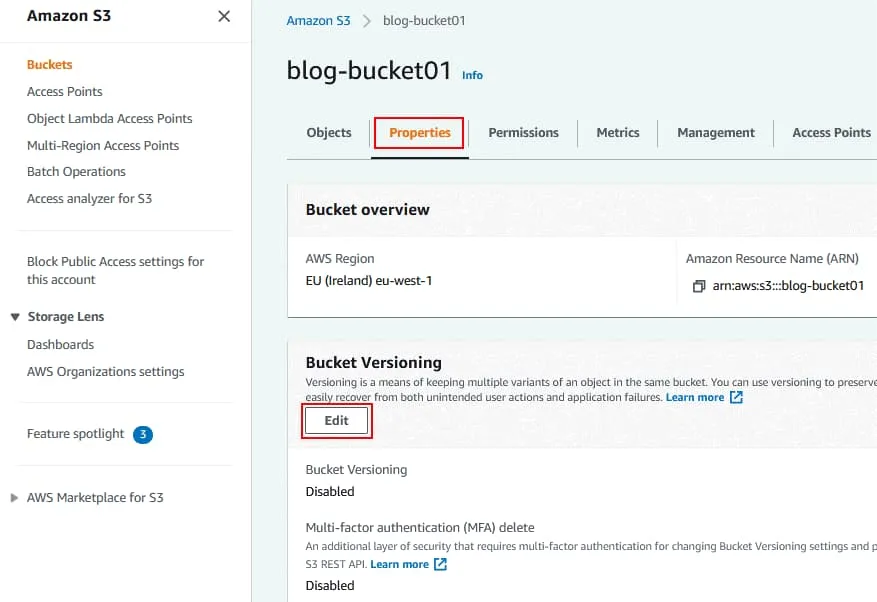
Il controllo delle versioni del bucket è disabilitato per impostazione predefinita.
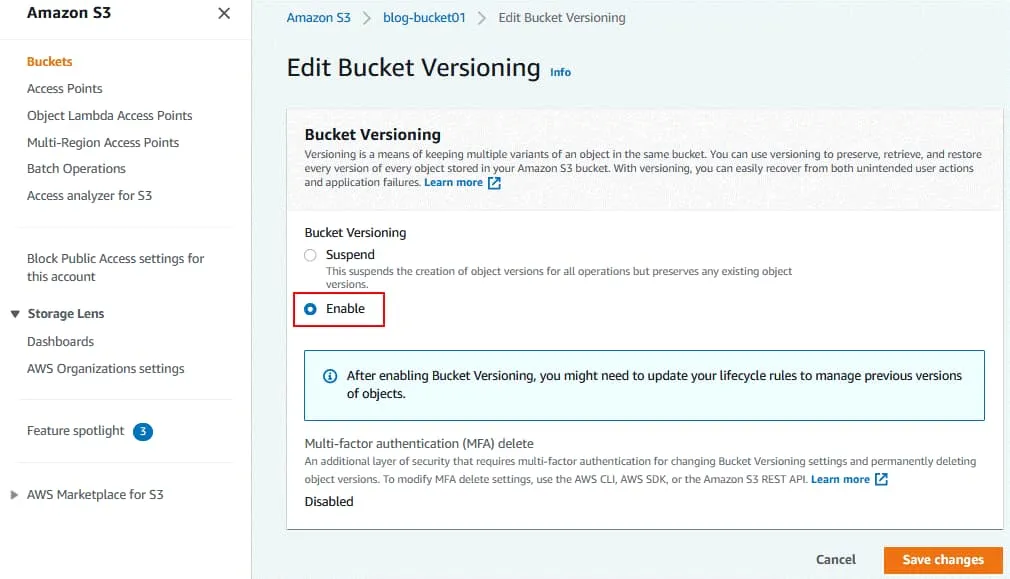
Fare clic su Abilitare per attivare il controllo delle versioni dei bucket.
Fare clic su Salvare le modifiche.
Viene visualizzato un suggerimento che indica che potrebbe essere necessario aggiornare le regole del ciclo di vita. Questo è il passaggio avanti.
Il messaggio viene visualizzato nella parte superiore della pagina se sono state applicate modifiche alla configurazione: Versione del bucket modificata con successo.
Regole del ciclo di vita
Per configurare le regole del ciclo di vita per il controllo delle versioni di Amazon S3, vai alla scheda Gestione nella pagina del bucket selezionato. Nella sezione Regole del ciclo di vita , fare clic su Crea regola del ciclo di vita.
Si apre la pagina Crea regola del ciclo di vita .
Configurazione della regola del ciclo di vita. Immettere il nome della regola del ciclo di vita, ad esempio Ciclo di vita del blog 01.
Scegliere l’ambito della regola. È possibile applicare filtri per applicare le regole del ciclo di vita a oggetti specifici o applicare la regola a tutti gli oggetti nel bucket.
Definire i tag degli oggetti per indicare gli oggetti a cui devono essere applicate le azioni del ciclo di vita. Immettere una chiave e un valore nei campi appropriati e fare clic sul pulsante Aggiungi tag per aggiungere il tag o sul pulsante Rimuovi per rimuovere il tag.

Azioni della regola del ciclo di vita. Scegliere le azioni che si desidera che questa regola esegua:
- Transizione current versioni di oggetti tra classi di storage
- Transizione previous versioni di oggetti tra classi di storage
- Scadenza corrente versioni degli oggetti
- Eliminazione definitiva precedente versioni di oggetti
- Elimina i marcatori di eliminazione scaduti o i caricamenti multiparte incompleti

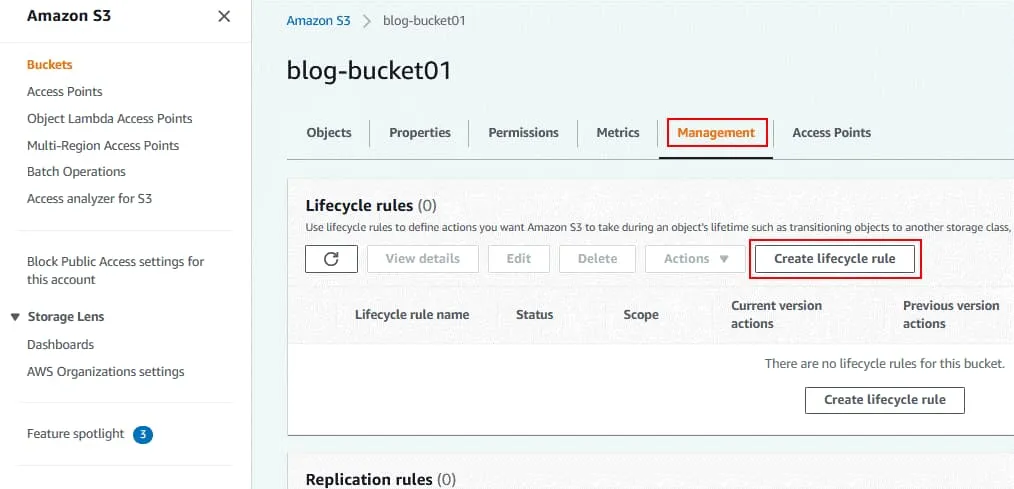
Trasferimento delle versioni non correnti degli oggetti tra classi di archiviazione.
Selezionare i trasferimenti delle classi di archiviazione e il numero di giorni dopo i quali gli oggetti diventano non correnti.
Nel mio esempio, gli oggetti vengono spostati dalla classe di storage S3 corrente a Standard-IA dopo 35 giorni.
Elimina definitivamente le versioni precedenti degli oggetti.
Immettere il numero di giorni dopo i quali le versioni precedenti devono essere eliminate. Il valore deve essere superiore al numero di giorni dopo i quali gli oggetti diventano non attuali. Nel mio esempio, gli oggetti vengono eliminati definitivamente dopo 40 giorni.
Fare clic su Crea regola per creare una regola del ciclo di vita.
Replica del bucket
In alternativa al backup automatico in Amazon S3, è possibile replicare il bucket in altre regioni. È necessario creare un secondo bucket che funga da bucket di destinazione in un’altra regione e creare una regola di replica. Dopo aver creato la regola di replica, tutte le modifiche apportate al bucket di origine vengono automaticamente riportate nel bucket di destinazione.
Individuare la scheda Regole di replica nella scheda Gestione scheda per il bucket di origine e fare clic su Creare una regola di replica.
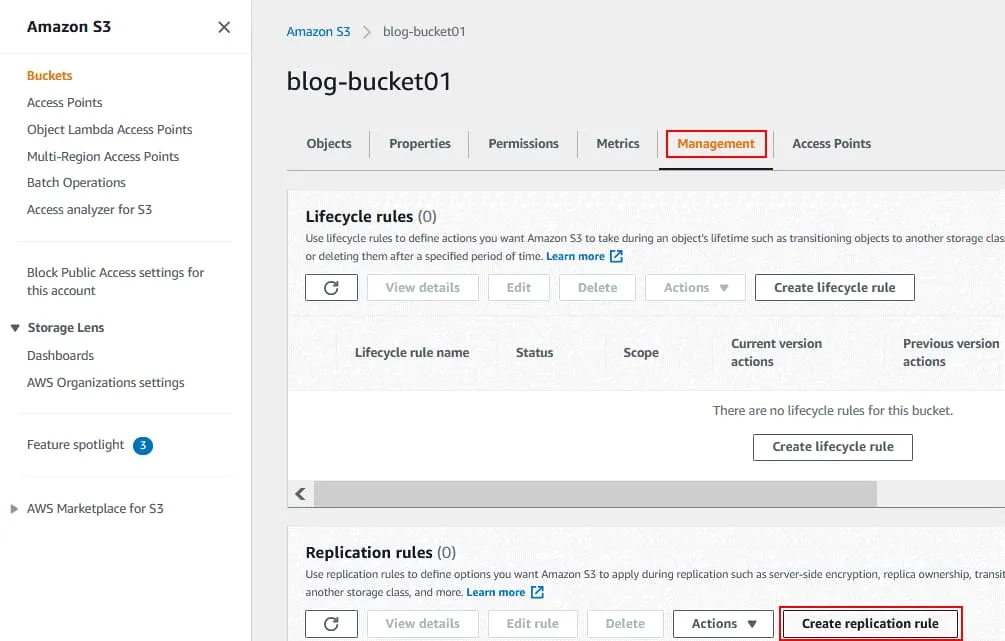
La pagina Creare una regola di replica si apre.
Immettere un nome per la regola di replica, ad esempio Replica del bucket S3 del blog.
Definire lo stato della regola al momento della creazione (enabled o disabilitato).
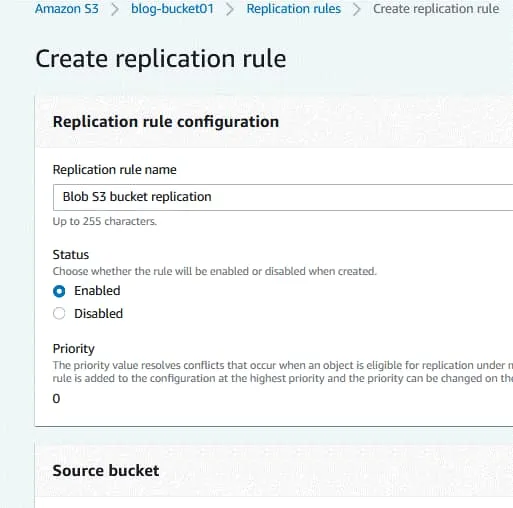
Bucket di origine. Il bucket di origine è già stato selezionato (blog-bucket01).
Scegliere un ambito di applicazione della regola. È possibile utilizzare la regola di replica per tutti gli oggetti nel bucket oppure configurare filtri e applicare la regola a oggetti personalizzati.
Destinazione. Immettere il nome del bucket di destinazione o fare clic su Sfoglia S3 e selezionare un bucket dall’elenco. È possibile selezionare un bucket in questo account o in un altro account. Se il controllo delle versioni AWS S3 è abilitato per il bucket di origine, il controllo delle versioni degli oggetti deve essere abilitato anche per il bucket di destinazione. Viene visualizzata una regione di destinazione per il bucket di destinazione selezionato.
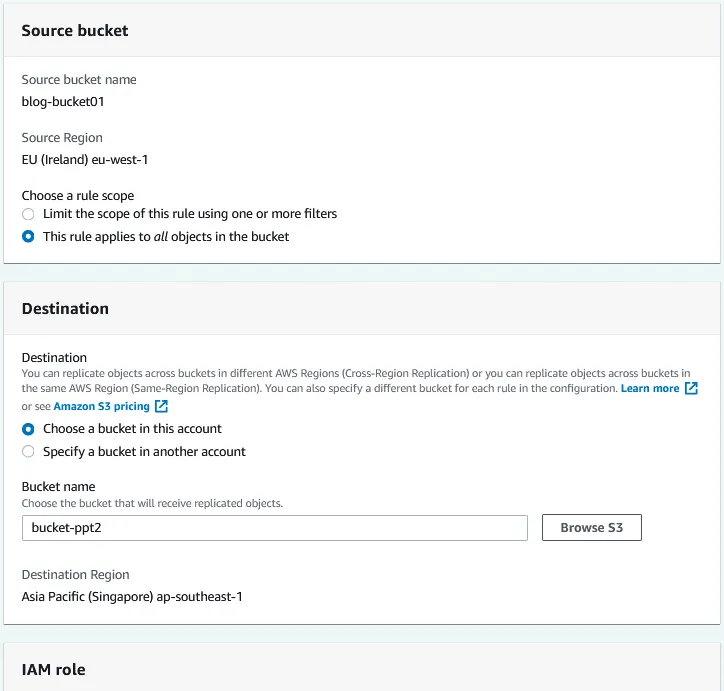
Configura il ruolo di gestione delle identità e degli accessi (IAM), quindi seleziona una classe di storage e opzioni di replica aggiuntive. Fai clic su Salva per salvare la configurazione e creare una regola di replica per il bucket.
Backup AWS S3 nella CLI
AWS CLI è una potente interfaccia a riga di comando che consente di lavorare con diversi servizi Amazon, tra cui Amazon S3. Esiste un utile comando sync che consente di eseguire il backup dei bucket Amazon S3 su una macchina Linux copiando i file dal bucket a una directory locale in Linux in esecuzione su un’istanza di Amazon EC2.
Una funzione del comando sync in AWS CLI è che i file in un file system locale (destinazione di backup Amazon S3) non vengono eliminati se questi file mancano nel bucket S3 di origine e viceversa. Questo è importante per il backup AWS S3 perché se alcuni file sono stati accidentalmente eliminati nel bucket S3, i file esistenti non vengono eliminati nella directory locale di una macchina Linux dopo la sincronizzazione.
Vantaggi:
- Supporto di bucket S3 di grandi dimensioni e scalabilità
- Supporto di thread multipli durante la sincronizzazione
- Possibilità di sincronizzare solo i file nuovi e aggiornati
- Elevata velocità di sincronizzazione grazie ad algoritmi intelligenti
Svantaggi:
- Linux in esecuzione su un’istanza di EC2 consuma lo storage dei volumi EBS. I costi di storage per i volumi EBS sono più elevati rispetto a quelli per i bucket S3.
In questo tutorial vengono utilizzati i comandi per Ubuntu Server.
Primo, è necessario installare AWS CLI.
Aggiornare l’albero dei repository:
sudo apt-get update
Installare AWS CLI:
sudo apt install awscli
o
Installare unzip:
sudo apt install unzip
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip"
unzip awscli-exe-linux-x86_64.zip
sudo ./aws/install
Verificare le credenziali AWS in Linux in esecuzione sull’istanza di EC2.
aws configure list
Aggiungi le credenziali per accedere ad AWS con AWS CLI da un’istanza Linux se le credenziali non sono state impostate:
aws configure
Inserisci i seguenti parametri:
ID chiave di accesso AWS
Chiave di accesso segreta AWS
Nome regione predefinito
Formato di output predefinito
Crea una directory in cui archiviare il backup in Amazon S3. Nel mio esempio, creo la directory ~/s3/ per archiviare i backup S3 e una sottodirectory con un nome identico al nome del bucket. I file archiviati nel bucket S3 devono essere copiati in questa directory locale sul computer Linux. ~ è la directory home di un utente, che nel mio caso è /home/ubuntu .
mkdir -p ~/s3/your_bucket_name
Sostituisci your_bucket_name con il nome del tuo bucket (blog-bucket01 nel nostro esempio).
mkdir -p ~/s3/blog-bucket01
Sincronizza il contenuto del bucket con la tua directory locale sull’istanza di EC2 che esegue Linux:
aws s3 sync s3:// blog-bucket01 /home/ubuntu/s3/ blog-bucket01/
Se la configurazione delle credenziali, il nome del bucket e il percorso di destinazione sono corretti, il download dei dati dal bucket S3 dovrebbe iniziare. Il tempo necessario per completare l’operazione dipende dalle dimensioni dei file nel bucket e dalla velocità della connessione Internet.
Backup automatico Amazon S3
È possibile configurare i lavori di backup automatico Amazon S3 con AWS CLI sync. Creare un file di script sync.sh per eseguire il backup AWS S3 (sincronizzare i file da un bucket S3 a una directory locale sull’istanza Linux) e quindi eseguire questo script in base alla pianificazione.
nano /home/ubuntu/s3/sync.sh
#!/bin/sh
# Display the current date and time
echo '-----------------------------'
date
echo '-----------------------------'
echo ''
# Display the script initialization message
echo 'Syncing remote S3 bucket...'
# Running the sync command
/usr/bin/aws s3 sync s3://{BUCKET_NAME} /home/ubuntu/s3/{BUCKET_NAME}/
# Echo "Script execution is completed"
echo 'Sync complete'
Sostituisci {BUCKET_NAME} con il nome del bucket S3 di cui desideri eseguire il backup.
Il percorso completo di aws (binario AWS CLI) è definito per consentire a crontab di eseguire correttamente l’applicazione aws nell’ambiente shell utilizzato da crontab.
Rendere lo script eseguibile:
sudo chmod +x /home/ubuntu/s3/sync.sh
Eseguire lo script per verificare che funzioni:
/home/ubuntu/s3/sync.sh
Modificare crontab (uno scheduler in Linux) dell’utente corrente per pianificare l’esecuzione dello script di backup in Amazon S3.
crontab -e
Potrebbe essere necessario selezionare un editor di testo per modificare la configurazione di crontab.
Il formato di crontab per la pianificazione delle attività è il seguente:
m h dom mon dow command
Dove: m – minuti; h – ore; dom – giorno del mese; dow – giorno della settimana.
Aggiungiamo una riga di configurazione affinché l’attività esegua la sincronizzazione ogni ora e salvi i risultati del backup AWS S3 nel file di log. Aggiungete questa riga alla fine della configurazione crontab.
0 * * * * /home/ubuntu/s3/sync.sh > /home/ubuntu/s3/sync.log
Il backup automatico Amazon S3 è configurato. Il file di log può essere utilizzato per verificare l’esecuzione delle attività di sincronizzazione.
Conclusione
Esistono diversi metodi per eseguire il backup di Amazon S3 e due di essi sono stati trattati in questo post del blog. È possibile abilitare il controllo delle versioni degli oggetti per un bucket per conservare le versioni precedenti degli oggetti, il che consente di recuperare i file se sono state apportate modifiche indesiderate. La replica di Amazon S3 è un altro strumento nativo per creare una copia dei file archiviati in un bucket Amazon S3 come oggetti. In questo caso, gli oggetti vengono replicati da un bucket a un altro. È anche possibile creare un backup di un bucket Amazon S3 utilizzando lo strumento di sincronizzazione in AWS CLI, che consente di sincronizzare i file in un bucket con una directory locale di una macchina Linux in esecuzione su un’istanza di EC2. Il backup automatico di Amazon S3 può essere pianificato utilizzando uno script e crontab.
In generale, l’archiviazione sul cloud Amazon S3 è molto affidabile e il backup in Amazon S3 è una pratica comune. Se si dispone di una solida strategia di protezione dei dati e di backup AWS, è consigliabile avere una copia di backup. In questo caso, si consiglia di eseguire il backup dei dati su Amazon S3 e su un’altra ubicazione. Utilizza NAKIVO Backup & Replication per proteggere i tuoi dati su macchine fisiche e virtuali. NAKIVO Backup & Replication è un robusto software di backup per la virtualizzazione che può essere utilizzato per proteggere le VM, nonché le istanze di Amazon EC2 e le macchine fisiche.



