Fondamentaux de la protection des données : comment sauvegarder un bucket Amazon S3
Amazon S3 est un service de stockage dans le cloud fiable fourni par Amazon Web Services (AWS). Les fichiers sont stockés sous forme d’objets dans des compartiments Amazon S3. Ce stockage est largement utilisé pour stocker des sauvegardes de données en raison de la grande fiabilité d’Amazon S3. Contrairement à Amazon Elastic Block Storage (EBS), où les données redondantes sont stockées dans un seul centre de données, dans Amazon S3, les données redondantes sont réparties sur plusieurs centres de données. Si un centre de données dans une zone devient indisponible, vous pouvez accéder aux données dans un autre centre de données. Dans certains cas, vous devrez peut-être sauvergarder les données stockées dans les compartiments Amazon S3 afin d’éviter toute perte de données due à une erreur humaine ou à une défaillance logicielle. Les données peuvent être supprimées ou corrompues si un utilisateur ayant accès à un compartiment S3 supprime des données ou les corrompt par écriture de modifications indésirables. Une défaillance logicielle peut entraîner des résultats similaires. 
Gestion des versions Amazon S3
Le versionnage des objets est une fonctionnalité efficace d’Amazon S3 qui protège vos données dans un compartiment contre la corruption, les modifications indésirables et la suppression. Lorsque des modifications sont apportées à un fichier (stocké sous forme d’objet dans S3), une nouvelle version de l’objet est créée. Plusieurs versions d’un même objet sont stockées dans un compartiment. Vous pouvez accéder aux versions précédentes de l’objet et les restaurer. Si l’objet est supprimé, le « marqueur de suppression » est appliqué à l’objet, mais vous pouvez annuler cette action et ouvrir une version précédente de l’objet avant sa suppression. La gestion des versions Amazon S3 peut être utilisée sans logiciel de sauvegarde S3 supplémentaire. Vous pouvez utiliser la politique de cycle de vie pour définir la durée de conservation des versions dans un compartiment S3 afin de disposer d’une forme de sauvegarde Amazon S3. Les coûts supplémentaires liés au stockage des versions supplémentaires ne devraient pas être élevés si vous configurez correctement la politique de cycle de vie et que les nouvelles versions remplacent les plus anciennes. Les anciennes versions peuvent être supprimées ou déplacées vers un stockage plus économique (par exemple, un stockage à froid) afin d’optimiser les coûts.
Comment activer le contrôle de version AWS S3
Connectez-vous à la console de gestion AWS par un compte disposant des autorisations suffisantes. Cliquez sur Services, puis sélectionnez S3 dans la catégorie Stockage.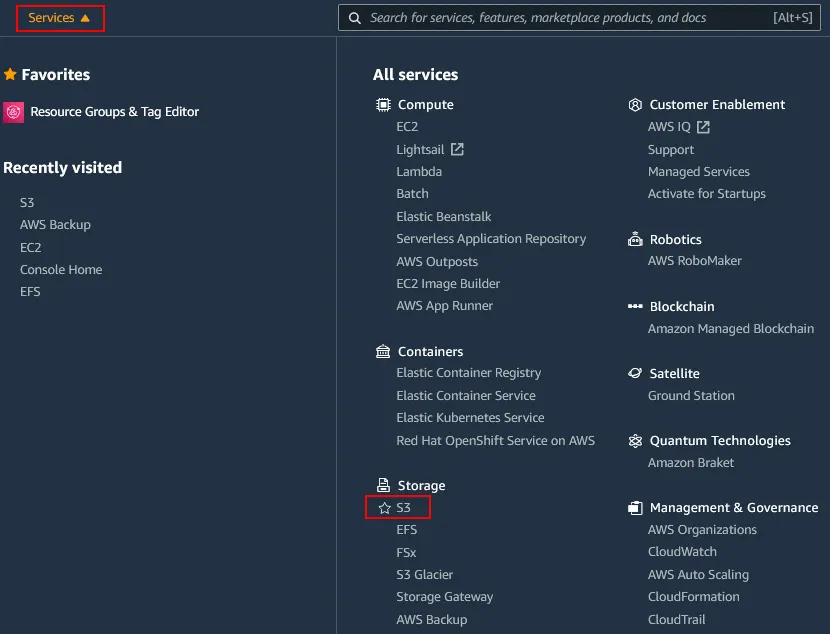 Dans le volet de navigation, cliquez sur Buckets et sélectionnez le bucket S3 pour lequel vous souhaitez activer le contrôle de version. Dans cet exemple, je sélectionne le compartiment dont le nom est blog-bucket01. Cliquez sur le nom du compartiment pour ouvrir les détails du compartiment.
Dans le volet de navigation, cliquez sur Buckets et sélectionnez le bucket S3 pour lequel vous souhaitez activer le contrôle de version. Dans cet exemple, je sélectionne le compartiment dont le nom est blog-bucket01. Cliquez sur le nom du compartiment pour ouvrir les détails du compartiment.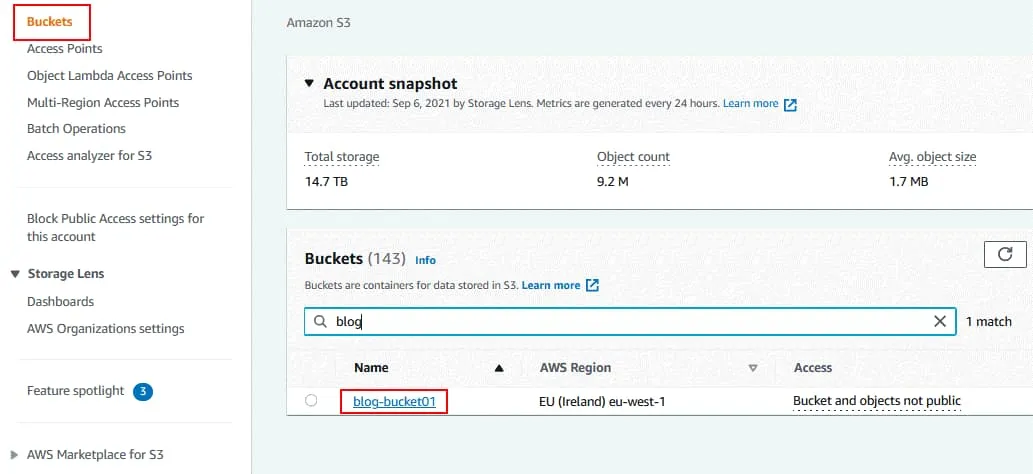 Ouvrez l’onglet Propriétés du compartiment sélectionné. Dans la section Versionnement du compartiment, cliquez sur Modifier.
Ouvrez l’onglet Propriétés du compartiment sélectionné. Dans la section Versionnement du compartiment, cliquez sur Modifier.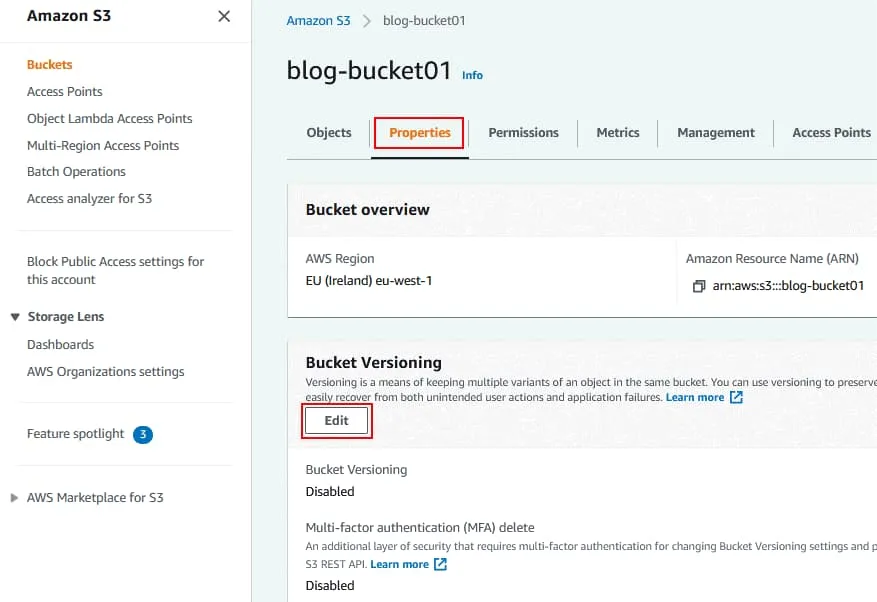 La gestion des versions des compartiments est désactivée par défaut. Cliquez sur Activer pour activer la gestion des versions des compartiments. Cliquez sur Enregistrer les modifications. Un conseil s’affiche pour vous indiquer que vous devrez peut-être mettre à jour vos règles de cycle de vie. C’est la suite.
La gestion des versions des compartiments est désactivée par défaut. Cliquez sur Activer pour activer la gestion des versions des compartiments. Cliquez sur Enregistrer les modifications. Un conseil s’affiche pour vous indiquer que vous devrez peut-être mettre à jour vos règles de cycle de vie. C’est la suite.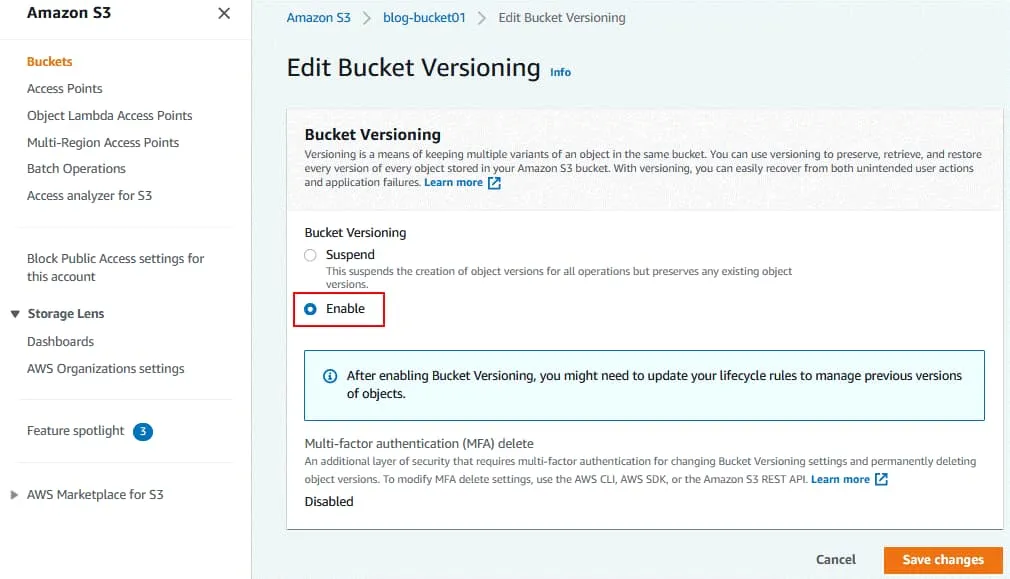 Le message s’affiche en haut de la page si les modifications de configuration ont été appliquées : Versionnement du compartiment modifié avec succès.
Le message s’affiche en haut de la page si les modifications de configuration ont été appliquées : Versionnement du compartiment modifié avec succès.
Règles relatives au cycle de vie
Pour configurer les règles de cycle de vie pour la gestion des versions Amazon S3, accédez à l’onglet Gestion de la page du compartiment sélectionné. Dans la section Règles du cycle de vie, cliquez sur Créer une règle du cycle de vie.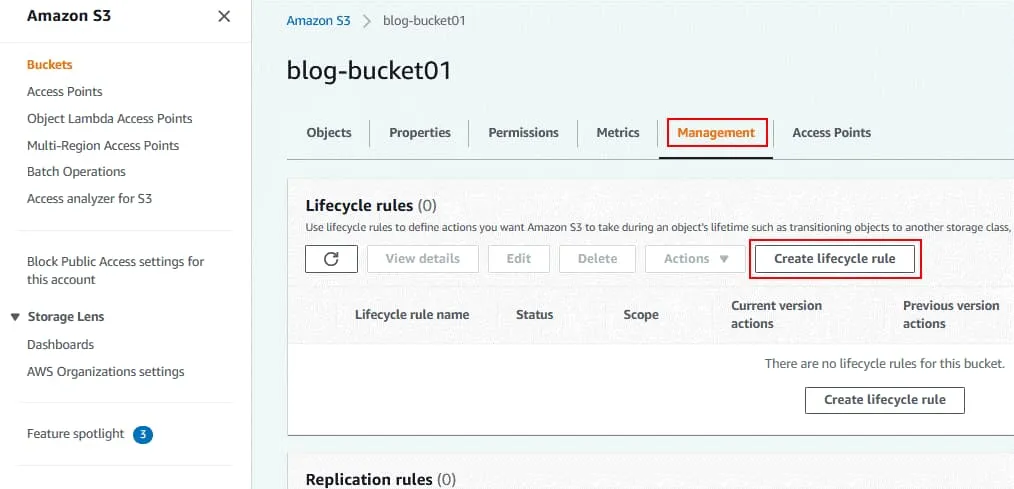 La page de la règle de cycle de vie s’ouvre. s la configuration de la règle de cycle de vie. Entrez le nom de la règle de cycle de vie, par exemple, Cycle de vie du blog 01. Choisissez la portée de la règle. Vous pouvez appliquer des filtres pour appliquer des règles de cycle de vie à des objets spécifiques ou appliquer la règle à tous les objets du compartiment. Définissez des balises d’objet pour désigner les objets auxquels des actions de cycle de vie doivent être appliquées. Entrez une clé et une valeur dans les champs appropriés, puis cliquez sur le bouton Ajouter une balise pour ajouter la balise ou sur le bouton Enlever pour supprimer la balise.
La page de la règle de cycle de vie s’ouvre. s la configuration de la règle de cycle de vie. Entrez le nom de la règle de cycle de vie, par exemple, Cycle de vie du blog 01. Choisissez la portée de la règle. Vous pouvez appliquer des filtres pour appliquer des règles de cycle de vie à des objets spécifiques ou appliquer la règle à tous les objets du compartiment. Définissez des balises d’objet pour désigner les objets auxquels des actions de cycle de vie doivent être appliquées. Entrez une clé et une valeur dans les champs appropriés, puis cliquez sur le bouton Ajouter une balise pour ajouter la balise ou sur le bouton Enlever pour supprimer la balise. Actions liées aux règles du cycle de vie. Choisissez les actions que vous souhaitez que cette règle effectue :
Actions liées aux règles du cycle de vie. Choisissez les actions que vous souhaitez que cette règle effectue :
- Transition des versions actuelles des objets entre les classes de stockage
- Transition des versions précédentes des objets entre les classes de stockage
- Expirer les versions actuelles des objets
- Supprimer définitivement les versions précédentes des objets
- Supprimer les marqueurs de suppression expirés ou les téléchargements multipartiels incomplets
 Transférez les versions non courantes des objets entre les classes de stockage. Sélectionnez les transitions entre les classes de stockage et le nombre de jours après lesquels les objets deviennent non courants. Dans mon exemple, les objets sont transférés from la classe de stockage S3 actuelle vers Standard-IA après 35 jours.Supprimer définitivement les versions précédentes des objets. Entrez le nombre de jours après lesquels les versions précédentes doivent être supprimées. La valeur doit être supérieure au nombre de jours après lesquels les objets deviennent obsolètes. Dans mon exemple, les objets sont définitivement supprimés après 40 jours. Cliquez sur Créer une règle pour créer une règle de cycle de vie.
Transférez les versions non courantes des objets entre les classes de stockage. Sélectionnez les transitions entre les classes de stockage et le nombre de jours après lesquels les objets deviennent non courants. Dans mon exemple, les objets sont transférés from la classe de stockage S3 actuelle vers Standard-IA après 35 jours.Supprimer définitivement les versions précédentes des objets. Entrez le nombre de jours après lesquels les versions précédentes doivent être supprimées. La valeur doit être supérieure au nombre de jours après lesquels les objets deviennent obsolètes. Dans mon exemple, les objets sont définitivement supprimés après 40 jours. Cliquez sur Créer une règle pour créer une règle de cycle de vie.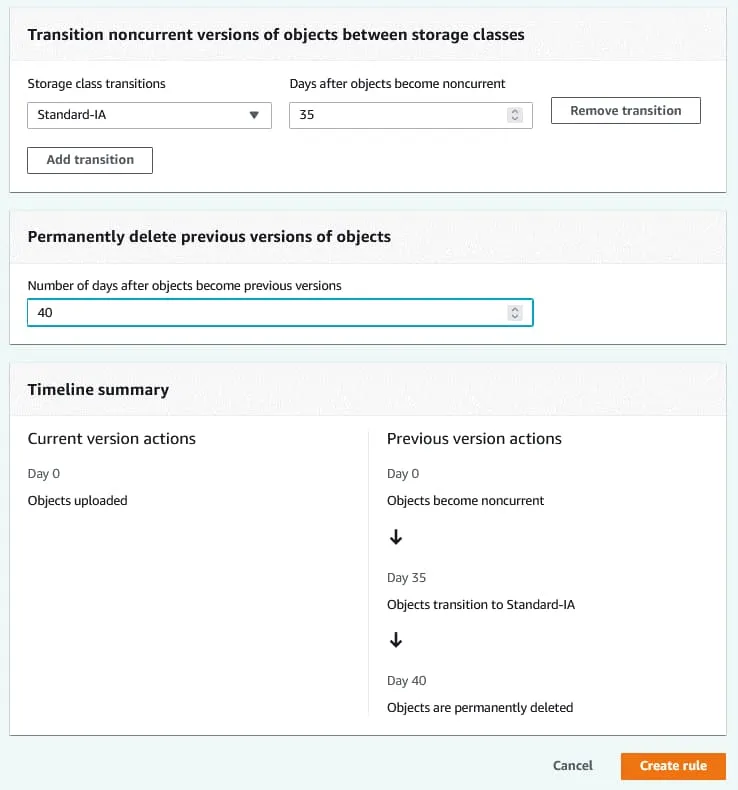
Répliquer le seau
Comme alternative à la sauvegarde automatique Amazon S3, vous pouvez répliquer le compartiment dans différentes régions. Vous devez créer un deuxième compartiment qui sera le compartiment de destination dans une autre région, puis créer une règle de réplication. Après avoir créé la règle de réplication, toutes les modifications apportées au compartiment source sont automatiquement répercutées dans le compartiment de destination. Recherchez la section Règles de réplication dans l’onglet GESTION de votre compartiment source, puis cliquez sur Créer une règle de réplication.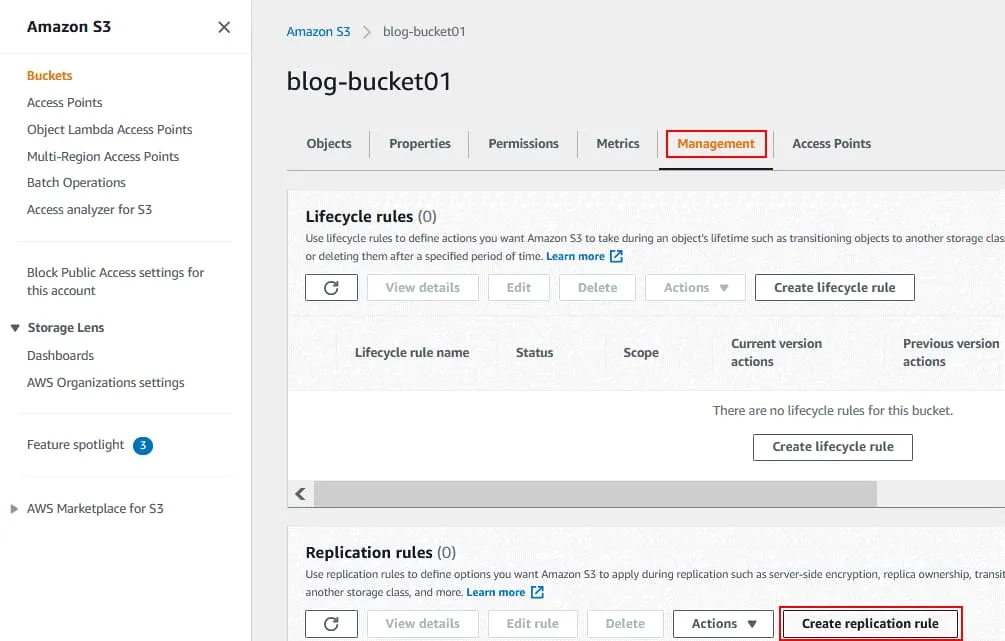 La page Créer une règle de réplication s’ouvre. Entrez un nom pour la règle de réplication, par exemple Réplication du compartiment S3 Blog. Définissez le statut de la règle lors de sa création (activé ou désactivé).
La page Créer une règle de réplication s’ouvre. Entrez un nom pour la règle de réplication, par exemple Réplication du compartiment S3 Blog. Définissez le statut de la règle lors de sa création (activé ou désactivé).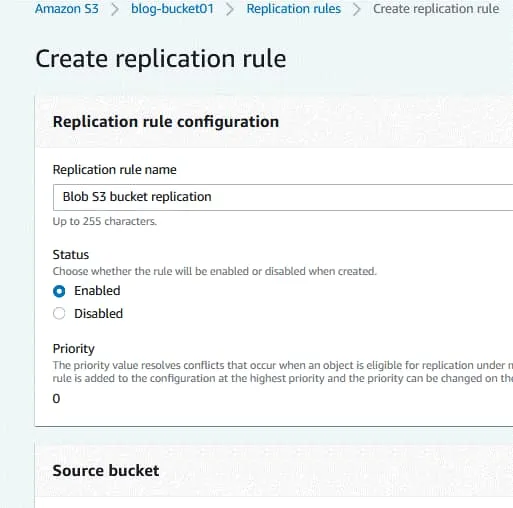 Source bucket. Le compartiment source a déjà été sélectionné (blog-bucket01). Choisissez une portée de règle. Vous pouvez utiliser la règle de réplication pour tous les objets du compartiment ou configurer des filtres et appliquer la règle à des objets personnalisés. destination. Entrez le nom du compartiment de destination ou cliquez sur Parcourir S3 et sélectionnez un compartiment from la liste. Vous pouvez sélectionner un compartiment dans ce compte ou dans un autre compte. Si la gestion des versions AWS S3 est activée pour le compartiment source, la gestion des versions des objets doit également être activée pour le compartiment de destination. Une région de destination s’affiche pour le compartiment de destination sélectionné.
Source bucket. Le compartiment source a déjà été sélectionné (blog-bucket01). Choisissez une portée de règle. Vous pouvez utiliser la règle de réplication pour tous les objets du compartiment ou configurer des filtres et appliquer la règle à des objets personnalisés. destination. Entrez le nom du compartiment de destination ou cliquez sur Parcourir S3 et sélectionnez un compartiment from la liste. Vous pouvez sélectionner un compartiment dans ce compte ou dans un autre compte. Si la gestion des versions AWS S3 est activée pour le compartiment source, la gestion des versions des objets doit également être activée pour le compartiment de destination. Une région de destination s’affiche pour le compartiment de destination sélectionné.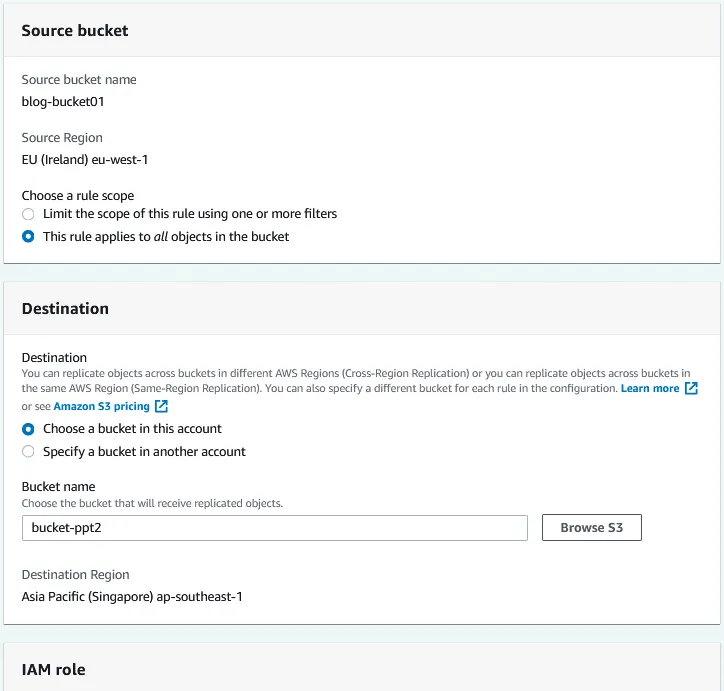 Configurez le rôle de gestion des identités et des accès (IAM), puis sélectionnez une classe de stockage et des options de réplication supplémentaires. Cliquez sur Enregistrer pour enregistrer la configuration et créer une règle de réplication pour le compartiment.
Configurez le rôle de gestion des identités et des accès (IAM), puis sélectionnez une classe de stockage et des options de réplication supplémentaires. Cliquez sur Enregistrer pour enregistrer la configuration et créer une règle de réplication pour le compartiment.
Sauvegarde AWS S3 à sauvegarder dans l’interface CLI
AWS CLI est une interface de ligne de commande puissante qui permet d’utiliser différents services Amazon, notamment Amazon S3. Il existe une commande de synchronisation utile qui vous permet de sauvergarder des compartiments Amazon S3 sur une machine Linux par le copier des fichiers du compartiment vers un répertoire local sous Linux fonctionnant sur une instance Amazon EC2. Une fonctionnalité de la commande de synchronisation dans AWS CLI est que les fichiers dans un système de fichiers local (destination de sauvergarde Amazon S3) ne sont pas supprimés si ces fichiers sont manquants dans le compartiment S3 source et vice versa. Ceci est important pour AWS S3 à sauvegarder car si certains fichiers ont été accidentellement supprimés dans le compartiment S3, les fichiers existants ne sont pas supprimés dans le répertoire local d’une machine Linux après la synchronisation. Avantages :
- Prise en charge des grands compartiments S3 et évolutivité
- Plusieurs threads sont pris en charge pendant la synchronisation.
- Possibilité de synchroniser uniquement les fichiers nouveaux et mis à jour
- Vitesse de synchronisation élevée grâce à des algorithmes intelligents
Inconvénients :
- Linux fonctionnant sur une instance EC2 consomme l’espace de stockage des volumes EBS. Les coûts de stockage pour les volumes EBS sont plus élevés que pour les compartiments S3.
Les commandes pour Ubuntu Server sont utilisées dans ce tutoriel. Tout d’abord, vous devez installer AWS CLI. Mettez à jour l’arborescence des référentiels :sudo apt-get update InstallezAWS CLI :sudo apt install awsclior Installezunzip :sudo apt installunzip curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o « awscliv2.zip »unzip awscli-exe-linux-x86_64.zip sudo ./aws/install Vérifiezles identifiants de connexion AWS dans Linux s’exécutant sur votre instance EC2.aws configure listAjoutez les identifiants de connexion pour accéder à AWS avec AWS CLI from l’instance Linux si elles n’ont pas encore été définies :aws configure Entrezles paramètres suivants :Clé d’accès AWSIDCléd’accès secrèteAWSNomde la régionpar défaut Format de sortie par défaut Créezun répertoire pour stocker votre sauvegarde vers Amazon S3. Dans mon exemple, je crée le répertoire ~/s3/ pour stocker les sauvegardes S3 à sauvegarder et un sous-répertoire dont le nom est identique à celui du compartiment. Les fichiers stockés dans le compartiment S3 doivent être copiés dans ce répertoire local sur la machine Linux. ~ est le répertoire personnel d’un utilisateur, qui est /home/ubuntu dans mon cas.mkdir -p ~/s3/your_bucket_nameRemplacez your_bucket_name par le nom de votre compartiment (blog-bucket01 dans notre exemple).mkdir -p ~/s3/blog-bucket01Synchronisez le contenu du compartiment avec votre répertoire local sur l’instance EC2 exécutant Linux :aws s3 sync s3:// blog-bucket01 /home/ubuntu/s3/ blog-bucket01/ Sila configuration des informations d’identification, le nom du compartiment et le chemin de destination sont corrects, le téléchargement des données à partir du compartiment S3 devrait commencer. Le temps nécessaire pour terminer l’opération dépend de la taille des fichiers dans le compartiment et de la vitesse de votre connexion Internet.
Sauvegarde automatique vers Amazon S3
Vous pouvez configurer des tâches de sauvegarde automatique Amazon S3 avec AWS CLI sync. Créez un fichier script sync.sh pour exécuter la sauvegarde AWS S3 (synchroniser les fichiers from un compartiment S3 vers un répertoire local sur votre instance Linux), puis exécutez ce script selon un programme.nano /home/ubuntu/s3/sync.sh#!/bin/sh# Afficher la date etl'heure actuellesecho'-----------------------------'dateecho '----------------------------'-'echo''# Afficher lemessage d'initialisation du scriptecho 'Synchronisation du compartiment S3 distant...'# Exécution de la commande de synchronisation/usr/bin/aws s3 sync s3://{BUCKET_NAME} /home/ubuntu/s3/{BUCKET_NAME}/# Echo « Exécution du script terminée »echo 'Synchronisation terminée' Remplacez {BUCKET_NAME} par le nom du compartiment S3 que vous souhaitez pour sauvergarder.Le chemin complet vers aws (binaire AWS CLI) est défini pour que crontab exécute correctement l’application aws dans l’environnement shell utilisé par crontab.Rendez le script exécutable :sudo chmod +x /home/ubuntu/s3/sync.sh Exécutezle script pour vérifier s’il fonctionne :/home/ubuntu/s3/sync.sh Modifiezle crontab (un planificateur sous Linux) de l’utilisateur actuel pour planifier l’exécution du script de sauvegarde vers Amazon S3.crontab -eVous devrez peut-être sélectionner un éditeur de texte pour modifier la configuration crontab. Le format crontab pour planifier les tâches est le suivant :m h dom mon dow command Où: m – minutes heures ; h – heures ; dom – jour du mois ; dow – jour de la semaine. Ajoutons une ligne de configuration pour que la tâche exécute la synchronisation chaque heure et enregistre les résultats de la sauvegarde AWS S3 dans le fichier journal. Ajoutez cette ligne à la fin de la configuration crontab.0 * * * * /home/ubuntu/s3/sync.sh > /home/ubuntu/s3/sync.logLa sauvegarde automatique Amazon S3 est configurée. Le fichier journal peut être utilisé pour vérifier l’exécution des tâches de synchronisation.
Conclusion
Il existe plusieurs méthodes pour effectuer une sauvegarde (à sauvegarder) Amazon S3, dont deux ont été abordées dans cet article de blog. Vous pouvez activer le versionnage des objets pour un compartiment afin de conserver les versions précédentes des objets, ce qui vous permet de récupérer les fichiers si des modifications indésirables ont été apportées à ceux-ci. La réplication Amazon S3 est un autre outil natif permettant de créer une copie des fichiers stockés dans un compartiment Amazon S3 sous forme d’objets. Dans ce cas, les objets sont répliqués from un compartiment à un autre. Vous pouvez également créer une sauvegarde d’un compartiment Amazon S3 par l’outil de synchronisation dans AWS CLI, qui vous permet de synchroniser les fichiers d’un compartiment avec un répertoire local d’une machine Linux fonctionnant sur une instance Amazon EC2. La sauvegarde automatique Amazon S3 peut être planifiée par l’intermédiaire d’un script et d’un crontab. En général, le stockage dans le cloud Amazon S3 est très fiable et la sauvegarde vers Amazon S3 est une pratique courante. Si vous disposez d’une stratégie solide en matière de protection des données et de sauvegarde AWS, vous devriez avoir une copie de sauvegarde. Dans ce cas, il est recommandé de sauvergarder les données sur Amazon S3 et sur un autre emplacement de destination. Utilisez NAKIVO Backup & Replication pour protéger vos données sur les machines physiques et virtuelles. NAKIVO Backup & Replication est un logiciel de sauvegarde de virtualisation robuste qui peut être utilisé pour sauvegarder les VMs, ainsi que les instances Amazon EC2 et les machines physiques. 


