Hyper-V 災害復旧のベストプラクティス
仮想環境においては、サービスの可用性や事業継続性に対する期待が非常に高まっています。今日の企業には、業務を中断することなく運営し、顧客にサービスを提供することが求められています。
さまざまな要因による障害から可用性を維持するためには、 災害復旧計画. このような計画により、必要な可用性レベルとデータ損失防止の目標を維持できるだけでなく、データ損失を最小限に抑えながら迅速な復旧を実現できます。このブログでは、Hyper-Vの災害復旧に関する役立つヒントをご紹介します。

VMのディザスタリカバリとは?
ディザスタリカバリとは、重大なインシデント発生後のダウンタイムを最小限に抑え、業務機能を可能な限り迅速に復旧させることを目的とした、一連の方針、手順、およびツールのことです。Hyper-Vのディザスタリカバリを含む仮想環境向けのディザスタリカバリ(DR)には、一般的に以下の要素が含まれます:
- ブロックレベルのイメージベースのVMバックアップおよびレプリケーション
- リモートDRサイトにおけるVMバックアップおよびレプリカの保持
- VMレプリカへのフェイルオーバー 災害が発生した場合
- VMバックアップを活用した長期保存と確実な復旧
Hyper-V 環境における仮想マシンの災害復旧
Microsoft Hyper-V には、仮想マシンの災害復旧を効率的に行うための機能が標準で備わっています。災害復旧計画にどの機能を含めるべきかは、予算、インフラストラクチャ、および事業規模によって決まります。ただし、Hyper-V 環境における仮想マシンの災害復旧は、通常、以下の要素に基づいて行われます。
- DRサイト。 インシデント発生時に、本番サイトやシステムが復旧するまでの間、組織が業務プロセスを移行できる場所。
- 代替となる仮想プラットフォームおよびデータベースサーバー。 災害発生時には、DRサイトにおいて、仮想マシンをホストするためのサーバーおよび仮想プラットフォームソフトウェアが稼働可能な状態にしておく必要があります。これにより、ダウンタイムを最小限に抑え、事業継続性を確保します。
- 災害復旧(DR)向けの仮想バックアップおよびレプリケーションソフトウェア。 Hyper-V は ボリューム シャドウ コピー サービス (VSS) テクノロジーにより、仮想マシンが稼働中であってもバックアップやスナップショットの作成が可能です。一方、Hyper-V レプリケーションでは、稼働中の仮想マシンのコピー(レプリカ)を利用して、災害発生時に仮想マシンを復旧することができます。最新のソフトウェアソリューションでは、バックアップ機能とレプリケーション機能を組み合わせることで、災害復旧を支援します。
これらの手段を活用することで、組織はHyper-V環境においてVMの災害復旧計画を作成し、それを確実に実行することができます。
Hyper-V 仮想マシンの災害復旧を成功させるための秘訣
Hyper-V 仮想マシンの災害復旧を成功させるためのヒントを以下にまとめました:
- VMのバックアップを定期的に実行し、テストを行ってください。 組織のニーズや優先順位に合わせてバックアップのスケジュールを設定してください。作成されたバックアップの有効性と整合性を定期的に確認してください。
- 定期的にレプリカを作成し、テストを行ってください。 特定のアプリケーションやVMが事業継続にとってどれほど重要かによって、ほぼ瞬時の復旧を保証するようにレプリケーションを設定できます。レプリカの整合性と実用性を確認するため、定期的にテストを行ってください。
- フェイルオーバーテストを実施する。 テストを実施することで、災害復旧(DR)インシデントが発生した場合に、重要な業務をDRサイトに移行できるかどうかを確認できます。フェイルオーバーテストは、DRプロセスを阻害する可能性のある弱点を特定するのに役立ちます。
- データ保護ソリューションを定期的に更新してください。 マイクロソフトは製品を絶えず更新しているため、新しいAPIやHyper-V拡張機能を活用するには、データ保護ソリューションも更新することが重要です。
- バックアップとレプリカを遠隔地に保存する。 このデータを遠隔地に保管することで、単一障害点によるリスクを排除することができます。
- 各VMにWindowsの更新プログラムを適用し、セキュリティ上の脆弱性を修正してください。 Hyper-Vは急速に変化・進化しており、マイクロソフトはHyper-V Integration Servicesを常に最新の状態に保つよう努めています。
- ハードウェアおよびソフトウェアのエラーを確認します。 システム障害やデータ損失を防ぐためには、RAMおよびディスクの検証テストを実施し、ディスクに関する警告を確認することが不可欠です。
- 物理マシンおよび仮想マシンには、十分なディスク容量を確保してください。 ディスクの空き容量は、信頼性の高いバックアップと高速なレプリケーションを実現しますが、VMの再起動時には十分なRAM容量が不可欠です。したがって、バックアップとレプリケーションを確実に成功させるためには、ストレージ容量を管理し、RAMの不足レベルについて通知できるデータ保護ソリューションを導入することが有効です。
- VSSに対応したデータ保護ソリューションを導入し、運用する。 VSSは、バックアップおよびレプリケーションジョブの実行中に、仮想マシンのパフォーマンスと状態を監視します。また、バックアップとレプリカを効果的に最適化するために、VSSを設定する必要があります。
NAKIVOのDRソリューションでインフラを保護する方法
Hyper-V 仮想マシンの災害復旧は、仮想マシンのバックアップとレプリカに依存しているため、災害復旧計画を実施するためのデータ保護ソリューションを選択する際には、これら両方の選択肢を検討すべきです。 NAKIVO Backup & Replication これは、Microsoft Hyper-V 仮想マシン(VM)に対して包括的なデータ保護を提供し、バックアップ機能とレプリケーション機能の両方を備えたソリューションの一つです。
- Microsoft Hyper-V 仮想マシンのバックアップ。 もし、次のような最新の画像ベースのソリューションを使用する場合は NAKIVO Backup & Replicationこれにより、OSや設定などを含む、その時点でのVMのコピーが作成されます。災害復旧(DR)の事態が発生した場合、バックアップ時の状態そのままに、バックアップからVMを復元することができます。例えば、 Hyper-V仮想マシンを即座に起動する または VMware vSphere 仮想マシンとして復元する.
できます NAKIVO を使用して Hyper-V 仮想マシンをバックアップする ソリューションのインベントリにHyper-Vホストを追加した後、メイン画面から新しいバックアップジョブを作成します。
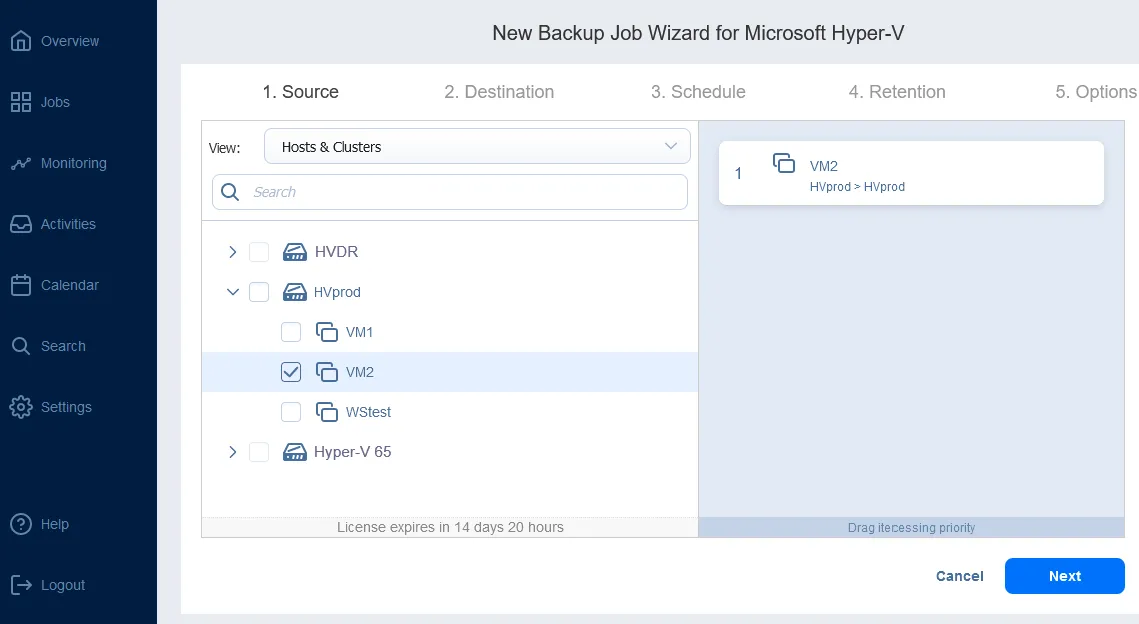
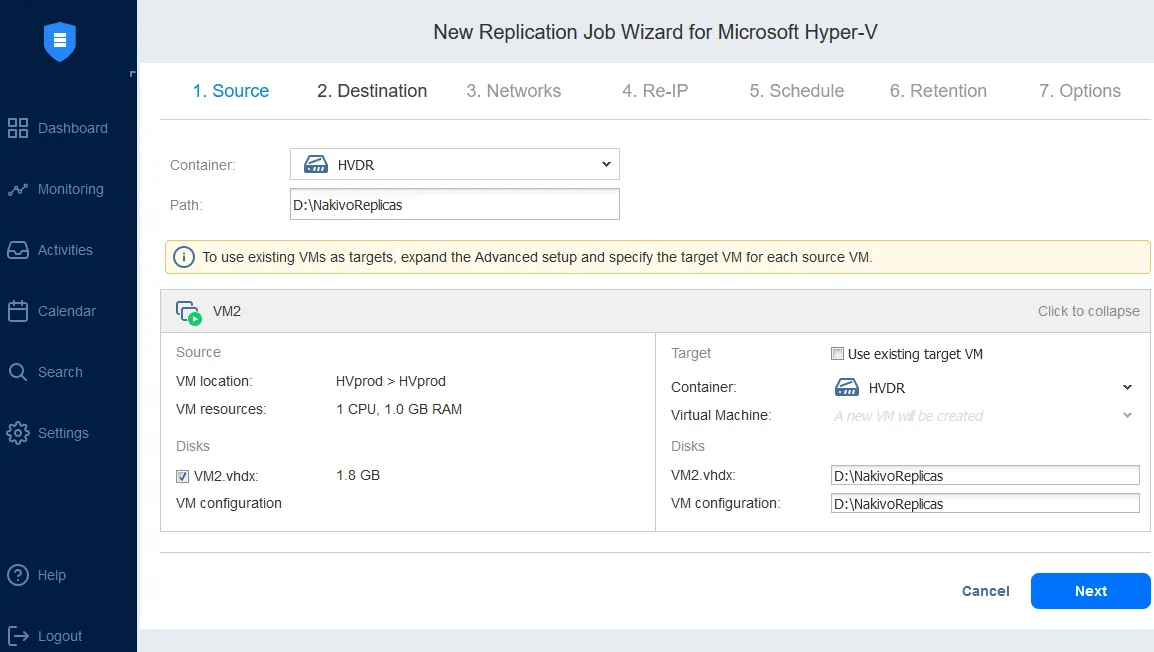
- Microsoft Hyper-V の仮想マシンレプリケーション。 を使用することで Hyper-V 仮想マシンのレプリケーションこれにより、プライマリVMと同一のコピー(VMレプリカ)を作成することができ、DR事象が発生し、即時の復旧が必要な場合には、このレプリカを起動するだけで済みます。レプリカへのワークロードのフェイルオーバー(つまり、VMやシステムをDRサイトへ移行すること)を行い、DRサイトでの運用を復旧させることは、事業継続性と高可用性を維持するために不可欠です。
NAKIVO を使用した Hyper-V レプリケーション ジョブの設定により、以下のことが可能になります ネットワークマッピングの設定 およびIP再割り当てルール。
- RTOおよびRPO。 リカバリポイント目標(RPO)とリカバリ時間目標(RTO)は、Hyper-V仮想マシンの災害復旧を計画する際に設定すべき重要な指標です。 RPOとRTO DR計画では、さまざまな重要なワークロードごとにこれらを定義しておく必要があり、それによってバックアップやレプリケーションの頻度が決定されます。
- RPOとは、事業に支障をきたすことなく企業が許容できるデータ損失の量を指します(2つのバックアップ/レプリケーションジョブ間の時間間隔として測定されます)。
- RTOとは、災害発生後に業務を復旧させ、その事象が組織に悪影響を及ぼすのを防ぐための所要時間のことです。VMのレプリケーションおよびフェイルオーバー操作を利用すれば、VMのバックアップからの復旧に比べて、はるかに短いRTOを実現できます。
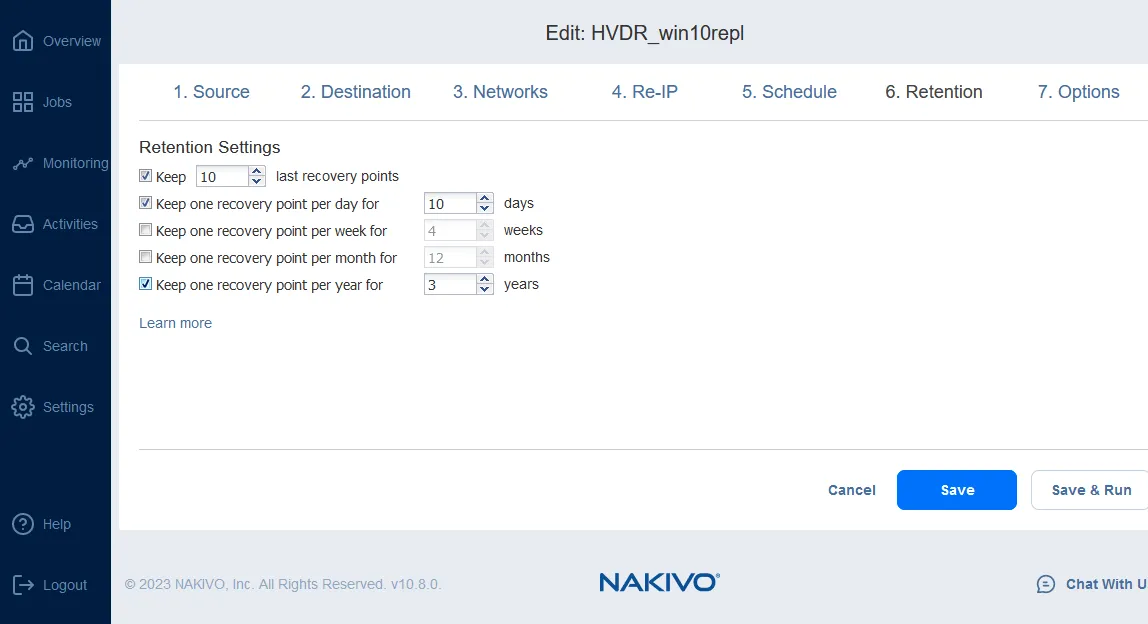
以下の機能を実装することで、保存期間の設定を行うことができます。 祖父・父・子の保持方針. これらの設定により、保持するVMレプリカの数が決定され、Hyper-Vの災害復旧に利用できます。
NAKIVO による Hyper-V 災害復旧のオーケストレーション
NAKIVO Backup & Replication 高度な機能を含む一連の機能を備えています サイト復旧 VMware、Hyper-V、およびAWS EC2環境に対応した機能です。Site Recoveryとは、特定の順序で組み合わせることで、VMの災害復旧ワークフロー(ジョブ)を作成できる一連のアクションおよび手順のことです。 サイト復旧ワークフロー で NAKIVO Backup & Replication 複数の拠点にわたるDRプロセスの調整と自動化を実現する。
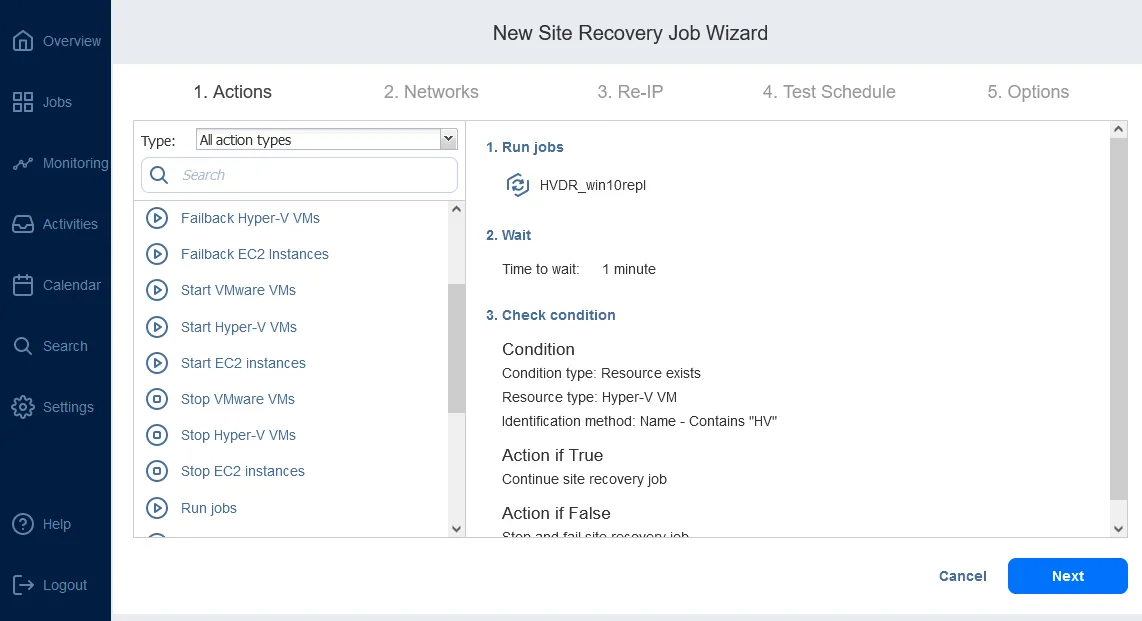
Site Recoveryのジョブには、(その他のDRアクションに加え)自動フェイルオーバーが含まれており、わずか数回のクリックでサイト全体を復旧させることができます。さらに、 NAKIVO Backup & Replication フェイルオーバーには、計画的なフェイルオーバーと緊急フェイルオーバーの2種類があります。
- 計画的なフェイルオーバー これは通常、差し迫った災害からシステムを保護するため、またはプライマリサイトでのメンテナンス作業中に使用されます。この場合、ソリューションは最後のデータ同期を実行した後、ワークロードをプライマリサイトからVMレプリカへ移行します。
- 緊急フェイルオーバー これは、プライマリサイトがすでにインシデントに見舞われた場合に作動します。このソリューションは、時間を節約しダウンタイムを短縮するため、データの同期を行わずに(時間を節約するため)、ワークロードをプライマリサイトからVMレプリカへ移行します。
さらに、 NAKIVO Backup & Replication Site Recoveryジョブをテストモード(スケジュールされたものまたはオンデマンド)で実行できます。これは、リカバリワークフローが計画通りに機能するか、またRTO(復旧目標時間)を満たせるかを確認するのに最適な方法です。
以下の機能を活用してサイト復旧ワークフローを作成する可能性 NAKIVO Backup & Replication これは、あらゆる企業にとって大きなメリットとなります。自社の具体的なビジネスニーズに合わせたDR戦略を策定し、事前に設定しておけば、万一災害が発生した際にも、わずか数回のクリックで実行することができます。さらに、DR戦略を継続的にテストし、最適化することで、ダウンタイムゼロ、RTOの短縮、高可用性、コスト削減といった、可能な限り最良の結果を実現できます。



